
Direct Digital Surface Model Generation by Semi-Global Vertical Line Locus Matching

Abstract
:1. Introduction
1.1. Background and Related Works
1.2. The Proposed Approach
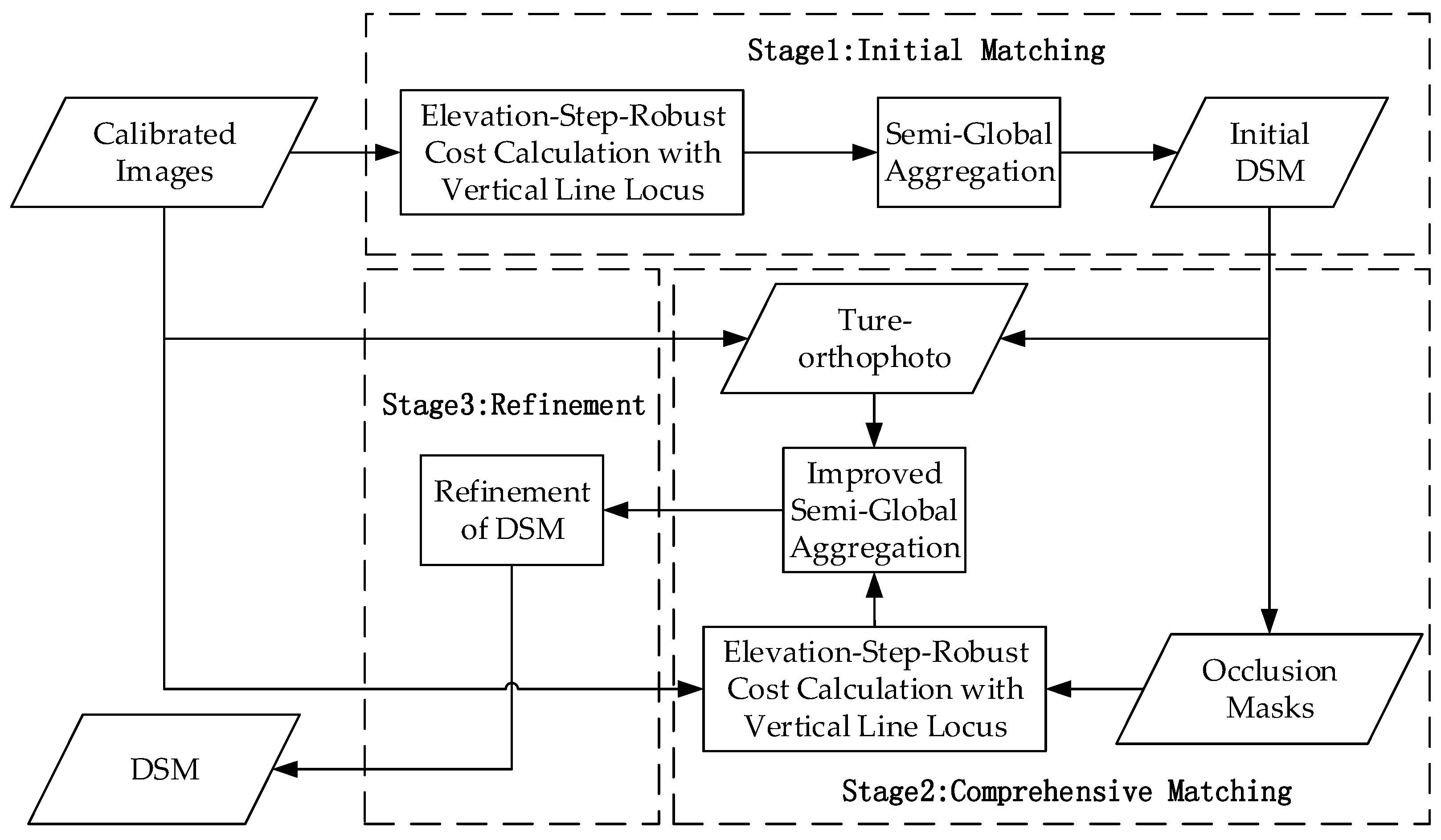
2. Method
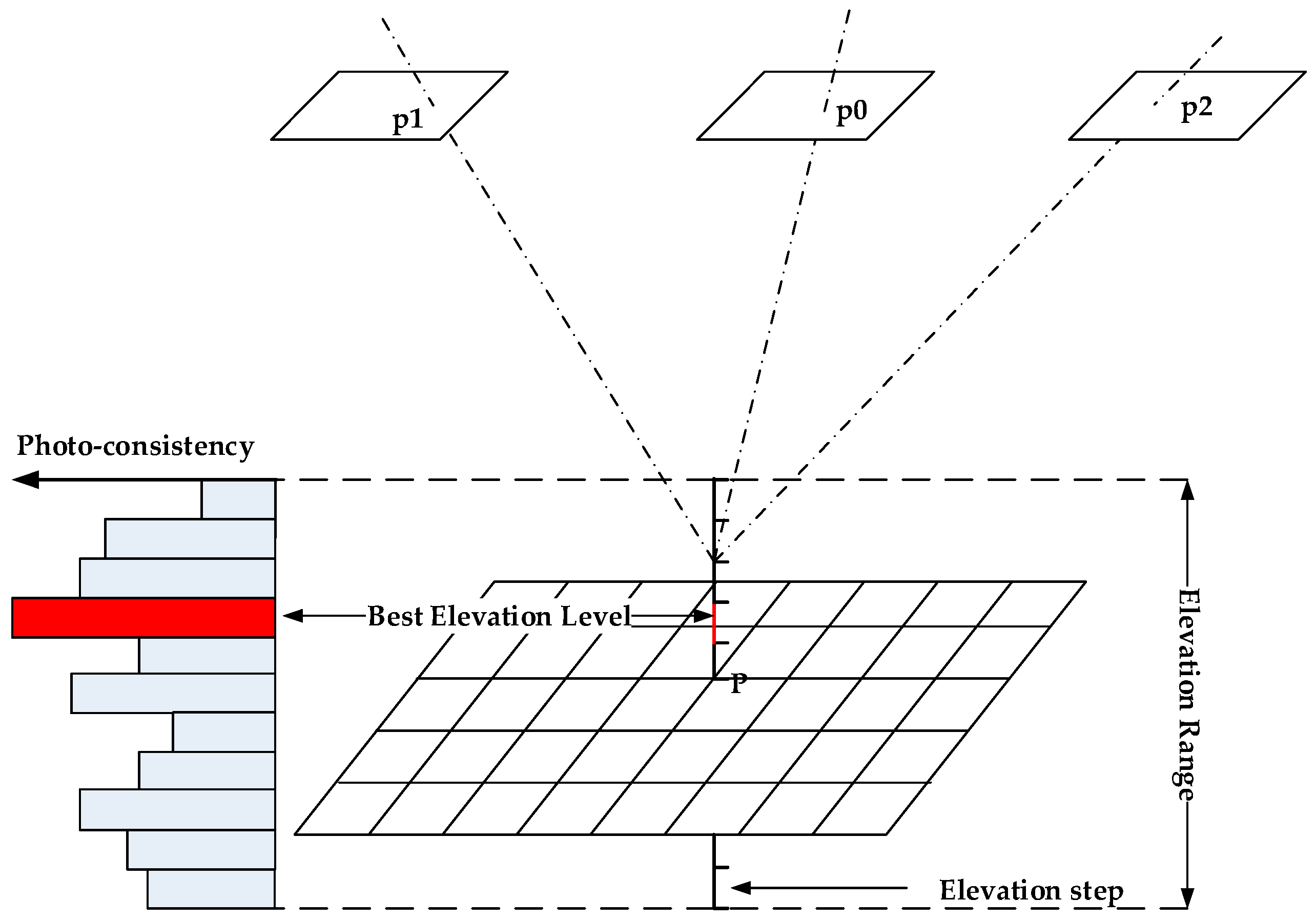
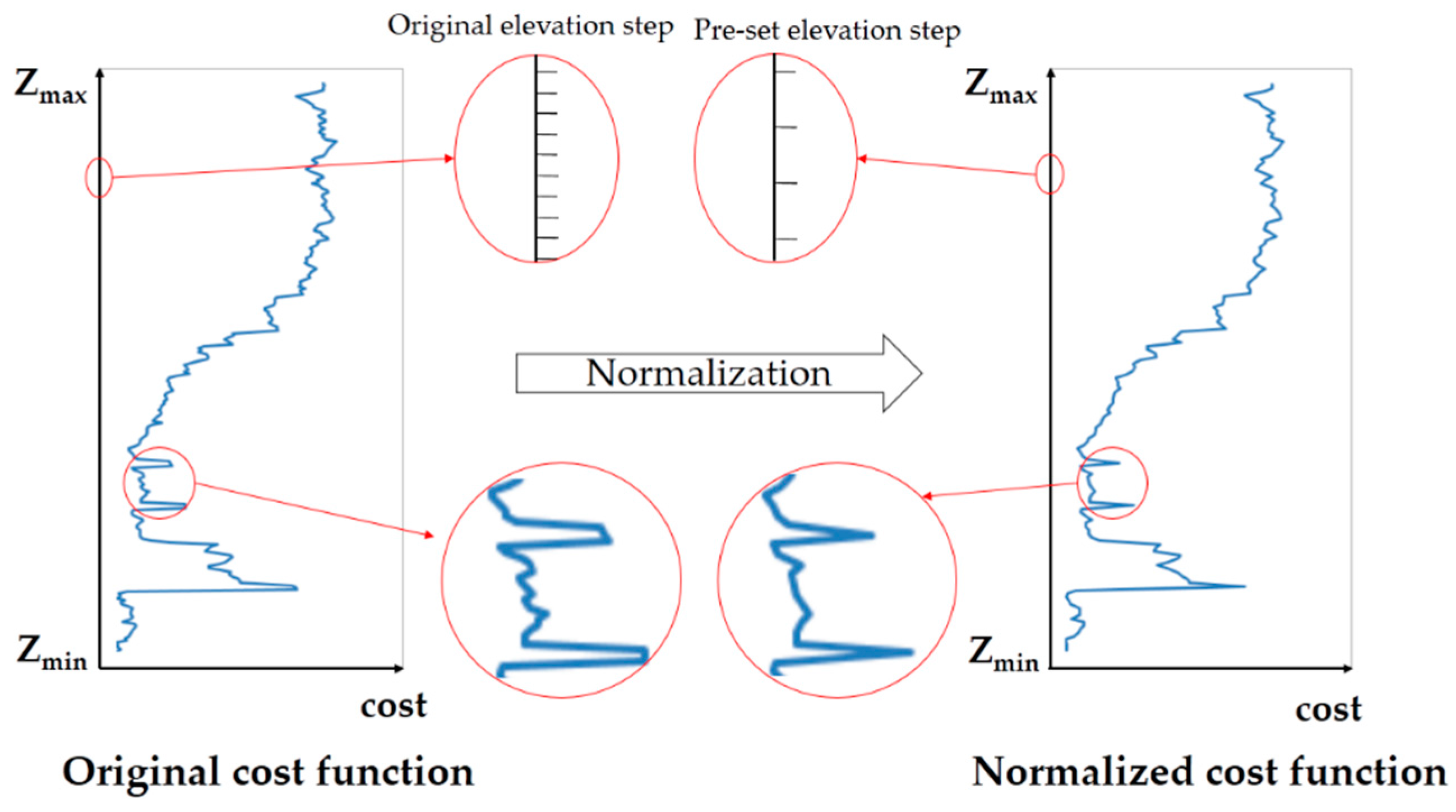
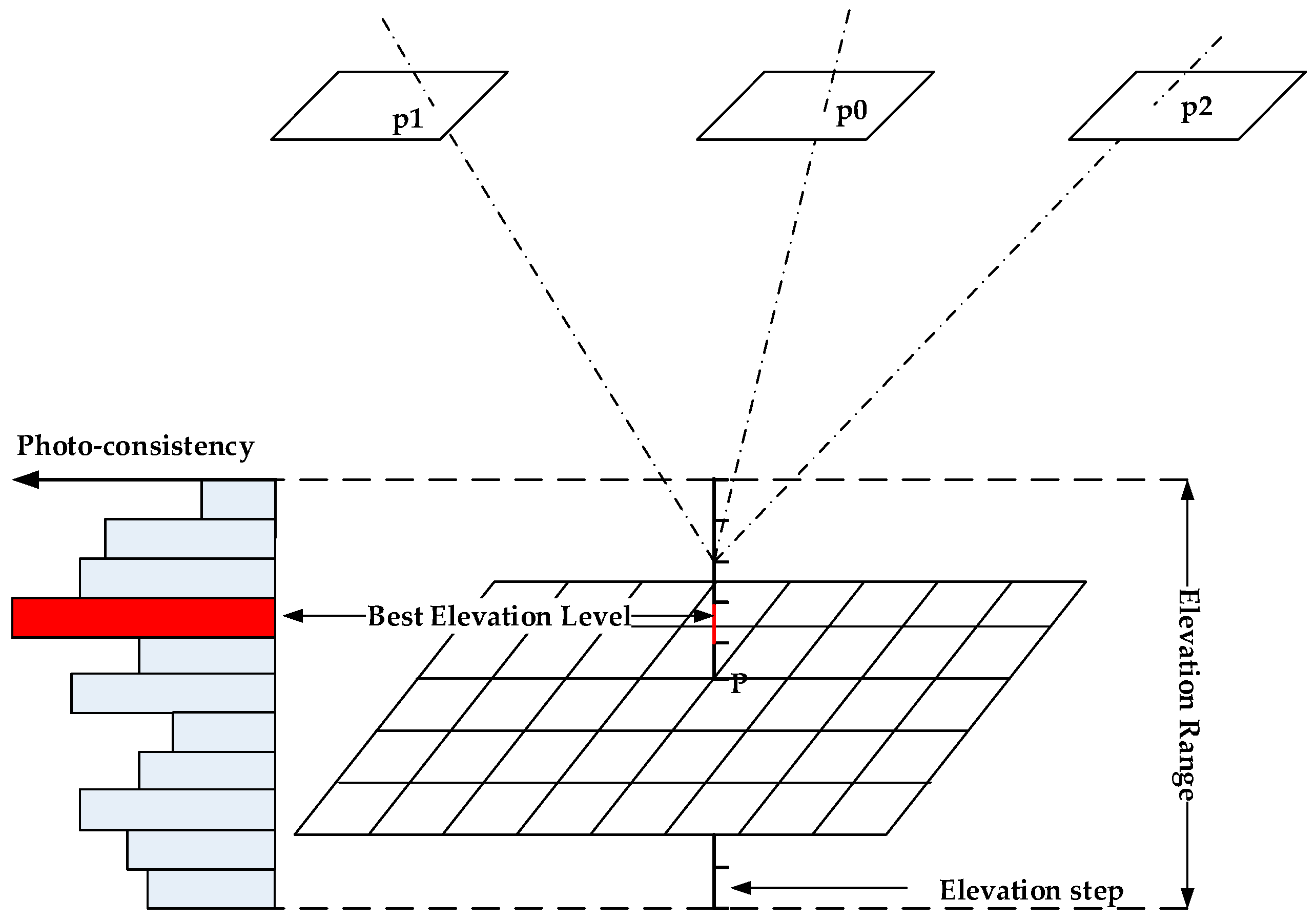
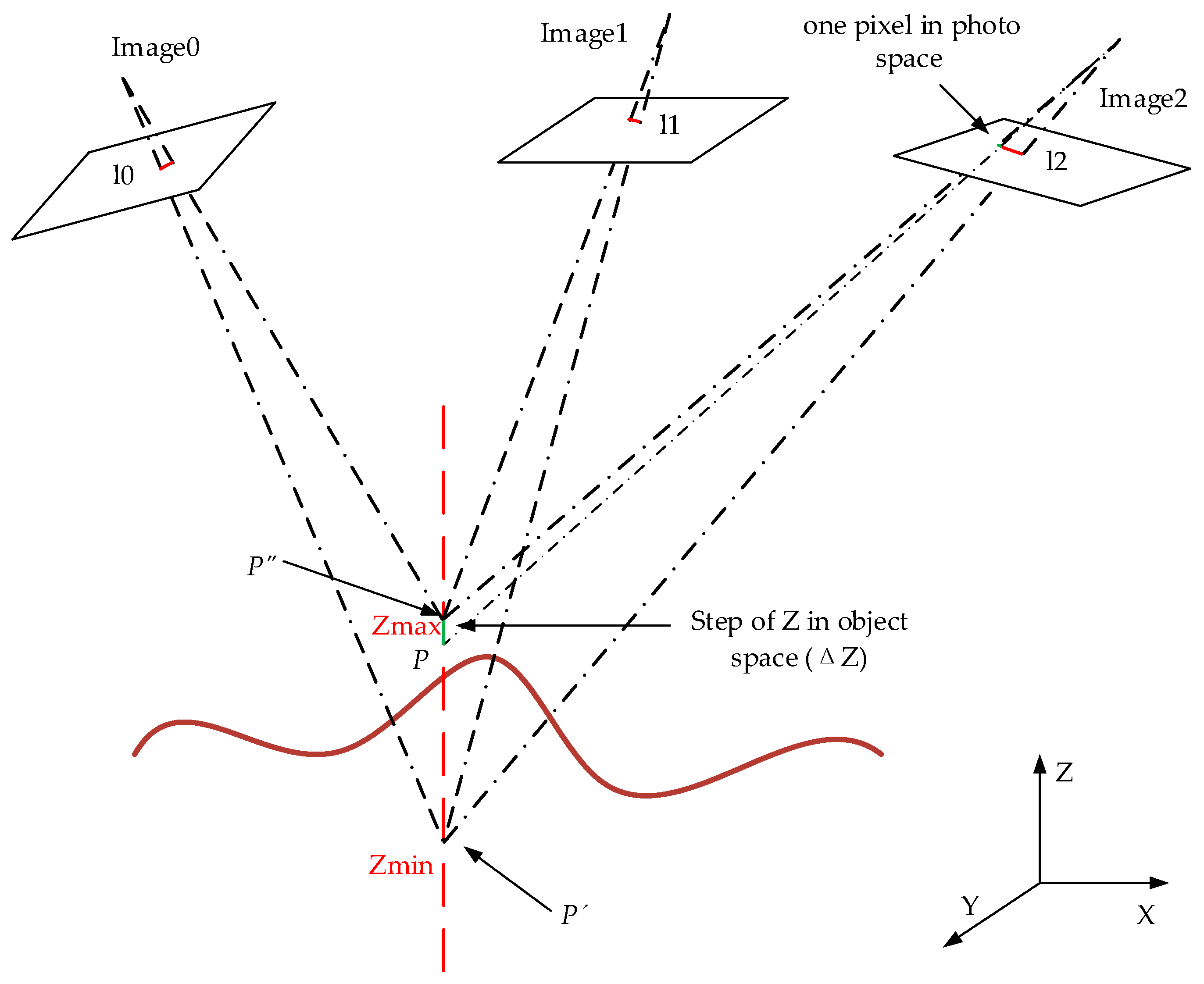
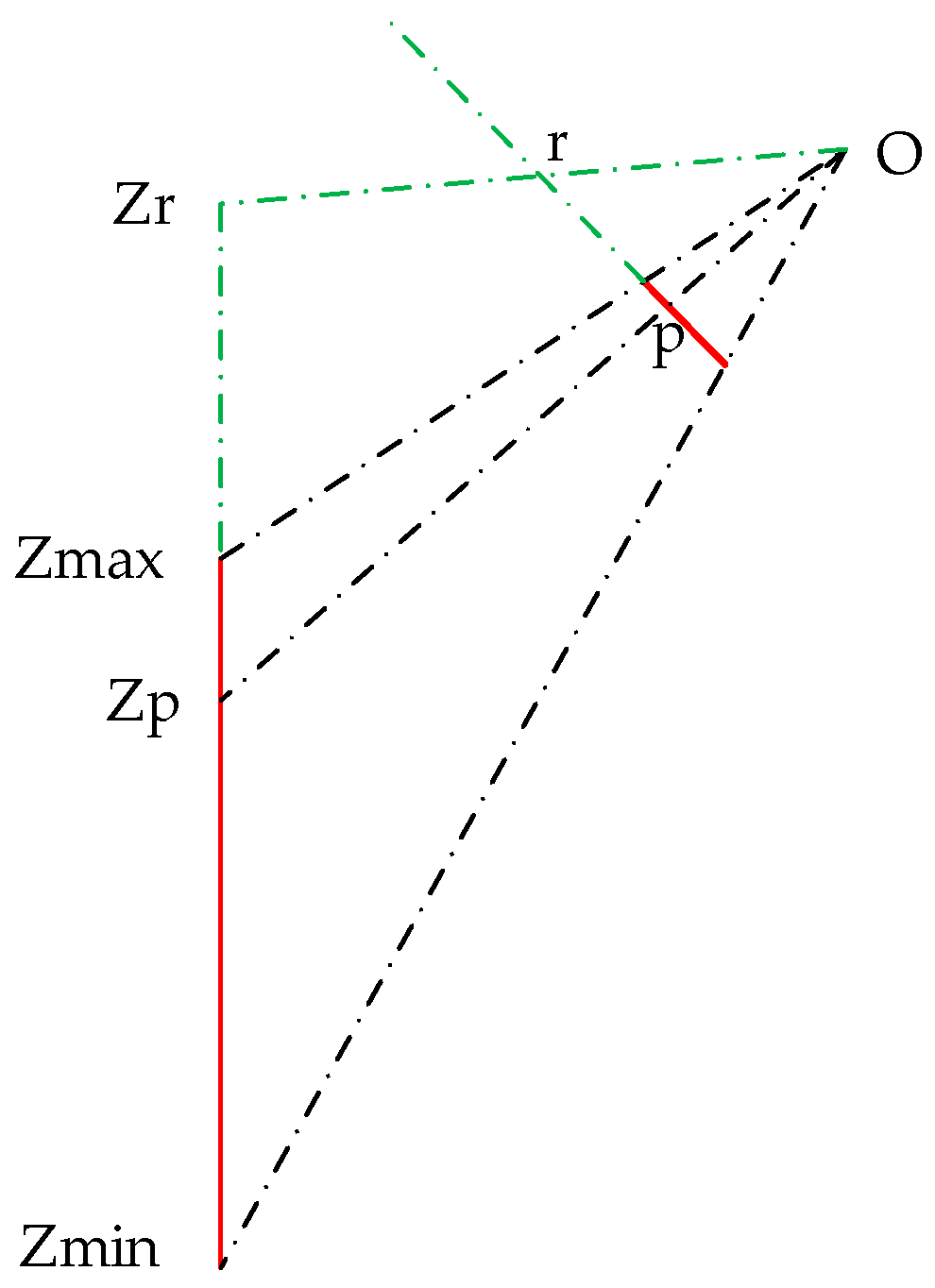
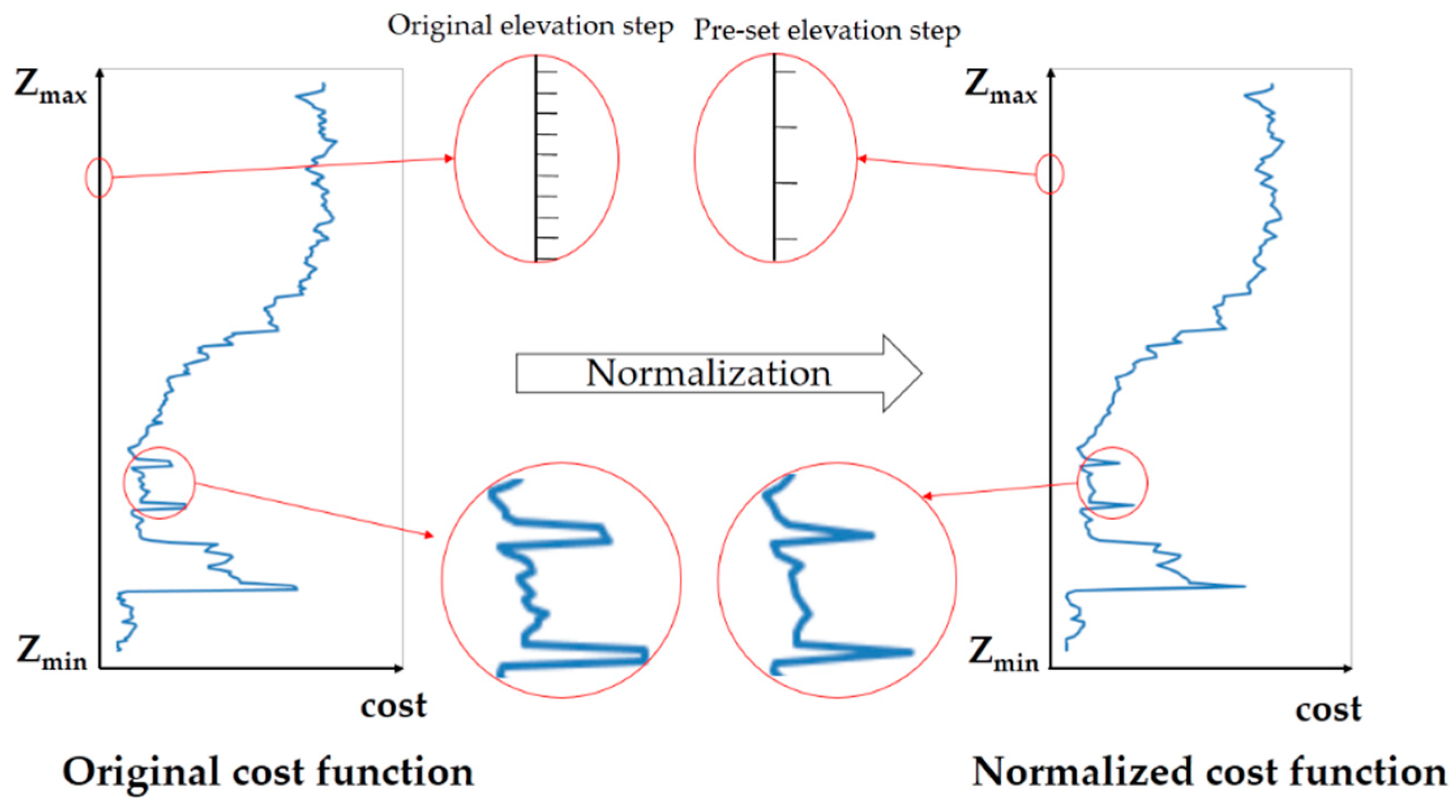
2.1. Elevation-Step-Robust Cost Calculation with Vertical Line Locus
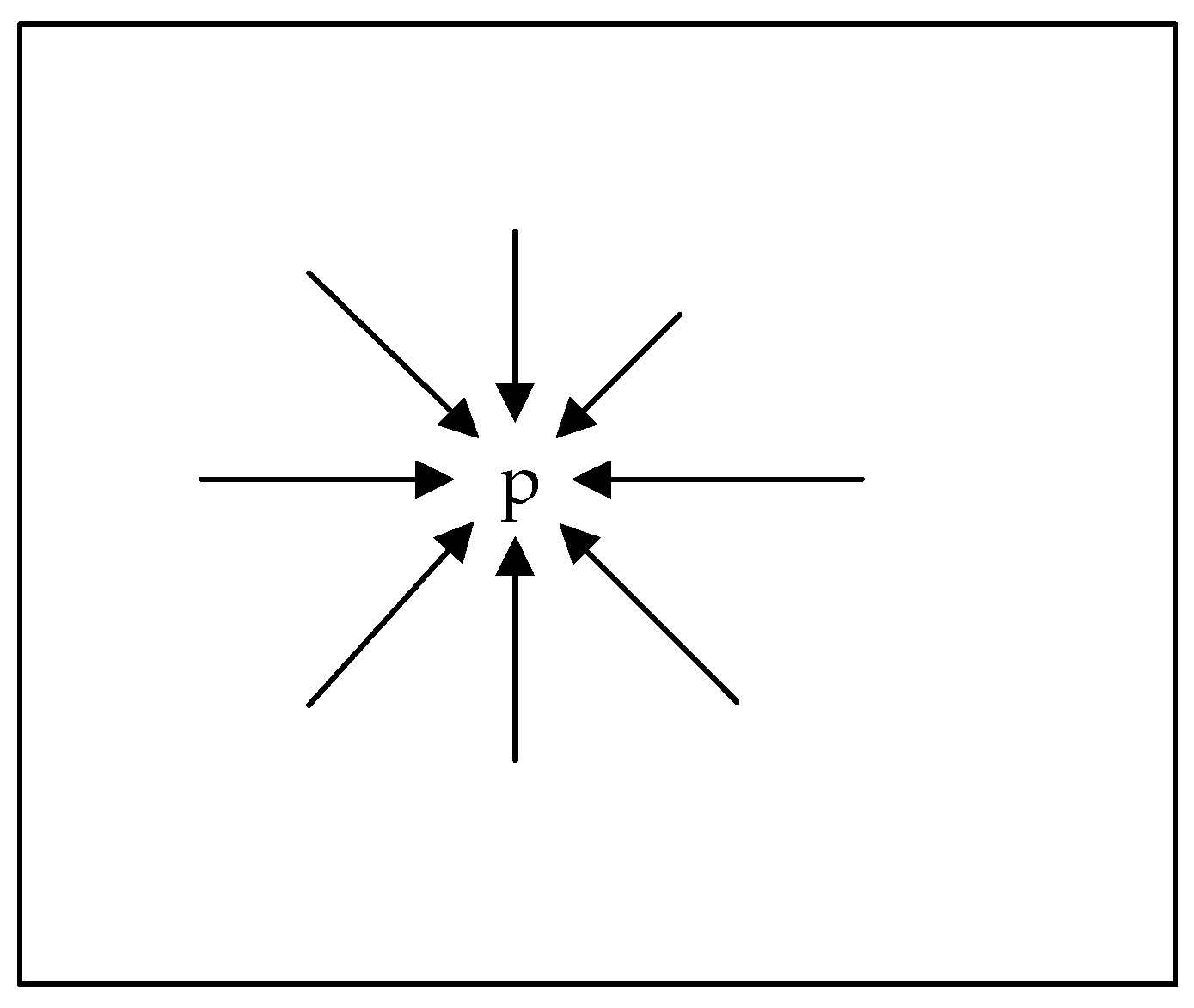
2.2. Initial DSM Generation with Semi-Global Aggregation
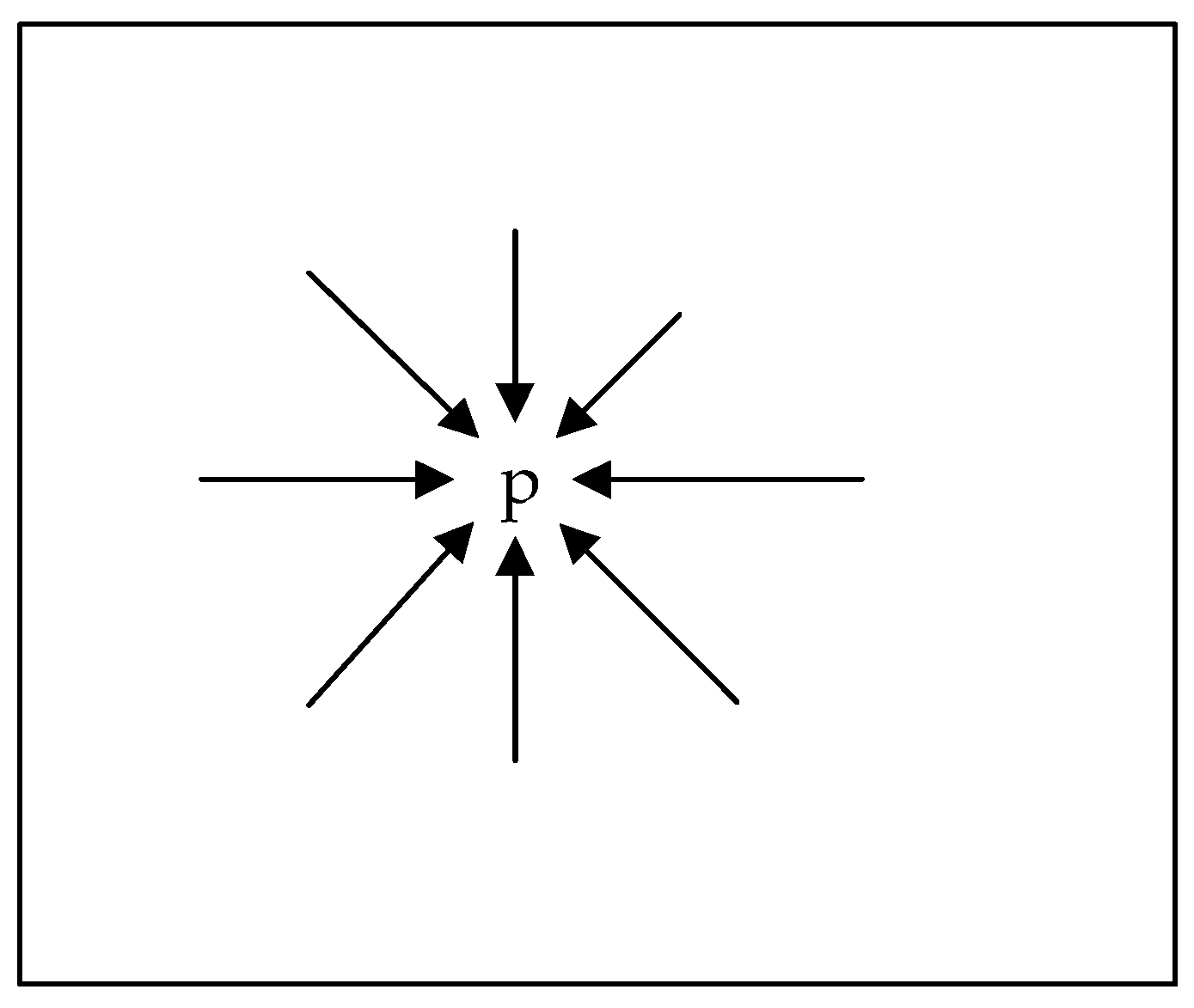
2.3. Cost Function Calculation with Handling Occlusion
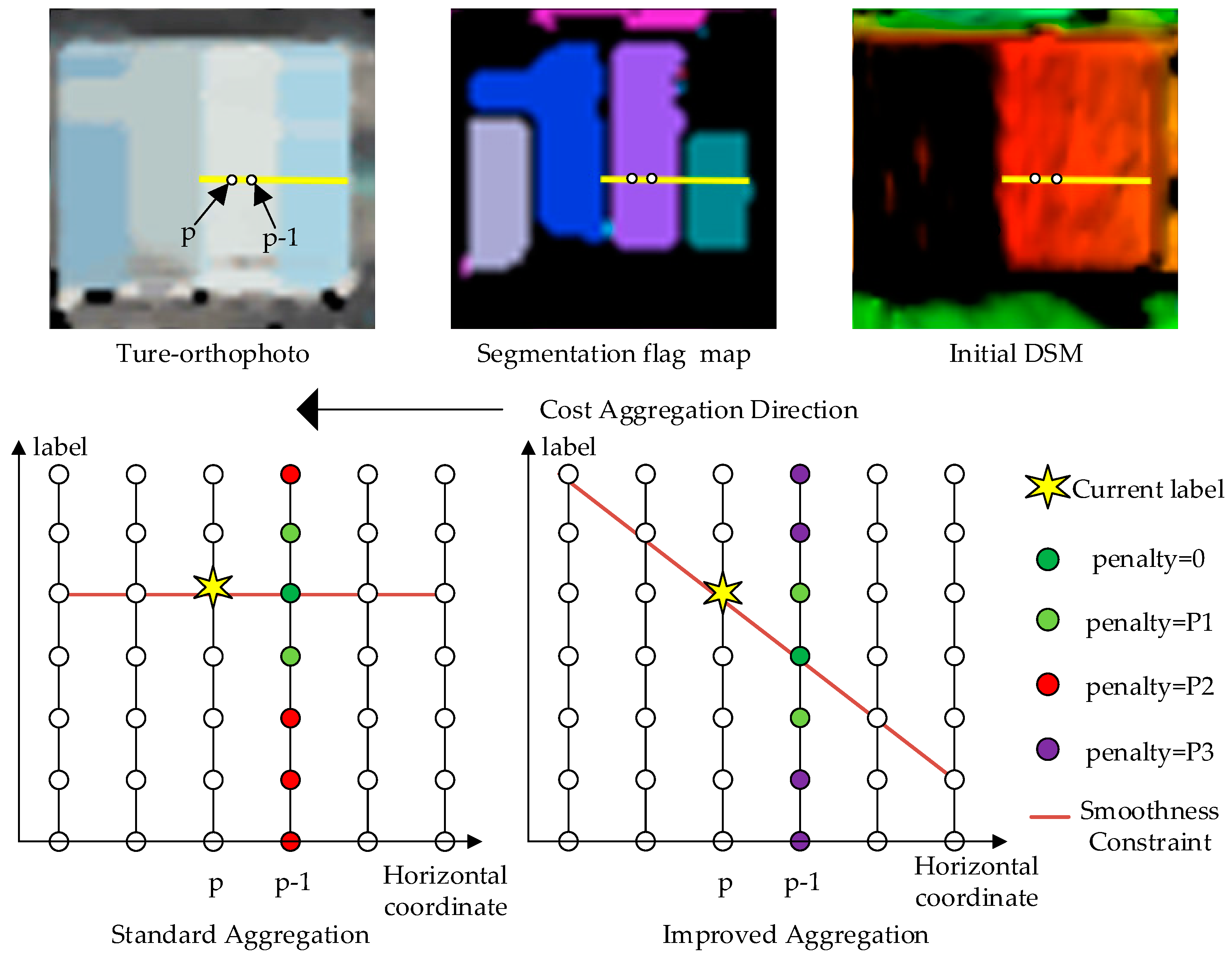
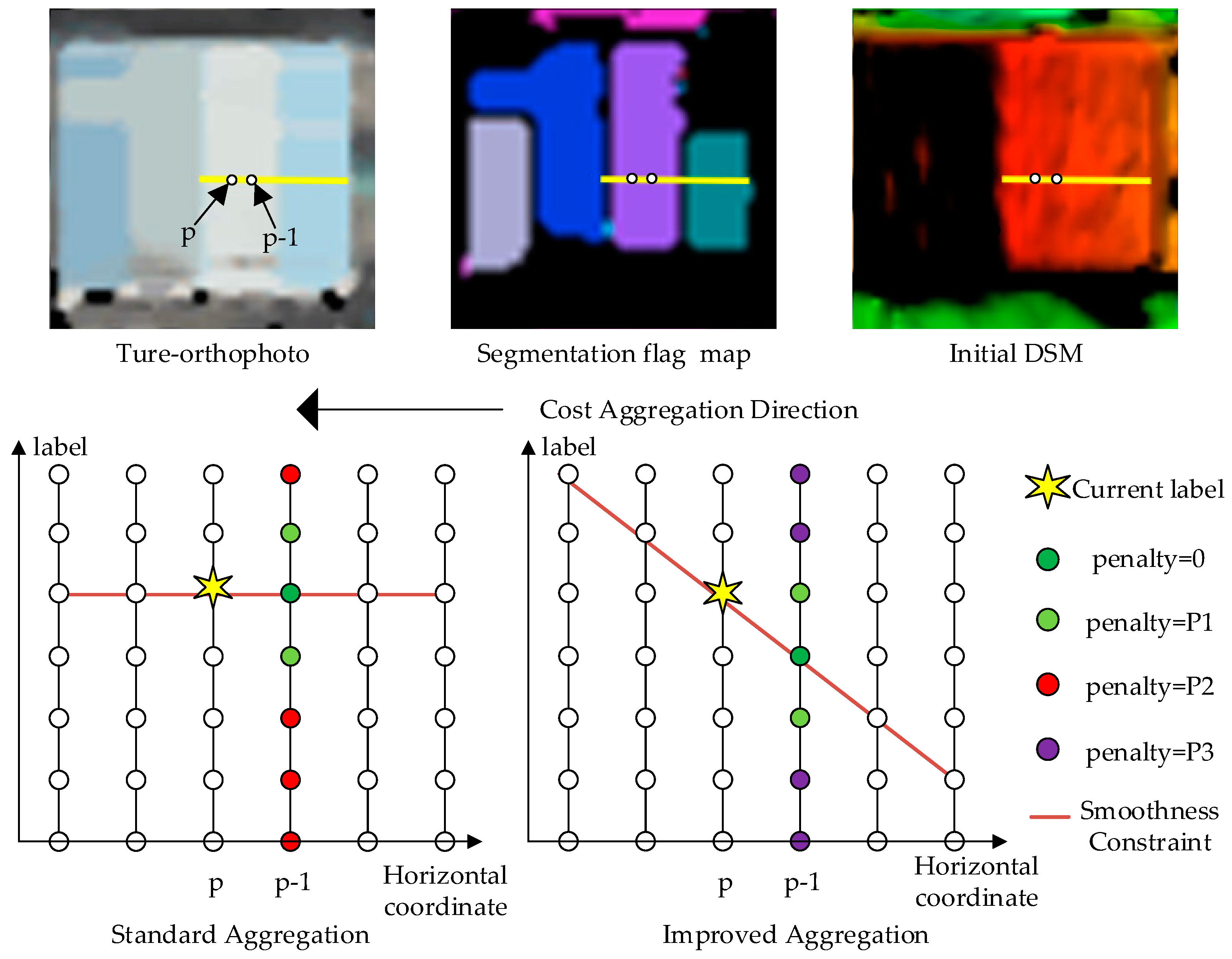
2.4. Improved Semi-Global Aggregation with Guidance of True-orthophoto
2.5. Refinement of the DSM
3. Results
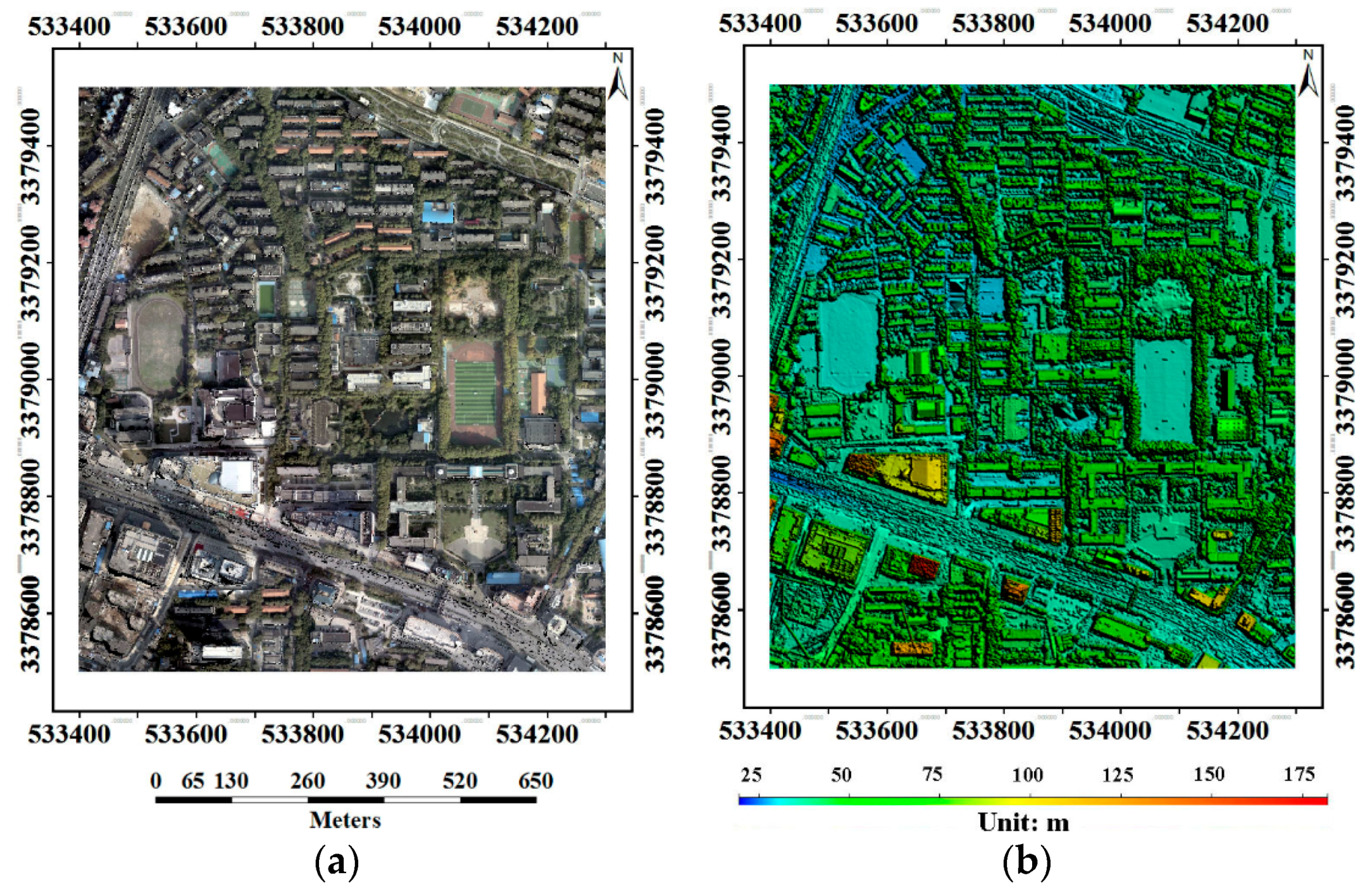
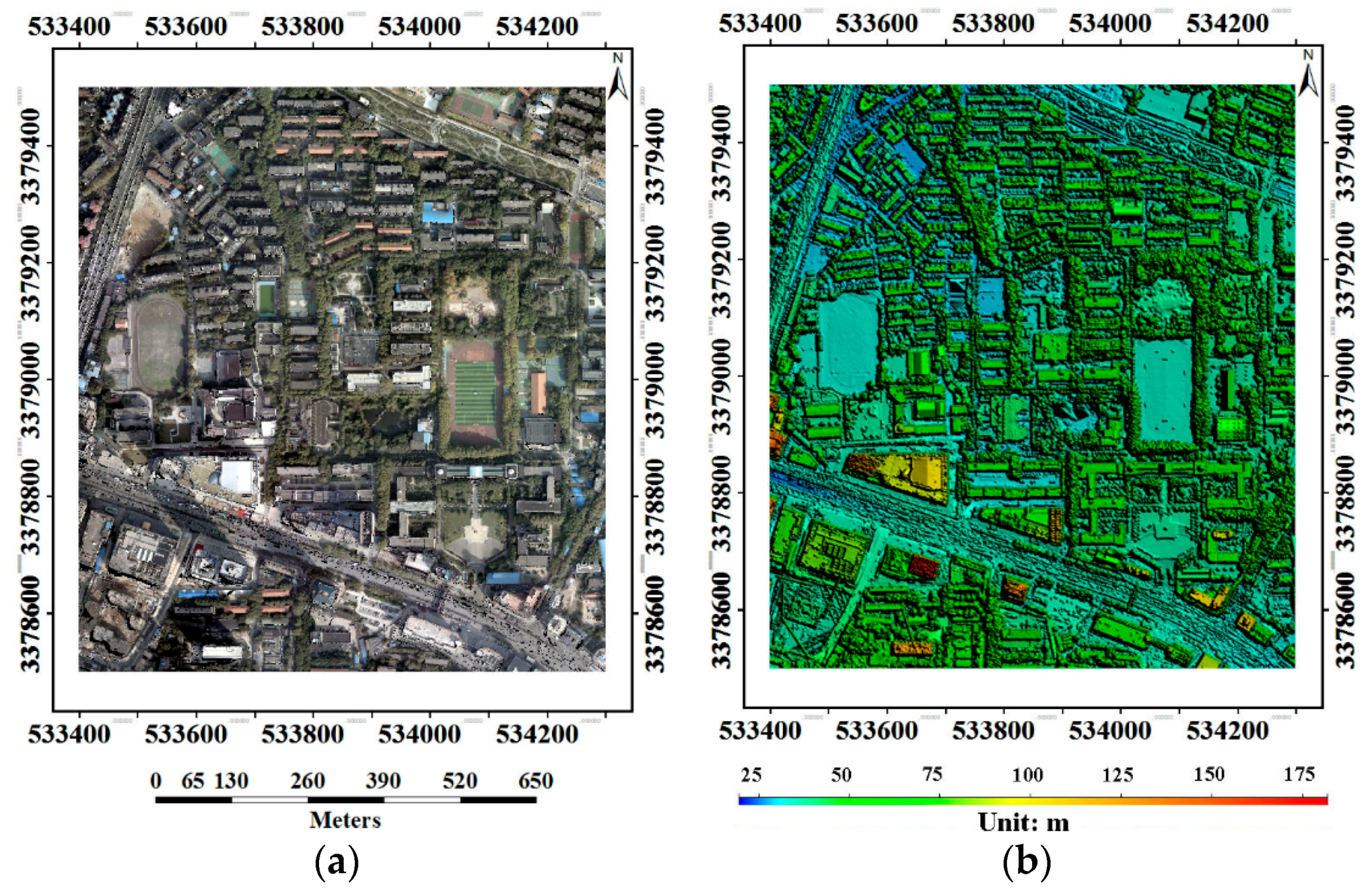
3.1. Data and Methods
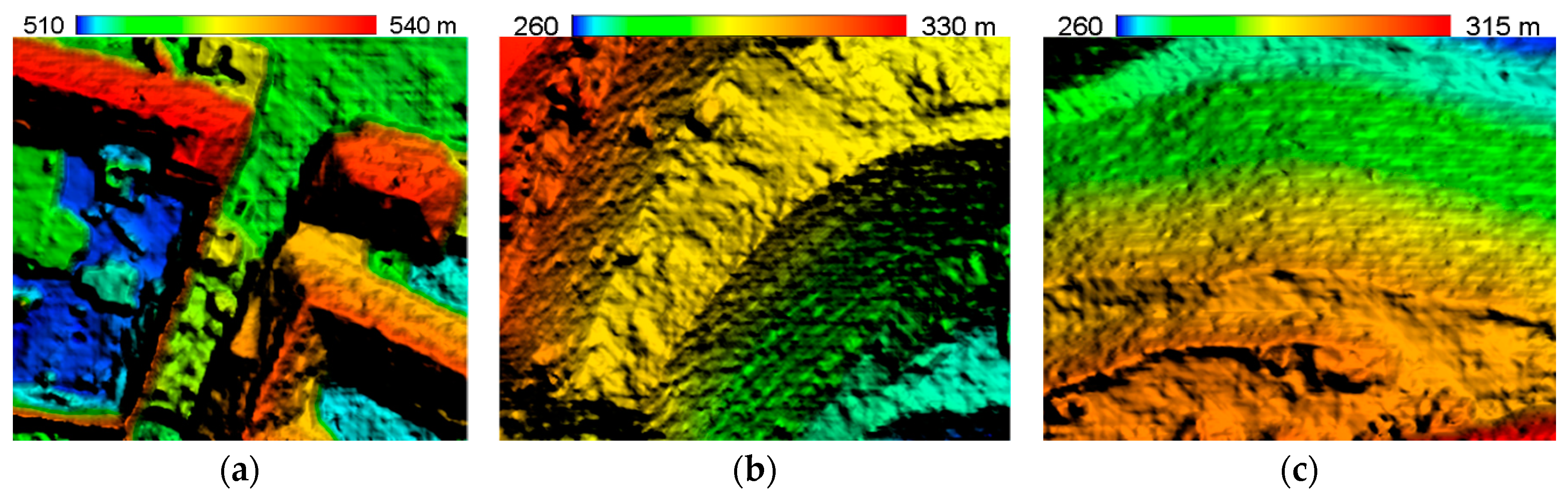
