Segmentation-Based Filtering of Airborne LiDAR Point Clouds by Progressive Densification of Terrain Segments

Abstract
:1. Introduction
- (1)
- After point cloud segmentation, segments are capable of reaching exactly up to the break lines or jump edges;
- (2)
- An explicit surface model can be used. Describing the expected terrain surface with a dedicated model allows including terrain characterization in the filter process [18];
- (3)
- The surface-based approach is useful in the wooded areas.
2. Previous Work
- (1)
- In slope-based approaches, the slope or height difference between two points is measured. The rationale behind these algorithms is that the steepest slopes in a landscape belong to objects and the terrain has a certain maximum slope. Thus, if the slope is above a certain threshold then the highest point is assumed to belong to an off-terrain object. Vosselman did the pioneering work [20] about slope-based filtering. Some extensions and variants of slope-based filters focus on the shape of structure elements [21], the determination of adaptive slope parameters [22], and topological analysis removing very large buildings [10]. The slope-based methods usually work well when object and terrain points are equally mixed. However, typical filter errors are encountered when this requirement is not met.
- (2)
- In surface-based approaches, the basic idea is to create a parametric surface with a corresponding buffer zone above it, the surface locates the buffer zone, and as before the buffer zone defines a region in 3D space where ground points are expected to reside [17]. Thus, the core step of this kind of methods is to create a surface approximating the bare earth [23]. Depending on the means of creating the surface, surface-based filtering methods can be further divided into three subcategories: morphology-based filters [23,24], iterative-interpolation-based filters [19,25,26], and progressive-densification-based filters [27]. Axelsson [27] first divided the whole point dataset into tiles, and then selected the lowest points in each block as the initial ground points, and finally a TIN of the identified ground points was constructed as the reference surface. For each triangle, one additional ground point was determined by investigating the parameters of the unclassified points in each triangle with the reference surface. The parameters were the distance to the TIN facets and the angles to the nodes. If a point was found with offsets below the threshold values, it was classified as a ground point and the algorithm proceeds with the next triangle. Before continuing with the next iteration, all ground points were added to the TIN. In this way, the triangulation was progressively densified until all points were classified as ground or object. Axelsson’s method is known as PTD [3,17]. The above surface-based approaches are preferred in engineering applications [28].
- (3)
- In segmentation-based approaches, it is commonly assumed that segments of objects are situated higher than the ground segments. Generally, segment-based filters generally consist of two steps, the first one being segmentation and the second one being filtering based on the generated segments. Lohmann [29] applied the compactness of these segments and the height difference to the neighboring segments in order to detect different types of areas. Lee [30] first obtained planar patches from the points with a region growing method, and then these patches are grouped into a set of surface clusters. It is assumed that the connected and continuous surface patches belong to the same object and that large vertical discontinuities usually do not exist between ground segments. The ground clusters are selected on the basis of a simple assumption that objects are above the ground and ground clusters are relatively large. Sithole and Vosselman [31] compared the neighboring segment heights in different directions and predefined a set of rules, finally each segment was classified as object or ground. Shen et al. [32] assumed that the ground segments are horizontal and lower than the adjacent object segments. Yan et al. [33] also presented an object-based filtering method. The above segment-based filters are typically designed for urban areas where many step edges can be found in the data. A shortcoming of these filters is that there is no intended terrain model as done in the in the above surface-based approaches. Additionally, too many small segments may be generated in forested areas, which will challenge the existing filters.
3. Method
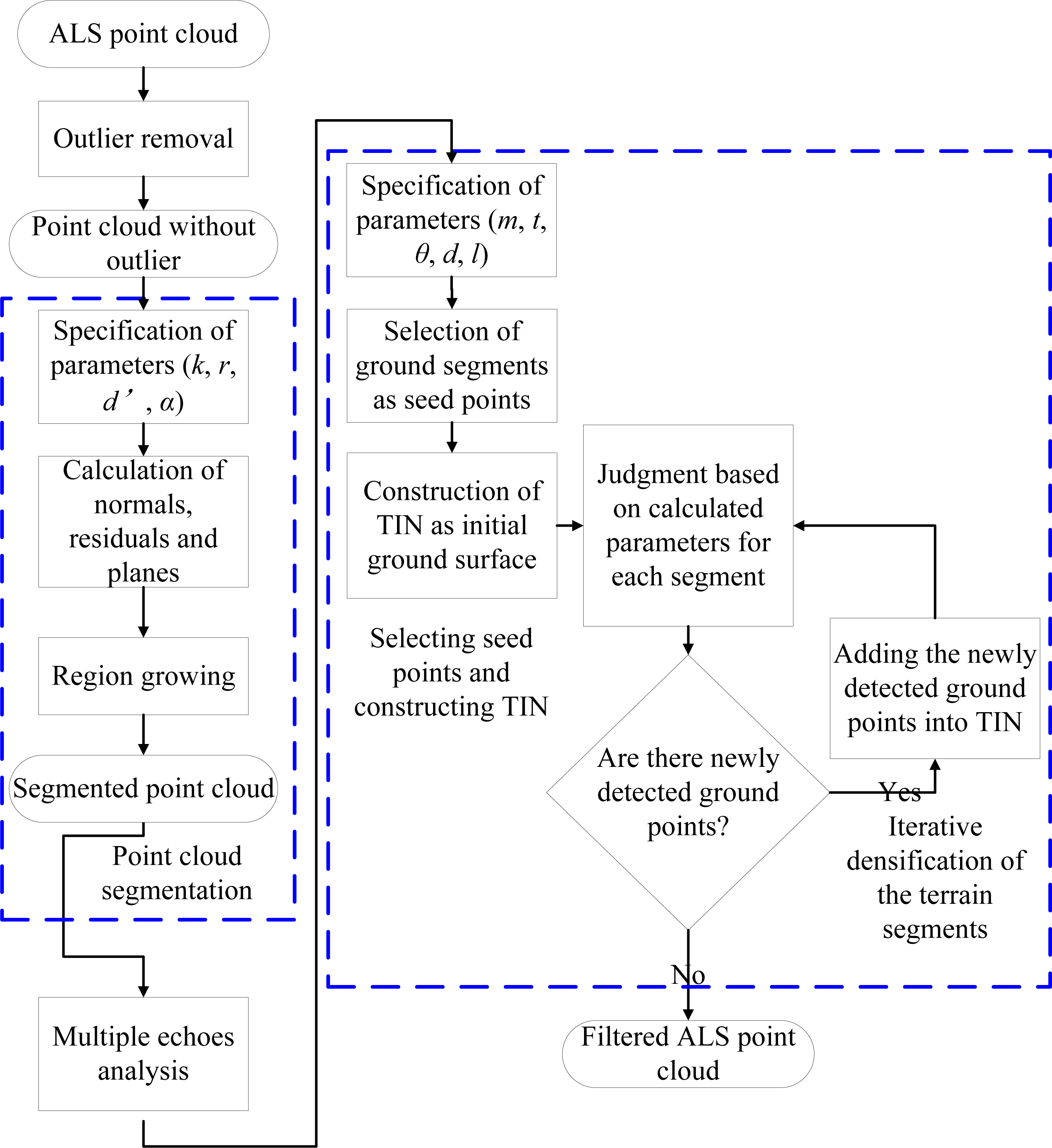
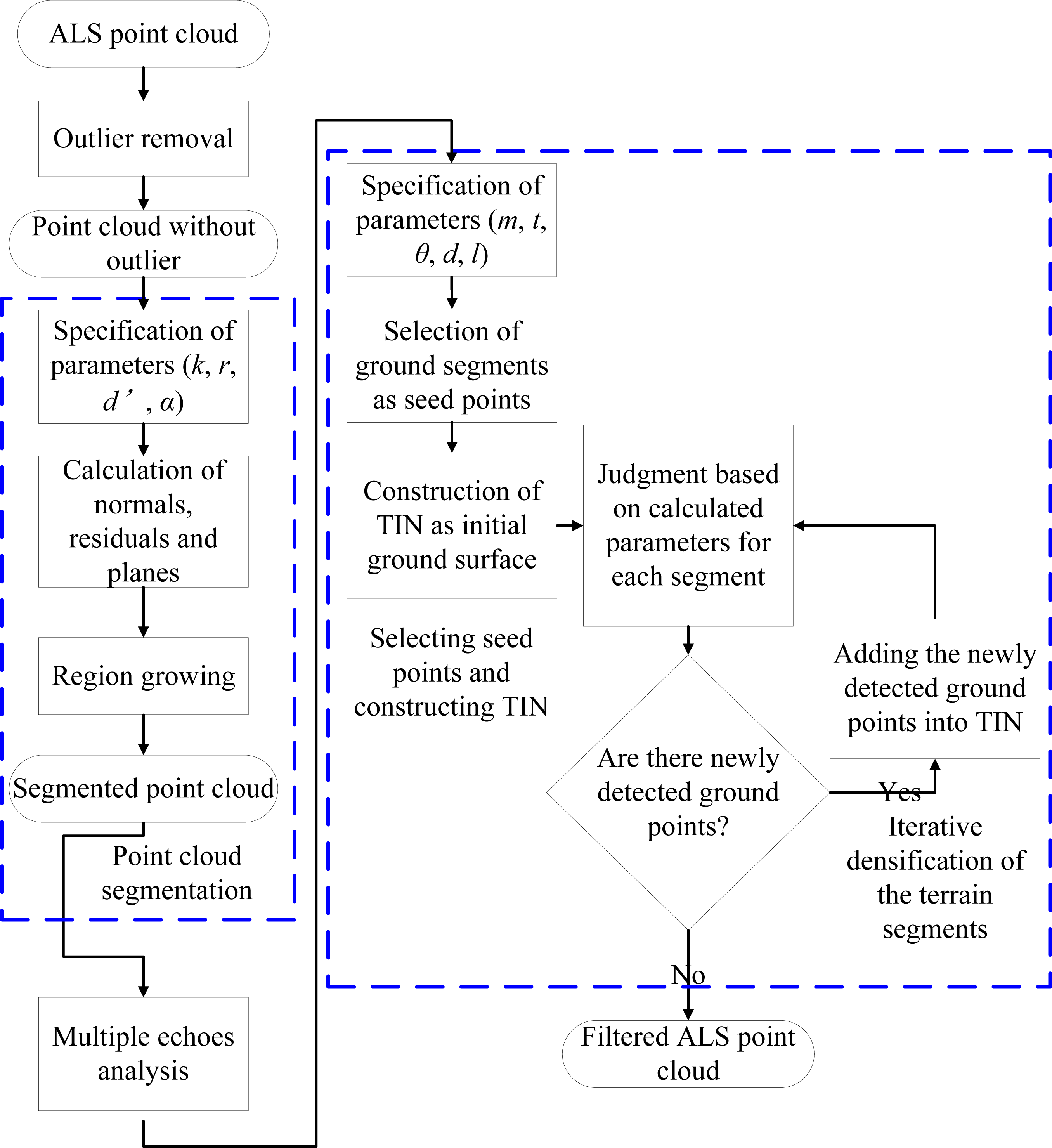
3.1. Outlier Removal
3.2. Point Cloud Segmentation
- (1)
- Normal and residual estimation. The normal for each point is estimated by fitting a plane to the neighboring points. Therefore, k nearest neighbors (KNN) [34] is employed for the neighborhood search. To fit a plane to a set of given points, in a least squares sense, we need to find the parameters that minimize the sum of squares of the orthogonal distances of the points from the estimated surface. The best-fitting plane is calculated using the principal component analysis (PCA), which is derived from the theory of the least-squares estimation. PCA is a popular method for computing plane normal approximations from point clouds, and the details of plane fitting refer to Rabbani [41].
