A Modal Logic of Epistemic Games

IRIT-CNRS, Université de Toulouse, 118 route de Narbonne, 31062 Toulouse, France
*
Authors to whom correspondence should be addressed.
Games 2010, 1(4), 478-526; https://doi.org/10.3390/g1040478
Submission received: 11 June 2010
/
Revised: 7 September 2010
/
Accepted: 22 October 2010
/
Published: 2 November 2010
(This article belongs to the Special Issue Epistemic Game Theory and Modal Logic)
Abstract
:We propose some variants of a multi-modal of joint action, preference and knowledge that support reasoning about epistemic games in strategic form. The first part of the paper deals with games with complete information. We first provide syntactic proofs of some well-known theorems in the area of interactive epistemology that specify some sufficient epistemic conditions of equilibrium notions such as Nash equilibrium and Iterated Deletion of Strictly Dominated Strategies (IDSDS). Then, we present a variant of the logic extended with dynamic operators of Dynamic Epistemic Logic (DEL). We show that it allows to express the notion IDSDS in a more compact way. The second part of the paper deals with games with weaker forms of complete information. We first discuss several assumptions on different aspects of perfect information about the game structure (e.g., the assumption that a player has perfect knowledge about the players’ strategy sets or about the preference orderings over strategy profiles), and show that every assumption is expressed by a corresponding logical axiom of our logic. Then we provide a proof of Harsanyi’s claim that all uncertainty about the structure of a game can be reduced to uncertainty about payoffs. Sound and complete axiomatizations of the logics are given, as well as some complexity results for the satisfiability problem.
1. Introduction
The aim of this article is to propose a modal logic framework that allows to reason about epistemic games in strategic form. In this kind of games players decide what to do according to some general principles of rationality while being uncertain about several aspects of the interaction such as other agents’ choices, other agents’ preferences, etc.
While epistemic games have been extensively studied in economics (in the so-called interactive epistemology area, see e.g., [1,2,3,4,5,6]) and while there have been few analyses of epistemic games in modal logic (see, e.g., [3,7,8,9]), no modal logic approach to epistemic games has been proposed up to now that addresses all the following issues at the same time:
- to provide a logic, and a corresponding formal semantics, which is sufficiently general:
- −
- to express solution concepts like Nash Equilibrium or Iterated Deletion of Strictly Dominated Strategies (IDSDS) and to derive syntactically the epistemic and rationality conditions on which such solution concepts are based,
- −
- to study epistemic games both with complete information and with incomplete information;
- to prove its soundness and completeness;
- to study its computational properties like decidability and complexity.
The article is organized in two parts: the first part is focused on strategic games with complete information, while the second one extends the analysis to strategic games with incomplete information.
In Section 2 we present a modal logic, called (Modal Logic of Epistemic Games), that supports reasoning about epistemic games with complete information in which an agent can only have uncertainty about other agents’ current choices. A complete axiomatization and complexity results for this logic are given.
Section 3 is devoted to the analysis in of the epistemic conditions of Nash equilibrium and IDSDS. We use the logic in order to provide syntactic proofs of some well-known theorems in the area of interactive epistemology such as the theorem that specifies some sufficient epistemic conditions of Nash equilibrium in terms of players’ rationality and knowledge about other players’ choices, and the theorem characterizing IDSDS in terms of common knowledge of rationality.
In Section 4 we make dynamic by extending it with constructions of Dynamic Epistemic Logic (DEL) [10,11,12], and we show that this dynamic version of allows to express the notion IDSDS in a more compact way than in the static . A complete axiomatization for this dynamic extension of the logic is given.
In Section 5 we show how our logical framework can be easily adapted in order to study strategic interaction with incomplete information about the game structure. In Section 6 we discuss several assumptions on different aspects of complete information about the game structure (e.g., the assumption that a player has perfect knowledge about the players’ strategy sets or about the players’ preference ordering over strategy profiles). We show that every assumption is expressed by a corresponding logical axiom. Consequently, a class of epistemic games characterized by a specific aspect of complete information about the game structure corresponds to a specific variant of the logic . We present some complexity results for these variants of the logic , that are interesting because they show how complexity of our logic varies from games with complete information to games with incomplete information.
We also provide a formal proof of Harsanyi’s claim that all uncertainty about the structure of a game can be reduced to uncertainty about payoffs. The novel aspect of our contribution is that we prove Harsanyi’s claim in a purely qualitative setting with no probabilities, while existing proofs are given in a quantitative setting with probabilities (see, e.g., [13]).
Proofs of theorems are given in an Annex at the end of the article.
Before concluding this introduction, we would like to emphasize an aspect of our work that could be interesting for a game-theorist.
As the logics presented in this paper are sound and complete, they allow to study strategic interaction both at the semantic level and at the syntactic level. In this sense, they provide a formal framework which unifies two approaches traditionally opposed by authors working in the area of formal interactive epistemology: the semantic approach and the syntactic approach.1 However, it is worth noting that syntactic derivations of various results concerning the epistemic foundations of game theory are not interesting in itself. Instead, this kind of analysis is useful to identify specific features that are important for the foundations of game theory, for example whether certain assumptions on the players’ knowledge are indeed necessary to prove results concerning the epistemic conditions of equilibrium notions such as Nash equilibrium and IDSDS. Typical assumptions on players’ knowledge are for example the assumption that knowledge is positively and negatively introspective (i.e. if I know that φ is true then I know that I know that φ is true, and if I do not know that φ is true then I know that I do not know that φ is true), the factivity principle that knowing that φ implies that φ is true, or the assumption that a player has perfect knowledge about some aspects of the game such as the players’ strategy sets and the players’ preference ordering over strategy profiles.
2. A logic of joint actions, knowledge and preferences
We present in this section the multi-modal logic (Modal Logic of Epistemic Games) integrating the concepts of joint action, knowledge and preference. This logic supports reasoning about epistemic games in strategic form in which an agent might be uncertain about the current choices of the other agents.
2.1. Syntax
The syntactic primitives of are the finite set of agents , the set of atomic formulas , a nonempty finite set of atomic action names . Non-empty sets of agents are called coalitions or groups, noted . We note the set of coalitions.
To every agent we associate the set of all possible ordered pairs agent/action , that is, . Besides, for every coalition C we note the set of all joint actions of this coalition, that is, . Elements in are C-tuples noted , , , . If , we write Δ instead of . Elements in Δ are also called strategy profiles. Given , we note the element in δ corresponding to agent i. Moreover, for notational convenience, we write .
The language of the logic is given by the following rule:
where p ranges over , i ranges over , and ranges over . The classical Boolean connectives ∧, →, ↔, ⊤ (tautology) and ⊥ (contradiction) are defined from ∨ and ¬ in the usual manner. We also follow the standard rules for omission of parentheses.
The formula reads “if coalition C chooses the joint action then φ holds”. Therefore, reads “coalition C does not choose the joint action ”.
is a necessity operator which enables to quantify over possible joint actions of all agents, that is, over the strategy profiles of the current game (the terms “joint actions of all agents" and “strategy profiles" are supposed here to be synonymous). reads “φ holds for every alternative strategy profile of the current game”, or simply “φ is necessarily true”.
Operators are standard epistemic modal operators. Construction is read as usual “agent i knows that φ is true”, whereas the construction is read “φ is true in all worlds which are for agent i at least as good as the current one concerning the strategy profile that is chosen”. We define as an abbreviation of . Operators are used in to define agents’ preference orderings over the strategy profiles of the current game. Similar operators are studied by [14] (see Section 3.1 for a discussion).
We use as an abbreviation of , i.e. every agent in C knows φ (if then is equivalent to ⊤). Then we define by induction for every natural number :
and for all ,
We define for all natural numbers , as an abbreviation of . expresses C’s mutual knowledge that φ up to n iterations, i.e., everyone in C knows φ, everyone in C knows that everyone in C knows φ, and so on until level n.
Finally, abbreviates , abbreviates and abbreviates . means “φ is possibly true”. Therefore reads “coalition C chooses the joint action and φ holds”, and simply reads “coalition C chooses the joint action ”.
The operator and the operators can be combined in order to express what a coalition of agents can do. In particular, has to be read “coalition C can choose the joint action ”. For the individual case, has to be read “agent i can choose action a” or also “action a is in the strategy set (action repertoire) of agent i”. Furthermore, is read “coalition can choose the joint action (strategy profile) δ” or also “δ is a strategy profile of the current game”.
2.2. Semantics
In this subsection, we introduce a Kripke-style possible world semantics of our logic .
Definition 1 (-frames)
-frames are tuples where:
- W is a nonempty set of possible worlds or states;
- ∼ is an equivalence relation on W;
- R is a collection of total functions one for every coalition , mapping every world in W to a joint action of the coalition such that:
- C1
- if and only if for every , ,2
- C2
- if for every there is such that and then there is a v such that and ;
- maps every agent i to an equivalence relation on W such that:
- C3
- if , then if and only if ,
- C4
- if then ;
- maps every agent i to a reflexive, transitive relation on W such that:
- C5
- if then ,
- C6
- if and then or .
means that coalition C performs the joint action at world w.
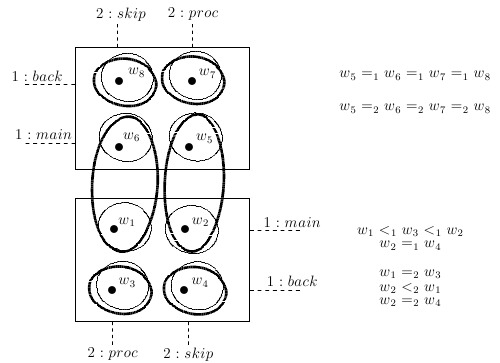
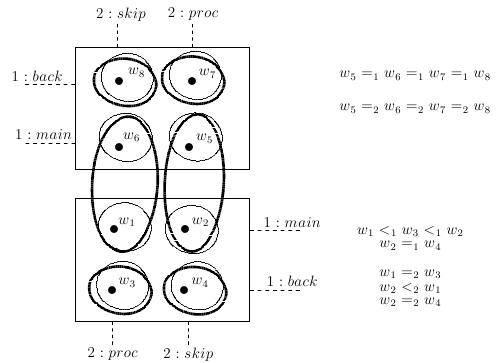
If then w and v correspond to alternative strategy profiles of the same game. For short, we say that v is alternative to w. Given a world w, we use the notation to denote the equivalence class made up of those worlds corresponding to alternative strategy profiles of the game of which w is one of the strategy profile. Consider e.g., and . In the frame in Figure 1 we have . This means that the joint action performed at (viz. ) and the one performed at (viz. ) are alternative strategy profiles of the same game defined by the equivalence class .
For every , if there exists such that C performs at v then we say that is possible at w (or can be performed at w).
means that, for agent i, world v is (epistemically) possible at w, whilst means that for agent i, world v is at least as good as world w. We write iff and , and iff and not .
Let us discuss the semantic constraints in Definition 1.
Figure 1.
The equivalence class represents the Prisoner’s Dilemma game [15] between two players 1 and 2 (action c stands for `cooperate’ and action d stands for `defect’). Thick ellipses are epistemic relations for 1, thin ellipses are epistemic relations for 2 (both 1 and 2 are uncertain about the other’s action).
