Fuzzy Multi-Criteria Based Trust Management in Heterogeneous Federated Future Internet Testbeds

 ,
,
Abstract
:1. Introduction
2. Related Work
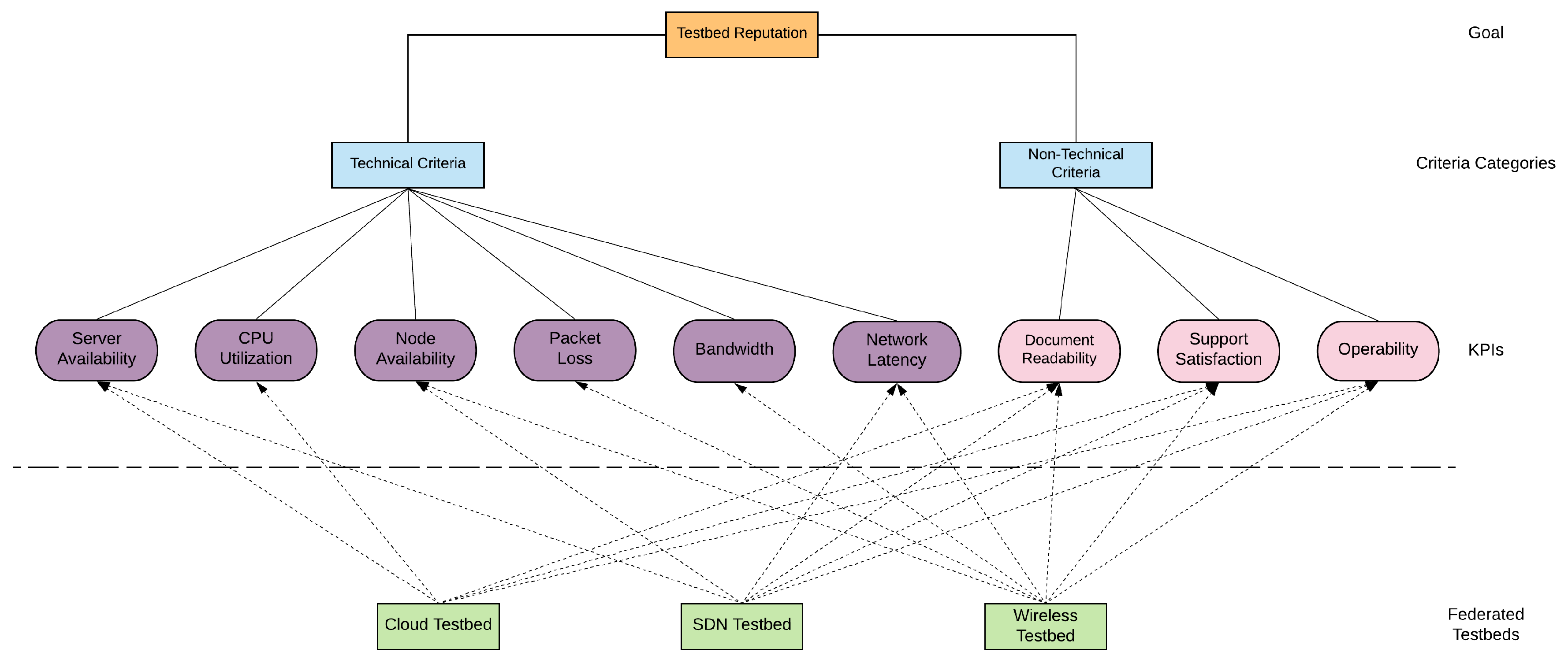
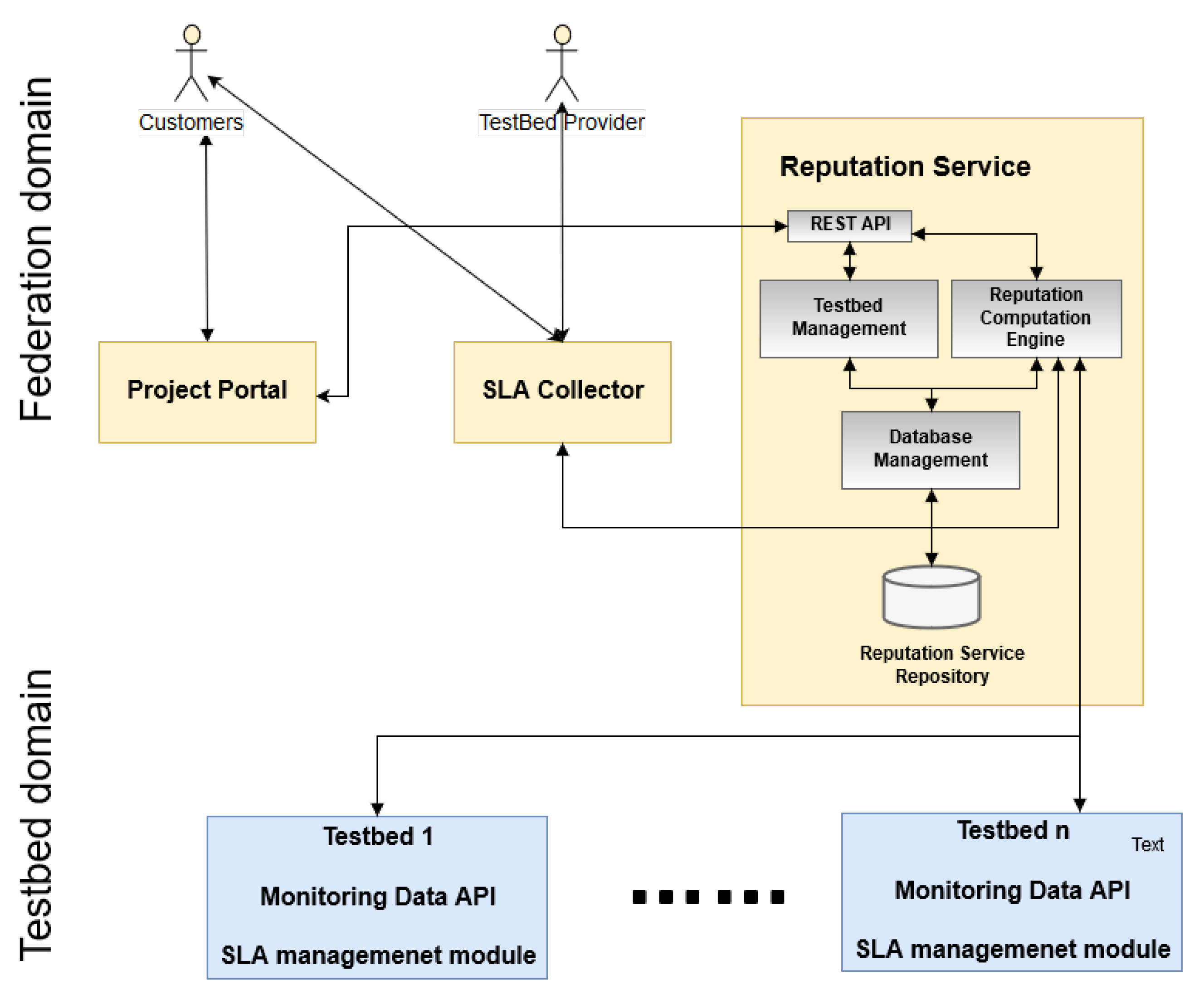
3. Proposed Fuzzy VIKOR Reputation System
3.1. Fuzzy VIKOR
3.2. User’s Credibility
| Algorithm 1 User credibility mechanism. |
