Forecasting of Energy-Related CO2 Emissions in China Based on GM(1,1) and Least Squares Support Vector Machine Optimized by Modified Shuffled Frog Leaping Algorithm for Sustainability

Abstract
:1. Introduction
- (1)
- In this paper, the CO2 emissions forecasting model based on GM(1,1) and LSSVM optimized by MSFLA (MSFLA-LSSVM) are put forward. First of all, the GM(1,1) model is used to forecast the main influencing factors of CO2 emissions. Then, the MSFLA-LSSVM model is adopted to forecast the CO2 emissions taking the forecasting value of the CO2 emissions influencing factors as the model input. Finally, through empirical analysis, it is verified that the MSFLA-LSSVM model has strong generalization ability and robustness for CO2 emission forecasting and the forecasting accuracy of MSFLA-LSSVM is better than that of SFLA-LSSVM, LSSVM and BP (back propagation) neural network models, which can achieve good forecasting results.
- (2)
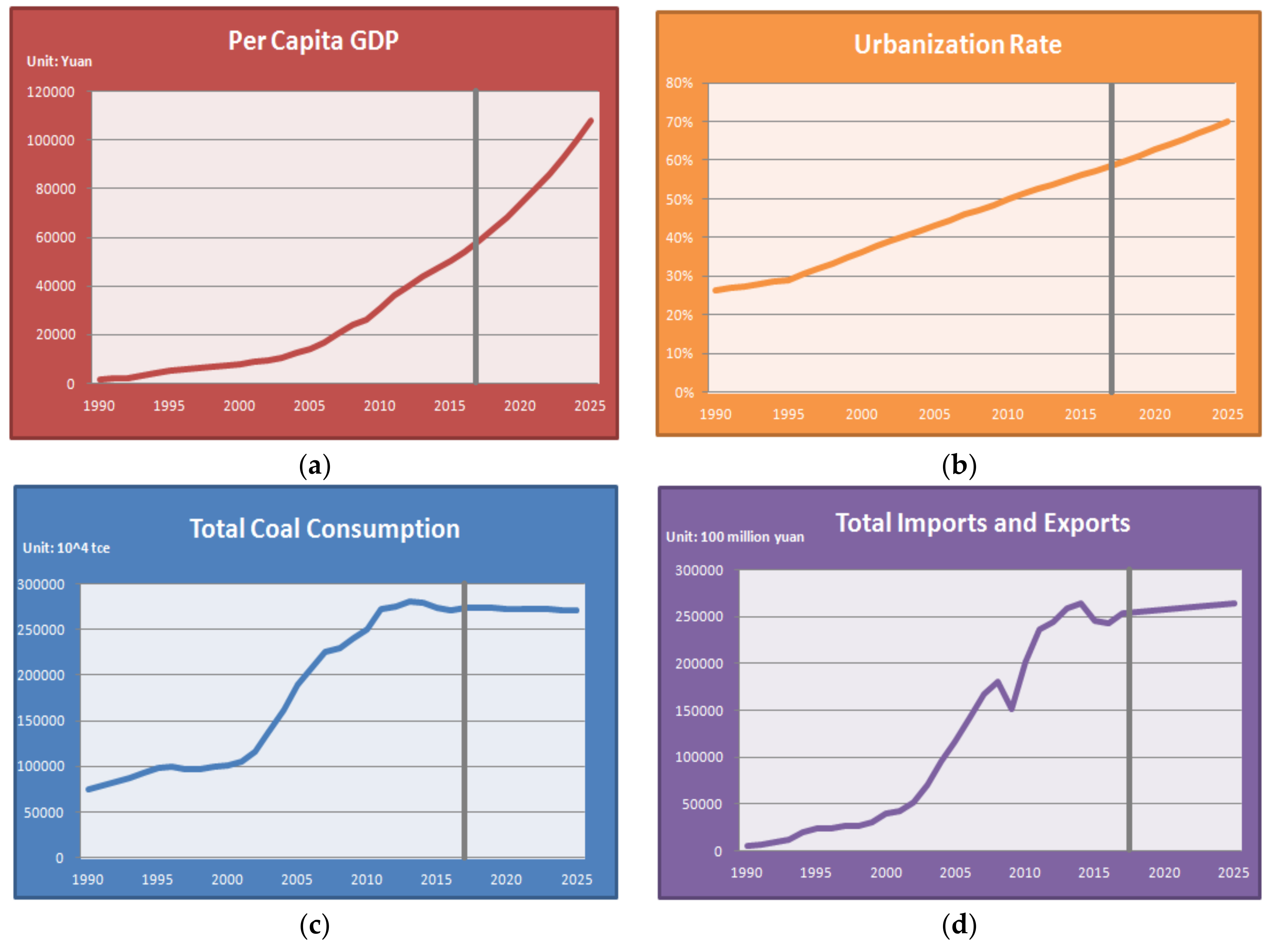
- The forecasting accuracy of CO2 emissions is affected by many factors. Considering population, per capita GDP, urbanization rate, industrial structure, energy consumption structure, energy intensity, total coal consumption, carbon emissions intensity, total imports and exports and other influencing factors of CO2 emissions, the main driving factors of CO2 emissions are screened as the model input according to the sorting of grey relational degrees to realize feature dimension reduction.
2. The Forecasting Model
2.1. GM(1,1)
2.2. LSSVM
2.3. Modified Shuffled Frog Leaping Algorithm
2.3.1. SFLA
2.3.2. MSFLA
2.4. MSFLA-LSSVM
- Step 1:
- Collect and preprocess data;
- Step 2:
- Set parameters of the algorithm and initialize the population;
- Step 3:
- Calculate and sort fitness values of individuals, perform the sub-population division operation;
- Step 4:
- Determine the optimal solution, the worst solution and the global optimal solution of each sub-population. According to the update strategy, the worst frog individuals in sub-populations are updated repeatedly until the maximum of iterations of the sub-population is reached;
- Step 5:
- Calculate the population fitness variance and determine whether the algorithm is lost in the local optimum. If the population falls into the local optimum, perturb and update the global optimal solution;
- Step 6:
- Judge the termination condition of the algorithm. When the global maximum of iterations is reached, the calculation is terminated and the optimal solution is output; otherwise, mix all frog individuals and turn to Step 3;
- Step 7:
- The optimal solution is substituted into the LSSVM model for forecasting.
