Deep Region of Interest and Feature Extraction Models for Palmprint Verification Using Convolutional Neural Networks Transfer Learning

 , , , and
, , , and
Abstract
:1. Introduction
1.1. Contributions
- To the best of our knowledge, this is the first study that extracts palmprint ROIs by convolutional neural networks. Lack of sample images and small intra-class variability are addressed using transfer learning.
- We successively apply a pre-trained CNN network to extract discriminative features along with a machine learning classifier to measure the similarity for one-to-one matching.
- We achieve an intersection over union (IoU) score of 93% for palmprint ROI extraction and equal error rate (EER) of 0.0125 for the verification task using the support vector machine (SVM) classifier for the contact-based Hong Kong Polytechnic University Palmprint (HKPU) database. This can be attributed to the superiority of discriminative deeply learned features over hand-crafted features.
1.2. Paper Organization
2. Related Work
2.1. ROI Extraction
2.2. Feature Extraction and Matching
3. Proposed Model
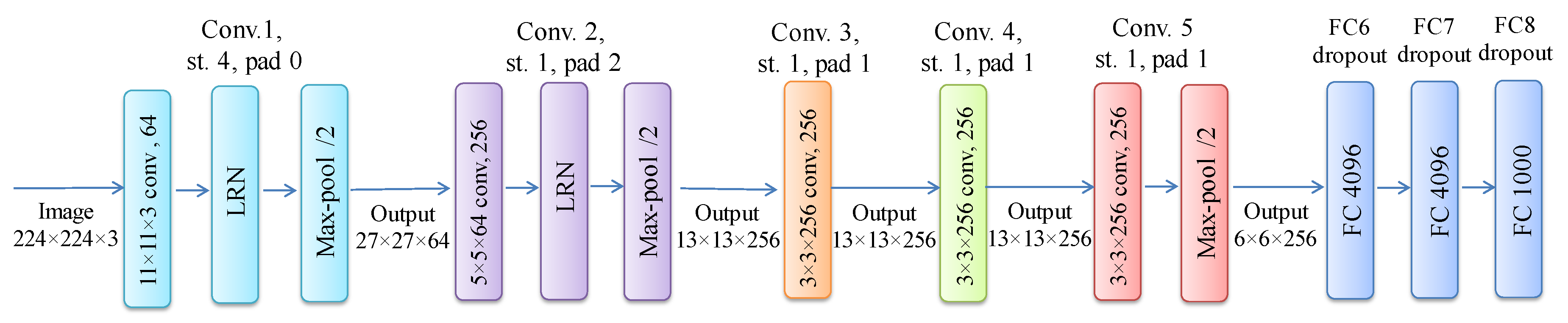
3.1. Background
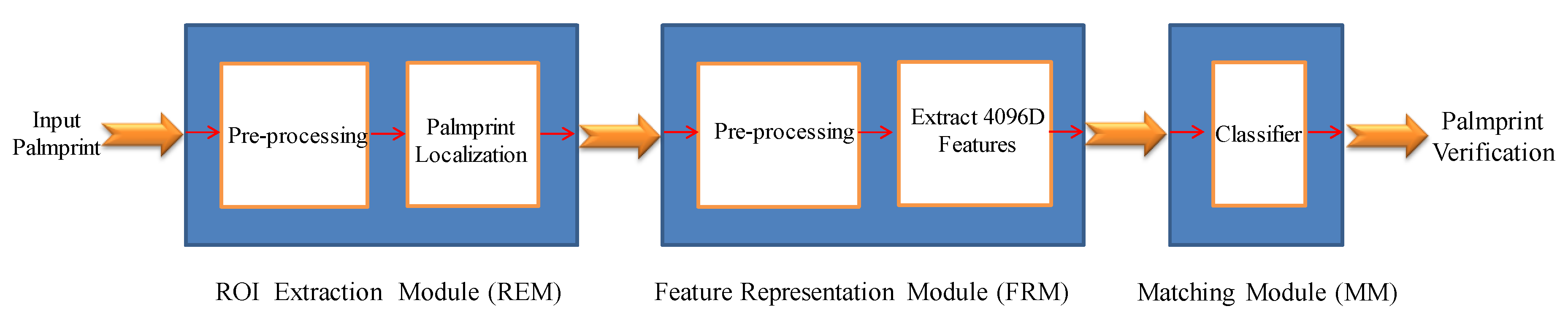
3.2. Outline
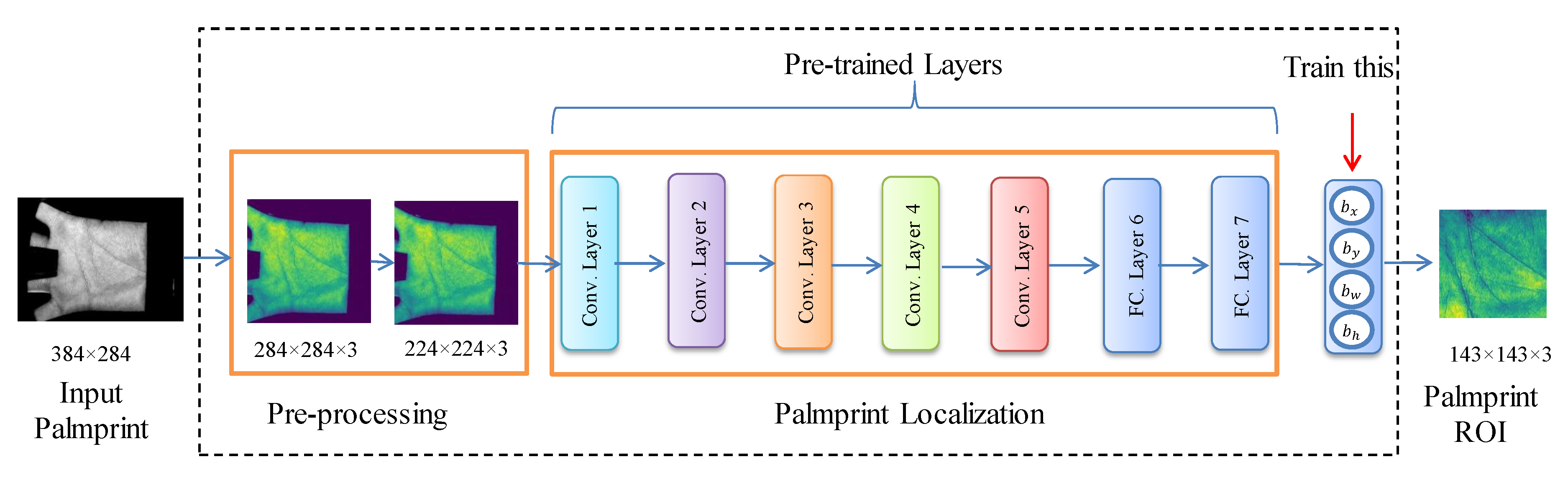
3.3. ROI Extraction Module
3.3.1. Pre-Processing
3.3.2. Palmprint Localization
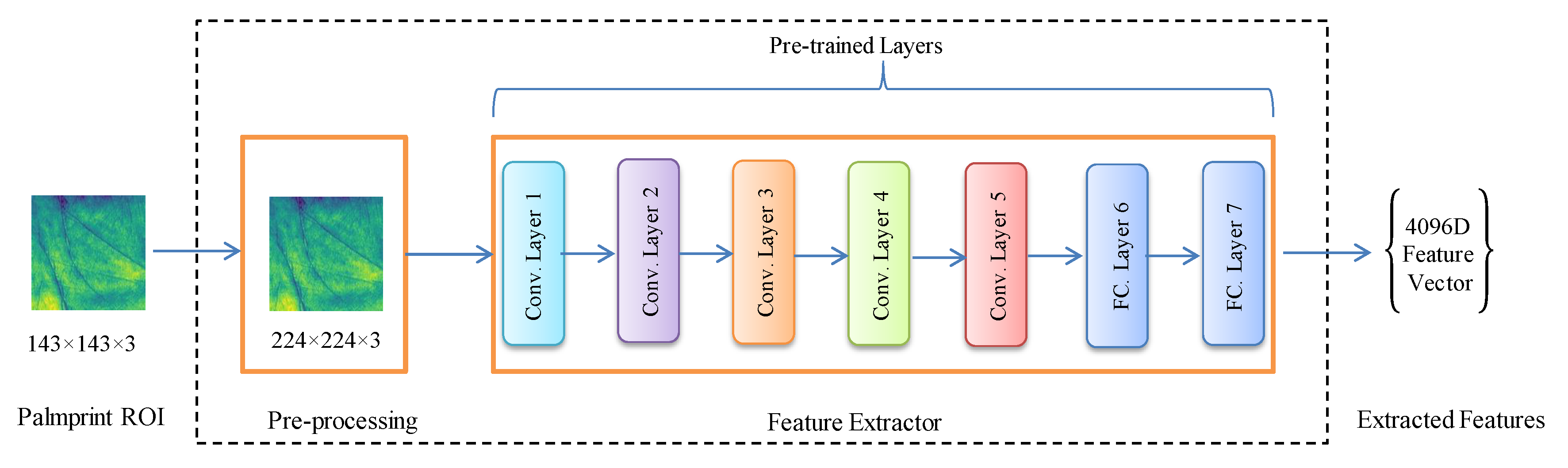
3.4. Feature Extraction Module
3.5. Matching Module
4. Experimental Results
4.1. Settings
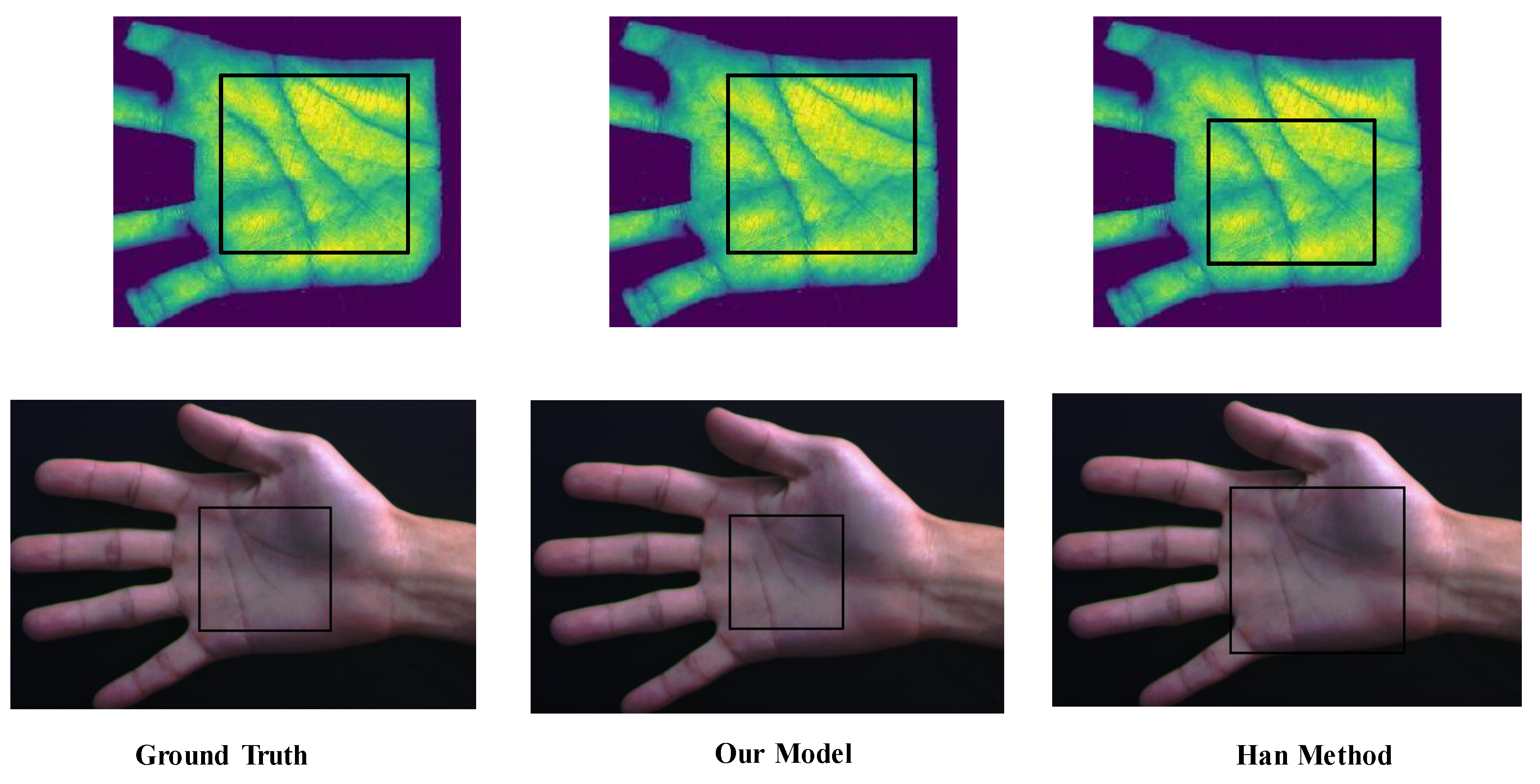
4.2. Evaluation of ROI Extraction Module
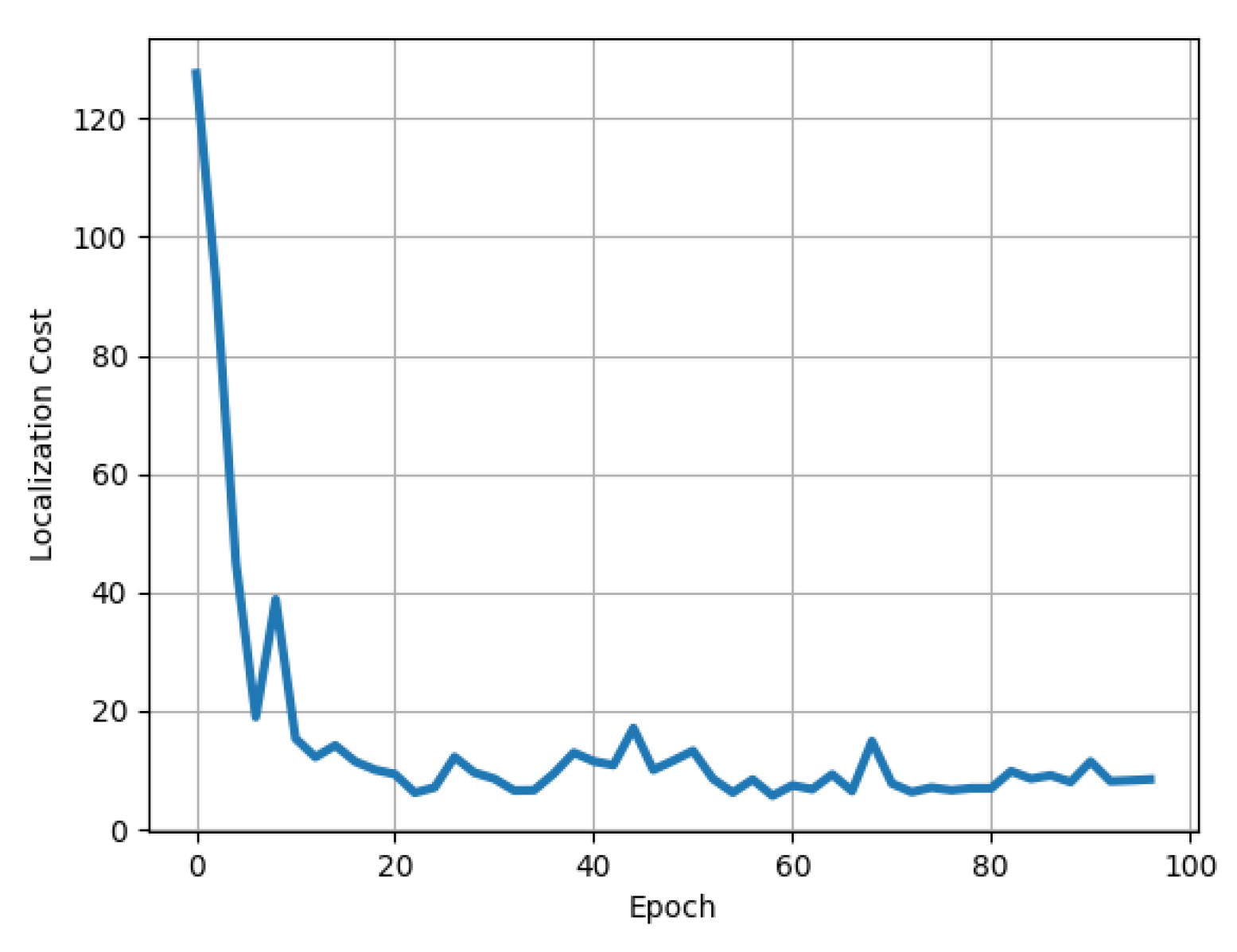
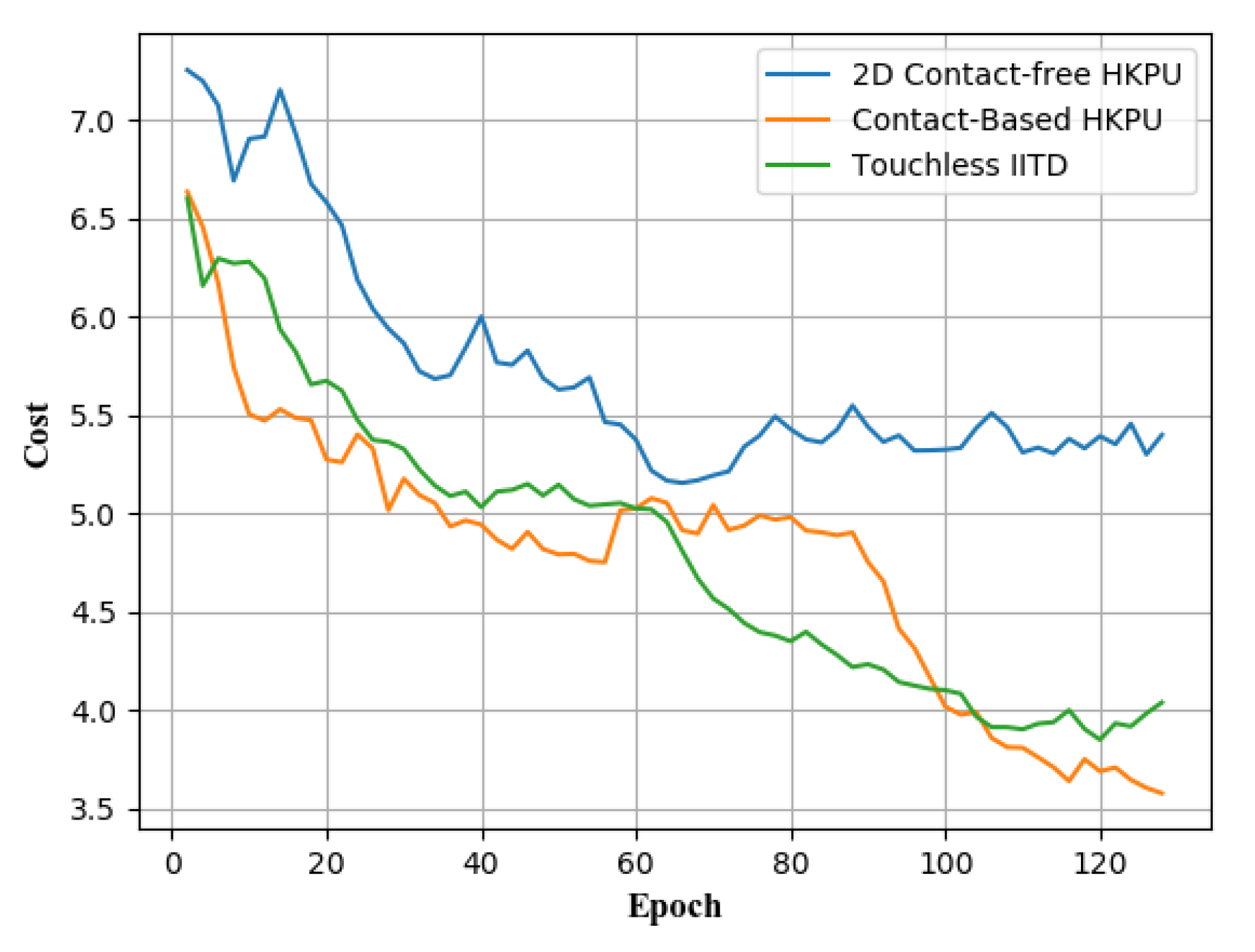
4.2.1. Training Phase
4.2.2. Testing Phase