|
4. Evaluation
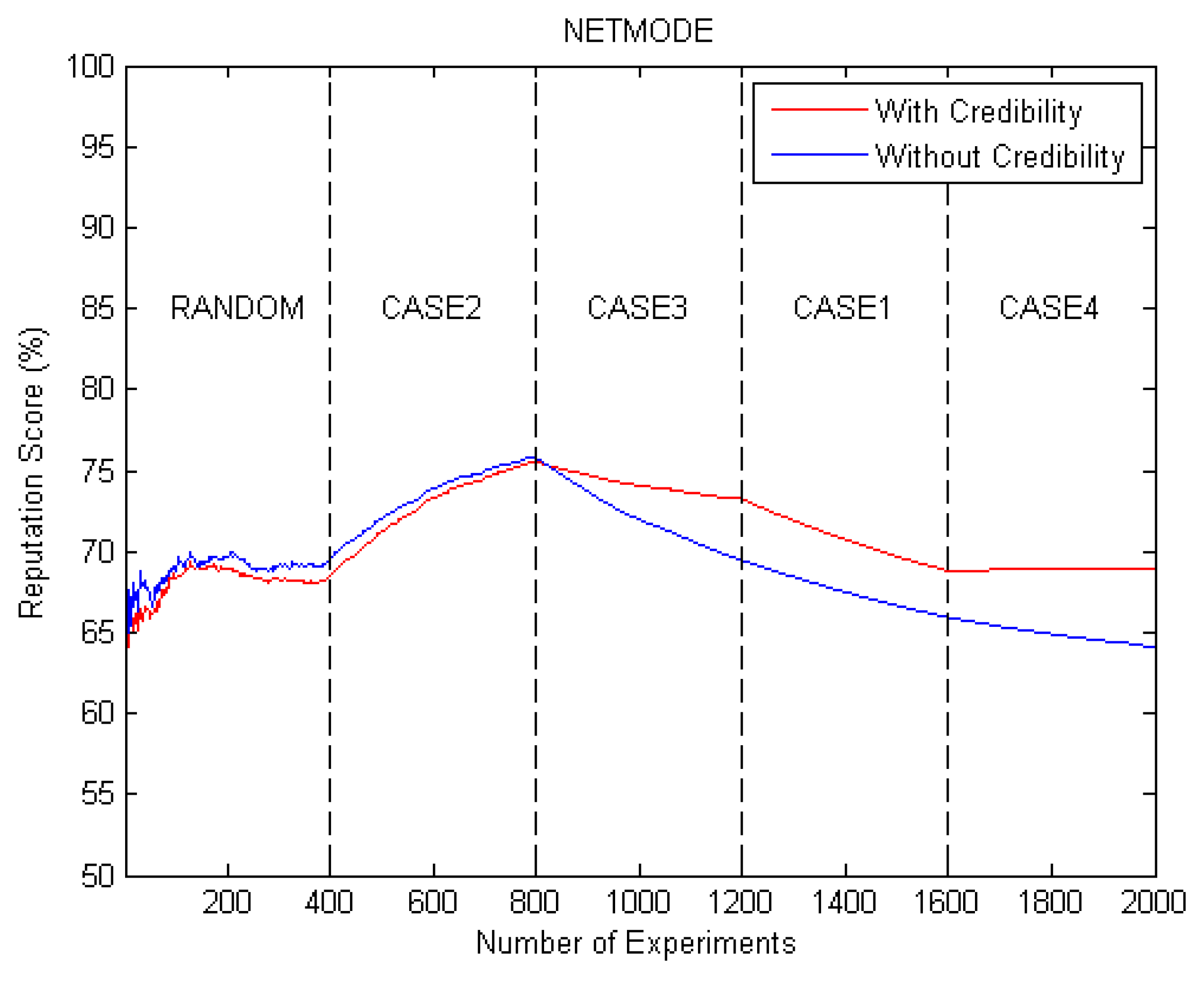
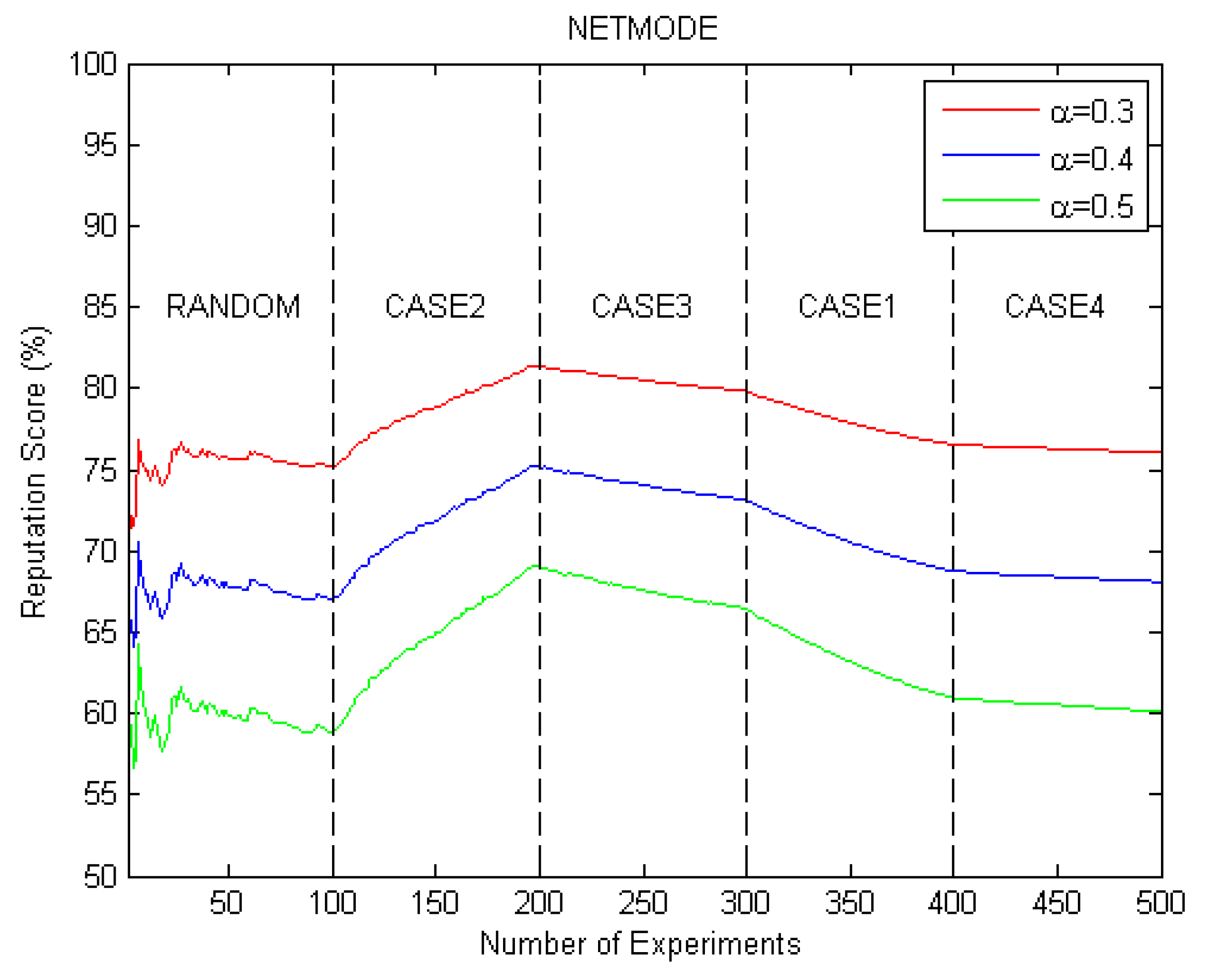
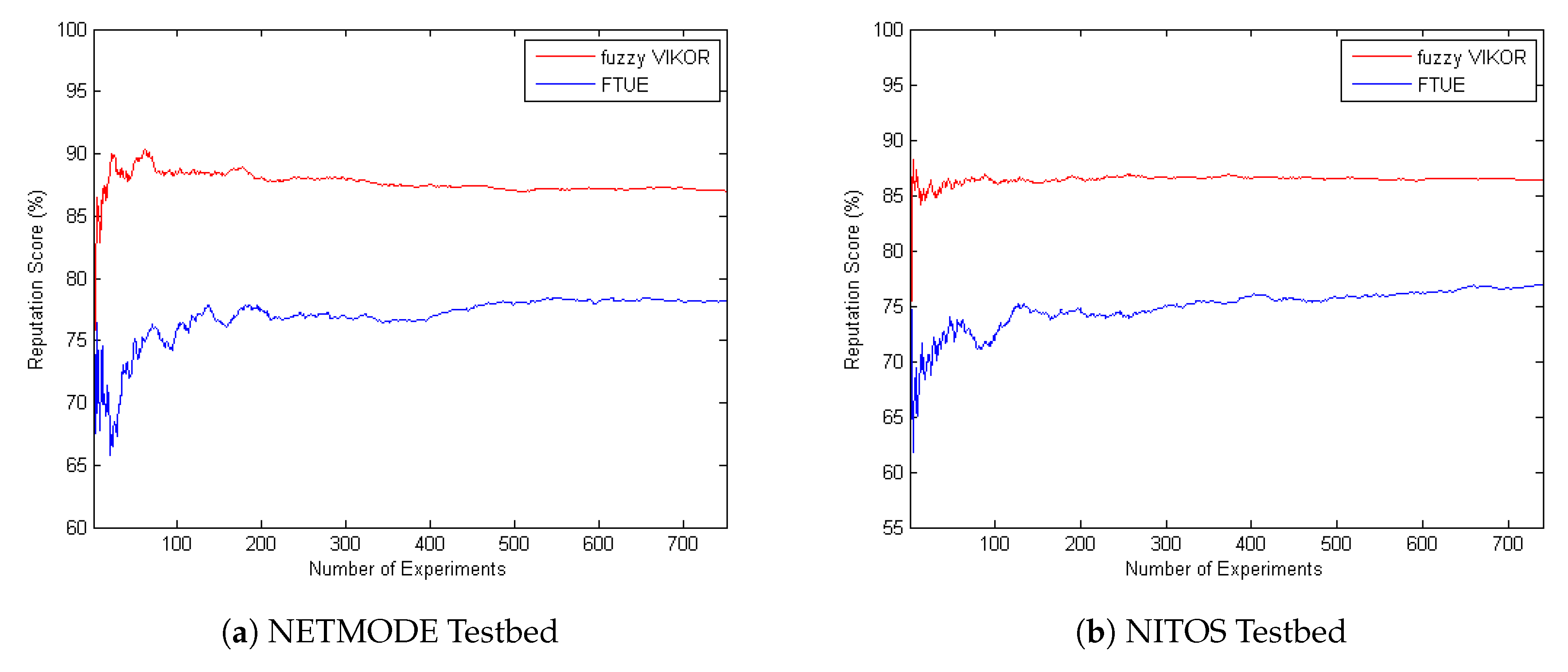
4.1. Fuzzy VIKOR Evaluation
4.2. Comparison with the FTUE Framework
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| QoS | Quality of Service |
| QoE | Quality of Experience |
