Segment LLL Reduction of Lattice Bases Using Modular Arithmetic

Department of Industrial Engineering and Management Sciences, Northwestern University, Evanston, IL 60208, USA
*
Author to whom correspondence should be addressed.
Algorithms 2010, 3(3), 224-243; https://doi.org/10.3390/a3030224
Submission received: 28 May 2010
/
Accepted: 29 June 2010
/
Published: 12 July 2010
(This article belongs to the Special Issue Algorithms for Applied Mathematics)
Abstract
:The algorithm of Lenstra, Lenstra, and Lovász (LLL) transforms a given integer lattice basis into a reduced basis. Storjohann improved the worst case complexity of LLL algorithms by a factor of using modular arithmetic. Koy and Schnorr developed a segment-LLL basis reduction algorithm that generates lattice basis satisfying a weaker condition than the LLL reduced basis with improvement than the LLL algorithm. In this paper we combine Storjohann’s modular arithmetic approach with the segment-LLL approach to further improve the worst case complexity of the segment-LLL algorithms by a factor of .
1. Introduction
Given row vectors an integer lattice L (for short lattice) is defined as
Several important theoretical and practical problems benefit from studying lattices. These include problems in geometry [1], cryptography [2], and integer programming [3]. An important problem, whose study dates back to 18th century, is the problem of finding i-th successive minimum of a lattice, . This problem involves finding the smallest number (and possibly an associated lattice element) such that there are i linearly independent elements in L of length at most [1, Chapter 8]. The shortest lattice vector problem is a special case of finding the shortest lattice vector only. This is a difficult problem to solve. For example, it is shown by Ajtai [4] that the problem of finding the shortest non-zero lattice vector under norm is NP-hard under randomized reduction [4]. Micciancio [5] showed that an α-approximate version of this problem (under randomized reduction) remains NP-hard for any . The problem of finding the shortest lattice vector under norm is shown in the class NP-complete by van Emde Boas [6].
Knowing that finding the exact shortest lattice basis is difficult in the worst case, the problem of finding approximate successive minima is addressed by many researchers. In this context various notions of reduced bases have been proposed. In particular, notions of LLL-reduced, semi-reduced, Korkine-Zolotarev reduced, Block 2k reduced, semi block 2k reduced, and segment reduced bases are used by Lenstra, Lenstra, and Lovász [7], Schönhage [8], Kannan [9], Schnorr [10], and Koy and Schnorr [11], respectively. We define these and additional concepts below.
1.1. Definitions of Reduced Lattice Bases
Without loss of generality we assume that are linearly independent. Superscript t is used to denote the transpose of a vector or a matrix. The norm is given by . denotes the nearest integer to a real number x (if non-unique then choose the candidate with smallest magnitude), denotes the smallest integer greater than or equal to x, and denotes the largest integer less than or equal to x. is the entry at the i-th row and j-th column of a matrix T. We use I to represent an identity matrix, and to represent its i-th column.
Let be such that the i-th row of B is given by for . For a given lattice basis the Gram-Schmidt algorithm determines the associated orthogonal vectors together with coefficients defined inductively by
This can be rewritten as , where denotes the matrix whose i-th row is , and Γ is a upper triangular matrix with and () is given in (1.1). Let . We denote by . Note that is the Gramian determinant of B. When we are considering k segments of B and , is the segment Gramian determinant, and for simplicity we denote it by , where k is fixed.
- D1.
- A basis is called size-reduced if The notion of a size reduced basis goes back to Hermite [12].
- D2.
- A basis is called (δ,η)-reduced if for , , , . For and it is called 2-reduced because the above inequality becomes . A basis is called δ-LLL reduced if it is size-reduced and δ-reduced. It is simply called LLL reduced if it is size-reduced and 2-reduced. The LLL reduced basis was introduced by Lenstra, Lenstra, and Lovász [7].
- D3.
- A basis is called semi-reduced if it is size-reduced and satisfies weaker conditions for .
- D4.
- A basis is called Korkine-Zolotarev basis if it is size-reduced and if for where is the orthogonal projection of L on the orthogonal complement of .
The concepts of block reduced and segment reduced basis are defined by dividing a basis into k blocks or segments, i.e., , and then specifying appropriate conditions on basis vectors within each block and among blocks.
- D5.
- A basis is called Block KZ reduced basis if it is size-reduced and if the projections of all -blocks on the orthogonal complement of for are Korkine-Zolotarev reduced.
- D6.
- A basis is called k-segment LLL reduced if the following conditions hold.
- C1.
- It is size-reduced.
- C2.
- for , , i.e., vectors within each segment of the basis are δ-reduced, and
- C3.
- Letting , two successive segments of the basis are connected by the following two conditions.
- C3.1.
- for.
- C3.2.
- for.
The case where is of special interest.
1.2. Discussion on Various Reduced Bases
The ratios are used to measure the quality of various reduced bases defined above. We call these approximation ratios. Known bounds on approximation ratios for various reduced bases, known algorithms for generating them, the worst case running time of these algorithms, and the bit-precision used in performing the computations (addition, subtraction, multiplication and division) in these algorithms are summarized in Table 1. The bounds in this table assume , and . Following [7,8] we use , where to measure the complexity of these algorithms. Note that when .
The work of Lenstra, Lenstra, and Lovász [7] is seminal on finding a reduced lattice basis, and its implication on the problem of finding successive minima. Their algorithm for finding an LLL reduced basis is polynomial time. In particular, for in the worst case it requires arithmetic operations using bit numbers. Since the development of the LLL algorithm significant effort has been directed towards developing methods for finding an improved quality basis in polynomial time, and finding a worse quality basis with a better worst case computational complexity. Research has also progressed towards generalizing the LLL algorithm to arbitrary norms [18,19].

