Rough Set Theory for Real Estate Appraisals: An Application to Directional District of Naples


Abstract
:1. Introduction
2. Rough Set Theory: Original Idea and Analytical Aspects
- is an information system, where U is a finite set of objects, Q is a finite set of attributes, being Vq a domain of q attribute, and is a function such that for every and .and : x and y are considered as indiscernible objects by the set of attributes P in S if (x,q) = (y,q), for every .The elementary groups of P relationships are defined as equivalence classes in S.Essentially, two objects with similar attributes fall in the same equivalence class and are considered indiscernible.
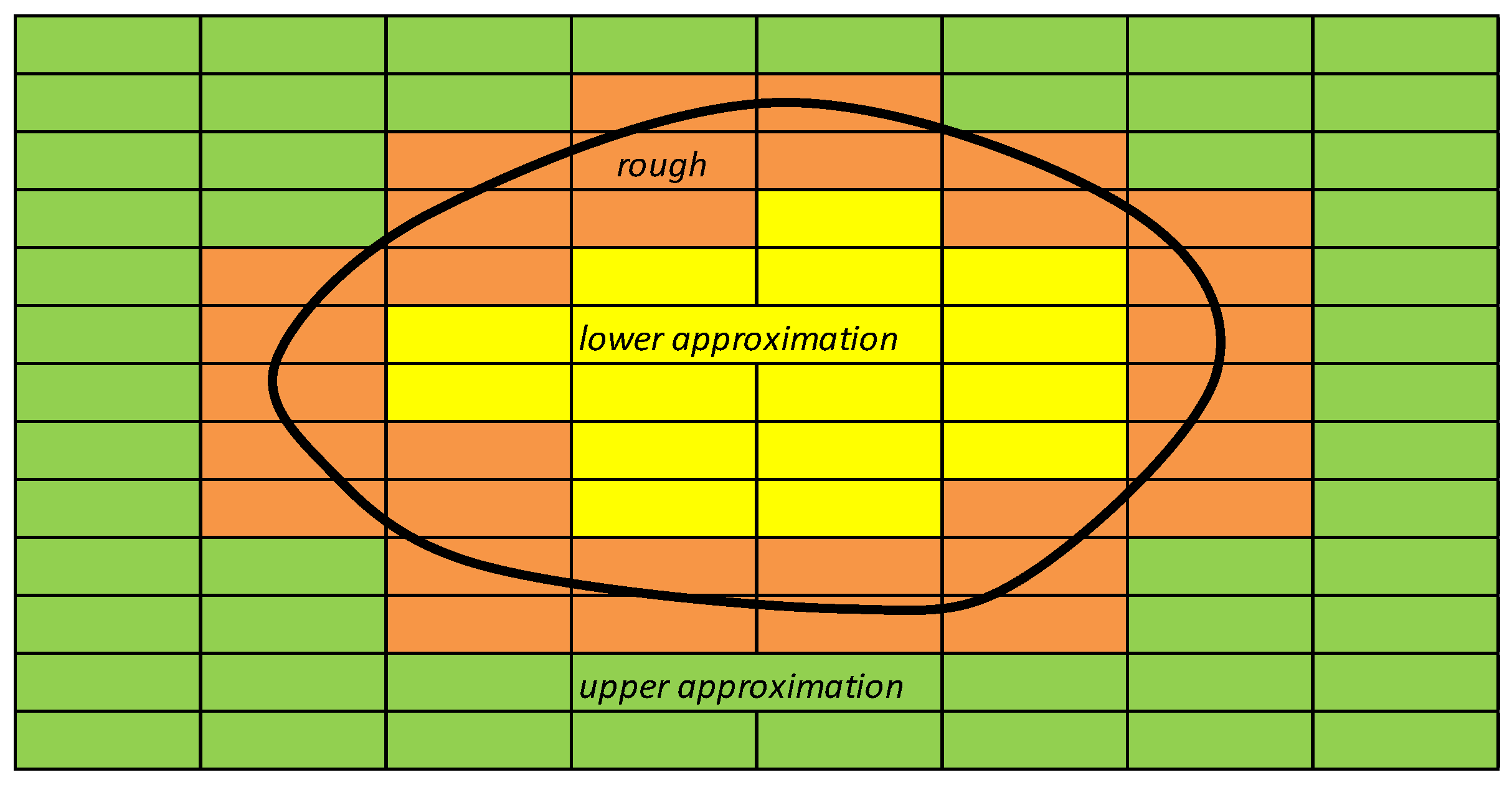
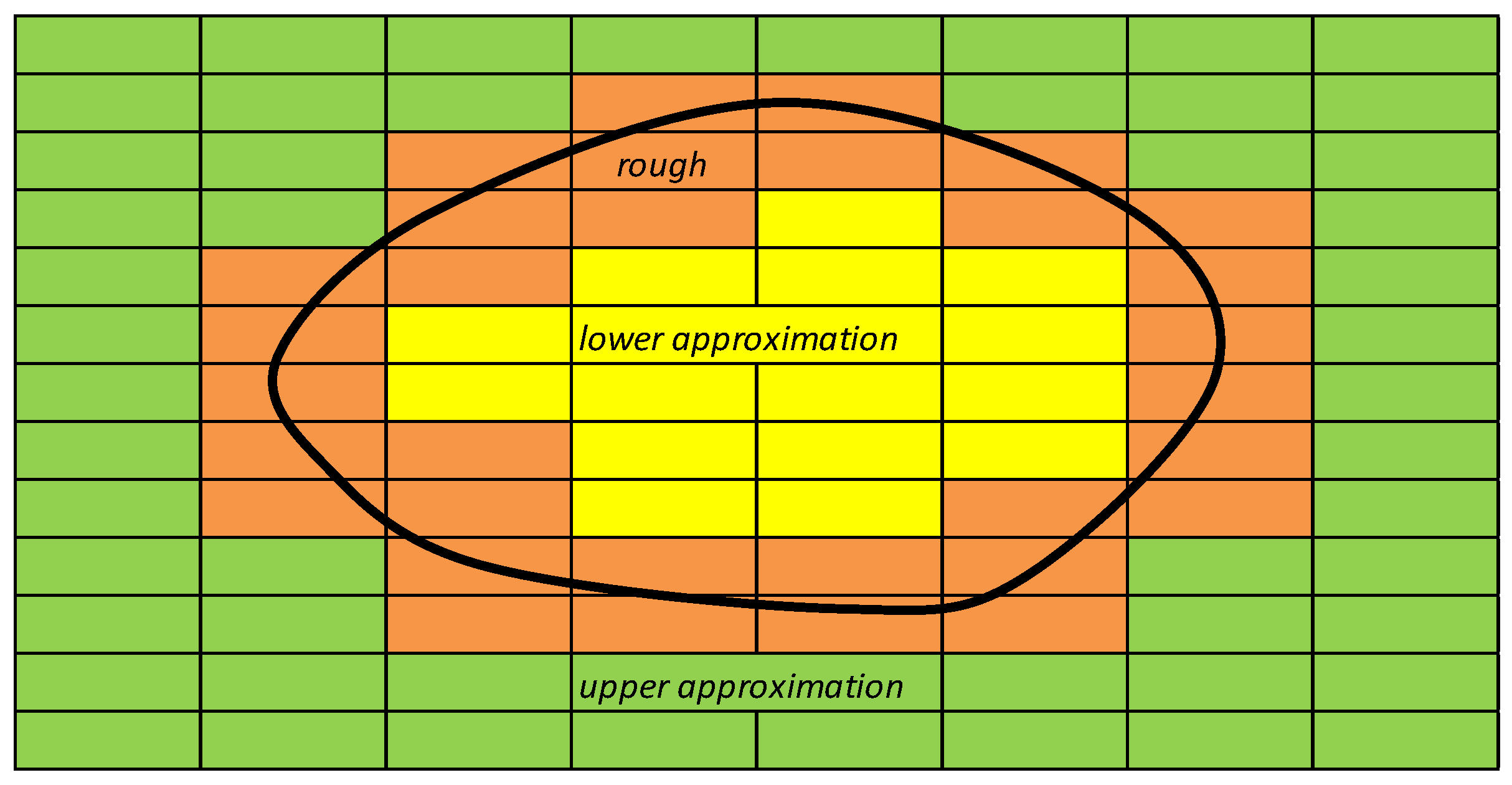
- Two types of attributes exist: “conditional” attributes represent the observations; “decisional” attributes represent the “judgments” detected or assigned for the overall set of conditional attributes, with reference to the specific object.If conditional attributes are equal but decisional attributes are different, the set of objects comes to be in a “rough” region (see Figure 2).The objects that may be distinguished are inserted in different equivalence classes, identified by approximations. Every equivalence class is identified by upper and lower approximation regions.For and , is defined as the lower approximation of Y and as the upper approximation of Y:where P* represents the family of all equivalence classes for each P relationship in U.The lower approximation represents the set of elements U “certainly” included in Y, applying the set of conditional attributes P; the upper approximation represents the set of elements U that “if possible” is included in Y, applying the same set of attributes P.The relationship between number of elements of the lower approximation and number of elements of the upper approximation is defined as “accuracy” of approximation:It also defines as “quality” of approximation’s classification the following relationship:where card(U) represents the total number of elements (objects) included in the set of observations U, n is the number of modalities (or classes) of conditional attribute, and is the number of objects contained in each lower approximation of the various classes n.The quality classification expresses synthetically the relationship between the numbers of correctly classified objects respect to the total number of objects.
