
Multi-Model Grand Ensemble Hydrologic Forecasting in the Fu River Basin Using Bayesian Model Averaging


Abstract
:1. Introduction
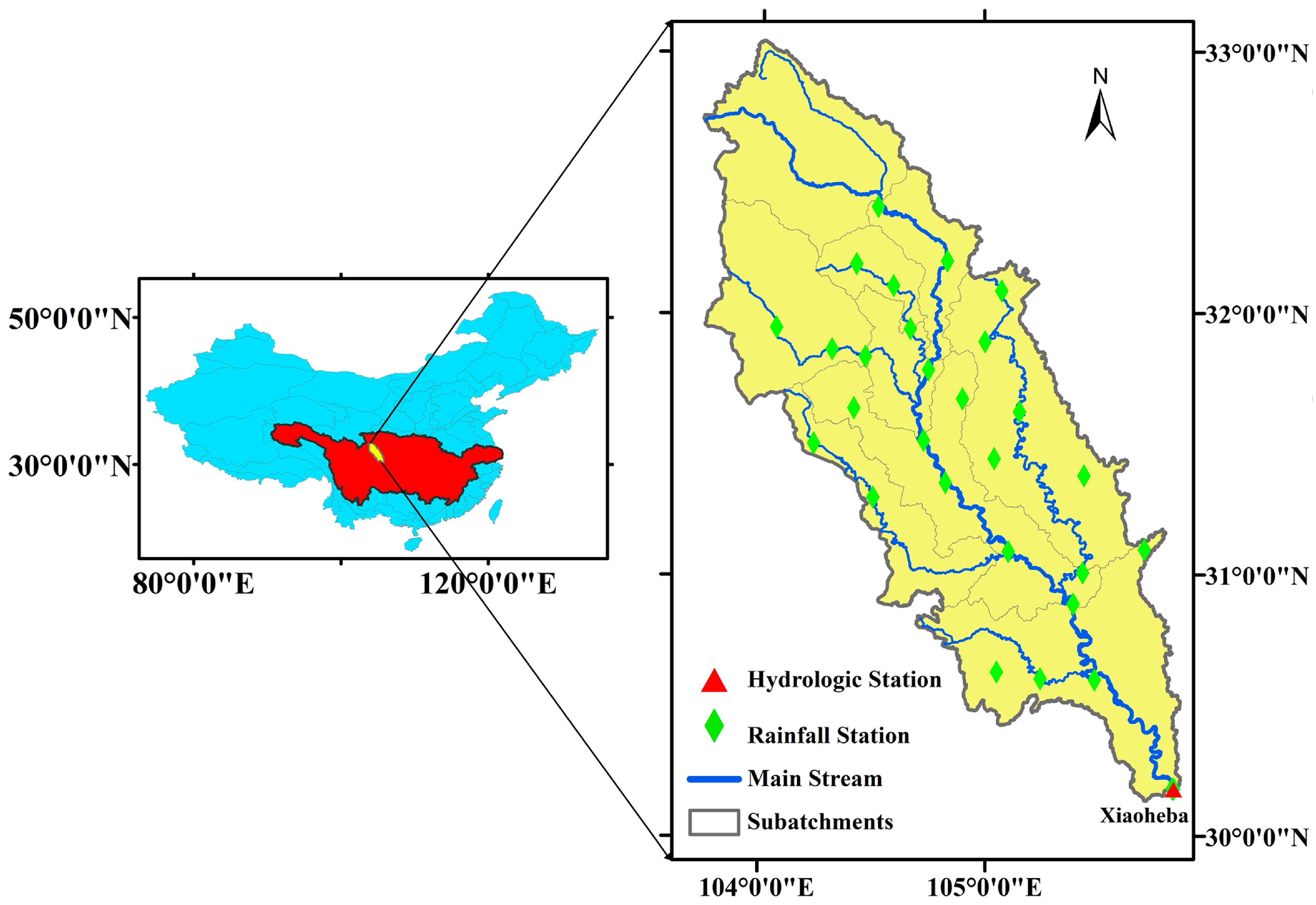
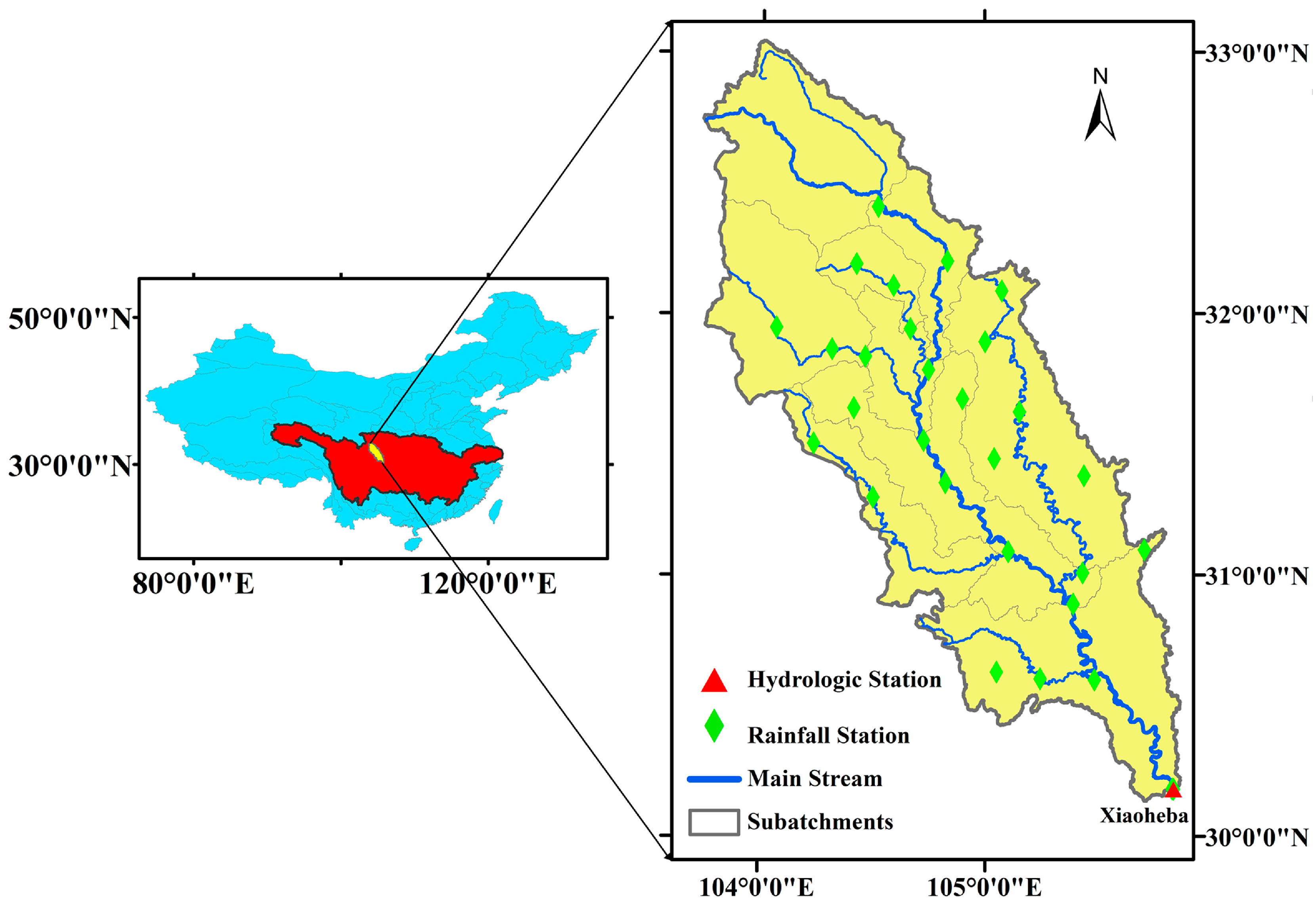
2. Study Area and Data
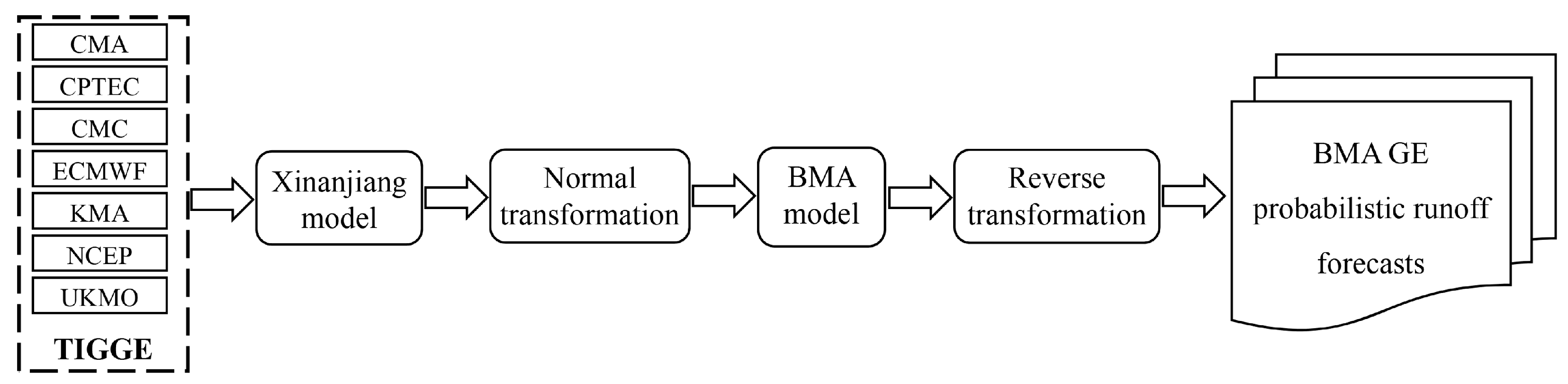
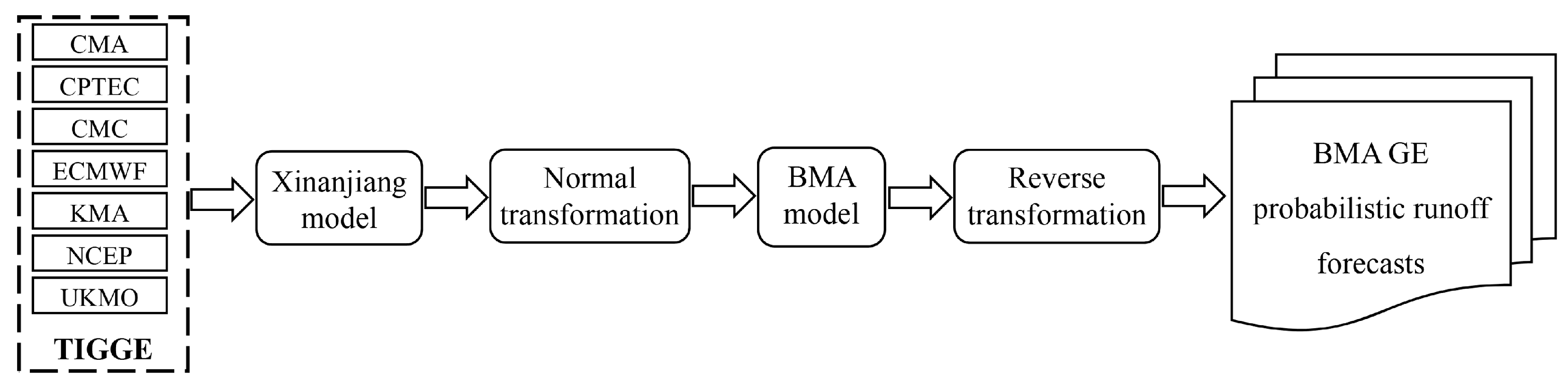
3. Methods
3.1. Bayesian Model Averaging (BMA) Model
3.2. Data Transformation
3.3. Verification Metrics
4. Results and Discussion
4.1. Experiment Completion and Perfection
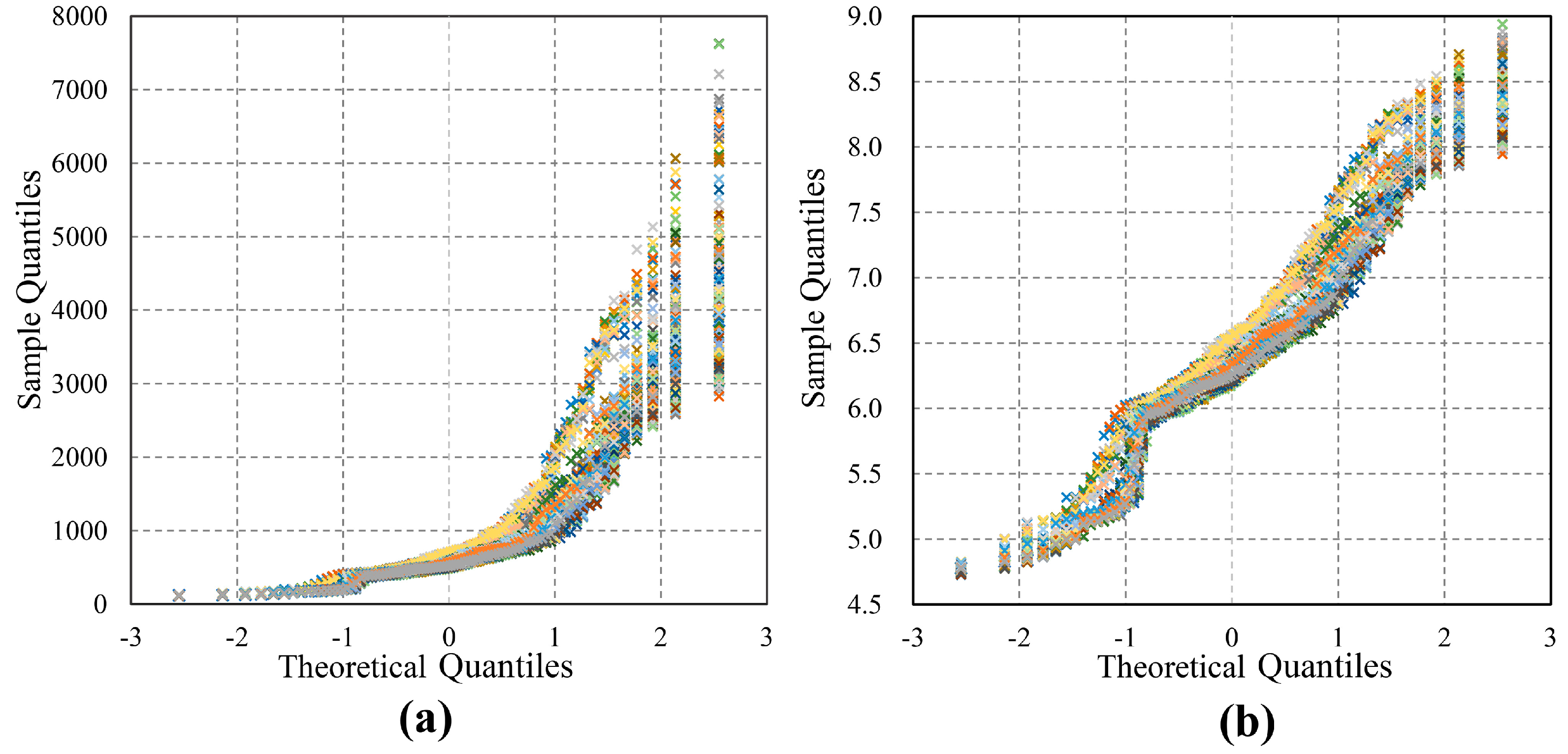
4.1.1. Estimation of the Box-Cox Coefficient
4.1.2. Optimization of the High-Dimensional Data Space
4.1.3. Estimation of the Length of Training Period
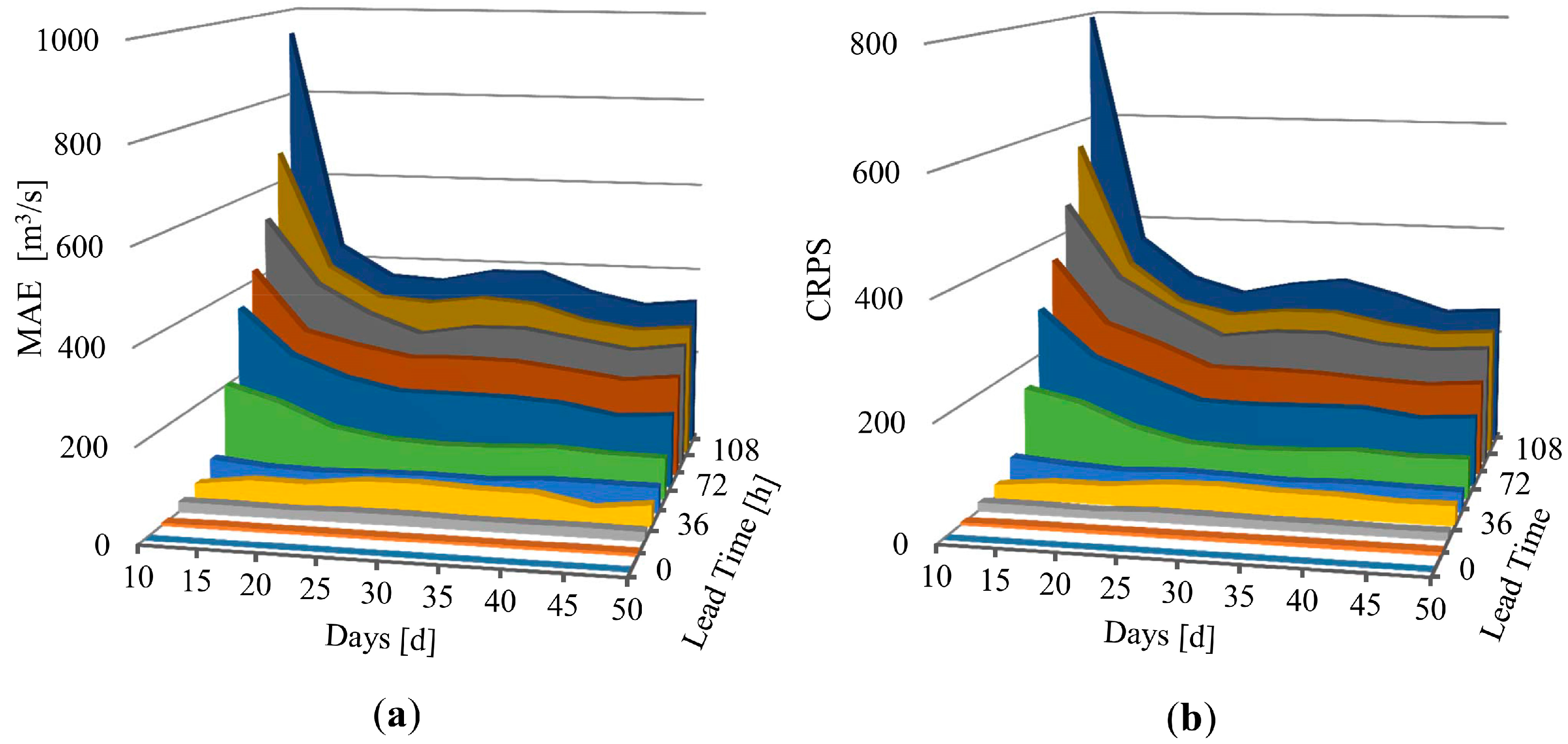
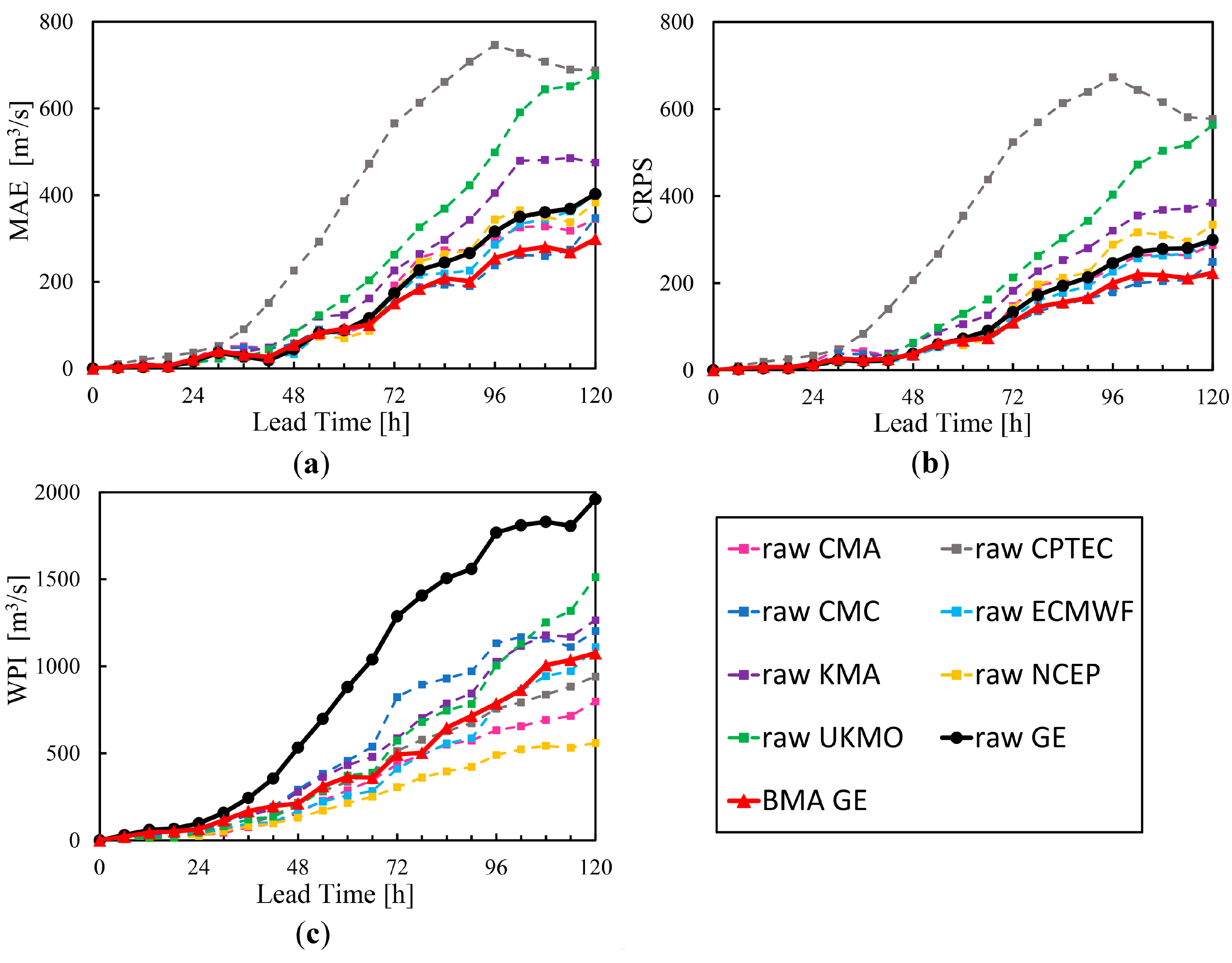
4.2. Forecast Performance Evaluation
4.2.1. Analysis of Verification Metrics
4.2.2. Analysis of BMA Weights
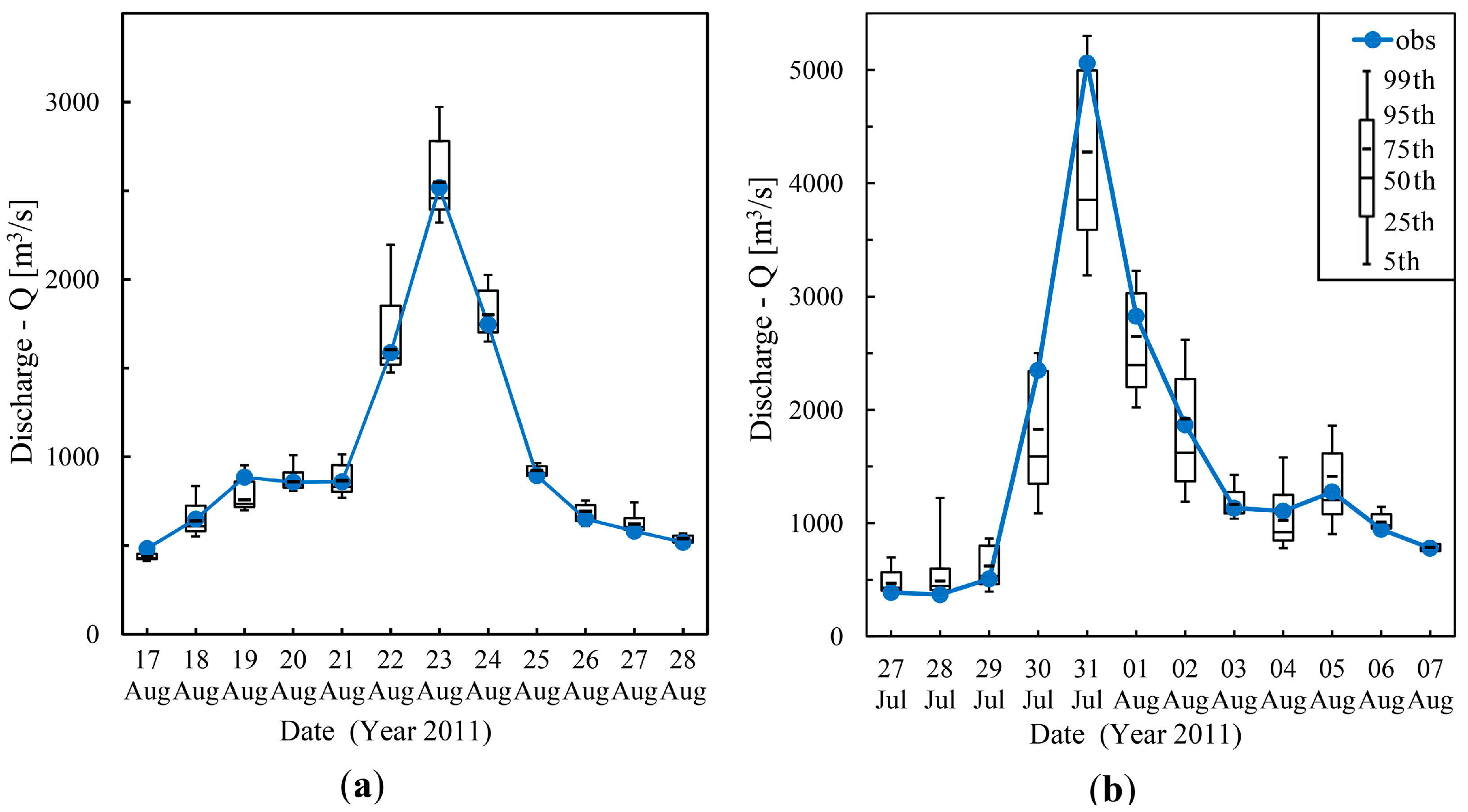
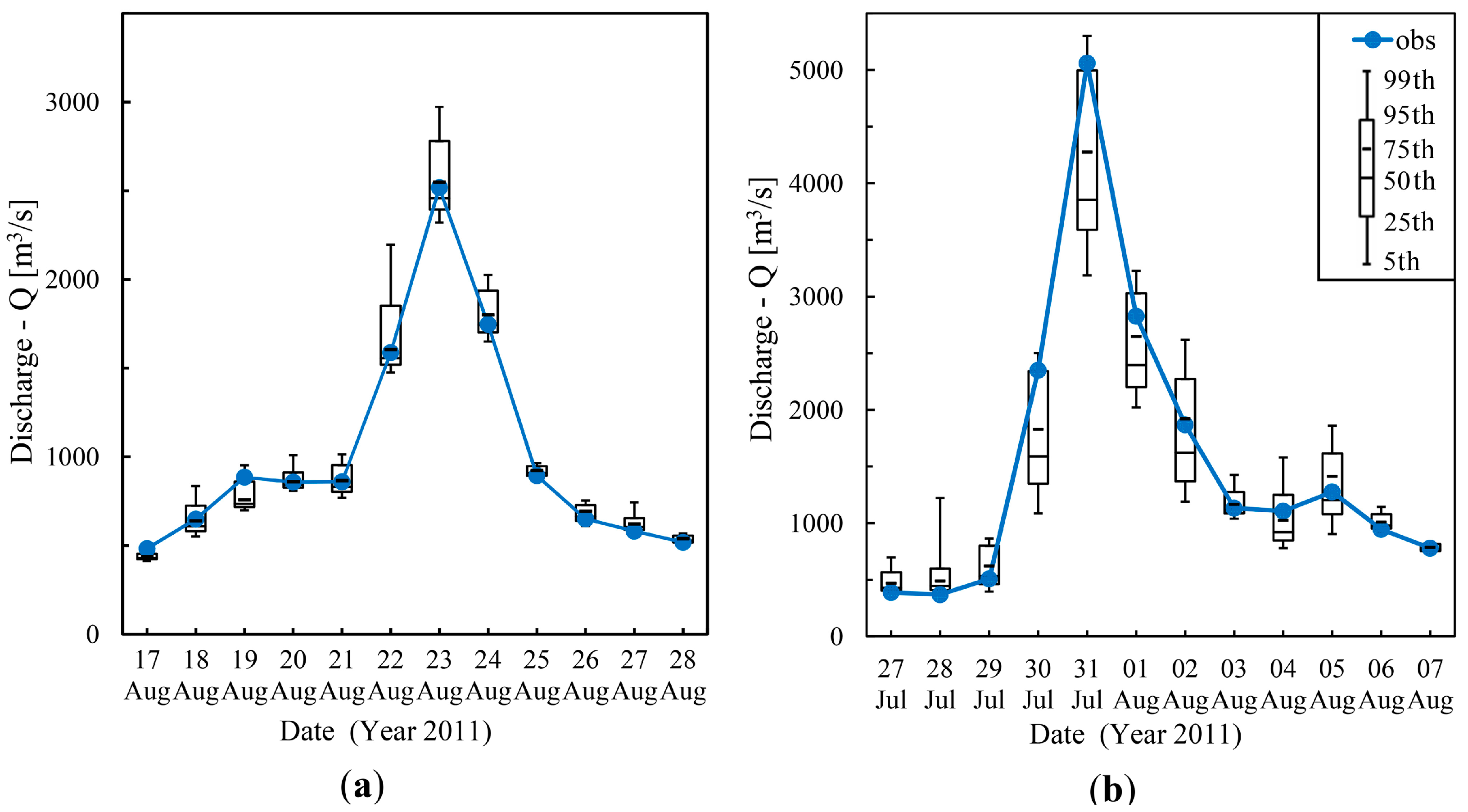
4.2.3. Analysis of Percentile Forecasts
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Roulin, E. Skill and relative economic value of medium-range hydrological ensemble predictions. Hydrol. Earth Syst. Sci. Discuss. 2006, 3, 1369–1406. [Google Scholar] [CrossRef]
