LPaMI: A Graph-Based Lifestyle Pattern Mining Application Using Personal Image Collections in Smartphones

 ,
,
Abstract
:1. Introduction
- We propose mining the lifestyle patterns of a user through his/her personal photo collection in a smartphone. In this way, our goal is to avoid dependency on external resources like GPS and online connectivity. Rather, we want to make maximum use of the local and free resources available. Nonetheless, the support of any external resource can be embedded to further enhance the lifestyle pattern mining capabilities.
- To mine the lifestyle patterns through the photo collections found on user smartphones, we present a prototype application, LPaMI, that recognises the OOIs via state-of-the-art scene recognition techniques. We then model the OOIs in the form of a graph(s) and apply various graph pattern mining techniques to learn the patterns.
- We have designed and implemented a prototype application for LPaMI to demonstrate its functionality and effectiveness. For each phase, like scene/OOI recognition, data migration, graph modelling, and graph pattern mining, we have implemented various state-of-the-art algorithms to present a robust and effective solution. Our implementation of data migration is in Spark environment to make the solution scalable in the case of big data with respect to personal images and to make it useable if the data source is changed from the mobile image collection to any other data repository.
- We also present an extensive evaluation of various phases using real-world datasets to prove the effectiveness of our proposal.
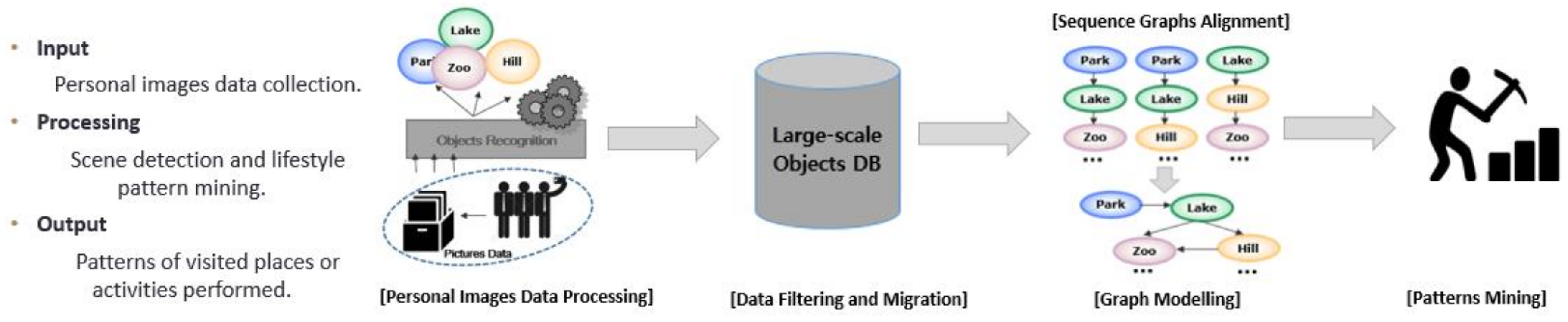
2. Overview of LPaMI
2.1. Features of LPaMI
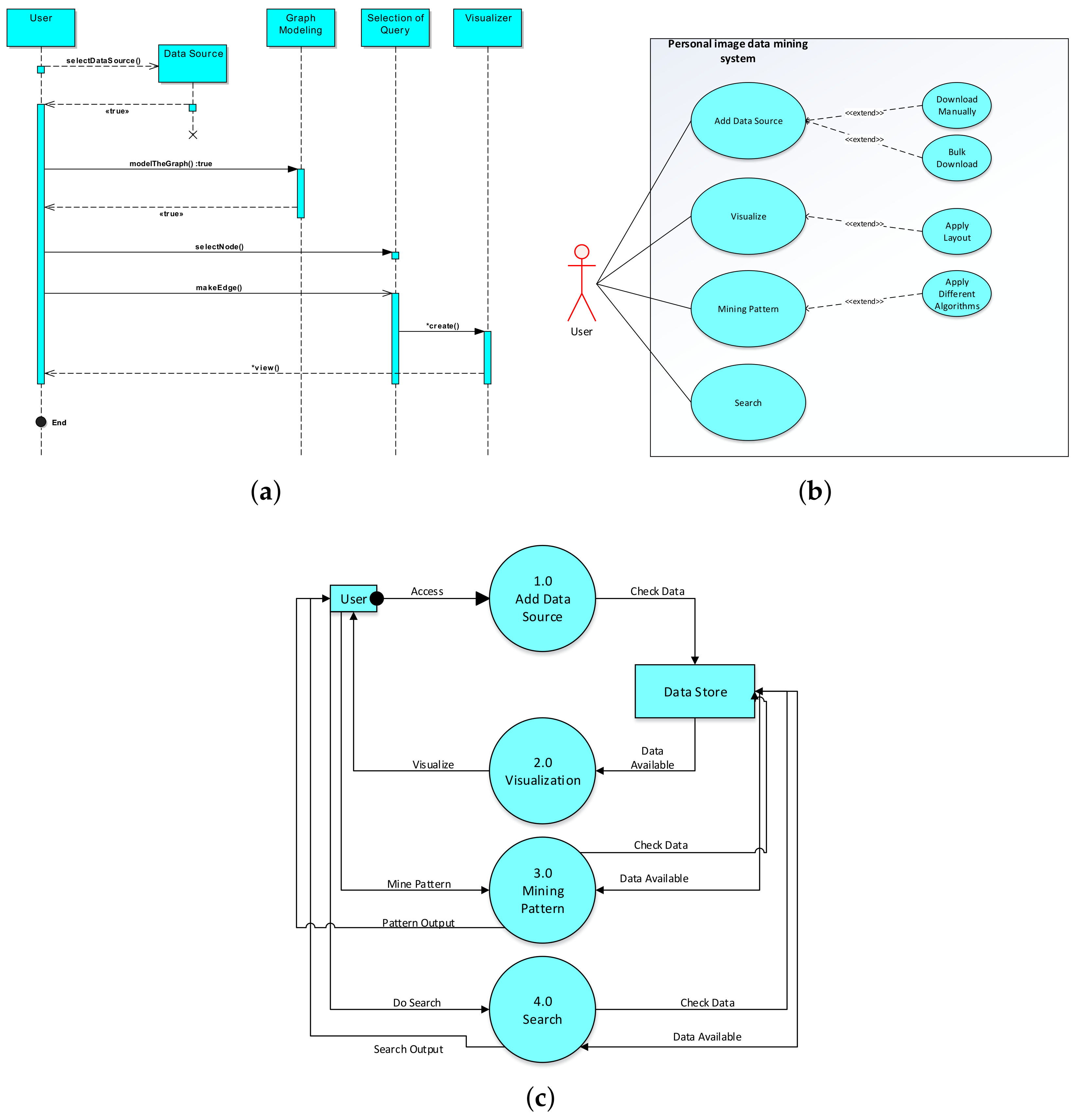
