Road Safety Risk Evaluation Using GIS-Based Data Envelopment Analysis—Artificial Neural Networks Approach

 , ,
, ,
Abstract
:1. Introduction
2. Literature Review
2.1. Risk and Road Safety Analysis
2.2. DEA for Road Safety Analysis
2.3. ANNs for Road Safety Analysis
2.4. DEA-ANNs Approach
2.5. GIS for Road Safety Analysis
2.6 ANN-GIS Approach
2.7. Research Gap
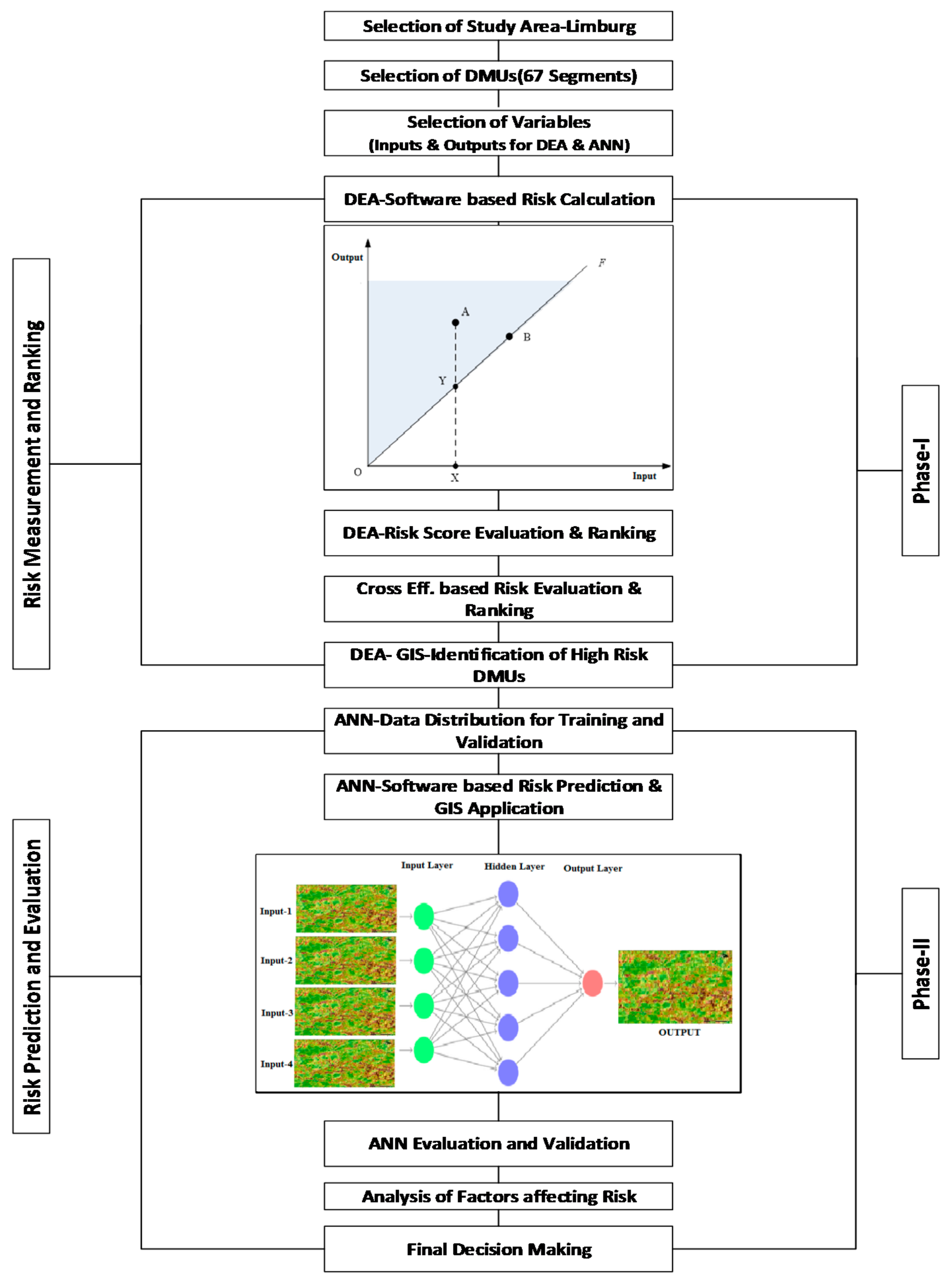
3. Materials and Methods
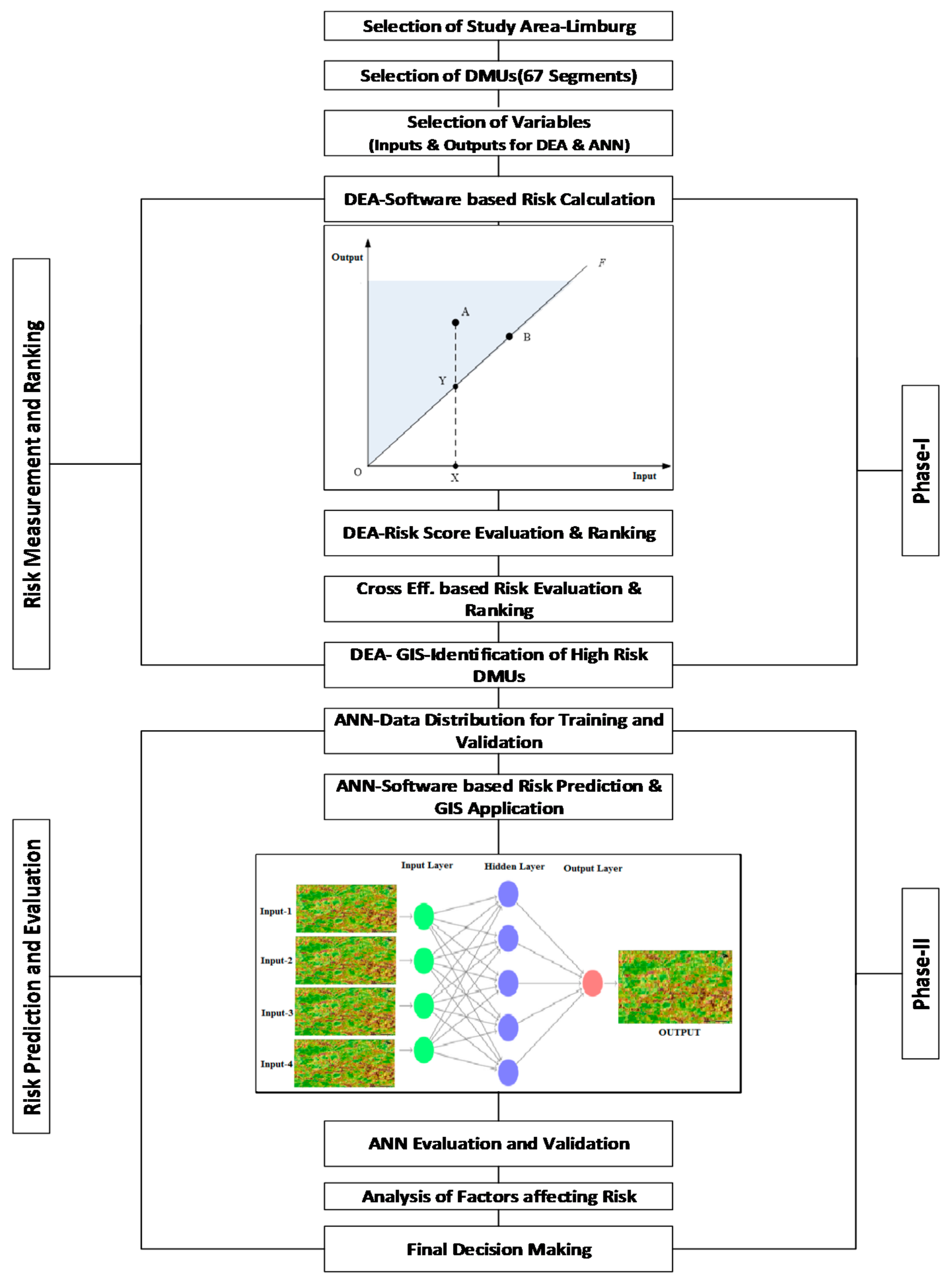
3.1. Basic Framework of the Analysis
3.2. Data Description and Selection of Variables
3.3. Phase-I: Application of DEA for Risk Calculation and Ranking
3.4. Phase-II: Application of ANNs Model for Risk Prediction and Evaluation
3.5. Model Selection Criteria
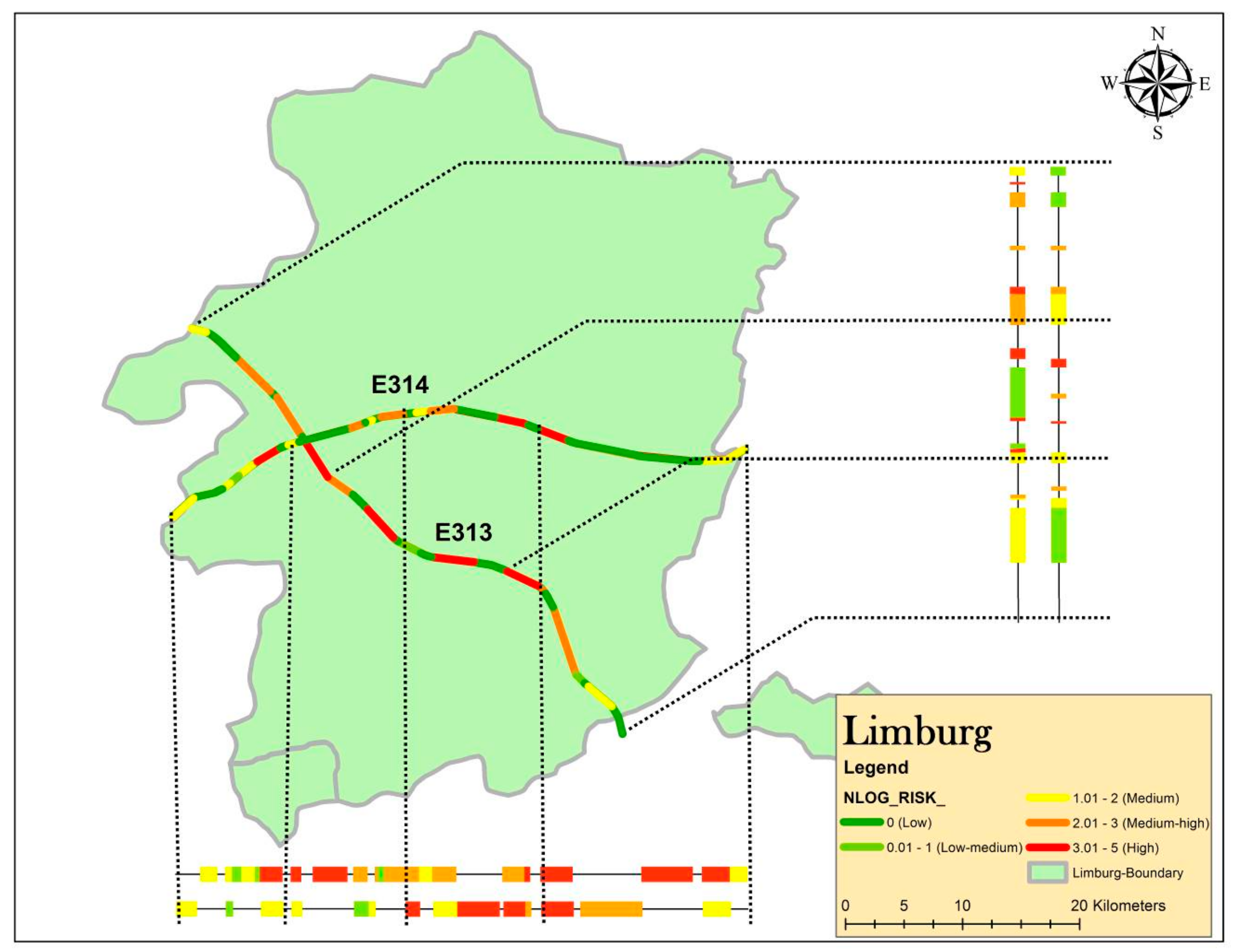
4. Results
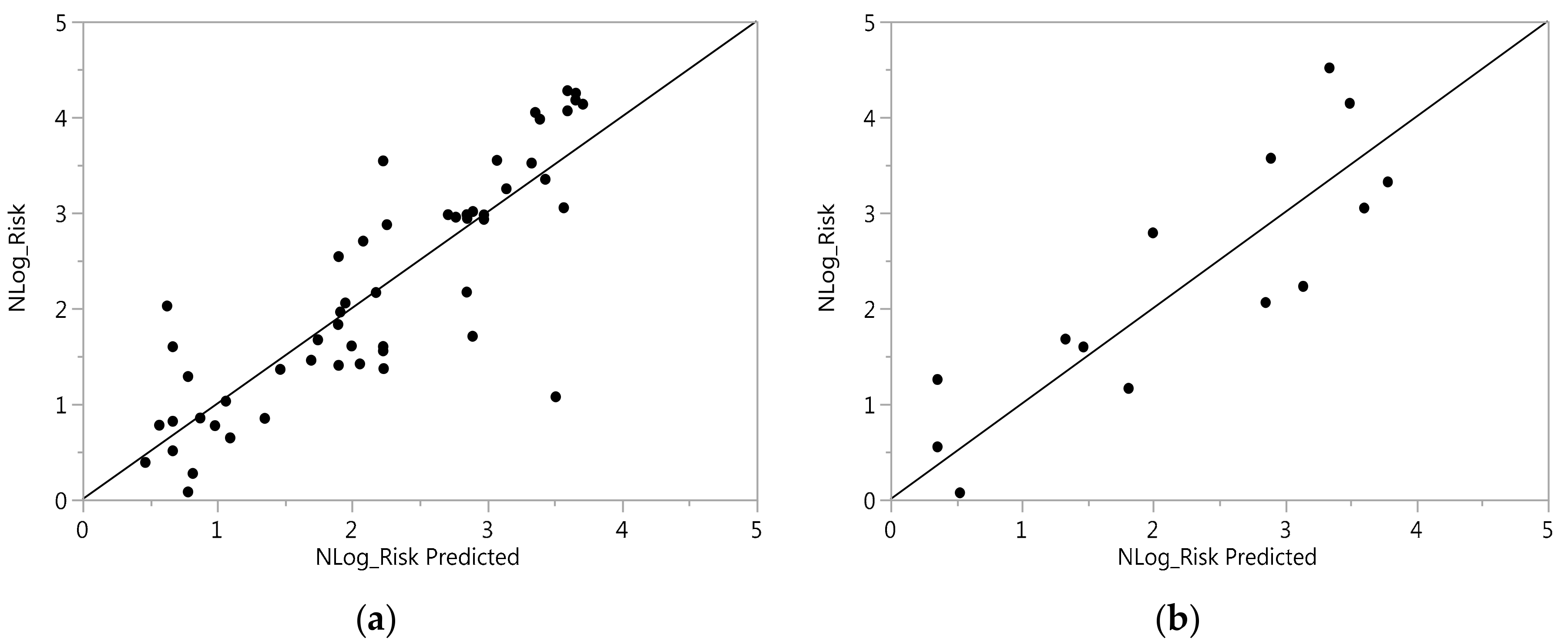
4.1. Performance of Model
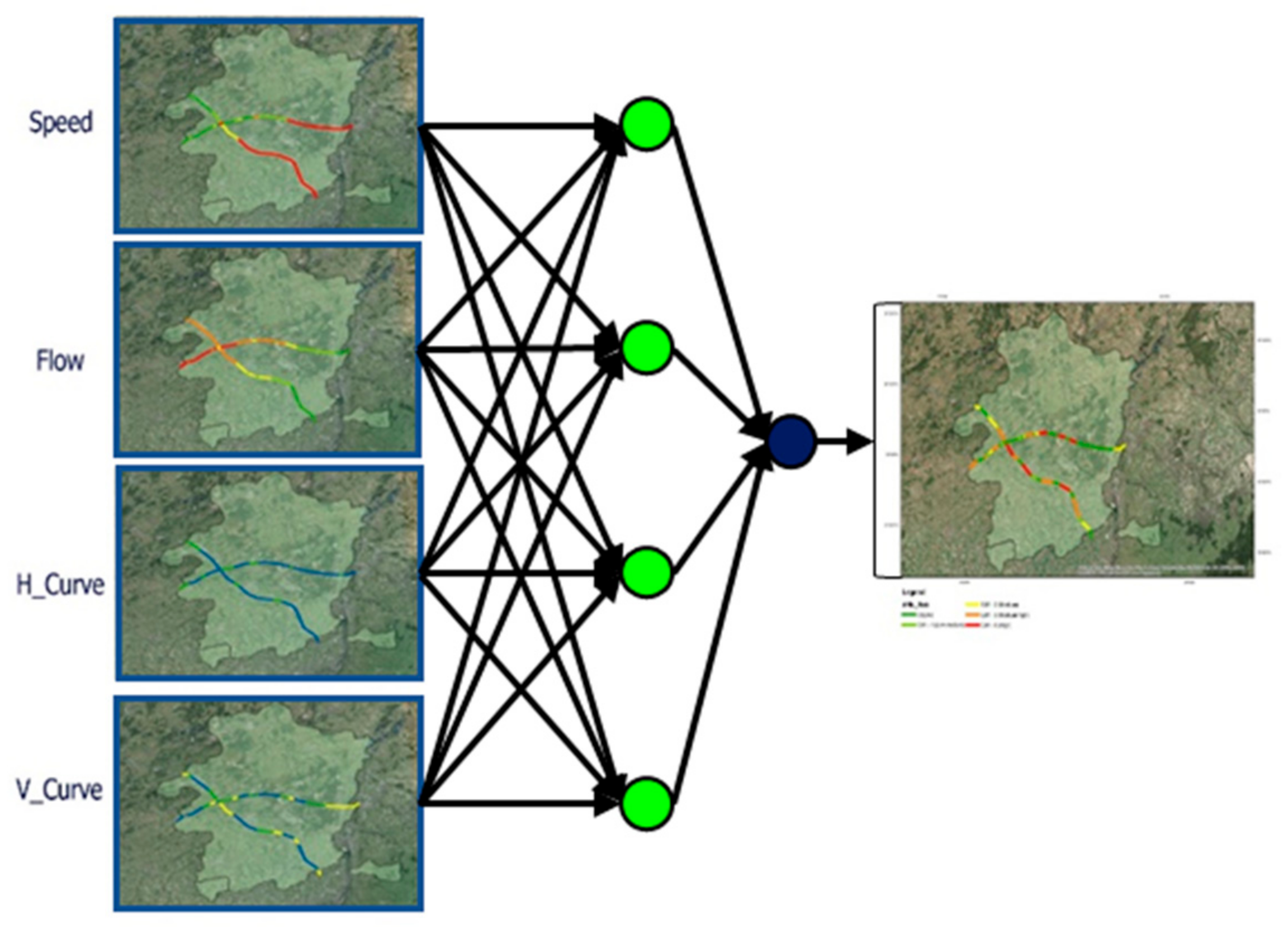
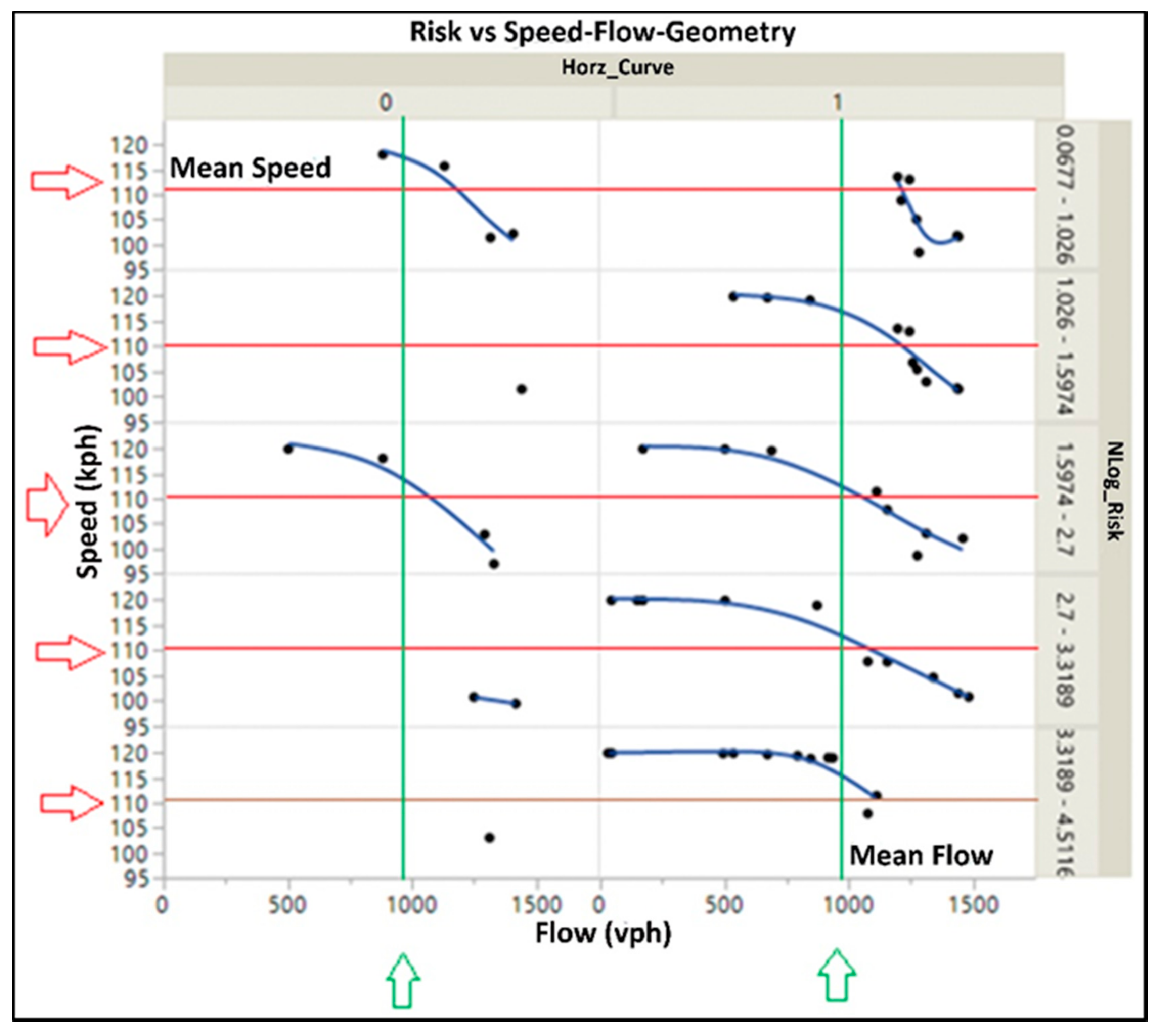
4.2. Analysis of Factors
4.2.1. Speed
4.2.2. Flow
4.2.3. Horizontal Curve
4.2.4. Vertical Curve
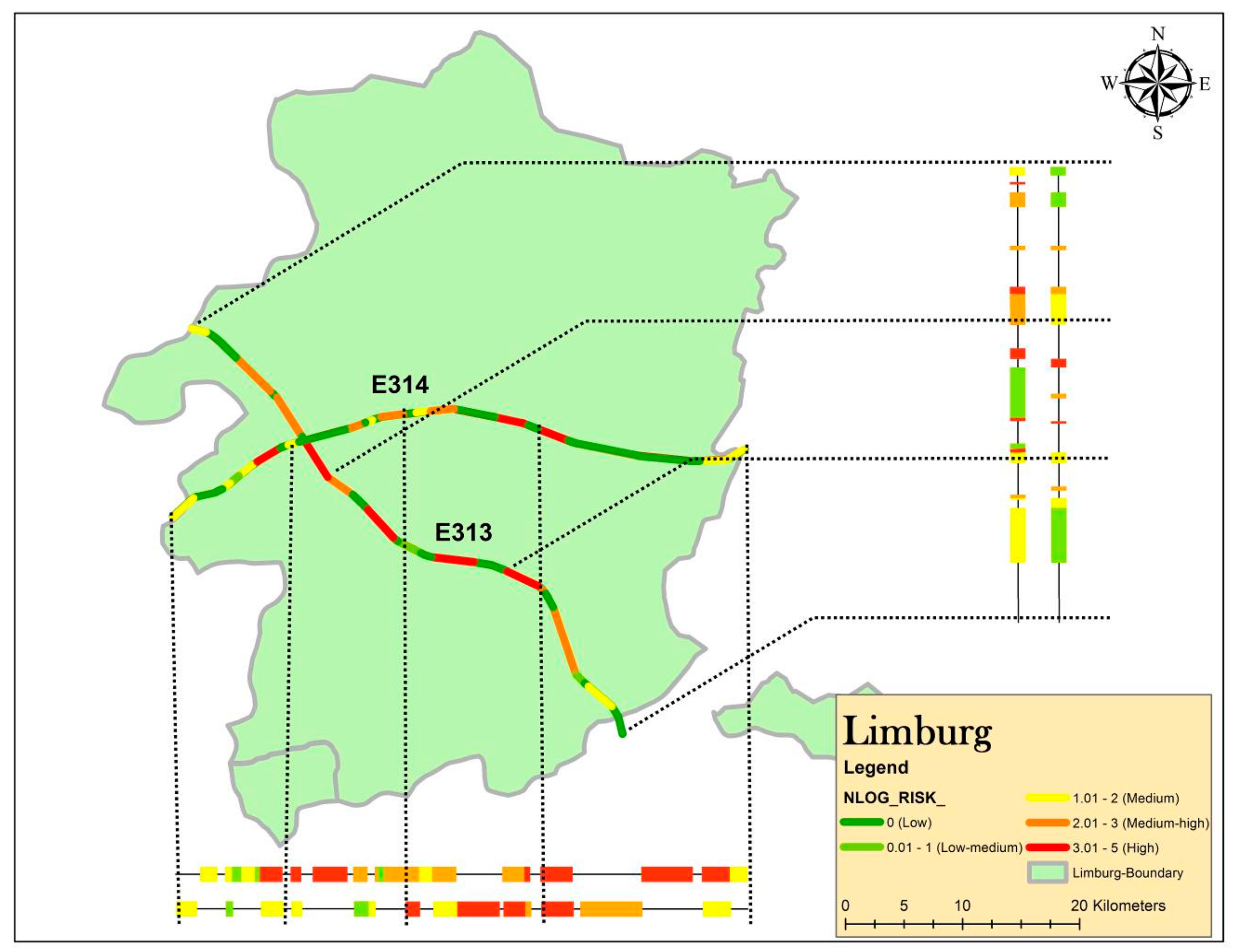
4.3. Safety Management and Financial Decision Making
4.4. Advantages and Limitations of Using the DEA-ANN Method
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Songchitruksa, P.; Tarko, A.P. The extreme value theory approach to safety estimation. Accid. Anal. Prev. 2006, 38, 811–822. [Google Scholar] [CrossRef] [PubMed]
- Golob, T.F.; Recker, W.W.; Alvarez, V.M. Tool to evaluate safety effects of changes in freeway traffic flow. J. Transp. Eng. 2004, 130, 222–230. [Google Scholar] [CrossRef]
- Kwon, H.B. Exploring the predictive potential of artificial neural networks in conjunction with DEA in railroad performance modeling. Int. J. Prod. Econ. 2017, 183, 159–170. [Google Scholar] [CrossRef]
- Hsiang, H.L.; Chen, T.Y.; Chiu, Y.H.; Kuo, F.H. A comparison of three-stage DEA and artificial neural network on the operational efficiency of semi-conductor firms in Taiwan. Mod. Econ. 2013, 4, 20. [Google Scholar]
- Sreekumar, S.; Mahapatra, S. Performance modeling of Indian business schools: A DEA-neural network approach. Benchmarking 2011, 18, 221–239. [Google Scholar] [CrossRef]
- Kwon, H.B. Performance modeling of mobile phone providers: A DEA-ANN combined approach. Benchmarking 2014, 21, 1120–1144. [Google Scholar] [CrossRef]
- Azadeh, A.; Azadeh, A.; Saberi, M.; Moghaddam, R.T.; Javanmardi, L. An integrated data envelopment analysis–artificial neural network–rough set algorithm for assessment of personnel efficiency. Expert Syst. Appl. 2011, 38, 1364–1373. [Google Scholar] [CrossRef]