4.3. Evaluation of Feature Extraction and Matching Modules
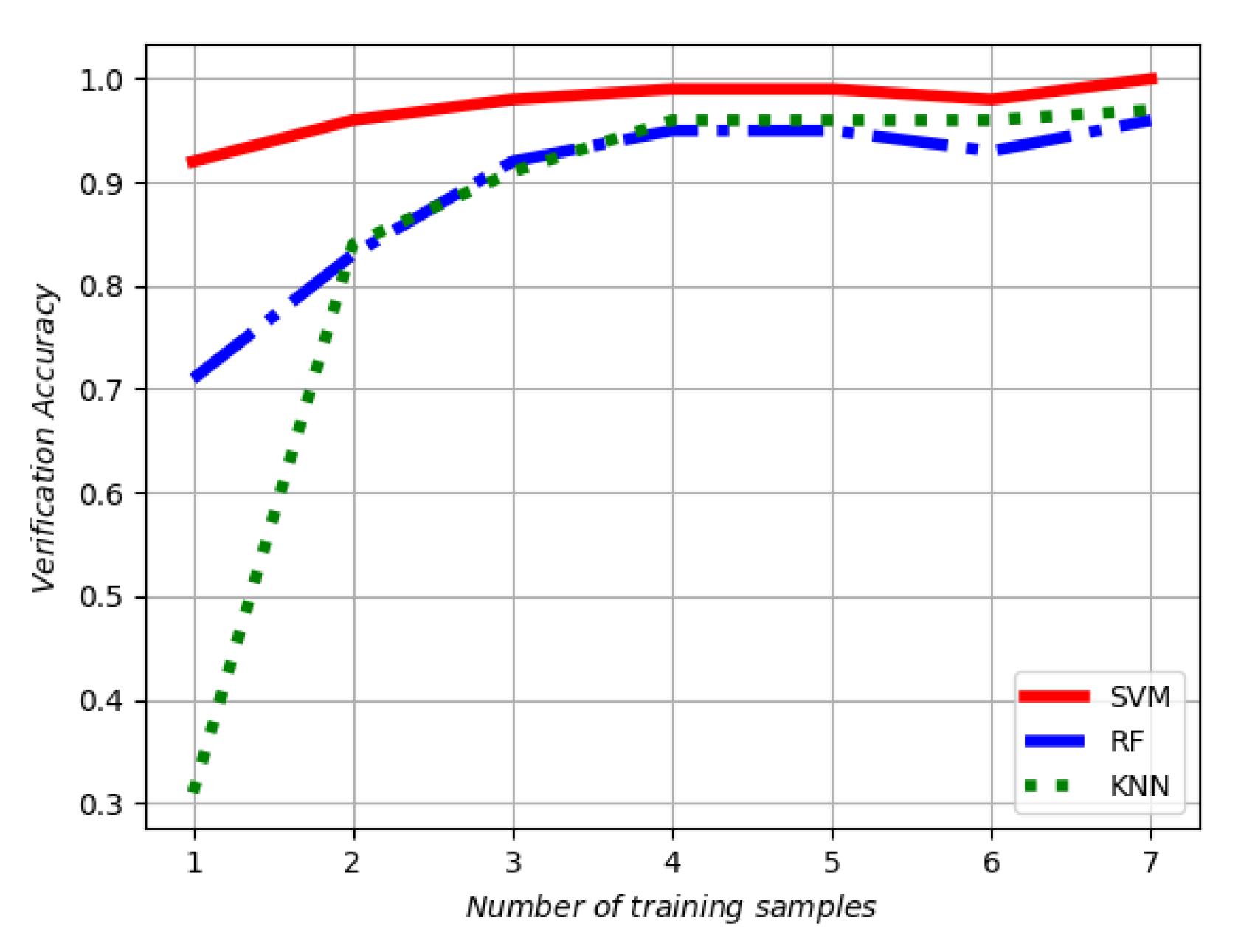
4.3.1. Accuracy
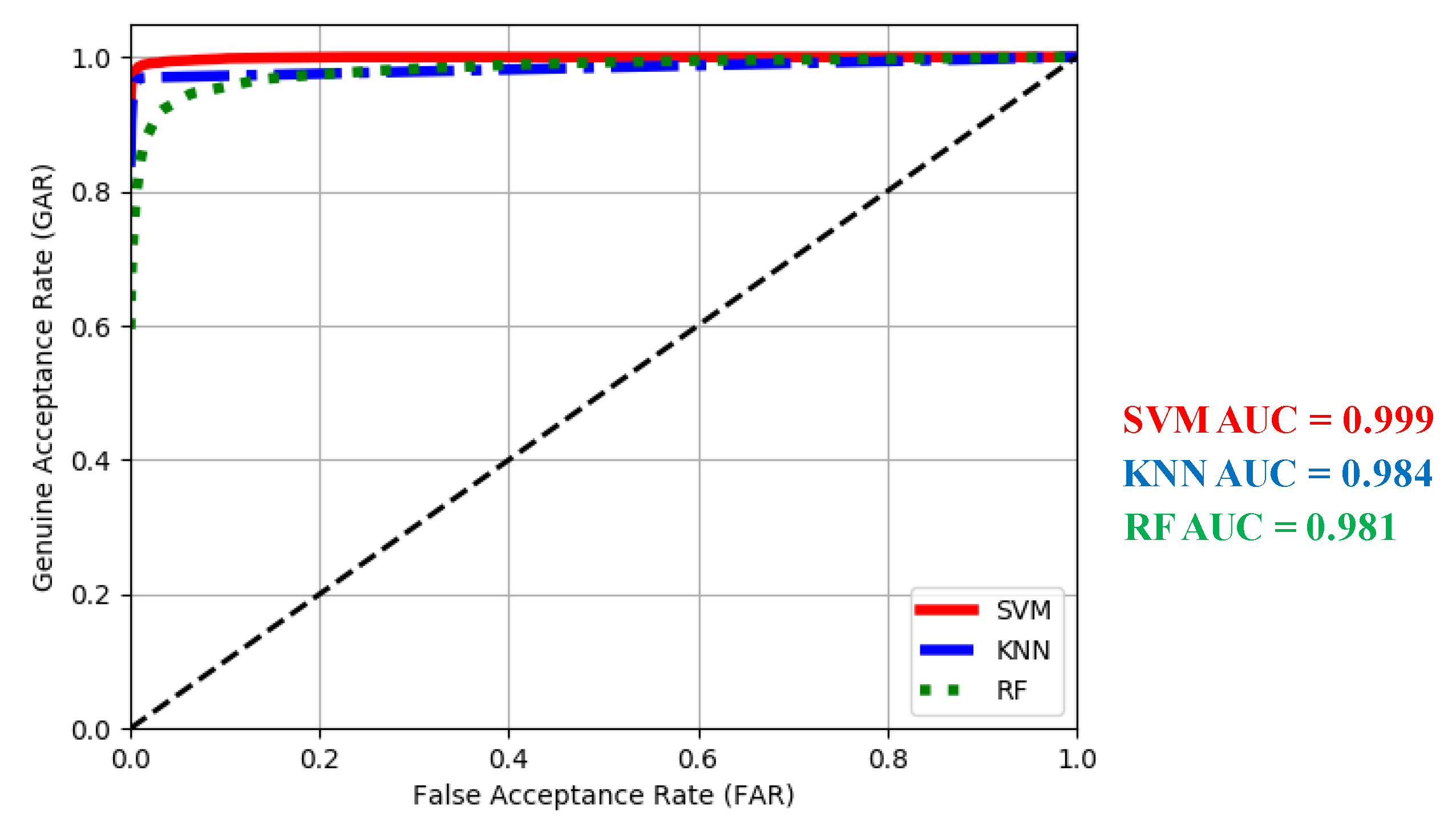
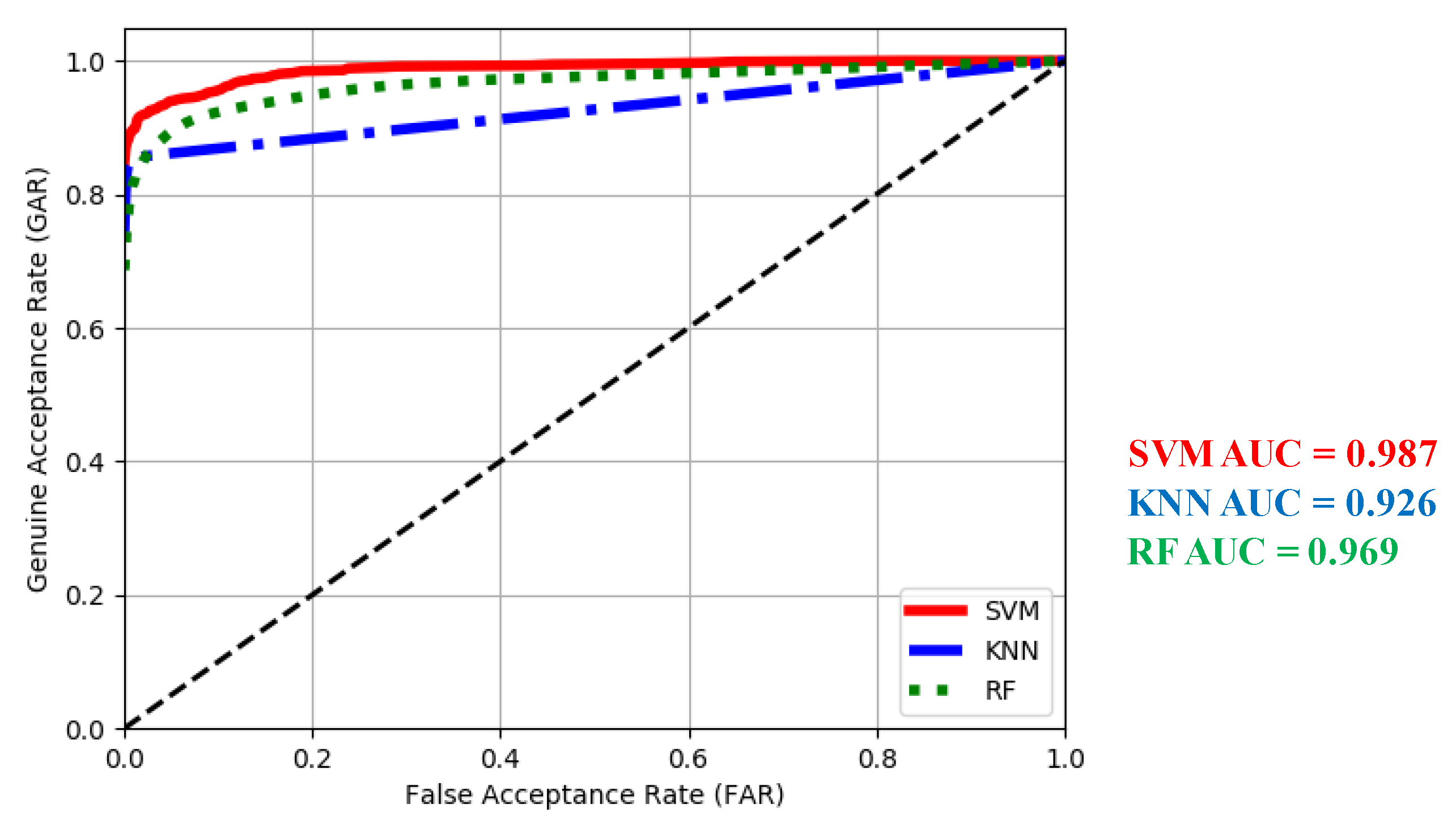
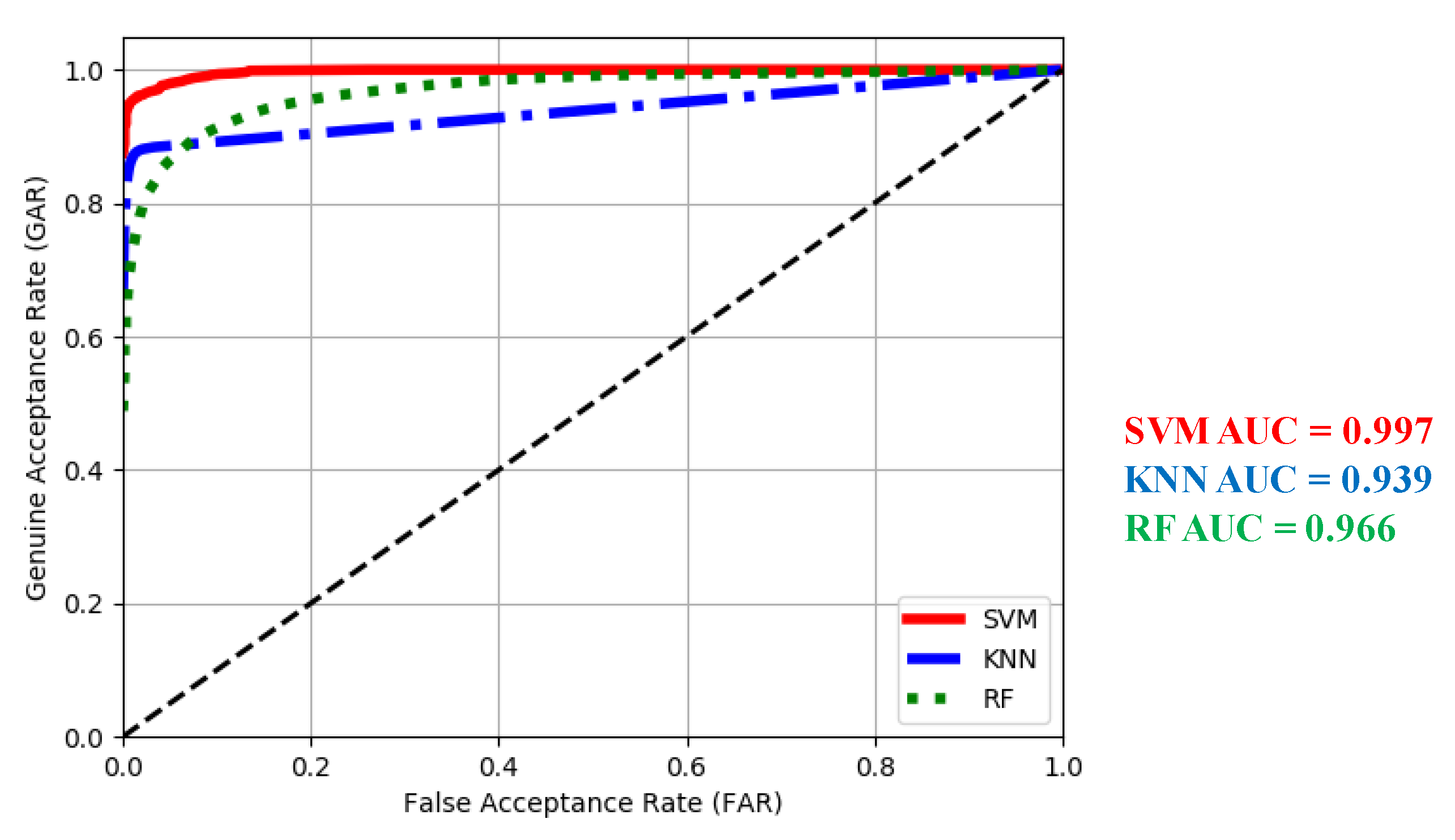
4.3.2. Receiver Operating Characteristic
4.3.3. Equal Error Rate
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Palma, D.; Montessoro, P.L.; Giordano, G.; Blanchini, F. Biometric Palmprint Verification: A Dynamical System Approach. IEEE Trans. Syst. Man Cybern. Syst. 2017. [Google Scholar] [CrossRef]
- Ito, K.; Aoki, T. Recent Advances in Biometric Recognition. ITE Trans. Media Technol. Appl. 2018, 6, 64–80. [Google Scholar] [CrossRef]
- Latha, Y.M.; Prasad, M.V. A Survey on Palmprint-Based Biometric Recognition System. In Innovative Research in Attention Modeling and Computer Vision Applications; IGI Global: Bangalore, India, 2015; p. 304. [Google Scholar]
- Kong, A.; Zhang, D.; Kamel, M. A survey of palmprint recognition. Pattern Recognit. 2009, 42, 1408–1418. [Google Scholar] [CrossRef]
- Meraoumia, A.; Laimeche, L.; Bendjenna, H.; Chitroub, S. Do we have to trust the deep learning methods for palmprints identification? In Proceedings of the Mediterranean Conference on Pattern Recognition and Artificial Intelligence, Tebessa, Algeria, 22–23 November 2016; pp. 85–91. [Google Scholar]
- Xu, Y.; Fei, L.; Wen, J.; Zhang, D. Discriminative and robust competitive code for palmprint recognition. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 232–241. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Bhanu, B.; Kumar, A. Deep Learning for Biometrics; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhang, D.; Kong, W.K.; You, J.; Wong, M. Online palmprint identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1041–1050. [Google Scholar] [CrossRef] [Green Version]
