
Improved Recommendations Based on Trust Relationships in Social Networks


1
School of Information Engineering, Hubei University of Economics, No. 8, Yangqiaohu Ave., Jiangxia Dist., Wuhan 430205, China
2
Graduate School of Information, Production and Systems, Waseda University, Hibikino 2–7, Wakamatsu-ku, Kitakyushu 808-0135, Japan
*
Author to whom correspondence should be addressed.
Future Internet 2017, 9(1), 9; https://doi.org/10.3390/fi9010009
Submission received: 24 February 2017
/
Revised: 15 March 2017
/
Accepted: 17 March 2017
/
Published: 21 March 2017
Abstract
:In order to alleviate the pressure of information overload and enhance consumer satisfaction, personalization recommendation has become increasingly popular in recent years. As a result, various approaches for recommendation have been proposed in the past few years. However, traditional recommendation methods are still troubled with typical issues such as cold start, sparsity, and low accuracy. To address these problems, this paper proposed an improved recommendation method based on trust relationships in social networks to improve the performance of recommendations. In particular, we define trust relationship afresh and consider several representative factors in the formalization of trust relationships. To verify the proposed approach comprehensively, this paper conducted experiments in three ways. The experimental results show that our proposed approach leads to a substantial increase in prediction accuracy and is very helpful in dealing with cold start and sparsity.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
In recent years, social networks have played an important role on the Internet, which focuses on interactions and relationships between people. The Internet can be regarded as a new platform, on which people pursue an increasing amount of activities that they have usually only done in the real world [1]. However, this platform is also troubled by information overload, which makes it difficult to find personalized information from the vast amounts of information on the Internet. To address this problem, recommendations have become increasingly popular. Although there are many studies on recommendations in social networks, most of them still suffer from typical problems such as cold start, sparsity, and unsatisfactory precision.
According to a Nielsen survey, more than 90% of users believe in what their friends have recommended, and 70% of users believe other users’ product scores on commodities on the Internet [2]. The survey reveals that trust relationships between users can determine the effect of recommendations to a great extent. Thus, trust has become a research hotspot in the field of information recommendation. As a result, an increasing amount of studies have been conducted on recommendations based on trust [3,4,5]. These methods, however, tend to be vague in defining trust relationships, and they rarely consider indirect trust. To solve these challenges, we investigate here the problem of how trust relationships can benefit recommendations in a social network.
In this paper, we first define a trust relationship and then propose an improved recommendation method that gives full consideration to the characteristics of recommending and adopts an efficient recommendation algorithm based on formalized trust relationships. In particular, the method differs from existing ones mainly in its effective and flexible dynamic trust mechanism; more specifically, it can calculate the comprehensive trust of a candidate user and choose the most credible user to improve the accuracy of prediction. Experimental results show that, compared to similar methods, the proposed method has higher accuracy and can better deal with problems in the current recommendation algorithms, such as cold start and sparsity.
The rest of the paper is organized as follows. In Section 2, we review related recommendation methods that consider trust and analyze their advantages and disadvantages. The quantifying about the factors of trust in social networks and the formalization of trust relationships are described in Section 3. In Section 4, we elaborate on our proposed algorithm, and evaluate the experiments in Section 5. A conclusion is given in Section 6.
2. Related Work
Trust is a new research hotspot that has been widely discussed by many scholars in recent years. In [4], the authors proposed a social network-based service recommendation method with trust enhancement known as the Relevant Trust Walker; however, this method neglects the fact that trust relationships between users are time-varying. Can and Bharat presented a trust model for P2P networks in [5], but due to the lack of flexibility, the model lost some parts as the points of peers changed. To improve the accuracy of top-k ranking predictions, a method based on an objective function for recommendation is presented in [6], in which users are divided into two classes of trustees and trusters. The experimental results show that the method has a satisfactory accuracy of recommendation in top-k ranking, but a partial recall due to time complexity. Based on the technology of Tensor Factorization, Kim and Yoon presented a trust model that represented the extra information as a tensor in [7]. The model can integrate multidimensional contextual information to provide satisfactory recommendations, but it lacks flexibility. In [8], the authors defined trust and reputation, and introduced corresponding computation methods. Specially, trust is divided into two subclasses—reliability trust and decision trust—and an agent-oriented recommendation system based on trust is also presented. The evaluation results show advantages of trust in movie recommendations. To deal with the issues of cold start and sparsity, Mohsen and Ester proposed a random walk model in [9] that can combine the trust-based and the collaborative filtering method to generate recommendations. The random allows users to define and measure the confidence of a recommendation; however, the trust concept they considered in the paper is context-independent. In [10], two novel methods that exploit trust networks to improve the results of top-N recommendations were proposed. The first method employs a random walk on a trust network by calculating the similarity of users in its termination condition. The second method combines collaborative filtering and a trust-based approach. To alleviate the cold-user problem, the authors used a special API (Application Programming Interface) to select the most valuable node in a certain venue to calculate the probability of similar favorite categories in [11]. The approach can achieve the established goal but is still troubled by the sparsity problem. In [12], the authors tried to handle the cold start problem by employing implicit social information to provide personalized news recommendations in a news reading community. They proposed a novel framework that treats implicit reader feedbacks as assistant information for recommendations. Krauss and Arbanowski introduced social preference ontologies to solve the problems of cold start and sparsity in [13]. Evaluation results show that the method performs well but domain concepts need to be identified to support preference ontologies.
Yilmazel and Kaleli analyzed the robustness of some typical recommendation approaches based on distributed data in [14]. They summarized reasons why these methods are vulnerable to attacks by malicious users. In order to restrain malicious recommendations and fraud service actions, Wang and Gui proposed a dynamic recommendation trust-evaluated model based on bidding in an E-Commerce environment in [15]. In this method, the value of trust is essentially computed based on the number of happy and unhappy interactions, but the definitions of the two statuses are not yet clear. In [16], Shambour and Lu developed an implicit trust filtering recommendation approach and an enhanced user-based collaborative filtering recommendation approach to select a trustworthy business partner to perform reliable business transactions. Since the paper computes the trust value based on mean ratings by users, its reliability and sensitivity is not high. Alejandro and Parapar made use of spectral clustering techniques to derive a cluster-based collaborative filtering algorithm in [17]. The method outperforms other standard state-of-the-art techniques in terms of ranking precision and is suitable for neighbor selection. A reputation measurement method was proposed to measure the reputation of services to block malicious users in Web service recommendations in [18]. By detecting malicious feedback ratings and commutating feedback similarities, the approach can identify the trustworthiness of web services and generate a prevention scheme so as to improve the process of Web service recommendations.