- Mostafa, M.M. Modeling the efficiency of top Arab banks: A DEA–neural network approach. Expert Syst. Appl. 2009, 36, 309–320. [Google Scholar] [CrossRef]
- Emrouznejad, A.; Anouze, A.L. Data envelopment analysis with classification and regression tree—A case of banking efficiency. Expert Syst. 2010, 27, 231–246. [Google Scholar] [CrossRef]
- Samoilenko, S.; Osei-Bryson, K.M. Using Data Envelopment Analysis (DEA) for monitoring efficiency-based performance of productivity-driven organizations: Design and implementation of a decision support system. Omega 2013, 41, 131–142. [Google Scholar] [CrossRef]
- Çelebi, D.; Bayraktar, D. An integrated neural network and data envelopment analysis for supplier evaluation under incomplete information. Expert Syst. Appl. 2008, 35, 1698–1710. [Google Scholar] [CrossRef]
- Kuo, R.J.; Wang, Y.C.; Tien, F.C. Integration of artificial neural network and MADA methods for green supplier selection. J. Clean. Prod. 2010, 18, 1161–1170. [Google Scholar] [CrossRef]
- Pendharkar, P.C. A hybrid radial basis function and data envelopment analysis neural network for classification. Comput. Oper. Res. 2011, 38, 256–266. [Google Scholar] [CrossRef]
- Al Haji, G. Towards a Road Safety Development Index (RSDI): Development of an International Index to Measure Road Safety Performance; Linköping University Electronic Press: Linköping, Sweden, 2005; p. 113. [Google Scholar]
- Yannis, G.; Papadimitriou, E.; Lejeune, P.; Treny, V.; Hemdorff, S.; Bergel, R.; Haddak, M.; Holló, P.; Cardoso, J.; Bijleveld, F.; et al. State of the Art Report on Risk and Exposure Data. SafetyNet, Building the European Road Safety Observatory, Workp 2 Deliv D2; European Road Safety Observatory: Brussels, Belgium, 2007; p. 120. [Google Scholar]
- Elke, H.; Tom, B.; Geert, W.; Koen, V. Benchmarking road safety: Lessons to learn from a data envelopment analysis. Accid. Anal. Prev. 2009, 41, 174–182. [Google Scholar]
- Wegman, F.; Oppe, S. Benchmarking road safety performances of countries. Saf. Sci. 2010, 48, 1203–1211. [Google Scholar] [CrossRef]
- Shen, Y.; Hermans, E.; Bao, Q.; Brijs, T.; Wets, G. Serious injuries: An additional indicator to fatalities for road safety benchmarking. Traffic Inj. Prev. 2015, 16, 246–253. [Google Scholar] [CrossRef] [PubMed]