2.5. The Forecasting Model Based on GM(1,1) and Least Squares Support Vector Machine Optimized by Modified Shuffled Frog Leaping Algorithm
3. Empirical Analysis
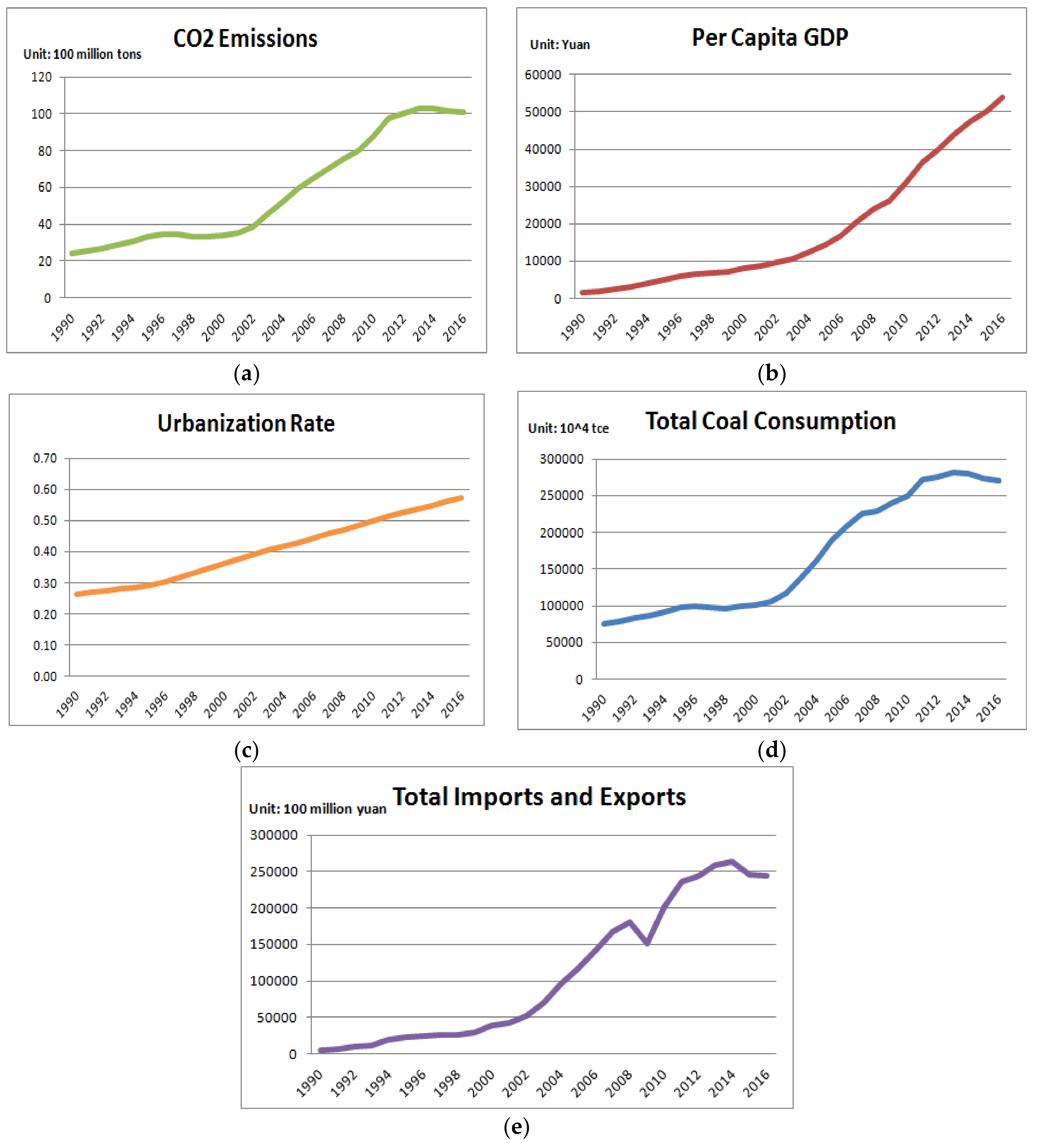
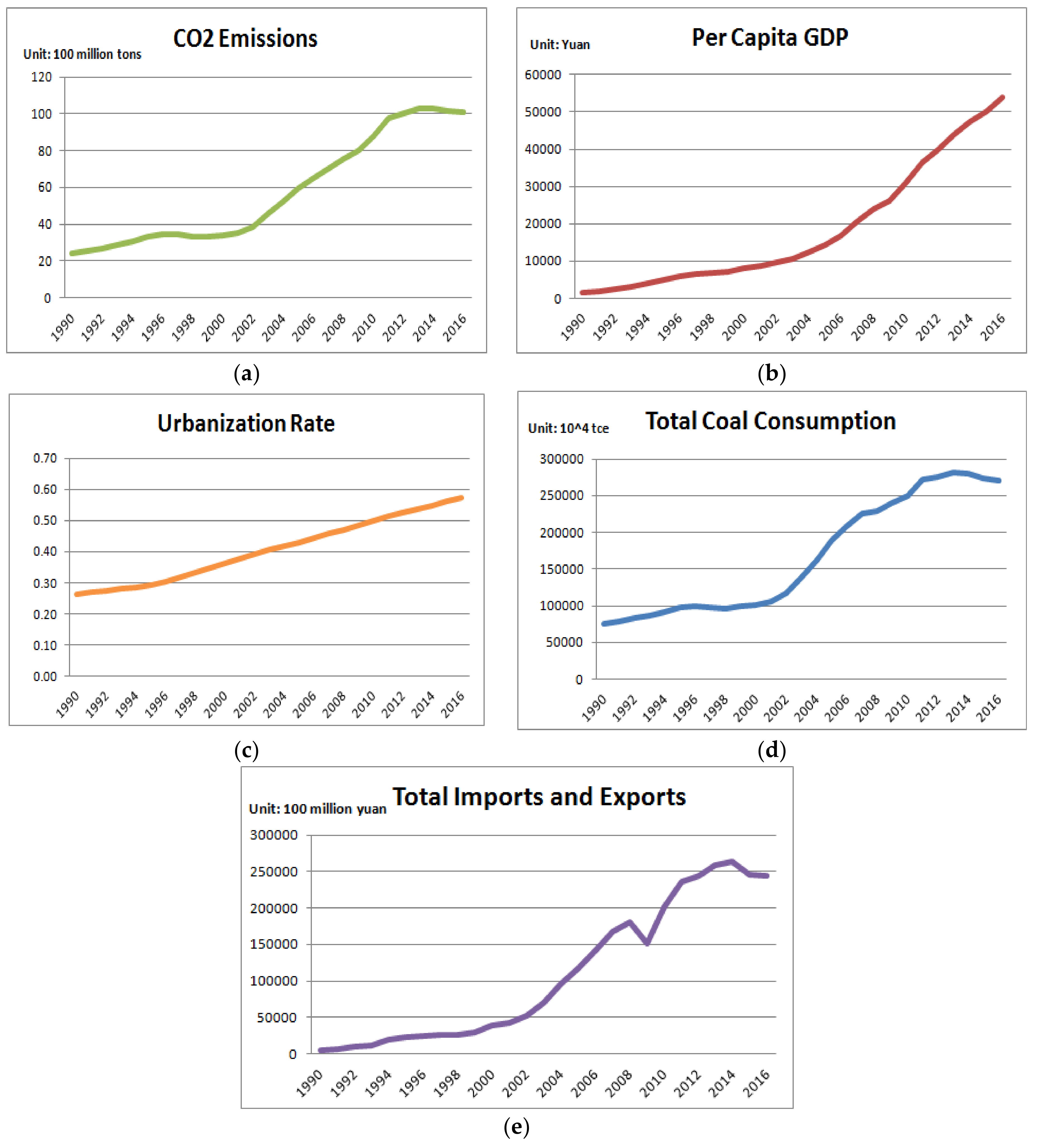
3.1. Screening of Influencing Factors for Model Input
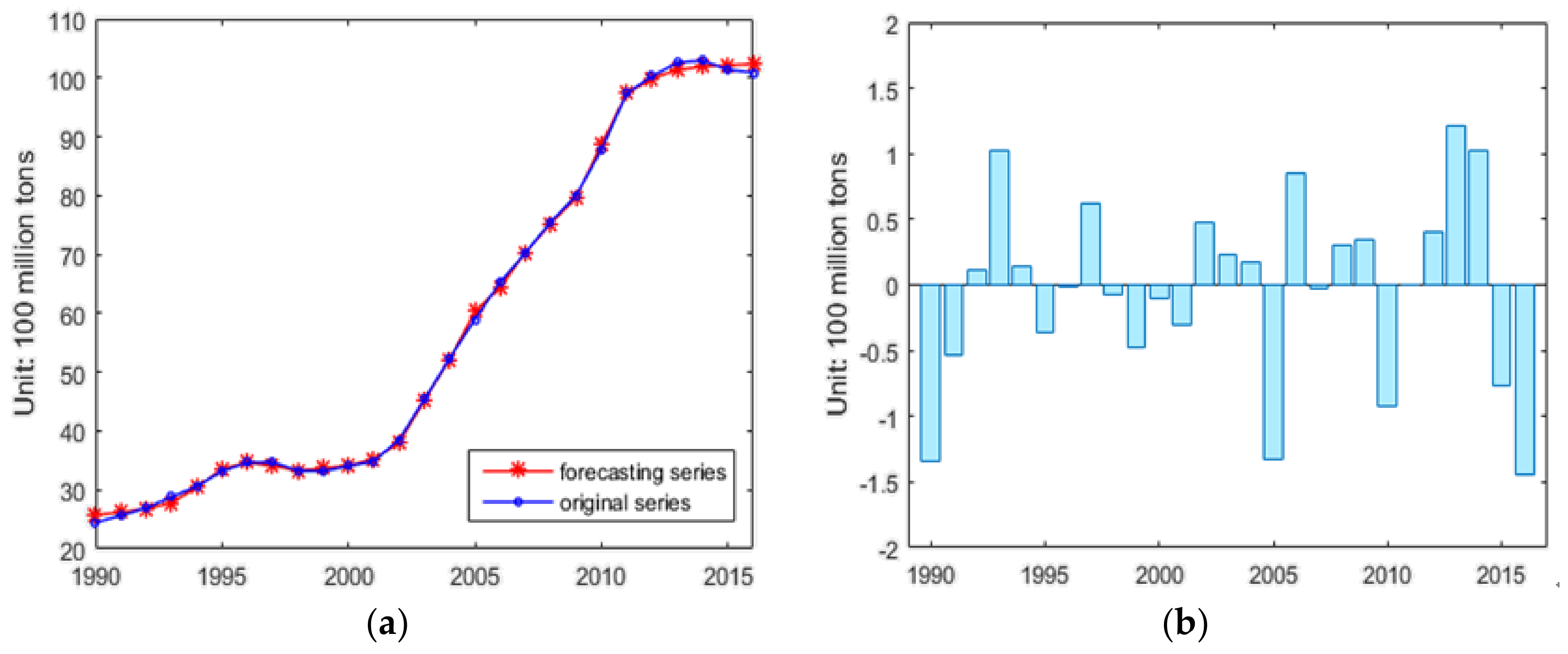
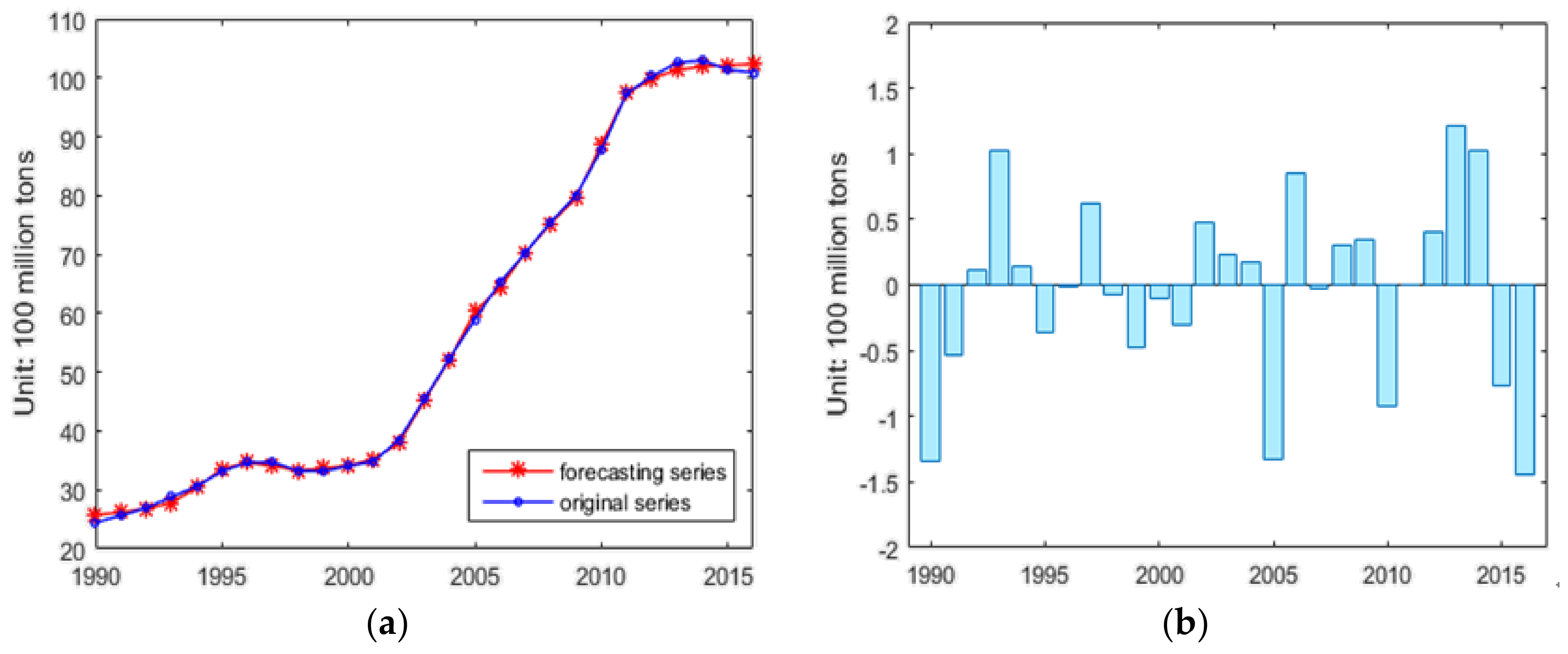
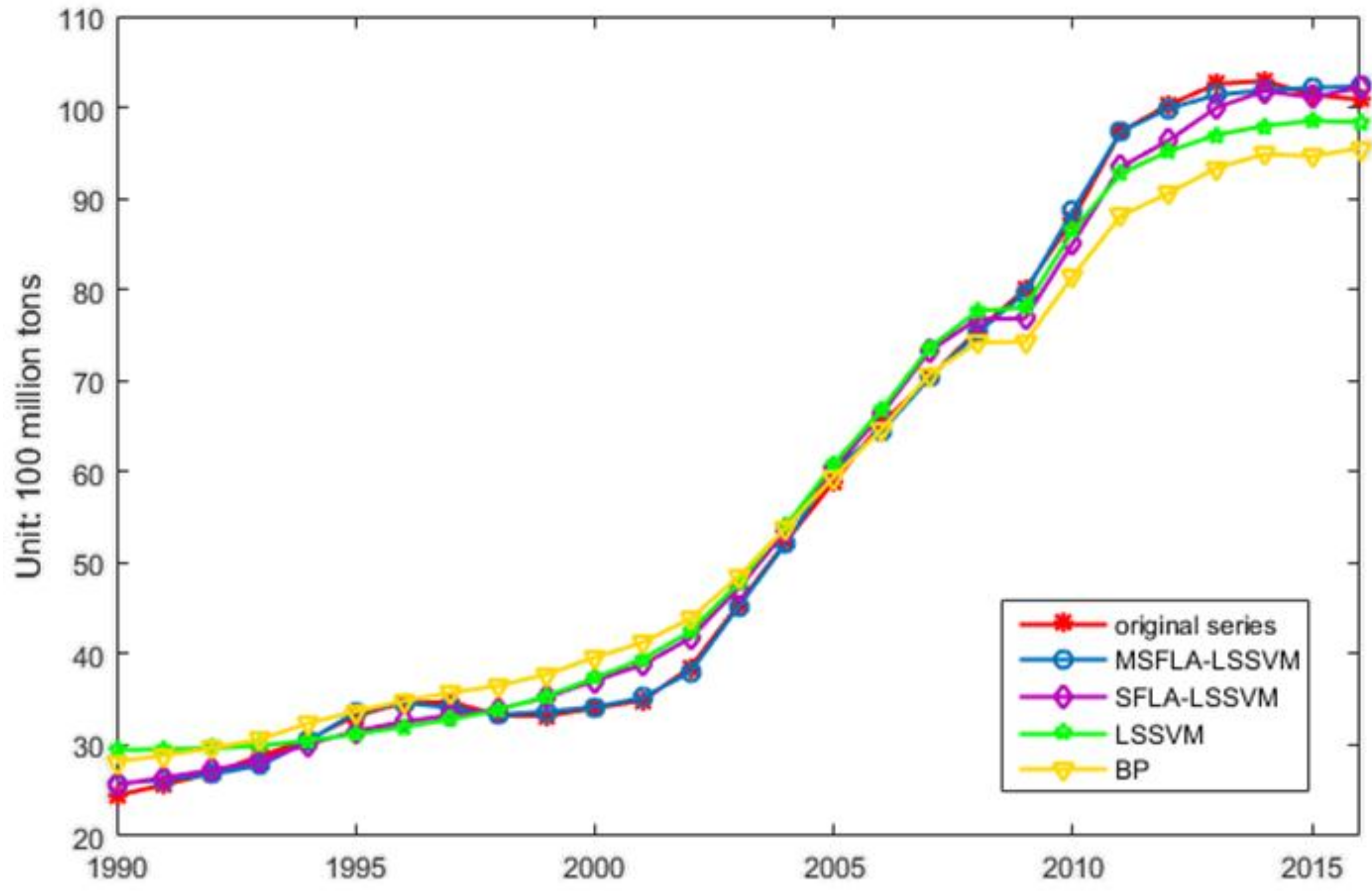
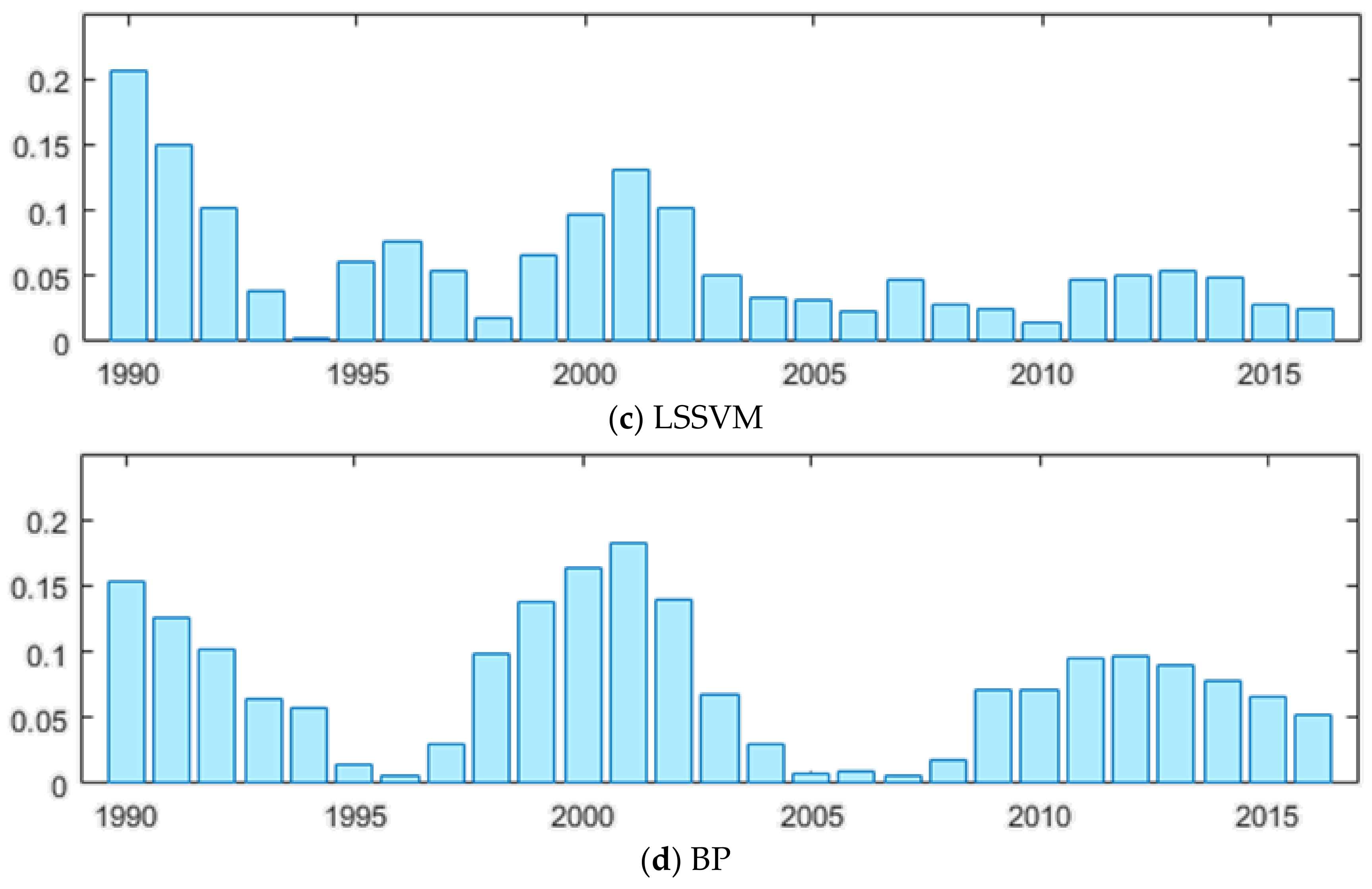
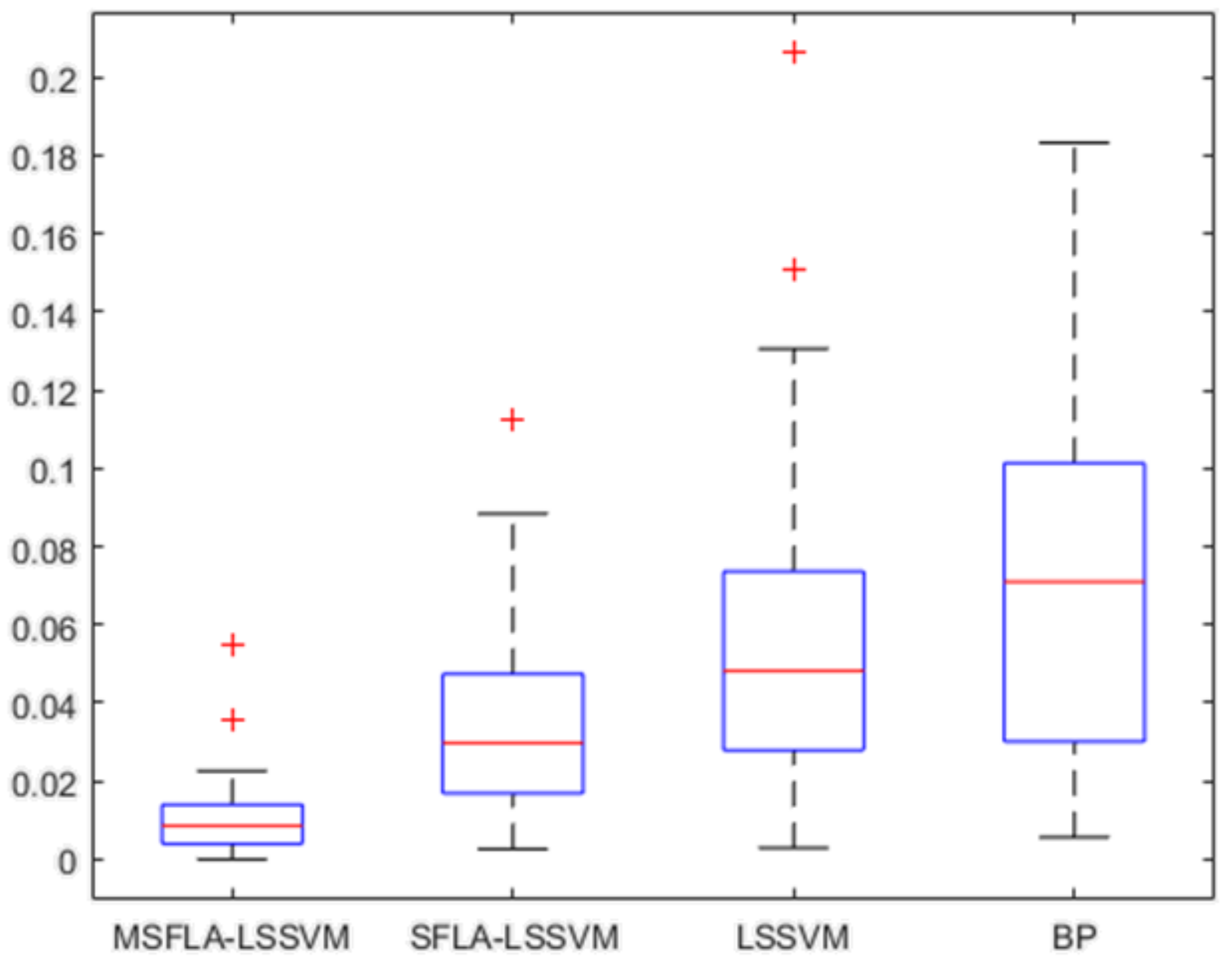
3.2. Forecasting Effect Test for MSFLA-LSSVM Model
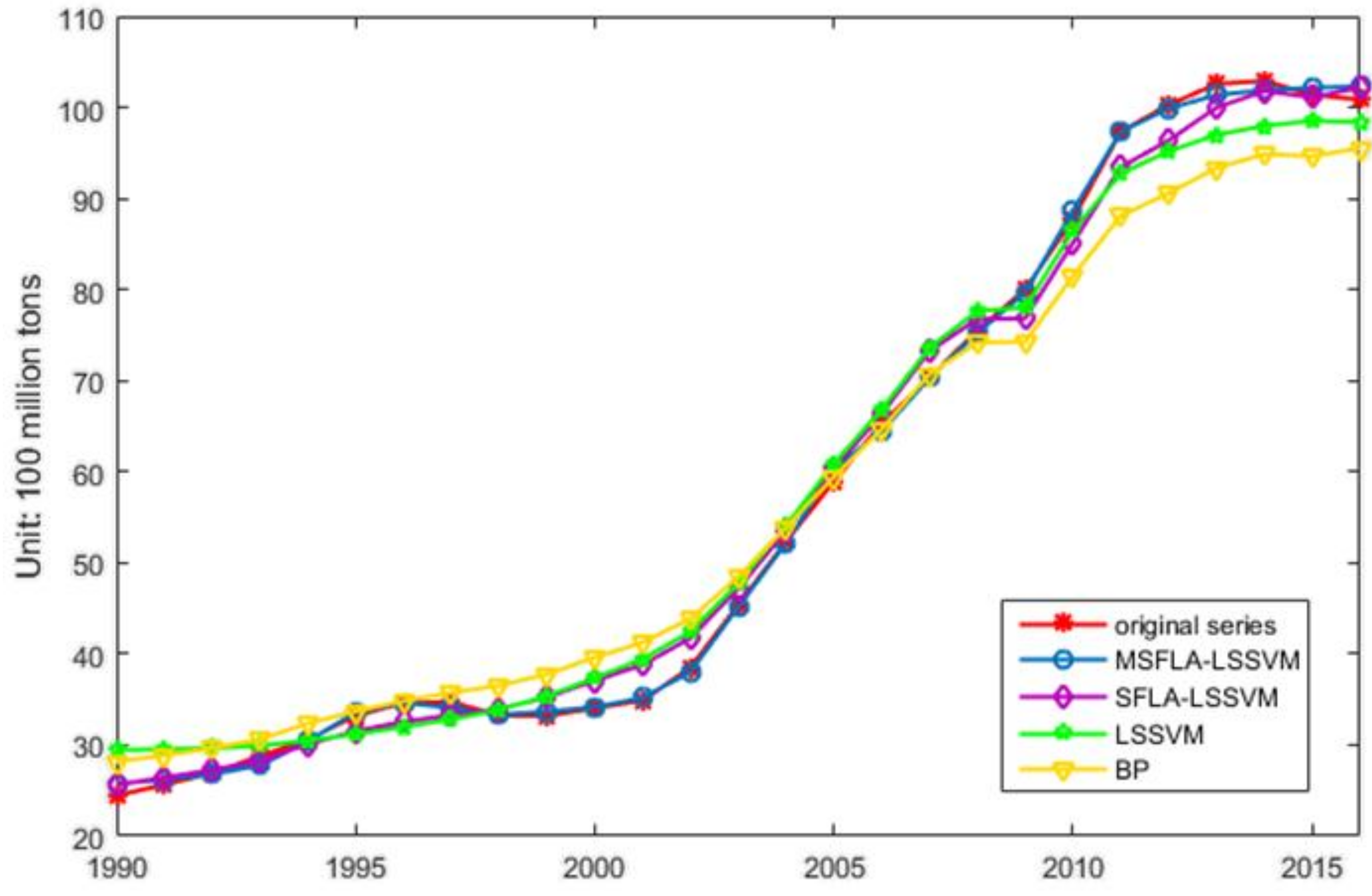
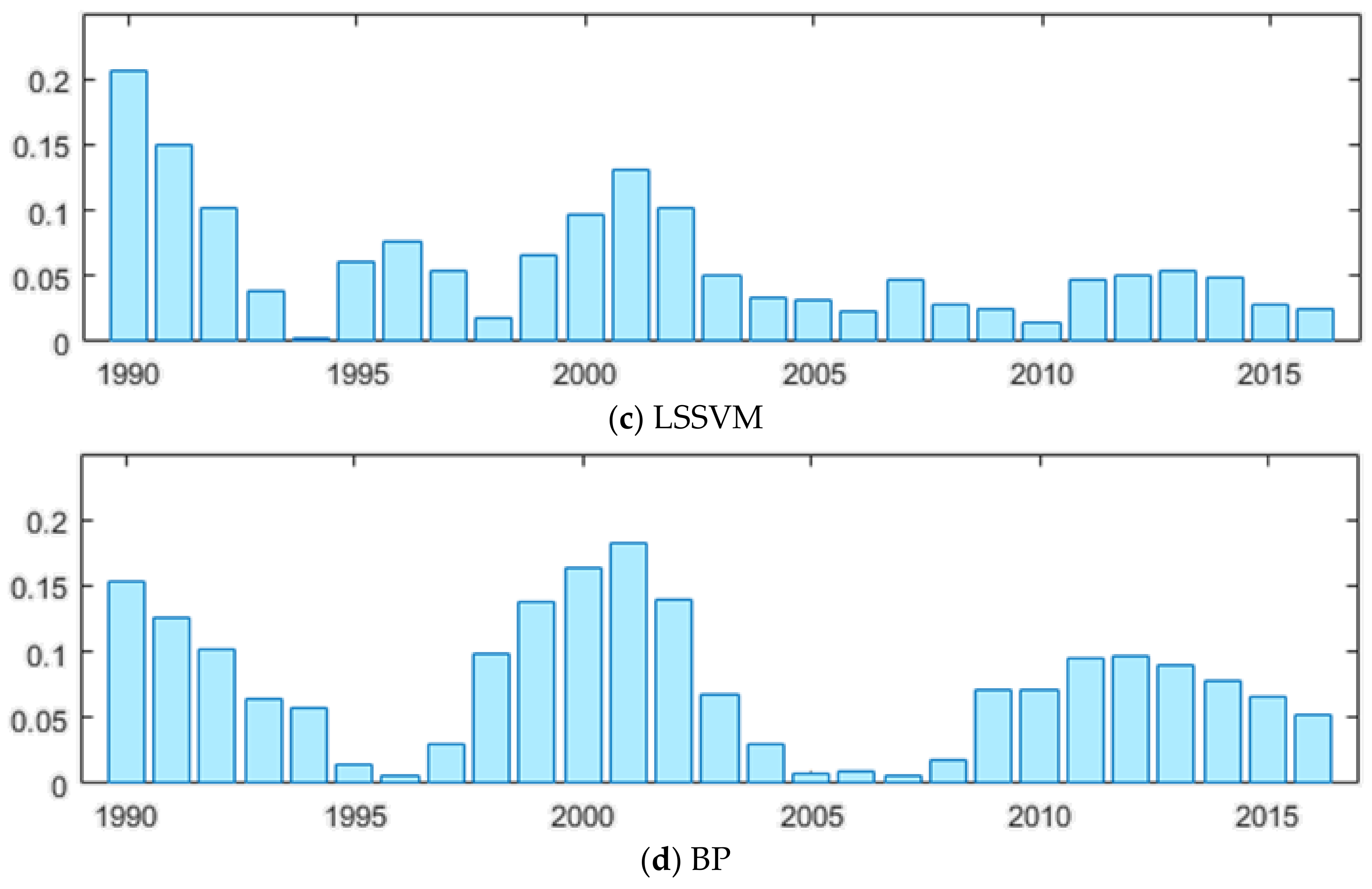
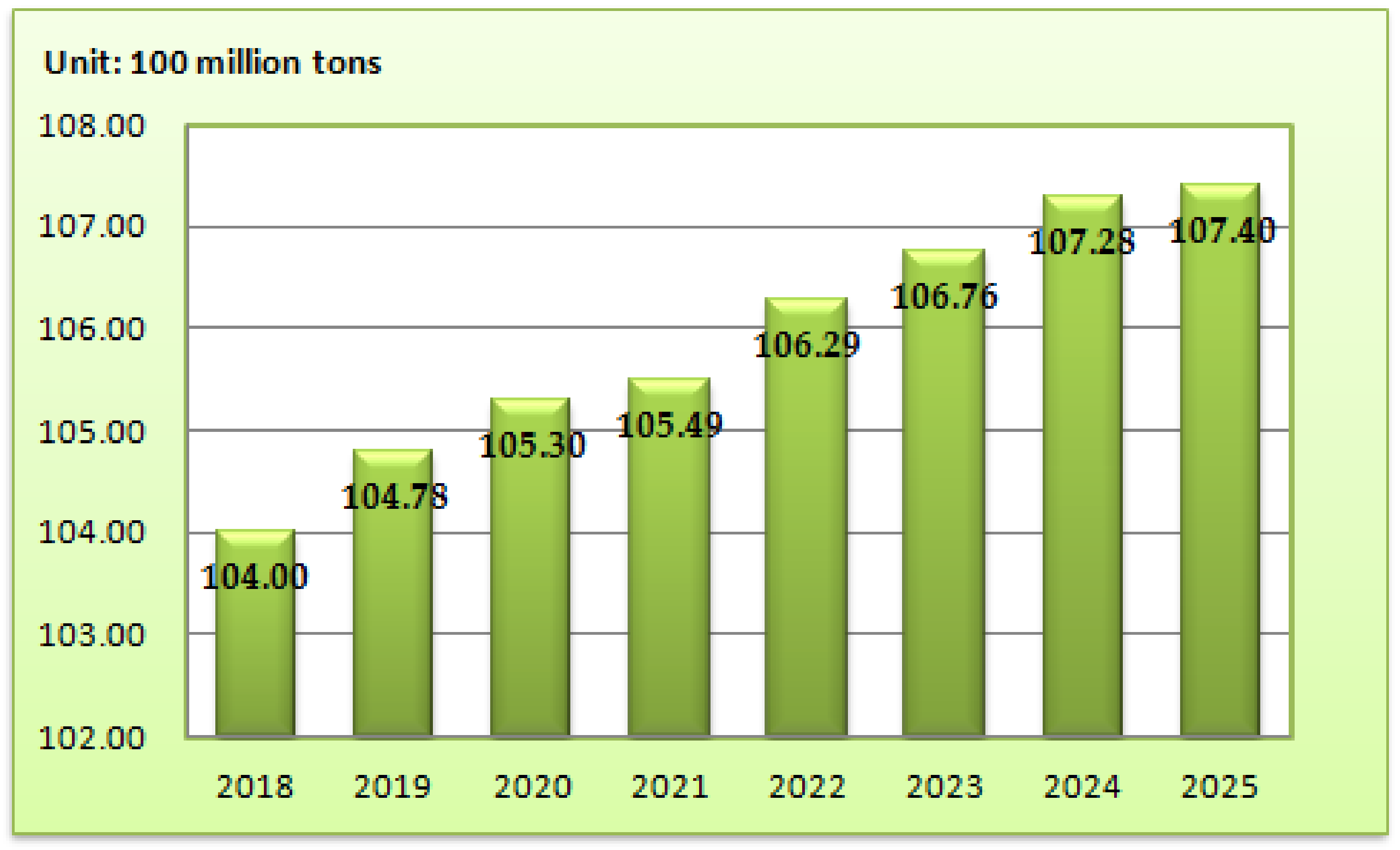
3.3. CO2 Emissions Forecasting Based on GM(1,1) and MSFLA-LSSVM Model
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Safdarnejad, S.M.; Hedengren, J.D.; Baxter, L.L. Plant-level dynamic optimization of Cryogenic Carbon Capture with conventional and renewable power sources. Appl. Energy 2015, 149, 354–366. [Google Scholar] [CrossRef]
- Safdarnejad, S.M.; Hedengren, J.D.; Baxter, L.L. Dynamic optimization of a hybrid system of energy-storing cryogenic carbon capture and a baseline power generation unit. Appl. Energy 2016, 172, 66–79. [Google Scholar] [CrossRef]
- Gopan, A.; Kumfer, B.M.; Phillips, J.; Thimsen, D.; Smith, R.; Axelbaum, R.L. Process design and performance analysis of a Staged, Pressurized Oxy-Combustion (SPOC) power plant for carbon capture. Appl. Energy 2014, 125, 179–188. [Google Scholar] [CrossRef]