To sum up, these methods generally provide recommendations by utilizing trust relationships between users, so they can achieve better precision. However, as mentioned earlier, their definitions of trust are not satisfactory, which limits their performances. Therefore, on the basis of our previous research [19,20], we are motivated to define trust afresh and present an improved recommendation based on trust relationships, to improve the accuracy of prediction, to solve cold start and sparsity, and thus to make better recommendations in social networks.
3. Factors in Trust Relationships
As stated earlier, trust relationships between users should be based on their interactions, and it should be quantified by the degree of trust. Moreover, they can be influenced by certain representative issues. In this section, we attempt to define and formalize these factors.
3.1. Definition of Trust
In this paper, we define it as a triple, which can be described as Equation (1).
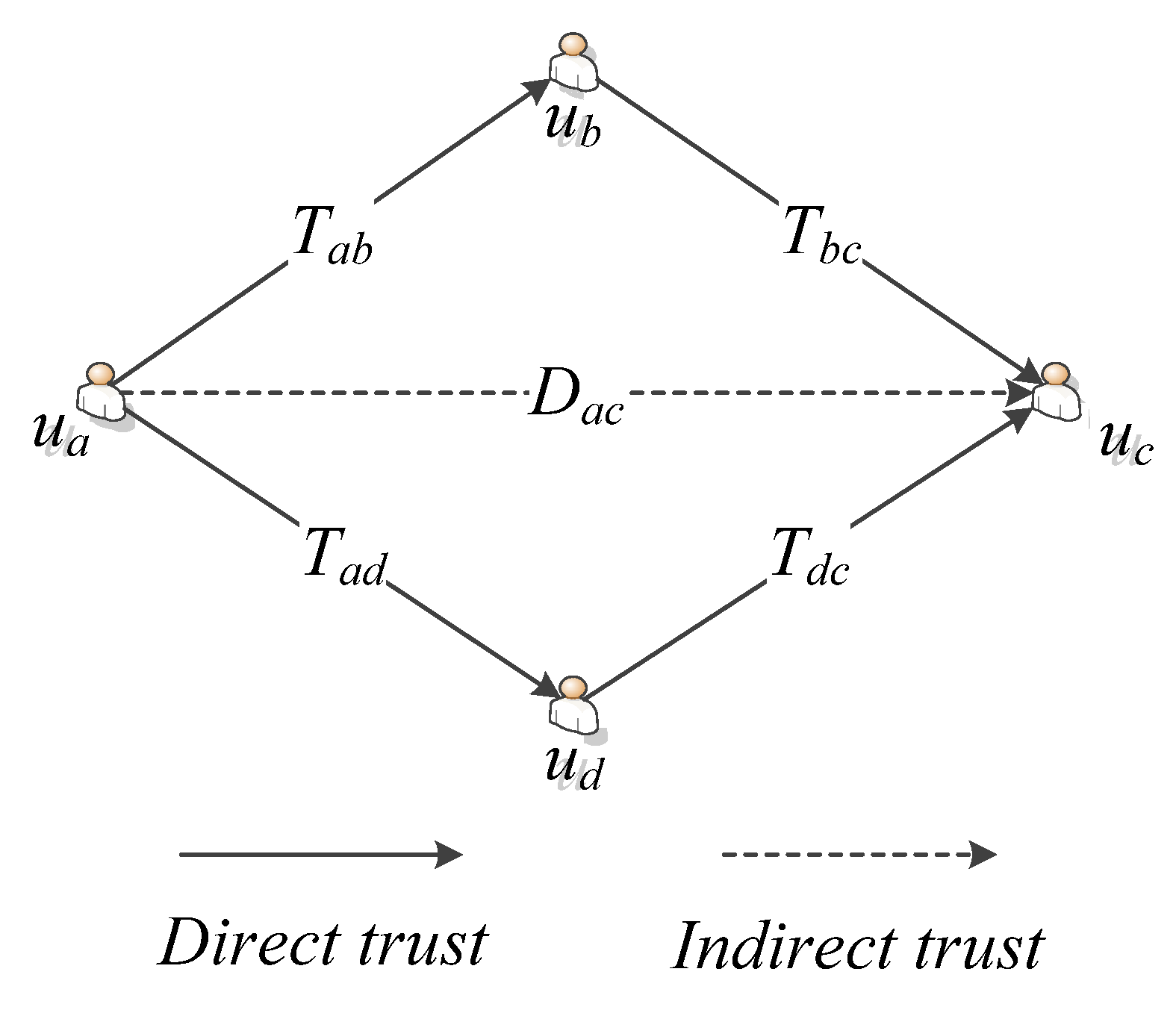
where T denotes the trust relationship, U is the set of users, P is the set of trust paths, and D expresses trust degrees. In addition, the value of D is determined by the form of P, and D > 0. Specifically, we define the length of P as the number of users in the trust path and mark it as L(P). L(P) ≥ 2, and if L(P) = 2, we call T a direct trust relationship; if L(P) > 2, then T is an indirect trust relationship.
Figure 1 shows an example of trust relations between users in a social network. In this figure, Tab, Tbc, Tad, and Tdc are direct trust relationships; Tac is an indirect trust relationship, and there are two indirect trust paths from user ua to user uc, namely, P1: ua→ub→uc and P2: ua→ud→uc. For an indirect trust relationship, we choose the most credible indirect path that has the highest trust degree as its trust path according to Equation (2).
where Pl denotes a possible trust path between two users, and Dmn is the trust degree of a direct trust in Pl. The equation shows that, if there are several candidate trust paths between two users, the direct path is chosen beforehand. Otherwise, the most credible indirect path will be considered.
3.2. Dynamic Update of Trust
This paper argues that trust relationships will be changed with the interactions of users; in other words, trust degrees should be calculated based on these interactions. What is more, it should reflect the dynamic update of trust. Hence, we calculate trust degree as follows:
where Iba is the set of items that ub has recommended to ua, raj and rbj are, respectively, the user experiences of ua and ub on item ij, and rmax is the max rating value in the range. In this paper, rating values are integers in the range [1,5].
It can be learned from Equation (3) that Dab ≠ Dba; if raj > rbj, then ua is satisfied with the recommendation from ub, Dab will be increased, and Tab will then be strengthened; if raj = rbj, then ua agrees to the recommendation from ub, and Dab will then stay at the previous level; if raj < rbj, then the trust from ua to ub will be damaged. Moreover, if Dab ≤ 0, the trust relationship will be released.
3.3. Similarity of Users
A recommendation from a trusted user is usually reliable, but since the target user and trusted users may differ in interests and preferences, the recommendation might not be a suitable one; that is, a trusted and similar user can better affect the target user’s ratings. Therefore, to improve the prediction accuracy, we should consider the similarities between users.