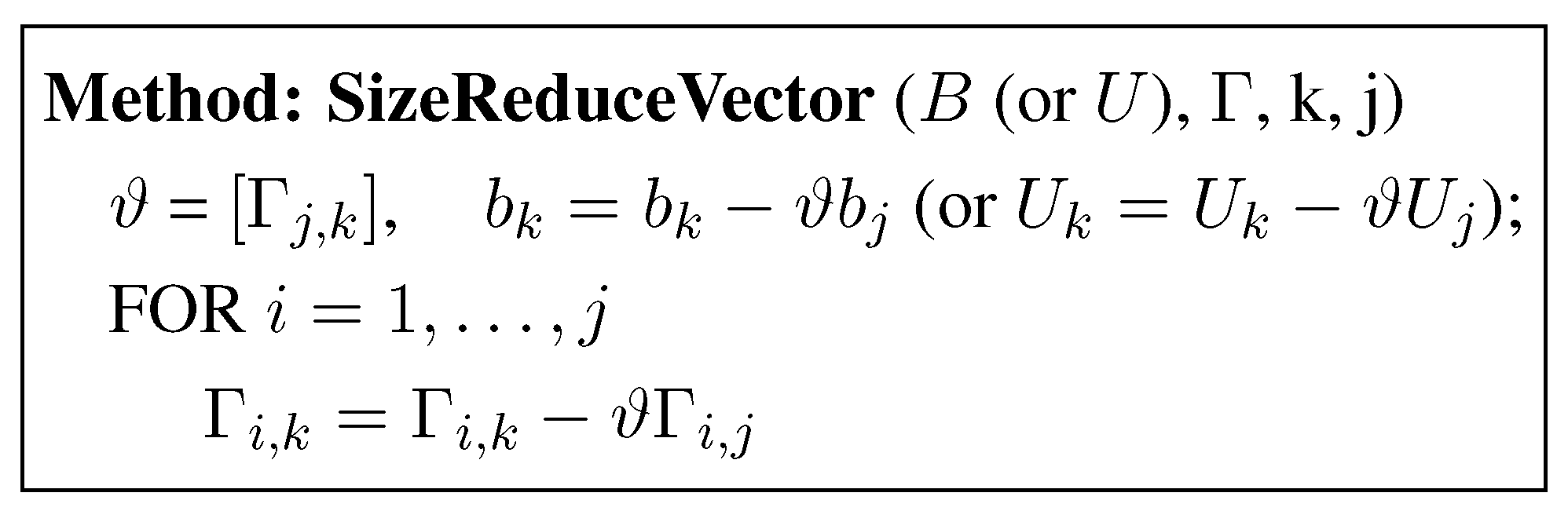{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
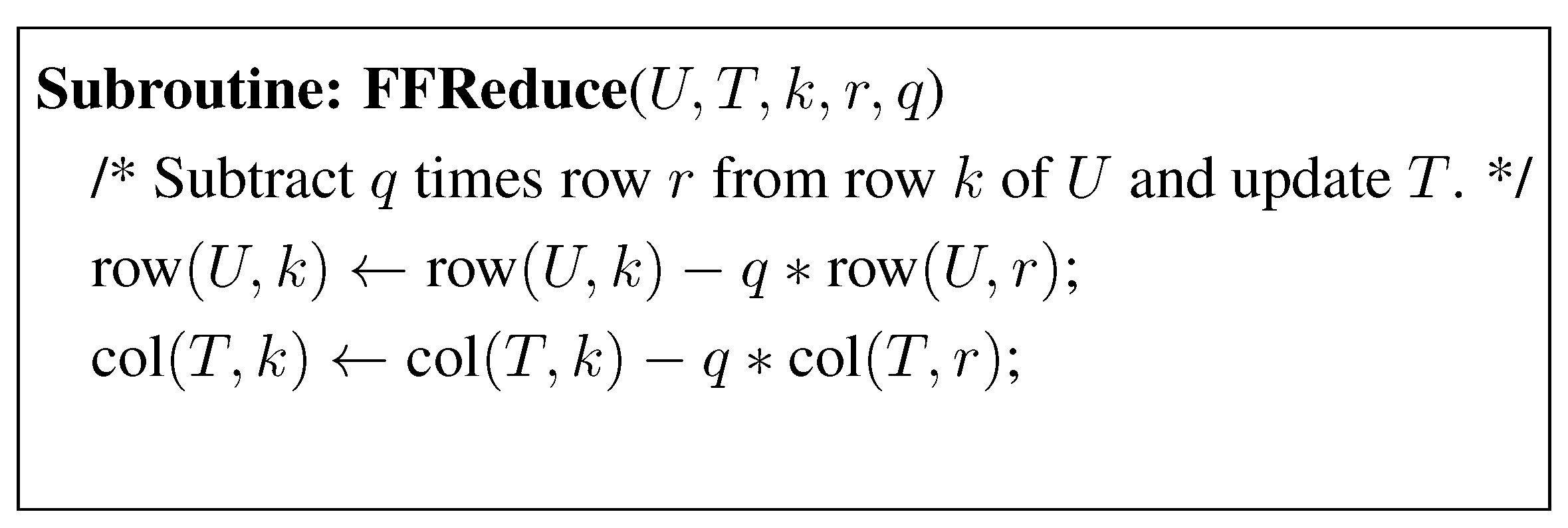{kind=link}
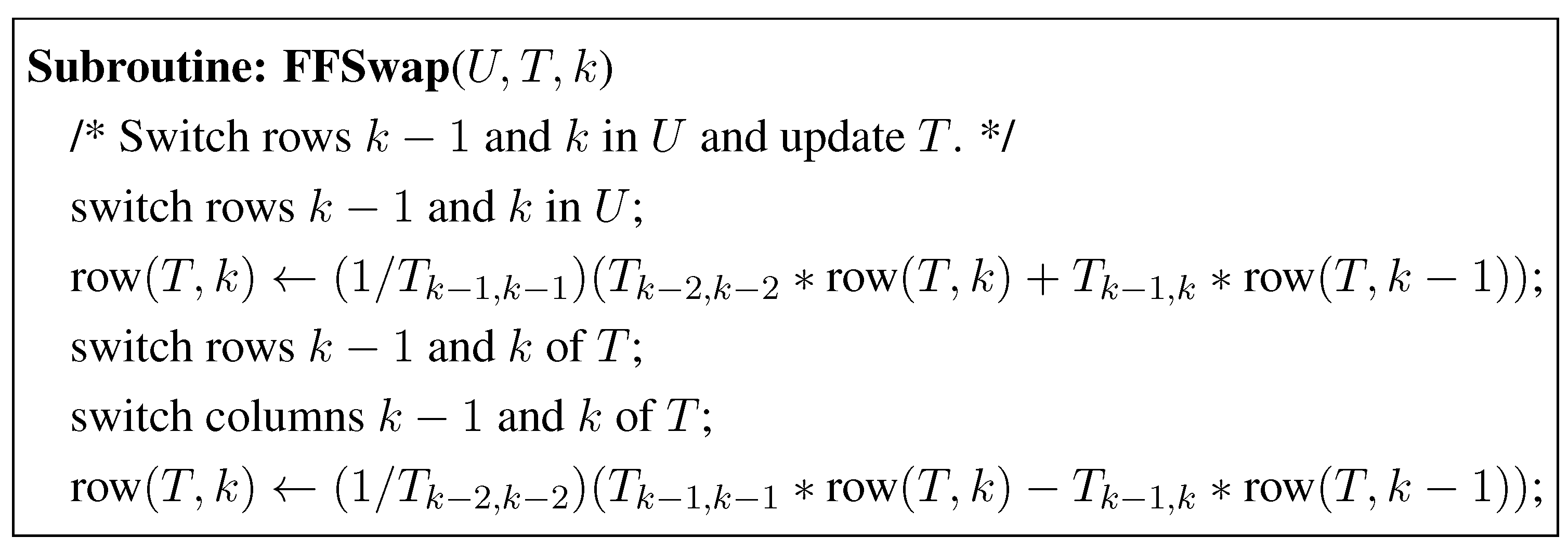{kind=link}
{kind=link}
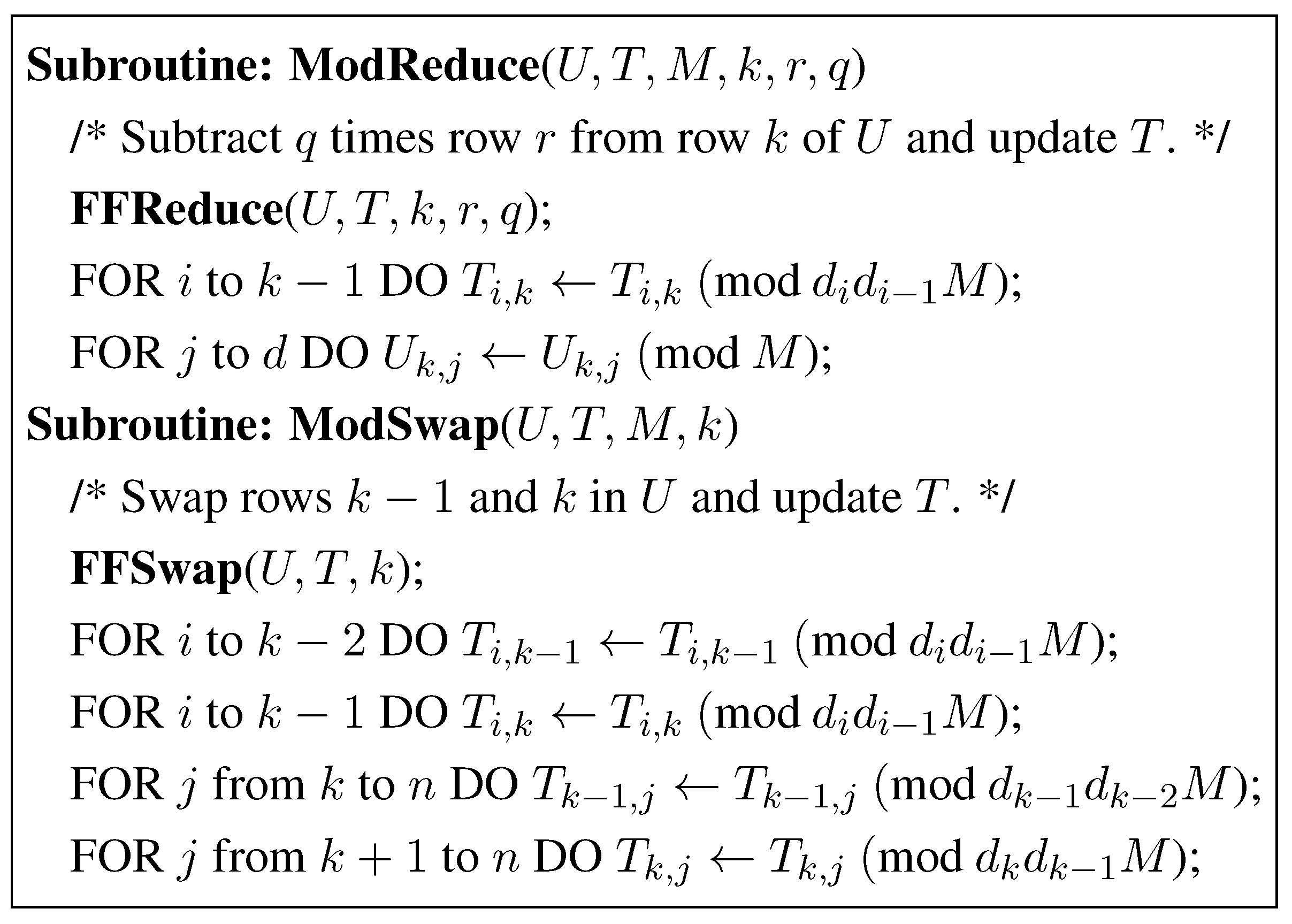{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Lower Bounds on | Upper Bounds on | Arithmetic Steps | Precision |
|---|---|---|---|---|
| LLL reduced [7] | ||||
| LLL reduced [13] | ||||
| Modular LLL [14] | ||||
| Semi-reduced [8] | ||||
| Kannan [9] | ||||
| Block KZ [10,15] 1 | ||||
| Segment LLL [11] | ||||
| Mod-Seg LLL | ||||
| Mod-Seg LLL FMM | ||||
| Nguyen and Stehle [16] | fl | |||
| Schnorr [17] SLL | fl |
1 is the Hermite constant which is defined as .
The algorithm by Schönhage [8] finds a semi-reduced basis. It requires less time over the LLL algorithm. However, the bounds on the approximation ratios for a semi-reduced basis are of a significantly lower quality. A better complexity for finding a semi-reduced basis is also proved by Storjohann [14].
Kannan [9] proposes an algorithm for finding Korkine-Zolotarev (KZ) basis that runs in arithmetic operations on bit integers. Kannan’s algorithm uses the LLL algorithm as a black box. This bound for finding a KZ basis is improved by Schnorr [10] to arithmetic operations using bit integers. The bound for Schnorr’s algorithm in Table 1 is given for performing a KZ reduction of a block of size . Schnorr [10] further introduces the notion of a semi block 2k reduced basis, and uses this concept to show that a -approximate shortest vector is found in arithmetic operation using bit integers. This leads to a hierarchy of algorithms for finding the shortest lattice vector, and a semi block 2k reduced basis. The complexity in Table 1 is a special case where .
