Exact Solution Analysis of Strongly Convex Programming for Principal Component Pursuit


{kind=link}
Abstract
:1. Introduction
1.1. Basic Problem Formulations
1.2. Contents and Notations
2. Important Lemmas
- (a).
- (b).
- (c).
- (a).
- (b).
- (a).
- (b).
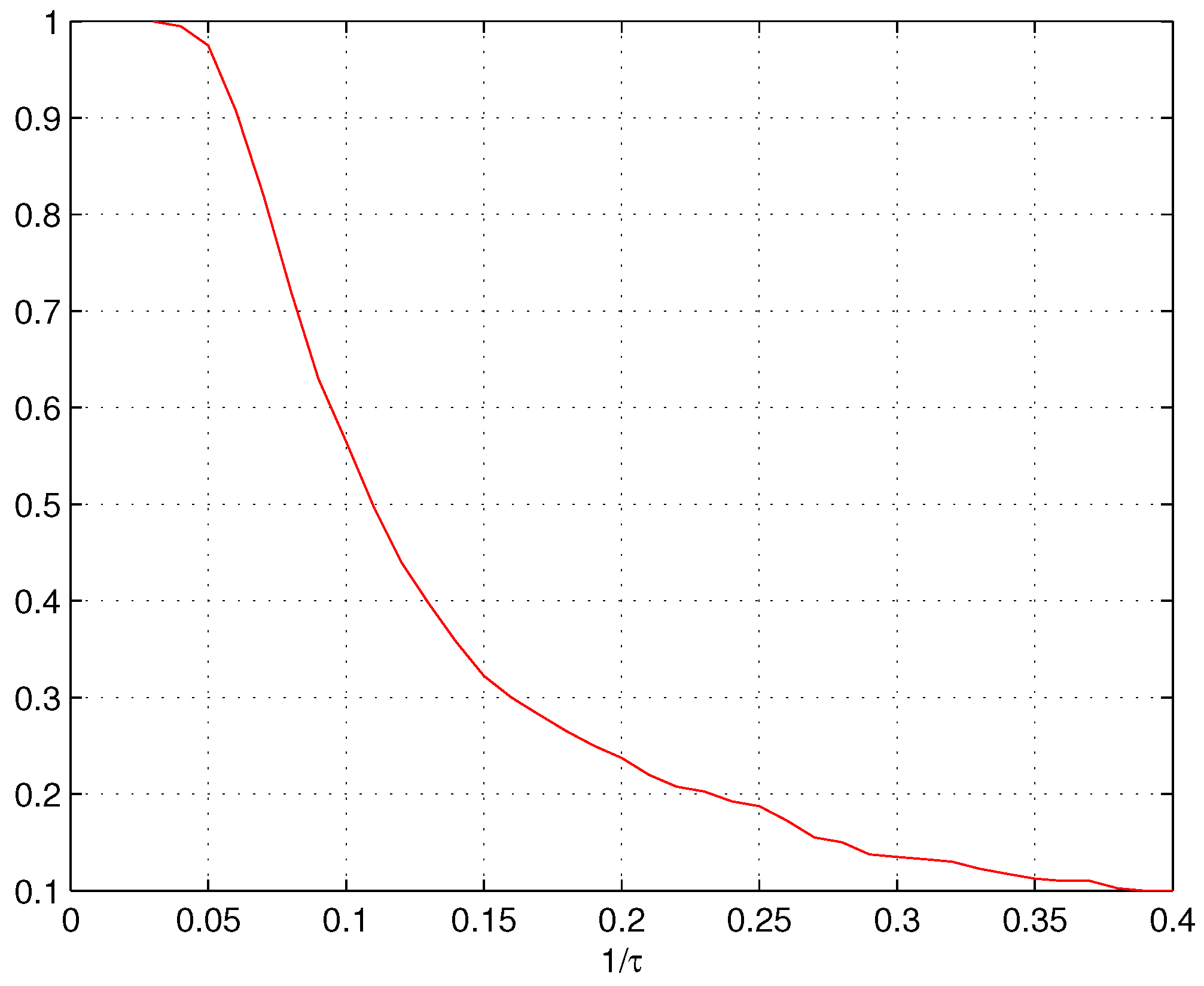
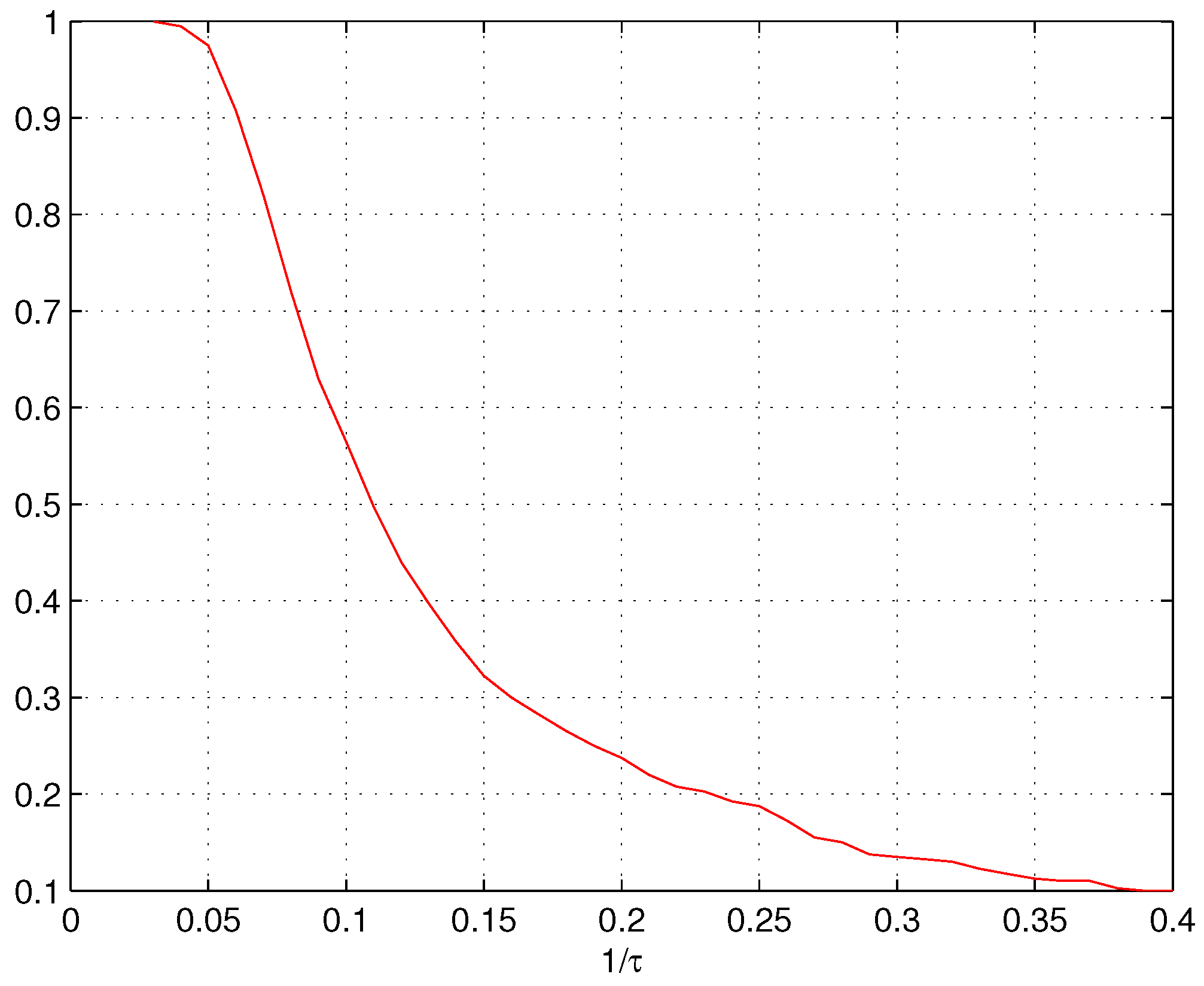
3. Estimating Parameter τ
4. Numerical Results
5. Results and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Fazel, M. Matrix Rank Minimization with Applications. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2002. [Google Scholar]
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimzation. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef]
- Candès, E.J.; Plan, Y. Matrix completion with noise. Proc. IEEE 2010, 98, 925–936. [Google Scholar] [CrossRef]
- Candès, E.J.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. IEEE Trans. Inf. Theory 2010, 56, 2053–2080. [Google Scholar] [CrossRef]
- Ellenberg, J. Fill in the blanks: Using math to turn lo-res datasets into hi-res samples. Wired. 2010. Available online: https://www.wired.com/2010/02/ff_algorithm/all/1 (accessed on 26 January 2016).
