1. Introduction
Classification using machine-learning approaches is commonly used over remote sensing data in various applications. Generally, supervised learning (SL) approaches are able to achieve better results than unsupervised learning (UL) methods due to incorporating prior knowledge in the form of ground truth data. Yet at the same time, this can be considered a drawback since SL requires labeled training data normally provided manually by a human expert. Even though this is probably the situation for the majority of fields to which SL is applied, it is particularly the case for remote sensing data classification. The reason is that ideally on-site visits are conducted to the locations from which the remote sensing data has been acquired, especially keeping in mind that SL benefits from larger number of labeled data during training. With a rather limited amount of training data available, the classification task becomes easily ill-posed due to the small sample size problem, where the number of training samples is considered too small in relation to the feature dimension. Due to this, the underlying classifier will lack discrimination and generalization capabilities. This becomes more evident when the classification problems are of more complex nature such as multi-class classification tasks where the number of classes might be equal or higher than the feature dimension.
In recent years, the interest in
semi-supervised learning (SSL) has increased because it can combine supervised and unsupervised learning approaches. This is especially valid for remote sensing classification applications as the acquired data from current systems are fairly large considering high- and very-high resolution data acquisition requiring more specific surface- or even object-based classification. The general notion behind SSL is to start from a set of labeled data and then to utilize the large amount of unlabeled data to improve the initial classifier [
1]. Therefore, the crucial part in this process is the automatic selection of reliable training data among the unlabeled data. This can be performed by several approaches such as unsupervised clustering methods [
2,
3], using self-training [
4] where one initial learner iteratively selects the most confident samples to add them to the training set, or co-training [
4] where two classifiers either work on different feature spaces or are completely different altogether and add new training samples to one another.
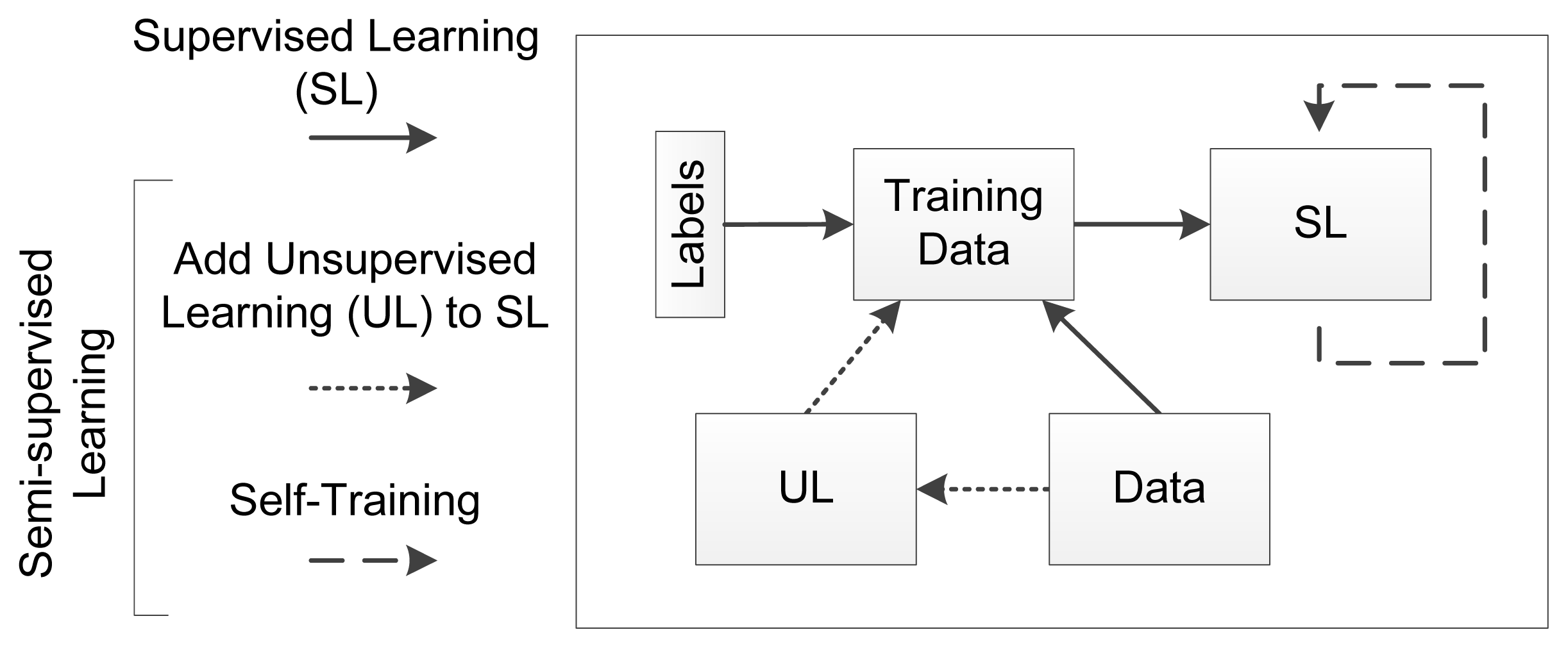
Figure 1 illustrates the relation of typical supervised learning (SL) to SSL, which might encapsulate an UL preceding a SL process or a self-training process over a SL process.
To aid the selection of reliable new training data for SSL, several assumptions [
5] are generally exploited where the first two are the most commonly used. Firstly, there is the
local smoothness/consistency assumption, where nearby points are more likely to have the same label such that there is a higher probability a point shares the same label with points in its local vicinity. This is the same assumption any SL algorithm exploits to learn from the training data and generalize a model or function applicable to any unseen data provided in the future. Typically, this is performed in the feature space; however, it can also be applied spatially over the neighborhood of each image pixel. Secondly, the
global cluster assumption exploiting the fact that points sharing the same structure, hence, would fall into the same cluster are likely to have the same label so that those unlabeled samples which are highly similar to a labeled sample should share its label. This includes approaches based on the
low-density separation assumption where in many clustering methods the cluster centers are considered of high-density zones so that the decision boundaries should lie within regions of lower density. In this case, rather than to find the high-density sample regions directly, the focus lies in finding such low-density regions to best draw decision boundaries among clusters. As another assumption, the
fitting constraint can be considered where a good classifier should not deviate too much from its initial label assignments during a learning process.
