Performance Evaluation of Machine Learning Algorithms for Urban Pattern Recognition from Multi-spectral Satellite Images


Abstract
:1. Introduction
- (1)
- What are the most important image features for class separability?
- (2)
- How sensitive are learning machines to the size of the feature vector?
- (3)
- How does the number of training instances influence the performance of the learning machines?
- (4)
- How well can a trained learning machine be transferred between different image types and image scenes?
- (5)
- How does image segmentation influence the classification results?
2. Data Specifications and Preprocessing
3. Image Segmentation and the Scale of Analysis
4. Classification Algorithms
4.1. Normal Bayes (NB)
4.2. K Nearest Neighbors (KNN)
4.3. Random Trees (RT)
4.4. Support Vector Machine (SVM)
5. Performance Evaluation of Classification Algorithms
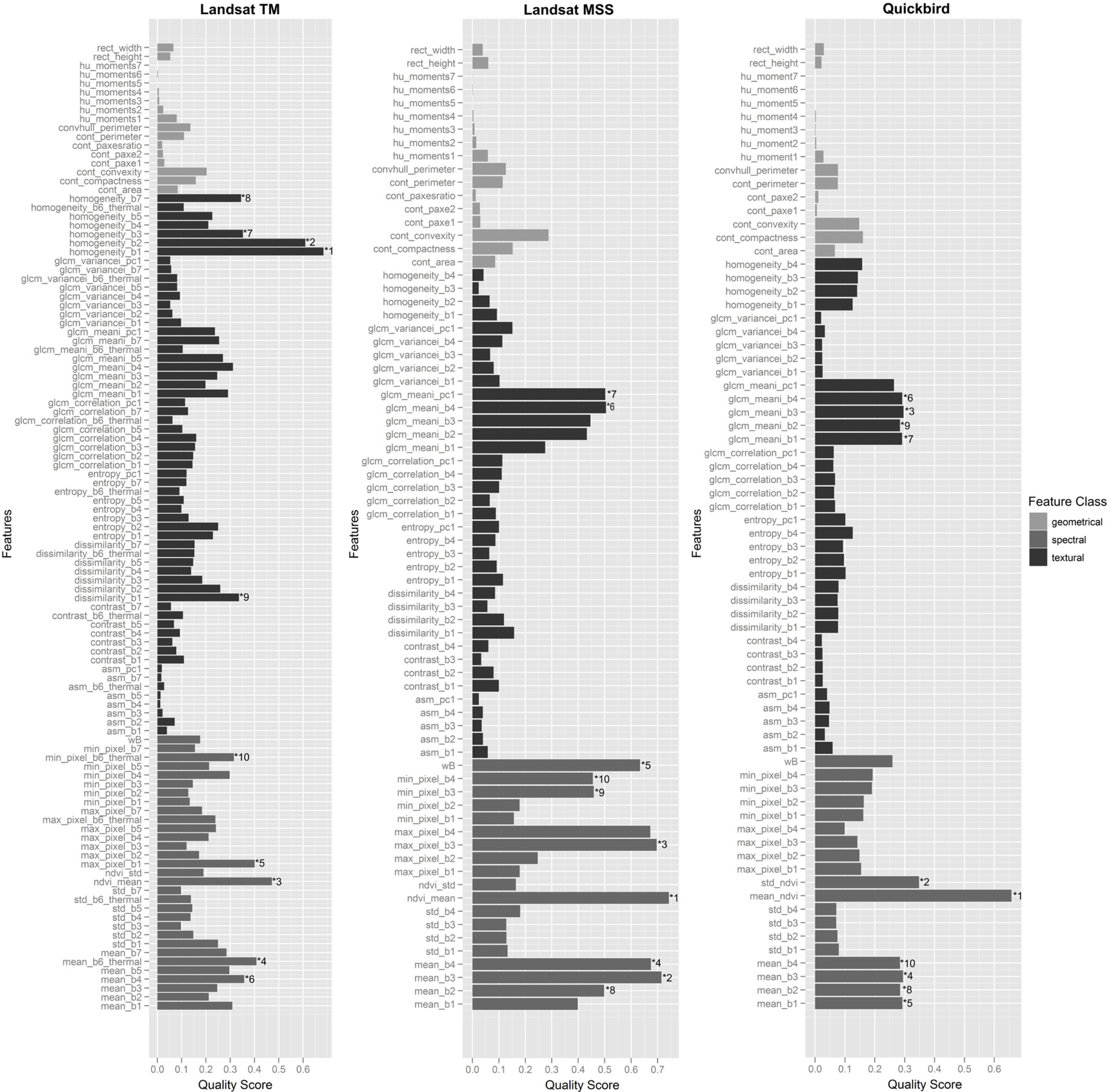
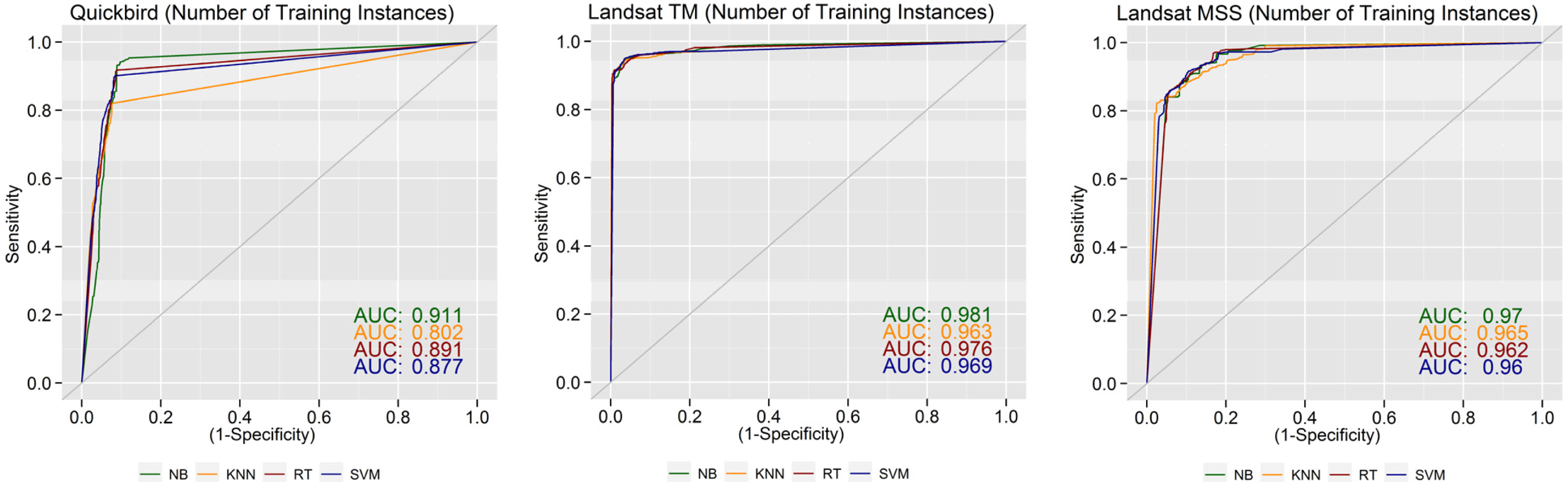
5.1. What are the Most Important Image Features for Class Separability?
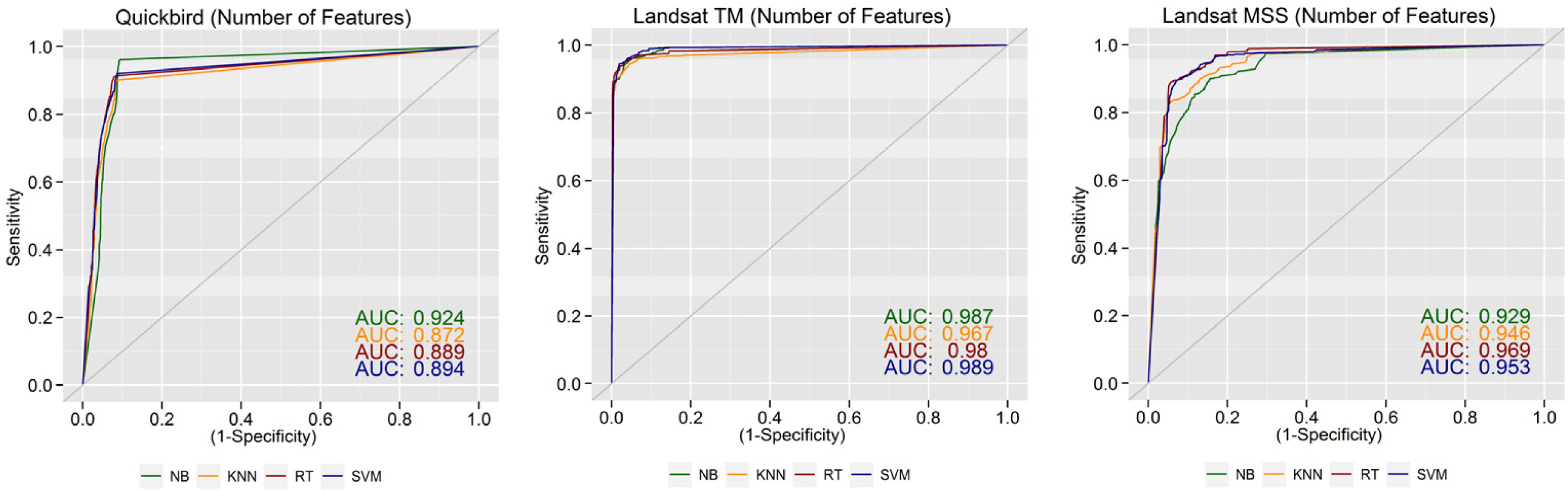
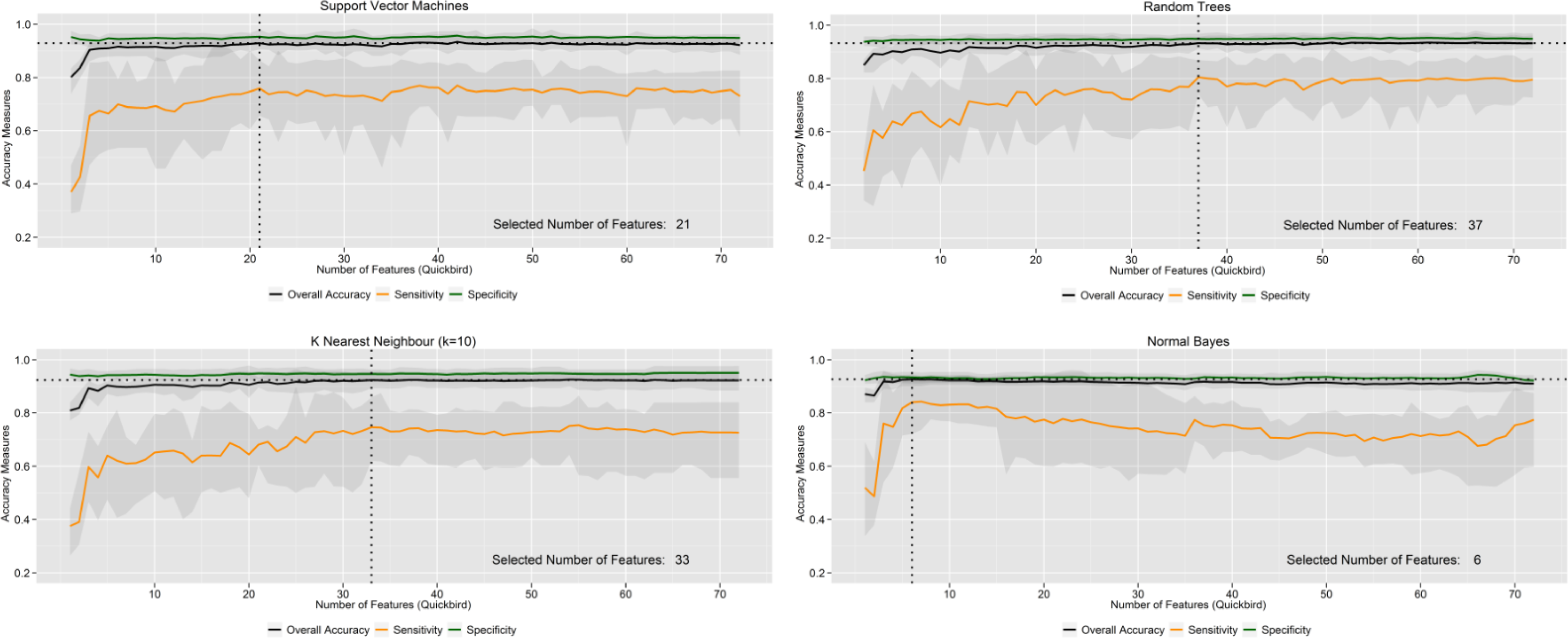
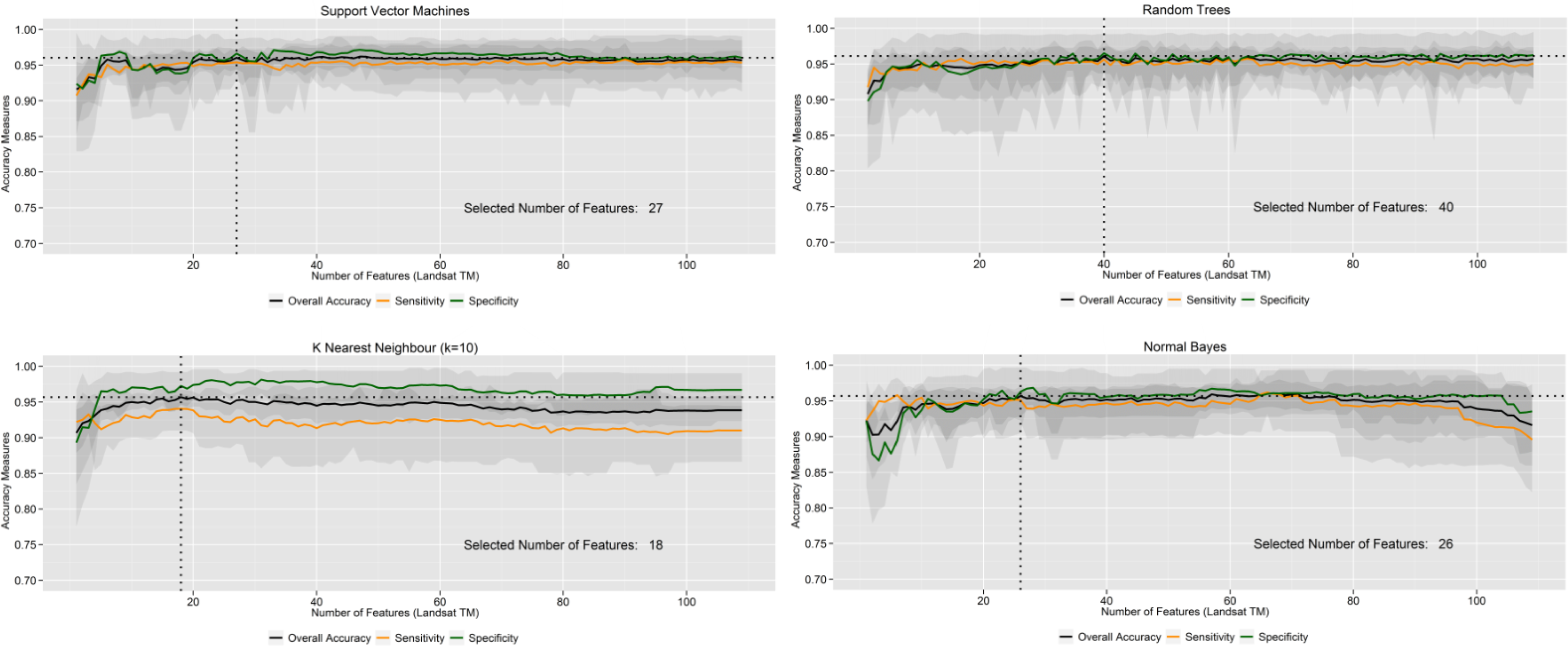
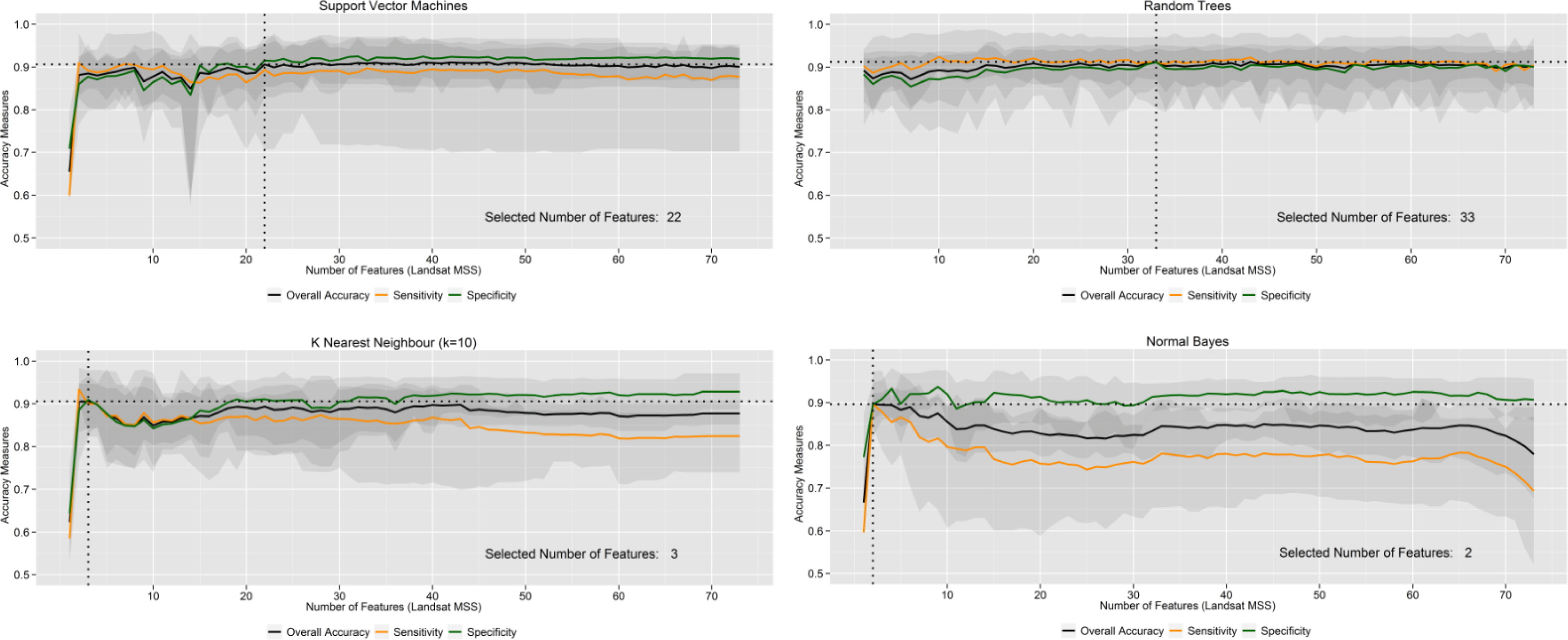
5.2. How Sensitive are Learning Machines to the Size of the Feature Vector?
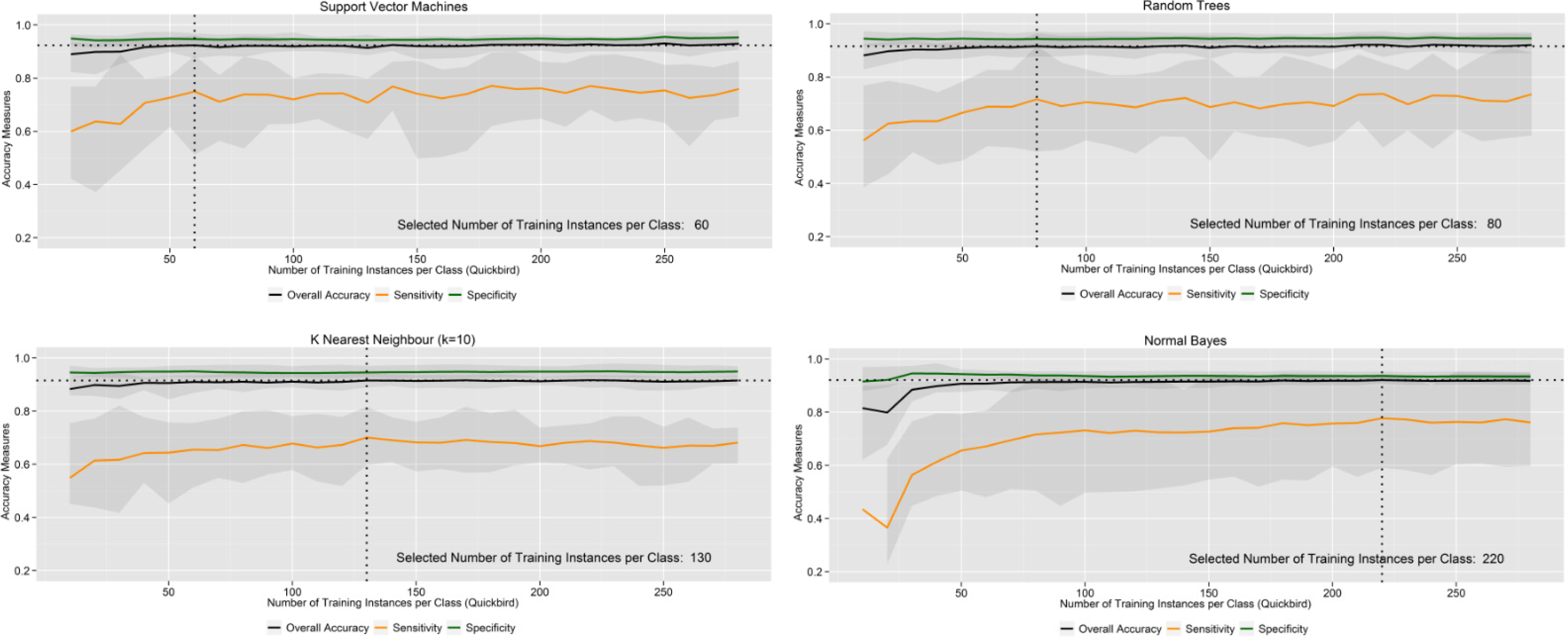
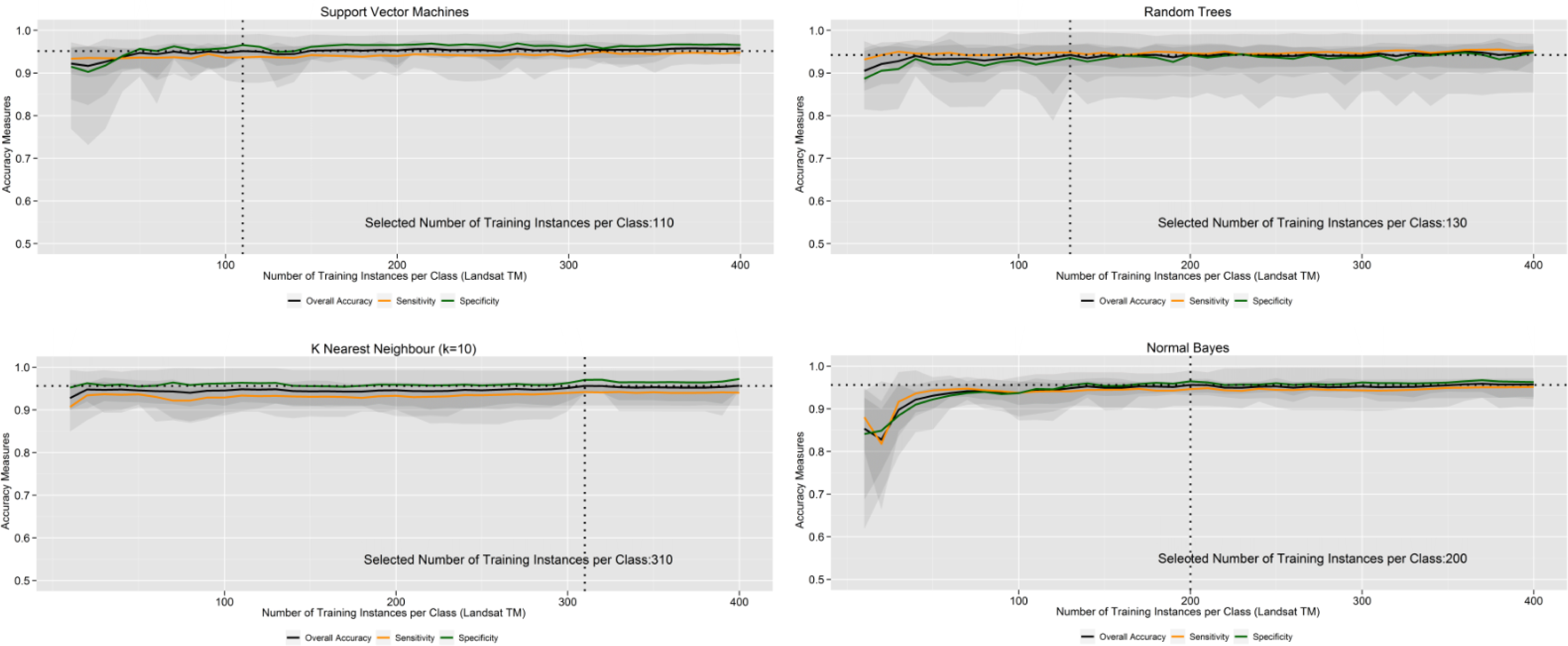
5.3. How does the Number of Training Instances Influence the Performance of the Learning Machines?
5.4. How well can a Trained Model be Transferred between Different Image Types and Image Scenes?
5.5. How does Image Segmentation Influence the Classification Results?