- (2)
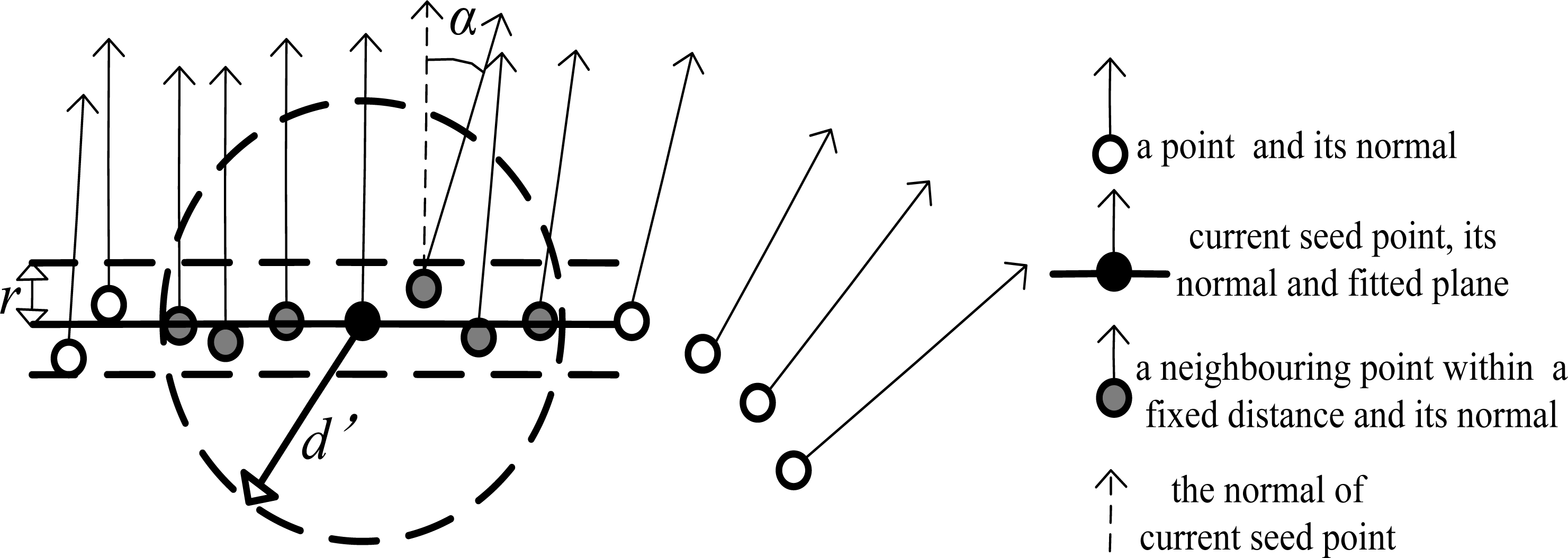
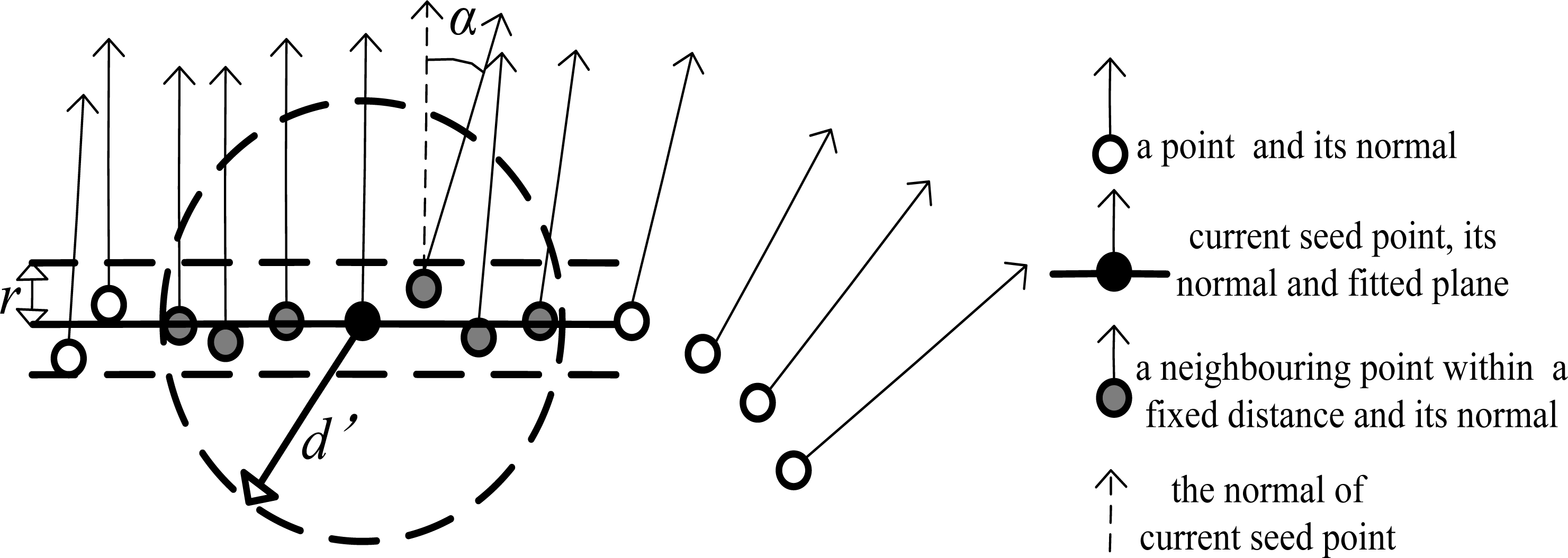
- Region growing with distance and normal difference constraint. This stage makes use of the above calculated normals, in accordance with user specified parameters to cluster points belonging to smooth surfaces. The process of region growing proceeds in the following steps:
- ① Input two smoothness thresholds in terms of the distance. The first threshold is the normal distance of a neighboring point to the current plane, denoted as r. The second threshold is the 3D distance between the current point and a neighboring point, denoted as d'.
- ② Input a smoothness threshold in terms of the angle between the normals of the current seed and its neighbors, denoted as α. Set all point to un-segmented.
- ③ If all the points have already been segmented, go to step ⑦. Otherwise, select the point with minimum residual from unlabeled points as the current seed, and build an empty list of seed points.
- ④ Select the fixed distance neighboring points of the current seed. Fixed distance neighbors (FDN) is used to search the neighboring points within a fixed distance d'. Add the points, whose angle difference to current seed is less than α and whose distance to the current plane is less than r, to current region; simultaneously, add the qualified points to the list of potential seed points.
- ⑤ If the potential seed point list is not empty, set the current seed to the next available seed and current plane to the next available seed’s plane, and go to step ④.
- ⑥ Add the current region to the segmentation and go to step ③, and clear the list of seed points. Note that the residuals of the labeled points should be excluded when the point with minimum residual is searched.
- ⑦ Finish the task of segmentation.