2.2. Formal Modelling Practices for LPaMI
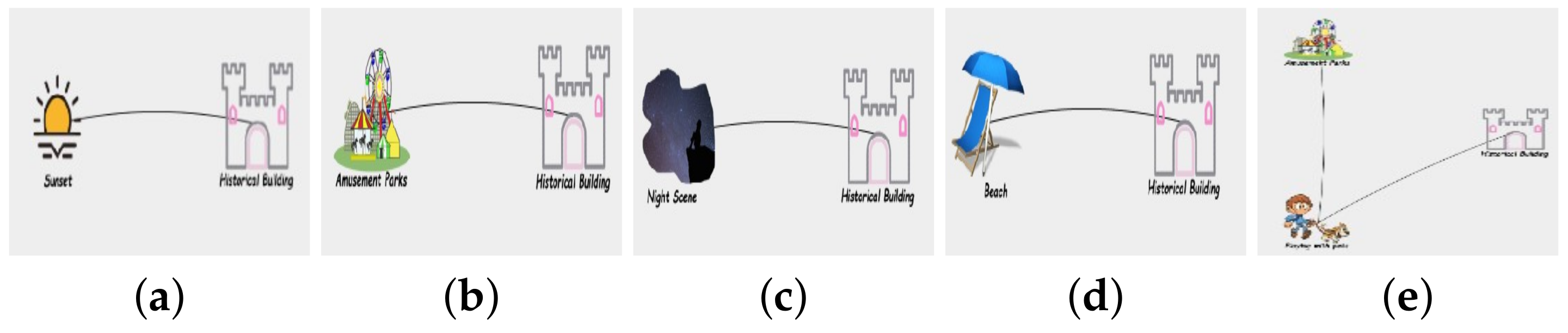
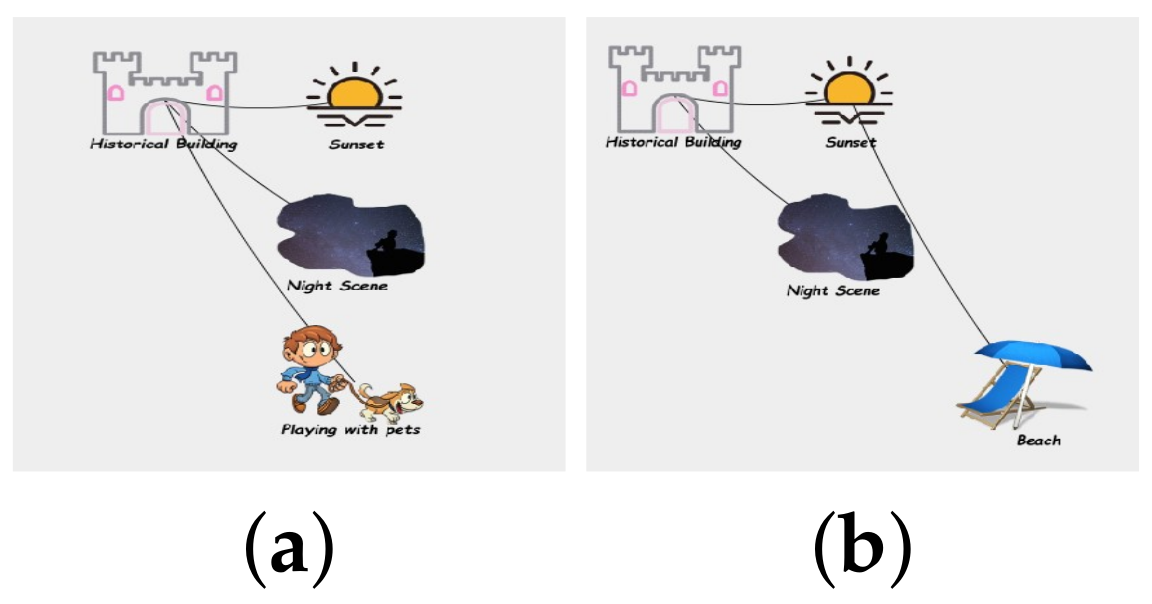
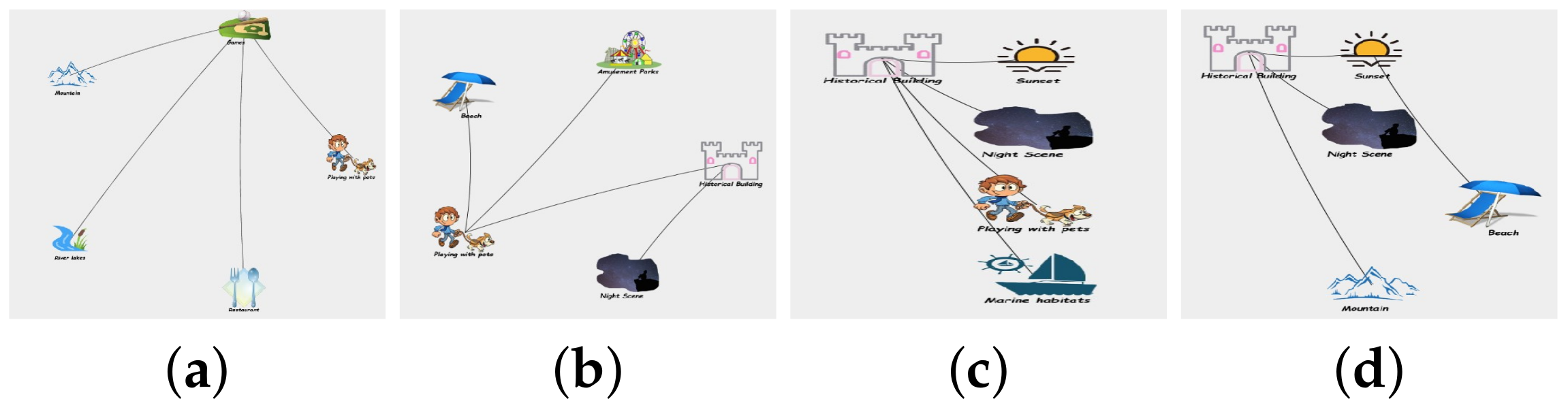
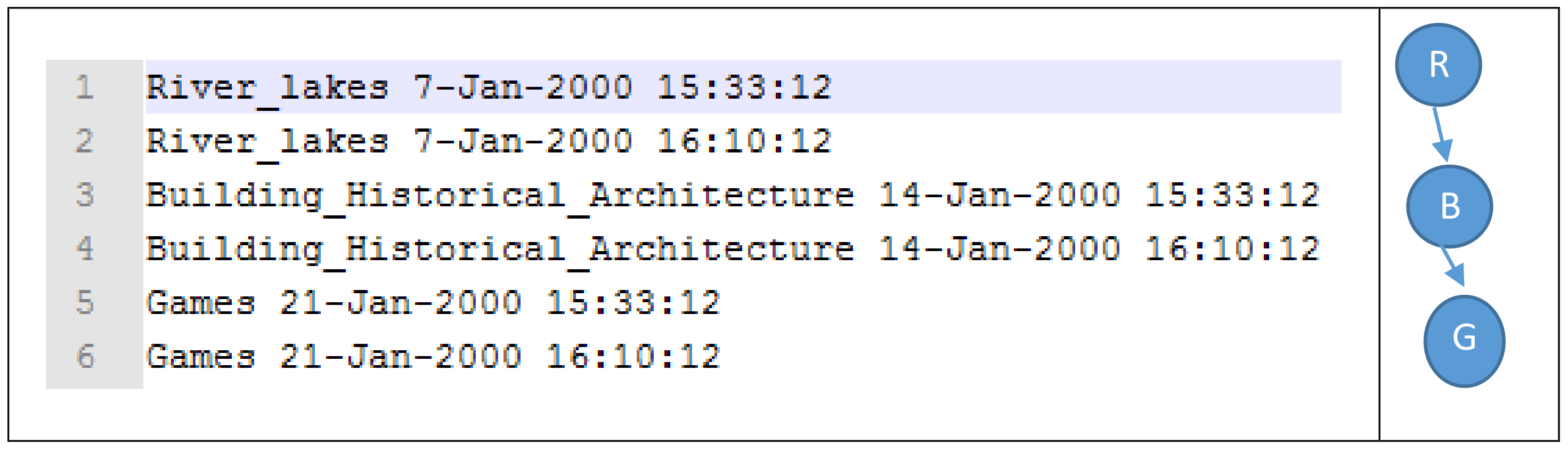
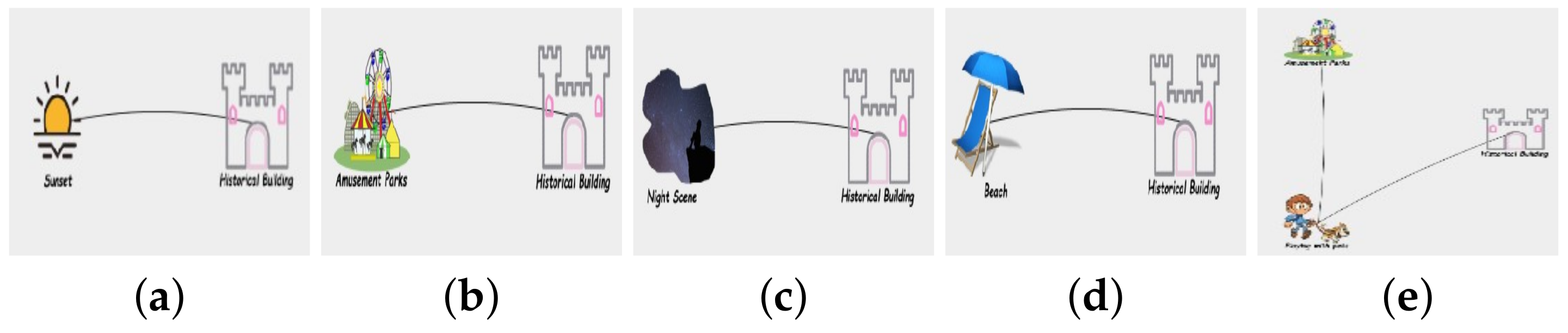
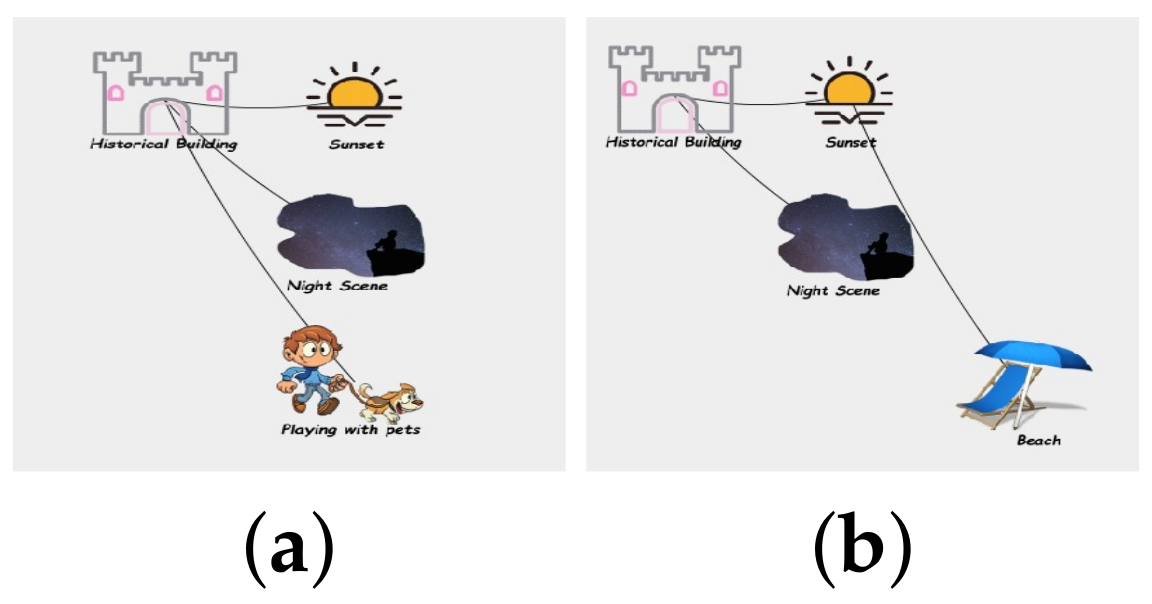
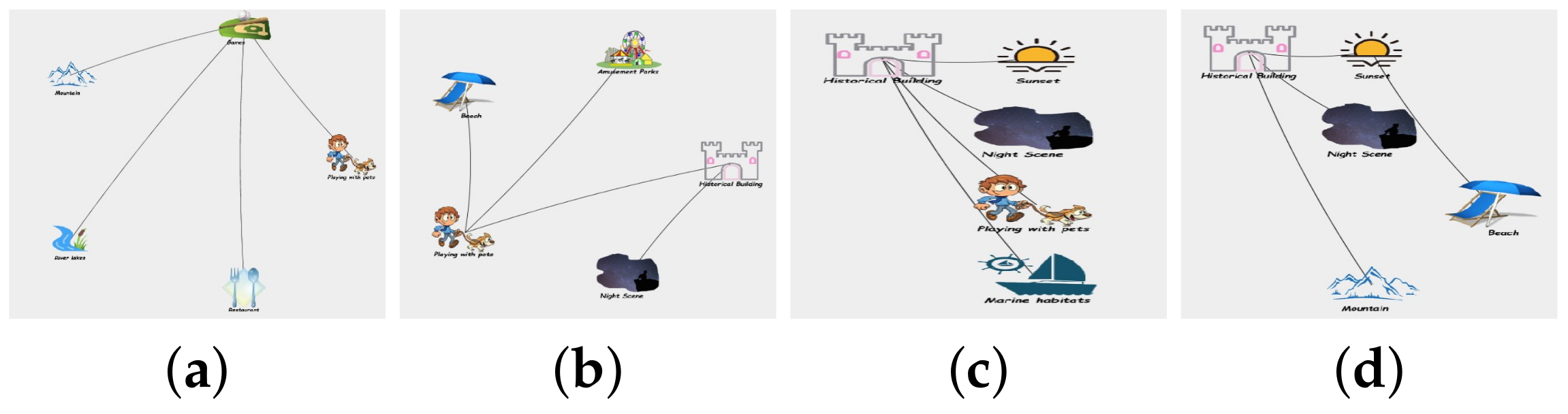
2.3. Example Illustration
| Algorithm 1 Pipleline Algorithm for LPaMI |
| Require: Image collection C of given application area obtained from the smartphone of a user U |
| Ensure: Patterns of interest mined for U |
| /* Object Recognition Phase */ |
| 1: Extract Objects of Interest from C into text files on disk |
| /* Data Migration Phase */ |
| 2: Load the data into staging area in the database |
| 3: Filter and clean the noise created during processing of the images |
| 4: Migrate the filtered data into the normalised data model |
| /* Data Transformation into Graph Format Phase */ |
| 5: Generate sequence graphs based on given time window |
| 6: Model a graph database or one large graph from the sequence graphs |
| /* Pattern Mining Phase */ |
| 7: Mine user-defined type of patterns of actions performed by U |
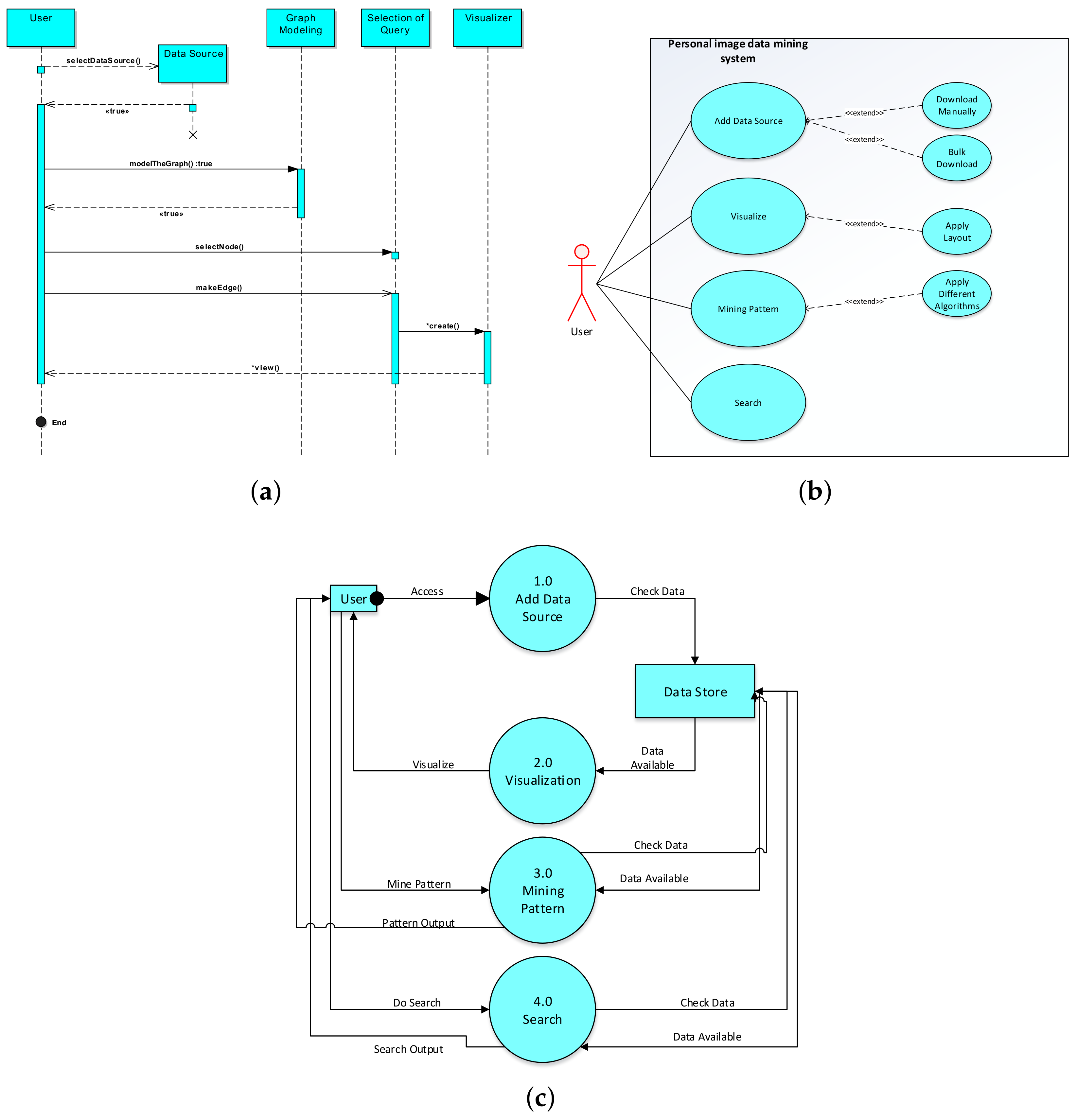
3. Component-Wise Details of LPaMI
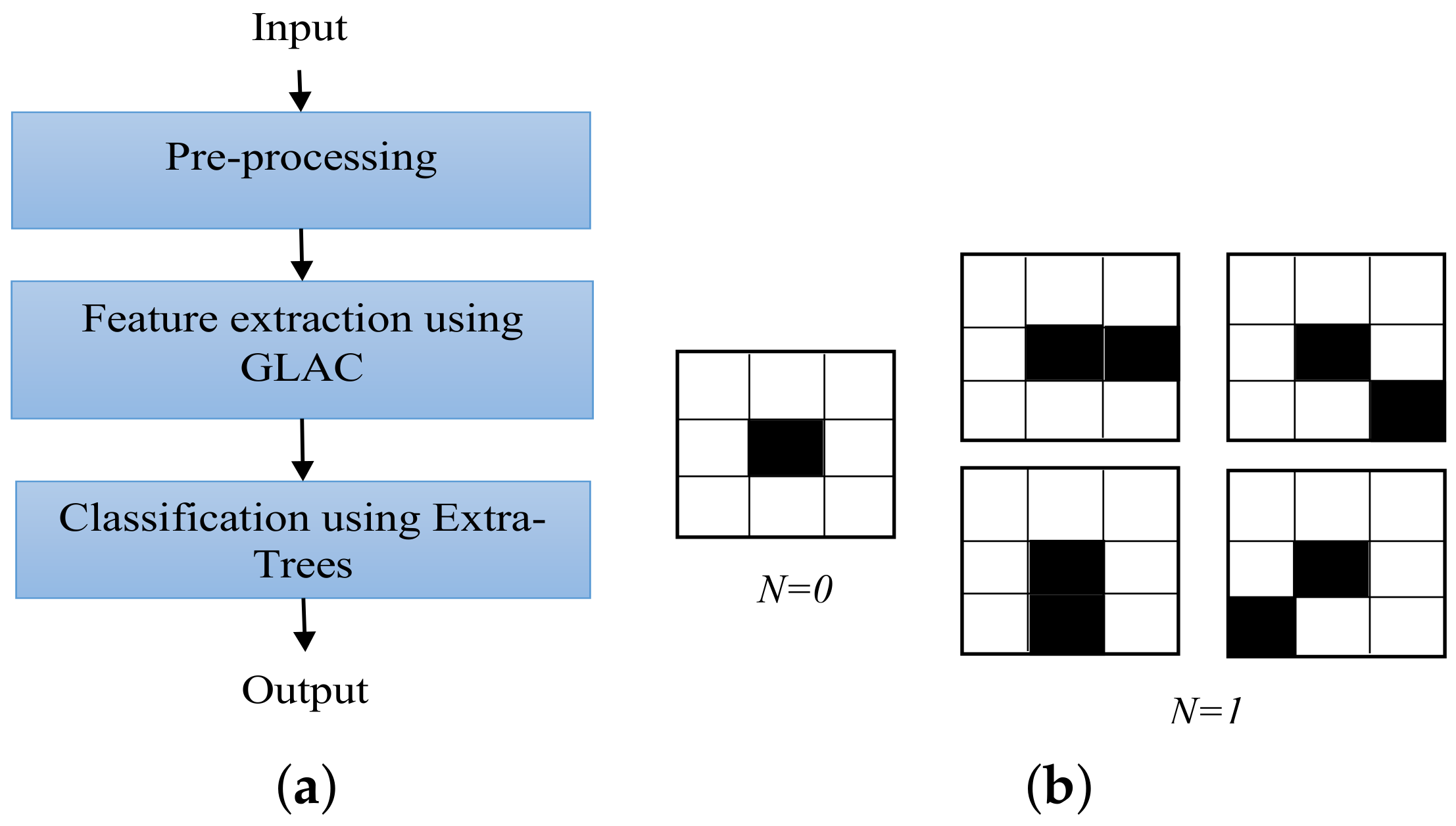
3.1. Recognizing OOIs from Photographs
3.1.1. Pre-Processing
3.1.2. Feature Extraction
3.1.3. Classification
| Algorithm 2 Recognition of Objects of Interest from Photographs |
| Require: Image collection C of a given application area obtained from the smartphone of a user U, Number of Trees , Number of Attributes , Splitting Node Size |
| Ensure: Classify the OOI and Extract the Date and Time from C onto the disk |
|