- Goswami, M.; O’connor, K.; Bhattarai, K. Development of regionalisation procedures using a multi-model approach for flow simulation in an ungauged catchment. J. Hydrol. 2007, 333, 517–531. [Google Scholar] [CrossRef]
- Barnston, A.G.; Mason, S.J.; Goddard, L.; Dewitt, D.G.; Zebiak, S.E. Multimodel ensembling in seasonal climate forecasting at IRI. Bull. Am. Meteorol. Soc. 2003, 84, 1783–1796. [Google Scholar] [CrossRef]
- Palmer, T.; Alessandri, A.; Andersen, U.; Cantelaube, P. Development of a European multimodel ensemble system for seasonal-to-interannual prediction (Demeter). Bull. Am. Meteorol. Soc. 2004, 85, 853–872. [Google Scholar] [CrossRef]
- Doblas-Reyes, F.J.; Hagedorn, R.; Palmer, T. The rationale behind the success of multi-model ensembles in seasonal forecasting—II. Calibration and combination. Tellus A 2005, 57, 234–252. [Google Scholar] [CrossRef]
- Hagedorn, R.; Doblas-Reyes, F.J.; Palmer, T. The rationale behind the success of multi-model ensembles in seasonal forecasting—I. Basic concept. Tellus A 2005, 57, 219–233. [Google Scholar] [CrossRef]
- Cloke, H.L.; Pappenberger, F. Ensemble flood forecasting: A review. J. Hydrol. 2009, 375, 613–626. [Google Scholar] [CrossRef]
- Pappenberger, F.; Bartholmes, J.; Thielen, J.; Cloke, H.L.; Buizza, R.; de Roo, A. New dimensions in early flood warning across the globe using grand-ensemble weather predictions. Geophys. Res. Lett. 2008, 35. [Google Scholar] [CrossRef]