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens 2010, 65, 2–16. [Google Scholar]
- Yan, G.; Mas, J.F.; Maathuis, B.H.P.; Zhang, X.; van Dijk, P.M. Comparison of pixel-based and object-oriented image classification approaches: A case study in a coal fire area, Wuda, Inner Mongolia, China. Int. J. Remote Sens 2006, 27, 4039–4055. [Google Scholar]
- Taubenböck, H.; Roth, A. A Transferable and Stable Object Oriented Classification Approach in Various Urban Areas and Various High Resolution Sensors. In Proceedings of the Joint Urban Remote Sensing Event, Paris, France, 11–13 March 2007; pp. 1–7.
- Weng, Q. Remote sensing of impervious surfaces in the urban areas: Requirements, methods, and trends. Remote Sens. Environ 2012, 117, 34–49. [Google Scholar]
- Schneider, A. Monitoring land cover change in urban and peri-urban areas using dense time stacks of Landsat satellite data and a data mining approach. Remote Sens. Environ 2012, 124, 689–704. [Google Scholar]
- Zhang, Q.; Wang, J.; Peng, X.; Gong, P.; Shi, P. Urban built-up land change detection with road density and spectral information from multi-temporal Landsat TM data. Int. J. Remote Sens 2002, 23, 3057–3078. [Google Scholar]
- Lillesand, T.M.; Kiefer, R.W.; Chipman, J.W. Remote Sensing and Image Interpretation; John Wiley & Sons: New York, NY, USA, 2008. [Google Scholar]
- Haralick, R.; Shanmugam, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Sys. Man Cyber 1973, 3, 610–621. [Google Scholar]
- Van der Werff, H.M.A.; van der Meer, F.D. Shape-based classification of spectrally identical objects. ISPRS J. Photogramm. Remote Sens 2008, 63, 251–258. [Google Scholar]