In the area of remote sensing image classification, SSL has recently attracted a lot of attention. Two decades ago, the early investigations showed how unlabeled samples could be beneficial for classification applications [
6]. In this work, the authors studied techniques to address the small sample size problem by using unlabeled observations and their potential advantages in enhanced statistic estimation. Their main conclusion was that more information could be obtained and utilized with the additional unlabeled samples. Based on these observations, a self-learning and self-improving adaptive classifier [
7] using generative learning was proposed to mitigate the small sample size problem that can severely affect the recognition accuracy of classifiers. To accomplish this in [
7], they iteratively utilized a weighted mixture of labeled and semi-labeled samples.
Following these pioneer works, there have been various SSL approaches over remote sensing data such as generative learning in form of semi-supervised versions of a spatially adaptive mixture-of-Gaussians model was proposed in [
8,
9]. Another approach uses graph-based methods, which rely upon the construction of a graph representation [
10], where vertices are the labeled and unlabeled samples and edges represent the similarity among samples in the dataset including, for example, contextual information via composite kernels [
11]. Furthermore, this graph-based approach was also employed within self-training, where the graph is used to assure reliability of newly added training examples [
12,
13]. However, the general issue of graph-based methods is that the label propagation relies on the inversion of a large matrix with a size equivalent of the total number of labeled and unlabeled pixels, which limits their application for remote sensing applications.
One of the most basic semi-supervised learning approaches is to consider the output of an unsupervised learning method as the input of a supervised learning approach. This has been applied to SAR images where unsupervised clustering in form of Deterministic Annealing was used as the training input for a Multi-Layer Perceptron [
2]. This type of combined approach has also been used with other classifier types such as Support Vector Machines (SVMs) using the output of the fuzzy C-means (FCM) clustering, which was further extended by Markov Random Fields exploiting contextual information from multiple SVM-FCM classification maps [
3]. A similar approach to the combination of supervised and unsupervised learning algorithms is the application of cluster kernels [
14,
15] employing SVM, where so-called bagged kernels are used to encode the similarity between unlabeled samples obtained via multiple runs of unsupervised k-means clustering.
Furthermore, SVM has been used within the context of self-training, where a binary transductive SVM has been adapted in a one-against-all topology [
16]. Besides that, one-class SVM has been applied to detect pixels belonging to one of the classes in the image and reject the others [
17]. Yet another semi-supervised SVM approach utilizes the so-called context-pattern in a form of 4- or 8-connected pixel neighborhoods to identify possible misleading initial training labels [
18]. Besides its popularity, the application of SVMs in the semi-supervised learning context has some shortcomings such as particularly high computational complexity, utilization of a non-convex cost function, and the usage of multiclass SVMs. These shortcomings have been addressed by using semi-supervised logistic regression algorithm [
19] and by replacing the SVMs with an artificial neural network [
20] offering much better scalability than SVM-based methods.
In the case of supervised learning, combining multiple classifiers to a committee or ensemble has demonstrated to improve classification performance over single classifier systems [
21] and its effectiveness has also been shown for remote sensing data [
22]. Generally, ensemble learning tries to improve generalization by combining multiple learners, whereas semi-supervised learning attempts to achieve strong generalization by exploiting the unlabeled data. Hence, fusing these two learning paradigms, even stronger learning systems can be generated by leveraging unlabeled data and classifier combination [
23]. Zhou and Li proposed the Tri-training approach [
24], which can be considered an extension of the co-training algorithms, where three classifiers are used and when two of them agree on a label of an unlabeled sample while the third disagrees; then, under a certain condition, the two classifiers will label this unlabeled sample for the training of the third classifier. Later, Tri-training was extended to Co-forest [
25] including more base classifiers adopting the “majority teaches minority” strategy. Additionally, semi-supervised boosting methods have been proposed such as Assemble [
26], which labels unlabeled data by the current ensemble and iteratively combines semi-labeled samples with the original labeled set to train a new base learner which is then added to the ensemble. The more generic SemiBoost [
27] combines classifier confidence and pairwise similarity to guide the selection of unlabeled examples. Bagging and boosting based ensemble approaches became popular within SSL, particularly self-training, with a general outline illustrated in
Scheme 1; however, they are not much adapted to remote sensing data as for other areas.
The general ensemble-based outline as given in
Scheme 1 was utilized by an approach named Semi-labeled Sample Driven Bagging using Multi-Layer Perceptron [
28] and k-Nearest Neighbor [
29] classifiers over multispectral data. Furthermore, ensembles have been applied to the concept of unsupervised learning where the Cluster-based ENsemble Algorithm [
30] applies Mixture of Gaussians (MoG) and support cluster machine to attack the quality problems of the training samples. In this case, the ensemble technique is used to find the best number of components going from coarse to fine to generate different sets of MoG. A self-trained ensemble with semi-supervised SVM has been proposed in [
31] for pixel-based classification where fuzzy C-Means clustering is employed to obtain confidence measures for unlabeled samples, which are then used in an ensemble of SVMs. Here, each SVM classifier starts with a different training set, which might be difficult within a small sample size problem when the initial labeled training data cannot be divided into multiple partitions.
There have been quite many SSL investigations over spectral-based remote sensing data where only a few particularly focused on ill-posed classification of the small sample size problem, which makes the selection of the initial training dataset more critical [
32]. However, SSL has not yet been considered in such a high scale that the polarimetric SAR (PolSAR) data reside particularly when it comes to the evaluation of the classification performance. In this study, the main questions that we shall tackle are: (1) how small can the initially labeled training set be to still achieve good results, with and without SSL? (2) while applying SSL initially with small size training data, is it possible to reach similar accuracies to a SL approach that is trained over a significantly larger dataset regardless from the number of iterations or unlabeled samples? With these two questions in mind, we focus on three main investigations regarding the small sample size problem over polarimetric SAR data. Firstly, before applying self-training we shall consider an unsupervised and a supervised approach to enlarge the initial user-annotated training data as an initial stage of the SL. Secondly, we shall investigate a bagging ensemble approach through combining the advantages of a multi-classifier system with semi-supervised learning. Thirdly, we shall consider different strategies within the self-training procedure on how to select from the pool of unlabeled samples to speed-up the learning process and also to improve both generalization and classification performance.
