3.1. Descriptions of Our Databases
Our algorithm is executed in the environment of a server-client-based intelligent TV. We aim to adopt our algorithm into an intelligent TV that can be used in underdeveloped countries where people cannot afford to buy smart TVs with high performance and cost. Therefore, most functionalities of the intelligent TV are provided by a low-cost STB. Additional functionalities requiring a high processing time are provided by a high-performance server, which is connected to the STB by a network. In this environment, our algorithm is executed on a STB (microprocessor without interlocked pipeline stages (MIPS)-based dual core 1.5 GHz, 1 GB double data rate 3 (DDR3) memory, 256/512 MB negative-and (NAND) memory) and server (3.5 GHz CPU and 8 GB of RAM). The STP is attached to a 60 in TV. Steps (1) and (2) of
Figure 1 are performed on the STP, and steps (3) to (7) are performed on the server.
There are many face databases, e.g., FEI [
48], PAL [
49], AR [
50], JAFFE [
51], YouTube Faces [
52], the Honda/UCSD video database [
53], and the IIT-NRC facial video database [
54]. However, most of them were not collected when a user was watching TV, and face images with in-plane rotation are not included. Therefore, we constructed our own database, which consists of images of users watching TV in natural poses, including face images with in-plane rotation. The database was collected using 15 people by separating them into five groups of three people for the experiments [
32]. In order to capture images of users looking at the TV screen naturally, each participant was instructed to watch TV without any restrictions. As a result, we captured a total of 1350 frames (database I) (15 persons × two quantities of participants (one person or three persons) × three seating positions (left, middle, and right) × three Z distances (1.5, 2, and 2.5 m) × five trials (looking naturally)). In addition, a total of 300 images (database II) (five persons × three Z distances (1.5 m, 2 m, and 2.5 m) × two lying directions (left and right) × 10 images) were collected for experiments when each person is lying on his or her side [
32]. For face registration for recognition, a total of 75 frames (15 people × five TV gaze points) were obtained at the Z distance of 2 m. Consequently, a total 1725 images were used for the experiments. We make our all databases (used in our research) [
55] available for others to use in their own evaluations.
Figure 10 shows examples of the experimental images. For registration, five images were acquired, as shown in
Figure 10a, when each user looked at five positions on the TV.
Figure 10b shows examples of the images for recognition, which were obtained at various Z-distances, seating positions, and lying directions.
Figure 10c shows examples of database II.
3.2. Experimental Results of the Face Detection and Recognition with Our Databases I and II
For the first experiment, we measured the accuracy of the face detection using database I. Accuracies were measured based on recall and precision, respectively, calculated as follows [
32]:
where
m is the total number of faces in the images;
#FP and
#TP are the number of false positives and true positives, respectively. False positives are cases where non-faces are incorrectly detected as faces. True positives are faces that are detected correctly. If the recall value is close to 1, the accuracy of the face detection is regarded as high. If the precision value is 1, all of the detected face regions are correct with an
#FP of 0. As explained before, we measured the accuracies of the face detection according to the participant groups as shown in
Table 2. In
Table 2, recall and precision in the case of equal error rate (EER) are shown in bold type. EER means the error rate when the difference between the recall and precision is minimized in the trade-off relations between recall and precision. The reason why the recall at the EER point for Group 2 was lower than those for the other groups is that the face detection was not successful for the female who had hair occluding part her face and a small face. The reason why the precision at the EER point for Groups 2 and 3 is lower than those for other groups is that the colors of the subjects’ clothes were similar to those of the facial skin, which caused false positives.
In
Table 3, we measured the face detection accuracies according to the Z distances of the subjects in order to evaluate the effect of the change of image size (resolution). In
Table 3, recall and precision in the case of equal error rate (EER) are shown in bold type as well. The recall at the EER point at a Z distance of 2.5 m is lower than for other cases because the face sizes are small, which caused the face detection to fail.
The rows in each group (or Z distance) in
Table 2 and
Table 3 show the changes of recall according to the decreases of precision. Because the recall and precision usually have a trade-off relationship (with a larger recall, a smaller precision is obtained, and vice versa), the changes of recall according to the decrease of precision are presented in our paper in order to show the accuracies of our face detection method more clearly through the various combinations of recall and precision.
In
Table 4 and
Table 5, we respectively measured the accuracies of the face detection according to the seating positions and the number of participants in each image. As shown in
Table 4 and
Table 5, the face detection accuracy is similar, irrespective of the seating position and number of people in each image.
