A Flexible Microarray Data Simulation Model

Microarray Platform, IGBMC, CNRS-INSERM-UdS, 1 rue Laurent Fries, Parc d'Innovation,67400 Illkirch, France
Microarrays 2013, 2(2), 115-130; https://doi.org/10.3390/microarrays2020115
Submission received: 1 March 2013
/
Revised: 7 April 2013
/
Accepted: 15 April 2013
/
Published: 17 April 2013
Abstract
:Microarray technology allows monitoring of gene expression profiling at the genome level. This is useful in order to search for genes involved in a disease. The performances of the methods used to select interesting genes are most often judged after other analyzes (qPCR validation, search in databases...), which are also subject to error. A good evaluation of gene selection methods is possible with data whose characteristics are known, that is to say, synthetic data. We propose a model to simulate microarray data with similar characteristics to the data commonly produced by current platforms. The parameters used in this model are described to allow the user to generate data with varying characteristics. In order to show the flexibility of the proposed model, a commented example is given and illustrated. An R package is available for immediate use.
1. Introduction
Microarray is now a mature technology in the field of molecular biology for monitoring of gene expression profiling at the genome level. Using two-color microarray technology, the biological activities of two samples are compared on an array on which thousands of specific deoxyribonucleic (DNA) sequences are printed or synthesized in situ. Two fluorescent dyes (generally red and green) are used for labeling of the samples for hybridization. Then, after washing, scanning and quantification of images corresponding to the red and green fluorescence of the array, numerical values, or intensities are associated with each probe (gene). These values are normalized to correct for undesirable technical variations [1,2]. Using one-color microarray technology, each sample is hybridized on one array. One fluorescence color is used, and expression intensities are obtained for genes on the arrays used. These values should also be normalized [3]. For a given gene, a ratio of values from two samples is used as a measurement of its expression change. Throughout this paper, we use logarithm two scale to transform the values. Hence, we use intensities and ratios for sample intensities and their ratios. In general, ratios are used for two-color microarray data, while intensities are used for one-color microarray data.
In a screening study, the goal is to select genes with differential expression from data whose characteristics are unknown. To study the performance of gene selection methods, we often use synthetic data, which can also serve in developing new methods. To properly play their role, synthetic data must resemble as closely as possible the real data they represent. This is achieved by simulating the physical phenomena through a model. The parameters of this model are approximations of the physical laws that govern the observed phenomenon, and a good knowledge of the physical laws is therefore required to obtain a good model. A complex model that takes into account several components of a phenomenon may become less flexible and may be difficult to modify in order to include new factors. In contrast, a simple model can be effective and easy to modify to take into account an unexpected situation.
One way to generate synthetic data is to use real microarray values as seeds [4,5,6,7]. In [4], data were generated using a normal distribution and a real microarray dataset. This dataset was used to estimate some hyperparameters, and the percentage of the differentially expressed (DE) genes was fixed; see details in [4]. The simulation data obtained in [4] may be useful for statistical methods, but they differ from observed data, since the -intensities obtained vary between the unrealistic bounds 16 and 30. In [5], two samples are selected from the control and the test samples. The measurements associated with their genes are modified (exchange of values between the two samples…) in order to obtain two statistically undistinguishable samples. Finally, a given number of down- and up-regulated genes is used in this dataset. This procedure necessitates a real microarray dataset, which cannot be available. The procedure proposed in [6] is a modular system, including all steps of the microarray technology. This includes slide layout, hybridization, scanning and image processing. Many models already available in the literature are used with new ones in [6]. The system of [6] results in data as close as possible to real biological data, but is quite complex, and the large number of its parameter settings may discourage its use. In [7], two simulation methods are used. In the first, the number of DE genes and the number of levels of changes for these genes are fixed. Then, for each gene, a mean and a standard deviation are drawn from a uniform distribution. Finally, these data (mean and standard deviation) are used as normal distribution parameters to get expression values for the genes. In the second simulation method, the mean and standard deviation of test (, ) and control () samples are estimated from observed real data and are used as normal distribution parameters to get expression values for all genes. There is no flexibility in the number of the DE genes of the method in [7]. A hierarchical model is used in [8,9], where the variance of each gene is simulated using two parameter settings and the distribution. This variance is then used to generate values from a normal distribution. DE genes are finally defined using levels compared to a threshold. The procedure used in [8,9] allows one to generate data with parameters derived from assumptions about real data. However, the percentage of the DE genes depends on a parameter that is difficult to control a priori. For some of the above methods, there is no distinction between the number of weakly expressed genes and those strongly expressed.
The model proposed in [10] provides synthetic data fairly close to the characteristics of true data. In this model, the level of expression of a gene is obtained by the superposition of several components. These components allow one to define the DE genes and the overall level of variability in the data. However, it lacks flexibility in choosing the number of DE genes and the number of genes over- and under-regulated. In this paper, we are interested in generating synthetic microarray data associated with two biological conditions. These conditions correspond to comparison of wild-type samples versus knock-out ones, treated samples versus non-treated ones, etc. For these situations, we use the generic terms of control versus test samples. Two condition biological data can be obtained using either one-color or two-color microarray technology leading to intensities or ratios, respectively. We assume that the same reference sample was used for ratio data.
2. Methods
We propose here a model that does not require knowledge of the physical laws governing gene expression to produce data with similar characteristics to the data commonly produced by current platforms. The user provides a subset of parameters that control the behavior of the data generated. We assume the following characteristics for microarray data:
- There are usually more genes with low intensities than genes with high intensities. One possible explanation for this observation is a non-response of all genes to given biological conditions.
- The -intensities of microarray data usually vary between zero and 20. Expression values are the results of 16- or 20-bit float per pixel images, representing probes on arrays.
- Under similar biological conditions, the expression level of a gene varies around an average value. Exceptionally different values will be due to technical problems.
- The total number of DE genes depends on the biological conditions used. The number of over-regulated and under-regulated genes may be different.
- The variability observed for weakly expressed genes is larger than that observed for highly expressed genes. This is mitigated with today’s scanners and tools. However, genes which are not really expressed still have non-zero values, and strongly expressed genes (saturated) receive a single value corresponding to the maximum level of quantification.
In the model described below, the expression levels are intensities. Ratios are derived from these values.
2.1. Model Used
Given n genes, and control and test samples, respectively, we used the following model:
where is a vector of values generated for gene, i, (). These values come from four sources. The values of vector are expression levels for samples. The values of vector allows one to define DE genes. These values are zero for control samples and for genes that are not DE, while for DE genes, non-zero values are associated with test samples. The additive noise vector, , has values independent of gene expression levels. Values associated with technical problems are cast in vector , which has only a few non-zero components (samples) for some genes. The current implementation of our model does not include any technical problem terms, , but we intend to take into account this component in the future.
To generate data using model (1) that satisfies the issues given above, we proceed as follows. The beta distribution is used to obtain n values varying between zero and one. Shape parameters ( and ) of this distribution were chosen to produce more small values than higher ones (issue 1). The n values obtained are scaled to fit real data (issue 2), which vary between a lower bound (lb) and an upper bound (ub). The scaled values represent average expression levels for the n genes (issue 3). Optionally, real data can be used as seed at this step. We assume that intensities for each gene are uniformly distributed around its average level. The range of variation of values from this distribution is assumed to be dependent on the gene average level and is expressed as a percentage through a parameter, , where is a parameter setting and is the average level of gene, i (issue 5). This leads to vector . Two parameters are used for generating vector , the percentage of DE genes () and a setting determining the number of up- and down-regulated genes (). The first values (control samples) of are set to zero. For gene i, an integer is randomly drawn from the set and is compared to to decide whether the corresponding gene is DE. If the answer is yes, a second integer is drawn from the set and is compared to to decide up and down assignment. normally distributed values are generated using a mean () and a standard deviation (). These values (or their opposite) form the second part (test samples) of vector for the up- (down-) regulated DE genes. Independent noise vector values are obtained using a normal distribution with zero mean and parameter () for standard deviation. The details of this algorithm are given in Algorithm 1 and described in the following sections.
2.2. Model Parameters
2.2.1. Data Size: n
This is the number of probes (genes) on the arrays. It is on the order of thousands, and the default setting is .
2.2.2. Number of Samples: and
These parameters are the number of control and test samples, respectively. Typically, the minimum number of samples per condition should be three to allow the use of statistical tests. The maximum value of these parameters rarely exceeds 100 (samples per biological condition); the default setting is seven for both.
2.2.3. Expression Level or Ratio: Ratio
This parameter option generates intensities or ratios data. With ratio = 0 (default setting), intensities data will be generated; otherwise, ratios data are returned.
| Algorithm 1: Steps of the micorarray data generation model. |
|
2.2.4. Beta Distribution Shape Parameters: and
To obtain more small values than high ones, we use a beta density distribution. Based on many histogram plots using various shape parameter values, we propose to set parameter to two and allow the user to choose a value for the parameter in the interval . The default setting for is four.
2.2.5. Intensities Variation Range: lb and ub
These parameters specify the intensities variation range. Quantification of microarray images is usually performed with 16- to 20-bit base, leading to to levels of gray. We suggest using values for parameters lb and ub from intervals and , respectively. These values are typically observed for actual Affymetrix GeneChip array data for gene expression profiling. Default settings are and . Observed minimum and maximum expression values will not exactly match the settings because of the variations used and possible additive noise.
2.2.6. Percentage of DE Genes: Pde
This parameter controls the number of differentially expressed genes the user would like to have in the data set. Its values are taken from the interval . A value (default setting) means that of the n probes in the data set should be DE.
2.2.7. Number of Up- and Down-Regulated Genes: Sym
This parameter results in nearly the same number of up- and down-regulated probes when sym = 0.5 (default setting). If the value of this parameter is less (greater) than , we will have more up- (down-) regulated probes in the data set.
2.2.8. Gene Average Level Variation Range: (Lambda1)
We assume that the values of each probe are uniformly distributed around an average value. An exponential distribution is used, , where is a user setting for decreasing rate. Then parameter, α, controls the width of the uniform distribution and is expressed as a percentage of the average level. allows a high variability in weakly expressed genes and, at the same time, a low variability for strongly expressed genes. We use the default value, , which allows an for an average expression level equal to two and an for an average expression level equal to 10. Increasing will lead to more variability for weakly expressed genes and a small variability for strongly expressed genes. Small values for (≈0.01) will lead to the same variability for all genes independently of their expression level.
2.2.9. Fold Change Variation Parameters: , and (Lambda2, Muminde and Sdde)
For a gene, the fold change is a shift of average expression levels between test and control samples. Assuming that (control and test) sample values of a given gene are uniformly distributed around an average level, the shift comes from a superposition of additional values to the test samples, see Figure 1. We assume a normal distribution for the shift values . However, the same mean is not used for all DE genes. Hence, we use a minimum value (setting ) and the exponential distribution to get , where is another setting. Default settings for these parameters are: , and . A higher value will lead to a small number of genes having a shift greater than ; a small value leads to the opposite situation. Parameters and may be chosen using a one sample Student t-test analysis. The statistic of the shift value is . The critical value for a significance level of for is . Hence, parameters may be chosen using the relation . The choice of additive noise standard deviation, (see below), will modify this inequality.