The rest of the paper is organized as follows. We introduce our semi-supervised ensemble scheme along with the proposed modifications in Section 2. Section 3 covers the PolSAR image data, internal parameters used and the experimental setup of the base classifiers used in the ensemble. Section 4 provides comparative evaluations and classification results over the PolSAR image dataset. Finally, Section 5 concludes the paper and discusses topics for future work.
4. Experimental Results and Discussions
Before presenting the classification results over the initial training sets, Ti, using self-training with the ensemble-based bagging approach, we shall first investigate the effects of the confidence threshold, the different proposed search neighborhoods, and the number of unlabeled samples selected. Furthermore, we shall evaluate and compare the performances of the enlarged training sets via the unsupervised SSL approaches, NN, and superpixels, SP. Along with the numerical performance evaluations represented as average classification accuracies over the 10 instance for the different training sets size Ti; we shall also present visual classification results.
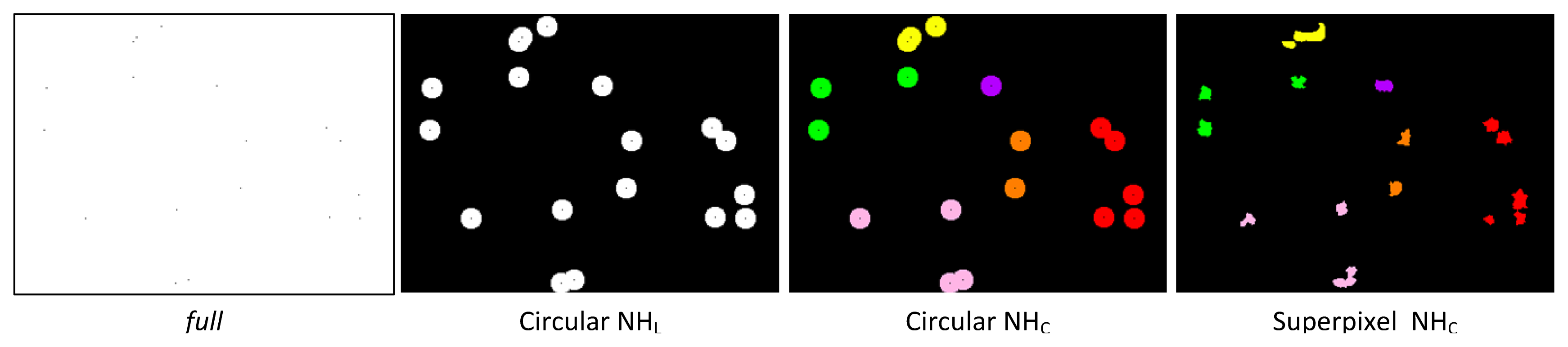
For evaluation of the effects with respect to the confidence threshold THR, we used a basic setup using the three search neighborhoods,
full, circular NH
L, and circular NH
c using DT and RF within the ensemble based self- training. We considered three values for THR: 0.7, 0.8, and 0.9. Individual results are shown in
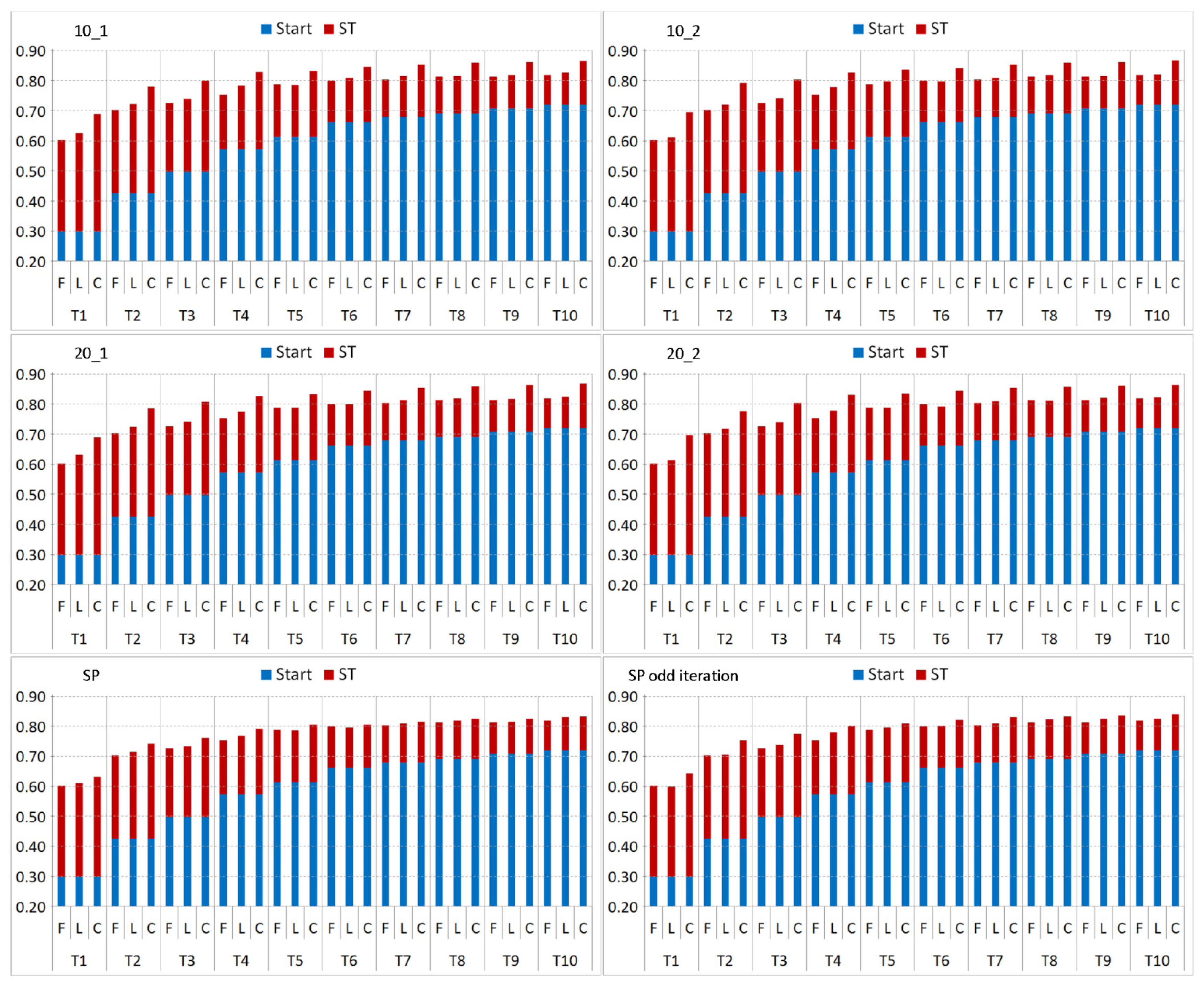
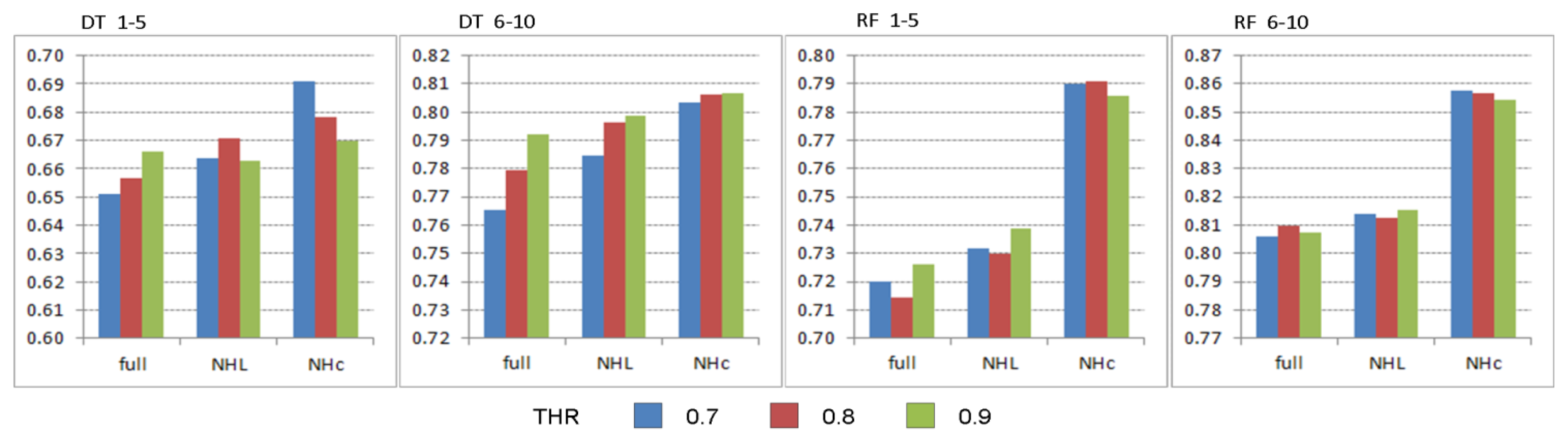
Figure 7 as average classification accuracies achieved over the smaller and larger sized training sets. Using RF, the different THRs perform on a similar level and differences among search neighborhoods with minor variations in the final classification accuracies, due to being a stronger classifier providing better class predictions over smaller training sets. However, the weaker classifier DT is more affected by the choice of THR as one probably would expect. The main observation is that the THR has