Introduction and Assessment of Measures for Quantitative Model-Data Comparison Using Satellite Images

Abstract
:1. Introduction
2. Nomenclature
2.1. Definition of Symbols
- ,
- ,
- and
- ,
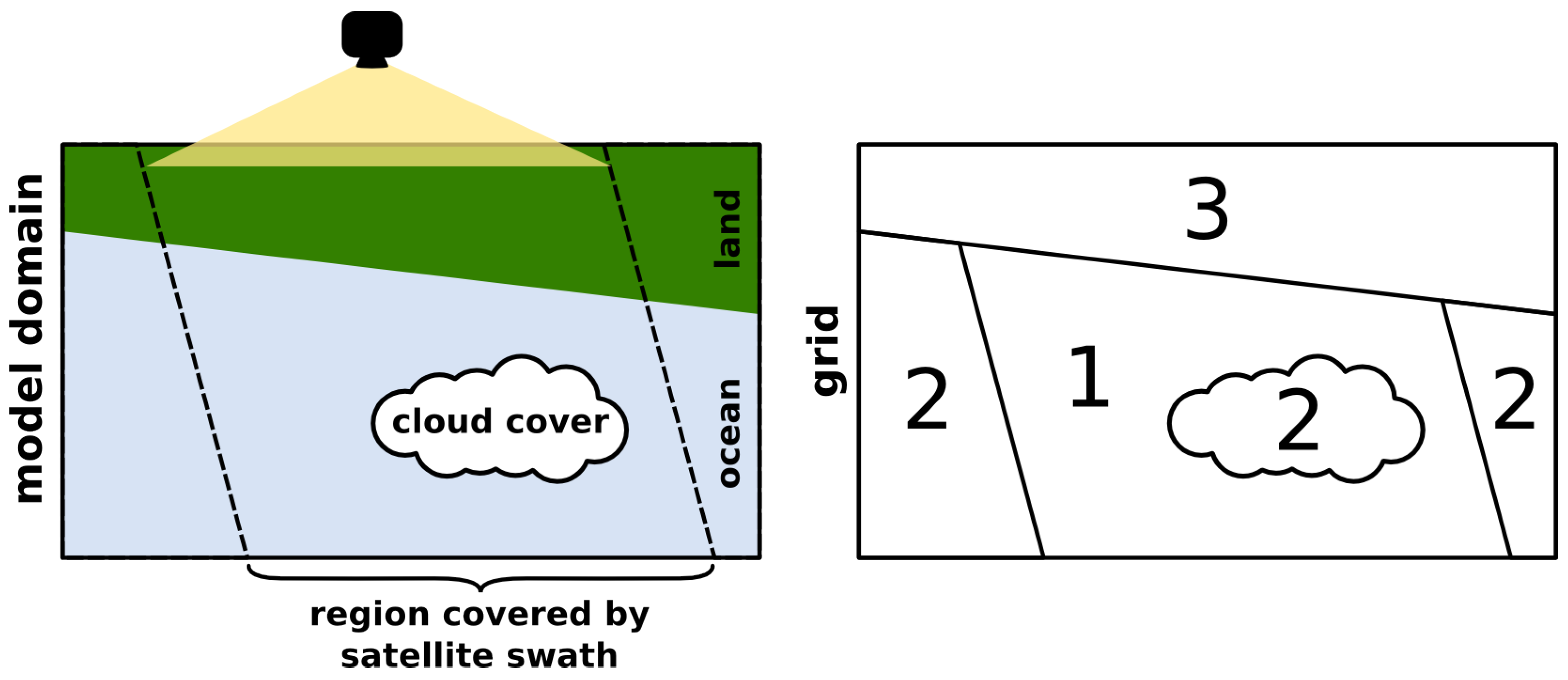
3. Image Comparison Methods
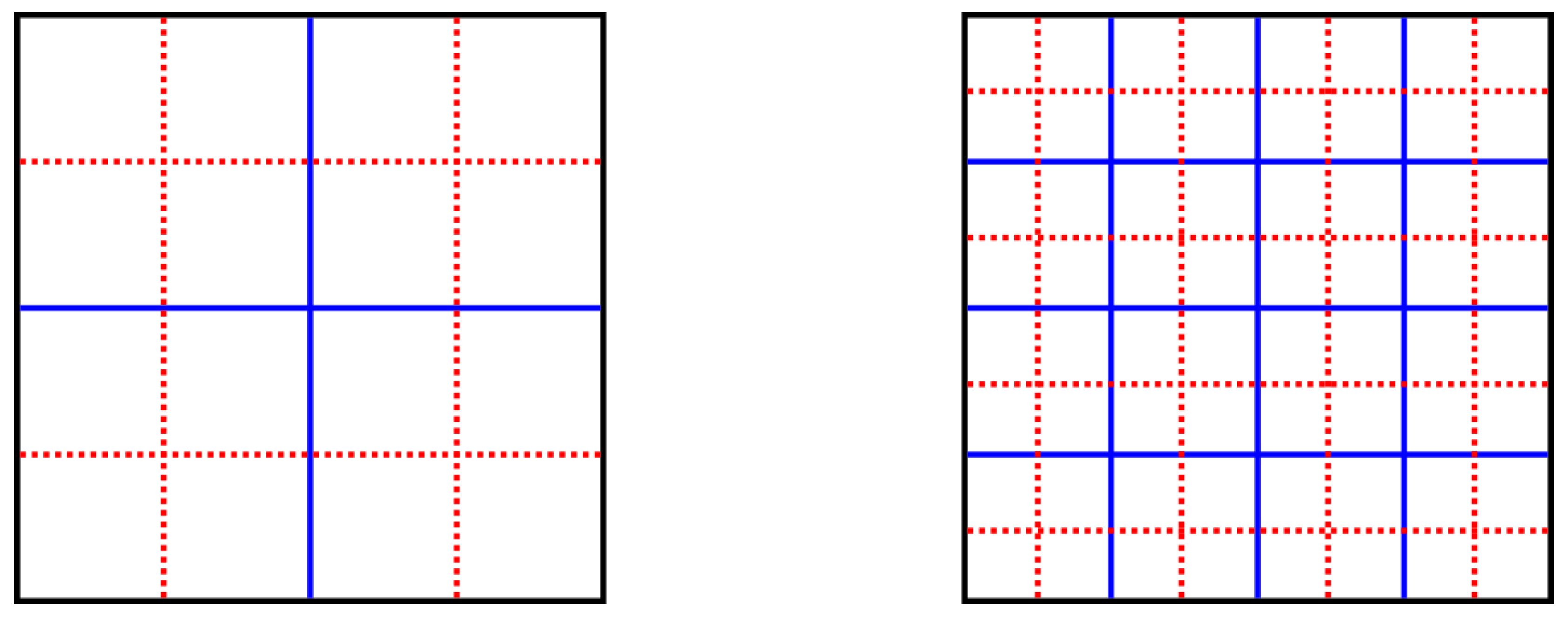
3.1. Parametrisations
3.2. Pixel-by-Pixel Measures
Root Mean Square Error (RMS)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| image comparison measure | p-b-p a | reference | scaling parameter | name | parametrization | complexity |
| root mean square error | √ | RMS | O | |||
| normalized cross-correlation | √ | NXC | O | |||
| entropic distance | √ | [17] | D2 | O | ||
| adapted Hausdorff distance | [18] | c | AHDd | , | O | |
| AHD2 d | , | |||||
| averaged distance | [16] | w, c | AVG d | O | ||
| Delta-g () | [19] | c b | DG | , | O | |
| image euclidean distance | [20] | σ | IE | O | ||
| adapted gray block distance | [21] | w | AGB | O e |
Normalized Cross-Correlation (NXC)
