1. Introduction
Suppose
is a probability space with
and
P is a known probability distribution. A stochastic linear complementarity problem takes the form:
where
is the underlying sample space, for given probability distribution
P and ∀
,
and
. (1) is denoted as SLCP
or SLCP; see [
1,
2,
3,
4]. If Ω has only one element, (1) is the standard linear complementarity problem (LCP), which has been studied in [
5,
6].
Generally, there is no
x satisfying (1) for all
. In order to obtain a reasonable solution of Problem (1), several types of models have been proposed (one can see [
1,
2,
3,
4,
7,
8,
9,
10,
11,
12,
13,
14]). One of them is the expected value (EV) method (see [
1]). The EV model is to find a vector
, such that:
where
,
, and
is the mathematical expectation. Another is the expected residual minimization (ERM) method (see [
2]). The ERM model is to find a vector
that minimizes the expected residual function:
where
is the
i-th line of random matrix
and
φ satisfies:
In addition to [
1,
2], Luo and Lin first considered a quasi-Monte Carlo method in [
8,
9]; they proved that the ERM method is convergent under mild conditions and studied the properties of the ERM problems. In [
10], Chen, Zhang and Fukushima considered SLCP including the expectation of matrix is positive semi-definite. Under the condition of a new error bound, they use the ERM formulation to solve the SLCP. In [
11], they also studied the ERM formulation, where the involved function is a stochastic
function. In [
12], Zhou and Caccetta put forward a new model of the stochastic linear complementarity problem with only finitely many elements. A feasible semi-smooth Newton method was also given. In [
14], Ma also considered a feasible semi-smooth Gauss–Newton method for solving this new stochastic linear complementarity problem. The stochastic linear complementarity problem with only finitely many elements is to find a vector
, such that:
where
Denote:
where
. Then, (3) is equivalent to:
where (4) is called the linear complementarity problem.
As we all know, in [
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29], many methods were given for solving the nonlinear complementarity problem (NCP) and linear complementarity problem (LCP), such as Kanzow and Petra, who presented a nonsmooth least squares reformulation of (4) in [
15]. They defined
as:
where
,
,
,
for
. This least squares formulation can gave a faster reduction of the complementarity gap
.
On the other hand, the authors of [
16,
18,
19] studied the generalized Fischer–Burmeister function, i.e.,
given by
. Additionally, their research work has shown that this class of functions enjoys some favorable properties as other NCP-functions. The given numerical results for the test problems from mixed complementarity problem library (MCPLIB) have shown that the descent method has better performance when
p decreases in
.
The main motivation of this paper is to use the advantages of [
12,
15,
16,
18,
19] to solve the stochastic linear complementary problem denoted as (3). Firstly, we put forward a new robust reformulation of the complementarity Problem (3). Then, based on the new robust reformulation, we propose a feasible nonsmooth Levenberg–Marquardt-type method to solve (3). The numerical results in
Section 4 showed that the given Method 1 is efficient for the related refinery production problem and the large-scale stochastic linear complementarity problems. We also make a comparison with Method 1 and the scaled trust region method (STRM) in [
20]; preliminary numerical experiments showed that the numerical results of Method 1 are as good as the numerical results of the STRM method. Additionally, it generates less iterations in contrast to the STRM method. Additionally, we also make a comparison with Method 1 and the method in [
13] for solving the related refinery production problem. The preliminary numerical experiments also indicate that Method 1 is quite robust. In other words, Method 1 has the following advantages.
Faster reduction of the complementarity gap .
Flexible NCP functions .
Randomly-chosen initial points and less calculation.
Now is the time to give a new reformulation of (4); the new reformulation of (4) is:
where
,
. Then,
x is a solution of (4) ⟺
. Additionally, solving (4) is also equivalent to finding a solution of the unconstrained optimization problem:
where:
Then, (4) and (5) can be rewritten as:
where:
Additionally, is a slack variable with . Then, we know that has equations with variables.
The remainder of this paper is organized as follows. In
Section 2, we review some background definitions and some useful properties. In
Section 3, we define a merit function
and give a feasible nonsmooth Levenberg–Marquardt-type method. Some discussions about this method are also given. In
Section 4, the numerical results indicate that the given method is efficient for solving stochastic linear complementarity problems, such as the related refinery production problem and the large-scale stochastic linear complementarity problems.
2. Preliminaries
In this section, we give some related definitions and some properties; some of them can be found in [
6,
14,
15,
19,
20,
21,
22,
23]; some of them are given for the first time.
Let
be a locally-Lipschitzian function. The B-subdifferential of
G at
x is:
where
is the differentiable points set and
is the Jacobian of
G at a point
.
The Clarke generalized Jacobian of
G is defined as:
Furthermore,
denotes the C-subdifferential of
G at
x.
If
exists for any
, we call
G is semi-smooth at
x.
Definition 1. ([6]) Matrix is called a:- (a)
-matrix, if each of its principal minors is nonnegative.
- (b)
P-matrix, if each of its principal minors is positive.
Definition 2. ([23]) Let ; the following statements are given:- (a)
We call G monotone, if , for .
- (b)
G is a function, if:for all , and .
Proposition 1. ([6]) is a -
matrix ⟺
, .
