
Automatic Taxonomic Classification of Fish Based on Their Acoustic Signals



Abstract
:1. Introduction
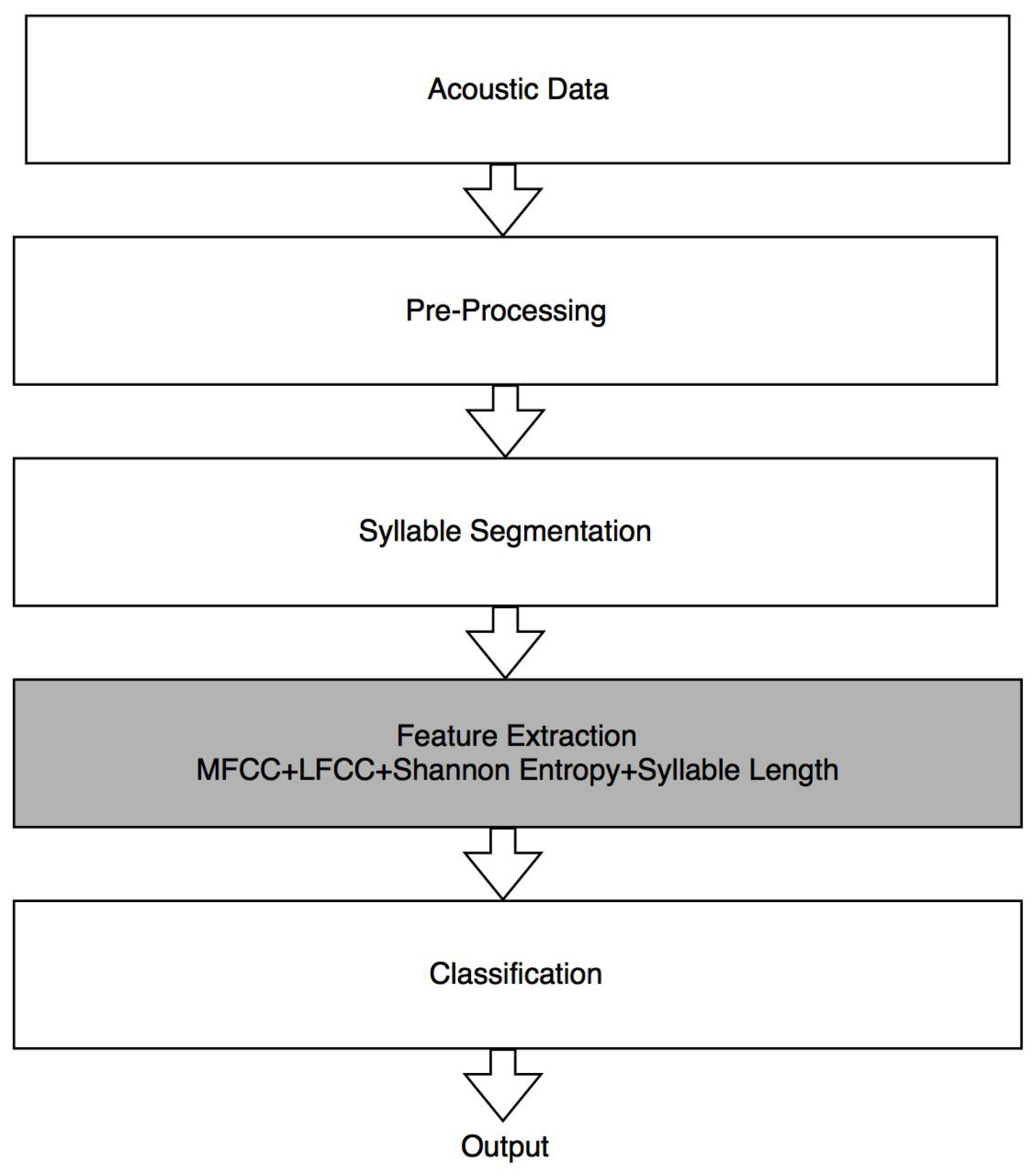
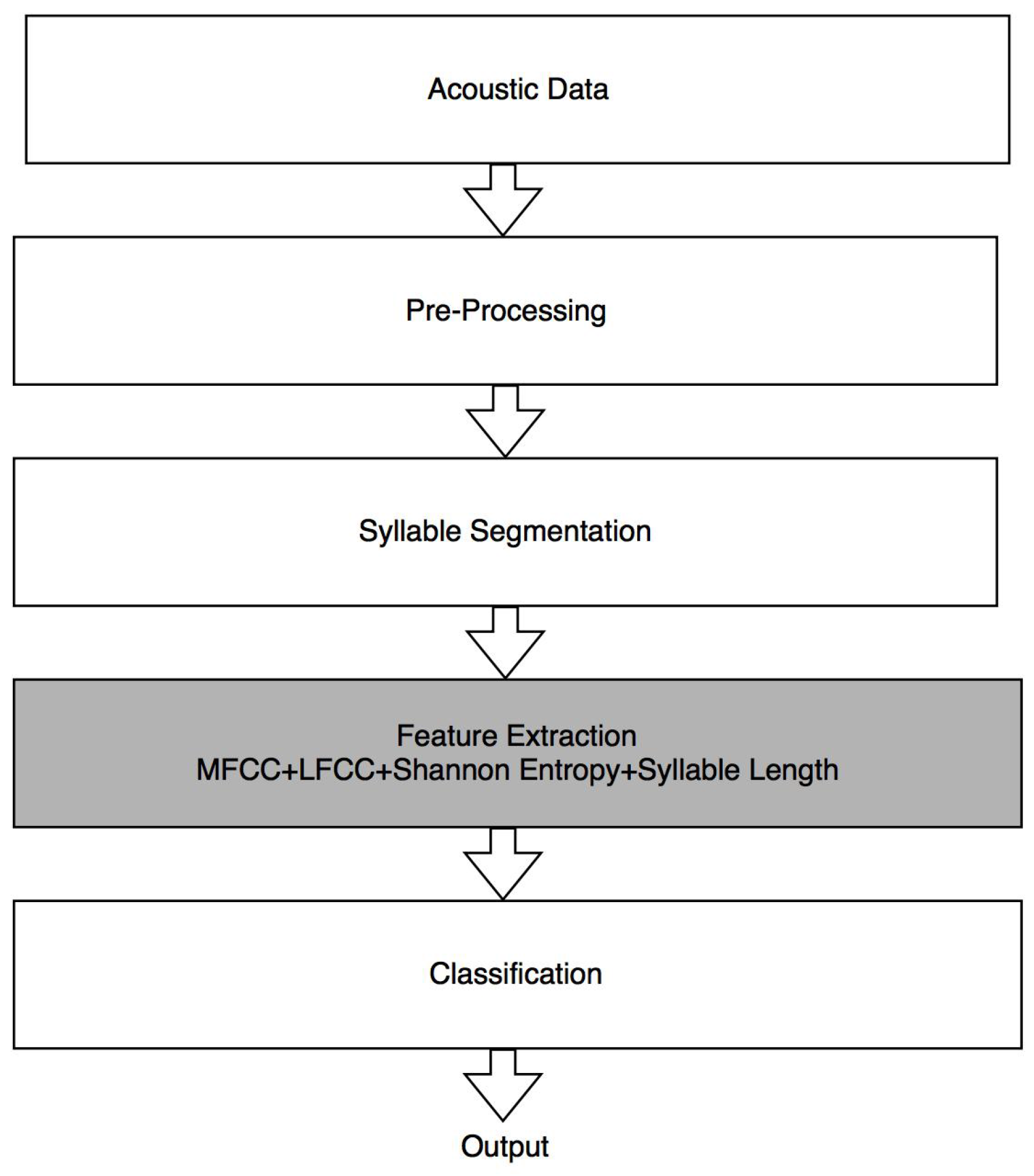
2. Proposed System
2.1. Acoustic Data
2.2. Preprocessing