- Connie, T.; Jin, A.T.B.; Ong, M.G.K.; Ling, D.N.C. An automated palmprint recognition system. Image Vis. Comput. 2005, 23, 501–515. [Google Scholar] [CrossRef]
- Han, Y.; Sun, Z.; Wang, F.; Tan, T. Palmprint recognition under unconstrained scenes. In Proceedings of the Asian Conference on Computer Vision, Tokyo, Japan, 18–22 November 2007; pp. 1–11. [Google Scholar]
- Badrinath, G.; Gupta, P. Palmprint based recognition system using phase-difference information. Future Gener. Comput. Syst. 2012, 28, 287–305. [Google Scholar] [CrossRef]
- Michael, G.K.O.; Connie, T.; Teoh, A.B.J. Touch-less palm print biometrics: Novel design and implementation. Image Vis. Comput. 2008, 26, 1551–1560. [Google Scholar] [CrossRef]
- Michael, G.K.O.; Connie, T.; Jin, A.T.B. An innovative contactless palm print and knuckle print recognition system. Pattern Recognit. Lett. 2010, 31, 1708–1719. [Google Scholar] [CrossRef]
- Choraś, M.; Kozik, R. Contactless palmprint and knuckle biometrics for mobile devices. Pattern Anal. Appl. 2012, 15, 73–85. [Google Scholar] [CrossRef]
- Doublet, J.; Lepetit, O.; Revenu, M. Contact less hand recognition using shape and texture features. In Proceedings of the 2006 8th International Conference on Signal Processing, Beijing, China, 16–20 November 2006; Volume 3. [Google Scholar]
- Aykut, M.; Ekinci, M. Developing a contactless palmprint authentication system by introducing a novel ROI extraction method. Image Vis. Comput. 2015, 40, 65–74. [Google Scholar] [CrossRef] [Green Version]
