In this section, we introduce the basic concept and preliminaries of graph pattern mining that can help understanding of the proposed algorithm, SVE-RGM. Thereafter, we describe details of our method including an overall architecture, a graph pattern growth technique and various pattern pruning techniques. We also propose techniques for effectively applying multiple minimum support and length-decreasing support constraints into graph mining environments without any unintended errors such as pattern losses. In addition, we show how the proposed method, SVE-RGM, operates through an overall mining procedure of the algorithm.
3.1. Preliminaries
Graph data are a structural format that can effectively express various data such as network data, chemical data and genome data. There are various definitions and theories for explaining such graph data in a mathematical manner [
34,
35,
42,
43], where we introduce essential preliminaries related to the proposed algorithm, including the definitions of graph patterns and the concept of frequent graph patterns (further information on graph theories refer to the literature cited in this paper [
18,
20,
42,
43]). We first describe a fundamental concept and several important definitions of graph pattern mining for better understanding of the proposed method. A graph pattern consists of multiple vertices and edges. In addition, graph types are classified as directed or undirected graphs depending on whether or not there are directions of edges in graphs. They can also be classified as simple or multi graphs on the basis of the number of edges between any two vertices in graphs. Moreover, other graph types can be created through numerous factors such as labels and self-edges (or loops). In this paper, we explain the proposed contents on the basis of undirected and labeled simple graph forms. However, it is trivial to consider other graph forms into our graph mining operations since we only have to consider a few additional characteristics.
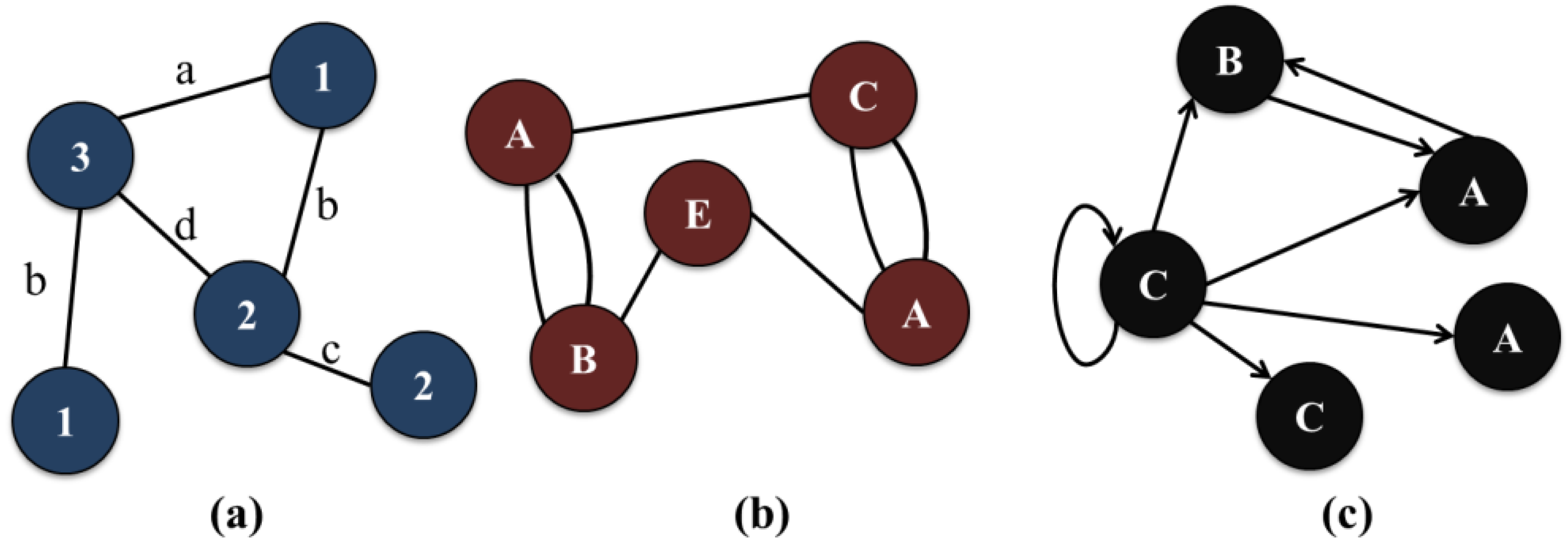
Figure 1 shows an example of various graph types.
Figure 1a is a simple, labeled and undirected graph without any self-edges, where each vertex and edge has its own name or label.
