
Data-Filtering System to Avoid Total Data Distortion in IoT Networking


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
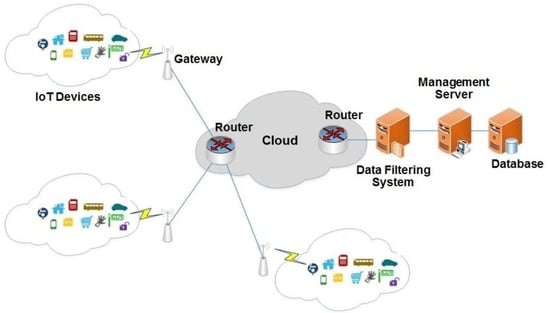
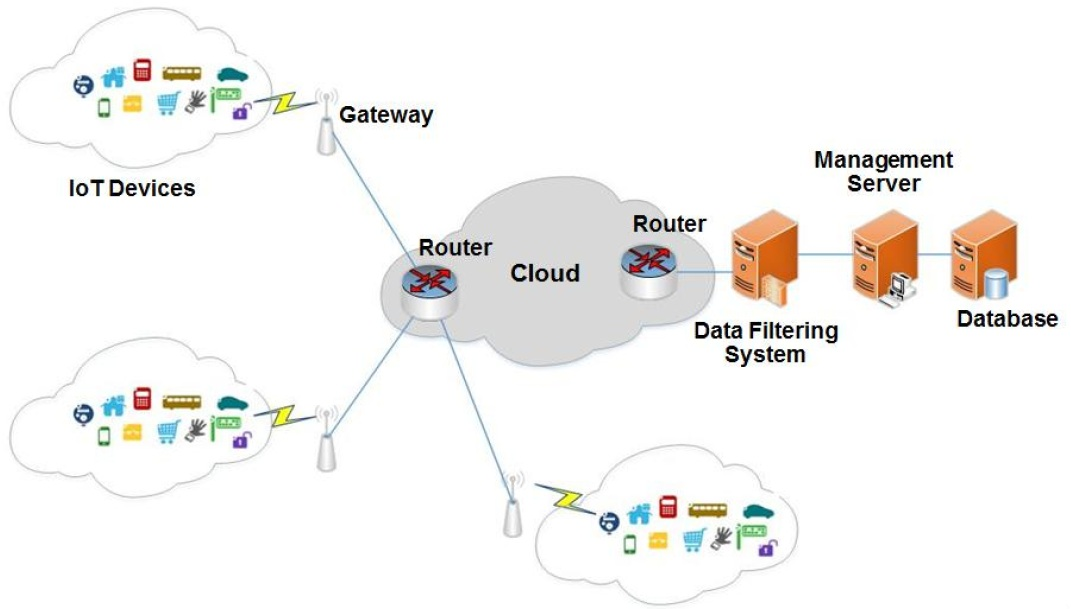
1. Introduction
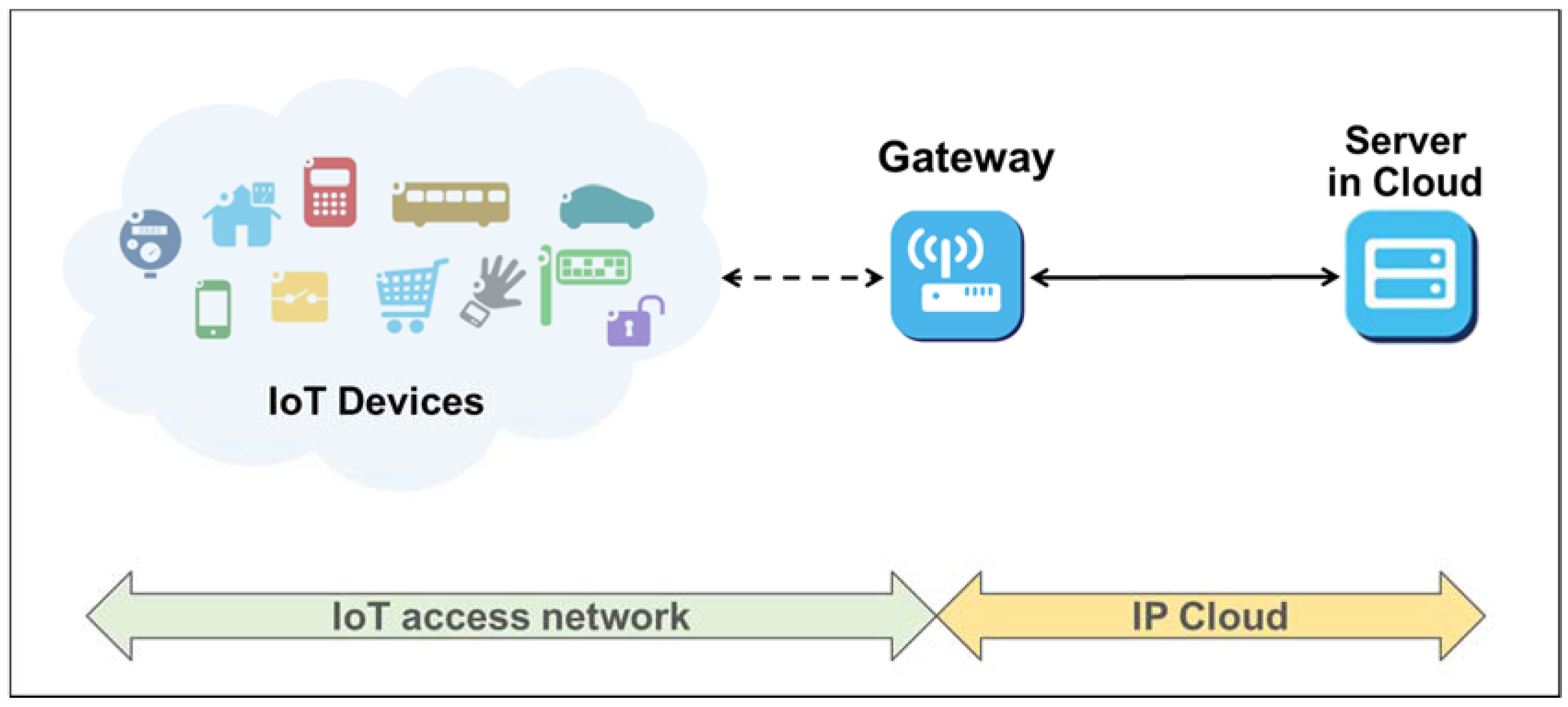
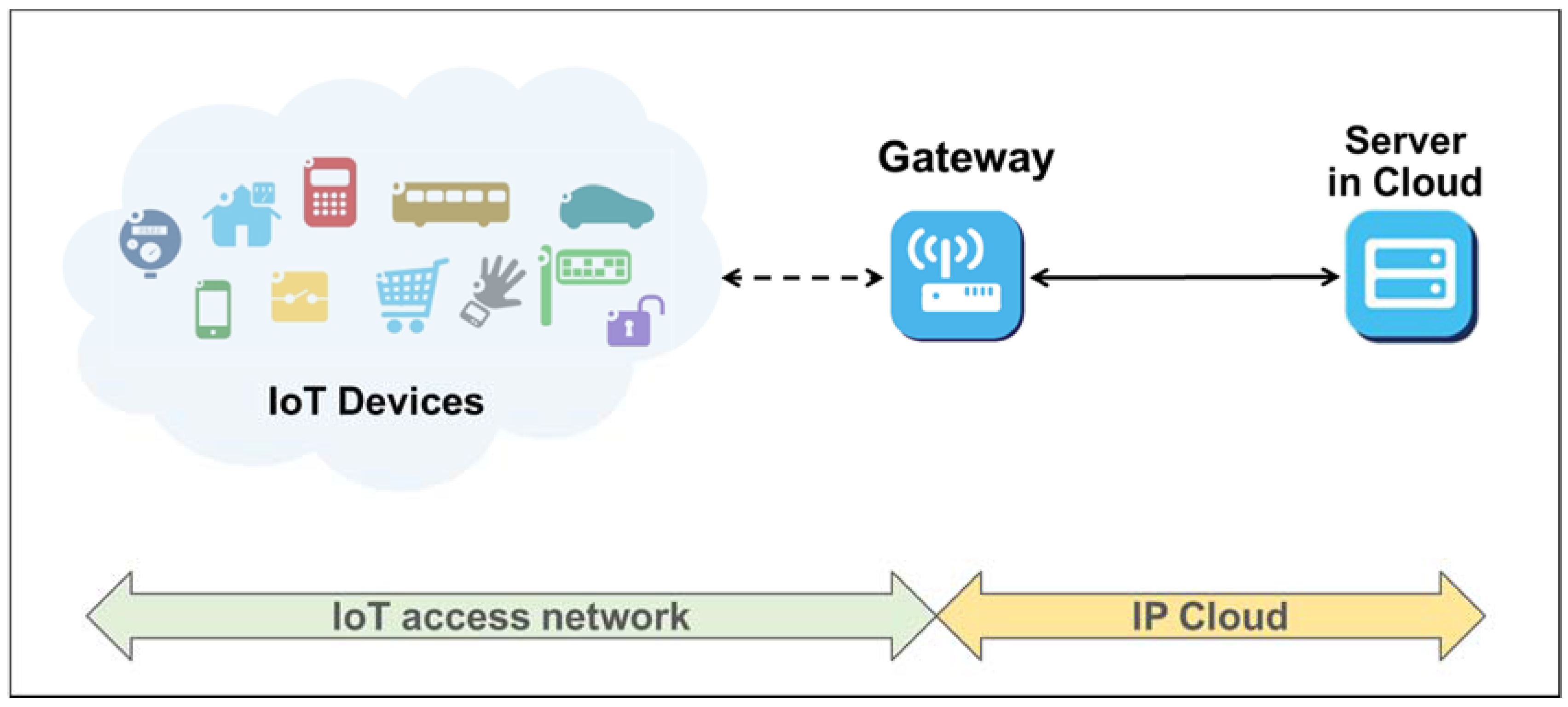
2. Background
- Energy constraints: Because IoT devices generally employ battery sources, energy consumption is the most important design consideration. For a long lifetime, IoT devices should minimize energy consumed for operations.
- Memory limitations: IoT devices are tiny portable devices or embedded system devices. Because the device size is small, they cannot adopt a lot of memory and storage on their electrical board.
- Unreliable communication: IoT devices exploit wireless communication in the industrial, scientific, and medical (ISM) frequency band for data delivery. Wireless