- He, Y.; Wetterhall, F.; Bao, H.; Cloke, H.; Li, Z.; Pappenberger, F.; Hu, Y.; Manful, D.; Huang, Y. Ensemble forecasting using TIGGE for the July–September 2008 floods in the upper huai catchment: A case study. Atmos. Sci. Lett. 2010, 11, 132–138. [Google Scholar] [CrossRef]
- Xu, J.; Zhang, W.; Zheng, Z.; Jiao, M.; Chen, J. Early flood warning for Linyi watershed by the GRAPES/XXT model using TIGGE data. Acta Meteorol. Sin. 2012, 26, 103–111. [Google Scholar] [CrossRef]
- Tian, X.; Xie, Z.; Wang, A.; Yang, X. A new approach for bayesian model averaging. Sci. China Earth Sci. 2012, 55, 1336–1344. [Google Scholar] [CrossRef]
- Raftery, A.E.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using bayesian model averaging to calibrate forecast ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef]
- Wilson, L.J.; Beauregard, S.; Raftery, A.E.; Verret, R. Calibrated surface temperature forecasts from the Canadian ensemble prediction system using bayesian model averaging. Mon. Weather Rev. 2007, 135, 1364–1385. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Clark, M.P.; Diks, C.G.; Duan, Q.; Robinson, B.A. Multi-objective calibration of forecast ensembles using bayesian model averaging. Geophys. Res. Lett. 2006, 33. [Google Scholar] [CrossRef]