In recommendation systems, we can generally obtain a set of users U, a set of items I and a user-item rating matrix R, which records user experiences; in particular, we denote the rating value on item ij by user ua as raj. Since R implies the factors of user interests and preferences, we can calculate the similarities between users based on it by utilizing typical methods. In this paper, we adopt the approach proposed in [4] to address the problem.
The rating matrix R is usually very large; thus, to effectively realize dimension reduction, R can be decomposed into two lower dimension metrics S and Q by matrix factorization. That is, R = SQT, where S and Q, respectively, denote implicit feature matrices of users and items, in which each line is a low dimensional feature vector of a user or an item. Then, for a given user ua and user ub, we calculate the similarity between them as follows:
where USimab is the similarity between ua and ub, va ∈ S, vb ∈ S, and they respectively denote the feature vector of ua and ub.
4. A Recommendation Algorithm Based on Trust Relationships
Based on formalized trust relationships, a target user’s acceptances of items can be predicted, and some recommendation can then be generated. In order to ensure the accuracy of prediction, we first define an index to evaluate the comprehensive trust to a trusted user:
where Cab is the comprehensive trust of ua to ub, and Ua is the set of users in the trust relationship of ua.
Then, the predicted ratings can be calculated by Equation (6).
where taj is the predicted rating value of item ij by target user ua, and Ib denotes the set of items rated by ub, who has the maximum comprehensive trust of ua, namely, Cab = Cm.
Based on the above, we present an Improved Recommendation Algorithm based on Trust Relationships (IRATR) in a social network, and its specific steps can be described as follows:
| Input: target user ua, the set of users U, the set of items I and the rating matrix R |
| Output: predicted ratings Ea for ua |
|
Due to the sparsity of the rating matrix, a user may not be recommended a certain item in traditional recommendation methods, but he/she can obtain a predicted rating on the item through an indirect trust path in IRATR. Moreover, based on the trust relationship, most of the final recommended items have only been rated by trusted neighbors of the target user, and they are well evaluated in these neighbors’ user experiences.
5. Experiment and Analysis
To verify the performance of the algorithm proposed in this paper, we performed the following simulation experiments to compare it with several representative methods and then analyzed the differences.
5.1. Experimental Setup
In our experiments, we selected the well-known Epinions dataset as the test dataset, which includes 49,290 users who rated a total of 139,738 different items at least once. The rating matrix contains 664,824 ratings records, and its density is less than 0.01%; that is, the matrix is large, sparse, and hence suitable for our experiments.
Although there are 487,181 issued trust statements in the Epinions dataset, they cannot be used directly because in the dataset there are only positive trust statements and because the trust statement value is always 1. In order to initialize trust relationships between users, we establish a direct trust relationship between two users by setting the trust degree as 1 while they occur in a trust statement. Then, based on these direct trust relationships, indirect trust relationships can be extracted.
The evaluation metric of recommendation performance that we used in our experiments is the Root Mean Squared Error (RMSE), which is defined as follows:
where rnj is the actual rating value on item ij by user un, tnj is the predicted value that un may give to ij, and N is the number of recommended items. Obviously, the smaller the value of RMSE is, the higher the accuracy of recommendations is.
To evaluate the performance of our proposed method we considered two comparison partners: TrustWalkerList [10] and Normalized Cut for neighbor Selection (NCut) [17]. TrustWalkerList is a method combining the collaborative filtering and trust-based approach, which can exploit a trust network to improve the quality of top-N recommendation by performing a random walk on the trust network, considering the similarity of users in its termination condition. NCut is essentially a user-based collaborative filtering method that outperforms other standard state-of-the-art techniques in terms of ranking precision based on graph partitioning. These two approaches are partly similar to our proposed method in terms of the algorithm principles.
We used the leave-one-out method [10] to evaluate the proposed recommendation method. Specifically, we first withheld a real rating value and tried to predict it through the three recommendation approaches. Then, we compared the accuracy of these approaches by analyzing the RMSE.
5.2. Results and Analysis
We conducted our experiments in three ways. First we performed the experiment towards the users with adequate user-item rating information. Meanwhile, since the main purpose of using trust relationships is to improve the quality of recommendations by solving the problems of cold start and sparsity, we also successively performed the experiments under the conditions of only cold start users and sparse data.
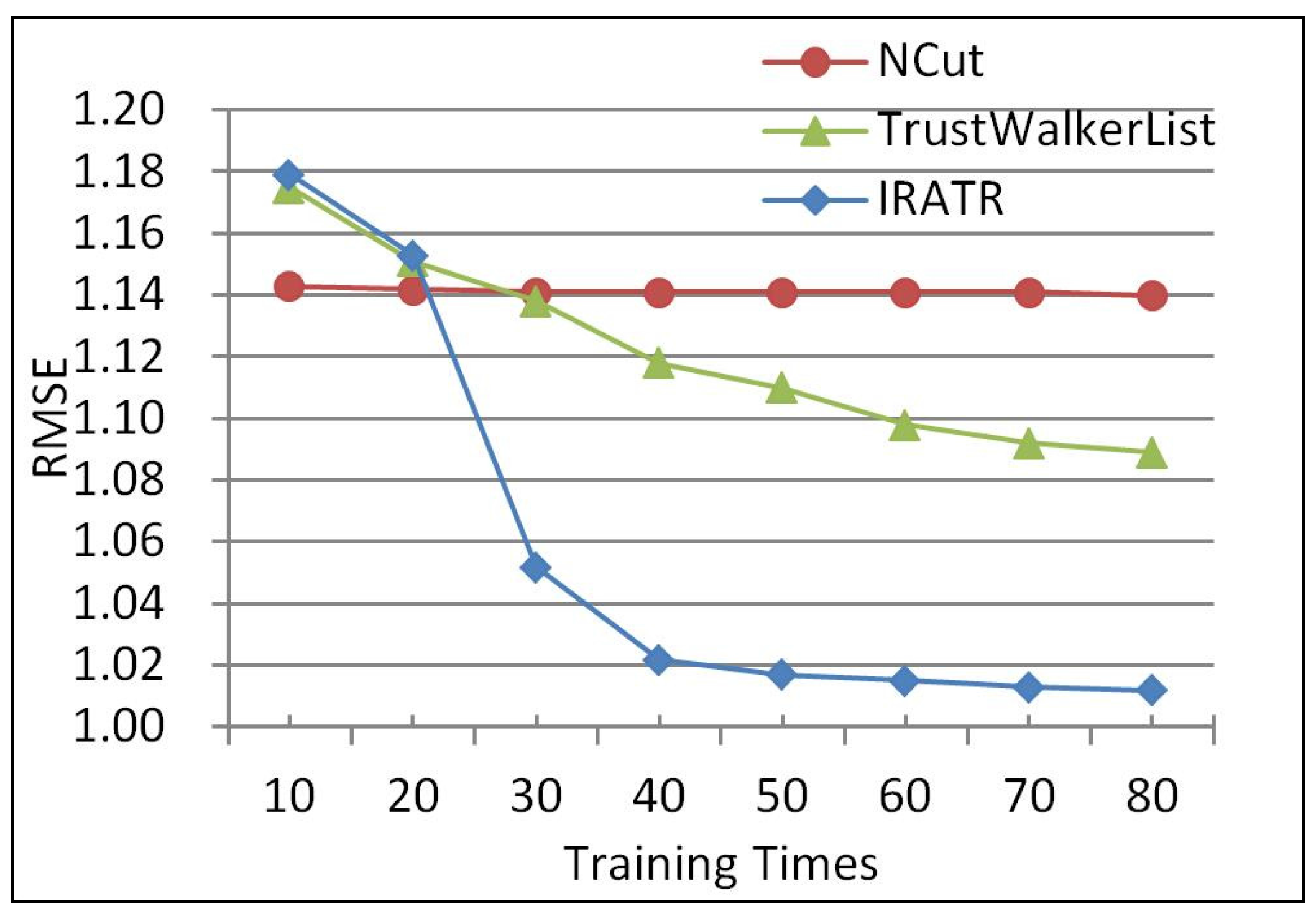
In the first experiment, we selected 1526 users and their rating values from Epinions dataset, of which 80% of records are assigned into the training set, and the remaining 20% are distributed into the test set. Since the initial trust degrees in the trust relationships are the same, we decided to train them for certain times, namely, training times to enrich their features. It was also concluded that the character of each trust relationship will be increasingly clear and independent with the growth of the number of training times. Figure 2 presents an RMSE for different methods at varying training times on all users.
