Cuckoo Search Algorithm with Lévy Flights for Global-Support Parametric Surface Approximation in Reverse Engineering

 , , ,
, , ,
Abstract
:1. Introduction
1.1. Surface Approximation in Reverse Engineering
1.2. Aims and Structure of the Paper
2. Previous Work
3. Description of the Problem
3.1. Basic Concepts and Definitions
3.2. The Surface Approximation Problem
4. The Cuckoo Search Algorithm
4.1. Nature-Inspired Algorithms
4.2. Basic Principles
- Each cuckoo lays one egg at a time in a randomly chosen nest.
- The nests with the best eggs (i.e., high quality of solutions) will be carried over to the next generations, thus ensuring that good solutions are preserved over time.
- The number of available host nests is always fixed. A host can discover an alien egg with a probability . This rule can be approximated by the fact that a fraction of the n available host nests will be replaced by new nests (with new random solutions at new locations).
4.3. The Algorithm
| Algorithm 1: Cuckoo Search via Lévy Flights |
| begin |
| Objective function , with |
| Generate initial population of N host nests |
| while or (stop criterion) |
| Get a cuckoo (say, i) randomly by Lévy flights |
| Evaluate its fitness |
| Choose a nest among N (say, j) randomly |
| if ( |
| Replace j by the new solution |
| end |
| A fraction () of worse nests are abandoned and new ones are built via Lévy flights |