Figure 1.
The equivalence class represents the Prisoner’s Dilemma game [15] between two players 1 and 2 (action c stands for `cooperate’ and action d stands for `defect’). Thick ellipses are epistemic relations for 1, thin ellipses are epistemic relations for 2 (both 1 and 2 are uncertain about the other’s action).
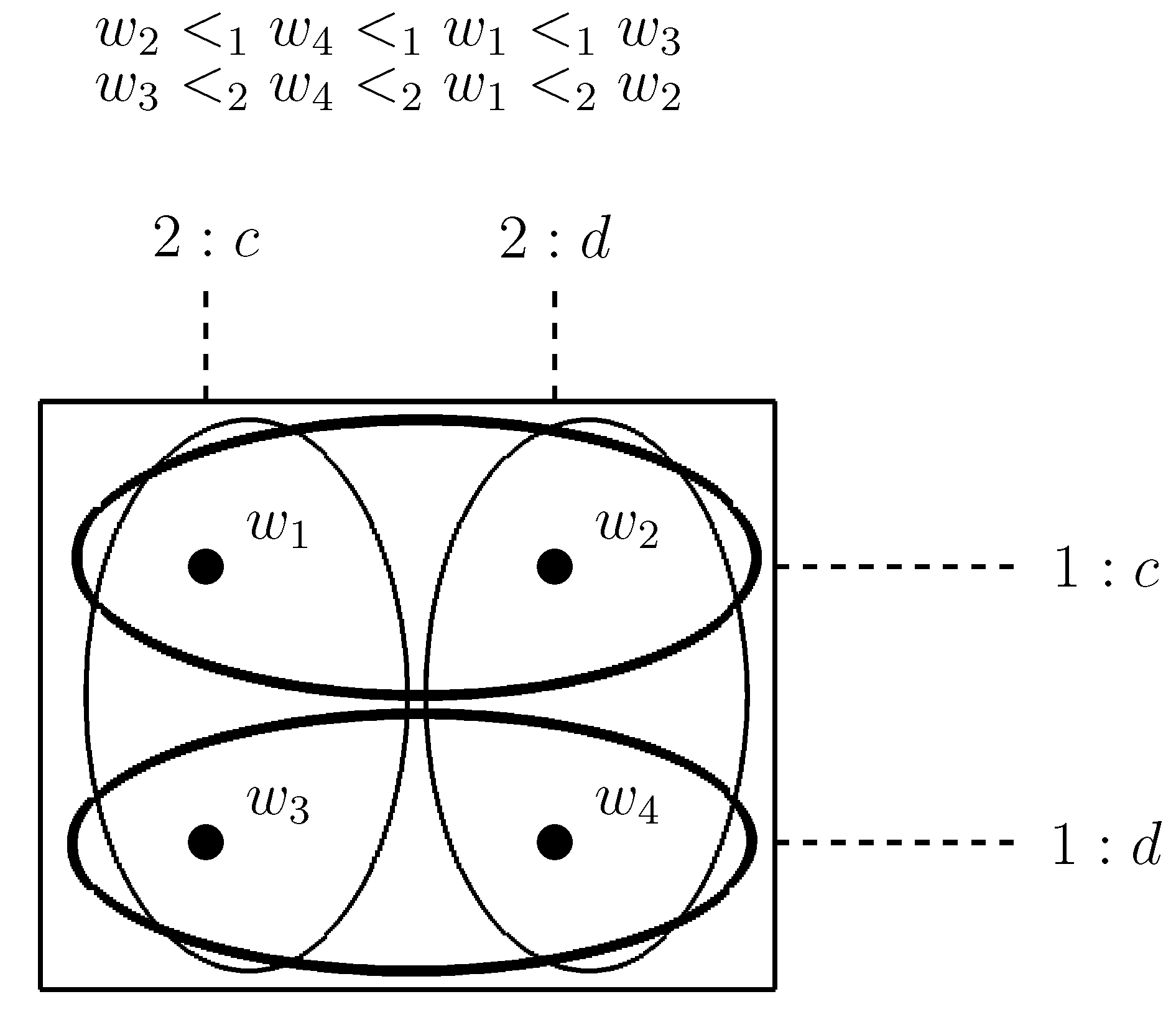
According to Constraint C1, at world w coalition C chooses the joint action if and only if, every agent i in C chooses the action at w. In other words, a certain joint action is performed by a coalition if and only if every agent in the coalition does his part of the joint action. According to the Constraint C2, if all individual actions in a joint action δ are possible at world w, then their simultaneous occurrence is also possible at world w.
Constraint C3 just says that an agent knows what he has decided to do. This is a standard assumption in interactive epistemology and epistemic analysis of games (see [3] for instance).
We suppose complete information about the specification of the game, including the players’ strategy sets (or action repertoires) and the players’ preference ordering over strategy profiles. This assumption is formally expressed by the Constraint C4: if world v is epistemically possible for agent i at w, then w and v correspond to alternative strategy profiles of the same game. Complete information about the structure of the game is a standard assumption in game theory. In Section 5, this assumption will be relaxed in order to deal with realistic situations in which an agent might be uncertain about his own utility and other agents’ utilities associated to a certain strategy profile, as well as about his own action repertoire and other agents’ action repertoires.
Finally, we have two constraints over the relations . We suppose that a world v is for agent i at least as good as w only if v is a world which is possible at w, i.e., only if v and w correspond to alternative strategy profiles of the same game (Constraint C5). Furthermore, we suppose that every agent has a complete preference ordering over the strategy profiles of the current game (Constraint C6).
Remark. Note that in the case of complete information (Constraint C4) the relation ∼ is superfluous because all other relations are included into ∼ (Constraints C5 and C6). So in this case we can suppose ∼ to be the universal relation and to be the well-known universal modality.3 We decided to introduce the relation ∼ in this part of the paper in order to be able to generalize the definition of model in the case of incomplete information (see Section 5). In fact, in the case of games with incomplete information, a player can imagine alternative games and there is no one-to-one correspondence between models and games (i.e., every model does not necessarily correspond to a unique strategic game). Therefore, the relation ∼ can no longer be supposed to be the universal relation.
Definition 2 (-models)
-models are couples where:
- F is a -frame;
- is a valuation function.
The truth conditions for Boolean operators and for operators , , and are:
- iff ;
- iff not ;
- iff or ;
- iff if then ;
- iff for all v such that ;
- iff for all v such that ;
- iff for all v such that .
2.3. Axiomatization and Complexity Results
We call the logic that is axiomatized by the principles given in Figure 2.
Note that the principles of modal logic S5 for the operator are: the four axiom schemas (K) , (T) , (4) , (B) , and the rule of inference (Necessitation) . The principles of modal logic S5 for the operators are: the four axiom schemas (K) , (T) , (4) , (B) , and the rule of inference (Necessitation) . The principles of modal logic S4 for the operators are: the three axiom schemas (K) , (T) , (4) , and the rule of inference (Necessitation) .
Note also that Axiom Indep is the counterpart of the so-called axiom of independence of agents of STIT logic (the logic of Seeing to it that) [19]. This axiom enables to express the basic game theoretic assumption that the set of strategy profiles of a game in strategic form is the cartesian product of the sets of individual actions for the agents in .
Figure 2.
Axiomatization of
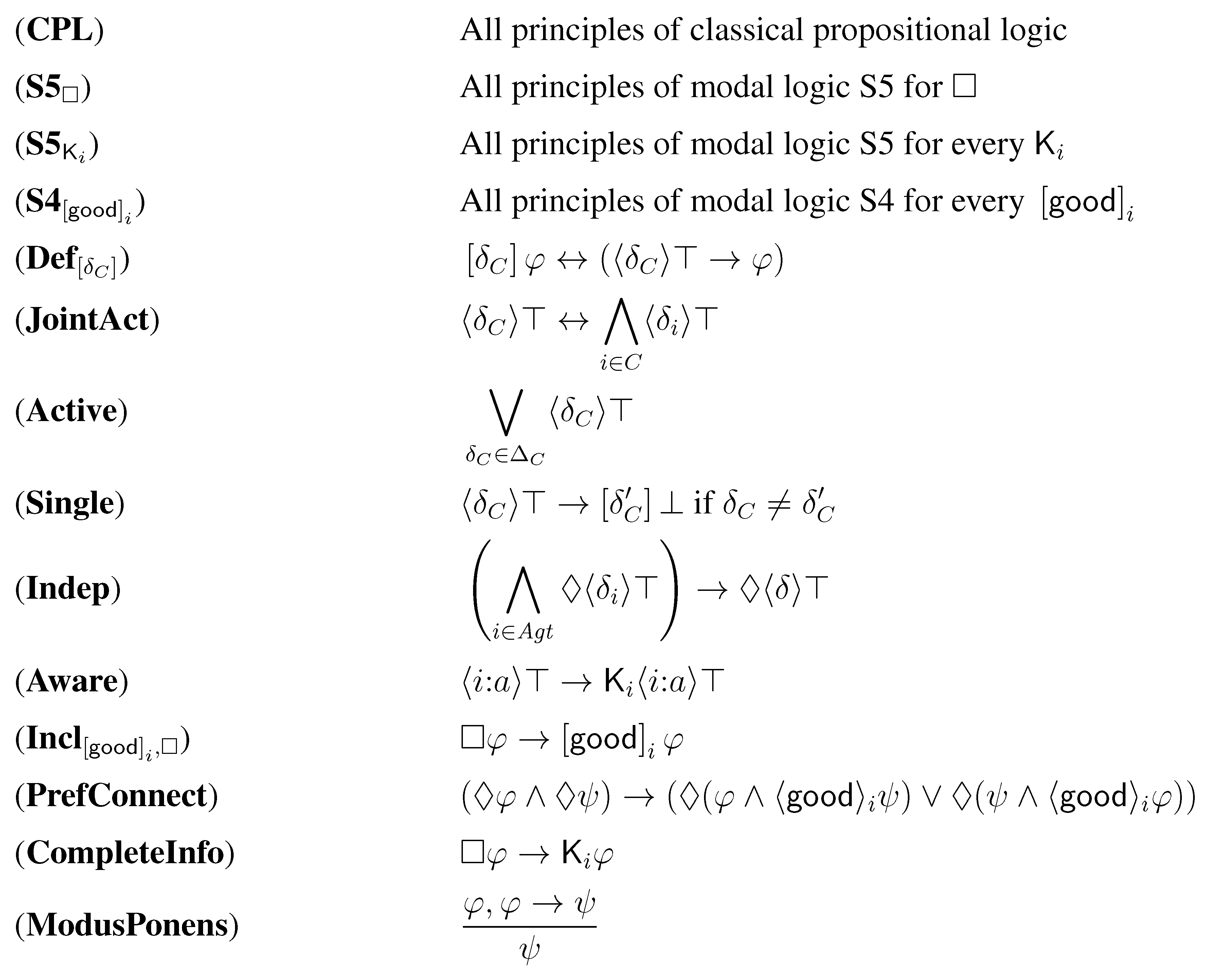
We write if φ is a theorem of , that is, if φ can be deduced by applying the axioms and the rules of inference of the logic .