From Figure 2, we can see that, when the number of training times is not bigger than 20, compared with NCut and TrustWalkerList, IRATR has no absolute advantage in accuracy. This is because NCut is essentially a traditional collaborative filtering method calculating the similarity of user/service with sufficient rating information, but TrustWalkerList and IRATR both need to deal with the trust between users, during which trust relationships are not clear. Along with the increase of training times, TrustWalkerList and IRATR perform better than NCut. When the number of training times is over 20, IRATR has the best accuracy owing to the gradually improved trust relationships. That is, IRATR can improve the accuracy of service recommendations by combining trust degree and user similarity. Consequently, the performance of the proposed IRATR precedes other algorithms on all users under the condition that user-item rating information is sufficient.
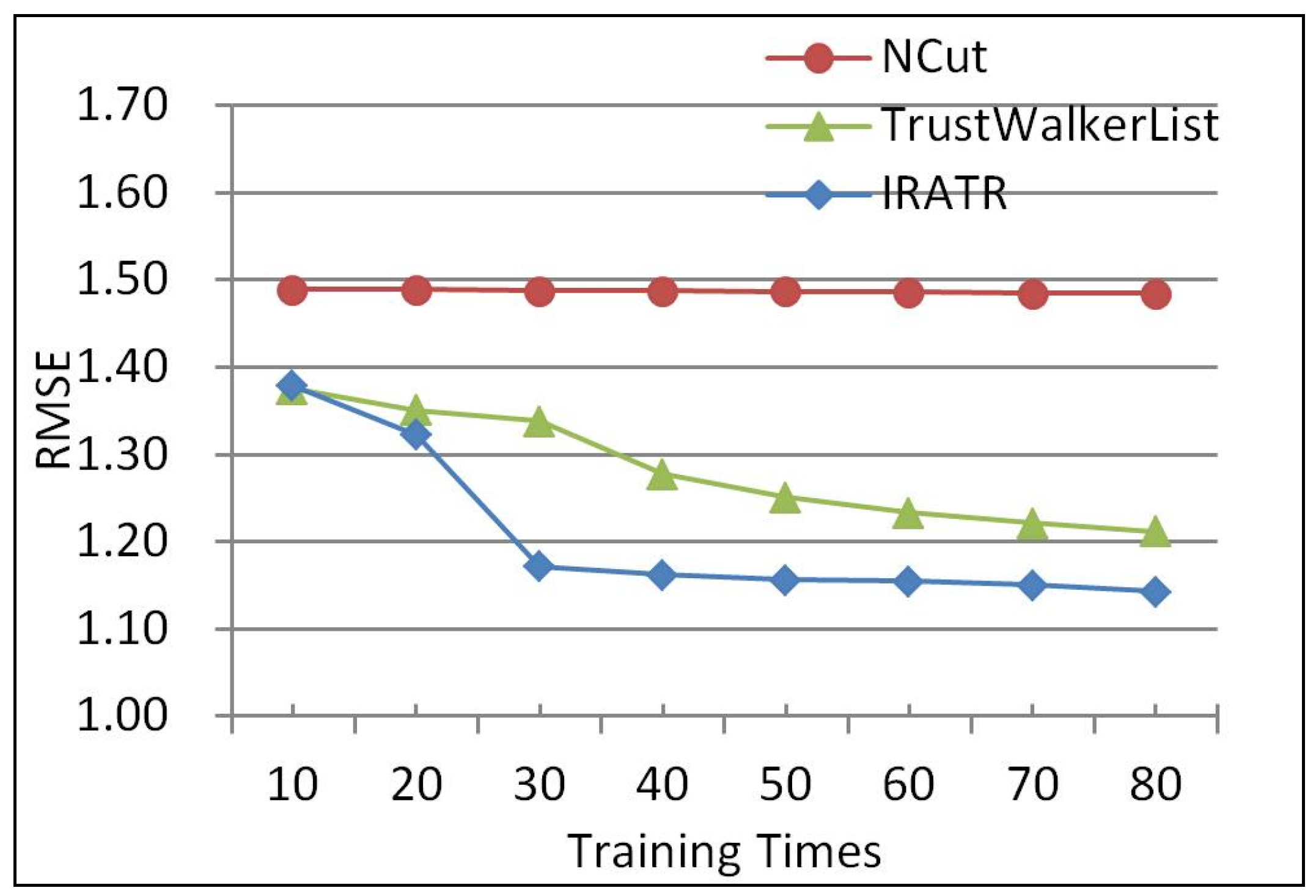
According to [21], users that provided from 1 to 4 ratings can be identified as cold start users, which in the Epinions dataset are in fact more than 50%. Therefore, we conducted the second experiment by repeating the content in the first one on cold start users to verify the ability of the three methods to solve cold start problems, and the experimental results are shown in Figure 3.