| Keep the best solutions (or nests with quality solutions) |
| Rank the solutions and find the current best |
| end while |
| Postprocess results and visualization |
| end |
5. Method
5.1. Overview of the Method
- data parameterization,
- surface fitting.
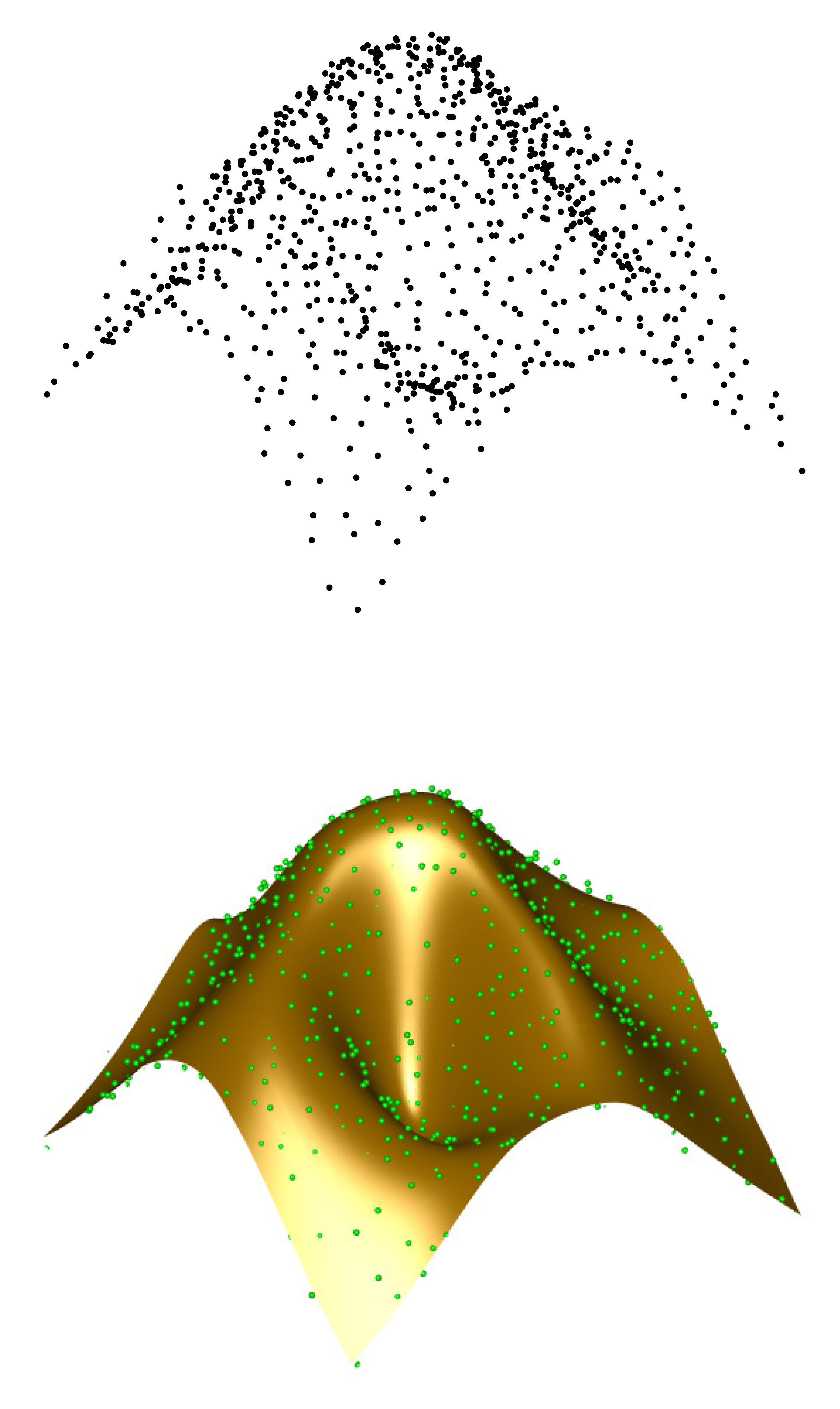
5.2. Data Parameterization
5.3. Data Fitting
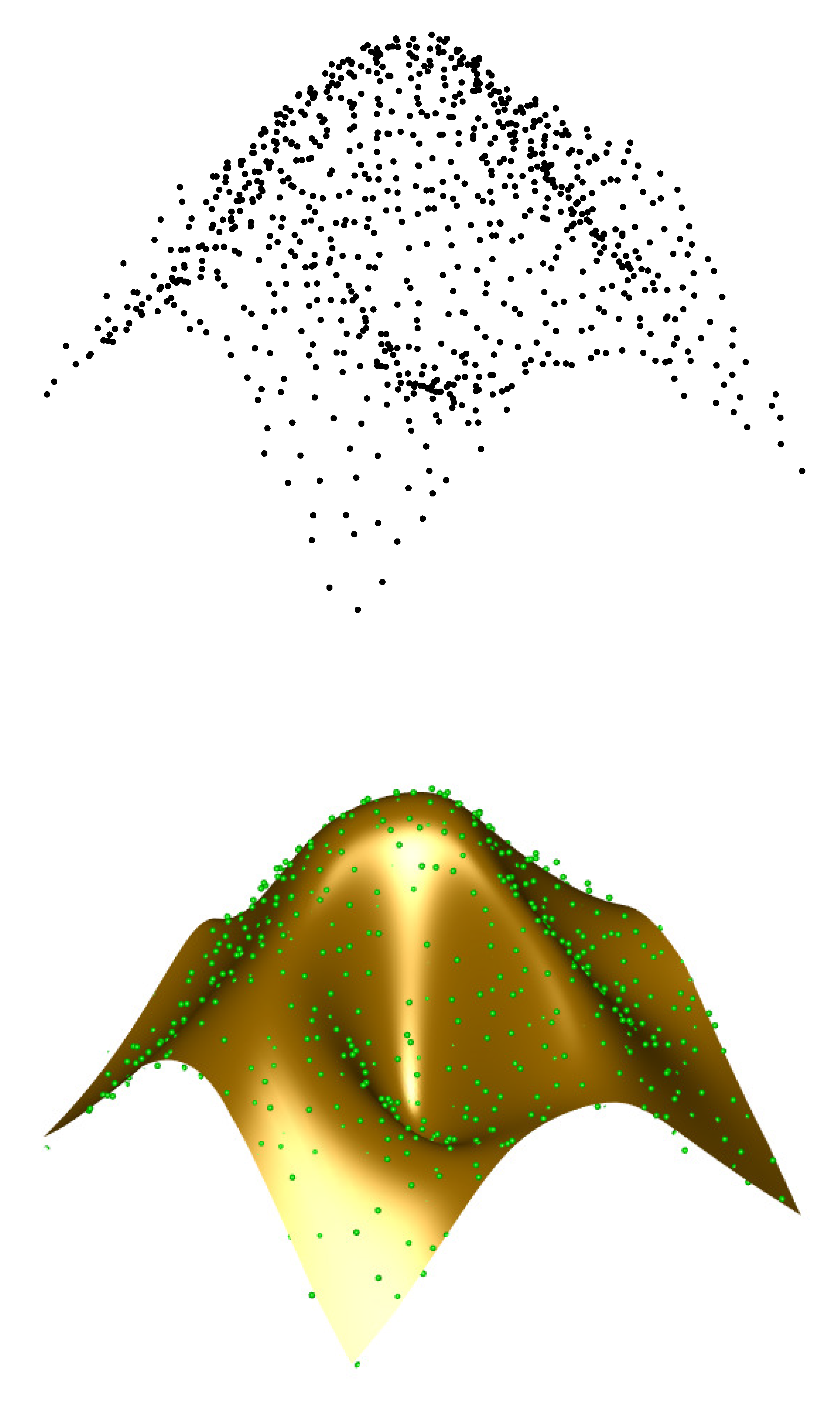
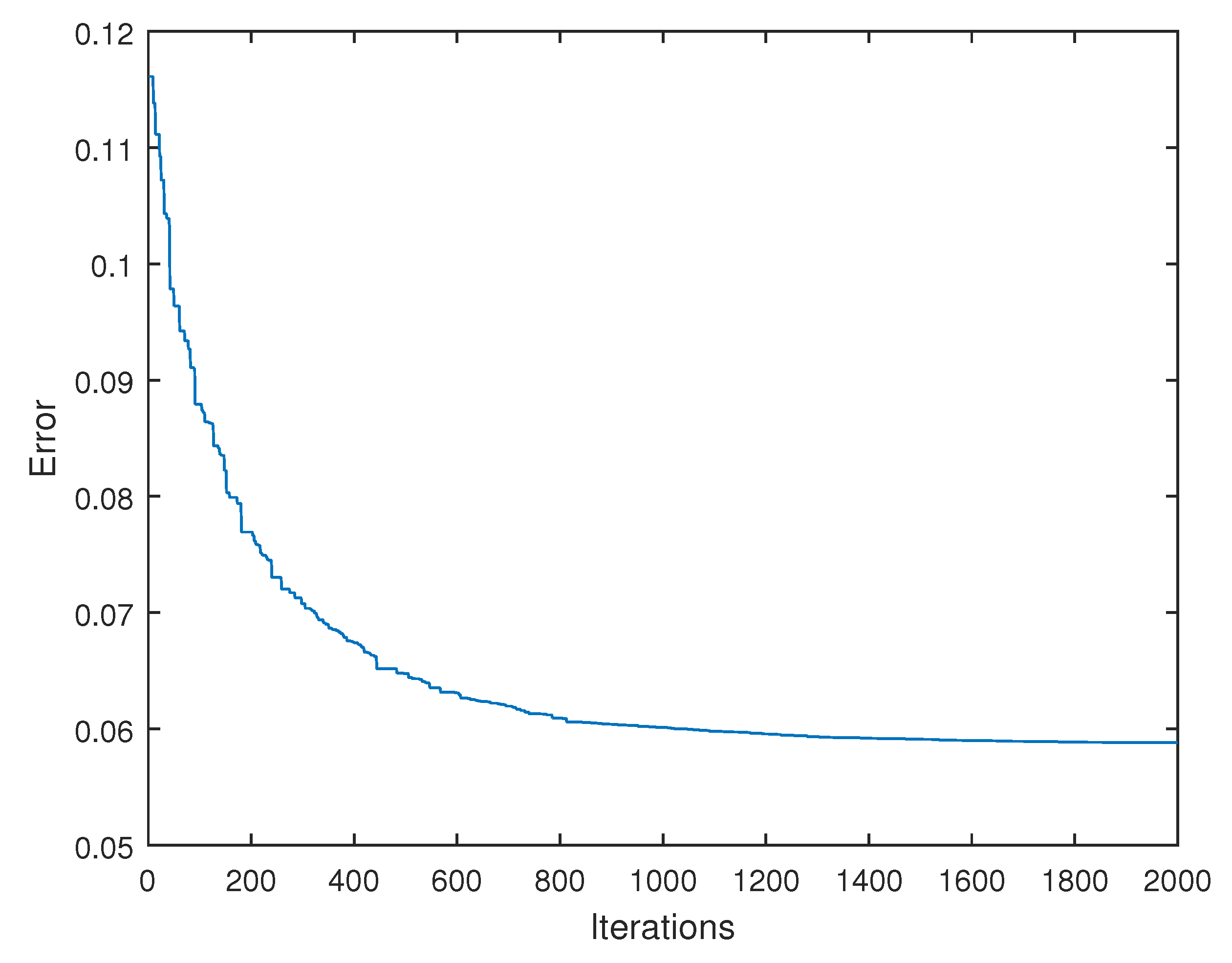