As the following Theorem 1 highlights, we can prove that the logic is sound and complete with respect to the class of -models.
Theorem 1. is determined by the class of -models.
Moreover we can prove a result about complexity of the satisfiability problem of the logic , that is, the complexity of the problem of deciding whether a given formula φ is -satisfiable or not. Here, we give a lower-bound and upper-bound for the complexity of the satisfiability problem (for more information about complexity theory, the reader may refer to [20]):
Theorem 2. If the number of agents is greater of equal to 2, the satisfiability problem of is EXPTIME-hard and in NEXPTIME.
We conjecture that the satisfiability problem of is EXPTIME-complete. Indeed, we think that this can be proved by the argument used for proving that the satisfiability problem of S5 with common knowledge [21] and the satisfiability problem of propositional dynamic logic (PDL) [22] are EXPTIME-complete.
2.4. A Variant of with Joint Determinism
We present here a variant of where models have an additional constraint of determinism for the joint actions of all agents: different worlds in an equivalence class correspond to the occurrences of different strategy profiles:
- CD
- if and and , then ;
A -model satisfying the constraint CD is called a -model.
The axiom corresponding to the Constraint CD is:
- (JointDet)
We call the logic that is axiomatized by the principles given in Figure 2 plus axiom JointDet.
Theorem 3. is determined by the class of -models.
Although the Constraint CD excludes pure uncertainty about uncertainty (i.e., cases where the same profile is played at two states on the basis of different information), it is interesting because it allows to establish a connection between our logical framework and Coalition Logic (CL) [23,24], where it is assumed that if every agent in opts for an action the next state of the world is uniquely determined. As shown in [25], the logic extended by the operator next of linear temporal logic (LTL) embeds Coalition Logic (CL) [23,24]. In particular, if we extend by the temporal operator (where means “φ will be true in the next state”) CL cooperation modalities of the form can be reconstructed in our logic as follows.
That is, the CL expression “coalition C can enforce an outcome state satisfying φ” (noted ) is translated in our logic as “there exists a joint action of the agents in C such that the agents in C can perform , and necessarily if the agents in C perform then φ will be true in the next state, no matter what the agents outside C do”.
Remark. It is worth noting that, while embeds Coalition Logic, the basic logic embeds Chellas’ STIT logic with agents and groups [26], under the hypothesis that the number of agents’ choices is bounded (see [27] for more details). In fact, differently from Coalition Logic, in STIT joint actions of all agents are not necessarily deterministic. STIT logic has formulas of the form that are read “group C sees to it that φ". The translation of STIT modalities of the form into would be the following:
That is, the STIT expression “group C sees to it that φ” is translated into as “there exists a joint action of the agents in C such that the agents in C perform , and necessarily if the agents in C perform then φ will be true, no matter what the agents outside C do”.
The constraint of joint determinism CD is also useful for complexity reasons. Indeed, if we add CD to our logic, the complexity of the satisfiability problem drops to NP.
Theorem 4. The satisfiability problem of is NP-complete.
3. A logical account of epistemic games
This section is devoted to the analysis in the modal logic of the epistemic aspects of strategic games. We first consider the basic game-theoretic concepts of best response and Nash equilibrium, and their relationships with the notion of epistemic rationality assumed in classical game theory. Finally, we provide an analysis of Iterated Deletion of Strictly Dominated Strategies (IDSDS).
3.1. Best Response and Nash Equilibrium
The modal operators and enable to capture in a notion of comparative goodness over formulas of the kind “φ is for agent i at least as good as ψ”, noted :
According to the previous definition, φ is for agent i at least as good as ψ if and only if, for every world v corresponding to a strategy profile of the current game in which ψ is true, there is a world u corresponding to a strategy profile of the current game in which φ is true and which is for agent i at least as good as world v. We can prove that is a total preorder. Indeed, the formulas (reflexivity), (transitivity) and (connectedness, also called completeness) are valid in . We define the corresponding strict ordering over formulas:
Formula has to read “φ is for agent i strictly better than ψ”. Finally, we define a notion of comparative goodness over strategy profiles and the corresponding strict ordering over strategy profiles:
Formula has to be read “strategy profile is for agent i at least as good as strategy profile δ” and formula has to be read “strategy profile is for agent i strictly better than strategy profile δ”.
Some basic concepts of game theory can be expressed in in terms of comparative goodness. We first consider best response. Agent i’s action a is said to be a best response to the other agents’ joint action , noted , if and only if i cannot improve his utility by deciding to do something different from a while the others choose the joint action , that is:
Remark. Note that the definition of best response given above only works for a complete preference relation . To see why, suppose that and , and consider the model such that , , , and . Here the relation does not satisfy the constraint C6 (i.e., is not complete). Intuitively, should be true at any world of because if i plays a while j plays a, he does not improve his utility by playing b. Nevertheless, as is false at any world of , we have that is also false at every world of .
Given a certain strategic game, the strategy profile (or joint action) δ is said to be a Nash equilibrium if and only if for every agent , i’s action is a best response to the other agents’ joint action :
From Axiom CompleteInfo, S5 for , Axioms K and T for the five -theorems in Lemma 1 are provable. They express complete information about the players’ preferences ordering over strategy profiles, complete information about the existence of a Nash equilibrium, and complete information about the players’ action repertoires. Surprisingly formulas of Lemma 1 are kinds of introspection properties, but they are provable without axioms of positive and negative introspections for knowledge: (4) or (5) .
Proposition 1. For all and :
It has to be noted that weak preference operators , used here to define some basic concepts of game theory, have been studied before by [14,17] and by [18], where complete axiomatizations for different kinds of preference logics and for a combination of preference logic with epistemic logic are given. In [14,17] Liu proposed a complete modal logic of knowledge and preference extended by dynamic operators of knowledge update and preference upgrade in the style of dynamic epistemic logic (DEL). In [18] van Benthem et al. studied different variants of preference logic that allow to express different readings of ceteris paribus preferences [28]. They first present a basic modal logic of weak and strict preference which allows to express the “all other things being normal” reading of ceteris paribus preferences. Then they present a more general modal logic in which modal operators of weak and strict preference are relativized to sets of formulas representing conditions to be kept equal. They show that this logic allows to express the “all other things being equal” reading of ceteris paribus preferences and to characterize the notion of Nash equilibrium as a preference for a given strategy profile for a game, given that others keep the same strategy. 4 One of the main contribution of our work is to propose a modal logic which integrates the notion of weak preference studied by Liu and van Benthem et al. with notions of action and knowledge, and which provides a suitable framework for a logical analysis of epistemic strategic games both with perfect information and with weaker forms of perfect information. The latter are the subject of the second part of the paper (Section 5 and Section 6).
3.2. Epistemic Rationality
The following formula characterizes a notion of rationality which is commonly supposed in the epistemic analysis of games (see, e.g., [4,7]):
This means that an agent i is rational if and only if, if he chooses a particular action a then for every alternative action b, there exists a joint action of the other agents that he considers possible such that, playing a while the others play is for i at least as good as playing b while the others play . This means that epistemic rationality simply consists in not choosing a strategy that is strictly dominated within the agent’s set of epistemic alternatives.
As formula and formula are equivalent in , the previous definition of rationality can be rewritten in the following equivalent form:
Theorem 5. For all :
- (5a)
- (5b)
Theorem 5 highlights that the concepts of rationality and irrationality are introspective. That is, an agent i is (resp. is not) epistemically rational if and only if he knows this. The syntactic proof of Theorem 5a given in the annex shows that it can be proved either by means of Axioms K, T, 4 and 5 for knowledge or by means of Axioms K, T and 5 for knowledge and a principle of introspection over preferences of the form “”. Theorem 5b is provable from Theorem 5a by means of Axioms T and 5 for knowledge.
The following theorem specifies some sufficient epistemic conditions of Nash equilibrium: if all agents are rational and every agent knows the choices of the other agents, then the selected strategy profile is a Nash equilibrium. This theorem has been stated for the first time by Aumann & Brandeburger [1,5].
Theorem 6. For all :
The syntactic proof of Theorem 6 in the annex at the end of the paper shows that it can be proved just by means of Axioms K and T for the epistemic modal operators. Axiom CompleteInfo, positive and negative introspection for knowledge ( and ) are not needed for the proof.
3.3. Iterated Deletion of Strictly Dominated Strategies
A strategy a for agent i is a strictly dominated strategy, noted , if and only if, if a can be performed then there is another strategy b such that, no matter what joint action the other agents choose, playing b is for i strictly better than playing a:
An example of strictly dominated strategy is cooperation in the Prisoner Dilemma (PD) game: whether one’s opponent chooses to cooperate or defect, defection yields a higher payoff than cooperation. Therefore, a rational player will never play a dominated strategy. So when trying to predict the behavior of rational players, we can rule out all strictly dominated strategies. The so-called Iterated Deletion of Strictly Dominated Strategies (IDSDS) (or iterated strict dominance) [15] is a procedure that starts with the original game and, at each step, for every player i removes from the game all i’s strictly dominated strategies, thereby generating a subgame of the original game, and that repeats this process again and again. IDSDS can be inductively characterized in our logic by defining a concept of strict dominance in the subgame of depth at most n, noted . For every :
where is defined as follows
for every and for every . According to this definition, a is a strictly dominated strategy for agent i in a subgame of depth at most n, noted , if and only if, if a is not strictly dominated for i in all subgames of depth then there is another strategy b such that b is not strictly dominated for i in all subgames of depth and, no matter what joint action the other agents choose, if the elements in are not dominated in all subgames of depth then playing b is for i strictly better than playing a. In other terms means that strategy does not survive after n rounds of IDSDS. We can prove by recurrence on n that the length of the formula is
where is the “Big Oh Notation” [20], is the number of actions and is the number of agents and n is the number of rounds of IDSDS. That is, the length of the formula is exponential in n. In Section 4, we are going to extend the language of in order to capture the concept of IDSDS with a more compact formula.
As the following -theorems highlight, the truth of depends on the game but does not depend on the world where the formula is evaluated.
Proposition 2. For all , for all , we have:
- ;
- .
The following Theorem 7 is the qualitative version of a probabilistic- based result of Stalnaker [29] who has been the first to use probabilistic Kripke structures in order to characterize the IDSDS procedure in terms of common knowledge of rationality (see [3,30] for some recent discussion of Stalnaker’s results). A similar result was also proved, with differing degrees of formality, by Bernheim [31], Pearce [32], Brandenburger & Dekel [33], and Tan & Werlang [34]. Note that Stalnaker’s proof is purely semantic. According to the Theorem 7, if there is mutual knowledge of rationality among the players to n levels and the agents play the strategy profile δ then, for every agent i, survives IDSDS until the subgame of depth .
Theorem 7. For all positive integer n, for all , we have:
(note that is just the abbreviation of ).
The syntactic proof of Theorem 7 given in the annex shows that, although Axiom CompleteInfo, positive and negative introspection for knowledge ( and ) are not needed for the proof, we need to assume that a player has complete information about the players’ strategy sets as well as about the players’ preference ordering over strategy profiles.