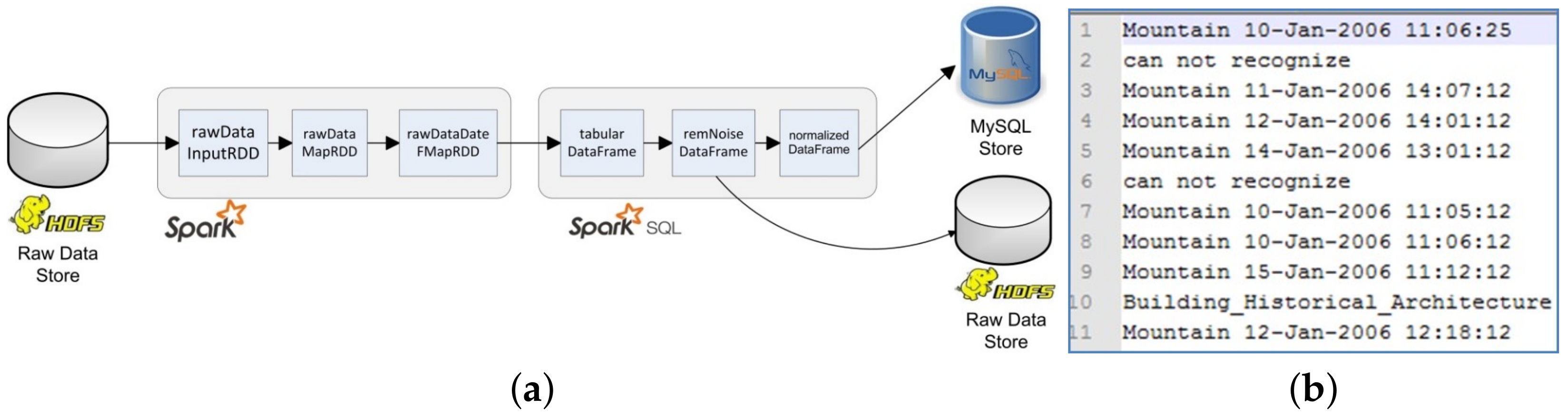
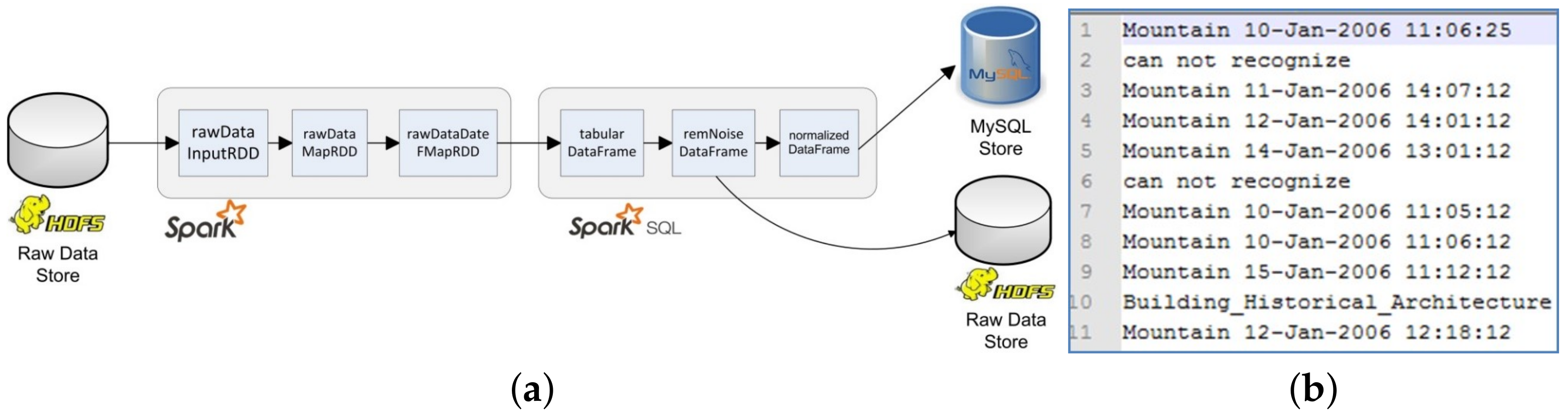
3.2. Data Filtering and Migration Phase
3.2.1. Data Migration from HDFS to Relational Database
3.2.2. Data Reading from HDFS
3.2.3. Data Processing in RDDs
3.2.4. Transformations, Data Processing, and Normalisation of DataFrames
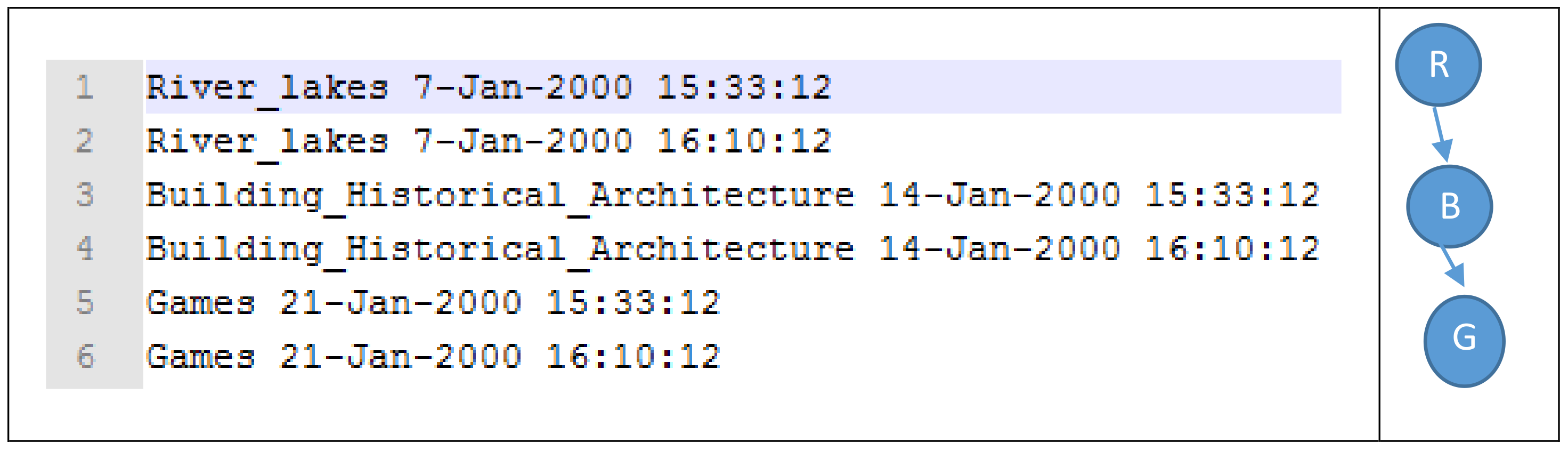
3.3. Modelling Data as a Graph
Graph Construction
| Algorithm 3 Data Transformation into Graph Format Phase |
| Require: Image data I is produced by Object Recognition and Data Migration Phases for Data Transformation, only such data tuples i have the recognised object o and time information t, given time window |
| Ensure: Graph data |
| /* Sequence Graphs Creation */ |
| Generate sequence graphs S based on given time window τ |
| 1: Assign each tuple into appropriate set where and . |
| 2: Align the created daily sequences using the MUSCLE algorithm, |
| 3: Create a set of sequence graphs . |
| /* Graph Formating */ |
| Model a graph database or one large graph G from the sequence graphs |
| 4: Identify vertices and edges and . |
| 5: Calculate graph statistics and assign attributes by function . |
| 6: Create the sequence graph ; a large graph |
3.4. Graph Pattern Mining
4. Experimental Evaluation
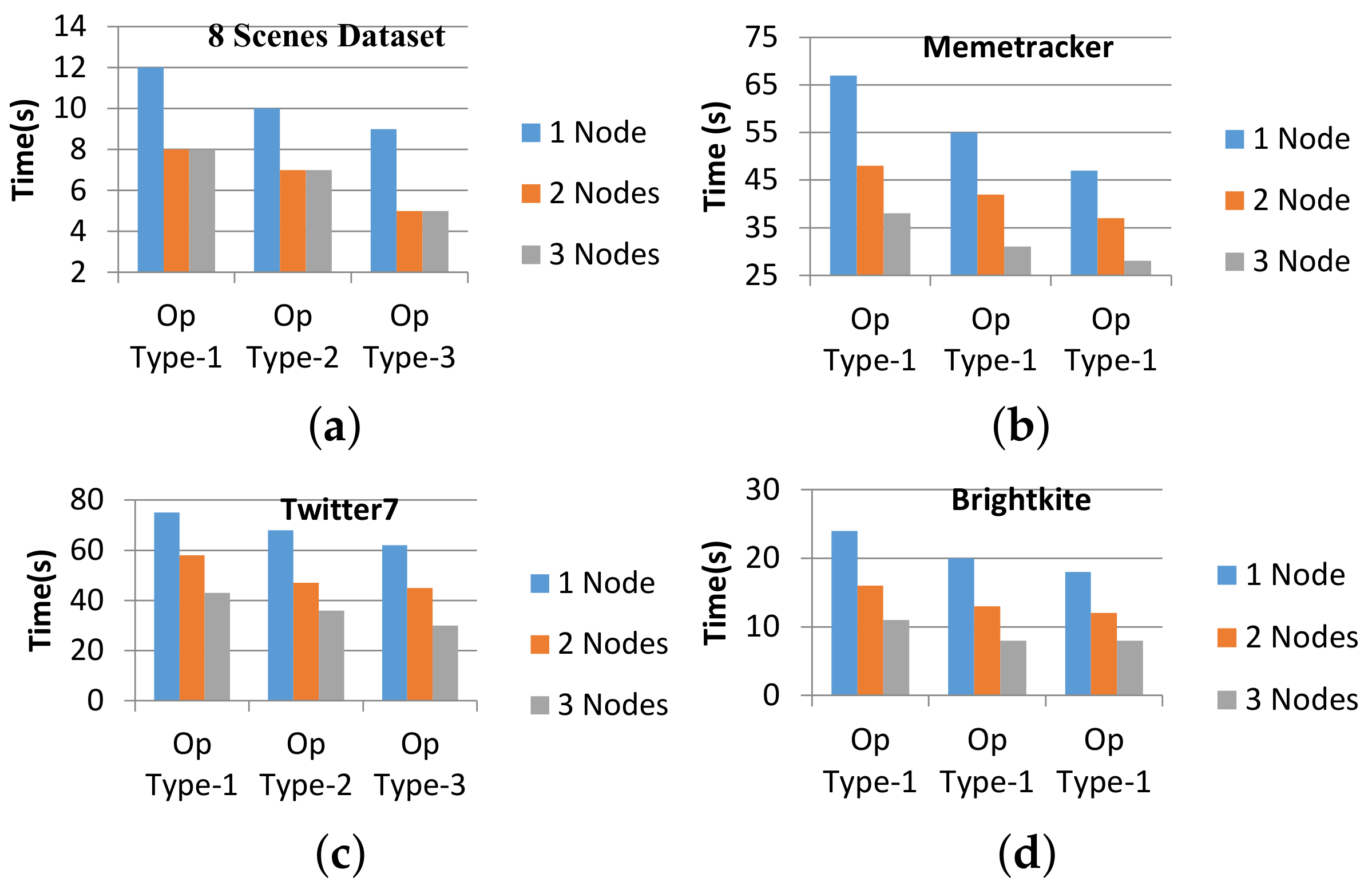
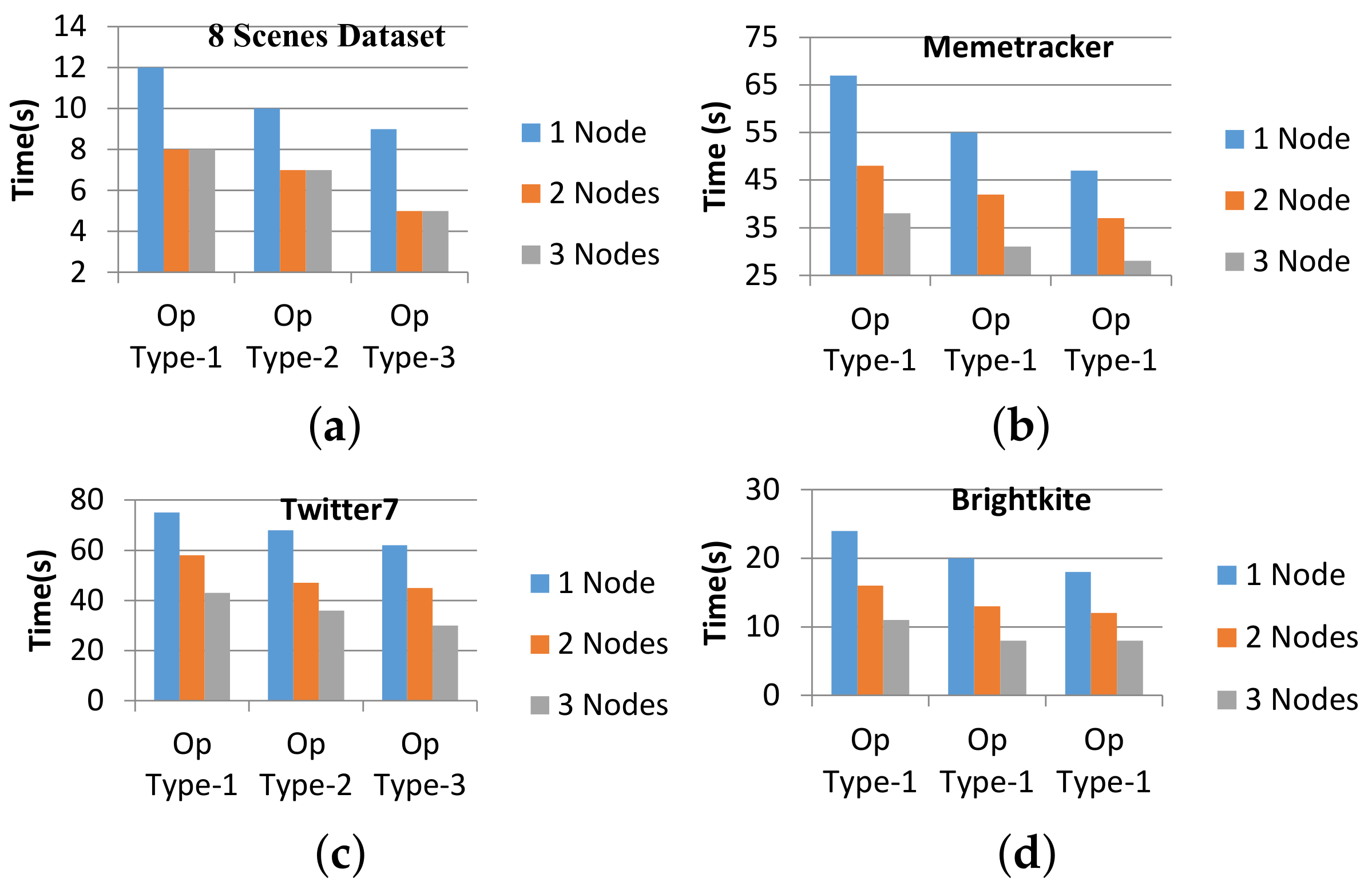
4.1. Dataset Description and System Configuration
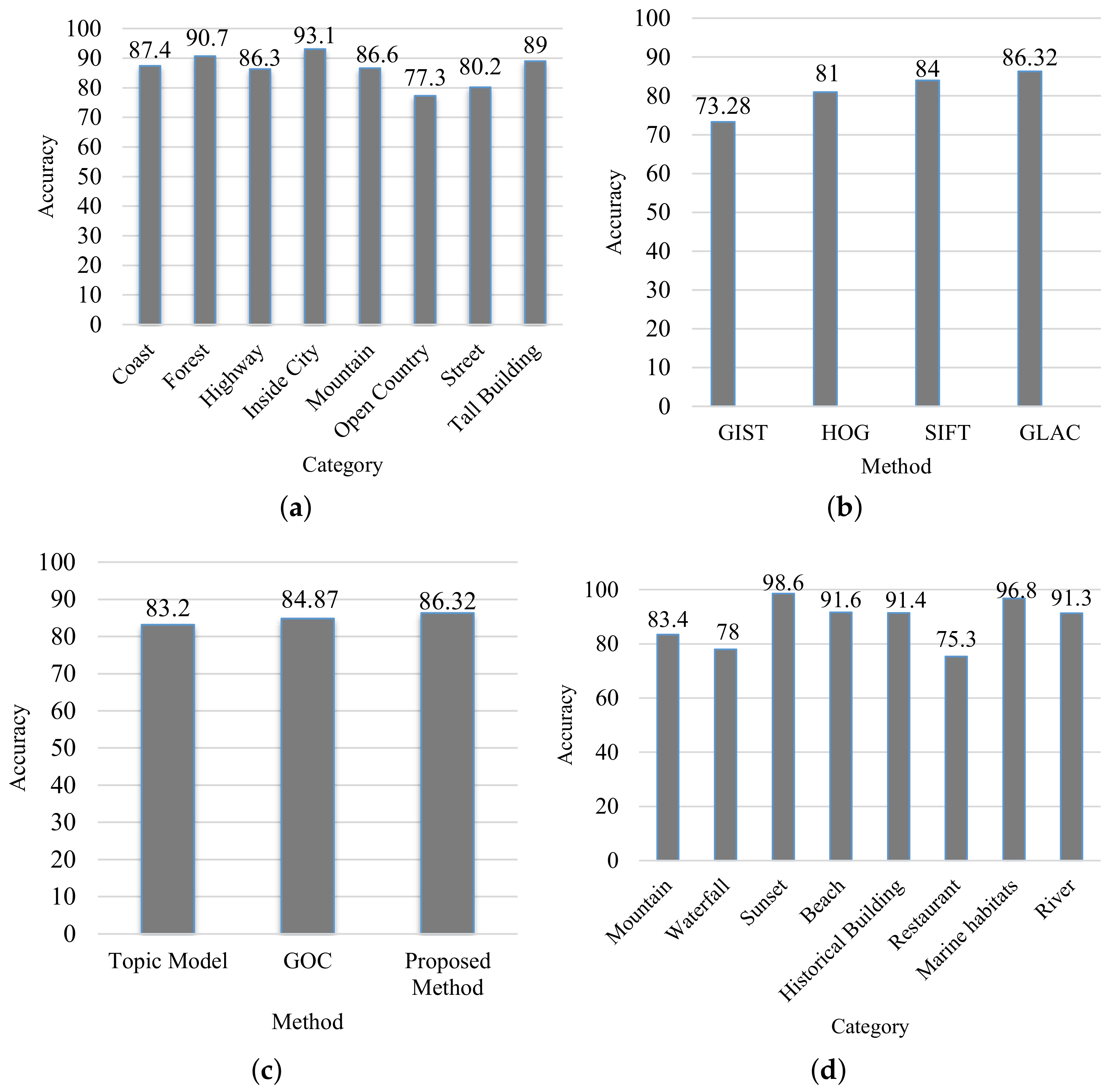
4.2. Performance Analysis
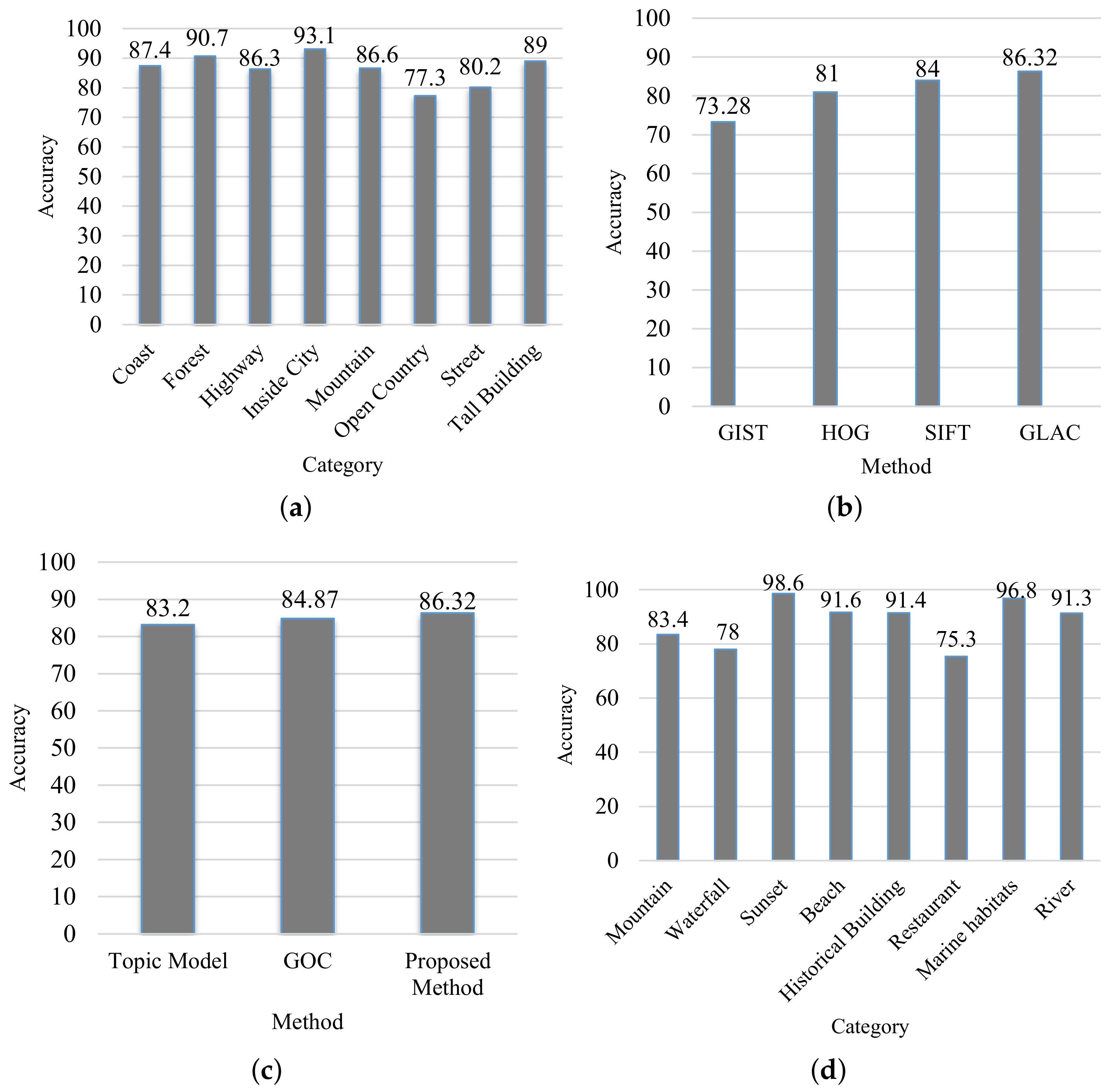
4.3. Effectiveness Analysis of LPaMI Using Graph Pattern Mining
5. Related Works
5.1. Learning User’s Lifestyle Patterns via Smartphone Data
5.2. Recognizing OOIs
5.3. Graph Modelling
5.4. Graph Pattern Mining