- Cohen, S.M.; Rochelle, G.T.; Webber, M.E. Optimizing post-combustion CO2, capture in response to volatile electricity prices. Int. J. Greenh. Gas Control 2012, 8, 180–195. [Google Scholar] [CrossRef]
- Ismail, Z.; Yahaya, A.; Shabri, A. Forecasting Gold Prices Using Multiple Linear Regression Method. Am. J. Appl. Sci. 2009, 6, 1509–1514. [Google Scholar] [CrossRef]
- Liu, D.; Bai, X.; Meng, J. Multiple linear regression forecasting model of total food yield in China based on forward selection variables method. J. Northeast Agric. Univ. 2010, 41, 24–128. [Google Scholar]
- Sehgal, V.; Tiwari, M.K.; Chatterjee, C. Wavelet Bootstrap Multiple Linear Regression Based Hybrid Modeling for Daily River Discharge Forecasting. Water Resour. Manag. 2014, 28, 2793–2811. [Google Scholar] [CrossRef]
- Ming, Z.; Liu, D.; Kaiyan, D.; Song, X.; Yulong, L.; Haiyan, Z. Pre-integrated Forecasting Method Research of Urban Electricity Consumption Based on System Dynamics and Econometric Model. J. Appl. Sci. 2013, 13, 4732–4737. [Google Scholar] [CrossRef]
- Dyson, B.; Chang, N.B. Forecasting municipal solid waste generation in a fast-growing urban region with system dynamics modeling. Waste Manag. 2005, 25, 669–679. [Google Scholar] [CrossRef]
- Venkatesan, A.K.; Ahmad, S.; Johnson, W.; Batista, J.R. Systems dynamic model to forecast salinity load to the Colorado River due to urbanization within the Las Vegas Valley. Sci. Total Environ. 2011, 409, 2616–2625. [Google Scholar] [CrossRef]
