A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory


1
College of Mechatronic Engineering, North Minzu University, Yinchuan 750021, China
2
The 713th Research Institute of China Shipbuilding Industry Corporation, Zhengzhou 450052, China
*
Author to whom correspondence should be addressed.
Information 2018, 9(7), 162; https://doi.org/10.3390/info9070162
Submission received: 10 May 2018
/
Revised: 25 June 2018
/
Accepted: 28 June 2018
/
Published: 2 July 2018
(This article belongs to the Special Issue Multiple-Criteria Decision-Making (MCDM) Techniques for Business Processes Information Management)
Abstract
:Within the context of increasingly serious global environmental problems, green supplier assessment has become one of the key links in modern green supply chain management. In the actual work of green supplier assessment, the information of potential suppliers is often ambiguous or even absent, and there are interrelationships and feedback-like effects among assessment indexes. Additionally, the thinking of experts in index importance judgment is always ambiguous and subjective. To handle the uncertainty and incompleteness in green supplier assessment, we propose a green supplier assessment method based on rough ANP and evidence theory. The uncertain index value is processed by membership degree. Trapezoidal fuzzy number is adopted to express experts’ judgment on the relative importance of the indexes, and rough boundary interval is used to integrate the judgment opinions of multiple experts. The ANP structure is built to deal with the interrelationship and feedback-like effects among indexes. Then, the index weight is calculated by ANP method. Finally, the green suppliers are assessed by a trust interval, based on evidence theory. The feasibility and effectiveness of the proposed method is verified by an application of a bearing cage supplier assessment.
1. Introduction
With the increasing awareness of global environmental protection and the increasing number of related environmental regulations, manufacturing enterprises are facing more stringent environmental requirements. Nowadays, green supply chains have become inevitable choices for manufacturing enterprises who wish to deal with environmental problems. Green supply chain management includes many links, such as green supplier assessment, green product design, green production, green marketing and waste recovery [1,2,3]. Green supplier assessment is in the upstream of the whole supply chain, and its effect on environmental protection and cost saving can be transmitted to every part of the downstream through the supply chain.
In the process of green supply chain management, various factors make the relationship between suppliers and manufacturing enterprises complicated and vague. However, competitors constantly adjust their strategies, and the supply chain must constantly improve to adapt to the complex environment which changes rapidly. In this context, green supplier assessment plays a very important role in reducing costs, and improving product quality and market competitiveness. Through effective assessment and supervisions of suppliers, problems can be found and solved in time, and the green and healthy development of the entire supply chain can be promoted [4,5,6,7,8,9]. It can be seen that green supplier assessment plays a decisive role in green supply chain management, which directly determines the competitiveness of the entire supply chain. The rise of the internet has provided convenience for manufacturing enterprises to assess green suppliers, but enterprises cannot quickly choose suppliers which meet their needs in the face of so many uneven suppliers. Considering finances and the effective utilization of resources, how to assess green supplier quickly and effectively becomes the key problem in modern green supply chain.
As seen in the present literature, there are many significant works on green supplier assessment. On the whole, the existing research mainly includes the following aspects.
- (1)
- Supplier assessment models based on Analytic Hierarchy Process (AHP) [10] or Analytic Network Process (ANP) [11]. Noci [12] used AHP to evaluate supplier’s environmental efficiency. Lee et al. [13] used the Delphi technique to distinguish the evaluation criterion difference between the traditional supplier and the green supplier, and then used Fuzzy Analytic Hierarchy Process (FAHP) to solve the green supplier selection process. Hsu and Hu [14] contained the interdependence between components of decision structure and used ANP for green supplier selection which reflected a more realistic result.
- (2)
- Supplier assessment model based on mathematical Programming. Yeh and Chuang [15] put forward a mathematical programming model of green partner selection, which includes four goals: cost, time, product quality, and green score. They adopted two multi-objective genetic algorithms (MOGA) to find a set of Pareto optimal solutions, and used weighted summation to generate more solutions. Yousefi et al. [16] used Dynamic Data Envelopment Analysis (D-DEA) and scenario-based robust model for supplier selection. In this supplier selection model, the shortcomings of the DEA model (the benchmarks were determined based on previous performance) were overcome, and the disadvantages of the D-DEA model (the decision unit couldn’t get a unified efficiency score) were avoided.
- (3)
- Supplier assessment model based on Technique for Order Preference by Similarity to an Ideal Solution (TOPSIS). Awasthi et al. [17] proposed a three-step method for green supplier evaluation: identification standard, expert score, evaluate expert score by fuzzy TOPSIS. The fuzzy TOPSIS method integrated profit and cost standard, and this method is suitable for the situation of lack of partial quantitative information. Kannan and Jabbour [18] used fuzzy TOPSIS to solve the problem of green supplier selection, and applies three types of fuzzy TOPSIS method to sort green suppliers.
- (4)
- Other hybrid models for supplier assessment. Gandhi et al. [5] proposed a combined approach using AHP and Decision-Making and Trial Evaluation Laboratory (DEMATEL) for evaluating success factors in implementation of green supply chain management and gave a case study in Indian manufacturing industries. Chatterjee et al. [19] combined DEMATEL and ANP in a rough context, and then proposed a rough DEMATEL-ANP (R’AMATEL) method to evaluate the performance of suppliers for green supply chain implementation in electronics industry. Wu et al. [20] used the Continuous Ordered Weighted Averaging (COWA) operator to transform the trapezoid fuzzy number into the exact real number to select the green supplier, and make a sensitivity analysis according to the degree of risk of decision-maker to rank the suppliers. Luo and Peng [21] proposed a multi-level supplier evaluation and selection model. In this model, AHP is used to determine the weights, and then TOPSIS is used for supplier evaluation. Kuo and Lin [22] integrated ANP and DEA and proposed a green supplier evaluation method. The interdependence between standards were considered by ANP, which allowed users to choose their own weight preferences to limit weights, expanded DEA method, and allowed more flexible number of decision units. Shi et al. [23] used the improved attribute reduction algorithm based on rough set to reduce the index of the green supplier evaluation index system, and then evaluated the data by RBF neural network training. Akman [24] identified the suppliers that should be included in the green supplier development plan through the C mean clustering algorithm and the VIKOR method. This method can be used to solve the problem of supplier classification and evaluation.