- The choice of the equivalence class is performed by “if then” rules, rules that are measured in terms of “precision” and “coverage” in relation to analyzed objects. The “precision” defines the rule (“if”) and identifies the objects, while “coverage” detects the fraction of objects that responds positively to the rule (then).
- The best rule is, precisely, defined as that which provides the best coverage (better generalization capacity).
3. Rough Set Theory Applied to Real Estate Appraisals
4. Case Study: Application of RST to Directional District of Naples
- IF Area = (51, 53) → Price Class = 1;
- IF Area = 50 ˄ Park = 0 → Price Class = 1;
- IF Area = 60 ˄ Maintenance = 0 ˄ Park = 0 → Price Class = 1;
- IF Area = 58 → Price Class = 2;
- IF Area = (50, 55) ˄ Park = 1 → Price Class = 2;
- IF Area = (80, 54, 52, 62, 67, 90) → Price Class = 3;
- IF Area = (120, 140, 108, 110) → Price Class = 5;
- Can also to be defined the “approximate” rules, which are a specificity of RST:
- IF Area = 55 ˄ Park = 0 → Price Class = 1 OR 2;
- IF Area = 60 ˄ Maintenance = 1 → Price Class = 1 OR 3;
- IF Area = 65 → Price Class = 1 OR 3;
- IF Area = 60 ˄ Park = 1 → Price Class = 2 OR 4.
5. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Del Giudice, V.; De Paola, P.; Forte, F. The appraisal of office towers in bilateral monopoly’s market: Evidence from application of Newton’s physical laws to the Directional Centre of Naples. Int. J. Appl. Eng. Res. 2016, 11, 9455–9459. [Google Scholar]
- Manganelli, B.; Del Giudice, V.; De Paola, P. Linear programming in a multi-criteria model for real estate appraisal. In Computational Science and Its Applications—ICCSA 2016, Part I; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9786, pp. 182–192. [Google Scholar]
- Del Giudice, V.; De Paola, P.; Manganelli, B. Spline smoothing for estimating hedonic housing price models. In Computational Science and Its Applications—ICCSA 2015, Part III; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9157, pp. 210–219. [Google Scholar]
- Del Giudice, V.; De Paola, P. Geoadditive Models for Property Market. Appl. Mech. Mater. 2014, 584–586, 2505–2509. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P. The effects of noise pollution produced by road traffic of Naples Beltway on residential real estate values. Appl. Mech. Mater. 2014, 587–589, 2176–2182. [Google Scholar] [CrossRef]
- Morano, P.; Tajani, F. Least median of squares regression and minimum volume ellipsoid estimator for outliers detection in housing appraisal. Int. J. Bus. Intell. Data Min. 2014, 9, 91–111. [Google Scholar] [CrossRef]
- Morano, P.; Tajani, F.; Locurcio, M. Land use, economic welfare and property values: An analysis of the interdependencies of the real estate market with zonal and macro-economic variables in the municipalities of Apulia Region (Italy). Int. J. Agric. Environ. Inf. Syst. 2015, 6, 16–39. [Google Scholar] [CrossRef]