Figure 3 shows that, compared to other algorithms, IRATR always has a lower error for cold start. In the experiment, NCut performed the worst. This is because few mutual items are rated by cold start users, which means that the similarities of most users or items cannot be accurately calculated in NCut. In contrast, TrustWalkerList can make recommendations without mutual-rated items by employing trust relationships, so its accuracy was a significant improvement. Compared with the other two algorithms, IRATR is obviously superior in accuracy. When the number of training times is not less than 30, the accuracy of IRATR is respectively improved by 28.5% and 8.6% on average compared to NCut and TrustWalkerList. IRATR has the lowest RMSE because it can choose more relevant trust users along with trust paths, rather than randomly select neighbors, and enhances the relevance of recommendations from trusted users.
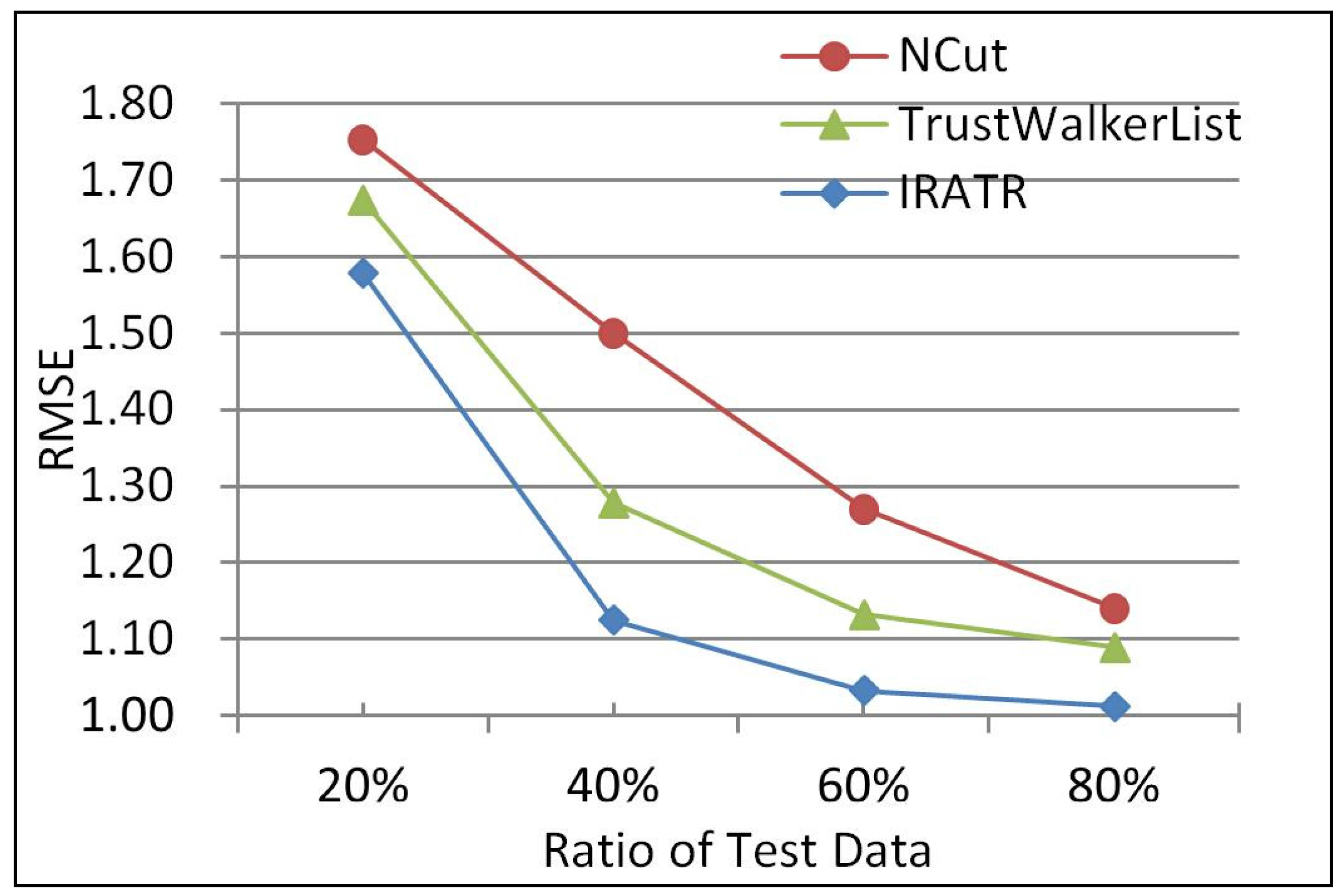
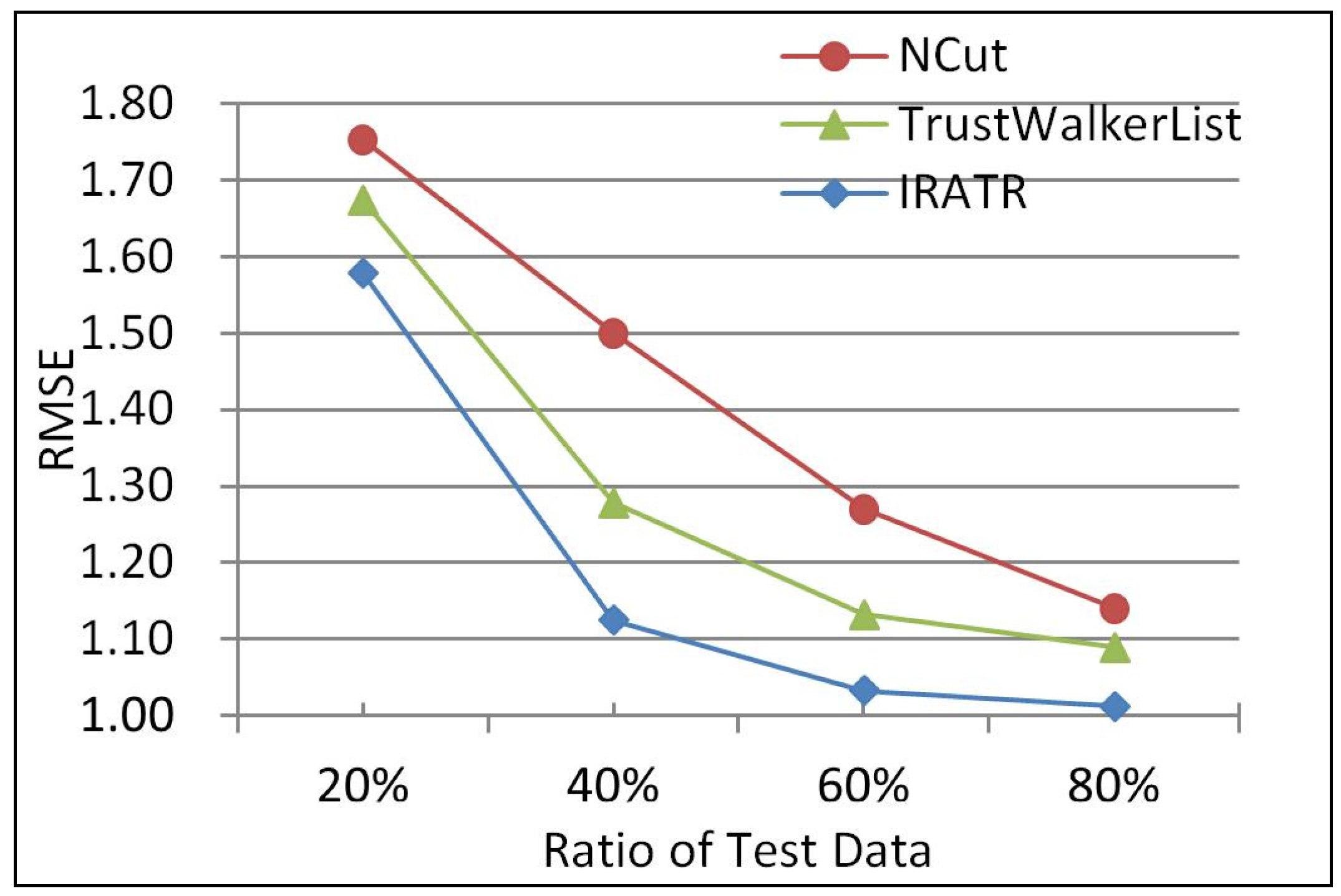
In order to test the ability of the three algorithms dealing with sparsity, we in turn set 20%, 40%, 60%, and 80% of the rating data as the test data in the third experiment to compare their RMSEs in different circumstances, and the experimental results are shown in Figure 4.