communication has a higher channel error than wired communication. In addition, because the ISM frequency band is used in many wireless technologies, the wireless technologies can affect data transmission among each other.
- High latency in communication: Network congestion, processing in the intermediate nodes, and low data rate in wireless cause high latency in data delivery.
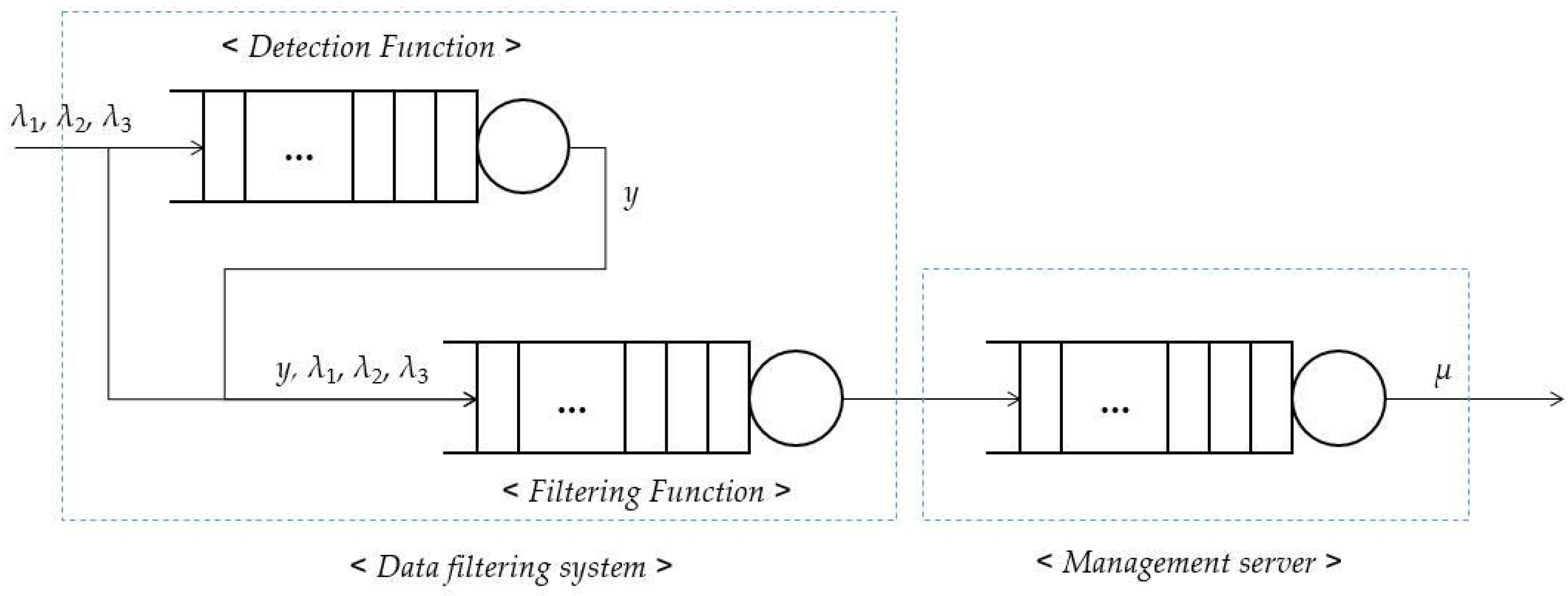
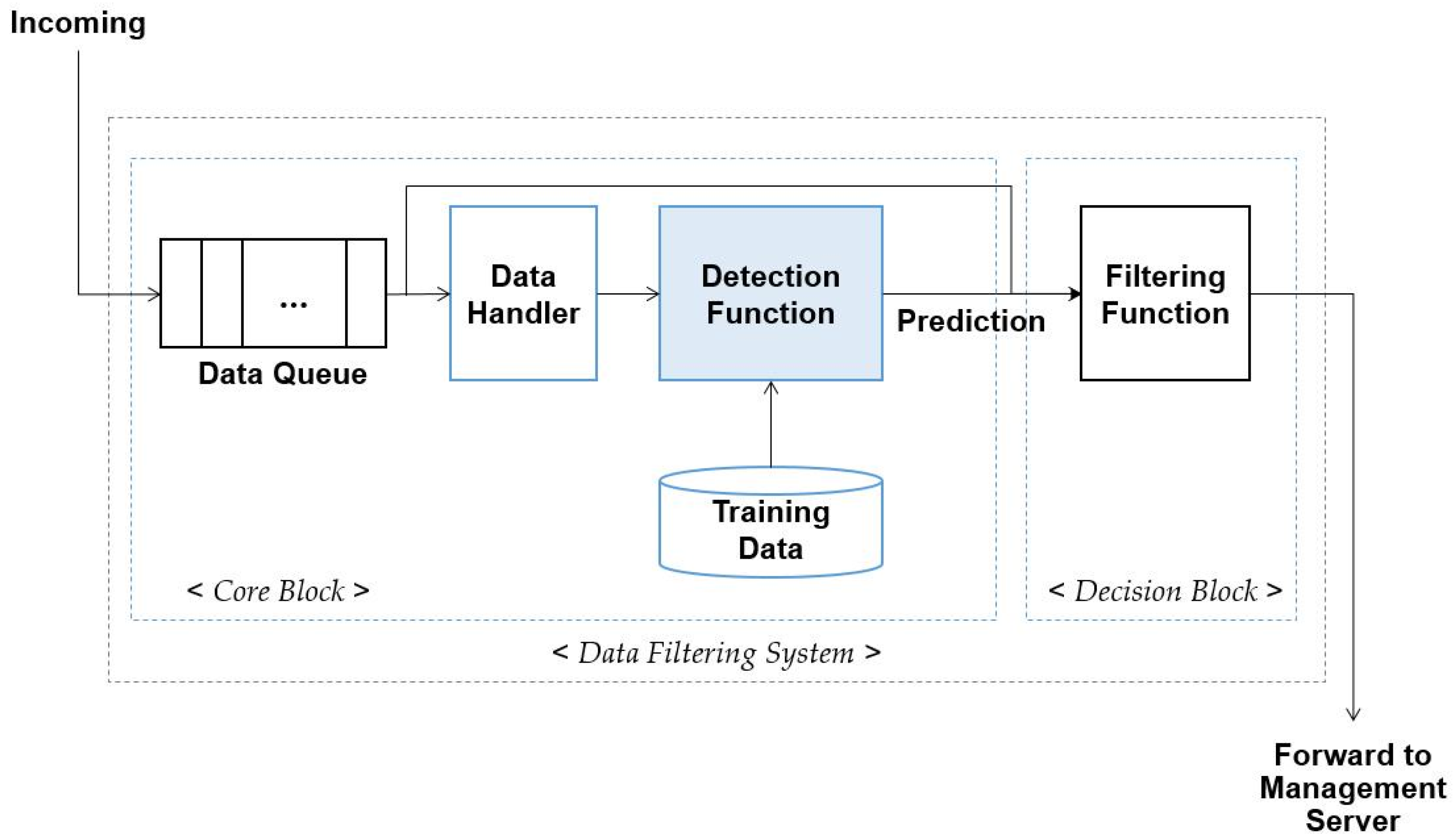
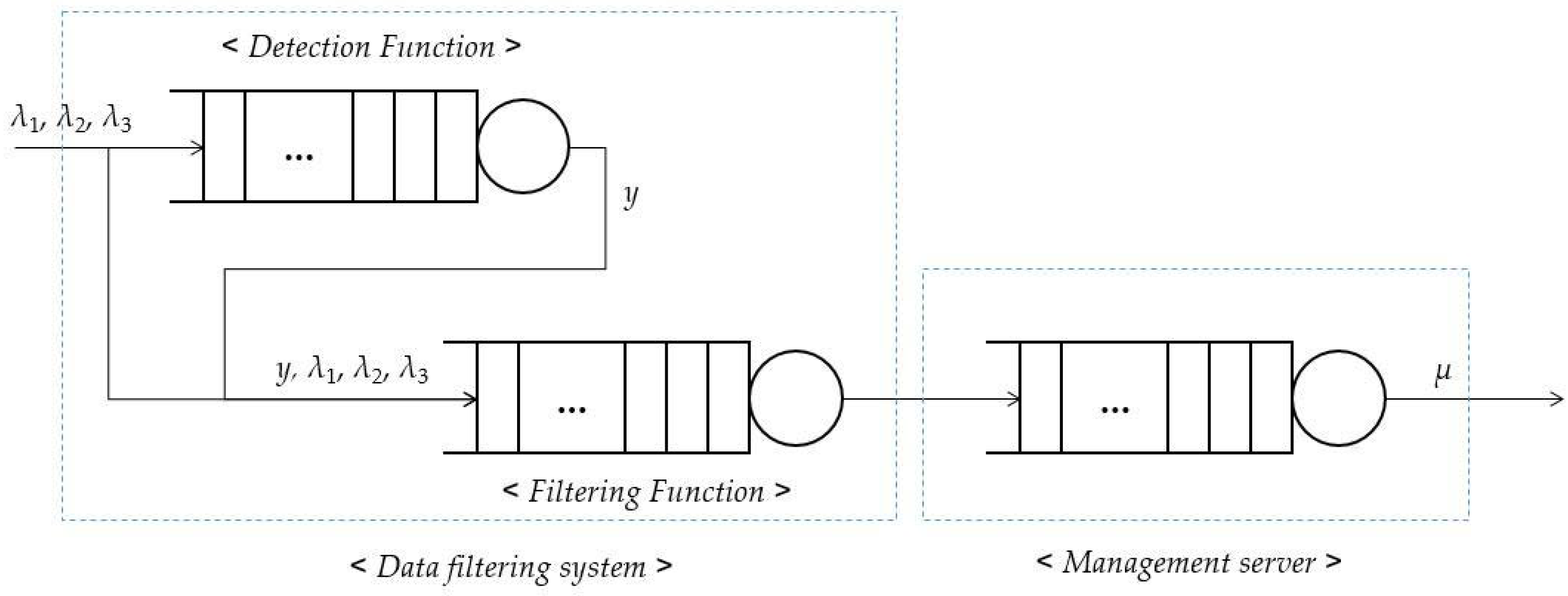
3. The Proposed Data-Filtering System
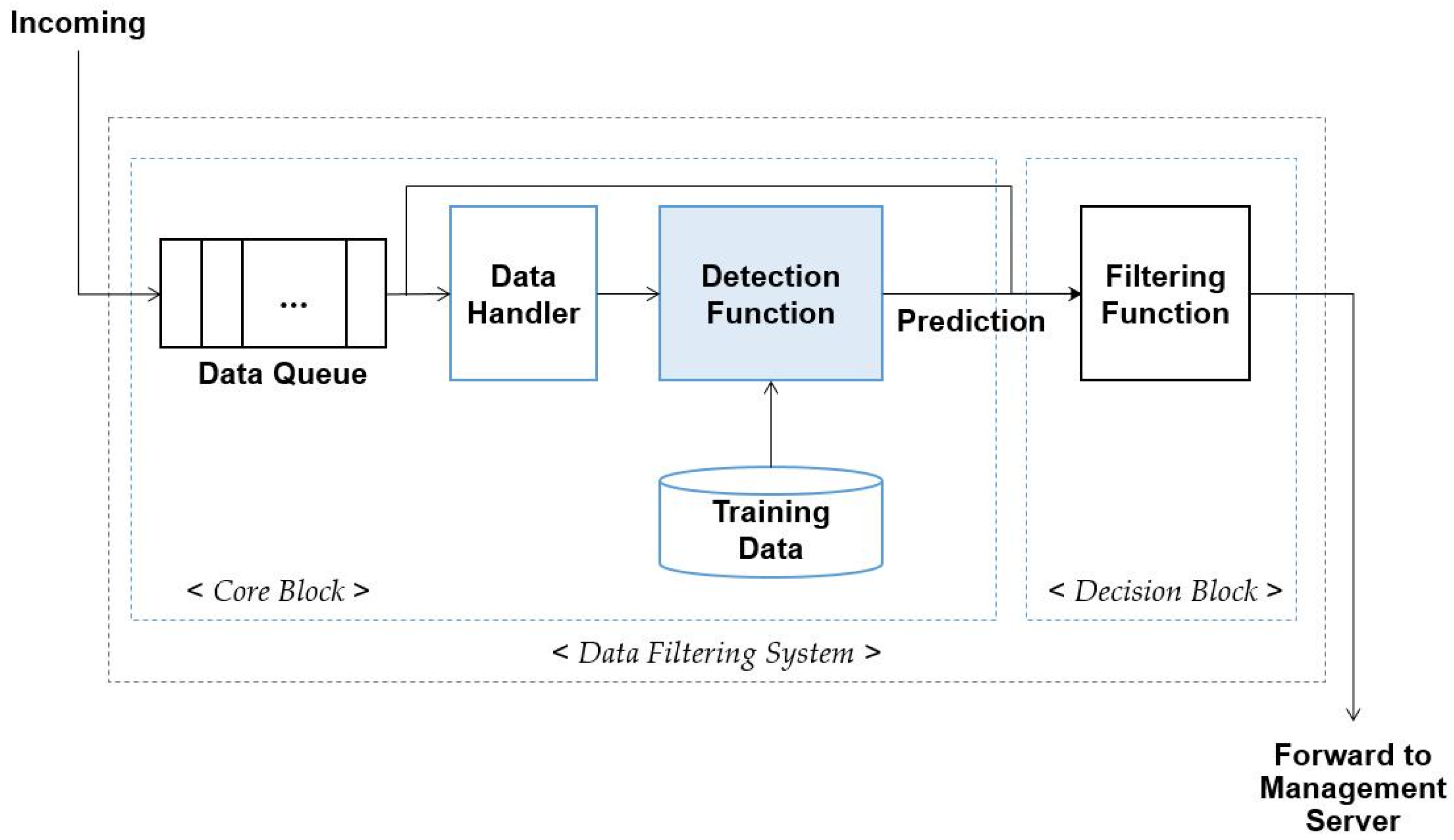
3.1. Detection of the Malfunctioning Data
3.2. Data-Filtering System
- If incoming data is the event data, the value of the data is placed in range of sensing levels of IoT devices.
- Several IoT devices sense the same event. That is, when an event occurs in the environment with many IoT devices, several devices transmit similar data. Thus, correlated data is entered to the data-filtering system.