Koy and Schnorr [20] propose the concept of a segment reduced basis, and give an algorithm for finding such a basis. Similar to the semi-reduction algorithm of Schönhage [8] the segment reduction algorithm works with a subset of vectors in the lattice basis at a time. However, it worsens the approximation ratios only slightly, and in a controllable fashion. Moreover, it also achieves an reduction in the worst case complexity over the LLL algorithm. Since the writing of the original draft of this paper improvements in computational complexity of the LLL and segment LLL algorithms have also been achieved by showing that the methods can be modified to perform computations using bit floating point numbers. In particular, Nguyen and Stehle [16] rearranged computations in the Cholesky factorization algorithm and used Babai’s nearest point algorithm to update the Cholesky factor coefficients to show that the LLL-algorithm can be correctly implemented with bit floating point precision computations. By making use of results from numerical analysis on Householder transformation using floating point arithmetic and rearrangement of computations in Gram-Schmidt algorithm Schnorr [17] has given an improved segment reduction algorithm that performs bit operations for input bases of length .
1.3. Paper Contribution and Organization
In this paper we show that the modular arithmetic computation approach of [14] can be combined with the segment concept in [20] to develop a modular segment reduction algorithm. The novelty of Storjohann’s is in rearranging the computations in LLL and delaying certain updates, which result in a computational savings by a factor of . The savings of in [20] result from localizing the updates. We show that by combining the strength of the modular arithmetic approach with the Segment LLL algorithm an further saving is possible in the worst case when initial integer basis vectors have magnitude and . We also show that it is possible to further improve this complexity by using fast matrix multiplication.
