Classification of Sperm Whale Clicks (Physeter Macrocephalus) with Gaussian-Kernel-Based Networks

Abstract
:
1. Introduction
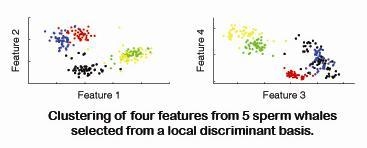
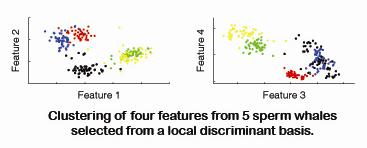
2. Data Acquisition, Preparation and Feature Selection
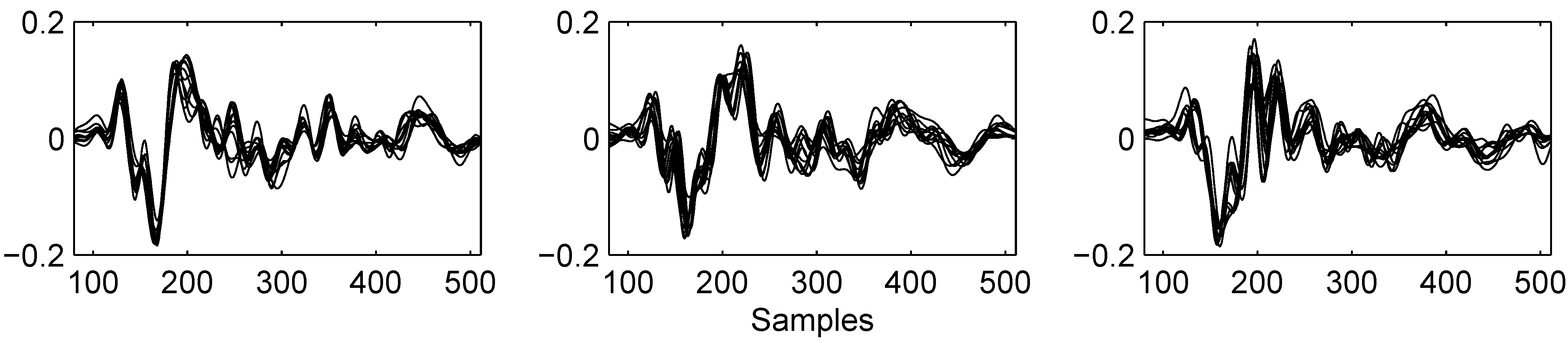
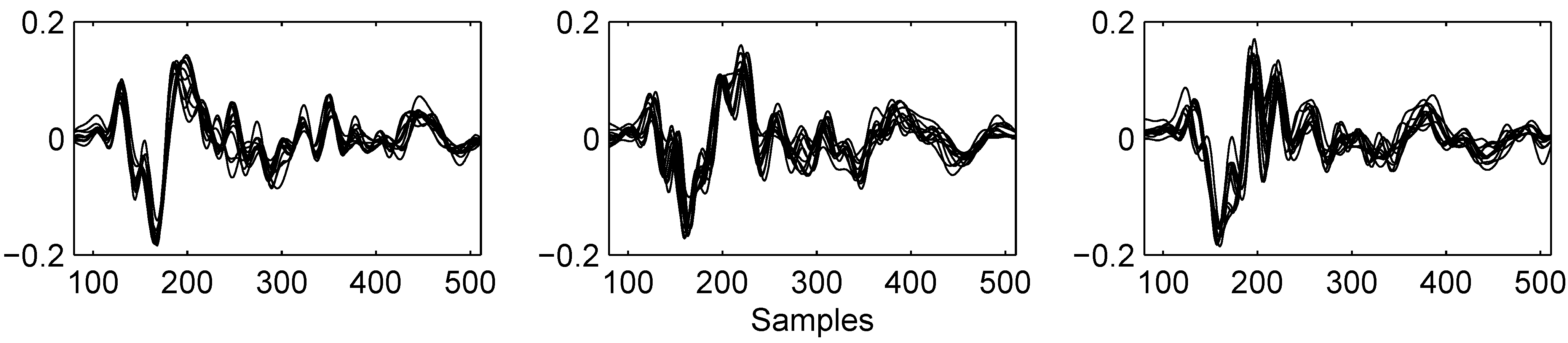
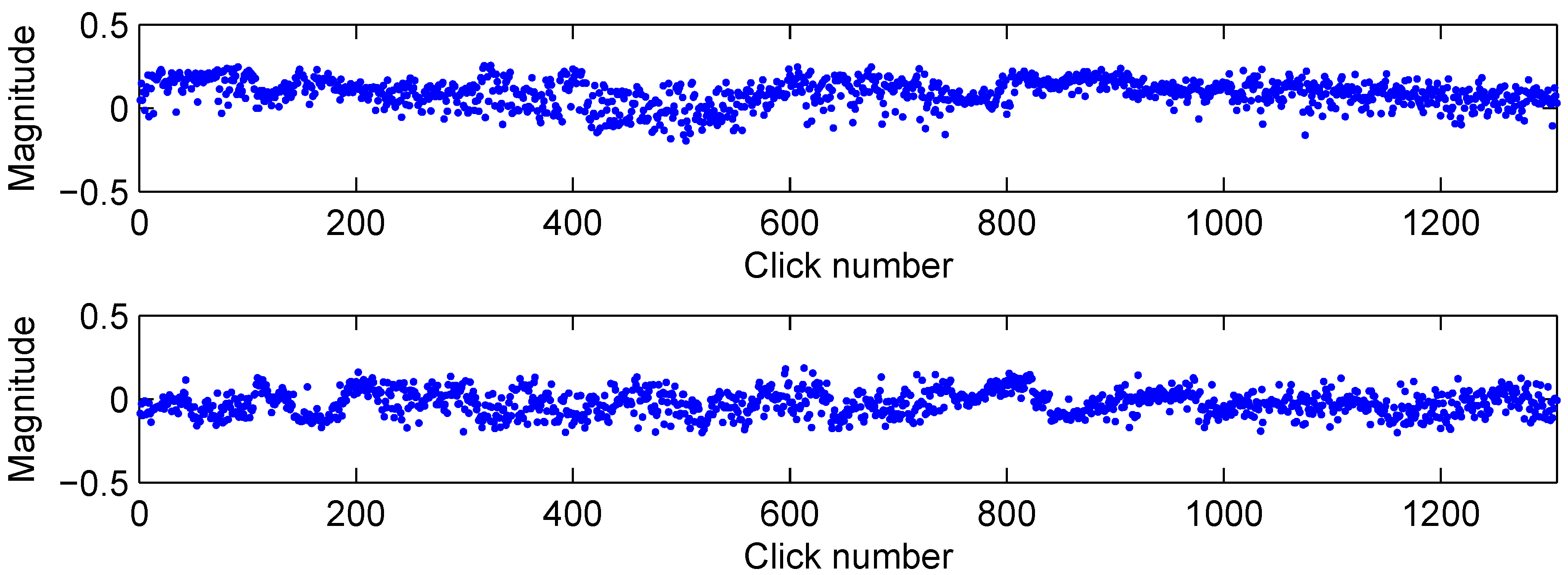
2.1. Data acquisition
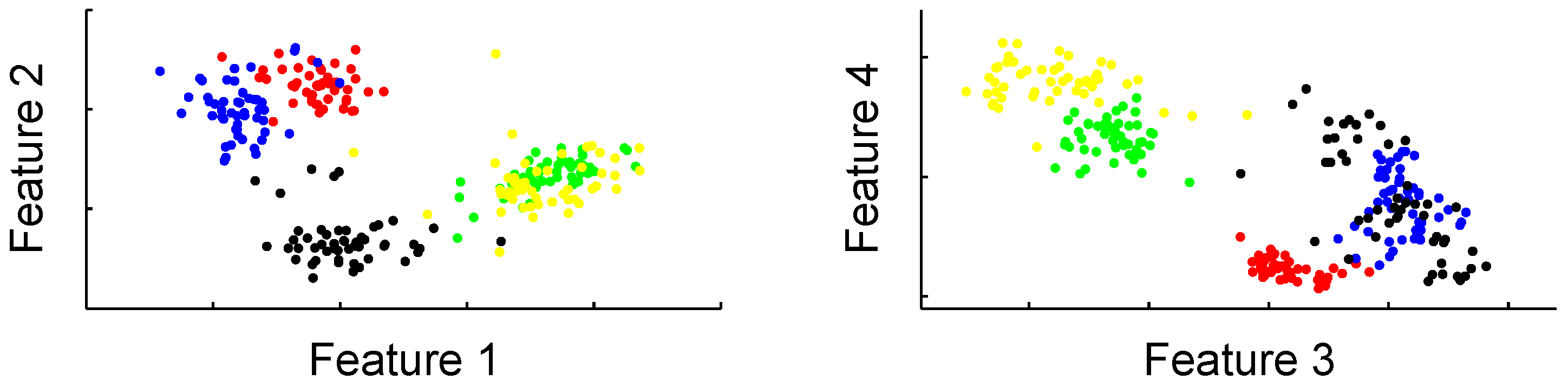
2.2. Data preparation and feature selection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| index | split | frq band (Hz) | power | index | split | frq band (Hz) | power |
|---|---|---|---|---|---|---|---|
| (1,2) | 5 | 1 - 1,500 | 3.5 | (1,1) | 5 | 1 - 1,500 | 3.4 |
| (1,3) | 5 | 1 - 1,500 | 3.0 | (1,4) | 5 | 1 - 1,500 | 2.3 |