| SLA | Service Level Agreement |
| SDN | Software-Defined Networks |
| NFV | Network Function Virtualization |
| VNF | Virtual Network Function |
| P2P | Peer-to-Peer |
| KPI | Key Performance Indicator |
| VIKOR | Visekriterijumsko Kompromisno Rangiranje |
| PICM | Pairwise Importance Comparison Matrix |
| CR | Consistency Ratio |
| AHP | Analytical Hierarchical Process |
| FEM | Fuzzy Evaluation Matrix |
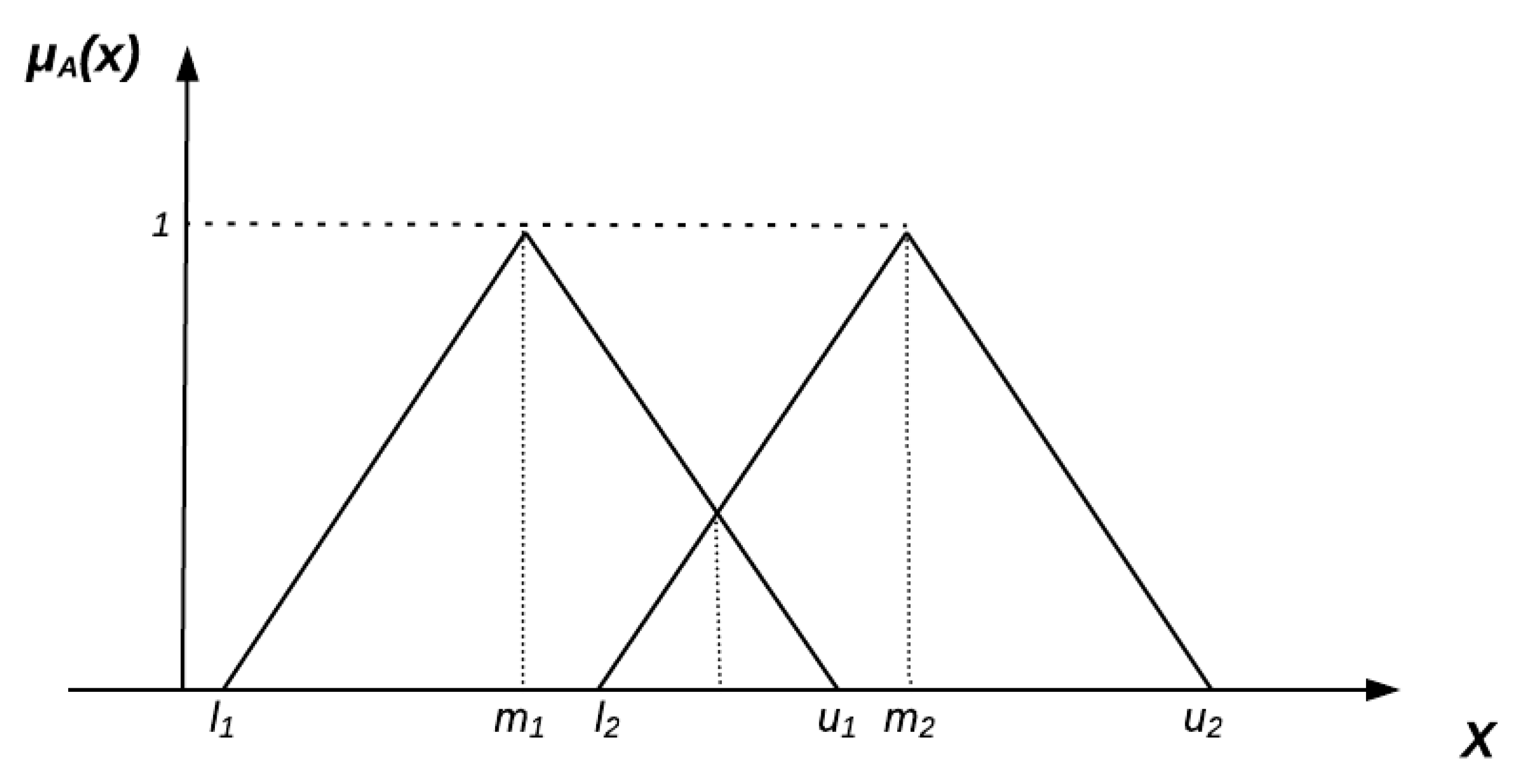
Appendix A. Preliminaries on Fuzzy Sets
- -
- , which means that it is a continuous and normalized fuzzy set.
- -
- For exactly one element , .
- -
- is a convex fuzzy set.

References
- Wahab, O.A.; Bentahar, J.; Otrok, H.; Mourad, A. A survey on trust and reputation models for Web services: Single, composite, and communities. Decis. Support Syst. 2015, 74, 121–134. [Google Scholar] [CrossRef]
- Gambetta, D. Can we trust. In Trust: Making and Breaking Cooperative Relations; Department of Sociology, University of Oxford: Oxford, UK, 2000; pp. 213–237. [Google Scholar]
- FP7 FED4FIRE Project. Federation for Future Internet Research and Experimentation. Available online: https://old.fed4fire.eu/ (accessed on 22 May 2018).
- H2020 FED4FIRE+ Project. Federation for FIRE Plus. Available online: https://www.fed4fire.eu/the-project/ (accessed on 22 May 2018).
