A Comparison of Advanced Regression Algorithms for Quantifying Urban Land Cover

 ,
,  and
and
Abstract
:1. Introduction
- (1)
- Which regression techniques effectively utilize synthetically mixed training data for producing accurate urban land cover maps?
- (2)
- How do coarser resolution images influence the performance of regression models?
- (3)
- Do more complex synthetic mixtures allow for coping with potential deficiencies of coarser resolution imagery?
2. Study Area and Materials
2.1. Study Area
2.2. Image Data
2.3. Spectral Library
2.4. Reference Data
3. Methods
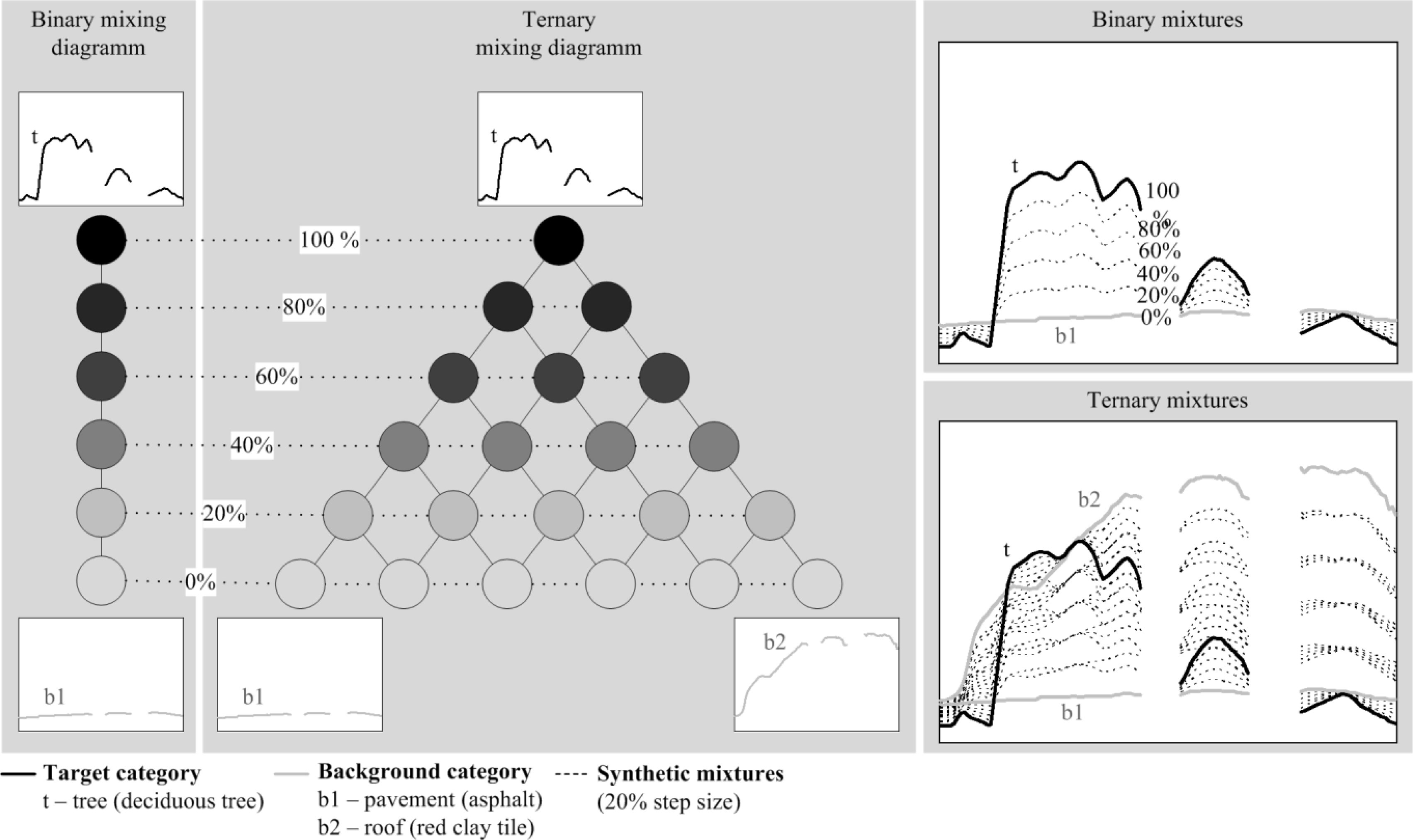
3.1. Synthetically Mixed Training Data
3.2. Support Vector Regression (SVR)
3.3. Kernel Ridge Regression (KRR)
3.4. Neural Network Regression (NN)
3.5. Random Forest Regression (RFR)
3.6. Partial Least Squares Regression (PLSR)
3.7. Validation
4. Experimental Setup and Results
4.1. Experimental Setup