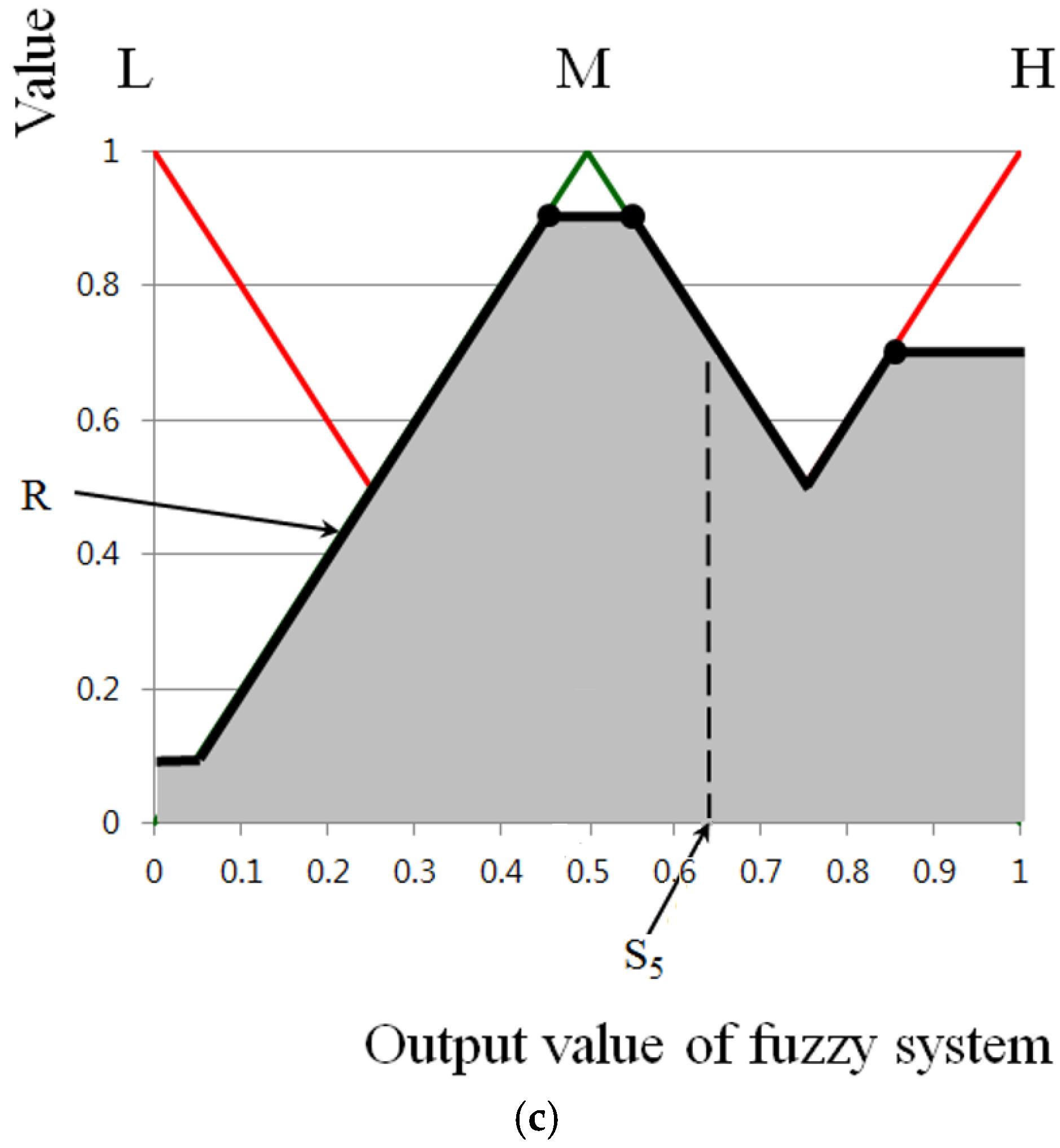
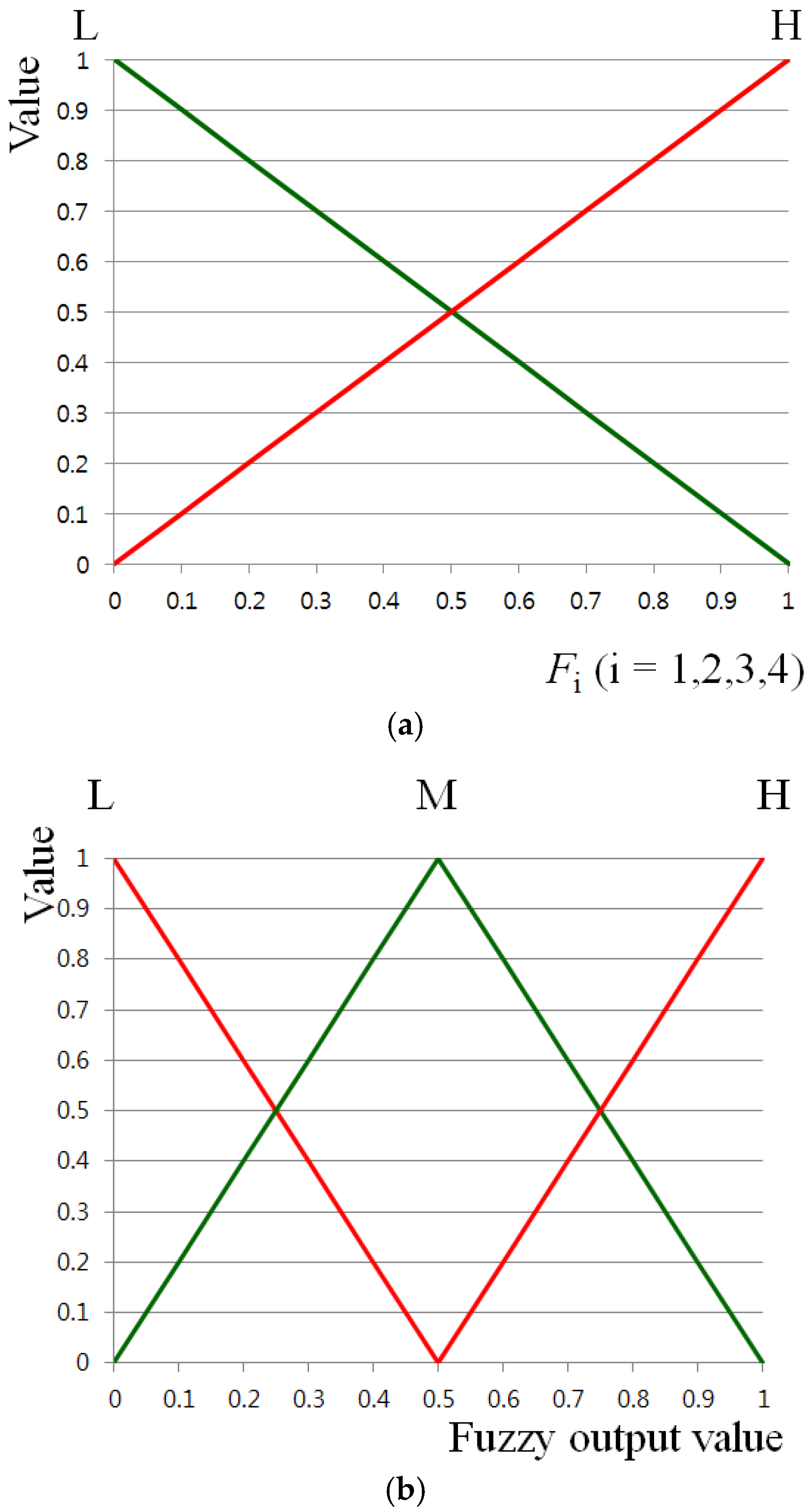
For the second experiment, we measured the accuracy of the face recognition with database I for various defuzzification methods. As explained in
Section 2.5, the MLBP histogram of the incoming face is compared (using the chi-squared distance) to the five images of three individuals used to train it and the nearest is chosen as the identity, provided the calculated matching distance is less than the threshold. That is, it is a nearest neighbor classifier and only three identities are included in the tests. We measured the accuracy of the face recognition using the genuine acceptance rate (GAR). As shown in
Table 6, the GAR by MOM with the MAX rule is higher than the GARs for other defuzzification methods. Using the MOM with the MAX rule, we compared the GAR of the proposed method to that of the previous one, as shown in
Table 7, where it is clear that the GAR of our method is higher than that of the previous method for all cases.