Figure 1b is a multiple graph that has two or more edges between vertices. As shown in
Figure 1b, edges labels may not be expressed if they do not need to be distinguished from one another or have the same label.
Figure 1c is a directed graph having a self-edge.
Definition 1. (Sub-graph) Let P be a sub-graph (or a graph pattern) composed of one or more elements (vertices and edges). Then, P can be denoted as two element groups. The first one is a set of vertices, V(P) = {v1, v2, …, vi}, and a set of edges, E(P) = {e1, e2, …, ej}.
Definition 2. (Graph isomorphism) Given a simple, labeled, and undirected graph pattern, P, its vertex and edge sets, V(P) and E(P) can also be denoted as follows: Given two graph patterns, X and Y, we can say that X and Y are isomorphic, if their own V(P) and E(P) results are the same as each other on the basis of Equation (1) although the shapes of X and Y seem to be different from each other. Note that since all the edges in P have no directions, (v1, v2) and (v2, v1) are equal to each other.
All of the possible graph patterns have one of the following graph types: path, free tree, and cyclic graph. In addition, paths and free trees can be included in cyclic graphs and paths can be contained in free trees. In other words, the coverage of graph pattern types is denoted as path free-tree cyclic graph.
Definition 3. (Degree of graph forms) all vertices except for both ends in a path have degree 2; meanwhile the end vertices have degree 1. Let X be a graph pattern. If X is a path with k vertices, X satisfies the following formula: In Equation (2),
D signifies a function that returns a degree number for an inputted vertex.
v1,
vn, |
V(P)| and |
E(P)| are the first and last vertices and the number of vertices and edges comprising
P, respectively. A free tree should have at least one vertex of which the degree is 3 or more. In addition, there is no cyclic relation in all of its edges. If
P is a free-tree with
k vertices, the following conditions are satisfied:
If
X has one or more cyclic edges,
X becomes a cyclic graph. Then,
X has the following relation between the numbers of vertices and edges.
By using Equations (2)–(4), we can easily distinguish what type every graph pattern is.
Definition 4. (Frequent graph pattern) Let DBG = {Tr1, Tr2,…, Trn} be a given database storing n graph data records (also called graph transactions), where each graph transaction, Tr, is composed of multiple vertices and edges. Given a graph pattern, P, we can calculate the support of P, S(P), as follows: In Equation (5), function Exist returns 1 if P is included in the corresponding Tr; otherwise, 0. Therefore, S(P) is to add all the results of Exist with respect to every Tr in DBG. In other words, the result of S(P) signifies how many times P appears in DBG. If S(P) is not smaller than a user-given minimum support threshold, we regard P as a frequent sub-graph or a frequent graph pattern. Thus, the final goal of traditional frequent graph pattern mining is to extract all the possible graph patterns of which the support values are higher than or equal to this single minimum support threshold.
3.3. Mining SRGs from Graph Databases
Figure 3 is an example of a simple graph database. Graph pattern mining approaches including the proposed method find interesting graph pattern information from such types of graph data. As shown in the procedure of
Figure 2, we first scan a given graph database to calculate support values of the elements within the graph transactions, composing the database. Note that we assume that edge elements in the example database have the same edge label, for better understanding of the proposed method as shown in
Figure 3. Therefore, support values for edges are not counted. Vertices that occur multiple times in a graph transaction are counted once [
34,
35,
44]. After the database scanning work is finished, the proposed algorithm scans information of length-decreasing support constraints corresponding to the given graph database and multiple minimum support constraints for the elements composing the database.
3.3.1. Length-Decreasing Support Constraints and Smallest Valid Extension on Graph Mining
Recall that small sub-graphs having a few elements tend to be interesting if they have relatively high support values and large sub-graphs with many of elements can be interesting even though their support values are relatively low. It becomes important features supporting the reason why length-decreasing support constraints need to be applied into the graph mining operations. The easiest method for mining sub-graphs according to length-decreasing support constraints [
41], tried to perform all of the possible pattern expansions, in order to confirm whether sub-graphs generated through the expansions satisfy each minimum support threshold, corresponding to their lengths. Therefore, this method causes fatal problems in terms of mining efficiency although correct results can be generated. To solve the problem, we define a length-decreasing support constraint function and its inverse function, and propose an
SVE technique using these functions.