Entropic Distance (D2)
3.3. Neighborhood-Based Measures
Adapted Hausdorff Distance (AHD, AHD2)
Averaged Distance (AVG)
Delta-g (DG)
Image Euclidean Distance (IE)
Adapted Gray Block Distance (AGB)
4. Image Comparison Tests & Results
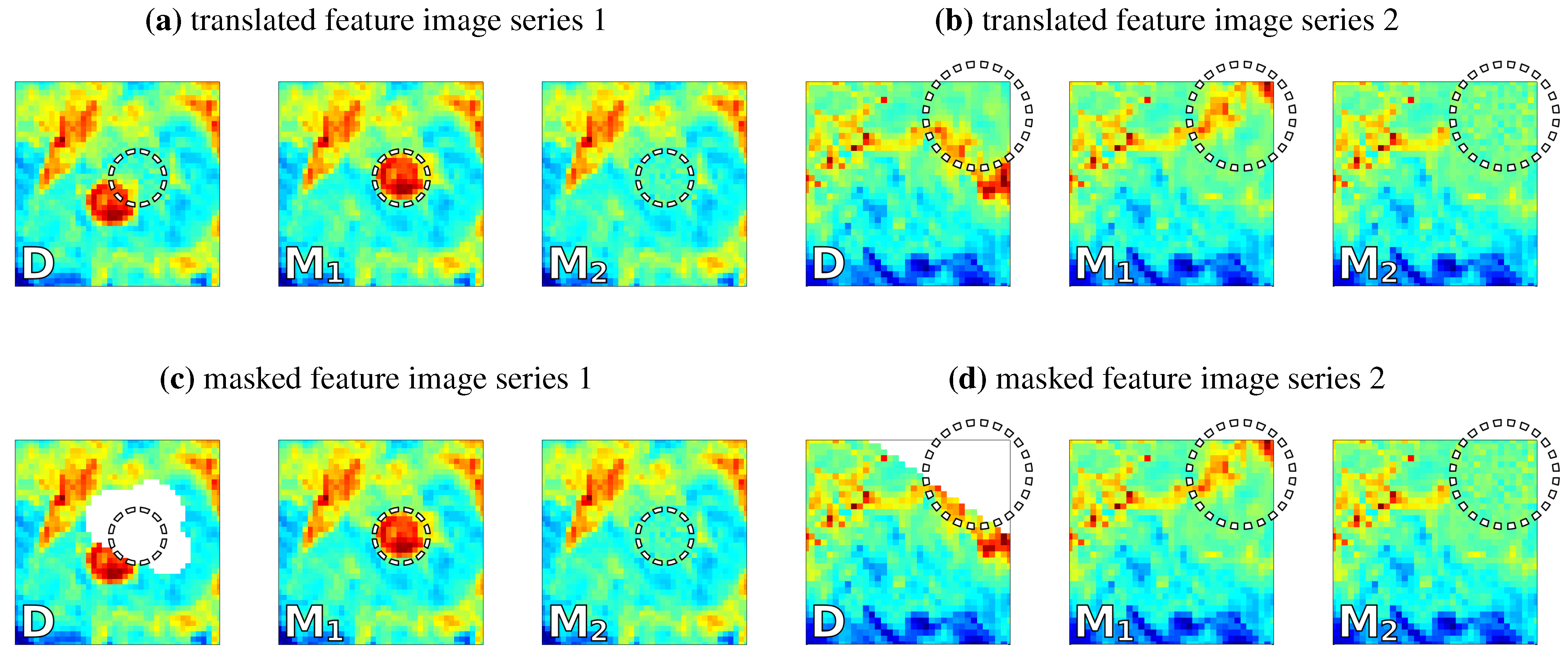
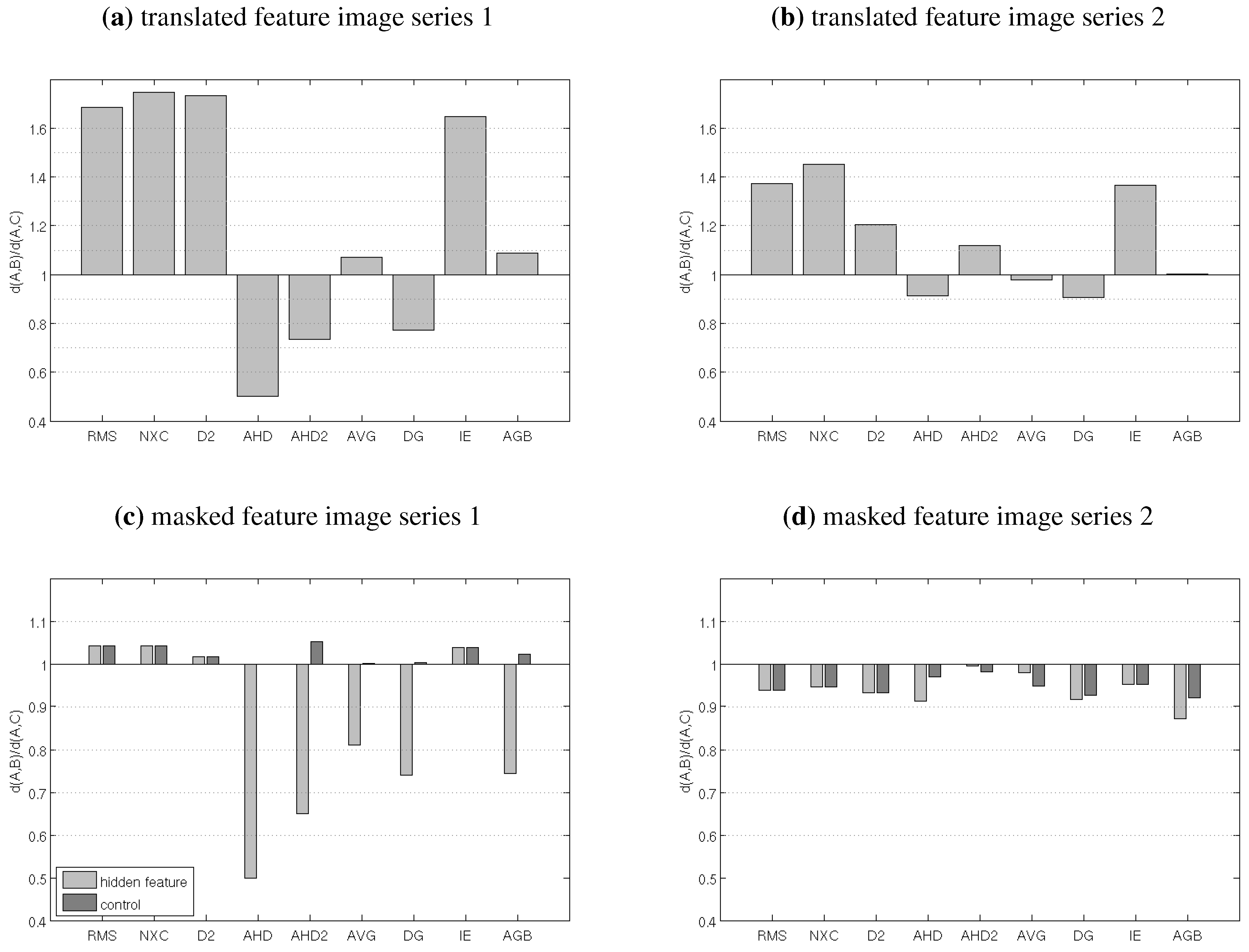
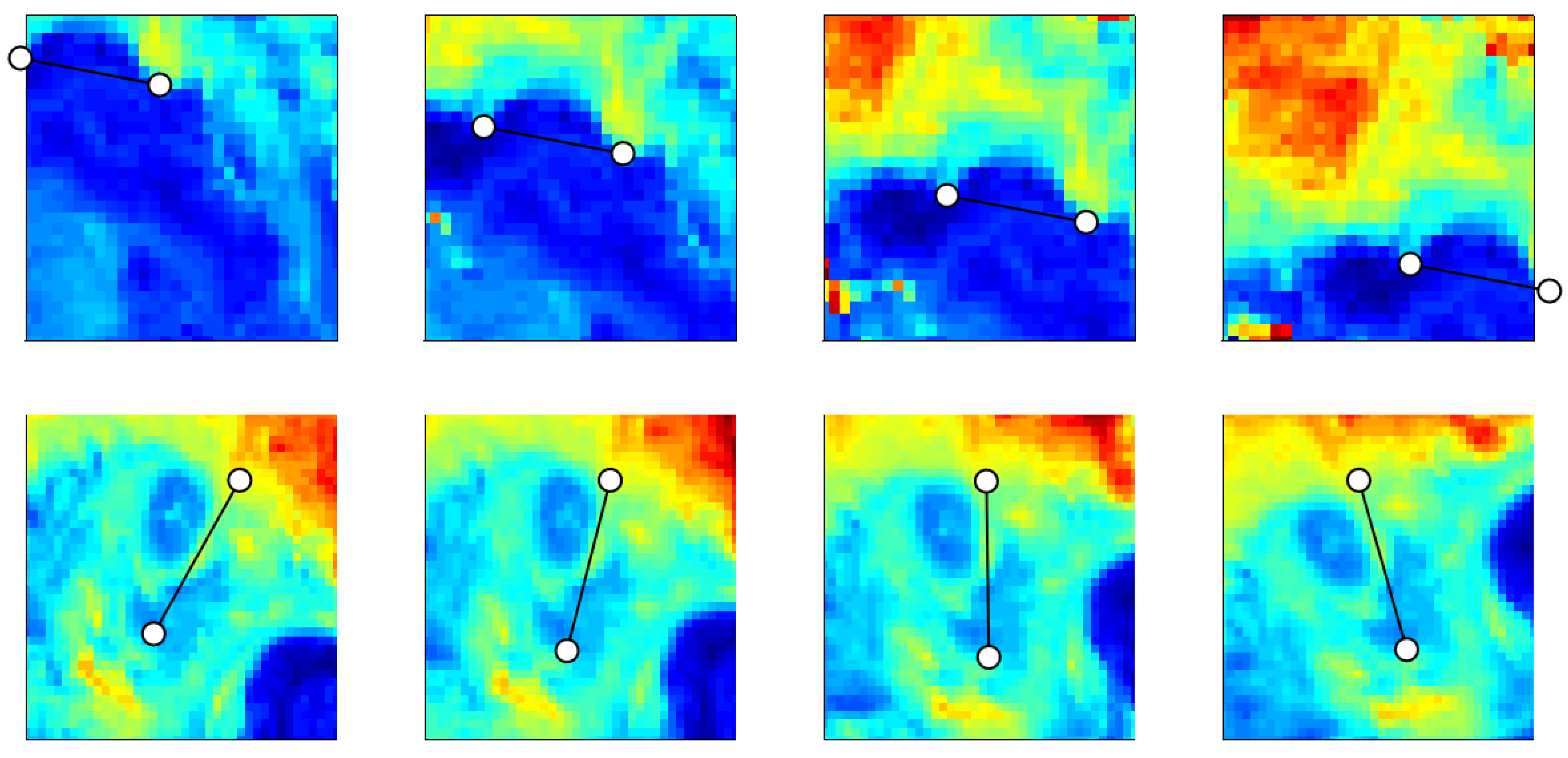
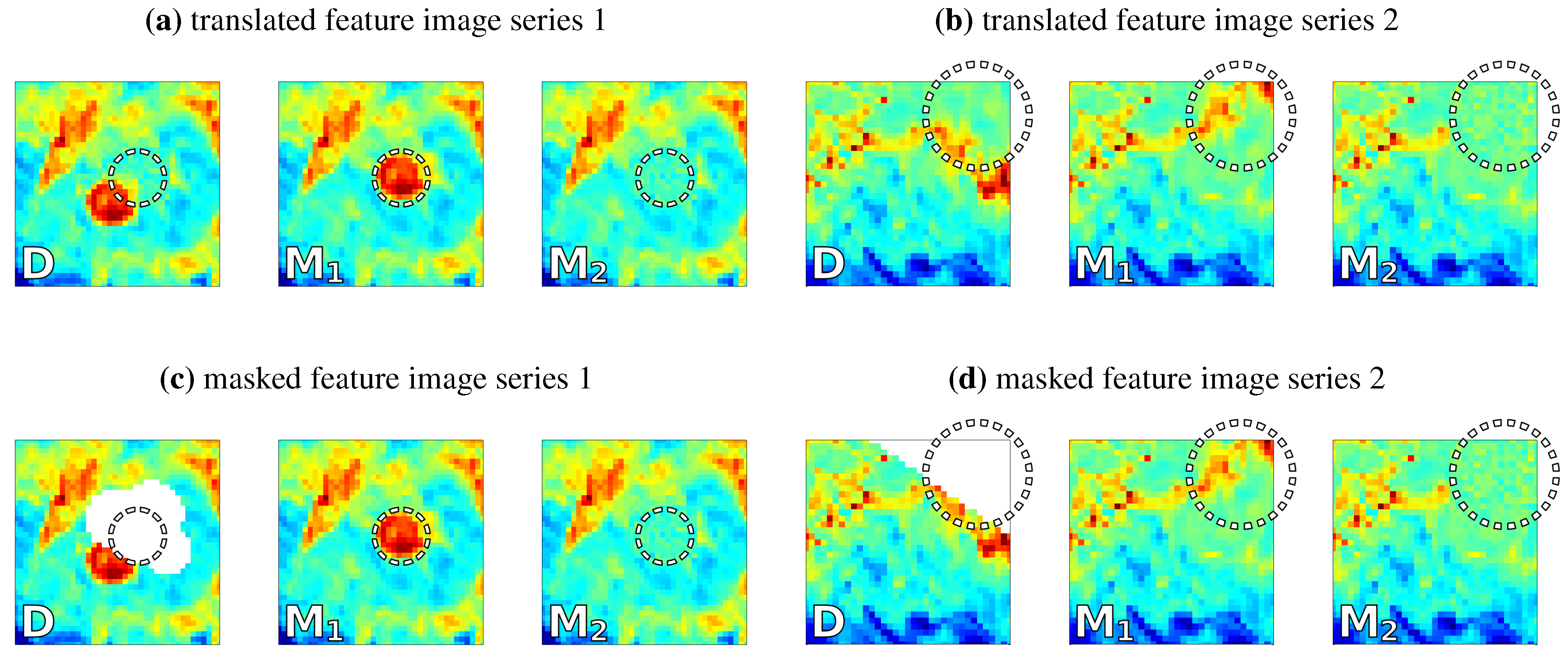
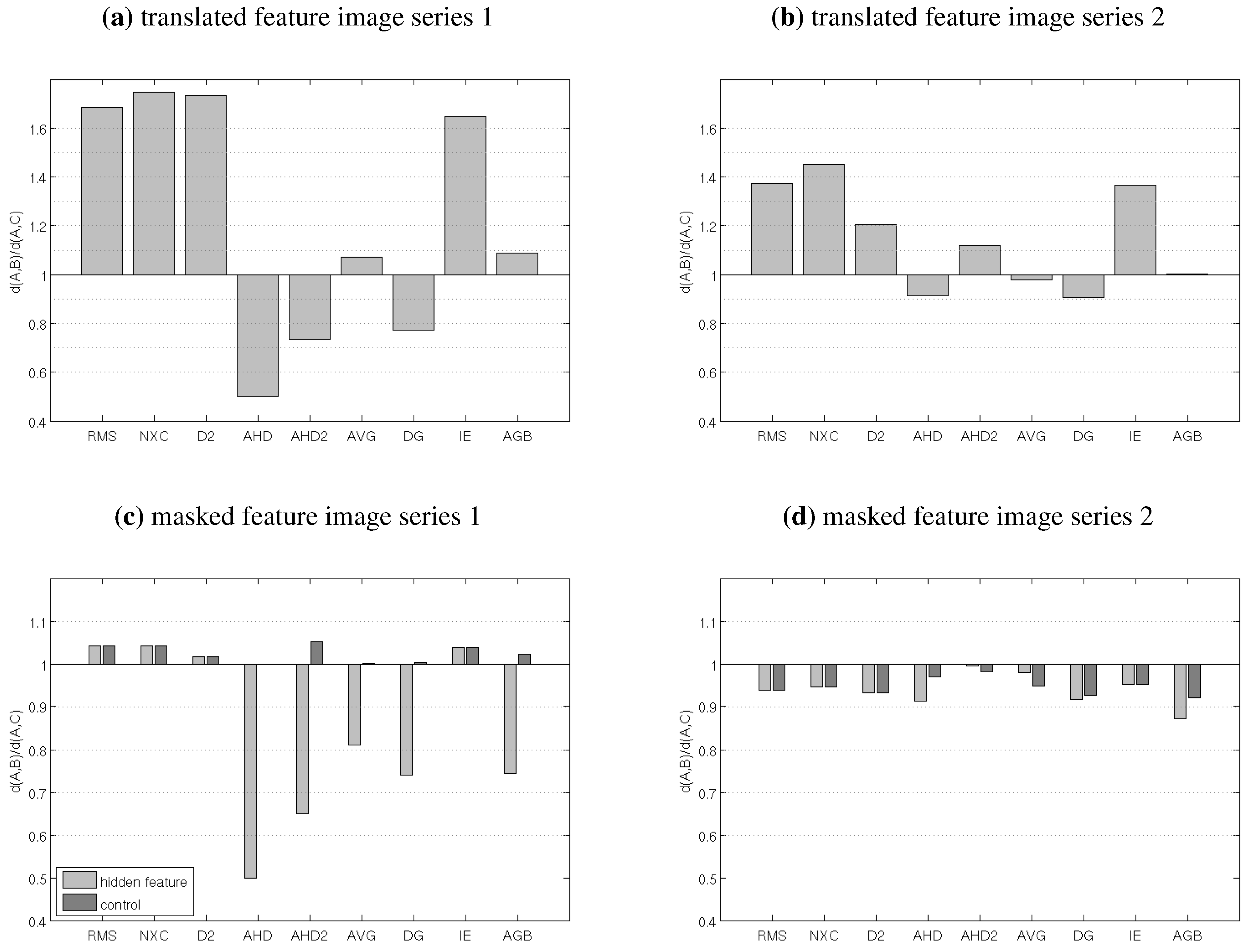
4.1. Test 1: Translated and Masked Features
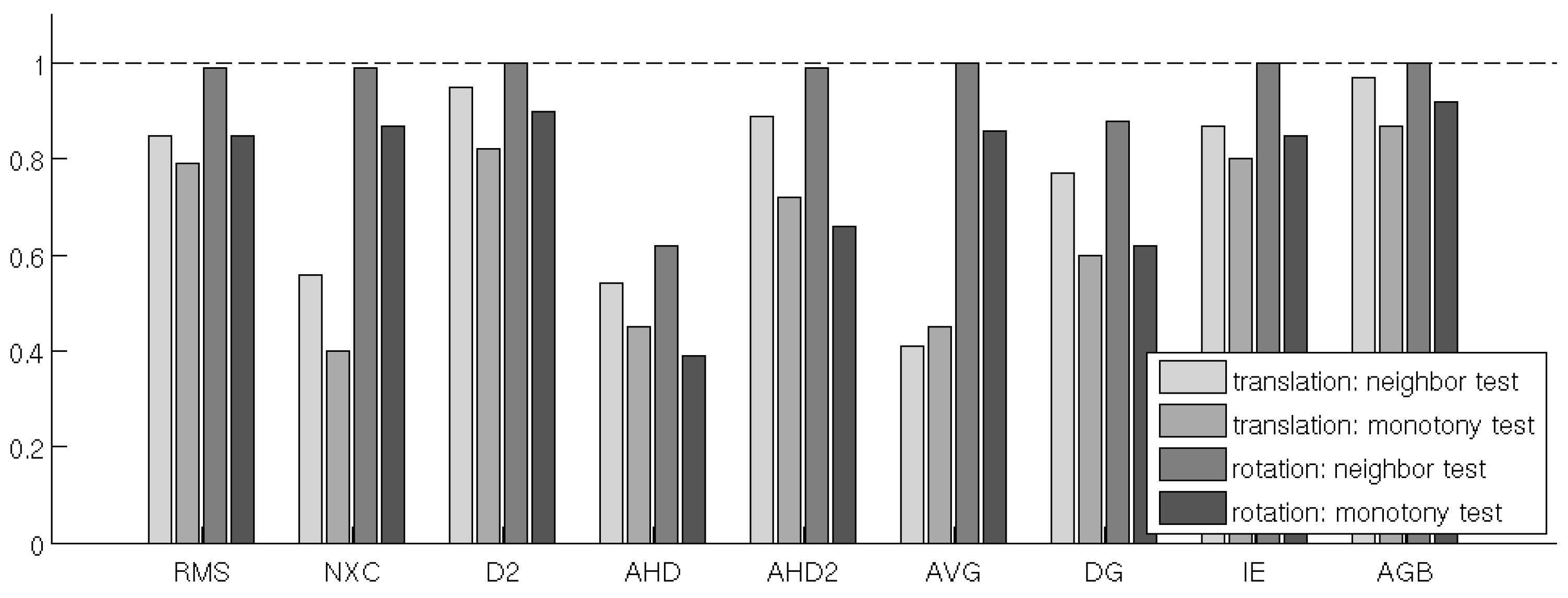
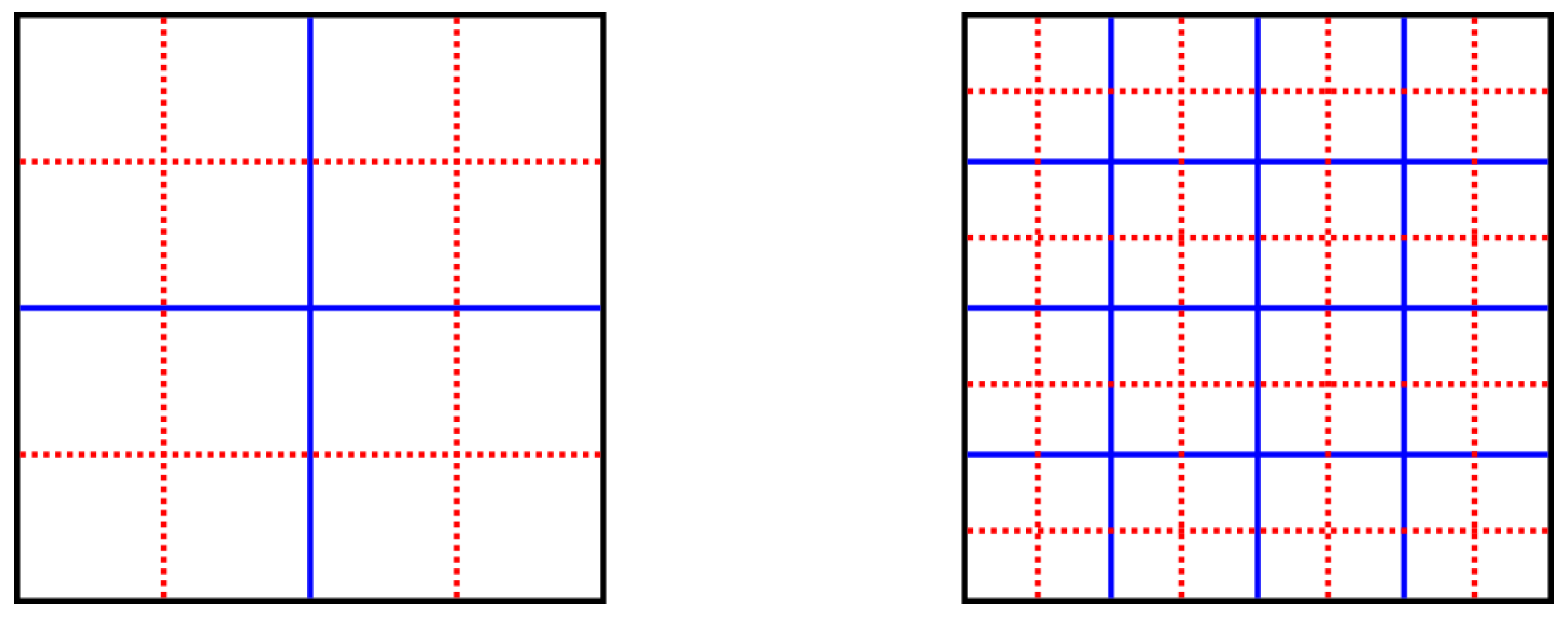
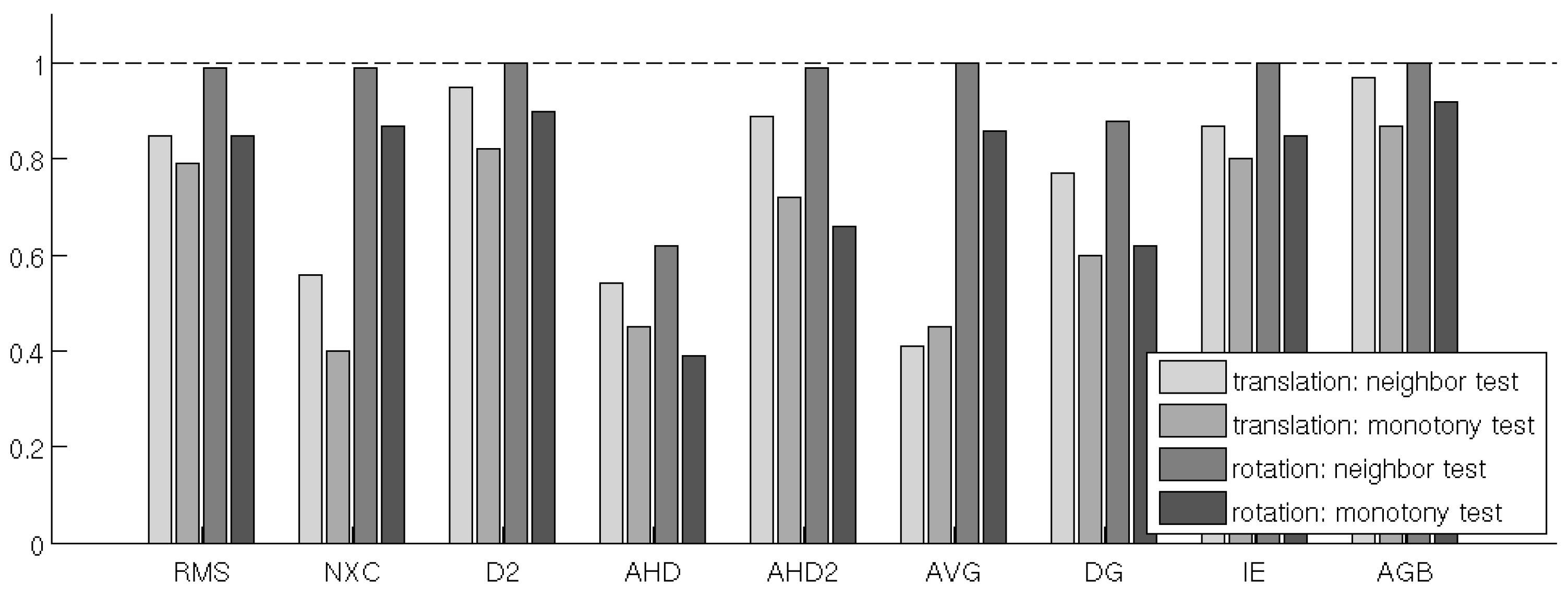
4.2. Test 2: Translation & Rotation of Images
- neighbor test:
- A comparison measure d passes the neighbor test if for any given image in the series, the distance to one of the neighboring images in the series is smaller than the minimum distance to any non-neighboring image, i.e., if
- monotonic test:
- d passes the monotonic test if, for the first image in the series, the distance to the other images in the series is monotonically increasing, i.e., if