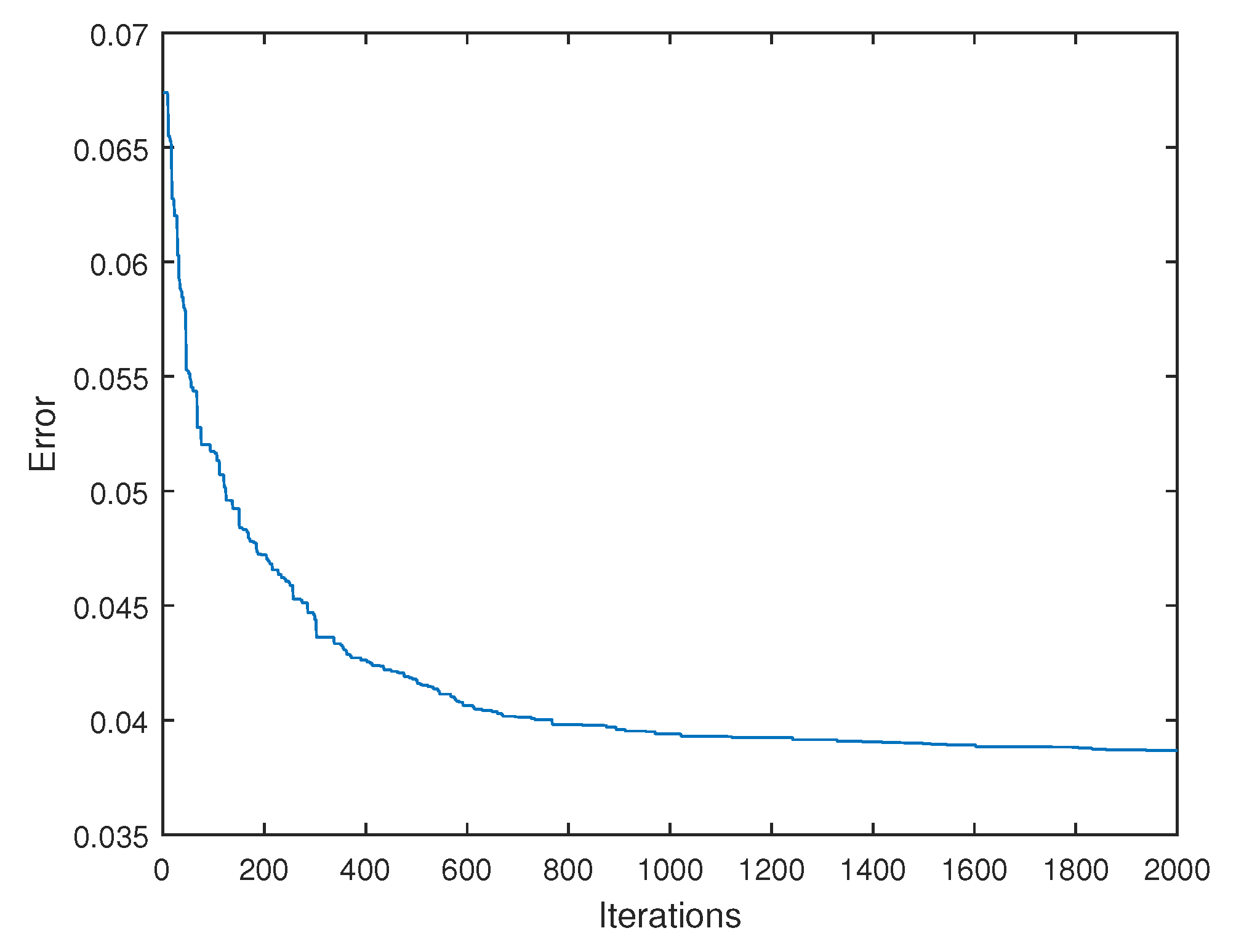
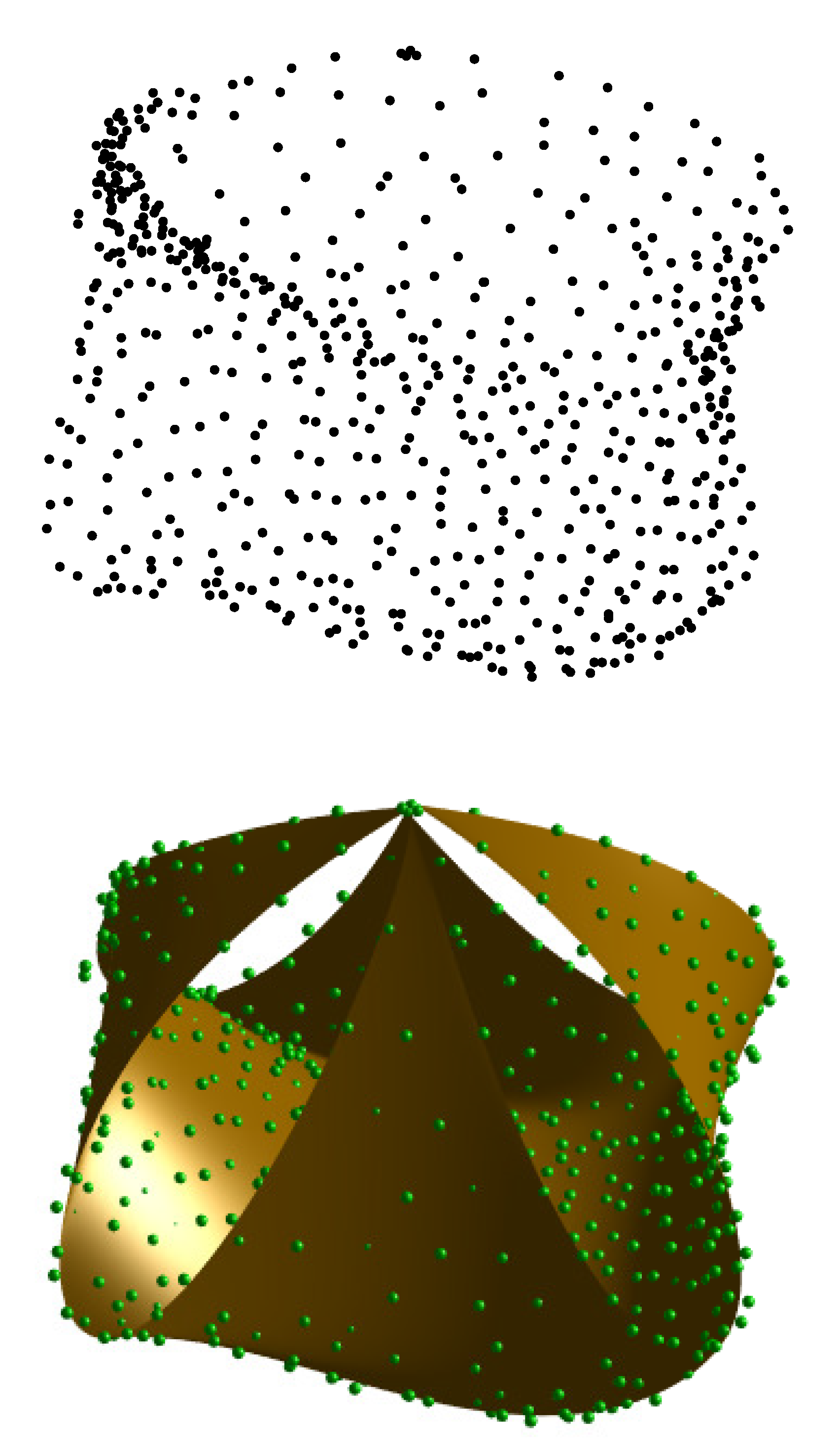
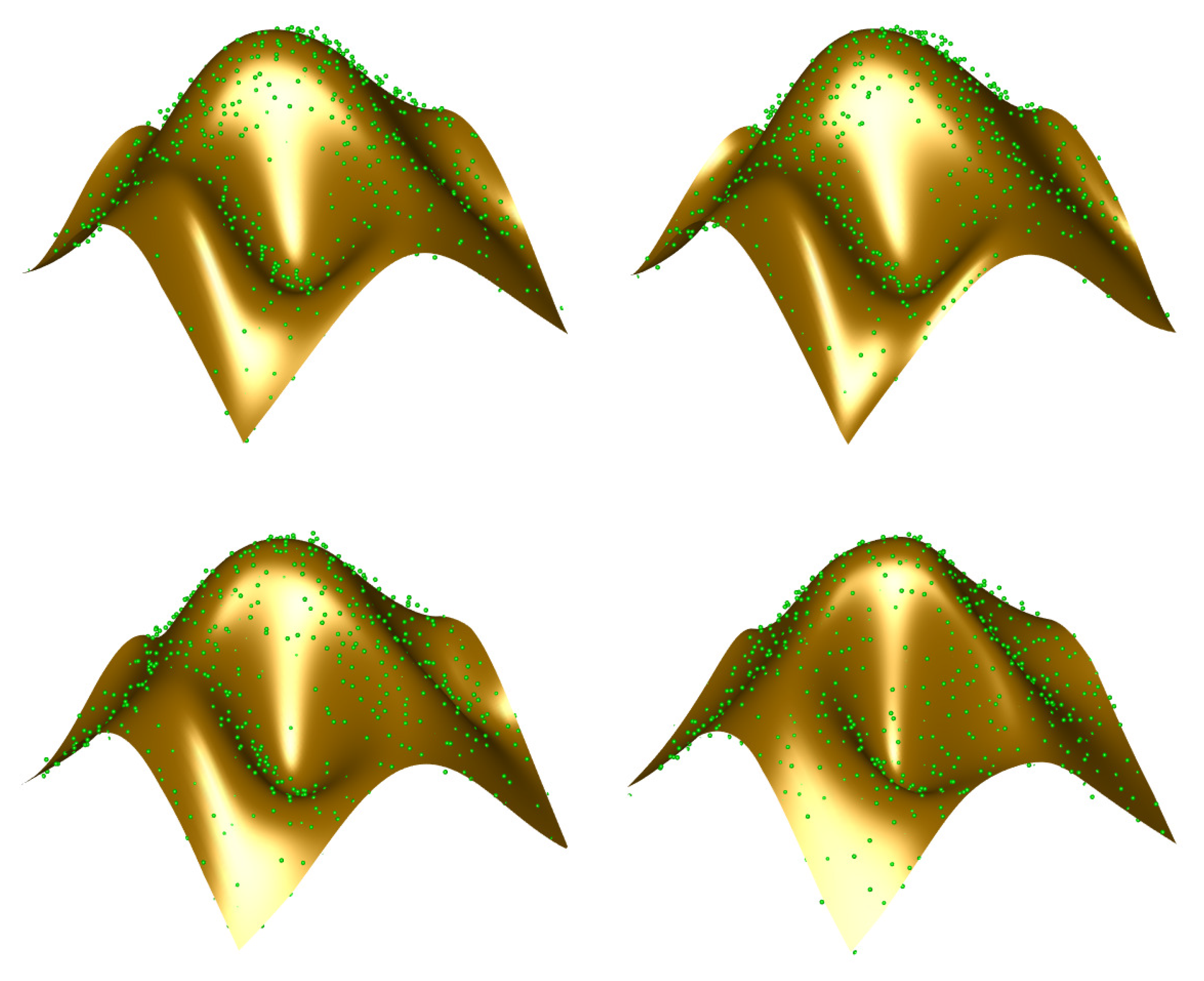
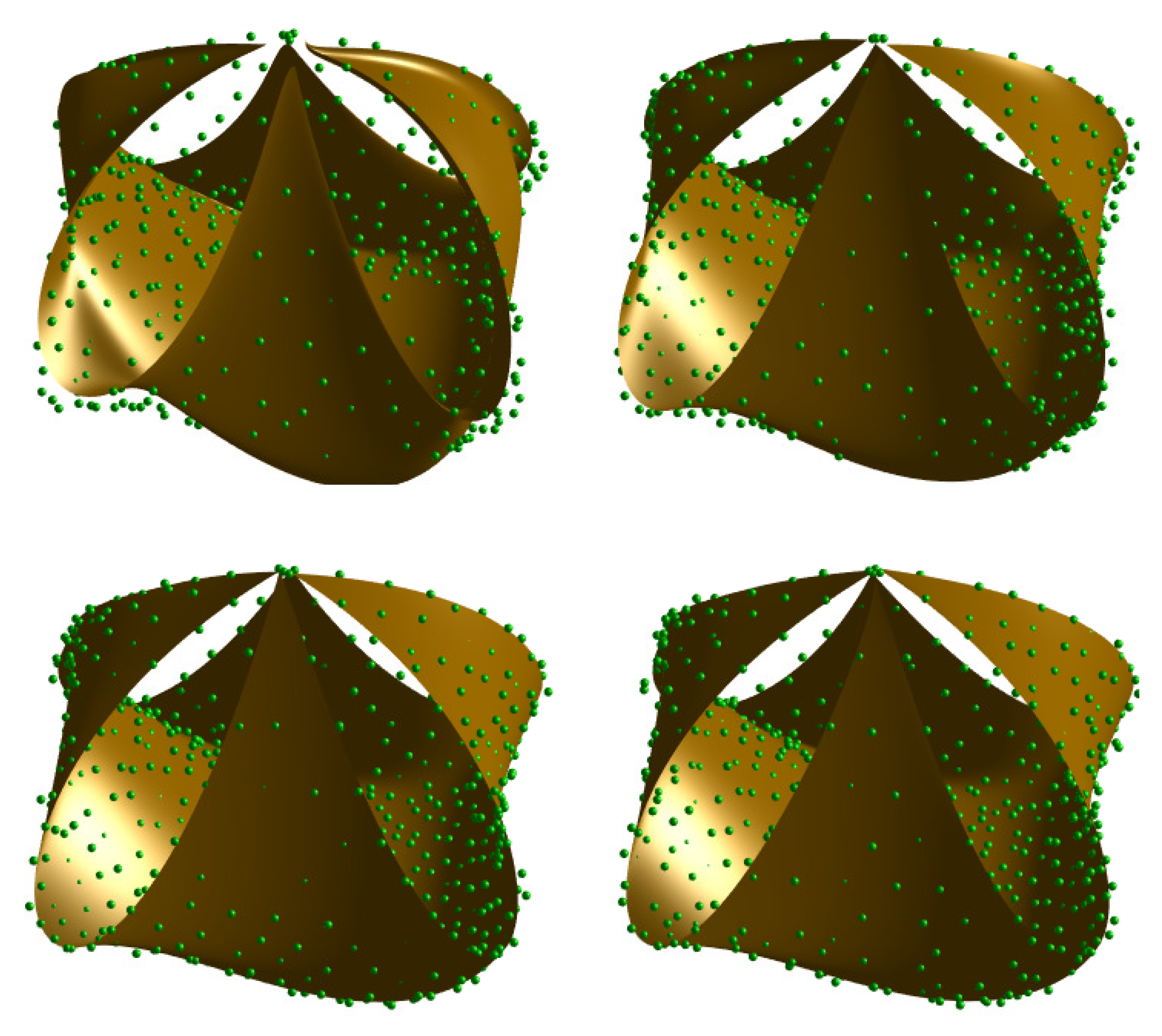
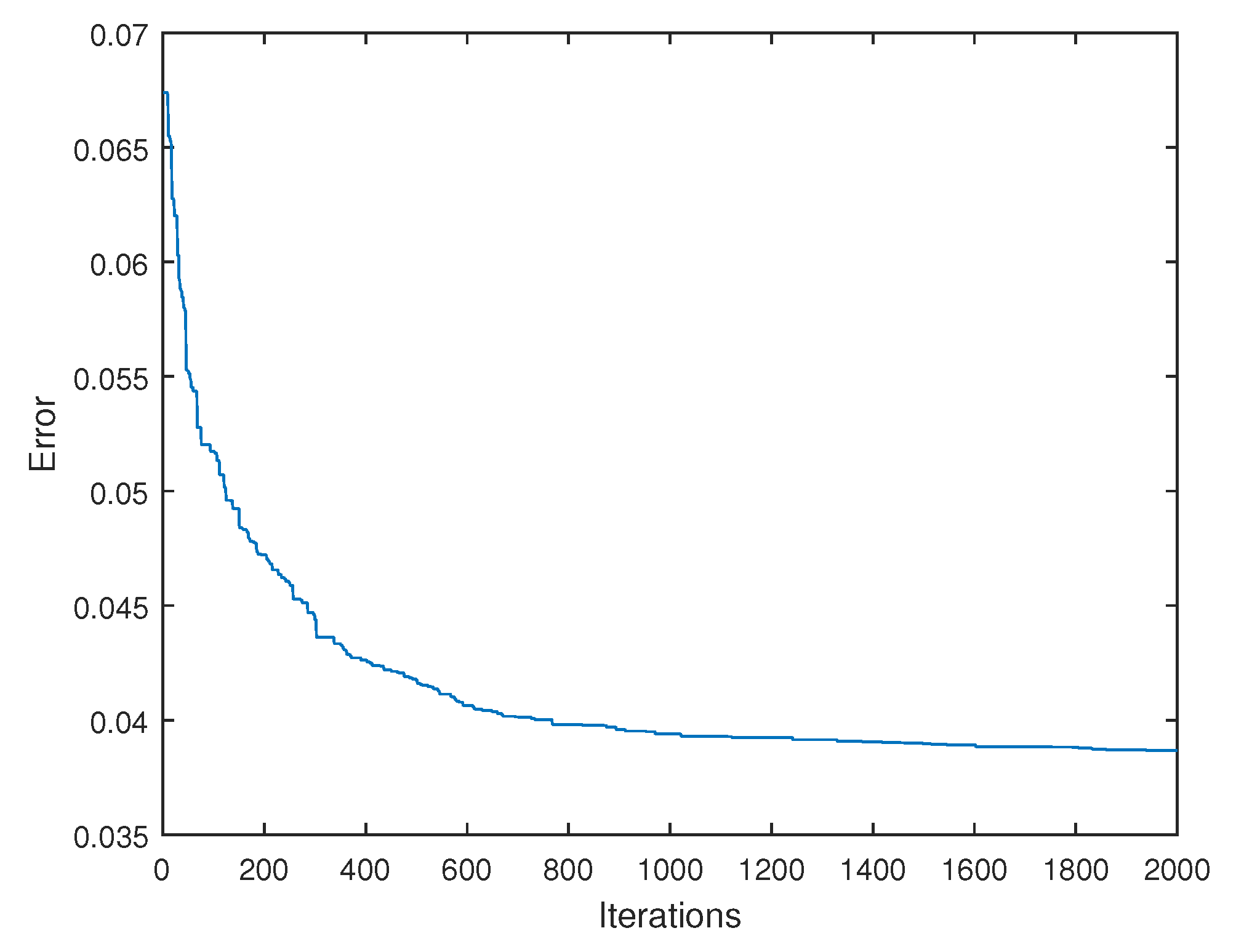
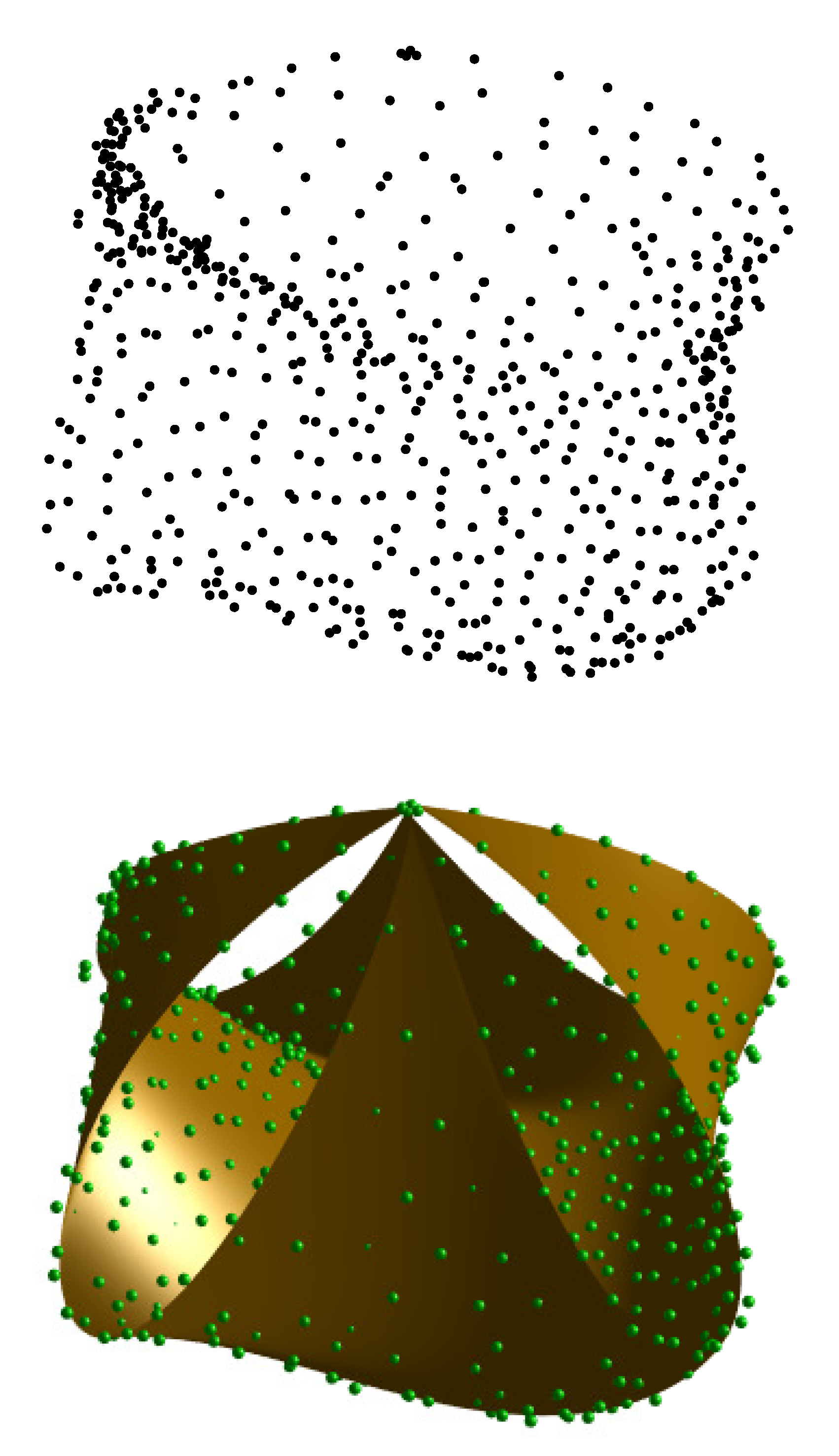
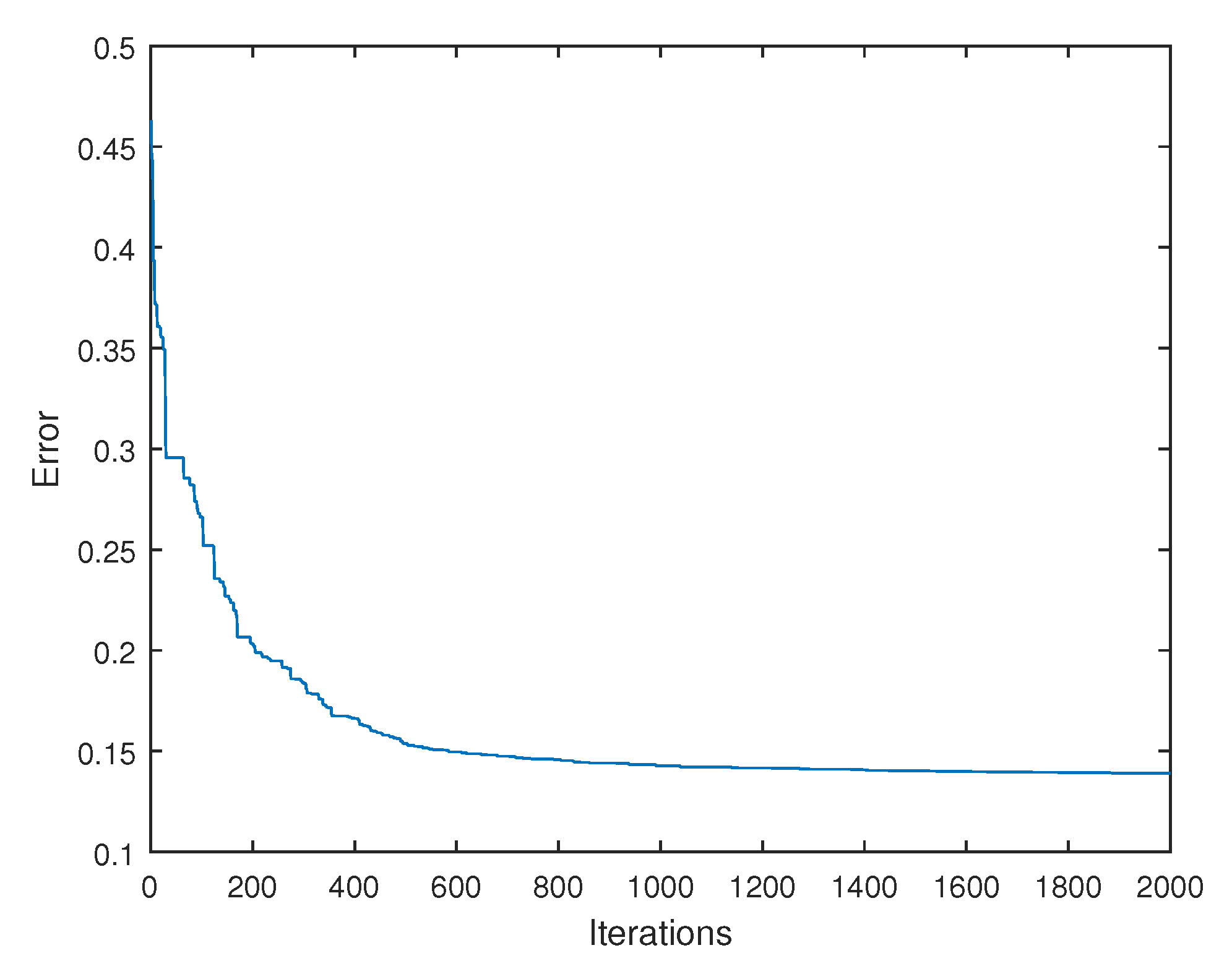
6. Results
6.1. Graphical and Numerical Results
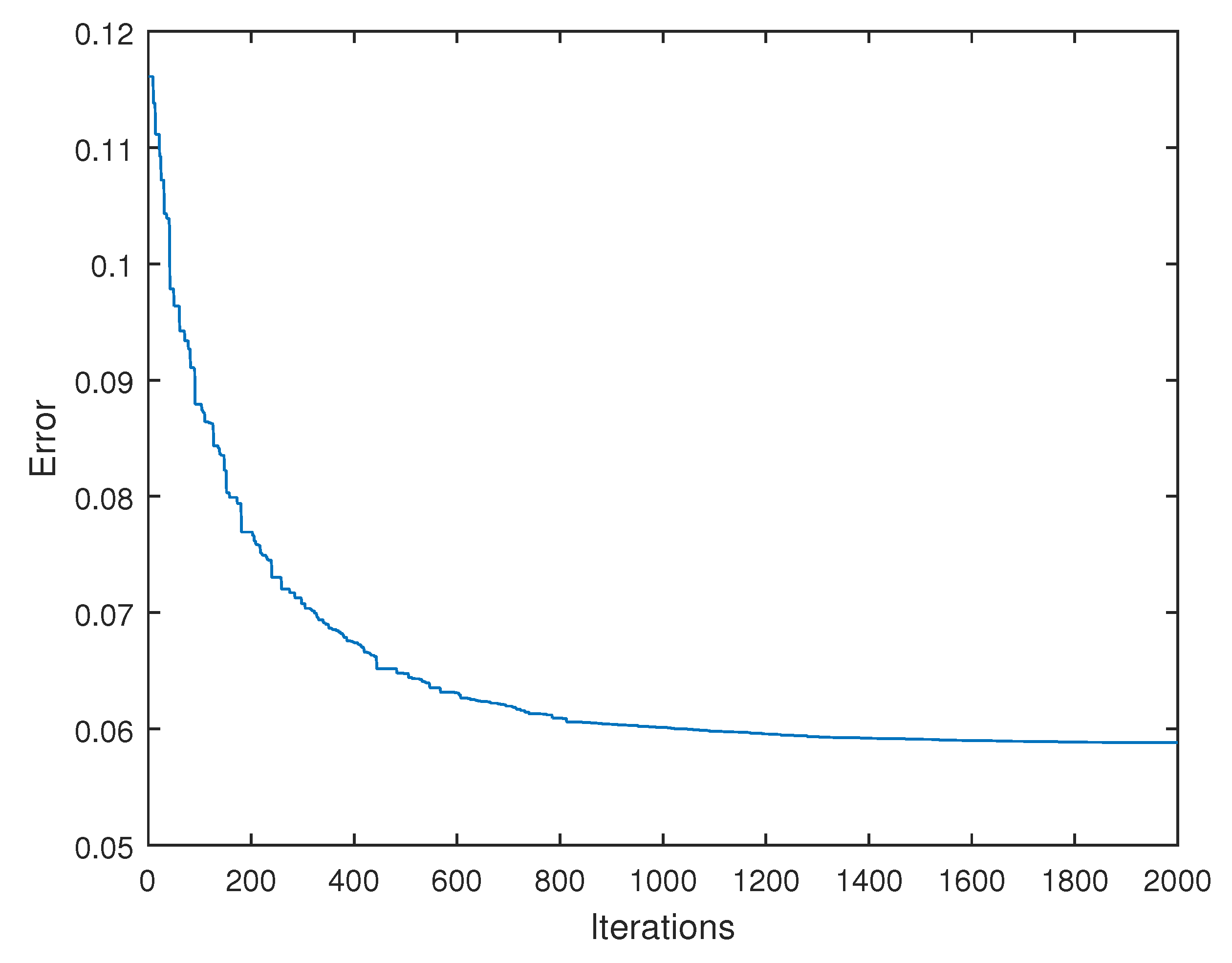
6.2. Parameter Tuning
- the population size , and
- the probability .