3.3. Multiple Echo Information Analysis
3.4. Progressive Densification of the Terrain Segments
- (1)
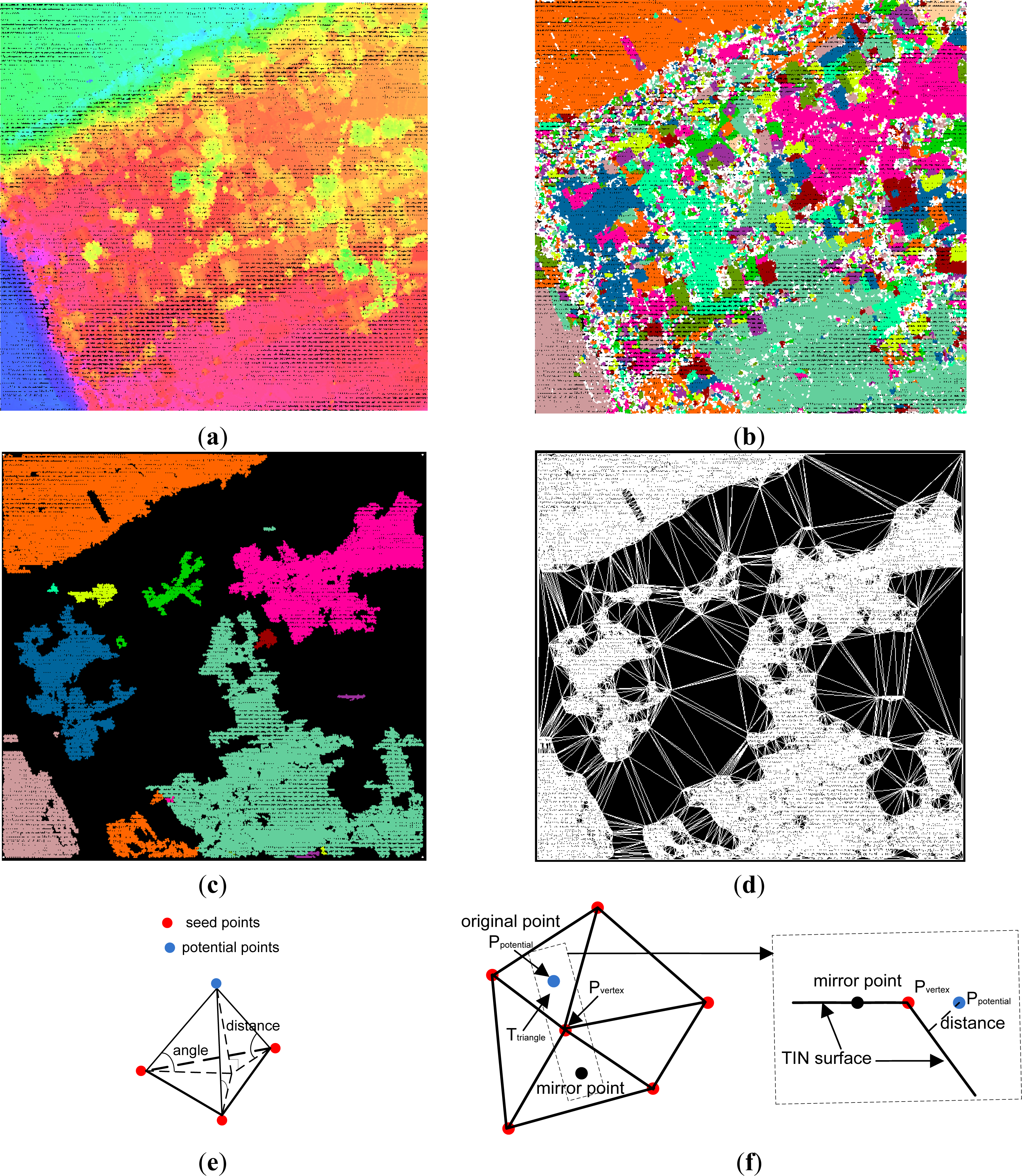
- Specifying parameters. There are five key parameters [3] to be preset, including:
- ① Maximum building size, m. m is a length threshold, and the algorithm can deal with buildings having a length of up to this value. It is used to define the grid cell size, and a grid cell is a tile of the point cloud (see the step (2)).
- ② Maximum terrain angle, t. t is a slope threshold, which decides how the judgment of an unclassified point is performed (either mirroring or not). If the slope of a triangle in the TIN is larger than t, any unclassified/potential point located inside of this triangle should be judged by a corresponding mirror point. The mirroring idea is from [27]. More details are presented in the step (3)-④, illustrated in Figure 4f.
- ③ Maximum angle, θ. θ is the maximum angle between a triangle plane and a line connecting a potential point with the closest triangle vertex. If an unclassified point has a larger angle than θ, it is labeled as an object measurement, otherwise as a ground measurement.
- ④ Maximum distance, d. d is the maximum orthogonal distance from a point to triangle plane during one iteration. If an unclassified point has a larger distance than d, it is labeled as an object measurement, otherwise as a ground measurement.
- ⑤ Minimum edge length, l. l is the minimum threshold for the maximum (horizontally projected) edge length of any triangle in the TIN. l is utilized to reduce the eagerness to add new points to the ground inside a triangle when every edge of a triangle is shorter than l. Note that l is measured in the horizontal plane. Thus, introduction of l helps to avoid adding unnecessary points to the ground model and reduces memory requirements.
- (2)
- Selecting seed terrain segments and constructing initial TINDetermine the bounding box of the given point cloud dataset, and fix the top left corner (xtopleft, ytopleft), bottom right corner (xbottomright, ytbottomright), width w and height h. The whole region of dataset is divided into several tiles (or grid cells) in rows and columns. Number of rows and columns are determined by the following formula:where nRow is the number of tiles in rows, nColumn is the number of tiles in columns, m is the above parameter about maximum building size, ceil(x) is a function used to return the smallest integral value that is not less than x. The segment with the lowest point in each tile is regarded as a terrain segment, and the points belonging to the terrain segments are selected as seed points of the dataset. Note that there is no repeating in the seed points. This means, if the lowest points in several tiles belong to the same segment, the points belonging to the same segment should be added into the seed points only once, as shown in Figure 4c,d. Additionally, the four corners on the bounding box should be added to the seed points, as shown in Figure 4c,d. Moreover, each corner’s height is equal to its closest seed point on horizontal plane. At last, a TIN is constructed based on the seed points, as shown in Figure 4d, and it represents an initial terrain model. Note the insertion of the four corners guarantees that any point in the point cloud dataset is located inside the TIN. After the TIN is constructed, the remaining points, except the seed points, are labeled as default object measurements.
- (3)
- LabelingJudging is performed in a segment-wise style. In other words, the potential points belonging to the same segment are judged as a whole. In detail, set all segments except the terrain ones in an unprocessed state. Find an unprocessed segment, and the points within the segment labeled as object measurements. Subsequently, make a judgment of each potential point in the segment as follows:
- ① Locate the potential point, Ppotential(xp, yp, zp). Find the triangle, Ttriangle, which the Ppotential is inside or on the edge of or on the vertex of.
- ② Calculate the slope of the triangle plane, Striangle. If Striangle is not larger than terrain angle t, go to ③. Otherwise, go to ④.
- ③ Calculate the following two parameters, Aangle and Ddistance, as shown in Figure 4e. This first is the angle between Ttriangle and a line connecting Ppotential with the closest triangle vertex, denoted as Aangle. The second is the distance from Ppotential to Ttriangle, denoted as Ddistance. If both of the following cases:
- Aangle ≤ θ
- Ddistance ≤ d
- ④ Mirroring Ppotential, as shown in Figure 4f. Find the vertex with highest elevation value in Ttriangle, denoted as Pvertex(xv, yv, zv). Ppotential is mirrored as follows:where (xmirror, ymirror, zmirror) are the 3D coordinates of the mirror point. Locate the mirror point, and calculate the angle and distance parameters as done in ③. If the mirror point is determined as a ground point, label Ppotential as ground measurement, and go to judgment of next point.
If all points within the current segment have been judged, set the segment in a processed state, and count the number of the ground points and the number of the object points. If the number of ground measurements is larger than the object measurements, label all of the points within the current segment as ground measurement. Otherwise, label them as object measurements again, and go to judgment of next unprocessed segment. However, if all segments are processed and labeled, go to step (4). - (4)
- The newly detected terrain segments are added into the TIN as follows:
- ① Locate the ground point, Pground(xg, yg, zg) in each terrain segment one by one. Find the triangle, T'triangle, which the Pground is inside or on the edge of or on the vertex of.
- ② Calculate the length of each edge of T'triangle in horizontal plane. If the length of any edge is larger than l, add Pground into the TIN. Otherwise, go to the judgment of the next newly detected ground point.
- (5)
- Repeat (3) and (4) until no further segment is added to the set of terrain segments anymore.
4. Experiments and Performance Evaluation
4.1. Experimental Data
- If intensity values of the two echoes are not same, they are both labeled as multiple echoes;
- Otherwise, calculate the 3D distance of the two echoes:
- ▪ If their distance is larger than an experienced threshold, 0.5 m, they are also labeled as multiple echoes;
- ▪ Otherwise, they are both labeled as single echoes.