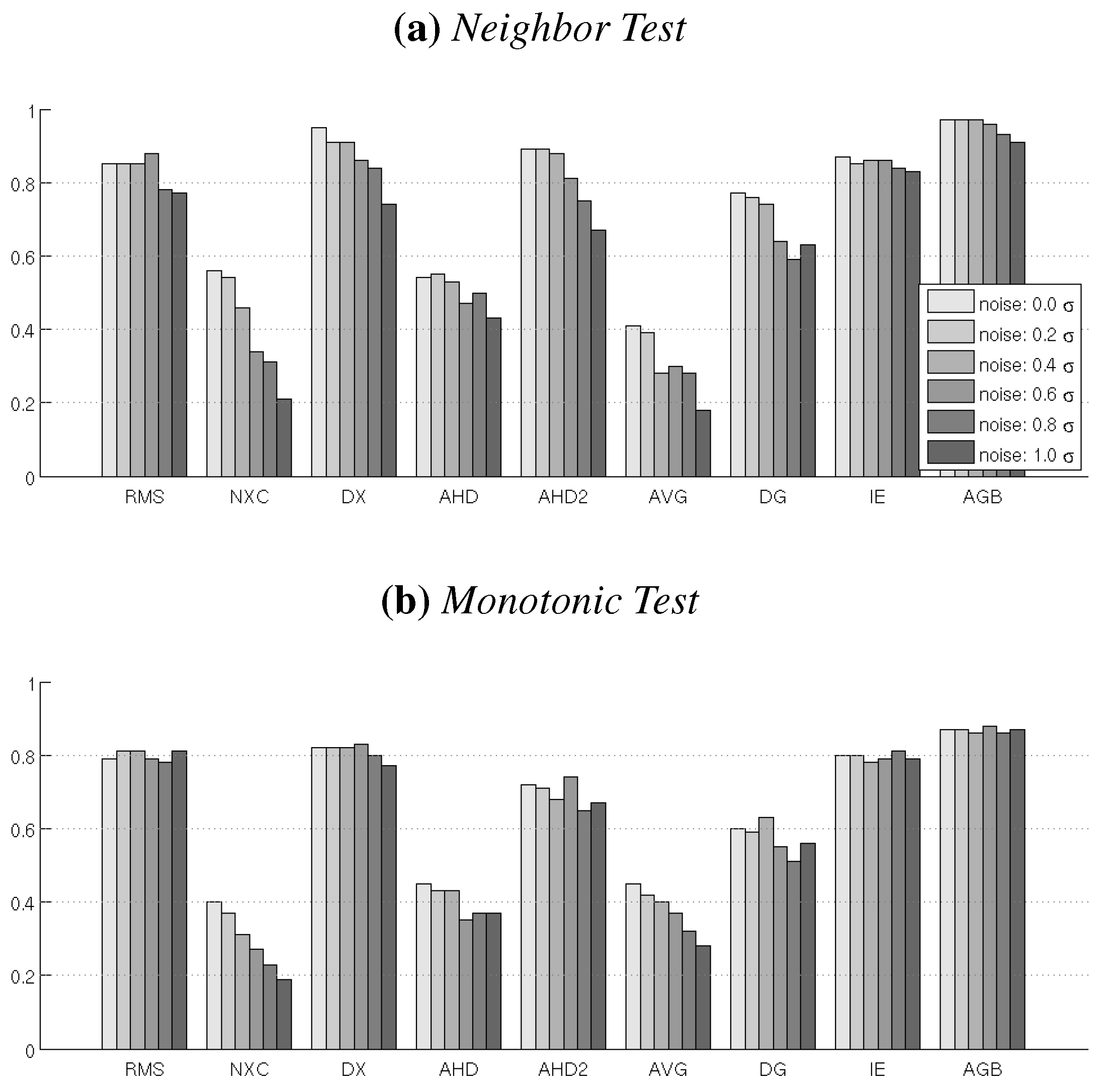
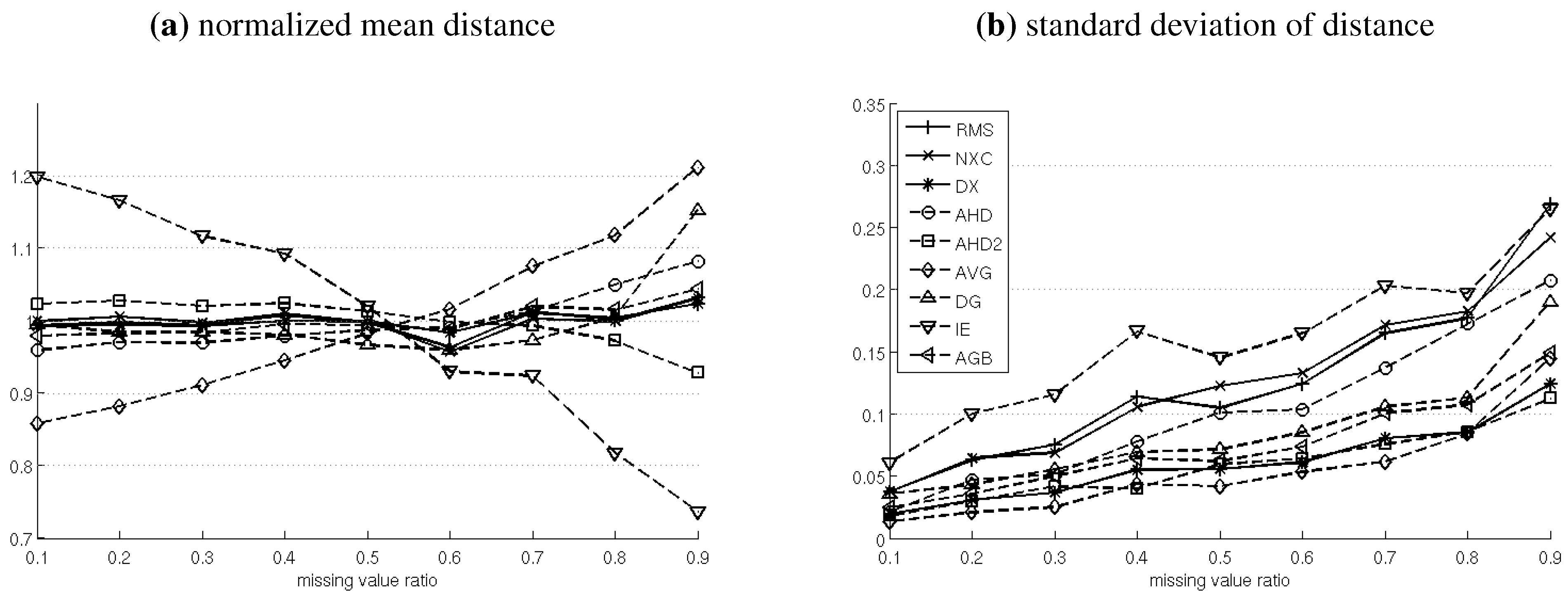
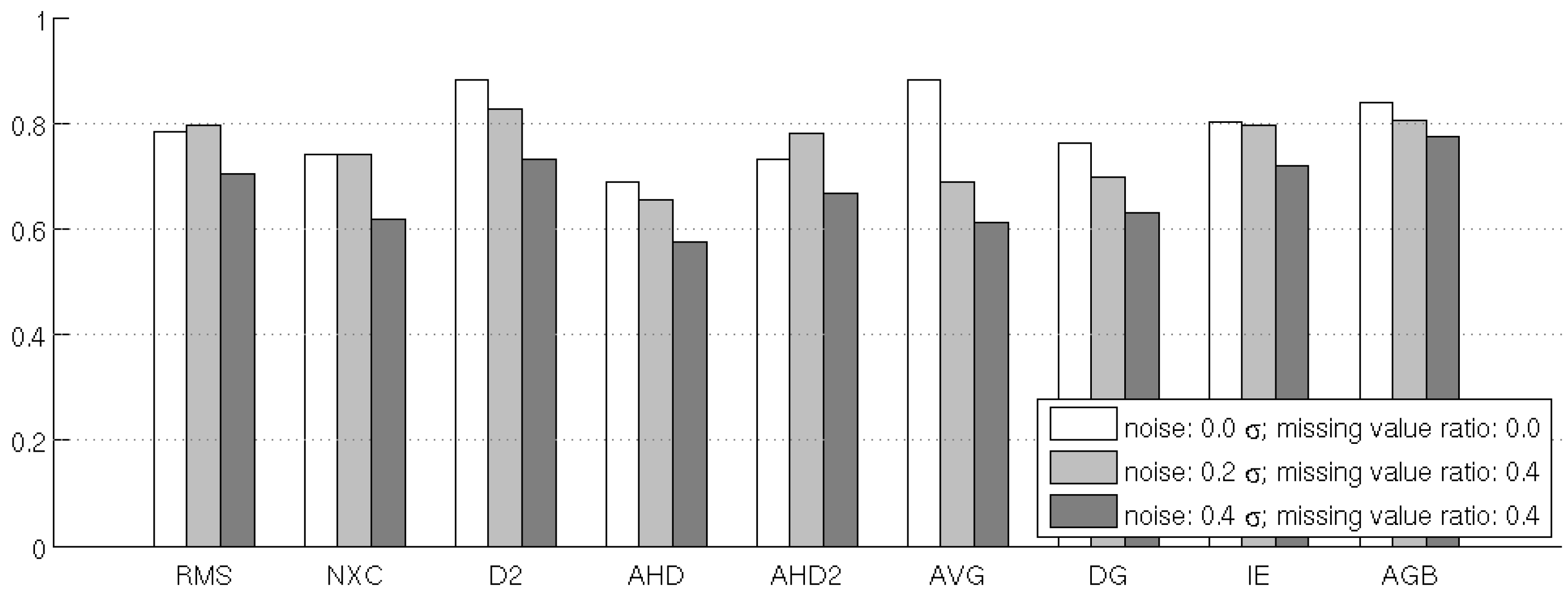
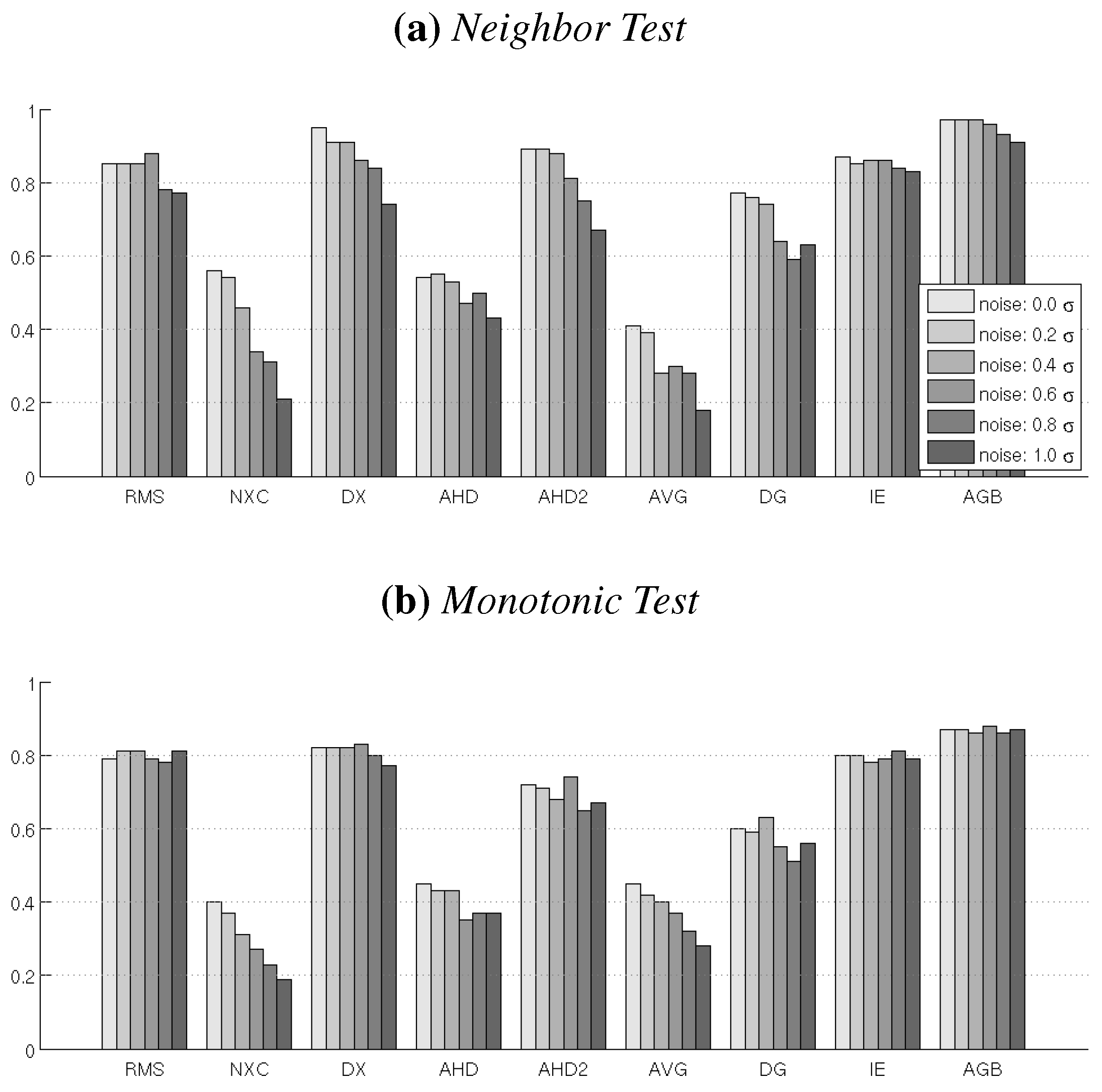
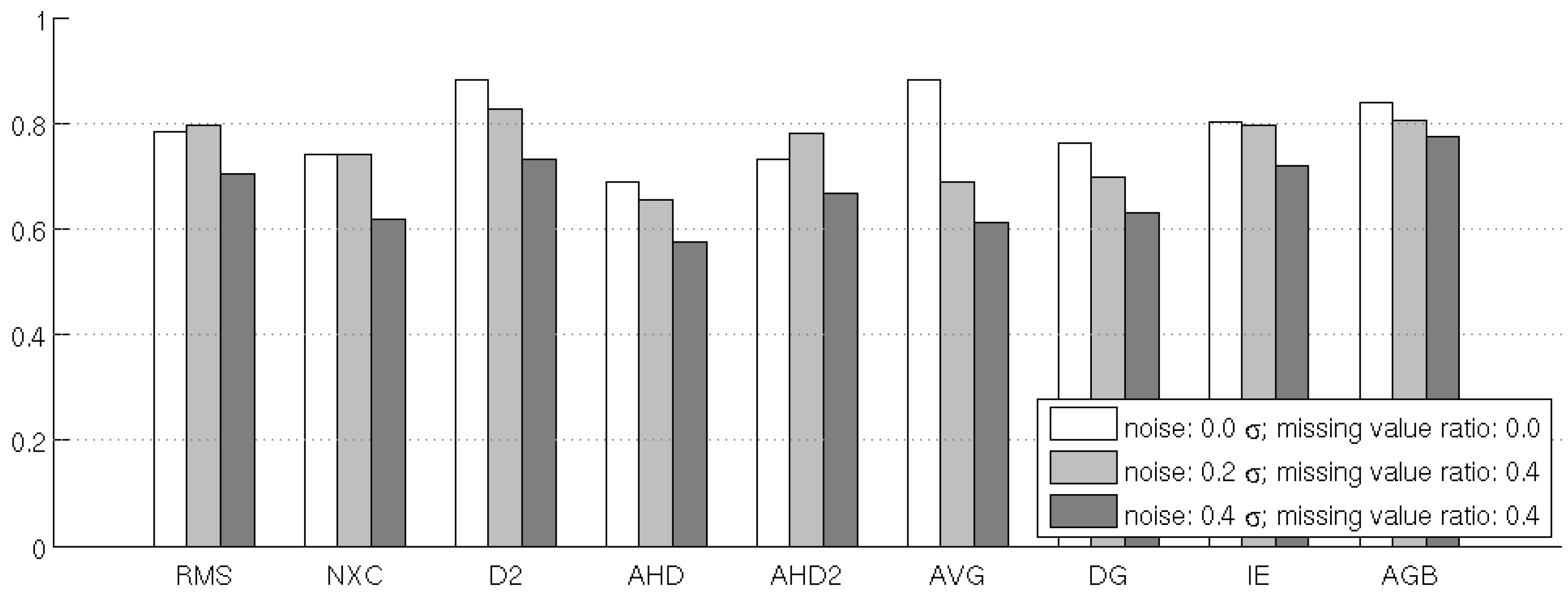
4.3. Test 3: Noise Sensitivity
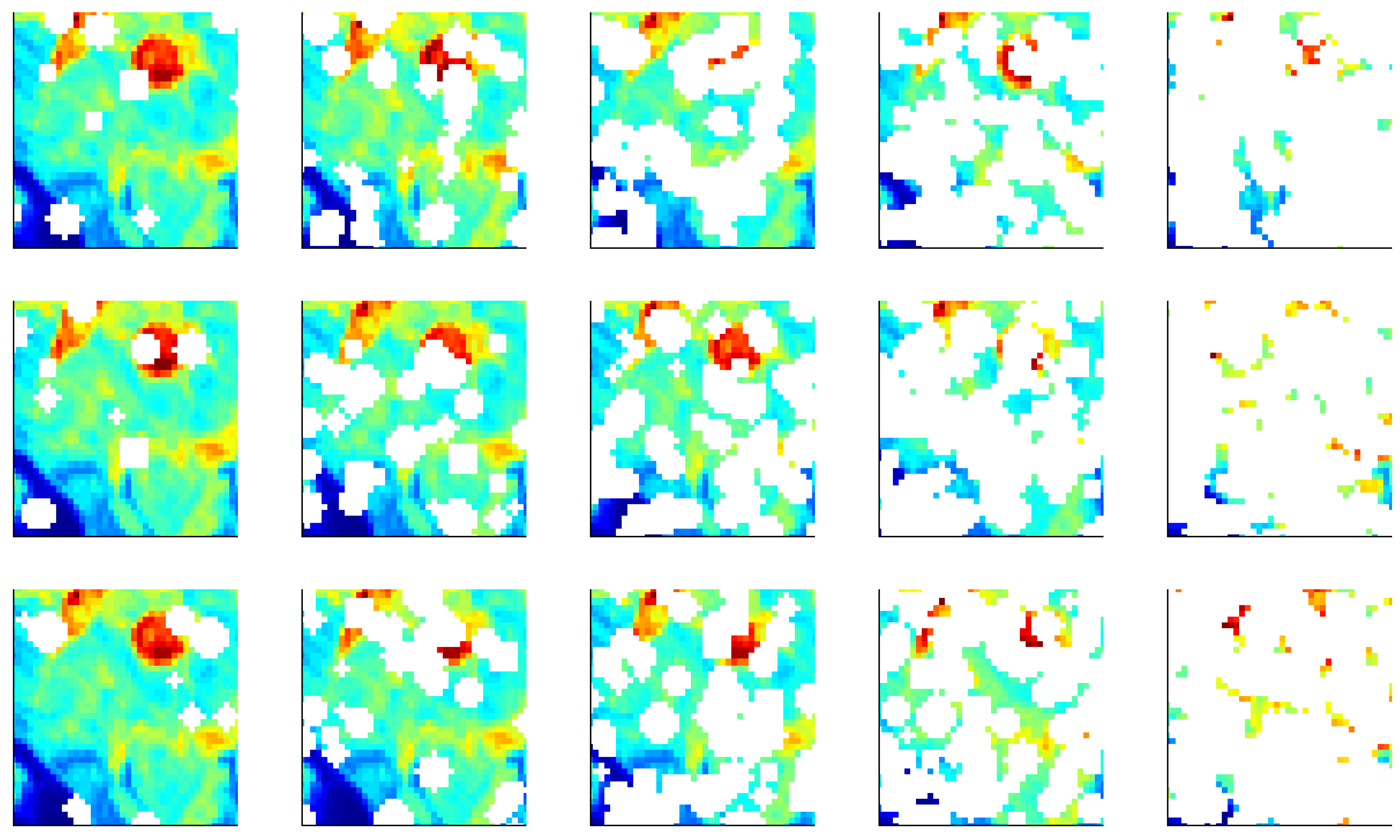
4.4. Test 4: NaN-Sensitivity
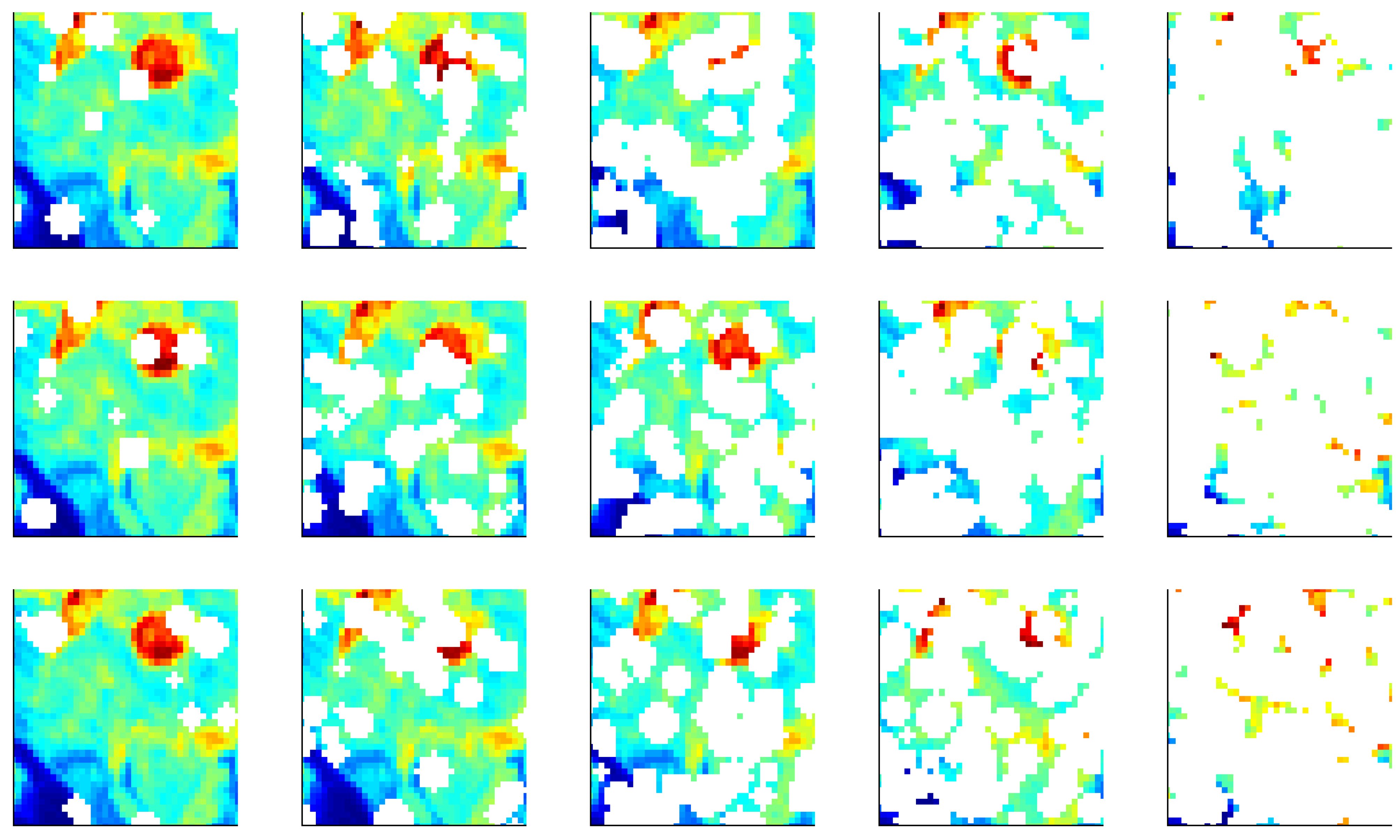
4.5. Test 5: NaN-Translation
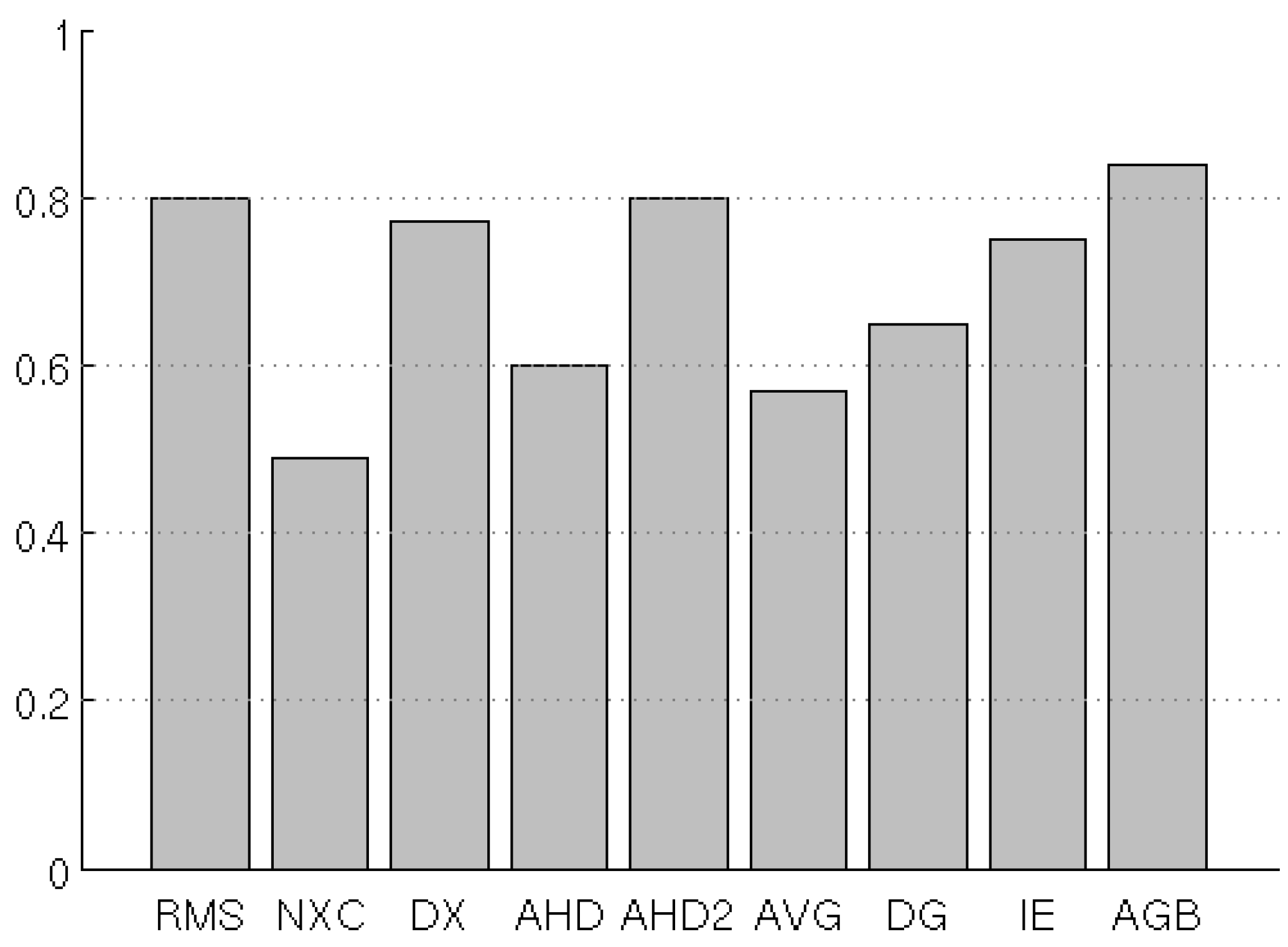
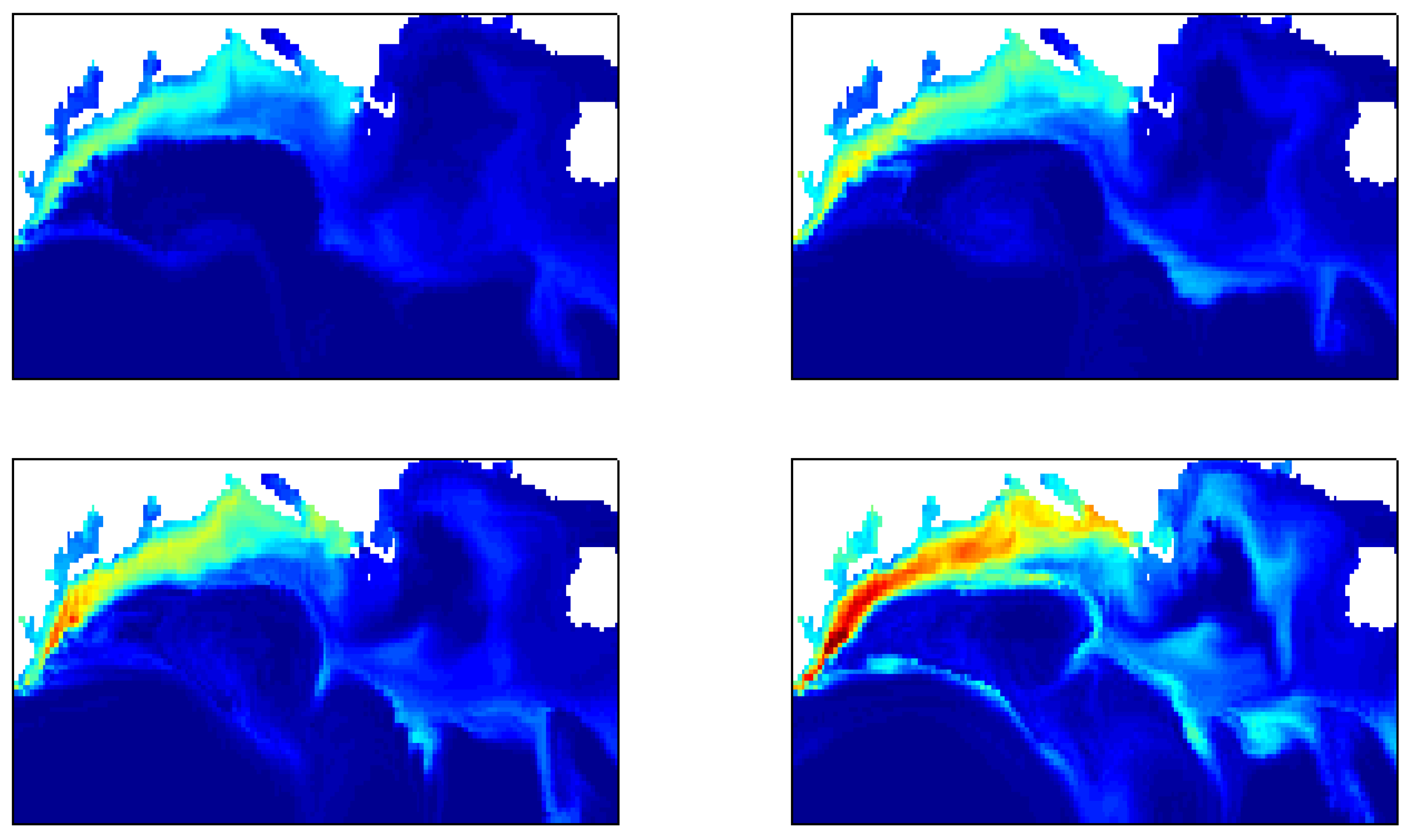
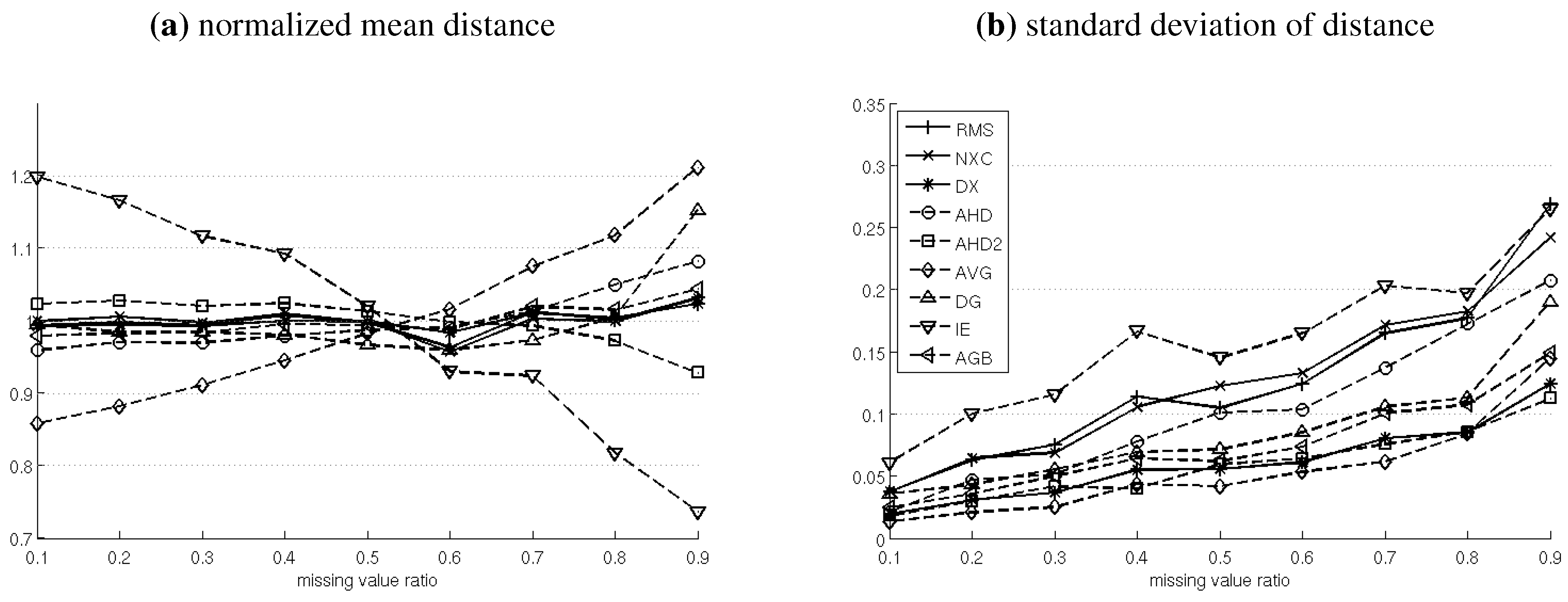
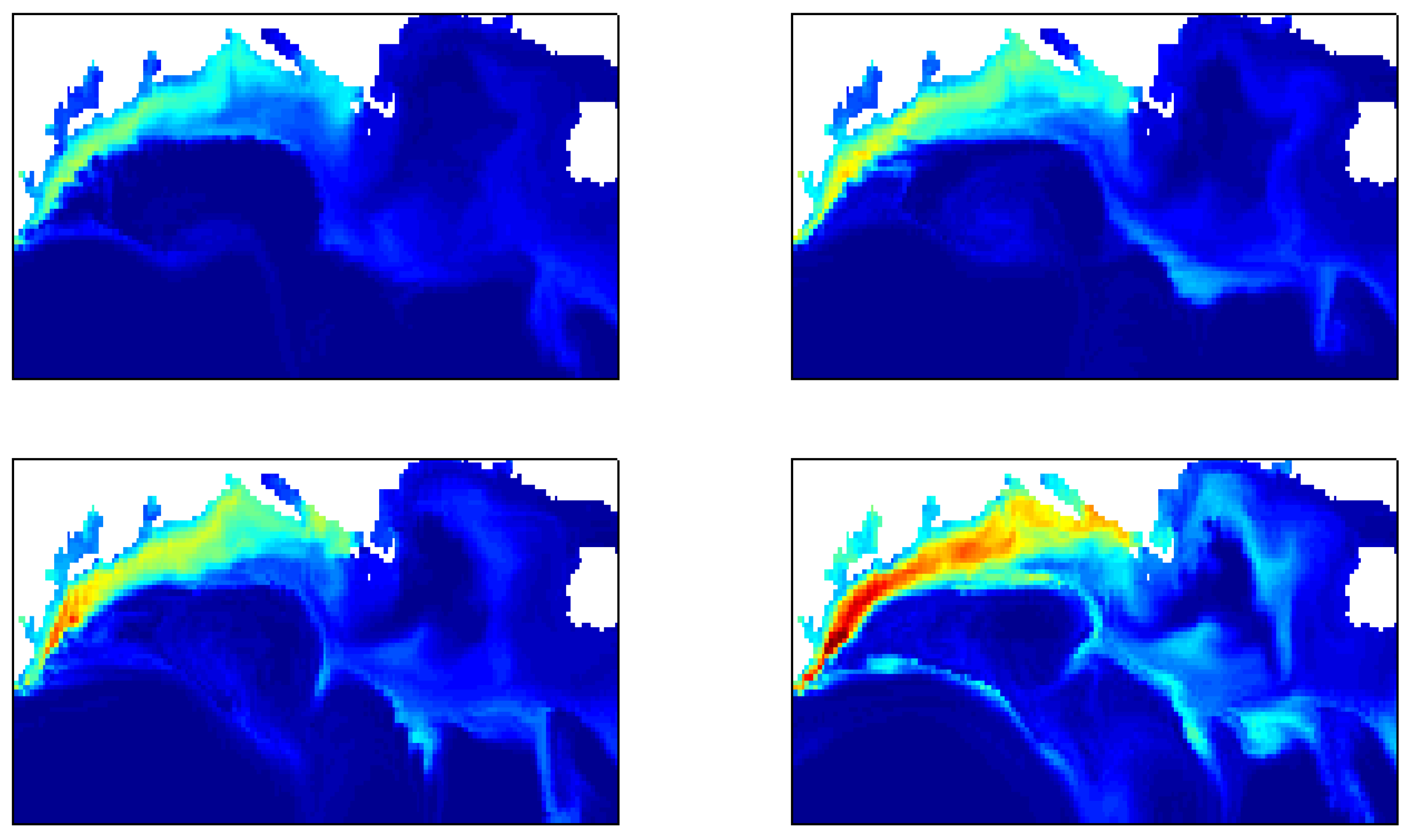
4.6. Test 6: Time-Series
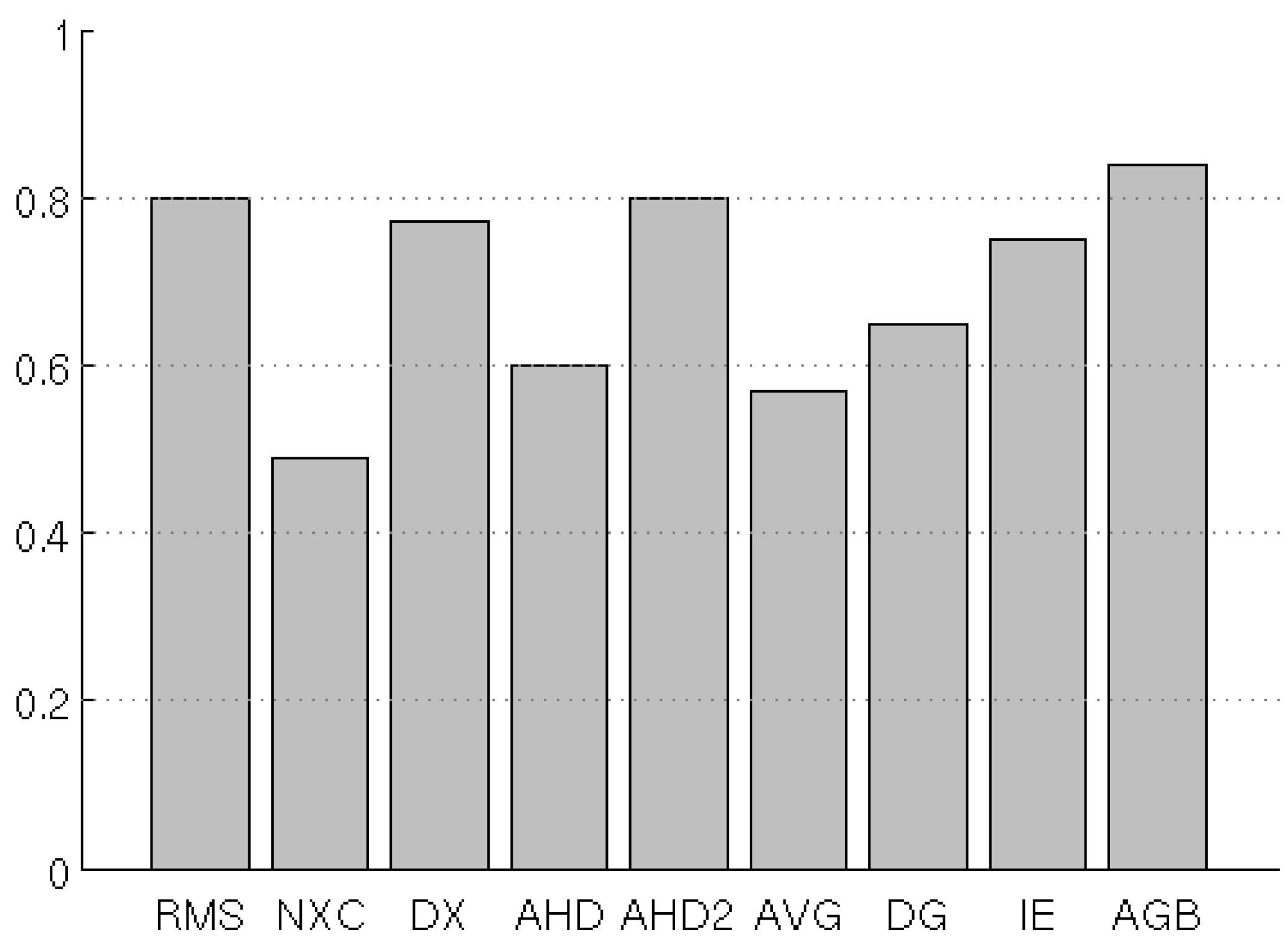
| Test | RMS | NXC | D2 | AHD | AHD2 | AVG | DG | IE | AGB |
| Test 1: translated & masked features | – | – | – | + | + | ○ | + | – | + |
| Test 2: translation & rotation | + | – | + | – | + | ○ | ○ | + | + |
| Test 3: noise sensitivity | + | – | + | – | ○ | – | – | + | + |
| Test 4: NaN-sensitivity | – | – | + | – | + | +a | ○ | –a | + |
