4.1. Selection of Predictor Factors
How to select proper predictor factors is the first task in streamflow forecasting by the RVM model. Several methods are commonly used to describe the relationship of spatiotemporal variability between climate variables and streamflow data. Here we used the correlation analysis method to investigate the major predictor factors which influence the annual streamflow process in the DHF and DJK Reservoir. The main steps are explained as follows. First, we calculate the correlations between the average annual streamflow and the average monthly indices of Z500 and SSTs from January to December at last year; and then, we select those variables which have stably high correlation (with a confidence level bigger than 0.95) as the predictor factors.
Those predictor factors selected above show good correlations (i.e., multi-collinearity), which would influence the generalization ability of the RVM model. Therefore, useful information included in these predictor factors cannot be utilized simultaneously. To solve this problem, we further employed the two-step stepwise regression method to pick the effectively primary predictors, and reduce the impact of multi-collinearity. Finally, we selected 6 predictor factors for the annual streamflow forecasting in the DHF Reservoir (
Table 1), and selected 7 predictor factors for the DJK Reservoir (
Table 2). From
Table 3 we can see that the multiple correlations using all selected factors in the first step exceed 0.8. However, the multiple correlations using those selected factors in the second step, with the values bigger than 0.92, become much better. It indicates that the combination of these predictor factors would have better forecasting performance, and they are used for the RVM modelling. Besides, these selected factors are also considered as the input signals of SVM.