| (2,11) | 5 | 1,500 - 3,000 | 1.3 | (1,31) | 5 | 1 - 1,500 | 1.2 |
| (1,9) | 5 | 1 - 1,500 | 1.0 | (1,21) | 5 | 1 - 1,500 | 0.95 |
| (1,10) | 5 | 1 - 1,500 | 0.80 | (2,8) | 5 | 1,500 - 3,000 | 0.80 |
| (1,13) | 5 | 1 - 1,500 | 0.79 | (1,18) | 5 | 1 - 1,500 | 0.79 |
| (1,14) | 5 | 1 - 1,500 | 0.76 | (1,22) | 5 | 1 - 1,500 | 0.73 |
| (1,16) | 5 | 1 - 1,500 | 0.65 | - |
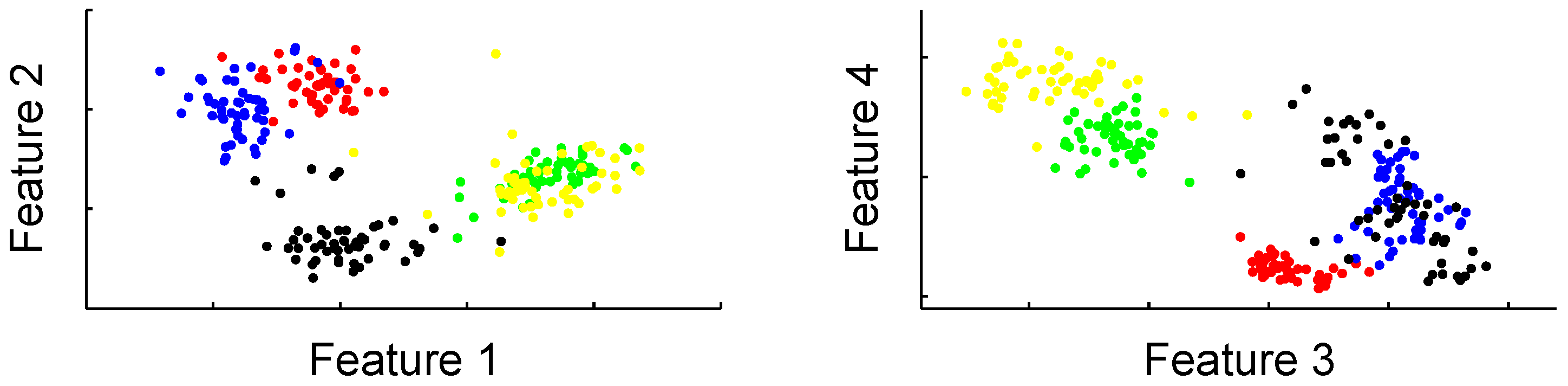
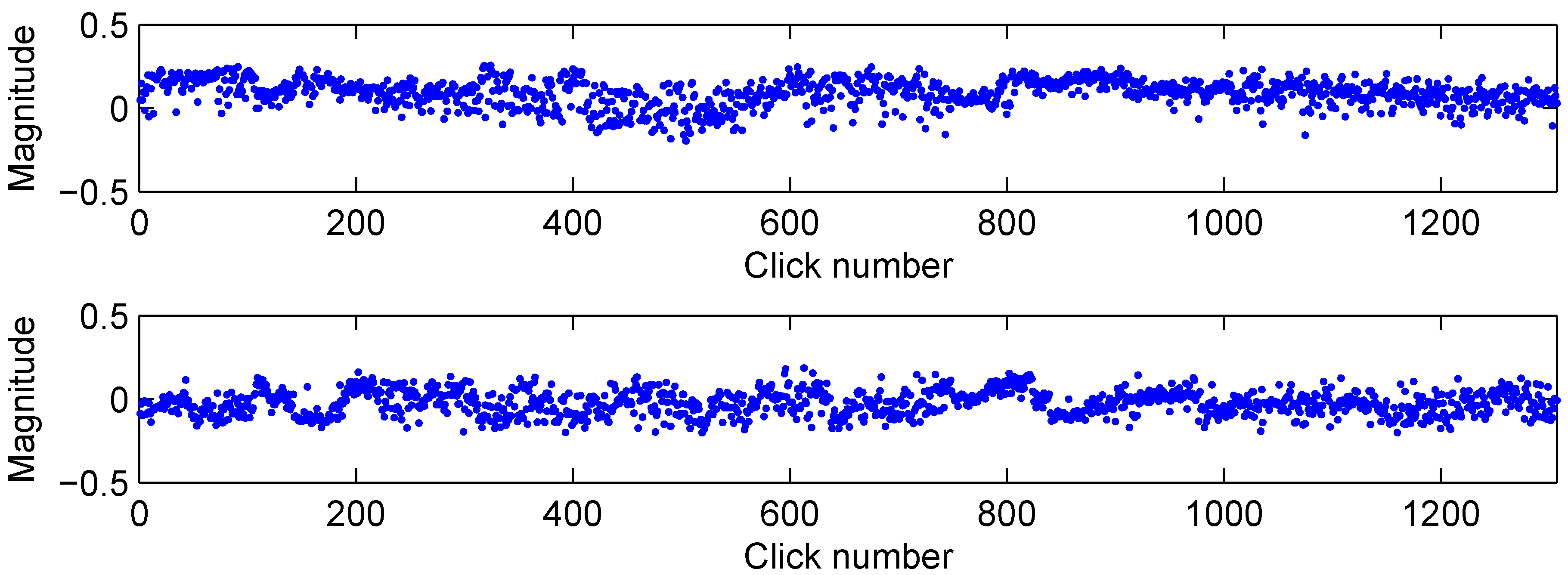
3. Classification Description
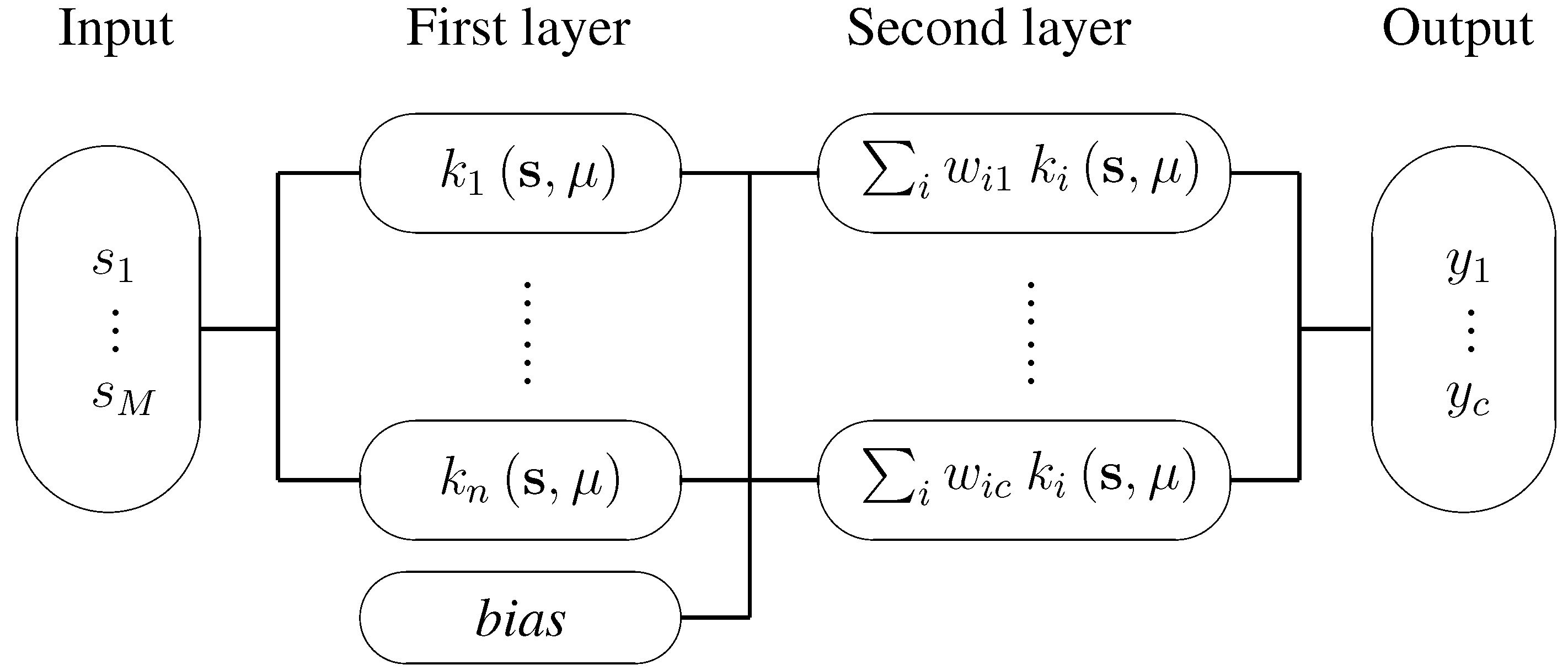
3.1. Radial basis function network
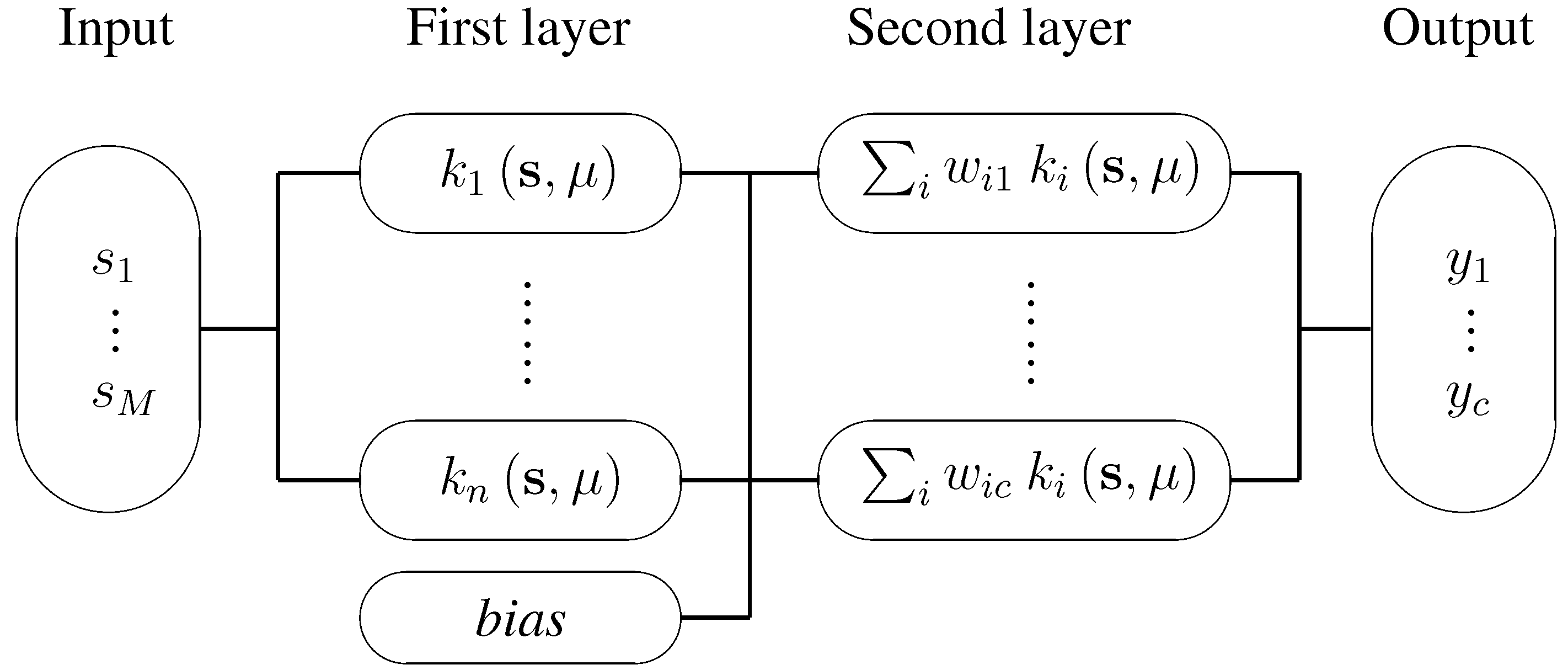
3.2. Support vector machine classification
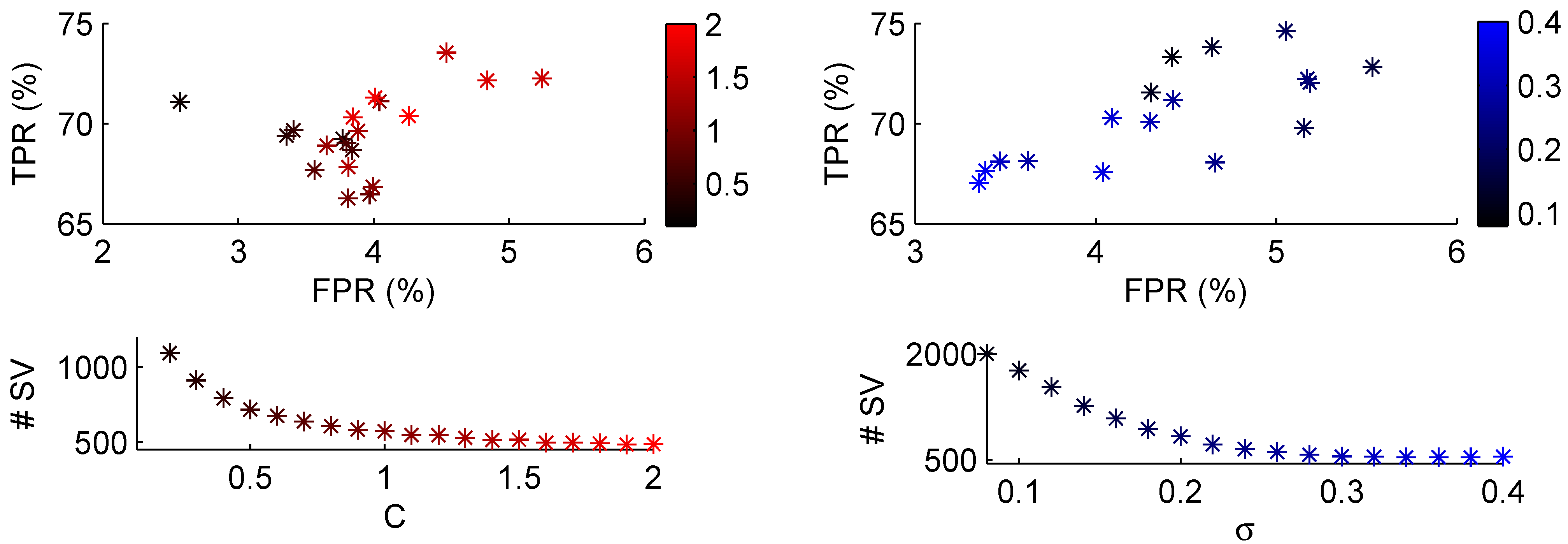
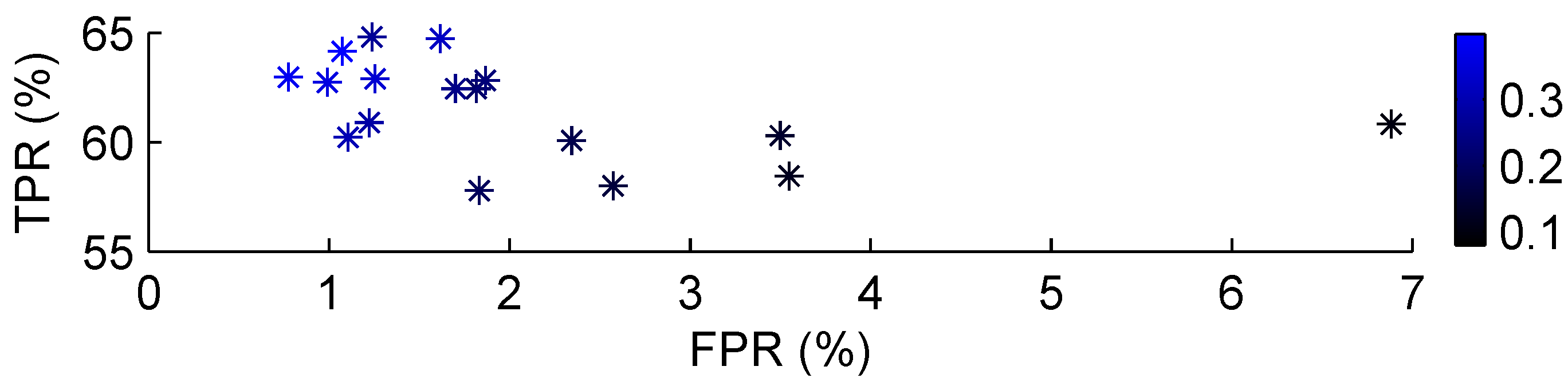
4. Classification Results
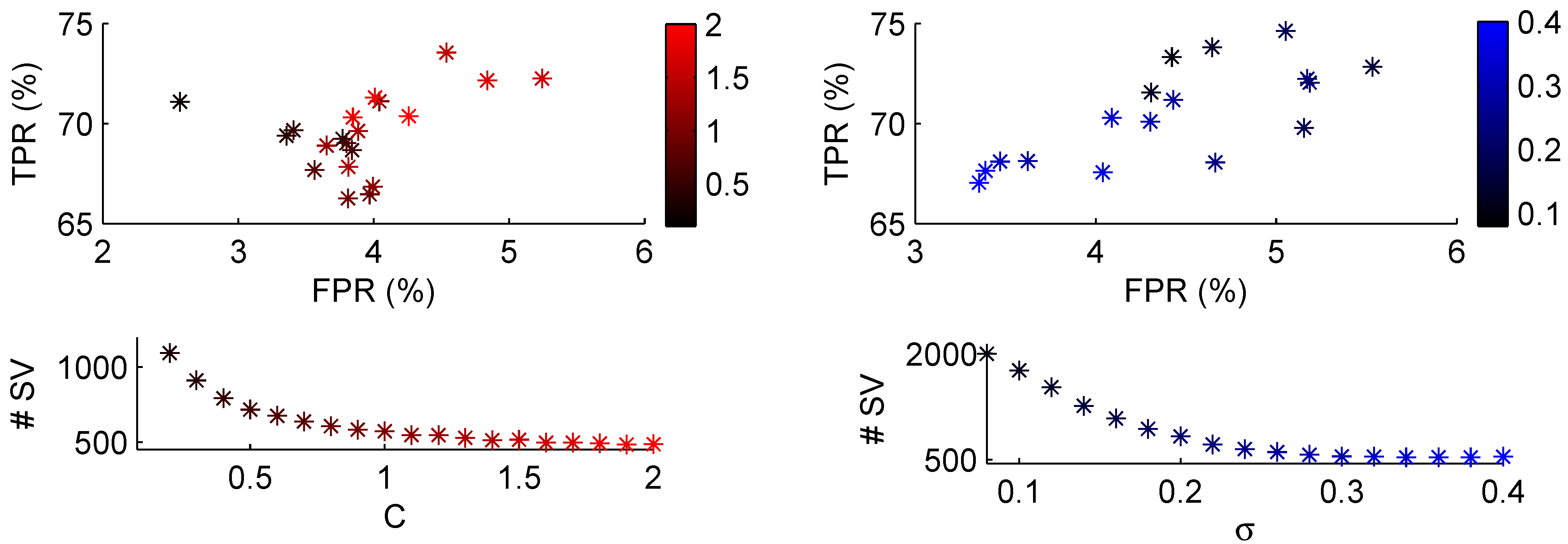