- Charnes, A.; Cooper, W.W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Shen, Y.; Hermans, E.; Brijs, T.; Wets, G.; Vanhoof, K. Road safety risk evaluation and target setting using data envelopment analysis and its extensions. Accid. Anal. Prev. 2012, 48, 430–441. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Hermans, E.; Ruan, D.; Wets, G.; Brijs, T.; Vanhoof, K. Evaluating trauma management performance in Europe: A multiple-layer data envelopment analysis model. Transp. Res. Rec. 2010, 2148, 69–75. [Google Scholar] [CrossRef]
- Shen, Y.; Hermans, E.; Bao, Q.; Brijs, T.; Wets, G. Road safety development in Europe: A decade of changes (2001–2010). Accid. Anal. Prev. 2013, 60, 85–94. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Shen, Y.; Hermans, E.; Bao, Q.; Brijs, T.; Wets, G.; Wang, W. Inter-national benchmarking of road safety: State of the art. Transp. Res. Part C 2015, 50, 37–50. [Google Scholar] [CrossRef]
- Bastos, J.T.; Shen, Y.; Hermans, E.; Brijs, T.; Wets, G.; Ferraz, A.C.P. Traffic fatality indicators in Brazil: State diagnosis based on data envelopment analysis research. Accid. Anal. Prev. 2015, 81, 61–73. [Google Scholar] [CrossRef] [PubMed]
- Williams, J.; Li, Y. A case study using neural networks algorithms: Horse racing predictions in Jamaica. In Proceedings of the International Conference on Artificial Intelligence (ICAI 2008), Las Vegas, NV, USA, 14–17 July 2008. [Google Scholar]
- Abdelwahab, H.; Abdel Aty, M. Development of artificial neural network models to predict driver injury severity in traffic accidents at signalized intersections. Transp. Res. Rec. 2001, 1746, 6–13. [Google Scholar] [CrossRef]
- Chong, M.M.; Abraham, A.; Paprzycki, M. Traffic accident analysis using decision trees and neural networks. arXiv, 2004; arXiv:cs/0405050. [Google Scholar]
- Yasin Çodur, M.; Tortum, A. An Artificial Neural Network Model for Highway Accident Prediction: A Case Study of Erzurum, Turkey. Promet-Traffic Transp. 2015, 27, 217–225. [Google Scholar]
- Zeng, Q.; Huang, H.; Pei, X.; Wong, S.C. Modeling nonlinear relationship between crash frequency by severity and contributing factors by neural networks. Anal. Sci Accid. Res. 2016, 10, 12–25. [Google Scholar] [CrossRef]
- Athanassopoulos, A.D.; Curram, S.P. A comparison of data envelopment analysis and artificial neural networks as tools for assessing the efficiency of decision making units. J. Oper. Res. Soc. 1996, 1000–1016. [Google Scholar] [CrossRef]
- Vaninsky, A. Combining data envelopment analysis with neural networks: Application to analysis of stock prices. J. Inf. Optim. Sci. 2004, 25, 589–611. [Google Scholar] [CrossRef]
