ℓ2,1 Norm and Hessian Regularized Non-Negative Matrix Factorization with Discriminability for Data Representation

1
College of Information and Technology, Northwest University of China, Xi’an 710127, China
2
Department of Computer Science, University of North Carolina at Charlotte, Charlotte, NC 28223, USA
*
Author to whom correspondence should be addressed.
Appl. Sci. 2017, 7(10), 1013; https://doi.org/10.3390/app7101013
Submission received: 4 September 2017
/
Revised: 26 September 2017
/
Accepted: 26 September 2017
/
Published: 30 September 2017
Abstract
:Matrix factorization based methods have widely been used in data representation. Among them, Non-negative Matrix Factorization (NMF) is a promising technique owing to its psychological and physiological interpretation of spontaneously occurring data. On one hand, although traditional Laplacian regularization can enhance the performance of NMF, it still suffers from the problem of its weak extrapolating ability. On the other hand, standard NMF disregards the discriminative information hidden in the data and cannot guarantee the sparsity of the factor matrices. In this paper, a novel algorithm called norm and Hessian Regularized Non-negative Matrix Factorization with Discriminability (HNMFD), is developed to overcome the aforementioned problems. In HNMFD, Hessian regularization is introduced in the framework of NMF to capture the intrinsic manifold structure of the data. norm constraints and approximation orthogonal constraints are added to assure the group sparsity of encoding matrix and characterize the discriminative information of the data simultaneously. To solve the objective function, an efficient optimization scheme is developed to settle it. Our experimental results on five benchmark data sets have demonstrated that HNMFD can learn better data representation and provide better clustering results.
1. Introduction
In many real-world applications, the input data is usually high-dimensional. On one hand, this is a serious challenge for storage and computation. On the other hand, it makes a lot of machine learning algorithms unworkable due to the curse of dimensionality [1]. Means of obtaining a concise and informative data representation for high-dimensional data has become a highly significant focus. Matrix factorization is one kind of popular and effective model of data representation, and finds two or more low-rank matrix factors and their product can well approximate the data matrix. Various matrix factorization methods have been proposed, adopting different constraints on matrix factors. The classical matrix factorization models include Principal Component Analysis (PCA) [2], Singular Value Decomposition (SVD), QR decomposition, vector quantization.
Among the various matrix factorization approaches, Non-negative Matrix Factorization (NMF) [3] is a promising one. In NMF, data matrix is decomposed into a non-negative basic matrix which reveals the latent semantic structure, and a non-negative encoding matrix , which denotes a new representation with respect to the basis matrix. Because of the non-negative constraints, NMF only allows pure additive combinations, and leads to a parts-based representation. Due to its psychological and physiological interpretation, NMF and its variants have been widely used in computer vision [3], pattern recognition [4], image processing [5], document analysis [6].
Standard NMF performs factorization in Euclidean space. It is unable to discover geometrical structures in data space, which is critical in real-world applications. Therefore, lots of recent work has focused on preserving the intrinsic geometry of the data space by adding different constraints to the objective function of NMF. Cai et al. [7] proposed graph regularized NMF (GNMF) by constructing a nearest neighbor graph while preserving the local geometrical information of the data space. Lu et al. [8] proposed Manifold Regularized Sparse NMF for hyperspectral unmixing, in which manifold regularization was introduced into sparsity-constrained NMF for unmixing. Gu et al. [9] proposed Neighborhood-Preserving Non-negative Matrix Factorization, which imposed an additional constraint on NMF that each item be able to be represented as a linear combination of its neighbors. All the mentioned graph regularized NMF methods construct a graph to encode the geometrical information and use graph Laplacian as a smooth operator. Despite the successful application of graph Laplacian in semi-supervised and unsupervised learning, it still suffers from the problems that the solution is biased towards a constant, as well as its lack of extrapolating power [10].
Sparsity regularization methods that focus on selecting the input variables that best describe the output have been widely investigated. Hoyer [11] proposed a sparse constraint NMF and added the norm constraint on the basis and encoding matrices, which were able to discover sparse representations better than those given by standard NMF. Cai et al. [12] proposed Unified Sparse Subspace Learning (USSL) for learning sparse projections by using a norm regularizer. The limitation of the norm penalty is that it is unable to guarantee successful models in cases of categorical predictors, for the reason that each dummy variable is selected independently [13]. So norm is not feasible for conducting feature selection. To settle this issue, Nie et al. [14] proposed a robust feature selection approach by imposing norm on loss functions. Yang et al. [15] proposed norm regularized discriminative feature selection for unsupervised learning. Gu et al. [16] combined feature selection and subspace learning simultaneously in a joint framework, which is based on using norm on the projection matrix and achieves the goal of feature selection. The norm penalty term encourages row sparsity as well as the correlations of all the features. Recently, some researchers proposed norm [17] regularized NMF [18,19], and low-rank regularized NMF [20,21] with improved performance for special purposes. The norm can usually induce sparser solutions than its counterpart, but it is usually unstable. The limitation of the low rank constraint is that it is not suited to feature selection in general.