It can be seen from Figure 4 that, with the increase in the proportion of the training set in the entire data set, the recommendation effect of these algorithms constantly improved. Among them, the accuracy of IRATR was always the best. Specifically, when the ratio of the test data was 40%, compared with NCut, the accuracy of IRATR improved by 33.4%, and compared with TrustWalkerList, the accuracy increased by 13.6%. The results show that the recommendation results of our proposed IRATR is far superior to those of NCut and TrustWalkerList, and the more sparse the data is, the more obvious the advantages are, suggesting that leveraging the trust relationships between users is certainly conducive to improving the recommendation effect, effectively alleviating data sparsity.
6. Conclusions
In this paper, we proposed an improved recommendation method to make satisfactory recommendations in social networks. Different from existing approaches, we defined trust relationship as a triple, which can be divided into two types—direct trust and indirect trust. By analyzing the factors of trust in a social network, we realized the formalization of a trust relationship. Based on this, we presented an improved recommendation algorithm named IRATR. Experimental results demonstrate that the proposed method can highly improve the accuracy of recommendations over existing methods and effectively deal with cold start and sparsity. Future improvements that need to be addressed are how to combine trust and clustering relationships to further improve algorithm performance, as well as how to study the spreading mechanism of trust to enrich the factors of such trust relationships.
Acknowledgments
This work is supported by the Natural Science Foundation of Hubei Province, China under Grant No. 2016CKB714.
Author Contributions
Hao Tian and Peifeng Liang conceived and designed the experiments; Peifeng Liang performed the experiments; Hao Tian analyzed the data; Peifeng Liang contributed analysis tools; Hao Tian wrote the paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Walter, F.E.; Battiston, S.; Schweitzer, F. A model of a trust-based recommendation system on a social network. Auton. Agents Multi-Agent Syst. 2008, 16, 57–74. [Google Scholar] [CrossRef]
- Liao, Q.; Wang, B.; Ling, Y.; Zhao, J.; Qiu, X. Improved Recommendation System Using Friend Relationship in SNS. Trans. Comput. Collect. Intell. 2015, XIX, 17–31. [Google Scholar]
- Wang, G.; Gui, X. Selecting and trust computing for transaction nodes in online social networks. Jisuanji Xuebao (Chin. J. Comput.) 2013, 36, 368–383. [Google Scholar] [CrossRef]
- Deng, S.; Huang, L.; Xu, G. Social network-based service recommendation with trust enhancement. Expert Syst. Appl. 2014, 41, 8075–8084. [Google Scholar] [CrossRef]
- Can, A.; Bharat, B. Sort: A self-organizing trust model for peer-to-peer systems. IEEE Trans. Dependable Secur. Comput. 2013, 10, 14–27. [Google Scholar] [CrossRef]
- Park, C.; Kim, D.; Oh, J.; Yu, H. Improving top-K recommendation with truster and trustee relationship in user trust network. Inf. Sci. 2016, 374, 100–114. [Google Scholar] [CrossRef]
- Kim, S.; Yoon, Y. Recommendation system for sharing economy based on multidimensional trust model. Multimed. Tools Appl. 2016, 75, 15297–15310. [Google Scholar] [CrossRef]
- Ozsoy, M.G.; Polat, F. Trust based recommendation systems. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara Falls, ON, Canada, 25–28 August 2013; pp. 1267–1274.
- Mohsen, J.; Ester, M. Trustwalker: A random walk model for combining trust-based and item-based recommendation. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, June 2009; pp. 397–406.
- Jamali, M.; Ester, M. Using a trust network to improve top-N recommendation. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 181–188.
- Castillejo, E.; Almeida, A.; López-de-Ipina, D. Social network analysis applied to recommendation systems: Alleviating the cold-user problem. Lect. Notes Comput. Sci. 2012, 7656, 306–313. [Google Scholar]
- Lin, C.; Xie, R.Q.; Guan, X.J.; Li, L.; Li, T. Personalized news recommendation via implicit social experts. Inf. Sci. 2014, 254, 1–18. [Google Scholar] [CrossRef]
- Krauss, C.; Arbanowski, S. Social preference ontologies for enriching user and item data in recommendation systems. In Proceedings of the 14th IEEE International Conference on Data Mining, Shenzhen, China, 14–17 December 2014; pp. 365–372.
- Yilmazel, B.Y.; Kaleli, C. Robustness analysis of arbitrarily distributed data-based recommendation methods. Expert Syst. Appl. 2016, 44, 217–229. [Google Scholar] [CrossRef]
- Wang, G.; Gui, X. DRTEMBB: Dynamic Recommendation Trust Evaluation Model Based on Bidding. J. Multimed. 2012, 7, 279–288. [Google Scholar] [CrossRef]
- Shambour, Q.; Lu, J. A hybrid trust-enhanced collaborative filtering recommendation approach for personalized government-to-business e-services. Int. J. Intell. Syst. 2011, 26, 814–843. [Google Scholar] [CrossRef]
- Alejandro, B.; Parapar, J. Using graph partitioning techniques for neighbor selection in user-based collaborative filtering. In Proceedings of the Sixth ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; pp. 213–216.