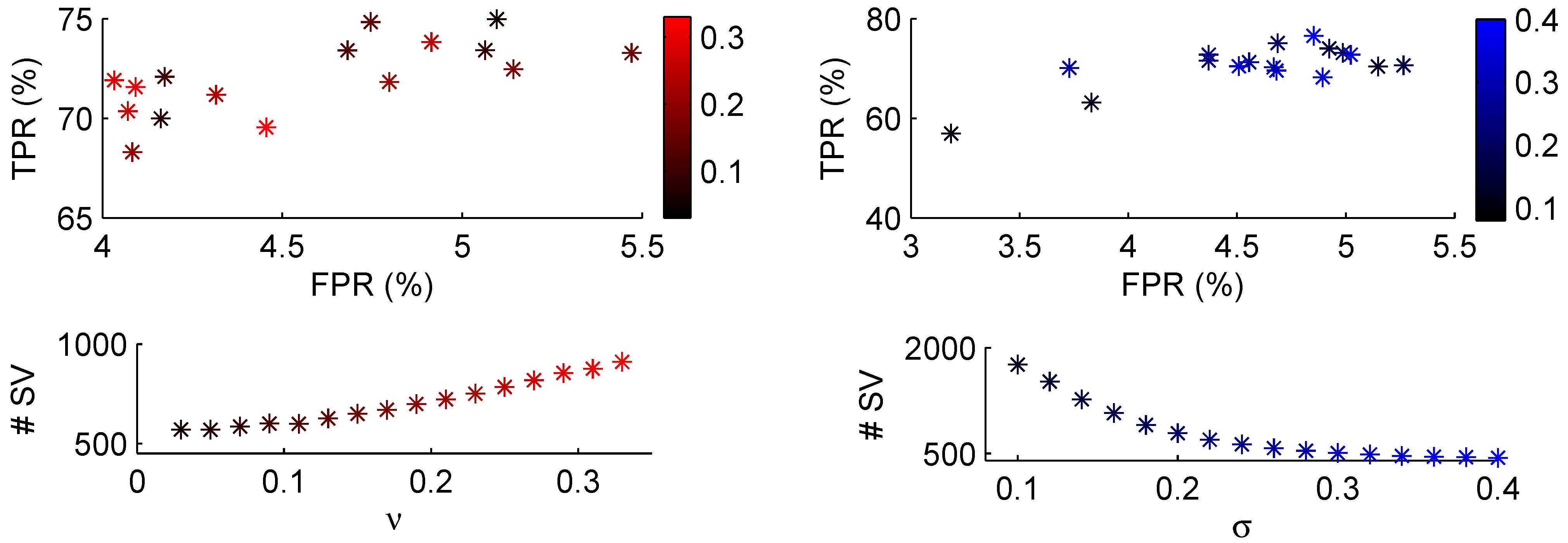
| C-SVM | ν-SVM | RBF | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Set | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | 83 | 5 | 12 | 3 | 0 | 0 | 0 | 4 | 78 | 5 | 12 | 3 | 0 | 0 | 0 | 3 | 86 | 5 | 6 | 3 | 0 | 4 | 0 | 6 |
| 2 | 8 | 66 | 0 | 0 | 0 | 0 | 1 | 6 | 9 | 69 | 0 | 0 | 0 | 0 | 1 | 6 | 3 | 67 | 0 | 0 | 0 | 0 | 2 | 7 |
| 3 | 1 | 0 | 79 | 1 | 0 | 0 | 0 | 2 | 3 | 0 | 79 | 1 | 1 | 0 | 0 | 2 | 9 | 3 | 91 | 1 | 1 | 2 | 1 | 5 |
| 4 | 0 | 0 | 0 | 80 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 85 | 3 | 0 | 0 | 1 | 0 | 0 | 0 | 92 | 3 | 0 | 0 | 1 |
| 5 | 0 | 2 | 3 | 15 | 97 | 0 | 0 | 3 | 0 | 2 | 3 | 10 | 96 | 0 | 0 | 1 | 1 | 8 | 3 | 3 | 96 | 0 | 2 | 2 |