The study of green supplier assessment, which is of great theoretical and practical significance, has been a hot topic all along. However, the existing research has obvious shortcomings and the research gaps are mainly as follows:
- (1)
- The information of the suppliers to be assessed is not clear enough in the actual work of green supplier assessment. There is often no information sharing between manufacturing enterprise and suppliers, and the information between them is often ambiguous or even absent. The deterministic assessing model can no longer meet the needs of the increasingly complex decision-making environment.
- (2)
- Green supplier assessment is a complex decision problem and its indexes are interrelated. When calculating the index weight, the core idea of traditional AHP is to divide the index system into isolated and hierarchical levels. Only the upper level elements’ dominating effect on the lower level elements is considered and the elements in the same level are deemed to be independent of each other. However, the relationships among the indexes are often interdependent and sometimes provide feedback-like effects in green supplier assessment. Therefore, traditional AHP cannot solve the complex relationships among indexes to obtain the weight in green supplier assessment.
- (3)
- The accurate number is used to describe the relative importance of the indexes in the expression of experts’ judgment in most of the existing research, which cannot reflect the ambiguities and subjectivity of the actual thinking. It is more reasonable to use fuzzy numbers [25] to express the experts’ judgment. After introducing fuzzy numbers to express experts’ judgment, analyzing and processing the imprecise and inconsistent information becomes a difficult problem.
To fill the research gaps in green supplier assessment, a green supplier assessment method for manufacturing enterprises based on rough ANP and evidence theory is proposed. We process the uncertain index value by membership degree, adopt trapezoidal fuzzy number to express experts’ judgment on the relative importance of the indexes, use rough boundary interval to integrate the judgment opinions of multiple experts, set up the ANP structure to deal with the interrelationship and the feedback-like effects among indexes and then calculate the index weight by ANP method, and finally solve the incomplete information problem by evidence theory and assess the green suppliers by trust interval.
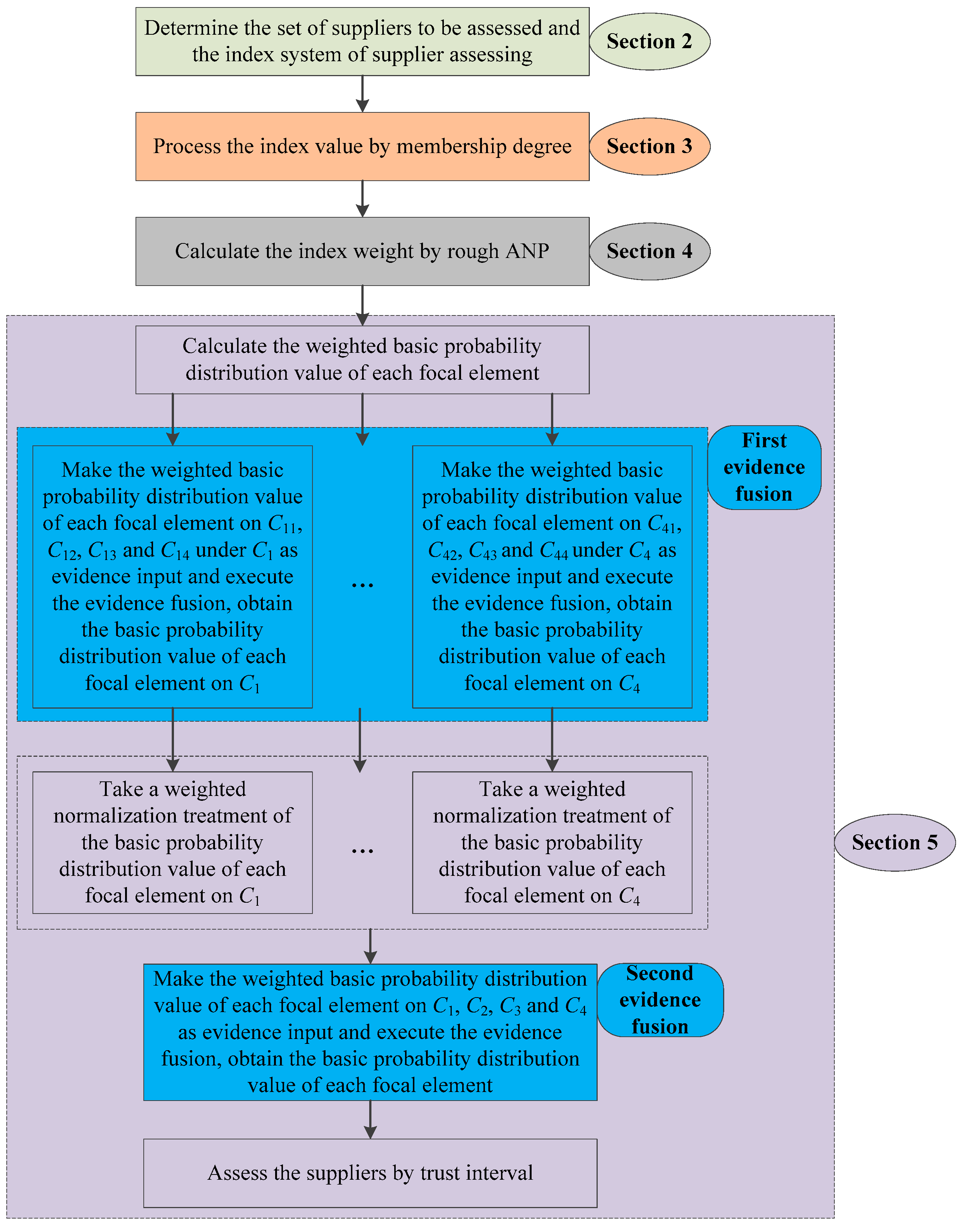
The rest of this paper is organized as follows. Section 2 establishes the index system of green supplier assessment; Section 3 uses membership degree method to process the uncertain index value of suppliers to be assessed; Section 4 adopts rough ANP to calculate the index weight; Section 5 gives the green supplier assessment procedure based on evidence theory; Section 6 provides an application case of bearing cage supplier assessment and discusses the feasibility and effectiveness of the proposed method for green supplier assessment. We conclude this paper in Section 7.
