
A Logistic Based Mathematical Model to Optimize Duplicate Elimination Ratio in Content Defined Chunking Based Big Data Storage System

Abstract
:
1. Introduction
- (1)
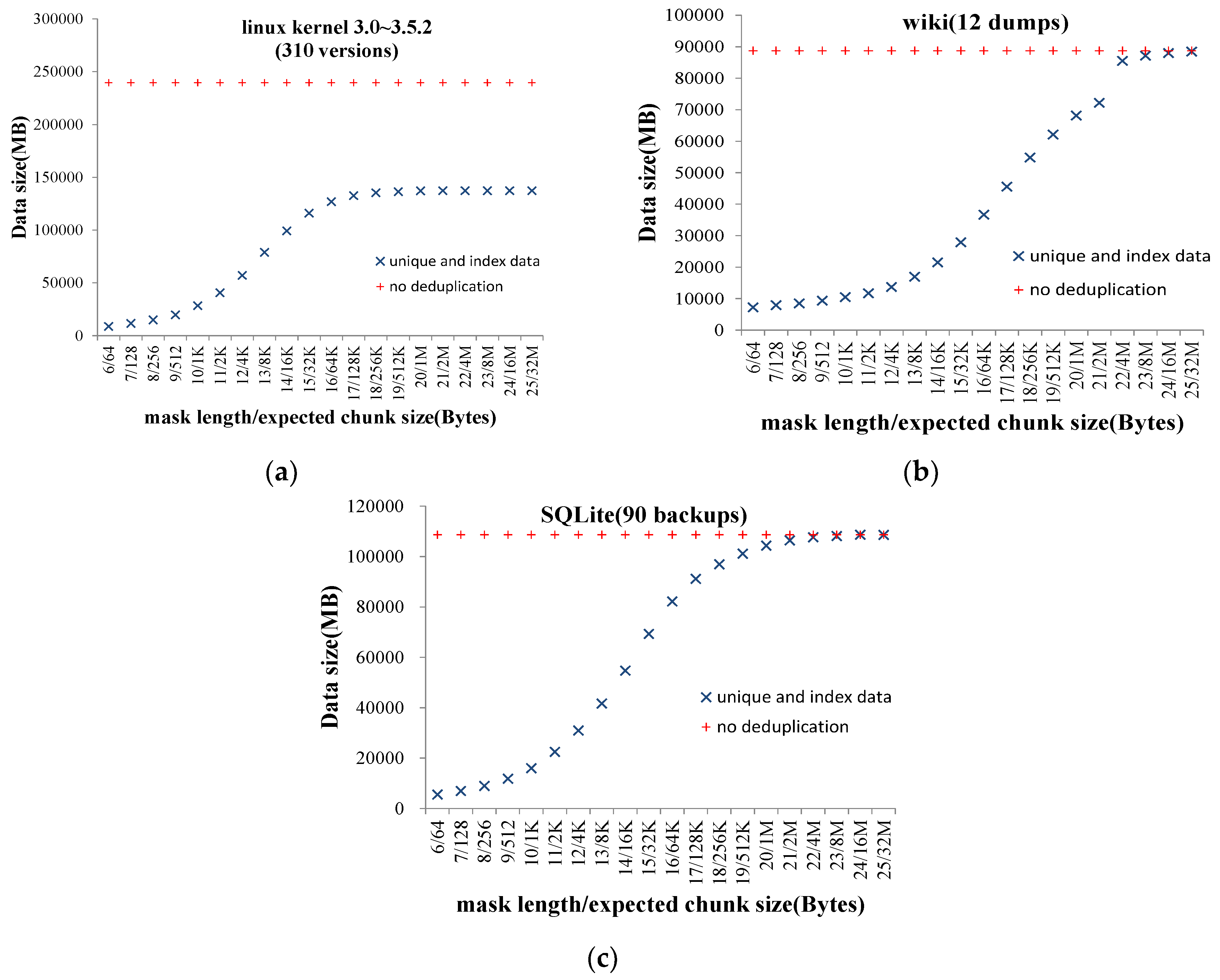
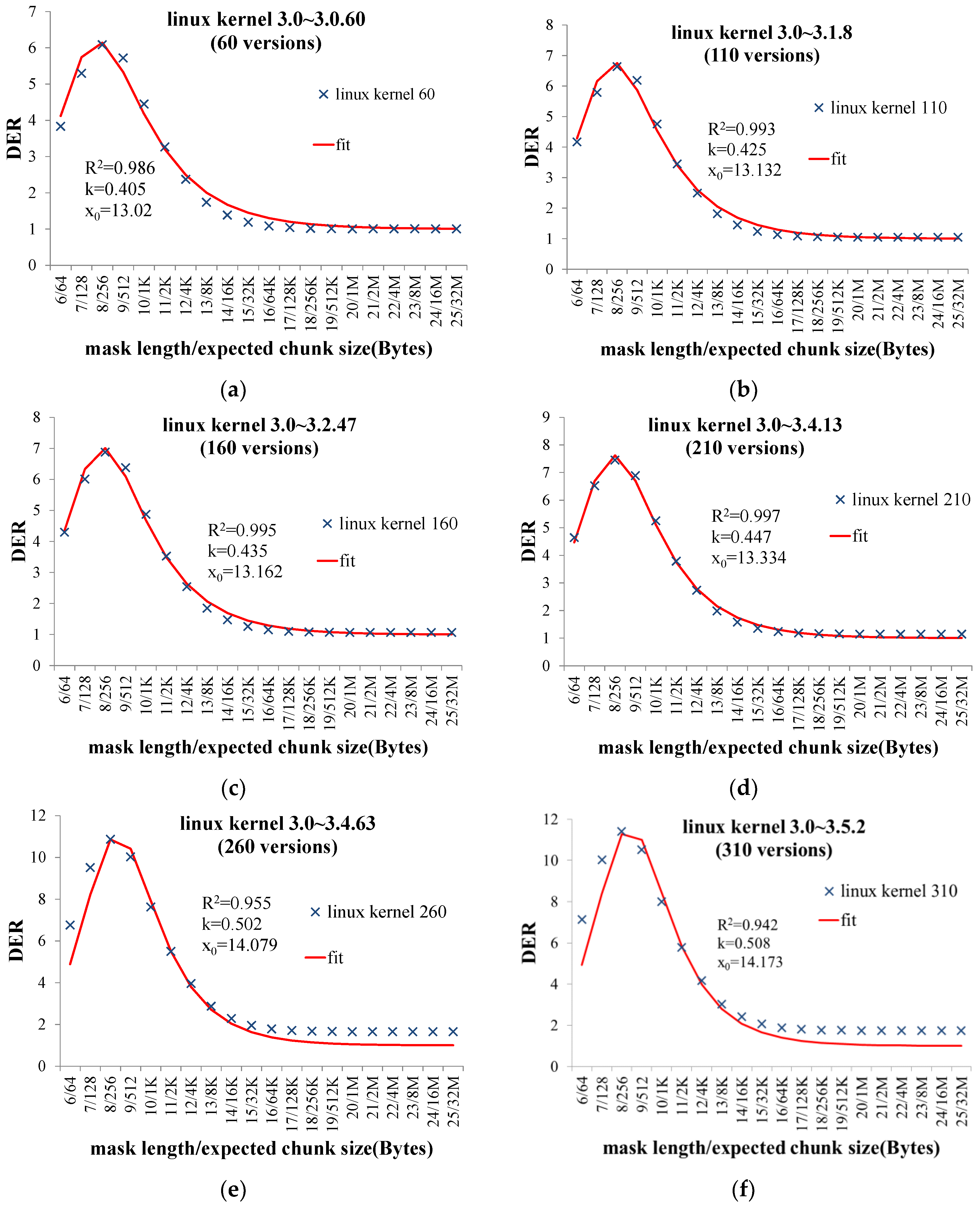
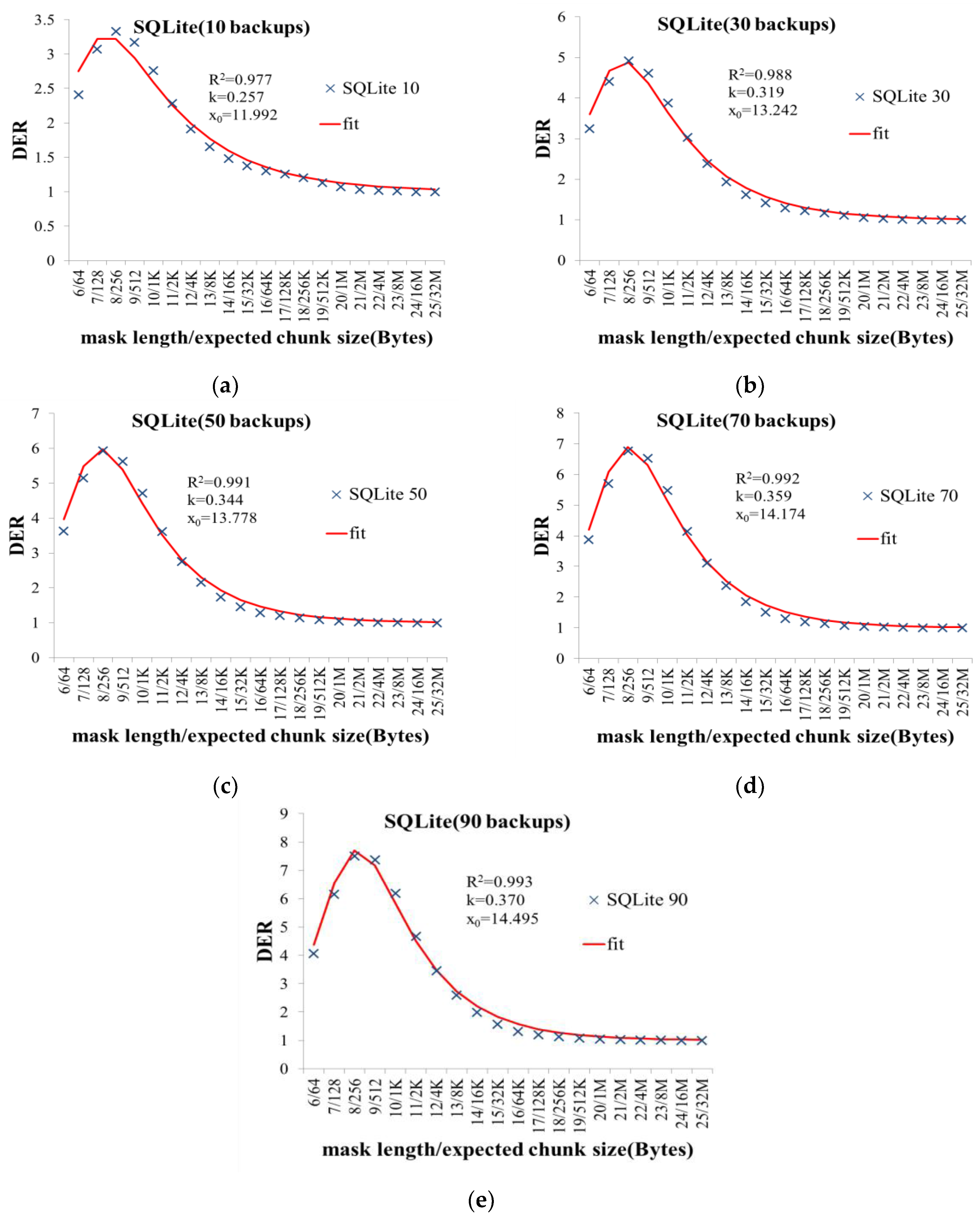
- With two realistic datasets, we showed that the expected chunk size 4 KB or 8 KB that is currently considered reasonable, cannot optimize DER.
