Ontology Alignment—A Survey with Focus on Visually Supported Semi-Automatic Techniques

Abstract
:1. Introduction
- Ontology mapping deals with relating concepts from different ontologies and is typically concerned with the representation and storage of mappings between the concepts.
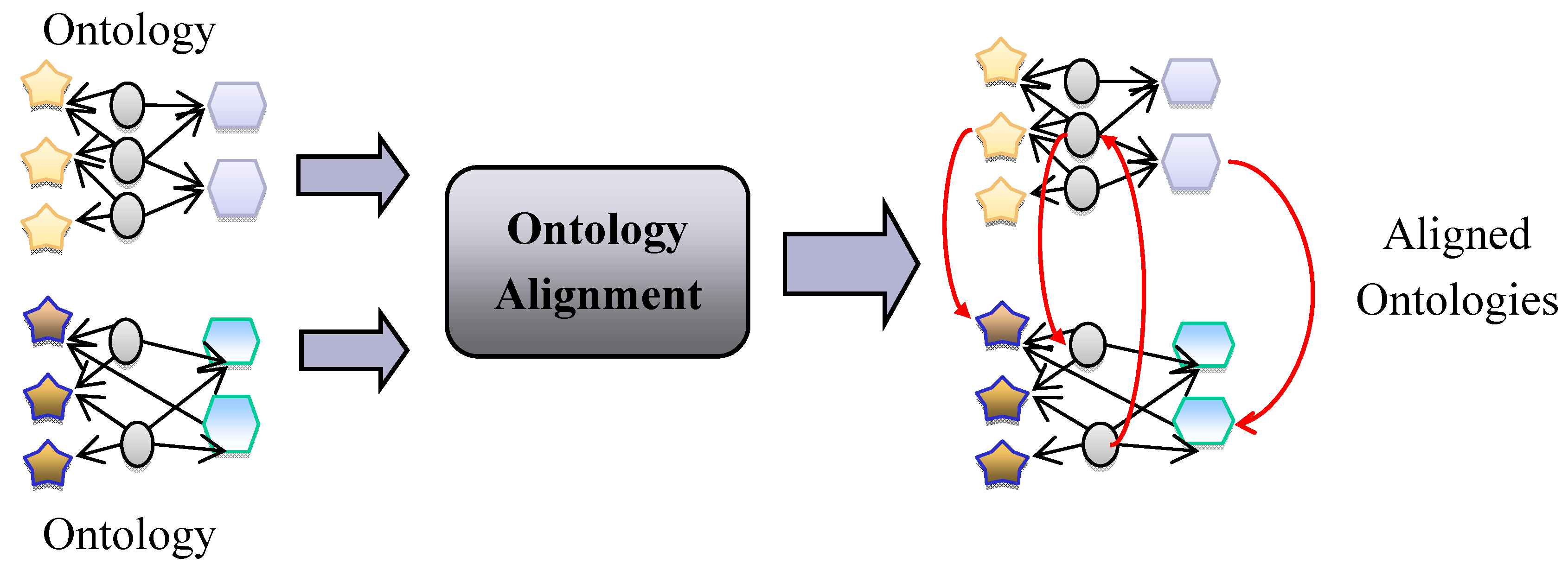
- Ontology alignment is the process of bringing ontologies into mutual agreement by the automatic discovery of mappings between related concepts. The ontologies themselves are unaffected by the alignment process.
- Ontology merging deals with producing a completely new ontology that ideally captures all knowledge from the original ontologies.
2. Ontology Alignment Techniques
2.1. Definitions
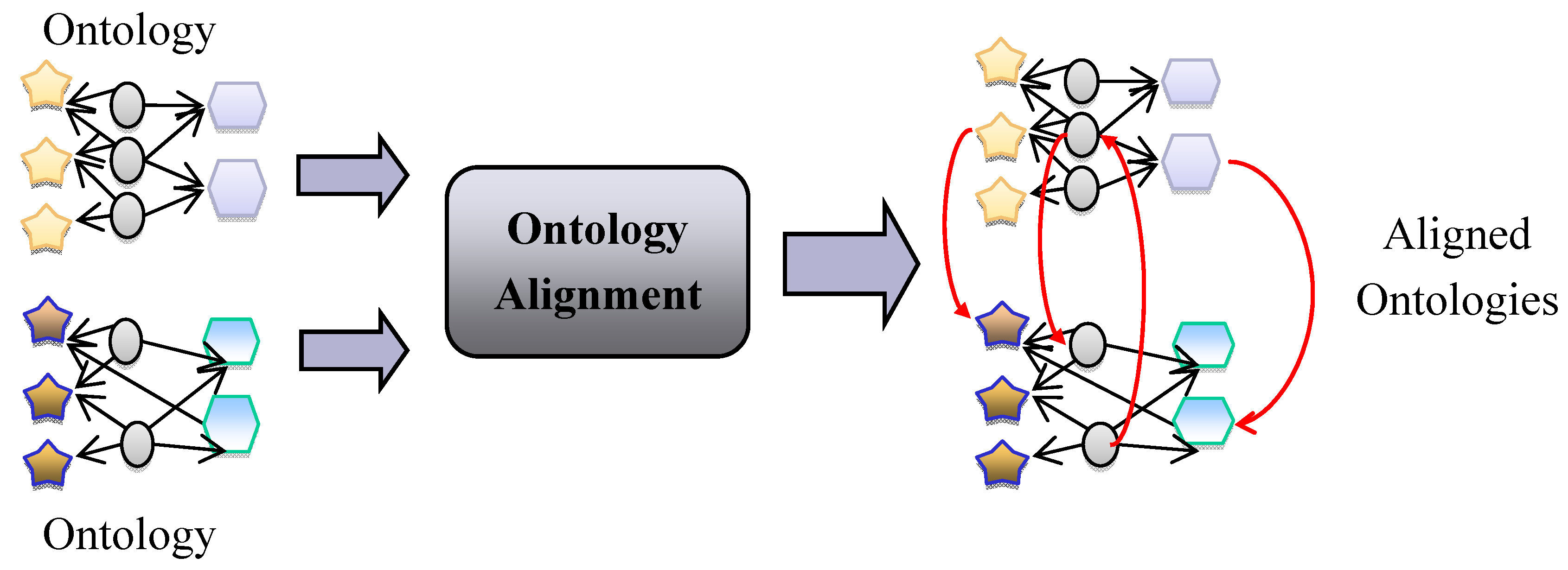
2.2. Alignment Approaches
2.3. Evaluation of Alignment Techniques
3. Requirements for Visual Semi-automatic Alignment Approaches
3.1. Process Driven Requirements
- a)
- Engineering of features describing the elements to be matched;
- b)
- Search for and selection of matching candidates;
- c)
- Similarity computation to determine relatedness between the candidates;
- d)
- Mapping discovery (mining) and storage of results;
- e)
- Presentation and interpretation of the mappings and related information;
- f)
- User feedback.
3.2. User Driven Requirements
- How to present the mappings to the user?
- Do users consider automatically generated mappings useful and trustworthy?
- What degree of automation is feasible (when human intervention becomes necessary)?
- What processes and workflows are users following when creating, inspecting, and managing the mappings?
- What are the requirements for cognitive support for ontology mapping tasks?
- What are appropriate representations and user interactions for specific tasks and processes?
- What is the role of collaboration and how do users wish to coordinate teamwork?
- Which existing tools and interactive interfaces do users prefer and why do they prefer them?
- What are the long and short term usage patterns of the systems?