- Hsu, C.C.; Chen, C.Y. Applications of improved grey prediction model for power demand forecasting. Energy Convers. Manag. 2003, 44, 2241–2249. [Google Scholar] [CrossRef]
- Lee, Y.S.; Tong, L.I. Forecasting energy consumption using a grey model improved by incorporating genetic programming. Energy Convers. Manag. 2011, 52, 147–152. [Google Scholar] [CrossRef]
- Matjafri, M.Z.; Lim, H.S. Prediction models for CO2 emission in Malaysia using best subsets regression and multi-linear regression. SPIE Proc. 2015, 9638, 12. [Google Scholar] [CrossRef]
- Zhong, Q. Prediction of energy consumption and CO2 emission by system dynamics approach. Chin. J. Eco-Agric. 2008, 16, 1043–1047. [Google Scholar] [CrossRef]
- Lin, C.S.; Liou, F.M.; Huang, C.P. Grey forecasting model for CO2 emissions: A Taiwan study. Adv. Mater. Res. 2011, 88, 3816–3820. [Google Scholar] [CrossRef]
- Huang, D.Z.; Gong, R.X.; Gong, S. Prediction of Wind Power by Chaos and BP Artificial Neural Networks Approach Based on Genetic Algorithm. J. Electr. Eng. Technol. 2015, 10, 41–46. [Google Scholar] [CrossRef]
- Bin, H.; Zu, Y.X.; Zhang, C. A Forecasting Method of Short-Term Electric Power Load Based on BP Neural Network. Appl. Mech. Mater. 2014, 538, 247–250. [Google Scholar] [CrossRef]
- Narayanakumar, S.; Raja, K. A BP Artificial Neural Network Model for Earthquake Magnitude Prediction in Himalayas, India. Circuits Syst. 2016, 7, 3456–3468. [Google Scholar] [CrossRef]