- Azadeh, A.; Javanmardi, L.; Saberi, M. The impact of decision-making units features on efficiency by integration of data envelopment analysis, artificial neural network, fuzzy C-means and analysis of variance. Int. J. Oper. Res. 2010, 7, 387–411. [Google Scholar] [CrossRef]
- Ülengin, F.; Kabak, Ö.; Önsel, S.; Aktas, E.; Parker, B.R. The competitiveness of nations and implications for human development. Socio-Econ. Plan. Sci. 2011, 45, 16–27. [Google Scholar] [CrossRef]
- Wu, D.D.; Yang, Z.; Liang, L. Using DEA-neural network approach to evaluate branch efficiency of a large Canadian bank. Expert Syst. Appl. 2006, 31, 108–115. [Google Scholar] [CrossRef]
- Wu, D. Supplier selection: A hybrid model using DEA, decision tree and neural network. Expert Syst. Appl. 2009, 36, 9105–9112. [Google Scholar] [CrossRef]
- Ciobanu, S.M.; Benedek, J. Spatial characteristics and public health consequences of road traffic injuries in Romania. Environ. Eng. Manag. 2015, 14, 2689–2702. [Google Scholar]
- Wang, C.; Quddus, M.A.; Ison, S.G. Impact of traffic congestion on road accidents: A spatial analysis of the M25 motorway in England. Accid. Anal. Prev. 2009, 41, 798–808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.; Li, T.; Sun, J.; Chen, F. Hotspot Identification for Shanghai Expressways Using the Quantitative Risk Assessment Method. Int. J. Environ. Res. Public Health 2016, 14, 20. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Yan, X.; Ma, L.; An, M. Crash prediction and risk evaluation based on traffic analysis zones. Math. Probl. Eng. 2014, 2014, 9. [Google Scholar] [CrossRef]
- Moradi, A.; Soori, H.; Kavousi, A.; Eshghabadi, F.; Jamshidi, E.; Zeini, S. Spatial analysis to identify high risk areas for traffic crashes resulting in death of pedestrians in Tehran. Med. J. Islam. Repub. Iran 2016, 30, 450. [Google Scholar] [PubMed]
- Steenberghen, T.; Dufays, T.; Thomas, I.; Flahaut, B. Intra-urban location and clustering of road accidents using GIS: a Belgian example. Int. J. Geogr. Inf. Sci. 2004, 18, 169–181. [Google Scholar] [CrossRef]
- Pirdavani, A.; Bellemans, T.; Brijs, T.; Wets, G. Application of geographically weighted regression technique in spatial analysis of fatal and injury crashes. J. Transp. Eng. 2014, 140, 04014032. [Google Scholar] [CrossRef]
- Pirdavani, A.; Bellemans, T.; Brijs, T.; Kochan, B.; Wets, G. Assessing the road safety impacts of a teleworking policy by means of geographically weighted regression method. J. Saf. Res. 2014, 39, 96–110. [Google Scholar] [CrossRef]