| 6 | 1 | 13 | 3 | 1 | 0 | 100 | 1 | 8 | 1 | 13 | 3 | 1 | 0 | 100 | 1 | 8 | 1 | 8 | 0 | 0 | 0 | 87 | 1 | 7 |
| 7 | 5 | 9 | 0 | 1 | 0 | 0 | 98 | 73 | 8 | 8 | 0 | 1 | 0 | 0 | 98 | 79 | 1 | 9 | 0 | 1 | 0 | 7 | 94 | 72 |
| und | 2 | 5 | 3 | 0 | 1 | 0 | 0 | 3 | 2 | 2 | 3 | 0 | 0 | 0 | 0 | 1 | ||||||||
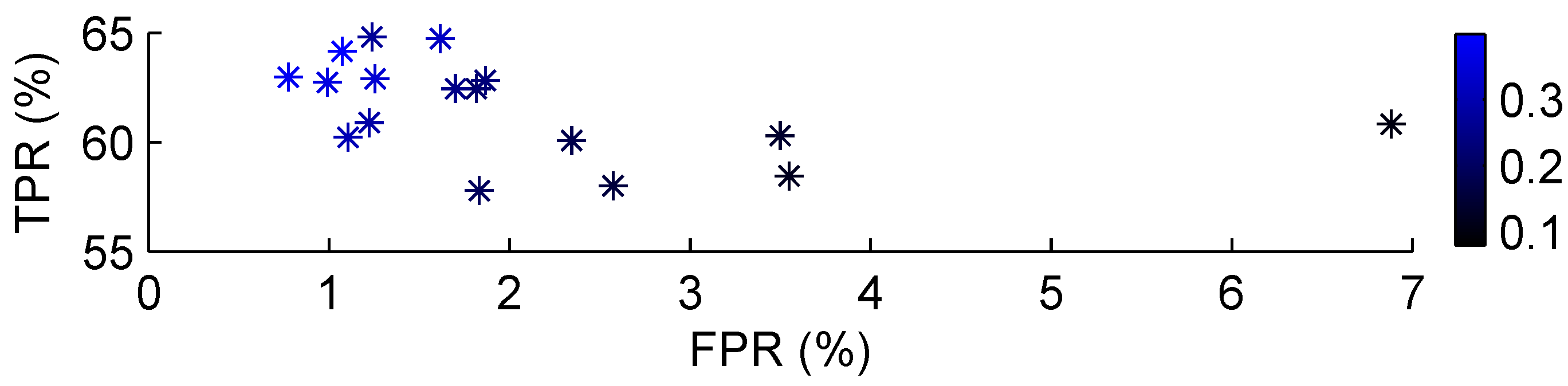
5. Conclusion
Acknowledgements
References
- Whitehead, H. Sperm Whales: Social Evolution in the Ocean, 1st Ed. ed; University Of Chicago Press: Chicago, IL, USA, 2003; pp. 79–81. [Google Scholar]
- Miller, P.; Johnson, M.; Tyack, P. Sperm whale behaviour indicates the use of echolocation click buzzes ’creaks’ in prey capture. Proc. R. Soc. Lond. B Biol. Sci. 2004, 271, 2239–2247. [Google Scholar] [CrossRef] [PubMed]