2. Index System
The first and very important segment of green supplier assessment is the establishment of a complete and overall index system. The attribute of the supplier’s product is the main representative of its ability, and the comprehensive ability of supplier can provide a strong support to its product. The comprehensive ability of supplier mainly includes internal competitiveness, external competitiveness and cooperation ability. Internal competitiveness of a supplier can be subdivided into its innovation capacity, manufacturing capacity and agility capacity. Furthermore, a supplier is not isolated and is inevitably restricted by its external competitiveness. External competitiveness of a supplier mainly includes its economic environment, geographical environment, social environment and legal environment. Additionally, cooperation ability of a supplier is affected by its technical compatibility degree, cultural compatibility degree, information platform compatibility degree, and reputation.
As shown in Figure 1, we establish the index system of green supplier assessment.
The green supplier assessment objective (AO) includes four first-level indexes: product attribute (C1), internal competitiveness (C2), external competitiveness (C3) and cooperation ability (C4).
- C1 is decomposed into four second-level indexes: cost (C1,1), quality (C1,2), service (C1,3) and flexibility (C1,4). C1,1 and C1,2 belong to quantitative type, and C1,3 and C1,4 belong to qualitative type.
- C2 is decomposed into three second-level indexes: innovation capacity (C2,1), manufacturing capacity (C2,2) and agility capacity (C2,3). C2,1, C2,2 and C2,3 all belong to qualitative type.
- C3 is decomposed into four second-level indexes: economic environment (C3,1), geographical environment (C3,2), social environment (C3,3) and legal environment (C3,4). C3,1, C3,2, C3,3 and C3,4 all belong to qualitative type.
- C4 is decomposed into four second-level indexes: technical compatibility degree (C4,1), cultural compatibility degree (C4,2), information platform compatibility degree (C4,3) and reputation (C4,4). C4,1, C4,2, C4,3 and C4,4 all belong to qualitative type.
3. Index Value Processing
For different types of indexes, different methods are used to get their values. To quantitative type index (i.e., C1,1 and C1,2), its value is obtained directly. To qualitative type index (i.e., C1,3, C1,4, C2,1, C2,2, C2,3 C3,1, C3,2, C3,3, C3,4, C4,1, C4,2, C4,3 and C4,4), its value, which is a score, is given by manager. If an index value can be accurately determined, it is a point value. If an index value is relatively fuzzy, it is an interval value. If an index value is completely unknown, it is a null value.
The suppliers to be assessed are . For the supplier (), the value on the index ( and ) is represented as . Then, the normalized index value is calculated as follows. If the index belongs to benefit-type, . If the index belongs to cost-type, . Here, the interval index value is replaced with its left and right ends.
We set five comment levels which are very bad (G1), bad (G2), middle (G3), good (G4), very good (G5). Furtherly, G1 and G5 are the comment level corresponding to the lowest normalized index value and the highest normalized index value , respectively. Similarly, the interval index value is replaced with its left and right ends. Then, a number sequence is obtained.
It is assumed that the corresponding numbers of the five comment levels are and . represents the membership degree of the index value to the comment level . On the index , the utility value of the supplier is represented as . The normalized index value of the supplier is a point-value , an interval value or a null value. When or (), . When and (), . When and (, and ), .
4. Index Weight Calculating
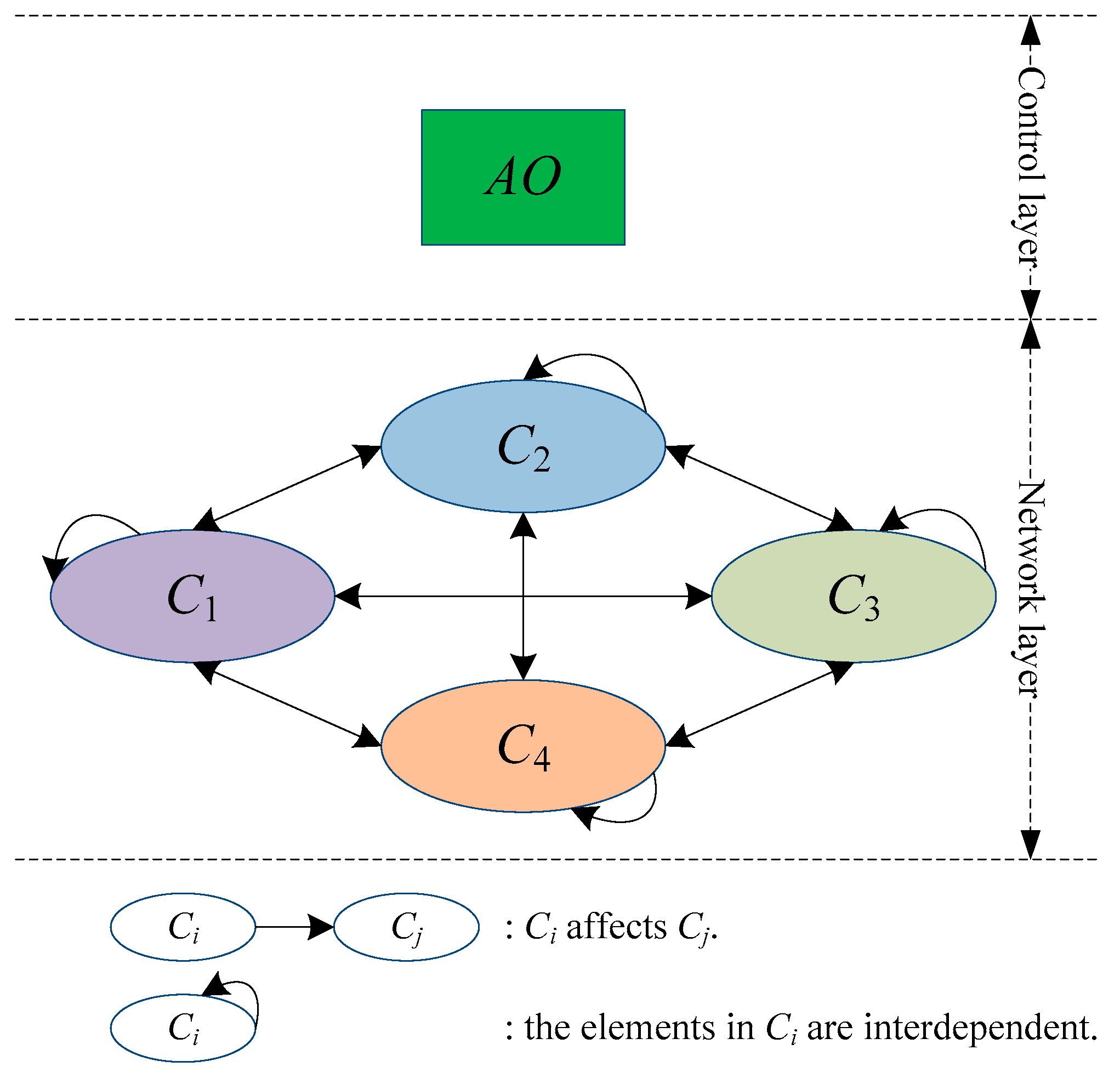
In ANP [11], the system elements are divided into two parts: (1) The first is called the control layer, including the problem objective and decision criteria. All decision criteria are considered independent of each other and are governed only by the problem objective. There can be no decision criteria in the control layer, but at least one objective; (2) The second part is the network layer, which is composed of all the elements that are controlled by the control layer, and its internal network structure is interacted.