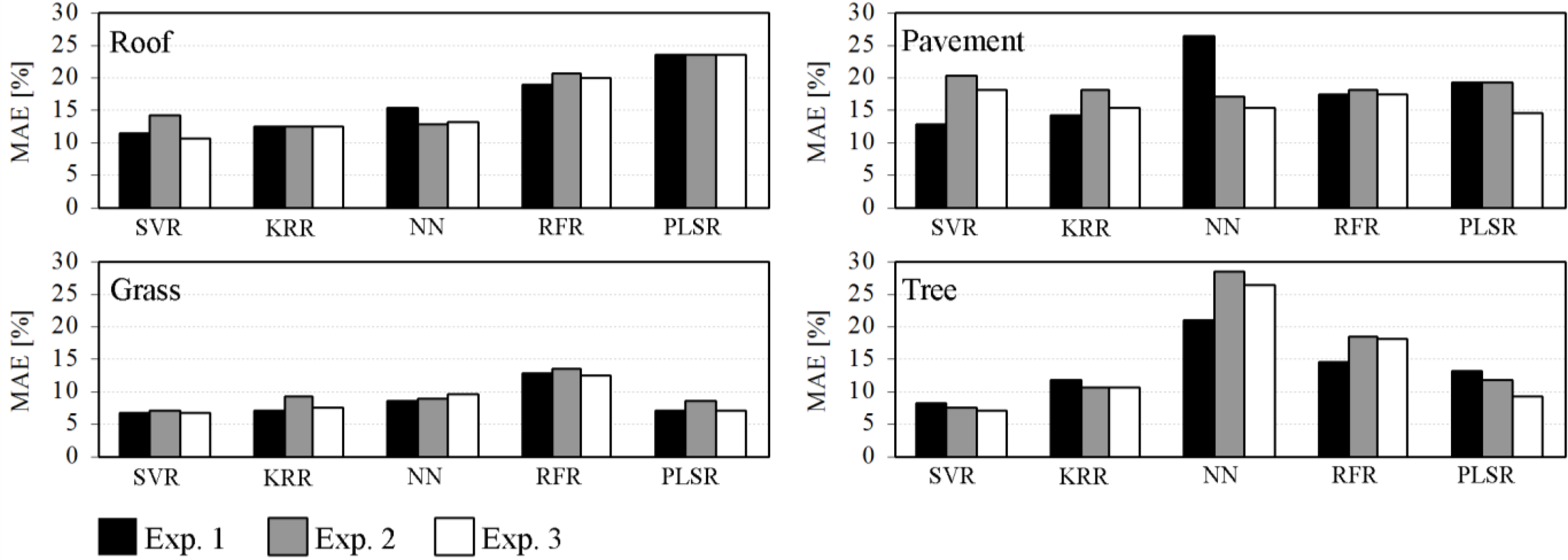
- Exp. 1: We investigated the efficiency of the regression techniques to utilize synthetically mixed training data for quantifying urban land cover. For each regressor and each target category, we trained one regression model using SyMix01. Subsequently, we applied the models to HyMap01 to derive fraction maps at 3.6 m spatial resolution.
- Exp. 2: We investigated the influence of coarser resolution image data on the quality of model predictions. We therefore applied regression models used in Exp. 1 to HyMap02 to derive fraction maps at 9 m spatial resolution.
- Exp. 3: We investigated whether more complex synthetic mixtures help to improve fraction estimates from the coarser resolution data. For each regressor and each target category, we trained one regression model using SyMix02. Subsequently, we derived a second set of fraction maps at 9 m spatial resolution by applying models to HyMap02.