Definition 5. (Length of graph) Let l be a length of a graph pattern, S. When S is a path or a free tree, l is the number of vertices in S. Meanwhile, if S is a cyclic graph, we consider l as follows. Let Sprev be a sub-graph pattern just before S becomes a cyclic graph, lprev be a length of Sprev, and k be the number of cyclic edges inserted into S. Then, l becomes an addition of lprev and k, where l can be denoted as l = L(S).
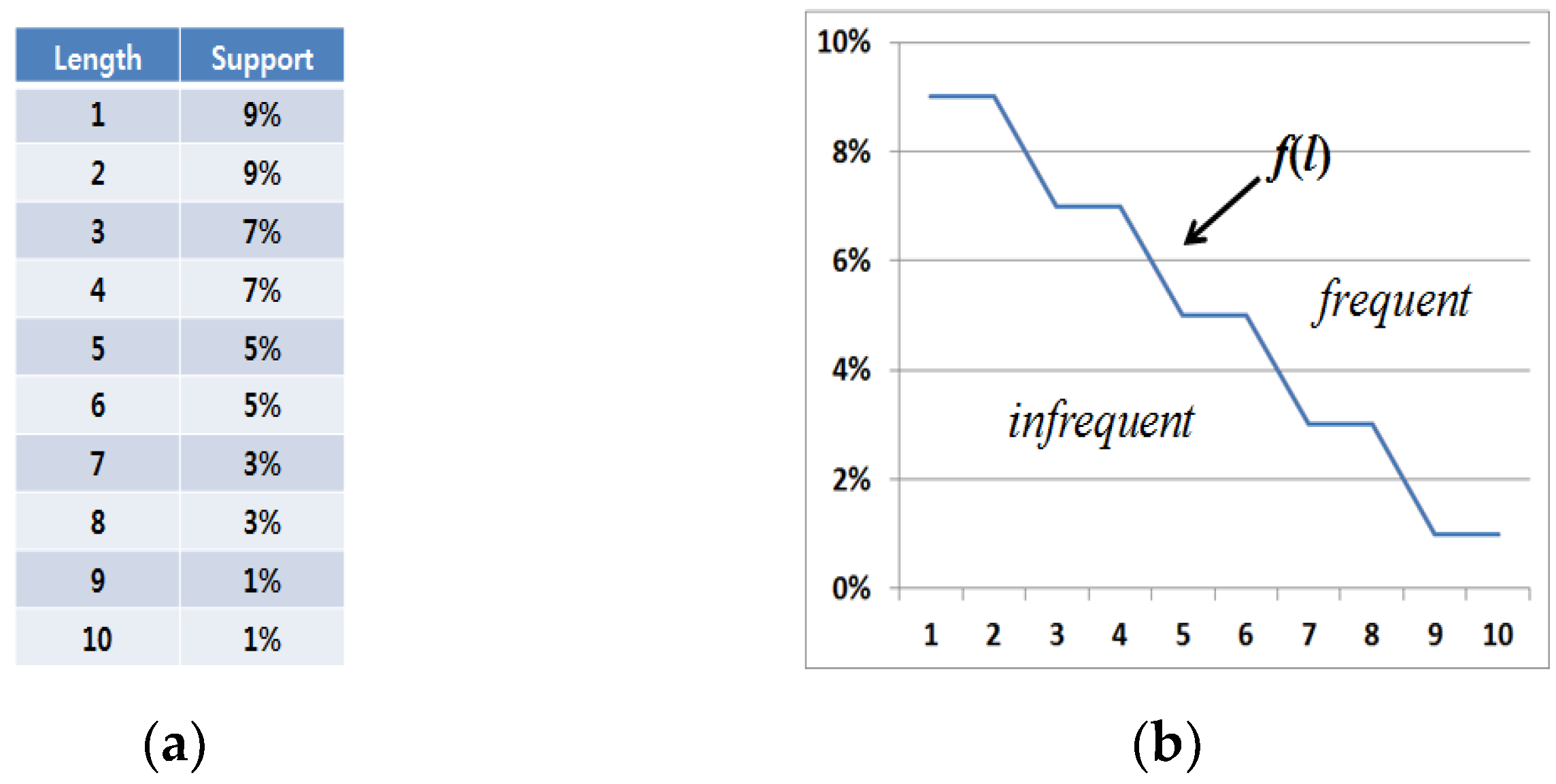
Figure 4 shows an example of length-decreasing support constraints. As shown in
Figure 4a, there are various minimum support threshold values in the proposed algorithm, and one threshold value is set for each length factor. Especially, threshold settings become gradually lower according to the increase of graph pattern lengths.
