An Object-Based Image Analysis Method for Enhancing Classification of Land Covers Using Fully Convolutional Networks and Multi-View Images of Small Unmanned Aerial System



Abstract
:
1. Introduction
2. Study Area and Data Preprocessing
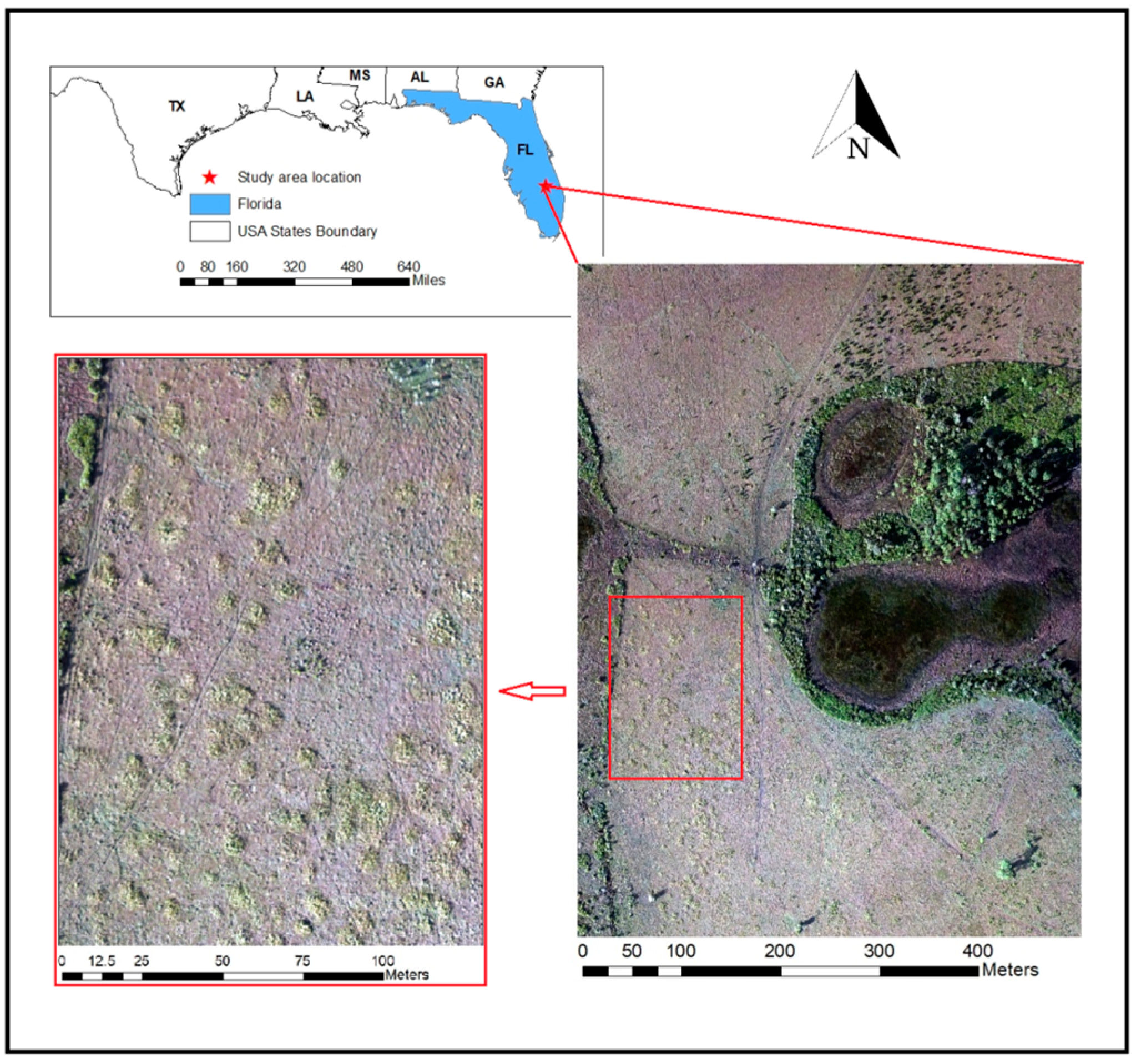
2.1. Study Area
2.2. UAS Image Acquisition and Preprocessing
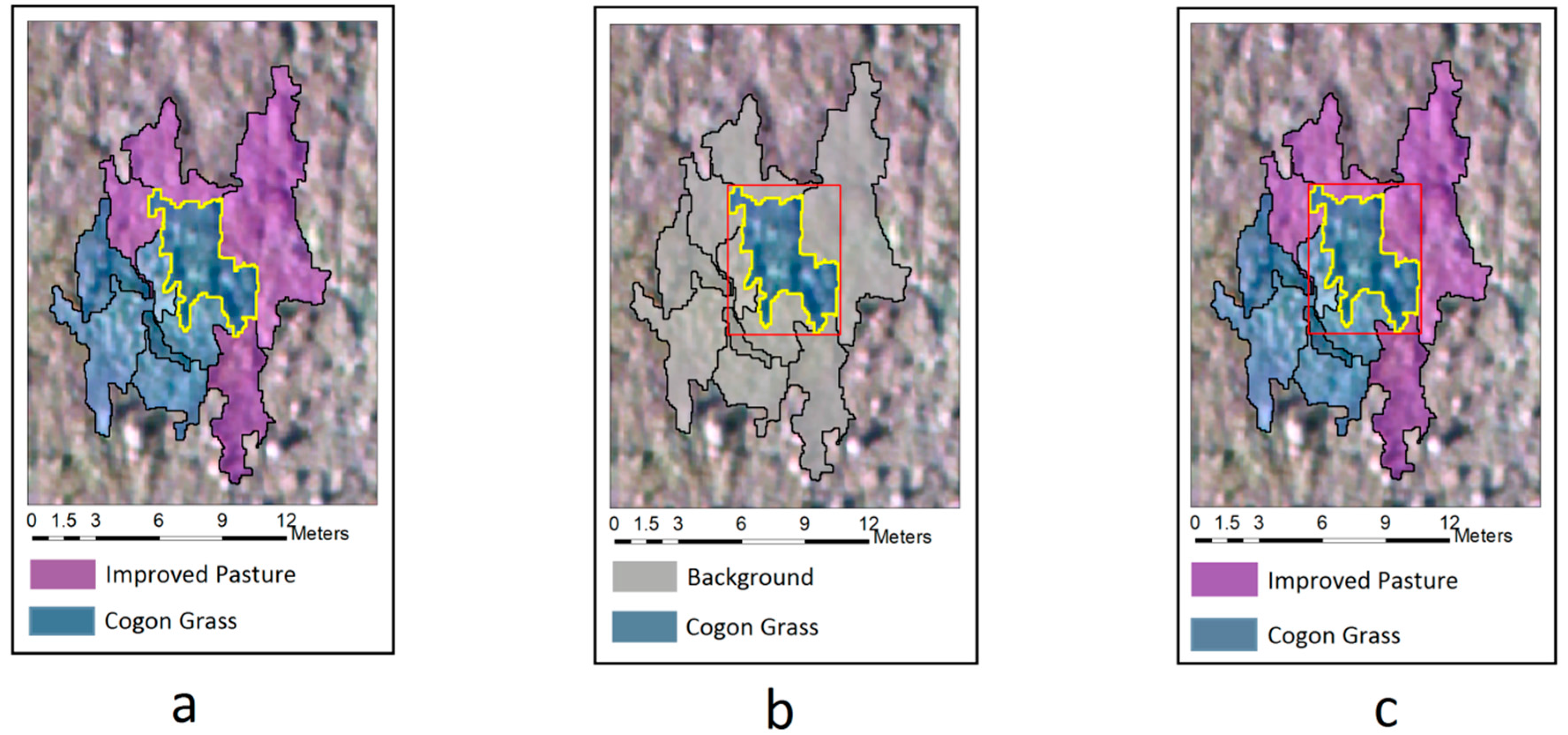
2.3. Orthoimage Creation and Segmentation
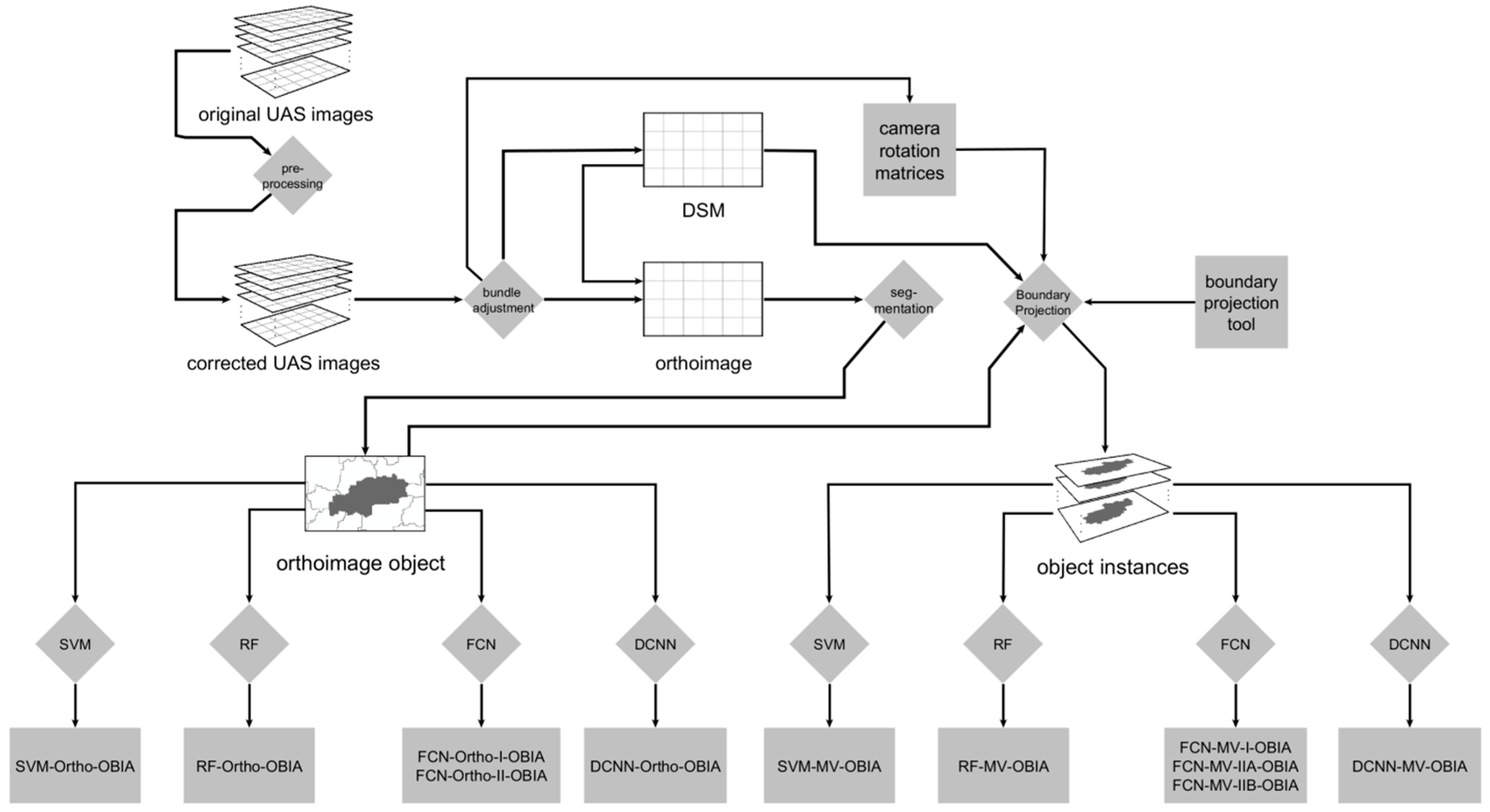
3. Methods
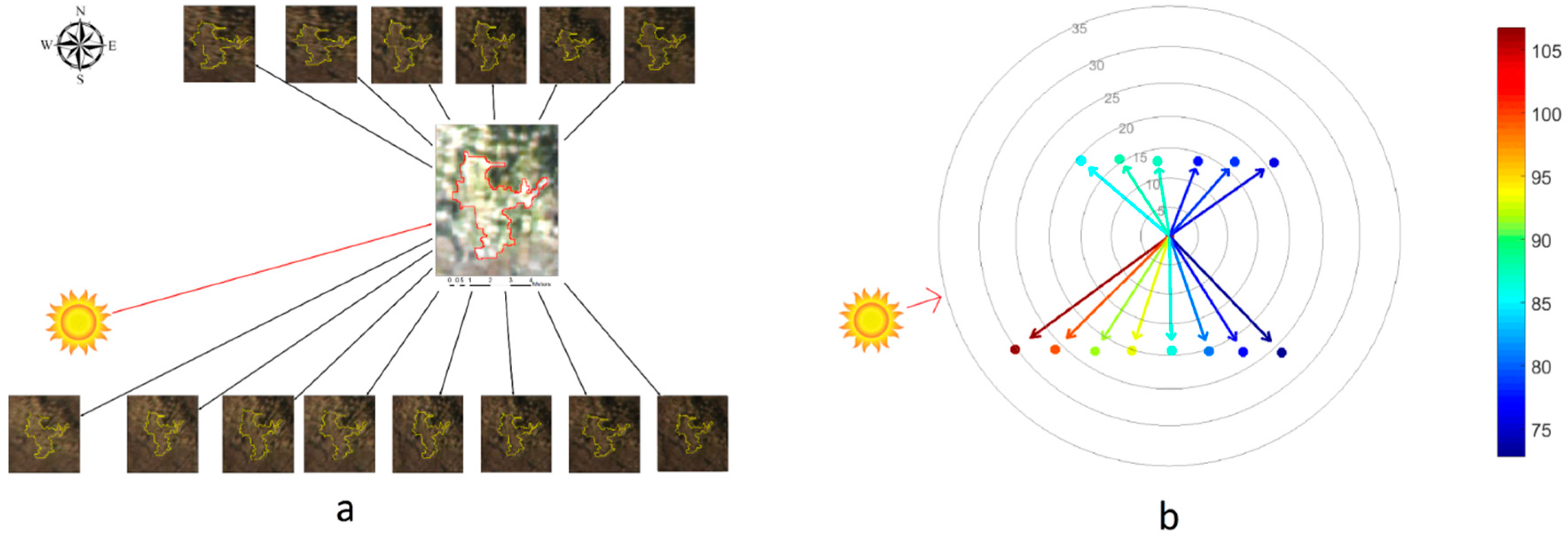
3.1. Multiview Data Generation
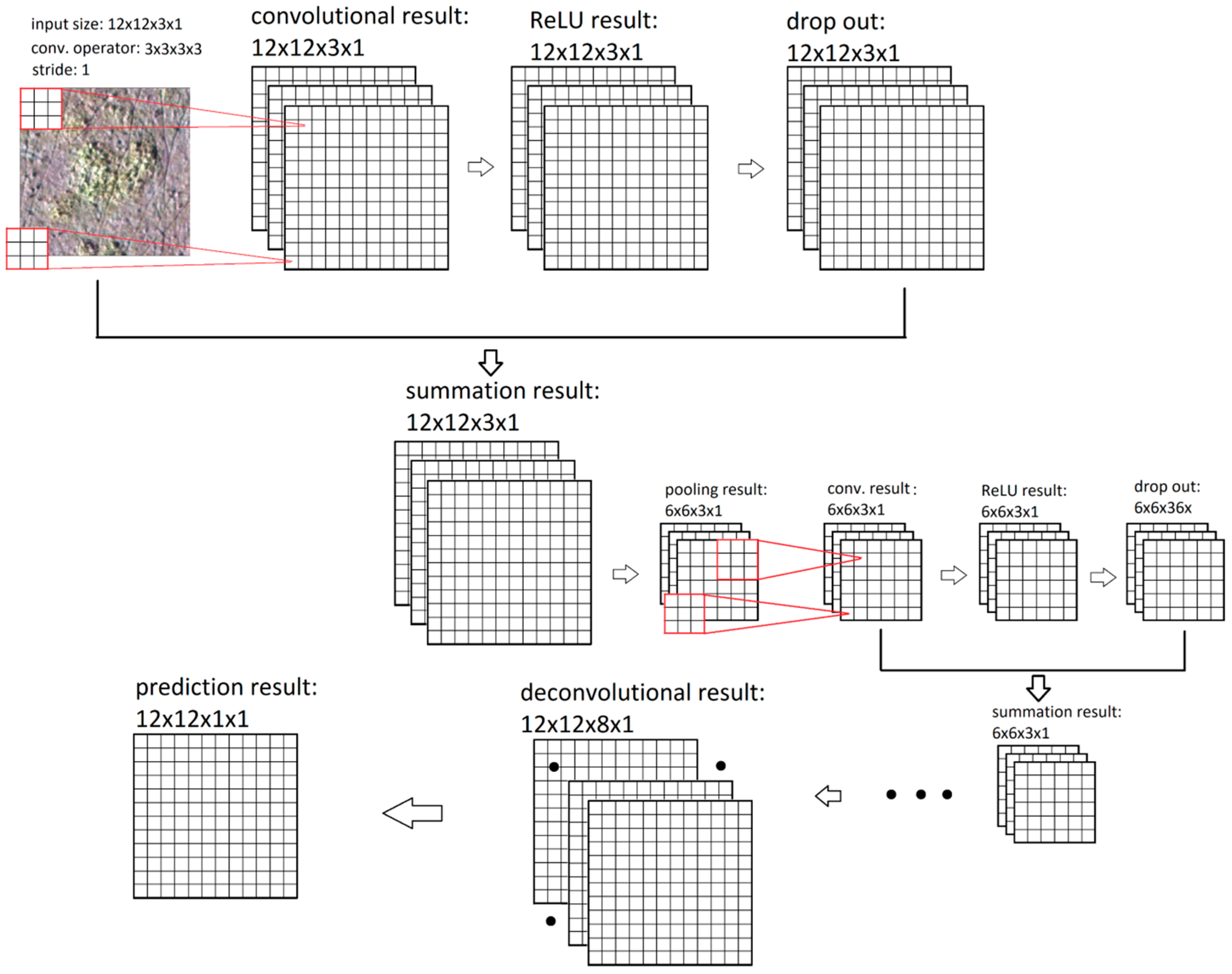
3.2. Fully Convolutional Networks
3.3. OBIA Classification Using Orthoimage with FCN
3.4. OBIA Classification Using Multi-View Data with FCN
3.4.1. Multi-View Training Samples without Context Information (MV-I Sample Generation)
3.4.2. Multi-View Training Samples with Exact Context Information (MV-IIA Sample Generation)
3.4.3. Multi-View Training Samples with Approximate Context Information (MV-IIB Sample Generation)
3.5. Benchmark Classification Methods
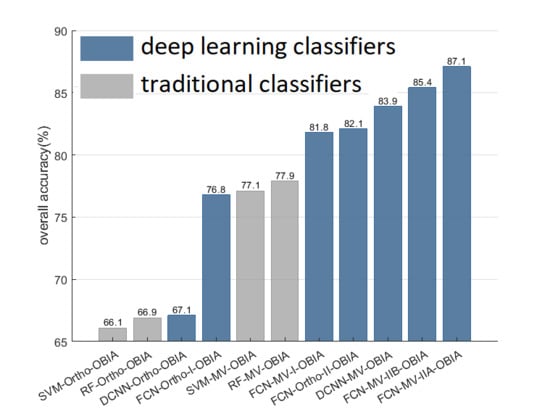