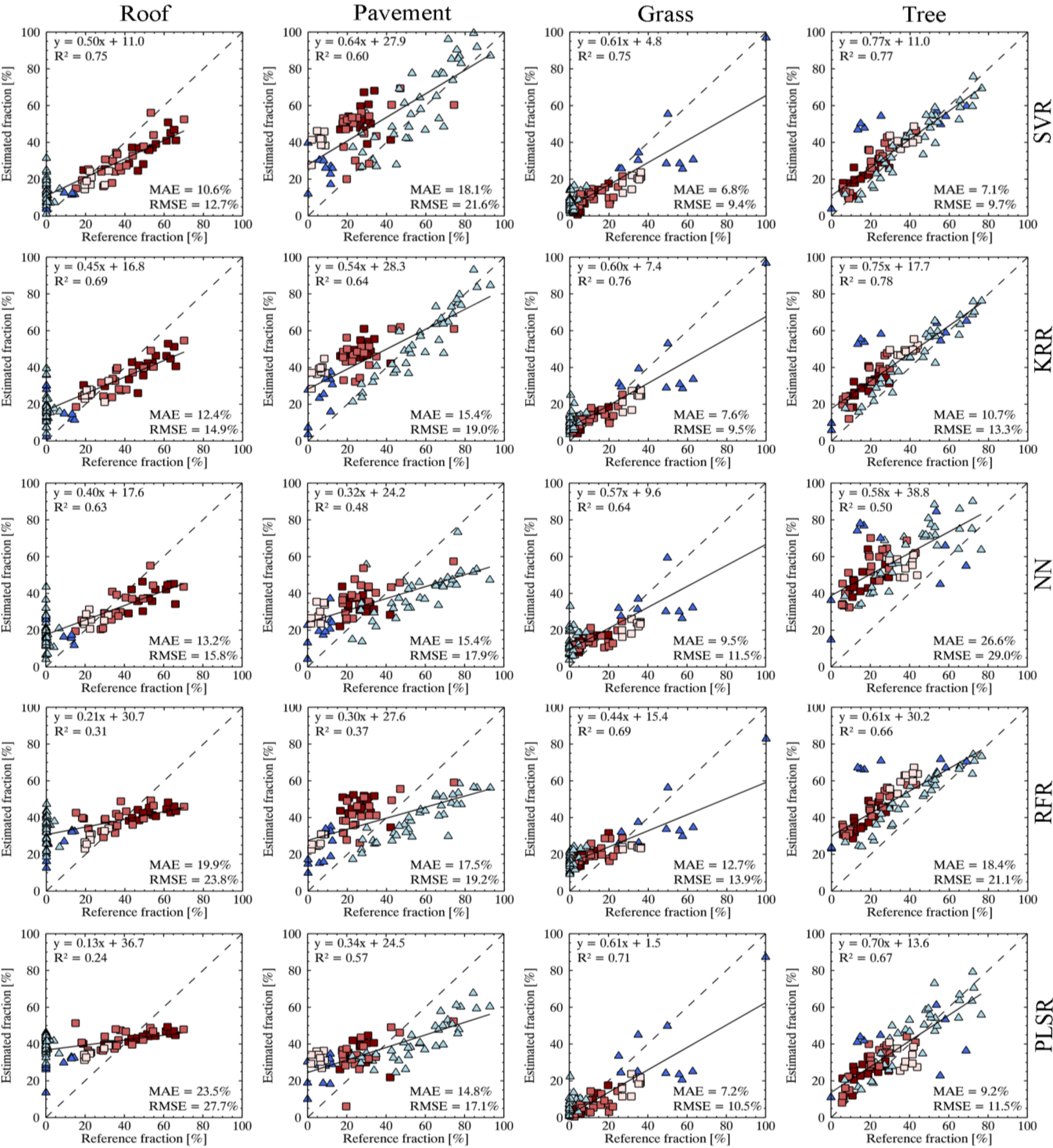
4.2. Average and Class-Wise Accuracies of Experimental Results
4.3. Quantifying Urban Land Cover at Multiple Spatial Scales Using SVR
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Heiden, U.; Segl, K.; Roessner, S.; Kaufmann, H. Determination of robust spectral features for identification of urban surface materials in hyperspectral remote sensing data. Remote Sens. Environ 2007, 111, 537–552. [Google Scholar]
- Herold, M.; Roberts, D.A.; Gardner, M.E.; Dennison, P.E. Spectrometry for urban area remote sensing—Development and analysis of a spectral library from 350 to 2400 nm. Remote Sens. Environ 2004, 91, 304–319. [Google Scholar]
- Small, C. High spatial resolution spectral mixture analysis of urban reflectance. Remote Sens. Environ 2003, 88, 170–186. [Google Scholar]
- Van der Linden, S.; Hostert, P. The influence of urban structures on impervious surface maps from airborne hyperspectral data. Remote Sens. Environ 2009, 113, 2298–2305. [Google Scholar]
- Franke, J.; Roberts, D.A.; Halligan, K.; Menz, G. Hierarchical multiple endmember spectral mixture analysis (MESMA) of hyperspectral imagery for urban environments. Remote Sens. Environ 2009, 113, 1712–1723. [Google Scholar]
- Roessner, S.; Segl, K.; Heiden, U.; Kaufmann, H. Automated differentiation of urban surfaces based on airborne hyperspectral imagery. IEEE Trans. Geosci. Remote Sens 2001, 39, 1525–1532. [Google Scholar]
- Herold, M.; Gardner, M.E.; Roberts, D.A. Spectral resolution requirements for mapping urban areas. IEEE Trans. Geosci. Remote Sens 2003, 41, 1907–1919. [Google Scholar]