Definition 6. (Length-decreasing support constraint (LDSC) function) For the length of graph pattern S, l, length-decreasing support constraint function, denoted as f(l) returns a minimum support threshold corresponding to l’s current value. Since f(l) is constant or becomes lower as l comes to be larger, the inequality, 0 ≤ f(l + 1) ≤ f(l) ≤ 1 is satisfied.
Definition 7. (Inverse function of LDSC) Given a support of graph pattern S, S(S), an inverse function of Definition 6 is denoted as f−1 (S(S)) and returns the minimum length that S must have in order to become a potentially frequent sub-graph pattern. Such a condition is also denoted as f−1 (S(S)) = min(l|f(l) ≤ S(S)).
Example 1. Given length-decreasing support constraint information in Figure 4a, the corresponding LDSC function, f(l) is denoted as shown in Figure 4b. Since f(1) = 9% (=0.09), f(2) = 9% (=0.09), f(3) = 7% (=0.07)… and f(10) = 1% (=0.01), it is certain that the function satisfies the inequality, 0 ≤ f(l + 1) ≤ f(l) ≤ 1. Let us assume that a sub-graph S has a support of 4% and a length of 5 respectively. Then, f−1(S(S)) returns 7 since the minimum value is 7 among the lengths corresponding to the supports lower than or equal to 4%. Therefore, S must have more than length of 7 to be frequent. However, it is eventually infrequent since its length is 5.
We can determine that certain sub-graphs included in the “infrequent” area as shown in
Figure 4b are invalid while ones contained in the “frequent” area become valid, where
f(
l) plays a role in distinguishing whether or not sub-graphs are frequent.
Through Definitions 5–7, we can draw the following SVE property for graph pattern mining based on length-decreasing support constraints, which helps perform the graph mining processes more efficiently by reducing the number of needless graph pattern expansions.
Definition 8. (Smallest Valid Extension (SVE) property for graph mining) Given an infrequent graph pattern S, any super pattern of S, S’ must have a length larger than the result of f−1(S(S)) before it becomes a potentially frequent sub-graph pattern.
Unlike traditional graph pattern mining, we need to consider the following additional characteristics in length-decreasing support constraint-based graph pattern mining. If a graph pattern is not valid in traditional graph pattern mining, we can omit the pattern and all of the corresponding operations related to the pattern because it and all of its possible super patterns become useless by the anti-monotone property. This property means that, if a certain pattern is infrequent, all the super patterns generated from the pattern are also infrequent. However, because the proposed algorithm applies different minimum support thresholds according to the length characteristics of generated graph patterns, the anti-monotone property cannot be maintained. In other words, although a certain sub-graph is infrequent in the current state, any of its super patterns may become frequent again as we conduct the graph pattern growth process. The previous approach [
41] solved such a problem by applying an overestimation technique into its pattern pre-pruning factor. This technique can perform
LDSC-based frequent graph pattern mining operations without any pattern loss, but it is a naïve technique that wastes computing resources in generating useless candidate patterns. However, based on the
SVE property, we can find permanently invalid patterns. The following lemma supports such an advantage.
Lemma 1. Let S and S’ be a certain sub-graph pattern and a super pattern of S and L(S) and L(S’) be the lengths of S and S’ respectively. If L(S’) < f−1(S(S)) such that S(S) < f(L(S)), then S’ is always an infrequent pattern.
Proof. Depending on the characteristics of frequent graph mining, it is always true that S(S) ≥ S(S’), and S(S) is in inverse proportion to f−1(S(S)). Therefore, we can induce the inequality, f−1(S(S)) ≤ f−1(S(S’)). In order that S’ expanded from the infrequent sub-graph S becomes frequent, these two conditions, S(S) < f(L(S)) and S(S’) ≥ f(L(S’)) must be satisfied. After we multiply the inverse function by the conditions, the result can be denoted as follows: L(S) ≤ f−1(S(S)) ≤ f−1(S(S’)) ≤ L(S’). Therefore, S’ becomes infrequent if it does not satisfy these conditions. Because the current mining step performed up to S, S’ has not yet been expanded. Therefore, we can determine the values of L(S), L(S’), and f−1(S(S)) but cannot know the value of f−1(S(S’)) (L(S’) can be inferred from L(S)). Therefore, if L(S’) ≥ f−1(S(S)) is false, i.e., L(S’) < f−1(S(S)) is true, S’ becomes an infrequent graph pattern. For this reason, we can know whether or not S’ is valid in advance even though any actual expansion process for S’ is not performed. ■
Note that the proposed overestimation technique is not an approximation method. Therefore, unlike the statistical approximation approach [
45], our method does not mine any false positives. Our overestimation technique is employed to check and discard permanently meaningless graph patterns without any pattern loss during the mining process. However, since every pattern satisfying the overestimated condition is not the finally valid result (called a candidate pattern), we check the actual support of each candidate in order to mine actually meaningful graph patterns selectively. By doing this, we can obtain a complete set of frequent graph patterns considering the length-deceasing support constraints and rarity of graphs.