- Eksler, V.; Lassarre, S. Evolution of road risk disparities at small-scale level: Example of Belgium. J. Pet. Sci. Eng. 2008, 39, 417–427. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Rosenbaum, M. Artificial neural networks linked to GIS for determining sedimentology in harbours. J. Pet. Sci. Eng. 2001, 29, 213–220. [Google Scholar] [CrossRef]
- Sameen, M.I.; Pradhan, B. Severity Prediction of Traffic Accidents with Recurrent Neural Networks. Appl. Sci. 2017, 7, 476. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S.; Buchroithner, M.F. A GIS-based back-propagation neural network model and its cross-application and validation for landslide susceptibility analyses. Comput. Environ. Urban Syst. 2010, 34, 216–235. [Google Scholar] [CrossRef]
- Elsafi, S.H. Artificial neural networks (ANNs) for flood forecasting at Dongola Station in the River Nile, Sudan. Alex. Eng. J. 2014, 53, 655–662. [Google Scholar] [CrossRef]
- Lee, S.; Park, I.; Koo, B.J.; Ryu, J.H.; Choi, J.K.; Woo, H.J. Macrobenthos habitat potential mapping using GIS-based artificial neural network models. Mar. Pollut. Bull. 2013, 67, 177–186. [Google Scholar] [CrossRef] [PubMed]
- Pijanowski, B.C.; Brown, D.G.; Shellito, B.A.; Manik, G.A. Using neural networks and GIS to forecast land use changes: A land transformation model. Comput. Environ. Urban Syst. 2002, 26, 553–575. [Google Scholar] [CrossRef]
- Yoo, C.; Kim, J.M. Tunneling performance prediction using an integrated GIS and neural network. Comput. Geotech. 2007, 34, 19–30. [Google Scholar] [CrossRef]
- Mas, J.F.; Puig, H.; Palacio, J.L.; Sosa López, A. Modelling deforestation using GIS and artificial neural networks. Environ. Model. Soft 2004, 19, 461–471. [Google Scholar] [CrossRef]
- Janssens, D.; Wets, G.; Timmermans, H.J.; Arentze, T.A. Modelling short-term dynamics in activity-travel patterns: Conceptual framework of the Feathers model. In Proceedings of the 11th World Conference on Transport Research, Berkeley, CA, USA, 24–28 June 2007. [Google Scholar]
- Avkiran, N.K. An application reference for data envelopment analysis in branch banking: Helping the novice researcher. Int. J. Bank Mark 1999, 17, 206–220. [Google Scholar] [CrossRef]
- Galagedera, D.; Silvapulle, P. Experimental evidence on robustness of data envelopment analysis. J. Oper. Res. Soc. 2003, 54, 654–660. [Google Scholar] [CrossRef]