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rashidi, P.; Cook, D.J. Mining and monitoring patterns of daily routines for assisted living in real world settings. In Proceedings of the 1st ACM International Health Informatics Symposium, Arlington, VA, USA, 11–12 November 2010; pp. 336–345. [Google Scholar]
- Frey, R.M.; Xu, R.; Ilic, A. Reality-mining with smartphones: Detecting and predicting life events based on app installation behavior. In Proceedings of the International Conference on Information Systems (ICIS 2015), Fort Worth, TX, USA, 13–16 December 2015. [Google Scholar]
- Do, T.M.T.; Blom, J.; Gatica-Perez, D. Smartphone usage in the wild: A large-scale analysis of applications and context. In Proceedings of the 13th International Conference on Multimodal Interfaces, Alicante, Spain, 14–18 November 2011; pp. 353–360. [Google Scholar]
- LiKamWa, R.; Liu, Y.; Lane, N.D.; Zhong, L. Moodscope: Building a mood sensor from smartphone usage patterns. Proceeding of the 11th Annual International Conference on Mobile Systems, Applications, and Services, Taipei, Taiwan, 25–28 June 2013; pp. 389–402. [Google Scholar]
- Srinivasan, V.; Moghaddam, S.; Mukherji, A.; Rachuri, K.K.; Xu, C.; Tapia, E.M. Mobileminer: Mining your frequent patterns on your phone. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 389–400. [Google Scholar]
- Xu, R.; Frey, R.M.; Fleisch, E.; Ilic, A. Understanding the impact of personality traits on mobile app adoption–Insights from a large-scale field study. Comput. Hum. Behav. 2016, 62, 244–256. [Google Scholar] [CrossRef]
- Gupta, N.J.; Kumar, V.; Panda, S. A camera-phone based study reveals erratic eating pattern and disrupted daily eating-fasting cycle among adults in India. PLoS ONE 2017, 12, e0172852. [Google Scholar] [CrossRef] [PubMed]