- Yang, J.F.; Cheng, H.Z. Application of SVM to power system short-term load forecast. Electr. Power Autom. Equip. 2004, 24, 30–32. [Google Scholar]
- Hong, W.C. Electric load forecasting by support vector model. Appl. Math. Model. 2009, 33, 2444–2454. [Google Scholar] [CrossRef]
- Gallo, C.; Contò, F.; Fiore, M. A Neural Network Model for Forecasting CO2 Emission. AGRIS Econ. Inform. 2014, 6, 31. [Google Scholar]
- Zhou, J.G.; Zhang, X.G. Projections about Chinese CO2 emissions based on rough sets and gray support vector machine. China Environ. Sci. 2013, 33, 2157–2163. [Google Scholar]
- De Giorgi, M.G.; Malvoni, M.; Congedo, P.M. Comparison of strategies for multi-step ahead photovoltaic power forecasting models based on hybrid group method of data handling networks and least square support vector machine. Energy 2016, 107, 360–373. [Google Scholar] [CrossRef]
- Li, X.; Wang, X.; Zheng, Y.H.; Li, L.X.; Zhou, L.D.; Sheng, X.K. Short-Term Wind Power Forecasting Based on Least-Square Support Vector Machine (LSSVM). Appl. Mech. Mater. 2013, 448, 1825–1828. [Google Scholar] [CrossRef]
- Zhao, H.; Guo, S.; Zhao, H. Energy-Related CO2 Emissions Forecasting Using an Improved LSSVM Model Optimized by Whale Optimization Algorithm. Energies 2017, 10, 874. [Google Scholar] [CrossRef]
- Yang, W.; Li, Q. Survey on Particle Swarm Optimization Algorithm. Eng. Sci. 2004, 6, 87–94. [Google Scholar]
- Trelea, I.C. The particle swarm optimization algorithm: Convergence analysis and parameter selection. Inform. Process. Lett. 2016, 85, 317–325. [Google Scholar] [CrossRef]