6.3. Implementation Issues
6.4. Computation Times
7. Discussion
7.1. Comparative Work
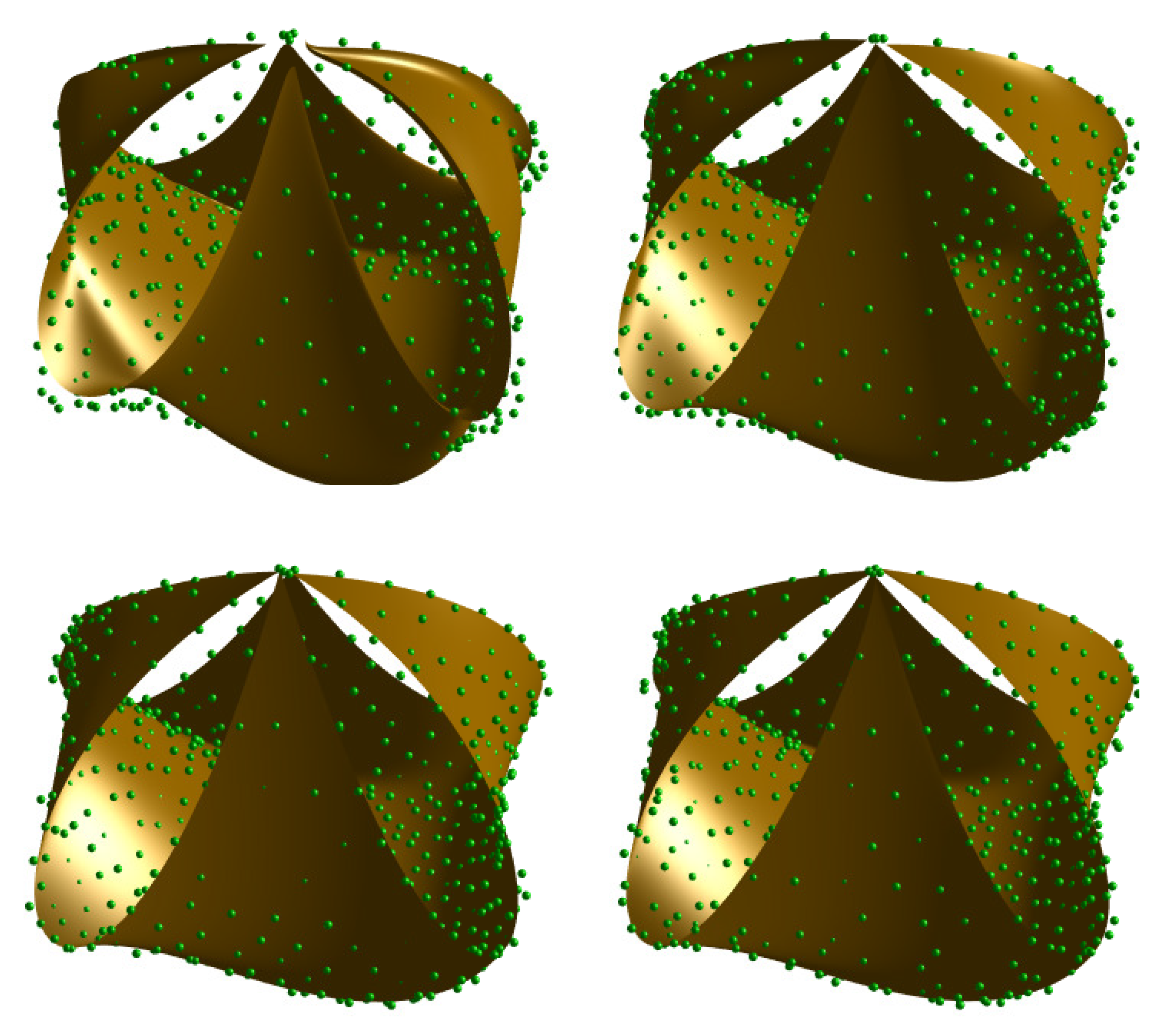
- Our method improves the most classical parameterization methods described in the literature in our comparison. The error rate of the alternative approaches with respect to our method shows that it provides a significant improvement, not just incremental enhancements. This fact is also visible in Figure 7, Figure 8 and Figure 9, where the resulting Bézier surfaces for the uniform, chordal, and centripetal parameterizations, and with our method are displayed for easier visual inspection for the three examples in our benchmark, respectively.
- Among these parametrization methods, the centripetal parameterization yields the closest results to ours in all cases. In fact, it might be a competitive method for some applications, but fails to yield even near-optimal solutions. This fact is clearly noticeable from Table 4 by simple visual inspection of the corresponding numerical values.
- In general, both the uniform and the chordal parameterization yields approximation surfaces of moderate quality. We also remark that the chordal approximation performs even worse than uniform parameterization for Example I while it happens the opposite way for Example III and they perform more or less similarly for Example II. These results are related to the fact that data points for Example I and Example II are noisy but organized, while they are unorganized for Example III. The uniform parameterization does not perform well for such uneven distribution of points.
- The comparison of CSA and its variant ICSA shows that they perform very similarly for the three examples in the benchmark. In fact, the mean value is slightly better for ICSA while the best value is better for CSA for the three examples. This means that the method ICSA tends to have less variation for different executions (as confirmed by the smaller values for the variance and standard deviation than CSA), but CSA is better at approaching to the global minima. However, the differences between both methods are very small and none of them seems to dominate the other for our benchmark.