After selecting the predictor factors for the annual streamflow forecasting in the DHF and DJK Reservoir, we determine the specific RVM model through the training and testing practice using different data (
Table 4). The Gauss radial basis function (RBF) is used as the Kernel function of RVM here. Various studies have indicated the favorable performance of the RBF kernel in hydrological forecasting [
17,
34,
35,
36]. In the RVM model, the “leave-one-out” cross validation is used to optimize parameters
σ, as the width of the RBF kernel. Through calculation, the optimal value 2.25 and 3.00 of parameter
σ is determined for the DHF and DJK Reservoir respectively. Furthermore, we also compare the results gotten from RVM with those from SVM.
4.3. Results Discussion
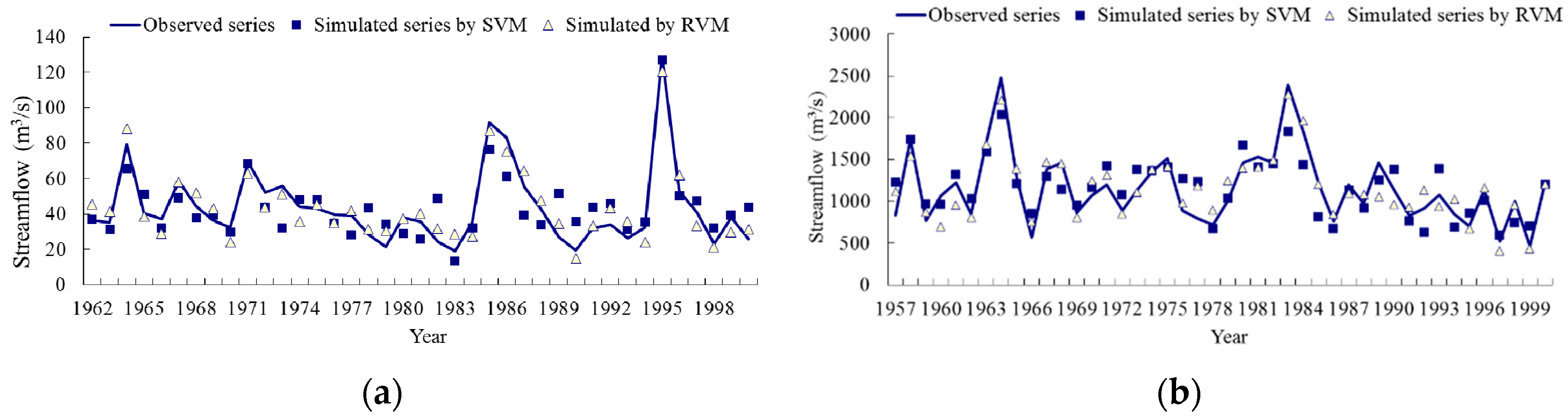
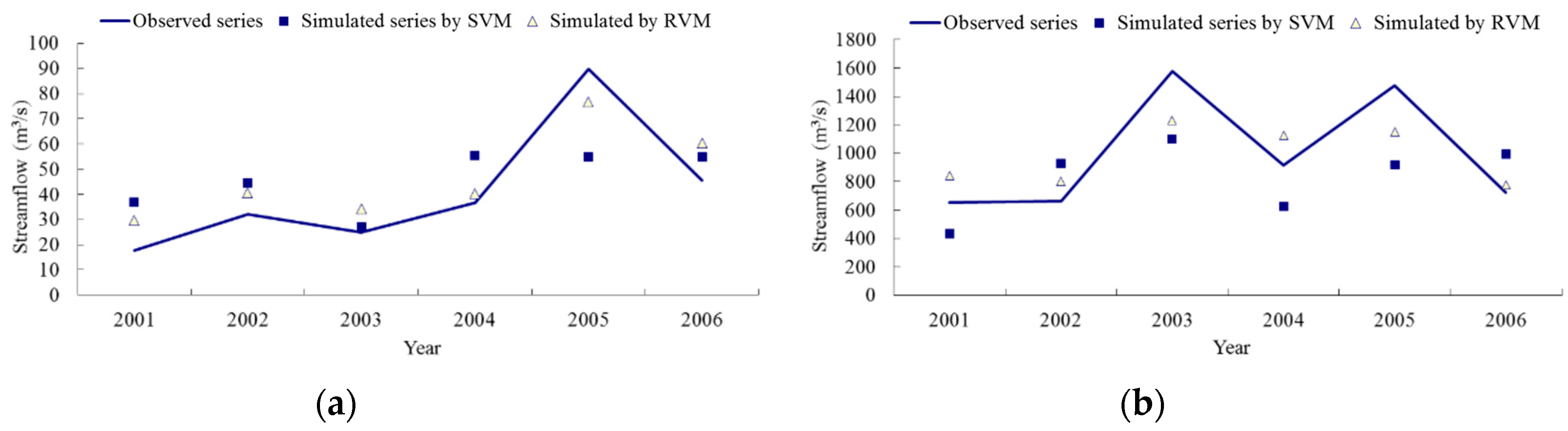
The observed streamflow data and the simulated data by SVM and RVM during the training period are shown in
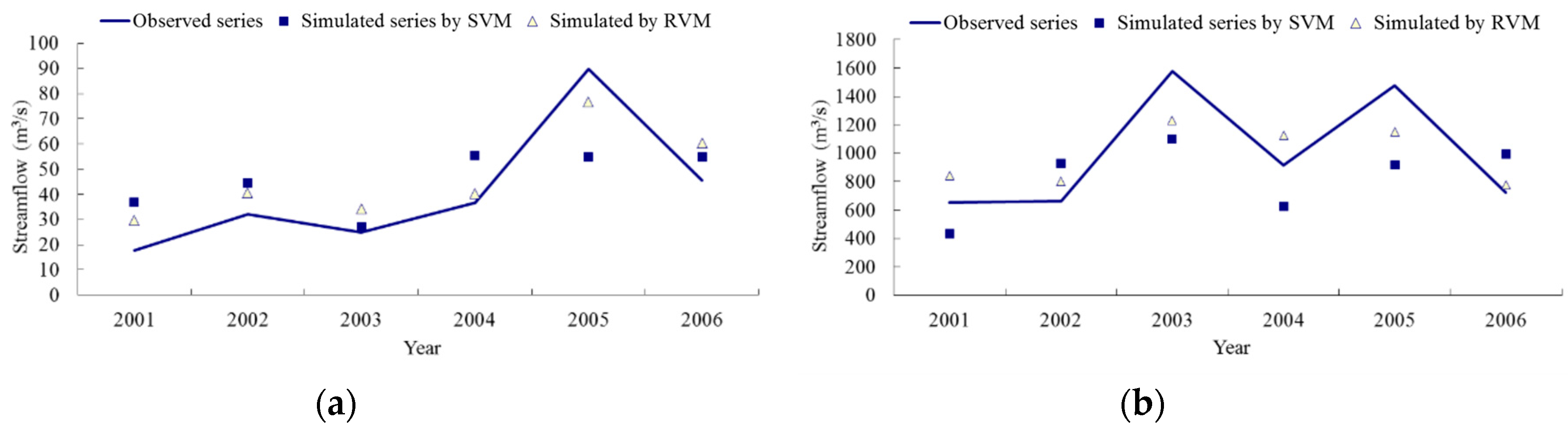
Figure 3 (left, DHF Reservoir; right, DJK Reservoir). The observed data and the simulated streamflow data by SVM and RVM during the testing period can be found in
Figure 4 (left, DHF Reservoir; right, DJK Reservoir). In
Figure 3 and
Figure 4 the solid line represents the observed data, and the hollow triangle shows the simulated data gotten from the RVM model, with the solid square indicating the simulated data by SVM.
Table 5 shows the forecasting performance of different models for the DHF Reservoir, and the results of the DJK Reservoir are presented
Table 6.