3.3.2. Pre-Pruning Infrequent Sub-Graphs by the SVE Property without Any Pattern Loss
Using the defined SVE property, we can determine information regarding what sub-graphs cause needless pattern expansions in advance. However, if they are directly pruned, fatal problems such as pattern losses can occur since applying the length-decreasing support constraints into graph mining generally breaks the anti-monotone property. That is, any infrequent sub-graphs can become frequent ones as their pattern expansion works are conducted. To solve the problems and maintain the anti-monotone property, we additionally consider the length information for graph transactions in graph databases as well as the SVE property.
Lemma 2. Let S and S’ be invalid graph patterns (S’ ⊃ S) and SETS’ = {Tr1, Tr2, …, Trn} be a set of graph transactions including S’. Then, if there is any element satisfying L(Tri) < f−1(S(S)) among the elements of SETS’ (1 ≤ I ≤ n), S’ can permanently be pruned.
Proof. In SETS’ = {Tr1, Tr2, …, Trn}, each Tr is a graph transaction with S’ in DBG, and n becomes the support of S’. If there is any Tri such that L(Tri) < f−1(S(S)) (1 ≤ i≤ n), it means that lengths of all super patterns generated from S’ are also smaller than f−1(S(S)) because the super patterns cannot have more lengths than L(Tri). Furthermore, since S’ and the super patterns of S’ do not satisfy the minimum length by the inverse function, neither of them naturally satisfies minimum support constraints. As a result, pruning S’ does not have any negative effect on maintenance of the anti-monotone property. That is, we can obtain intended mining results without any problem. ■
Example 2. Let us consider the example in Figure 4 and assume that a certain sub-graph, S, has a length of 2 and a support of 5%, a super pattern of S, S’, has a length of 3 and a support of 4% and a set of graph transactions for S’, SETS’ includes 4 graph transactions (denoted as SETS’ = {Tr1, Tr2, Tr3, Tr4}), where the length for each Tr is set to 7, 4, 10, and 5 respectively. Then, S’ becomes an invalid pattern according to the SVE property and Lemma 1. Furthermore, since L(Tr2) is smaller than f−1(S(S)), any super patterns of S’ also become useless ones and therefore, S’ can directly be pruned.
Based on Lemma 2, we can prune all of the permanently useless patterns and omit the corresponding mining operations in advance without any pattern loss.
3.3.3. Multiple Minimum Supports of Vertex and Edge Elements on Graph Mining
In addition to the length-decreasing support constraints, we additionally consider multiple minimum supports of graph elements (vertices and edges) in this paper. Recall that meaningful graph patterns with low supports may not be extracted if a given minimum support threshold is high in traditional graph pattern mining, otherwise an enormous number of useless patterns should be mined if we lower the threshold to find such useful ones. By considering multiple, minimum support constraints of vertex and edge elements, as well as the length-decreasing support constraints, we can obtain a smaller number of more meaningful pattern results. In contrast to traditional graph pattern mining that has a single minimum support threshold, the proposed method has a different threshold for each element to consider the multiple minimum support constraints on graph pattern mining.
Definition 9. (Minimum support constraints of vertices and edges) Given a graph database with multiple graph transactions Tr, DBG = {Tr1, Tr2, …, Trn}, a set of x vertices and y edges comprising DBG can be denoted as V(DBG) = {v1, v2, …, vx} and E(DBG) = {e1, e2, …, ey}, respectively. Then, each of minimum support threshold, δ, is set for each element as shown in Table 1, where they are assigned by a user, respectively.
In traditional graph pattern mining, there is only one factor for deciding whether or not a found graph pattern is frequent without the characteristics of its elements. Meanwhile, we need to consider a different way to apply the multiple minimum support constraints into our method.