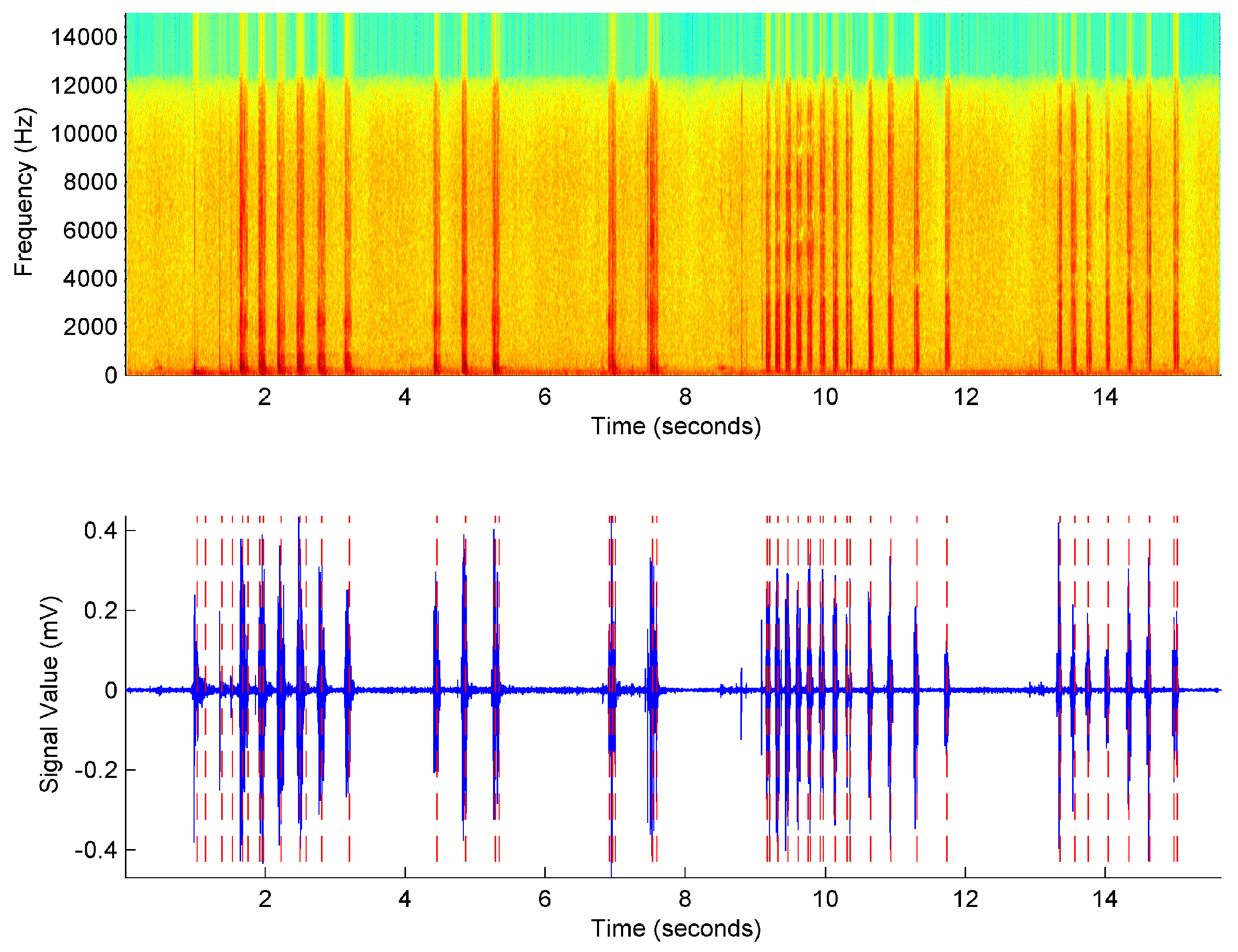
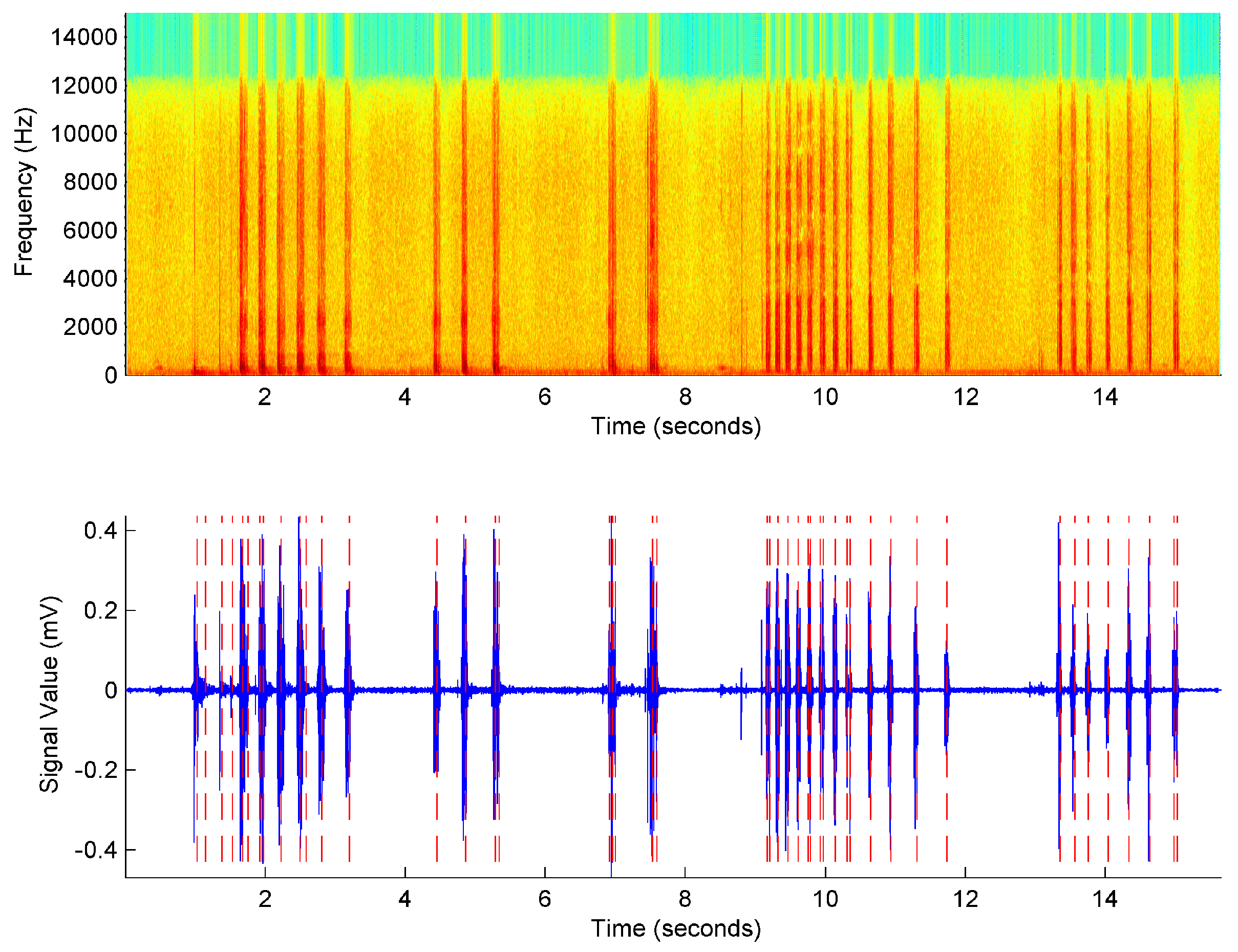
2.3. Segmentation
- Find the highest amplitude peak such as and set the position of the nth syllable in . The amplitude of this point is calculated as Equation (1):
- Trace the adjacent peaks between and until , where is the stopping criterion. Thus, the starting and ending times of the nth syllable are defined as and .
- Repeat the process from step 1 until the end of the spectrogram.
3. Feature Extraction
4. Classification Methods
4.1. K-Nearest Neighbor
4.2. Random Forest
- A set of N syllables are randomly extracted with replacement from the training data.
- Let M be the number of coefficients in a syllable. At each node m, random features are selected such as seeking the best split over these m variables.