an effect on the final classification performance with respect to the underlying search neighborhood. The DT performance regarding THR seems to be proportional to the size of the used search neighborhood. With a smaller THR is seems beneficial to have a smaller search neighborhood, whereas with higher THR the size of the search neighborhood does not seem to have major effects as performances vary just within a small margin. This is expected as the weaker learner DT is not able to learn and generalize too well from such tiny to small training sets. Due to these observations and as the overall classification performances for the different THRs average out over the different search neighborhoods, we consider THR = 0.8 for the remainder of our experiments over both base learners.
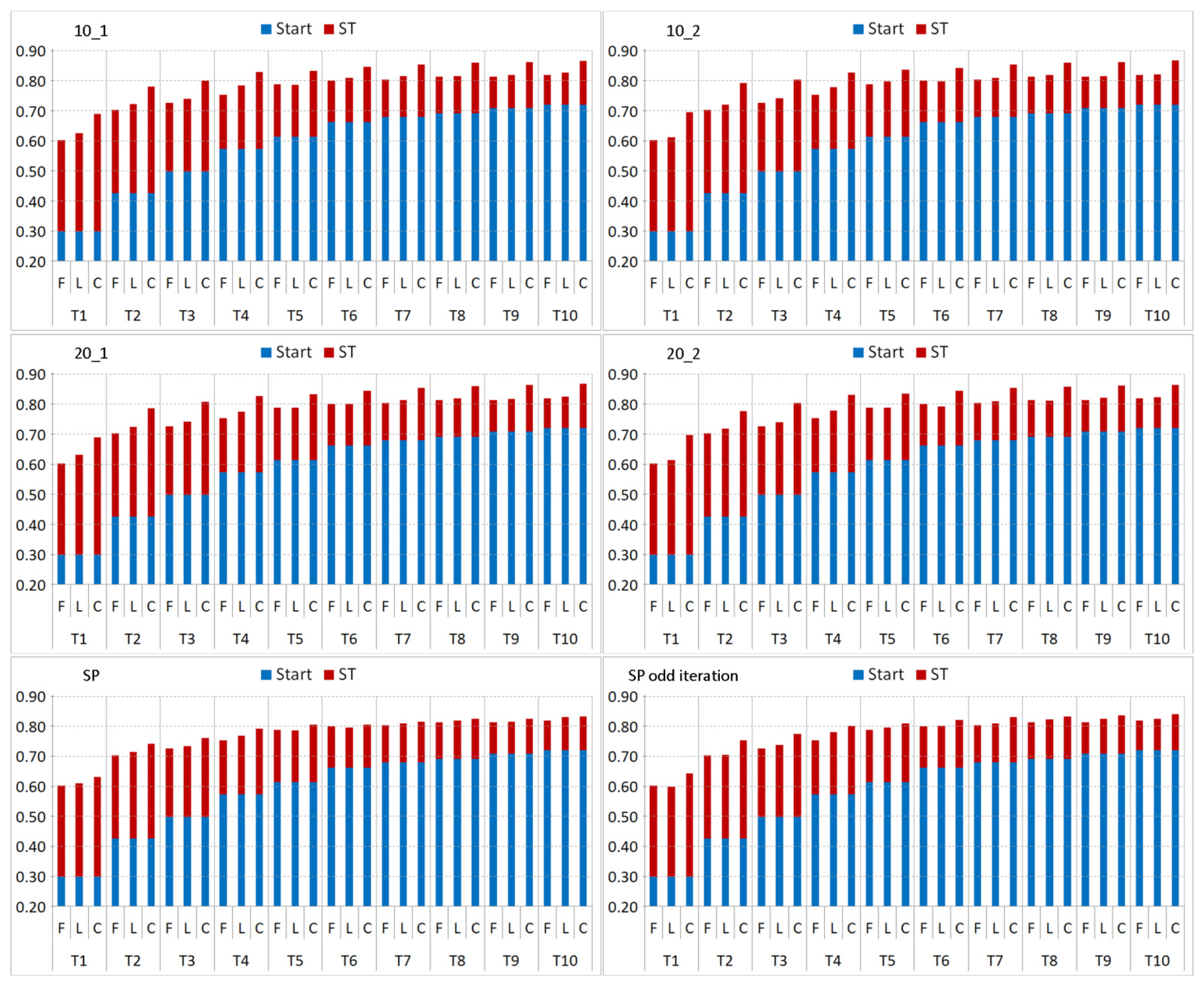
Regarding the evaluation of the different search neighborhoods (SNHs), the overall differences in total gain after 50 iterations of ST is minimal with all SNHs reaching similar classification results (
Figure 8) and ST improvements (
Figure 9) for different T
i. We can see that especially with the small T
i (T
1–T
5) larger ST improvements can be obtained compared to their initial lower classification accuracies indicating that there is more potential for improvements. It is also anticipated that the ST improvements with the larger T
i (T
6–T
10) are no longer that significant (only around 10%–15%) as their initial classification accuracies are already around 60%–70% due to larger training data. In general, differences among the SNHs
full, NH
L, and NH
C are observed as expected. Applying NH
L results in slightly better results than using
full since NH
L is a smaller subset of
full whereas NH
C limits the SNH for one class to the spatial proximity of its particular labeled samples. The performance difference between
full and NH
L disappears for the larger sets, T
5–10, since NH
L suffers from the same problem,
i.e., no or limited amount of new information is available due to larger number of labeled samples.