This paper is organized as follows. In the next section we review the LLL basis reduction algorithm of Lenstra, Lenstra, and Lovász [7]. In addition we explain the basic computational observations of Storjohann in this section. In Section 3 we give Storjohann’s modular LLL reduction algorithm and give the essential results from [14]. Additional notation and concepts needed to describe the modular approach are also given in this section. In Section 4 we give the segment basis reduction algorithm. In Section 5 we describe the modular segment reduction algorithm proposed in this paper, and give its worst case complexity result.
2. Methods for LLL-Reduced Lattice Bases
2.1. The LLL Basis Reduction Algorithm
The LLL algorithm performs two essential computational steps. These are: (i) Size reduction of B by ensuring that , ; (ii) swap of two adjacent rows of B, and subsequent restoration of Γ. We now explain these two steps.
Size Reduction of B
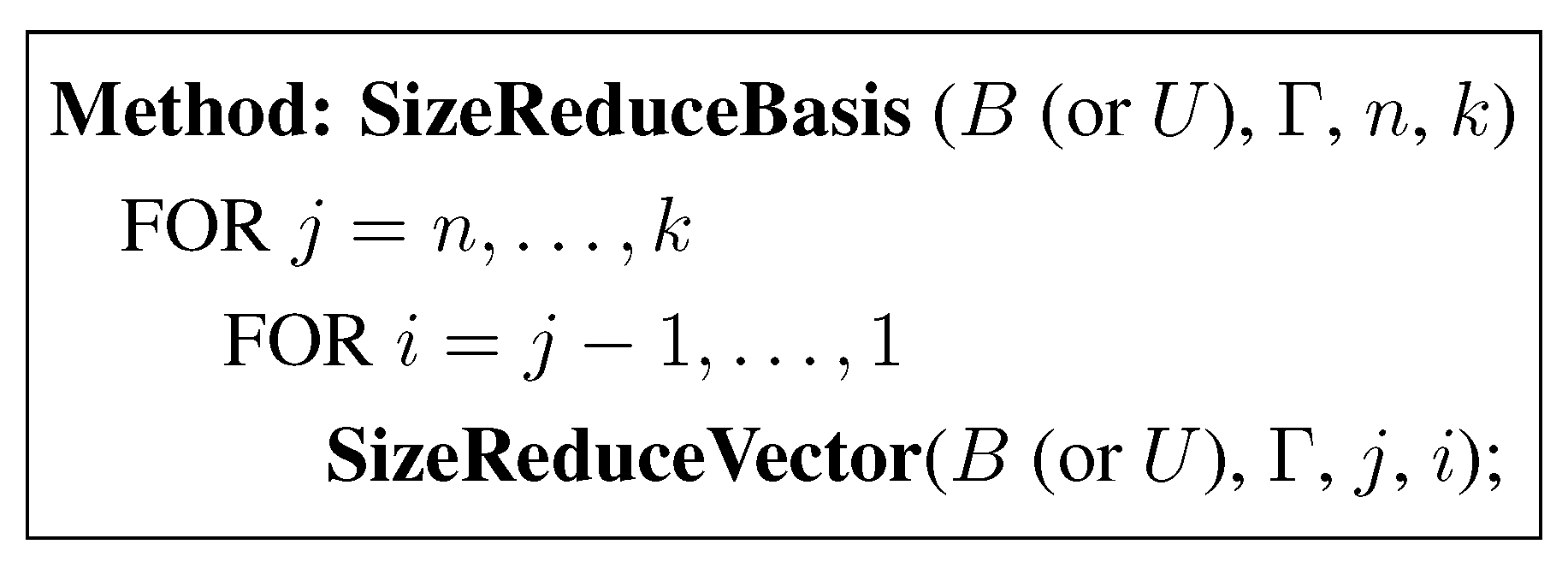
Let []=[ () be a basis obtained from . It can be rewritten as , where is an elementary unimodular matrix. It is easy to see that , where . Note that is unchanged as a result of this operation. The operation results in . This computation is called the size reduction of against , . Note that is obtained from Γ (i.e., Γ is updated) in arithmetic operations. After initial Γ is computed, we can size reduce the entire basis by recursively applying this step in the order . This is summarized in the methods SizeReduceVector and SizeReduceBasis. The method SizeReduceBasis is presented in a more general setting to allow for size reduction of limited number of vectors in B. Also, note that B need not be updated since all the information required to reduce B is contained in Γ. The update of B can be stored in a sequence of elementary unimodular matrices or their product. We represent this matrix by U.
Figure 1.
Size Reduction of a Basis Vector.