- Doherty, A.R.; Hodges, S.E.; King, A.C.; Smeaton, A.F.; Berry, E.; Moulin, C.J.; Lindley, S.; Kelly, P.; Foster, C. Wearable cameras in health. Am. J. Prev. Med. 2013, 44, 320–323. [Google Scholar] [CrossRef] [PubMed]
- Zheng, D.; Hu, T.; You, Q.; Kautz, H.A.; Luo, J. Towards Lifestyle Understanding: Predicting Home and Vacation Locations from User’s Online Photo Collections. In Proceedings of the 9th International AAAI Conference on Web and Social Media, Oxford, UK, 26–29 May 2015; pp. 553–561. [Google Scholar]
- Lim, K.H.; Wang, X.; Chan, J.; Karunasekera, S.; Leckie, C.; Chen, Y.; Tan, C.L.; Gao, F.Q.; Wee, T.K. PersTour: A Personalized Tour Recommendation and Planning System. In Proceedings of the 27th ACM Conference on Hypertext and Social Media (HT’16), Halifax, NS, Canada, 13–16 July 2016. [Google Scholar]
- Korakakis, M.; Mylonas, P.; Spyrou, E. Xenia: A context aware tour recommendation system based on social network metadata information. In Proceedings of the 2016 11th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Thessaloniki, Greece, 20–21 October 2016; pp. 59–64. [Google Scholar]
- Spyrou, E.; Mylonas, P. A survey on Flickr multimedia research challenges. Eng. Appl. Artif. Intell. 2016, 51, 71–91. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’07), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Perronnin, F.; Liu, Y.; Sánchez, J.; Poirier, H. Large-scale image retrieval with compressed fisher vectors. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3384–3391. [Google Scholar]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale orderless pooling of deep convolutional activation features. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014; pp. 392–407. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Kobayashi, T.; Otsu, N. Image feature extraction using gradient local auto-correlations. In European Conference on Computer Vision; Springer: Berlin, Germany, 2008; pp. 346–358. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Edgar, R.C. MUSCLE: Multiple sequence alignment with high accuracy and high throughput. Nucleic Acids Res. 2004, 32, 1792–1797. [Google Scholar] [PubMed]
- Yan, X.; Han, J. gSpan: Graph-based substructure pattern mining. In Proceedings of the 2002 IEEE International Conference on Data Mining (ICDM 2003), Maebashi City, Japan, 9–12 December 2002; pp. 721–724. [Google Scholar]
- Nijssen, S.; Kok, J.N. The gaston tool for frequent subgraph mining. Electron. Notes Theor. Comput. Sci. 2005, 127, 77–87. [Google Scholar] [CrossRef]
- Duong, V.T.; Khan, K.U.; Jeong, B.S.; Lee, Y.K. Top-k frequent induced subgraph mining using sampling. In Proceedings of the Sixth International Conference on Emerging Databases: Technologies, Applications, and Theory, Jeju, Korea, 17–19 October 2016; pp. 110–113. [Google Scholar]
- Elseidy, M.; Abdelhamid, E.; Skiadopoulos, S.; Kalnis, P. Grami: Frequent subgraph and pattern mining in a single large graph. Proc. VLDB Endow. 2014, 7, 517–528. [Google Scholar] [CrossRef]
- Ur Rehman, M.H.; Liew, C.S.; Wah, T.Y.; Shuja, J.; Daghighi, B. Mining personal data using smartphones and wearable devices: A survey. Sensors 2015, 15, 4430–4469. [Google Scholar] [CrossRef] [PubMed]