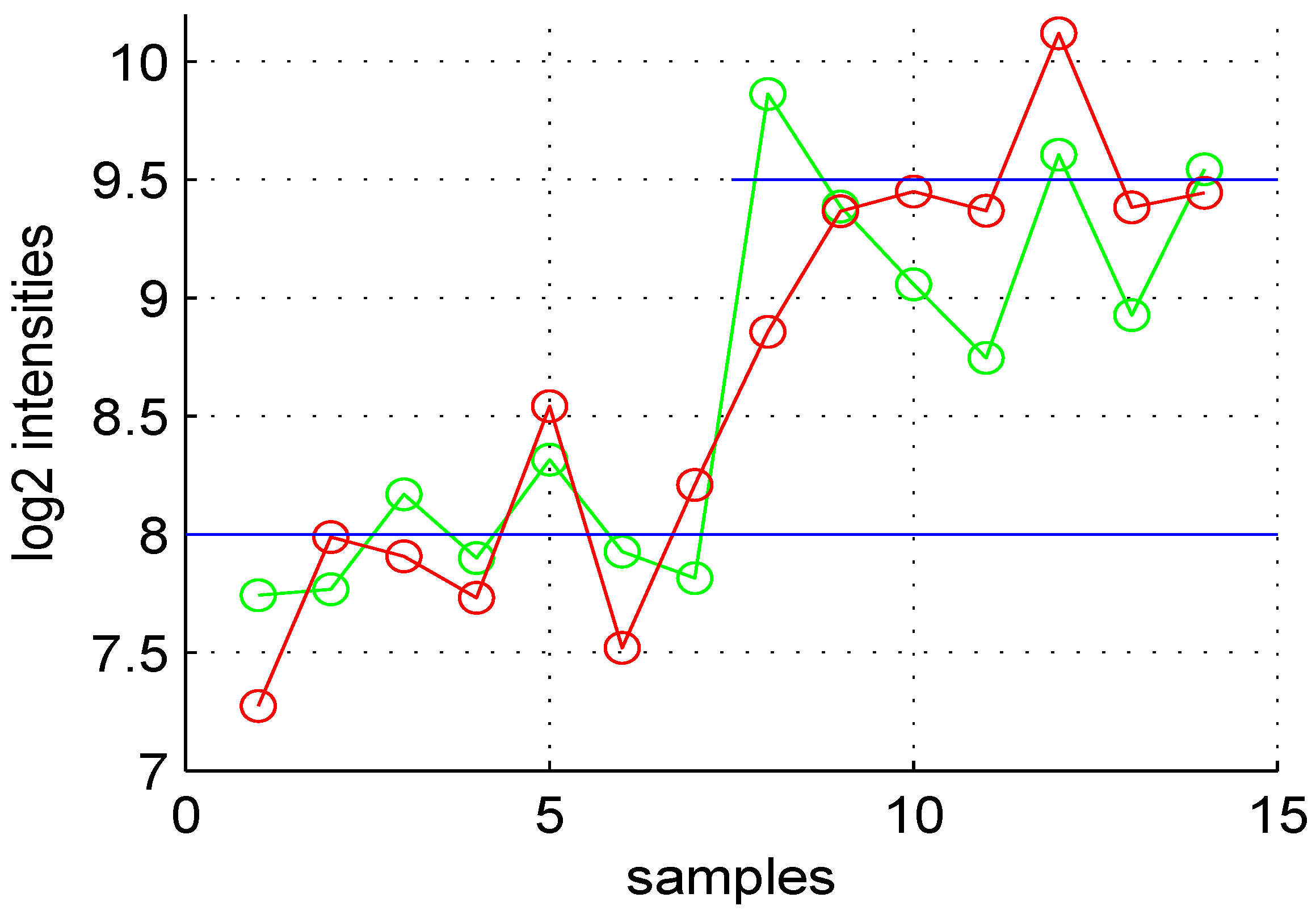
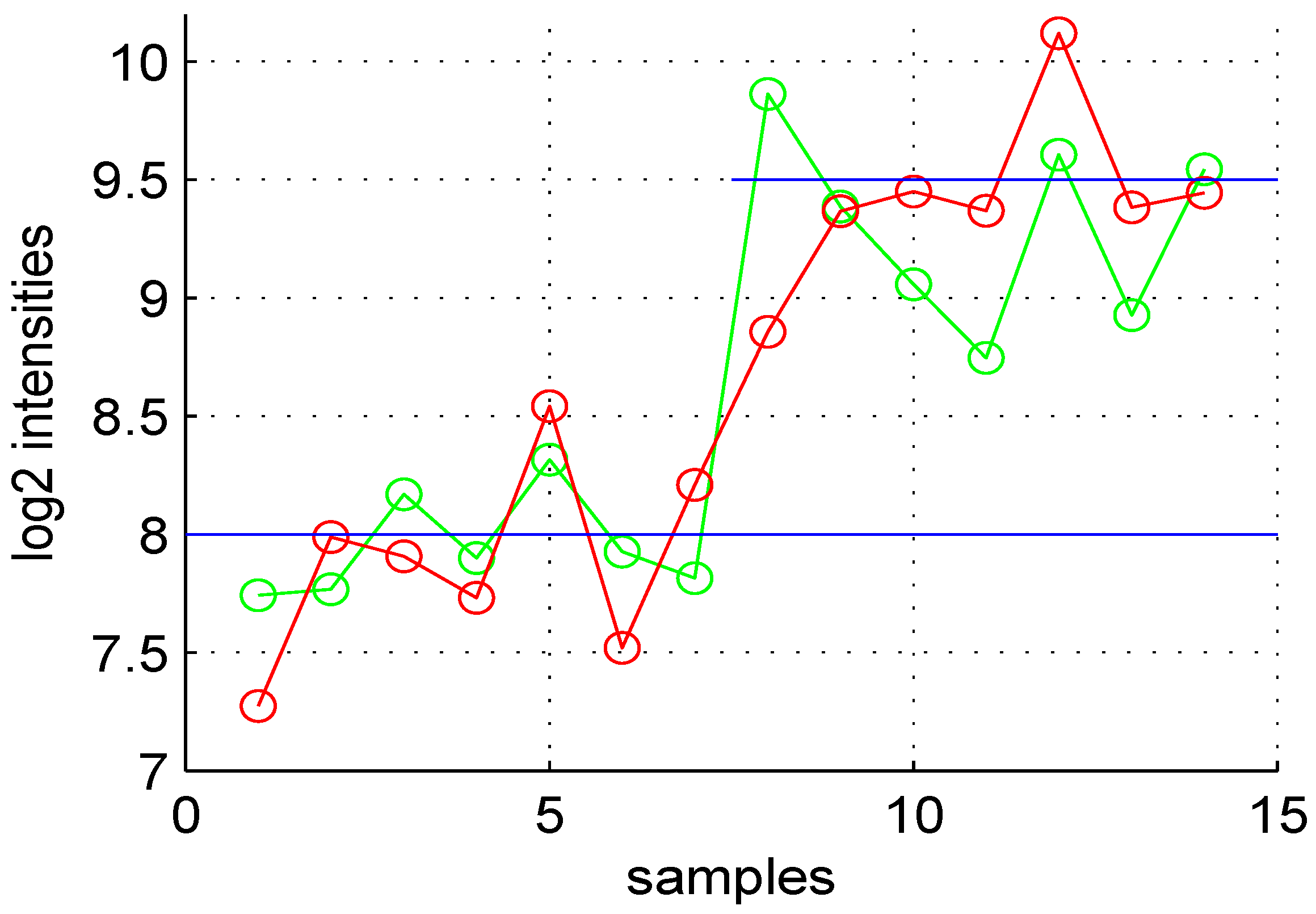
Figure 1.
Variation of expression levels of a DE gene. The first seven points are for control samples, and the last seven points correspond to test samples. The average value of this gene in the control is eight and for the test sample (blue horizontal lines). The green points correspond to noise free data, while the red are observed values for control and test samples.
Figure 1.
Variation of expression levels of a DE gene. The first seven points are for control samples, and the last seven points correspond to test samples. The average value of this gene in the control is eight and for the test sample (blue horizontal lines). The green points correspond to noise free data, while the red are observed values for control and test samples.
2.2.10. Additive Noise Standard Deviation: (Sdn)
This parameter represents a normal distribution standard deviation for additive noise. The default value is . A zero value for this parameter will lead to noise-free data. Too high values can lead to a number of DE genes different to those specified in pde.
2.2.11. Computer Random Generator Seed: Rseed
This parameter is used for computer random number initialization. It will allow one to generate the same data at different times. The default value is 50.
3. Results and Discussion
To evaluate the performance of the proposed model, we performed simulations, in which we studied the influence of different parameter settings. Their default values are: , , , , , , , , , , , , ). We performed 100 independent simulations by changing the initialization of the generator through parameter, rseed. For each simulation, we performed a Student t-test and selected genes with a p-value less than . Using the DE information, selected genes were split into two: true and false DE genes. The p-value threshold, , leads to an expected error (false discovery rate) equal to for default settings. When studying one parameter, the others are set to their default value.