4.3. Support Vector Machine
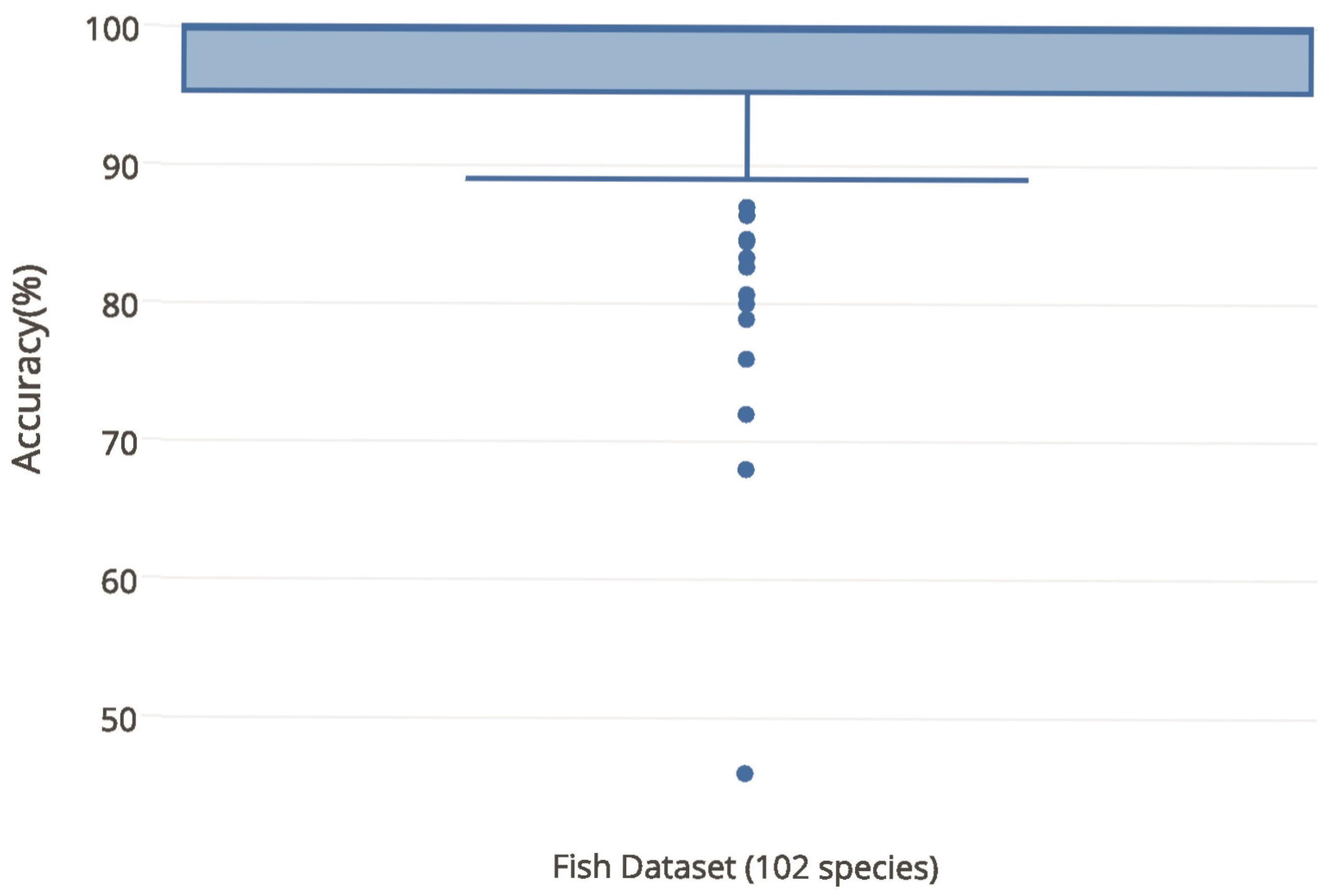
5. Experimental Procedure
Results and Discussions
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kaatz, I.M. Multiple sound-producing mechanisms in teleost fish and hypotheses regarding their behavioural significance. Bioacoustics 2002, 12, 230–233. [Google Scholar] [CrossRef]
- Rountree, R.A.; Gilmore, R.G.; Goudey, C.A.; Hawkins, A.D.; Luczkovich, J.J.; Mann, D.A. Listening to fish: applications of passive acoustics to fisheries science. Fisheries 2006, 31, 433–446. [Google Scholar] [CrossRef]
- Ladich, F. Sound production and acoustic communication. In The Senses of Fish; Springer: Berlin, Germany, 2004; pp. 210–230. [Google Scholar]
- Zelick, R.; Mann, D.A.; Popper, A.N. Acoustic communication in fish and frogs. In Comparative Hearing: Fish and Amphibians; Springer: Berlin, Germany, 1999; pp. 363–411. [Google Scholar]
- Tavolga, W.N.; Popper, A.N.; Fay, R.R. Hearing and Sound Communication in Fish; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Vasconcelos, R.O.; Fonseca, P.J.; Amorim, M.C.P.; Ladich, F. Representation of complex vocalizations in the Lusitanian toadfish auditory system: Evidence of fine temporal, frequency and amplitude discrimination. Proc. Biol. Sci. 2011, 278, 826–834. [Google Scholar] [CrossRef] [PubMed]
- Kasumyan, A. Sounds and sound production in fish. J. Ichthyol. 2008, 48, 981–1030. [Google Scholar] [CrossRef]
- Morrissey, R.; Ward, J.; DiMarzio, N.; Jarvis, S.; Moretti, D. Passive acoustic detection and localization of sperm whales (Physeter macrocephalus) in the tongue of the ocean. Appl. Acoust. 2006, 67, 1091–1105. [Google Scholar] [CrossRef]
- Marques, T.A.; Thomas, L.; Ward, J.; DiMarzio, N.; Tyack, P.L. Estimating cetacean population density using fixed passive acoustic sensors: An example with Blainville’s beaked whales. J. Acoust. Soc. Am. 2009, 125, 1982–1994. [Google Scholar] [CrossRef] [PubMed]
- Hildebrand, J.A. Anthropogenic and natural sources of ambient noise in the ocean. Mar. Ecol. Prog. Ser. 2009, 395, 5–20. [Google Scholar] [CrossRef]
- Mellinger, D.K.; Stafford, K.M.; Moore, S.; Dziak, R.P.; Matsumoto, H. Fixed passive acoustic observation methods for cetaceans. Oceanography 2007, 20, 36. [Google Scholar] [CrossRef]
- Fagerlund, S. Bird species recognition using support vector machines. EURASIP J. Appl. Signal Process. 2007, 2007, 64. [Google Scholar] [CrossRef]
- Acevedo, M.A.; Corrada-Bravo, C.J.; Corrada-Bravo, H.; Villanueva-Rivera, L.J.; Aide, T.M. Automated classification of bird and amphibian calls using machine learning: A comparison of methods. Ecol. Inform. 2009, 4, 206–214. [Google Scholar] [CrossRef]