- Gamba, P.; Dell’Acqua, F. Spectral resolution in the context of very high resolution urban remote sensing. In Urban Remote Sensing; Quattrochi, D.W., Ed.; CRC Press Inc: New York, NY, USA, 2006; pp. 377–391. [Google Scholar]
- Van der Linden, S.; Janz, A.; Waske, B.; Eiden, M.; Hostert, P. Classifying segmented hyperspectral data from a heterogeneous urban environment using support vector machines. J. Appl. Remote Sens 2007, 1, 013543. [Google Scholar]
- Powell, R.L.; Roberts, D.A.; Dennison, P.E.; Hess, L.L. Sub-pixel mapping of urban land cover using multiple endmember spectral mixture analysis: Manaus, Brazil. Remote Sens. Environ 2007, 106, 253–267. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens 2005, 43, 1351–1362. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens 2004, 42, 1778–1790. [Google Scholar]
- Pal, M.; Mather, P.M. Some issues in the classification of DAIS hyperspectral data. Int. J. Remote Sens 2006, 27, 2895–2916. [Google Scholar]
- Colgan, M.S.; Baldeck, C.A.; Feret, J.-B.; Asner, G.P. Mapping savanna tree species at ecosystem scales using support vector machine classification and BRDF correction on airborne hyperspectral and LiDAR data. Remote Sens 2012, 4, 3462–3480. [Google Scholar]
- Im, J.; Jensen, J.R.; Jensen, R.R.; Gladden, J.; Waugh, J.; Serrato, M. Vegetation cover analysis of hazardous waste sites in Utah and Arizona using hyperspectral remote sensing. Remote Sens 2012, 4, 327–353. [Google Scholar]
- Clark, M.L.; Roberts, D.A. Species-level differences in hyperspectral metrics among tropical rainforest trees as determined by a tree-based classifier. Remote Sens 2012, 4, 1820–1855. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L. (Eds.) Kernel Methods for Remote Sensing Data Analysis; John Wiley & Sons, Inc: New York, NY, USA, 2009.