- Influence of interface usability and quality of automatic alignments on acceptance of interactive systems.
- How can one most adequately utilize machine and human advantages?
- Presentation of mapping candidates together with the estimated confidence and, if possible, with the inclusion of information on why the mapping was generated.
- Navigation and exploration of ontologies providing detailed information on every element of the explored ontology.
- Overview of the alignment results for identification of regions with promising matching candidates.
- Capability to adjust the level of detail for the viewed data, as well as the choosing of the area of interest which shall be explored.
- Filtering depending on features of the mappings, such as terms describing the concepts, mapping confidence, status of the mapping (confirmed, rejected, not inspected), etc.
- Confirming and rejecting automatically generated mappings as well as adding and removing mappings manually. If possible, this should be done such that the system will learn from users’ interventions.
- Collaboration via communication, commenting, tagging, and the voting on and annotating of mappings and ontology elements.
- Ability to partition the mapping task into chunks assignable to team members and to monitor team member progress.
- Saving and loading of users’ changes.
4. Visual Interfaces for Ontology Alignment
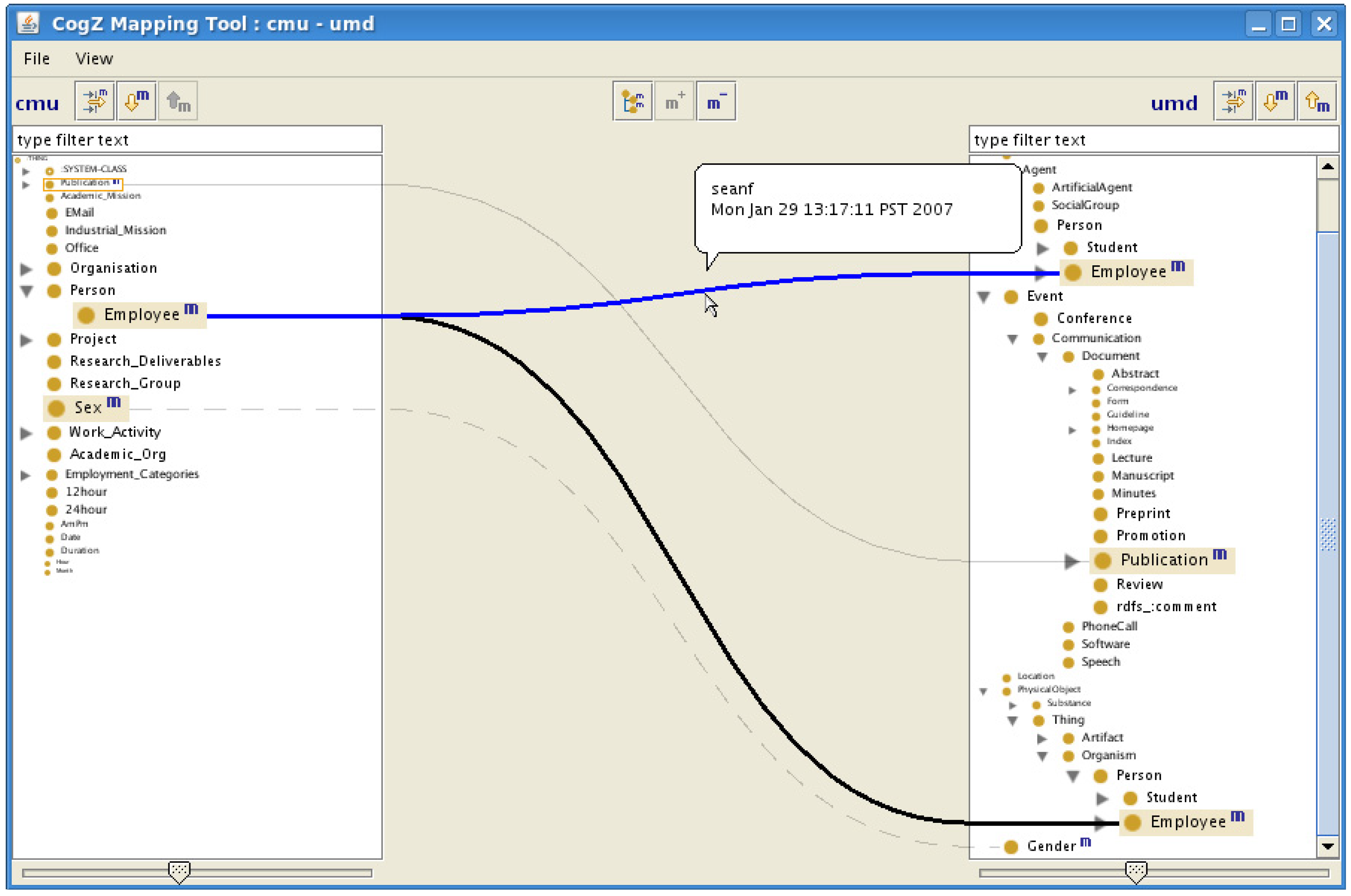
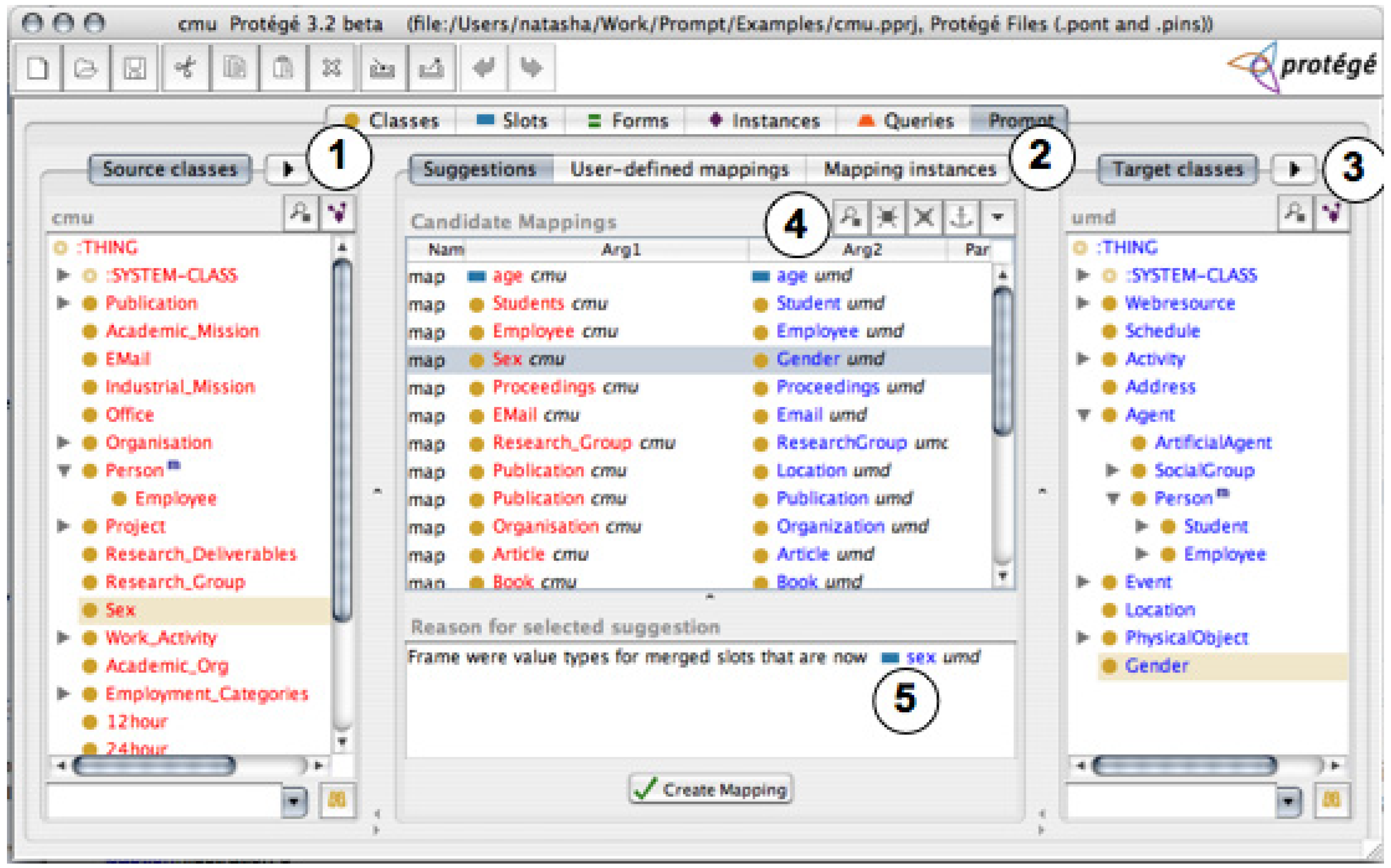
4.1. Interfaces Based on Linked Trees Widgets
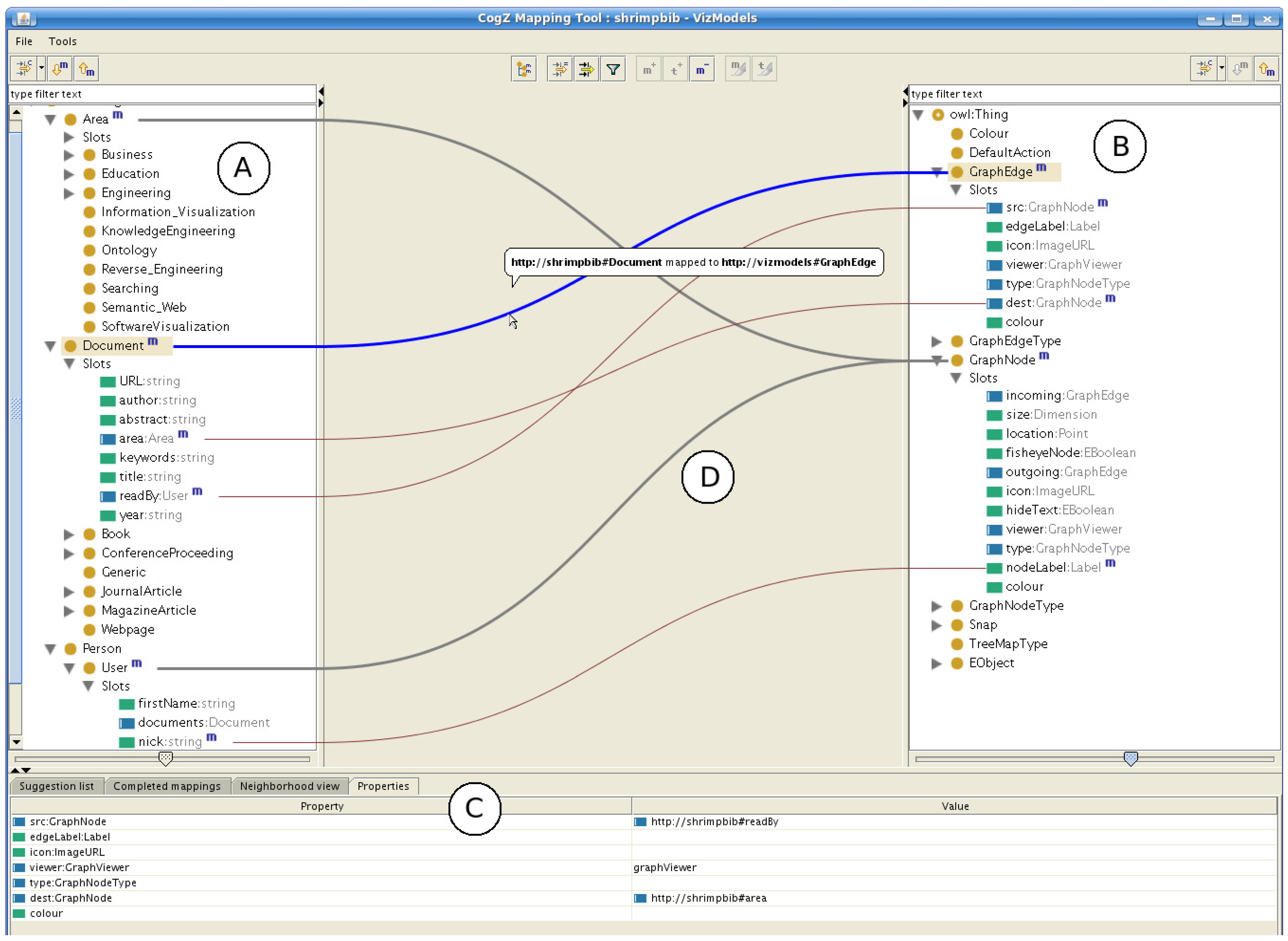

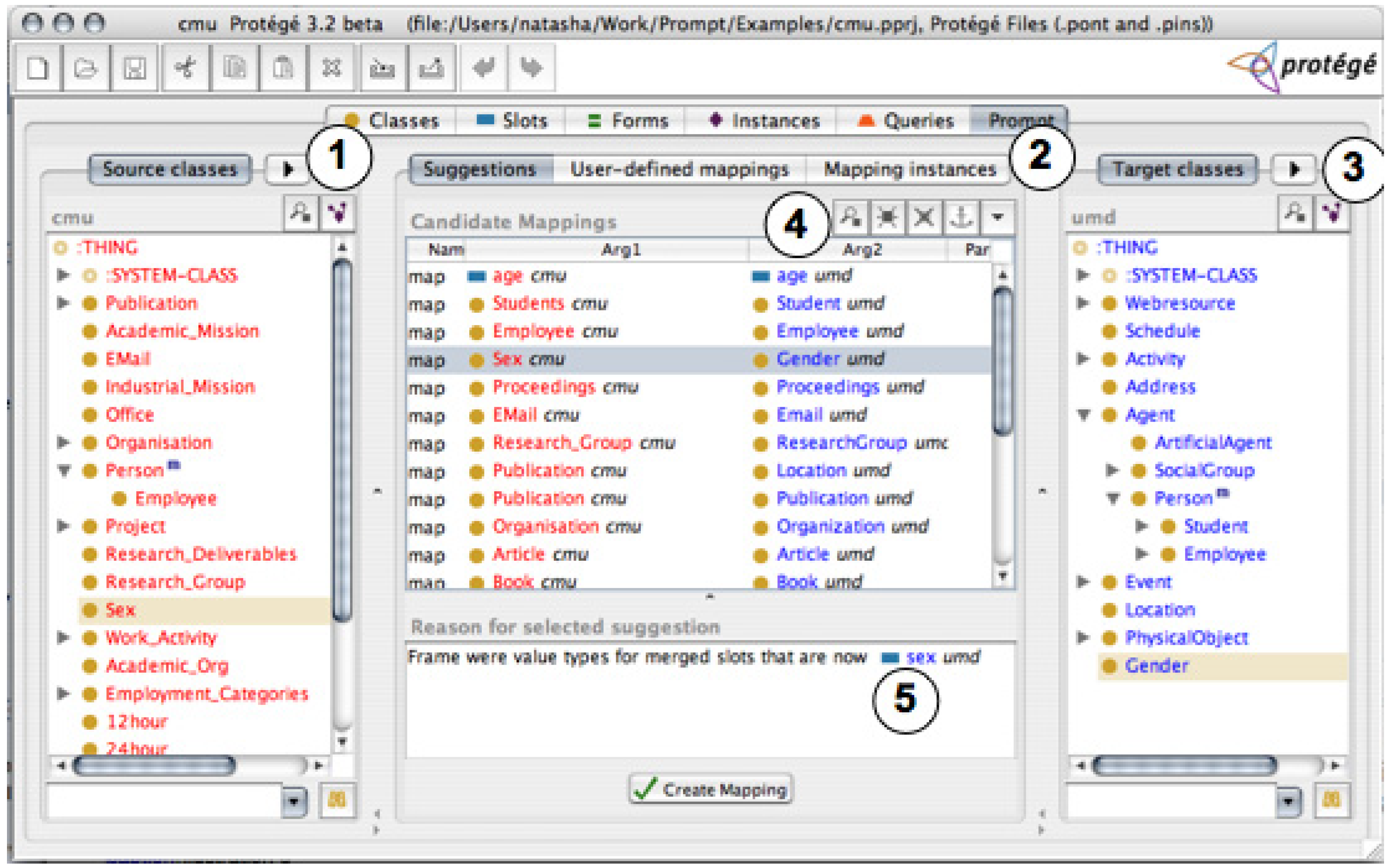
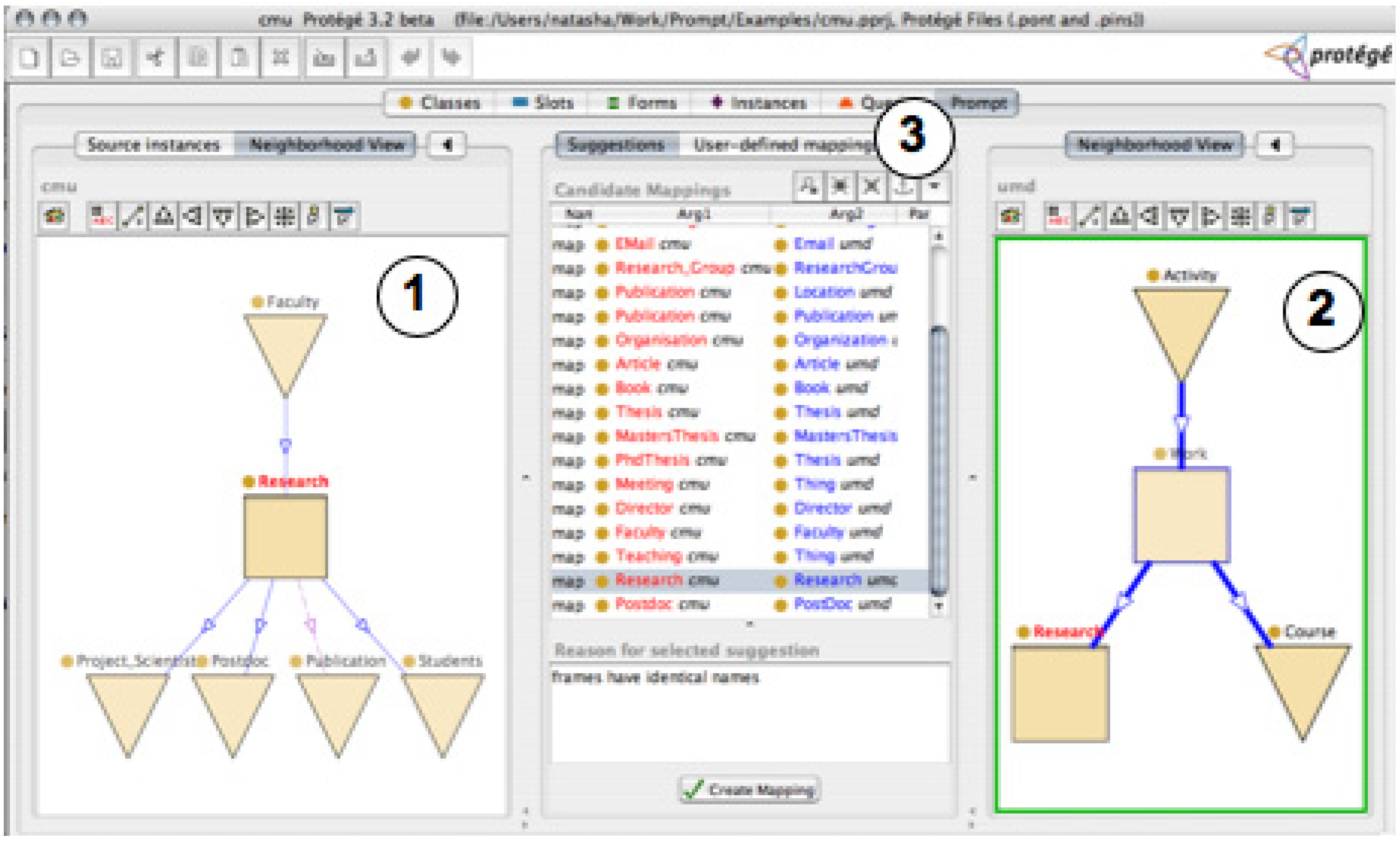
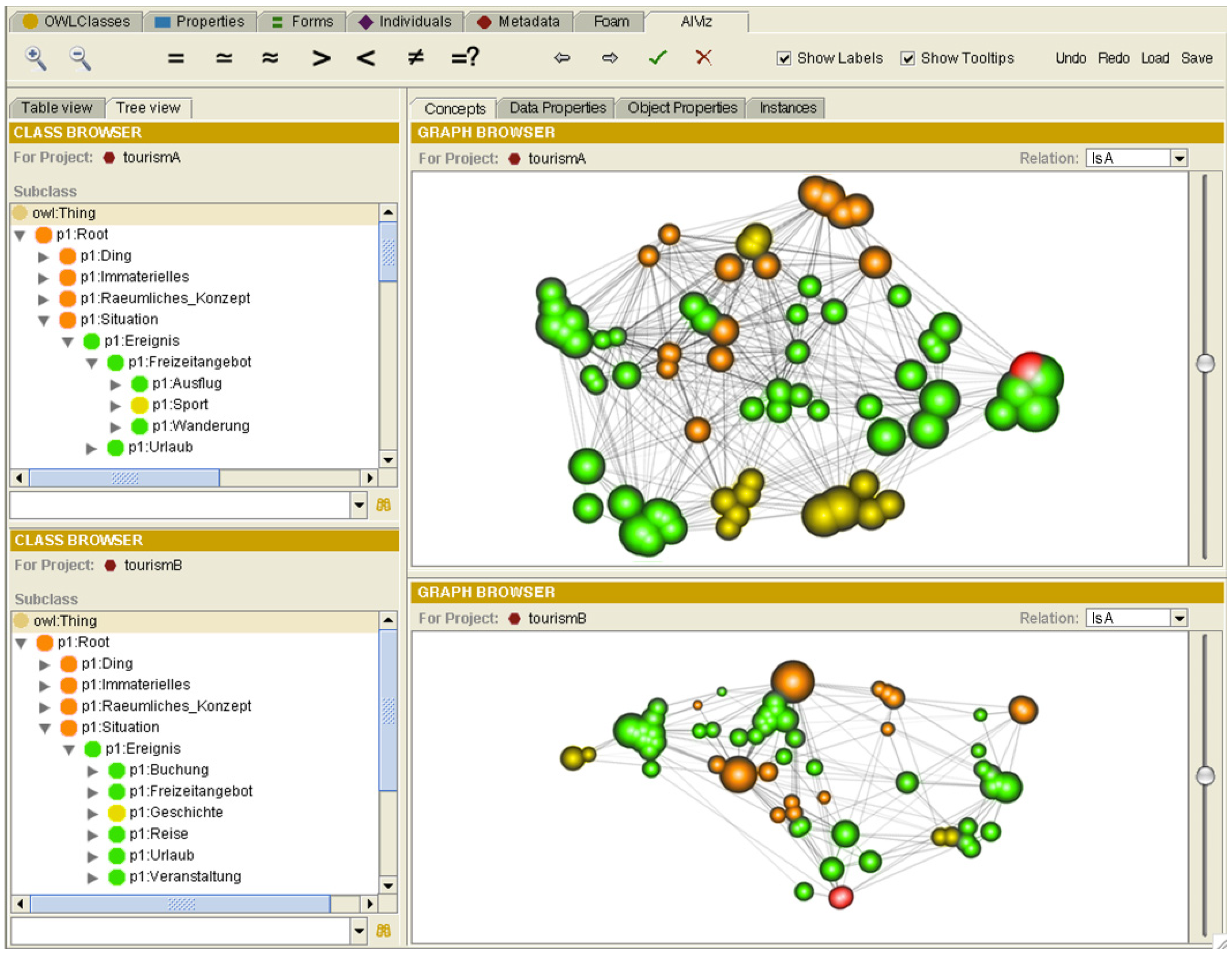
4.2. Interfaces Based on Graph Visualization
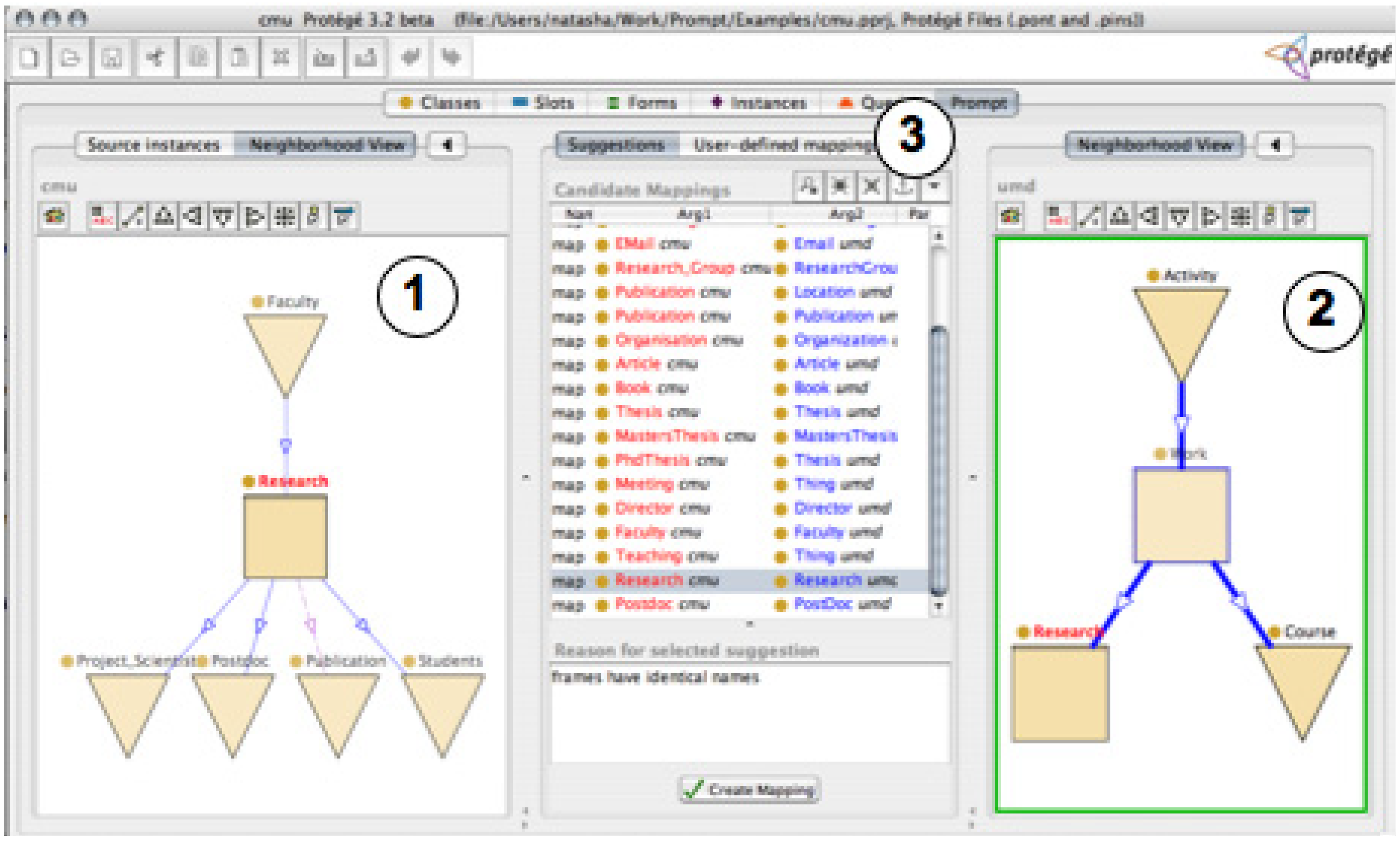
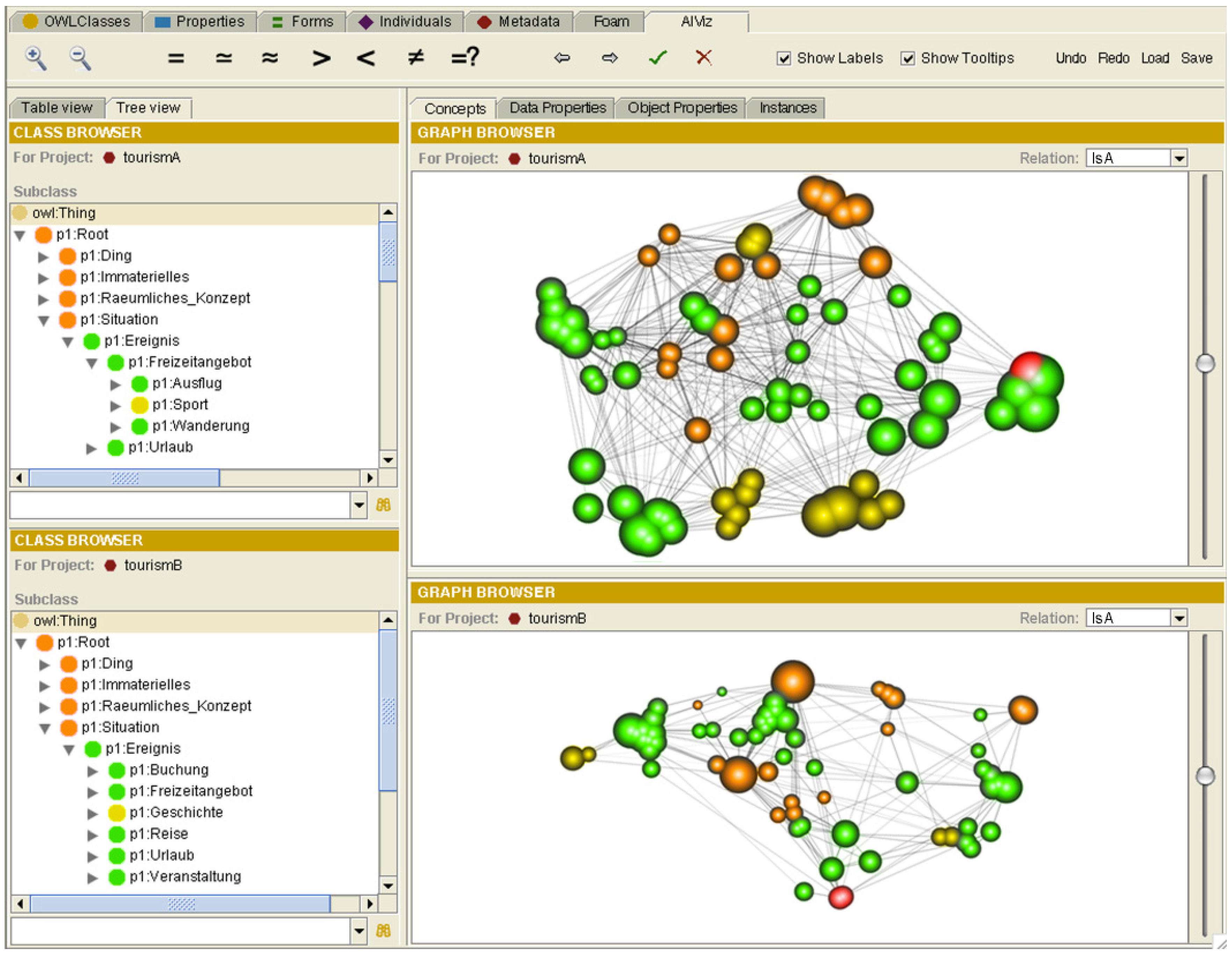
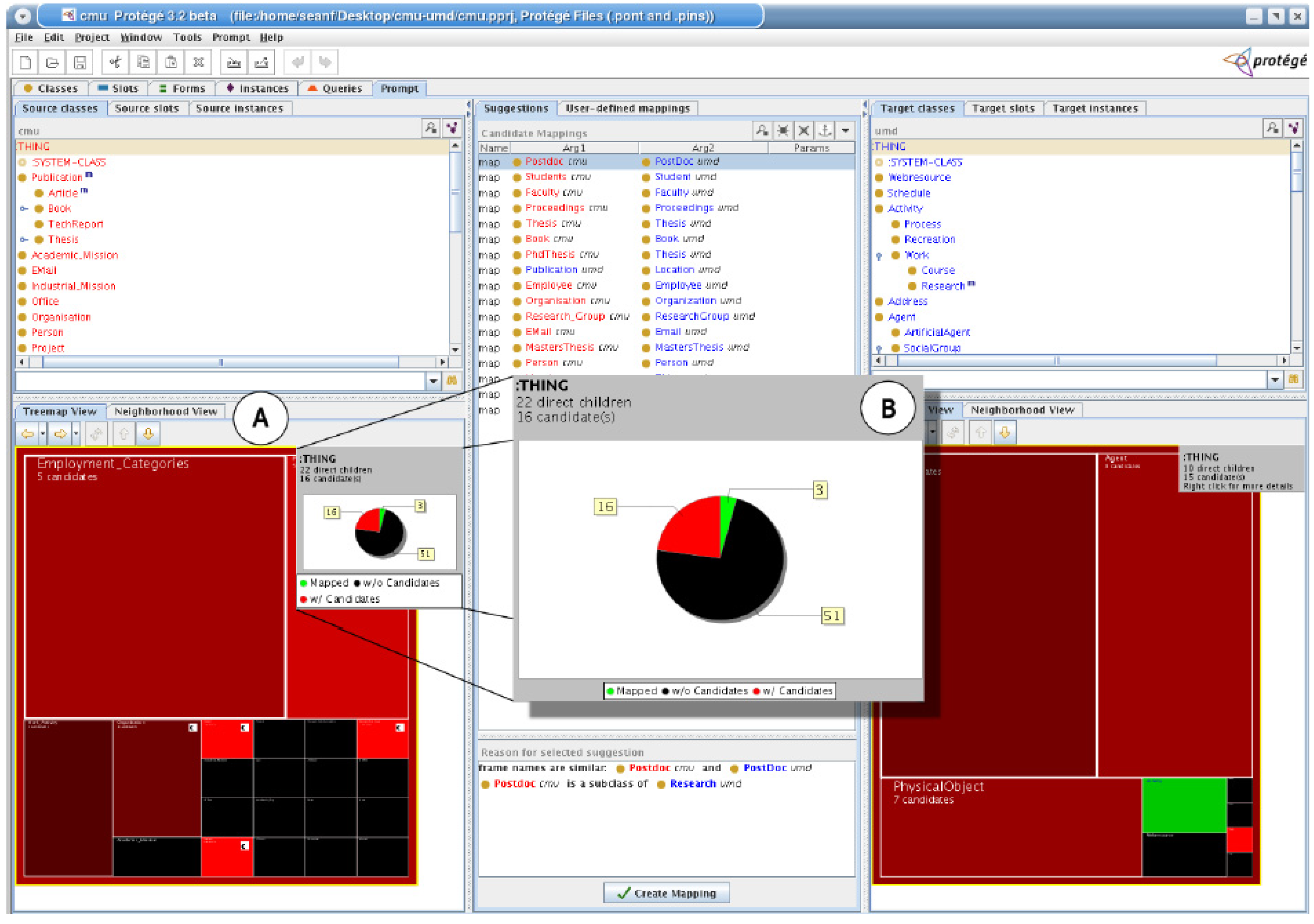
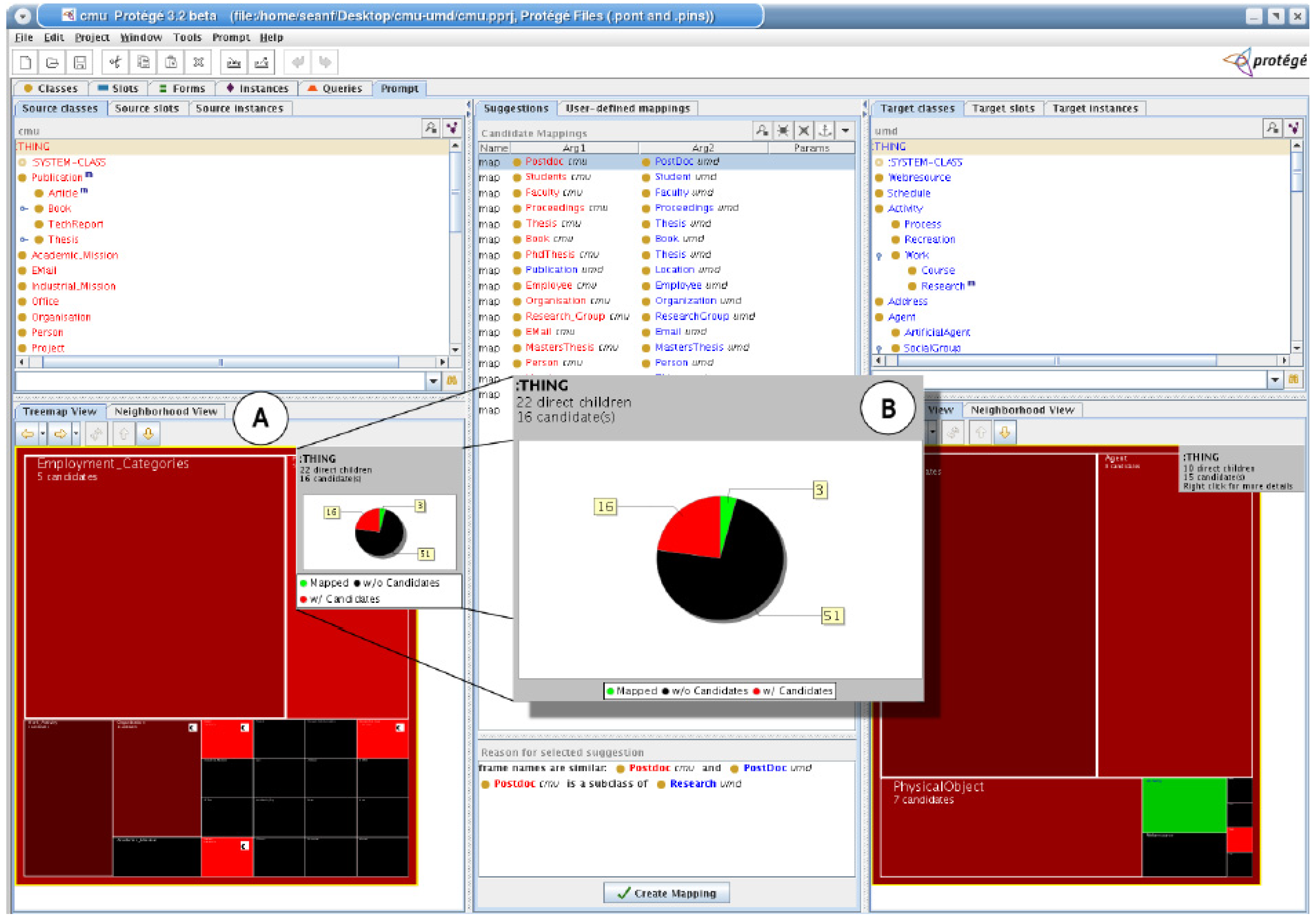
4.3. Treemap-based Interfaces
5. Requirement Fulfilment Summary and Suggestions for Future Research