- Ganchev, T.; Potamitis, I.; Fakotakis, N. Acoustic monitoring of singing insects. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2007), Honolulu, HI, USA, 15–20 April 2007.
- Henríquez, A.; Alonso, J.B.; Travieso, C.M.; Rodríguez-Herrera, B.; Bolaños, F.; Alpízar, P.; López-de Ipina, K.; Henríquez, P. An automatic acoustic bat identification system based on the audible spectrum. Expert Syst. Appl. 2014, 41, 5451–5465. [Google Scholar] [CrossRef]
- Gillespie, D.; Caillat, M.; Gordon, J.; White, P. Automatic detection and classification of odontocete whistles). J. Acoust. Soc. Am. 2013, 134, 2427–2437. [Google Scholar] [CrossRef] [PubMed]
- Esfahanian, M.; Zhuang, H.; Erdol, N. On contour-based classification of dolphin whistles by type. Appl. Acoust. 2014, 76, 274–279. [Google Scholar] [CrossRef]
- Bosch, P.; López, J.; Ramírez, H.; Robotham, H. Support vector machine under uncertainty: An application for hydroacoustic classification of fish-schools in Chile. Expert Syst. Appl. 2013, 40, 4029–4034. [Google Scholar] [CrossRef]
- Huang, P.X.; Boom, B.J.; Fisher, R.B. Underwater Live Fish Recognition Using a Balance-Guaranteed Optimized Tree. In Computer Vision—ACCV 2012; Springer: Berlin, Germany, 2012; pp. 422–433. [Google Scholar]
- Kottege, N.; Kroon, F.; Jurdak, R.; Jones, D. Classification of underwater broadband bio-acoustics using spectro-temporal features. In Proceedings of the Seventh ACM International Conference on Underwater Networks and Systems, Los Angeles, CA, USA, 5–6 November 2012; p. 19.
- Ruiz-Blais, S.; Camacho, A.; Rivera-Chavarria, M.R. Sound-based automatic neotropical sciaenid fish identification: Cynoscion jamaicensis. In Proceedings of the Meetings on Acoustics (Acoustical Society of America), Indianapolis, IN, USA, 27–31 October 2014.
- Nehorai, A.; Paldi, E. Acoustic vector-sensor array processing. IEEE Trans. Signal Process. 1994, 42, 2481–2491. [Google Scholar] [CrossRef]
- Chen, S.; Xue, C.; Zhang, B.; Xie, B.; Qiao, H. A Novel MEMS Based Piezoresistive Vector Hydrophone for Low Frequency Detection. In Proceedings of the IEEE International Conference on Mechatronics and Automation (ICMA 2007), Harbin, China, 5–8 August 2007; pp. 1839–1844.
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inform. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Machine learning 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Froese, R.; Pauly, D. FishBase. Available online: http://www.fishbase.org/ (accessed on 26 July 2016).
- Fish, M.P.; Mowbray, W.H. Sounds of Western North Atlantic Fish. A Reference File of Biological Underwater Sounds; John Hopkins Press: Baltimore, MD, USA, 1970. [Google Scholar]
- Dosits. Dosits. University of Rhode Island. Available online: http://www.dosits.org/ (accessed on 26 July 2016).