For the circular NHL and NHC, the initial size rad and the incremental expansion by radInc seems to have marginal effects since in either case the SNH area will not significantly change with each iteration. Overall, the four different combinations result in rather similar outcomes with marginal variations due to the random sample selection. Based on the observations, the influence of parameters rad and radInc are related to the SAR image resolution. Considering the two SP growing methods, in both cases results using NHL are similar to full due to the fast rate the SP SNH grows. However, main differences can be observed for NHC. Firstly, both methods results are below the ones obtained by circular growing, and in either case, no ST improvements for larger Ti are achieved after 10 iterations. Within the first 10 ST iterations, the best performance is achieved. Afterwards no further benefits of adding new samples can be made with NHC since the SNH area is the same size as full.
For the main classification performance evaluations, we shall consider the NHC approaches for the circular combination with rad = 10 and radInc = 1. This mimics the slower growth while the superpixel approach will much faster while expanding the SNH every odd ST iteration. We shall abbreviate the two SNH approaches with NHo for the circular and NHsp for the superpixel methods.
Next, we shall investigate the effect of the number of unlabeled samples that are added per ST iteration. Due to small sample number per class, we only consider the same amount of unlabeled samples as labeled per class for initial pixel training sets Ti. Thus, for enlarging Ti with NN and SP, we evaluated the effect of adding different number of unlabeled samples per ST iteration. For this, we consider multiples (xL) of labeled samples per class, namely x1, x2, x4, and x6. This means, for example, that in case of x4, unlabeled data size is up to 4 times of the size of labeled samples that they can be added per class. Thus with i = 2, this results in 8 possible candidates if their confidence scores are higher than THR. Based on our previous observations, we shall consider NHo and NHsp, in particular.