- Sloughter, J.M.L.; Raftery, A.E.; Gneiting, T.; Fraley, C. Probabilistic quantitative precipitation forecasting using bayesian model averaging. Mon. Weather Rev. 2007, 135, 3209–3220. [Google Scholar] [CrossRef]
- Sloughter, J.M.; Gneiting, T.; Raftery, A.E. Probabilistic wind speed forecasting using ensembles and bayesian model averaging. J. Am. Stat. Assoc. 2010, 105, 25–35. [Google Scholar] [CrossRef]
- Schmeits, M.J.; Kok, K.J. A comparison between raw ensemble output, (modified) bayesian model averaging, and extended logistic regression using ECMWF ensemble precipitation reforecasts. Mon. Weather Rev. 2010, 138, 4199–4211. [Google Scholar] [CrossRef]
- Yang, C.; Yan, Z.; Shao, Y. Probabilistic precipitation forecasting based on ensemble output using generalized additive models and bayesian model averaging. Acta Meteorol. Sin. 2012, 26, 1–12. [Google Scholar] [CrossRef]
- Liu, J.; Xie, Z. BMA probabilistic quantitative precipitation forecasting over the huaihe basin using TIGGE multimodel ensemble forecasts. Mon. Weather Rev. 2014, 142, 1542–1555. [Google Scholar] [CrossRef]
- Duan, Q.; Ajami, N.K.; Gao, X.; Sorooshian, S. Multi-model ensemble hydrologic prediction using bayesian model averaging. Adv. Water Resour. 2007, 30, 1371–1386. [Google Scholar] [CrossRef]