From
Table 5 we can find that for the streamflow forecasting in the DHF Reservoir, the values of three indices R, RMSE and E in the training period, gotten from the SVM model, are 0.91, 7.58 m
3/s and 0.89, which are similar as those gotten from the RVM model, with the R, RMSE and E value of 0.95, 6.78 m
3/s and 0.90. However, the RVM model performs much better than the SVM model during the testing period. To be specific, the indices R and E in the testing period gotten from the SVM model is 0.74 and 0.63, which are much smaller than those of 0.83 and 0.78 for the RVM model, but the index RMSE value of 19.01 m
3/s for the SVM model is much bigger than that of 13.76 m
3/s for the RVM model. The results from the DHF Reservoir indicate the better performance of the RVM model compared with SVM. Many previous studies used the traditional auto-regression models and the ANN, wavelet-based ANN models to conduct streamflow forecasting in the DHF reservoir [
38,
39]. Those results indicated the poor performance of the auto-regression models, which are just based on linear characteristics and long-memories of time series, and cannot deal with the decadal variability of streamflow process; besides, although those results gotten from the ANN or wavelet-based ANN models considered the influences of climate factors, they had the relative errors bigger than 20%. Comparatively, the results gotten form the RVM model in this study have higher accuracy, thus it is thought that RVM also performs better than those traditional auto-regression models and ANN models.
As for the DJK Reservoir, the results gotten from the RVM model are also much better than those of the SVM model, no matter considering the training period or testing period. In the training period, the RVM model reduces the RMSE value with respect to SVM by 14.7% (163.06 m
3/s compared to 191.18 m
3/s), and increase the R and E value by 9.5% (0.92 compared to 0.84) and 4.9% (0.85 compared to 0.81) respectively. In the testing period, the RVM model reduces the RMSE value by 31.6% (231.92 m
3/s compared to 339.01 m
3/s) compared with SVM, and increase the R and E value by 31.3% (0.88 compared to 0.67) and 19.3% (0.68 compared to 0.57) respectively. Previous studies have compared the different capabilities of the traditional auto-regression models and ANN models with that of the SVM model [
40], and indicated that the forecasting results gotten from the later have high accuracy, more stability and reliability. By comprehensively analyzing the results here and the previous study results, it can be found that the RVM model performs the best among these models for the streamflow forecasting in the DJK reservoir.
Presently the SVM model has been widely applied in the streamflow simulation and forecasting, and a great number of studies have verified the ability of the SVM model in vast majority of cases; especially, its better performance compared with conventional auto-regression models or ANN models has been clearly verified in the DJK reservoir basin. Therefore, SVM can be taken as the reference to evaluate the ability of the RVM model, while other data-driven models and the results gotten from them, as discussed above, were not considered and compared again. On the whole, all the results in the two reservoirs indicate the better performance of RVM compared with SVM for long-term streamflow forecasting, although the results in the testing period is a little worse compared with those in the training period. In addition, our previous study results also indicated the better performance of the RVM model for monthly and seasonal streamflow forecasting in the two reservoirs, compared with the SVM model [
41,
42]. Because the RVM model is based on the Bayesian theory, posterior distributions of all parameters and characteristics of hydrological variables can be accurately and reasonably evaluated, following which more accurate forecasting results can be gotten, but the SVM model cannot do this. Thereby, it is thought that the RVM model can be effective method for long-term streamflow forecasting.
Besides, the two reservoir basins chosen for the study have obviously different underlying surface conditions and climate conditions; further, the average streamflow magnitudes in the two basins are about 40 m
3/s and 1000 m
3/s, also showing obvious difference. It can be found that the results in the DHF Reservoir is better that that in the DJK Reservoir when using the SVM model, indicating the worse performance of the SVM model for those streamflow process with big magnitudes. From
Figure 3 we know that both the RVM and SVM model show good performance for the forecasting of peak and small values of streamflow process in the DHF Reservoir; however, peak values of streamflow process in the DJK Reservoir can only been accurately simulated by the RVM model, which cannot be achieved by the SVM model. Especially, for those peak values bigger than 2000 m
3/s in the streamflow process in the DJK Reservoir, the relative errors gotten from RVM are about 20% in 2003 and 2005, but the results of SVM are much worse, with the relative errors bigger than 40%. As a result, it is thought here that the limited ability of forecasting peak magnitudes of streamflow process cause the poor performance of the SVM model. Comparatively, all the results gotten from the RVM model are stable and accurate, not matter analyzing the DHF or DJK Reservoir. Therefore, it is thought that the RVM model also has a wide applicability for long-term forecasting of streamflow process with a magnitude of dozens to thousands discharge units.






{kind=link}
{kind=link}
{kind=link}
{kind=link}