What’s more, discriminative information is very important for learning a better representation. For example, by exploiting the partial label information as hard constraints of NMF, Liu [22] developed a semi-supervised Constrained NMF (CNMF), which obtained better discriminating power. Li et al. [23] proposed robust structured NMF a semi-supervised NMF learning algorithm, which learns a robust discriminative data representation by pursuing the block-diagonal structure and the norm loss function. But under unsupervised scenario, we cannot have the label information. In fact, we could add approximate orthogonal constraints to obtain some discriminative information under unsupervised conditions. Unfortunately, standard NMF ignores this important information.
To address these flaws, a novel NMF algorithm, called norm and Hessian Regularized Non-negative Matrix Factorization with Discriminability (HNMFD), is developed in this paper, which is designed to include local geometrical structure preservation, row sparsity and to exploit discriminative information at the same time. Firstly, Hessian regularization is introduced in the framework of NMF to preserve the intrinsic manifold of the data. Then, norm constraints are added on the coefficient matrix to ensure that the representation vectors are row sparse. Furthermore, approximate orthogonal constraints are added to capture some discriminative informational in the data. An optimization scheme is developed to solve the objective function.
2. Related Works
This section presents a brief review of related works. At first, we describe the notations used throughout the paper.
2.1. Common Notations
In this paper, we use lowercase boldface letters and uppercase boldface letters denote vectors and matrices, respectively. For matrix , we denote its -th element by . The -th element of a vector is denoted by . Given a set of items, we use matrix to represent the non-negative original data matrix where the -th column vector is according to the feature vector for the -th item. Throughout this paper, denotes the Frobenius norm of matrix .
2.2. NMF
NMF is an effective decomposition for multivariate non-negative data. Given a non-negative matrix , each column of is a data vector. The goal of NMF is to find two low-rank matrices and that minimize the following objective function [3]:
It is easy to see that when both and are taken as variables simultaneously, the objective function is not convex. But when is fixed, is convex in and vice versa. So Lee and Seung [24] developed an iterative multiplicative updating rule as follows:
By constructing auxiliary functions, is proved to be non-increasing under the above update rules [24].
2.3. GNMF
In [7], Cai et al. developed a graph regularized non-negative matrix factorization (GNMF) method to obtain a compact data representation that discovers hidden concept, and respects the intrinsic geometric structure simultaneously. GNMF minimizes the objective function as follows:
where is called graph Laplacian, denotes the weight matrix constructed by finding the nearest neighbors for each data point, and is a diagonal matrix whose entries are column sums of , i.e., .
The objective function is also not convex when both and are taken as variables simultaneously. Therefore it is unlikely to find the global minima. The Using the following update rules [7], local minima of the objective function can be obtained:
Cai et al. [7] has proved that the objective function is non-increasing under the above updating rules.
3. Norm and Hessian Regularized Non-Negative Matrix Factorization with Discriminability
In this section, a novel norm and Hessian Regularized Non-negative Matrix Factorization with Discriminability (HNMFD) model is developed, which performs Hessian regularized Non-negative Matrix Factorization (HNMF) and preserves discriminative information, as well as maintaining row sparsity for encoding matrices simultaneously. Then, an alternating optimization scheme is developed to solve its objective function.
3.1. Hessian Regularized Non-Negative Matrix Factorization
Hessian energy is motivated by Eells-energy for mapping between manifolds [25]. Given a smooth manifold and a map function , the Eells-energy of can be written as [10]:
where is the second covariant derivation of , is the tangent space at point and is the natural volume element. Using normal coordinate, can be written as:
where and are normal coordinates. So given point , the norm of the second covariant derivative is just the Frobenius norm of the Hessian of in standard coordinate. Thus the resulting functional is called Hessian regularizer :
Let represent the set of nearest neighbors of , the Hessian of on can be approximated as follows:
The operator can be computed by fitting a second-order polynomial in normal coordinates to . Let and , the estimate of the Frobenius norm of the Hessian of at is thus given by
where and the total estimated Hessian energy is the sum over all data points as follows:
where is denoted as the Hessian regularization matrix, and is the accumulated matrix summing up all the matrices .
Applying Hessian energy as the regularization term in NMF to estimate the local manifold structure, the Hessian regularized NMF (HNMF) can be formulated as:
where is the regularization parameter.
3.2. Sparseness Constraints
To distinguish the importance of different features, we try to encourage the significant features to be non-zero values, and the insignificant features to be zero, after the iterative update. Since each row of encoding matrix corresponds to a feature in the original space, we add norm regularization to the encoding matrix , which can enforce some rows in to tend to zero. For new representation matrix , a row sparseness regularizer is introduced into the objective function to shrink some row vectors in to be zero. In this way, we are able to preserve the important features and remove the irrelevant features. The norm of matrix is defined as:
where represents the -th row of .