- Ajami, N.K.; Duan, Q.; Sorooshian, S. An integrated hydrologic bayesian multimodel combination framework: Confronting input, parameter, and model structural uncertainty in hydrologic prediction. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Hemri, S.; Fundel, F.; Zappa, M. Simultaneous calibration of ensemble river flow predictions over an entire range of lead times. Water Resour. Res. 2013, 49, 6744–6755. [Google Scholar] [CrossRef]
- Zhao, R. The Xinanjiang model applied in China. J. Hydrol. 1992, 135, 371–381. [Google Scholar]
- Zhao, R.; Liu, X.; Singh, V. The Xinanjiang model. In Computer Models of Watershed Hydrology; Water Resources Publications: Fort Collins, CO, USA, 1995; pp. 215–232. [Google Scholar]
- Bougeault, P.; Toth, Z.; Bishop, C.; Brown, B.; Burridge, D.; Chen, D.H.; Ebert, B.; Fuentes, M.; Hamill, T.M.; Mylne, K. The thorpex interactive grand global ensemble. Bull. Am. Meteorol. Soc. 2010, 91, 1059–1072. [Google Scholar] [CrossRef]
- Swinbank, R.; Kyouda, M.; Buchanan, P.; Froude, L.; Hamill, T.M.; Hewson, T.D.; Keller, J.H.; Matsueda, M.; Methven, J.; Pappenberger, F. The TIGGE project and its achievements. Bull. Am. Meteorol. Soc. 2016, 97, 49–67. [Google Scholar] [CrossRef]
- Duan, Q.; Sorooshian, S.; Gupta, V. Effective and efficient global optimization for conceptual rainfall-runoff models. Water Resour. Res. 1992, 28, 1015–1031. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the em algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions; Wiley: New York, NY, USA, 1997; p. 274. [Google Scholar]
