
Objective Classification of Rainfall in Northern Europe for Online Operation of Urban Water Systems Based on Clustering Techniques


Abstract
:1. Introduction
2. Materials and Methods
2.1. Rain Gauge Dataset
2.2. Clustering for Event Type Identification Offline Based on Spatial and Temporal Characteristics
2.2.1. Defining Features to Characterize Rain Events
- criteria focusing on the maximal observed rain intensity:
- mean rain intensity during an event averaged over all gauges (MAVINT),
- maximum rain intensity observed at any gauge during an event (MAXRMAX),
- criteria focusing on the spatial variation of the observed rainfall:
- spatial variation of the mean rain intensities observed at the different gauges during an event, expressed as standard deviation of the mean rain intensities (SDAVINT),
- spatial variation of the maximal rain intensities observed at the different gauges during an event, expressed as standard deviation of the maximal rain intensities (SDRMAX),
- spatial variation of the instantaneous rain intensities observed at the different gauges, expressed as standard deviation of rain intensities measured at all gauges in the same time step, averaged over the whole event (SPATSD),
- percentage of time steps without rain during a rain event, averaged over all rain gauges (MNLEN), and
- criteria focusing on the temporal variation of observations during an event:
- absolute difference between measurements for consecutive time steps, averaged over all time steps and then all gauges. Only non-zero observations were considered. This property describes the degree of variation from one time step to another (MDEV).
2.2.2. Clustering into Event Types
2.2.3. Validating Spatial and Temporal Variability of the Identified Groups of Rain Events
2.3. Identifying Event Types Online in the Course of a Rain Event
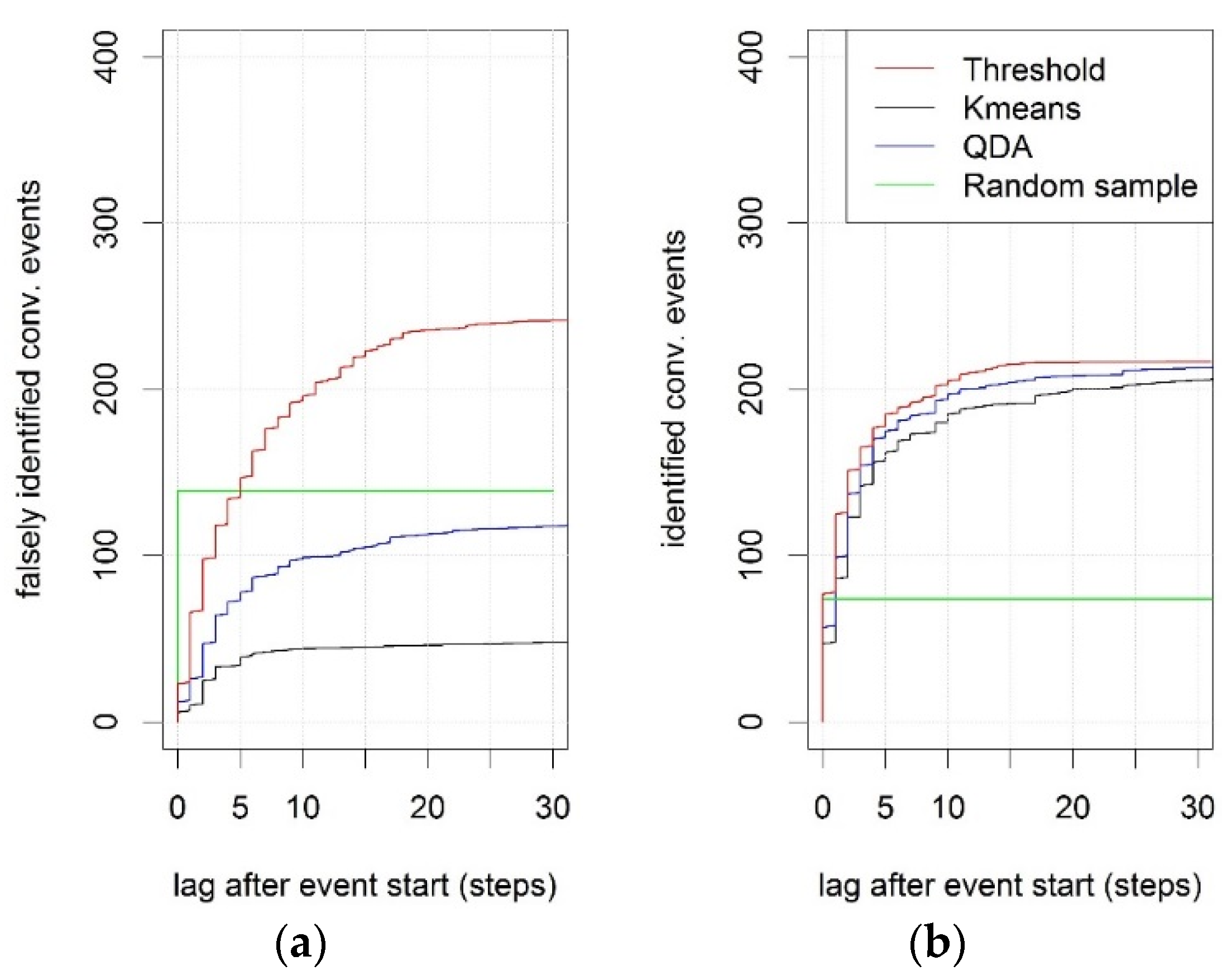
- Threshold on the observed rain intensity—A rain event was classified as convective if the 10-min rain intensity exceeded a threshold of 5.0 mm/h. The threshold was tuned manually during the calibration period to yield a high number of correctly identified convective events and a low number of false hits and was similarly applied in other studies [9].