- GENI Project. Global Environment for Network Innovations. Available online: http:// www.geni.net (accessed on 22 May 2018).
- Dechouniotis, D.; Leontiou, N.; Dimitropoulos, X.; Kind, A.; Denazis, S. Unveiling the underlying relationships over a network for monitoring purposes. Int. J. Netw. Manag. 2009, 19, 513–526. [Google Scholar] [CrossRef]
- Leontiou, N.; Dechouniotis, D.; Denazis, S.; Papavassiliou, S. A hierarchical control framework of load balancing and resource allocation of cloud computing services. Comput. Electr. Eng. 2018, 67, 235–251. [Google Scholar] [CrossRef]
- Kapoukakis, A.; Kafetzoglou, S.; Androulidakis, G.; Papagianni, C.; Papavassiliou, S. Reputation-Based Trust in federated testbeds utilizing user experience. In Proceedings of the 2014 IEEE 19th International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Athens, Greece, 1–3 December 2014; pp. 56–60. [Google Scholar]
- Ding, W.; Yan, Z.; Deng, R.H. A survey on future Internet security architectures. IEEE Access 2016, 4, 4374–4393. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Zhao, W.; Yang, J. A trust and reputation model based on Bayesian network for web services. In Proceedings of the 2010 IEEE International Conference on Web Services, Miami, FL, USA, 5–10 July 2010; pp. 251–258. [Google Scholar]
- Malik, Z.; Bouguettaya, A. Rateweb: Reputation assessment for trust establishment among web services. VLDB J. 2015, 18, 885–911. [Google Scholar] [CrossRef]
- Yahyaoui, H. A trust-based game theoretical model for Web services collaboration. Knowl. Based Syst. 2012, 27, 162–169. [Google Scholar] [CrossRef]
- Ganeriwal, S.; Balzano, L.K.; Srivastava, M.B. Reputation-based framework for high integrity sensor networks. ACM Trans. Sens. Netw. 2008, 4, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Zadorozhny, V.I.; Oleshchuk, V.A.; Li, F.Y. A Novel Approach to Trust Management in Unattended Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2014, 13, 1409–1423. [Google Scholar] [CrossRef]
- Li, W.; Song, H. ART: An Attack-Resistant Trust Management Scheme for Securing Vehicular Ad Hoc Networks. IEEE Trans. Intell. Trans. Syst. 2016, 17, 960–969. [Google Scholar] [CrossRef]
- Noor, T.H.; Sheng, Q.Z.; Yao, L.; Dustdar, S.; Ngu, A.H.H. CloudArmor: Supporting Reputation-Based Trust Management for Cloud Services. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 367–380. [Google Scholar] [CrossRef]
- Manuel, P. A trust model of cloud computing based on Quality of Service. Ann. Oper. Res. 2015, 233, 281–292. [Google Scholar] [CrossRef]
- Tang, W.; Yan, Z. CloudRec: A Mobile Cloud Service Recommender System Based on Adaptive QoS Management. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Washington, DC, USA, 20–22 August 2015; pp. 9–16. [Google Scholar]
- Yan, Z.; Zhang, P.; Vasilakos, A.V. A security and trust framework for virtualized networks and software-defined networking. Sec. Commun. Netw. 2016, 9, 3059–3069. [Google Scholar] [CrossRef]
- Marconett, D.; Yoo, S.B. FlowBroker: A software-defined network controller architecture for multi-domain brokering and reputation. J. Netw. Syst. Manag. 2015, 23, 328–359. [Google Scholar] [CrossRef]
- Kamvar, S.D.; Schlosser, M.T.; Garcia-Molina, H. The eigentrust algorithm for reputation management in p2p networks. In Proceedings of the ACM International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 640–651. [Google Scholar]
- Garg, A.; Battiti, R. The Reputation, Opinion, Credibility and Quality (ROCQ) Scheme; Technical Report DIT-04-104; University of Trento: Trento, Italy, 2004; Available online: http://eprints.biblio.unitn.it/705/1/TR-04-104.pdf (accessed on 22 May 2018).