- (2)
- We present a logistic based mathematical model to reveal the hidden relationship between the DER and the expected chunk size. The experimental results with two realistic datasets showed that this mathematical model is correct.
- (3)
- Based on the proposed model, we discussed how to set the expected chunk size to make DER close to the optimum.
2. Related Work
3. Background
3.1. The Symbol Definitions
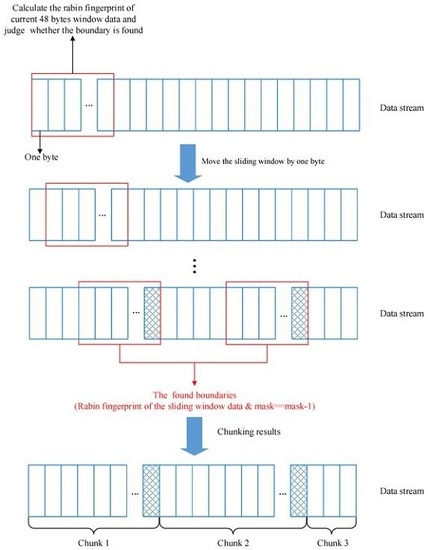
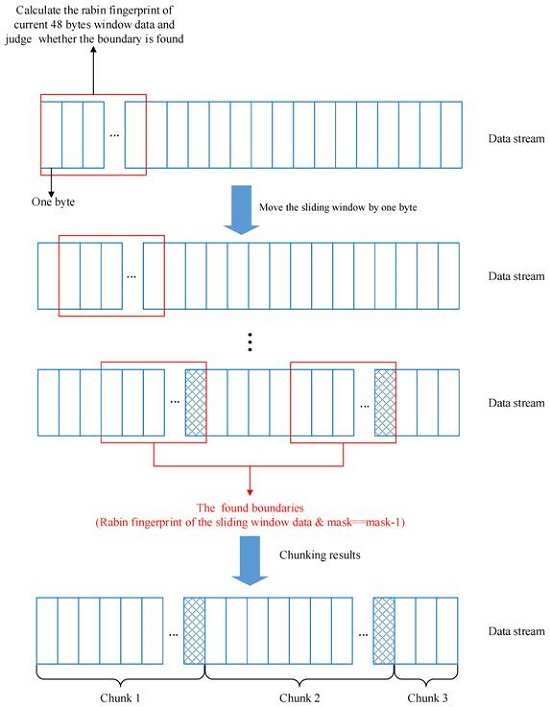
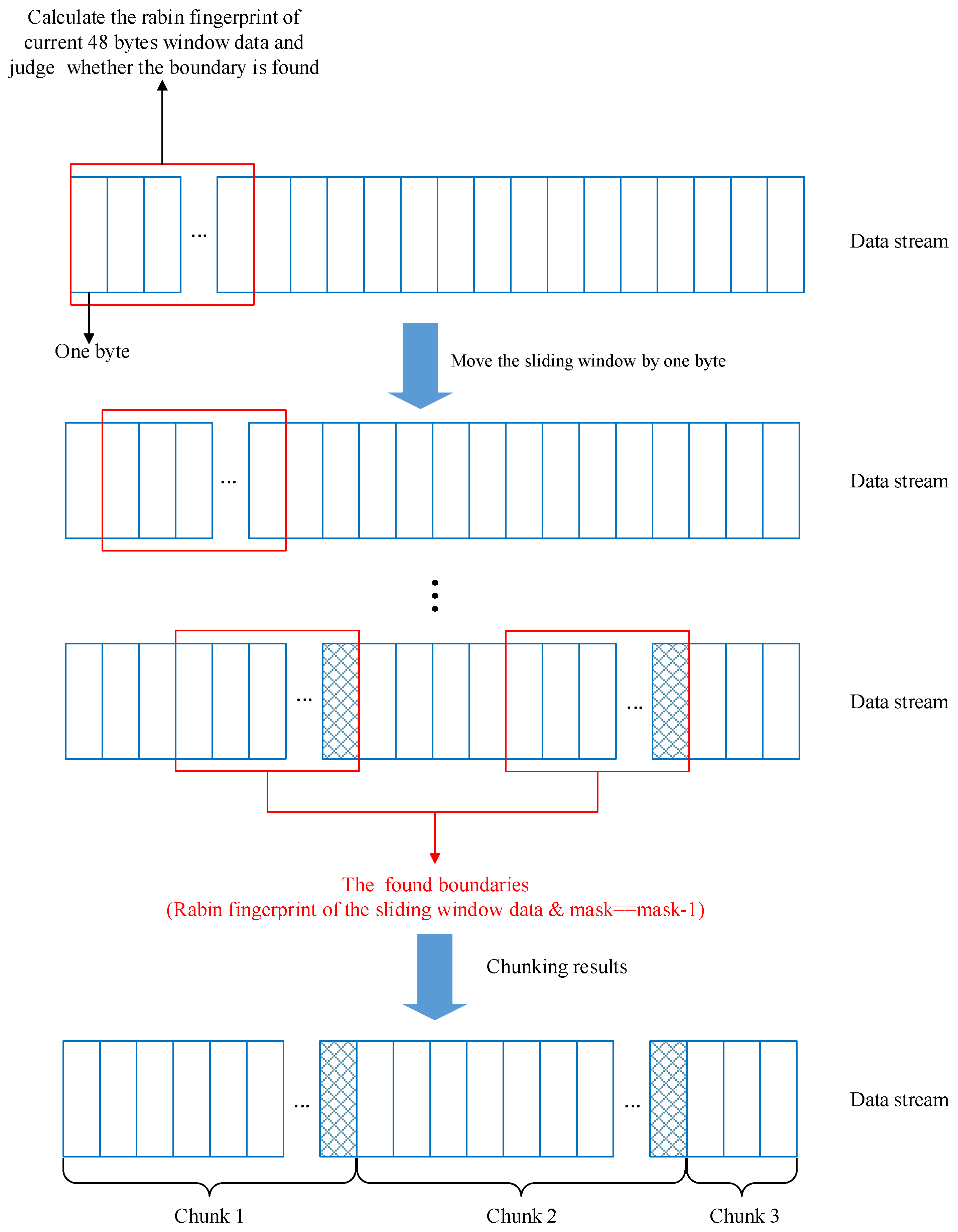
3.2. The Principal of CDC
3.3. The Expected Chunk Size
4. Modeling DER with the Expected Chunk Size
4.1. Modeling the Metadata Size
4.2. Modeling the Unique and Index Data Size
4.3. Modeling the DER
5. Experiment
5.1. Experimental Setup
- (1)
- CPU: 2 Intel Xeon E5-2650 v2 2.6 GHz 8-core processors;
- (2)
- RAM: 128 GB DDR3;
- (3)
- Disk: 1.2 T MLC PCIe SSD card;
- (4)
- Operating system: CentOS release 6.5 (Final).
5.2. Datasets
- (1)
- The Linux kernel source code dataset [22]. The total size is 233.95 GB, and the total versions are 260, including version from 3.0 to 3.4.63;
- (2)
5.3. Experimental Results
5.4. Discussion of Optimizing DER by Setting the Expected Chunk Size
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- EMC. (2012), EMC DATA DOMAIN white papaer. Available online: http://www.emc.com/collateral/software/white-papers/h7219-data-domain-data-invul-arch-wp.pdf (accessed on 18 July 2016).
