1. Introduction
In China, the rapid development of the social economy and changes in the industrial structure have accelerated urbanization. A key characteristic of urbanization is the constant expansion of urban areas into farm land and forested areas. The loss of agricultural lands threatens and damages the ecological environment and directly affects the livability of cities and the sustainability of economic development. Therefore, methods of extracting and evaluating urban spatial information in China are extremely important.
The Defense Meteorological Satellite Program-Operational Linescan System (DMSP-OLS) nighttime light data are a valuable resource for regional and global urban mapping, as well as for the study of human activities [
1,
2,
3]. On nights without cloud cover, nighttime light sensors can effectively detect city lights, even low-intensity lights within small-scale residential areas or in cars, and then quickly extract the city information. Not only do DMSP-OLS data have a small storage capacity, but also a long time series compared with traditional remote sensing images that can provide a wide range of urban land use information, thus playing a significant role in the extraction of urban areas and the analysis of dynamic changes of urban spatial patterns [
4,
5,
6,
7]. A number of methods have been developed to map urban areas using DMSP-OLS data, and these approaches can generally be divided into two categories: supervised classification and un-supervised classification. Experiential threshold, mutation detection, and comparison methods based on high-resolution data have considerably improved the acquisition of urban spatial information and are representative of the un-supervised classification of the nighttime light remote sensing field [
8,
9,
10,
11,
12], whereas the support vector machine (SVM) method uses sample selection and nighttime light image classification to acquire urban information, and is representative of a commonly employed supervised classification method [
13,
14,
15]. Cao et al. [
16] proposed an SVM-based region-growing algorithm using DMSP-OLS and SPOT normalized differential vegetation index (NDVI) data to extract the urban extent of 25 Chinese cities with different levels of economic development, including Beijing, Shanghai, Hangzhou, Zhengzhou, and Lanzhou [
16]. This algorithm uses several simple criteria to build initial training sets of urban and non-urban pixels. In particular, the growth of seed pixels (a window with 3 × 3 pixels), which is involved in the iterative classification procedure, is capable of running continuous training for the SVM classifier with the aim of semi-automatically extracting the urban extent. Pandey et al. used a second-order polynomial regression equation to intercalibrate DMSP-OLS data as a necessary experimental preparation and then employed the same algorithm as Cao et al. to extract urban areas in India [
17]. Yang et al. presented a stratified SVM-based method to map urban land in China, which addressed the problem of extracting urban land over a large area with obvious regional variations [
18]. However, the above unsupervised classification methods present a number of limitations in the process of sample threshold selection, such as excessive subjective interventions (according to statistical data, accumulated experience, and visual observation-derived assumptions), data sources for selection that present a lack of diversity and inherent defects, and a low degree of overall automation. All of these limitations have led to a reduction in the credibility of extraction results based on these methods. Although other methods have attempted to fully exploit the features of nightlight, the detailed classification of SVM classifiers, and present classification results that are more accurate than those obtained by unsupervised methods that rely on thresholds, areas with blooming vegetation and abundant vegetation (and water pixels) are not totally removed from urban pixels because of the improper selection of samples and human intervention in the classification processes. Thus, further improvements are required to ensure the accuracy of SVM classifications.
Optical remote sensing data with high resolution, such as data extracted from remote sensing image indices and other high-quality land cover data products, are the major datasets used for urban information extraction [
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34], and such data are far superior to those of DMSP-OLS in terms of image resolution. However, most of these data products have limited temporal coverage and present limited usefulness for a dynamic analysis at large scales. For example, although the class accuracy of each land-cover classification of GlobeLand30 data is generally at a high level [
35], this product is still limited by time constraints (i.e., it only contains two terms of data with benchmark years of 2000 and 2010); thus, it cannot meet the practical requirements for monitoring urban spatial change within a long-term time series. More importantly, problems related to the same objects using different spectra and different objects using similar spectra remain unresolved, which increases the difficulty of distinguishing between urban and bare lands simply based on the spectral information obtained from several bands of surface reflectance data. Furthermore, exploring regional or global areas is labor intensive and time consuming because of the massive data volumes involved [
36]. Thus, to precisely and reliably extract urban areas, DMSP-OLS data are used as the main data source of the data integration, and spectral information from the surface reflectance data is only used as an auxiliary source.
To address the problems associated with current extraction methods and to improve the credibility and effectiveness of classification results, we proposed a sample-optimized approach that utilizes SVM classification to semi-automatically extract urban built-up areas using an integration of multi-source data. The proposed approach consists of three main steps: (1) Initial sample generation and classification based on the maximum and minimum intervals of the digital numbers from the DMSP-OLS data and the initial training of samples into two-classes of urban built up and non-urban built up areas, which were selected and entered into the first SVM classification; (2) Refined sample selection and optimization using a probability threshold for determining pixels that contain vegetation cover, which uses the Landsat-derived normalized differential vegetation index (NDVI) as a constraint, and artificial surfaces, which uses the GlobeLand30 product as a constraint. The relationships among the three data sources as well as with the training sets were established to optimize the process of SVM classification; (3) An iterative classification and data extraction process for urban built-up areas was developed based on trials evaluating the relationship between the results obtained here and previous results using corresponding refined samples, and the iterative optimization process was terminated when the values reached a certain threshold, which generated the final urban built-up extraction results. All the ideas of our proposed approach are novel in the nighttime light data application field, which differs from other SVM-based extraction methods combined with DMSP-OLS data. To validate the flexibility and robustness of the proposed method, a case study was conducted for several typical regions in western China in 2010. The aim of this study is not to provide an approach for using Landsat or other types of global land-cover datasets alone or to apply classification methods based on the data sources above; rather, the goal is to improve the accuracy of generating training samples for information extraction with a high degree of automation, rationality, and credibility.
The remainder of this paper is organized as follows.
Section 2 describes the study area and data sources;
Section 3 introduces the proposed method;
Section 4 provides the experimental and analytical results; and
Section 5 presents the conclusions.