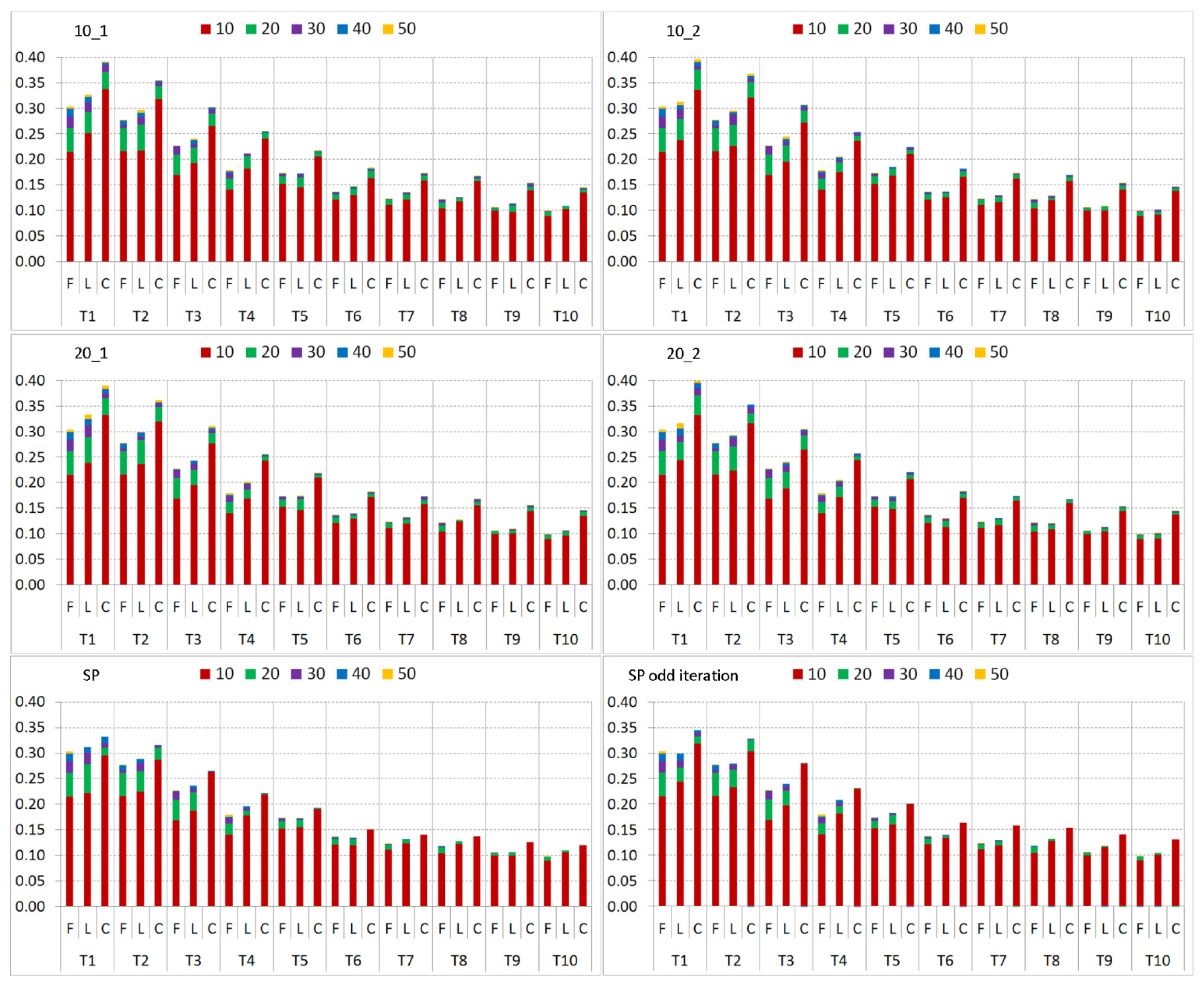
Figure 10 demonstrates the differences of several search neighborhoods (SNHs) and number of
xL combinations with respect to the best classification result achieved among all combinations. The general observation confirms the expected result, that is, adding more unlabeled samples than the initially labeled samples will bias the learning process towards the unlabeled samples particularly in case of the smaller training sets,
i.e., T
1–5, as shown in the plot for Decision Tree (DT) over NN
i using SNH mode,
full. However, this effect is reduced for T
6–10 due to the relatively larger size of the initial training data. When using NH
sp, it shows the same behavior for different
xL combinations as it will reach the area of
full since the search process quickly suffers from the same issues. Yet note that the effects are not as severe since the SNH still has to grow within the first ST iterations, which reduces the chance of the weak DT learner to add erroneous samples during the first ST iterations. Applying NH
o appears to provide best results among all combinations with
x4 combination being a trade-off to
x2 and
x6 combinations as a balance between the number of labeled and unlabeled samples. Yet classification accuracy differences among them are rather small,
i.e., only within 1%. For the larger training sets of NN
6–10 using NH
o, there seems to be no benefit of adding more unlabeled samples due to larger number of labeled samples that are already available and providing initial classification accuracy level higher than 70%. In that regard, performance differences for
x4 and
x6 to
x1 and
x2 combinations are negligible. Concerning the superpixel enlarged initial training sets, results using SNHs,
full and NH
sp seem to follow similar behavior for different
xL combinations. However, classification accuracies are achieved within a 1% range due to the larger training set sizes and this makes it easier to compensate for larger number of unlabeled samples. In case of SP
i, the number of unlabeled samples does not significantly affect the final results, as the labeled data size during the initial training iterations is so large that only minor ST improvements can be made.
Regarding the evaluation using Random Forest (RF), we can observe similar behavior for the different training sizes. As for DT with NNi using the SNH mode as full, more unlabeled samples result in higher probabilities of selecting erroneous samples due to the larger SNH. For NHsp, due to the homogeneous superpixels, the size of unlabeled samples has a marginal effect because the additional samples over the same superpixel area will have a rather similar feature structure especially with a stronger classifier that is capable of providing higher confidence scores. Nonetheless, we can observe that for NHo the opposite effect is visible, where more samples can now make a significant influence. One of the reasons is that the circular NH grows with respect to the spatial distance to a labeled sample location—not as in case of superpixels by sample homogeneity. More important than this is the fact that with NHo the SNH grows slower so that not all similar samples are added within the same ST iteration. The addition of similar samples is spread over time and many ST iterations For the enlargement of Ti by superpixels as for DT, similar observations can be made for NN6–10 and SP, where the effect of the unlabeled samples is reduced with higher number of labeled samples.
The initial classification performances of T
i and their corresponding self-training (ST) improvements for search neighborhoods
full, NH
o, and NH
sp are shown in
Figure 11. In our setup using DT as the base classifier, we can observe that similar level of classification accuracies can be achieved using self-training over T
1, T
2, and T
3 compared to the initial results of T
4, T
7, and T
10, respectively. Similarly, when employing RF with the sets T
1 and T
2 using self-training, classification results comparable to T
5 and T
10 can be realized. This is not surprising because the stronger base classifier such as RF can achieve higher classification accuracies particularly for small training sets such as T
1 and T
2, and this results in better label predictions of the unlabeled samples in the first ST iterations. Note that for both base classifiers, the classification accuracy level that is achieved by self-training while using initially 3–5 times less amount of manually labeled data, is similar to the one obtained with its SL counterpart. Such a crucial reduction on the manually labeled data for training is indeed a noteworthy accomplishment of the ST approach; however, we shall carry out further investigations to evaluate different options and to maximize the gain.