- K-means clustering—The variables used for grouping rain events into clusters offline (Section 2.2 and Section 3) were computed recursively during a rain event, whenever new observations became available. Using the loadings derived from principal component analysis in the offline situation, the variables were transformed into the same first three principal components that were used offline. Based on the computed features, the nearest cluster centre defined during offline classification was identified. If the corresponding cluster was considered a cluster of events with “high” variability, the rain event would be classified as being of “high” variability.
- Quadratic discriminant analysis (QDA) [28]—Principal components were computed recursively in the same way as described for the clustering procedure in point 2 above. This recursive computation was performed during both calibration and validation periods. The discriminant model was trained during the calibration period based on the clusters derived during offline classification (Section 3). For each of the clusters identified offline, the mean and the variance of the three principal components were computed and used to define a separate multivariate normal distribution for each cluster. After training the discriminant model during the calibration period, it was applied to the validation period. Here, the discriminant model would compute the likelihood (probability density) for each newly obtained value to be a member of each cluster. The value was then classified into the cluster which scored the highest likelihood [28].
- Random sampling—This is a benchmark where an event is randomly classified based on the percentages of events of “high” and “low” variability identified during offline classification for the calibration period. As convective events are unlikely to occur during winter, we distinguished between summer and winter periods. 29.2% of the rain events were convective in the period from 1 May until 31 October, and 2.7% during the winter months.