- Zwickl, D.J. Genetic algorithm approaches for the phylogenetic analysis of large biological sequence datasets under the maximum likelihood criterion. Diss. Theses Gradworks 2006, 3, 257–260. [Google Scholar]
- Deb, K. An efficient constraint handling method for genetic algorithms. Comput. Meth. Appl. Mech. Eng. 2000, 186, 311–338. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Akay, B.; Karaboga, D. A modified Artificial Bee Colony algorithm for real-parameter optimization. Inform. Sciences 2012, 192, 120–142. [Google Scholar] [CrossRef]
- Wang, B.Y.; Wang, D.Y.; Zhang, S.M. A Short-Term Distributed Load Forecasting Algorithm Based on Spark and IPPSO_LSSVM. Appl. Mech. Mater. 2015, 713–715, 1385–1388. [Google Scholar]
- Wen, T.; Tang, H.; Wang, Y.; Lin, C.Y.; Xiong, C.R. Landslide displacement prediction using the GA-LSSVM model and time series analysis: A case study of Three Gorges Reservoir, China. Nat. Hazard Earth Syst. Sci. 2017, 17, 2181–2198. [Google Scholar] [CrossRef]
- Mustaffa, Z.; Yusof, Y. Optimizing LSSVM using ABC for non-volatile financial prediction. Aust. J. Basic Appl. Sci. 2011, 7, 549. [Google Scholar]
- Eusuff, M.M.; Lansey, K.E. Optimization of Water Distribution Network Design Using the Shuffled Frog Leaping Algorithm. J. Water Resour. Plan. Manag. 2003, 129, 210–225. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, Q.; Jia, M. Improved shuffled frog leaping algorithm-based BP neural network and its application in bearing early fault diagnosis. Neural Comput. Appl. 2016, 27, 375–385. [Google Scholar] [CrossRef]