- Raab, R.L.; Lichty, R.W. Identifying subareas that comprise a greater metropolitan area: The criterion of county relative efficiency. J. Reg. Sci. 2002, 42, 579–594. [Google Scholar] [CrossRef]
- Shmueli, G.; Patel, N.R.; Bruce, P.C. Data Mining for Business Analytics: Concepts, Techniques and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Jmp, A.; Proust, M. Specialized Models; AS Institute Inc.: Cary, NC, USA, 2013. [Google Scholar]
- Tso, G.K.; Yau, K.K. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Elvik, R. Speed and road safety: Synthesis of evidence from evaluation studies. Transp. Res. Rec. 2005, 1908, 59–69. [Google Scholar] [CrossRef]
- Kweon, Y.J.; Kockelman, K. Safety effects of speed limit changes: Use of panel models, including speed, use, and design variables. Transp. Res. Rec. 2005, 1908, 148–158. [Google Scholar] [CrossRef]
- WHO. World Report on Road Traffic Injury Prevention; World Health Organization: Geneva, Switzerland, 2004. [Google Scholar]
- Garber, N.; Ehrhart, A. Effect of speed, flow, and geometric characteristics on crash frequency for two-lane highways. Transp. Res. Rec. 2000, 1717, 76–83. [Google Scholar] [CrossRef]
- Golob, T.F.; Recker, W.; Pavlis, Y. Probabilistic models of freeway safety performance using traffic flow data as predictors. Saf. Sci. 2008, 46, 1306–1333. [Google Scholar] [CrossRef]
- Xie, F.; Feng, Q. Research of effects of accident on traffic flow characteristics. In Proceedings of the International Conference on Mechatronic Sciences, Electric Engineering and Computer (MEC), Shengyang, China, 20–22 December 2013. [Google Scholar]
- Zhang, Y. Analysis of the Relation between Highway Horizontal Curve and Traffic Safety. In Proceedings of the International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Zhangjiajie, China, 11–12 April 2009. [Google Scholar]
- Vayalamkuzhi, P.; Amirthalingam, V. Influence of geometric design characteristics on safety under heterogeneous traffic flow. Transp. Res. Rec. 2016, 3, 559–570. [Google Scholar] [CrossRef]
- Ma, M.; Yan, X.; Abdel Aty, M.; Huang, H.; Wang, X. Safety analysis of urban arterials under mixed-traffic patterns in Beijing. Transportation Research Record. Transp. Res. Rec. 2010, 2193, 105–115. [Google Scholar] [CrossRef]
- Zero, T. Towards Zero: Achieving Ambitious Road Safety Targets through a Safe System Approach; OECD: Paris, France, 2008. [Google Scholar]
- Yannis, G.; Evgenikos, P.; Papadimitriou, E. Best Practice for Cost-Effective Road Safety Infrastructure Investments; Conference of European Directors of Road (CEDR): Paris, France, 2008. [Google Scholar]