2. Study Areas and Materials
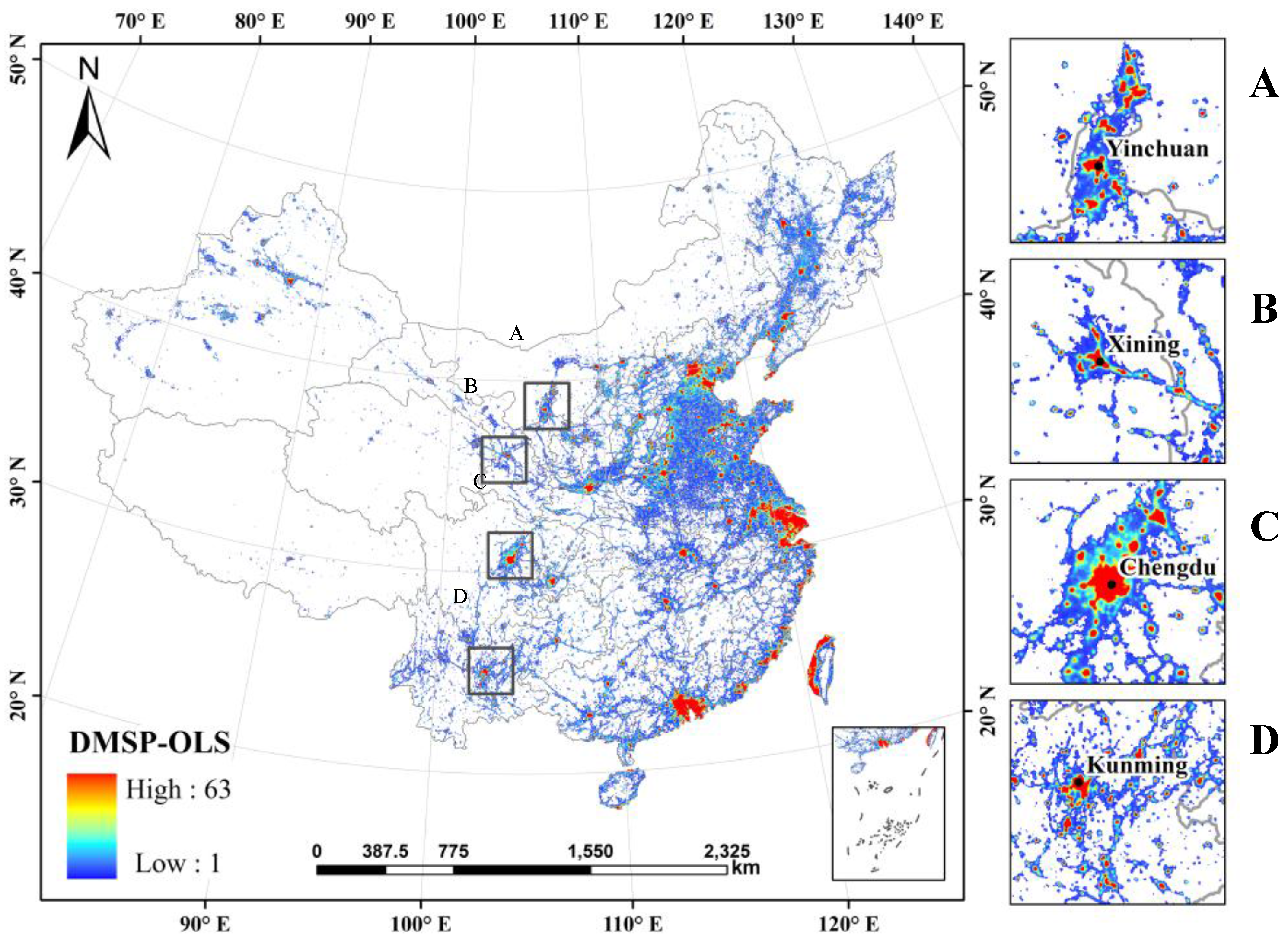
Although China has been experiencing rapid urbanization since the 1980s, large discrepancies remain in the economic development of different regions, especially in western China. With the deepening implementation of the “China Western Development” strategy, which is a Chinese national strategy for economic development and diplomatic efforts, the regional cooperation and coordinated development of cities located in western China are getting increasingly closer. In this study, four provincial capital cities, including Yinchuan, Xining, Chengdu, and Kunming, were selected as typical representative cities of western China, which are regularly among the first echelon of social economic development in Western China. These cities push forward the strategy steadily and achieve significant outcomes in many fields. Particularly in 2010, the population of these cities varied from less than 1.5 million (Yinchuan) to over 11 million (Chengdu), and the per capita gross domestic product (GDP) ranged from less than 40,000 RMB (or 6100 USD) for Xining to over 70,000 RMB (or 10,000 USD) for Chengdu [
37].
DMSP-OLS data, GlobeLand30 product data, and Landsat image data were used in this research, and the major characteristics of each data source are summarized in
Table 1. All the selected datasets were acquired in 2010.
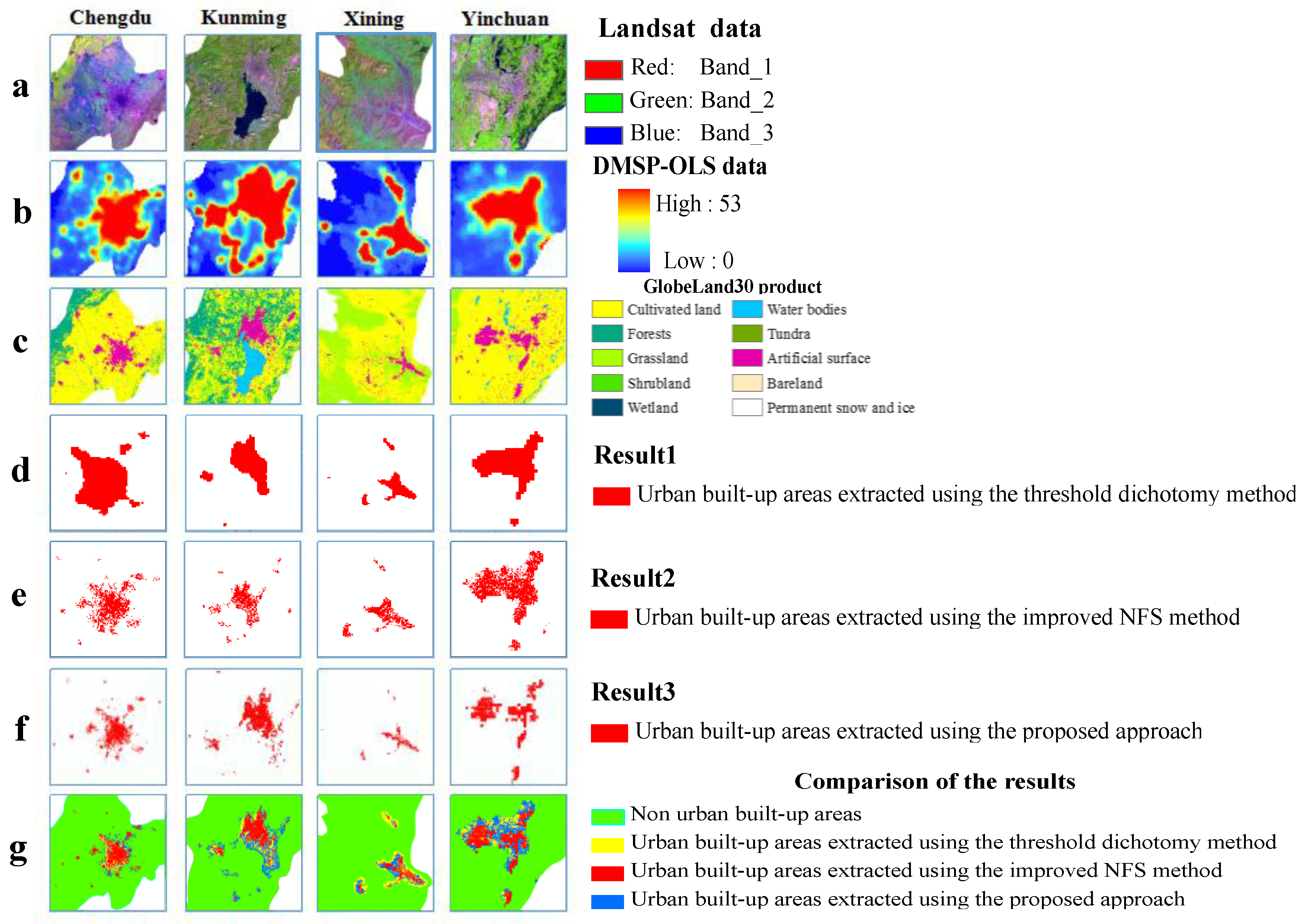
The DMSP-OLS nighttime light data with a 1-km spatial resolution were provided by the National Geophysical Data Center. Stable nighttime light images (
Figure 1), which represent a nighttime light data product, are annual raster graphic images that show the average nighttime light intensity, which includes lights in urban and rural areas and permanent lights in other places, but excludes noise, such as moonlit clouds or fires [
38]. The digital number (DN) values of these images represent the average light intensity, which ranges from 0 to 63. A value of 0 indicates a completely dark area, which is not the focus of this study, whereas a higher DN value represents greater light intensity in a particular area. The geographic coordinate projection of the data is the World Geodetic System 1984 (or WGS-84), which is transformed into the Asia Lambert conformal conic projection to more accurately calculate the scope of the urban built-up areas in the next stages.