Proposition 2. ([21]) Suppose G is a locally-Lipschitzian function and strongly semi-smooth at x. Additionally, it is also directionally differentiable in a neighborhood of x; we get: Definition 3. We call an R-regular solution of the complementarity problem , , if is nonsingular and is a P-matrix, where , , .
Proposition 3. ([15]) The generalized gradient of at a point is defined as:where .
The generalized gradient of at a point is defined as , where:, if .
Definition 4. When , then (4) is called strictly feasible at .
Proposition 4. ([15]) All can be defined as:where , , , , and are given in Proposition 3. Proposition 5. ([15]) Suppose that (4) is R-regular at , then, all elements of have full rank. For any
we know that:
where
I is the
identity matrix. Hence, by Proposition 5, we know that the following proposition is set up.
Proposition 6. Suppose (4) is R-regular at and is a solution of (9). Then, all are nonsingular.
Proposition 7. If (4) is R-regular at a solution , then, there exits , such that for all with where .
Proof of Proposition 7. The proof is similar to the ([
15], Lemma 2.5) and therefore omitted here. ☐
In the following part of this paper, we rewrite Ψ as:
where
is defined as:
Proposition 8. The function defined in (8) satisfies:- (a)
, for any .
- (b)
If and is a matrix, we know that is a solution of (4).
- (c)
If (4) is strictly feasible and is monotone, then are compact for all .
Proof of Proposition 8. The proof is similar to the one of ([
15], Theorem 2.7), so we skip the details here. ☐
3. The Feasible Nonsmooth Levenberg–Marquardt-Type Method and Its Convergence Analysis
In this section, we define a merit function and give a feasible nonsmooth Levenberg–Marquardt-type method. At the same time, we also give some discussions about this method.
Let
; define a merit function of (9) by:
If (3) has a solution, then solving (9) is equivalent to finding a global solution of the following constrained optimization problem:
If
z satisfies:
where
is an orthogonal projection operator onto
, then
z is a stationary point of (10). Obviously, (11) is equivalent to the following problem:
Lemma 1. ([14]) Let be an orthogonal projection operator onto .
The following statements hold:- (a)
for all .
- (b)
For any , for all .
Proposition 9. ([15]) The merit function θ has the following properties.- (a)
is continuously differentiable on with for any .
- (b)
Assume is monotone, if has a strictly feasible solution, then for all we know that the level set:is bounded.
For some monotone stochastic linear complementarity problems, the stationary points of (10) may not be a solution. Such as let
,
,
,
,
,
, and
, (see [
12] ).
By simple computation, we know that the above of problem is a monotone SLCP, obviously; all points
are feasible, but this example has no solution. By:
and (0, 1, 0) is a stationary point of the constraint optimization problem:
However, is not a solution of this example.
Therefore, in the following proposition, we give some conditions for (3).
Proposition 10. For monotone Problem (3), let be a stationary point of (10). If then is a solution of (3).
Proof of Proposition 10. Assuming that
is a stationary point of (10), if
by (12), we know that
is the stationary point of the following problem:
Similar to the proof of Theorem 3 in [
24], it can be shown that
is a solution of
Thus,
is a solution of (3). ☐
Now, we present the feasible nonsmooth Levenberg–Marquardt-type method for solving (3).
Method 1. Choose .
Set .
- Step 1.
If , stop.
- Step 2.
Choose , , and find the solution of the equations: - Step 3.
Ifthen set , and go to Step 1; otherwise, go to Step 4. - Step 4.
Compute , such that:where .
Set , , and go to Step 1.
We now investigate the convergence properties of Method 1. In the following sections, we assume that Method 1 generates an infinite sequence.
Theorem 1. Method 1 is well defined for a monotone SLCP (3). If Method 1 does not stop at a stationary point in finite steps, an infinite sequence is generated with and any accumulation point of the sequence is a stationary point of θ.
Proof of Theorem 1. Method 1 is well defined for the reason of
, and
is always a descent direction for
θ. Now, we consider the following two situations respectively.
- (I)
If the direction
is accepted by an infinite number of times in Step 3 of Method 1, we get:
Since
implies
we have:
From [
17], we know that
is monotonically decreasing. Obviously, this implies that the sequence
is also monotonically decreasing. Since
is accepted by an infinite number of times in view of our assumptions, therefore we get
for
by
This means that any accumulation point of
is the solution of (10); therefore, it is also a stationary point of
.
- (II)
This case is the negation of Case (I); without loss of generality, we assume that the Levenberg–Marquardt direction is never accepted. If the direction
is accepted by an infinite number of times in Step 4 of Method 1, we have:
By (b) in Lemma 1, taking
,
, we get:
that is,
where
with
. By the
Armijo line search properties, we know that any accumulation point of
is a stationary point of
θ, and this completes the proof.
☐
Theorem 2. Let be a R-regular solution; then the whole sequence generated by Method 1 converges to Q-quadratically.