- Konrad, E.; Grlowska, E.; Pawlak, Z. Knowledge Representation Systems-Definability of Informations; ICS Research Report 433; Polish Academy of Sciences: Warsaw, Poland, 1981. [Google Scholar]
- Konrad, E.; Orlowska, E.; Pawlak, Z. On Approximate Concept Learning; Technical Report 81-7; Technische Universitat Berlin: Berlin, Germany, 1981. [Google Scholar]
- Pawlak, Z. Mathematical Foundations of Information Retrieval; ICS Research Report 101; Polish Academy of Sciences: Warsaw, Poland, 1973. [Google Scholar]
- Pawlak, Z. Rough sets. Int. J. Inf. Comput. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Pawlak, Z.; Grzymda-Busse, J.W.; Slowinski, R.; Ziark, W.O. Rough sets. Commun. ACM 1995, 38, 89–95. [Google Scholar] [CrossRef]
- D’Amato, M. Appraising properties with rough set theory. J. Prop. Invest. Financ. 2002, 20, 406–418. [Google Scholar] [CrossRef]
- D’Amato, M. A comparison between RST and MRA for mass Comparing Rough Set Theory with Multiple Regression Analysis 61 appraisal purposes. A case in Bari. Int. J. Strateg. Prop. Manag. 2004, 8, 205–217. [Google Scholar]
- D’Amato, M. Rough Set Theory as property valuation methodology: The whole story. In Advances in Mass Appraisal. An International Perspective; d’Amato, M., Kauko, T., Eds.; RICS Real Estate Series; Blackwell Publisher: Hoboken, NJ, USA, 2008. [Google Scholar]
- Manganelli, B.; Murgante, B. Analyzing periurban fringe with rough Set. Int. J. Comput. Electr. Autom. Control Inf. Eng. 2012, 71, 111–117. [Google Scholar]
- Pawlak, Z.; Słowinski, R. Rough Set Approach to Multi-Attribute Decision Analysis; ICS Research Report 36; Warsaw University of Technology: Warsaw, Poland, 1993. [Google Scholar]
- Greco, S.; Matarazzo, B.; Slowinski, R. Rough sets theory for multicriteria decision analysis. Eur. J. Oper. Res. 2001, 129, 1–47. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough set approach to knowledge-based decision support. Eur. J. Oper. Res. 1997, 99, 48–57. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets Theory and its applications to data analysis. Cybern. Syst. 1998, 29, 661–688. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data, System Theory, Knowledge Engineering and Problem Solving; Kluwer Academic Publishers: Dordecht, Holland, 1991; Volume 9. [Google Scholar]
- Predki, B.; Slowinski, R.; Stefanowski, J.; Susmaga, R.; Wilk, S. ROSE—Software Implementation of the Rough Set Theory. In Rough Sets and Current Trends in Computing; Polkowski, L., Skowron, A., Eds.; Lecture Notes in Artificial Intelligence; Springer: Berlin, Germany, 1998; Volume 1424, pp. 605–608. [Google Scholar]
- Predki, B.; Wilk, S. Rough Set Based Data Exploration Using ROSE System. In Foundations of Intelligent Systems; Ras, Z.W., Skowron, A., Eds.; Lecture Notes in Artificial Intelligence; Berlin, Germany, 1999; Volume 1609, pp. 172–180. [Google Scholar]
- Laboratory of Intelligent Decision Support System—IDSS, Poznan University of Technology. Available online: http://idss.cs.put.poznan.pl/site/rose.html (accessed on 1 September 2016).