5.1. Requirements Fulfilled by Interfaces Based on Linked Trees
5.2. Requirements Fulfilled by Graph-based Interfaces
5.3. Requirements Fulfilled by Treemap-based Interfaces
5.4. Suggestions for Future Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirement/Interface | Linked Trees-based | Graph-based | Treemap-based |
|---|---|---|---|
| 1. Detailed mapping information provided | + 1 | + 1 | + 1 |
| 2. Ontology navigation and exploration | − | + | − |
| 3. Overview of alignment results | − | −/+ | + |
| 4. Selectable level of detail and area of interest | +/− | + | + |
| 5. Filtering | −/+ | −/+ | − |
6. Conclusions
Acknowledgements
References and Notes
- Gruber, T.R. Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum. Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- de Bruijn, J.; Ehrig, M.; Feier, C.; Martíns-Recuerda, F.; Scharffe, F.; Weiten, M. Ontology mediation, merging, and aligning. In Semantic Web Technologies: Trends and Research in Ontology-Based Systems; Davies, J., Studer, R., Warren, P., Eds.; John Wiley & Sons Ltd.: Chichester, UK, 2006. [Google Scholar]
- Kotis, K.; Lanzenberger, M. Ontology Matching: Status and Challenges. IEEE Intell. Syst. 2008, 23, 84–85. [Google Scholar] [CrossRef]
- Euzenat, J.; Le Bach, T.; Barrasa, J.; Bouquet, P.; De Bo, J.; Dieng, R.; Ehrig, M.; Hauswirth, M.; Jarrar, M.; Lara, R.; Maynard, D.; Napoli, A.; Stamou, G.; Stuckenschmidt, H.; Shvaisko, P.; Tessaris, S.; Van Acker, S.; Zaihrayeu, I. D2.2.3: State of the Art on Ontology Alignment; KWEB/2004/D2.2.3/v1.2; Technical Report for Knowledge Web Project IST-2004-507482; Knowledge Web Consortium, August 2004. [Google Scholar]
- Gal, A.; Shvaiko, P. Advances in Ontology Matching. In Advances in Web Semantics I: Ontologies, Web Services and Applied Semantic Web; Springer-Verlag: Berlin, Heidelberg, Germany, 2008; pp. 176–198. [Google Scholar]
- Do, H.-H.; Rahm, E. COMA: A system for flexible combination of schema matching approaches. In Proceedings of the 28th international conference on Very Large Data Bases, Hong Kong, China, 20–23 August 2002; pp. 610–621.