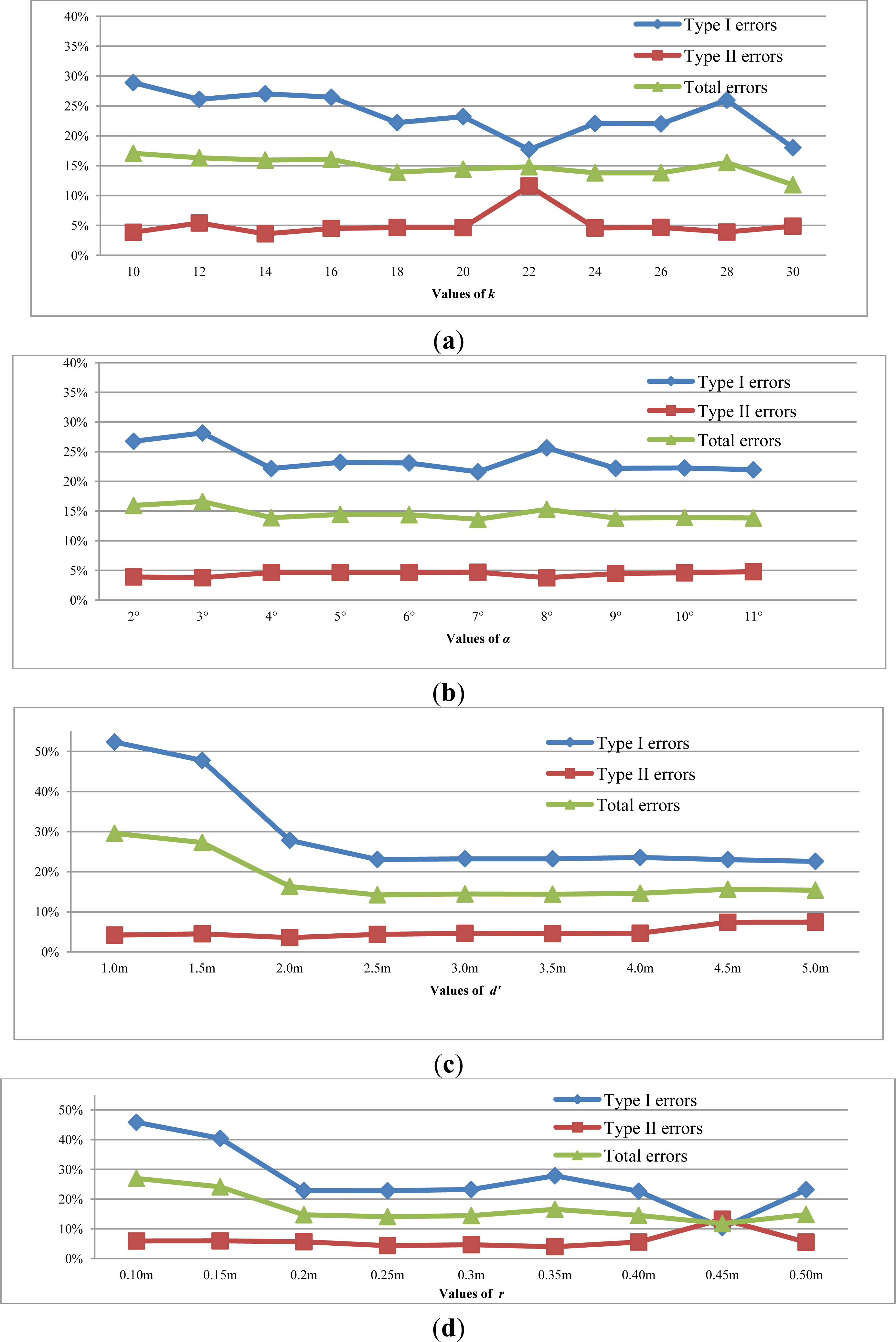
4.2. Specification of the Input Parameters
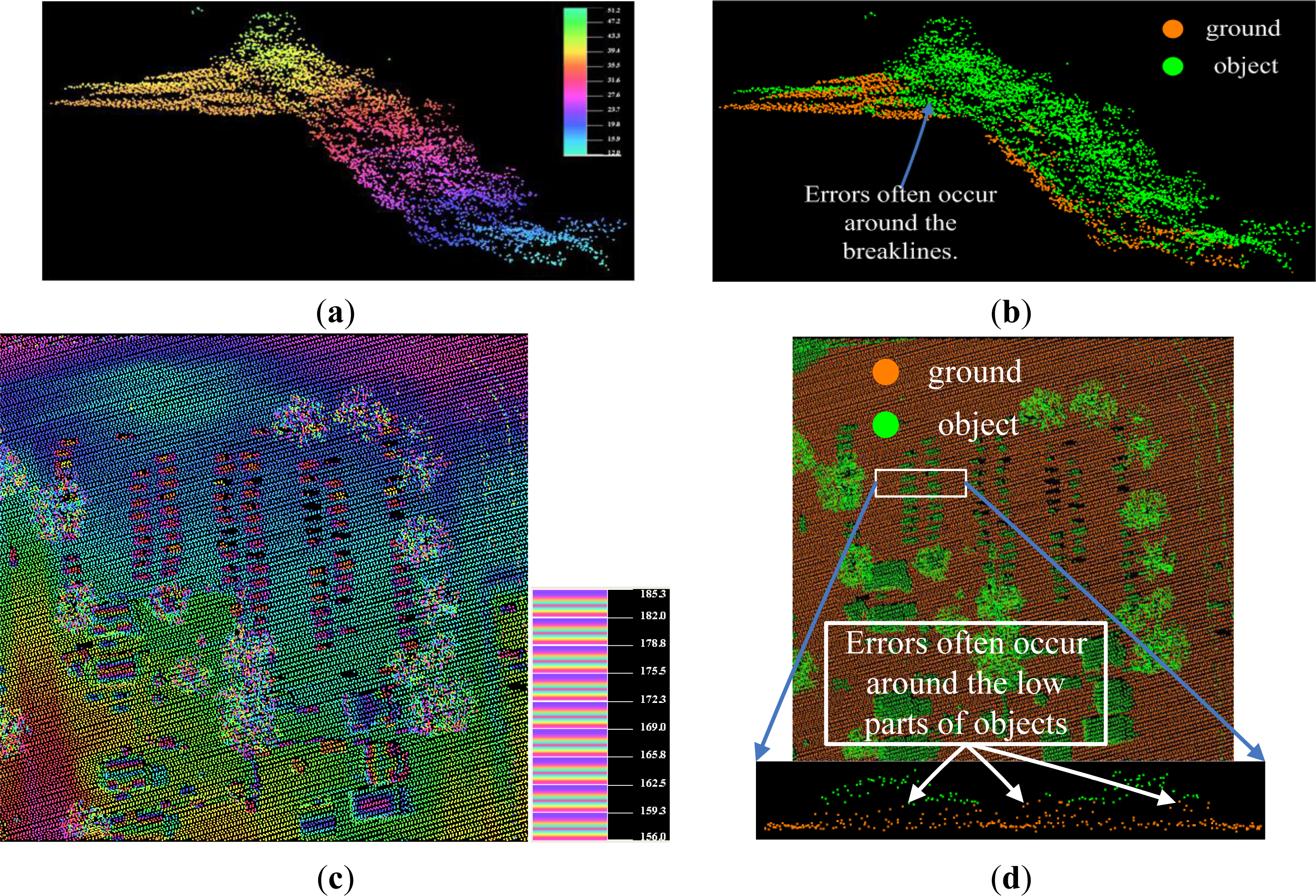
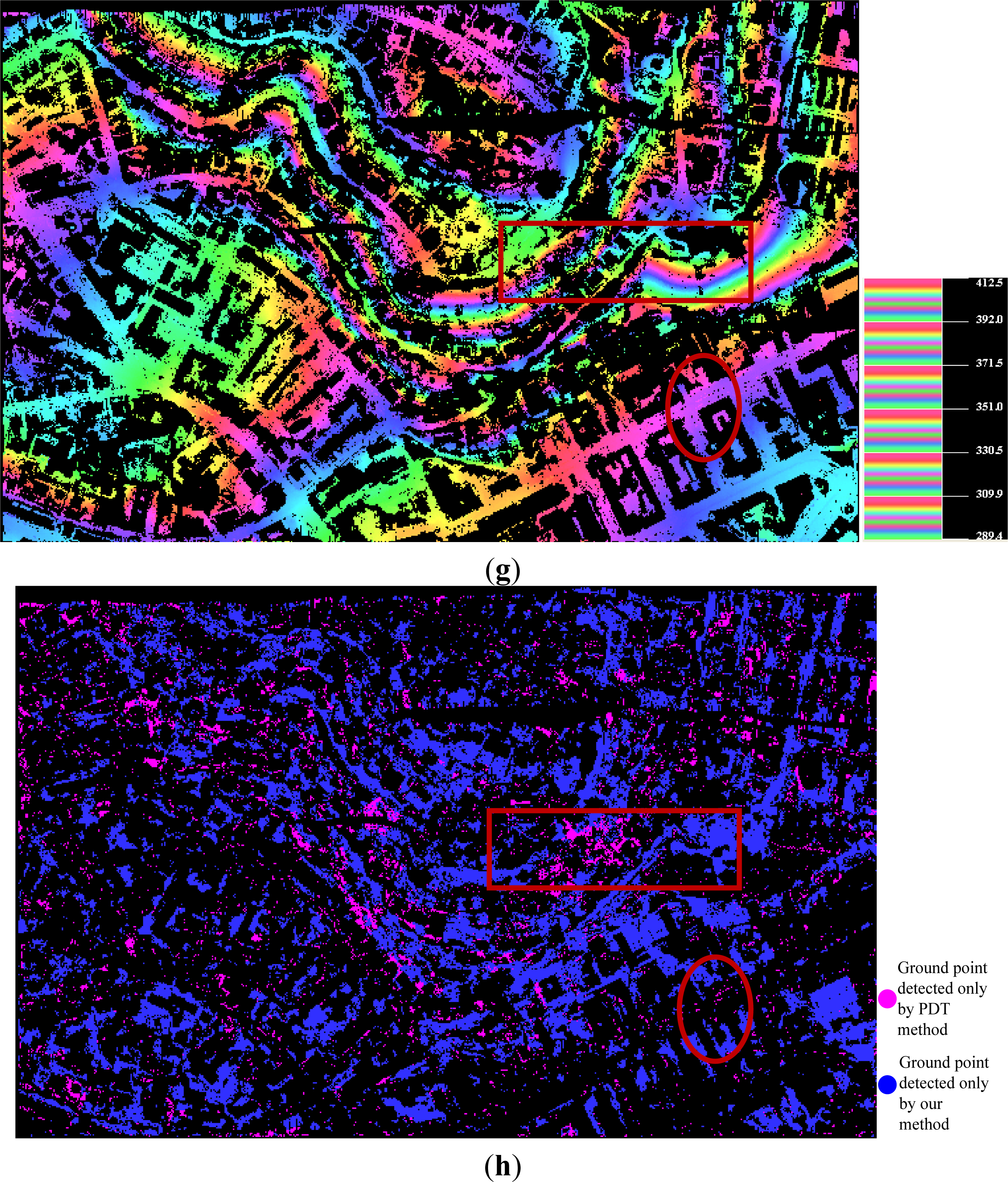
4.3. Results
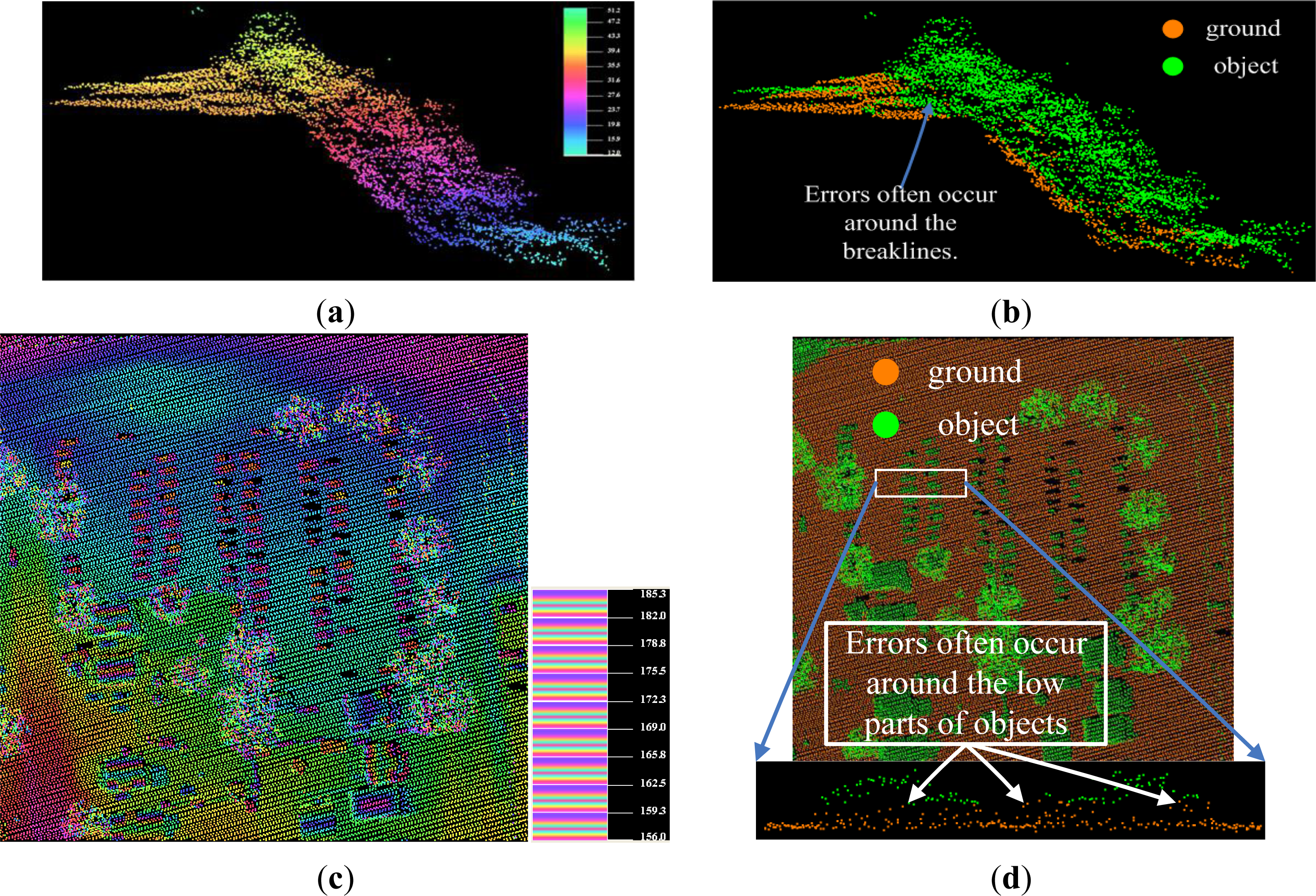
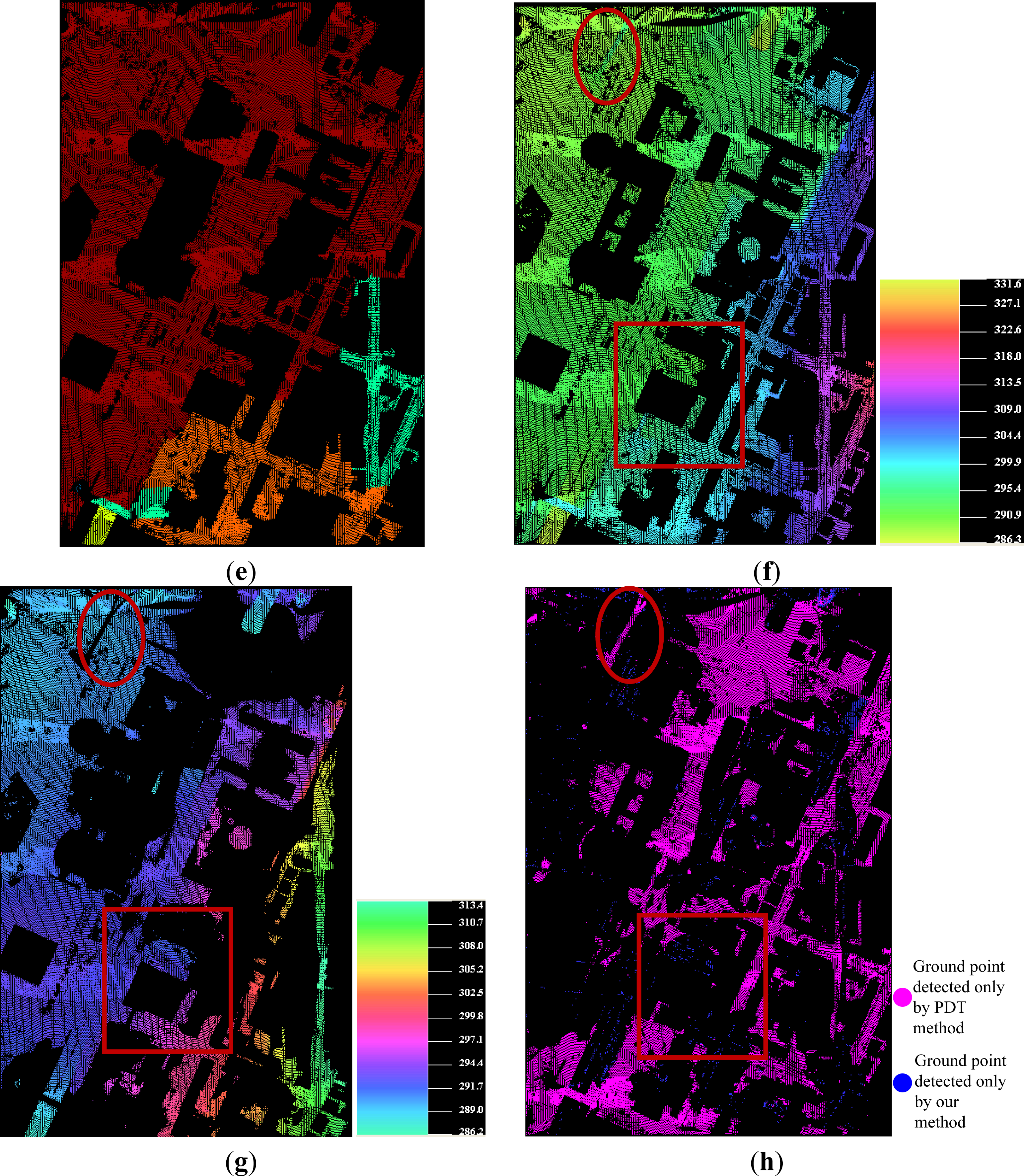