- Larr, P.; Riebe, A. Real estate appraisals: Recommendations to reduce risk. J. Commer. Lend. 1995, 77, 24–26. [Google Scholar]
- Mallinson, M.; French, N. Uncertainty in property valuation—The nature and relevance of uncertainty and how it might be measured and reported. J. Prop. Invest. Financ. 2000, 18, 13–32. [Google Scholar] [CrossRef]
- Ekelid, M.; Lind, H.; Lundström, S.; Persson, E. Treatment of uncertainty in appraisals of commercial properties some evidence from Sweden. J. Prop. Valuat. Invest. 1998, 16, 386–396. [Google Scholar] [CrossRef]
- Young, P. Market valuation with no market—Valuing properties with little evidence. J. Prop. Valuat. Invest. 1994, 12, 9–27. [Google Scholar] [CrossRef]
- Adair, A.; Hutchison, N. The reporting of risk in real estate appraisal property risk scoring. J. Prop. Invest. Financ. 2005, 23, 254–268. [Google Scholar] [CrossRef]
- Miller, K.D.; Waller, H.G. Scenarios, real options and integrated risk management. Long Range Plan. 2003, 36. [Google Scholar] [CrossRef]
- French, N.; Gabrielli, L. Discounted cash flow—Accounting for uncertainty. J. Prop. Invest. Financ. 2005, 23. [Google Scholar] [CrossRef]
- Alessandri, T.; Ford, D.; Lander, D.; Leggio, K.; Taylor, M. Managing risk and uncertainty in complex capital projects. Q. Rev. Econ. Financ. 2004, 44, 751–767. [Google Scholar] [CrossRef]
- Del Giudice, V.; De Paola, P.; Forte, F.; Manganelli, B. The monetary valuation of environmental externalities through the analysis of real estate prices. Sustainability 2017, 9, 229. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| No. | Area (m2) | Maintenance | Parking Space | Price (€) | Price Class |
|---|---|---|---|---|---|
| 1 | 51 | 1 | 0 | 60,828 | 1 |
| 2 | 53 | 0 | 0 | 71,315 | 1 |
| 3 | 55 | 0 | 0 | 79,705 | 1 |
| 4 | 60 | 1 | 0 | 79,705 | 1 |
| 5 | 60 | 0 | 0 | 79,705 | 1 |
| 6 | 60 | 0 | 0 | 79,705 | 1 |
| 7 | 50 | 1 | 0 | 82,222 | 1 |
| 8 | 65 | 0 | 0 | 82,222 | 1 |
| 9 | 55 | 0 | 0 | 92,290 | 2 |
| 10 | 58 | 0 | 0 | 92,290 | 2 |
| 11 | 60 | 0 | 1 | 96,485 | 2 |
| 12 | 50 | 1 | 1 | 100,680 | 2 |
| 13 | 55 | 0 | 1 | 100,680 | 2 |
| 14 | 50 | 0 | 1 | 109,070 | 2 |
| 15 | 54 | 0 | 1 | 113,265 | 3 |
| 16 | 52 | 0 | 1 | 113,265 | 3 |
| 17 | 80 | 0 | 1 | 117,460 | 3 |
| 18 | 65 | 0 | 0 | 117,460 | 3 |
| 19 | 80 | 0 | 0 | 125,850 | 3 |
| 20 | 62 | 0 | 0 | 125,850 | 3 |
| 21 | 60 | 1 | 0 | 142,630 | 3 |
| 22 | 67 | 0 | 1 | 151,020 | 3 |
| 23 | 90 | 1 | 1 | 159,410 | 3 |
| 24 | 60 | 0 | 1 | 167,800 | 4 |
| 25 | 108 | 0 | 1 | 226,530 | 5 |
| 26 | 110 | 0 | 1 | 234,920 | 5 |
| 27 | 120 | 0 | 0 | 236,598 | 5 |
| 28 | 120 | 1 | 0 | 251,700 | 5 |
| 29 | 140 | 0 | 1 | 251,700 | 5 |
| 30 | 140 | 1 | 1 | 268,480 | 5 |
| Description | Area (m2) | Maintenance (m2) | Parking Space (m2) | Price (€) |
|---|---|---|---|---|
| Std. Deviation | 27.63 | 0.45 | 0.51 | 62,400.24 |
| Median | 60.00 | 0.00 | 0.00 | 113,265.00 |
| Average | 73.00 | 0.27 | 0.47 | 133,694.65 |
| Min | 50.00 | 0.00 | 0.00 | 60,827.50 |
| Max | 140.00 | 1.00 | 1.00 | 268,480.00 |
| Price Class | Min | Max | Difference |
|---|---|---|---|
| 1 | 60,000 | 85,000 | 25,000 |
| 2 | 85,000 | 110,000 | 25,000 |
| 3 | 110,000 | 165,000 | 50,000 |
| 4 | 165,000 | 210,000 | 50,000 |
| 5 | Over 210,000 | - | |
| List of equivalence classes in which conditional attributes have equal modalities | {1}; {2}; {5, 6}; {7}; {10}; {12}; {13}; {14}; {15}; {16}; {17}; {19}; {20}; {22}; {23}; {25}; {26}; {27}; {28}; {29}; {30}; {3}; {4}; {8}; {9}; {11}; {18}; {21}; {24}. |
| LOWER APPROXIMATION CLASS 1: all objects that are indistinguishable as well as having a price belonging to Class 1 | {1}; {2}; {5, 6}; {7}. |