Definition 10. (Minimum support constraints of graph patterns) Let P be a graph pattern extracted from DBG. Then, a set of vertices and edges can be denoted as V(P) = {v1, v2, …, vi} and E(P) = {e1, e2, …, ej}, respectively. According to Definition 9, we know that each element has its own minimum support threshold set by a user, and P is composed of multiple elements. Hence, the minimum support threshold for P, T(P), is computed as the minimum value among the threshold values of P’s elements.
If S(P) is not lower than T(P), we can say that P is a valid graph pattern satisfying the rarity of graph elements based on the multiple minimum support constraints. The reason why we compute and use the minimum support threshold for each mined graph pattern is that we can consider the different rarity of each pattern in this way.
Definition 11. (SVE-based Rare Graph pattern (SRG)) Given a graph pattern, X, we call X an SRG if S(X) ≥ f(L(X)) and S(X) ≥ T(X). In other words, SRGs mean sub-graph patterns that satisfy both the length-decreasing support and multiple minimum support constraints.
Consequently, the main goal of the proposed algorithm, SVE-RGM, is to mine all of the possible SRGs from a given graph database without any pattern loss.
3.3.4. Pre-Pruning Invalid Graph Patterns Based on Multiple Minimum Support Constraints
Recall that fatal pattern losses can be caused if we do not apply the additional considerations mentioned in
Section 3.3.2. Similarly, we can also suffer from such a pattern loss problem if we directly prune graph patterns that do not satisfy their own multiple minimum support constraints. As mentioned above, elements of a graph pattern have their own threshold values set by a user. Therefore, the anti-monotone property is not satisfied with this situation. In other words, although a certain graph pattern has a support that does not satisfy the corresponding multiple minimum support constraint in the current state, any super pattern of it may become a valid result again in the process of graph pattern expansion. Hence, if we pre-prune such patterns without any additional consideration, fatal pattern losses can occur. Moreover, an enormous number of interesting patterns can be lost by unintended pruning of a few elements or graph patterns. Satisfying the anti-monotone property during the mining process is one of the most important rules to improve mining efficiency without any negative effect such as pattern losses. For this reason, we employ an overestimation method for maintaining the anti-monotone property without any pattern loss on the proposed algorithm.
Definition 12. (Overestimated minimum support constraint) DBG has multiple graph transactions and the corresponding elements as mentioned in Definition 9. Then, the overestimated minimum support constraint for DBG, O(DBG), is computed as the smallest value among the valid minimum support constraints of all the elements comprising DBG (it is also called Least Minimum Support (LMS)). In other words, let SETT(DBG) = {δ1, δ2, …, δx+y} (δ1 ≥δ2 ≥ … ≥ δx+y) be a sorted set of minimum support constraints for all the elements in DBG (x and y are the numbers of vertices and edges, respectively). Then, we start comparing the smallest threshold δx+y with the real support of the element corresponding to δx+y. After that, δ(x+y)−1 is compared to the corresponding element support. Such a comparison is performed until we find the first element of which the support is higher than or equal to the corresponding minimum support constraint, δk (1 ≤ k ≤ x + y). Then, we consider δk as O(DBG).
Consequently, SRGs extracted from the proposed algorithm are graph patterns that satisfy Lemmas 1 and 2 and the condition of Definition 12.
3.4. Improving Efficiency of Graph Mining Performance Based on Symmetry Features of Graphs
From the suggested definitions and constraints, we allowed the proposed method to mine a smaller number of meaningful graph pattern results, called SRGs. As mentioned above, the length-decreasing minimum support and multiple minimum support constraints also increase the mining efficiency of the proposed algorithm, SVE-RGM, by reducing the search space effectively. In addition, we can also raise the mining efficiency with the correctness of the algorithm maintained. Recall that the proposed method performs its own mining operations in a depth-first search manner. This also means that a few useless graph patterns may cause the proposed algorithm to generate an enormous number of invalid or duplicated pattern results. In contrast to the case of traditional frequent pattern mining that considers only an item-based simple format, a numerous number of duplicated graph patterns can be generated in graph pattern mining because of the complicated structures of graph data. In particular, we have to conduct graph isomorphism tests for the mined patterns in order to prevent duplicated ones from being extracted.