We illustrate the effect of the 10 different training set instances of T
1 and T
2 in
Figure 12. The plots show that for instances of T
1 and T
2 DT are struggling with the small number of labeled samples to achieve improvements via ST. As mentioned earlier, the initial labeled samples are critical to determine the success of applying SSL particularly for such a weaker learner as DT. It can be noticed that using RF (as a mini-ensemble of three DTs) is overcoming this problem and significant improvements are achieved within the first 10 ST iterations. Furthermore, as T
1 is a subset of T
2, it can be seen that the one additional sample per class has a positive influence yet will not always overcome the weakness of the first sample or might even have a negative effect.
Evaluating the three different methods on “how” and “where” to pick the unlabeled samples from, we can observe clear differences for the two base classifiers employed. For the weaker classifier, DT, the full search neighborhood provides slightly better or similar results than NHo and NHsp for T1 and T2, whereas for the larger sets T3–10, NHo and NHsp yield higher accuracies. The reason lies in the fact that DT, as a rather weak learner is not capable of learning from such small sample sizes with one and two labeled samples per class. For T1, note that DT still benefits from new samples during the iterations, t = 40 and t = 50. However, note that ST improvements of 18%–22% are achieved due to the extremely low initial classification accuracies on the labeled samples while the overall classification accuracies being below 50%. As for the larger sets, T3–10, the larger training data size in a greater search neighborhood while increasing the number of possible unlabeled candidates within NHo and NHsp. Yet the number of these candidates is still significantly smaller than the one for full and this yields a higher chance to semi-labeled samples with lower class confidence values providing more diversity but in the same time, higher risk of erroneous semi-labeling. However, performance differences observed among different search neighborhoods are minimal, i.e., using NHo provides a mere ~2% higher classification accuracies. As for RF, classification performances over T1–4 using NHo are the highest among all other alternatives. This is related to the stronger classifier that has a superior learning capabilities with less number of samples so that the smaller search neighborhood of NHo and NHsp becomes then quite beneficial in providing more diverse samples into the learning process. Both base classifiers indeed benefit from selecting samples closer to the initially labeled samples while having a stronger classifier with a better learning ability is obviously more advantageous.
Furthermore, when looking into the self-training iterations in
Figure 11, we can observe that using NH
o and NH
sp can yield further improvements particularly during the earlier iterations (
i.e., t = 10). With the
full search neighborhood, either a minimum number of 20–30 iterations are needed to achieve the same results or for a larger T
i, similar accuracies cannot be achieved even after 50 iterations when using DT as the base classifier. The same behavior can also be observed for RF, where results obtained after 10 iterations applying NH
o and NH
sp outperform accuracies achieved after 50 iterations applying
full as the search neighborhood. Note further that performing self-training over these initial training sets achieves similar or better results than using NN
i or SP
i, respectively. This is due to the fact that the neighborhood,
full, can result in larger numbers of unlabeled samples with high classifier confidence scores that are greater than THR. Hence, there is a greater chance for the highly accurate semi-labeled samples to be selected; however, this yields adding no or less new information into the self-training process. In case of NH
o and NH
sp, the number of possible unlabeled samples as new candidates is limited, therefore, giving a higher chance of adding more diversity due to the samples with a lower confidence score. When using NH
sp, the best performance is achieved within the first 10 iterations, after that its SNH area grows beyond
full. Since the classification accuracy with NH
sp after 10 iterations is already better than the one achieved with
full using 50 iterations, no further benefits of adding new samples can be observed with NH
sp.
When enlarging T
i to NN
i, the initial classification performance is improved as illustrated in
Figure 13, which is anticipated due to the availability of more samples. As we have the ground truth available, we could verify that 96.3% of the NN
i samples are correctly labeled whereas the majority of the remaining 3.7% is unknown since no ground truth is available on those sections. Even though, it is expected that NN
1 and T
9 results are not comparable because the NN
1 samples will have a similar feature structure providing less diversity among the samples compared to the nine labeled samples in T
9. This is also observable for the NN
2–4 results as they are not able to match the initial classification accuracy of T
10 besides NN
2–4 being significantly larger.
The initial classification improvements on the average are ~18% and ~10% for NN
1–5 and NN
6–10, respectively. Note that employing self-training is still able to provide an increase in the classification accuracy over all NN
i yet the improvements are getting insignificant, as the initial accuracies are higher (see
Figure 13). At the end, this results in classification performance employing NH
o/NH
sp being just marginally better by 0.5% for DT and ~2.5% for RF, on the average than using
full.
When DT is used as the base classifier, the main performance difference compared to the results with Ti is that NNi is highly beneficial for labeled dataset size of i = 2 when improving the final classification accuracy by 6%–7%. Similar observation can be made for RF trained over the NN1 where an accuracy improvement of around 6% is visible for the search neighborhood full compared to their T1 results. However, employing NHo and NHsp over both training sets T1 and NN1, the difference shrinks to 2%. For training sets larger than T3, the performance difference between the application of Ti and NNi is minimal. The reason for this is that both NNi and NHo/NHsp enhance the initial training set Ti based on the same idea: by selecting unlabeled samples from the close neighborhood of the provided labeled samples.
Similar observations and comparative evaluations between the superpixel method and NN
i can be made. As visible in the plot given in
Figure 14, compared to NN
1, the classification accuracy over the SP
1 can be improved by 15% and 11% for DT and RF, respectively, whereas performance differences for the other training set sizes are getting less. Similar to NN
i, such improvements occur as a result of significantly larger dataset size for self-training,
i.e., around 100 semi-labelings per labeled pixel. However, when verified with the ground truth, we can note that the accuracy of the correctly labeled superpixel samples using superpixel method is lower than the one for NN (around 10%), yet there are still at least 86 of 100 samples with the correct labels whereas the other 14% are mainly unknown. It is obvious that the relative drop in the semi-labeling accuracy is compensated by the significantly larger number of samples providing more diversity. Moreover, the superpixel method already covers most potential candidates within the vicinity of the initially labeled samples and thus reduces the effect of NH
o and NH
sp. When the search strategies
full is employed the amount of new information is quite limited and note that it is now further reduced due to the larger diversity already introduced by the larger training data. Hence, this significantly reduces any potential performance gain. The same effect can also be observed for the larger T
i or NN
i training sets. This means that an upper bound of classification accuracy can be achieved by employing different sized training sets.