3.1. Parameter Pde
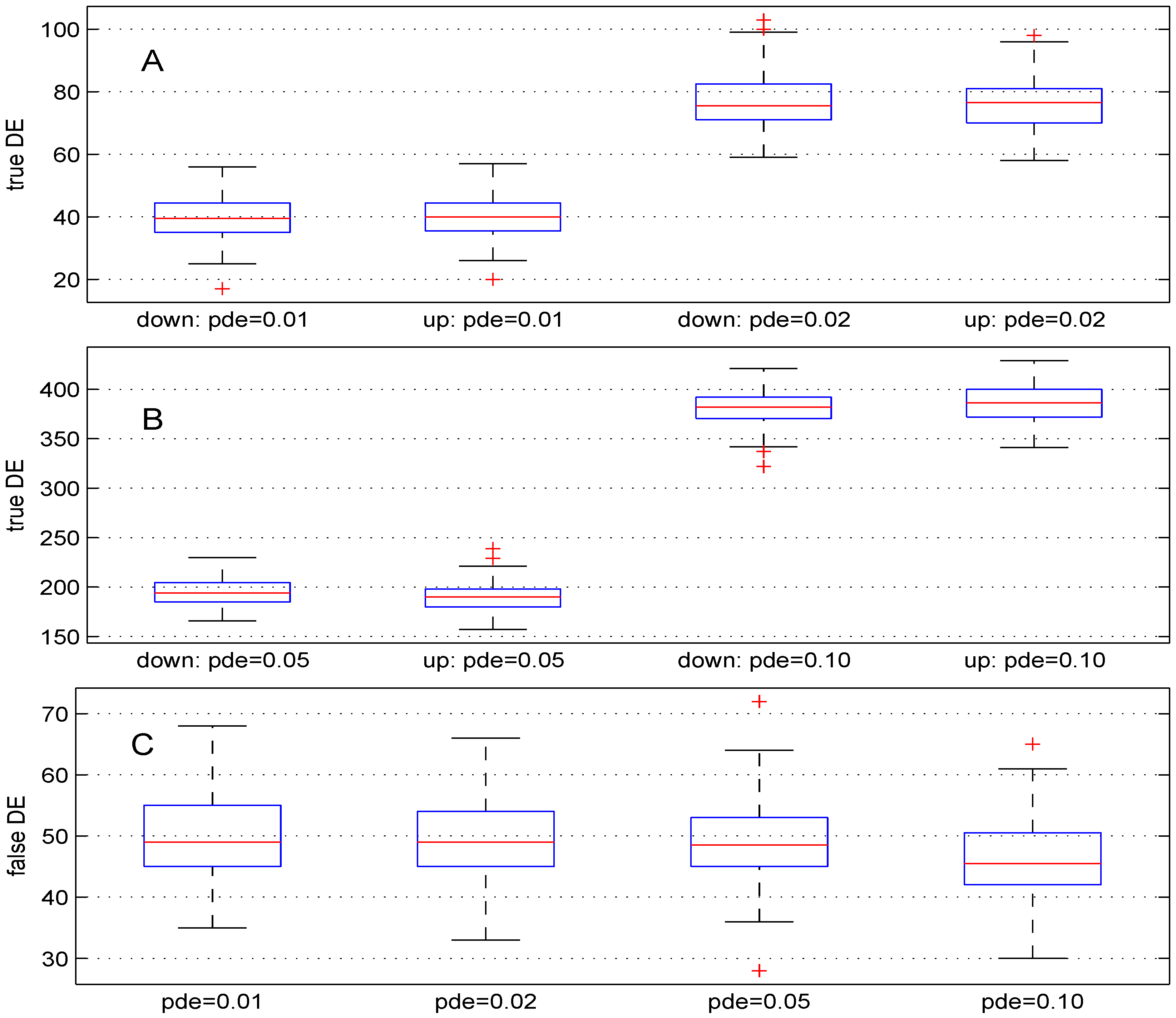
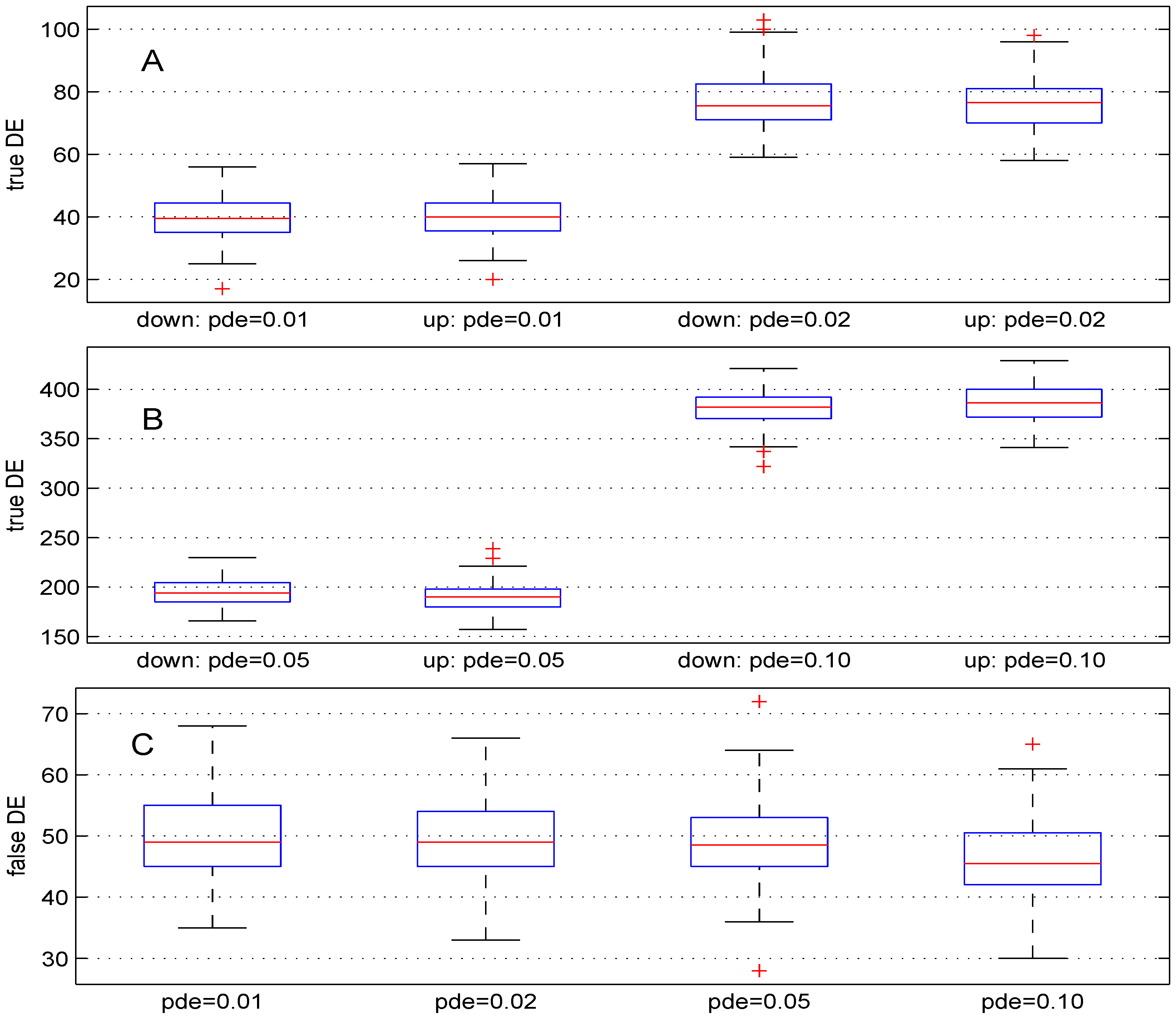
We used four different values (, , and ). For these values, the theoretical numbers of DE genes are, respectively, 100, 200, 500 and . The boxplots in Figure 2 show the results obtained. The median numbers of true down- (up-) regulated genes are (40), (), 194 (190) and 382 () for the above values of parameter pde, respectively. In comparison with the expected number of DE genes, the recovery powers of the Student t-test are , , and . Better power results can be obtained for this test by using smaller value for parameter . Panel C of Figure 2 shows the number of false DE genes obtained using the four values for parameter pde. The median numbers of the false DE genes are 49, 49, and for the above values of parameter pde, respectively.
Figure 2.
Boxplots of the number of down- and up-regulated genes (true DE, false DE) with four values of the parameter pde. 100 simulations were used for these results.
Figure 2.
Boxplots of the number of down- and up-regulated genes (true DE, false DE) with four values of the parameter pde. 100 simulations were used for these results.
3.2. Parameter Sym
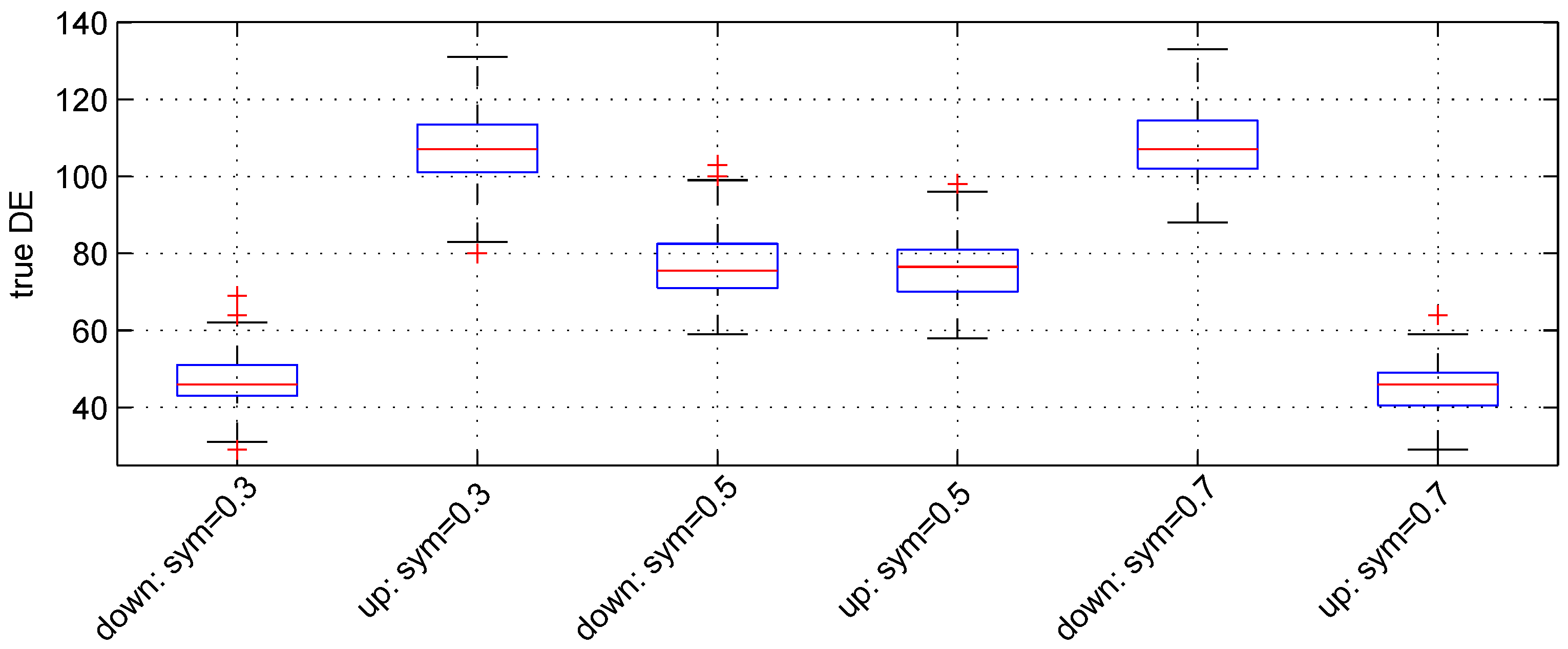
We used the following three values: , and . For these values, the expected numbers for pairs of down- and up-regulated genes are, respectively, (), () and (). Figure 3 shows the boxplot of results obtained. The median numbers of true down- and up-regulated genes observed are (46, 107), (, ) and (107, 46) for the above values of parameter , respectively. Hence, the recovery powers of the Student t-test are , and .