3.3. Discriminative Constraints
To characterize some discriminative information in the learned representation matrix , we follow the works done in [26,27], in which a scaled indicator matrices were developed. Given an indicated matrix , where if the -th data point belongs to the -th category. The scaled indicated matrix is defined as , where each column of is:
where is the number of samples in the -th group. We encourage the new representation to capture the discriminative information in . Intuitively, we only need to approximate , i.e., , where is any small constant. Unfortunately, in unsupervised scenarios, we cannot obtain any label information in advance. However, we find that the scaled indicator matrix is strictly orthogonal
where is a identity matrix. Since is orthogonal, should be orthogonal too. However, this constraint is too strict. So we relax the orthogonal constraint and let be approximately orthogonal, i.e.,
3.4. Objective Function
By integrating (12) and (14) into Hessian regularized NMF, the objective function of HNMFD is defined as:
where , and are regularization parameters.
3.5. Optimization
In this section, we will introduce an iterative algorithm which can give the solution to Equation (15). As far as we can see, the objective function of HNMFD is not convex in both and , so we cannot result in a closed-form solution. In the following, we will present an alternative scheme which can obtain local minima. Firstly, the optimization problem of Equation (15) can be rewritten as follows:
let and be the Lagrange multiplier for constraint and , respectively, then the Lagrange function can be written as follows:
3.5.1. Updating
The partial derivation of with respect to is:
Using the Karush–Kuhn–Tucker (KKT) conditions, , we get
The above equation leads to the following updating formula:
3.5.2. Updating
The partial derivation of with respect to is:
where is a diagonal matrix with the -th diagonal element as .
Using the KKT condition , we get
where , , . Equation (22) leads to the following updating formula:
The algorithm is shown in Algorithm 1.
| Algorithm 1: Optimization of HNMFD |
| Input: , , , Output: , 1 Randomly initialize , ; 2 Repeat 3 Fixing , updating by Equation (20); 4 Fixing , updating by Equation (23); 5 Until Equation (15) converged or max no. iterations reached. |
3.6. Computational Complexity Analysis
In this section, we discuss the extra computational cost of our proposed algorithm. HNMFD needs to construct the neatest neighbor graph. Suppose the multiplicative updates stops after t iterations, the complexity for updating HNMFD is . Thus the overall complexity of HNMFD is , which is similar to that of GNMF.
3.7. Proof of Convergence
Theorem 1.
The function value in Equation (15) is non-increasing under the rules in Equations (20) and (23).
The updating rule for is the same as in the classical NMF. Thus in Equation (15) is non-increasing under Equation (20). In the next, we will prove that is non-creasing under Equation (23). The proof uses the auxiliary function [18] defined as follows.
Definition 1.
is an auxiliary function for if
is satisfied.
Lemma 1.
If is an auxiliary function for , then is non-increasing under the updating rule
Proof for Lemma 1.
☐
In this next section, we will show that the updating rule for in Equation (23) is exactly the rule in Equation (24) with a proper auxiliary function. We use to denote the part of that is only relevant to .
Lemma 2.
Function
is an auxiliary function for .
Proof for Lemma 2.
Since is evident, we only need show that . By comparing to Taylor series expansion of , we get . Similar proof can be see in [7]. ☐
Proof for Theorem 1.
By substituting in Equation (24) with Equation (25), we obtain the updating rule as below,
which is identical to Equation (23). Since is the auxiliary function of , is non-increasing under this updating rule. So in Equation (15) is non-increasing under Equation (23). ☐
4. Experiment
In this section, we evaluate the performance of HNMFD. To demonstrate the advantages of the proposed method, we have compared the results of the proposed method with related state-of-the-art methods. All statistical significance tests were performed using a significance level of 0.05. We used Student’s t-tests in the experiments.
To perform data clustering for NMF-based method, the original data were firstly transformed by different NMF algorithms to generate new representations. Then, new representations were fed to Kmeans clustering algorithm to obtain the final clustering result.
4.1. Data Sets
We use five real-world data sets to evaluate the proposed method. These datasets are described below:
The Yale face dataset consists of 165 gray-scale face images of 15 persons. There are 11 images per subject, each with a different facial expression or configuration: center-light, with/without glasses, normal, right-light, sad, sleepy, surprised and wink.
The ORL face dataset contains 10 different face images for 40 different persons; each of the 400 images has been collected against a dark, homogeneous background, with the subjects in an upright, frontal position, with some tolerance for side movement.
The UMIST face dataset contains 575 images of 20 people, each covering a range of poses from profile to frontal views. Subjects cover a range in terms of race, sex and appearance.
The COIL20 data set contains 32 32 gray scale images of 20 objects, viewed from varying angles.