- Aykut, M.; Ekinci, M. AAM-based palm segmentation in unrestricted backgrounds and various postures for palmprint recognition. Pattern Recognit. Lett. 2013, 34, 955–962. [Google Scholar] [CrossRef]
- Ito, K.; Sato, T.; Aoyama, S.; Sakai, S.; Yusa, S.; Aoki, T. Palm region extraction for contactless palmprint recognition. In Proceedings of the 2015 International Conference on Biometrics (ICB), Phuket, Thailand, 19–22 May 2015; pp. 334–340. [Google Scholar]
- Harun, N.; Rahman, W.E.Z.W.A.; Abidin, S.Z.Z.; Othman, P.J. New algorithm of extraction of palmprint region of interest (ROI). J. Phys. 2017, 890, 012024. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Zuo, W.; Yue, F. A comparative study of palmprint recognition algorithms. ACM Comput. Surv. 2012, 44, 2. [Google Scholar] [CrossRef]
- Jia, W.; Hu, R.X.; Gui, J.; Zhao, Y.; Ren, X.M. Palmprint recognition across different devices. Sensors 2012, 12, 7938–7964. [Google Scholar] [CrossRef] [PubMed]
- Raghavendra, R.; Busch, C. Texture based features for robust palmprint recognition: A comparative study. EURASIP J. Inf. Secur. 2015, 2015, 5. [Google Scholar] [CrossRef]
- Fei, L.; Lu, G.; Jia, W.; Teng, S.; Zhang, D. Feature Extraction Methods for Palmprint Recognition: A Survey and Evaluation. IEEE Trans. Syst. Man Cybern. Syst. 2018. [Google Scholar] [CrossRef]
- Malik, J.; Girdhar, D.; Dahiya, R.; Sainarayanan, G. Accuracy improvement in palmprint authentication system. Int. J. Image Graph. Signal Process. 2015, 7, 51. [Google Scholar] [CrossRef]
- Kong, A.K.; Zhang, D. Competitive coding scheme for palmprint verification. Pattern Recognit. 2004, 1, 520–523. [Google Scholar]