Proof of Theorem 2. By Proposition 6, there is a constant
, such that, for all
where
is a sufficiently small positive constant, the matrices
are nonsingular, and
hold. Furthermore, by Proposition 2, there exists a constant
, such that:
for all
where
is a sufficiently small positive constant. Moreover, in view of the upper semicontinuity of the C-subdifferential, we have:
where
,
,
, and
is a sufficiently small positive constant. Denote
for
. Note that, from (13) and Lemma 1, we have:
Since
F is a locally-Lipschitzian function and
, by premultiplying this equation by
and taking norms both sides, we get:
where
Therefore, similar to the proof of ([
20], Theorem 2.3), we know that the rate of convergence is Q-quadratic. This completes the proof. ☐
4. Numerical Results
In this section, firstly, we make a numerical comparison between Method 1 and the scaled trust region method (STRM) in [
20]. We apply Method 1 and the scaled trust region method to solve Examples 1 and 2. Secondly, we use Method 1 to solve the related refinery production problem, which also has been studied in [
4,
13]. Finally, numerical results about large-scale stochastic linear complementarity problems are also presented. We implement Method 1 in MATLAB and test the method on the given test problems using the reformulation from the previous section. Additionally, all of these problems were done on a PC (Acer) with
i5-3210
M and RAM of 2 GB. Throughout the computational experiments, the parameters in Method 1 are taken as:
The stopping criteria for Method 1 are or .
The parameters in the STRM method (see [
20]) are taken as:
The stopping criteria for the STRM method are or .
In the tables of the numerical results, DIM denotes the dimension of the problem (the dimension of the variable x); denotes the solution of ; In the following part of this section, we give the detailed description of the given test problems.