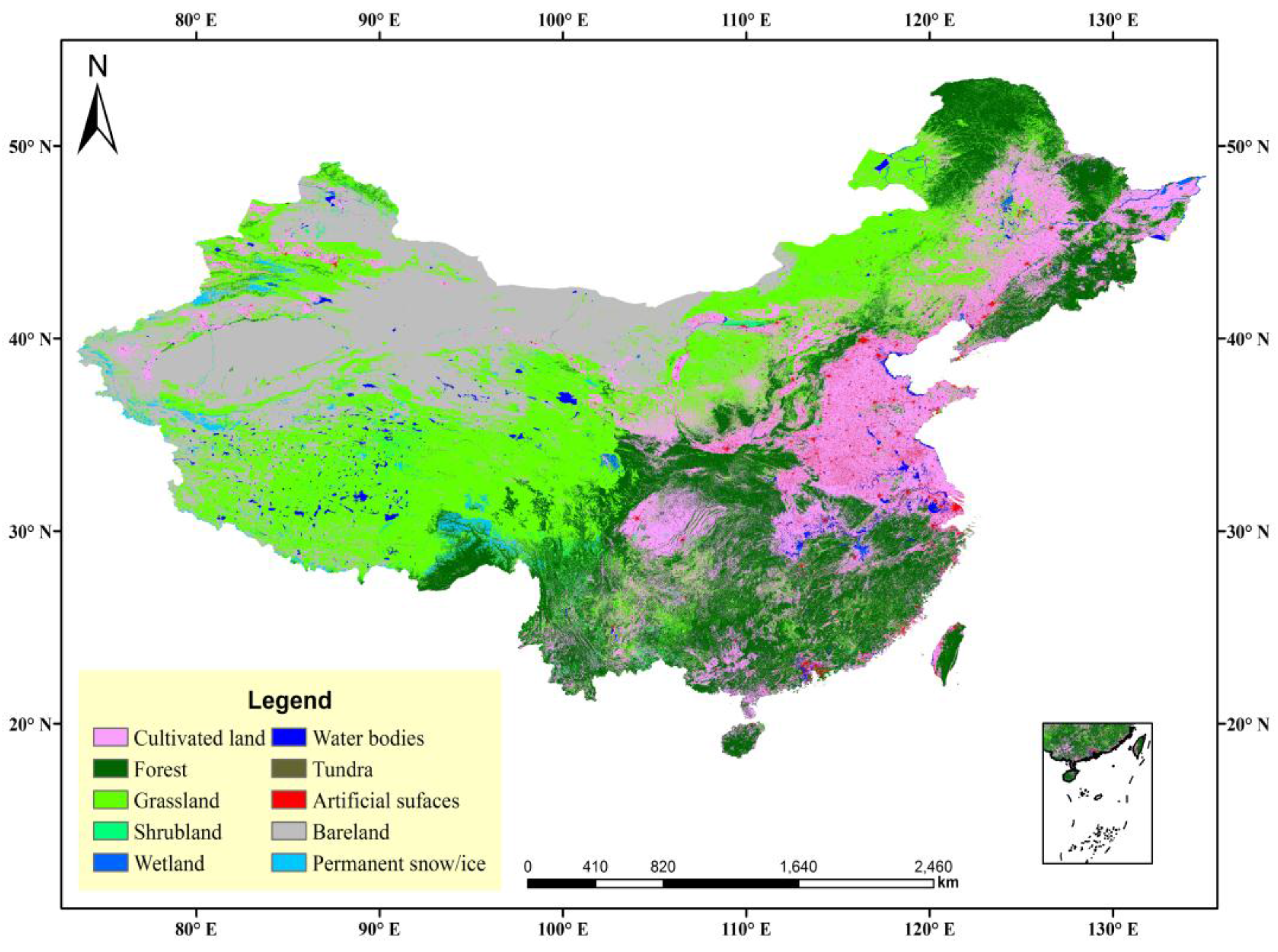
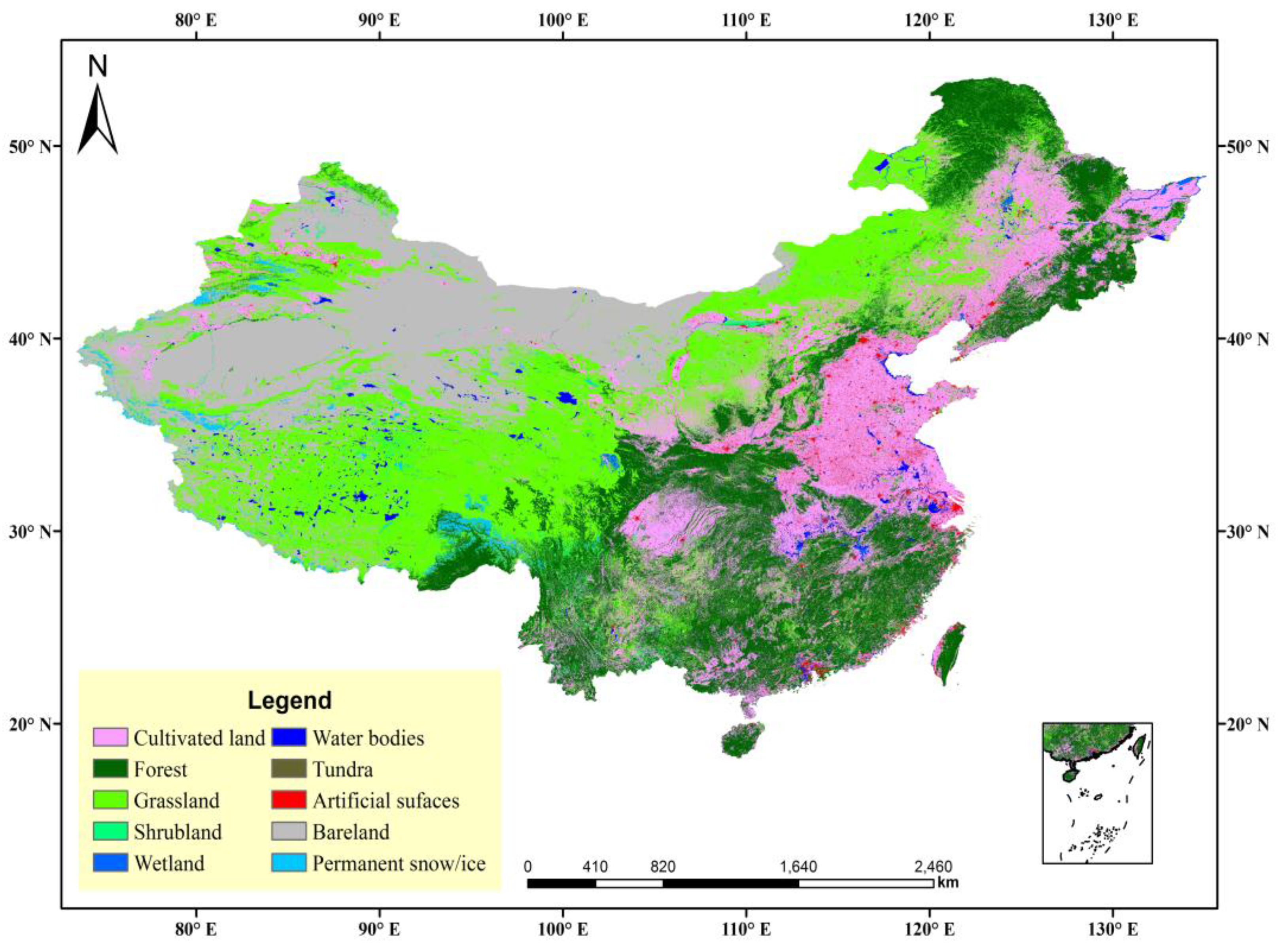
The primary data source was Landsat data from the benchmark years of 2000 and 2010, and the supplemental data included China’s Environmental Disaster Mitigation satellite images and Beijing-1 data in partial areas. Compared with DMSP-OLS data with 1000 m resolution, GlobeLand30 was the latest product with 30 m resolution at a much higher level, which developed based on a pixel classification-object abstraction-knowledge check (POK) method [
39]. Ten types of land cover were included: forests, grassland, shrub land, wetlands, bare land, tundra, cultivated land, water bodies, permanent snow/ice, and artificial surfaces (
Figure 2). The data were divided by the attribute values of these land cover types to extract artificial surfaces as an independent layer. Artificial surfaces were represented by land cover types covered with asphalt, concrete, gravel, bricks, tiles, and other building materials resulting from human activity, and they included residential areas, transportation, telecommunication, industry, and mining infrastructure. The product information officially verified by GlobeLand30 was reported in the top international scientific journal “Nature” in Volume 514 in 2014. More authoritative information can also be found on the official website of GlobeLand30 [
40], which officially reports that the overall accuracy (OA) of an average GlobeLand30 classification is approximately 80.33% globally, the Kappa indicator of the classification is 0.75, and the user accuracy of the artificial surface class for the GlobeLand30 product is approximately 86.70% [
39].