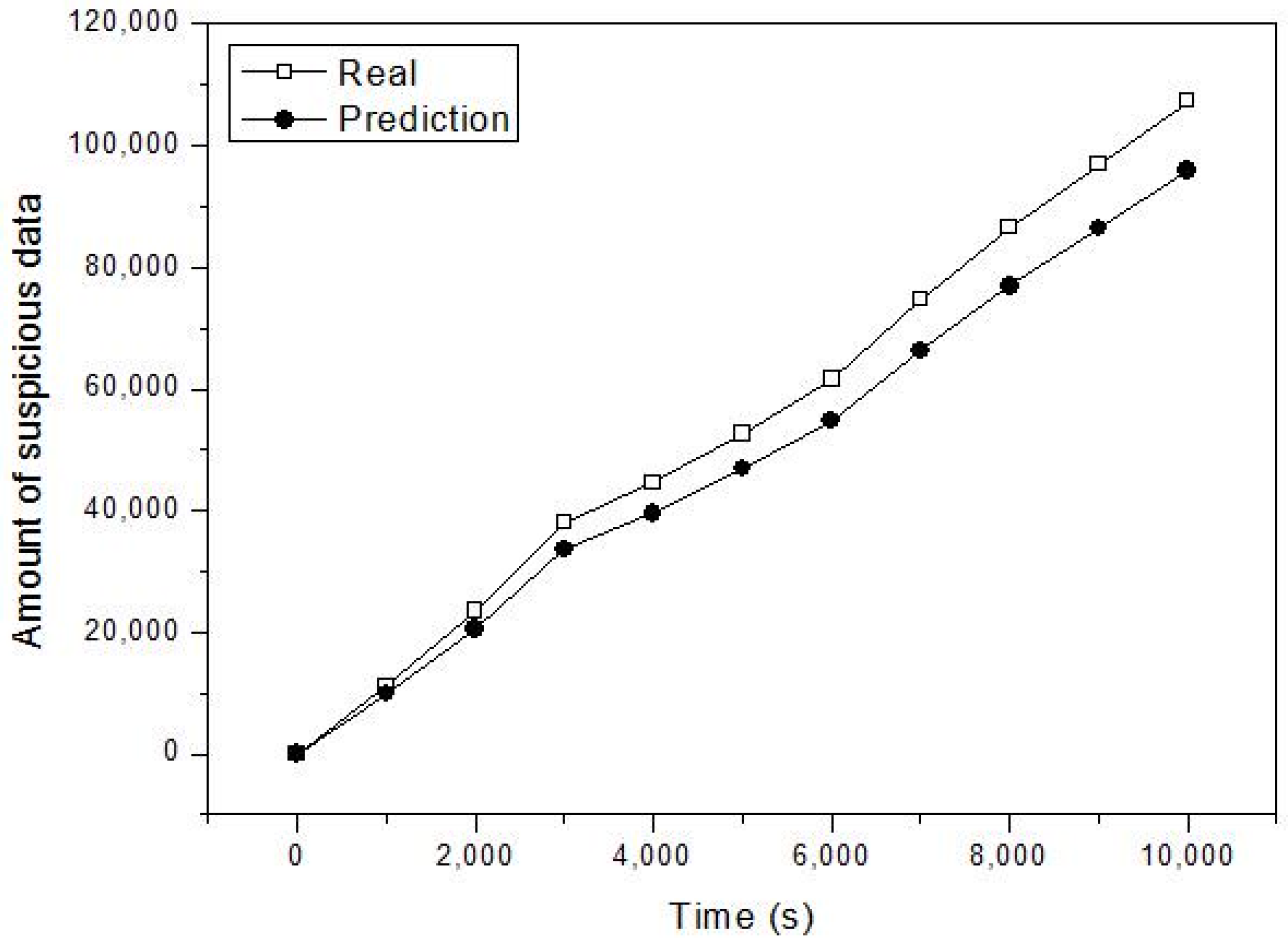
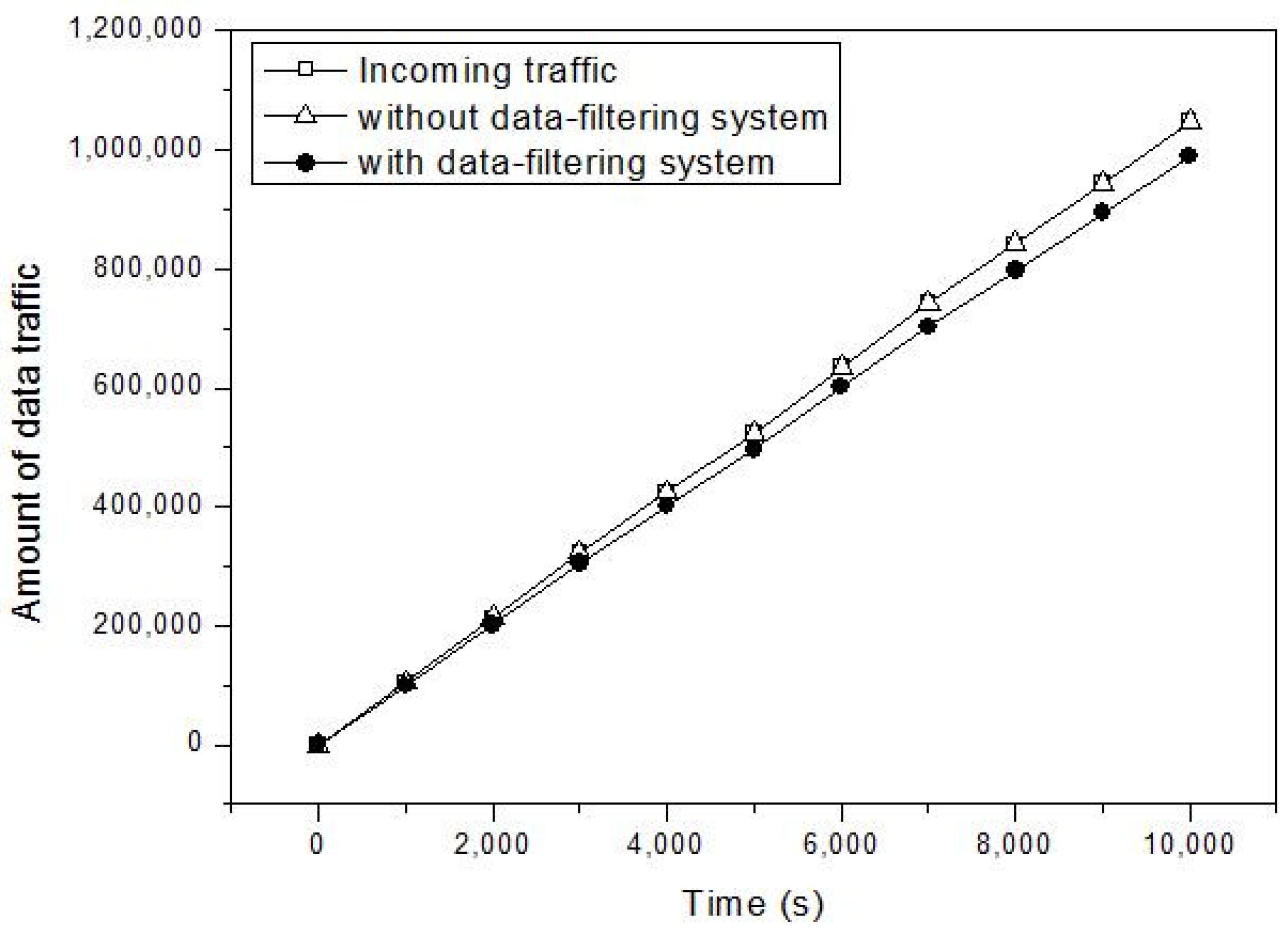
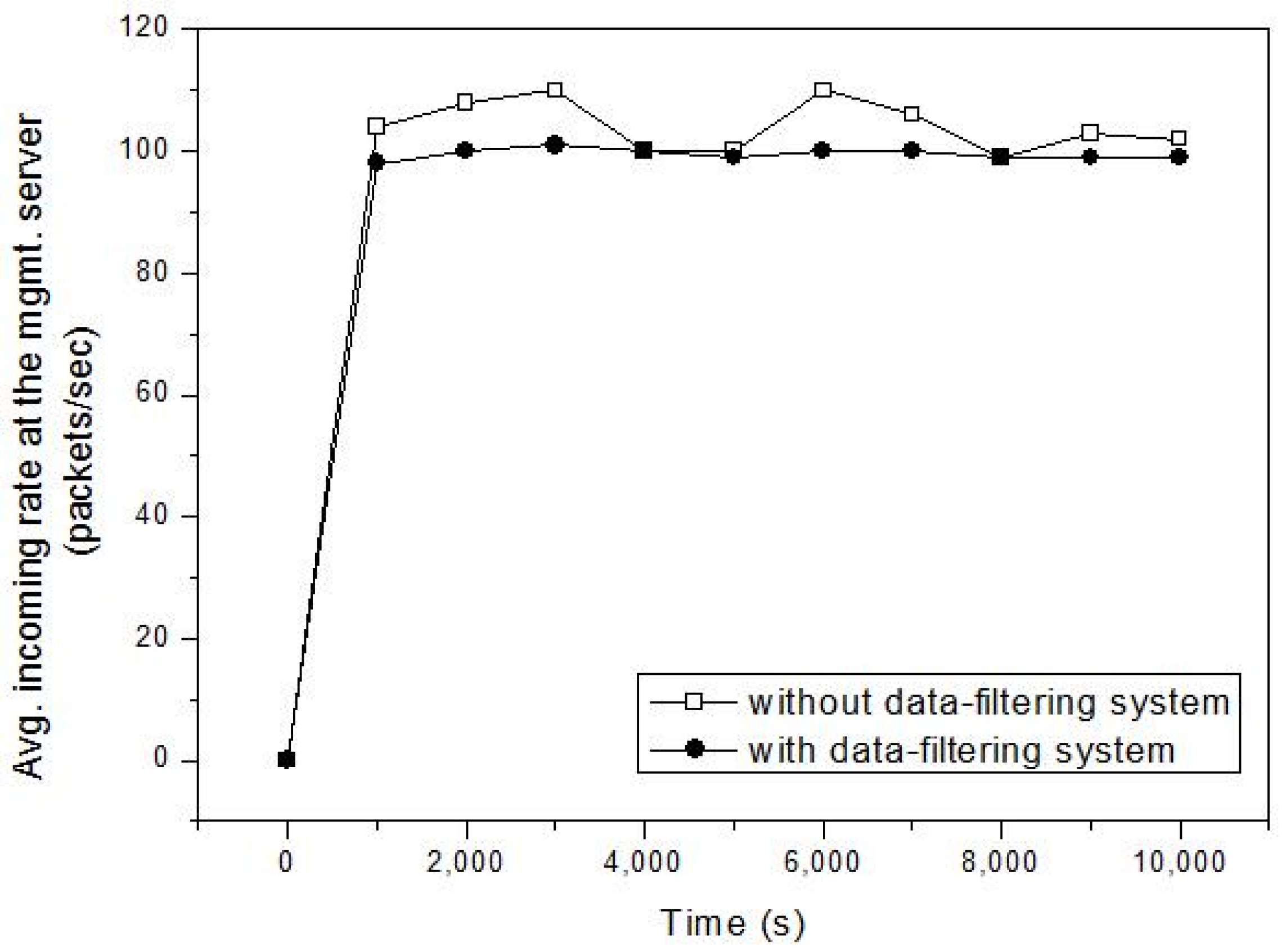
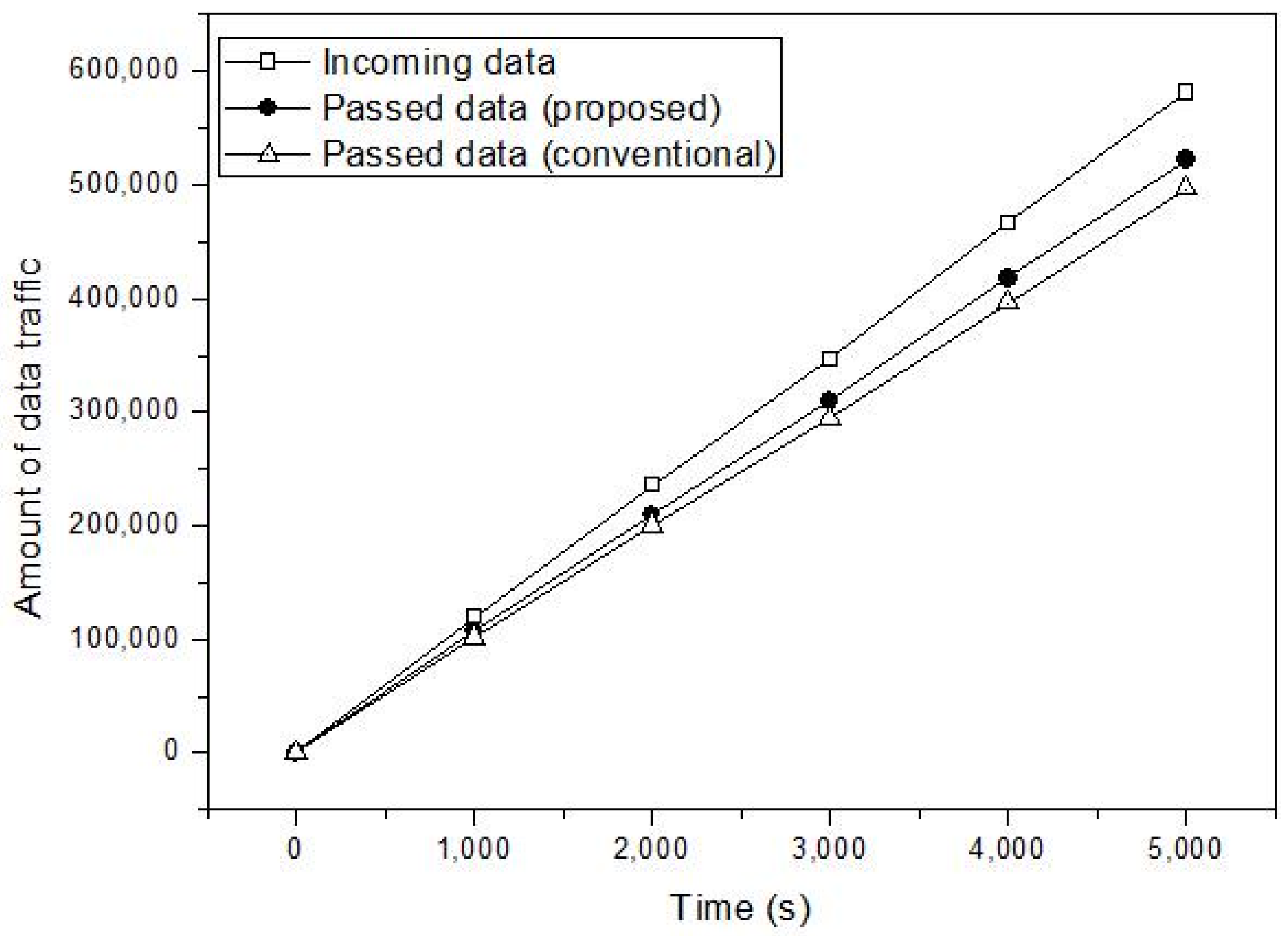
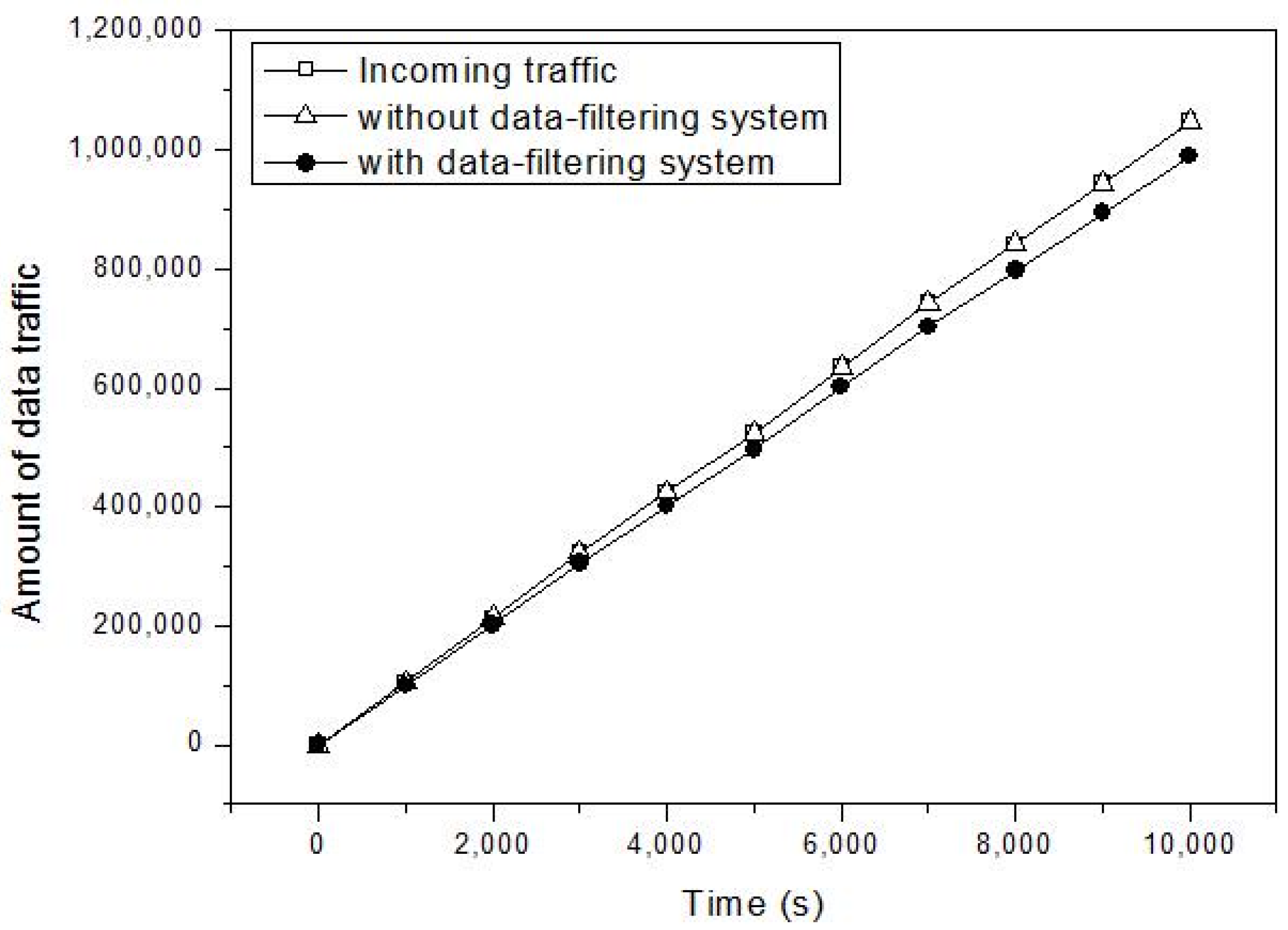
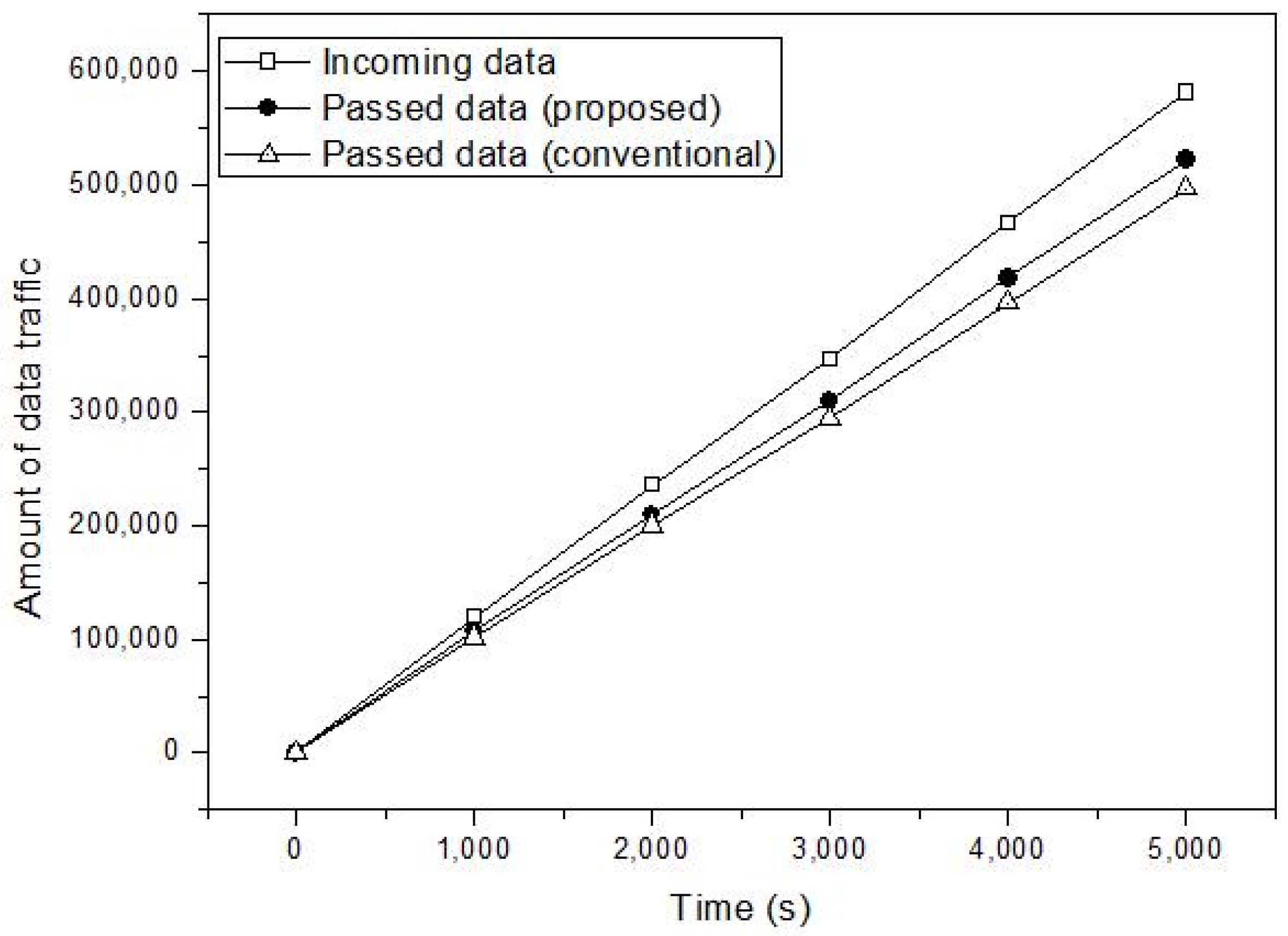
4. Performance Evaluation
4.1. Simulation Model
4.2. Simulation Study
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Sundmaeker, H.; Guillemin, P.; Friess, P.; Woelfflé, S. Vision and Challenges for Realizing the Internet of Things; Publications Office of the European Union: Luxembourg City, Luxembourg, 2010. [Google Scholar]
- Wang, Y.; Chen, I.-R.; Wang, D.-C. A survey of mobile cloud computing applications: Perspectives and challenges. Wirel. Pers. Commun. 2015, 80, 1687–1701. [Google Scholar] [CrossRef]