3. Results and Discussion
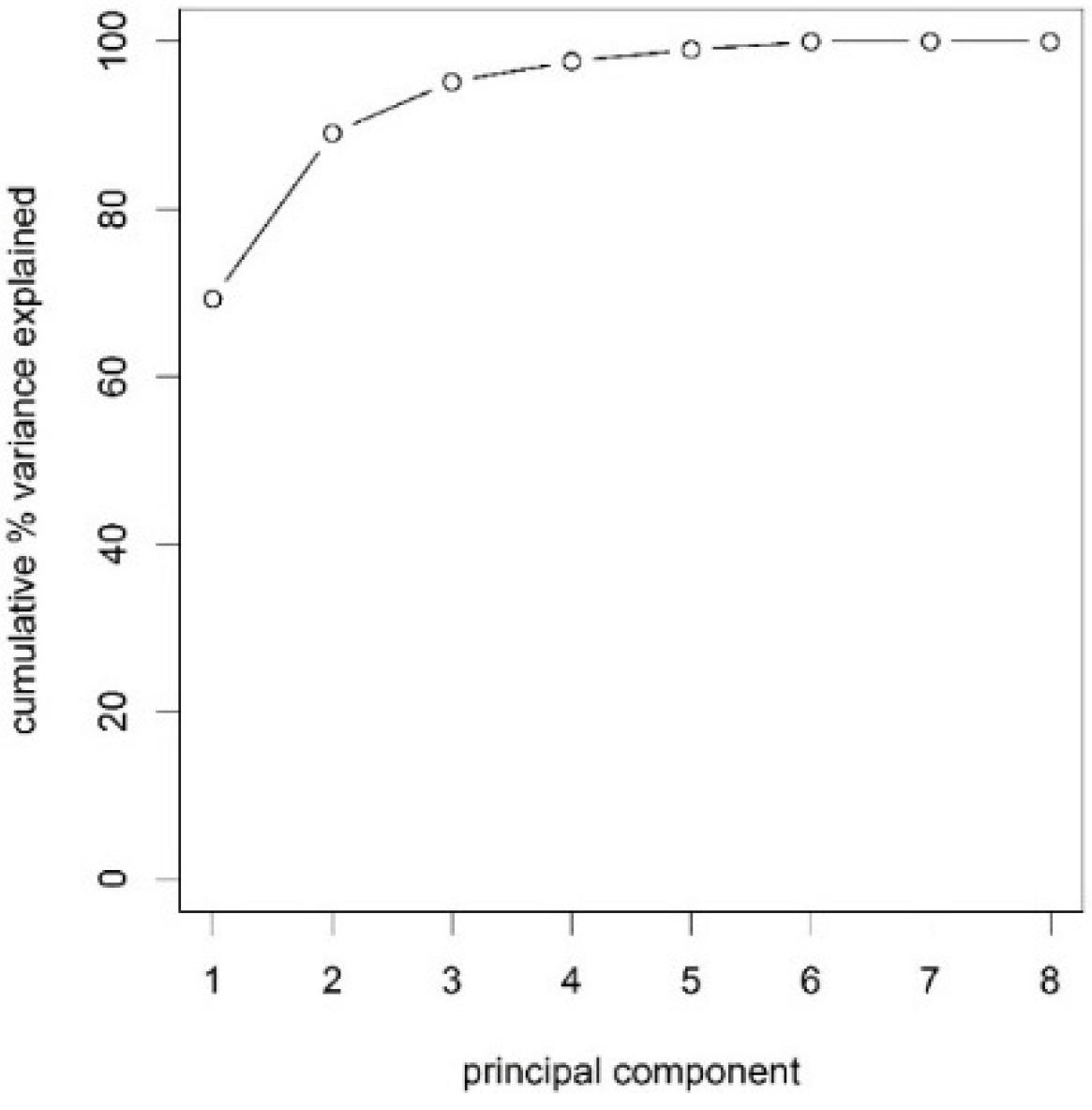
3.1. Reduction of Identification Variables Using Principal Component Analysis
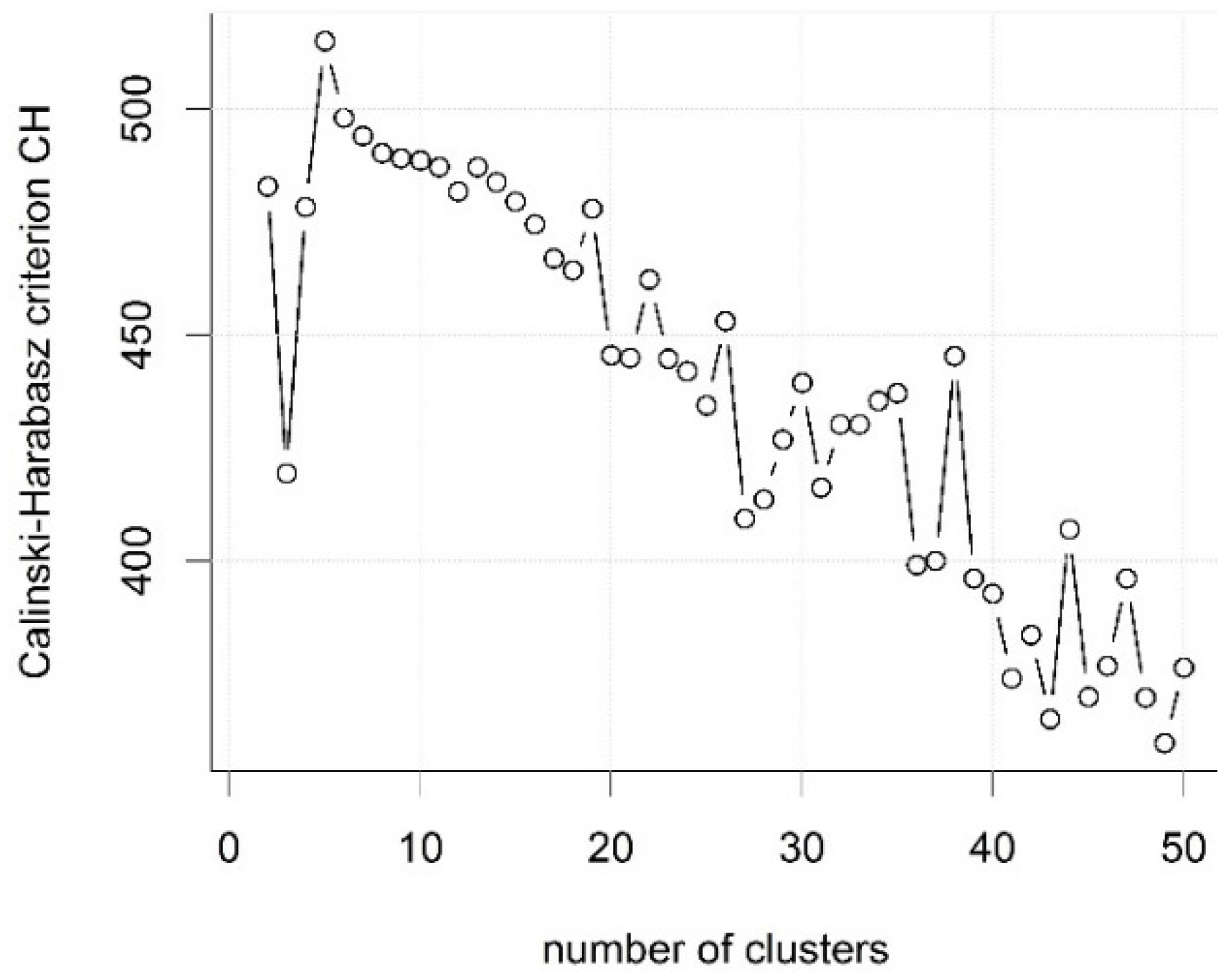