The CMU PIE face dataset contains 32 32 gray scale face images of 68 people. Each person has 42 facial images under various light and illumination conditions.
The important statistics of these datasets are summarized in Table 1.
4.2. Evaluation Metrics
In our experiments, we set the number of clusters equal to the number of classes for all algorithms. To evaluate the performance of clustering, we use Accuracy and Normalized Mutual Information (NMI) to measure the clustering results.
Accuracy is defined as follows:
where and are cluster labels of item in the clustering results and ground truth, respectively. If , equals 1 and otherwise equals 0, and is the permutation mapping function which maps to the equivalent cluster label in ground truth.
The NMI is defined as follows:
where is the mutual information between and . If is identical with , . If the two cluster sets are completely independent, .
4.3. Baseline
To demonstrate how the clustering performance can be enhanced by HNMFD, we compare the following state-of-the-art clustering algorithms:
4.4. Clustering Results
Table 2 presents the clustering accuracy of all of the algorithms on each of the three data sets, while Table 3 presents the normalized mutual information. The observations are as follows.
Firstly, NMF-based methods, including NMF, GNMF and HNMFD, outperform the Kmeans method. This suggests the superiority of parts-based data representation for perceiving the hidden matrix factors.
Secondly, Ncut and GNMF exploit geometrical information, and achieve more superior performance than Kmeans and NMF methods. This suggests that geometrical information is very important in learning the hidden factors.
Finally, on all the data sets, HNMFD always outperforms the other clustering methods. This demonstrates that by exploiting the power of Hessian regularization, group sparse regularization and discriminative information, new method can learn a more meaningful representation.
4.5. Parameter Sensitivity
HNMFD has three parameters, , and . We investigated their influence on HNMFD’s performance by varying one parameter at a time while fixing the other two. For each specific setting, we run HNMFD 10 times and record the average performance.
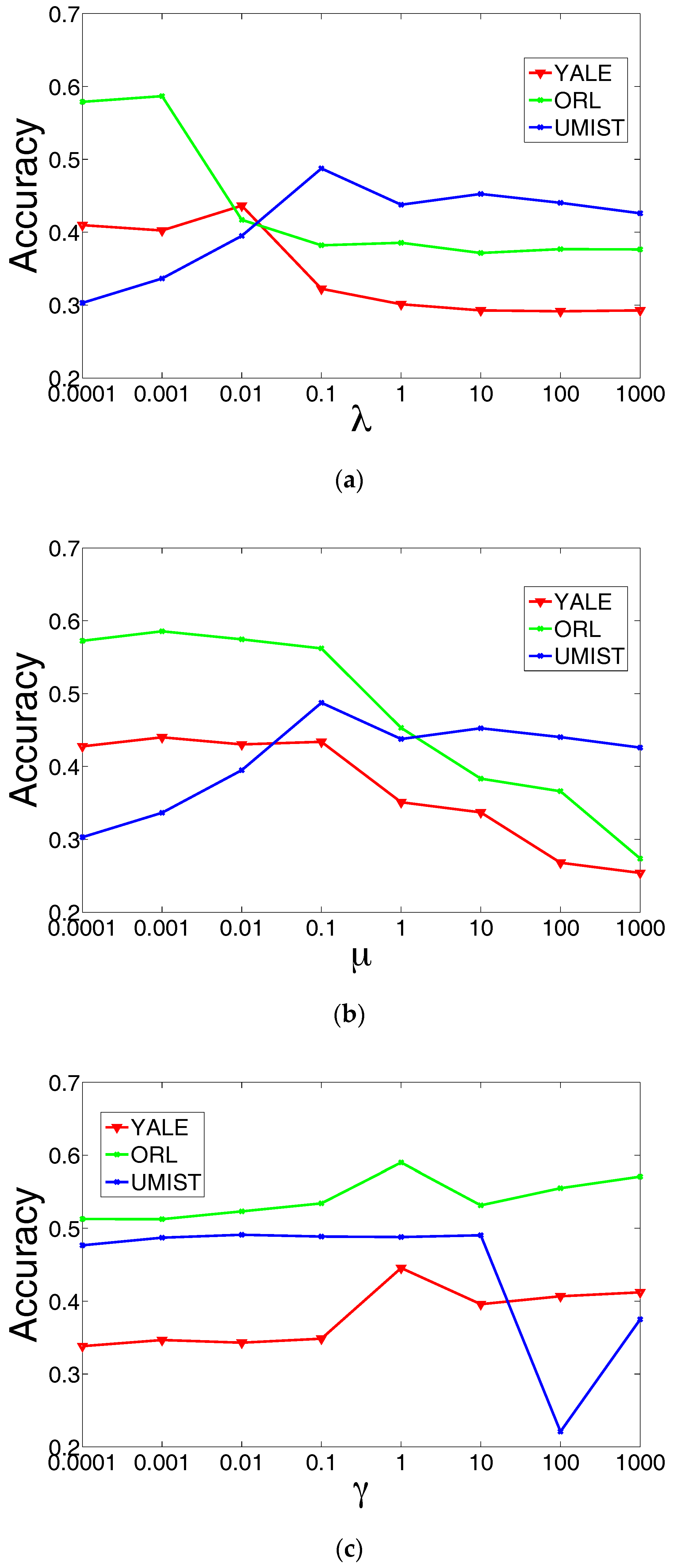
We plot the performance of HNMFD with respect to in Figure 1a. Parameter measures the importance of the graph embedding regularization terms of HNMFD. A too small may cause graph regularization so weak that the local geometrical information of data cannot be effectively characterize, while too big may cause a trivial solution. HNMFD shows superior performance when equals 0.01, 0.001 and 0.1 for YALE, ORL and UMIST, respectively.