- Schölkopf, B.; Smola, A.J. Learning with Kernels-Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Tuia, D.; Camps-Valls, G. Urban image classification with semisupervised multiscale cluster kernels. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens 2011, 4, 65–74. [Google Scholar]
- Roberts, D.A.; Gardner, M.; Church, R.; Ustin, S.; Scheer, G.; Green, R.O. Mapping chaparral in the Santa Monica Mountains using multiple endmember spectral mixture models. Remote Sens. Environ 1998, 65, 267–279. [Google Scholar]
- Roberts, D.A.; Quattrochi, D.A.; Hulley, G.C.; Hook, S.J.; Green, R.O. Synergies between VSWIR and TIR data for the urban environment: An evaluation of the potential for the hyperspectral infrared imager (HyspIRI) decadal survey mission. Remote Sens. Environ 2012, 117, 83–101. [Google Scholar]
- Bauer, M.E.; Loffelholz, B.C.; Wilson, B. Estimating and mapping impervious surface area by regression analysis of Landsat imagery. In Remote Sensing of Impervious Surfaces; Weng, Q., Ed.; CRC Press: London, UK, 2008; pp. 3–19. [Google Scholar]
- Van de Voorde, T.; Jacquet, W.; Canters, F. Mapping form and function in urban areas: An approach based on urban metrics and continuous impervious surface data. Landsc. Urban Plann 2011, 102, 143–155. [Google Scholar]
- Pu, R.; Gong, P.; Michishita, R.; Sasagawa, T. Spectral mixture analysis for mapping abundance of urban surface components from the Terra/ASTER data. Remote Sens. Environ 2008, 112, 939–954. [Google Scholar]
- Van de Voorde, T.; de Roeck, T.; Canters, F. A comparison of two spectral mixture modelling approaches for impervious surface mapping in urban areas. Int. J. Remote Sens 2009, 30, 4785–4806. [Google Scholar]
- Im, J.; Lu, Z.; Rhee, J.; Quackenbush, L.J. Impervious surface quantification using a synthesis of artificial immune networks and decision/regression trees from multi-sensor data. Remote Sens. Environ 2012, 117, 102–113. [Google Scholar]
- Yuan, F.; Wu, C.; Bauer, M.E. Comparison of spectral analysis techniques for impervious surface estimation using Landsat imagery. Photogramm. Eng. Remote Sens 2008, 74, 1045–1055. [Google Scholar]
- Yang, L.M.; Xian, G.; Klaver, J.M.; Deal, B. Urban land-cover change detection through sub-pixel imperviousness mapping using remotely sensed data. Photogramm. Eng. Remote Sens 2003, 69, 1003–1010. [Google Scholar]
- Esch, T.; Himmler, V.; Schorcht, G.; Thiel, M.; Wehrmann, T.; Bachofer, F.; Conrad, C.; Schmidt, M.; Dech, S. Large-area assessment of impervious surface based on integrated analysis of single-date Landsat-7 images and geospatial vector data. Remote Sens. Environ 2009, 113, 1678–1690. [Google Scholar]
- Walton, J.T. Subpixel urban land cover estimation: Comparing cubist, random forests, and support vector regression. Photogramm. Eng. Remote Sens 2008, 74, 1213–1222. [Google Scholar]
- Camps-Valls, G.; Bruzzone, L.; Rojo-Alvarez, J.L.; Melgani, F. Robust support vector regression for biophysical variable estimation from remotely sensed images. IEEE Geosci. Remote Sens. Lett 2006, 3, 339–343. [Google Scholar]
- Verrelst, J.; Munoz, J.; Alonso, L.; Delegido, J.; Pablo Rivera, J.; Camps-Valls, G.; Moreno, J. Machine learning regression algorithms for biophysical parameter retrieval: Opportunities for Sentinel-2 and -3. Remote Sens. Environ 2012, 118, 127–139. [Google Scholar]
- Yu, K.; Leufen, G.; Hunsche, M.; Noga, G.; Chen, X.; Bareth, G. Investigation of leaf diseases and estimation of chlorophyll concentration in seven barley varieties using fluorescence and hyperspectral indices. Remote Sens 2013, 6, 64–86. [Google Scholar]
- Bacour, C.; Baret, F.; Beal, D.; Weiss, M.; Pavageau, K. Neural network estimation of LAI, fAPAR, fCover and LAIxC(ab), from top of canopy MERIS reflectance data: Principles and validation. Remote Sens. Environ 2006, 105, 313–325. [Google Scholar]
- Cernicharo, J.; Verger, A.; Camacho, F. Empirical and physical estimation of canopy water content from CHRIS/PROBA data. Remote Sens 2013, 5, 5265–5284. [Google Scholar]
- Okujeni, A.; van der Linden, S.; Tits, L.; Somers, B.; Hostert, P. Support vector regression and synthetically mixed training data for quantifying urban land cover. Remote Sens. Environ 2013, 137, 184–197. [Google Scholar]
- Stuffler, T.; Förster, K.; Hofer, S.; Leipold, M.; Sang, B.; Kaufmann, H.; Penné, B.; Mueller, A.; Chlebek, C. Hyperspectral imaging—An advanced instrument concept for the EnMAP mission (Environmental Mapping and Analysis Programme). Acta Astronaut 2009, 65, 1107–1112. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning-Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Haykin, S. Neural Networks—A Comprehensive Foundation, 2nd ed.; Prentice Hall: New York, NY, USA, 1999. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn 2001, 45, 5–32. [Google Scholar]
- Wold, S.; Sjostrom, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemometr. Intell. Lab. Syst 2001, 58, 109–130. [Google Scholar]
- Cadenasso, M.L.; Pickett, S.T.A.; Schwarz, K. Spatial heterogeneity in urban ecosystems: Reconceptualizing land cover and a framework for classification. Front. Ecol. Environ 2007, 5, 80–88. [Google Scholar]
- Pauleit, S.; Duhme, F. Assessing the environmental performance of land cover types for urban planning. Landsc. Urban Plann 2000, 52, 1–20. [Google Scholar]
- Schläpfer, D.; Richter, R. Geo-atmospheric processing of airborne imaging spectrometry data. Part 1: Parametric orthorectification. Int. J. Remote Sens 2002, 23, 2609–2630. [Google Scholar]
- Cocks, T.; Jenssen, R.; Stewart, A.; Wilson, I.; Shields, T. The HyMap™ airborne hyperspectral sensor: The system, calibration and performance. Proceedings of the 1’st EARSeL Workshop on Imaging Spectroscopy, Zurich, Switzerland, 6–8 October 1998; pp. 37–42.