- Fei, L.; Xu, Y.; Tang, W.; Zhang, D. Double-orientation code and nonlinear matching scheme for palmprint recognition. Pattern Recognit. 2016, 49, 89–101. [Google Scholar] [CrossRef]
- Zhang, L.; Li, H.; Niu, J. Fragile bits in palmprint recognition. IEEE Signal Process. Lett. 2012, 19, 663–666. [Google Scholar] [CrossRef]
- Luo, Y.T.; Zhao, L.Y.; Zhang, B.; Jia, W.; Xue, F.; Lu, J.T.; Zhu, Y.H.; Xu, B.Q. Local line directional pattern for palmprint recognition. Pattern Recognit. 2016, 50, 26–44. [Google Scholar] [CrossRef]
- Dai, J.; Feng, J.; Zhou, J. Robust and efficient ridge-based palmprint matching. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1618–1632. [Google Scholar] [PubMed]
- Roux, V.; Aoyama, S.; Ito, K.; Aoki, T. Performance improvement of phase-based correspondence matching for palmprint recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 70–77. [Google Scholar]
- Liu, E.; Jain, A.K.; Tian, J. A coarse to fine minutiae-based latent palmprint matching. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2307–2322. [Google Scholar] [PubMed]
- Chen, F.; Huang, X.; Zhou, J. Hierarchical minutiae matching for fingerprint and palmprint identification. IEEE Trans. Image Process. 2013, 22, 4964–4971. [Google Scholar] [CrossRef] [PubMed]
- Morales, A.; Ferrer, M.A.; Kumar, A. Towards contactless palmprint authentication. IET Comput. Vis. 2011, 5, 407–416. [Google Scholar] [CrossRef]
- Kumar, A.; Shekhar, S. Personal identification using multibiometrics rank-level fusion. IEEE Trans. Syst. Man Cybern. Part C 2011, 41, 743–752. [Google Scholar] [CrossRef]