We plot the performance of HNMFD with respect to in Figure 1b. Parameter controls the orthogonality of the learned representation. When is too small, the orthogonal constraint will be too weak, and HNMFD may be ill-defined. When is too large, the constraint may dominate the objective function of HNMFD, and the learned representation will be too sparse, which is also unfaithful to the real-world situation. We can observe that HNMFD is able to achieve encouraging performance when equals 0.001, 0.001 and 0.1 for YALE, ORL and UMIST respectively.
We plot the performance of HNMFD with respect to in Figure 1c. Parameter controls the degree of sparsity of the encoding matrix. Sparsity constraints that are too weak or too heavy will be bad for the learned representation. We find that HNMFD consistently outperforms the best baseline methods on the three datasets when .
4.6. Convergence Analysis
The updating rules for minimizing the objective function of HNMFD are essentially iterative. We have provided its convergence proof. Next, we analyze how fast the rules can converge.
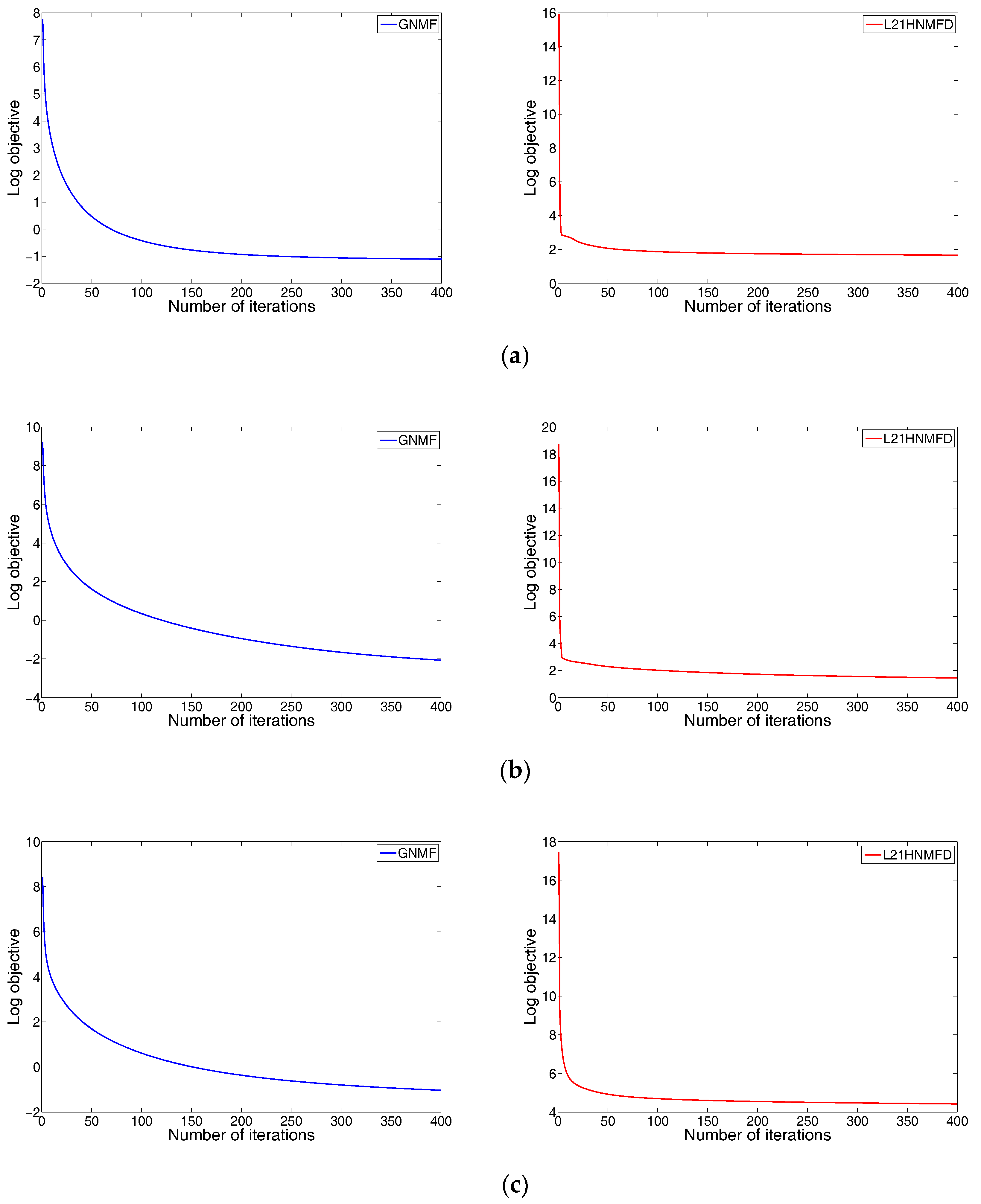
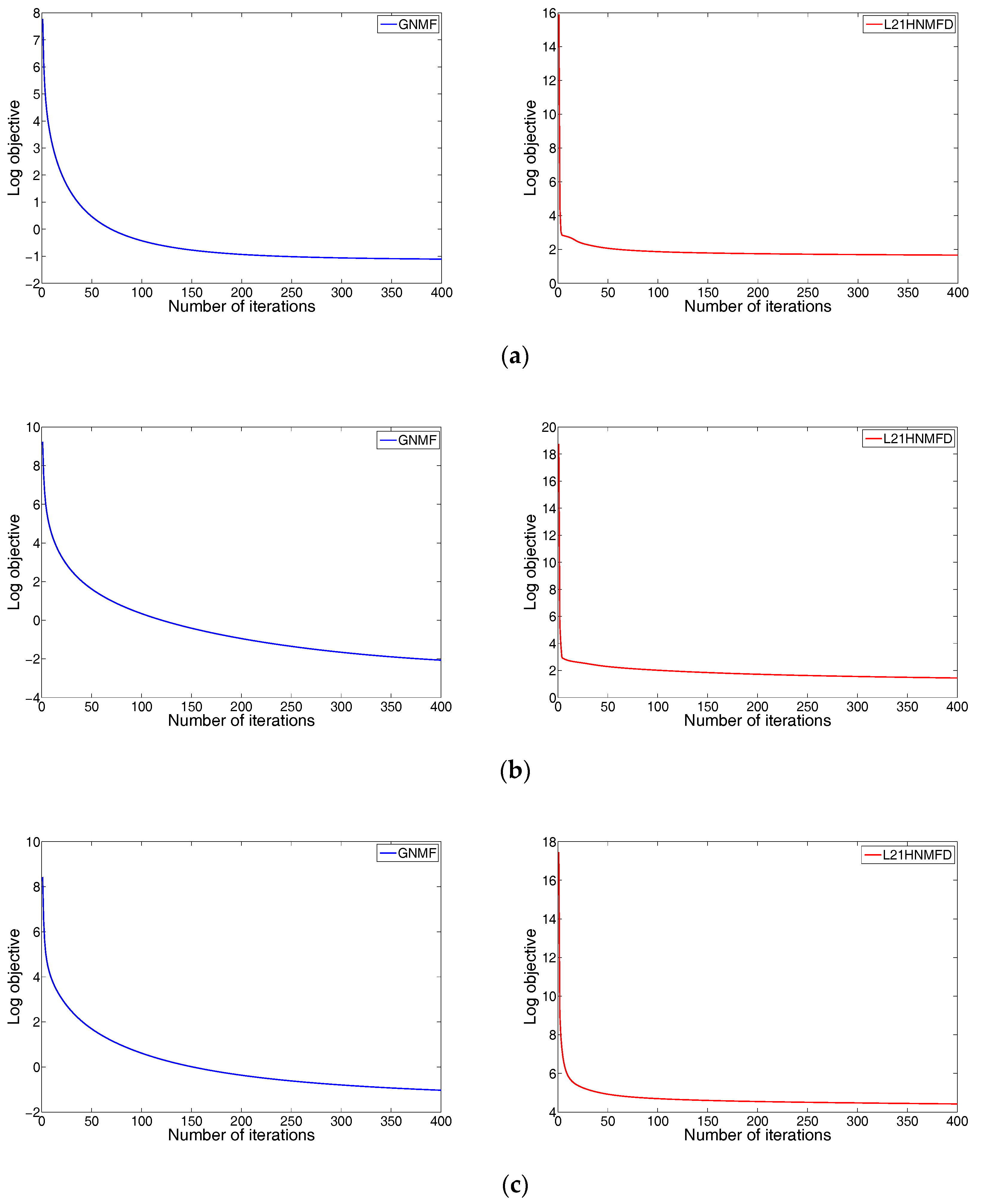
We investigate the empirical convergence properties of both GNMF and HNMFD on three datasets. For each figure, the x-axis denotes the iterative number and the y-axis is the value of objective function with log scale. Figure 2a–c show the objective function value against the number of iterations performed for data set YALE, ORL and UMIST, respectively. We observed that, at the beginning, the objective function values for both GNMF and HNMFD dropped drastically, and were able to converge very fast, usually within 100 iterations.