7.2. Statistical Analysis
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Patrikalakis, N.M.; Maekawa, T. Shape Interrogation for Computer Aided Design and Manufacturing; Springer: Heidelberg, Germany, 2002. [Google Scholar]
- Pottmann, H.; Leopoldseder, S.; Hofer, M.; Steiner, T.; Wang, W. Industrial geometry: Recent advances and applications in CAD. Comput. Aided Des. 2005, 37, 751–766. [Google Scholar] [CrossRef]
- Varady, T.; Martin, R. Reverse Engineering. In Handbook of Computer Aided Geometric Design; Farin, G., Hoschek, J., Kim, M., Eds.; Elsevier Science: Amsterdam, The Netherlands, 2002. [Google Scholar]
- Dierckx, P. Curve and Surface Fitting with Splines; Oxford University Press: Oxford, UK, 1993. [Google Scholar]
- Farin, G. Curves and Surfaces for CAGD, 5th ed.; Morgan Kaufmann: San Francisco, CA, USA, 2002. [Google Scholar]
- Maekawa, T.; Matsumoto, Y.; Namiki, K. Interpolation by geometric algorithm. Comput. Aided Des. 2007, 39, 313–323. [Google Scholar] [CrossRef]
- Marinov, M.; Kobbelt, L. Optimization methods for scattered data approximation with subdivision surfaces. Graph. Models 2005, 67, 452–473. [Google Scholar] [CrossRef]
- Sclaroff, S.; Pentland, A. Generalized implicit functions for computer graphics. In Proceedings of the 18th Annual Conference on Computer Graphics and Interactive Techniques, Providence, RI, USA, 27–30 April 1991; Volume 25, pp. 247–250. [Google Scholar]
- Carr, J.C.; Beatson, R.K.; Cherrie, J.B.; Mitchell, T.J.; Fright, W.R.; McCallum, B.C.; Evans, T.R. Reconstruction and representation of 3D objects with radial basis functions. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 12–17 August 2001; pp. 67–76. [Google Scholar]
- Lim, C.; Turkiyyah, G.; Ganter, M.; Storti, D. Implicit reconstruction of solids from. cloud point sets. In Proceedings of the Third ACM Symposium on Solid Modeling and Applications, Salt Lake City, UT, USA, 17–19 May 1995; pp. 393–402. [Google Scholar]
- Forsey, D.R.; Bartels, R.H. Surface fitting with hierarchical splines. ACM Trans. Graph. 1995, 14, 134–161. [Google Scholar] [CrossRef]
- Pratt, V. Direct least-squares fitting of algebraic surfaces. In Proceedings of the 14th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, California, 27–31 July 1987; Volume 21, pp. 145–152. [Google Scholar]
- Chih, M. A more accurate second-order polynomial metamodel using a pseudo-random number assignment strategy. J. Oper. Res. Soc. 2013, 64, 198–207. [Google Scholar] [CrossRef]
- Bajaj, C.; Bernardini, F.; Xu, G. Automatic reconstruction of surfaces and scalar fields from 3D scans. In Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 6–11 August 1995; pp. 109–118. [Google Scholar]
- Jones, M.; Chen, M. A new approach to the construction of surfaces from contour data. Comput. Graph. Forum 1994, 13, 75–84. [Google Scholar] [CrossRef]
- Meyers, D.; Skinnwer, S.; Sloan, K. Surfaces from contours. ACM Trans. Graph. 1992, 11, 228–258. [Google Scholar] [CrossRef]
- Park, H.; Kim, K. Smooth surface approximation to serial cross-sections. Comput. Aided Des. 1997, 28, 995–1005. [Google Scholar] [CrossRef]
- Maekawa, I.; Ko, K. Surface construction by fitting unorganized curves. Graph. Models 2002, 64, 316–332. [Google Scholar] [CrossRef]
- Echevarría, G.; Iglesias, A.; Gálvez, A. Extending neural networks for B-spline surface reconstruction. Lect. Notes Comput. Sci. 2002, 2330, 305–314. [Google Scholar]
- Gu, P.; Yan, X. Neural network approach to the reconstruction of free-form surfaces for reverse engineering. Comput. Aided Des. 1995, 27, 59–64. [Google Scholar] [CrossRef]
- Ma, W.Y.; Kruth, J.P. Parameterization of randomly measured points for least squares fitting of B-spline curves and surfaces. Comput. Aided Des. 1995, 27, 663–675. [Google Scholar] [CrossRef]
- Eck, M.; Hoppe, H. Automatic reconstruction of B-Spline surfaces of arbitrary topological type. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 325–334. [Google Scholar]
- Piegl, L.; Tiller, W. The NURBS Book; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Hoffmann, M. Numerical control of Kohonen neural network for scattered data approximation. Numer. Algorithms 2005, 39, 175–186. [Google Scholar] [CrossRef]
- Knopf, G.K.; Kofman, J. Adaptive reconstruction of free-form surfaces using Bernstein basis function networks. Eng. Appl. Artif. Intell. 2001, 14, 577–588. [Google Scholar] [CrossRef]
- Barhak, J.; Fischer, A. Parameterization and reconstruction from 3D scattered points based on neural network and PDE techniques. IEEE Trans. Vis. Comput. Graph. 2001, 7, 1–16. [Google Scholar] [CrossRef]
- Liu, X.; Tang, M.; Frazer, J.H. Shape reconstruction by genetic algorithms and artificial neural networks. Eng. Comput. 2003, 20, 129–151. [Google Scholar] [Green Version]
- Gálvez, A.; Iglesias, A.; Cobo, A.; Puig-Pey, J.; Espinola, J. Bézier curve and surface fitting of 3D point clouds through genetic algorithms, functional networks and least-squares approximation. Lect. Notes Comput. Sci. 2007, 4706, 680–693. [Google Scholar]
- Iglesias, A.; Echevarría, G.; Gálvez, A. Functional networks for B-spline surface reconstruction. Future Gener. Comput. Syst. 2004, 20, 1337–1353. [Google Scholar] [CrossRef]
- Iglesias, A.; Gálvez, A. Hybrid functional-neural approach for surface reconstruction. Math. Probl. Eng. 2014. [Google Scholar] [CrossRef]
- Yang, X.-S. Nature-Inspired Metaheuristic Algorithms, 2nd. ed.; Luniver Press: Frome, UK, 2010. [Google Scholar]
- Yang, X.-S. Engineering Optimization: An Introduction with Metaheuristic Applications; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Gálvez, A.; Iglesias, A. Efficient particle swarm optimization approach for data fitting with free knot B-splines. Comput. Aided Des. 2011, 43, 1683–1692. [Google Scholar] [CrossRef]
- Yoshimoto, F.; Harada, T.; Yoshimoto, Y. Data fitting with a spline using a real-coded algorithm. Comput. Aided Des. 2003, 35, 751–760. [Google Scholar] [CrossRef]
- Gálvez, A.; Iglesias, A.; Avila, A.; Otero, C.; Arias, R.; Manchado, C. Elitist clonal selection algorithm for optimal choice of free knots in B-spline data fitting. Appl. Soft Comput. 2015, 26, 90–106. [Google Scholar] [CrossRef]
- Ulker, E.; Arslan, A. Automatic knot adjustment using an artificial immune system for B-spline curve approximation. Inf. Sci. 2009, 179, 1483–1494. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, C.; Yang, B.; Li, P. Adaptive knot adjustment using a GMM-based continuous optimization algorithm in B-spline curve approximation. Comput. Aided Des. 2011, 43, 598–604. [Google Scholar] [CrossRef]
- Gálvez, A.; Iglesias, A. A new iterative mutually-coupled hybrid GA-PSO approach for curve fitting in manufacturing. Appl. Soft Comput. 2013, 13, 1491–1504. [Google Scholar] [CrossRef]
- Gálvez, A.; Iglesias, A. Particle swarm optimization for non-uniform rational B-spline surface reconstruction from clouds of 3D data points. Inf. Sci. 2012, 192, 174–192. [Google Scholar] [CrossRef]
- Gálvez, A.; Iglesias, A.; Puig-Pey, J. Iterative two-step genetic-algorithm method for efficient polynomial B-spline surface reconstruction. Inf. Sci. 2012, 182, 56–76. [Google Scholar] [CrossRef]
- Garcia-Capulin, C.H.; Cuevas, F.J.; Trejo-Caballero, G.; Rostro-Gonzalez, H. Hierarchical genetic algorithm for B-spline surface approximation of smooth explicit data. Math. Probl. Eng. 2014, 2014. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, C.; Xu, L.; Yang, B.; Feng, Z. IGA-based point cloud fitting using B-spline surfaces for reverse engineering. Inf. Sci. 2013, 245, 276–289. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing, Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Yang, X.S.; Deb, S. Engineering optimization by cuckoo search. Int. J. Math. Model. Numer. Optim. 2010, 1, 330–343. [Google Scholar]
- MatlabCentral Repository. Available online: http://www.mathworks.com/matlabcentral/fileexchange/29809-cuckoo-search-cs-algorithm (accessed on 25 December 2017).