Therefore, we set up the ANP structure of green supplier assessment as shown in Figure 2. The control layer only has one element: the green supplier assessment objective (AO), and the network layer has four element groups: product attribute (C1), internal competitiveness (C2), external competitiveness (C3) and cooperation ability (C4). Each element group affects each other and contains different elements. The elements in the same element group also affect each other. For example, internal competitiveness (C2) is affected by product attribute (C1), external competitiveness (C3) and cooperation ability (C4), and innovation capacity (C2,1), manufacturing capacity (C2,2) and agility capacity (C2,3) also affect each other.
According to the ANP structure of green supplier assessment shown in Figure 2, the control layer has the element AO and the network layer has the element groups C1, C2, …, CN (here, N = 4). The element group Ci (i = 1, 2, …, N) contains the elements . The control layer element AO is taken as the criterion and the element (l = 1, 2, …, ) in (j = 1, 2, …, N) is taken as the sub-criterion. Based on the influence of the elements in Ci on , the indirect dominance comparison of the elements in Ci are conducted.
Here, the influence of the elements in Ci on are assessed according to the personal experience and subjective judgment of experts, so using exact numbers to describe the influence of the elements in Ci on is unreasonable. In contrast, the fuzzy number can reflect the inherent uncertainty of the expert’s preference. At the same time, when integrating the opinions of multiple experts, the assessment of the influence of the elements in Ci on by experts is obviously with indiscernibility. The rough boundary interval in rough sets theory [26,27,28,29] can describe the indiscernibility as a set boundary area instead of a membership function, which can better integrate the assessment of multiple experts.
Based the index weight obtaining method in Reference [30], we design a rough ANP method to determine the index weight in green supplier assessment. The specific process of the designed rough ANP is as follows.
Step 1: Under the control layer element AO, we conduct the indirect dominance comparison of the elements in Ci according to their influence on .
There are q experts participating in the indirect dominance comparison of the elements in Ci. The fuzzy reciprocal judgement matrix given by the expert k (k = 1, 2, …, q) is as follows:
where represents the indirect dominance score of the element compared to the element giver by the expert k, here g,h = 1, 2, …, ni and g ≠ h. is a trapezoidal fuzzy number and . and are all positive real numbers and . Then the consistency of the matrix given by each expert is verified. If it is qualified, the next step will be carried out; otherwise, this step will be returned.
Then, is split into , , and . Based on , the rough group decision matrix is constructed where , g,h = 1, 2, …, ni and g ≠ h.
The rough boundary interval of (k = 1, 2, …, q) is where are the rough lower limit and rough upper limit of in the set .
Thus, the rough boundary interval of can be expressed as . According to the calculation rule of rough boundary interval, the mean form of can be obtained as where are the rough lower limit and rough upper limit of the set .
The rough judgement matrix is constructed as . Then, is split into the rough lower limit matrix and the rough upper limit matrix .
The eigenvectors corresponding to the maximum eigenvalues of and are and respectively, where are the value of and on the h (h = 1, 2, …, ni) dimension. Then, a set can be obtained where . Similarly, we also get the other sets: , and .
Thereupon, the eigenvector is obtained, where , h = 1, 2, …, ni. Then, the eigenvector is normalized as where .
Step 2: We represent as follows:
where the column vector is the normalized influence degree sorting vector of the elements in on the element in . If the elements in is not affected by the elements in , .