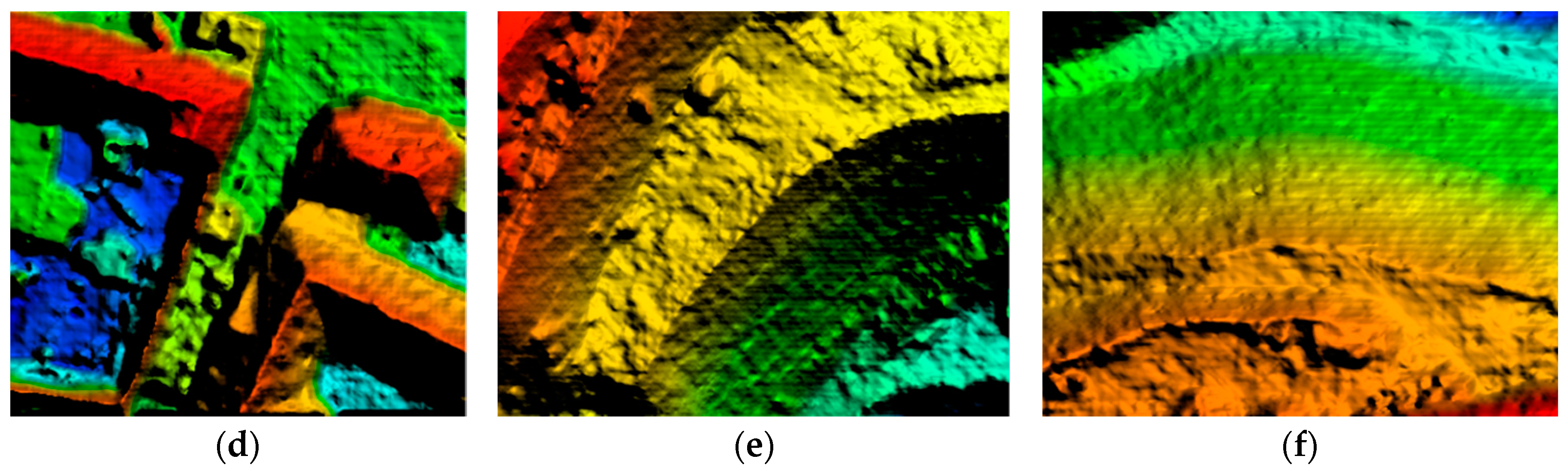
3.2. Experiment on Elevation-Step-Robust Cost Calculation
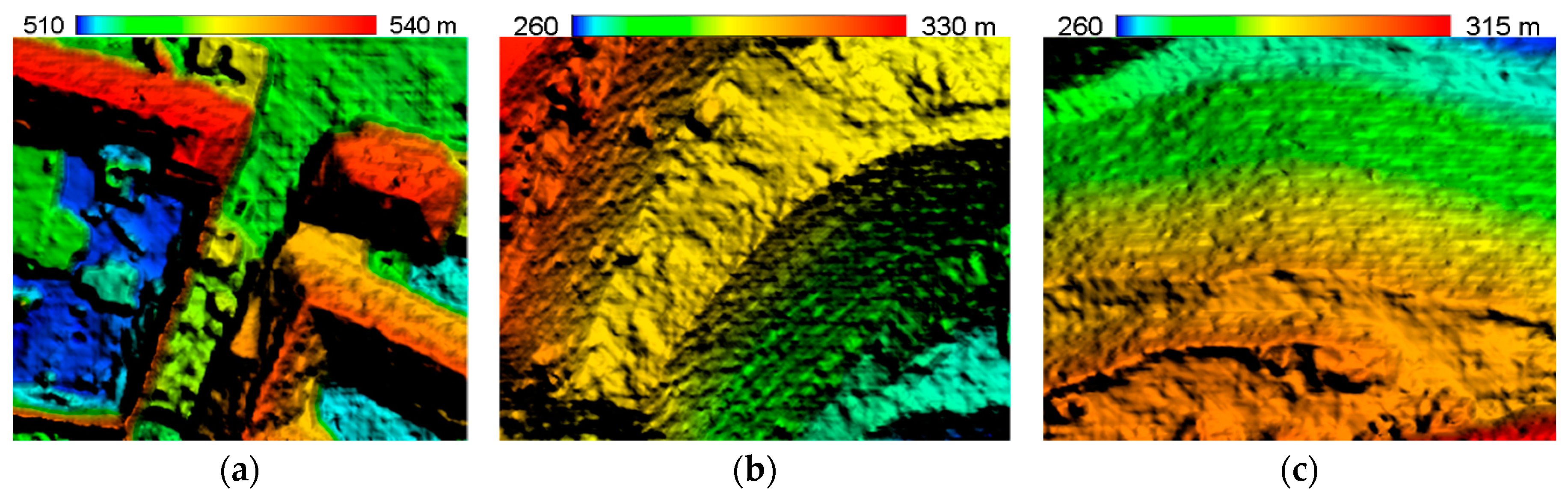
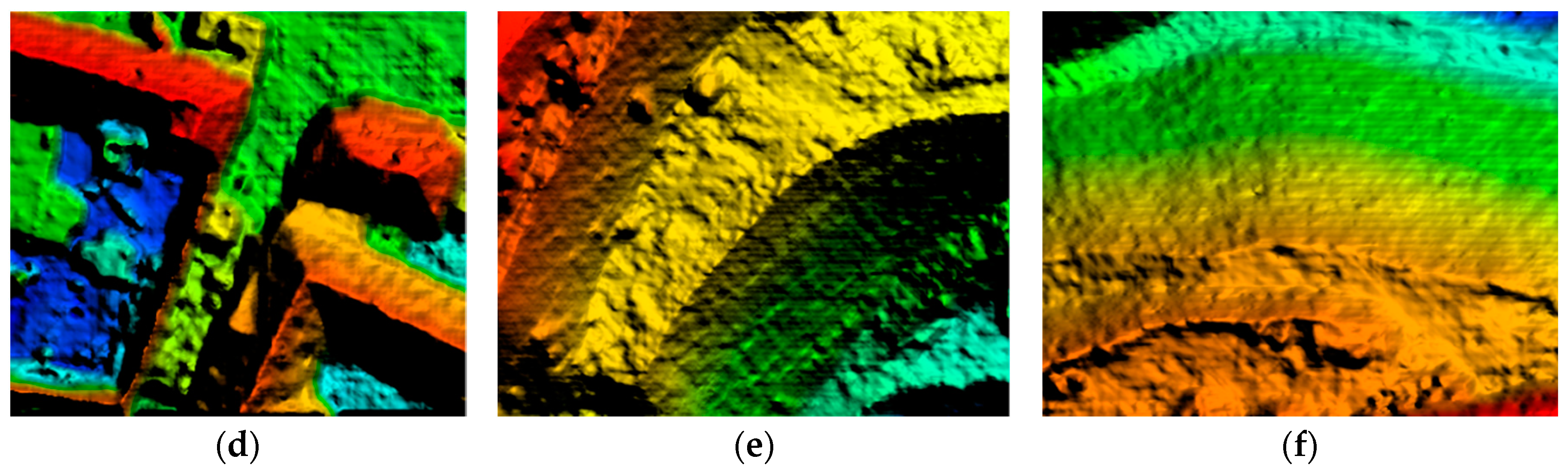
3.3. Experiment on SGVLL with Handling Occlusion
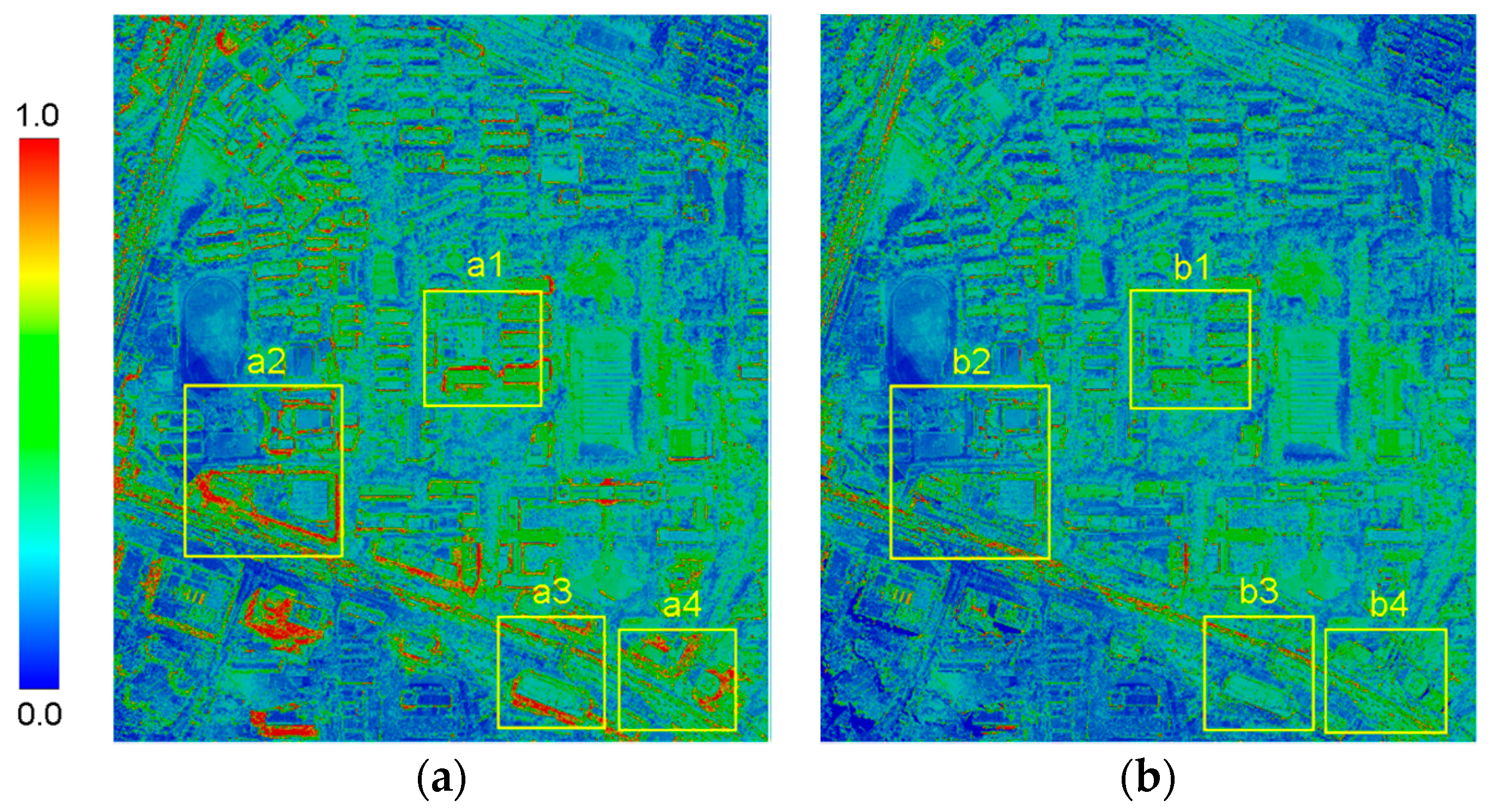
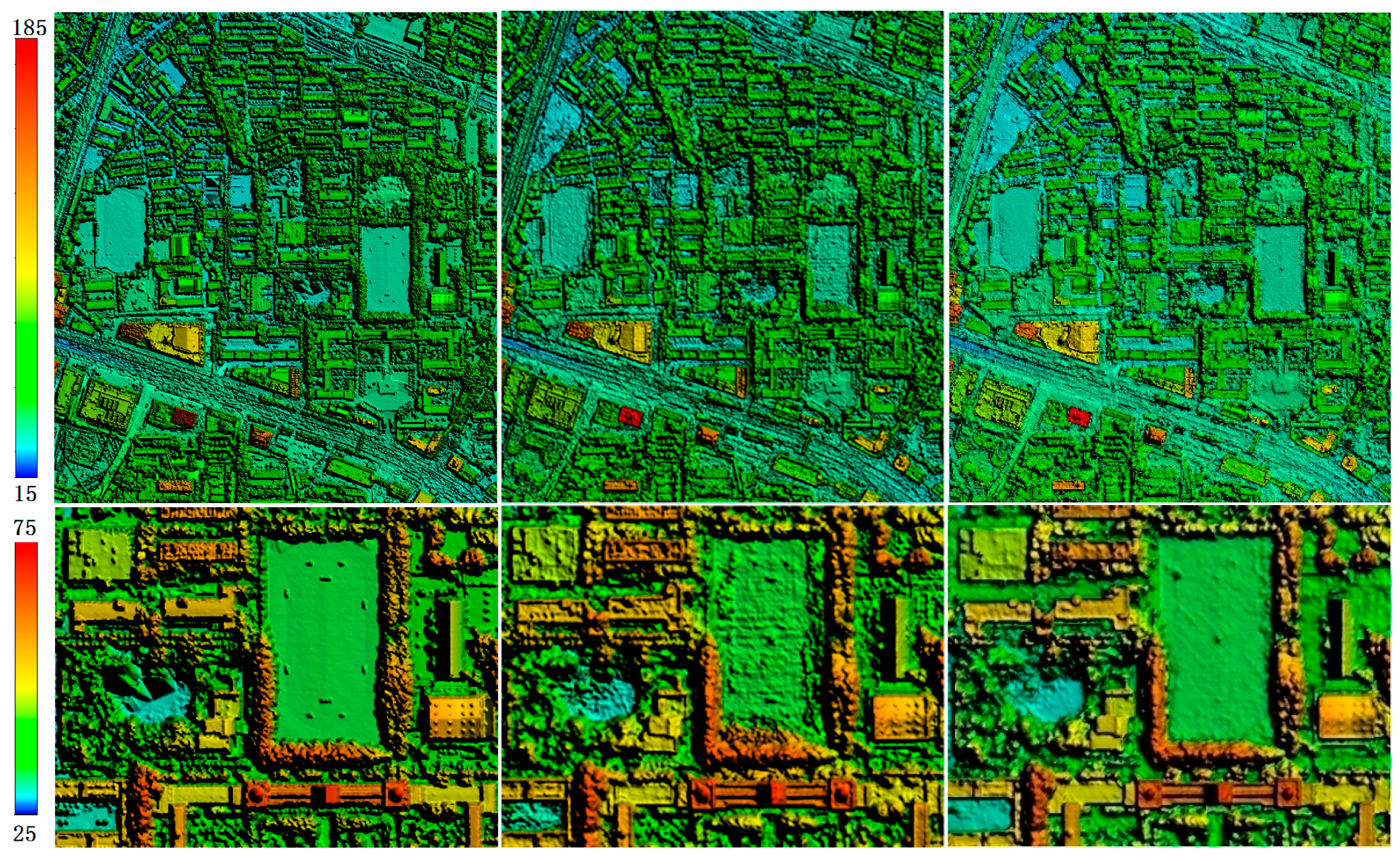
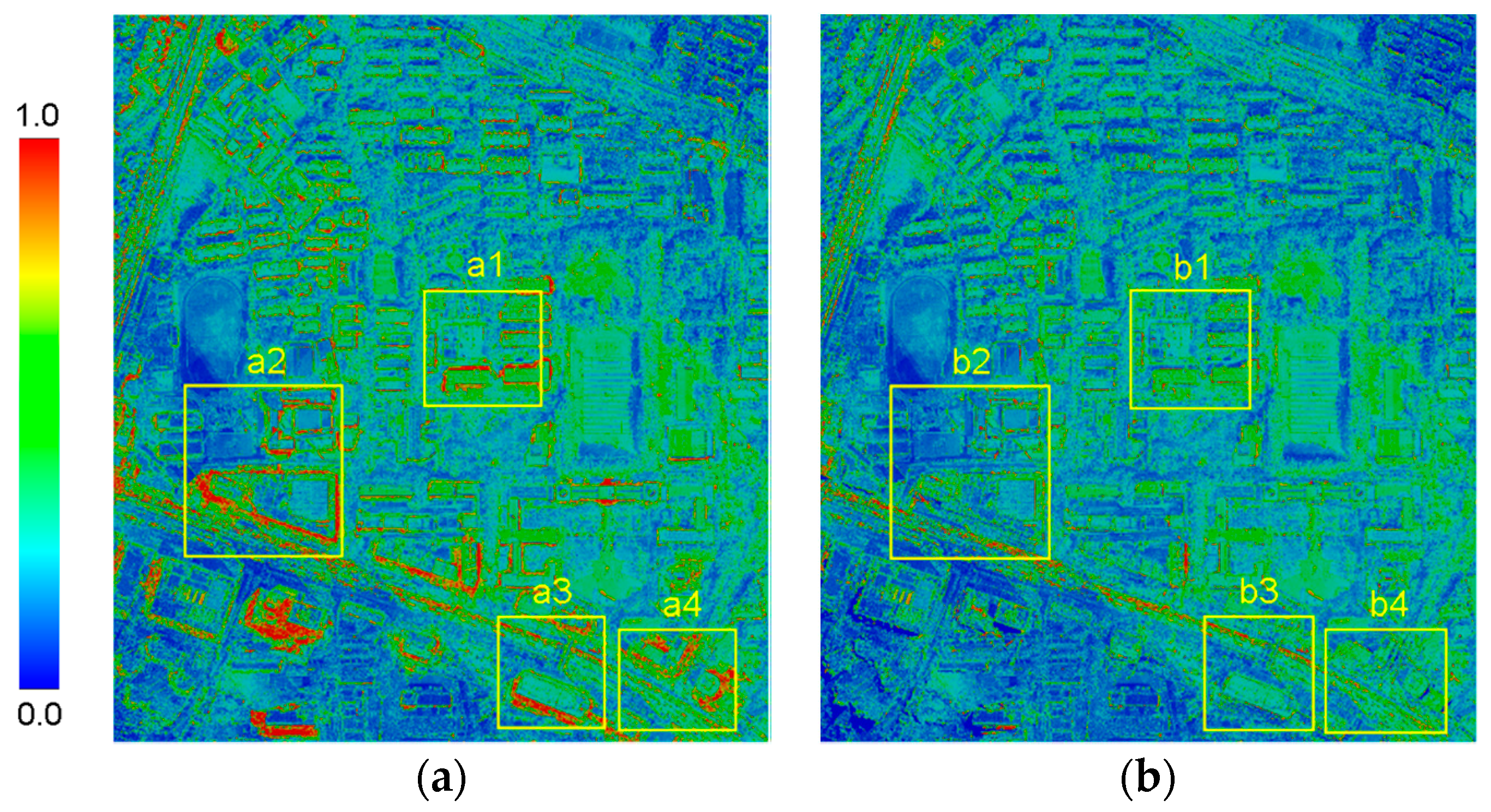
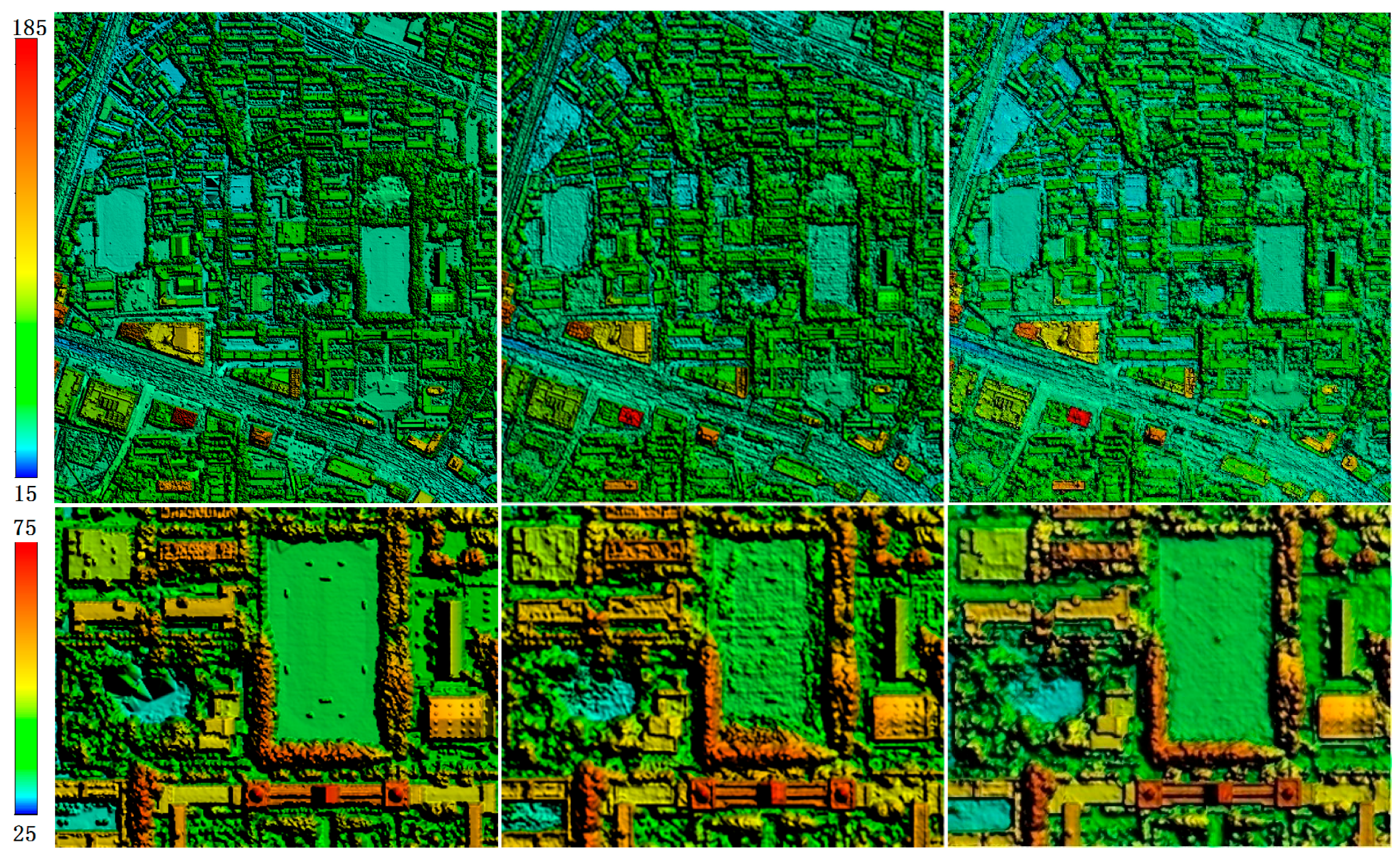
3.4. Experiment on Improved Semi-Global Aggregation
3.5. DSM Quality Assessment
4. Discussion
4.1. Advancements of the Proposed Method
4.2. Limitations of the Proposed Method
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| DSM | Digital surface model |
| SGVLL | Semi-global vertical line locus |
| GSD | Ground sampling distance |
| ZNCC | Zero-mean normalized correlation coefficient |
| WTA | Winner takes all |
References
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Hirschmüller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Yoon, K.; Kweon, I.S. Adaptive Support-Weight approach for correspondence search. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 650–656. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q. A Non-local cost aggregation method for stereo matching. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1402–1409.
- Bleyer, M.; Gelautz, M. A layered stereo matching algorithm using image segmentation and global visibility constraints. ISPRS J. Photogramm. Remote Sens. 2005, 59, 128–150. [Google Scholar] [CrossRef]
- Xu, S.B.; Zhang, F.H.; He, X.F.; Shen, X.K.; Zhang, X.P. PM-PM: PatchMatch with potts model for object segmentation and stereo matching. IEEE Trans. Image Process. 2015, 24, 2182–2196. [Google Scholar] [PubMed]
- Hirschmüller, H.; Scharstein, D. Evaluation of stereo matching costs on images with radiometric differences. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1582–1599. [Google Scholar] [CrossRef] [PubMed]
- Tombari, F.; Mattoccia, S.; Stefano, L.D.; Addimanda, E. Classification and evaluation of cost aggregation methods for stereo correspondence. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Hosni, A.; Rhemann, C.; Bleyer, M.; Rother, C.; Gelautz, M. Fast Cost-volume filtering for visual correspondence and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 504–511. [Google Scholar] [CrossRef] [PubMed]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef] [PubMed]
- Newcombe, R.; Izadi, S.; Hilliges, O.; Molyneaux, D. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011.
- Rumpler, M.; Wendel, A.; Bischof, H. Probabilistic range image integration for DSM and true-orthophoto generation. In Proceedings of the Scandinavian Conference on Image Analysis, Espoo, Finland, 17–20 June 2013.
- Jacquet, B.; Hane, C.; Angst, R.; Pollefeys, M. Multi-body depth-map fusion with non-intersection constraints. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014.
- Seitz, S.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A Comparison and evaluation of multi-view stereo reconstruction algorithms. In Proceedings of the Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006.
- Kolmogorov, V.; Zabih, R. Multi-camera scene reconstruction via graph cuts. In Proceedings of the European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002.