In addition, reference data for urban built-up areas are mainly sourced from the China Urban Construction Statistical Yearbook of 2011 [
41]. Information on boundaries of urban administrative divisions and urban spatial structures is gathered from the 1:4 million scale vector datasets in the National Fundamental Geographic Information System.
Finally, Landsat product images were acquired to obtain data on the vegetated areas extracted according to the NDVI process. Using Landsat 5, Landsat 7, and Landsat 8 satellite data collected since the 1980s, the Center for Earth Observation and Digital Earth of the Chinese Academy of Sciences (CEODE) selected images with fine quality and produced several different series of advanced remote-sensing data products subjected to atmospheric correction, ortho-rectification, projection transformation, masking, clipping, and other types of processing. According to the study areas, we used four images from this product (2010) with a spatial resolution of 30 m, which were acquired directly from the Product Data Service Plan at the CEODE [
42].
3. Methods
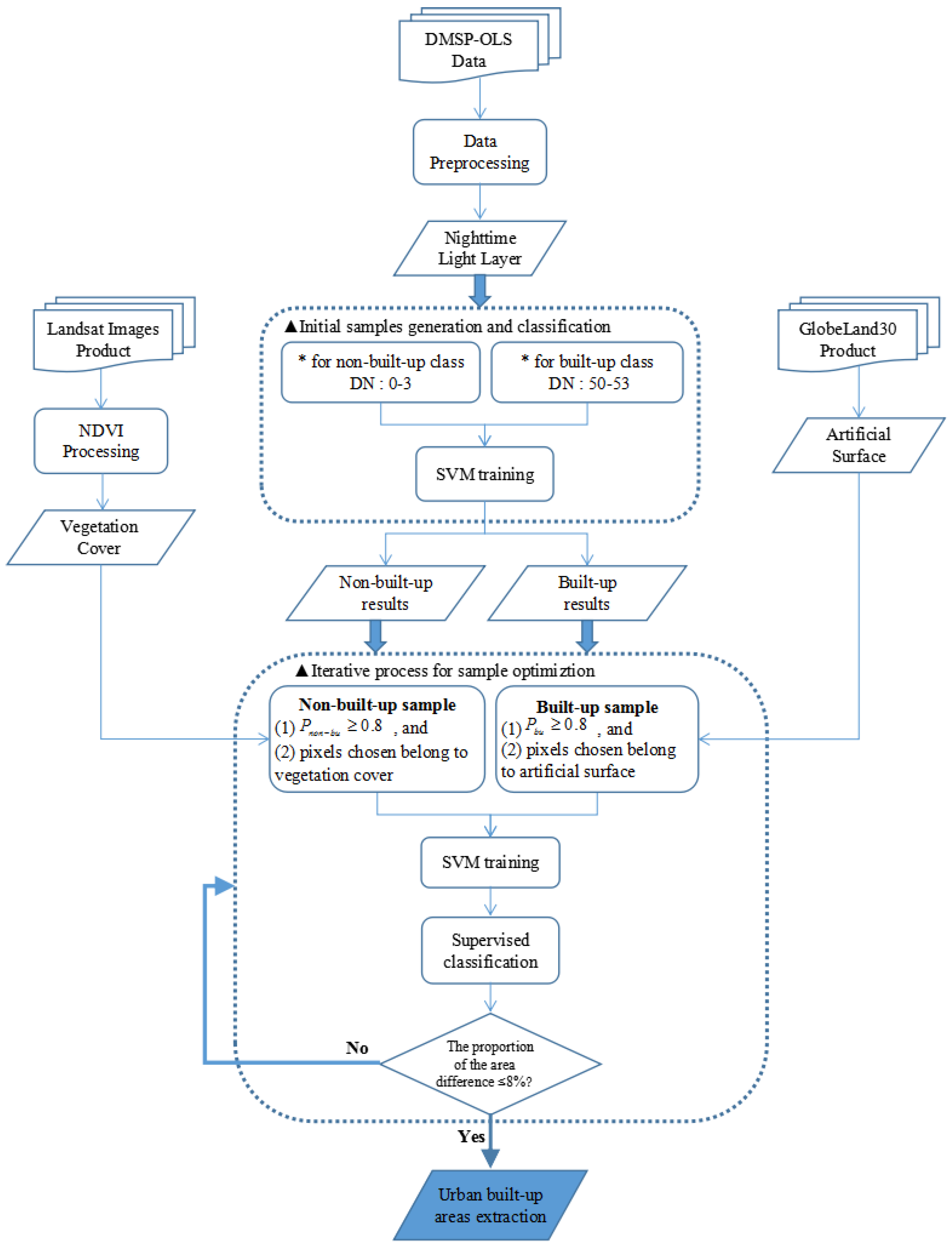
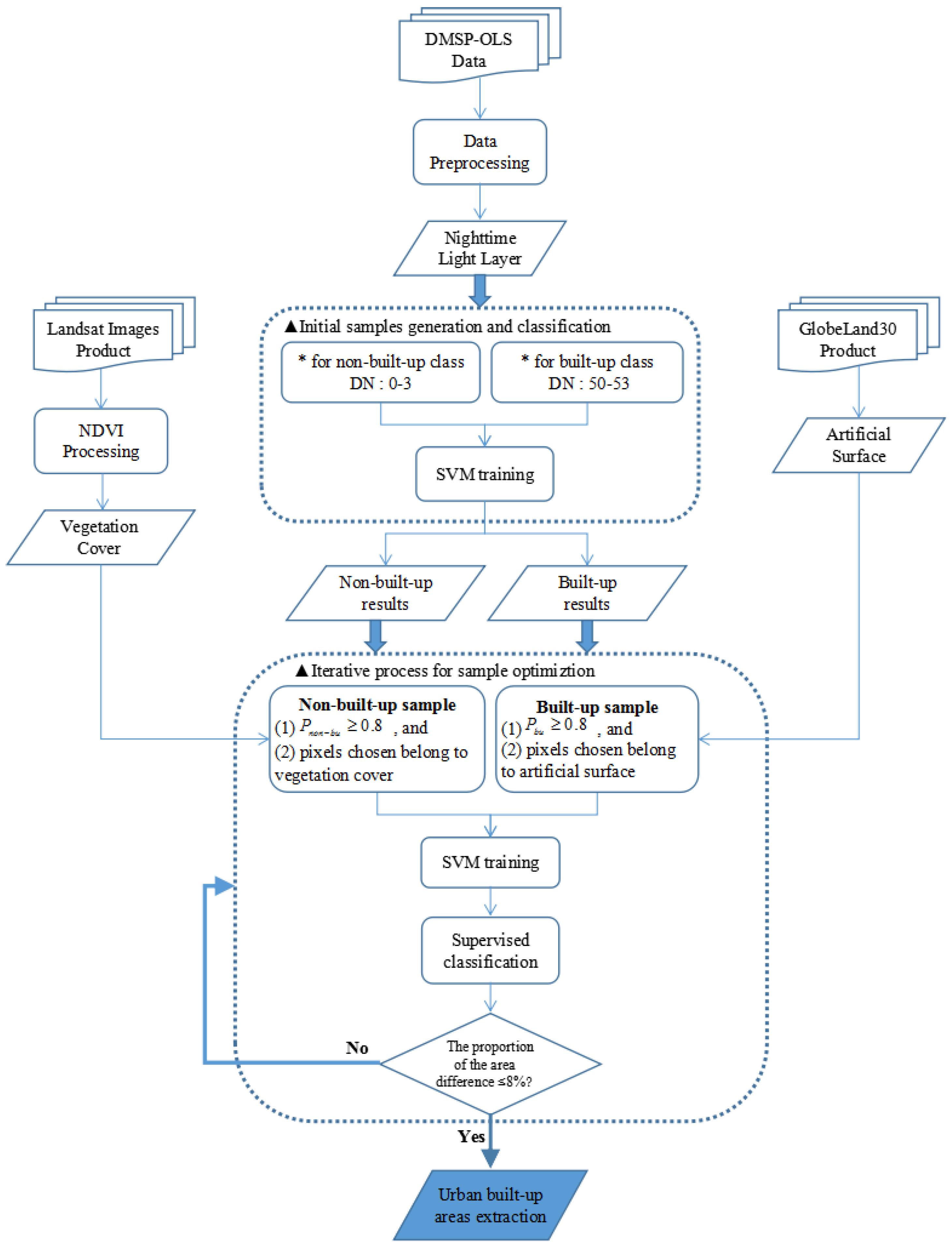
A sample-optimized approach for SVM classification was proposed to extract urban built-up areas with a high degree of credibility. The flowchart of the proposed approach is shown in
Figure 3, and it consists of several steps: (1) preprocessing of the DMSP-OLS and Landsat data; (2) initial sample generation and classification; (3) iterative sample optimization process; and (4) SVM classification for urban built-up area data extraction. As the core of this approach, steps 2–4 are introduced in a single section.
3.1. Data Pre-Processing
DMSP-OLS datasets currently include images covering the 22 years from 1992 to 2013. Because satellites are subject to rapid upgrades, the data from different types of satellites present varying quality and light saturation phenomena [
43,
44]. Therefore, this article used the calibration method for long time series DMSP-OLS nighttime light image datasets, proposed by Cao et al. in 2009, to preprocess the remote sensing data for nighttime lights in 2010 [
45]. The major steps are the mutual calibration of the raw data images and the calibration between each image series (fusion for data in the same year and calibration for data in different years). A mutual calibration is adopted for long time series datasets using the regression model presented in Formula (1) after the re-sampling and re-projection processes:
In Formula (1), the
DN represents the pixel value of the images ready to be calibrated;
DNcal represents the pixel value of the calibrated images, and
a and
b are two parameters obtained after the power regression. The parameter values for the power regression of the calibrated images and reference images in the test as well as estimates of other relevant coefficients, such as R
2, from 2006 to 2012, are listed in
Table 2. The corresponding power equation was used to perform a mutual calibration of the images for each period in China (including the data from 2010). This saturation correction processing of the DMSP-OLS data generated
DN values for the DMSP-OLS data in the range of (0, 63) to (0, 53). A masking process was then performed for the images resulting from the aforementioned steps, and were then used against the administrative backdrop of Chengdu, Kunming, Xining, and Yinchuan.
In addition, vegetation-cover data were extracted using the NDVI from Landsat images, and this information was combined into the sample optimization process in the subsequent steps. The NDVI is a superior vegetation indicator and can effectively reflect the growth, coverage, and dynamic seasonal changes in vegetation [
46,
47,
48]. For remote sensing images, the NDVI in Formula (2) is calculated as follows:
Vegetation has strong reflectivity in the near-infrared (NIR) band and weak reflectivity in the red (R) band, which are represented by band 4 and band 3 in the Landsat images, respectively. After the normalized ratio calculation, the brightness of the vegetation in the images could be enhanced to the fullest and other ground objects could be restrained. The NDVI ranges between −1 and 1. Because of the differences among the distribution of vegetation cover in different regions, the optimal threshold between vegetated and non-vegetated cover was defined based on a histogram distribution of the NDVI values after an extensive statistical analysis of the entire number of pixels from the corresponding regions. Pixels with NDVI values that exceeded this threshold were considered vegetation cover; this is a required step for the experiment.