- Kim, S.; Na, W. Safe data transmission architecture based on cloud for Internet of Things. Wirel. Pers. Commun. 2016, 86, 287–300. [Google Scholar] [CrossRef]
- Kang, Y. New approach to the platform for the application development on the Internet of Things environment. J. Platf. Technol. 2015, 3, 21–27. [Google Scholar]
- Lin, C.-Y.; Zeadally, S.; Chen, T.-S.; Chang, C.-Y. Enabling cyber physical systems with wireless sensor networking technologies. Int. J. Distrib. Sens. Netw. 2012, 2012. [Google Scholar] [CrossRef]
- Gunes, V.; Peter, S.; Givargis, T.; Vahid, F. A Survey on concepts, applications, and challenges in cyber-physical systems. KSII Trans. Int. Inf. Syst. 2014, 8, 4242–4267. [Google Scholar]
- Sato, A.; Huang, R.; Yen, N.Y. Design of fusion technique-based mining engine for smart business. Hum.-Centric Comput. Inf. Sci. 2015, 5. [Google Scholar] [CrossRef]
- Chelli, K. Security issues in wireless sensor networks: Attacks and countermeasures. In Proceedings of the World Congress on Engineering (WCE), London, UK, 1–3 July 2015.
- Sen, J. A survey on wireless sensor network security. Int. J. Commun. Netw. Inf. Secur. 2009, 1, 55–78. [Google Scholar]
- Albers, P.; Camp, O. Security in Ad Hoc networks: A general intrusion detection architecture enhancing trust-based approaches. In Proceedings of the International Workshop on Wireless Information Systems (WIS), Ciudad Real, Spain, 2–3 April 2002.
- Karlof, C.; Wagner, D. Secure routing in wireless sensor networks: Attacks and countermeasures. In Proceedings of the IEEE International Workshop on Sensor Network Protocols and Applications (SNPA), Anchorage, AK, USA, 11 May 2003.
- Culler, D.; Estrin, D.; Srivastava, M. Guest editors introduction: Overview of sensor networks. IEEE Comput. 2004, 37, 41–49. [Google Scholar] [CrossRef]