- Zhang, L. Automatic Digital Surface Model (DSM) Generation from Linear Array Images; Swiss Federal Institute of Technology: Zurich, Switzerland, 2004. [Google Scholar]
- Zhu, Z.K.; Stamatopoulos, C.; Fraser, C.S. Accurate and occlusion-robust multi-view stereo. ISPRS J. Photogramm. Remote Sens. 2015, 109, 47–61. [Google Scholar] [CrossRef]
- Seitz, S.M.; Dyer, C.R. Photorealistic scene reconstruction by voxel coloring. Int. J. Comput. Vis. 1999, 35, 151–173. [Google Scholar] [CrossRef]
- Vogiatzis, G.; Torr, P.; Cipolla, R. Multi-view stereo via volumetric graph-cuts. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 15–21 October 2005.
- Kutulakos, K.N.; Seitz, S.M. A theory of shape by space carving. Int. J. Comput. Vis. 2000, 38, 199–218. [Google Scholar] [CrossRef]
- Jin, H.L.; Soatto, S.; Yezzi, A.J. Multi-view stereo reconstruction of dense shape and complex appearance. Int. J. Comput. Vis. 2005, 63, 175–189. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. 2010, 32, 1362–1376. [Google Scholar] [CrossRef] [PubMed]
- Shan, Q.; Curless, B.; Furukawa, Y.; Hernandez, C.; Seitz, S.M. Occluding contours for multi-view stereo. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014.
- Shao, Z.; Yang, N.; Xiao, X.; Zhang, L.; Peng, Z. A multi-view dense point cloud generation algorithm based on low-altitude remote sensing images. Remote Sens. 2016, 8, 381–397. [Google Scholar] [CrossRef]
- Linder, W. Digital Photogrammetry-A Practical Course; Springer: Berlin/Heidelberge, Germany, 2006. [Google Scholar]
- Ji, S.; Fan, D.Z.; Zhang, Y.S.; Yang, J.Y. MVLL Multi-image matching model and its application in ADS40 linear array images. Geomat. Inf. Sci. Wuhan Univ. 2009, 34, 28–31. [Google Scholar]
- Santel, F.; Linder, W.; Heipke, C. Stereoscopic 3D-image sequence analysis of sea surfaces. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, XXXI-B5, 708–712. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Angulo, J. (Max, min)-convolution and mathematical morphology. In Proceedings of the International Symposium on Mathematical Morphology, Reykjavik, Iceland, 27–29 May 2015; pp. 485–496.