Figure 3.
Boxplots of the number of down- and up-regulated genes (true DE) with three values of the parameter sym. 100 simulations were used for these results.
Figure 3.
Boxplots of the number of down- and up-regulated genes (true DE) with three values of the parameter sym. 100 simulations were used for these results.
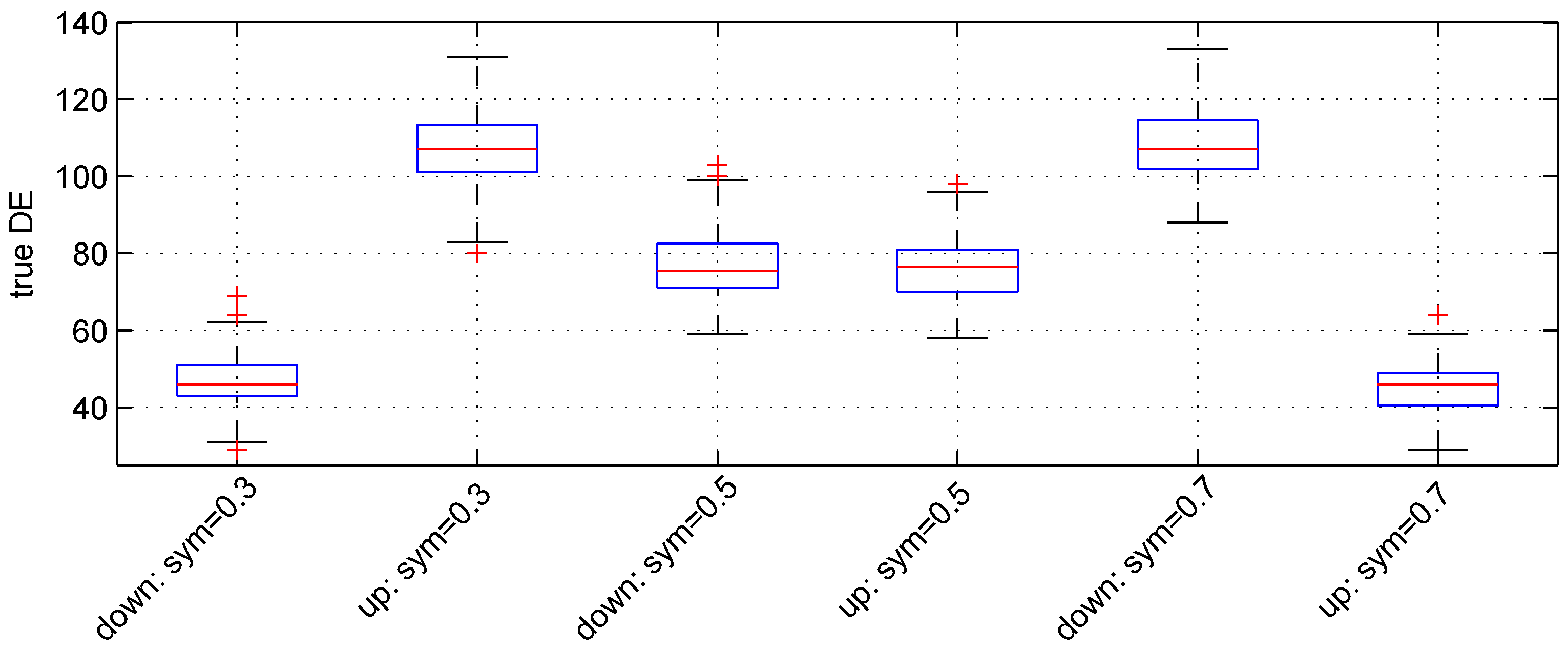
The median number of false DE genes is 49 for the three values of parameter sym.
3.3. Parameter
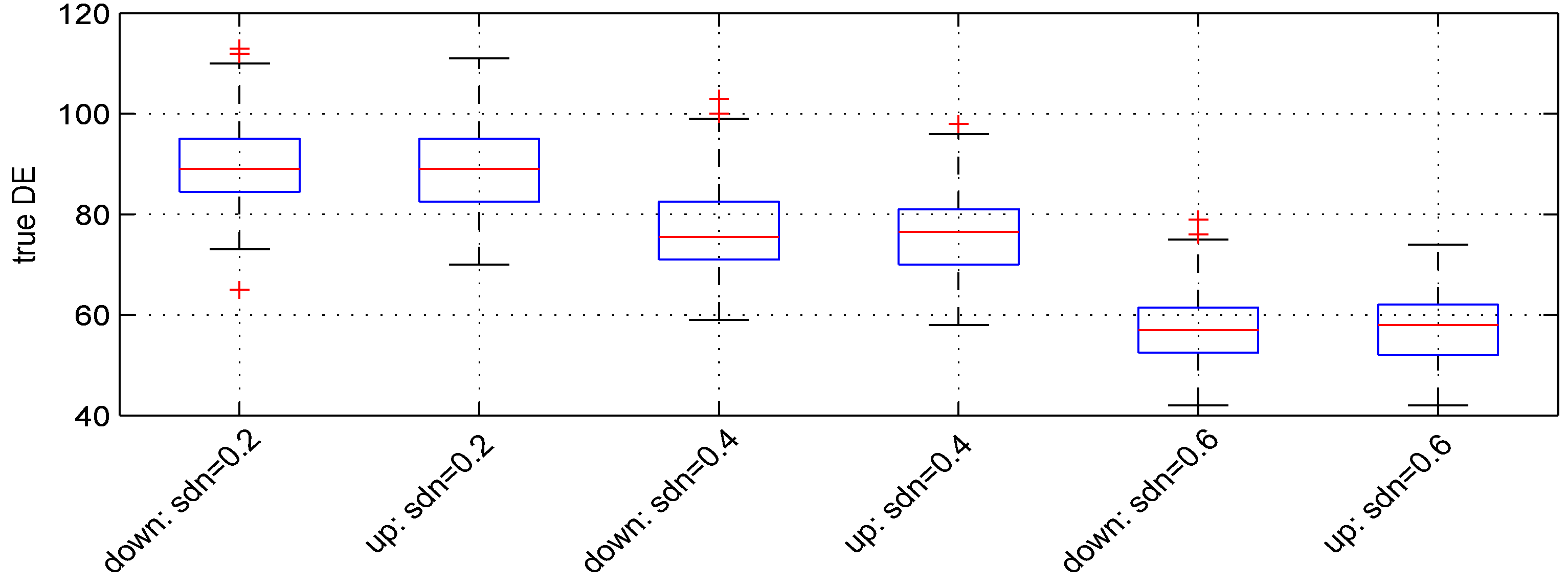
We used three values: , and . Figure 4 shows the boxplots of the results obtained. The median numbers of down- and up-regulated genes observed are (89, 89), (, ) and (57, 58), leading to detection powers of , and , respectively. The t-test detection power decreases when increases.
Figure 4.
Boxplots of the number of down- and up-regulated genes (true DE) with three values of the parameter . 100 simulations were used for these results.
Figure 4.
Boxplots of the number of down- and up-regulated genes (true DE) with three values of the parameter . 100 simulations were used for these results.

The median numbers of false DE genes are 54, 49 and 49 for the 3 values of parameter , respectively.
3.4. Parameters , , , and
We performed simulations to examine the influence of these parameters. For each parameter, 100 simulations were used, and the results obtained are summarized in Table 1. Increasing the parameter setting introduces more change for the DE genes, while its decrease leads to the opposite effect. Parameter acts as noise. The effect of the modification of some parameters is investigated further in the MA plot representations described in the following paragraph.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Number of down- and up-regulated detected genes using the Student t-test and various parameter settings.