3.2. Offline Classification Using k-Means Clustering
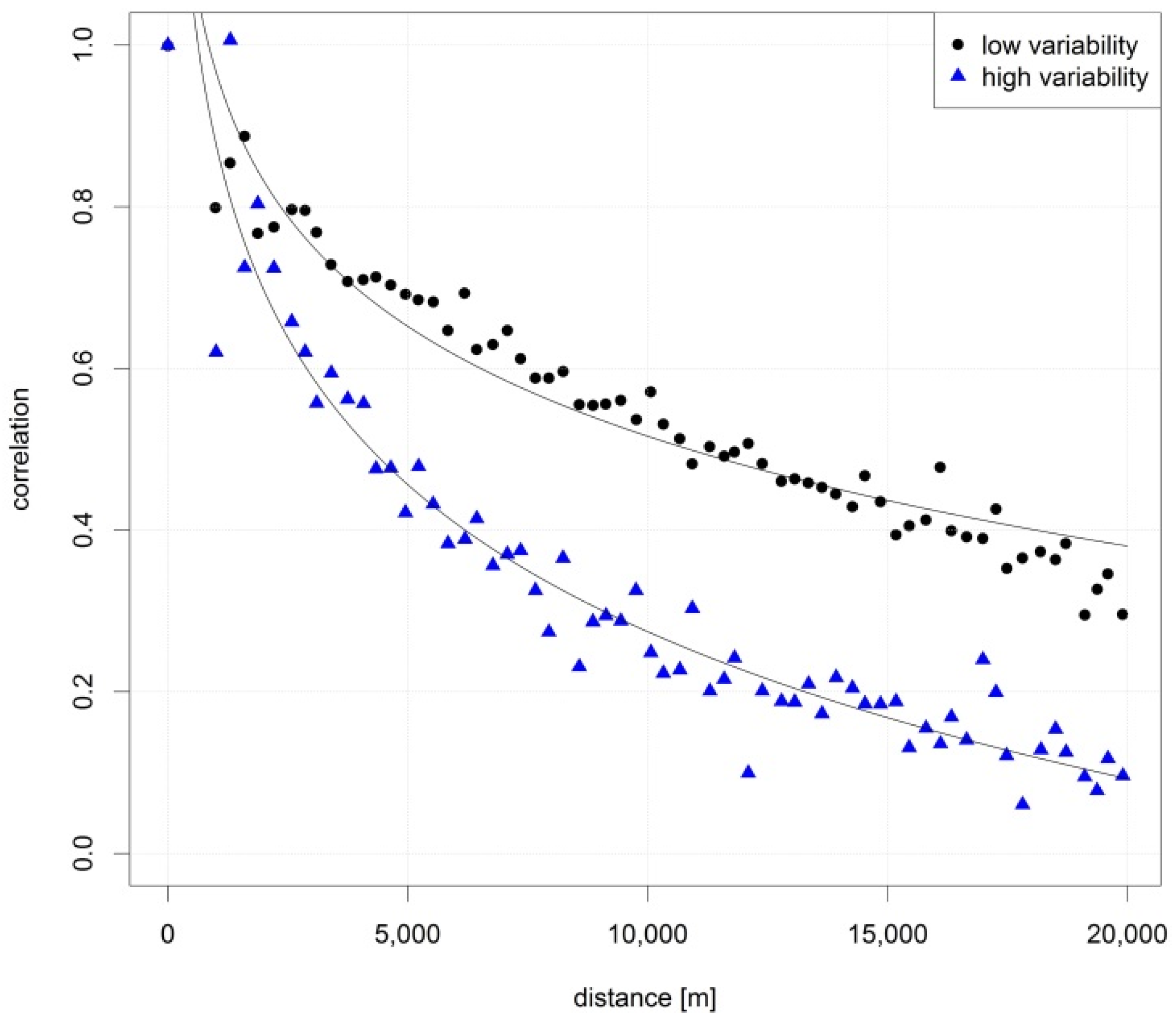
3.3. Temporal and Spatial Variability of the Event Groups Identified
3.4. Identifying Convective Rain Events in an Online Setting
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- NOAA National Weather Service Glossary. Available online: www.weather.gov/glossary/ (accessed on 29 November 2015).