Table 1 summarizes the sufficient conditions for the syntactic proof of Theorem 7 together with the sufficient conditions for the syntactic proofs of Theorems 5 and 6. It highlights an interesting aspect of our syntactic analysis of games based on modal logic: the fact that we can easily verify whether certain assumptions about knowledge and information over the game structure are indeed necessary to prove results concerning the epistemic foundations of game theory.
It has to be noted that Theorem 7 provides only one direction of the characterization result for the IDSDS procedure as formulated in the game-theoretic literature, according to which IDSDS is fully characterized by the epistemic condition of common knowledge of rationality between the players (see, e.g., [3,29,30]).
The other direction states approximately that, for every strategic game, if δ is the strategy profile that is chosen and that survives to the infinite procedure IDSDS, then there is (a state in) an epistemic model for that game in which the profile δ is played and the players have common knowledge of rationality.
This statement is formally expressed by the following theorem (a similar result is proved in [3]).
Theorem 8. Consider an arbitrary -model , a world w in M and such that for all positive integers n we have . Then, there is a model such that for all positive integers n we have .
The idea is that, for every strategic game, if δ is the strategy profile of this game which is chosen and that survives after n rounds of the procedure IDSDS, for all positive integers n, then it is possible to find an “epistemic configuration” for the players which satisfies common knowledge of rationality between the players. In other words, if δ is a strategy profile of a given strategic game that survives after all rounds of the procedure IDSDS then it is always possible to justify the choice of δ by the fact that the players have common knowledge of rationality.

{kind=link}
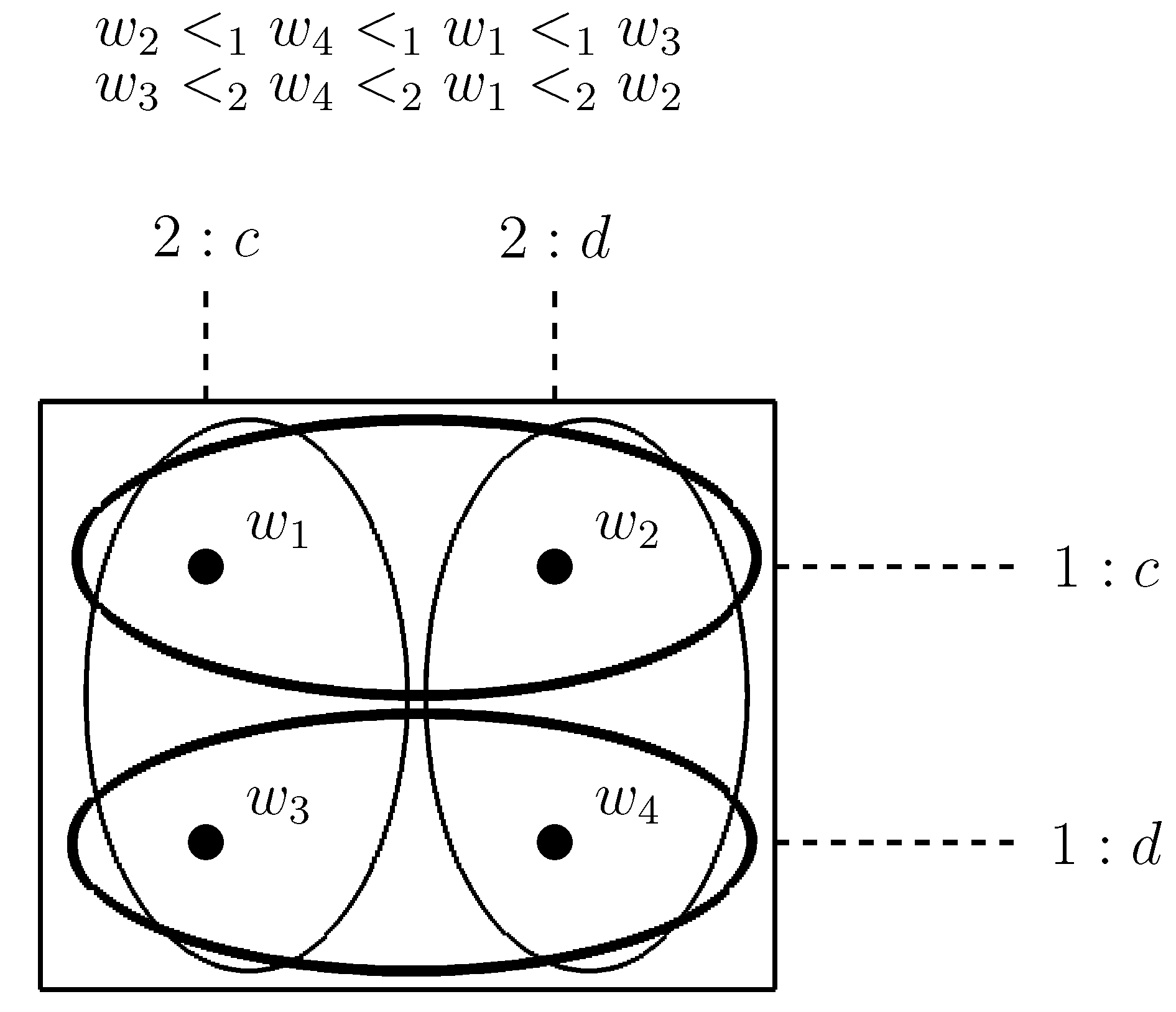{kind=link}
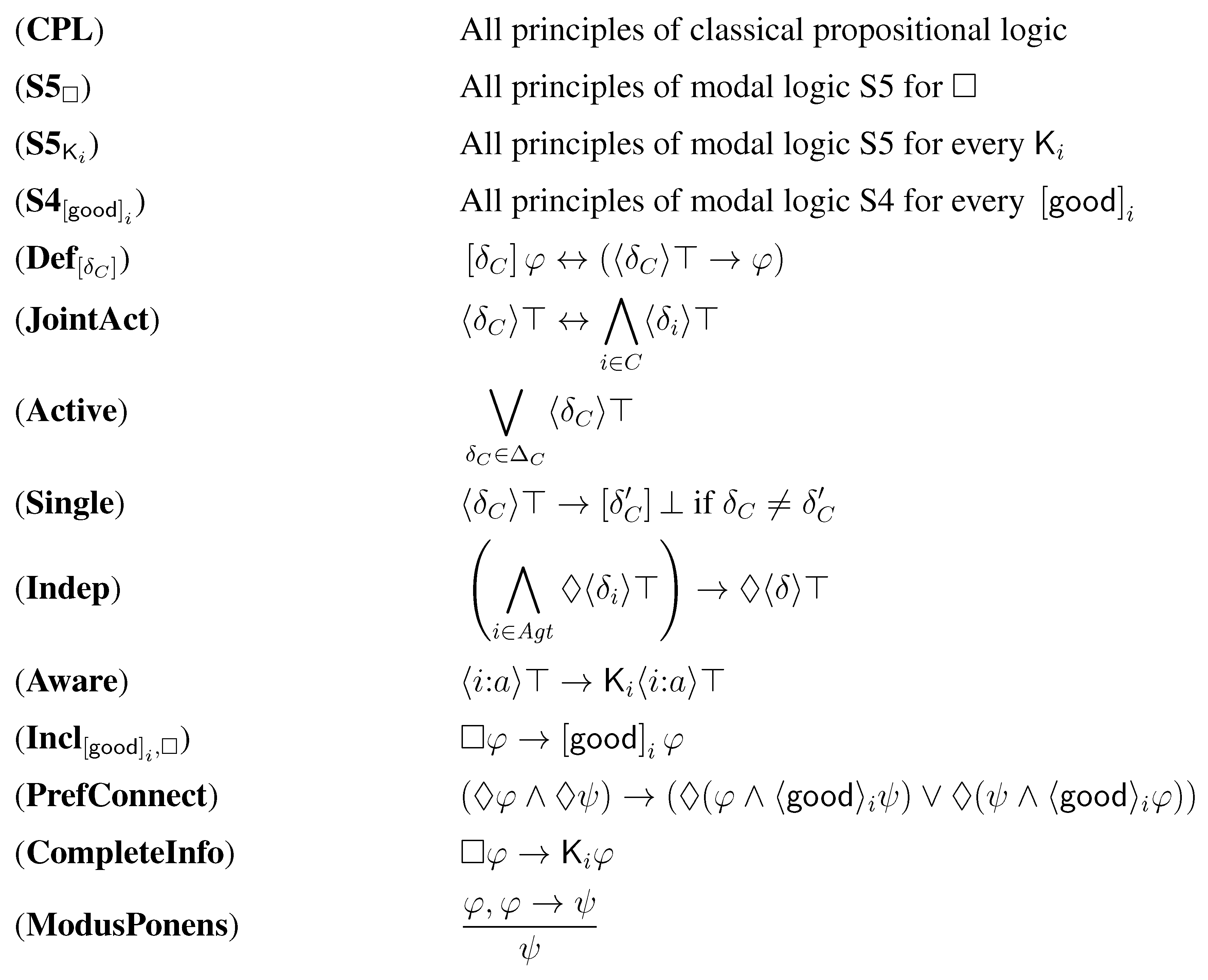{kind=link}
{kind=link}
| Assumptions about knowledge operators | Assumptions about information | Result |
| over game structure | ||
| KT45 | none | Theorem 5 |
| KT5 | introspection over preferences: | Theorem 5 |
| KT | none | Theorem 6 |
| KT | complete information about | Theorem 7 |
| players’ preference ordering | ||
| over strategy profiles: | ||
| complete information about | ||
| players’ strategy sets: | ||
Note that Theorem 8 is different from stating that the logic cannot prove the negation of conjunctions of this type: a given profile δ is played, survives after n rounds of IDSDS and rationality of players is common knowledge up to degree n. By the completeness of this just means that the conjunction is consistent in . Indeed, the latter trivially holds, as we can always exhibit the trivial model such that , and for every , and in which holds for every n.
3.4. Discussion: Related Works on Modal Logic Analysis of Epistemic Games under Complete Information
Although several modal logics of games in strategic forms have been proposed in recent times (see, e.g., [25,35]), few modal logics of epistemic games under complete information exist. Among them we should mention [3,8,9,36]. Let us compare our modal logic with some of these alternative approaches.
De Bruin [8] has developed a logical framework which enables to reason about the epistemic aspects of strategic games and of extensive games. His system deals with several game-theoretic concepts like the concepts of knowledge, rationality, Nash equilibrium, iterated strict dominance, backward induction. Nevertheless, de Bruin’s approach differs from ours in several respects. First of all, our logical approach to epistemic games is minimalistic since it relies on few primitive concepts: knowledge, action, historical necessity and preference. All other notions such Nash equilibrium, rationality, iterated strict dominance are defined by means of these four primitive concepts. On the contrary, in de Bruin’s logic all those notions are atomic propositions managed by a ad hoc axiomatization (see, e.g., ([8], pp. 61,65) where special propositions for rationality and iterated strict dominance are introduced). Secondly, we provide a semantics and a complete axiomatization for our logic of epistemic games. De Bruin’s approach is purely syntactic: no model-theoretic analysis of games is proposed nor completeness result for the proposed logic is given. Finally, de Bruin does not provide any complexity results for his logic while we provide complexity results for the satisfiability problem of our logic.
