Algorithm for Extracting Digital Terrain Models under Forest Canopy from Airborne LiDAR Data

Abstract
:1. Introduction
1.1. LiDAR-Based Forest Inventory
1.2. DTM Extraction in Forested Terrain
1.3. Challenges in DTM Extraction in Forested Terrain
- (i)
- overcome the problems of low data density and the lack of overlapping between DTM patches by iteratively generating a series of coarse DTMs (repeated sampling) using patch widths of varying sizes and combining the coarse DTMs to form the final DTM;
- (ii)
- develop an interpolation strategy for estimating elevation values at places where both spline and trend surface interpolation fail (gap-filling); and
- (iii)
- compare the performance of the proposed algorithm with two other algorithms for generating DTMs in forested terrain using data sets from three different tropical test sites, which are characterized by both low point density and varying degrees of terrain roughness.
2. Material and Methods
2.1. Study Area
2.1.1. Site 1
2.1.2. Site 2
2.1.3. Site 3
2.2. Test Data
2.2.1. LiDAR Data
2.2.2. Field Measurements
2.3. Methods
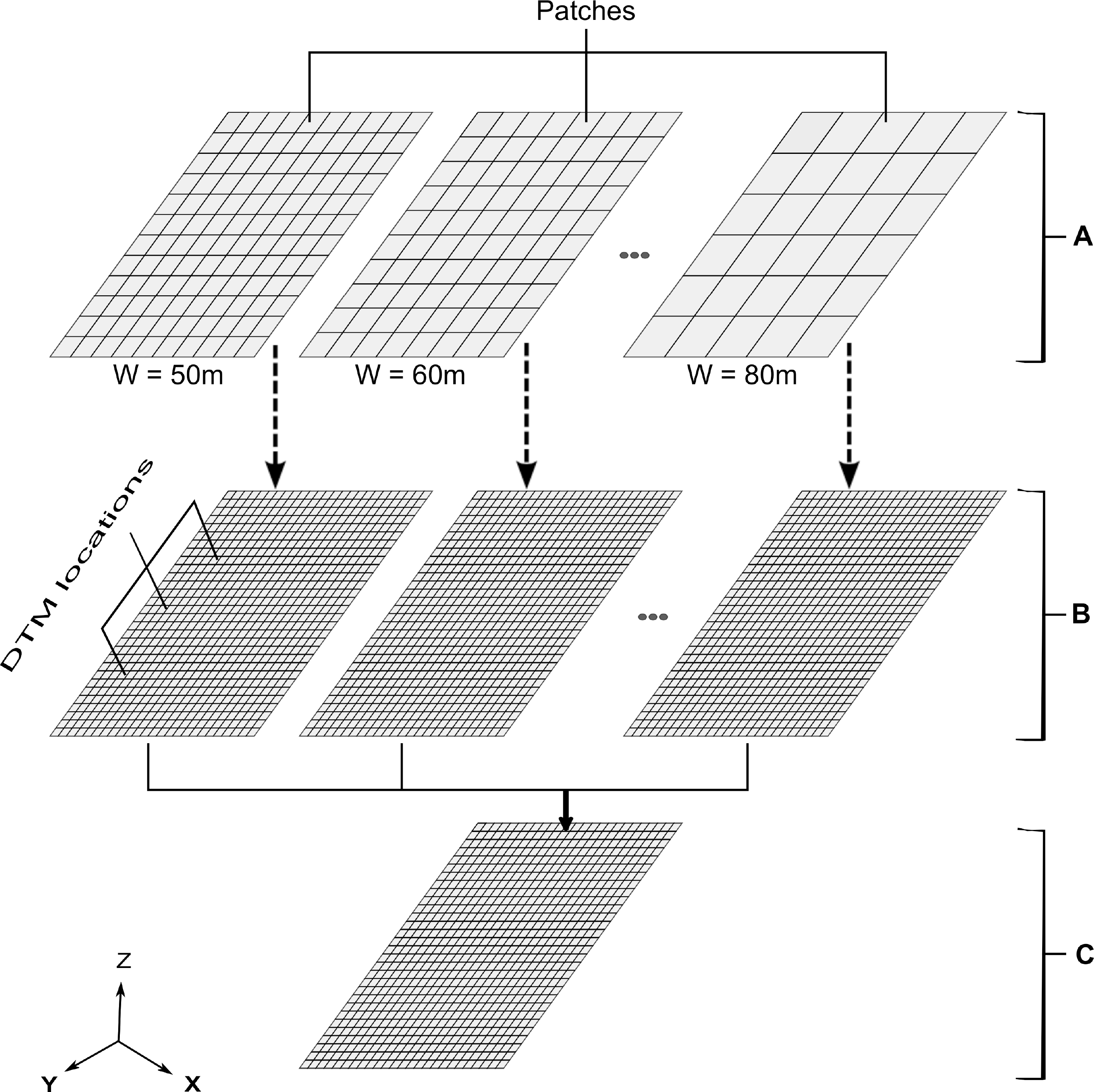
2.3.1. Repeated DTM Sampling
2.3.2. Generating Gridded DTM Samples
2.3.3. Generating Initial DTM
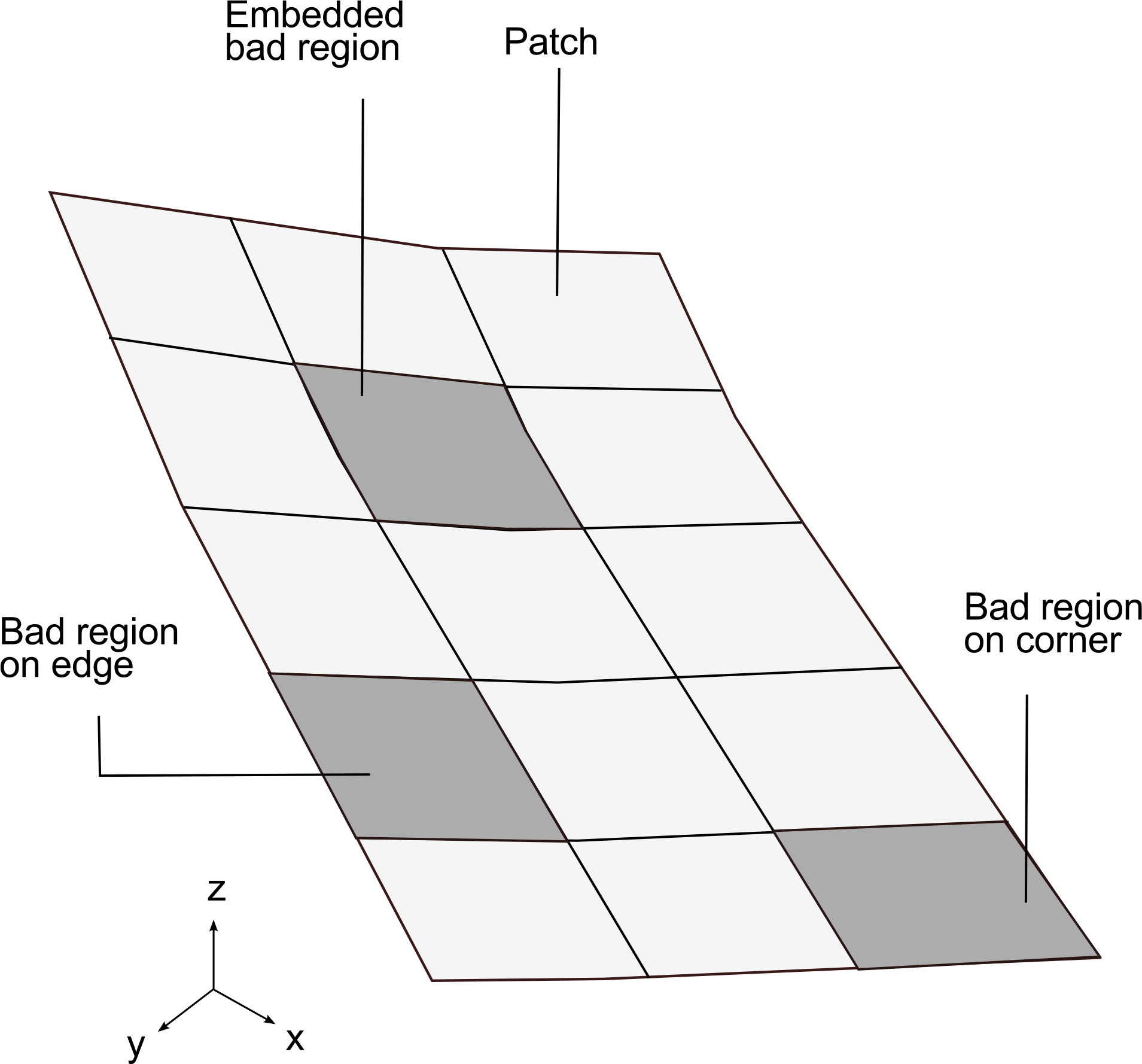
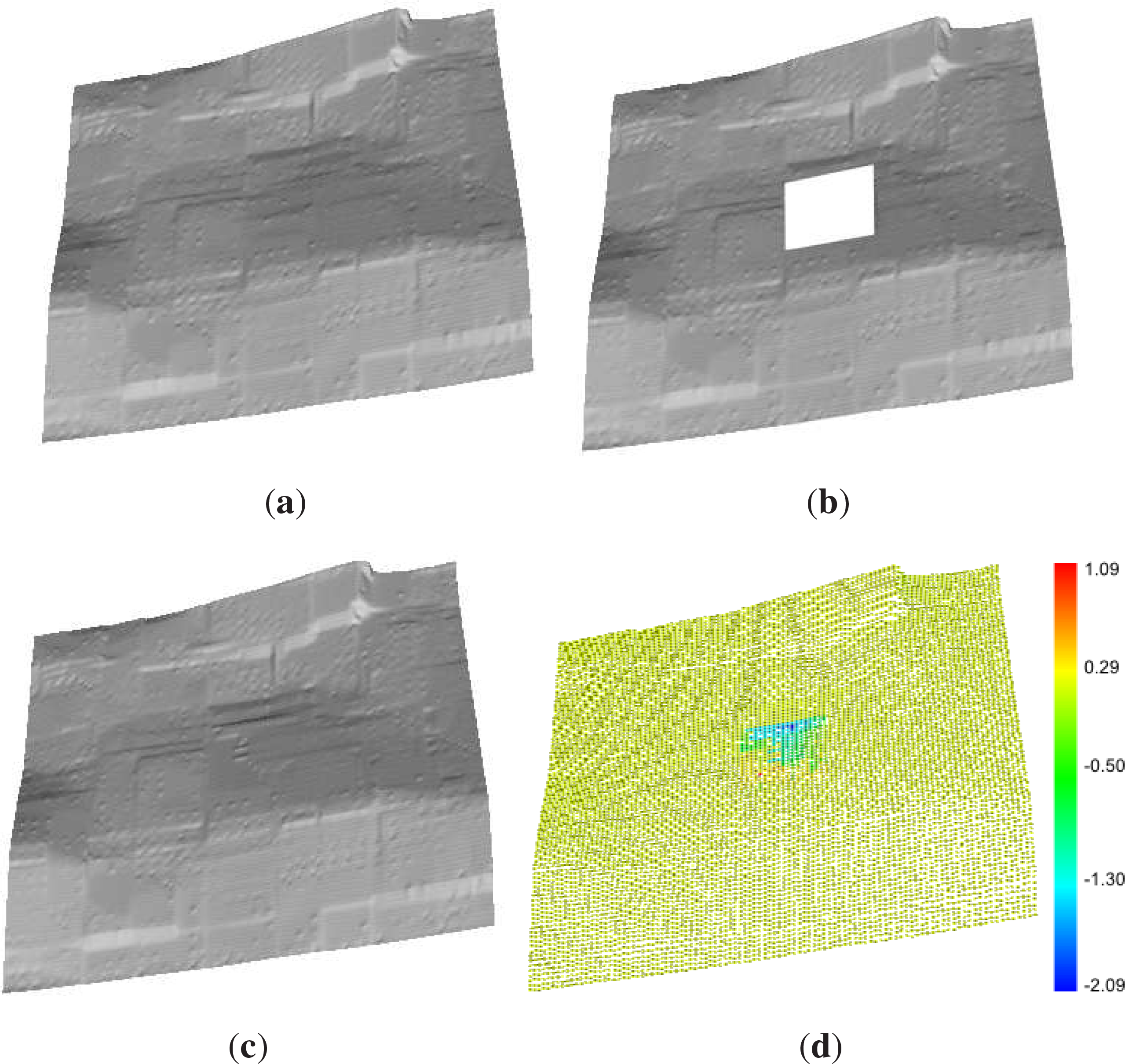
2.3.4. Filling Gaps
- (i)
- locate the next bad DTM location to be repaired;
- (ii)
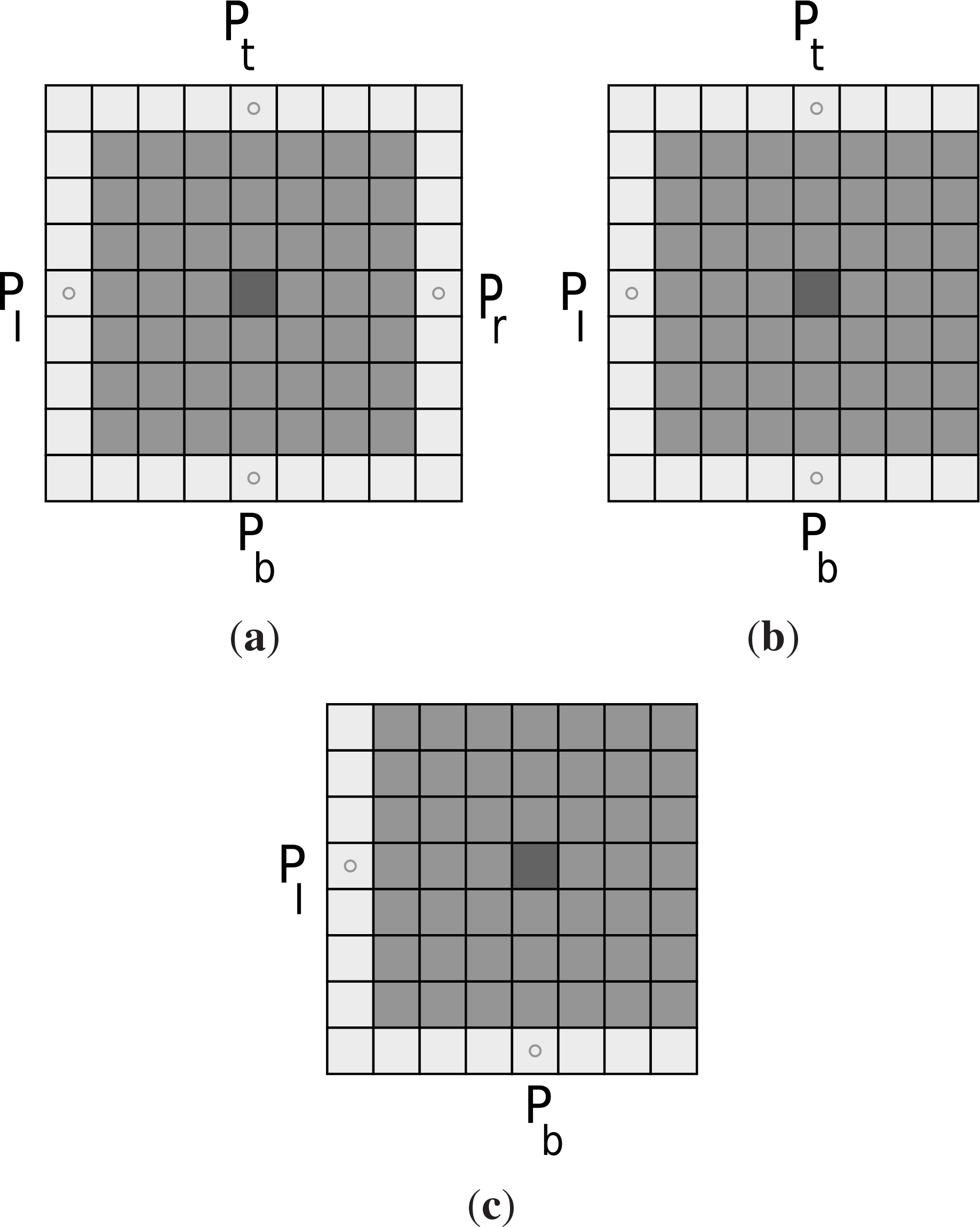
- locate the coordinates of the first valid DTM location above the current bad point in the current column (see Figure 4); if none exists, take the x and y coordinates of the topmost point and assign a large positive value (L) for the z coordinate (elevation) and form the top point Pt :(xt, yt, zt); Here, we use the terms above and below with respect to the positions of the points in the vertical direction and the terms left and right with respect to the position of the points in the horizontal direction.
- (iii)