In
Table 8,
Table 9 and
Table 10, we compared the face recognition accuracy (GAR) of our method to that of the previous method with respect to the Z distance, sitting position, and number of people in each image, respectively. The GAR for various Z distances was measured in order to evaluate the effect of the change of the image size (resolution). The reason why the GAR at a Z distance of 2 m is higher than those at other Z distances is that the registration for face recognition was done with the face images captured at a Z distance of 2 m. The reason why the GAR at a Z distance of 2.5 m is lower than for other cases is that the face sizes in the images are smaller. As shown in
Table 8,
Table 9 and
Table 10, we confirm that the GARs of our method are higher than those of the previous method in all cases, and the GARs of our method are not affected by the Z distance, sitting position, or the number of people in each image.
For the next experiments, we compared the GARs of various face recognition methods [
47,
56,
57,
58,
59,
60] with our face detection method. In previous research [
47], Ahonen et al. proposed LBP-based feature extraction for face recognition. PCA has been widely used to represent facial features based on eigenfaces [
56,
57]. Li et al. proposed a local non-negative matrix factorization (LNMF)-based method for the part-based representation of facial features [
58]. In a previous study [
59], they proposed support vector machine-discriminant analysis (SVM-DA)-based feature extraction for face recognition in order to overcome the limitations of the linear discriminant analysis method that assumes that all classes have Gaussian density functions. Froba et al. proposed the modified census transform (MCT)-based facial feature extraction method which uses the average value of a 3 × 3 pixel mask, in contrast to the LBP method which uses the center value of a 3 × 3 pixel neighborhood [
60]. As shown in
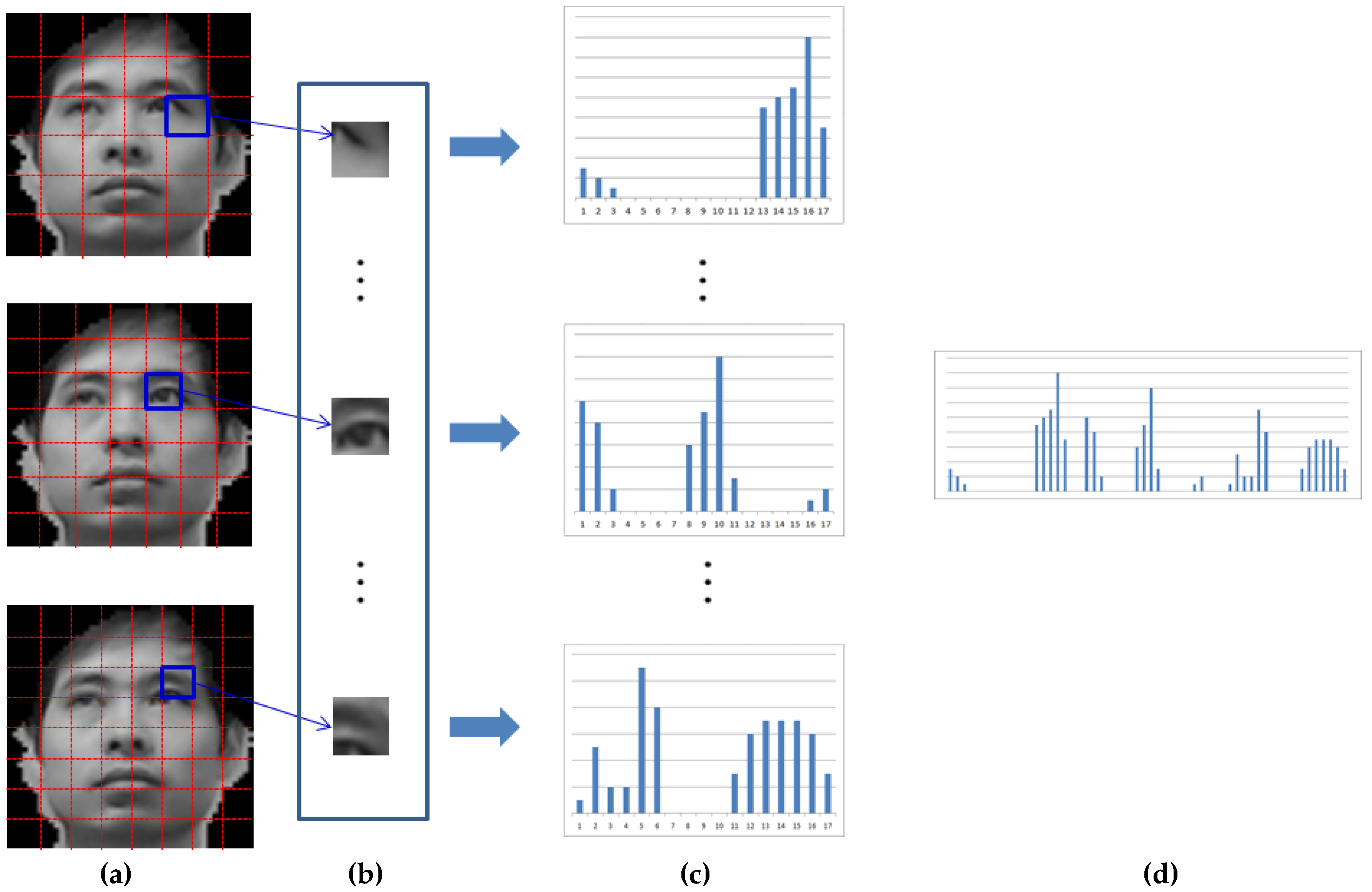
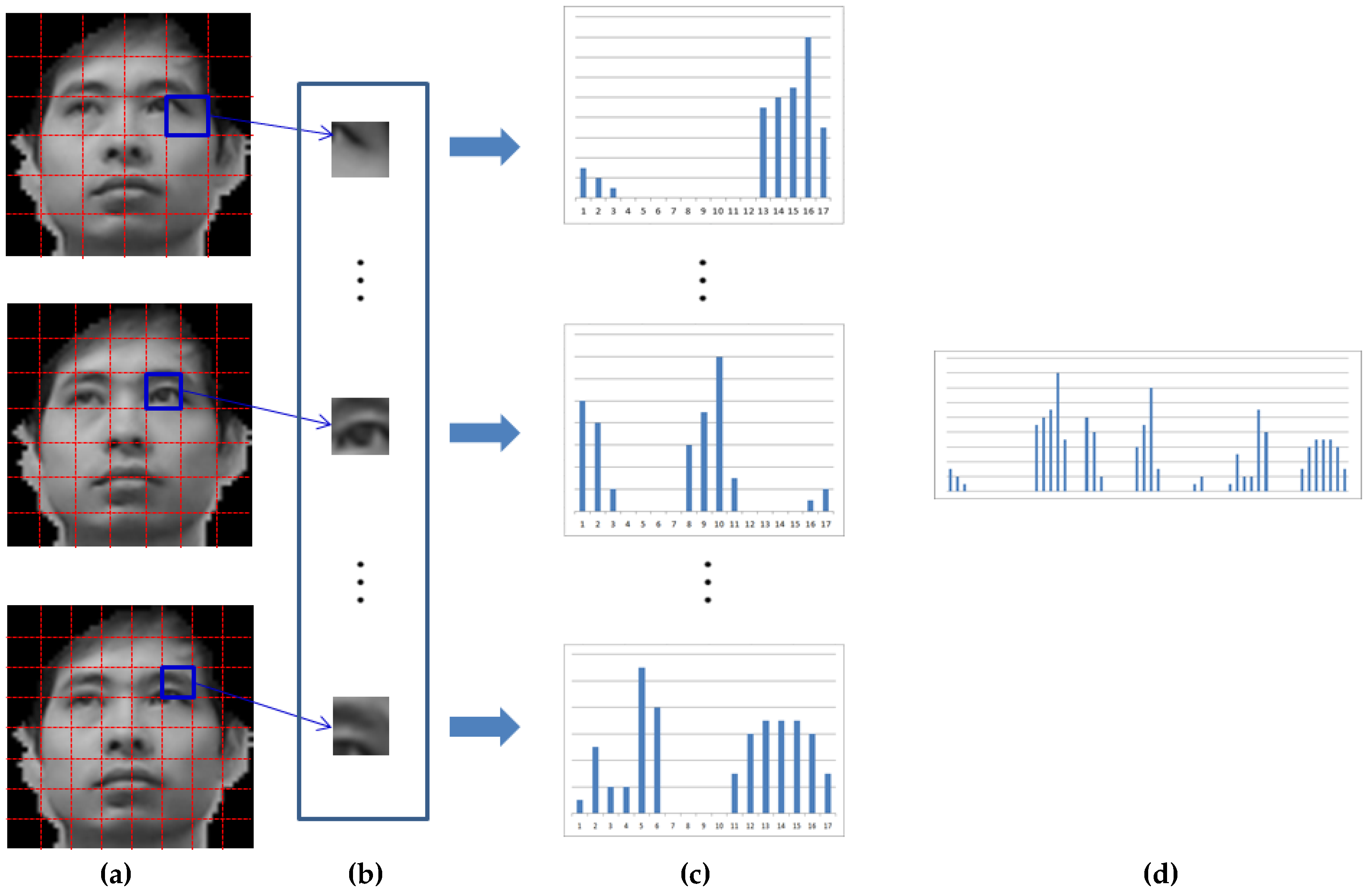
Table 11, the GAR of our MLBP-based recognition method with our face detection method is higher than those of other methods. By using the MLBP histogram features of three levels, as shown in
Figure 9, both local and global features can be efficiently used for face recognition, which improves the accuracy of the face recognition.