- Valian, E.; Tavakoli, S.; Mohanna, S.; Hahgi, A. Improved cuckoo search for reliability optimization problems. Comput. Ind. Eng. 2013, 64, 459–468. [Google Scholar] [CrossRef]
- Derac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evolut. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Iterm | Example I | Example II | Example III |
|---|---|---|---|
| 841 | 1681 | 628 | |
| 1754 | 3562 | 1328 | |
| SNR | 20.75 | 12.5 | 18 |
| Degree |
| Iterm | Example I | Example II | Example III |
|---|---|---|---|
| Mean value (X): | 1.323329 × 10 | 1.170657 × 10 | 4.035762 × 10 |
| var (X): | 4.513201 × 10 | 1.233936 × 10 | 9.392598 × 10 |
| std (X): | 9.500738 × 10 | 1.570946 × 10 | 4.334189 × 10 |
| Mean value (Y): | 1.324084 × 10 | 9.279757 × 10 | 3.775183 × 10 |
| var (Y): | 5.311829 × 10 | 2.451310 × 10 | 3.939023 × 10 |
| std (Y): | 3.259395 × 10 | 7.001871 × 10 | 2.806785 × 10 |
| Mean value (Z): | 2.281740 × 10 | 6.965113 × 10 | 2.538050 × 10 |
| var (Z): | 5.682211 × 10 | 7.304708 × 10 | 1.648420 × 10 |
| std (Z): | 3.371115 × 10 | 3.822226 × 10 | 1.815720 × 10 |
| Iterm | Example I | Example II | Example III |
|---|---|---|---|
| (mean) | × 10 | × 10 | × 10 |
| (best) | × 10 | × 10 | × 10 |
| (var) | × 10 | × 10 | × 10 |
| (std) | × 10 | × 10 | × 10 |
| RMSE (mean) | × 10 | × 10 | × 10 |
| RMSE (best) | × 10 | × 10 | × 10 |
| Surface Example | Fitting Error | Uniform Param. | Chordal Param. | Centripetal Param. | Cuckoo Search (CSA) | Improved CSA (ICSA) |
|---|---|---|---|---|---|---|
| Example I | (mean) | × 10 | × 10 | × 10 | 5.880665 × 10 | 5.758827 × 10 |
| E.R. (in %) | (193.6) | (255.9) | (152.8) | (101.6) | − | |
| (best) | × 10 | × 10 | × 10 | 2.073165 × 10 | × 10 | |
| E.R. (in %) | (270.7) | (335.5) | (239.2) | − | (102.0) | |
| (var) | × 10 | × 10 | × 10 | × 10 | × 10 | |
| (std) | × 10 | × 10 | × 10 | × 10 | × 10 | |
| RMSE (mean) | × 10 | × 10 | × 10 | × 10 | 8.275019 × 10 | |
| E.R. (in %) | (139.5) | (160.4) | (123.9) | (101.1) | − | |
| RMSE (best) | × 10 | × 10 | × 10 | 4.964996 × 10 | × 10 | |
| E.R. (in %) | (164.5) | (183.2) | (154.6) | − | (101.0) | |
| Example II | (mean) | × 10 | × 10 | × 10 | × 10 | 3.775440 × 10 |
| E.R. (in %) | (126.6) | (125.8) | (113.8) | (102.5) | − | |
| (best) | × 10 | × 10 | × 10 | 1.541309 × 10 | × 10 | |
| E.R. (in %) | (245.8) | (253.8) | (191.9) | − | (135.8) | |
| (var) | × 10 | × 10 | × 10 | × 10 | × 10 | |
| (std) | × 10 | × 10 | × 10 | × 10 | × 10 | |
| RMSE (mean) | × 10 | × 10 | × 10 | × 10 | 4.739144 × 10 | |
| E.R. (in %) | (112.5) | (112.2) | (106.7) | (101.2) | − | |
| RMSE (best) | × 10 | × 10 | × 10 | 3.028035 × 10 | × 10 | |
| E.R. (in %) | (156.7) | (159.3) | (138.5) | − | (116.5) | |
| Example III | (mean) | × 10 | × 10 | × 10 | × 10 | 1.367894 × 10 |
| E.R. (in %) | (550.4) | (416.1) | (310.1) | (101.6) | − | |
| (best) | × 10 | × 10 | × 10 | 8.072414 × 10 | × 10 | |
| E.R. (in %) | (617.9) | (428.1) | (124.3) | − | (127.1) | |
| (var) | × 10 | × 10 | × 10 | × 10 | × 10 | |
| (std) | × 10 | × 10 | × 10 | × 10 | × 10 | |
| RMSE (mean) | × 10 | × 10 | × 10 | × 10 | 1.475864 × 10 | |
| E.R. (in %) | (234.6) | (204.0) | (176.1) | (100.9) | − | |
| RMSE (best) | × 10 | × 10 | × 10 | 1.133762 × 10 | × 10 | |
| E.R. (in %) | (248.6) | (206.9) | (111.5) | − | (112.7) |
| Comparison | Index | Example I | Example II | Example III |
|---|---|---|---|---|
| CSA vs. Uniform | p-value (Wilcoxon sign): | 8.663083 × 10 | 1.572960 × 10 | 7.556929 × 10 |
| signed rank: | 1192 | 1029 | 1275 | |
| h: | 1 | 1 | 1 | |
| p-value (Wilcoxon sum): | 3.191585 × 10 | 1.115515 × 10 | 7.032679 × 10 | |
| rank sum: | 3267 | 3086 | 3775 | |
| h: | 1 | 1 | 1 | |
| CSA vs. Chordal | p-value (Wilcoxon sign): | 8.534226 × 10 | 4.000165 × 10 | 1.110095 × 10 |
| signed rank: | 1273 | 1063 | 1225 | |
| h: | 1 | 1 | 1 | |
| p-value (Wilcoxon sum): | 8.003963 × 10 | 3.919684 × 10 | 1.032414 × 10 | |
| rank sum: | 3734 | 3122 | 3675 | |
| h: | 1 | 1 | 1 | |
| CSA vs. Centripetal | p-value (Wilcoxon sign): | 6.394483 × 10 | 8.626159 × 10 | 1.087244 × 10 |
| signed rank: | 1105 | 460 | 1269 | |
| h: | 1 | 1 () | 1 | |
| p-value (Wilcoxon sum): | 8.317099 × 10 | 0.148521 × 10 | 1.109774 × 10 | |
| rank sum: | 3172 | 2325 | 3688 | |
| h: | 1 | 1 () | 1 | |
| CSA vs. ICSA | p-value (Wilcoxon sign): | 4.784510 × 10 | 8.280511 × 10 | 4.900625 × 10 |
| signed rank: | 441 | 615 | 709 | |
| h: | 0 | 0 | 0 | |
| p-value (Wilcoxon sum): | 3.883964 × 10 | p = 7.275182 × 10 | 3.024247 × 10 | |
| rank sum: | 2125 | 2475 | 2675 | |
| h: | 0 | 0 | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iglesias, A.; Gálvez, A.; Suárez, P.; Shinya, M.; Yoshida, N.; Otero, C.; Manchado, C.; Gomez-Jauregui, V. Cuckoo Search Algorithm with Lévy Flights for Global-Support Parametric Surface Approximation in Reverse Engineering. Symmetry 2018, 10, 58. https://doi.org/10.3390/sym10030058
Iglesias A, Gálvez A, Suárez P, Shinya M, Yoshida N, Otero C, Manchado C, Gomez-Jauregui V. Cuckoo Search Algorithm with Lévy Flights for Global-Support Parametric Surface Approximation in Reverse Engineering. Symmetry. 2018; 10(3):58. https://doi.org/10.3390/sym10030058
Chicago/Turabian StyleIglesias, Andrés, Akemi Gálvez, Patricia Suárez, Mikio Shinya, Norimasa Yoshida, César Otero, Cristina Manchado, and Valentin Gomez-Jauregui. 2018. "Cuckoo Search Algorithm with Lévy Flights for Global-Support Parametric Surface Approximation in Reverse Engineering" Symmetry 10, no. 3: 58. https://doi.org/10.3390/sym10030058