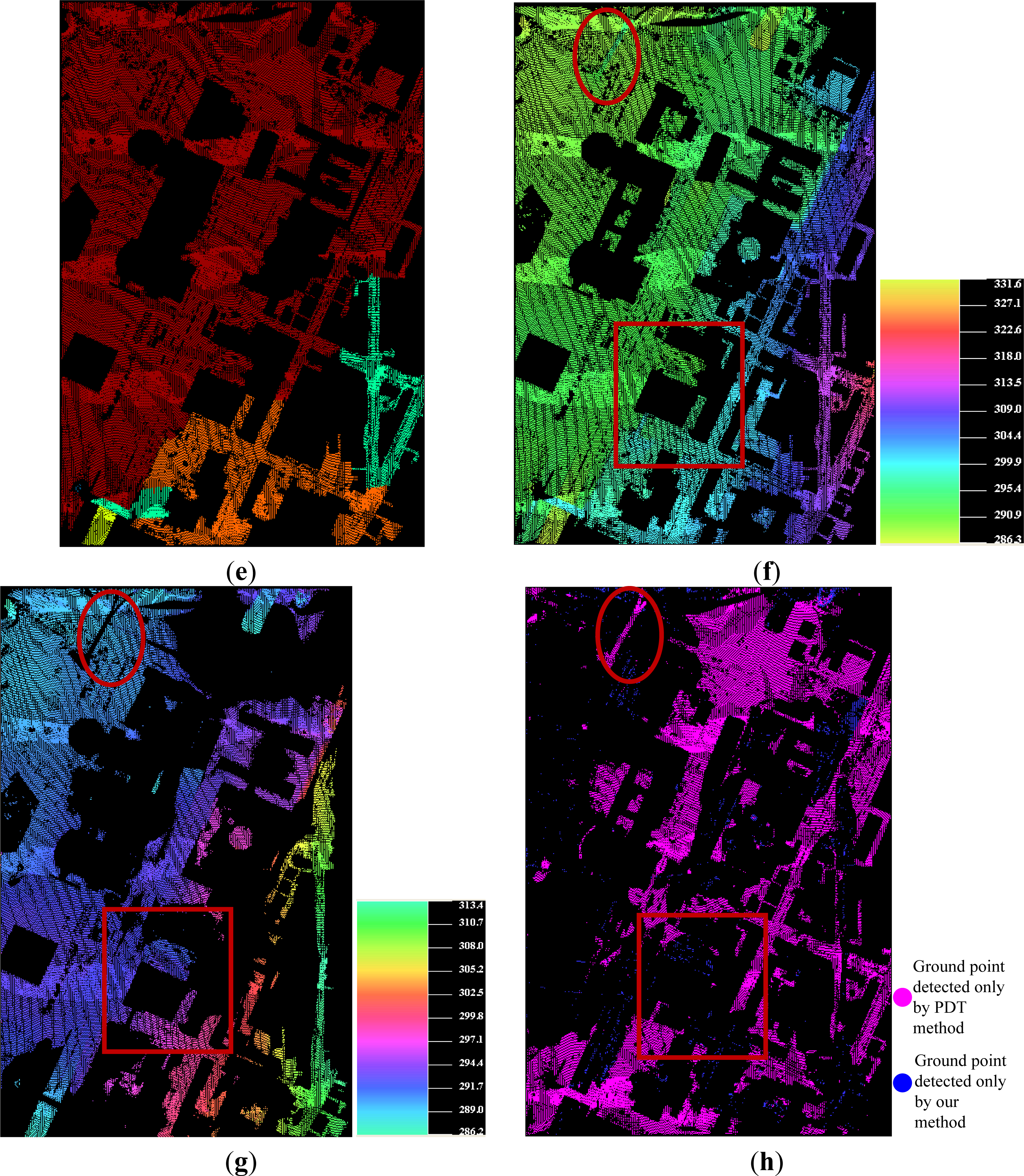
- if the objects are closely attached to the underlying terrain surface, as the bridge shown in the ellipse regions of Figures 6f and 11e;
- if the objects are both small and very close to the ground surfaces, as shown in Figure 9f.