- Wright, J.; Yang, A.; Ganesh, A.; Ma, Y.; Sastry, S. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Chambolle, A.; Lions, P.L. Image recovery via total variation minimization and related problems. Numer. Math. 1997, 76, 167–188. [Google Scholar] [CrossRef]
- Claerbout, J.F.; Muir, F. Robust modeling of erratic data. Geophysics 1973, 38, 826–844. [Google Scholar] [CrossRef]
- Papadimitriou, C.; Raghavan, P.; Tamaki, H.; Vempala, S. Latent semantic indexing: A probabilistic analysis. In Proceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Seattle, WA, USA, 1–4 June 1998; Volume 61.
- Argyriou, A.; Evgeniou, T.; Pontil, M. Convex multi-task feature learning. Mach. Learn. 2008, 73, 243–272. [Google Scholar] [CrossRef]
- Bouwmans, T.; Sobral, A.; Javed, S.; Jung, S.; Zahzah, E. Decomposition into Low-rank plus Additive Matrices for Background/Foreground Separation: A Review for a Comparative Evaluation with a Large-Scale Dataset. Comput. Vis. Pattern Recognit. 2016. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2009, 58, 1–37. [Google Scholar] [CrossRef]
- Cai, J.F.; Osher, S.; Shen, Z. Linearized Bregman Iterations for Compressed Sensing. Math. Comp. 2009, 78, 1515–1536. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. 2009; arXiv:0905.0233. [Google Scholar]
- Cai, J.-F.; Canès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2008, 20, 1956–1982. [Google Scholar] [CrossRef]
- Zhang, H.; Cai, J.-F.; Cheng, L.; Zhu, J. Strongly Convex Programming for Exact Matrix Completion and Robust Principal Component Analysis. Inverse Probl. Imaging 2012, 6, 357–372. [Google Scholar] [CrossRef]
- Ganesh, A.; Min, K.; Wright, J.; Ma, Y. Principal Component Pursuit with Reduced Linear Measurements. 2012; arXiv:1202.6445v1. [Google Scholar]
- Ledoux, M. The Concentration of Measure Phenomenon; American Mathematical Society: Providence, RI, USA, 2001. [Google Scholar]
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, Q.; Wan, Q. Exact Solution Analysis of Strongly Convex Programming for Principal Component Pursuit. Information 2017, 8, 17. https://doi.org/10.3390/info8010017
You Q, Wan Q. Exact Solution Analysis of Strongly Convex Programming for Principal Component Pursuit. Information. 2017; 8(1):17. https://doi.org/10.3390/info8010017
Chicago/Turabian StyleYou, Qingshan, and Qun Wan. 2017. "Exact Solution Analysis of Strongly Convex Programming for Principal Component Pursuit" Information 8, no. 1: 17. https://doi.org/10.3390/info8010017