- Härmä, A. Automatic identification of bird species based on sinusoidal modeling of syllables. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’03), Hong Kong, China, 6–10 April 2003.
- Zhou, X.; Garcia-Romero, D.; Duraiswami, R.; Espy-Wilson, C.; Shamma, S. Linear versus mel frequency cepstral coefficients for speaker recognition. In Proceedings of the 2011 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Waikoloa, HI, USA, 11–15 December 2011; pp. 559–564.
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Powers, D.M. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness and Correlation; Bioinfo Publications: Pune, India, 2011. [Google Scholar]
- Ogunlana, S.; Olabode, O.; Oluwadare, S.; Iwasokun, G. Fish Classification Using Support Vector Machine. Afr. J. Comp. ICT 2015, 8, 75–82. [Google Scholar]
- Iscimen, B.; Kutlu, Y.; Reyhaniye, A.N.; Turan, C. Image analysis methods on fish recognition. In Proceedings of the 2014 22nd IEEE Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014; pp. 1411–1414.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
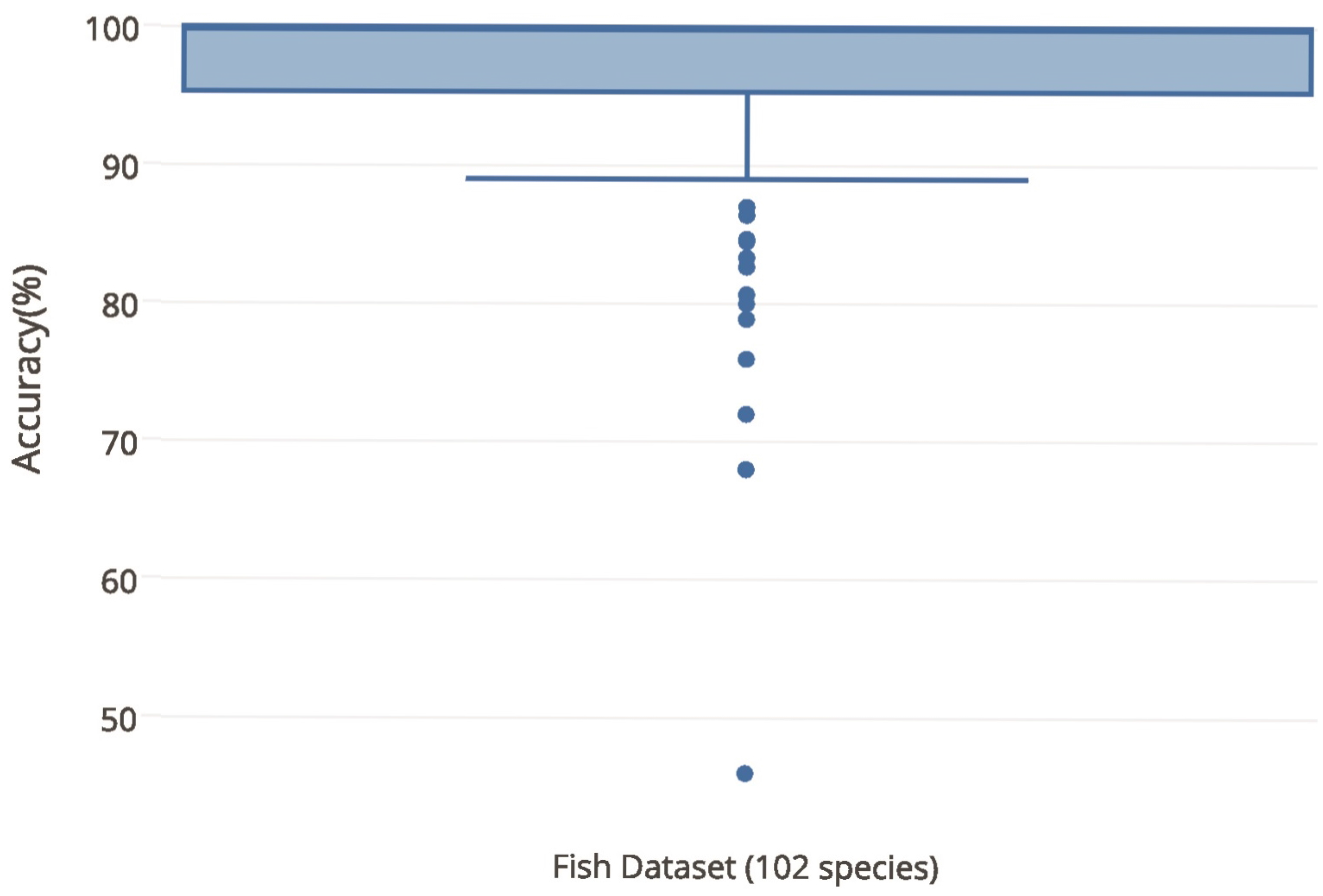
| Dataset | Features | Classification | Training time (s) | Test time (s) | Accuracy Median % ± Std. |
|---|---|---|---|---|---|
| Fish dataset (102 species) | MFCC | KNN | 0.04 | 0.01 | 91.94% ± 15.27% |
| RF | 0.76 | 0.01 | 90.34% ± 15.01% | ||
| SVM | 0.28 | 0.09 | 91.20% ± 18.25% | ||
| LFCC | KNN | 0.04 | 0.01 | 89.05% ± 16.04 | |
| RF | 0.76 | 0.01 | 87.41% ± 16.46% | ||
| SVM | 0.25 | 0.09 | 81.60% ± 28.14% | ||
| MFCC + LFCC | KNN | 0.05 | 0.02 | 94.27% ± 11.10% | |
| RF | 1.29 | 0.02 | 93.63% ± 10.59% | ||
| SVM | 0.31 | 0.10 | 94.72% ± 12.13% | ||
| MFCC + LFCC + SE + SL | KNN | 0.05 | 0.02 | 95.24% ± 8.59% | |
| RF | 1.14 | 0.01 | 93.56% ± 11.42% | ||
| SVM | 0.34 | 0.10 | 95.58% ± 8.59% |
| Training Data (%) | Accuracy Median (%) ± Std. | Precision | Recall | F-Measure |