- Lane, N.D.; Mohammod, M.; Lin, M.; Yang, X.; Lu, H.; Ali, S.; Doryab, A.; Berke, E.; Choudhury, T.; Campbell, A. Bewell: A smartphone application to monitor, model and promote wellbeing. In Proceedings of the 5th International ICST Conference on Pervasive Computing Technologies for Healthcare, Dublin, Ireland, 23–26 May 2011; pp. 23–26. [Google Scholar]
- Fahim, M.; Khattak, A.M.; Chow, F.; Shah, B. Tracking the sedentary lifestyle using smartphone: A pilot study. In Proceedings of the 18th International Conference on Advanced Communication Technology (ICACT), PyeongChang, Korea, 31 January–3 February 2016; pp. 296–299. [Google Scholar]
- Fahim, M.; Khattak, A.M.; Baker, T.; Chow, F.; Shah, B. Micro-context recognition of sedentary behaviour using smartphone. In Proceedings of the 2016 Sixth International Conference on Digital Information and Communication Technology and Its Applications (DICTAP), Konya, Turkey, 21–23 July 2016; pp. 30–34. [Google Scholar]
- Ganti, R.K.; Srinivasan, S.; Gacic, A. Multisensor fusion in smartphones for lifestyle monitoring. In Proceedings of the 2010 International Conference on Body Sensor Networks (BSN), Singapore, 7–9 June 2010; pp. 36–43. [Google Scholar]
- Wang, R.; Chen, F.; Chen, Z.; Li, T.; Harari, G.; Tignor, S.; Zhou, X.; Ben-Zeev, D.; Campbell, A.T. StudentLife: Assessing mental health, academic performance and behavioral trends of college students using smartphones. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WC, USA, 13–17 September 2014; pp. 3–14. [Google Scholar]
- Sheng, X.; Tang, J.; Wang, J.; Li, T.; Xue, G.; Yang, D. LIPS: Lifestyle Learning via Mobile Phone Sensing. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–7. [Google Scholar]
- Core ML, A Machine Learning Framework in iOS. Available online: https://developer.apple.com/machine-learning/ (accessed on 25 October 2017).