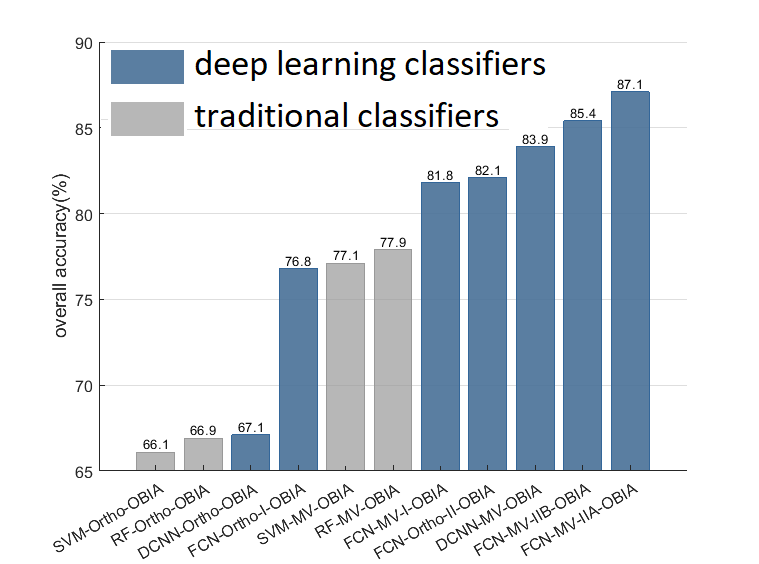
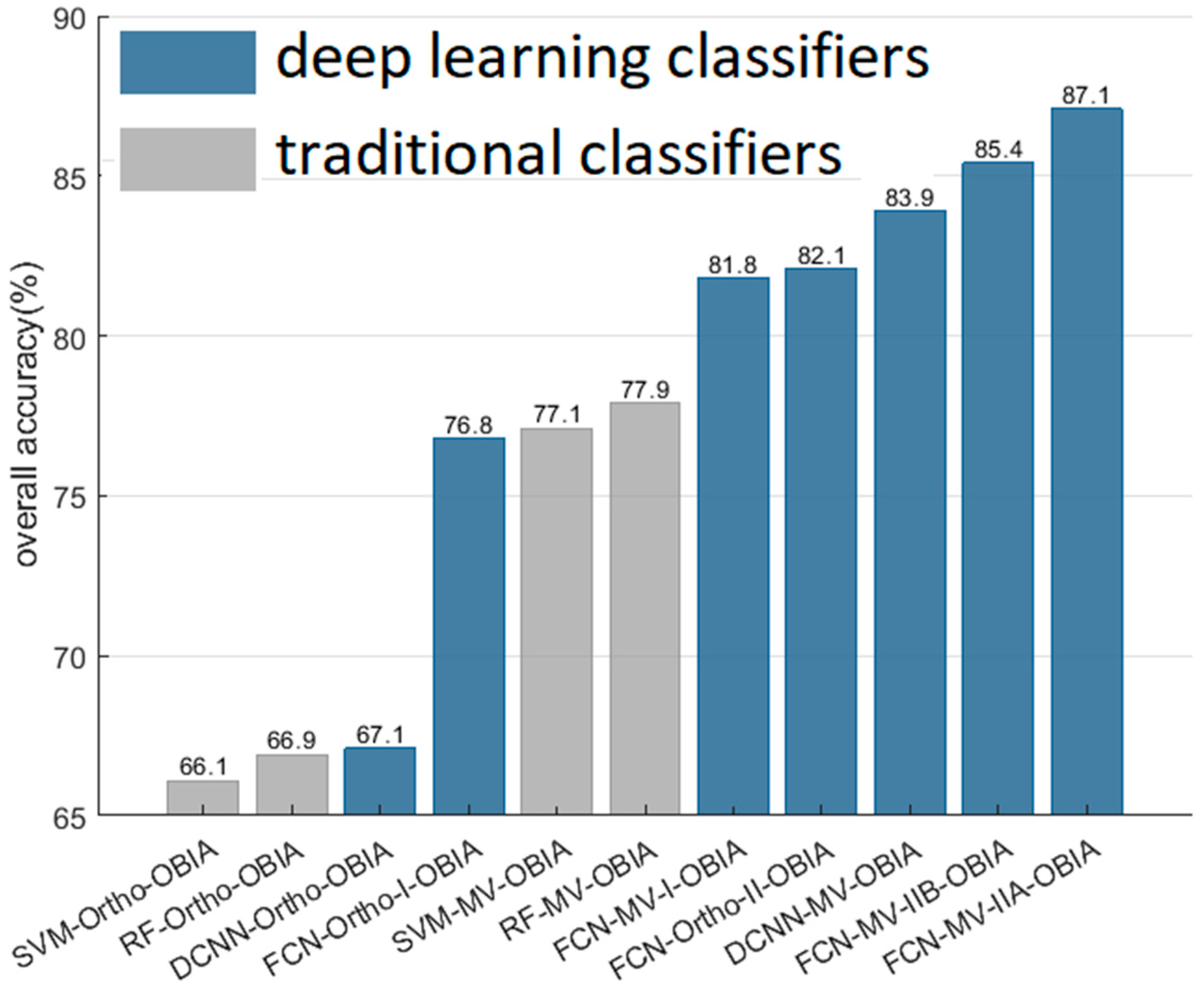
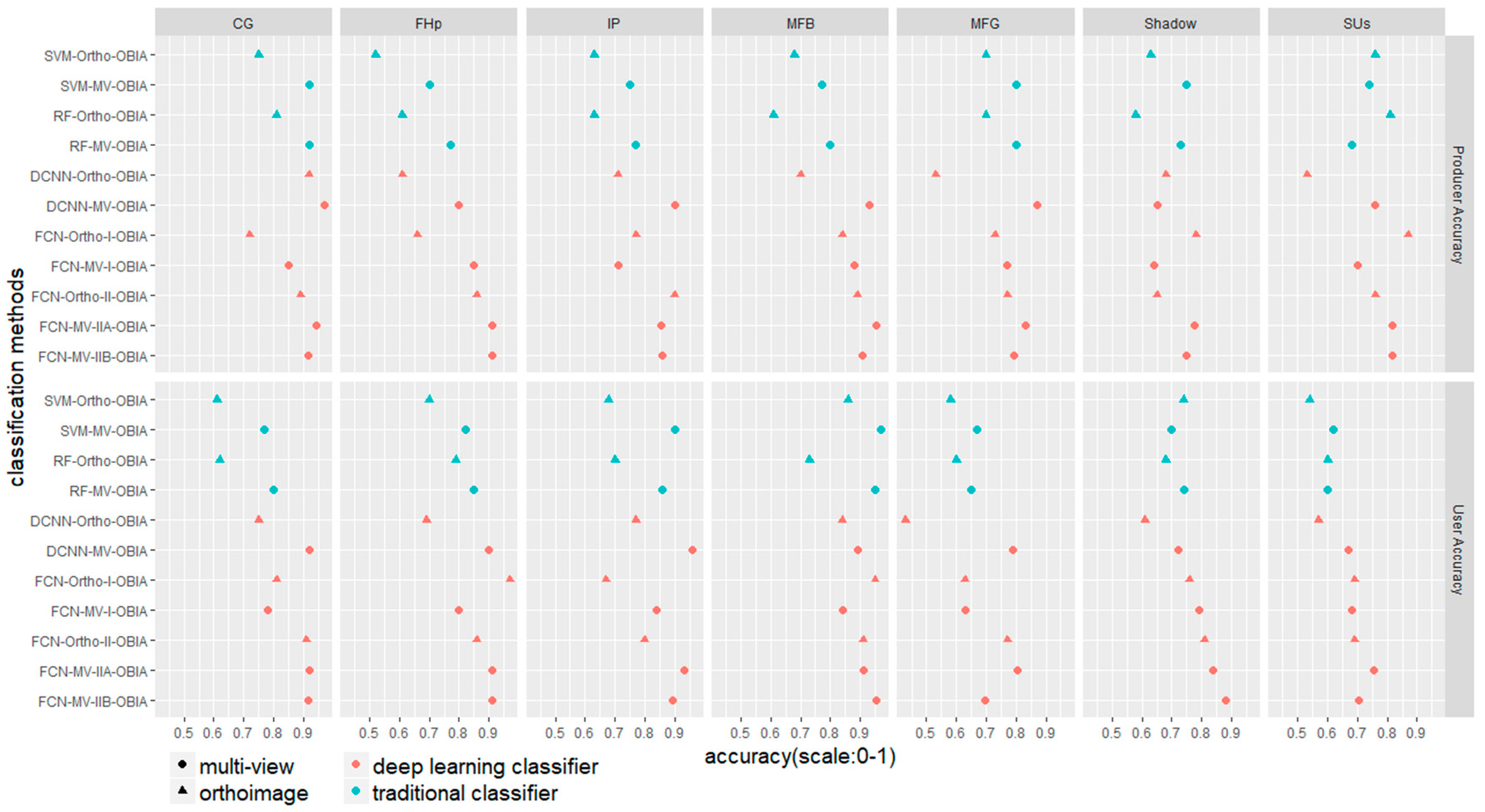
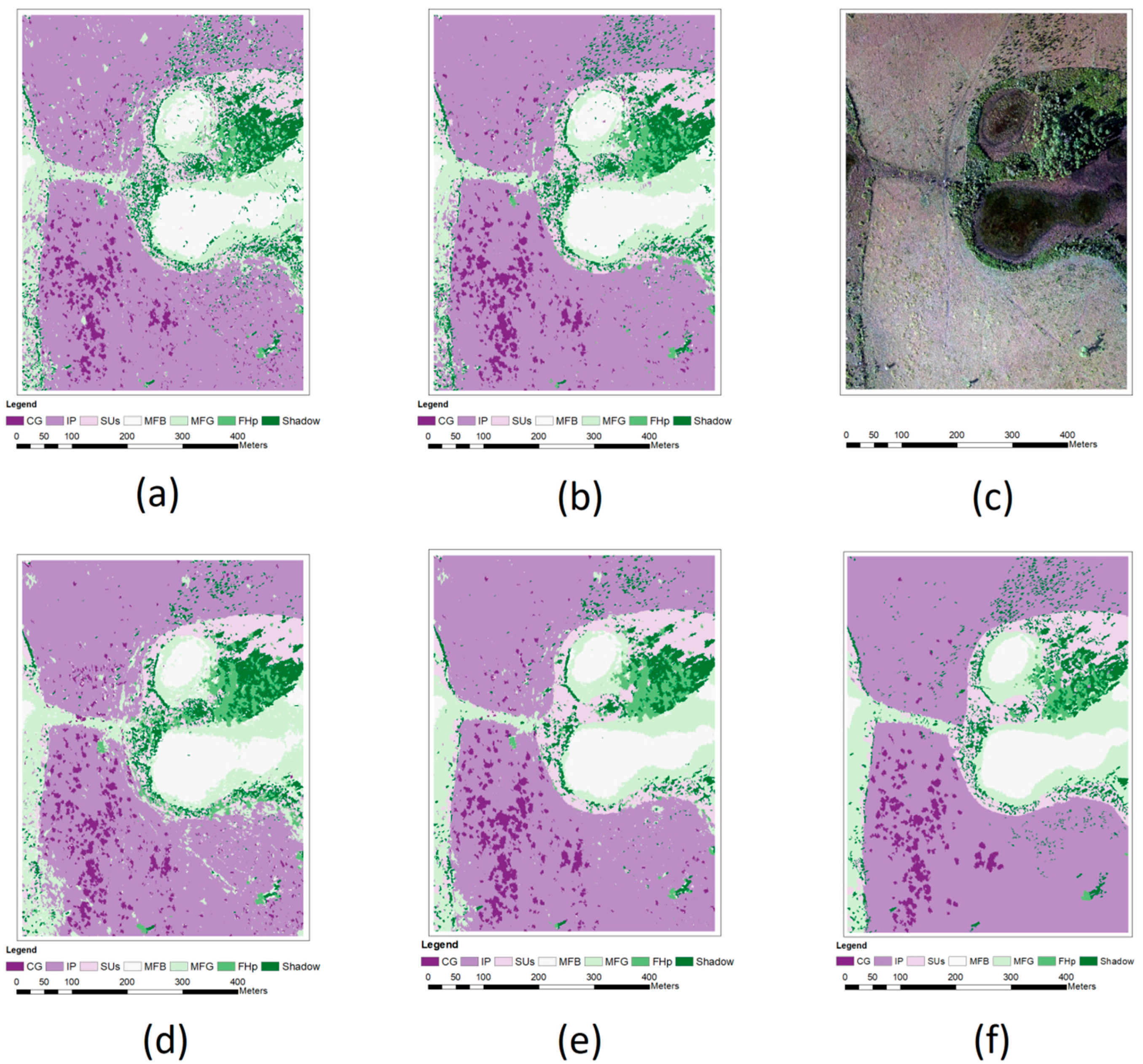
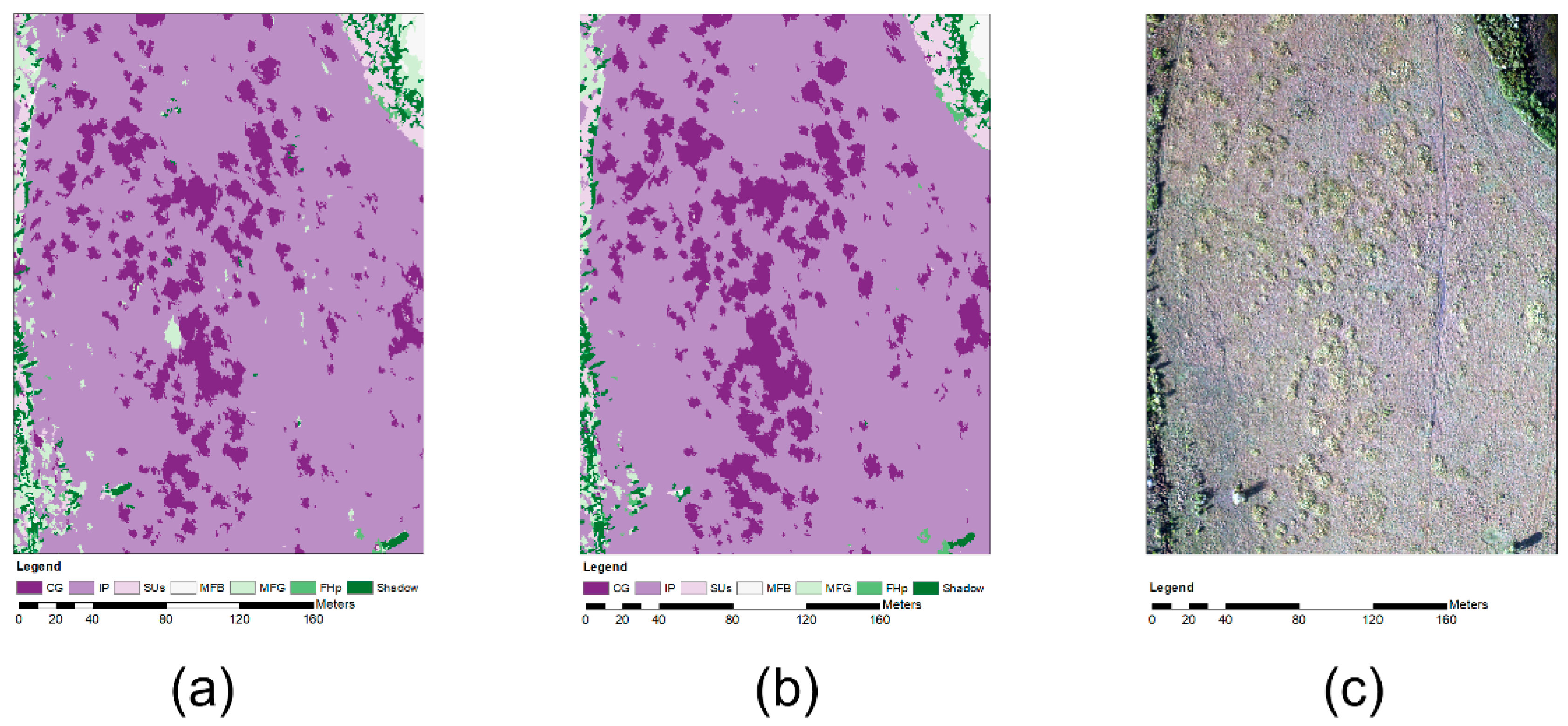
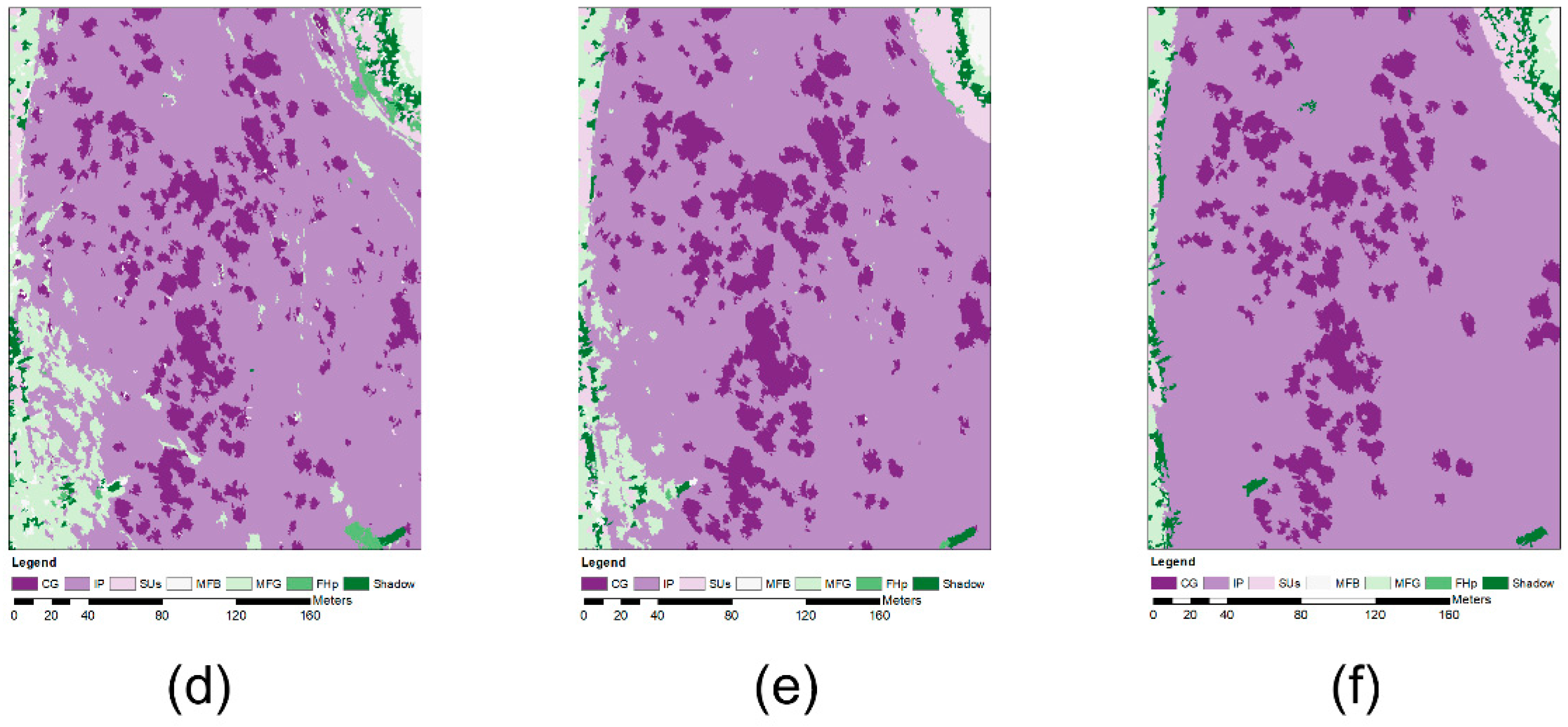
4. Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rango, A.; Laliberte, A.; Steele, C.; Herrick, J.E.; Bestelmeyer, B.; Schmugge, T.; Roanhorse, A.; Jenkins, V. Using unmanned aerial vehicles for rangelands: Current applications and future potentials. Environ. Pract. 2006, 8, 159–168. [Google Scholar] [CrossRef]
- Colomina, I.; Molina, P. Unmanned aerial systems for photogrammetry and remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef]
- Im, J.; Jensen, J.; Tullis, J. Object-based change detection using correlation image analysis and image segmentation. Int. J. Remote Sens. 2008, 29, 399–423. [Google Scholar] [CrossRef]
- Ke, Y.; Quackenbush, L.J.; Im, J. Synergistic use of QuickBird multispectral imagery and LIDAR data for object-based forest species classification. Remote Sens. Environ. 2010, 114, 1141–1154. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Grybas, H.; Melendy, L.; Congalton, R.G. A comparison of unsupervised segmentation parameter optimization approaches using moderate-and high-resolution imagery. GISci. Remote Sens. 2017, 54, 515–533. [Google Scholar] [CrossRef]
- Pande-Chhetri, R.; Abd-Elrahman, A.; Liu, T.; Morton, J.; Wilhelm, V.L. Object-based classification of wetland vegetation using very high-resolution unmanned air system imagery. Eur. J. Remote Sens. 2017, 50, 564–576. [Google Scholar] [CrossRef]
- Wang, C.; Pavlowsky, R.T.; Huang, Q.; Chang, C. Channel bar feature extraction for a mining-contaminated river using high-spatial multispectral remote-sensing imagery. GISci. Remote Sens. 2016, 53, 283–302. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Suk, H.-I.; Lee, S.-W.; Shen, D. Alzheimer’s Disease Neuroimaging Initiative. Hierarchical feature representation and multimodal fusion with deep learning for AD/MCI diagnosis. NeuroImage 2014, 101, 569–582. [Google Scholar] [CrossRef] [PubMed]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R. An empirical evaluation of deep learning on highway driving. arXiv, 2015; arXiv:1504.01716. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Wang, J. Semisupervised classification for hyperspectral image based on multi-decision labeling and deep feature learning. ISPRS J. Photogramm. Remote Sens. 2016, 120, 99–107. [Google Scholar] [CrossRef]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster damage detection through synergistic use of deep learning and 3D point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS J. Photogramm. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Chen, G.; Weng, Q.; Hay, G.J.; He, Y. Geographic Object-based Image Analysis (GEOBIA): Emerging trends and future opportunities. GISci. Remote Sens. 2018, 55, 159–182. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A.; Jon, M.; Wilhelm, V.L. Comparing Fully Convolutional Networks, Random Forest, Support Vector Machine, and Patch-Based Deep Convolutional Neural Networks for Object-Based Wetland Mapping Using Images from Small Unmanned Aircraft System. GISci. Remote Sens. 2018, 55, 243–264. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Tuia, D. Learning rotation invariant convolutional filters for texture classification. arXiv, 2016; arXiv:1604.06720. [Google Scholar]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Celikyilmaz, A.; Sarikaya, R.; Hakkani-Tur, D.; Liu, X.; Ramesh, N.; Tur, G. A New Pre-training Method for Training Deep Learning Models with Application to Spoken Language Understanding. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 3255–3259. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Xie, M.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Transfer learning from deep features for remote sensing and poverty mapping. arXiv, 2015; arXiv:1510.00098. [Google Scholar]
- Koukal, T.; Atzberger, C.; Schneider, W. Evaluation of semi-empirical BRDF models inverted against multi-angle data from a digital airborne frame camera for enhancing forest type classification. Remote Sens. Environ. 2014, 151, 27–43. [Google Scholar] [CrossRef]
- Su, L.; Chopping, M.J.; Rango, A.; Martonchik, J.V.; Peters, D.P. Support vector machines for recognition of semi-arid vegetation types using MISR multi-angle imagery. Remote Sens. Environ. 2007, 107, 299–311. [Google Scholar] [CrossRef]
- Abuelgasim, A.A.; Gopal, S.; Irons, J.R.; Strahler, A.H. Classification of ASAS multiangle and multispectral measurements using artificial neural networks. Remote Sens. Environ. 1996, 57, 79–87. [Google Scholar] [CrossRef]
- Longbotham, N.; Chaapel, C.; Bleiler, L.; Padwick, C.; Emery, W.J.; Pacifici, F. Very high resolution multiangle urban classification analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1155–1170. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Li, S.; Jiang, H.; Pang, W. Joint Multiple Fully Connected Convolutional Neural Network with Extreme Learning Machine for Hepatocellular Carcinoma Nuclei Grading. Comput. Biol. Med. 2017, 84, 156–167. [Google Scholar] [CrossRef] [PubMed]
- Pei, M.; Wu, X.; Guo, Y.; Fujita, H. Small bowel motility assessment based on fully convolutional networks and long short-term memory. Knowl.-Based Syst. 2017, 121, 163–172. [Google Scholar] [CrossRef]
- Huang, L.; Xia, W.; Zhang, B.; Qiu, B.; Gao, X. MSFCN-multiple supervised fully convolutional networks for the osteosarcoma segmentation of CT images. Comput. Methods Programs Biomed. 2017, 143, 67–74. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Zhang, C.; Zhou, D.; Wang, X.; Bai, X.; Liu, W. Traffic sign detection and recognition using fully convolutional network guided proposals. Neurocomputing 2016, 214, 758–766. [Google Scholar] [CrossRef]
- ISPRS. 2D Semantic Labeling—Vaihingen Data. 2017. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html (accessed on 8 October 2017).
- Piramanayagam, S.; Schwartzkopf, W.; Koehler, F.; Saber, E. Classification of remote sensed images using random forests and deep learning framework. In Proceedings of the SPIE Remote Sensing, Edinburgh, UK, 26–28 September 2016; pp. 100040–100048. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv, 2016; arXiv:1606.02585. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. arXiv, 2016; arXiv:1612.01337. [Google Scholar]
- Grasslands, L. Blue Head Ranch. Available online: https://www.grasslands-llc.com/blue-head-florida (accessed on 1 November 2017).