Figure 2.
Size Reduction of a Basis.

Swap of Two Adjacent Rows of B
Let [] = [] be a basis obtained from . It can be rewritten as , where is a permutation matrix that permutes the -th row with the k-th row of B. This operation requires updating and of and the coefficients of column/row and k of Γ. This can be done by the following recurrence using , :
We refer to the procedure implementing above recurrence by Swap (B (or U),.
The absolute value of the coefficients in the -th and k-th rows of Γ obtained after the swap can become larger than , a further size reduction step is performed to ensure that these coefficients are less than . Note that while the restoration of Γ resulting from swap requires arithmetic operations, the size reduction step requires operations. Hence, the worst case effort resulting from a swap of two adjacent rows is .
The Lenstra, Lenstra, and Lovász [7] algorithm for finding an LLL-reduced basis is summarized in Figure 3. The number of swaps and the effort needed to restore the size reduced property of B determines the worst case complexity of the LLL algorithm.
Lenstra, Lenstra, and Lovász [7] maintain size reduced property of B for two reasons. The first reason is in checking the condition in the IF statement of the LLL algorithm. This allows us to produce an LLL-reduced basis upon the termination of their algorithm. Second, the size reduced property of B is used to bound the size of intermidate numbers generated in the algorithm, which is necessary to establish polynomial time complexity of the algorithm.
Figure 3.
The LLL Basis Reduction Algorithm.