- Locate the coordinates of the first valid DTM location below the current bad point in the current column (see Figure 4); if none exists, take the x and y coordinates of the bottom most point and assign a large positive value for the z coordinate and form the bottom point Pb :(xb, yb, zb);
- (iv)
- Locate the coordinates of the first valid DTM location on the left of the current bad point in the current row (see Figure 4); if none exists take the x and y coordinates of the leftmost point and assign a large positive value for the z coordinate and form the left point Pl :(xl, yl, zl);
- (v)
- locate the coordinates of the first valid DTM location on the right of the current bad point in the current row (see Figure 4); if none exists take the x and y coordinates of the rightmost point and assign a large positive value for the z coordinate and form the right point Pr :(xr, yr, zr);
- (vi)
- Determine if the bad DTM location is in a bad region lying on a corner by checking if any of the following conditions are true: zt = zr = L, or zt = zl = L, or zb = zl = L, or zb = zr = L; if any of these conditions hold, go to Step (i);
- (vii)
- Determine which direction (vertical or horizontal) has a larger slope (steeper) by comparing the magnitudes of the slopes of the lines segments and ;
- (viii)
- If the vertical direction is steeper, use the line segment to interpolate the elevation value at the current bad point, otherwise use the line segment .
Estimating Unknown Elevation Values
2.3.5. Generating the Final DTM
3. Results and Discussion
3.1. Minimizing Border Effects
3.2. Comparison with Field Measurements
3.3. Comparison with Existing Algorithms
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Wehr, A.; Lohr, U. Airborne laser scanning—An introduction and overview. ISPRS J. Photogramm. Remote Sens 1999, 54, 68–82. [Google Scholar]
- Næsset, E. Determination of mean tree height of forest stands using airborne laser sanner data. ISPRS J. Photogramm. Remote Sens 1997, 52, 49–56. [Google Scholar]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. Remote Sens 1998, 53, 193–203. [Google Scholar]
- Axelsson, P. Processing of laser scanner data—Algorithms and applications. ISPRS J. Photogramm. Remote Sens 1999, 54, 138–147. [Google Scholar]
- Pfeifer, N.; Reiter, T.; Briese, C.; Rieger, W. Interpolation of high quality ground models from laser scanner data in forested areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 1999, 32, 31–36. [Google Scholar]
- Reutebuch, S.E.; Andersen, H.E.; McGaughey, R.J. Light Detection and Ranging(LiDAR): An emerging tool for multiple resource inventory. J. For 2005, 103, 286–292. [Google Scholar]
- Clark, M.L.; Roberts, D.A.; Ewel, J.J.; Clark, D.B. Estimation of tropical rain forest aboveground biomass with small-footprint LiDAR and hyperspectral sensors. Remote Sens. Environ 2011, 115, 2931–2942. [Google Scholar]
- Lemmens, M. Airborne LiDAR. In Geo-information; Gatrell, J.D., Jensen, R.R., Eds.; Springer Netherlands: Dordrecht, The Netherlands, 2011; Volume 5, pp. 153–170. [Google Scholar]
- Full-Waveform Airborne Laser Scanning as a Tool for Archaeological Reconnaissance. Available online: http://w3.riegl.com/uploads/tx_pxpriegldownloads/Doneus_ROME_01.pdf (accessed on 15 July 2014).