Example 1. Consider with:where and .
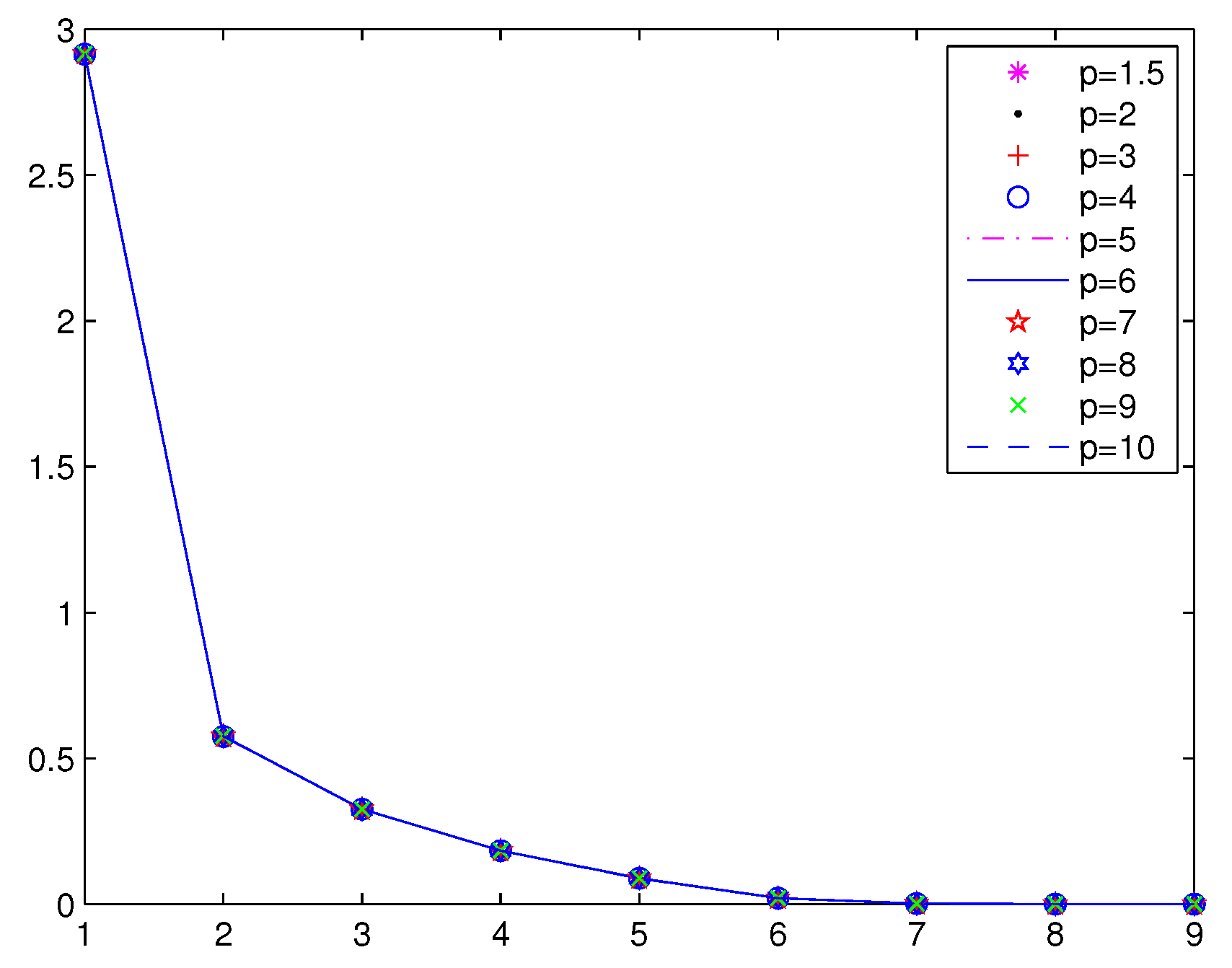
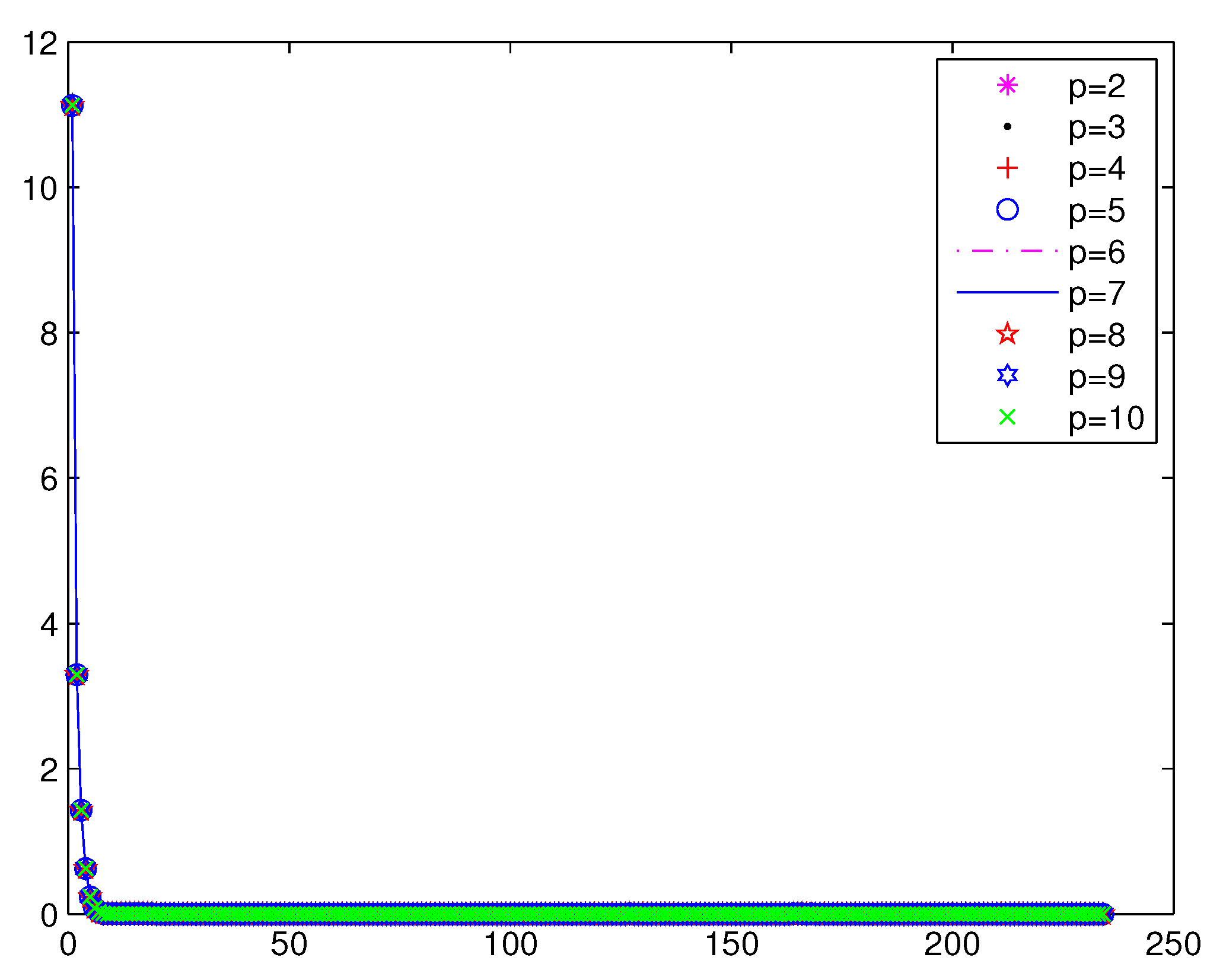
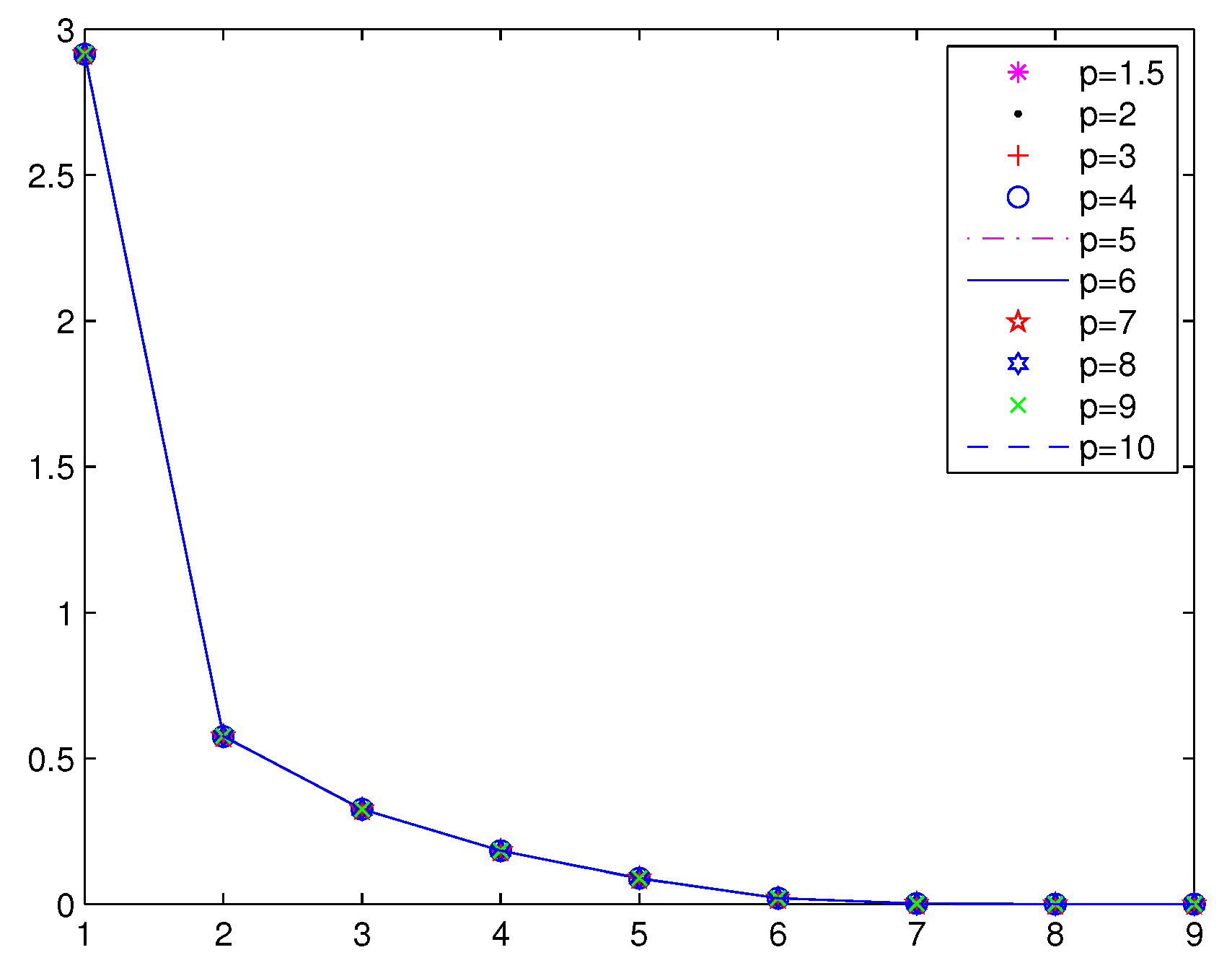
Numerical results of Example 1 are given in
Table 1,
Figure 1 and
Figure 2, respectively.
are chosen randomly in
;
are chosen randomly in
and
.
From
Table 1, we can see that the merit functions associated with
, for example
, are more effective than the Fischer–Burmeister merit function, for which exactly
.
In
Table 2, we give the numerical comparison of Method 1 with fmincon, which is a MATLAB tool box for constrained optimization. We use the sequential quadratic programming (SQP) method in the fmincon tool box to solve Example 1 by
and the same initial points.
From
Table 2, we can see that Method 1 is more effective than fmincon.
Example 2. Consider with:where and .
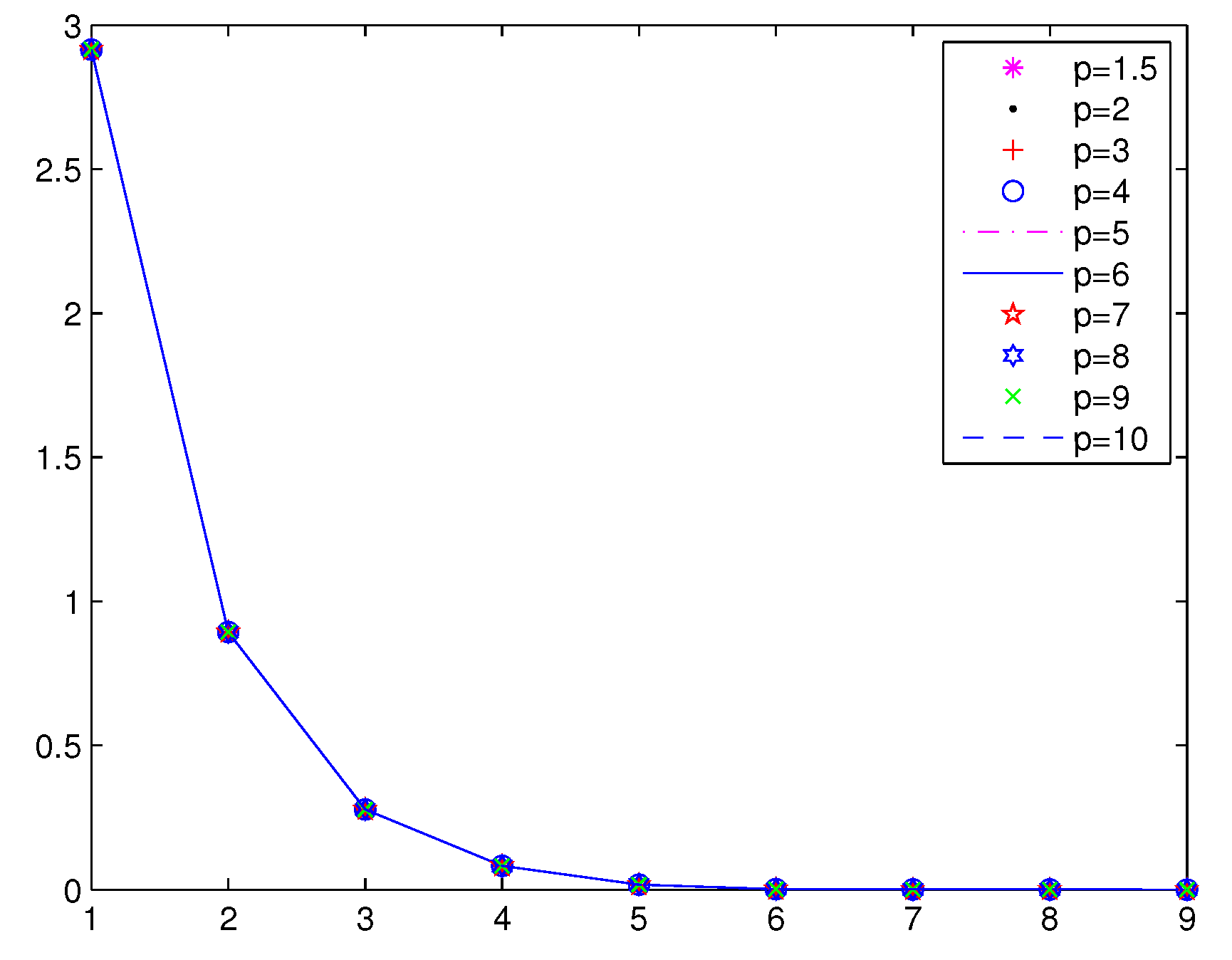
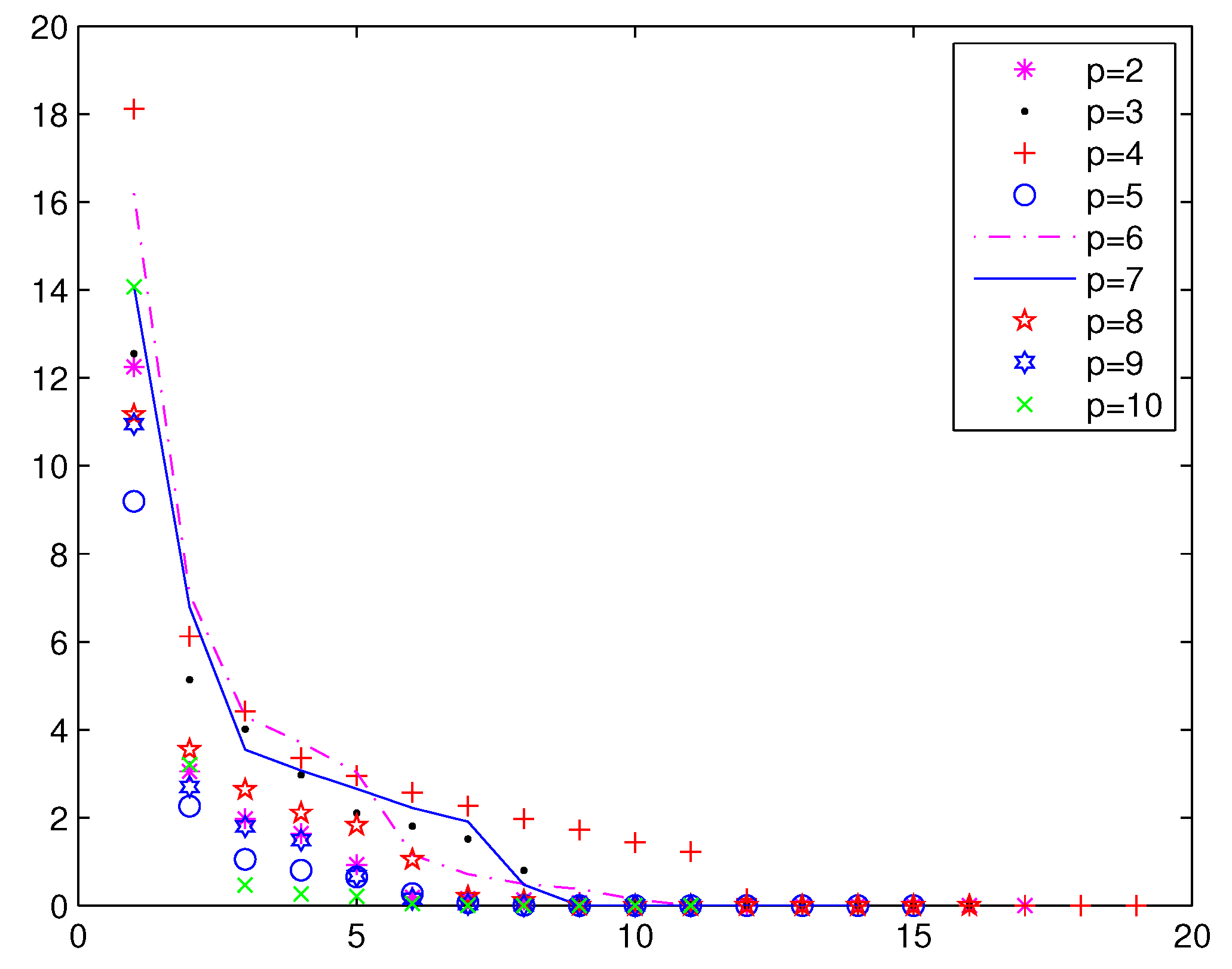