5. Conclusions and Future Work
In this paper, we have discussed a novel matrix factorization method, called norm and Hessian Regularized Non-negative Matrix Factorization with Discriminability (HNMFD), for data representation. On one hand, HNMFD uses Hessian regularization to preserve the local manifold structures of data. On the other hand, HNMFD exploits the norm constraint to obtain sparse representation, and uses an approximation orthogonal constraint to characterize the discriminative information of the data. Experimental results on 5 real-world datasets suggest that HNMFD is able to learn a better part-based representation. This paper only considers single-view cases. In the future, we will consider multi-view cases, and learn a meaningful representation for multi-view data.
Acknowledgments
This research was supported by the National High-tech R&D Program of China (863 Program) (No. 2014AA015201) and the Program for Changjiang Scholars and Innovative Research Team in University (No. IRT13090). The content of the information does not necessarily reflect the position or the policy of the Government, and no official endorsement should be inferred.
Author Contributions
All authors contributed equally to this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Verleysen, M.; François, D. The Curse of Dimensionality in Data Mining and Time Series Prediction. In Proceedings of the Computational Intelligence and Bioinspired Systems, Barcelona, Spain, 8–10 June 2005; pp. 758–770. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [PubMed]
- Guillamet, D.; Vitria, J. Classifying faces with nonnegative matrix factorization. In Proceedings of the 5th Catalan Conference for Artificial Intelligence, Castellón, Spain, 24–25 October 2002; pp. 24–31. [Google Scholar]
- Zafeiriou, S.; Petrou, M. Nonlinear non-negative component analysis algorithms. IEEE Trans. Image Process. 2010, 19, 1050–1066. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Liu, X.; Gong, Y. Document clustering based on non-negative matrix factorization. In Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, Toronto, ON, Canada, 28 July–1 August 2003; pp. 267–273. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1548–1560. [Google Scholar] [PubMed]
- Lu, X.; Wu, H.; Yuan, Y.; Yan, P.; Li, X. Manifold regularized sparse NMF for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 2815–2826. [Google Scholar] [CrossRef]
- Gu, Q.; Zhou, J. Neighborhood Preserving Nonnegative Matrix Factorization. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009; pp. 1–10. [Google Scholar]
- Kim, K.I.; Steinke, F.; Hein, M. Semi-supervised regression using Hessian energy with an application to semi-supervised dimensionality reduction. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 979–987. [Google Scholar]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Cai, D.; He, X.; Han, J. Spectral regression: A unified approach for sparse subspace learning. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 73–82. [Google Scholar]
- Zou, H.; Yuan, M. The F∞-norm support vector machine. Stat. Sin. 2008, 18, 379–398. [Google Scholar]
- Nie, F.; Huang, H.; Cai, X.; Ding, C.H. Efficient and robust feature selection via joint ℓ2,1-norms minimization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 1813–1821. [Google Scholar]
- Yang, Y.; Shen, H.T.; Ma, Z.; Huang, Z.; Zhou, X. ℓ2,1-norm regularized discriminative feature selection for unsupervised learning. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI11), Barcelona, Spain, 16–22 July 2011; pp. 1589–1594. [Google Scholar]
- Gu, Q.; Li, Z.; Han, J. Joint feature selection and subspace learning. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI11), Barcelona, Spain, 16–22 July 2011; pp. 1294–1299. [Google Scholar]
- Xu, Z.; Chang, X.; Xu, F.; Zhang, H. L1/2 regularization: A thresholding representation theory and a fast solver. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1013–1027. [Google Scholar] [PubMed]
- Qian, Y.; Jia, S.; Zhou, J.; Robles-Kelly, A. Hyperspectral unmixing via L1/2 sparsity-constrained nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4282–4297. [Google Scholar] [CrossRef]
- Wang, W.; Qian, Y. Adaptive L1/2 Sparsity-Constrained NMF With Half-Thresholding Algorithm for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2618–2631. [Google Scholar] [CrossRef]
- Tsinos, C.G.; Rontogiannis, A.A.; Berberidis, K. Distributed Blind Hyperspectral Unmixing via Joint Sparsity and Low-Rank Constrained Non-Negative Matrix Factorization. IEEE Trans. Comput. Imaging 2017, 3, 160–174. [Google Scholar] [CrossRef]
- Li, X.; Cui, G.; Dong, Y. Graph regularized non-negative low-rank matrix factorization for image clustering. IEEE Trans. Cybern. 2016, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Wu, Z. Non-negative matrix factorization with constraints. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, Georgia, 11–15 July 2010; pp. 506–511. [Google Scholar]
- Li, Z.; Tang, J.; He, X. Robust Structured Nonnegative Matrix Factorization for Image Representation. IEEE Trans. Neural Netw. Learn. Syst. 2017, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Proceedings of the Advances in Neural Information Processing Systems 13 (NIPS 2000), Denver, CO, USA, 27 November–2 December 2000; pp. 556–562. [Google Scholar]
- Steinke, F.; Hein, M. Non-parametric regression between manifolds. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 1561–1568. [Google Scholar]
- Ye, J.; Zhao, Z.; Wu, M. Discriminative k-means for clustering. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–10 December 2008; pp. 1649–1656. [Google Scholar]
- Yang, Y.; Xu, D.; Nie, F.; Yan, S.; Zhuang, Y. Image clustering using local discriminant models and global integration. IEEE Trans. Image Process. 2010, 19, 2761–2773. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
Figure 1.