As shown in
Table 12, the GARs of our MLBP-based recognition method with our face detection method are higher than others irrespective of the change of image resolution which is caused by the change of Z distance. As explained before, because the MLBP-based method can use both local and global features for face recognition, the change of image resolution affects the facial features less using MLBP compared to other methods. In
Table 11 and
Table 12, all the methods were applied to the same data of the face ROI detected by our face detection method for fair comparisons.
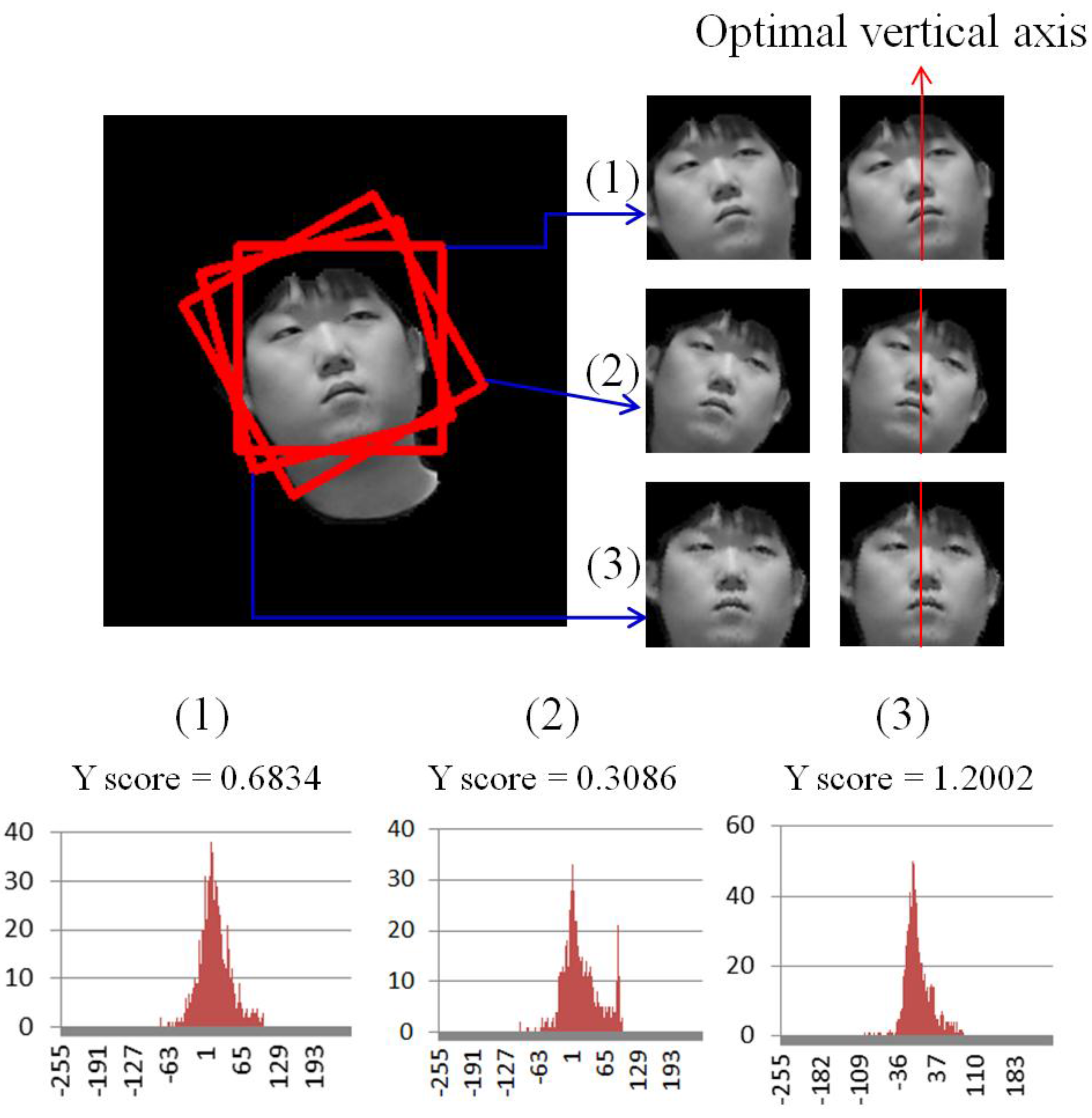
Our research is mainly focused on selecting one correct (upright) face image among multiple (in-plane-rotated) face candidates (without the procedure of detecting eye positions or keypoints) based on a fuzzy system, and on enhancing the performance of face recognition by using only the selected face image. That is, the main goal of our research is face detection robust to in-plane rotation (not facial feature extraction or face recognition). In all the methods of
Table 11 and
Table 12, our face detection method is also commonly used. That is, PCA means PCA-based face recognition with our face detection method. In the same manner, LBP means LBP-based face recognition with our face detection method. Therefore,
Table 11 and
Table 12 just show the accuracies of various face recognition methods with our face detection method. PCA, LBP and MCT are not originally designed to be robust to in-plane rotation. Nevertheless, the reason why we selected PCA, LBP and MCT, etc. (instead of state-of-the-art methods such as deep learning-based face recognition, etc.), for comparisons in
Table 11 and
Table 12 is to show that our face detection method can be used with any kind of traditional or even old-fashioned method whose accuracies are lower than the state-of-the-art methods for face recognition. If we use a recognition method showing high accuracies such as the deep learning-based method in
Table 11 and
Table 12, it is difficult to analyze whether the high accuracies of recognition are caused by our face detection method or the recognition method itself. Therefore, we include only the comparisons with traditional methods in
Table 11 and
Table 12.
For the next test, we performed an additional experiment with database II, which includes extremely rotated faces, as shown in
Figure 10c. The recall and precision of the face detection are, respectively, 96.67% and 99.39%, which are similar to those of database I in
Table 2,
Table 3,
Table 4 and
Table 5. As shown in
Table 13, the GAR of our method is 95.15%, which is higher than that of the previous method. In addition, the GAR of our method is similar to those of
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. This result confirms that our method can be applied to highly rotated face images.
Figure 11 shows the examples for which our face recognition method is successful.
Figure 12 shows the examples where the face recognition failed. The failures (left person of the left figure of
Figure 12 and right person of the right figure of