| Test 5: NaN-translation | + | – | + | – | + | – | ○ | ○ | + |
| Test 6: time-series | ○ | – | + | – | ○ | ○ | – | ○ | + |
5. Discussion
6. Conclusions
Acknowledgments
References
- Allen, J.; Holt, J.; Blackford, J.; Proctor, R. Error quantification of a high-resolution coupled hydrodynamic-ecosystem coastal-ocean model: Part 2. Chlorophyll-a, nutrients and SPM. J. Marine Syst. 2007, 68, 381–404. [Google Scholar] [CrossRef]
- Stow, C.; Jolliff, J.; McGillicuddy, D.; Doney, S.; Allen, J.; Friedrichs, M.; Rose, K.; Wallhead, P. Skill assessment for coupled biological/physical models of marine systems. J. Marine Syst. 2009, 76, 4–15. [Google Scholar] [CrossRef]
- Lehmann, M. K.; Fennel, K.; He, R. Statistical validation of a 3-D bio-physical model of the western North Atlantic. Biogeosciences 2009, 6, 1961–1974. [Google Scholar] [CrossRef]
- Bennett, A. Inverse Modeling of the Ocean and Atmosphere; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Dowd, M. Bayesian statistical data assimilation for ecosystem models using Markov Chain Monte Carlo. J. Marine Syst. 2007, 68, 439–456. [Google Scholar] [CrossRef]