- Aumueller, D.; Do, H.-H.; Massmann, S.; Rahm, E. Schema and ontology matching with COMA++. In Proceedings of the ACM SIGMOD, Baltimore, MD, USA, 14–16 June 2005; pp. 906–908.
- Euzenat, J.; Valtchev, P. Similarity-based ontology alignment in OWL-lite. In Proceedings of the 16th European Conference on Artificial Intelligence, Valencia, Spain, 22–27 August 2004; pp. 333–337.
- Noy, N.; Musen, M. Anchor-PROMPT: Using non-local context for semantic matching. In Proceedings of IJCAI 2001 Workshop on Ontology and Information Sharing, Seattle, WA, USA, August 2001; pp. 63–70.
- Giunchiglia, F.; Shvaiko, P.; Yatskevich, M. S-match: An algorithm and an implementation of semantic matching. In Proceedings of the 1st European Semantic Web Symposium, Heraklion, Greece, 10–12 May 2004; pp. 61–75.
- Madhavan, J.; Bernstein, P.; Rahm, E. Generic schema matching with Cupid. In Proceedings of the 27th International Conference on Very Large Data Bases, Roma, Italy, 11–14 September 2001; pp. 49–58.
- Melnik, S.; Garcia-Molina, H.; Rahm, E. Similarity Flooding: A Versatile Graph Matching Algorithm and its Application to Schema Matching. In Proceedings of 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 117–128.
- Ehrig, M.; Staab, S. QOM—Quick Ontology Mapping. In Proceedings of the 3rd International Semantic Web Conference, Hiroshima, Japan, 7–11 November 2004; pp. 683–697.
- Li, J.; Tang, J.; Li, Y.; Luo, Q. RiMOM: A Dynamic Multi-Strategy Ontology Alignment Framework. IEEE Trans. Knowl. Data Eng. 2009, 21, 1218–1232. [Google Scholar] [CrossRef]
- Bouquet, P.; Serafini, L.; Zanobini, S. Semantic coordination: A new approach and an application. In Proceedings of the 2nd International Semantic Web Conference, Sanibel Island, FL, USA, 20–23 October 2003; pp. 130–145.
- DOLCE: A Descriptive Ontology for Linguistic and Cognitive Engineering, 2009. Available online: http://www.loa-cnr.it/DOLCE.html/ (accessed on 13 July 2010).