Over both neighborhood approaches NN
i and SP
i of the proposed self-training method, we perform comparative evaluations among the three training set types.
Figure 15 presents the plots that sum up the differences of the classification accuracies obtained by individual NN
i and SP
i approaches with respect to their initial training set, T
i. When using DT as the base classifier, the neighborhood superpixel approach contributes by at least 5% to the classification accuracy for the most of the training sample sizes used whereas the highest gain is achieved when the two smallest training sets are enlarged by their 8-connected neighbors. When using RF as the base classifier, improvements are observed for all sets over the search neighborhood
full where accuracy differences over NN
i and SP
i are around +2% and +6%, respectively. We observe that when exploiting the closer spatial neighborhood of labeled samples via NH
o, neither the 8-neighbor contextual information approach nor the superpixels approach leads to any significant performance improvement due to the aforementioned reasons.
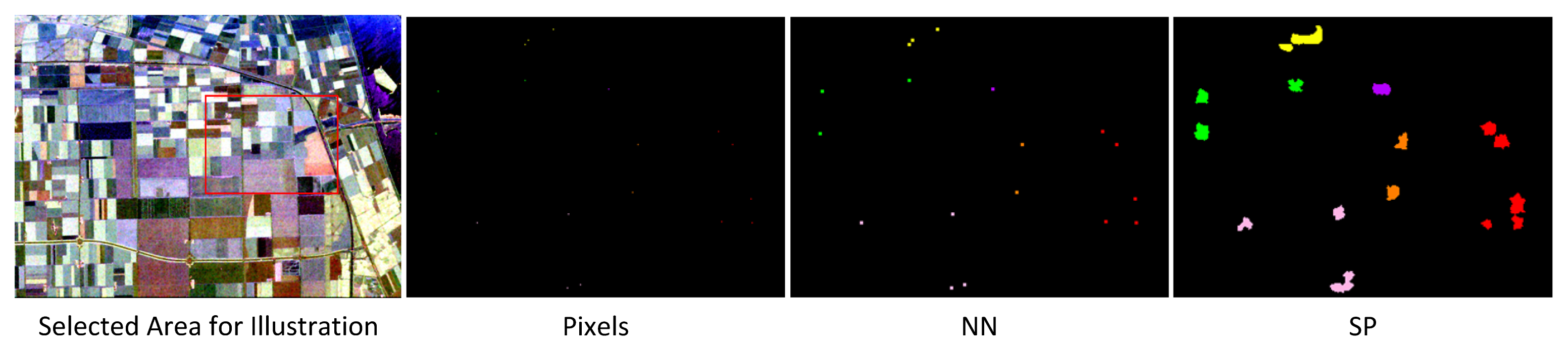
Along with the numerical evaluations, we shall further present visual classification results, from the initial to the final classification output.
Figure 16 illustrates the sample classification maps using RF as the base classifier within the ensemble-based bagging approach. In the figure, we also visually compare the effects of search neighborhoods,
full and NH
o, over the classification performance and the top row shows the initial results over an instance of T
2. The images displaying the “difference to ground truth” show the major misclassification of a particular class while white indicating correct labels. Thus, larger white areas represent a better match with the ground truth. The green circles for the classification results annotated with the ST iteration number 10 in row 2 indicate the classification difference between the two search neighborhoods,
full and NH
o, compared to the initial results from the labeled samples in the first row. In particular, this row shows the difference between the classification performances achieved using two neighborhood approaches, NH
o and
full both visually and numerically. For the following rows, the green and red circles indicate higher improvements or degradations, respectively, compared to the corresponding previous row. Overall, it is clear from the figure that major improvements after 10 iterations are achieved by applying NH
o and during the rest of the 20 iterations, only minor improvements are observed. As visible in the final numerical classification results, the application of the other neighborhood approach,
full, yields an improvement for the major areas after 20 iterations, yet does not achieve better results.
For visual and numerical comparisons of the different SSL approaches,
Figure 17 shows results for the initial T
i, NN
i, SP
i, T
i in self-training, and initial T
10 training sets. The first four are based on an instance of T
2 while T
10 is chosen based on the numerical results for RF. It is worth noting that the visual classification results achieved by RF with SL over the set T
10 and with SSL by self-training over T
2 applying NH
o are quite similar. The green circles mark the best classification performance in a particular area among all classification results. The comparison shows that the classification over T
2 with the application of SSL employing NH
o produces the best classification map.
This is a significant accomplishment achieved by SSL along with a classifier initially trained with a small-sized training dataset particularly when comparing to the classifier trained over the set T10 and thus having 5 times more user-labeled samples to form the training dataset. In this example, the visual results favor NN2 to SP2; however, this is vice versa when numerical results are compared. This is related to the particular T2 instance and the corresponding superpixels. This shows that the starting point can be particularly critical for SSL especially when small sample sized training sets are used for the initial training.
Finally, we shall provide a brief comparison among various classifiers. They have been evaluated over different training set sizes such as 52, 104, 208, and 1041 samples, which correspond to 0.25‰, 0.5‰, 1%, and 5% of the 208 000 pixel ground truth, respectively. All classifier parameters have been optimized for the best classification performance; and their classification accuracies are averaged over 100 runs using HαA features and shown in
Table 1. Details about the optimization process and setup for the supervised classifiers can be found in [
41]. As an additional comparison, we also added the classification results using the covariance matrix 〈[
C]〉 to
Table 1 besides the HαA feature results.
Our previous experiments and evaluations have shown that SSL and ST using small-labeled data are able to achieve similar classification performances compared to supervised learning with larger labeled data sets using the same underlying classifier. The same observation can be made for typical classifiers such as KNN, MLP, and SVMs as illustrated in
Figure 18. The most interesting fact is that training sets with 6 or more samples per class using superpixels to enlarge the initial labeled data combined with the ensemble-based self-training is able to achieve comparable classification performances with various SL methods using as high as 1000 labeled samples.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}