Figure 12) are caused by false matching by the MLBP method, although the correct face boxes are selected by our method.
Our method (including fuzzy system–based face detection and MLBP-based face recognition) does not require any training procedure. Even for face candidate detection, we used the original Adaboost face detector provided by the OpenCV library (version 2.4.9 [
61]) without additional training. Therefore, all the experimental data were used for testing.
For the next experiment, we measured the processing time of our method. Experimental results show that the processing time per each image is approximately 152 ms. Therefore, our system can be operated at a speed of approximately six or seven frames per second. The processing time of our method is smaller than that of the previous method (185 ms) [
32] because only a single face region is selected per individual for recognition. The target applications for TV of our method are the systems for automatic audience rating surveys, program recommendation services, personalized advertising, and TV child locks. Face detection and recognition do not necessary need to be executed at every frame (real-time speed) in these applications. Therefore, our system at the current processing speed of approximately six or seven frames per second can be used for these applications.
Previous research on rotation-invariant face detection exists [
62,
63]. Their method can detect the correct face region from the face images including various rotations of a face based on the real Adaboost method [
62]. However, the processing time of their method is so high (about 250 ms for a 320 × 240 image on a Pentium 4 2.4 GHz PC) that their method cannot be used in our system. In previous research [
63], they show that their method can also locate the correct face region from face images including various rotations of a face by a neural network. However, the processing time of their method is so high (about six seconds to process a 160 × 120 pixel image on an SGI O2 workstation (Silicon Graphics Inc., Sunnyvale, CA, USA) with a 174 MHz R10000 processor (Silicon Graphics Inc., Sunnyvale, CA, USA)) that their method cannot be used in our system, either. In our system, the total processing time per one input image (1280 × 720 pixels) by our method is taken as 152 ms on a desktop computer (3.5 GHz CPU and 8 GB of RAM) including the processing time of steps (1) and (2) of
Figure 1 on a set-top box (STB) (MIPS-based dual core 1.5 GHz, 1 GB DDR3 memory, 256/512 MB NAND memory). Although the processing time of the previous methods [
62,
63] includes only the procedure of face detection, our processing time of 152 ms includes both face detection and recognition. In addition, the face images in our research are considerably blurred as shown in
Figure 13c,d compared to those in their research because our face images are acquired at far distance of a maximum of 2.5 m (from the camera to the user). Therefore, their methods for face detection based on the training of the real Adaboost or a neural network are difficult to apply to face images in our research.