- Dubnicki, C.; Gryz, L.; Heldt, L.; Kaczmarczyk, M.; Kilian, W.; Strzelczak, P.; Szczepkowski, J.; Ungureanu, C.; Welnicki, M. Hydrastor: A scalable secondary storage. In Proceedings of the 7th USENIX Conference on File and Storage Technologies, San Francisco, CA, USA, 24–27 February 2009; pp. 197–210.
- Min, J.; Yoon, D.; Won, Y. Efficient deduplication techniques for modern backup operation. IEEE Trans. Comput. 2011, 60, 824–840. [Google Scholar] [CrossRef]
- Quinlan, S.; Dorward, S. Venti: A New Approach to Archival Data Storage. In Proceedings of the 1st USENIX Conference on File and Storage Technologies, Monterey, CA, USA, 28–30 January 2002; pp. 89–101.
- Tsuchiya, Y.; Watanabe, T. DBLK: Deduplication for primary block storage. In Proceedings of the IEEE 27th Symposium on Mass Storage Systems and Technologies, Denver, CO, USA, 23–27 May 2011; pp. 1–5.
- Srinivasan, K.; Bisson, T.; Goodson, G.; Voruganti, K. iDedup: Latency-aware, inline data deduplication for primary storage. In Proceedings of the 10th USENIX conference on File and Storage Technologies, San Jose, CA, USA, 14–17 February 2012; pp. 24–35.
- Muthitacharoen, A.; Chen, B.; Mazieres, D. A low-bandwidth network file system. In Proceedings of the Eighteenth ACM Symposium on Operating Systems Principles, Banff, AB, Canada, 21–24 October 2001; pp. 174–187.
- You, L.L.; Karamanolis, C. Evaluation of efficient archival storage techniques. In Proceedings of the 21st IEEE/12th NASA Goddard Conference on Mass Storage Systems and Technologies, Greenbelt, MD, USA, 13–16 April 2004; pp. 227–232.
- Romański, Ł.H.B.; Kilian, W.; Lichota, K.; Dubnicki, C. Anchor-driven subchunk deduplication. In Proceedings of the 4th Annual International Conference on Systems and Storage, Haifa, Israel, 30 May–1 June 2011; pp. 1–13.
- Bolosky, W.J.; Corbin, S.; Goebel, D.; Douceur, J.R. Single instance storage in Windows 2000. In Proceedings of the 4th USENIX Windows Systems Symposium, Seattle, WA, USA, 3–4 August 2000; pp. 13–24.
- Sun, Z.; Shen, J.; Yong, J. A novel approach to data deduplication over the engineering-oriented cloud systems. Integr. Comput. Aided Eng. 2013, 20, 45–57. [Google Scholar]
- Kubiatowicz, J.; Bindel, D.; Chen, Y.; Czerwinski, S.; Eaton, P.; Geels, D.; Gummadi, R.; Rhea, S.; Weatherspoon, H.; Weimer, W.; et al. OceanStore: An architecture for global-scale persistent storage. SIGPLAN Not. 2000, 35, 190–201. [Google Scholar] [CrossRef]
- Rabin, M.O. Fingerprint by Random Polynomials. (TR-15–81)1981. Available online: http://www.xmailserver.org/rabin.pdf (accessed on 18 July 2016).
- Kruus, E.; Ungureanu, C.; Dubnicki, C. Bimodal content defined chunking for backup streams. In Proceedings of the 8th USENIX Conference on File and Storage Technologies, San Jose, CA, USA, 23–26 February 2010; pp. 239–252.
- Eshghi, K.; Tang, H.K. A framework for analyzing and improving content-based chunking algorithms. 2005. Hewlett-Packard Labs Technical Report TR 30. Available online: http://www.hpl.hp.com/techreports/2005/HPL-2005–30R1.pdf (accessed on 18 July 2016).
- Bobbarjung, D.R.; Jagannathan, S.; Dubnicki, C. Improving duplicate elimination in storage systems. ACM Trans. Storage 2006, 2, 424–448. [Google Scholar] [CrossRef]
- Lillibridge, M.; Eshghi, K.; Bhagwat, D.; Deolalikar, V.; Trezise, G.; Camble, P. Sparse indexing: Large scale, inline deduplication using sampling and locality. In Proceedings of the 7th USENIX Conference on File and Storage Technologies, San Francisco, CA, USA, 24–27 February 2009; pp. 111–123.