- Ullrich, A.; Studnicka, N.; Hollaus, M.; Briese, C.; Wagner, W.; Doneus, M.; Mücke, W. Improvements in DTM generation by using full-waveform airborne laser scanning data. Proceedings of the 7th International Conference on Laser Scanning and Digital Aerial Photography, Today and Tomorrow, Moscow, Russia, 6–7 December 2007; 6.
- Jakubowski, M.K.; Guo, Q.; Kelly, M. Tradeoffs between LiDAR pulse density and forest measurement accuracy. Remote Sens. Environ 2013, 130, 245–253. [Google Scholar]
- Junttila, V.; Finley, A.O.; Bradford, J.B.; Kauranne, T. Strategies for minimizing sample size for use in airborne LiDAR-based forest inventory. For. Ecol. Manag 2013, 292, 75–85. [Google Scholar]
- Akay, A.; Oguz, H.; Karas, I.; Aruga, K. Using LiDAR technology in forestry activities. Environ. Monit. Assess 2009, 151, 117–125. [Google Scholar]
- Wang, C.; Glenn, N.F. A linear regression method for tree canopy height estimation using airborne LiDAR data. Can. J. Remote Sens 2008, 34, S217–S227. [Google Scholar]
- Takahashi, T.; Yamamoto, K.; Senda, Y.; Tsuzuku, M. Estimating individual tree heights of sugi (Cryptomeria japonica D. Don) plantations in mountainous areas using small-footprint airborne LiDAR. J. For. Res 2005, 10, 135–142. [Google Scholar]
- Van Leeuwen, M.; Nieuwenhuis, M. Retrieval of forest structural parameters using LiDAR remote sensing. Eur. J. For. Res 2010, 129, 749–770. [Google Scholar]
- Clark, M.L.; Clark, D.B.; Roberts, D.A. Small-footprint LiDAR estimation of sub-canopy elevation and tree height in a tropical rain forest landscape. Remote Sens. Environ 2004, 91, 68–89. [Google Scholar]
- Yamamoto, K.; Takahashi, T.; Miyachi, Y.; Kondo, N.; Morita, S.; Nakao, M.; Shibayama, T.; Takaichi, Y.; Tsuzuku, M.; Murate, N. Estimation of mean tree height using small-footprint airborne LiDAR without a digital terrain model. J. For. Res 2011, 16, 425–431. [Google Scholar]
- Nilsson, M. Estimation of tree heights and stand volume using an airborne LiDAR system. Remote Sens. Environ 1996, 56, 1–7. [Google Scholar]
- Guo, Z.; Fang, J.; Pan, Y.; Birdsey, R. Inventory-based estimates of forest biomass carbon stocks in China. For. Ecol. Manag 2010, 259, 1225–1231. [Google Scholar]
- Herold, M.; Román-Cuesta, R.; Mollicone, D.; Hirata, Y.; van Laake, P.; Asner, G.; Souza, C.; Skutsch, M.; Avitabile, V.; MacDicken, K. Options for monitoring and estimating historical carbon emissions from forest degradation in the context of REDD+. Carbon Balance Manag 2011, 6, 1–7. [Google Scholar]
- Avtar, R.; Sawada, H. Use of DEM data to monitor height changes due to deforestation. Arab. J. Geosci 2012, 6, 4859–4871. [Google Scholar]
- Liu, X. Airborne LiDAR for DEM generation: Some critical issues. Progress Phys. Geogr 2008, 32, 31–49. [Google Scholar]
- Kraus, K.; Pfeifer, N. Advanced DTM generation from LiDAR data. Int. Arch. Photogramm. Remote Sens 2001, XXXIV-3/W4, 23–30. [Google Scholar]
- Vosselman, G. Slope based filtering of laser altimetry data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2000, XXXIII, 935–942. [Google Scholar]
- Sithole, G. Filtering of laser altimetry data using a slope adaptive filter. Int. Arch. Photogramm. Remote Sens 2001, XXXIV-3/W4, 203–210. [Google Scholar]
- Chen, Q.; Gong, P.; Baldocchi, D.; Xie, G. Filtering airborne laser scanning data with morphological methods. Photogramm. Eng. Remote Sens 2007, 73, 175–185. [Google Scholar]