- Richter, R.; Schläpfer, D. Geo-atmospheric processing of airborne imaging spectrometry data. Part 2: Atmospheric/topographic correction. Int. J. Remote Sens 2002, 23, 2631–2649. [Google Scholar]
- SenStadt, Berlin Urban and Environmental Information System (UEIS). Available online: http://www.stadtentwicklung.berlin.de/umwelt/umweltatlas (accessed on 4 July 2014).
- Heiden, U.; Heldens, W.; Roessner, S.; Segl, K.; Esch, T.; Mueller, A. Urban structure type characterization using hyperspectral remote sensing and height information. Landsc. Urban Plann 2012, 105, 361–375. [Google Scholar]
- Schiefer, S.; Hostert, P.; Damm, A. Correcting brightness gradients in hyperspectral data from urban areas. Remote Sens. Environ 2006, 101, 25–37. [Google Scholar]
- Borel, C.C.; Gerstl, S.A.W. Nonlinear spectral mixing models for vegetative and soil surfaces. Remote Sens. Environ 1994, 47, 403–416. [Google Scholar]
- Roberts, D.A.; Smith, M.O.; Adams, J.B. Green vegetation, nonphotosynthetic vegetation, and soils in AVIRIS data. Remote Sens. Environ 1993, 44, 255–269. [Google Scholar]
- Somers, B.; Asner, G.P.; Tits, L.; Coppin, P. Endmember variability in spectral mixture analysis: A review. Remote Sens. Environ 2011, 115, 1603–1616. [Google Scholar]
- Rabe, A.; van der Linden, S.; Hostert, P. ImageSVM, Version 2.1. Available online: http://www.imagesvm.net/ (accessed on 4 July 2014).
- Rivera Caicedo, J.P.; Verrelst, J.; Munoz-Mari, J.; Moreno, J.; Camps-Valls, G. Toward a semiautomatic machine learning retrieval of biophysical parameters. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens 2014, 7, 1249–1259. [Google Scholar]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sens. Environ 2008, 112, 2999–3011. [Google Scholar]
- Friedl, M.A.; Brodley, C.E. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ 1997, 61, 399–409. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth & Brooks/Cole Advanced Books & Software: Monterey, CA, USA, 1984. [Google Scholar]
- Waske, B.; van der Linden, S.; Oldenburg, C.; Jakimow, B.; Rabe, A.; Hostert, P. ImageRF—A user-oriented implementation for remote sensing image analysis with random forests. Environ. Modell. Softw 2012, 35, 192–193. [Google Scholar]
- Smith, M.L.; Martin, M.E.; Plourde, L.; Ollinger, S.V. Analysis of hyperspectral data for estimation of temperate forest canopy nitrogen concentration: Comparison between an airborne (AVIRIS) and a spaceborne (Hyperion) sensor. IEEE Trans. Geosci. Remote Sens 2003, 41, 1332–1337. [Google Scholar]
- Schmidtlein, S.; Feilhauer, H.; Bruelheide, H. Mapping plant strategy types using remote sensing. J. Veg. Sci 2012, 23, 395–405. [Google Scholar]
- Feilhauer, H.; Asner, G.P.; Martin, R.E.; Schmidtlein, S. Brightness-normalized partial least squares regression for hyperspectral data. J. Quant. Spectrosc. Radiat. Transf 2010, 111, 1947–1957. [Google Scholar]