- Avcıbaş, İ.; Sankur, B.; Sayood, K. Statistical evaluation of image quality measures. J. Electron. Imag. 2002, 11, 206–245. [Google Scholar]
- Mannino, A.; Russ, M.; Hooker, S. Algorithm development and validation for satellite-derived distributions of DOC and CDOM in the US Middle Atlantic Bight. J. Geophys. Res. 2008, 113, C07051. [Google Scholar]
- Lehmann, T.; Sovakar, A.; Schmiti, W.; Repges, R. A comparison of similarity measures for digital subtraction radiography. Comput. Biol. Med. 1997, 27, 151–167. [Google Scholar] [CrossRef]
- Le Moigne, J.; Tilton, J. Refining image segmentation by integration of edge and region data. IEEE T. Geosci. Remote Sens. 1995, 33, 605–615. [Google Scholar] [CrossRef]
- Alberga, V. Similarity measures of remotely sensed multi-sensor images for change detection applications. Remote Sens. 2009, 1, 122–143. [Google Scholar] [CrossRef]
- Holyer, R.; Peckinpaugh, S. Edge detection applied to satellite imagery of the oceans. IEEE T. Geosci. Remote Sens. 1989, 27, 46–56. [Google Scholar] [CrossRef]
- Cayula, J.; Cornillon, P. Edge detection algorithm for SST images. J. Atmos. Ocean. Tech. 1992, 9, 67–80. [Google Scholar] [CrossRef]
- Belkin, I.; O’Reilly, J. An algorithm for oceanic front detection in chlorophyll and SST satellite imagery. J. Marine Syst. 2009, 78, 319–326. [Google Scholar] [CrossRef]
- Nichol, D. Autonomous extraction of an eddy-like structure from infrared images of the ocean. IEEE T. Geosci. Remote Sens. 1987, 25, 28–34. [Google Scholar] [CrossRef]
- Santini, S.; Jain, R. Similarity measures. IEEE T. Pattern Anal. 1999, 21, 871–883. [Google Scholar] [CrossRef]
- Di Gesú, V.; Starovoitov, V. Distance-based functions for image comparison. Pattern Recog. Lett. 1999, 20, 207–214. [Google Scholar] [CrossRef]
- Di Gesú, V.; Roy, S. Pictorial indexes and soft image distances. Springer: Berlin/Heidelberg, Germany, 2002; pp. 63–79. [Google Scholar] [CrossRef]