So we get the hyper-matrix under the control layer element AO as follows:
Step 3: The sub-block of is column normalized, but isn’t column normalized. To solve this problem, we conduct the indirect dominance comparison of the element groups according to their influence on under the control layer element AO. Here, we adopt a similar approach to Step 1 and get the relative importance matrix of element groups as follows:
where the column vector is the normalized influence degree sorting vector of the element groups on .
The weighted form of the hyper-matrix is , where .
Step 4: We do the square operation of the weighted hyper-matrix until the result converges to a stable limit hyper-matrix as follows:
Any column of is the limit relative ranking vector of all elements in the network layer. So we can get the weight vector of the index system shown in Figure 1 as follows:
where are the weights of , .
Furtherly, the weight of () is obtained as follows:
5. Green Supplier Assessment
5.1. Related Concepts of Evidence Theory
We assume that there are M suppliers to be assessed. Based on evidence theory [31,32], the set of the suppliers to be assessed is defined as the identification framework . All possible sets in are represented by the power set . If each element in is incompatible with each other, the number of elements in is . Then, a set function , which satisfies and , is defined. The set function is known as the basic probability distribution function on . Here, represents a supplier to be assessed. is the basic probability distribution value of and represents the trust degree for , Any supplier to be assessed satisfying the condition “” is called a focal element.
For , the fusion rule of the basic probability distribution functions on is as follows:
where .
The normalization constant K is defined as follows:
The total trust degree of on can be expressed as the belief function , and the uncertainty degree of on can be expressed as the plausible function . For a supplier on , represents the sum of the possibility measurement for all subsets of , and represents the sum of the uncertainty measurement for all subsets of . The confirmation degree of is represented by the trust interval .
Therefore, reflects the sum of exact reliability which the evidences support , and reflects the sum of reliability which the evidences do not negate . As a result, and can be considered as the minimum and maximum probability bounds respectively, so can form the trust interval.
Based on the above analysis, assessing the suppliers by trust interval is more reliable than by maximum belief function or maximum plausible function [30,31]. We assume that the supplier is better than supplier with a degree of (). If the trust intervals of and are and respectively, is defined as follows:
The decision rules based on trust interval are as follows:
- If , is better than (recorded as );
- If , is worse than (recorded as );
- If , and are equal (recorded as );
- For three suppliers , and , if and , is better than and is better than , so .
5.2. Green Supplier Assessing Procedure
On the index , the weighted basic probability distribution value of the focal element (s < 2N) is represented as . In this paper, we use as the evidence input of green supplier assessment.
The utility value of each focal element except can be calculated through index value processing. The special focal element can indicate the uncertainty of the expert on an index. If we don’t consider the influence of , the green supplier assessment problem will become a simple probability distribution problem, and the advantages of evidence theory will not be applied. Meanwhile, the trust degree of expert in each index is different and the uncertainty of index is reflected by the probability distribution of . Thus the probability distribution value of on different indexes should also be treated differently.
In the green supplier assessment problem, the index weight is obviously not fixed in the case of different requirements. When costs need to be reduced, C11 is more important than other indexes and its weight must be higher than other indexes, and the basic probability distribution value of on C11 should be smaller than other indexes. Therefore, the index weight calculated by rough ANP is introduced to adjust the preference of experts and solve the probability distribution problem of on different indexes. Then, the weighted basic probability distribution value of each focal element on each index is obtained as .
We take a weighted normalization treatment for the basic probability distribution values of all focal elements and calculate , as follows:
6. Case Study
6.1. An Application Case of Bearing Cage Supplier Assessment
For a bearing manufacturing enterprise, there are three bearing cage suppliers to be assessed. The set of suppliers to be assessed is . The best bearing cage supplier need to be selected after green supplier assessment. The index value of quantitative type (C11 and C12) is obtained directly from the enterprise resources planning system (ERP) of the bearing manufacturing enterprise, and the index value of qualitative type (other indexes) is obtained by the method of expert’s scoring (i.e., 0.1, 0.3, 0.5, 0.7 and 0.9). The index values of three bearing cage suppliers are shown in Table 1. The units of the index value on and are RMB and mm (error value) respectively.
Then, the normalized index values of three bearing cage suppliers are shown in Table 2.
Five comment levels: very bad (G1), bad (G2), middle (G3), good (G4) and very good (G5) are set. Taking the normalized index values , and for an example, we can get and , so , and . The corresponding numbers of the five comment levels are and . To the normalized index value , the membership degrees are and , so . The utility values of three bearing cage suppliers are shown in Table 3.
Next, the index weight is calculated by rough ANP. There are four experts: expert 1, expert 2, expert 3 and expert 4.
Taking the indirect dominance comparison of the elements in according to their influence on under the control layer element AO for an example, the fuzzy reciprocal judgement matrices given by the four experts are shown as follows:
We check the consistency of and and all of them are qualified.
Then, () is split into , , and . For example, is as follows:
Based on , the rough group decision matrix is constructed as follows:
For the partition = 3/2 in the element , its upper approximation set is {3/2, 7/3} and lower approximation set is {3/2, 1, 1}, then = (3/2 + 1 + 1)/3 = 1.17, = (3/2 + 7/3)/2 = 1.92 and = [1.17, 1.92]. Similarly, = [1, 1.46], = [1.46, 2.33]. So = {[1.17, 1.92], [1, 1.46], [1, 1.46], [1.46, 2.33]}.
According to the calculation rule of rough boundary interval, the mean form of is obtained as = [1.16, 1.79]. Then, the rough judgement matrix is constructed as follows:
is split into the rough lower limit matrix and the rough upper limit matrix . The eigenvectors corresponding to the maximum eigenvalues of and are = [0.71, 0.44, 0.45, 0.30]T and = [0.65, 0.49, 0.47, 0.34]T respectively. Then, we get a set = {0.68, 0.47, 0.46, 0.32}. Similarly, we also get the other sets: = {0.73, 0.51, 0.66, 0.58}, = {0.82, 0.67, 0.73, 0.69} and = {0.95, 0.77, 0.83, 0.75}.