In [36] van der Hoek & Pauly investigate how modal logics can be used to describe and reason about games. They show how epistemic logic can be combined with constructions expressing agents’ preferences over strategy profiles in order to study the epistemic aspects of strategic games and to define a concept of rationality similar to the one discussed in Section 3.2. Although van der Hoek & Pauly discuss the combination of action, preference and epistemics for the analysis of epistemic games they do not provide a unified modal logic framework combining operators for knowledge, for preference and for action with a complete axiomatization and with a study of its computational properties like decidability and complexity. The latter is one of the main contribution of our work.
Roy [9] has recently proposed a modal logic integrating preference, knowledge and intention. In his approach every world in a model is associated to a nominal which directly refers to a strategy profile in a strategic game. This approach is however limited in expressing formally the structure of a strategic game. In particular, in Roy’s logic there is no principle like the Axiom Indep explaining how possible actions of individual agents are combined to form a strategy profile δ of the current game. Another limitation of Roy’s approach is that it does not allow to express the concept of (weak) rationality that we have been able to define in Section 3.2 (see [9], pp. 101). As discussed in the previous sections this is a crucial concept in interactive epistemology since it is used for giving epistemic justifications of several solution concepts like Nash equilibrium and IDSDS (see Theorems 6 and 7).
Bonanno [3] combines modal operators for belief and common belief with constructions expressing agents’ preferences over individual actions and strategy profiles, and applies them to the semantic characterization of solution concepts like Iterated Deletion of Strictly Dominated Strategies (IDSDS) and Iterated Deletion of Inferior Profiles (IDIP). As in [9], in Bonanno’s logic every world in a model corresponds to a strategy profile of the current game. Although this logic allows to express the concept of weak rationality, it is not sufficiently general to enable to express in the object language solution concepts like Nash equilibrium and IDSDS (note that the latter is defined by Bonanno only in the metalanguage).
It is to be noted that, differently from , most modal logics of epistemic games in strategic form (including Roy’s logic and Bonanno’s logic) postulate a one-to-one correspondence between models and games (i.e. every model of the logic corresponds to a unique strategic game, and worlds in the model are all strategy profiles of this game). Such an assumption is quite restrictive since it prevents from analyzing in the logic games with incomplete information about the game structure in which an agent can imagine alternative games. We will show in Section 5 that this is something we can do in our logical framework by removing Axiom CompleteInfo from .
4. Game Transformation
We provide in this section an alternative and more compact characterization of the procedure IDSDS in our logic . To this aim, we introduce special events whose effect is to transform the current game by removing certain strategies from it. In particular, these special events can be used to delete a strictly dominated strategy from the current game. These special events are similar to the notion of announcement in Dynamic Epistemic Logic (DEL) [10,11,12].
is the set of game transformation formulas and is defined by the following rule:
where , and . Thus, game transformation formulas are of the form `if property ψ necessarily holds in the current game, then action a should not be performed by agent i’.
is the set of game transformation events and is defined as .
We extend the language with dynamic operators of the form with . The formula has to be read `φ holds, after the occurrence of the game transformation event ’. We call the extended logic. The truth condition for is:
with and:
Thus, an event removes from the model M all worlds in which χ is false. Every epistemic relations , every preference orderings , every function , and the valuation π are restricted to the worlds in which χ is true.
In the resulting structure , the relations , , , verify the constraints of Definition 1. This result is summed up in the following theorem.
Theorem 9. Let . If M is a model then is a model.
Remark. The syntactic restriction on game transformation formulas is given in order to ensure that the updated model is still a model. In fact, Theorem 9 does not hold if we allow χ to be any formula in . For instance suppose M is a model such that , , , , and . If then the updated model is no longer a -model because it does not satisfy the constraint C2.
We have reduction axioms for the dynamic operators .
Theorem 10. The following schemata are valid in the logic .
The principles R1.-R7. are called reduction axioms because, read from left to right, they reduce the complexity of those operators in a formula. In particular the principles R1.-R7. explains how to transform any formula φ of the language with dynamic operators in a formula without dynamic operators. More generally, we have an axiomatization result.
Theorem 11. The logic is completely axiomatized by the axioms and inference rules of together with the schemata of Theorem 10 together with the following rule of replacement of proved equivalence:
where is the formula φ in which we have replaced all occurrences of by .
Now, consider the following formula:
where has been defined in Subsection 3.3. The effect of the game transformation event is to delete from every game in the model M all worlds in which a strictly dominated strategy is played by some agent.
As the following Theorem 12 highlights, the procedure IDSDS that we have characterized in Section 3.3 in the static can be characterized in a more compact way in . Suppose δ is the selected strategy profile. Then, δ survives IDSDS until the subgame of depth if and only if, the event can occur times in sequence.
Theorem 12. For all , for all , .
The above theorem says that if δ is performed, then the formula , defined in Subsection 3.3, whose length is exponential in n and the more compact formula are equivalent. Indeed the length of the formula is where n is the number of IDSDS rounds, is the number of agents and is the maximal number of actions.
We conjecture that there is no formula more compact than such that . If our conjecture is true, Theorem 12 would imply that the representation of IDSDS in is necessarily more succinct than the representation of IDSDS in (i.e., there is no representation of IDSDS in that is equally or more succinct than the representation of IDSDS in ). The latter is indeed a variant of the result given in [37] showing that S5 with public announcements is more succinct than S5.
Finally, here is a compact reformulation of Theorem 7 in :
Theorem 13. For all , .
It has to be noted that the approach to game dynamics based on Dynamic Epistemic Logic (DEL) proposed here is inspired by [7] in which strategic equilibrium is defined by fixed-points of operations of repeated announcement of suitable epistemic statements and rationality assertions. However, the analysis of epistemic games proposed in [7] is mainly semantical and the author does not provide a full-fledged modal language for epistemic games which allows to express in the object language solution concepts like Nash Equilibrium or IDSDS, and the concept of rationality. Moreover, van Benthem’s analysis does not include any completeness result for the proposed framework and there is no proposal of reduction axioms for a combination of DEL with a static logic of epistemic games. On the contrary, these two aspects are central in our analysis.
5. Incomplete information
We here consider a more general class of games that includes strategic games with incomplete information about the game structure including the players’ strategy sets (or action repertoires) and the players’ preference ordering over strategy profiles. This kind of games have been explored in the past by Harsanyi [38]. A more recent analysis is given by [39].
We are interested here in verifying whether the results obtained in Section 3.2 and Section 3.3 can be generalized to this kind of games, that is:
- Are rationality of every player and every agent’s knowledge about other agents’ choices still sufficient to ensure that the selected strategy profile is a Nash equilibrium in a strategic game with incomplete information about the game structure?
- Is mutual knowledge of rationality among the players still sufficient to ensure that the selected strategy profile survives iterated deletion of dominated strategies in a strategic game with incomplete information about the game structure?
We have a positive answer to the previous first question. Indeed, the formula
is derivable in . But we have a negative answer to the second question. Indeed, the following formula is invalid in for every and for every such that :
This can be proved as follows. We suppose and we exhibit in Figure 3 a -model M and a world in M in which for all n, is true. We call Alarm Game the scenario corresponding to this model.
Figure 3.
Alarm Game. Again thick circles represent epistemic possibility relations for agent 1 whereas thin circles represent epistemic possibility relations for agent 2. The two equivalence classes and correspond to two different games where agents have different preference ordering over strategy profiles.
Figure 3.
Alarm Game. Again thick circles represent epistemic possibility relations for agent 1 whereas thin circles represent epistemic possibility relations for agent 2. The two equivalence classes and correspond to two different games where agents have different preference ordering over strategy profiles.

Scenario description. We call Alarm Game the scenario represented by the model in Figure 3. Agent 1 is a thief who intends to burgle agent 2’s apartment. Agent 1 can enter the apartment either by the main door or by the back door (action or action ). Agent 2 has two actions available. Either he does nothing (action ) or he follows a security procedure (action ) which consists in locking the two doors and in activating a surveillance camera on the main door. Entering the apartment by the main door when agent 2 does nothing (i.e., the strategy profile executed at world ) and entering by the back door when agent 2 does nothing (i.e., the strategy profile executed at world ) are for agent 1 the best situations and are for him equally preferable. Indeed, in both cases agent 1 will successfully enter and burgle the apartment. On the contrary, trying to enter the apartment by the back door when 2 follows the security procedure (i.e., the strategy profile executed at world ) is for 1 strictly better than trying to enter by the main door when 2 follows the security procedure (i.e., the strategy profile executed at world ). Indeed, in the former case agent 1 will be simply unable to burgle the apartment, in the latter case not only he will be unable to burgle the apartment but also he will disclose his identity. The two possible situations in which agent 1 does not succeed in burgling the apartment (worlds and ) are equally preferable for agent 2 and are for 2 strictly better than the situations in which agent 1 successfully burgles the apartment (worlds and ).
At world agent 1 enters by the main door while agent 2 follows the security procedure. This is a world in the model M in which agent 1 has some uncertainty. Indeed, in this world agent 1 can imagine the alternative game defined by the equivalence class in which he enters by the main door while agent 2 does nothing (world ). We suppose that in such a game, even if agent 2 follows the security procedure, agent 1 will succeed in burgling his apartment (i.e., the equivalence class represents the situation in which the security procedure does not work). This is the reason why the four strategy profiles , , and are equally preferable for the two agents.
Concerning the automated reasoning aspects of the logic , we conjecture that the complexity of its satisfiability problem is PSPACE. Indeed, we think that it is possible to build a tableau method using only a polynomial amount of memory for the satisfiability problem of . In other terms, we conjecture that if we move from to , the complexity decreases from EXPTIME-hard to PSPACE. We here provide an unsurprising lower-bound for the complexity of .
Theorem 14. The satisfiability problem of a given formula φ in a -model is PSPACE-hard.
The situation is different when we add the Axiom JointDet of joint determinism discussed in Section 2.4. Let us call the logic resulting from adding Axiom JointDet of joint determinism to the logic and -models the class of models resulting from adding the corresponding Constraint CD to -models. While the complexity of the satisfiability problem for was NP-complete, it increases to PSPACE-complete for . More precisely:
Theorem 15.
- If and then the satisfiability problem of a given formula φ in a -model is NP-complete.
- If or then the satisfiability problem of a given formula φ in a -model is PSPACE-complete.
6. Weaker Forms of Complete Information
In the previous section, we have removed Axiom CompleteInfo of the form from the logic to obtain a new logic in which agents may have incomplete information about all aspects of the game they play, including the players’ strategy sets (or action repertoires) and the players’ preference ordering over strategy profiles.
Nevertheless, in some cases we would like to suppose that agents have complete information about some specific aspects of the game they play. For example, we would like to suppose that:
- an agent has complete information about his strategy sets even though he may have incomplete information about other agents’ strategy sets or,
- that an agent has complete information about the strategy set of every agent even though he may have incomplete information about agents’ preference ordering over strategy profiles.