- Torralba, A. Contextual priming for object detection. Int. J. Comput. Vis. 2003, 53, 169–191. [Google Scholar] [CrossRef]
- Li, H.; Wang, F.; Zhang, S. Global and local features based topic model for scene recognition. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Anchorage, AK, USA, 9–12 October 2011; pp. 532–537. [Google Scholar]
- Gao, C.; Sang, N.; Huang, R. Spatial multi-scale gradient orientation consistency for place instance and Scene category recognition. Inf. Sci. 2016, 372, 84–97. [Google Scholar] [CrossRef]
- Wu, J.; Rehg, J.M. Where am I: Place instance and category recognition using spatial PACT. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Song, X.; Jiang, S.; Herranz, L.; Kong, Y.; Zheng, K. Category co-occurrence modeling for large scale scene recognition. Pattern Recognit. 2016, 59, 98–111. [Google Scholar] [CrossRef]
- Ceccaroni, L.; Codina, V.; Palau, M.; Pous, M. PaTac: Urban, ubiquitous, personalized services for citizens and tourists. In Proceedings of the Third International Conference on Digital Society (ICDS’09), Cancun, Mexico, 1–7 February 2009; pp. 7–12. [Google Scholar]
- Castillo, L.; Armengol, E.; Onaindía, E.; Sebastiá, L.; González-Boticario, J.; Rodríguez, A.; Fernández, S.; Arias, J.D.; Borrajo, D. SAMAP: An user-oriented adaptive system for planning tourist visits. Expert Syst. Appl. 2008, 34, 1318–1332. [Google Scholar] [CrossRef]
- Lee, C.S.; Chang, Y.C.; Wang, M.H. Ontological recommendation multi-agent for Tainan City travel. Expert Syst. Appl. 2009, 36, 6740–6753. [Google Scholar] [CrossRef]
- Sebastia, L.; Giret, A.; Garcia, I. A Multi Agent Architecture for Tourism Recommendation. In Trends in Practical Applications of Agents and Multiagent Systems; Springer: Berlin, Germany, 2010; pp. 547–554. [Google Scholar]
- Lee, J. A graph-based approach for modeling and indexing video data. In Proceedings of the 8th IEEE International Symposium on Multimedia (ISM’06), San Diego, CA, USA, 11–13 December 2006; pp. 348–355. [Google Scholar]
- Inokuchi, A.; Washio, T.; Motoda, H. An apriori-based algorithm for mining frequent substructures from graph data. In Proceedings of the 4th European Conference on Principles of Data Mining and Knowledge Discovery, Lyon, France, 13–16 September 2000; pp. 13–23. [Google Scholar]
- Bifet, A.; Holmes, G.; Pfahringer, B.; Gavaldà, R. Mining frequent closed graphs on evolving data streams. In Proceedings of the 17th ACM SIGKDD International Conference On Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 591–599. [Google Scholar]
- Huan, J.; Wang, W.; Prins, J.; Yang, J. Spin: Mining maximal frequent subgraphs from graph databases. In Proceedings of the 10th ACM SIGKDD International Conference On Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 581–586. [Google Scholar]
- Kuramochi, M.; Karypis, G. Finding frequent patterns in a large sparse graph. Data Min. Knowl. Discov. 2005, 11, 243–271. [Google Scholar] [CrossRef]
- Kuramochi, M.; Karypis, G. Grew-a scalable frequent subgraph discovery algorithm. In Proceedings of the 4th IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004; pp. 439–442. [Google Scholar]
- Jiang, C.; Coenen, F.; Zito, M. A survey of frequent subgraph mining algorithms. Knowl. Eng. Rev. 2013, 28, 75–105. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Algorithm | Output |
|---|---|---|
| Set of sequence graphs | gSpan | Frequent patterns |
| Set of sequence graphs | Gaston | Maximal frequent patterns |
| Set of sequence graphs | kFISM | Top-k frequent induced patterns |
| Cumulated graph | GRAMI | Frequent patterns |
| Name | Instances | Class Labels | Type of Evaluation |
|---|---|---|---|
| 8-Scenes (8S) [1] | 2688 | 8 | accuracy of processing OOIs |
| INRIA Holidays [2] | 900 | 8 | accuracy of processing OOIs, pattern mining |
| Memetracker (MT) | 13 M | execution time of data migration phase | |
| Brightkite (BK) | 4.4 M | execution time of data migration phase | |
| Twitter7 (T7) | 15 M | execution time of data migration phase |
| Data Migration Mode | Set of Operations |
|---|---|
| Type-1 | 1. Data loading 2. Mapping data attributes 3. In-memory SQL operations 4. Data cleaning 5. Save to the HDFS in Parquet file format 6. Data normalisation |
| Type-2 | 1. Data loading 2. Mapping data attributes 3. In-memory SQL operations 4. Data cleaning 5. Save to the HDFS in Parquet file format 6. Data normalisation |
| Type-3 | 1. Data loading 2. Mapping data attributes 3. In-memory SQL operations 4. Data cleaning 5. Save to the HDFS in Parquet file format 6. Data normalisation |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, K.U.; Alam, A.; Dolgorsuren, B.; Uddin, M.A.; Umair, M.; Sang, U.; Duong, V.T.T.; Xu, W.; Lee, Y.-K. LPaMI: A Graph-Based Lifestyle Pattern Mining Application Using Personal Image Collections in Smartphones. Appl. Sci. 2017, 7, 1200. https://doi.org/10.3390/app7121200
Khan KU, Alam A, Dolgorsuren B, Uddin MA, Umair M, Sang U, Duong VTT, Xu W, Lee Y-K. LPaMI: A Graph-Based Lifestyle Pattern Mining Application Using Personal Image Collections in Smartphones. Applied Sciences. 2017; 7(12):1200. https://doi.org/10.3390/app7121200
Chicago/Turabian StyleKhan, Kifayat Ullah, Aftab Alam, Batjargal Dolgorsuren, Md Azher Uddin, Muhammad Umair, Uijeong Sang, Van T.T. Duong, Weihua Xu, and Young-Koo Lee. 2017. "LPaMI: A Graph-Based Lifestyle Pattern Mining Application Using Personal Image Collections in Smartphones" Applied Sciences 7, no. 12: 1200. https://doi.org/10.3390/app7121200