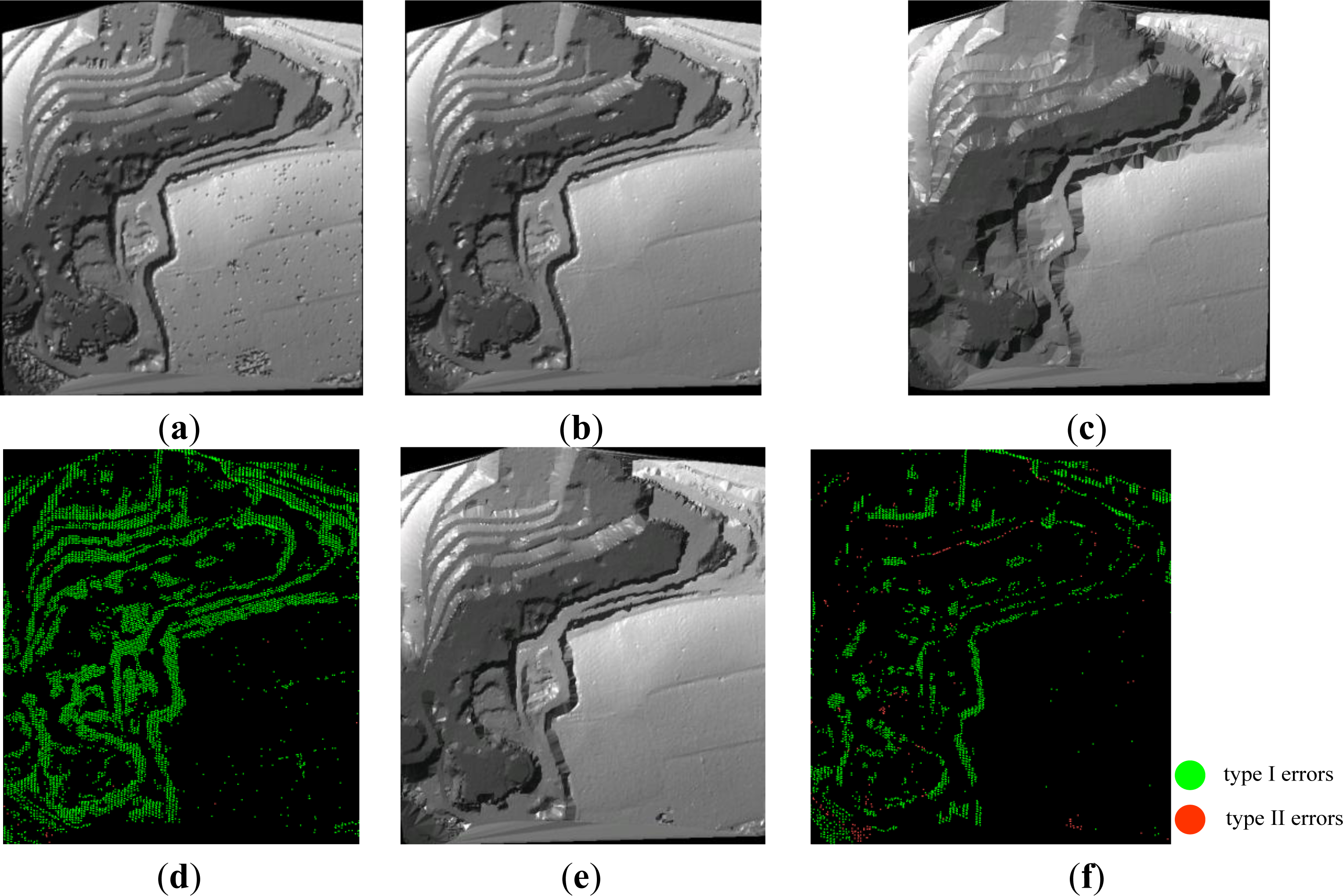
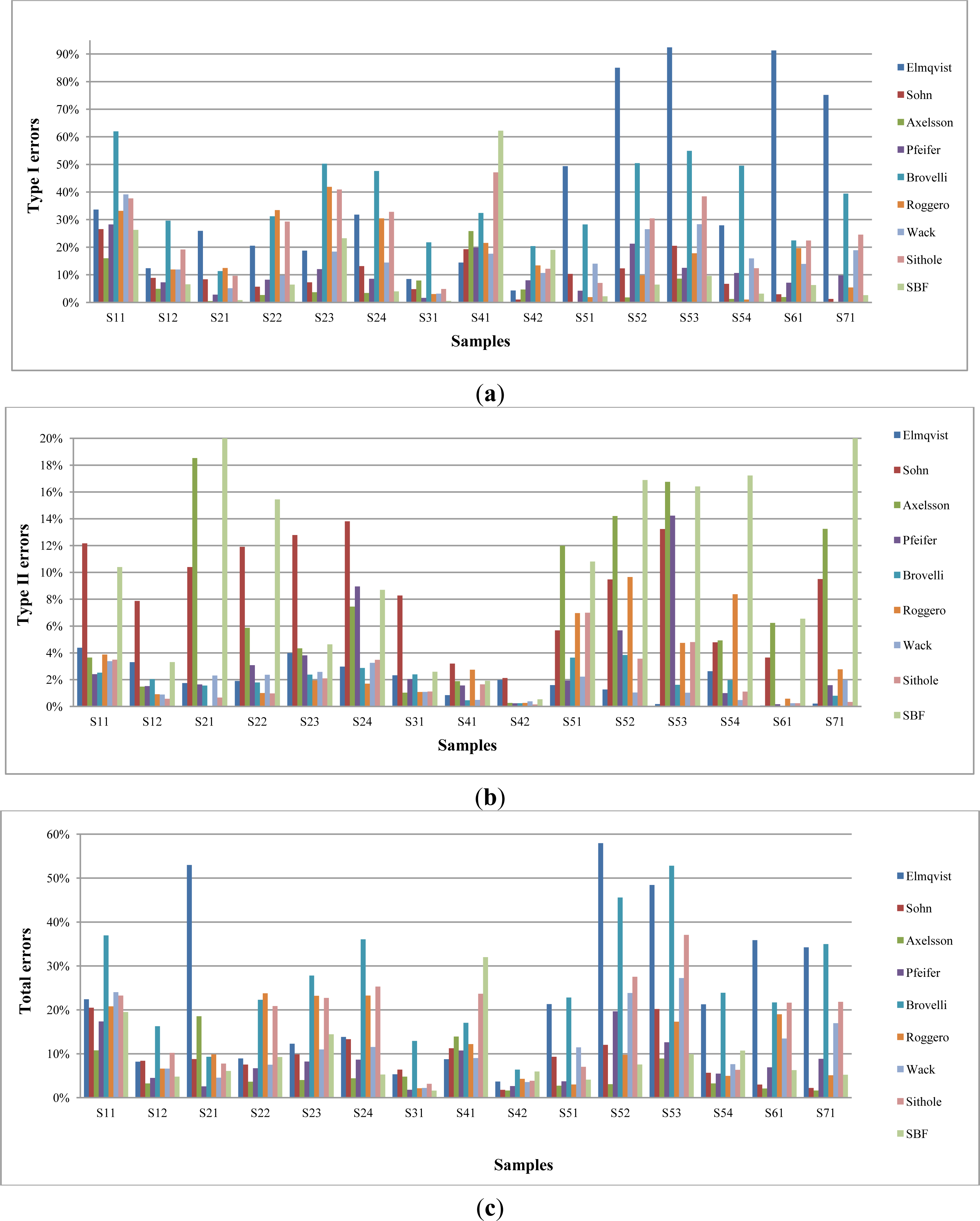
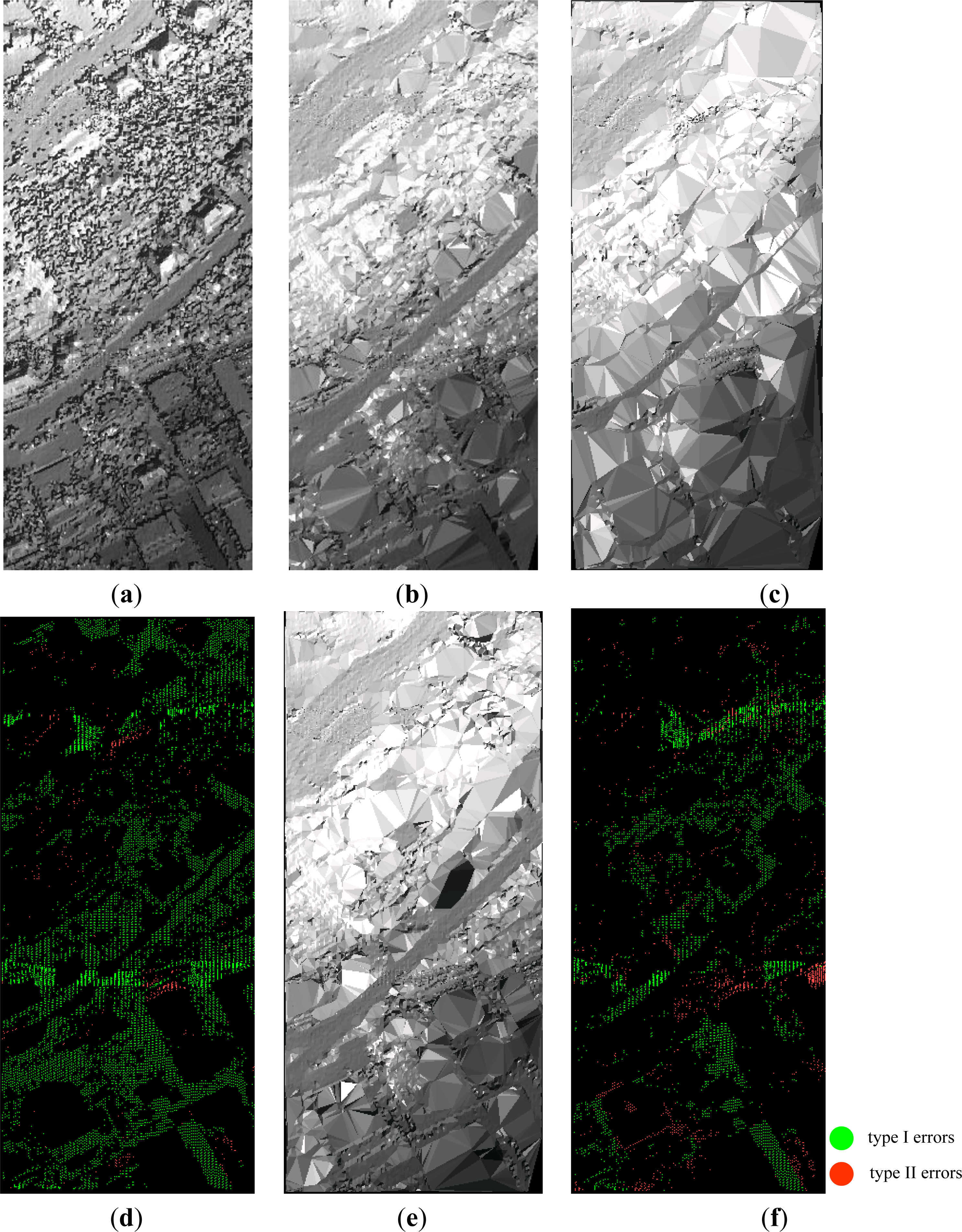
4.4. Performance Evaluation between SBF and PTD
4.5. Performance Evaluation between SBF and the Others
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhang, J.X.; Lin, X.G.; Ning, X.G. SVM-based classification of segmented airborne LiDAR point clouds in urban areas. Remote Sens 2013, 5, 3749–3775. [Google Scholar]
- Shan, J.; Sampath, A. Urban DEM generation from raw Lidar data: A labeling algorithm and its performance. Photogramm. Eng. Remote Sens 2005, 71, 217–226. [Google Scholar]
- Zhang, J.X.; Lin, X.G. Filtering airborne LiDAR data by embedding smoothness-constrained segmentation in progressive TIN densification. ISPRS J. Photogramm 2013, 81, 44–59. [Google Scholar]
- Maas, H.G.; Vosselman, G. Two algorithms for extracting building models from raw laser altimetry data. ISPRS J. Photogramm. Remote Sens 1999, 54, 153–163. [Google Scholar]
- Rutzinger, M.; Rottensteiner, F.; Pfeifer, N. A comparison of evaluation techniques for building extraction from airborne laser scanning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens 2009, 2, 11–20. [Google Scholar]
- Huang, H.; Brenner, C.; Sester, M. A generative statistical approach to automatic 3D building roof reconstruction from laser scanning data. ISPRS J. Photogramm. Remote Sens 2013, 79, 29–43. [Google Scholar]
- Wang, R. 3D building modeling using images and LiDAR: A review. Int. J. Image Data Fusion 2013, 4, 273–292. [Google Scholar]
- Oude Elberink, S.; Vosselman, G. 3D information extraction from laser point clouds covering complex road junctions. Photogramm. Rec 2009, 24, 23–36. [Google Scholar]
- Koch, B.; Heyder, U.; Weinacker, H. Detection of individual tree crowns in airborne LiDAR data. Photogramm. Eng. Remote Sens 2006, 72, 357–363. [Google Scholar]
- Liu, J.P.; Shen, J.; Zhao, R.; Xu, S.H. Extraction of individual tree crowns from airborne LiDAR data in human settlements. Math. Comput. Model 2013, 58, 524–535. [Google Scholar]
- Hyyppä, J.; Yu, X.; Hyyppä, H.; Vastaranta, M.; Holopainen, M.; Kukko, A.; Kaartinen, H.; Jaakkola, A.; Vaaja, M.; Koskinen, J.; et al. Advances in forest inventory using airborne laser scanning. Remote Sens 2012, 4, 1190–1207. [Google Scholar]
- Wang, C.; Menenti, M.; Stoll, M.P.; Feola, A.; Belluco, E.; Marani, M. Separation of ground and low vegetation signatures in LiDAR measurements of salt-marsh environments. IEEE Trans. Geosci. Remote Sens 2009, 47, 2014–2023. [Google Scholar]
- French, J.R. Airborne LiDAR in support of geomorphological and hydraulic modelling. Earth Surf. Process. Landf 2003, 28, 321–335. [Google Scholar]
- Hutton, C.J.; Brazier, R.E. Quantifying riparian zone structure from airborne LiDAR: Vegetation filtering, anisotropic interpolation, and uncertainty propagation. J. Hydrol 2012, 442–443, 36–45. [Google Scholar]