|---|---|---|---|---|
| 5 | 81.77% ± 21.08% | 0.8114 | 0.8168 | 0.8141 |
| 10 | 83.27% ± 19.17% | 0.8385 | 0.8318 | 0.8351 |
| 20 | 88.15% ± 15.18% | 0.8826 | 0.8807 | 0.8817 |
| 30 | 92.57% ± 13.92% | 0.9191 | 0.9244 | 0.9218 |
| 40 | 94.99% ± 7.99% | 0.9426 | 0.9490 | 0.9458 |
| 50 | 95.58% ± 8.59% | 0.9535 | 0.9558 | 0.9546 |
| Dataset | Accuracy Median (%) ± Std. | Precision | Recall | F-Measure |
|---|---|---|---|---|
| “Unnatural sounds” | 95.21% ± 8.26% | 0.9452 | 0.9520 | 0.9486 |
| “Natural sounds” | 98.17% ± 6.48% | 0.9839 | 0.9817 | 0.9828 |
| Reference | Database | Features | Classification | Accuracy |
|---|---|---|---|---|
| [21] | 2 species | Drumming frequency, pitch, short and long term partial loudness | Threshold | 80% and 90% |
| [18] | 3 species | Morphology, spatial location, acoustic energy and bathymetry | SVM | 89.55% |
| [36] | 2 species | Morphology | SVM | 78.59% |
| [19] | 10 species | Color, texture and morphology | BGOT | 91.70% |
| [37] | 15 species | Euclidean network technique, quadratic network technique and triangulation technique | Bayesian | 75.71% |
| This work | Fish dataset (102 species) | MFCC/LFCC/SE/SL | SVM | 95.58% ± 8.59% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noda, J.J.; Travieso, C.M.; Sánchez-Rodríguez, D. Automatic Taxonomic Classification of Fish Based on Their Acoustic Signals. Appl. Sci. 2016, 6, 443. https://doi.org/10.3390/app6120443
Noda JJ, Travieso CM, Sánchez-Rodríguez D. Automatic Taxonomic Classification of Fish Based on Their Acoustic Signals. Applied Sciences. 2016; 6(12):443. https://doi.org/10.3390/app6120443
Chicago/Turabian StyleNoda, Juan J., Carlos M. Travieso, and David Sánchez-Rodríguez. 2016. "Automatic Taxonomic Classification of Fish Based on Their Acoustic Signals" Applied Sciences 6, no. 12: 443. https://doi.org/10.3390/app6120443