- Blumenberg, S. Benchmarking Financial Processes with Data Envelopment Analysis. 2005. Available online: www.is-frankfurt.de/publikationenNeu/BenchmarkingFinancialProcesses1208.pdf (accessed on 20 June 2017).
- Charnes, A.; Cooper, W.W.; Lewin, A.Y.; Seiford, L.M. Data Envelopment Analysis: Theory, Methodology, and Applications; Springer Science & Business Media: New York, NY, USA, 2013. [Google Scholar]
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Benardos, A. Applying artificial neural networks in slope stability related phenomena. In Proceedings of the 13th International Congress-Bulletin of the Geological Society of Greece (BGSG), Chania, Greece, 5–8 September 2013; pp. 1901–1911. [Google Scholar]


{kind=link}
{kind=link}
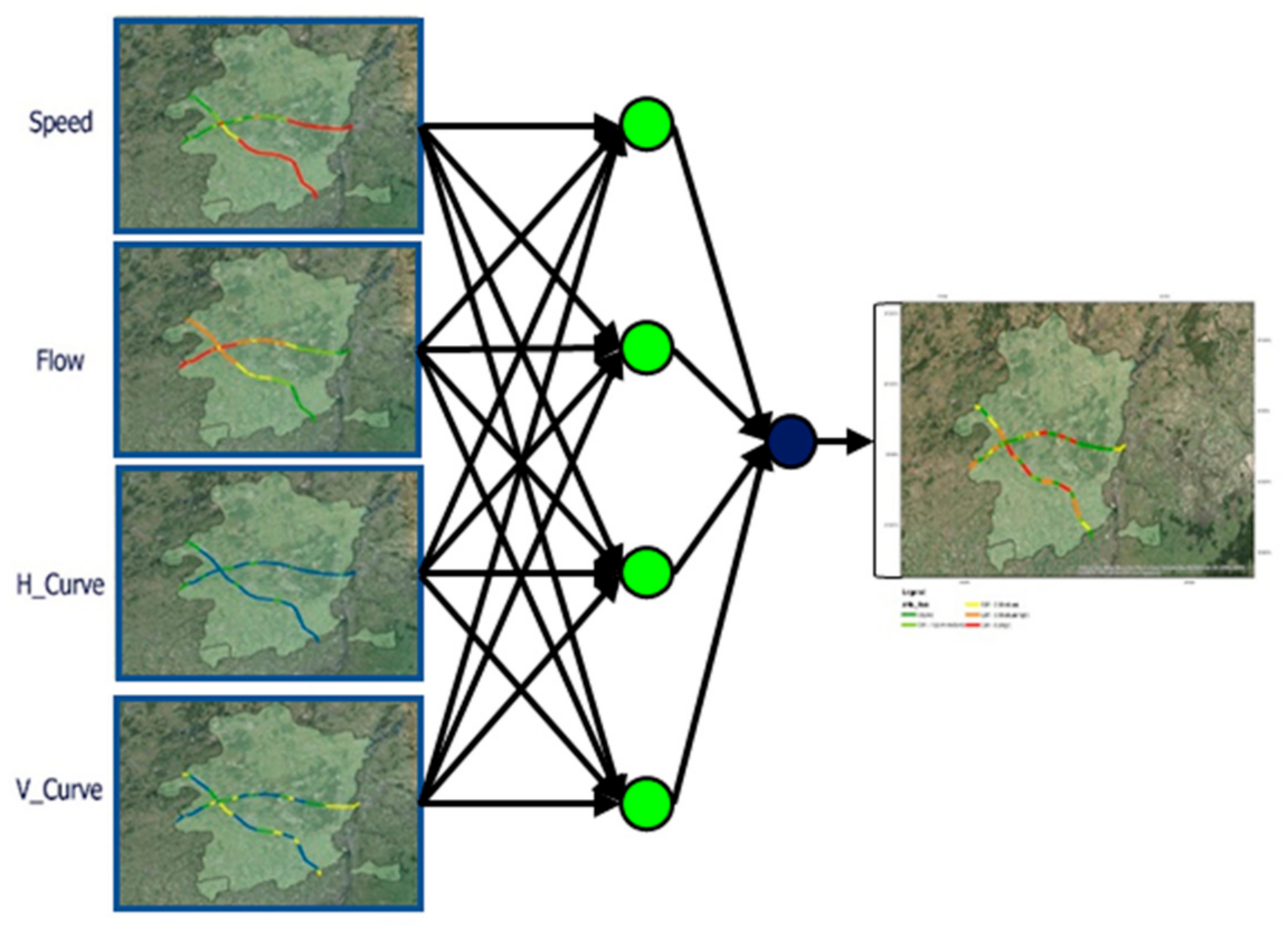{kind=link}
{kind=link}
{kind=link}
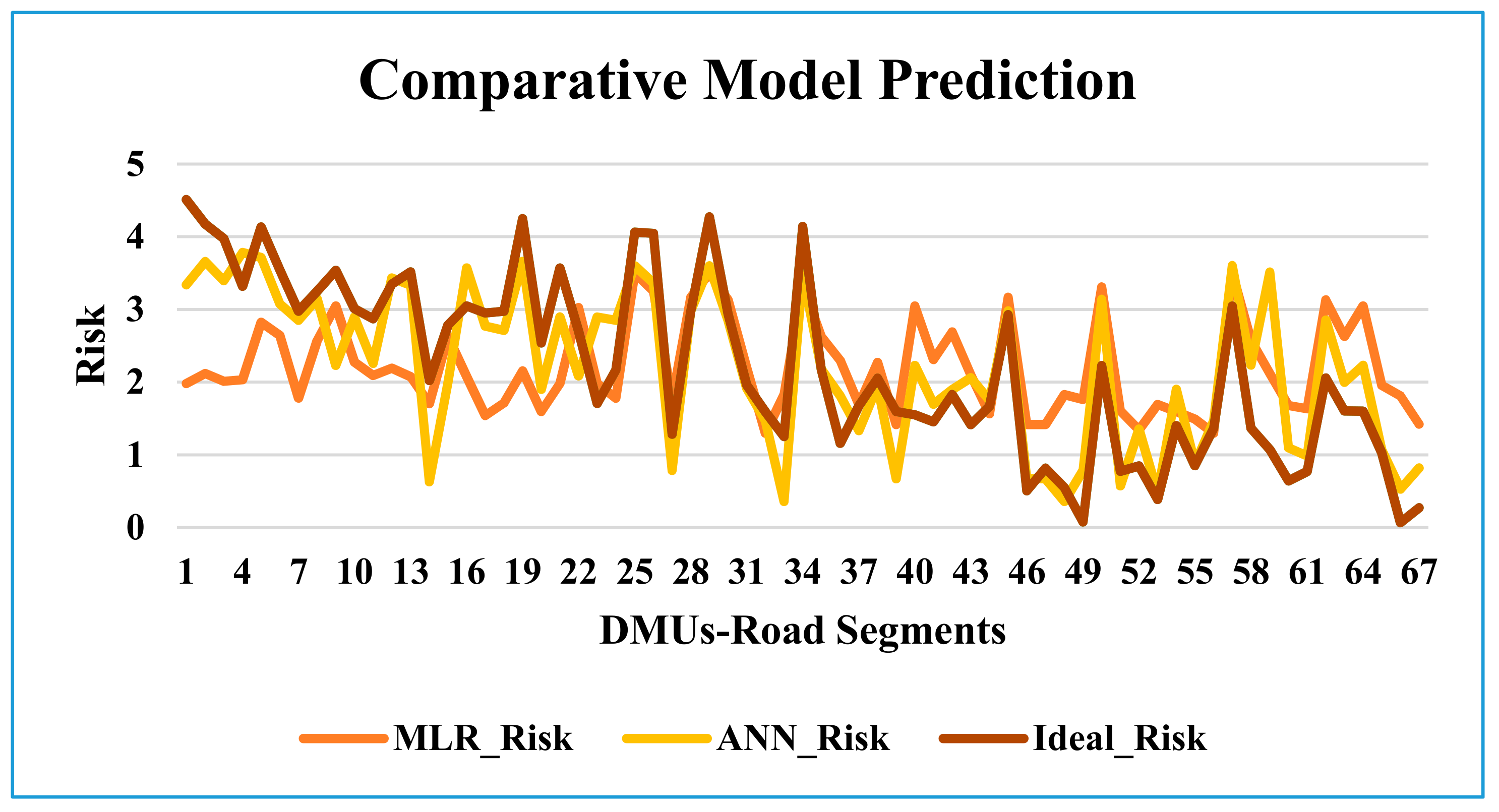{kind=link}
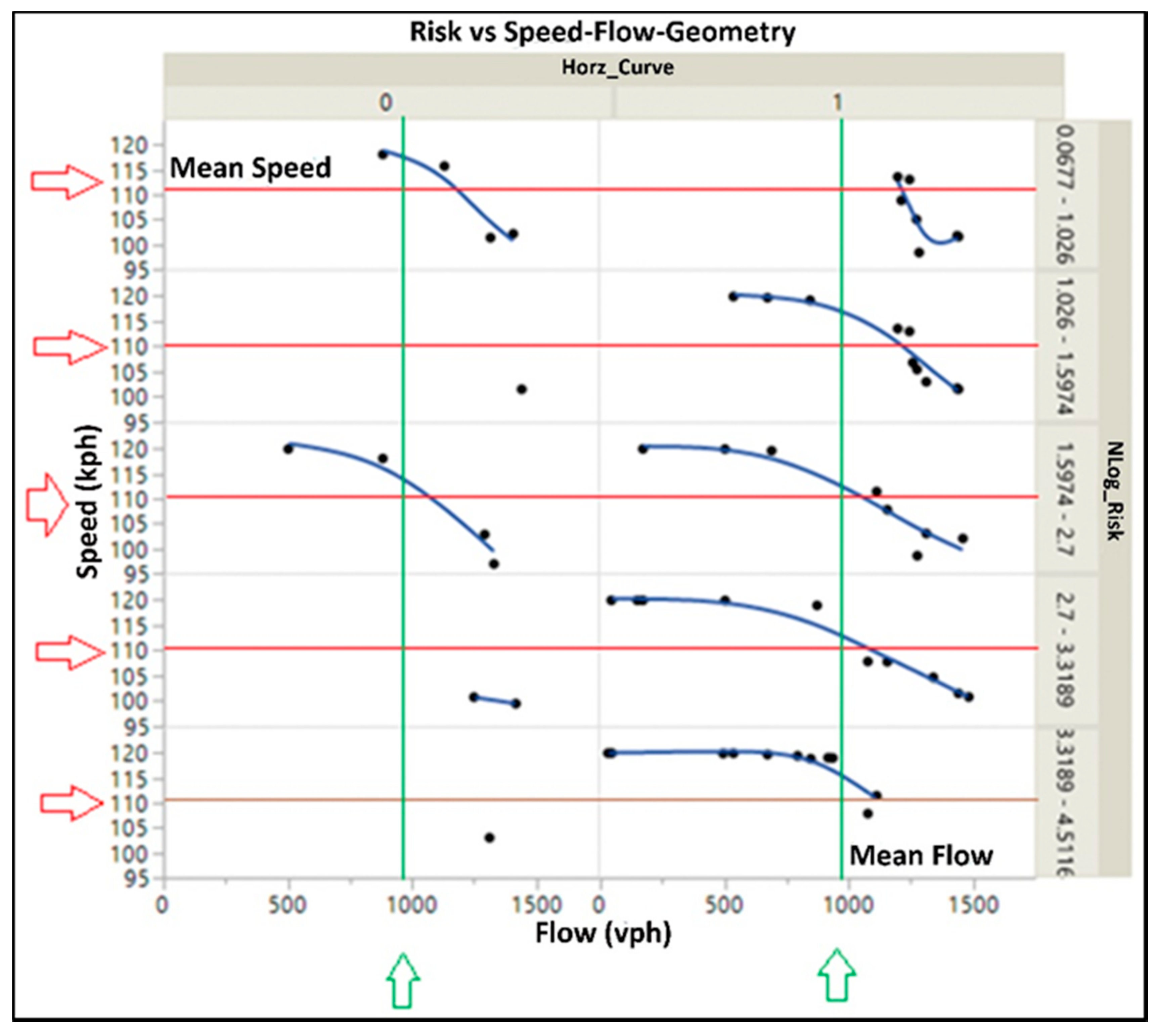{kind=link}
| Stage | Variables | Description | Mean | SD | Min. | Max. |
|---|---|---|---|---|---|---|
| 1st Stage DEA | NoC | No. of Crashes | 9.58 | 13.12 | 1 | 74 |
| NoAP | No. of Affected Persons (Injured and Killed) | 14.36 | 19.55 | 1 | 105 | |
| V/C | Average Volume to Capacity on each segment | 0.4405 | 0.1807 | 0.08 | 0.6435 | |
| VMT | Total daily Vehicles Miles Travelled on each Segment | 1828 | 1388 | 77 | 5186 | |
| VHT | Total daily Vehicles hours Travelled on each Segment | 1093 | 879 | 38 | 3616 | |
| 2nd Stage ANN | Flow | Average annual daily traffic on each segment (vph) | 968.1 | 449.6 | 31.5 | 1483.4 |
| Speed | Average Travel Speed for each segment (kph) | 110.99 | 8.23 | 96.89 | 120 | |
| Horz_Curve | 0 = Tangent, 1 = Curve | -- | -- | 0 | 1 | |
| Vert_Curve | 1 = Upward, 2 = Downward, 3 = Flat | -- | -- | 1 | 3 |
| Rating DMU | Rated DMU | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | …… | n | |
| 1 | …… | ||||
| 2 | …… | ||||
| . | . | . | . | . | . |
| n | …… | ||||
| Mean | …… | ||||
| DMUs | Input 1 | Input 2 | Input 3 | Output 1 | Output 2 | CE-RISK VALUE | RANK |
|---|---|---|---|---|---|---|---|
| Road Seg. | V/C | VMT | VHT | NoC | NoAP | ||
| 1 | 0.368518 | 3039.221 | 1541.607 | 74 | 105 | 91.06902 | 1 |
| 29 | 0.139052 | 109.169 | 54.58458 | 6 | 8 | 71.72984 | 2 |
| 19 | 0.603085 | 183.7303 | 118.162 | 12 | 20 | 69.92395 | 3 |
| 2 | 0.384021 | 2494.327 | 1268.376 | 49 | 76 | 65.10151 | 4 |
| 34 | 0.07999 | 82.51051 | 41.25526 | 3 | 6 | 62.90294 | 5 |