| Parameters | (down, up) | power |
|---|---|---|
| (100, 100) | ||
| (41, 40) | ||
| (, 90) | ||
| (82, 83) | ||
| (69, ) | ||
| (76, 6) | ||
| (81, 81) | ||
| (89, 88) | ||
| (92, 92) | ||
| (66, 66) | ||
| (92, 91) | ||
| (, ) | ||
| (75, 76) | ||
| (76, ) |
3.5. Volcano and MA Plots
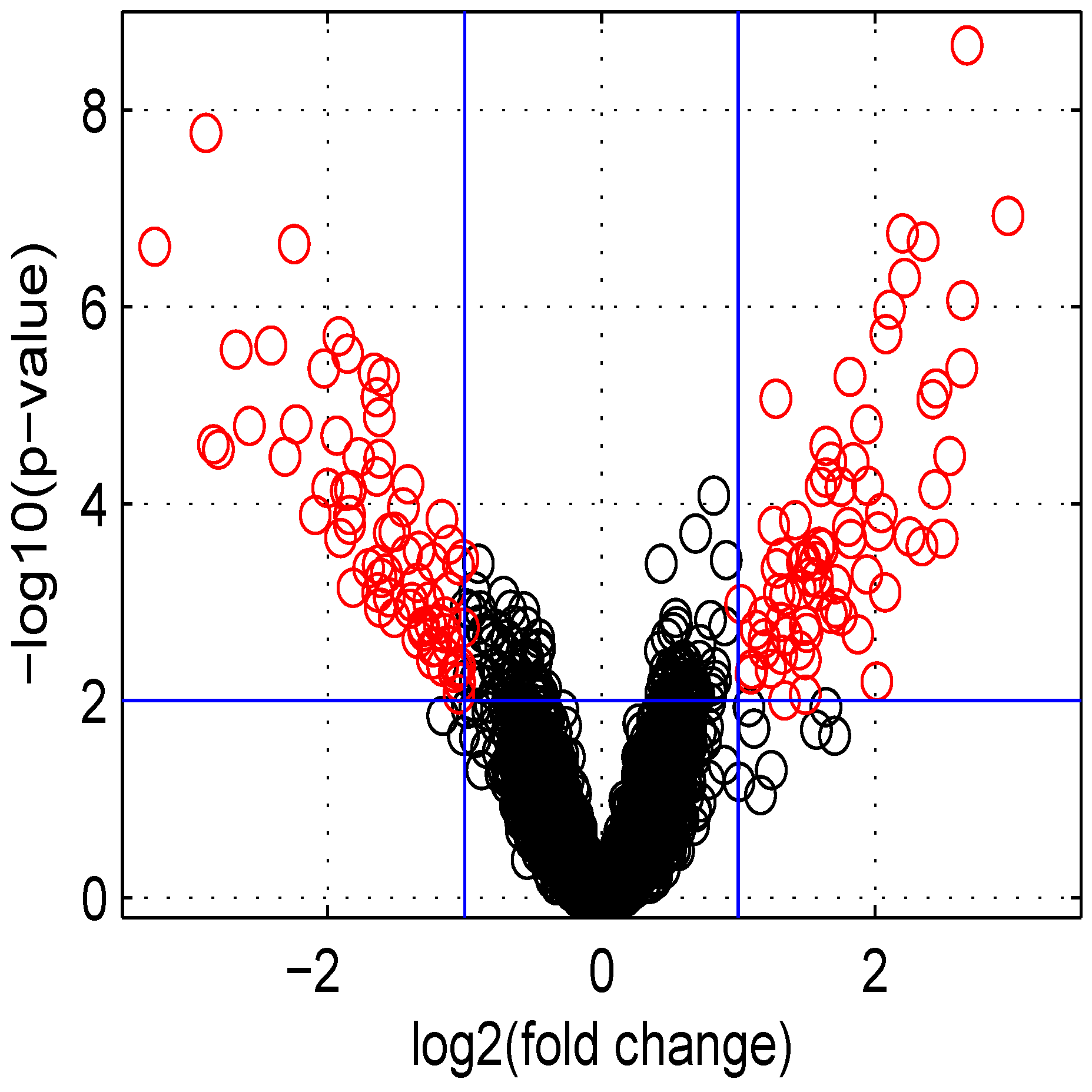
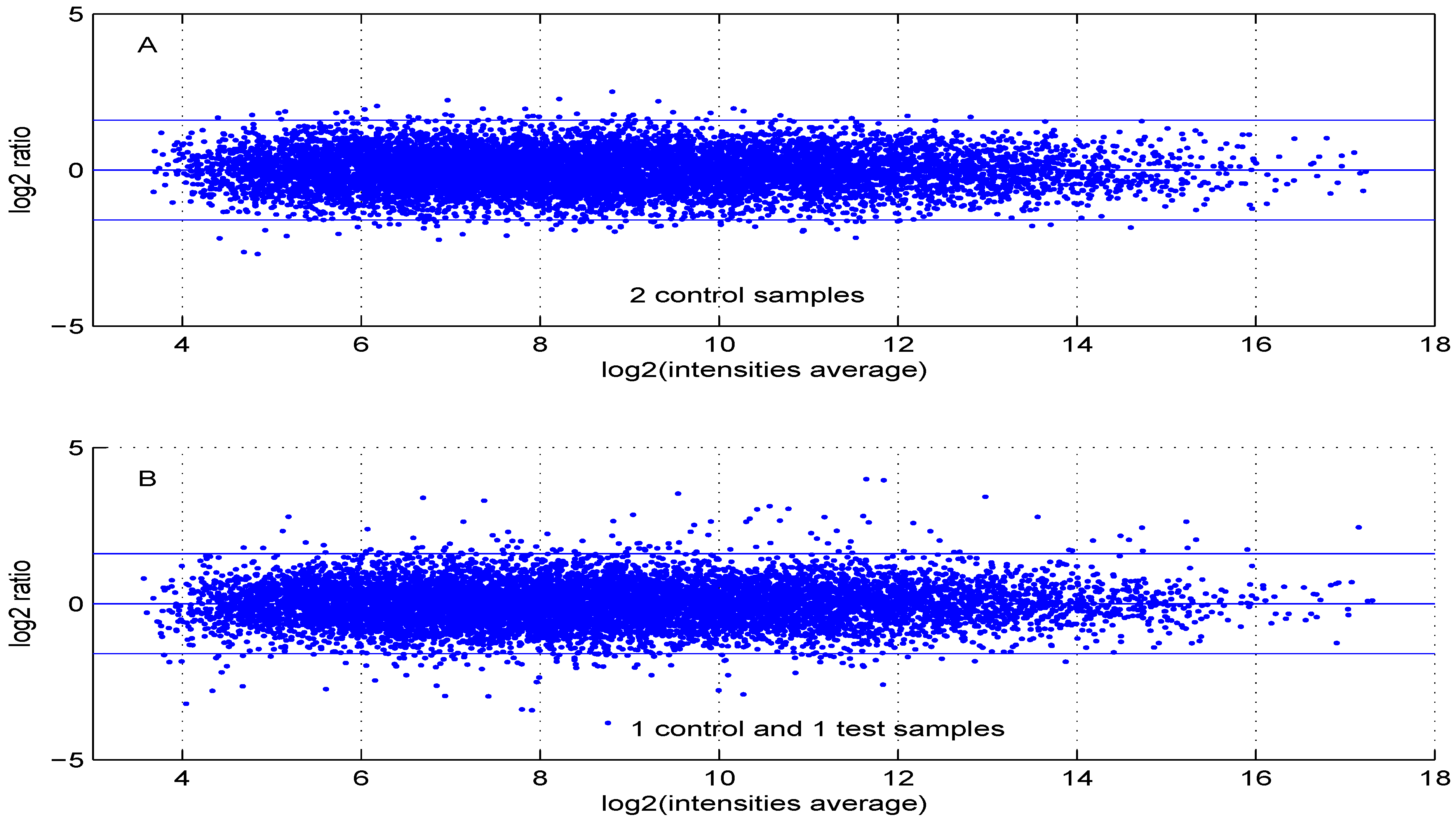
Using default settings, we performed one simulation. Then we computed the Student t-test p-value and fold change for all genes. These values were used in the volcano plot of Figure 5. Red circles represent genes having a p-value less than and a fold change greater than two or less than . Intensity measurements of two samples can be used to create two new variables: and , where and are intensities of samples and , respectively. A value, one () for M means that the corresponding gene is up- (down-) regulated