- Chong, I.-G.; Jun, C.-H. Performance of some variable selection methods when multicollinearity is present. Chemometr. Intell. Lab. Syst 2005, 78, 103–112. [Google Scholar]
- Westad, F.; Martens, H. Variable selection in near infrared spectroscopy based on significance testing in partial least squares regression. J. Near Infrared Spectrosc 2000, 8, 117–124. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Urban Category | Surface Material | No. Spectra |
|---|---|---|
| Roof | Red clay tile | 4 (a) |
| Red cement tile | 3 (a) | |
| Bitumen | 5 (b) | |
| Brown roof tile | 1 | |
| Brown roof shingle | 1 | |
| White roof material (polyethylene) | 1 | |
| White roof material (unknown) | 1 | |
| Zinc roof material | 1 | |
| Pavement | Asphalt | 4 (a, b) |
| Concrete | 2 (b) | |
| Grass | Grass (intensively manicured) | 2 (a) |
| Grass (extensively manicured) | 1 | |
| Grass (dry) | 2 (a) | |
| Tree | Deciduous tree | 7 (a) |
| Other | Tartan (sports ground) | 1 |
| Railtrack (concrete sleepers) | 1 | |
| Railtrack (wooden sleepers) | 1 | |
| Sand (playground) | 1 | |
| Soil | 1 | |
| Water | 1 | |
| Training Data Set | Roof | Pavement | Grass | Tree |
|---|---|---|---|---|
| SyMix01 | 1673 | 881 | 761 | 993 |
| SyMix02 | 3092 | 1970 | 1202 | 1254 |
| Experiment | Data | Method | MAE (%) | RMSE (%) | R2 | Slope | Intercept |
|---|---|---|---|---|---|---|---|
| Exp. 1 | HyMap01 SyMix01 | SVR | 9.8 | 12.5 | 0.76 | 0.62 | 12.5 |
| KRR | 11.5 | 13.8 | 0.77 | 0.60 | 13.8 | ||
| NN | 17.9 | 20.8 | 0.61 | 0.49 | 20.8 | ||
| RFR | 16.0 | 18.4 | 0.53 | 0.35 | 18.4 | ||
| PLSR | 15.8 | 18.8 | 0.55 | 0.46 | 18.8 | ||
| Exp. 2 | HyMap02 SyMix01 | SVR | 12.3 | 15.3 | 0.66 | 0.56 | 15.3 |
| KRR | 12.7 | 15.5 | 0.70 | 0.57 | 15.5 | ||
| NN | 16.8 | 19.2 | 0.54 | 0.46 | 19.2 | ||
| RFR | 17.8 | 20.4 | 0.50 | 0.38 | 20.4 | ||
| PLSR | 15.9 | 18.5 | 0.51 | 0.41 | 18.5 | ||
| Exp. 3 | HyMap02 SyMix02 | SVR | 10.7 | 13.4 | 0.71 | 0.63 | 13.4 |
| KRR | 11.5 | 14.2 | 0.71 | 0.59 | 14.2 | ||
| NN | 16.2 | 18.5 | 0.56 | 0.47 | 18.5 | ||
| RFR | 17.1 | 19.5 | 0.51 | 0.39 | 19.5 | ||
| PLSR | 13.7 | 16.7 | 0.55 | 0.45 | 16.7 | ||
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Okujeni, A.; Van der Linden, S.; Jakimow, B.; Rabe, A.; Verrelst, J.; Hostert, P. A Comparison of Advanced Regression Algorithms for Quantifying Urban Land Cover. Remote Sens. 2014, 6, 6324-6346. https://doi.org/10.3390/rs6076324
Okujeni A, Van der Linden S, Jakimow B, Rabe A, Verrelst J, Hostert P. A Comparison of Advanced Regression Algorithms for Quantifying Urban Land Cover. Remote Sensing. 2014; 6(7):6324-6346. https://doi.org/10.3390/rs6076324
Chicago/Turabian StyleOkujeni, Akpona, Sebastian Van der Linden, Benjamin Jakimow, Andreas Rabe, Jochem Verrelst, and Patrick Hostert. 2014. "A Comparison of Advanced Regression Algorithms for Quantifying Urban Land Cover" Remote Sensing 6, no. 7: 6324-6346. https://doi.org/10.3390/rs6076324