| UPPER APPROXIMATION CLASS 1: all objects that may belong to Class 1 | {1}; {2}; {5, 6}; {7}; {3}; {9}; {4}; {21}; {8}; {18}. |
| Number of objects in the class: 8 | |
| Number of objects in the lower approximation: 5 | |
| Number of objects in the upper approximation: 11 | |
| Accuracy: 0.4545 | |
| LOWER APPROXIMATION CLASS 2: all objects that are indistinguishable as well as having a price belonging to Class 2 | {10}; {12}; {13}; {14}. |
| UPPER APPROXIMATION CLASS 2: all objects that may belong to Class 2 | {10}; {12}; {13}; {14}; {3}; {9}; {11}; {24}. |
| Number of objects in the class: 6 | |
| Number of objects in the lower approximation: 4 | |
| Number of objects in the upper approximation: 8 | |
| Accuracy: 0.5000 | |
| LOWER APPROXIMATION CLASS 3: all objects that are indistinguishable as well as having a price belonging to Class 3 | {15}; {16}; {17}; {19}; {20}; {22}; {23}. |
| UPPER APPROXIMATION CLASS 3: all objects that may belong to Class 3 | {15}; {16}; {17}; {19}; {20}; {22}; {23}; {4}; {21}; {8}; {18}. |
| Number of objects in the class: 9 | |
| Number of objects in the lower approximation: 7 | |
| Number of objects in the upper approximation: 11 | |
| Accuracy: 0.6364 | |
| LOWER APPROXIMATION CLASS 4: all objects that are indistinguishable as well as having a price belonging to Class 4 | |
| UPPER APPROXIMATION CLASS 4: all objects that may belong to Class 4 | {11}; {24}. |
| Number of objects in the class: 1 | |
| Number of objects in the lower approximation: 0 | |
| Number of objects in the upper approximation: 2 | |
| Accuracy: 0.0000 | |
| LOWER APPROXIMATION CLASS 5: all objects that are indistinguishable as well as having a price belonging to Class 5 | {25}; {26}; {27}; {28}; {29}; {30}. |
| UPPER APPROXIMATION CLASS 5: all objects that may belong to Class 5 | {25}; {26}; {27}; {28}; {29}; {30}. |
| Number of objects in the class: 6 | |
| Number of objects in the lower approximation: 6 | |
| Number of objects in the upper approximation: 6 | |
| Accuracy: 1.0000 | |
| Object | Area = 130 m2 | Maintenance = 0 | Parking Space = 1 | Rj (Min Rj Rule) | Rule Selected |
|---|---|---|---|---|---|
| k-threshold | 27.63 | 0.45 | 0.51 | ||
| Rj Rule 1 | 0.0000 | 1.0000 | 0.0000 | 0 | Rule 7 |
| Rj Rule 2 | 0.0000 | 1.0000 | 0.0000 | 0 | |
| Rj Rule 3 | 0.0000 | 1.0000 | 0.0000 | 0 | |
| Rj Rule 4 | 0.0000 | 1.0000 | 0.0000 | 0 | |
| Rj Rule 5 | 0.0000 | 1.0000 | 1.0000 | 0 | |
| Rj Rule 6 | 0.0000 | 1.0000 | 0.0000 | 0 | |
| Rj Rule 7 | 0.2838 | 1.0000 | 0.0000 | 0.2838 |
| Percentages of Errors (MRA) | ||||
| 0%–10% | 10%–20% | 20%–30% | more than 30% | Mean Absolute Percentage Error |
| 46.67% | 23.33% | 20.00% | 10.00% | 14.44% |
| Percentages of Errors (RST) | ||||
| 0%–10% | 10%–20% | 20%–30% | more than 30% | Mean Absolute Percentage Error |
| 50.00% | 36.66% | 6.67% | 6.67% | 12.29% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Del Giudice, V.; De Paola, P.; Cantisani, G.B. Rough Set Theory for Real Estate Appraisals: An Application to Directional District of Naples. Buildings 2017, 7, 12. https://doi.org/10.3390/buildings7010012
Del Giudice V, De Paola P, Cantisani GB. Rough Set Theory for Real Estate Appraisals: An Application to Directional District of Naples. Buildings. 2017; 7(1):12. https://doi.org/10.3390/buildings7010012
Chicago/Turabian StyleDel Giudice, Vincenzo, Pierfrancesco De Paola, and Giovanni Battista Cantisani. 2017. "Rough Set Theory for Real Estate Appraisals: An Application to Directional District of Naples" Buildings 7, no. 1: 12. https://doi.org/10.3390/buildings7010012