Thereupon, we obtain the normalized eigenvector = [0.30, 0.23, 0.25, 0.22]T.
Similarly, we obtain the normalized eigenvector = [0.28, 0.41, 0.17, 0.14]T and = [0.33, 0.34, 0.13, 0.20]T. So we obtain as follows:
After the similar calculating, we get the hyper-matrix under the control layer element G as follows:
Then we conduct the indirect dominance comparison of the element groups according to their influence on under the control layer element AO. As a result, we get the relative importance matrix of element groups as follows:
The weighted form of the hyper-matrix is , where ( and ). The square operation of the weighted hyper-matrix is done continuously and converges to a stable limit hyper-matrix. So we get the weight vector of the index system shown in Figure 1 as follows: = [0.12, 0.11, 0.10, 0.09, 0.06, 0.06, 0.07, 0.05, 0.04, 0.04, 0.04, 0.06, 0.05, 0.05, 0.06]T. In the case of ensuring the weight proportional relationship among , we expand the weight vector of to [0.95, 0.87, 0.79, 0.71]T. Similarly, the weight vector of is expanded to [0.81, 0.81, 0.95]T, the weight vector of is expanded to [0.95, 0.76, 0.76, 0.76]T, and the weight vector of is expanded to [0.95, 0.79, 0.79, 0.95]T. Furtherly, the weight vector of is obtained as [0.42, 0.19, 0.17, 0.22]T. The relative weight vector of the index is [0.95, 0.43, 0.38, 0.50]T.
Based on evidence theory, the set of the three suppliers to be assessed is defined as the identification framework: . According to Equation (11), the weighted basic probability distribution values of all focal elements are calculated based on the utility values of three bearing cage suppliers shown in Table 3 and the above relative weight vector as follows:
- (1)
- = 0.0825, = 0.1252, = 0.7423, = 0.0500;
- (2)
- = 0.4121, = 0.4121, = 0.0458, = 0.1300;
- (3)
- = 0.3456, = 0.3999, = 0.0444, = 0.2100;
- (4)
- = 0.0374, = 0.3363, = 0.3363, = 0.2900;
- (5)
- = 0.1272, = 0.2820, = 0.4008, = 0.1900;
- (6)
- = 0.3141, = 0.4463, = 0.0496, = 0.1900;
- (7)
- = 0.3684, = 0.5234, = 0.0582, = 0.0500;
- (8)
- = 0.8550, = 0.0950, = 0.0500;
- (9)
- = 0.0691, = 0.6218, = 0.0691, = 0.2400;
- (10)
- = 0.3683, = 0.3508, = 0.0409, = 0.2400;
- (11)
- = 0.2947, = 0.4188, = 0.0465, = 0.2400;
- (12)
- = 0.8550, = 0.0950, = 0.0500;
- (13)
- = 0.6449, = 0.0726, = 0.0726, = 0.2100;
- (14)
- = 0.0790, = 0.7110, = 0.2100;
- (15)
- = 0.3912, = 0.5029, = 0.0559, = 0.0500.
Then we make , , and as the evidence input and execute the first evidence fusion respectively. Here, , , , . The basic probability distribution values of all focal elements are calculated as follows:
- (1)
- = 0.0491, = 0.6871, = 0.1938, = 0.0700;
- (2)
- = 0.2305, = 0.7000, = 0.0345, = 0.0350;
- (3)
- = 0.8165, = 0.1122, = 0.0033, = 0.0679;
- (4)
- = 0.0104, = 0.9841, = 0.0008, = 0.0046.
With the consideration of the relative weight vector of the index , we normalize the basic probability distribution values , , and . The weighted basic probability distribution values of all focal elements are calculated as follows:
- (1)
- = 0.0466, = 0.6527, = 0.1841, = 0.1165;
- (2)
- = 0.0991, = 0.3010, = 0.0148, = 0.5851;
- (3)
- = 0.3103, = 0.0426, = 0.0013, = 0.6458;
- (4)
- = 0.0052, = 0.4921, = 0.0004, = 0.5023.
Then, we make as the evidence input and execute the second evidence fusion. The basic probability distribution values are calculated as follows:
- (1)
- = 0.0042;
- (2)
- = 0.4160;
- (3)
- = 0.0006;
- (4)
- = 0.5792;
Therefore, the belief function and plausible function of the three suppliers are calculated, and then the trust interval are obtained as follows:
- (1)
- = [0.0042, 0.5834];
- (2)
- = [0.4160, 0.9952];
- (3)
- = [0.0006, 0.5798].
According to the decision rules based on trust interval in Section 5.1, we obtain the results as follows:
- (1)
- P(x1 > x2) = 0, so ;
- (2)
- P(x1 > x3) = 1, so .
Finally, we get the green supplier assessing results that are and the best bearing cage supplier is .
6.2. Discussion
In this paper, the index system, which contains four first-level indexes and fifteen second-level indexes, is established. The indexes in the index system are interrelated and sometimes provide feedback-like effects. Since the suppliers to be assessed are independent, we calculate the index weight by rough ANP. Then we process the uncertain index value by membership degree and get the utility value of a supplier on each index. At last, we solve the information incomplete problem in green supplier assessing by evidence theory.
From the case study in Section 6, the green supplier assessment result is . Based on the Overall view of Table 1, it is also known that is the best, is the worst and is middle. The details are as follows:
- To , the performance is the best on ten of the fifteen indexes (i.e., quality (C1,2), service (C1,3), flexibility (C1,4), manufacturing capacity (C2,2), agility capacity (C2,3), geographical environment (C3,2), legal environment (C3,4), technical compatibility degree (C4,1), information platform compatibility degree (C4,3) and reputation (C4,4)).