- Li, W.; Zhang, L.; Zhang, D.; Lu, G.; Yan, J. Efficient joint 2D and 3D palmprint matching with alignment refinement. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 795–801. [Google Scholar]
- Zhang, D.; Guo, Z.; Gong, Y. An online system of multispectral palmprint verification. In Multispectral Biometrics; Springer: Berlin, Germany, 2016; pp. 117–137. [Google Scholar]
- Fei, L.; Xu, Y.; Zhang, D. Half-orientation extraction of palmprint features. Pattern Recognit. Lett. 2016, 69, 35–41. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, D.; Yang, J.; Yang, J.Y. A two-phase test sample sparse representation method for use with face recognition. IEEE Trans. Circ. Syst. Video Technol. 2011, 21, 1255–1262. [Google Scholar]
- Gui, J.; Jia, W.; Zhu, L.; Wang, S.L.; Huang, D.S. Locality preserving discriminant projections for face and palmprint recognition. Neurocomputing 2010, 73, 2696–2707. [Google Scholar] [CrossRef]
- Jia, W.; Hu, R.X.; Lei, Y.K.; Zhao, Y.; Gui, J. Histogram of oriented lines for palmprint recognition. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 385–395. [Google Scholar] [CrossRef]
- Xu, Y.; Fei, L.; Zhang, D. Combining left and right palmprint images for more accurate personal identification. IEEE Trans. Image Process. 2015, 24, 549–559. [Google Scholar] [PubMed]
- Raghavendra, R.; Busch, C. Novel image fusion scheme based on dependency measure for robust multispectral palmprint recognition. Pattern Recognit. 2014, 47, 2205–2221. [Google Scholar] [CrossRef]
- Dai, J.; Zhou, J. Multifeature-based high-resolution palmprint recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 945–957. [Google Scholar] [PubMed]