- Pan, Q.K.; Wang, L.; Gao, L.; Li, J. An effective shuffled frog-leaping algorithm for lot-streaming flow shop scheduling problem. Int. J. Adv. Manuf. Technol. 2011, 52, 699–713. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Influencing Factor | Grey Relational Degree |
|---|---|
| Population | 0.7752 |
| Per capita GDP | 0.8218 |
| Urbanization rate | 0.8516 |
| Industrial structure | 0.7584 |
| Energy consumption structure | 0.7513 |
| Energy intensity | 0.6546 |
| Total coal consumption | 0.9631 |
| Carbon emissions intensity | 0.6517 |
| Total imports and exports | 0.8116 |
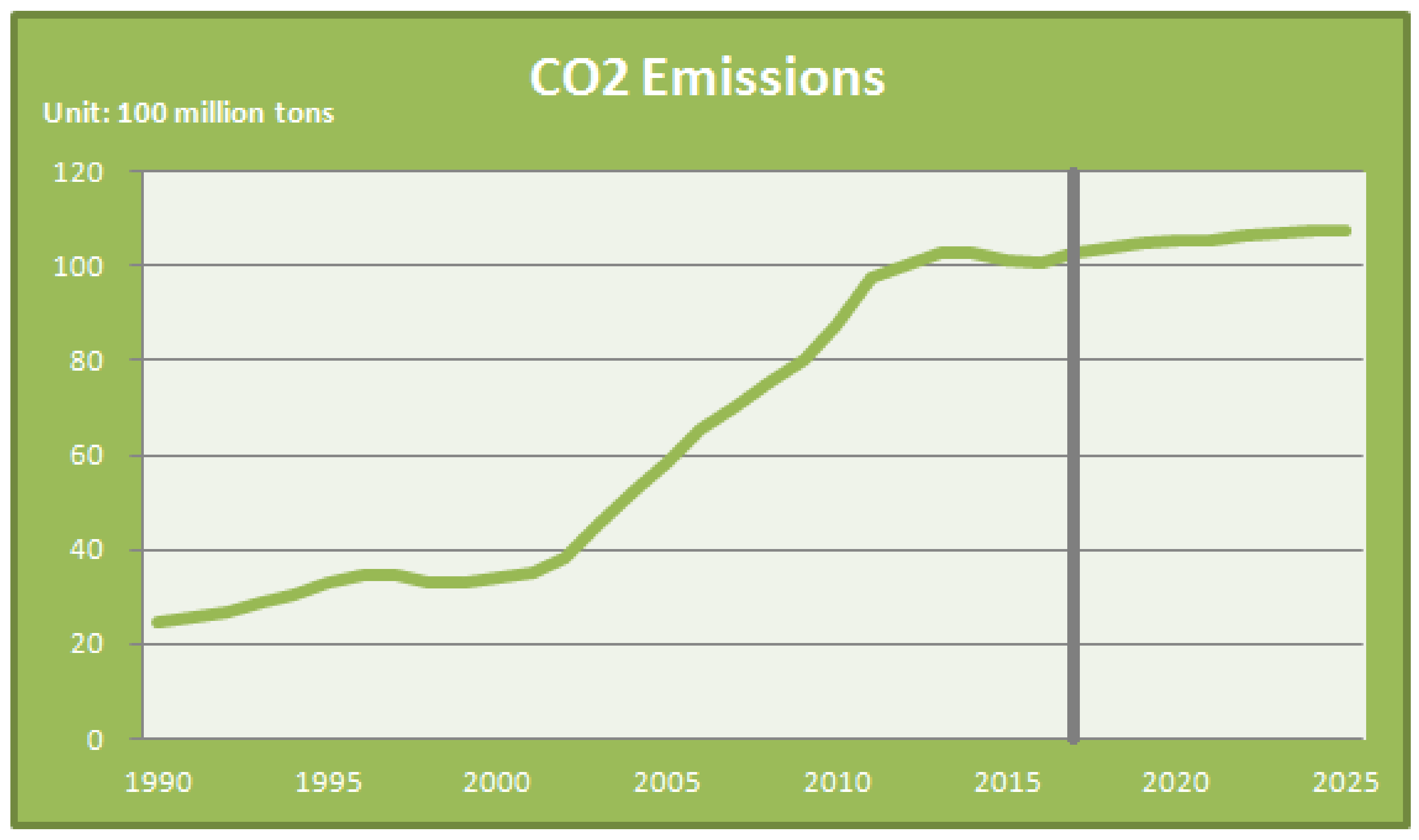
| Year | Actual Value (100 Million Tons) | Forecasting Value (100 Million Tons) | RE (%) |
|---|---|---|---|
| 1990 | 24.42 | 25.7652 | 5.4901 |
| 1991 | 25.66 | 26.1883 | 2.0751 |
| 1992 | 26.90 | 26.7878 | 0.4341 |
| 1993 | 28.79 | 27.7606 | 3.5654 |
| 1994 | 30.58 | 30.4319 | 0.4920 |
| 1995 | 33.20 | 33.5666 | 1.0954 |
| 1996 | 34.63 | 34.6415 | 0.0306 |
| 1997 | 34.70 | 34.0794 | 1.7745 |
| 1998 | 33.24 | 33.3170 | 0.2214 |
| 1999 | 33.18 | 33.6607 | 1.4469 |
| 2000 | 34.05 | 34.1477 | 0.2816 |
| 2001 | 34.88 | 35.1770 | 0.8640 |
| 2002 | 38.50 | 38.0218 | 1.2489 |
| 2003 | 45.40 | 45.1682 | 0.5197 |
| 2004 | 52.34 | 52.1643 | 0.3270 |
| 2005 | 58.97 | 60.3021 | 2.2597 |
| 2006 | 65.29 | 64.4434 | 1.3010 |
| 2007 | 70.31 | 70.3398 | 0.0452 |
| 2008 | 75.53 | 75.2229 | 0.4075 |