- Kobler, A.; Pfeifer, N.; Ogrinc, P.; Todorovski, L.; Os̆tir, K.; Dz̆eroski, S. Repetitive interpolation: A robust algorithm for DTM generation from Aerial Laser Scanner Data in forested terrain. Remote Sens. Environ 2006, 108, 9–23. [Google Scholar]
- Bao, Y.; LiïijŇ, G.; Cao, C.; Li, X.; Zhang, H.; He, Q.; Bai, L.; Chang, C. Classification of LiDAR point cloud and generation of DTM from LiDAR height and intensity data in forested area. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2008, XXXVII, 313–318. [Google Scholar]
- Mongus, D.; Z̆alik, B. Parameter-free ground filtering of LiDAR data for automatic DTM generation. ISPRS J. Photogramm. Remote Sens 2012, 67, 1–12. [Google Scholar]
- Sithole, G.; Vosselman, G. Experimental comparison of filter algorithms for bare-earth extraction from airborne laser scanning point clouds. ISPRS J. Photogramm. Remote Sens 2004, 59, 85–101. [Google Scholar]
- Hyyppä, H.; Yu, X.; Hyyppä, J.; Kaasalainen, H.; Honkavaara, E.; Rönnholm, P. Factors affecting the quality of DTM generation in forested areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2005, 36, 85–90. [Google Scholar]
- Holmgren, J.; Nilsson, M.; Olsson, H. Simulating the effects of LiDAR scanning angle for estimation of mean tree height and canopy closure. Can. J. Remote Sens 2003, 29, 623–632. [Google Scholar]
- Hopkinson, C. The influence of flying altitude, beam divergence, and pulse repetition frequency on laser pulse return intensity and canopy frequency distribution. Can. J. Remote Sens 2007, 33, 312–324. [Google Scholar]
- Hopkinson, D.; Chasmer, L.E.; Zsigovics, G.; Creed, I.F.; Sitar, M.; Treitz, P.; Maher, R.V. Errors in LiDAR ground elevation and wetland vegetation height estimates. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2004, 36, 108–113. [Google Scholar]
- Takahashi, T.; Yamamoto, K.; Miyachi, Y.; Senda, Y.; Tsuzuku, M. The penetration rate of laser pulses transmitted from a small-footprint airborne LiDAR: A case study in closed canopy, middle-aged pure sugi (Cryptomeria japonica D. Don) and hinoki cypress (Chamaecyparis obtusa Sieb. et Zucc.) stands in Japan. J. For. Res 2006, 11, 117–123. [Google Scholar]
- Fisher, P.F.; Tate, N.J. Causes and consequences of error in digital elevation models. Prog. Phys. Geogr 2006, 30, 467–489. [Google Scholar]
- Meng, X.; Currit, N.; Zhao, K. Ground filtering algorithms for airborne LiDAR data: A review of critical issues. Remote Sens. 2010, 2, 833–860. [Google Scholar]
- Maguya, A.; Junttila, V.; Kauranne, T. Adaptive algorithm for large scale dtm interpolation from LiDAR data for forestry applications in steep forested terrain. ISPRS J. Photogramm. Remote Sens 2013, 85, 74–83. [Google Scholar]
- Sah, B.P.; Hämäläinen, J.M.; Sah, A.K.; Honji, K.; Foli, E.G.; Awudi, C. The use of satellite imagery to guide field plot sampling scheme for biomass estimation in Ghanaian forest. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci 2012, I-4, 221–226. [Google Scholar]
- Gautam, B.; Peuhkurinen, J.; Kauranne, T.; Gunia, K.; Tegel, K.; Latva-Käyrä, P.; Rana, P.; Eivazi, A.; Kolesnikov, A.; Hämäläinen, J.; et al. Estimation of forest carbon using LiDAR-Assisted Multi-Resource Programme (LAMP) in Nepal. Presented at International Conference on Advanced Geospatial Technologies for Sustainable Environment and Culture, Pokhara, Nepal, 12–13 September 2013.