- Lu, J.; Hu, J.; Tan, Y.P. Discriminative deep metric learning for face and kinship verification. IEEE Trans. Image Process. 2017, 26, 4269–4282. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Wang, X.; Tang, X. Hybrid deep learning for face verification. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1489–1496. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Wang, K. Identifying Humans by Matching Their Left Palmprint with Right Palmprint Images Using Convolutional Neural Network; DLPR Proceedings; The Hong Kong Polytechnic University: Hong Kong, China, 2016; pp. 1–6. [Google Scholar]
- Dian, L.; Dongmei, S. Contactless palmprint recognition based on convolutional neural network. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 1363–1367. [Google Scholar]
- Svoboda, J.; Masci, J.; Bronstein, M.M. Palmprint recognition via discriminative index learning. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 4232–4237. [Google Scholar]
- Minaee, S.; Wang, Y. Palmprint recognition using deep scattering convolutional network. arXiv, 2016; arXiv:1603.09027. [Google Scholar]
- Jalali, A.; Mallipeddi, R.; Lee, M. Deformation invariant and contactless palmprint recognition using convolutional neural network. In Proceedings of the 3rd International Conference on Human-Agent Interaction, Kyungpook, Korea, 21–24 October 2015; pp. 209–212. [Google Scholar]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A simple deep learning baseline for image classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv, 2014; arXiv:1405.3531. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- 2D Contact-free HKPU. Available online: http://www4.comp.polyu.edu.hk/~csajaykr/myhome/database_request/3dhand/Hand3D.htm (accessed on 13 May 2018).