In order to perform the mining operations more efficiently, our algorithm applies the following order types of graph pattern growth: (1) path → cyclic graph and (2) path → free tree → cyclic graph. In other words, a certain vertex is selected as a prefix at first and a path is generated by adding another vertex and edge that can be attached to the prefix. Then, we can obtain a graph pattern in a path form. After that, there are three options for the next step. That is, it can be extracted as a longer path, a free tree, or a cyclic graph according to the attached vertex and edge types. Recall that a few useless graph patterns can cause an enormous number of invalid or duplicated pattern results. From the above features, we can determine that removing duplicated path creations has a large effect on reducing the number of useless pattern creations. In this regard, symmetry features of paths can be used as effective factors that can lead to correct choices not to cause any duplicated path result. Let P = {v1, e1, v2, e2, …, ek-1, vk} be a given path and N = {v,e’} be a pair of one vertex and edge that are supposed to be attached to P. Then, when expanding P with N, we have two choices; the first one is to add N to the front of P and the second one is to add N to the rear of P because of the characteristics of paths. If we add N to P without any consideration, an enormous number of duplicated graph patterns can be generated as the graph pattern growth works are conducted during the mining process. Meanwhile, if we set a specific constraint for limiting expansion directions of paths, we can effectively prevent such a problem.
A path has at least two vertices and one edge. Then, we can determine whether or not the path is symmetric. In other words, given a path, P = {v1, e1, v2, e2, …, ek-1, vk}, we can extract two strings from P as follows: v1-e1-v2-e2-…-ek-1-vk (original string) and vk-ek-1-vk-1-ek-2-…-e1-v1 (inverse string). Then, if they are equal to each other, we consider P as a symmetric path. In this case, we do not need to consider what direction we have to choose because any selection leads to the same result. If the first string is lower than the second one in terms of a lexicographical order, we expand P by attaching new elements to the front of P. Meanwhile, if the first string is higher than the second one, we add the new ones to the rear of P. From the above path expansion technique based on the symmetry features of paths, we can omit any path expansion causing duplicated path creation. In addition, once the symmetry result of P is calculated, we can easily determine the symmetry result of its expanded path in a few additional computations. Let Symtotal(P), Symfront(P), and Symrear(P) be symmetry functions for the entire part of P ({v1, e1, v2, e2, …, ek-1, vk}), the front part of P ({v1, e1, v2, e2, …, ek-2, vk-1}) and the rear part of P ({v2, e2, v3, e3, …, ek-1, vk}), where each function returns 0 when the corresponding string is symmetric, 1 when the corresponding original string is lower than the inverse one and −1 when the original one is higher than the inverse one. Using this method, we can easily know the symmetry result of super patterns of P. Let P’ be a longer path that adds a new vertex and edge to P. Then, if the new elements have been attached to the front of P’, we can determine that Symtotal(P) = Symrear(P’). Meanwhile, if the new ones have been added to the rear of P’, it is true that Symtotal(P) = Symfront(P’). Therefore, based on these characteristics, we can efficiently determine the symmetry results of mined patterns. By restricting directions of graph expansion based on the symmetry features of paths, we can improve the mining efficiency of the proposed method.
One of the most important considerations in frequent graph pattern mining is to enumerate all of the possible graph patterns without any redundancy. In contrast to the itemset format traditional frequent pattern mining focuses on, a graph pattern is composed of multiple vertices and edges, where the vertices can be ordered in many ways. Therefore, one graph pattern can also be denoted as a large number of topologically equivalent copies. Hence, it is essential to check graph isomorphism whenever a graph pattern is mined. Especially, checking graph isomorphism is a well-known NP-hard problem that can cause enormous computational overheads. However, as mentioned above, we do not have to check graph isomorphism for the path format because we established the symmetry-based constraint for paths in advance and allow paths to be enumerated on the constraint. When any path is expanded as a free-tree, we employ the backbone strategy of
Gaston, which is different from the canonical representation used in
gSpan. By using the technique, we can prevent any duplication of free-trees from being caused in the mining process without performing any works for graph isomorphism (the correctness of the backbone strategy was proved by showing that the
Gaston algorithm extracted the same results as those of other approaches like
gSpan [
34,
35]). When a path or a free-tree is expanded as a cyclic graph, we have no choice but to conduct graph isomorphism operations. However, we can reduce computational overheads by using the minimum spanning tree format when comparing cyclic graphs. A cyclic graph can be expressed as a minimum spanning tree, which is simpler than its original one. Therefore, we can compare graphs more quickly than doing in a naïve manner.