- Møhl, B.; Wahlberg, M.; Madsen, P.; Heerfordt, A.; Lund, A. The monopulsed nature of sperm whale clicks. J. Acoust. Soc. Am. 2003, 114, 1143–1154. [Google Scholar] [CrossRef] [PubMed]
- Thode, A.; Mellinger, D.; Stienessen, S.; Martinez, A.; Mullin, K. Depth-dependent acoustic features of diving sperm whales (Physeter macrocephalus) in the Gulf of Mexico. J. Acoust. Soc. Am. 2002, 112, 308–321. [Google Scholar] [CrossRef] [PubMed]
- Goold, J.; Jones, S. Time and frequency domain characteristics of sperm whale clicks. J. Acoust. Soc. Am. 1995, 98, 1279–1291. [Google Scholar] [CrossRef] [PubMed]
- van der Schaar, M.; Delory, E.; van der Weide, J.; Kamminga, C.; Goold, J.; Jaquet, N.; André, M. A comparison of model and non-model based time-frequency transforms for sperm whale click classification. J. Mar. Biol. Assoc. 2007, 87, 27–34. [Google Scholar] [CrossRef]
- Kamminga, C.; Cohen Stuart, A. Wave shape estimation of delphinid sonar signals, a parametric model approach. Acoust. Lett. 1995, 19, 70–76. [Google Scholar]
- Kamminga, C.; Cohen Stuart, A. Parametric modelling of polycyclic dolphin sonar wave shapes. Acoust. Lett. 1996, 19, 237–244. [Google Scholar]
- Huynh, Q.; Cooper, L.; Intrator, N.; Shouval, H. Classification of underwater mammals using feature extraction based on time-frequency analysis and BCM theory. IEEE T. Signal Proces. 1998, 46, 1202–1207. [Google Scholar] [CrossRef]
- Murray, S.; Mercado, E.; Roitblat, H. The neural network classification of false killer whale (Pseudorca crassidens) vocalizations. J. Acoust. Soc. Am. 1998, 104, 3626–3633. [Google Scholar] [CrossRef] [PubMed]
- van der Schaar, M.; Delory, E.; Català, A.; André, M. Neural network based sperm whale click classification. J. Mar. Biol. Assoc. 2007, 87, 35–38. [Google Scholar] [CrossRef]
- Schölkopf, B.; Sung, K.K.; Burges, C.; Girosi, F.; Niyogi, P.; Poggio, T.; Vapnik, V. Comparing support vector machines with gaussian kernels to radial basis function classifiers. IEEE T. Signal Proces. 1997, 45, 2758–2765. [Google Scholar] [CrossRef]
- Debnath, R.; Takahashi, H. Learning Capability: Classical RBF Network vs. SVM with Gaussian Kernel. In Proceedings of Developments in Applied Artificial Intelligence: 15th International Conference on Industrial and Engineering. Applications of Artificial Intelligence and Expert Systems, IEA/AIE 2002, Cairns, Australia, June 17-20, 2002; Vol. 2358.