In other terms, we would like to build variants of in which some formulas of Lemma 1 are derivable.
6.1. Complete Information about Strategy Sets
We show here how to relax the Axiom CompleteInfo in order to express the assumption of complete information about strategy sets without necessarily assuming complete information over the payoffs.
If we replace Axiom CompleteInfo by the following axiom schemas:
for all and , then every agent i has complete information about his strategy set. That is, if an agent i can perform an action a then agent i knows that he can perform action a. Axiom CompleteInfoStrategyi corresponds to the following semantic constraint on models. For every and :
- C7
- if and there is v such that and then, there is z such that and .
If we replace Axiom CompleteInfo by the following axiom schemas:
for all and , then an agent i has complete information about the strategy sets of every agent. That is, if an agent j can perform an action a then every agent i knows that agent j can perform action a. Axiom CompleteInfoStrategyi,j corresponds to the following semantic constraint on models. For every and :
- C8
- if and is v such that and then, there is z such that and .
Remark. Note also that CompleteInfoStrategyi and CompleteInfoStrategyi,j are respectively equivalent to and thanks to Axiom 5 for the epistemic operators .
In the sequel we call the logic that results from adding the previous Axiom CompleteInfoStrategyi,j to the logic discussed in Section 5, and we call -models the corresponding models that results from adding the semantic constraint C8 to the -models. is the logic of epistemic strategic games in which the only uncertainty is about agents’ preference ordering over strategy profiles.
6.2. An Analysis of the Harsanyi Transformation
We conclude our discussion about games with incomplete information by shedding light on Harsanyi’s claim that all uncertainty about the structure of a game can be reduced to uncertainty about payoffs [38].
Harsanyi proposed a way of transforming a game with uncertainty over both the payoffs and the strategy choices of the players into a game with no strategy-set uncertainty, without affecting the epistemic implications. In particular, Harsanyi proposed a way of reducing all kinds of imperfect information about the structure of a game to imperfect information about the strategy choices without affecting the rationality or irrationality of a player.
The basic idea of Harsanyi’s transformation is that having a strategy with a highly undesirable payoff is for a player equivalent to not having the strategy at all. Suppose we start with a game with uncertainty over both the payoffs and the strategy choices of the players. This means that, some player i has a strategy a in his strategy set and another player j does not know this or some player i does not have a strategy a in his strategy set and another player j does not know this. To eliminate player’s j strategy-set uncertainty is sufficient to add the strategy a to the set of strategies which in player j’s opinion are included in player i’s strategy space and to assign the lowest possible payoff to the new strategy profiles in which player i chooses strategy a. If player j is rational then the game transformation does not affect his choice, as his decision is not affected by the highly undesirable options that have been added by the game transformation.
We here provide a formal proof of Harsanyi’s claim in a purely qualitative setting with no probabilities. See [13] for a formal proof of Harsanyi’s claim in a quantitative setting using interactive belief systems à la Aumann & Brandeburger [1] with probabilities.
Let us start with a model of the logic in which players may have incomplete information about all aspects of the game. We want to show that we can build a corresponding model of the logic in which players can only have incomplete information about payoffs and which satisfies the same formulas as M.
Let be the partition of W induced by the equivalence relation ∼. We note the elements of . Let be the set of strategy profiles with respect to the model M.
The model can be defined as follows.
- for every ,
- for every , if and only if there is such that
- for every and ,
- for every and ,
- for every and ,
- for every and ,
- for every and ,
- for every and ,
- for every ,
It is straightforward to check that the new model is indeed a -model without strategy-set uncertainty.
The following Theorem 16 is a formal characterization of Harsanyi’s claim. It says that an agent i is rational at a given world w of model M if and only if, agent i is rational at world w of model which is obtained by removing strategy-set uncertainty from model M.
Theorem 16. For every and for every , if and only if .
The following corollary of Theorem 16 highlights that Harsanyi transformation does not affect common knowledge about the rationality or irrationality of a player.
Corollary 1. For every , for every and for every , we have if and only if .
7. Conclusions
We have presented a multi-modal logic that enables to reason about epistemic games in strategic form. This logic, called (Modal Logic of Epistemic Games), integrates the concepts of joint action, preference and knowledge. We have shown that provides a highly flexible formal framework for the analysis of the epistemic aspects of strategic interaction. Indeed, can be easily adapted in order to integrate different assumptions on players’ knowledge about the structure of a game.
Directions for future research are manifold. In this article (Section 3.2) we only considered the notion of individualistic rationality assumed in classical game theory: an agent decides to perform a certain action only if the agent believes that this action is a best response to what he expects the others will do. Our plan is to extend the present modal logic analysis of epistemic games to other forms of rationality such as fairness and reciprocity [40]. According to these notions of rationality, rational agents are not necessarily self-interested but they also consider the benefits of their choices for the group. Moreover, their decisions can be affected by their beliefs about other agents’ willingness to act for the well-being of the group. In [41] we did some first steps into this direction.
Another aspect we intend to investigate in the future is a generalization of our approach to mixed strategies. Indeed, at the current stage the multi-modal logic only enables to reason about pure strategies. To this aim, we will have to extend by modal operators of probabilistic beliefs as the ones studied by [42,43]. We also postpone to future work an analysis of the epistemic conditions of Bayesian equilibrium in the resulting logical framework.
Supplementary Materials
CorrectionAcknowledgements
We would like to thank the anonymous reviewer for his very helpful comments.
This research is supported by the french project “Social ties in economics: experiments and theory” financed by the Agence Nationale de la Recherche (ANR), “Jeunes Chercheuses et Jeunes Chercheurs” program.
References
- Aumann, R.J.; Brandenburger, A. Epistemic Conditions for Nash Equilibrium. Econometrica 1995, 63, 1161–1180. [Google Scholar] [CrossRef]
- Aumann, R. Interactive Epistemology I: Knowledge. Int. J. Game Theory 1999, 28, 263–300. [Google Scholar] [CrossRef]
- Bonanno, G. A syntactic approach to rationality in games with ordinal payoffs. In Proceedings of the 8th Conference on Logic and the Foundations of Game and Decision Theory (LOFT 2008), Amsterdam, The Netherlands, 3–5 July, 2008; Amsterdam University Press: Amsterdam, The Netherlands; pp. 59–86.
- Battigalli, P.; Bonanno, G. Recent Results on Belief, Knowledge and the Epistemic Foundations of Game Theory. Res. Econ. 1999, 53, 149–225. [Google Scholar] [CrossRef]
- Brandenburger, A. Knowledge and Equilibrium in Games. J. Econ. Perspect. 1992, 6, 83–101. [Google Scholar] [CrossRef]
- Gintis, H. The Bounds of Reason: Game Theory and the Unification of the Behavioral Sciences; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Van Benthem, J. Rational Dynamics and Epistemic Logic in Games. Int. Game Theory Rev. 2007, 9, 13–45. [Google Scholar] [CrossRef]
- De Bruin, B. Explaining Games: On the Logic of Game Theoretic Explanations. Ph.D thesis, University of Amsterdam, Amsterdam, The Netherlands, 2004. [Google Scholar]
- Roy, O. Thinking before Acting: Intentions, Logic, Rational Choice. Ph.D thesis, University of Amsterdam, Amsterdam, The Netherlands, 2008. [Google Scholar]
- Van Ditmarsch, H.P.; van der Hoek, W.; Kooi, B. Dynamic Epistemic Logic; Springer: Dordrecht, The Netherlands, 2007. [Google Scholar]
- Baltag, A.; Moss, L.S. Logics for Epistemic Programs. Synthese 2004, 139, 165–224. [Google Scholar] [CrossRef]
- Gerbrandy, J.; Groeneveld, W. Reasoning about Information Change. J. Logic Lang. Info. 1997, 6, 147–196. [Google Scholar] [CrossRef]
- Hu, H.; Stuart, H.W. An Epistemic Analysis of the Harsanyi Transformation. Int. J. Game Theory 2001, 30, 517–525. [Google Scholar] [CrossRef]
- van Benthem, J.; Liu, F. Dynamic Logic of Preference Upgrade. J. Appl. Non-Classical Logics 2007, 17, 157–182. [Google Scholar] [CrossRef]
- Osborne, M.J.; Rubinstein, A. A Course in Game Theory; MIT Press: Cambridge, MA, USA, 1994. [Google Scholar]
- Lewis, C.I.; Langford, C.H. Symbolic Logic; Dover Publications: New York, NY, USA, 1932. [Google Scholar]
- Liu, F. Changing for the Better: Preference Dynamics and Agent Diversity. Ph.D thesis, University of Amsterdam, Amsterdam, The Netherlands, 2008. [Google Scholar]
- Van Benthem, J.; Girard, P.; Roy, O. Everything Else Being Equal: A Modal Logic for Ceteris Paribus Preferences. J. Phil. Logic 2009, 38, 83–125. [Google Scholar] [CrossRef]
- Belnap, N.; Perloff, M.; Xu, M. Facing the Future: Agents and Choices in Our Indeterminist World; Oxford University Press: New York, NY, USA, 2001. [Google Scholar]
- Papadimitriou, C.H. Computational Complexity; Addison Wesley: Reading, MA, USA, 1994. [Google Scholar]
- Halpern, J.Y.; Moses, Y. A Guide to Completeness and Complexity for Modal Logics of Knowledge and Belief. Artif. Intell. 1992, 54, 319–379. [Google Scholar] [CrossRef]
- Pratt, V. A Near-Optimal Method for Reasoning about Action. J. Comput. Syst. Sci. 1980, 20, 231–254. [Google Scholar] [CrossRef]
- Pauly, M. Logic for Social Software. Ph.D thesis, University of Amsterdam, Amsterdam, The Netherlands, 2001. [Google Scholar]
- Pauly, M. A Modal Logic for Coalitional Power in Games. J. Logic Comput. 2002, 12, 149–166. [Google Scholar] [CrossRef]
- Lorini, E. A Dynamic Logic of Agency II: Deterministic DLA, Coalition Logic, and Game Theory. J. Logic Lang. Info. 2010, 19, 327–351. [Google Scholar] [CrossRef]
- Horty, J.F. Agency and Deontic Logic; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Herzig, A.; Lorini, E. A Dynamic Logic of Agency I: STIT, Abilities and Powers. J. Logic Lang. Info. 2010, 19, 89–121. [Google Scholar] [CrossRef]
- Von Wright, G.H. The Logic of Preference; Edinburgh University Press: Edinburgh, UK, 1963. [Google Scholar]
- Stalnaker, R. On the Evaluation of Solution Concepts. Theor. Decis. 1994, 37, 49–73. [Google Scholar] [CrossRef]
- Board, O. Knowledge, Beliefs, and Game-Theoretic Solution Concepts. Oxford Rev. Econ. Policy 2002, 18, 418–432. [Google Scholar] [CrossRef]
- Bernheim, D. Axiomatic Characterizations of Rational Choice in Strategic Environments. Scand. J. Econ. 1986, 88, 473–488. [Google Scholar] [CrossRef]
- Pearce, D. Rationalizable Strategic Behavior and the Problem of Perfection. Econometrica 1984, 52, 1029–1050. [Google Scholar] [CrossRef]
- Brandeburger, A.; Dekel, E. Rationalizability and Correlated Equilibria. Econometrica 1987, 55, 1391–1402. [Google Scholar] [CrossRef]
- Tan, T.; Werlang, S. The Bayesian Foundation of Solution Concepts of Games. J. Econ. Theory 1988, 45, 370–391. [Google Scholar] [CrossRef]
- Van der Hoek, W.; Jamroga, W.; Wooldridge, M. A Logic for Strategic Reasoning. In Proceedings of the Fourth International Joint Conference on Autonomous Agens and Multiagent Systems (AAMAS 2005), Utrecht, The Netherlands, 25–29 July, 2005; ACM Press: New York, NY, USA, 2005; pp. 157–164. [Google Scholar]
- Van der Hoek, W.; Pauly, M. Modal Logic for Games and Information. In Handbook of Modal Logic (3); Blackburn, P., Van Benthem, J., Wolter, F., Eds.; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Lutz, C. Complexity and Succinctness of Public Announcement Logic. In Proceedings of the Fifth Interional Joint Conference naton Autonomous Agents and Multiagent Systems (AAMAS 2006), Hakodate, Japan, 8–12 May, 2006; ACM Press: New York, USA, 2006; pp. 137–143. [Google Scholar]
- Harsanyi, J.C. Games with Incomplete Information Played by ‘Bayesian’ Players. Manag. Sci. 1967, 14, 159–182. [Google Scholar] [CrossRef]
- Halpern, J.Y.; Rego, L. Generalized Solution Concepts in Games with Possibly Unaware Players. In Proceedings of the Eleventh Conference on Theoretical Aspects of Rationality and Knowledge (TARK 2007), Brussels, Belgium, 25–27 June, 2007; 2007; pp. 253–262. [Google Scholar]
- Fehr, E.; Schmidt, K.M. Theories of Fairness and Reciprocity: Evidence and Economic Applications. In Advances in Economics and Econometrics; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Lorini, E. A Logical Account of Social Rationality in Strategic Games. In Proceedings of the 9th Conference on Logic and the Foundations of Game and Decision Theory (LOFT 2010), Toulouse, France, 5–7 July, 2010.