- Dotto, C.B.S.; Allen, R.; Wong, T.; Deletic, A. Development of an integrated software tool for strategic planning and conceptual design of water sensitive cities. In Proceedings of the 9th International Conference on Urban Drainage Modelling, Belgrade, Serbia, 3–7 September 2012; Prodanovic, D., Plavsic, J., Eds.; University of Belgrade-Faculty of Civil Engineering Belgrade: Belgrade, Serbia, 2012. [Google Scholar]
- Vieux, B.E.; Vieux, J.E. Statistical evaluation of a radar rainfall system for sewer system management. Atmos. Res. 2005, 77, 322–336. [Google Scholar] [CrossRef]
- Kirstetter, P.-E.; Andrieu, H.; Delrieu, G.; Boudevillain, B. Identification of vertical profiles of reflectivity for correction of volumetric radar data using rainfall classification. J. Appl. Meteorol. Climatol. 2010, 49, 2167–2180. [Google Scholar] [CrossRef]
- Jonsdottir, H.; Nielsen, H.A.; Madsen, H.; Eliasson, J.; Palsson, O.P.; Nielsen, M.K. Conditional parametric models for storm sewer runoff. Water Resour. Res. 2007, 43, 1–9. [Google Scholar] [CrossRef]
- Löwe, R.; Thorndahl, S.; Mikkelsen, P.S.; Rasmussen, M.R.; Madsen, H. Probabilistic online runoff forecasting for urban catchments using inputs from rain gauges as well as statically and dynamically adjusted weather radar. J. Hydrol. 2014, 512, 397–407. [Google Scholar] [CrossRef]
- Philipp, A.; Bartholy, J.; Beck, C.; Erpicum, M.; Esteban, P.; Fettweis, X.; Huth, R.; James, P.; Jourdain, S.; Kreienkamp, F.; et al. Cost733cat—A database of weather and circulation type classifications. Phys. Chem. Earth 2010, 35, 360–373. [Google Scholar] [CrossRef]
- Huth, R.; Beck, C.; Philipp, A.; Demuzere, M.; Ustrnul, Z.; Cahynová, M.; Kyselý, J.; Tveito, O.E. Classifications of atmospheric circulation patterns. Ann. N. Y. Acad. Sci. 2008, 1146, 105–152. [Google Scholar] [CrossRef] [PubMed]
- Feidas, H.; Giannakos, A. Classifying convective and stratiform rain using multispectral infrared Meteosat Second Generation satellite data. Theor. Appl. Climatol. 2011, 108, 613–630. [Google Scholar] [CrossRef]
- Llasat, M.-C. An objective classification of rainfall events on the basis of their convective features: Application to rainfall intensity in the northeast of spain. Int. J. Climatol. 2001, 21, 1385–1400. [Google Scholar] [CrossRef]
- Ricciardelli, E.; Cimini, D.; Di Paola, F.; Romano, F.; Viggiano, M. A statistical approach for rain intensity differentiation using Meteosat Second Generation-Spinning Enhanced Visible and InfraRed Imager observations. Hydrol. Earth Syst. Sci. 2014, 18, 2559–2576. [Google Scholar] [CrossRef] [Green Version]
- Thyregod, P.; Carstensen, J.; Madsen, H.; Arnbjerg-Nielsen, K. Integer valued autoregressive models for tipping bucket rainfall measurements. Environmetrics 1999, 10, 395–411. [Google Scholar] [CrossRef]
- Thorndahl, S.; Nielsen, J.E.; Rasmussen, M.R. Bias adjustment and advection interpolation of long-term high resolution radar rainfall series. J. Hydrol. 2014, 508, 214–226. [Google Scholar] [CrossRef]
- Schellart, A.N.A.; Liguori, S.; Krämer, S.; Saul, A.J.; Rico-Ramirez, M.A. Comparing quantitative precipitation forecast methods for prediction of sewer flows in a small urban area. Hydrol. Sci. J. 2014, 59, 1418–1436. [Google Scholar] [CrossRef]
- Vieux, B.E.; Bedient, P.B. Assessing urban hydrologic prediction accuracy through event reconstruction. J. Hydrol. 2004, 299, 217–236. [Google Scholar] [CrossRef]
- Achleitner, S.; Fach, S.; Einfalt, T.; Rauch, W. Nowcasting of rainfall and of combined sewage flow in urban drainage systems. Water Sci. Technol. 2009, 59, 1145–1151. [Google Scholar] [CrossRef] [PubMed]
- Berne, A.; Krajewski, W.F. Radar for hydrology: Unfulfilled promise or unrecognized potential? Adv. Water Resour. 2013, 51, 357–366. [Google Scholar] [CrossRef]
- Meneses, E.J.; Löwe, R.; Brødbæk, D.; Courdent, V.; Petersen, S.O. SURFF-Operational Flood Warnings for Cities Based on Hydraulic 1D-2D Simulations and NWP. In Proceedings of the 10th International Conference on Urban Drainage Modelling (UDM), Mont-Sainte-Anne, QC, Canada, 20–23 September 2015.