- Doan, A.; Madhavan, J.; Dhamankar, R.; Domingos, P.; Halevy, A.Y. Learning to Match Ontologies on the Semantic Web. VLDB J. 2003, 12, 303–319. [Google Scholar] [CrossRef]
- Noy, N.F.; Musen, M.A. The PROMPT Suite: Interactive Tools for Ontology Merging and Mapping. Int. J. Hum. Comput. Stud. 2003, 59, 983–1024. [Google Scholar] [CrossRef]
- Mitra, P.; Wiederhold, G. Resolving terminological heterogeneity in ontologies. In Proceedings of Workshop on Ontologies and Semantic Interoperability at the 15th European Conference on Artificial Intelligence, Lyon, France, 21–26 July 2002.
- Ontology Alignment Evaluation Initiative (OAEI), 2009. Available online: http://oaei.ontologymatching.org/ (accessed on 13 July 2010).
- Euzenat, J.; Ferrara, A.; Hollink, L.; Hollink, L.; Isaac, A.; Joslyn, C.; Malaisé, V.; Meilicke, C.; Nikolov, A.; Pane, J.; Sabou, M.; Scharffe, F.; Shvaiko, P.; Spiliopoulos, V.; Stuckenschmidt, H.; Šváb-Zamazal, O.; Svátek, V.; Trojahn, C.; Vouros, G.; Shenghui, W. Results of the Ontology Alignment Evaluation Initiative 2009. Available online: http://oaei.ontologymatching.org/2009/results/oaei2009.pdf/ (accessed on 13 July 2010).
- Shneiderman, B. Inventing discovery tools: Combining information visualization with data mining. Inform. Visual. 2002, 1, 5–12. [Google Scholar] [CrossRef]
- Wong, P.C.; Thomas, J. Visual Analytics. IEEE Comput. Graph. Appl. 2004, 24, 20–21. [Google Scholar] [CrossRef] [PubMed]
- Keim, D.A.; Mansmann, F.; Oelke, D.; Ziegler, H. Visual Analytics: Combining Automated Discovery with Interactive Visualizations. Discov. Sci. 2008, 5255, 2–14. [Google Scholar]
- Shneiderman, B. The Eyes Have It: A Task by Data Type Taxonomy for Information Visualizations. In Proceedings of the 1996 IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–6 September 1996; p. 336.
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From Data Mining to Knowledge Discovery: An Overview. In Advances in Knowledge Discovery and Data Mining; AAAI Press/The MIT Press: Menlo Park, CA, 1996; pp. 1–34. [Google Scholar]
- Falconer, S.M.; Noy, N.F.; Storey, M.-A. Ontology Mapping—A User Survey. In Proceedings of the 2nd International Workshop on Ontology Matching at ISWC 07 and ASWC 07, Busan, Korea, 11 November 2007.
- Conroy, C.; O'Sullivan, D.; Lewis, D. Towards Ontology Mapping for Ordinary People. In Proceedings of European Semantic Web Conference, PhD Symposium, Tenerife, Spain, 1–5 June 2008.
- Falconer, S.M.; Noy, N.; Storey, M.-A. Towards understanding the needs of cognitive support for ontology mapping. In Proceedings of the Ontology Matching Workshop (5th International Semantic Web Conference), Athens, Giorgia, USA, 5 November 2006; pp. 25–36.
- Lanzenberger, M.; Sampson, J.J.; Rester, M.; Naudet, Y.; Latour, T. Visual ontology alignment for knowledge sharing and reuse. J. Knowl. Manage. 2008, 12, 192–120. [Google Scholar] [CrossRef]
- Katifori, A.; Halatsis, C.; Lepouras, G.; Vassilakis, C.; Giannopoulou, E. Ontology Visualization Methods—A Survey. In ACM Computing Surveys (CSUR); ACM: New York, NY, USA, 2007; Volume 39. [Google Scholar]
- Lanzenberger, M.; Sampson, J.; Rester, M. Visualization in Ontology Tools. In Proceedings of the International Conference on Complex, Intelligent and Software Intensive Systems, Fukuoka, Japan, 16–19 March 2009; pp. 705–711.
- Cruz, I.F.; Sunna, W.; Makar, N.; Bathala, S. A visual tool for ontology alignment to enable geospatial interoperability. J. Visual Lang. Comput. 2007, 18, 230–254. [Google Scholar] [CrossRef]
- Falconer, S.M.; Storey, M.-A. A cognitive support framework for ontology mapping. In Proceedings of International Semantic Web Conference, Busan, Korea, November 2007; pp. 114–127.
- Falconer, S.M.; Bull, R.I.; Grammel, L.; Storey, M.-A. Creating visualizations through ontology mapping. In Proceedings of the 2nd International Workshop on Ontology Alignment and Visualization, Fukuoka, Japan, 16–19 March 2009.
- Herman, I.; Melancon, G.; Marshall, M.S. Graph Visualization and Navigation in Information: A Survey. In IEEE Transactions on Visualization and Computer Graphics, Los Alamitos, CA, USA; 2000; Volume 6, pp. 24–43. [Google Scholar]
- Cui, W. A Survey on Graph Visualization. PhD Qualifying Exam (PQE) Report. Computer Science Department, Hong Kong University of Science and Technology: Kowloon, Hong Kong, 2007. Available online: http://www.cse.ust.hk/~weiwei/PQE/WeiweiPQE.pdf/ (accessed on 13 July 2010).
- Kolli, R.; Doshi, P. OPTIMA: Tool for Ontology Alignment with Application to Semantic Reconciliation of Sensor Metadata for Publication in SensorMap. In Proceedings of the second IEEE International Conference on Semantic Computing, Santa Clara, CA, USA, 4–7 August 2008; pp. 484–485.
- Lanzenberger, M.; Sampson, J. AlViz—A Tool for Visual Ontology Alignment. In Proceedings of the 10th International Conference on Information Visulization, London, UK, July 2006; Banissi, E., Burkhard, R.A., Ursyn, A., et al., Eds.; IEEE Computer Science Society: Washington, DC, USA, 2006; pp. 430–440. [Google Scholar]
- Shneiderman, B. Tree visualization with Tree-maps: A 2-d space-filling approach. ACM Trans. Graphic. 1991, 11, 92–99. [Google Scholar] [CrossRef]
- Kerwin, T. Survey of treemap techniques, retrieved 2009. Available online: http://www.cse.ohio-state.edu/~kerwin/treemap-survey.html/ (accessed on 13 July 2010).
- Müller, F. Granularity based multiple coordinated views to improve the information seeking process. PhD Thesis, University of Konstanz, Konstanz, Germany, 2005. [Google Scholar]
- Sabol, V.; Kienreich, W.; Muhr, M.; Klieber, W.; Granitzer, M. Visual Knowledge Discovery in Dynamic Enterprise Text Repositories. In Proceedings of the 13th International Conference on Information Visualisation, Barcelona, Spain, 14–17 July 2009; pp. 361–368.
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Granitzer, M.; Sabol, V.; Onn, K.W.; Lukose, D.; Tochtermann, K. Ontology Alignment—A Survey with Focus on Visually Supported Semi-Automatic Techniques. Future Internet 2010, 2, 238-258. https://doi.org/10.3390/fi2030238
Granitzer M, Sabol V, Onn KW, Lukose D, Tochtermann K. Ontology Alignment—A Survey with Focus on Visually Supported Semi-Automatic Techniques. Future Internet. 2010; 2(3):238-258. https://doi.org/10.3390/fi2030238
Chicago/Turabian StyleGranitzer, Michael, Vedran Sabol, Kow Weng Onn, Dickson Lukose, and Klaus Tochtermann. 2010. "Ontology Alignment—A Survey with Focus on Visually Supported Semi-Automatic Techniques" Future Internet 2, no. 3: 238-258. https://doi.org/10.3390/fi2030238