3.2. Sample Optimization in SVM Classification
Because greater DN values for lights indicate a greater possibility of a point belonging to an urban area, researchers have successively combined the SVM classification with nightlight time data [
49,
50] and have adjusted and set an “optimal threshold” according to certain features, such as areas or shapes that cannot be universally applied to cities at different scales, geographical locations, and different development stages. Accordingly, Cao et al. [
16] attempted to utilize the region-growing concept in SVM sample training, in which the input urban pixels that meet the baseline criteria for a definitive selection were assigned as seeds. Then, all pixels that utilized a window of 3 × 3 pixels for each seed were classified simultaneously by the SVM-based classifier in the iterative procedure.
Although the above sample selection approach based on neighboring seeds achieved good results in the accuracy assessments and avoided the tedious trial-and-error procedure, it could not guarantee the accuracy of the training samples in the SVM classification. In addition, the reliability of the classification results required further improvement. Therefore, a sample-optimized approach was proposed that combines the SVM classification, a post-probability threshold, and multi-source data integration. There are three steps within the proposed sample-optimized procedure: generation and classification of initial samples, selection and optimization of refined samples, and iterative classification and urban built-up area extraction.
3.2.1. Initial Samples Generation and Classification
Because built-up urban areas are illuminated artificially at night, their corresponding pixels in nighttime light images have larger DN values than the surrounding dark rural areas [
51,
52]. Based on previous results, the DN value range (50, 53) was selected as the maximum interval of the built-up class, and the DN value range (0, 3) was selected as the minimum interval of the non-built-up class. Patches with DN values in these ranges served as the initial training sets and were input into the SVM classifier using a radial basis function kernel. Although patches with DN values within the range (3, 50) must be further identified, the initial classification results roughly segmented the images into urban built-up areas and non-built-up urban areas.
3.2.2. Refined Samples Selection and Optimization
The SVM method is capable of identifying the class label and generating the post-probability of each class, which represents one of the most important indices in SVM classification. Previous studies have converted the outputs of the SVM into pairwise coupling post-probabilities, and various types of post-probabilities have been generated from such pairwise coupling post-probabilities. In this paper, for two categories of land-cover features, the posterior probability of SVM can be obtained by pairwise coupling according to its predicted output values. Such pixel-specific post-probability can be used as land cover composition information, which means that every pixel has a different attribute probability for each surface feature class, and the pixel is assigned to the class with the highest probability as its class information [
53]. Therefore, we defined a post-probability value
P to set the likelihood for each pixel and determined the “true” probability of a pixel belonging to a specific classification category. Pixels with all rule probabilities less than
P are unclassified. In addition, a critical threshold value
T defined as 0.8 represented a highly credible threshold value probability outputted after SVM classification for both built-up and non-built-up classes (i.e.,
and
), to select samples with higher credibility from the results of previous classifications. The threshold value
T (i.e.,
T = 0.8) indicates a high credibility level based on the class probabilities of SVM classification. It is important to note that the value of
T is defined after many trials. Although it may be somewhat subjective, it is indeed a basic input guarantee for our sample optimization process in the next step, so as to extract reliable and sufficient results.