- Debnath, B.; Sengupta, S.; Li, J. ChunkStash: Speeding up inline storage deduplication using flash memory. In Proceedings of the 2010 USENIX Conference on USENIX Annual Technical Conference, Boston, MA, USA, 23–25 June 2010; pp. 1–16.
- Symantec. About Deduplication Chunk Size. Available online: https://sort.symantec.com/public/documents/vis/7.0/aix/productguides/html/sf_admin/ch29s01s01.htm (accessed on 18 July 2016).
- IBM. (2016). Determining the Impact of Deduplication on a Tivoli Storage Manager Server Database and Storage Pools. Available online: http://www-01.ibm.com/support/docview.wss?uid=swg21596944 (accessed on 18 July 2016).
- Suzaki, K.; Yagi, T.; Iijima, K.; Artho, C.; Watanabe, Y. Impact on Chunk Size on Deduplication and Disk Prefetch. In Recent Advances in Computer Science and Information Engineering, 125 ed.; Springer: Berlin, Germany, 2012; Volume 2, pp. 399–413. [Google Scholar]
- Linux. (2016). The Linux Kernel Archives. Available online: http://kernel.org/ (accessed on 18 July 2016).
- Wikipedia. (2015). svwiki dump. Available online: http://dumps.wikimedia.org/svwiki/20150807/ (accessed on 18 July 2016).
- D.RichardHipp. (2016), SQLite homepage. Available online: http://sqlite.org/ (accessed on 18 July 2016).
- TPCC. (2010, 2009–02–11). TPC BENCHMARK™ C Standard Specification. Available online: http://www.tpc.org/tpc_documents_current_versions/pdf/tpc-c_v5.11.0.pdf (accessed on 18 July 2016).
- Liu, A. Deduputil homepage. Available online: https://sourceforge.net/projects/deduputil/ (accessed on 18 July 2016).
- Harnik, D.; Khaitzin, E.; Sotnikov, D. Estimating Unseen Deduplication-from Theory to Practice. In Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST 16), Santa Clara, CA, USA, 22–25 February 2016; pp. 277–290.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Name of Symbol | The Meaning of Symbol |
|---|---|
| x | The mask length in binary |
| μ | The expected chunk size |
| So | The original data size |
| W | The size of the sliding window |
| Nm | The metadata number after deduplication |
| Sm | The metadata size after deduplication |
| Su | The unique and fingerprint index data size after deduplication |
| Sd | The total data size after deduplication |
| m | The single metadata size |
| L | The upper bound of the logistic function;; |
| k | The steepness of the logistic curve |
| x0 | The x-value of the logistic curve’s midpoint |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Dong, X.; Zhang, X.; Guo, F.; Wang, Y.; Gong, W. A Logistic Based Mathematical Model to Optimize Duplicate Elimination Ratio in Content Defined Chunking Based Big Data Storage System. Symmetry 2016, 8, 69. https://doi.org/10.3390/sym8070069
Wang L, Dong X, Zhang X, Guo F, Wang Y, Gong W. A Logistic Based Mathematical Model to Optimize Duplicate Elimination Ratio in Content Defined Chunking Based Big Data Storage System. Symmetry. 2016; 8(7):69. https://doi.org/10.3390/sym8070069
Chicago/Turabian StyleWang, Longxiang, Xiaoshe Dong, Xingjun Zhang, Fuliang Guo, Yinfeng Wang, and Weifeng Gong. 2016. "A Logistic Based Mathematical Model to Optimize Duplicate Elimination Ratio in Content Defined Chunking Based Big Data Storage System" Symmetry 8, no. 7: 69. https://doi.org/10.3390/sym8070069