- Vrugt, J.A.; Diks, C.G.; Clark, M.P. Ensemble Bayesian model averaging using Markov chain Monte Carlo sampling. Environ. Fluid Mech. 2008, 8, 579–595. [Google Scholar] [CrossRef]
- Vrugt, J.A.; Ter Braak, C.; Diks, C.; Robinson, B.A.; Hyman, J.M.; Higdon, D. Accelerating Markov chain Monte Carlo simulation by differential evolution with self-adaptive randomized subspace sampling. Int. J. Nonlinear Sci. Numer. Simul. 2009, 10, 273–290. [Google Scholar] [CrossRef]
- Zsoter, E.; Pappenberger, F.; Smith, P.; Emerton, R.E.; Dutra, E.; Wetterhall, F.; Richardson, D.; Bogner, K.; Balsamo, G. Building a multi-model flood prediction system with the TIGGE archive. J. Hydrometeorol. 2016. [Google Scholar] [CrossRef]
- Hemri, S.; Lisniak, D.; Klein, B. Multivariate postprocessing techniques for probabilistic hydrological forecasting. Water Resour. Res. 2015, 51, 7436–7451. [Google Scholar] [CrossRef]
- Box, G.E.; Cox, D.R. An analysis of transformations. J. R. Stat. Soc. Ser. B (Methodol.) 1964, 26, 211–252. [Google Scholar]
- Gneiting, T.; Balabdaoui, F.; Raftery, A.E. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. Ser. B 2007, 69, 243–268. [Google Scholar] [CrossRef]