- Di Paola, F.; Casella, D.; Dietrich, S.; Mugnai, A.; Ricciardelli, E.; Romano, F.; Sanò, P. Combined MW-IR Precipitation Evolving Technique (PET) of convective rain fields. Nat. Hazards Earth Syst. Sci. 2012, 12, 3557–3570. [Google Scholar] [CrossRef]
- Kursinski, A.L.; Mullen, S.L. Spatiotemporal variability of hourly precipitation over the Eastern Contiguous United States from Stage IV multisensor analyses. J. Hydrometeorol. 2008, 9, 3–21. [Google Scholar] [CrossRef]
- Korsholm, U.; Petersen, C.; Sass, B.; Nielsen, N.; Jensen, D.; Olsen, B.; Gill, R.; Vedel, H. A new approach for assimilation of 2D radar precipitation in a high-resolution NWP model. Meteorol. Appl. 2015, 22, 48–59. [Google Scholar] [CrossRef]
- Nielsen, J.E.; Jensen, N.E.; Rasmussen, M.R. Calibrating LAWR weather radar using laser disdrometers. Atmos. Res. 2013, 122, 165–173. [Google Scholar] [CrossRef]
- Pedersen, L.; Jensen, N.E.; Madsen, H. Calibration of Local Area Weather Radar-Identifying significant factors affecting the calibration. Atmos. Res. 2010, 97, 129–143. [Google Scholar] [CrossRef]
- Baldwin, M.E.; Kain, J.S.; Lakshmivarahan, S. Development of an automated classification procedure for rainfall systems. Mon. Weather Rev. 2005, 133, 844–862. [Google Scholar] [CrossRef]
- Jørgensen, H.K.; Rosenørn, S.; Madsen, H.; Mikkelsen, P.S. Quality control of rain data used for urban runoff systems. Water Sci. Technol. 1998, 37, 113–120. [Google Scholar] [CrossRef]
- Institute for Technical and Scientific Hydrology Ltd. Hystem-Extran 7.7. Institute for Technical and Scientific Hydrology Ltd.: Hanover, Germany, 2015. [Google Scholar]
- Little, M.A.; Rodda, H.J.E.; Mcsharry, P.E. Bayesian objective classification of extreme UK daily rainfall for flood risk applications. Hydrol. Earth Syst. Sci. Discuss. 2008, 5, 3033–3060. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S; Springer: New York, NY, USA, 2002; Volume 4. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Oksanen, J.; Blanchet, F.G.; Kindt, R.; Legendre, P.; Minchin, P.R.; O’Hara, R.B.; Simpson, G.L.; Solymos, P.; Stevens, M.H.H.; Wagner, H. Vegan: Community Ecology Package 2014. Available online: https://cran.r-project.org/web/packages/vegan/index.html (accessed on 12 March 2015).