two-fold. A plot of M ( ratio) versus A ( intensities average) is denoted “MA plot" [11]. The MA plots in Figure 6 are obtained using either two control samples (panel A) or one control and one test sample (panel B).
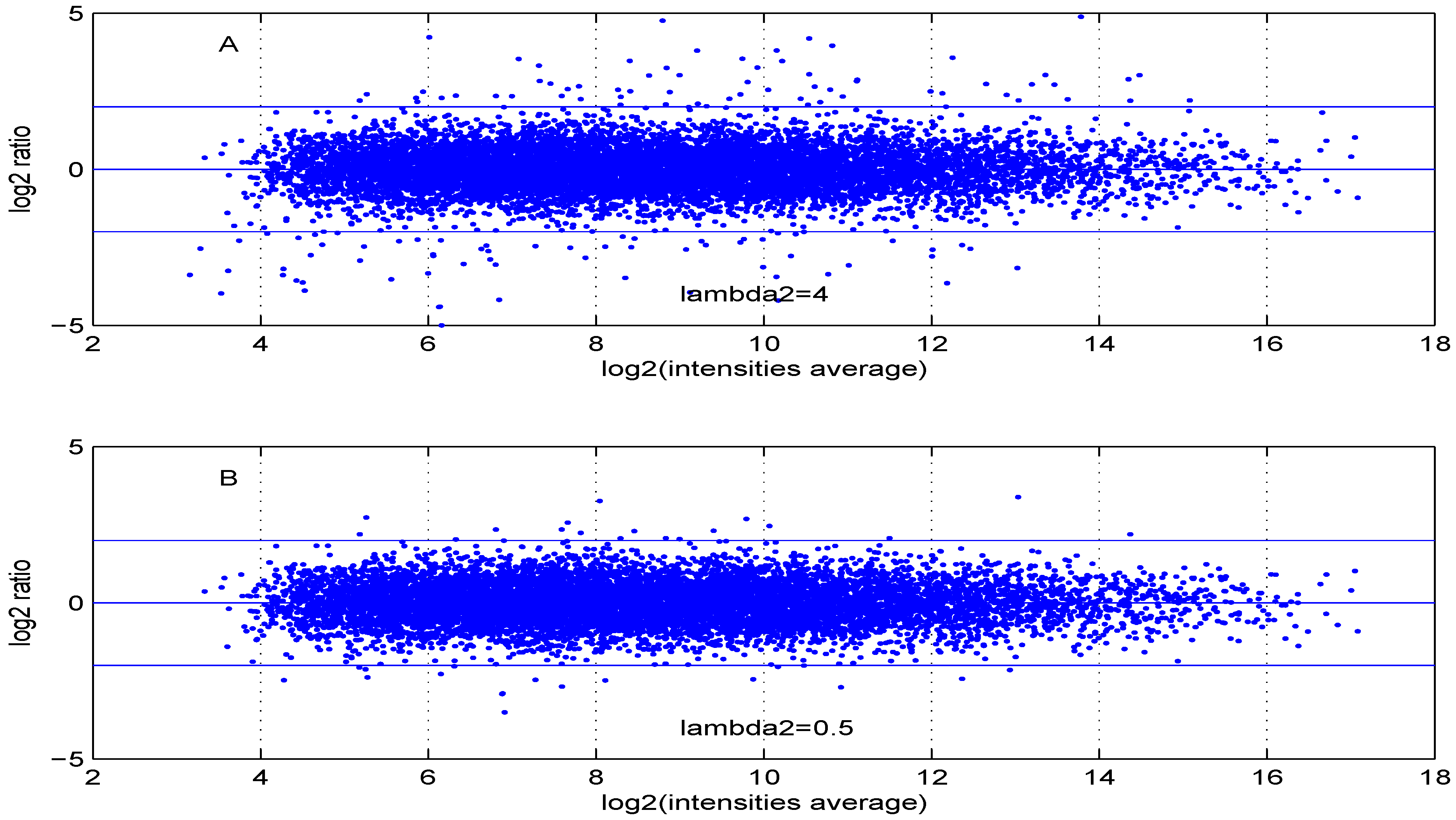
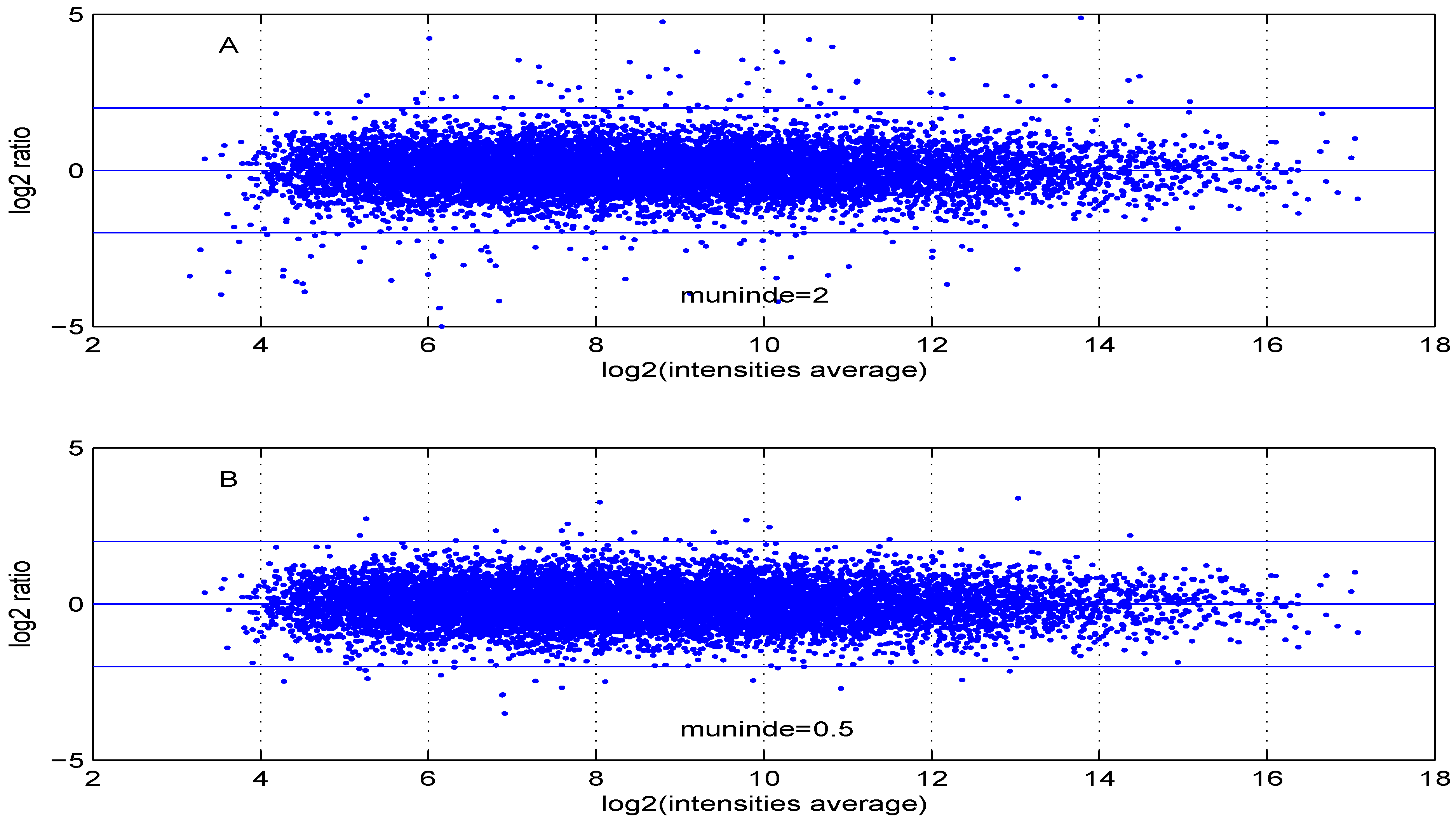
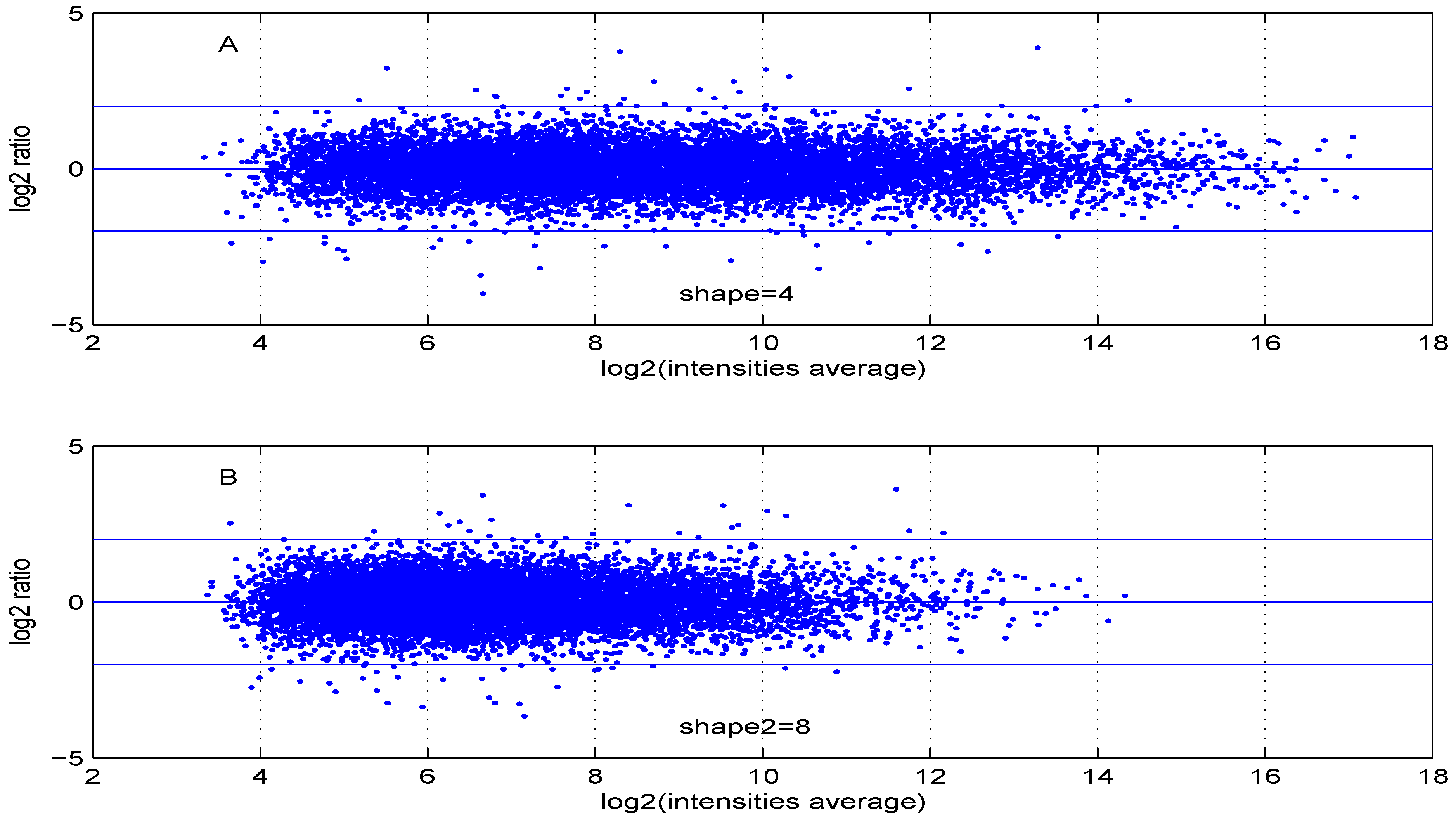
Additional MA plots in Figure 7, Figure 8, Figure 9 and Figure 10 showing the effect of some parameter settings. A small value for leads to a less dense cloud of points. A larger change is observed for higher values of than for smaller ones. The same applies to parameter, . Increasing the parameter value leads to a decrease of the dynamic range of the data.
Figure 5.
Volcano plot of data obtained.
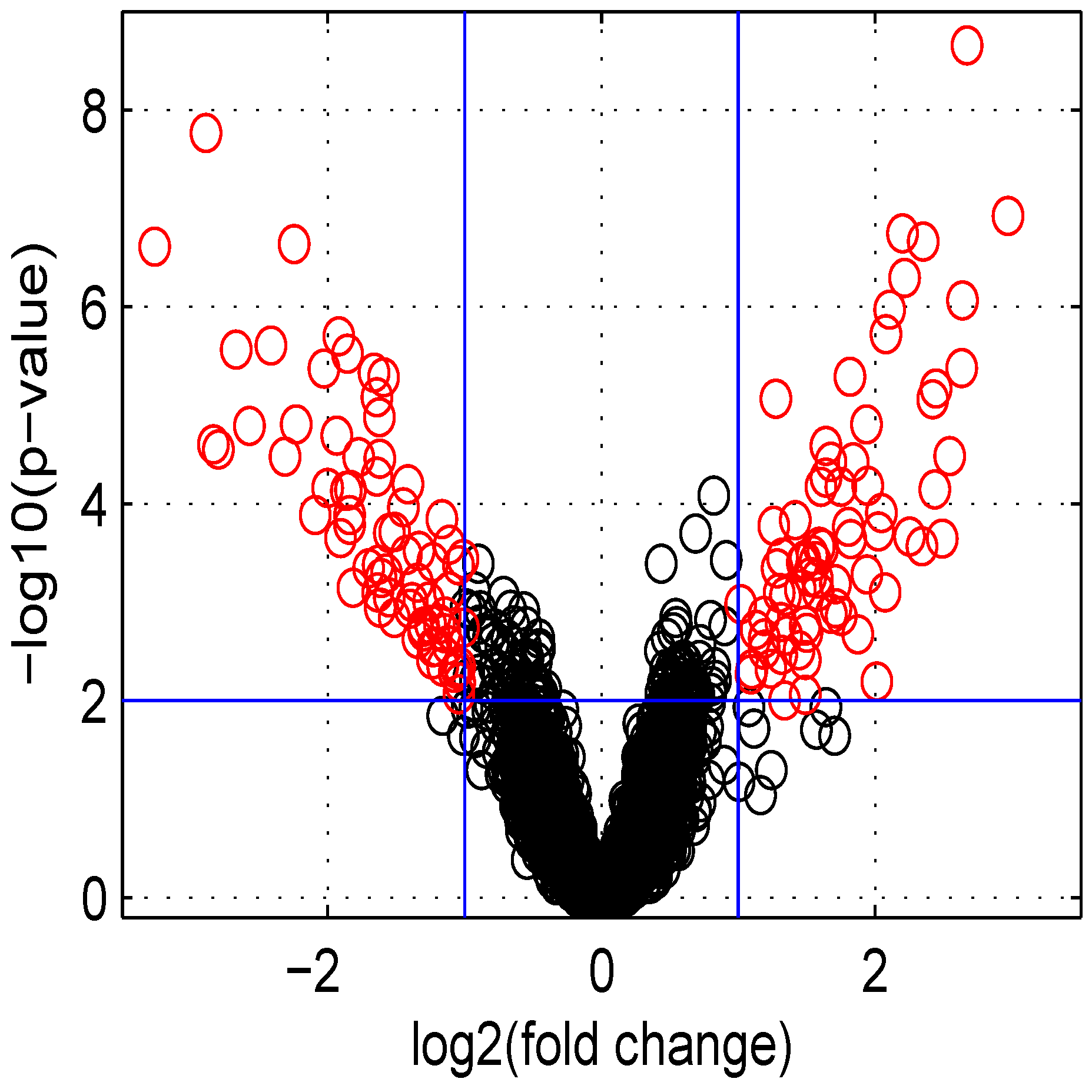
Figure 6.
MA plot using (A) two control samples or (B) one control and one test sample data.