For the selection of refined samples, the probability threshold T was defined with two constraints, i.e., the vegetation cover and artificial surface classifications obtained in the data preprocessing stage, and then the relationships among the three data sources as well as with the SVM training sets were established.
As shown in
Table 3, the training sets of the urban built-up class were selected as the pixels that belonged to artificial surfaces, and they also met
. Training sets of the non-urban built-up class included the vegetation-covered pixels based on NDVI processing, and they also met
. In each iteration, the value
T was used as a condition that constrains the posterior probability value
P. It also constrains the selection of the training sample together with vegetation elements and artificial surface elements. After the refined selection process for both classes was completed, these training samples can be involved in the process of SVM classification. Misclassification alarms and false alarms will be greatly reduced according to the designed progressive iterative optimization process for SVM classification.
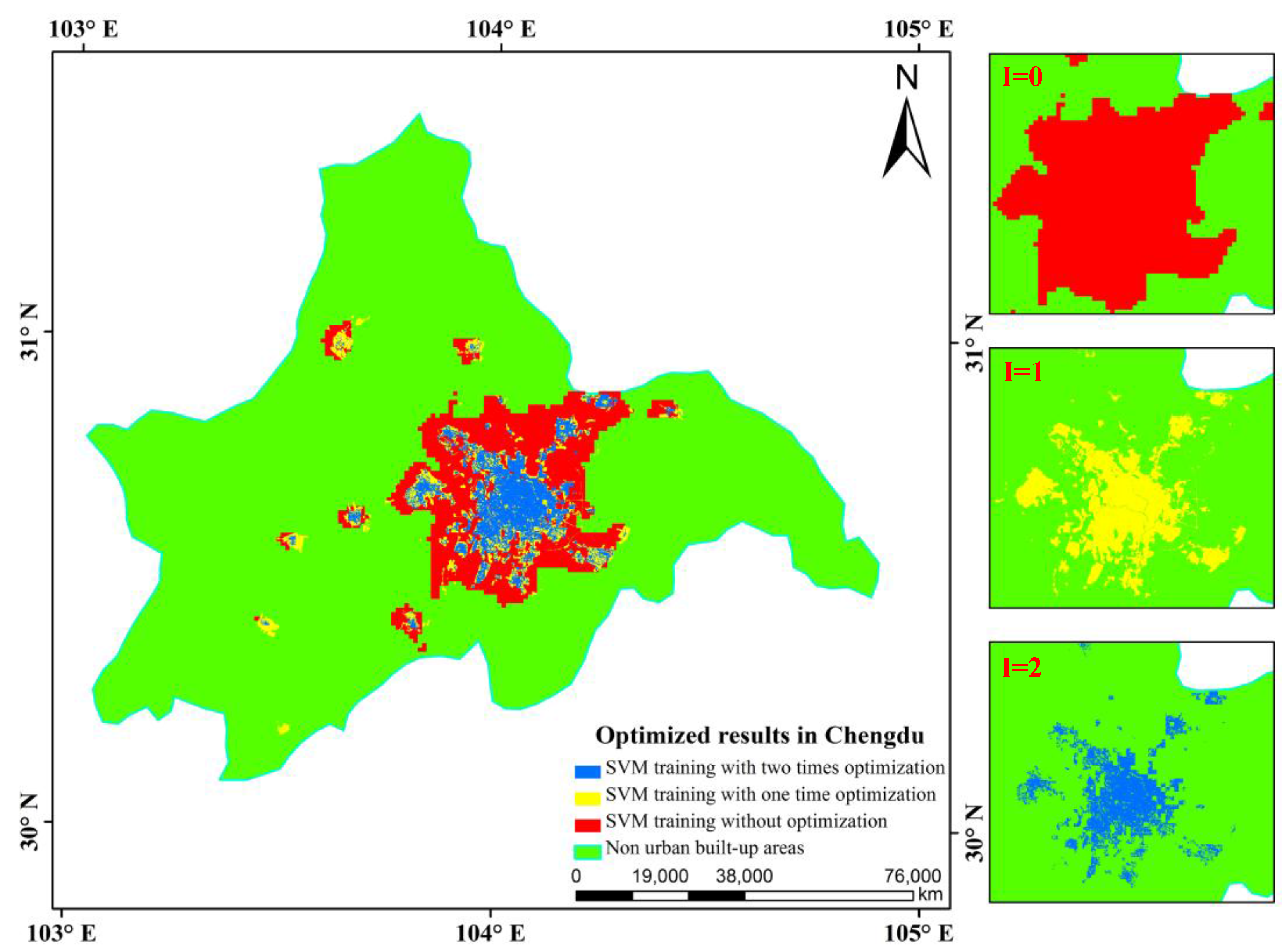
3.2.3. Iterative Classification and Urban Built-Up Area Extraction
When each SVM classification was finished, the total areas of built-up patches were easily calculated from the present and the previous results via the corresponding selected samples, which are denoted as
Areapresent and
Areaprevious, respectively.
θ is defined as the proportion of the area difference between
Areapresent and
Areaprevious to the total area of pattern spots (
Areatotal) in Formula (3):
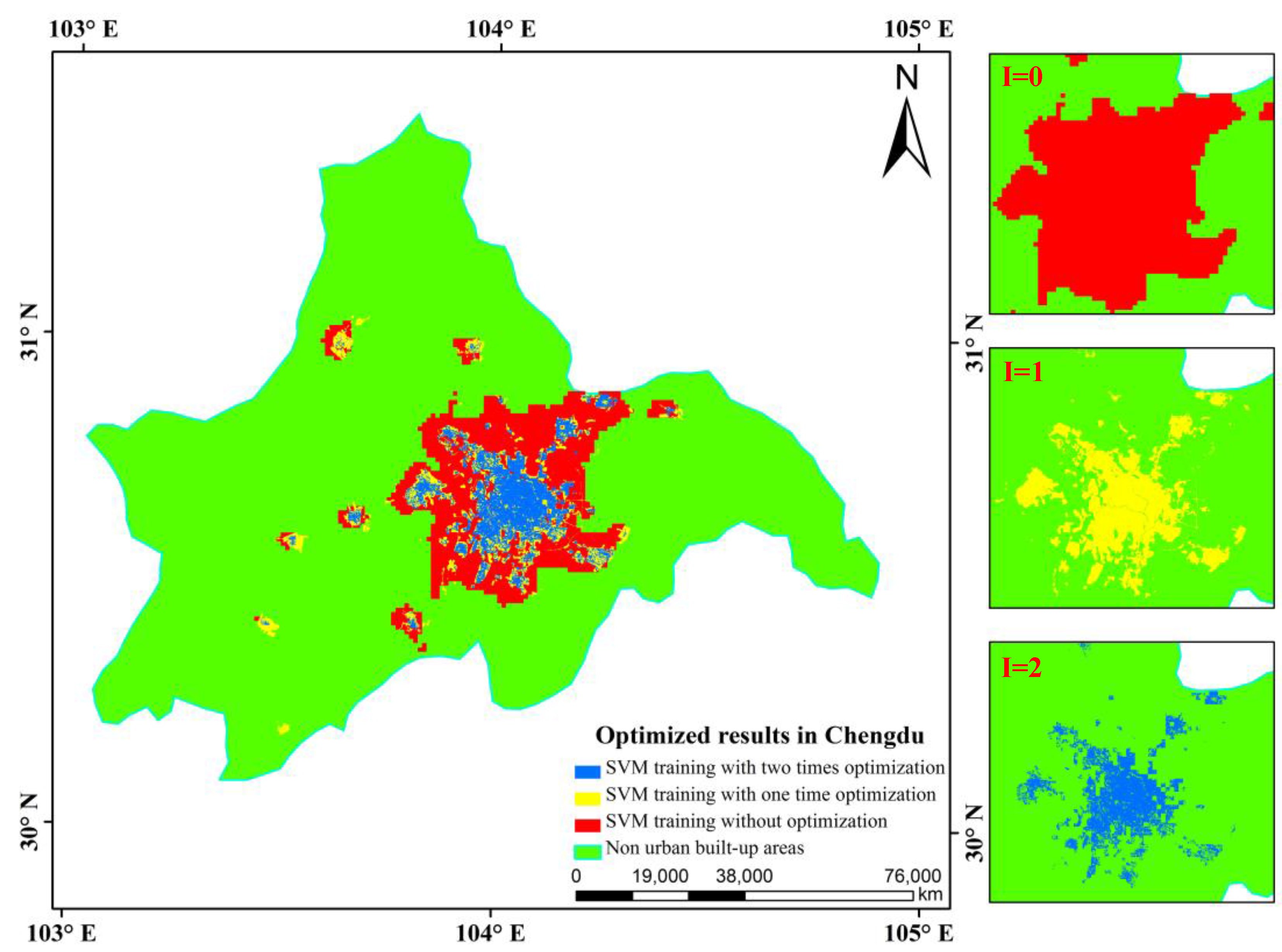
Based on many trials evaluating the relationship among Areapresent, Areaprevious, and θ, the iterative optimization process was conducted until θ finally reached full convergence, such as θ ≤ 0.08, which can guarantee the high accuracy requirement for the actual sample iteration and optimization and allow the continuous sample-optimized classification method to extract the optimal built-up results. This iterative updating procedure increases the rationality and objectivity of classifications and avoids possible problems caused by verbose and repeated processes. Thus, the credibility and ability to automate the classification results are both greatly enhanced.