In addition, we include the comparative experiments by our method with other rotation-invariant face detection methods [
63]. Because our fuzzy-based method is applied to both databases I and II without any parameter tuning or training according to the type of database, the neural network of their method [
63] is trained with all the images of databases I and II for fair comparison, and the testing performance are shown with databases I and II, separately.
As shown in
Table 14, the accuracy of face detection by our method is higher than that by the previous method with database I. The reason why the accuracy of the previous method is lower than that of our method is that the face images in database I are blurred and the pixel resolution of the face images in database I is very low, as shown in
Figure 13c. As shown in
Table 15, the accuracy of face detection by our method is also higher than that of the previous method with database II. The reason why the accuracy of the previous method is lower than that of our method is that the pixel resolution of face images in database II is very low and there also exist many variations of in-plane rotation of the face images in addition to the blurring effect as shown in
Figure 13d.
3.4. Discussions
There has been a great deal of previous researches on keypoint detection of a face image in References [
33,
34,
35]. However, in most previous research including References [
33,
34,
35], keypoint detection has been done with face images of high pixel resolution which are captured at close distance to the camera. In contrast, the input images captured at a far distance from the camera (maximum 2.5 m) are used in our research because our study aims at face recognition at far distances in the environment of watching TV. Consequently, the image pixel resolution of a face area is so low (less than 40 × 50 pixels), in addition to the blurring of the face image as shown in
Figure 13c,d, that the previous methods of keypoint detection or eye detection are difficult to apply to the face images used in our research.
As an experiment, we measured the accuracies of eye detection by the conventional Adaboost eye detector [
17] and subblock-based template matching [
65]. Experimental results showed that the recall and precision of eye detection by the Adaboost eye detector within the detected face region were about 10.2% and 12.3%, respectively. In addition, the recall and precision of eye detection by subblock-based template matching within the detected face region were about 12.4% and 13.7%, respectively. These results show that reliable eye positions or keypoints are difficult to detect in our blurred face images of low pixel resolution. Therefore, the procedures of detecting keypoints, alignment (removing in-plane rotation), and face recognition cannot be used in our research.
To overcome these problems, we propose the method of selecting one correct (upright) face image among multiple (in-plane-rotated) face candidates (without the procedure of detecting eye positions or keypoints) based on a fuzzy system, and enhancing the performance of the face recognition by using only the selected face image.
If we synthetically modify (manually rotate) the images of the open dataset, the discontinuous region (between the face and its surrounding areas) occurs in the image as shown in
Figure 14b (from the YouTube dataset) and
Figure 14e (from the Honda/UCSD dataset), which causes a problem in face detection and the correct accuracy of face detection is difficult to measure with these images. In order to prevent the discontinuous region, we can rotate the whole image. However, the background is also rotated as shown in
Figure 14c,f, where an unrealistic background (which does not exist in the real world) is produced in the rotated image, which affects the correct measurement of the face detection accuracy.
As explained before, as shown in
Figure 13c,d, the pixel resolution of images used in our research of face recognition is very low in addition to the blurring effect of a face image compared to images in open databases such as the LFPW [
33], BioID [
34], HELEN [
35], YouTube Faces (
Figure 14a), and Honda/UCSD (
Figure 14d) datasets. These kinds of focused images of high pixel resolution cannot be acquired in our research environment of watching TV where the user’s face is captured by a low-cost web camera at the Z distance of a maximum of 2.5 m between the camera and user (as shown in
Figure 13c,d). Therefore, the experiments with these open databases cannot reflect the correct measurement of the face recognition accuracy in the environment of watching TV. There is no other open database (acquired at the Z distance of a maximum of 2.5 m) that includes large areas of background and face images of in-plane rotation like our dataset includes, as shown in
Figure 13c,d.
Our method cannot deal with occluded or profiled faces. However, the cases of occluded or profiled faces do not occur in our research environment where the use is usually watching TV, as shown in
Figure 10. That is because more than two people do not occlude their faces and a profiled face caused by the severe out-of-plane rotation of a face cannot happen when watching TV. Therefore, we do not consider the cases of occluded or profiled faces in our research.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}