- Schölkopf, B.; Smola, A.; Williamson, R.; Bartlett, P. New support vector algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.; Lin, C.; Schölkopf, B. A Tutorial on ν-Support Vector Machines. 2003. Available online: http://www.csie.ntu.edu.tw/˜cjlin/papers/nusvmtutorial.pdf accessed April 12, 2007.
- Jaquet, N.; Dawson, S.; Douglas, L. Vocal behavior of male sperm whales: Why do they click? J. Acoust. Soc. Am. 2001, 109, 2254–2259. [Google Scholar] [CrossRef] [PubMed]
- Donoho, D.; Duncan, M.; Huo, X.; Levi, O. Wavelab 850. 2007. Available online: ˜wavelab/ accessed September 28, 2007.
- Saito, N.; Coifman, R. Local discriminant bases. In Proceedings of Mathematical Imaging: Wavelet Applications in Signal and Image Processing II, San Diego, CA, USA, July 27-29, 1994; Vol. 2303.
- Delory, E.; Potter, J.; Miller, C.; Chiu, C.-S. Detection of blue whales A and B calls in the northeast Pacific Ocean using a multi-scale discriminant operator. In Proceedings of the 13th Biennial Conference on the Biology of Marine Mammals, b Maui, Hawaii, USA, 1999. published on CD-ROM (arl.nus.edu.sg).
- Strang, G.; Nguyen, T. Wavelets and Filter Banks; Wellesley-Cambridge: Wellesley, MA, USA, 1997. [Google Scholar]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University: Oxford, UK, 1995. [Google Scholar]
- Theodoridis, S.; Koutroumbas, K. Pattern Recognition, 3rd Ed. ed; Academic Press: Maryland Heights, MO, USA, 2006. [Google Scholar]
- Hamerly, G.; Elkan, C. Learning the k in k-means. In Proceedings of the 17th Annual Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, December 2003.
- D’Agostino, R.; Stephens, M. Goodness-Of-Fit Techniques (Statistics, a Series of Textbooks and Monographs); Marcel Dekker: New York, NY, USA, 1986. [Google Scholar]
- Romeu, J. Anderson-Darling: A Goodness of Fit Test for Small Samples Assumptions, Technical Report 3; RAC START, 2003.
- Katsavounidis, I.; Kuo, C.; Zhang, Z. A new initialization technique for generalized lloyd iteration. IEEE Signal Proc. Let. 1994, 1, 144–146. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Gunn, S. Matlab Support Vector Machine Toolbox. 2001. Available online: http://www.isis.ecs.soton.ac.uk/resources/svminfo/ accessed September 27, 2006.
- Halkias, X.; Ellis, D. Estimating the number of marine mammals using recordings from one microphone. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing ICASSP-06, Toulouse, France, May 14-19, 2006.
- Ioup, J.; Ioup, G. Self-organizing maps for sperm whale identification. In Proceedings ot Twenty-Third Gulf of Mexico Information Transfer Meeting; McKay, M., Nides, J., Eds.; U.S. Department of the Interior, Minerals Management Service: New Orleans, LA, USA, 11 January 2005; pp. 121–129. [Google Scholar]
© 2009 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license http://creativecommons.org/licenses/by/3.0/.
Share and Cite
Van der Schaar, M.; Delory, E.; André, M. Classification of Sperm Whale Clicks (Physeter Macrocephalus) with Gaussian-Kernel-Based Networks. Algorithms 2009, 2, 1232-1247. https://doi.org/10.3390/a2031232
Van der Schaar M, Delory E, André M. Classification of Sperm Whale Clicks (Physeter Macrocephalus) with Gaussian-Kernel-Based Networks. Algorithms. 2009; 2(3):1232-1247. https://doi.org/10.3390/a2031232
Chicago/Turabian StyleVan der Schaar, Mike, Eric Delory, and Michel André. 2009. "Classification of Sperm Whale Clicks (Physeter Macrocephalus) with Gaussian-Kernel-Based Networks" Algorithms 2, no. 3: 1232-1247. https://doi.org/10.3390/a2031232