- Wang, S.G.; Zheng, Z.B.; Wu, Z.P.; Lyu, M.R.; Yang, F.C. Reputation measurement and malicious feedback rating prevention in web service recommendation systems. IEEE Trans. Serv. Comput. 2015, 8, 755–767. [Google Scholar] [CrossRef]
- Tian, H. Research on User-Centered Web Service Discovery and Its Application in Financial Services; Wuhan University: Wuhan, China, 2014. [Google Scholar]
- Tian, H.; Fan, H.; Du, W. Research on Web service discovery based on user community relations. J. Commun. 2015, 36, 28–36. [Google Scholar]
- Massa, P.; Avesani, P. Trust-aware recommender systems. In Proceedings of the First ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 17–24.
Figure 1.
A trust relation sample.
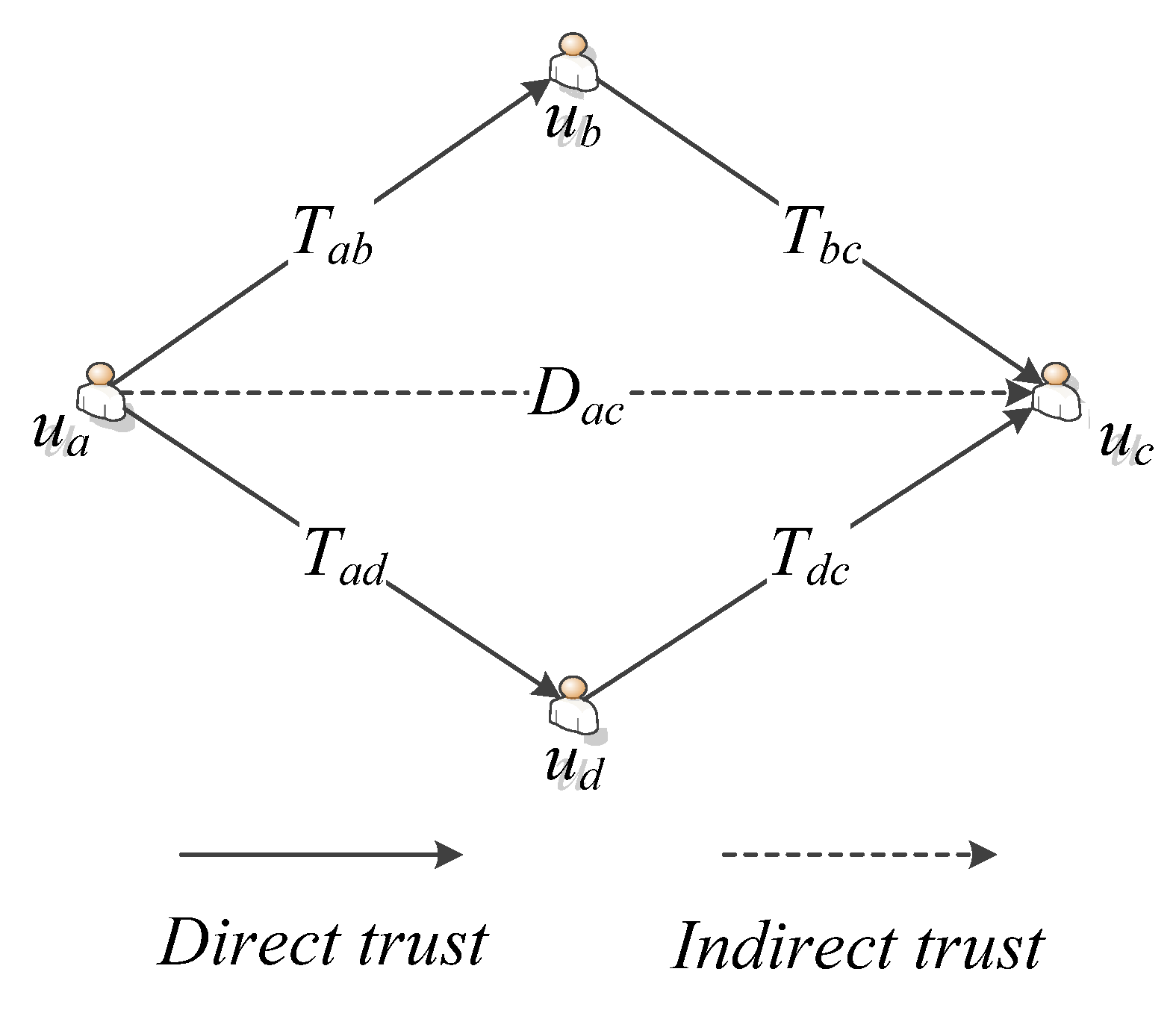
Figure 2.
Comparison on all users.