- McGaughey, R.J.; Carson, W.W. Fusing LiDAR data, photographs, and other data using 2D and 3D visualization techniques. Proceedings of Terrain Data: Applications and Visualization—Making the Connection, Charleston, SC, USA, 28–30 October 2003; pp. 16–24.
- Terrascan. Terrasolid’s Software for LiDAR Data Processing and 3D Vector Data Creation, 2012. Available online: http://www.terrasolid.com/products/terrascanpage.html (accesed on 28 January 2014).
Appendix
A. Parameters Used to Generate Test DTMs in Terrascan

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
B. Parameters Used to Generate Test DTMs in FUSION
| Ground filtering: | groundfilter/gparam:−1/wparam:2/tolerance:0.1/iterations:10 <output laser data (LDA) file> 2 <input LAS file> |
| DTM generation: | gridsurfacecreate/median:8/spike:20 <output DTM file> 2 MM 112 22 <input LDA file> |















| Parameter | Value | ||
|---|---|---|---|
| Site 1 | Site 2 | Site 3 | |
| Projection | UTM | UTM | UTM |
| Datum | WGS84 | WGS84 | WGS84 |
| Aerial platform | Helicopter | Helicopter | Fixed wing aircraft |
| Flying altitude | 2200 m AGL | 850 m AGL | 1300 m AGL |
| Flying speed | 80 knots | 124 knots | 120 knots |
| Sensor type | Leica ALS-50 II | Leica ALS-50 II | Leica ALS-50 II |
| Scan angle | 20 degrees | Unknown | 13.5 degrees |
| Sensor pulse rate | 52.9 Khz | 115.8 Khz | 81 Khz |
| Sensor scan speed | 20.4 lines/s | Unknown | 47.6 lines/s |
| Average pulse density | 0.8 points/m2 | 14 points/m2 | 2 points/m2 |
| Swath width at ground level | 1601.47 m | 350 m | 644 m |
| Beam footprint at ground level | 50 cm | Unknown | 31 cm |
| Date collected | March 2011–April 2011 | September 2011 | December 2011–January 2012 |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Maguya, A.S.; Junttila, V.; Kauranne, T. Algorithm for Extracting Digital Terrain Models under Forest Canopy from Airborne LiDAR Data. Remote Sens. 2014, 6, 6524-6548. https://doi.org/10.3390/rs6076524
Maguya AS, Junttila V, Kauranne T. Algorithm for Extracting Digital Terrain Models under Forest Canopy from Airborne LiDAR Data. Remote Sensing. 2014; 6(7):6524-6548. https://doi.org/10.3390/rs6076524
Chicago/Turabian StyleMaguya, Almasi S., Virpi Junttila, and Tuomo Kauranne. 2014. "Algorithm for Extracting Digital Terrain Models under Forest Canopy from Airborne LiDAR Data" Remote Sensing 6, no. 7: 6524-6548. https://doi.org/10.3390/rs6076524