- Hersbach, H. Decomposition of the continuous ranked probability score for ensemble prediction systems. Weather Forecast. 2000, 15, 559–570. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Massey, F.J., Jr. The Kolmogorov-Smirnov test for goodness of fit. J. Am. Stat. Assoc. 1951, 46, 68–78. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, A.E.; Gneiting, T. Calibrating multimodel forecast ensembles with exchangeable and missing members using bayesian model averaging. Mon. Weather Rev. 2010, 138, 190–202. [Google Scholar] [CrossRef]
- Pappenberger, F.; Bartholmes, J.; Thielen, J.; Anghel, E. TIGGE: Medium Range Multi Model Weather Forecast Ensembles in Flood Forecasting (a Case Study); European Centre for Medium-Range Weather Forecasts: Reading, UK, 2008. [Google Scholar]
- Bogner, K.; Pappenberger, F.; Cloke, H.L. Model combination and weighting methods in operational flood forecasting. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 7–12 April 2013; Volume 15, p. 13629.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Centre | Country/Domain | Horizontal Resolution | Ensemble Members (Perturbed) | Forecast Length (Hours) |
|---|---|---|---|---|
| CMA | China | TL213 | 14 | 240 |
| CPTEC | Brazil | T126 | 14 | 360 |
| CMC | Canada | 0.9° × 0.9° | 20 | 384 |