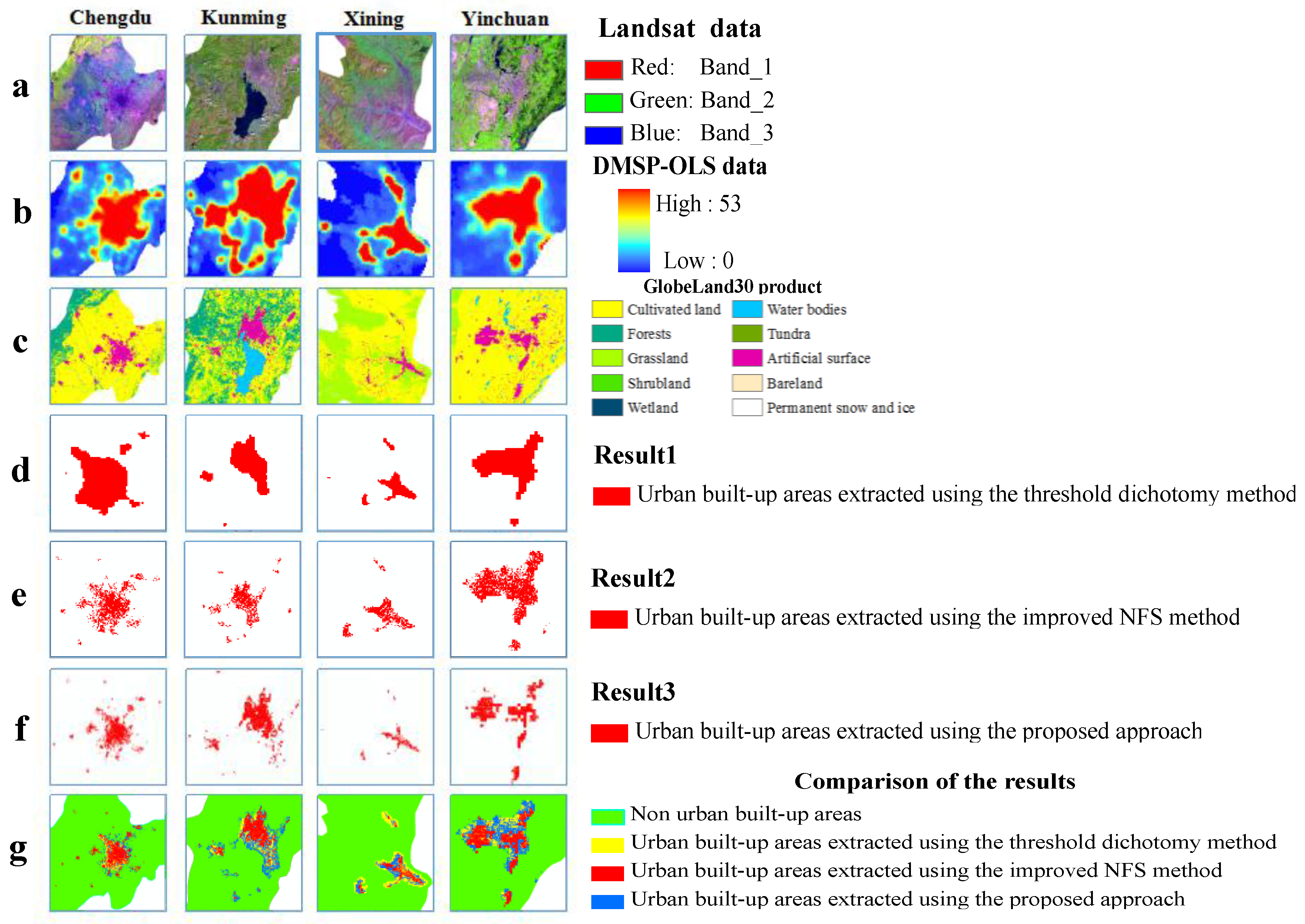
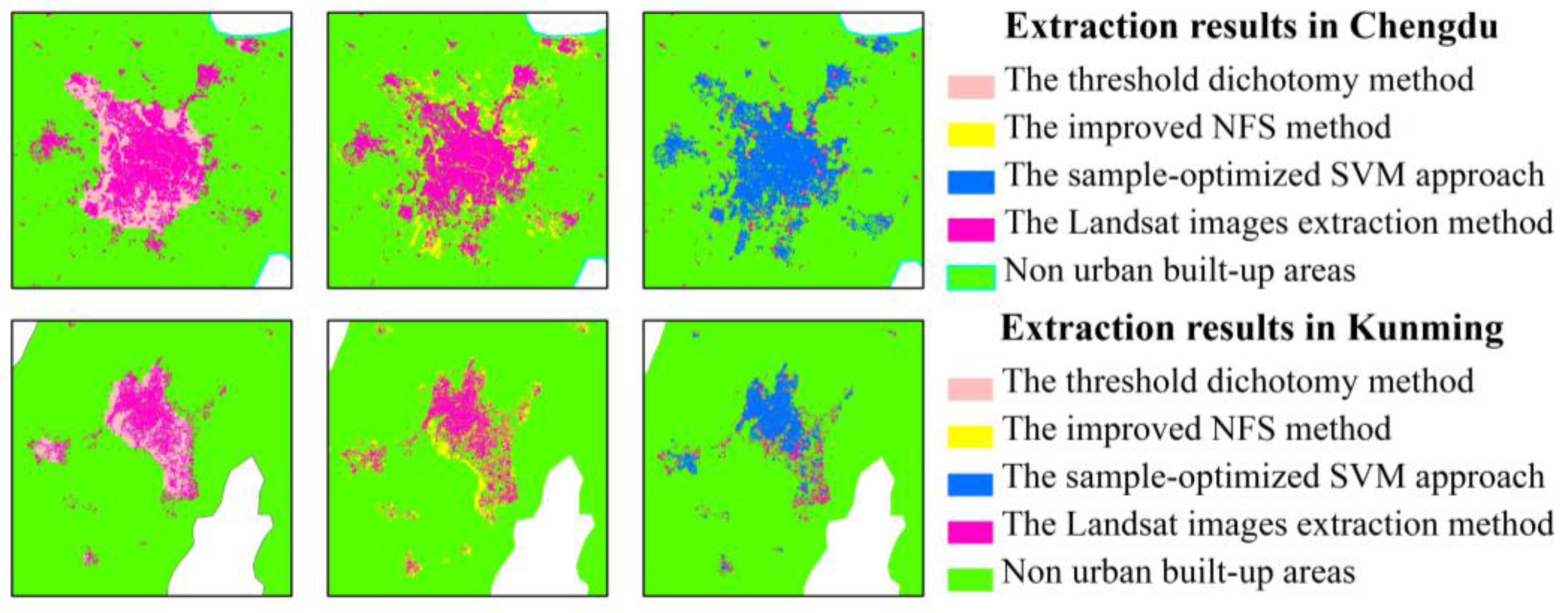
3.3. Two Methods for Experimental Comparison
In our experiments, two data extraction methods were used to compare the performance of the proposed method. The first method was the threshold dichotomy method [
54,
55], which primarily performs continuous circular comparisons between urban land patterns in a spot area and statistical data from the varied nightlight DN values until the urban land pattern spot area is extracted by the specific threshold value that best approximates the statistical data, and this area is where the urban land is ultimately classified. The second method was the improved neighborhood focal statistic (NFS) method [
56], which primarily identifies central and marginal urban areas using maximum and minimum NFS calculations of DMSP-OLS data while eliminating vegetated features and water bodies using multi-source geographic data integration to extract the optimal urban areas. Studies have indicated that both methods are useful for extracting urban built-up area data.