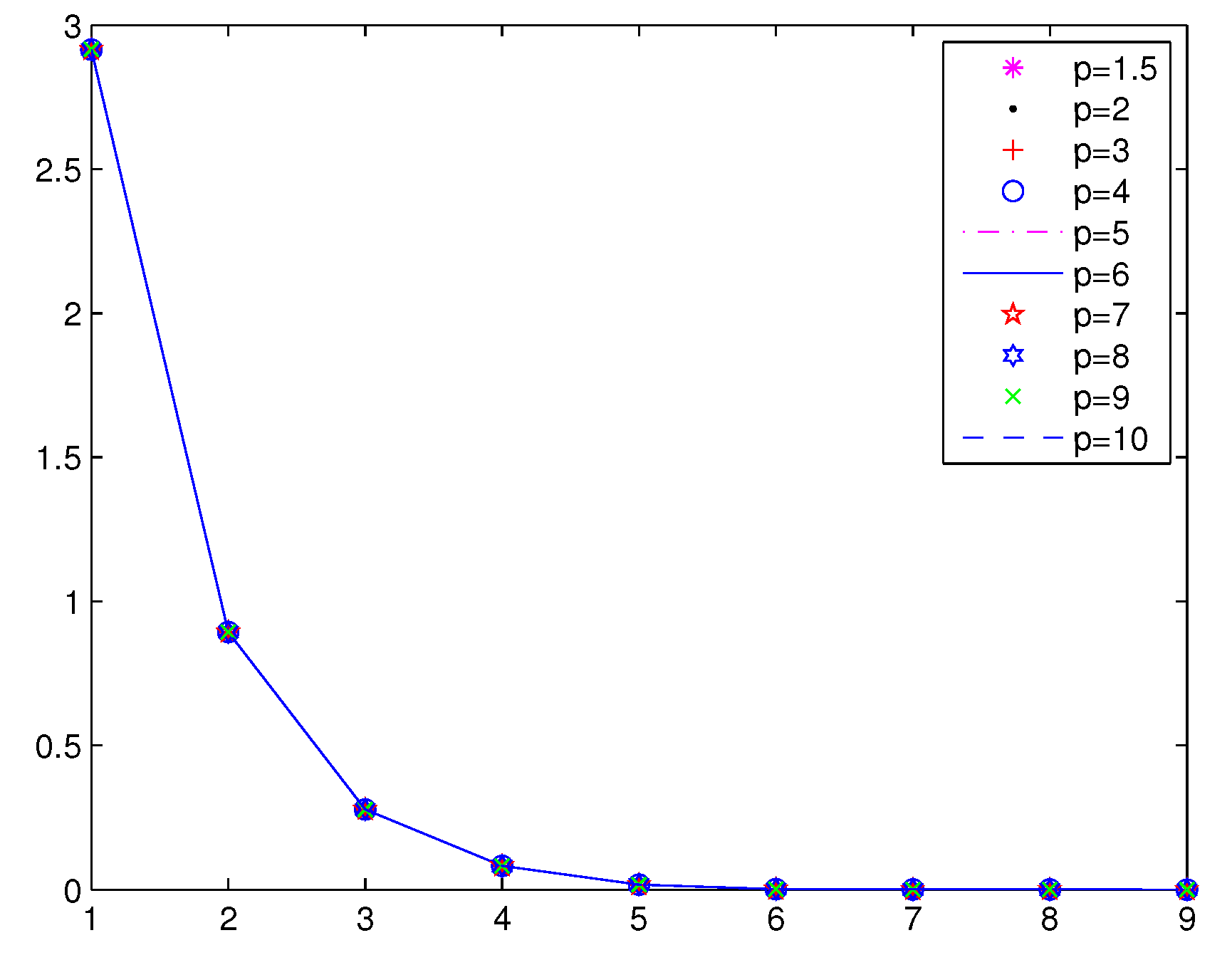
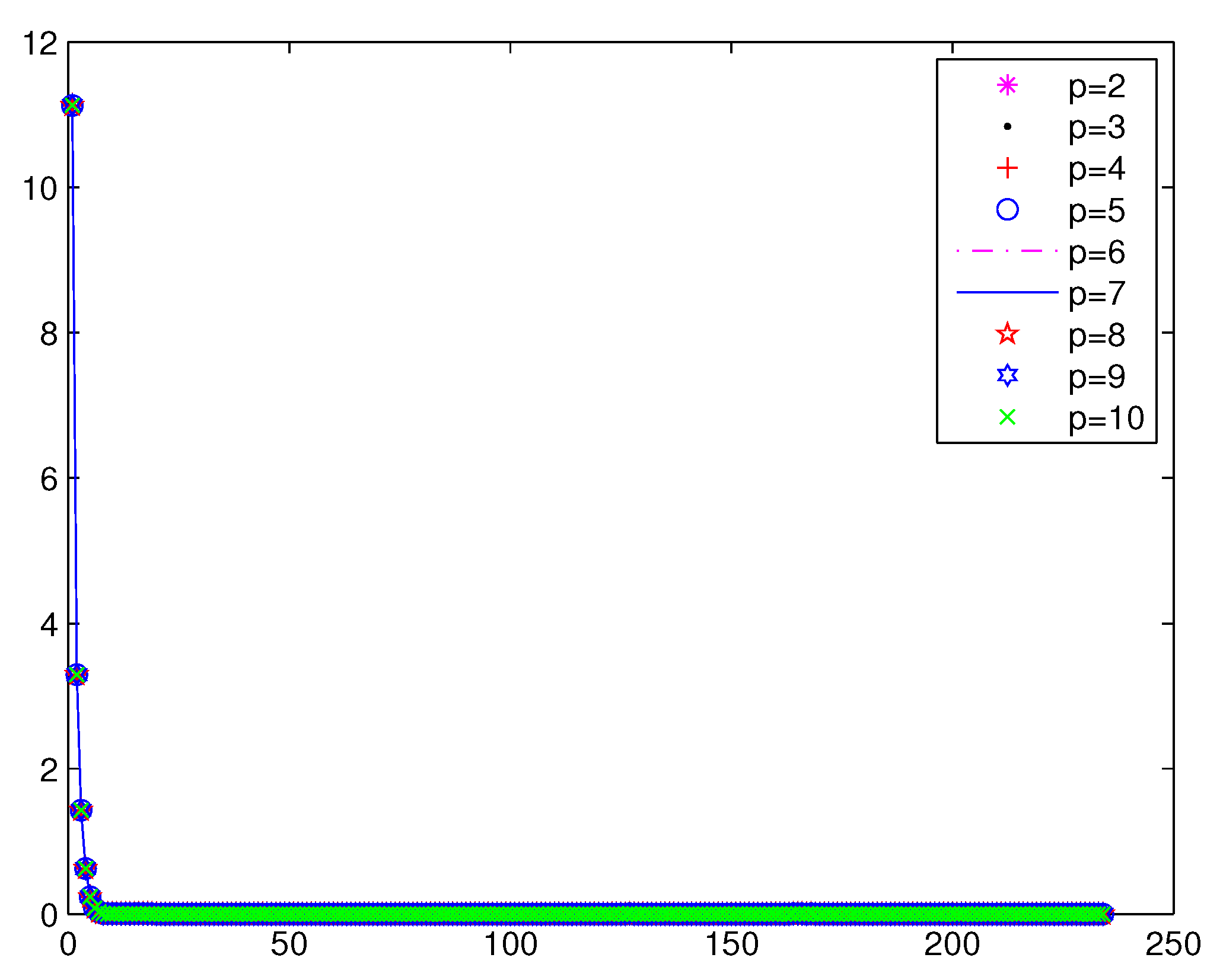
Numerical results are given in
Table 3,
Figure 2 and
Figure 3;
are chosen randomly in
;
are chosen randomly in
; and
.
From
Table 3,
Figure 3 and
Figure 4, we can see that the iterations of Method 1 are less than the STRM method. In Method 1, when
, the function value falls faster. When
p is larger, a greater number of iterations is needed in the STRM method.
In
Table 4, we also give the comparison of Method 1 with fmincon. For the propose of comparison, we fixed
and the same initial points.
From
Table 4, we can see that Method 1 is also more effective than fmincon.
Example 3. This example is a refinery production problem, which is also considered in [2,13]. The problem is defined as:
where
,
,
and
satisfy the following distribution:
Generate samples
respectively, from their 99% confidence intervals (except uniform distributions):