- Halpern, J. Reasoning about Uncertainty; MIT Press: Cambridge, MA, USA, 2003. [Google Scholar]
- Fagin, R.; Halpern, J. Reasoning about Knowledge and Probability. J. Assn. Comput. Mach. 1994, 41, 340–367. [Google Scholar] [CrossRef]
- Blackburn, P.; de Rijke, M.; Venema, Y. Modal Logic; Cambridge University Press: Cambridge, UK, 2001. [Google Scholar]
- Sahlqvist, H. Completeness and Correspondence in the First and Second Order Semantics for Modal Logics. In Proceedings of the Third Scandinavian Logic Symposium; 1975; 82, pp. 110–143. [Google Scholar]
- Chen, C.; Lin, I. The Complexity of Propositional Modal Theories and the Complexity of Consistency of Propositional Modal Theories. Logical Found. Comput. Sci. 1994, 813, 69–80. [Google Scholar]
- Chellas, B.F. Modal Logic: An Introduction; Cambridge University Press: Cambridge, UK, 1980. [Google Scholar]
- Savitch, W. Relationships between Nondeterministic and Deterministic Tape Complexities*. J. Comput. Syst. Sci. 1970, 4, 177–192. [Google Scholar] [CrossRef]
A. ANNEX: Proofs of Some Theorems
A.1. Proof of Theorems 1 and 3
is determined by the class of -models. is determined by the class of -models.
Proof. We only provide a sketch of the proof of Theorem 3. The proof of Theorem 1 is a straightforward adaptation of the proof of Theorem 3. It is sufficient to remove the constraint (S6) from the following definition 3.
It is straightforward to show that all axioms in Figure 2 are valid and that the rules of inference preserve validity in the class of -models. The other part of the proof is shown using two major steps.
Step 1. We provide an alternative semantics for in terms of standard Kripke models whose semantic conditions correspond one-to-one to the axioms in Table 2. The definition of Kripke -models is the following one.
Definition 3 (Kripke -model) Kripke -models are tuples where:
- W is a nonempty set of possible worlds or states;
- ∼ is an equivalence relation on W;
- maps every joint action to a transition relation between possible worlds such that:
- S1
- if and only if, for every ,
- S2
- if then ,
- S3
- ,
- S4
- if then or ,
- S5
- if for every there is such that and then there is a v such that and ;
- S6
- if and and , then ;
- maps every agent i to an equivalence relation on W such that:
- S6
- if , then if and only if ,
- S7
- if then ;
- maps every agent i to a reflexive, transitive relation on W such that:
- S8
- if then ,
- S9
- if and then or ;
- is a valuation function.
Truth conditions of formulas in Kripke -models are again standard for atomic formulas and the Boolean operators. The truth conditions for Boolean operators and for operators , and are the ones of Section 2.2. The truth condition for operators are:
- iff for all .
Step 2. The second step shows that the semantics in terms of -models of Definition 2 and the semantics in terms of Kripke -models of Definition 3 are equivalent. As the logic is sound and complete for the class of Kripke -models and is sound for the class of -models, we have that for every formula φ, if φ is valid in the class of Kripke -models then φ is valid in the class of -models. Consequently, for every formula φ, if φ is satisfiable in the class of -models then φ is satisfiable in the class of Kripke -models. Therefore, in this second step we just need to show that for every formula φ, if φ is satisfiable in the class of Kripke -models then φ is satisfiable in the class of -models.
Suppose φ is satisfiable in the class of Kripke -models. This means that there is a Kripke -model and world w such that . We can now build a -model which satisfies φ. The model is defined as follows:
- ;
- for every and , if and only if ;
- for every , ;
- for every , ;
- .
A.2. Proof of Theorem 2
Proof. Let us start to prove that the satisfiability problem of is EXPTIME-hard when . Let us consider two distinct agents . Let us consider a modal formula φ made of operators , and . It is easy to check that the following two statements are equivalent:
- φ is satisfiable in the logic where and are S5-operators and is the universal modality;
- φ is satisfiable in .
But the satisfiability problem of S5 plus the universal modality is EXPTIME-hard as it is the case for the satisfiability problem of K plus the universal modality [46]. Indeed, we can reduce the satisfiability problem of S5 plus the universal modality to the satisfiability problem of K plus the universal modality by translating a formula of K plus the universal modality into S5 plus universal modality. Let x be an extra proposition. The translation works as follows:
- where is the K-operator;
- where is the K-operator;
- for all , where is the universal operator.
Now let us prove that the satisfiability problem of is NEXPTIME. We are going to prove that we can make a filtration of any model, preserving both the semantic constraints of Definition 1 and the truth of formulas (see [47] for a general introduction to the filtration method in modal logic). Let us consider a -model where we suppose ∼ to be the universal modality, without loss of generality. As usual, we consider a formula φ, the set of all subformulas of φ and the equivalence relation ≡ over W defined by iff for all , iff . We note the equivalence class of ≡ containing w. Let us define by:
- ;
- ;
- ;
- iff for all formulas , iff and ;
- iff for all formulas , implies ;
- .
This filtration implies that if a formula φ is satisfiable, then it is satisfiable in a model of size where is the length of the formula φ. A possible algorithm for solving the satisfiability of φ may be as follows:
- Guess non-deterministically a -model whose size is bounded by where π only gives truthness of propositions occurring in φ;
- Guess non-deterministically a world w of M;
- Check if .
A.3. Proof of Theorem 4
Proof. The satisfiability problem of is clearly NP-hard because it is a conservative extension of the classical propositional logic whose satisfiability problem in NP-complete (Cook’s Theorem [20]).
Now let us prove it is in NP. Clearly if a formula φ is -satisfiable, there exists a -model whose size is bounded by . Here is an non-deterministic algorithm to check if a given formula φ is satisfiable:
- Guess non-deterministically a -model whose size is bounded by where π only gives truthness of propositions occurring in φ;
- Guess non-deterministically a world w of M;
- Check if .
This algorithm non-deterministically runs in polynomial time. So the satisfiability problem of is in NP.
A.4. Proof of Theorem 5a
For all , we have:
Lemma 1.
Proof.
- ;from Active;
- by 1. and Boolean principles;
- by Boolean principles;
- ifby Aware;
- by 4. and Boolean principles;
- if ; by Single;
- ifby Necessitation of from 6;
- ifby Axiom K for plus ModusPonens from 7;
- by Boolean principles from 8.
- by 2, 3, 5 and 9.
Now let us prove Theorem 5a. We give here a version of the proof that uses Axioms K, T, 4 and 5 for epistemic modal operators.
Proof.
- by Definition of ;
- by Axiom 5 for ;
- by Axiom 4 for plus Boolean principles;
- by 1, 2, 3 and Boolean principles;
- by modal logic K principles;
- by Lemma 1;
- by 4, 5, 6 and Boolean principles;
- by modal logic K principles;
- by 7 and 8;
- by Axiom T of ;
- by 9 and 10.
We give another version of the proof of Theorem 5a that uses Axioms K, T and 5 for epistemic modal operators and introspection over preferences “”.
Proof.
- by Definition of ;
- by Axiom 5 for ;
- by 1 and 2;
- by modal logic K principles;
- by Lemma 1;
- by 2, 4, 5 and Boolean principles;
- by modal logic K principles;
- by Lemma 1 (or introspection over preferences);
- by 8 and 9;
- by Axiom T of ;
- by 10 and 11.
A.5. Proof of Theorem 6
For all , we have:
Proof.
- ifby Single;
- ifby necessitation of ;
- ifby 2, axiom K of plus ModusPonens;
- ifby 3 and Boolean principles;
- by axiom T of S5Ki.
- ifby JonitAct;
- forby 5 and 6;
- by Boolean principles and 7;
- by Boolean principle “”;
- by distributivity of ∧ over ;
- by 4 plus Boolean principles;
- by Axiom T of ;
- by 12 and Boolean principles;
- by 8, 9, 10, 11 and 13;
- by 14 and Boolean principles.
A.6. Proof of Theorem 7
For all ,
Proof.
Lemma 2.
Proof. The proof of the lemma consists in proving by induction on n that and . We leave the proof of these two -theorems based on Lemma 1 to the reader.
Here we prove .
- by Axiom JointAct
- by Axiom T of ;
- ifBy 1, 2, axiom T for and Boolean principles;
- by CompleteInfo or (Lemma 1 considered as axioms plus axiom T for );
- by Axiom T for ;
- by 4, 5 and Boolean principles;
- by Boolean principles;
- ifby 3, 6, 7 and Boolean principles;
- by 8 and Boolean principles.
let and let us prove that if the theorem 7 is true for all then it is true for .