- Hu, M.K. Visual pattern recognition by moment invariants. IRE Trans. Inf. Theory 1962, 8, 179–187. [Google Scholar]
- Zhang, D.; Lu, G. Review of shape representation and description techniques. Pattern Recognit 2004, 37, 1–19. [Google Scholar]
- Peura, M; Iivarinen, J. Efficiency of simple shape descriptors. Asp. Vis. Form 1997, 443–451. [Google Scholar]
- Langley, P. Selection of Relevant Features in Machine Learning. In Proceedings of the AAAI Fall Symposium, New Orleans, LA, USA, 4–6 November 1994; pp. 127–131.
- Koprinska, I. Feature Selection for Brain-Computer Interfaces. In Proceedings of the 13th Pacific-Asia International Conference on Knowledge Discovery and Data Mining: New Frontiers in Applied Data Mining, Bangkok, Thailand, 27–30 April 2009; pp. 106–117.
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Novack, T.; Esch, T.; Kux, H.; Stilla, U. Machine learning comparison between WorldView-2 and QuickBird-2-simulated imagery regarding object-based urban land cover classification. Remote Sens 2011, 3, 2263–2282. [Google Scholar]
- Prandi, F.; Brumana, R.; Fassi, F. Semi-automatic objects recognition in urban areas based on fuzzy logic. J. Geogr. Inf. Syst 2010, 2, 55–62. [Google Scholar]
- Benz, U.C.; Hofmann, P.; Willhauck, G.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. Remote Sens 2004, 58, 239–258. [Google Scholar]
- Tzotsos, A.; Argialas, D. A. Support Vector Machine Approach for Object Based Image Analysis. In Proceedings of 1st International Conference on Object-based Image Analysis, Salzburg, Austria, 4–5 July 2006.