- Holm, L.G.; Plucknett, D.L.; Pancho, J.V.; Herberger, J.P. The World’s Worst Weeds; University Press: Hong Kong, China, 1977. [Google Scholar]
- Rutchey, K.; Schall, T.; Doren, R.; Atkinson, A.; Ross, M.; Jones, D.; Madden, M.; Vilchek, L.; Bradley, K.; Snyder, J. Vegetation Classification for South Florida Natural Areas; US Geological Survey: St. Petersburg, FL, USA, 2006. [Google Scholar]
- Koukal, T.; Atzberger, C. Potential of multi-angular data derived from a digital aerial frame camera for forest classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 30–43. [Google Scholar] [CrossRef]
- Im, J.; Quackenbush, L.J.; Li, M.; Fang, F. Optimum Scale in Object-Based Image Analysis. Scale Issues Remote Sens. 2014, 197–214. [Google Scholar] [CrossRef]
- Audet, C.; Dennis, J.E., Jr. Analysis of generalized pattern searches. SIAM J. Optim. 2002, 13, 889–903. [Google Scholar] [CrossRef]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv, 2012; arXiv:1207.0580. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010; Springer: Berlin, Germany, 2010; pp. 177–186. [Google Scholar]
- eCognition® Developer 8.8 User Guide; Trimble Documentation: Munich, Germany, 2012.
- Scholkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Yegnanarayana, B. Artificial Neural Networks; PHI Learning Pvt. Ltd.: Delhi, India, 2009. [Google Scholar]
- Kuusk, A. The hot spot effect in plant canopy reflectance. In Photon-Vegetation Interactions; Springer: Berlin, Germany, 1991; pp. 139–159. [Google Scholar]
- Gupta, N.; Bhadauria, H. Object based Information Extraction from High Resolution Satellite Imagery using eCognition. Int. J. Comput. Sci. Issues (IJCSI) 2014, 11, 139. [Google Scholar]
- Yu, Q.; Gong, P.; Clinton, N.; Biging, G.; Kelly, M.; Schirokauer, D. Object-based detailed vegetation classification with airborne high spatial resolution remote sensing imagery. Photogramm. Eng. Remote Sens. 2006, 72, 799–811. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Lin, C.-J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Mahdavi, S.; Salehi, B.; Granger, J.; Amani, M.; Brisco, B.; Huang, W. Remote sensing for wetland classification: A comprehensive review. GISci. Remote Sens. 2017. [Google Scholar] [CrossRef]
- Amani, M.; Salehi, B.; Mahdavi, S.; Granger, J.; Brisco, B. Wetland classification in Newfoundland and Labrador using multi-source SAR and optical data integration. GISci. Remote Sens. 2017, 54, 779–796. [Google Scholar] [CrossRef]
- Amani, M.; Salehi, B.; Mahdavi, S.; Granger, J.E.; Brisco, B.; Hanson, A. Wetland Classification Using Multi-Source and Multi-Temporal Optical Remote Sensing Data in Newfoundland and Labrador, Canada. Can. J. Remote Sens. 2017, 43, 360–373. [Google Scholar] [CrossRef]
- Rapinel, S.; Hubert-Moy, L.; Clément, B. Combined use of LiDAR data and multispectral earth observation imagery for wetland habitat mapping. Int. J. Appl. Earth Obs. Geoinf. 2015, 37, 56–64. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Brisco, B.; Mahdavi, S.; Amani, M.; Granger, J.E. Fisher Linear Discriminant Analysis of coherency matrix for wetland classification using PolSAR imagery. Remote Sens. Environ. 2018, 206, 300–317. [Google Scholar] [CrossRef]
- Wilusz, D.C.; Zaitchik, B.F.; Anderson, M.C.; Hain, C.R.; Yilmaz, M.T.; Mladenova, I.E. Monthly flooded area classification using low resolution SAR imagery in the Sudd wetland from 2007 to 2011. Remote Sens. Environ. 2017, 194, 205–218. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class ID | Class Name | Description |
|---|---|---|
| CG | Cogon grass | Cogon grass (Imperata cylindrica) is an invasive, non-native grass which occurs in Florida and several other Southeastern US states. |
| IP | Improved Pasture | A sown pasture that includes introduced pasture species, usually grasses in combination with legumes. These are generally more productive than the local native pastures, have higher protein and metabolizable energy and are typically more digestible. In our case, we also assume it is not infested by Cogon grass. |
| SUs | Saw Palmetto Shrubland | Saw Palmetto (Serenoa repens) dominant shrubland. |
| MFB | Broadleaf Emergent Marsh | Broadleaf emergent dominated freshwater marsh. It can be found throughout Florida. |
| MFG | Graminoid Freshwater Marsh | Graminoid dominated freshwater marsh. It can be found throughout Florida. |
| FHp | Hardwood Hammock-Pine Forest | A co-dominate mix (40/60 to 60/40) of Slash Pine (Pinus elliottii var. densa) with Laural Oak (Quercus laurifolia), Live Oak (Q. virginiana), and/or Cabbage Palm (Sabal palmetto). |
| Shadow | Shadow | Shadow of all kinds of objects in the study area. |
| Items | Description |
|---|---|
| UAS Type | Light UAS with Fixed wing |
| Sensor Name | Canon EOS REBEL SL1 |
| Sensor Type | CCD |
| Pixel Dimension | 5184 × 3456 |
| Length of focus | 20 mm |
| Sensor Size | 22.3 × 14.9 mm |
| Channels | RGB |
| Takeoff time | 29/10/2015 16:54:51 EDT a |
| Landing time | 29/10/2015 17:49:33 EDT a |
| Takeoff Latitude | 27.22736549° |
| Takeoff Longitude | −81.51152802° |
| Average Wind Speed | 5.1 m/s |
| Average Altitude | 302.7 m |
| Average Pixel Size | 6.5 cm |
| Forward overlap | 83% |
| Side overlap | 50% |
| FOV b across-track | 58° |
| FOV b along-track | 41° |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Abd-Elrahman, A. An Object-Based Image Analysis Method for Enhancing Classification of Land Covers Using Fully Convolutional Networks and Multi-View Images of Small Unmanned Aerial System. Remote Sens. 2018, 10, 457. https://doi.org/10.3390/rs10030457
Liu T, Abd-Elrahman A. An Object-Based Image Analysis Method for Enhancing Classification of Land Covers Using Fully Convolutional Networks and Multi-View Images of Small Unmanned Aerial System. Remote Sensing. 2018; 10(3):457. https://doi.org/10.3390/rs10030457
Chicago/Turabian StyleLiu, Tao, and Amr Abd-Elrahman. 2018. "An Object-Based Image Analysis Method for Enhancing Classification of Land Covers Using Fully Convolutional Networks and Multi-View Images of Small Unmanned Aerial System" Remote Sensing 10, no. 3: 457. https://doi.org/10.3390/rs10030457