- Tan, X.; Sun, C.; Wang, D.; Guo, Y.; Pham, T.D. Soft cost aggregation with multi-resolution fusion. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 17–32.
- Kang, S.; Szeliski, R.; Chai, J. Handling occlusions in dense multi-view stereo. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 103–110.
- Zeng, G.; Paris, S.; Quan, L.; Sillion, F. Progressive surface reconstruction from images using a local prior. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 15–21 October 2005; pp. 1230–1237.
- Habib, A.F.; Kim, E.M.; Kim, C.J. New methodologies for true orthophoto generation. Photogramm. Eng. Remote Sens. 2007, 73, 25–36. [Google Scholar] [CrossRef]
- Céspedes, I.; Huang, Y.; Ophir, J.; Spratt, S. Methods for estimation of subsample time delays of digitized echo signals. Ultrason. Imaging 1995, 17, 142–171. [Google Scholar] [CrossRef] [PubMed]
- Haala, N. The Landscape of Dense Image Matching Algorithms; Photogrammetric Week ’13; Fritsch, D., Ed.; Wichmann: Berlin/Offenbach, Germany, 2013; pp. 271–284. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Indicator | Wuhan University | München Subset | Vaihingen/Enz Subset |
|---|---|---|---|---|
| GSD: 0.2 m, Raster: 4503 × 4998 pix | GSD: 0.2 m, Raster: 1348 × 998 pix | GSD: 0.3 m, Raster: 3717 × 2177 pix | ||
| SURE | RMSE/m | 3.63 | 0.97 | 0.58 |
| ME/m | −2.95 | 0.06 | −0.07 | |
| Time/min | 81 | 35 | 63 | |
| SGVLL | RMSE/m | 3.17 | 1.35 | 0.84 |
| ME/m | −2.40 | 0.05 | −0.05 | |
| Time/min | 48 | 14 | 30 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhang, Y.; Mo, D.; Zhang, Y.; Li, X. Direct Digital Surface Model Generation by Semi-Global Vertical Line Locus Matching. Remote Sens. 2017, 9, 214. https://doi.org/10.3390/rs9030214
Zhang Y, Zhang Y, Mo D, Zhang Y, Li X. Direct Digital Surface Model Generation by Semi-Global Vertical Line Locus Matching. Remote Sensing. 2017; 9(3):214. https://doi.org/10.3390/rs9030214
Chicago/Turabian StyleZhang, Yanfeng, Yongjun Zhang, Delin Mo, Yi Zhang, and Xin Li. 2017. "Direct Digital Surface Model Generation by Semi-Global Vertical Line Locus Matching" Remote Sensing 9, no. 3: 214. https://doi.org/10.3390/rs9030214