- Lin, X.G.; Zhang, R.; Shen, J. A template-matching based approach for extraction of roads from very high resolution remotely sensed imagery. Int. J. Image Data Fusion 2012, 3, 149–168. [Google Scholar]
- Meng, X.; Currit, N.; Zhao, K. Ground filtering algorithms for airborne LiDAR data: A review of critical issues. Remote Sens 2010, 2, 833–860. [Google Scholar]
- Sithole, G.; Vosselman, G. Experimental comparison of filter algorithms for bare earth extraction from airborne laser scanning point clouds. ISPRS J. Photogramm. Remote Sens 2004, 59, 85–101. [Google Scholar]
- Tóvári, D.; Pfeifer, N. Segmentation based robust interpolation-a new approach to laser data filtering. Int. Arch. Photogramm. Remote Sens 2005, 36, 79–84. [Google Scholar]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. Remote Sens 1998, 53, 193–203. [Google Scholar]
- Vosselman, G. Slope based filtering of laser altimetry data. Int. Arch. Photogramm. Remote Sens 2000, 33, 935–942. [Google Scholar]
- Sithole, G.; Vosselman, G. Filtering of laser altimetry data using a slope adaptive filter. Int. Arch. Photogramm. Remote Sens 2001, 34, 203–210. [Google Scholar]
- Susaki, J. Adaptive slope filtering of airborne LiDAR data in urban areas for digital terrain model (DTM) generation. Remote Sens 2012, 4, 1804–1819. [Google Scholar]
- Chen, Q.; Gong, P.; Baldocchi, D.; Xie, G. Filtering airborne laser scanning data with morphological methods. Photogramm. Eng. Remote Sens 2007, 73, 175–185. [Google Scholar]
- Zhang, K.Q.; Chen, S.C.; Whitman, D.; Shyu, M.L.; Yan, J.H.; Zhang, C.C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens 2003, 41, 872–882. [Google Scholar]
- Briese, C.; Pfeifer, N.; Dorninger, P. Applications of the robust interpolation for DTM determination. Int. Arch. Photogramm. Remote Sens 2002, 34, 55–61. [Google Scholar]
- Kobler, A.; Pfeifer, N.; Ogrinc, P.; Todorovski, L.; Oštir, K.; Džeroski, S. Repetitive interpolation: A robust algorithm for DTM generation from aerial laser scanner data in forested terrain. Remote Sens. Environ 2007, 108, 9–23. [Google Scholar]
- Axelsson, P.E. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens 2000, 32, 110–117. [Google Scholar]
- Zhu, X.K.; Toutin, T. Land cover classification using airborne LiDAR products in Beauport, Québec, Canada. Int. J. Image Data Fusion 2013, 4, 252–271. [Google Scholar]
- Lohmann, P. Segmentation and filtering of laser scanner digital surface models. Int. Arch. Photogramm. Remote Sens 2002, 34, 311–315. [Google Scholar]
- Lee, I. A Feature Based Approach to Automatic Extraction of Ground Points for DTM Generation from LiDAR Data. Proceedings of the ASPRS Annual Conference, Denver, CO, USA, 23–28 May 2004.