3.5. Algorithm Description: SVE-RGM
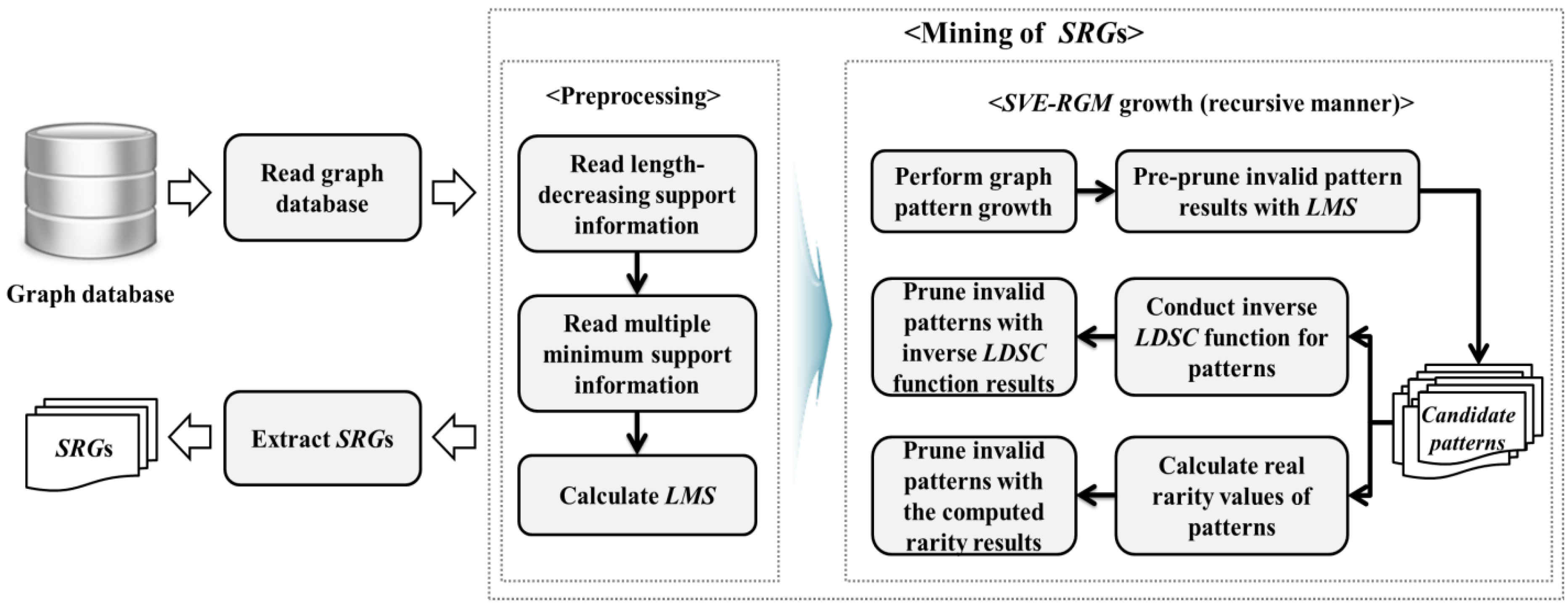
Figure 5 represents overall mining steps of the proposed algorithm,
SVE-RGM. In the main procedure,
SVE-RGM, the lowest value in
LDSC is set as a minimum support threshold,
δ and the algorithm computes
LMS from the
MMS data (lines 1–3). After that, it finds valid vertices and edges from
DBG through the calculated minimum support and
LMS value (lines 3–6). Then, for each frequent vertex, the algorithm extracts valid sub-graph patterns according to length-decreasing support constraints and multiple minimum support thresholds as it performs a series of graph pattern expansion works (lines 7–11). When function
Expand_subgraphs is called,
SVE-RGM determines whether
G is frequent or not and then assigns a flag,
true or
false, into the
isFrequent variable (lines 1–4), where
G is entered to
P if
G is frequent (line 3). Thereafter, for each edge in
E, appropriate pattern expansion works are selectively conducted according to the state of
G such as a path, a free tree, and a cyclic graph (lines 6–8). After that, if the support of the expanded pattern,
G’, is not smaller than
LMS, the algorithm conducts the subsequent works (line 9). If
isFrequent is
false, then the algorithm decides whether to prune
G’ (lines 10–13). If
G’ is not pruned,
SVE-RGM calls
Expand_subgraphs recursively to perform the next pattern expanding operations (lines 14–16). After all of mining operations terminate, we can gain a complete set of
SRGs considering the length-decreasing support constraints and the multiple minimum support constraints for rarity of graph patterns.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}