Influence of different parameter settings on the performance of HNMFD in 3 datasets: (a) varying while fixing and ; (b) varying while fixing and ; and (c) varying while fixing and .
Figure 1.
Influence of different parameter settings on the performance of HNMFD in 3 datasets: (a) varying while fixing and ; (b) varying while fixing and ; and (c) varying while fixing and .

Figure 2.
Convergence curve of GNMF and HNMFD. (a) YALE, (b) ORL and (c) UMIST.

{kind=link}
{kind=link}
Table 1.
Statistics of the datasets.
| Dataset | Size | Categories | Dimensionality |
|---|---|---|---|
| YALE | 165 | 15 | 1024 |
| ORL | 400 | 40 | 1024 |
| UMIST | 575 | 20 | 644 |
| COIL20 | 1440 | 20 | 1024 |
| PIE | 2856 | 68 | 1024 |
Table 2.
Clustering Accuracy on the 5 datasets (%).
| Dataset | Kmeans | NMF | NCut | GNMF | Ours |
|---|---|---|---|---|---|
| YALE | 37.85 ± 2.36 | 40.15 ± 2.89 | 40.73 ± 2.39 | 41.42 ± 3.10 | 42.94 ± 2.65 |
| ORL | 52.15 ± 2.86 | 54.17 ± 2.00 | 57.60 ± 3.00 | 57.95 ± 3.41 | 59.22 ± 1.54 |
| UMIST | 40.71 ± 1.92 | 41.12 ± 2.71 | 41.37 ± 1.74 | 44.50 ± 2.59 | 50.16 ± 1.16 |
| COIL20 | 63.19 ± 4.85 | 63.25 ± 3.17 | 70.19 ± 2.80 | 75.92 ± 2.79 | 78.03 ± 1.70 |
| PIE | 24.22 ± 0.85 | 51.08 ± 2.27 | 66.60 ± 2.14 | 75.61 ± 3.32 | 77.81 ± 2.33 |
Table 3.
Normalized Mutual Information on the 5 datasets (%).
| Dataset | Kmeans | NMF | NCut | GNMF | Ours |
|---|---|---|---|---|---|
| YALE | 43.58 ± 2.42 | 45.00 ± 2.71 | 45.91 ± 2.15 | 46.08 ± 2.12 | 46.88 ± 2.11 |
| ORL | 70.93 ± 1.69 | 73.36 ± 1.46 | 75.13 ± 1.50 | 75.52 ± 1.93 | 76.09 ± 0.95 |
| UMIST | 60.08 ± 1.65 | 60.32 ± 0.85 | 62.11 ± 1.76 | 63.53 ± 1.27 | 66.13 ± 1.26 |
| COIL20 | 74.32 ± 2.00 | 72.65 ± 1.21 | 78. 40 ± 1.57 | 86.92 ± 2.79 | 89.90 ± 1.79 |
| PIE | 53.55 ± 1.02 | 78.68 ± 109 | 81.87 ± 1.63 | 89.07 ± 0.82 | 91.27 ± 2.57 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Luo, P.; Peng, J.; Fan, J. ℓ2,1 Norm and Hessian Regularized Non-Negative Matrix Factorization with Discriminability for Data Representation. Appl. Sci. 2017, 7, 1013. https://doi.org/10.3390/app7101013
AMA Style
Luo P, Peng J, Fan J. ℓ2,1 Norm and Hessian Regularized Non-Negative Matrix Factorization with Discriminability for Data Representation. Applied Sciences. 2017; 7(10):1013. https://doi.org/10.3390/app7101013
Chicago/Turabian StyleLuo, Peng, Jinye Peng, and Jianping Fan. 2017. "ℓ2,1 Norm and Hessian Regularized Non-Negative Matrix Factorization with Discriminability for Data Representation" Applied Sciences 7, no. 10: 1013. https://doi.org/10.3390/app7101013
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.