- To , the performance is the worst on twelve of the fifteen indexes (i.e., cost (C1,1), quality (C1,2), service (C1,3), manufacturing capacity (C2,2), agility capacity (C2,3), economic environment (C3,1), geographical environment (C3,2), social environment (C3,3), legal environment (C3,4), technical compatibility degree (C4,1), cultural compatibility degree (C4,2) and reputation (C4,4)).
- To , the performance is the worst on four indexes (i.e., flexibility (C1,4), innovation capacity (C2,1), geographical environment (C3,2) and information platform compatibility degree (C4,3)), and the performance is the best on five indexes (i.e., cost (C1,1), quality (C1,2), economic environment (C3,1), social environment (C3,3), cultural compatibility degree (C4,2) and reputation (C4,4)).
Thus, it can be seen that the assessing results are in accordance with the actual situation.
According to the utility value in Table 3, we compare the results of the proposed method with those based on Fuzzy Synthetic Evaluation (FSE) [33,34,35] and Fuzzy Analytic Hierarchy Process (FAHP) [36,37,38] as shown in Table 4.
As shown in Table 4, the results of the three methods, which all shows is the best supplier, are generally consistent. However, there are differences in the ranking between and . By FSE method and FAHP method, the complex and interrelated index system is simplified and the index interrelationship information is partially lost. By the proposed method, the weights of the indexes are processed by rough ANP and the index interrelationship information is successfully translated into the hyper-matrix through comparison among indexes.
In addition, green supplier assessment based on rough ANP and evidence theory can provide group decision-making information for enterprise managers, and the index weight can accurately reflect which index has the greatest impact on the supplier selection, thus providing the decision-making basis for the enterprise to reduce the cost and improve the competitiveness. The above analysis and the comparison in Table 4 verify the feasibility and effectiveness of the proposed method for green supplier assessing.
7. Conclusions
In the context of increasingly serious global environmental problems, an ideal manufacturer requires efficient, green suppliers. To handle the uncertainty and incompleteness in green supplier assessment, we propose a green supplier assessment method based on rough ANP and evidence theory. To the best of our knowledge, this is the first attempt to deal with green supplier assessment in a manufacturing enterprise using the hybrid method of rough ANP and evidence theory. The most prominent advantage of the proposed method is that it overcomes the shortcomings of traditional AHP by considering the dependencies and uncertainty across the indexes and processing experts’ judgment on the relative importance of the indexes by fuzzy number and rough boundary interval. It can provide a simple and effective way for weight calculating. By comparing our method with FSE and FAHP approach, we have shown that the proposed method provides a systematic and optimal tool of decision-making for green supplier assessment.
The proposed method provides a way for simplified modeling of complex Multi-criteria Decision Making (MCDM) problems. The decision-making systems are becoming more and more complex nowadays, filled with imprecise and vague information. Evidence theory is adept in capturing such kind of uncertain information, and it provides us with a flexible and effective tool to deal with the green supplier selection problem under uncertain environment. Although the model has been verified on a small case including three potential suppliers and fifteen indexes, it is capable for solving more similar complex problems.
The method proposed in this paper could help us to reduce the risks of making poor investment decisions when dealing with complex networks of green suppliers. In future studies, we will demonstrate on the application of large-scale data sets and the consideration of experts’ reliability.
Author Contributions
Conceptualization, L.L. and H.W.; Methodology, L.L.; Validation, L.L.; Formal Analysis, L.L.; Investigation, L.L.; Writing-Original Draft Preparation, L.L. and H.W.
Funding
This research was funded by Ningxia Natural Science Fund, Grant No. NZ17113 and Ningxia first-class discipline and scientific research projects (electronic science and technology), Grant No. NXYLXK2017A07.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jiang, W.; Huang, C. A Multi-criteria Decision-making Model for Evaluating Suppliers in Green SCM. Int. J. Comput. Commun. Control 2018, 13, 337–352. [Google Scholar] [CrossRef]
- Mangla, S.K.; Kumar, P.; Barua, M.K. Flexible Decision Modeling for Evaluating the Risks in Green Supply Chain Using Fuzzy AHP and IRP Methodologies. Glob. J. Flex. Syst. Manag. 2015, 16, 19–35. [Google Scholar] [CrossRef]
- Banaeian, N.; Mobli, H.; Fahimnia, B.; Nielsen, I.E.; Omid, M. Green Supplier Selection Using Fuzzy Group Decision Making Methods: A Case Study from the Agri-Food Industry. Comput. Oper. Res. 2016, 89, 337–347. [Google Scholar] [CrossRef]
- Yu, F.; Yang, Y.; Chang, D. Carbon footprint based green supplier selection under dynamic environment. J. Clean. Prod. 2018, 170, 880–889. [Google Scholar] [CrossRef]
- Gandhi, S.; Mangla, S.K.; Kumar, P.; Kumar, D. A combined approach using AHP and DEMATEL for evaluating success factors in implementation of green supply chain management in Indian manufacturing industries. Int. J. Logist. Res. Appl. 2016, 19, 537–561. [Google Scholar] [CrossRef]