5. Conclusions
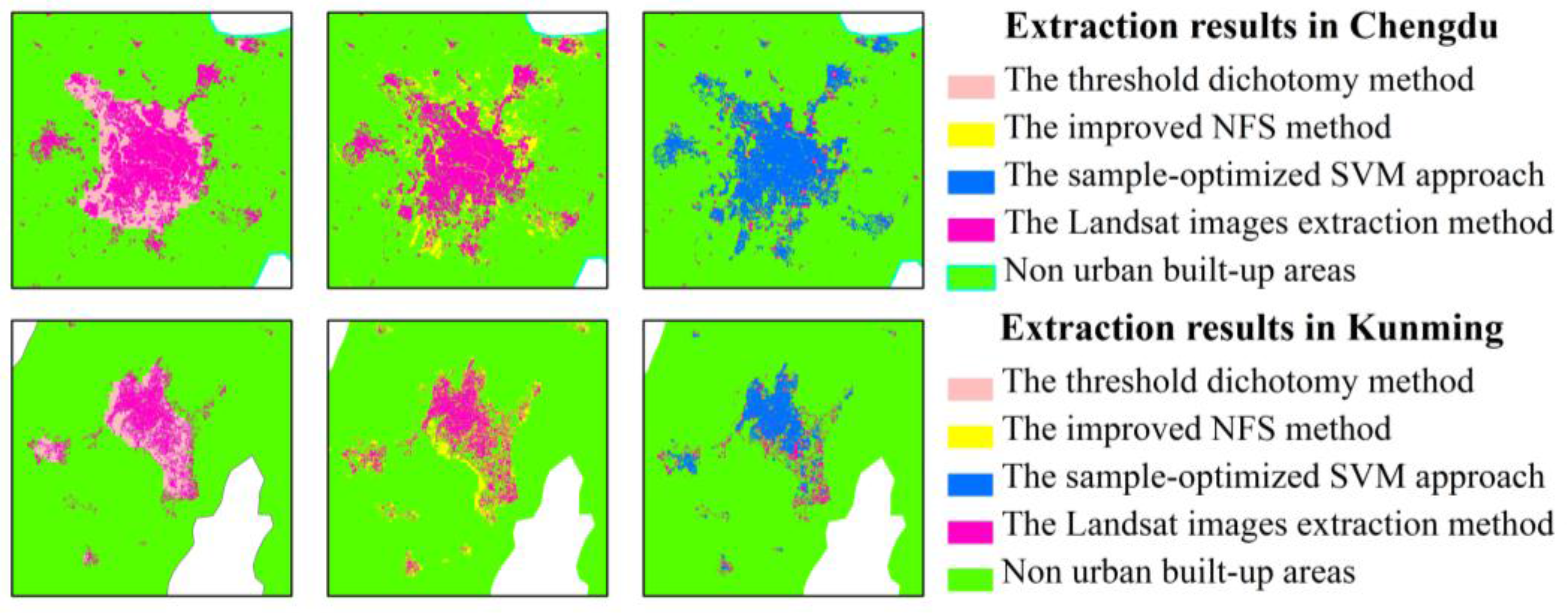
This paper presented a sample-optimized approach for SVM classification based on a combination of DMSP-OLS nighttime light layer data, artificial surface data from the GlobeLand30 product, and vegetated regions from Landsat images, which were used as criteria for the selection of training samples to identify optimized samples that represent built-up areas and non-built-up areas according to an iterative updating procedure. This method can successfully remove the above land-cover categories such as vegetation and bare land from the built-up areas, and obtain the areas which have been developed and constructed with basic municipal utilities and public facilities in the urban administration region. Our proposed approach is novel in the nighttime light data application field and different from other SVM-based extraction methods using DMSP-OLS data in the cited literature. In terms of the overall distribution of extracted built-up urban patches, the samples identified by the proposed method were finer than those of the threshold dichotomy method and the improved NFS method.
An empirical experiment and a detailed accuracy assessment indicated the following: (1) the results extracted using the proposed approach were accurate for pattern spots of urban built-up areas and highly consistent with those extracted using Landsat images in 2010; (2) the results of the experimental comparison with the two other methods confirmed the effectiveness of the proposed approach because it generated improved CE and OE ratios and higher OA and Kappa coefficients; (3) the proposed approach integrates various factor features into the steps of the SVM sample configuration, which is superior to a simple overlay analysis of all the feature layers, and the combination of factor features with the classification probability threshold optimized samples to satisfy the condition requirements for an iterative updating process that can reduce false and misclassification errors; (4) by exploiting the classification accuracy of the GlobeLand30 product, the proposed approach merges the advantages of multi-source remote sensing in representing urban information to obtain highly accurate final urban extraction results. This paper mainly focused on the relationship between DMSP-OLS nighttime light data and the SVM classification; thus, our work is highly specific and unique from an application perspective.
Limitations included the insufficient temporal types in the GlobeLand30 product and the coarse resolution and blooming effect of the DMSP-OLS data; thus, the accuracy of the urban spatial information extracted using the proposed approach requires further investigation. However, this approach optimizes the sample selection process without relying on statistical data and improves the efficiency and precision of SVM classifications. In addition, the proposed method largely avoids the drawbacks associated with using a single data source. The proposed approach is a timely and cost-effective method of monitoring the spatial patterns and temporal dynamics of urban areas as well as geographic conditions on a national scale. In future works, we will devote additional efforts towards improving the proposed approach by investigating spatio-temporal variations in some typical regions, such as ghost towns, as well as regional dynamic monitoring based on updates to the GlobeLand30 products and the availability of additional long time series data.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}