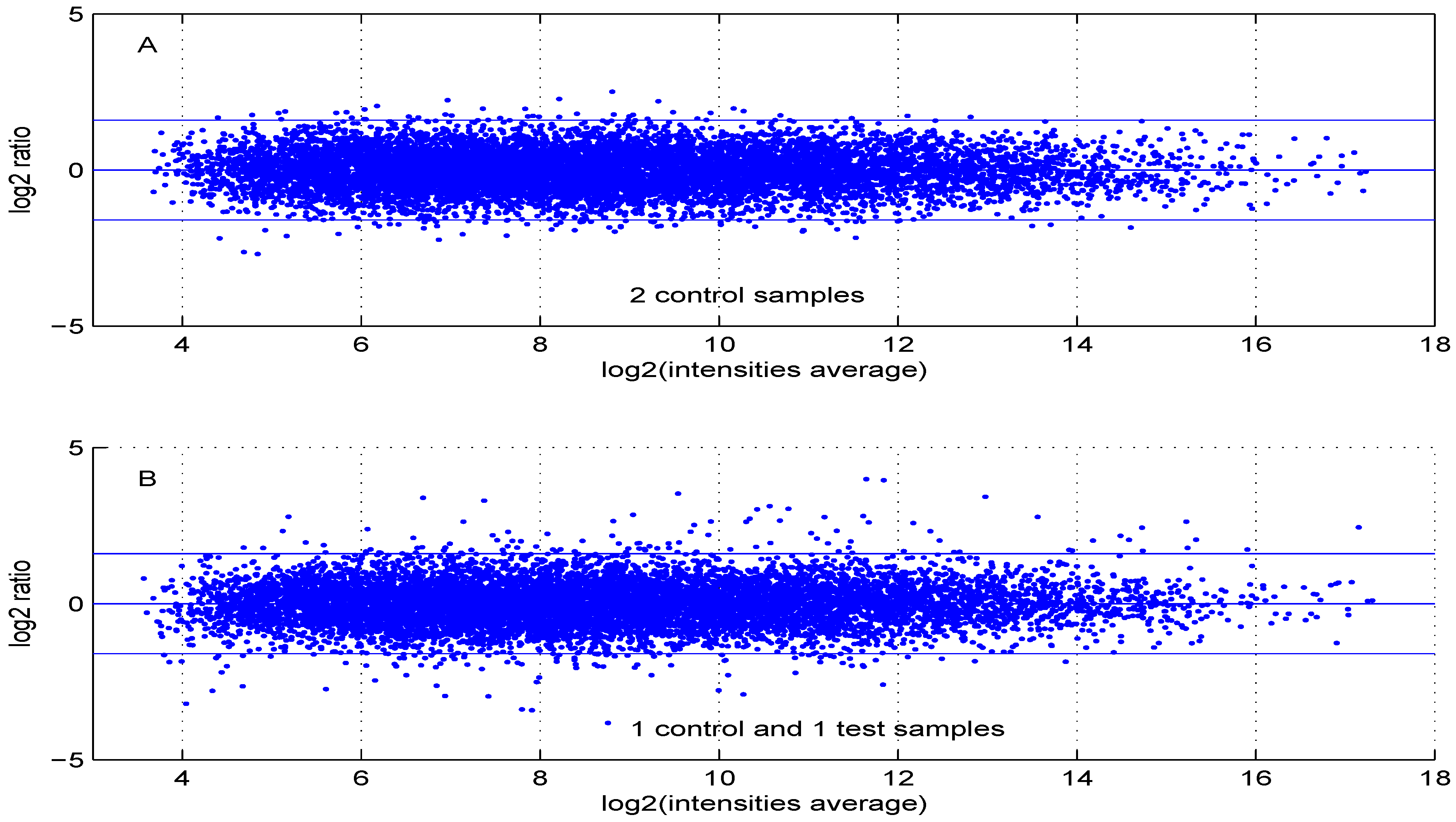
Figure 7.
MA plot with one control and one test sample, using (A) or (B) .
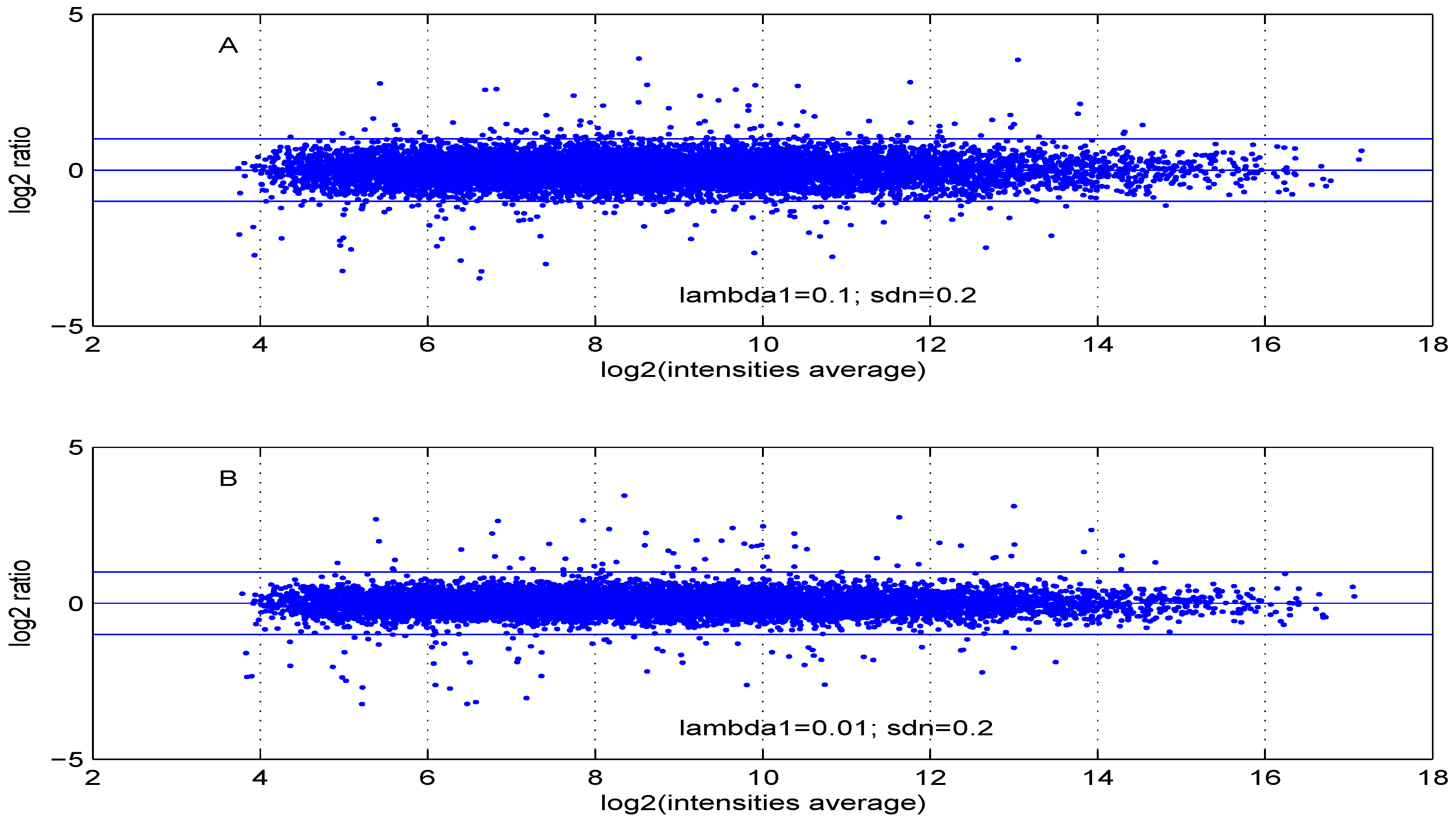
Figure 8.
MA plot with one control and one test sample, using (A) or (B) .
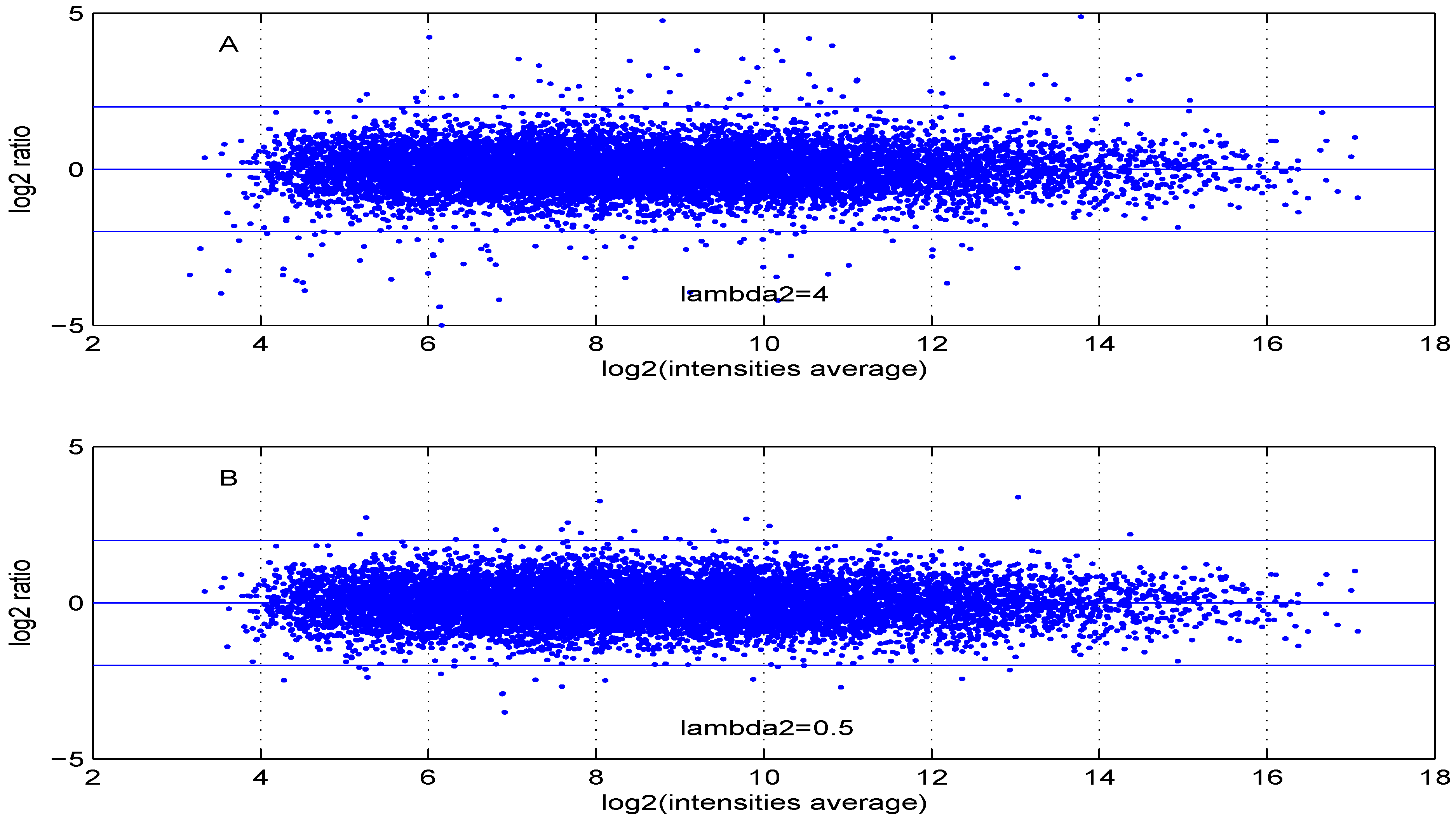
Figure 9.