Figure 4 rearranges the computations in the LLL algorithm of Figure 3 without changing the algorithm. For the moment we are not concerned with the issue of the size of intermediate numbers. In particular, the algorithm in Figure 4 will produce the same basis as the algorithm in Figure 3. In fact, if the computations are performed in infinite precision, then the step indicated in ♠ is not even necessary. If this step is deleted, then the cost of the restoration of Γ after each swap reduces from to arithmetic operations. Storjohann [14] achieves this while maintaining finite precision with computation on integers of appropriate length by using modular arithmetic.
Figure 4.
The LLL Basis Reduction Algorithm with Rearranged Computations.

3. Storjohann’s Improvements
We now describe Storjohann’s [14] modifications. The LLL algorithm is first described as a fraction free algorithm to allow all computations on integer (not rational) numbers. The modular arithmetic modification that allows one to maintain finite precision is given subsequently.
3.1. The LLL-Reduction with Fraction Free Computations
For the matrix we have an integral lower triangular matrix F and an integral upper triangular matrix T such that (See Geddes, Czapor, and Labahn [21]). F and T are called the fraction free factors of . Fraction free factors of a matrix are computed in arithmetic operations using standard matrix multiplication. It is known that
where . Recall that is positive definite since the row vectors of B are linearly independent. Hence T and F are unique. Also, , , while taking , and are integers because are in . Note also that .
Storjohann [14] gave a fast matrix multiplication algorithm for computing F and T. It requires bit operations on integers of bit length , where and ϵ is a positive constant when the fast matrix multiplication algorithm of Coppersmith and Winograd [22] is used. and when the standard matrix multiplication is used.
In Figure 5 we give Storjohann’s rearrangement of the computations of Figure 4 using fraction free computation. The ModifiedLLL algorithm performs two types of unimodular operations. (i) FFReduce: subtracting a multiple of a row of B from another row of B, and (ii) FFSwap: swapping a row of B with an adjacent row of B. The ModifiedLLL algorithm works by recording the unimodular row operations on B in a unimodular matrix U initially set to be an identity matrix, and updating the entries of T. There is no need to update B or in the algorithm, except in a post processing step. It is sufficient to update matrices U and T during the algorithm’s iterations. The fraction free updates of U and T corresponding to these unimodular operations are given in Figure 6 and Figure 7, respectively. Note that one execution of FFReduce or FFSwap is performed in arithmetic operations.
Figure 5.
Modified LLL Basis Reduction Algorithm.

Figure 6.
Fraction Free Subtract Subroutine.

Figure 7.
Fraction Free Swap Subroutine.