For each divide the into cells , .
For each calculate the average of ; it belongs to .
For each the estimated probability of is where is the number of .
Let
, and set the joint distribution of
,
for
,
,
,
.
In the following part of this section, we use Method 1 to solve the constrained optimization problem:
where
and:
Now, we examine the following two conditions:
The numerical results of Example 3 are given in
Table 5 and
Table 6, where
is the merit function;
;
.
is the initial production cost; and
.
In [
13], in the case of
. Kall and Wallace get the optimal solution
; initial production cost
. Here, by Method 1, we get the optimal solution
and the production cost is
.
Remark 1. The computation cost of our method is greatly reduced. In fact, when we think about the general case of and varying the random distribution of discrete approximation by a 5-, 9-, 7- and 11-point distribution, respectively. This yields a joint discrete distribution of realizations. Then, is a function of 17,335 17,335) dimensions. This is a more complex optimization problem.
In the following part of this subsection, we give a large-scale stochastic linear complementarity problem named the stochastic Murty problem. When
the large-scale stochastic linear complementarity problem reduces to the Murty problem, which is intensively studied in [
25,
26,
27,
28,
29].
Example 4. (Stochastic Murty problem) Consider with:where , .
and .
In
Table 7, we give the comparison of Method 1 with the SQP method in the fmincon tool box, when the dimensions of Example 4 are 10, 100, 200, 300 and 400; where
.
are chosen randomly in
.
are chosen randomly in
,
.
Remark 2. By the numerical results of Example 4, we can see that Method 1 is very suitable to solve large-scale SLCP. Moreover, Method 1 can be used flexible by adjusting the value of p.




{kind=link}
{kind=link}
{kind=link}
{kind=link}