- by Axiom T for plus Boolean principles;
- by induction;
- by Definition of and Boolean principles;
- by 1, 2, 3;
- ;by Boolean principles
- ifby JointAct, definition of and Boolean principles;
- by distributivity of ∧ over ;
- by modal logic K principle “” ;
- by induction;
- by necessitation rule on 9;
- by modal logic K principles applied on 10;
- by Lemma A.6;
- from 8, 11 and 12;
- by 13 and Boolean principles;
- by Boolean principles;
- ifby 5, 6, 7, 14, 15;
- ifby 4 and 16;
- by 17.
A.7. Proof of Theorem 8
Consider an arbitrary -model , a world w in M and such that for all positive integers n we have . Then, there is a model such that for all positive integers n we have .
Proof. The proof is based on the following Lemma 3.
Lemma 3. For all , we have
In other words, player i’s strategy a survives after n rounds of IDSDS if and only if, a survives after rounds of IDSDS and in the subgame of depth n, for every alternative strategy b of i, there is a joint action of the other agents that survives after rounds of IDSDS such that playing a while the others play is for i at least as good as playing b while the others play .
Lemma 3 ensures that the definition of can be rewritten in the following shorter equivalent form:
Let us consider w such that for all positive integers n, . We can now show how to build the accessibility relations of the model in such a way that for all positive integers n. The construction goes as follows.
For all positive integers n, let be the subset of all joint actions such that . As , we have . Let us define . As Δ is finite, there exists a positive integer such that and for all positive integers , . Let Ω be the set of all worlds u such that and such that there exists such that . Note that .
For all , we define as follows:
- for all , iff either or .
Now, let us prove that for all , for all , we have . Let be such that . As , we have . By Lemma 3, it implies that for all , there exists such that and . But by definition of , we have equivalence between and . So for all , we have . As for all we have , we obtain for all positive integers n.
A.8. Proof of Theorem 9
If M is a model then is a model.
Proof. It is just a routine to verify that and every are equivalence relations, every is reflexive and transitive, and the model satisfies the semantic constraints C1, C4, C5 and C6.
Let us prove that satisfies constraints C2 and C3.
We first prove that satisfies constraint C2. We introduce the following useful notation. Suppose . Then, iff there is such that .
Now, suppose for every there is such that and . It follows that for every there is such that and . The latter implies that there is v such that and (by the semantic constraint C2). Now, suppose for all if then . It follows that: there is and such that and . The latter implies that there is and such that and for all , . We conclude that there is no such that which leads to a contradiction.
We now consider constraint C3. Suppose and . It follows that and which implies , because M satisfies constraint C3. The latter implies . Now, suppose and . It follows that and which implies , because M satisfies constraint C3. The latter implies .
A.9. Proof of Theorem 10
Proof. The proofs of R1-R6 go as in Dynamic Epistemic Logic (DEL) (see [10]). We here prove R7.
- ,
- IFF if then ,
- IFF if then (by Axiom Def|δC|),
- IFF if then or ,
- IFF if then, if then ,
- IFF if then, ,
- IFF if then, ,
- IFF if .
A.10. Proof of Theorem 11
The logic is completely axiomatized by the axioms and inference rules of together with the schemata of Theorem 10.
Proof. By means of the principles R1-R7 in Theorem 10, it is straightforward to prove that for every formula there is an equivalent formula. In fact, each reduction axiom R2-R7, when applied from the left to the right by means of the rule of replacement of proved equivalence, yields a simpler formula, where “simpler” roughly speaking means that the dynamic operator is pushed inwards. Once the dynamic operator attains an atom it is eliminated by the equivalence R1. Hence, the completeness of is a straightforward consequence of Theorem 1.
A.11. Proof of Theorem 12
For all , for all , .
Lemma 4. .
Proof.
- by Active;
- by 1 and T for and Boolean principles;
- by Active;
- by 3;
- by 2 and 4;
- by Definition and Boolean principles;
- by 6 and Boolean principles to propagate ;
- for all ;by 7 and Boolean principles (induction on n);
- ifby Boolean principles and because is transitive (as , all sequence are such that there exists such that );
- by Definition of and Boolean principles;
- by 8, 9, 10;
- by 11 and Boolean principles;
- by 5 and 12;
- by 13 and Boolean principle.
Lemma 5. .
Proof. We prove it by induction. Let us consider the case where by convention.
- by Definition of and Boolean principles;
- by Lemma 4 and Boolean principles;
- by 1 and Boolean principles;
- by 2 and 3;
- by 1 and Boolean principles;
- by 4 and Boolean principles;
- by Boolean principles and Indep;
- by Proposition 2 and K() principles;
- by definitions of , , JointAct and Boolean principles;
- by R2. and R7.
- ;by Boolean principles;
- by Boolean principles and 10;
- .by R2. and R4.;
- by 5, 6, 7, 8, 9, 11, 12, 13.
- by 13, 12;
- ;by Definition of and Boolean principles;
- by 16, modal logic K() principles and Boolean principles;
- by ;
- by 15, 17, 18;
- by 14 and 19.
Now let us consider the inductive case.
- by Definition of ;
- by Boolean principles and rules R2. and R3. (we can distribute over Boolean connectives);
- by Boolean principles and Axiom R2., R3., R4. and R6.;
- by induction and 3;
- by Boolean principles (we remove the multiple “”);
- by 1, 2, 4, 5.
Now let us finish the proof:
- by definition of and Boolean principles;
- by 1 and Boolean principles (induction on n);
- by Boolean principles (see definition of );
- by rule R7.;
- by 3, 4, Lemma 5, R2. and R3.;
- by induction with 5;
- by rule R2. and R3.;
- by 7 and induction;
- by R2., R4. and T for and Boolean principles;
- by Lemma 5 and induction;
- by 2, 3, 6;
- by 8, 9, 10;
- by 11 and 12.
A.12. Proof of Theorem 13.
For all , .
Proof. By Theorem 7, Theorem 12 and Boolean principles.
A.13. Proof of Theorem 14
The satisfiability problem of a given formula φ in a -model is PSPACE-hard.
Proof. Let us prove that that the satisfiability problem of is PSPACE-hard. Let i be an agent. Let us consider a formula φ written only with atomic propositions and with modal operators and . We have equivalence between:
- φ is satisfiable in a -model;
- φ is satisfiable in a model of the logic S5 (i.e. the fusion of the logic S5 for and S5 for ).
A.14. Proof of Theorem 15
- If and then the satisfiability problem of a given formula φ in a -model is NP-complete.
- If or the satisfiability problem of a given formula φ in a -model is PSPACE-complete.
Now let us prove that the satisfiability problem of a given formula φ in a -model is PSPACE-hard in other cases. First let us consider the case where . Let us consider two distinct agents i, . Let φ be a formula written only with atomic propositions and with epistemic modal operators and . We have equivalence between:
- φ is satisfiable in a -model;
- φ is satisfiable in the logic S5 (i.e., the fusion of the logic S5 for and S5 for ).
Now let us the consider the case where and . Let a and b be two distinct actions. We prove that we can reduce the satisfiability problem of a given formula φ in a -model to the satisfiability problem of K. Here is a possible translation:
- where is the K-operator;
- where is the K-operator;
- for all propositions p;
- for all propositions p.
Now we are going to prove that the satisfiability problem of is PSPACE. We do not give all the details but we give the idea for a tableau method [21] for the logic . The tableau method is a non-deterministic procedure. The creation of a model proceeds as follows:
- We start the procedure by guessing a “grid”, that is to say an equivalence class for the relation ∼ of maximal size and also its preference relation as in the algorithm of Theorem 2. We also choose non-deterministically a world w in this class.
- We adapt the classical tableau method rules for the epistemic modal logic [21], that is to say:
- −
- Suppose that a world w contains a formula of the form . Then we propagate the formula ψ in all nodes v such that .
- −
- Suppose that a world w contains a formula of the form . Then we create an equivalence class for ∼, we choose a point v such that in this equivalence class and we propagate ψ in v.
- Suppose that a node w contains a formula . Then we propagate the formula ψ in all nodes v such that ;
- Suppose that a node w contains a formula . Then we choose non-deterministically a world v such that and we propagate ψ in v.
- Suppose that a node w contains a formula . Then we propagate the formula ψ in all nodes v such that ;
- Suppose that a node w contains a formula . Then we choose non-deterministically a world v such that and we propagate ψ in v.
During the construction, we explore the structure in depth first so that we only need to have one branch in memory at each step. Thus, the algorithm is a non-deterministic procedure that uses only a polynomial amount of memory. So the satisfiability problem of is in NPSPACE. According the Savitch’s theorem [48], it is in PSPACE.
A.15. Proof of Theorem 16
For every and for every , if and only if .
Proof. (⇒) We first prove the left-to-right direction. Suppose that and . The latter means that for every there is such that .
The latter means that for every there is such that:
- there is such that and
- for all if and and then there is such that and .
- C.
- there is such that .
Take two arbitrary worlds and suppose that and and . By definition of , we have and . Consider now the following three cases.
CASE 1. Suppose . Then, by definition of , we have that and . Therefore, from item B, it follows that there is such that and . From the latter, by definition of , we conclude that there is such that and .
CASE 2. Suppose that and that there is such that and . From the former, by definition of , it follows that . From the latter, by definition of , it follows that there is such that and . Therefore, we have that there is such that and .
CASE 3. Suppose that and that there is no such that and . From the former, by definition of , it follows that . From the latter, by definition of (and the fact that ), it follows that there is such that and and . Therefore, we have that there is such that and .
From the previous three cases, it follows that:
- D.
- for all if and and then there is such that and .
From the items C and D we conclude that .
(⇐) Let us prove the right-to-left direction. Suppose that and . The latter means that for every there is such that .
The latter means that for every there is such that:
- E.
- there is such that and
- F.
- for all if and and then there is such that and .
- G.
- there is such that .
Take two arbitrary worlds and suppose that and and . By Definition of , and we have and and . Thus, by the previous item F, there is such that and . But as we have . Thus and .
It follows that:
- H.
- for all if and and then there is such that and .
From the items G and H we conclude that .
A.16. Proof of Corollary 1
For every , for every and for every , we have if and only if .
Proof. Define a world v to be C-reachable from world w in n steps (with ), and note this , if and only if there exist worlds such that and and for all , there exists such that . Define . We have if and only if for all .
By definition of , we have for all . Therefore, if and only if for all .
Moreover, according to Theorem 16, for every we have if and only if . Therefore, we have that for all if and only if for all .
It follows that, if and only if .
- 1.See [2] for an analysis of the relation between the two approaches.
- 2.Note that for notational convenience we write instead of .
- 4.The normality reading of ceteris paribus preferences expresses preferences which hold under certain normal conditions, whereas the equality reading expresses preferences which hold when certain facts are kept constant.
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Lorini, E.; Schwarzentruber, F. A Modal Logic of Epistemic Games. Games 2010, 1, 478-526. https://doi.org/10.3390/g1040478
AMA Style
Lorini E, Schwarzentruber F. A Modal Logic of Epistemic Games. Games. 2010; 1(4):478-526. https://doi.org/10.3390/g1040478
Chicago/Turabian StyleLorini, Emiliano, and François Schwarzentruber. 2010. "A Modal Logic of Epistemic Games" Games 1, no. 4: 478-526. https://doi.org/10.3390/g1040478