The LLL and ModifiedLLL algorithms use to measure progress. The FFSwap step of the algorithm reduces Δ by a factor δ [7]. This is because when and are swapped, remains constant, and the new value of is reduced at least by a factor δ. As a consequence is reduced by a factor δ, while all other do not change. The value of Δ is unchanged in the FFReduce step of the algorithm because does not change after this step. Since , Case 1 in the ModifiedLLL algorithm occurs only times. Hence this part of the algorithm is executed in arithmetic operations. Case 2 of the algorithm can also occur at most times, each requiring arithmetic operations. Hence, this part of the algorithm is executed in arithmetic operations. Finally a δ-LLL reduced basis is generated by , which is performed in operations under standard matrix multiplication, and in using the algorithm of Coppersmith and Winograd [14,22]. Lenstra, Lenstra, and Lovász [7] showed that the bit length of the numbers on which the arithmetic operations are performed is bounded by . This gives the complexity result in Table 1, where for simplicity.
The following lemma gives bounds on the size of intermediate lattice bases generated during the LLL and ModifiedLLL algorithms. This property is used when using computations with modular arithmetic.
Lemma 1
[7]. Let B be an input basis to the LLL and ModifiedLLL algorithms. The quantities and are non-increasing in the LLL and ModifiedLLL algorithms. Furthermore, upon termination
Proof:
Recall that size reduction/subtract does not change , consequently for all i, is unchanged in this step. Swapping and decreases by a factor of δ and the updated is bounded by old . Hence, the non-increasing property is established. We have , since in the beginning, and throughout the LLL and ModifiedLLL algorithms. The bounds obviously hold at termination. ☐
3.2. The Modified LLL Algorithm with Modular Arithmetic
Storjohann [14] uses modular arithmetic to keep the intermediate numbers bounded during the algorithm’s iterations. Given an integer a, and an integer , we write to mean the unique integer r congruent to a modulo M in the symmetric range, that is, with . Similarly, stands for the same operation for all entries of matrix U.
The modular basis reduction algorithm of Storjohann [14] is given in Figure 8 and Figure 9. Its worst case computational complexity is given in Table 1. The notable difference of this algorithm from the ModifiedLLL algorithm is in the modular arithmetic operation that is performed in the methods ModReduce and ModSwap.
Let so that by Lemma 1 the entries in the reduced basis matrix upon the termination of the ModifiedLLL algorithm are bounded in magnitude by . The modular approach hinges on the observation that , where . Note that in the “infinite" precision version of the algorithm, where the ♠ step is not performed, one allows U to grow. However, in the modular arithmetic version the elements of U and T remain bounded.
Figure 8.
The Modular LLL Basis Reduction Algorithm.

Figure 9.
ModSubtract and ModSwap subroutines.

We have shown above how to bound the entries of U by during the course of the algorithm. Lemma 1 has already bounded the diagonal entries of T throughout the algorithm. The following lemma gives a way to keep the off diagonal entries of T bounded.
Lemma 2
[14]. Let T be the matrix of (3.5), M a positive integer, and i and j indices with . There exists a unit upper triangular integral matrix V such that is identical to T except in the (i,j)-th entry which is reduced modulo . Furthermore, V can be chosen so that is the identity matrix.
Storjohann [14] constructed the matrix V in Lemma 2 as follows. Let be the strictly upper triangular matrix with column j equal to column i of and all other entries zero, let , and take . Note that is also a basis for L. Since the matrix is not calculated; the corresponding operation should be recorded in U. However, U remains unchanged, because and . The entries of matrix T corresponding to this row transformation on B are updated by multiplying T with V, which has the desired effect of reducing modulo . This modular reduction is performed in the ModReduce and ModSwap calculation. We remark that because of the above operation the intermediate lattice bases B that correspond to the matrix T may no longer be polynomially bounded in the size of the starting B, however, it is no longer important because an intermediate B is never recorded.
4. The Segment LLL Reduction of Lattice Bases
Recently Koy and Schnorr [20] introduced the concept of a segment LLL reduced basis (See Definition D7), and gave an algorithm for finding such a basis. The segment LLL reduced basis satisfies a slightly weaker condition, however, it is computed by Koy and Schnorr [20] in fewer arithmetic operations. The algorithm of Koy and Schnorr works on two segments of B, i.e., at a time. This algorithm is outlined in Figure 10. The work in the SegmentLLL algorithm comes from the calls to a subroutine Loc-LLL(l) given in Figure 11. Subroutine Loc-LLL(l) performs a local LLL basis reduction on the segment [ and records the operations in a unimodular matrix , as explained below.
Figure 10.
The Segment LLL Basis Reduction Algorithm.

The Local-LLL reduction (Subroutine Loc-LLL(l)) works on and Γ. The matrix Γ in (4.6) is partitioned into segments with each segment has basis vectors.
Figure 11.
The Local LLL Iterations.

When working in Loc-LLL(l) all LLL swaps and size reductions are restricted to the input segment. Only the matrix is updated while performing the segment LLL swaps and size reductions. The unimodular operations updating , and the operations required to update are stored in the matrix . The updates for and are performed only after it is no longer possible to perform an LLL-swap based on the information in . and are updated as follows:
Here and are matrices recorded at the beginning and end of the Local LLL-reduction step in Loc-LLL(l). Since only matrix is updated during the LLL unimodular operations in this segment the corresponding updates of and are performed using arithmetic operations. The total number of swaps in all calls to Loc-LLL(l) is bounded by , hence the total work in the Local LLL-reduction step is bounded by arithmetic operations. The cost of updating and , and performing the Segment Size Reduction step in each execution of Loc-LLL(l) is arithmetic operations.
Let denote the number of times that the condition
holds and l is decreased. The number of times Loc-LLL(l) is called is . Koy and Schnorr [20] showed that . Hence the total work in the Segment Size Reduction step of Loc-LLL(l) is arithmetic operations when . This leads to the computational complexity result in Table 1 when and . We have omitted details on the bounds on the length of the elements in and Γ (see Koy and Schnorr [20] for details).
5. The Modular Segment LLL Reduction with Modular Arithmetic
5.1. Algorithm and Its Complexity
We are now in a position to give our segment LLL reduction algorithm with modular arithmetic. It finds a segment LLL reduced basis with an improvement in the computational complexity when . This algorithm is given in Figure 12. The major difference in the ModSegmentLLL and SegmentLLL algorithms is in performing the ModLocSegmentLLL step presented in Figure 13. In this subroutine we perform updates using modular arithmetic while working with . The subroutines ModReduce and ModSwap require operations in comparison to the worst case operations in the algorithm of Koy and Schnorr described in the previous section.
Figure 12.
The Modular Segment LLL Basis Reduction.

Figure 13.
The Modular Local Segment LLL Basis Reduction.

Figure 14.
Size Reduction of a Segment Using Modular Arithmetic.