- IITD Touchless Palmprint Database. Available online: http://www4.comp.polyu.edu.hk/~csajaykr/IITD/Database_Palm.htm (accessed on 13 May 2018).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. OSDI 2016, 16, 265–283. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier in MM | Number of Training Samples | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
| SVM | 0.927 | 0.968 | 0.989 | 0.994 | 0.994 | 0.989 | 1 |
| KNN | 0.310 | 0.844 | 0.917 | 0.963 | 0.968 | 0.963 | 0.974 |
| RF | 0.718 | 0.836 | 0.924 | 0.955 | 0.959 | 0.931 | 0.963 |
| Classifier in MM | Number of Training Samples | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| SVM | 0.966 | 0.971 | 0.983 | 0.983 | 0.885 | 0.983 |
| KNN | 0.365 | 0.909 | 0.943 | 0.949 | 0.828 | 0.879 |
| RF | 0.915 | 0.929 | 0.944 | 0.956 | 0.810 | 0.909 |
| Classifier in MM | Number of Training Samples | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
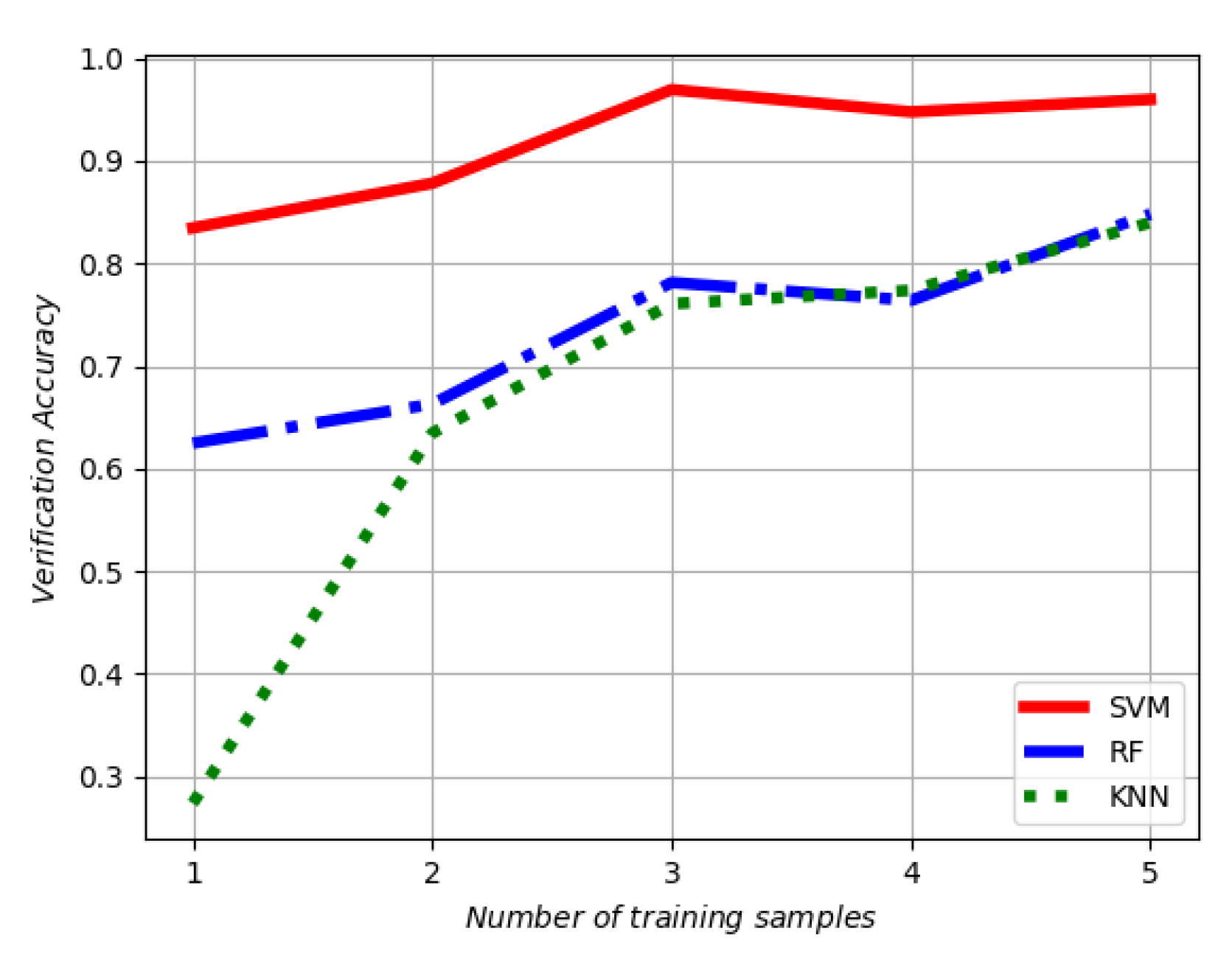
| SVM | 0.834 | 0.878 | 0.969 | 0.947 | 0.969 |
| KNN | 0.27 | 0.63 | 0.760 | 0.773 | 0.84 |
| RF | 0.640 | 0.660 | 0.783 | 0.766 | 0.841 |
| Method | PriLine | CompCode | DOC | E-BOCV | Classifier in Our Proposed Model | ||
|---|---|---|---|---|---|---|---|
| SVM | KNN | RF | |||||
| EER (%) | 0.133 | 0.026 | 0.019 | 0.053 | 0.0125 | 0.0156 | 0.0625 |
| Method | CompCode | DOC | LLPD-MRFT | LLPD-Gabor | Classifier in Our Proposed Model | ||
|---|---|---|---|---|---|---|---|
| SVM | KNN | RF | |||||
| EER (%) | 0.101 | 0.062 | 0.031 | 0.028 | 0.0276 | 0.0328 | 0.0889 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Izadpanahkakhk, M.; Razavi, S.M.; Taghipour-Gorjikolaie, M.; Zahiri, S.H.; Uncini, A. Deep Region of Interest and Feature Extraction Models for Palmprint Verification Using Convolutional Neural Networks Transfer Learning. Appl. Sci. 2018, 8, 1210. https://doi.org/10.3390/app8071210
Izadpanahkakhk M, Razavi SM, Taghipour-Gorjikolaie M, Zahiri SH, Uncini A. Deep Region of Interest and Feature Extraction Models for Palmprint Verification Using Convolutional Neural Networks Transfer Learning. Applied Sciences. 2018; 8(7):1210. https://doi.org/10.3390/app8071210
Chicago/Turabian StyleIzadpanahkakhk, Mahdieh, Seyyed Mohammad Razavi, Mehran Taghipour-Gorjikolaie, Seyyed Hamid Zahiri, and Aurelio Uncini. 2018. "Deep Region of Interest and Feature Extraction Models for Palmprint Verification Using Convolutional Neural Networks Transfer Learning" Applied Sciences 8, no. 7: 1210. https://doi.org/10.3390/app8071210