MA plot with one control and one test sample, using (A) or (B) .
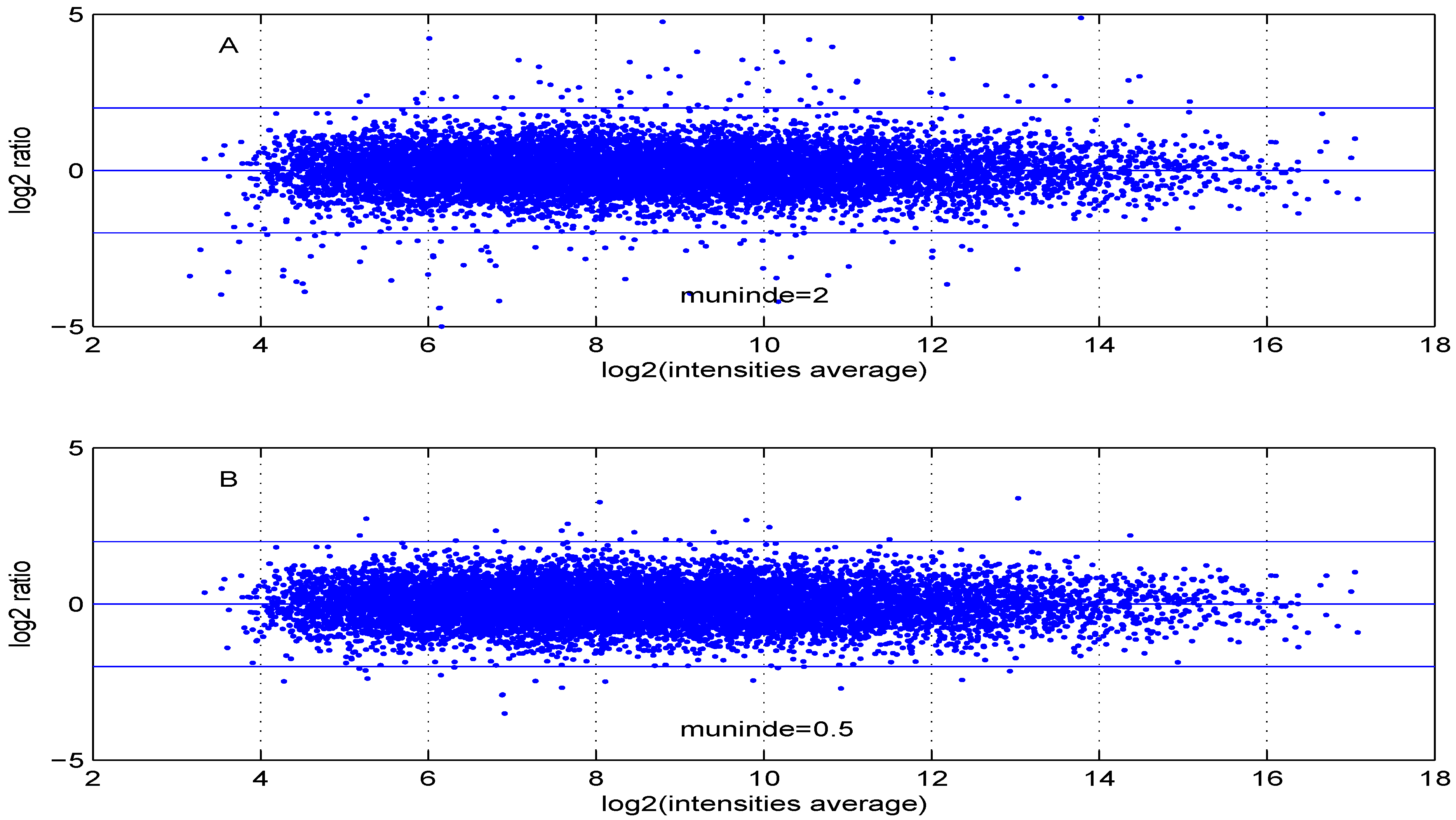
Figure 10.
MA plot with one control and one test sample, using (A) or (B) .

3.6. Discussion
The choice of some setting parameters for the proposed model is easy and can be dictated by the experimental design. This applies to n, , and ratio. Parameters lb and ub and sym and pde concern the dynamic range of variation of the data to generate and define the DE genes. The intervals indicated for lb and ub are those observed for data from common platforms. Parameters, , and , have no effect if real microarray data are used as a seed. The number of DE genes (pde) and the proportion of under- and over-regulated genes (sym) is at the discretion of the user. The parameter, rseed, allows one to produce the same data at different times using the same computer. This parameter is also useful for generating test data for different analysis algorithms. Settings, , , , and , control the global behavior of the data generated. More precisely, allows one to make gene changes dependent on the average level of expression. introduces variation in the expression changes for DE genes. These changes are defined by and . Parameter, , also acts as noise. The parameter, , allows one to perturb the data generated. The example of Figure 4 shows that the data obtained can differ from those expected for large values of . The signal to noise ratio (defined as the ratio of standard deviations) for default settings is . This rises to for .
An interesting microarray study was reported in [12]. In that study, the same RNA samples were processed by many laboratories using three leading microarray platforms: Affymetrix (five labs), two-color cDNA (three labs) and two-color oligonucleotides (two labs). The results presented show a good agreement across-platforms in contrast to some results previously reported in the literature, see, for instance, references cited in [12]. The microarray data generated for the study described in [12] are available from the Gene Expression Omnibus [13] under accession number GSE2521. These data can be used as seed for our model, which can then be integrated into user friendly data analysis software, such as Partek Genomics Suite, GeneSpring GX, etc., for demonstration and/or teaching purposes.
3.7. R Code
For immediate use of the proposed model, we provide an R code function madsim.R (MicroArray Data Simulation Model), which is deposed as a package on the Comprehensible R Archive Network (CRAN) server for download [14]. The outputs of this function are the data generated (xdata) and the indexes of DE genes (xid). Real data can be used as seed for each gene. An example of such data is available in the data folder of the package. Further explanations are available from the package’s help function.
4. Conclusions
We proposed in this paper a simulation model of microarray data. This model is very flexible and allows one to generate data with similar characteristics to the data commonly produced by current platforms. We showed a commented example of its possible use. We considered the case of data from two biological conditions. This model can be extended to multiple biological conditions in different ways: (a) modify to take into account additional biological conditions and several levels for the parameters, and , and (b) use as is, then place data side by side.
Acknowledgments
This work was supported by the Centre National pour la Recherche Scientifique. We are grateful to Julie D. Thompson for critical reading of the manuscript and helpful comments. We thank anonymous reviewers for their helpful comments.
References
- Dabney, A.R.; Storey, J.D. A new approach to intensity-dependent normalization of two-channel microarrays. Biostatistic 2007, 8, 128–139. [Google Scholar] [CrossRef] [PubMed]
- Fujita, A.; Sato, J.R.; de Oliveira Rodrigues, L.; Ferreira, C.E.; Sogoyar, M.C. Evaluating different methods of microarrays data normalization. BMC Bioinformatics 2006, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Irizarry, R.A.; Hobbs, B.; Collin, F.; Beazer-Barclay, Y.D.; Antonellis, K.J.; Scherf, U.; Speed, T.P. Exploration, normalization and summaries of high-density oligonucleotide array probe level data. Biostatistic 2003, 4, 249–264. [Google Scholar] [CrossRef] [PubMed]
- Lonnstedt, I.; Speed, T. Repicated microarray data. Stat. Sinica 2002, 12, 31–46. [Google Scholar]
- Martin, D.E.; Demougin, P.; Hall, M.N.; Bellis, M. Rank difference analysis of microarrays RDAM, a novel approach to statistical analysis of microarray expression profiling data. BMC Bioinformatics 2004, 5. [Google Scholar] [CrossRef] [Green Version]
- Nykter, M.; Aho, T.; Ahdesmäki, M.; Ruusuvuori, P.; Lehmussola, A.; Yli-Harja, O. Simulation of microarray data with realistic characteristics. BMC Bioinformatics 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Witten, D.M.; Tibshirani, R. A Comparison of Fold-Change and the t-Test for Microarray Data Analysis; Department of Statistics, Stanford University: Stanford, CA, USA, 2007; p. 17. Available online: http://www-stat.stanford.edu/ tibs/ftp/FCTComparison.pdf (accessed on 1 March 2013).
- Smyth, G.K. Linear models and empirical bayes methods for assessing differential expression in microarray experiments. Stat. Appl. Genet. Mol. Biol. 2004, 3. Article 3. Available online: http://www.statsci.org/smyth/pubs/ebayes.pdf (accessed on 1 March 2013). [Google Scholar] [CrossRef] [PubMed]
- McCarthy, D.J.; Smyth, G.K. Testing significance relative to a fold-change threshold is a TREAT. Bioinformatics 2009, 25, 765–771. [Google Scholar] [CrossRef] [PubMed]
- Kooperberg, C.F.; Aragaki, A.D.; Strand, A.; Olson, J.M. Significance testing for small microarray experiments. Stat. Med. 2005, 24, 2281–2298. [Google Scholar] [CrossRef] [PubMed]
- Dudoit, S.; Yang, Y.H.; Callow, M.J.; Speed, T.P. Stistical methods for identifying differentially expressed genes in replicated cDNA microarray experiments. Stat. Sinica 2002, 12, 111–139. [Google Scholar]
- Irizarry, R.A.; Warren, D.; Spencer, F.; Kim, I.F.; Biswal, S.; Frank, B.C.; Gabrielson, E.; Garcia, J.G.N.; Geoghegan, J.; Germino, G.; et al. Multiple-laboratory comparison of microarray platforms. Nat. Methods 2005, 2, 345–350. [Google Scholar] [CrossRef] [PubMed]
- Gene Expression Omnibus. Available online: http://www.ncbi.nlm.nih.gov/geo/ (accessed on 1 March 2013).
- The R Project for Statistical Computing. Available online: http://www.r-project.org (accessed on 1 March 2013).
© 2013 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Dembélé, D. A Flexible Microarray Data Simulation Model. Microarrays 2013, 2, 115-130. https://doi.org/10.3390/microarrays2020115
AMA Style
Dembélé D. A Flexible Microarray Data Simulation Model. Microarrays. 2013; 2(2):115-130. https://doi.org/10.3390/microarrays2020115
Chicago/Turabian StyleDembélé, Doulaye. 2013. "A Flexible Microarray Data Simulation Model" Microarrays 2, no. 2: 115-130. https://doi.org/10.3390/microarrays2020115