- Huttenlocher, D.; Klanderman, G.; Rucklidge, W. Comparing images using the Hausdorff distance. IEEE T. Pattern Anal. 1993, 15, 850–863. [Google Scholar] [CrossRef]
- Wilson, D.; Baddeley, A.; Owens, R. A New Metric for Grey-Scale Image Comparison. Int. J. Comput. Vision 1997, 24, 5–17. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y.; Feng, J. On the Euclidean distance of images. IEEE T. Pattern Anal. 2005, 27, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Juffs, P.; Beggs, E.; Deravi, F. A multiresolution distance measure for images. IEEE Sig. Proc. Lett. 1998, 5, 138–140. [Google Scholar] [CrossRef]
- Dubuisson, M.; Jain, A. A modified Hausdorff distance for object matching. In Proceedings of the 12th IAPR International Conference on Computer Vision & Image Processing, Jerusalem, Israel, 1994; pp. 566–568.
- Sim, D.; Kwon, O.; Park, R. Object matching algorithms using robust Hausdorff distance measures. IEEE T. Image Proc. 1999, 8, 425–429. [Google Scholar]
- Fennel, K.; Wilkin, J.; Previdi, M.; Najjar, R. Denitrification effects on air-sea CO2 flux in the coastal ocean: simulations for the Northwest North Atlantic. Geophys. Res. Lett. 2008, 35, L24608. [Google Scholar] [CrossRef]
© 2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license http://creativecommons.org/licenses/by/3.0/.
Share and Cite
Mattern, J.P.; Fennel, K.; Dowd, M. Introduction and Assessment of Measures for Quantitative Model-Data Comparison Using Satellite Images. Remote Sens. 2010, 2, 794-818. https://doi.org/10.3390/rs2030794
Mattern JP, Fennel K, Dowd M. Introduction and Assessment of Measures for Quantitative Model-Data Comparison Using Satellite Images. Remote Sensing. 2010; 2(3):794-818. https://doi.org/10.3390/rs2030794
Chicago/Turabian StyleMattern, Jann Paul, Katja Fennel, and Michael Dowd. 2010. "Introduction and Assessment of Measures for Quantitative Model-Data Comparison Using Satellite Images" Remote Sensing 2, no. 3: 794-818. https://doi.org/10.3390/rs2030794