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Pebesma, E.J. Multivariable geostatistics in S: The gstat package. Comput. Geosci. 2004, 30, 683–691. [Google Scholar] [CrossRef]
- Madsen, H. Time Series Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2008. [Google Scholar]
- Storm- and Wastewater Informatics SWI. Available online: http://www.swi.env.dtu.dk/ (accessed on 12 March 2015).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | MAVINT | SDAVINT | SPATSD | MAXRMAX | SDRMAX | MNLEN | MDEV |
|---|---|---|---|---|---|---|---|
| MAVINT | 1.00 | 0.90 | 0.87 | 0.77 | 0.78 | 0.26 | 0.76 |
| SDAVINT | 0.90 | 1.00 | 0.76 | 0.63 | 0.73 | 0.41 | 0.57 |
| SPATSD | 0.87 | 0.76 | 1.00 | 0.89 | 0.89 | 0.11 | 0.88 |
| MAXRMAX | 0.77 | 0.63 | 0.89 | 1.00 | 0.96 | 0.09 | 0.85 |
| SDRMAX | 0.78 | 0.73 | 0.90 | 0.96 | 1.00 | 0.18 | 0.78 |
| MNLEN | 0.26 | 0.41 | 0.11 | 0.09 | 0.18 | 1.00 | −0.01 |
| MDEV | 0.76 | 0.57 | 0.88 | 0.85 | 0.78 | −0.01 | 1.00 |
| Principal Component | MAVINT | SDAVINT | SPATSD | MAXRMAX | SDRMAX | MNLEN | MDEV |
|---|---|---|---|---|---|---|---|
| Component 1 | −0.412 | −0.376 | −0.427 | −0.411 | −0.420 | −0.105 | −0.388 |
| Component 2 | 0.111 | 0.323 | −0.123 | −0.187 | – | 0.866 | −0.285 |
| Component 3 | 0.442 | 0.574 | – | −0.398 | −0.321 | −0.426 | −0.175 |
| Cluster | Mavint | Sdavint | Spatsd | Maxrmax | Sdrmax | Mnlen | Mdev | Variability in Rain Event | Events in Cluster |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 6.15 | 6.30 | 4.91 | 4.39 | 4.91 | 1.28 | 3.40 | High | 6 |
| 2 | 0.63 | 0.47 | 0.78 | 0.87 | 1.00 | 0.40 | 0.72 | High | 51 |
| 3 | −0.43 | −0.42 | −0.36 | −0.36 | −0.46 | −0.94 | −0.28 | Low | 217 |
| 4 | −0.24 | −0.17 | −0.43 | −0.40 | −0.34 | 1.06 | −0.53 | Low | 163 |
| 5 | 1.76 | 1.60 | 3.11 | 2.96 | 3.18 | 0.09 | 2.41 | High | 17 |
| SUM | 454 |
| Classification Result | Threshold | k-means Clustering | QDA | Random Sampling |
|---|---|---|---|---|
| Lag (median) | 1 | 2 | 2 | 0 |
| Lag (standard deviation) | 3.96 | 7.51 | 6.27 | 0 |
| TH % (No. of events) | 100.0% (217) | 96.8% (210) | 99.5% (216) | 31.8% (69) |
| TL % (No. of events) | 71.3% (614) | 94.3% (812) | 86.2% (742) | 84.2% (725) |
| Accuracy % ACC = (TH + TL)/(no. of events) | 77.1% | 94.8% | 88.9% | 73.7% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Löwe, R.; Madsen, H.; McSharry, P. Objective Classification of Rainfall in Northern Europe for Online Operation of Urban Water Systems Based on Clustering Techniques. Water 2016, 8, 87. https://doi.org/10.3390/w8030087
Löwe R, Madsen H, McSharry P. Objective Classification of Rainfall in Northern Europe for Online Operation of Urban Water Systems Based on Clustering Techniques. Water. 2016; 8(3):87. https://doi.org/10.3390/w8030087
Chicago/Turabian StyleLöwe, Roland, Henrik Madsen, and Patrick McSharry. 2016. "Objective Classification of Rainfall in Northern Europe for Online Operation of Urban Water Systems Based on Clustering Techniques" Water 8, no. 3: 87. https://doi.org/10.3390/w8030087