| ECMWF | Europe | TL399 (up to day 10) | 50 | 360 |
| KMA | Korea | N320 | 23 | 288 |
| NCEP | United States | T126 | 20 | 384 |
| UKMO | United Kingdom | N126 | 23 | 360 |
| Lead Time | Weights | ||||||
|---|---|---|---|---|---|---|---|
| CMA | CPTEC | CMC | ECMWF | KMA | NCEP | UKMO | |
| 24 h | 0.064 | 0.008 | 0.648 | 0.201 | 0.017 | 0.025 | 0.038 |
| 48 h | 0.167 | 0.000 | 0.071 | 0.741 | 0.000 | 0.021 | 0.000 |
| 72 h | 0.062 | 0.000 | 0.105 | 0.792 | 0.010 | 0.000 | 0.031 |
| 96 h | 0.001 | 0.000 | 0.182 | 0.740 | 0.003 | 0.000 | 0.074 |
| 120 h | 0.000 | 0.000 | 0.312 | 0.672 | 0.000 | 0.015 | 0.001 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, B.; Zhang, X.; Pappenberger, F.; Zhang, T.; Fang, Y. Multi-Model Grand Ensemble Hydrologic Forecasting in the Fu River Basin Using Bayesian Model Averaging. Water 2017, 9, 74. https://doi.org/10.3390/w9020074
Qu B, Zhang X, Pappenberger F, Zhang T, Fang Y. Multi-Model Grand Ensemble Hydrologic Forecasting in the Fu River Basin Using Bayesian Model Averaging. Water. 2017; 9(2):74. https://doi.org/10.3390/w9020074
Chicago/Turabian StyleQu, Bo, Xingnan Zhang, Florian Pappenberger, Tao Zhang, and Yuanhao Fang. 2017. "Multi-Model Grand Ensemble Hydrologic Forecasting in the Fu River Basin Using Bayesian Model Averaging" Water 9, no. 2: 74. https://doi.org/10.3390/w9020074