- Karl, H. Protocols and Architectures for Wireless Sensor Networks; John Wiley & Sons: Chichester, UK, 2005. [Google Scholar]
- Kim, D.-Y.; Jin, Z.; Choi, J.; Lee, B.; Cho, J. Transmission power control with the guaranteed communication reliability in WSN. Int. J. Distrib. Sens. Netw. 2015, 2015. [Google Scholar] [CrossRef]
- Kim, D.-Y.; Cho, J.; Jeong, B.S. Practical data transmission in cluster-based sensor networks. KSII Trans. Int. Inf. Syst. 2010, 4, 224–242. [Google Scholar] [CrossRef]
- Gaur, M.S.; Pant, B. Trusted and secure clustering in mobile pervasive environment. Hum.-Centric Comput. Inf. Sci. 2015, 5. [Google Scholar] [CrossRef]
- Pughat, A.; Sharma, V. A review on stochastic approach for dynamic power management in wireless sensor networks. Hum.-Centric Comput. Inf. Sci. 2015, 5. [Google Scholar] [CrossRef]
- Wood, A.D.; Stankovic, J.A. Denial of service in sensor networks. IEEE Comput. 2002, 35, 54–62. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009. [Google Scholar] [CrossRef]
- Lee, J.; Sun, M.; Lebanon, G. A comparative study of collaborative filtering algorithms. 2012; arXiv:1205.3193. [Google Scholar]
- Miyahara, K.; Pazzani, M.J. Collaborative filtering with the simple Bayesian classifier. In Proceedings of the Pacific Rim International Conference on Artificial Intelligence, Melbourne, Australia, 28 August–1 September 2000.
- Miyahara, K.; Pazzani, M.J. Improvement of collaborative filtering with the simple Bayesian classifier. IPSJ J. 2002, 43, 3429–3437. [Google Scholar]
- Marsland, S. Machine Learning an Algorithmic Perspective; Chapman & Hall: New York, NY, USA, 2009. [Google Scholar]
- Harrington, P. Machine Learning in Action; Manning publications: Shelter Island, NY, USA, 2012. [Google Scholar]
- Trivedi, K.S. Probability and Statistics with Reliability, Queuing and Computer Science Applications; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Ross, S.M. Probability Models for Computer Science; Harcourt/Academic Press: Burlington, VT, USA, 2002. [Google Scholar]
- MacDougall, M.H. Simulating Computer Simulations, Techniques and Tool; MIT Press: Cambridge, MA, USA, 1987. [Google Scholar]




© 2017 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, D.-Y.; Jeong, Y.-S.; Kim, S. Data-Filtering System to Avoid Total Data Distortion in IoT Networking. Symmetry 2017, 9, 16. https://doi.org/10.3390/sym9010016
Kim D-Y, Jeong Y-S, Kim S. Data-Filtering System to Avoid Total Data Distortion in IoT Networking. Symmetry. 2017; 9(1):16. https://doi.org/10.3390/sym9010016
Chicago/Turabian StyleKim, Dae-Young, Young-Sik Jeong, and Seokhoon Kim. 2017. "Data-Filtering System to Avoid Total Data Distortion in IoT Networking" Symmetry 9, no. 1: 16. https://doi.org/10.3390/sym9010016