- Sithole, G.; Vosselman, G. Filtering of airborne laser scanner data based on segmented point clouds. Int. Arch. Photogramm. Remote Sens 2005, 36, 66–71. [Google Scholar]
- Shen, J.; Liu, J.P.; Lin, X.G.; Zhao, R. Object-based classification of airborne light detection and ranging point clouds in human settlements. Sens. Lett 2012, 10, 221–229. [Google Scholar]
- Yan, M.; Blaschke, T.; Liu, Y.; Wu, L. An object-based analysis filtering algorithm for airborne laser scanning. Int. J. Remote Sens 2012, 33, 7099–7116. [Google Scholar]
- Arya, S.; Mount, D.M.; Netanyahu, N.S.; Silverman, R.; Wu, A.Y. An optimal algorithm for approximate nearest neighbor searching in fixed dimensions. J. ACM 1998, 45, 891–923. [Google Scholar]
- Filin, S.; Pfeifer, N. Segmentation of airborne laser scanning data using a slope adaptive neighborhood. ISPRS J. Photogramm. Remote Sens 2006, 60, 71–80. [Google Scholar]
- Melzer, T. Non-parametric segmentation of ALS point clouds using mean shift. J. Appl. Geod 2007, 1, 159–170. [Google Scholar]
- Wang, M.; Tseng, Y.H. Automatic segmentation of LiDAR data into coplanar point clusters using an octree-based split-and-merge algorithm. Photogramm. Eng. Remote Sens 2010, 76, 407–420. [Google Scholar]
- Rottensteiner, F. Automatic generation of high-quality building models from LiDAR data. IEEE Comput. Graph. Appl 2003, 23, 42–50. [Google Scholar]
- Vosselman, G.; Klein, R. Visualization and Structuring of Point Clouds. In Airborne and Terrestrial Laser Scanning, 1st ed; Vosselman, G., Maas, H.G., Eds.; Whittles Publising: Dunbeath, UK, 2010; pp. 43–79. [Google Scholar]
- Chen, D.; Zhang, L.; Li, J.; Liu, R. Urban building roof segmentation from airborne lidar point clouds. Int. J. Remote Sens 2012, 33, 6497–6515. [Google Scholar]
- Rabbani, T. Automatic Reconstruction of Industrial Installations Using Point Clouds and Images. Netherlands Commission of Geodesy, Delft, The Netherlands, 2006. [Google Scholar]
- Moffiet, T.; Mengersen, K.; Witte, C.; King, R.; Denham, R. Airborne laser scanning: Exploratory data analysis indicates potential variables for classification of individual trees or forest stands according to species. ISPRS J. Photogramm. Remote Sens 2005, 59, 289–309. [Google Scholar]
- Wang, O. Using Aerial LiDAR to Segment and Model Buildings. University of California, Santa Cruz, CA, USA, 2006. [Google Scholar]
- Darmawati, A.T. Utilization of Multiple Echo Information for Classification of Airborne Laser Scanning Data. International Institute for Geo-information Science and Observation, Enschede, The Netherlands, 2008. [Google Scholar]
- Höfle, B.; Hollaus, M.; Hagenauer, J. Urban vegetation detection using radiometrically calibrated small-footprint full-waveform airborne LiDAR data. ISPRS J. Photogramm. Remote Sens 2012, 67, 134–147. [Google Scholar]
- A Two-Dimensional Quality Mesh Generator and Delaunay Triangulator. Available online: http://www.cs.cmu.edu/~quake/triangle.html (accessed on 11 October 2011).
- ANN: A Library for Approximate Nearest Neighbor Searching. Available online: http://www.cs.umd.edu/~mount/ANN/ (accessed on 15 March 2010).
- Seetharaman, K.; Palanivel, N. Texture characterization, representation, description, and classification based on full range gaussian markov random field model with bayesian approach. Int. J. Image Data Fusion 2013, 4, 342–362. [Google Scholar]
- Akiwowo, A.; Eftekhari, M. Feature-based detection using Bayesian data fusion. Int. J. Image Data Fusion 2013, 4, 308–323. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Classic PTD Method | SBF Method | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Scene | m (m) | t (°) | θ(°) | d (m) | l (m) | k (points) | r (m) | d' (m) | α (°) |
| CSite1 | 20 | 80 | 6 | 1.4 | 1 | 20 | 0.3 | 3 | 10 |
| CSite2 | 60 | 88 | 6 | 1.4 | 1 | 20 | 0.3 | 3 | 5 |
| CSite3 | 35 | 88 | 6 | 1.4 | 1 | 20 | 0.3 | 3 | 10 |
| CSite4 | 60 | 88 | 6 | 1.4 | 1 | 20 | 0.3 | 3 | 10 |
| CSite5 | 10 | 70 | 6 | 1.0 | 2 | 20 | 0.3 | 3 | 15 |
| CSite6 | 40 | 70 | 6 | 1.4 | 2 | 20 | 0.3 | 3 | 5 |
| CSite7 | 20 | 70 | 6 | 1.4 | 2 | 20 | 0.3 | 3 | 10 |
| Indicators | Total Number of Points (points) | Number of Outliers (points) | Classic PTD Method | SBF Method | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Scene | O | S | G | Time Cost (s) | O | S | G | Time Cost (s) | ||
| CSite1 | 1,366,408 | 2,485 | 118,375 | 1,929 | 445,430 | 24.77 | 198,176 | 516,993 | 611,671 | 891.17 |
| CSite2 | 486,800 | 7,088 | 30,005 | 74 | 161,562 | 7.83 | 43,860 | 235,493 | 253,587 | 128.70 |
| CSite3 | 377,028 | 393 | 37,693 | 144 | 146,310 | 6.84 | 51,994 | 174,523 | 188,240 | 104.34 |
| CSite4 | 518,060 | 2,609 | 33,135 | 76 | 182,140 | 8.94 | 45,748 | 16,984 | 241,026 | 78.46 |
| CSite5 | 628,576 | 199 | 42,956 | 17,084 | 447,742 | 17.13 | 104,601 | 436,082 | 485,118 | 302.18 |
| CSite6 | 551,698 | 2,222 | 18,106 | 972 | 375,519 | 12.52 | 45,107 | 293,497 | 443,170 | 78.81 |
| CSite7 | 393,264 | 1,086 | 11,096 | 2,742 | 312,449 | 10.51 | 27,399 | 304,661 | 346,347 | 83.73 |
| Dataset NO. | Type of Error | PTD (%) | SBF (%) | Dataset NO./Types | Type of Error | PTD (%) | SBF (%) |
|---|---|---|---|---|---|---|---|
| Sample 11 | I | 51.29 | 26.28 | Sample 51 | I | 6.05 | 2.22 |
| II | 3.40 | 10.40 | II | 3.59 | 10.81 | ||
| T | 30.85 | 19.50 | T | 5.51 | 4.09 | ||
| Sample 12 | I | 21.13 | 6.56 | Sample 52 | I | 21.11 | 6.46 |
| II | 1.84 | 3.31 | II | 3.77 | 16.89 | ||
| T | 11.72 | 4.78 | T | 19.29 | 7.56 | ||
| Sample 21 | I | 1.67 | 0.85 | Sample 53 | I | 28.98 | 9.62 |
| II | 8.97 | 24.45 | II | 1.66 | 16.41 | ||
| T | 3.29 | 6.08 | T | 27.87 | 9.90 | ||
| Samp22 | I | 44.74 | 6.43 | Sample 54 | I | 9.09 | 3.16 |
| II | 3.08 | 15.44 | II | 2.27 | 17.23 | ||
| T | 31.74 | 9.24 | T | 5.43 | 10.72 | ||
| Sample 23 | I | 53.77 | 23.21 | Sample 61 | I | 27.18 | 6.26 |
| II | 3.22 | 4.64 | II | 4.15 | 6.55 | ||
| T | 29.85 | 14.43 | T | 26.39 | 6.27 | ||
| Sample 24 | I | 58.81 | 3.99 | Sample 71 | I | 32.19 | 2.62 |
| II | 10.98 | 8.70 | II | 1.86 | 25.65 | ||
| T | 45.68 | 5.28 | T | 28.76 | 5.22 | ||
| Sample 31 | I | 7.87 | 0.54 | Minimum | I | 1.67 | 0.54 |
| II | 4.13 | 2.59 | II | 0.82 | 0.54 | ||
| T | 6.15 | 1.61 | T | 3.29 | 1.61 | ||
| Sample 41 | I | 70.31 | 62.22 | Maximum | I | 70.31 | 62.22 |
| II | 0.82 | 1.92 | II | 10.98 | 25.65 | ||
| T | 35.48 | 32.00 | T | 35.48 | 32.00 | ||
| Sample 42 | I | 19.37 | 19.02 | Average | I | 30.24 | 11.96 |
| II | 1.40 | 0.54 | II | 3.68 | 11.06 | ||
| T | 6.66 | 5.95 | T | 20.98 | 9.51 |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Lin, X.; Zhang, J. Segmentation-Based Filtering of Airborne LiDAR Point Clouds by Progressive Densification of Terrain Segments. Remote Sens. 2014, 6, 1294-1326. https://doi.org/10.3390/rs6021294
Lin X, Zhang J. Segmentation-Based Filtering of Airborne LiDAR Point Clouds by Progressive Densification of Terrain Segments. Remote Sensing. 2014; 6(2):1294-1326. https://doi.org/10.3390/rs6021294
Chicago/Turabian StyleLin, Xiangguo, and Jixian Zhang. 2014. "Segmentation-Based Filtering of Airborne LiDAR Point Clouds by Progressive Densification of Terrain Segments" Remote Sensing 6, no. 2: 1294-1326. https://doi.org/10.3390/rs6021294