- Bruzzone, L.; Marconcini, M. Toward the Automatic Updating of Land-Cover Maps by a Domain-Adaptation SVM Classifier and a Circular Validation Strategy. IEEE Trans. Geosci. Remote Sens 2009, 47, 1108–1122. [Google Scholar]
- Bruzzone, L.; Prieto, D.F. Unsupervised retraining of a maximum likelihood classifier for the analysis of multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens 2001, 39, 456–460. [Google Scholar]
- Leiva-Murillo, J.M.; Gómez-Chova, L.; Camps-Valls, G. Multitask remote sensing data classification. IEEE Trans. Geosci. Remote Sens 2013, 51, 151–161. [Google Scholar]
- Parker, J.A.; Kenyon, R.V.; Troxel, D.E. Comparison of interpolating methods for image resampling. IEEE Trans. Med. Imaging 1983, 2, 31–39. [Google Scholar]
- Neteler, M.; Mitasova, H. Open Source GIS: A Grass GIS Approach; Springer: Heidelberg, Germany, 2002. [Google Scholar]
- Pohl, C.; van Genderen, J.L. Multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens 1998, 19, 823–854. [Google Scholar]
- Felzenszwalb, P.; Huttenlocher, D. Efficient graph-based image segmentation. Int. J. Comput. Vis 2004, 59, 167–181. [Google Scholar]
- ISPRS Data Sets: Ikonos. 2003. Available online: http://www.isprs.org/data/ikonos (accessed on 8 April 2013).
- Clinton, N.; Holt, A.; Scarborough, J.; Yan, L.; Gong, P. Accuracy assessment measures for object-based image segmentation goodness. Photogramm. Engine. Remote Sens 2010, 76, 289–299. [Google Scholar]
- Zhang, H.; Fritts, J.E.; Goldman, S.A. Image segmentation evaluation: a survey of unsupervised methods. Computerv. Image Underst 2008, 110, 260–280. [Google Scholar]
- Johnson, B.; Xie, Z. Unsupervised image segmentation evaluation and refinement using a multi-scale approach. ISPRS J. Photogramm. Remote Sens 2011, 66, 473–483. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV; O’Reilly: Sebastopol, CA, USA, 2008. [Google Scholar]
- Fukunaga, K. Introduction to Statistical Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 1990. [Google Scholar]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst 2007, 14, 1–37. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn 2001, 45, 5–32. [Google Scholar]
- Breiman, L.; Cutler, A. Random forests. Available online: http://www.stat.berkeley.edu/users/breiman/RandomForests (accessed on 07 March 2013).
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ 2003, 86, 554–565. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2000. [Google Scholar]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Mini. Knowl. Discov 1998, 2, 121–167. [Google Scholar]
- Yang, H.; Ma, B.; Du, Q.; Yang, C. Improving urban land use and land cover classification from high-spatial-resolution hyperspectral imagery using contextual information. J. Appl. Remote Sens 2010. [Google Scholar] [CrossRef]
- Kononenko, I. Estimating Attributes: Analysis and Extensions of Relief. In Proceedings of the International Conference on Machine Learning, New Brunswick, NJ, USA, 10–13 July 1994; pp. 171–182.
- WEKA3: Data Mining with Open Source Machine Learning Software. 2012. Available online: http://www.cs.waikato.ac.nz/ml/weka (accessed on 29 October 2012).
- Robnik-Sikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach Learn 2003, 53, 23–69. [Google Scholar]
- Nguyen, M.H.; De la Torre, F. Optimal feature selection for support vector machines. Pattern Recognit 2010, 43, 584–591. [Google Scholar]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar]
- Southworth, J. An assessment of Landsat TM band 6 thermal data for analyzing land cover in tropical dry forest regions. Int. J. Remote Sens 2004, 25, 689–706. [Google Scholar]
- Martimor, P.; Arino, O.; Berger, M.; Biasutti, R.; Carnicero, B.; Del Bello, U.; Fernandez, V.; Gascon, F.; Silvestrin, P.; Spoto, F.; et al. Sentinel-2 Optical High Resolution Mission for GMES Operational Services. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 2677–2680.