| 5 | 0.277711 | 2190.904 | 1096.683 | 38 | 50 | 62.28254 | 6 |
| 25 | 0.139052 | 76.73981 | 38.36996 | 3 | 6 | 58.10739 | 7 |
| 26 | 0.236548 | 202.3093 | 101.2386 | 9 | 11 | 57.15026 | 8 |
| 3 | 0.360649 | 2683.937 | 1361.267 | 40 | 61 | 53.2604 | 9 |
| 21 | 0.53409 | 594.7792 | 336.9631 | 13 | 24 | 35.40002 | 10 |
| - | - | - | - | - | - | - | - |
| 53 | 0.631117 | 4275.086 | 3046.694 | 2 | 3 | 1.47492 | 64 |
| 67 | 0.592324 | 1093.968 | 734.8267 | 1 | 1 | 1.312419 | 65 |
| 49 | 0.498964 | 3214.268 | 1780.697 | 1 | 2 | 1.08319 | 66 |
| 66 | 0.574944 | 1714.219 | 1098.003 | 1 | 1 | 1.068806 | 67 |
| Parameters | Estimates-Hidden Layer | ||||
|---|---|---|---|---|---|
| Code | H1_1 | H1_2 | H1_3 | H1_4 | |
| Flow | 0.258908 | −2.00717 | 0.868246 | 4.984629 | |
| Speed | −1.26756 | 3.435496 | −1.83834 | 2.048267 | |
| Horz_Curve | 0 | 2.150204 | 13.66468 | −1.03056 | 1.968045 |
| Vert_Curve | 1 | 2.141838 | −2.07175 | 1.313892 | 0.014534 |
| 2 | −3.21511 | 7.986301 | −3.09312 | −0.53461 | |
| Intercept | 1.90514 | −1.87443 | 0.481882 | −4.76064 | |
| Int | H1_1 | H1_2 | H1_3 | H1_4 | |
| NLog_Risk | 2.221 | −2.34861 | 6.612427 | −1.8978 | 2.041027 |
| Cross Validation | |||||
| Sample Size | Training | 53 | Validation | 14 | |
| R2 (Training) | 0.788 | R2 (Validation) | 0.775 | RMSE | 0.624 |
| Factor | Main Effect | Total Effect | Comparison |
|---|---|---|---|
| Flow | 0.224 | 0.908 |  |
| Speed | 0.064 | 0.47 | |
| Vert_Curve | 0.072 | 0.426 | |
| Horz_Curve | 0.052 | 0.288 |
| Model | R2 Predicted | R2 (K-Fold) Validation | RMSE |
|---|---|---|---|
| Sample Size | 53 | 14 | |
| ANN | 0.788 | 0.774 | 0.624109 |
| MLR | 0.276 | 0.147 | 1.0789985 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, S.A.R.; Brijs, T.; Ahmad, N.; Pirdavani, A.; Shen, Y.; Basheer, M.A. Road Safety Risk Evaluation Using GIS-Based Data Envelopment Analysis—Artificial Neural Networks Approach. Appl. Sci. 2017, 7, 886. https://doi.org/10.3390/app7090886
Shah SAR, Brijs T, Ahmad N, Pirdavani A, Shen Y, Basheer MA. Road Safety Risk Evaluation Using GIS-Based Data Envelopment Analysis—Artificial Neural Networks Approach. Applied Sciences. 2017; 7(9):886. https://doi.org/10.3390/app7090886
Chicago/Turabian StyleShah, Syyed Adnan Raheel, Tom Brijs, Naveed Ahmad, Ali Pirdavani, Yongjun Shen, and Muhammad Aamir Basheer. 2017. "Road Safety Risk Evaluation Using GIS-Based Data Envelopment Analysis—Artificial Neural Networks Approach" Applied Sciences 7, no. 9: 886. https://doi.org/10.3390/app7090886