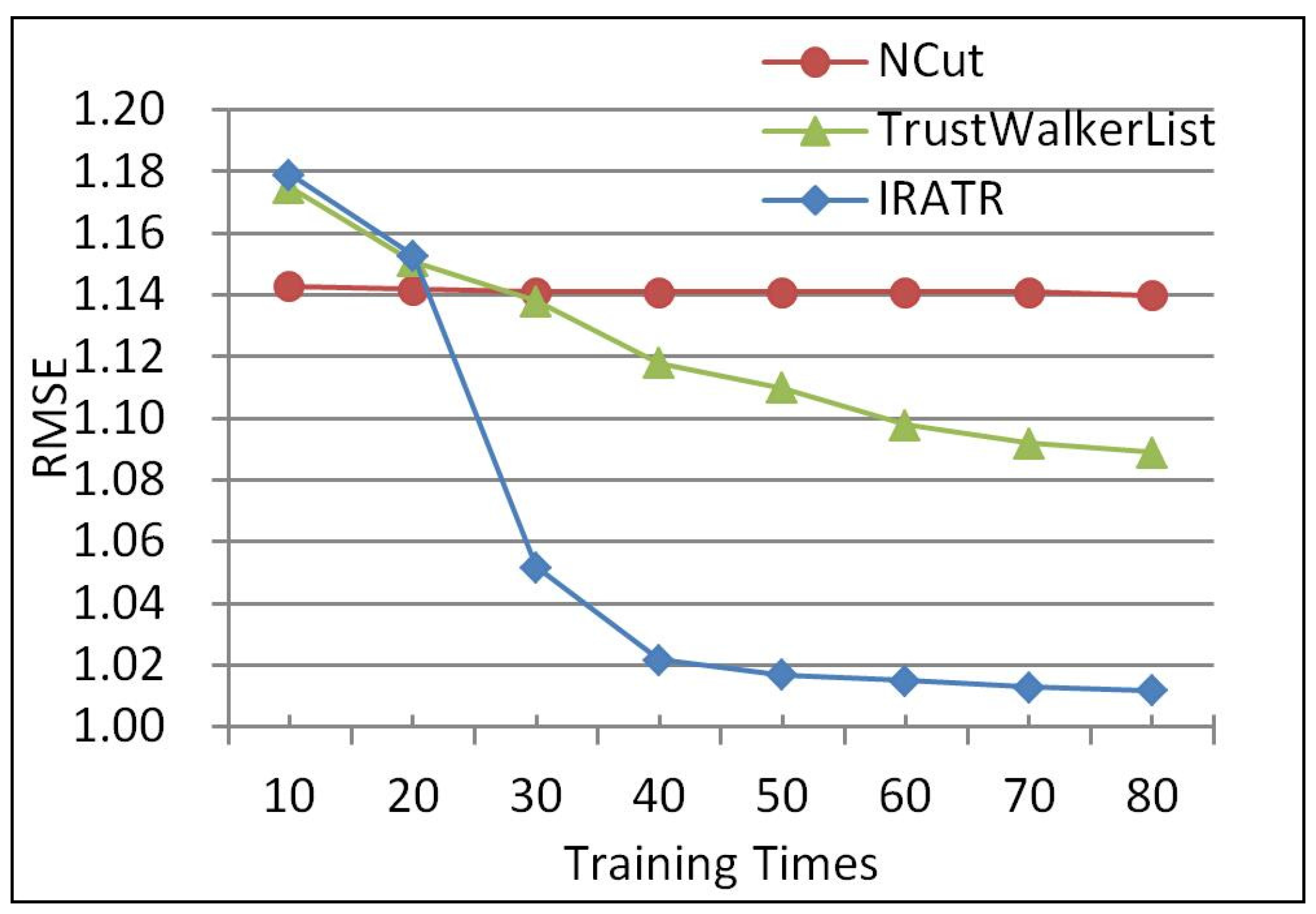
Figure 3.
Comparison on cold start users.
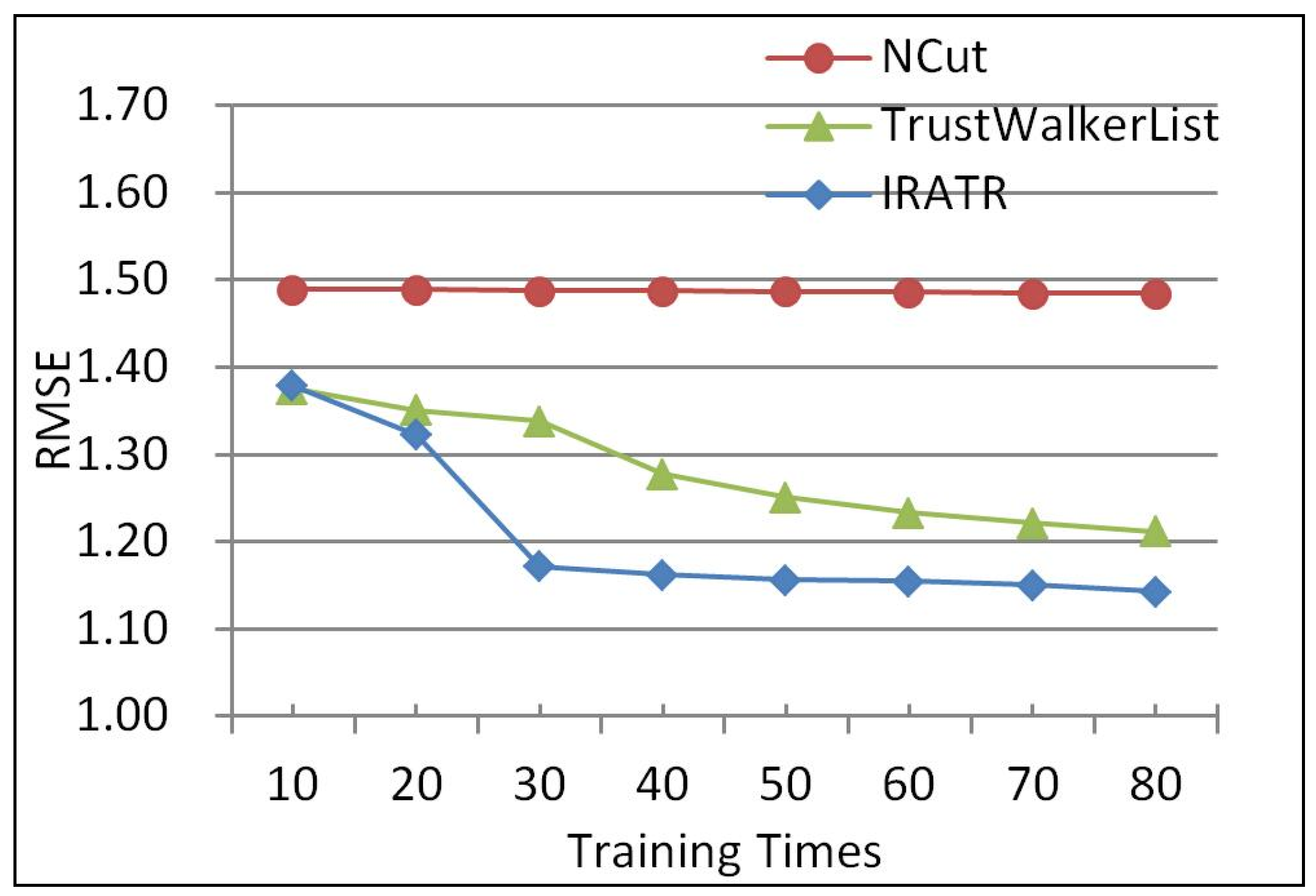
Figure 4.
Comparison at different sparsity.
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tian, H.; Liang, P. Improved Recommendations Based on Trust Relationships in Social Networks. Future Internet 2017, 9, 9. https://doi.org/10.3390/fi9010009
AMA Style
Tian H, Liang P. Improved Recommendations Based on Trust Relationships in Social Networks. Future Internet. 2017; 9(1):9. https://doi.org/10.3390/fi9010009
Chicago/Turabian StyleTian, Hao, and Peifeng Liang. 2017. "Improved Recommendations Based on Trust Relationships in Social Networks" Future Internet 9, no. 1: 9. https://doi.org/10.3390/fi9010009
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.