- Wieland, M.; Pittore, M.; Parolai, S.; Zschau, J. Exposure estimation from multi-resolution optical satellite imagery for seismic risk assessment. ISPRS Int. J. Geo-Inf 2012, 1, 69–88. [Google Scholar]
- Pittore, M.; Wieland, M. Toward a rapid probabilistic seismic vulnerability assessment using satellite and ground-based remote sensing. Nat. Hazards 2013, 68, 115–145. [Google Scholar]
- Wieland, M.; Pittore, M.; Parolai, S.; Zschau, J.; Moldobekov, B.; Begaliev, U. Estimating building inventory for rapid seismic vulnerability assessment: Towards an integrated approach based on multi-source imaging. Soil Dyn. Earthq. Eng 2012, 36, 70–83. [Google Scholar]
- Tyagunov, S.; Pittore, M.; Wieland, M.; Parolai, S.; Bindi, D.; Fleming, K.; Zschau, J. Uncertainty and sensitivity analyses in seismic risk assessments on the example of Cologne, Germany. Nat. Hazards Earth Syst. Sci. Discuss 2014, 1, 7285–7332. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image | Type | Spectral Res. (μm) | Radiom. Res. (bit) | Geom. Res. (m) | Size (px) | Date Coverage | Preprocessing |
|---|---|---|---|---|---|---|---|
| IK | Ikonos | 0.45–0.9 (4 bands) | 11 | 1 (pan) 4 (mul) | 800 × 500 | 22.02.03 Hobart | pan-sharpened |
| QB | Quickbird | 0.45–0.90 (4 bands) | 11 | 0.6 (pan) 2.4 (mul) | 1500 × 1200 | 29.09.09 Bishkek | pan-sharpened |
| WV2 | WorldView-2 | 0.45–0.89 (4 bands) | 11 | 0.5 (pan) 2.4 (mul) | 1200 × 800 | 12.10.11 Karakol | pan-sharpened |
| MSS | Landsat MSS | 0.52–1.10 (4 bands) | 8 | 60 (mul) | 1000 × 700 | 22.08.77 Bishkek | - |
| TM | Landsat TM | 0.45–12.5 (7 bands) | 8 | 30 (mul) 120 (TIR) | 1000 × 700 | 08.07.09 Bishkek | resampled to 30m (TIR) |
| ETM | Landsat ETM | 0.45–12.5 (7 bands) | 8 | 15 (pan) 30 (mul) 60 (TIR) | 2000 × 1200 | 14.08.01 Bishkek | pan-sharpened, resampled to 15 m (TIR) |
| Feature ID | Image Feature Description | Feature Class | Implementation |
|---|---|---|---|
| mean_bx | Mean spectral value in image band x | spectral | OpenCV |
| std_bx | Standard deviation in image band x | spectral | OpenCV |
| ndvi_mean | Mean value of NDVI; NDVI =(NIR − Red)/(NIR + Red) | ||
| ndvi_std | Standard deviation of NDVI | spectral | custom C/C++ |
| max_pixel_bx | Maximum brightness value in image band x | spectral | custom C/C++ |
| min_pixel_bx | Minimum brightness value in image band x | spectral | custom C/C++ |
| wB | Weighted brightness, with I being the number of image bands, J being the number of pixels per segment and p being the brightness values of the pixels; | spectral | custom C/C++ |
| asm_bx | Angular Second Moment derived from the GLCM* in band x; | textural | custom C/C++ |
| contrast_bx | Contrast derived from the GLCM* in band x; | textural | custom C/C++ |
| dissimilarity_bx | Dissimilarity derived from the GLCM* in band x; | textural | custom C/C++ |
| entropy_bx | Entropy derived from the GLCM* in band x; | textural | custom C/C++ |
| glcm_correlation_bx | Correlation derived from the GLCM* in band x; | textural | custom C/C++ |
| glcm_meani_bx | Mean derived from the GLCM* in band x; | textural | custom C/C++ |
| glcm_variancei_bx | Variance derived from the GLCM* in band x; | textural | custom C/C++ |
| homogeneity_bx | Homogeneity derived from the GLCM* in band x; | textural | custom C/C++ |
| Feature ID | Image Feature Description | Feature Class | Implementation |
|---|---|---|---|
| cont_area | Area of the segment in pixel counts | geometrical | OpenCV |
| cont_perimeter | Perimeter of the contour outlining the segment | geometrical | OpenCV |
| convhull_perimeter | Perimeter of the convex hull of the contour outlining the segment | geometrical | OpenCV |
| cont_convexity | Convexity of the contour outlining the segment; | geometrical | custom C/C++ |
| cont_paxe1 | Principal axes 1 of the contour outlining the segment | geometrical | custom C/C++ |
| cont_paxe2 | Principal axes 2 of the contour outlining the segment | geometrical | custom C/C++ |
| cont_paxes_ratio | Ratio of principle axes; with C being the covariance matrix of a contour | geometrical | custom C/C++ |
| cont_compactness | Compactness of the contour outlining the segment; | geometrical | custom C/C++ |
| hu_moments1 | Hu Moment 1 | geometrical | OpenCV |
| hu_moments2 | Hu Moment 2 | geometrical | OpenCV |
| hu_moments3 | Hu Moment 3 | geometrical | OpenCV |
| hu_moments4 | Hu Moment 4 | geometrical | OpenCV |
| hu_moments5 | Hu Moment 5 | geometrical | OpenCV |
| hu_moments6 | Hu Moment 6 | geometrical | OpenCV |
| hu_moments7 | Hu Moment 7 | geometrical | OpenCV |
| rect_height | Rectangular height | geometrical | OpenCV |
| rect_width | Rectangular width | geometrical | OpenCV |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Wieland, M.; Pittore, M. Performance Evaluation of Machine Learning Algorithms for Urban Pattern Recognition from Multi-spectral Satellite Images. Remote Sens. 2014, 6, 2912-2939. https://doi.org/10.3390/rs6042912
Wieland M, Pittore M. Performance Evaluation of Machine Learning Algorithms for Urban Pattern Recognition from Multi-spectral Satellite Images. Remote Sensing. 2014; 6(4):2912-2939. https://doi.org/10.3390/rs6042912
Chicago/Turabian StyleWieland, Marc, and Massimiliano Pittore. 2014. "Performance Evaluation of Machine Learning Algorithms for Urban Pattern Recognition from Multi-spectral Satellite Images" Remote Sensing 6, no. 4: 2912-2939. https://doi.org/10.3390/rs6042912