We now explain the steps in ModLocSegmentLLL. While working with the matrix , let us partition
similar to the partitioning of Γ in (4.6). We perform two types of unimodular operations on in the ModLocSegmentLLL algorithm. The Preprocess C and Postprocess C steps are performed to ensure that the lattice basis vectors corresponding to C are size reduced before and after performing the Local δ-Reduction step. This allows us to bound the size of matrix Q needed to update E after completing the Local δ-Reduction step.
The calls to ModReduce and ModSwap are as in the case of the ModularLLL algorithm with the important difference that they are now performed on a segment. ModReduce subtracts a multiple of a row (column) from another row (column). This unimodular operation is recorded by updating modulo β. The constant β used in the ModSegmentLLL algorithm is taken to be a multiple of M. A choice of β is specified below in Lemma 4. This inferior value is used in the intermediate computations because during the algorithm we don’t have a bound on the elements of . However, the fact that the initial and terminating are size reduced ensures that a proper bound on β is still possible. The subroutine ModSwap performs all necessary computations to update C and when two rows of are swapped. The elements of C are recorded modulo . As in the case of Storjohann’s modification of the LLL algorithm, there is no need to record the modulo operations in .
The matrix is further updated in the Postprocess C step by incorporating all the unimodular transformations recorded in W while working on the size reduction of the basis vectors corresponding to C. Here the elements of are recorded modulo β. Note that while is recorded modulo β, U is recorded modulo M. Updating A and U is straightforward. In Section 5.2 we show that the computations involving and A can be performed with integers of bit length. To this end we use the results from Storjohann [14] for his analysis of the semi-reduction algorithm.
The total computational effort in Steps 1, 3, 4, and 5 of the ModLocSegmentLLL algorithm is arithmetic operations. Following [20] and [14, Theorem 18], there are at most swaps in all the executions of the ModLocSegmentLLL algorithm, each swap requiring arithmetic operations. Hence, we improve the total computational efforts in Step 2 [Modular Segment Iterations] of the ModSegmentLLL algorithm to arithmetic operations. Since there are a total of calls to the ModLocSegmentLLL algorithm we are led to the following theorem.
Theorem 1
Using standard matrix multiplication, for and , Step 2 of Algorithm ModSegmentLLL performs arithmetic computations. We can perform these computations using integers of bit length .
The proof of the first statement in Theorem 1 is already complete. The second statement on the bit length needed for computations in proved in Section 5.2. We note that Step 1 of the ModSegmentLLL algorithm computes F and T, and Step 3 performs a global size reduction. Step 1 is performed in arithmetic operations on integers of bit length [14]. Step 3 is also performed in arithmetic operations on integers of bit length . Therefore, we have the following corollary.
Corollary 1
For a basis and , the running time of Algorithm ModSegmentLLL is bounded by arithmetic operations using integers of bit length .
The bound in Corollary 1 is better than the bound in Algorithm SegmentLLL when , which is possible in the worst case. Section 5.2 is devoted to showing the correctness of Algorithm ModSegmentLLL and proving Theorem 1.
5.2. Correctness of the ModSegmentLLL Algorithm
The following lemma allows us to compute U modulo M, and T modulo during the ModSegmentLLL algorithm.
Lemma 3
Upon termination, the reduced basis from the SegmentLLL and ModSegmentLLL algorithms has the following upper bound
throughout the algorithm.
Proof:
Follow the proof of Lemma 2, while observing that size reduction or modular reduction of the elements in T leave unchanged. ☐
The following lemma of Schönhage allows to give a proper value of β, which is used to reduce the entries of and C modulo β. We now show that , A, C, and E are correctly updated using integers of bits.
Lemma 4
[8] Let , be size-reduced bases. The unimodular matrix that transforms to , satisfies
where and is the j-th column of .
Lemma 4 allows to take , where while reducing the entries of modulo β. Note that taking β as a multiple of M is important because is used to update U whose elements are computed modulo M.
Updating E
Let R be the diagonal matrix with the i-th diagonal entry for , and H the diagonal matrix with and for , where are the diagonal entries of . Following Storjohann’s development of his algorithm for finding a semi-reduced basis in [14, Equation (29)], we can show that the matrix E is updated by
These computations are performed in a specific order to maintain integrality of operations: (i) backtrack fraction free Gaussian elimination by pre-multiplying E by ; (ii) pre-multiply by the basis modular transformation matrix ; (iii) forwardtrack fraction free Gaussian elimination by pre-multiplying the result from (ii) by .
To establish a bound on the magnitudes of the integers in , we need to bound . Let S be the diagonal matrix with the i-th diagonal entry for so that is unit upper triangular with all off diagonal entries , (Recall that the basis vectors corresponding to are size-reduced). In particular, the entries in are minors of which is bounded by using Hadamard’s inequality. It follows that the entries in are bounded by because . We get
The above inequality shows that the entries of are bounded by bit length. Furthermore, if is computed by multiplying E with matrices in Q from right to left, then all intermediate matrices are fraction free, and the computations are performed on integers of size . This completes the proof for the correctness of the algorithm.
5.3. The Modular Segment LLL using Fast Matrix Multiplication
The complexity of Step 2 of the ModSegmentLLL algorithm is bounded by the following theorem when using fast matrix multiplication.
Theorem 2
If , , then using fast matrix multiplications Step 2 of the ModSegmentLLL algorithm can be performed in operations using integers of bit length .
Proof:
As discussed above, there are at most LLL-exchanges, each requiring arithmetic operations for a local δ-reduction. According to [20, Theorem 3], there are calls of the ModLocSegmentLLL algorithm. Each call requires arithmetic operations for updating matrices A and T. The complexity of Step 2 of the ModSegmentLLL algorithm is bounded by
when . ☐
Storjohann [14] showed that the fraction free Gaussian elimination and Step 3 of the algorithm can be performed in arithmetic operations for with integers of bit length . The bound in Theorem 2 is where . Hence Step 2 of Algorithm ModSegmentLLL dominates the overall effort giving the following corollary.
Corollary 2
For , and the running time of Algorithm ModSegmentLLL is bounded by operations using integers of bit length when using fast matrix multiplication.
6. Concluding Remarks
Schnorr [17, Section 6] remarked that it is possible to further improve the running time of the iterated subsegment algorithm in [17] using modular arithmetic. This is possible since the iterated subsegment algorithm runs in operations by recursively transporting local transforms from a segment-level to the next higher segment. Note that by comparison the basic segment-LLL algorithm analyzed in this paper requires operations while using standard arithmetic, and operations while using fast matrix multiplications. In all cases the modular arithmetic computations are performed on numbers of length . Unfortunately the worst-case bit-length required for the modular arithmetic is large, and floating point arithmetic is more practical. Numerical experience using implementations based on floating point arithmetic were reported in [23] for the LLL algorithm and in [11] for the segment-LLL reduction algorithm. The possibility of combining modular arithmetic with floating point computations remains a topic of future research.
Acknowledgement
The research of both authors was funded by NSF grants DMI-0200151, DMI-0522765, and ONR grant N00014-01-1-0048/P00002 and N00014-09-10518.
References
- Cassels, J.W.S. An Introduction to the Geometry of Numbers; Springer-Verlag: Berlin, Germany, 1971. [Google Scholar]
- Dwork, C. Lattices and their application to cryptography. Availible online: http://www.dim.uchile.cl/m̃kiwi/topicos/00/dwork-lattice-lectures.ps (accessed on 15 June 2010).
- Lenstra, H.W. Integer programming with a fixed number of variables. Math. Operat. Res. 1983, 8, 538–548. [Google Scholar] [CrossRef]
- Ajtai, M. The shortest vector problem in L2 is NP-hard for randomized reductions. In Proceedings of the 30th ACM Symposium on Theory of Computing, Dallas, TX, USA, May 1998; pp. 10–19.
- Micciancio, D. The shortest vector in a lattice is hard to approximate to within some constant. SIAM J. Comput. 2001, 30, 2008–2035. [Google Scholar] [CrossRef]
- van Emde Boas, P. Another NP-complete partition problem and the complexity of computing short vectors in lattices; Technical report MI-UvA-81-04; University of Amsterdam: Amsterdam, The Netherlands, 1981. [Google Scholar]
- Lenstra, A.K.; Lenstra, H.W.; Lovász, L. Factoring polynomials with rational coefficients. Math. Ann. 1982, 261, 515–534. [Google Scholar] [CrossRef]
- Schönhage, A. Factorization of univariate integer polynomials by diophantine approximation and improved lattice basis reduction algorithm. In Proceedings of 11th Colloquium Automata, Languages and Programming; Springer-Verlag: Antwerpen, Belgium, 1984; LNCS 172, pp. 436–447. [Google Scholar]
- Kannan, R. Improved algorithms for integer programming and related lattice problems. In Proceedings of the 15th Annual ACM Symposium On Theory of Computing, Boston, MA, USA, May 1983; pp. 193–206.
- Schnorr, C.P. A hierarchy of polynomial time lattice basis reduction algorithms. Theor. Comput. Sci. 1987, 53, 201–224. [Google Scholar] [CrossRef]
- Koy, H.; Schnorr, C.P. Segment LLL-reduction with floating point orthogonalization. LNCS 2001, 2146, 81–96. [Google Scholar]
- Hermite, C. Second letter to Jacobi. Crelle J. 1850, 40, 279–290. [Google Scholar] [CrossRef]
- Schnorr, C.P. A more efficient algorithm for lattice basis reduction. J. Algorithms 1988, 9, 47–62. [Google Scholar] [CrossRef]
- Storjohann, A. Faster Algorithms for Integer Lattice Basis Reduction; Technical Report 249; Swiss Federal Institute of Technology: Zurich, Switzerland, 1996. [Google Scholar]
- Schnorr, C.P. Block Korkin-Zolotarev Bases and Suceessive Minima; Technical Report 92-063; University of California at Berkley: Berkley, CA, USA, 1992. [Google Scholar]
- Nguyen, P.Q.; Stehlé, D. Floating-point LLL revisited. LCNS 2005, 3494, 215–233. [Google Scholar]
- Schnorr, C.P. Fast LLL-type lattice reduction. Inf. Comput. 2006, 204, 1–25. [Google Scholar] [CrossRef]
- Kaib, M.; Ritter, H. Block Reduction for Arbitrary Norms. Availible online: http://www.mi.informatik.uni-frankfurt.de/research/papers.html (accessed on 15 June 2010).
- Lovász, L.; Scarf, H. The generalized basis reduction algorithm. Math. Operat. Res. 1992, 17, 754–764. [Google Scholar] [CrossRef]
- Koy, H.; Schnorr, C.P. Segment LLL-reduction of lattice bases. LNCS 2001, 2146, 67–80. [Google Scholar]
- Geddes, K.O.; Czapor, S.R.; Labahn, G. Algorithms for Computer Algebra; Kluwer: Boston, MA, USA, 1992. [Google Scholar]
- Coppersmith, D.; Winograd, S. Matrix multiplication via arithmetic progressions. J. Symbol. Comput. 1990, 9, 251–280. [Google Scholar] [CrossRef]
- Stehlé, D. Floating-point LLL: Theoretical and practical aspects. In The LLL Algorithm; Springer-verlag: New York, NY, USA, 2009; Chapter 5. [Google Scholar]
- Schönhage, A.; Strassen, V. Schnelle Multiplikation grosser Zahlen. Computing 1971, 7, 281–292. [Google Scholar] [CrossRef]
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an Open Access article distributed under the terms and conditions of the Creative Commons Attribution license http://creativecommons.org/licenses/by/3.0/.
Share and Cite
MDPI and ACS Style
Mehrotra, S.; Li, Z. Segment LLL Reduction of Lattice Bases Using Modular Arithmetic. Algorithms 2010, 3, 224-243. https://doi.org/10.3390/a3030224
AMA Style
Mehrotra S, Li Z. Segment LLL Reduction of Lattice Bases Using Modular Arithmetic. Algorithms. 2010; 3(3):224-243. https://doi.org/10.3390/a3030224
Chicago/Turabian StyleMehrotra, Sanjay, and Zhifeng Li. 2010. "Segment LLL Reduction of Lattice Bases Using Modular Arithmetic" Algorithms 3, no. 3: 224-243. https://doi.org/10.3390/a3030224