| 2009 | 80.01 | 79.6572 | 0.4411 |
| 2010 | 87.76 | 88.6834 | 1.0517 |
| 2011 | 97.34 | 97.3347 | 0.0007 |
| 2012 | 100.29 | 99.8869 | 0.3977 |
| 2013 | 102.58 | 101.3635 | 1.1859 |
| 2014 | 102.92 | 101.9012 | 0.9892 |
| 2015 | 101.38 | 102.1496 | 0.7591 |
| 2016 | 100.87 | 102.3212 | 1.4387 |
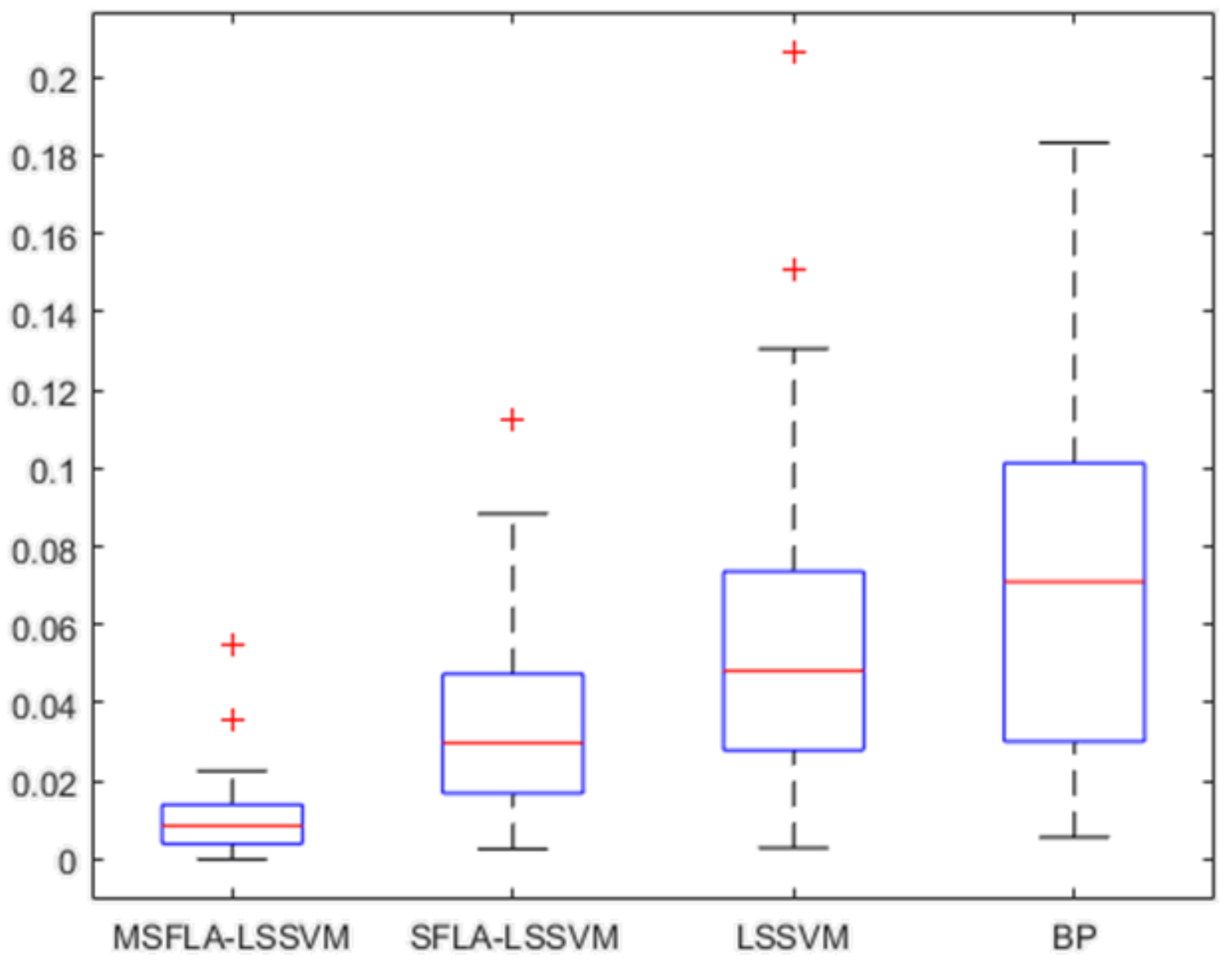
| Model | MAPE (%) | RMSE (100 Million Tons) | MAE (100 Million Tons) |
|---|---|---|---|
| MSFLA-LSSVM | 1.1165 | 0.7013 | 0.5425 |
| SFLA-LSSVM | 3.7209 | 2.1616 | 1.8467 |
| LSSVM | 5.9740 | 3.1515 | 2.8041 |
| BP | 7.5416 | 4.9479 | 3.9981 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, S.; Niu, D.; Han, Y. Forecasting of Energy-Related CO2 Emissions in China Based on GM(1,1) and Least Squares Support Vector Machine Optimized by Modified Shuffled Frog Leaping Algorithm for Sustainability. Sustainability 2018, 10, 958. https://doi.org/10.3390/su10040958
Dai S, Niu D, Han Y. Forecasting of Energy-Related CO2 Emissions in China Based on GM(1,1) and Least Squares Support Vector Machine Optimized by Modified Shuffled Frog Leaping Algorithm for Sustainability. Sustainability. 2018; 10(4):958. https://doi.org/10.3390/su10040958
Chicago/Turabian StyleDai, Shuyu, Dongxiao Niu, and Yaru Han. 2018. "Forecasting of Energy-Related CO2 Emissions in China Based on GM(1,1) and Least Squares Support Vector Machine Optimized by Modified Shuffled Frog Leaping Algorithm for Sustainability" Sustainability 10, no. 4: 958. https://doi.org/10.3390/su10040958