- Brinn, M.; Bastin, N.; Bavier, A.C.; Berman, M.; Chase, J.S.; Ricci, R. Trust as the Foundation of Resource Exchange in GENI. ICST Trans. Sec. Saf. 2015, 15, e1. [Google Scholar] [CrossRef]
- Garg, S.K.; Versteeg, S.; Buyya, R. SMICloud: A Framework for Comparing and Ranking Cloud Services. In Proceedings of the 2011 Fourth IEEE International Conference on Utility and Cloud Computing, Victoria, NSW, Australia, 5–8 December 2011; pp. 210–218. [Google Scholar]
- Kaya, T.; Kahraman, C. Multicriteria renewable energy planning using an integrated fuzzy VIKOR & AHP methodology: The case of Istanbul. Energy 2010, 35, 2517–2527. [Google Scholar]
- Alabool, H.M.; Mahmood, A.K. Trust-based service selection in public cloud computing using fuzzy modified VIKOR method. Aust. J. Basic Appl. Sci. 2013, 7, 211–220. [Google Scholar]
- Coyle, G. The analytic hierarchy process (AHP). In Practical Strategy: Structured Tools and Techniques; Pearson Education Ltd.: Harlow, UK, 2004; pp. 1–11. [Google Scholar]
- Chang, D.Y. Applications of the extent analysis method on fuzzy AHP. Eur. J. Oper. Res. 1996, 95, 649–655. [Google Scholar] [CrossRef]
- GSRT HELNET Project. Available online: https://nitlab.inf.uth.gr/NITlab/projects/40-projects/current/599-helix (accessed on 22 May 2018).
- NETMODE Testbed. Available online: http://www.netmode.ntua.gr/main/index.php?option=com_content&view=article&id=103&Itemid=83 (accessed on 22 May 2018).
- NITOS Testbed. Available online: https://nitlab.inf.uth.gr/NITlab/nitos (accessed on 22 May 2018).
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Linguistic Term | Membership Function |
|---|---|
| Absolutely Strong (AS) | (2,5/2,3) |
| Very Strong (VS) | (3/2, 2, 5/2) |
| Fairly Strong (FS) | (1, 3/2, 2) |
| Slightly Strong (SS) | (1, 1, 3/2) |
| Equal (E) | (1, 1, 1) |
| Slightly Weak (SW) | (2/3, 1, 1) |
| Fairly Weak (FW) | (1/2, 2/3, 1) |
| Very Weak (VW) | (2/5, 1/2, 2/3) |
| Absolutely Weak (AW) | (1/3, 2/5, 1/2) |
| Linguistic Term | Membership Function |
|---|---|
| Extremely Poor (EP) | (0.1,1,2) |
| Very Poor (VP) | (1,2,3) |
| Poor (P) | (2,3,4) |
| Medium Poor (MP) | (3,4,5) |
| Fair (F) | (4,5,6) |
| Medium Good (MG) | (5,6,7) |
| Fair Good (FG) | (6,7,8) |
| Good (G) | (7,8,9) |
| Very Good (VG) | (8,9,10) |
| Excellent (E) | (9,10,10) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dechouniotis, D.; Dimolitsas, I.; Papadakis-Vlachopapadopoulos, K.; Papavassiliou, S. Fuzzy Multi-Criteria Based Trust Management in Heterogeneous Federated Future Internet Testbeds. Future Internet 2018, 10, 58. https://doi.org/10.3390/fi10070058
Dechouniotis D, Dimolitsas I, Papadakis-Vlachopapadopoulos K, Papavassiliou S. Fuzzy Multi-Criteria Based Trust Management in Heterogeneous Federated Future Internet Testbeds. Future Internet. 2018; 10(7):58. https://doi.org/10.3390/fi10070058
Chicago/Turabian StyleDechouniotis, Dimitrios, Ioannis Dimolitsas, Konstantinos Papadakis-Vlachopapadopoulos, and Symeon Papavassiliou. 2018. "Fuzzy Multi-Criteria Based Trust Management in Heterogeneous Federated Future Internet Testbeds" Future Internet 10, no. 7: 58. https://doi.org/10.3390/fi10070058