- Mangla, S.K.; Kumar, P.; Barua, M.K. Risk analysis in green supply chain using fuzzy AHP approach: A case study. Resour. Conserv. Recycl. 2015, 104, 375–390. [Google Scholar] [CrossRef]
- Mangla, S.K.; Kumar, P.; Barua, M.K. Prioritizing the responses to manage risks in green supply chain: An Indian plastic manufacturer perspective. Sustain. Prod. Consum. 2015, 1, 67–86. [Google Scholar] [CrossRef]
- Tang, X.; Wei, G. Models for Green Supplier Selection in Green Supply Chain Management with Pythagorean 2-Tuple Linguistic Information. IEEE Access 2018, 6, 18042–18060. [Google Scholar] [CrossRef]
- Mangla, S.K.; Govindan, K.; Luthra, S. Critical success factors for reverse logistics in Indian industries: A structural model. J. Clean. Prod. 2016, 129, 608–621. [Google Scholar] [CrossRef]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill: New York, NY, USA, 1980. [Google Scholar]
- Saaty, T.L. Fundamentals of the analytic network process—Dependence and feedback in decision-making with a single network. J. Syst. Sci. Syst. Eng. 2004, 13, 129–157. [Google Scholar] [CrossRef]
- Noci, G. Designing ‘green’ vendor rating systems for the assessment of a supplier’s environmental performance. Eur. J. Purch. Supply Manag. 1997, 3, 103–114. [Google Scholar] [CrossRef]
- Lee, A.H.I.; Kang, H.Y.; Hsu, C.F.; Hung, H.C. A green supplier selection model for high-tech industry. Expert Syst. Appl. 2009, 36, 7917–7927. [Google Scholar] [CrossRef]
- Hsu, C.W.; Hu, A.H. Applying hazardous substance management to supplier selection using analytic network process. J. Clean. Prod. 2009, 17, 255–264. [Google Scholar] [CrossRef]
- Yeh, W.C.; Chuang, M.C. Using multi-objective genetic algorithm for partner selection in green supply chain problems. Expert Syst. Appl. 2011, 38, 4244–4253. [Google Scholar] [CrossRef]
- Yousefi, S.; Shabanpour, H.; Fisher, R.; Saen, R.F. Evaluating and ranking sustainable suppliers by robust dynamic data envelopment analysis. Measurement 2016, 83, 72–85. [Google Scholar] [CrossRef]
- Awasthi, A.; Chauhan, S.S.; Goyal, S.K. A fuzzy multicriteria approach for evaluating environmental performance of suppliers. Int. J. Prod. Econ. 2010, 126, 370–378. [Google Scholar] [CrossRef]
- Kannan, D.; Jabbour, C.J.C. Selecting green suppliers based on GSCM practices: Using fuzzy TOPSIS applied to a Brazilian electronics company. Eur. J. Oper. Res. 2014, 233, 432–447. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Wu, J.; Cao, Q.W.; Li, H. A Method for Choosing Green Supplier Based on COWA Operator under Fuzzy Linguistic Decision-Making. J. Ind. Eng. Eng. Manag. 2010, 24, 61–65. [Google Scholar]
- Luo, X.X.; Peng, S.H. Research on the Vendor Evaluation and Selection Based on AHP and TOPSIS in Green Supply Chain. Soft Sci. 2011, 25, 53–56. [Google Scholar]
- Kuo, R.J.; Lin, Y.J. Supplier selection using analytic network process and data envelopment analysis. Int. J. Prod. Res. 2012, 50, 2852–2863. [Google Scholar] [CrossRef]
- Shi, L. Green Supplier Evaluation of RS-RBF Neural Network Model. Sci. Technol. Manag. Res. 2012, 32, 198–201. [Google Scholar]
- Akman, G. Evaluating suppliers to include green supplier development programs via fuzzy c-means and VIKOR methods. Comput. Ind. Eng. 2015, 86, 69–82. [Google Scholar] [CrossRef]
- Pamučar, D.; Petrović, I.; Ćirović, G. Modification of the Best-Worst and MABAC methods: A novel approach based on interval-valued fuzzy-rough numbers. Expert Syst. Appl. 2018, 91, 89–106. [Google Scholar] [CrossRef]
- Li, L.; Mo, R.; Chang, Z.; Zhang, H. Priority evaluation method for aero-engine assembly task based on balanced weight and improved TOPSIS. Comput. Integr. Manuf. Syst. 2015, 21, 1193–1201. (In Chinese) [Google Scholar]
- Wang, X.; Xiong, W. Rough AHP approach for determining the importance ratings of customer requirements in QFD. Comput. Integr. Manuf. Syst. 2010, 16, 763–771. (In Chinese) [Google Scholar]
- Vasiljević, M.; Fazlollahtabar, H.; Stević, Z.; Vesković, S. A rough multicriteria approach for evaluation of the supplier criteria in automotive industry. Decis. Mak. Appl. Manag. Eng. 2018, 1, 82–96. [Google Scholar] [CrossRef]
- Pamučar, D.; Stević, Ž.; Zavadskas, E.K. Integration of interval rough AHP and interval rough MABAC methods for evaluating university web pages. Appl. Soft Comput. 2018, 67, 141–163. [Google Scholar] [CrossRef]
- Zhu, G.N.; Hu, J.; Qi, J.; Gu, C.C.; Peng, Y.H. An integrated AHP and VIKOR for design concept evaluation based on rough number. Adv. Eng. Inform. 2015, 29, 408–418. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Sarabi-Jamab, A.; Araabi, B.N. How to decide when the sources of evidence are unreliable: A multi-criteria discounting approach in the Dempster–Shafer theory. Inf. Sci. 2018, 448, 233–248. [Google Scholar] [CrossRef]
- Li, R.; Jin, Y. The early-warning system based on hybrid optimization algorithm and fuzzy synthetic evaluation model. Inf. Sci. 2017, 435, 296–319. [Google Scholar] [CrossRef]
- Haider, H.; Hewage, K.; Umer, A.; Ruparathna, R.; Chhipi-Shrestha, G.; Culver, K.; Holland, M.; Kay, J.; Sadiq, R. Sustainability Assessment Framework for Small-sized Urban Neighbourhoods: An Application of Fuzzy Synthetic Evaluation. Sustain. Cities Soc. 2017, 36, 21–32. [Google Scholar] [CrossRef]
- Zhu, J. Evaluation of supplier strength based on fuzzy synthetic assessment method. In Proceedings of the International Conference on Test and Measurement, Hong Kong, China, 5–6 December 2009; pp. 247–250. [Google Scholar]
- Deepika, M.; Kannan, A.S.K. Global supplier selection using intuitionistic fuzzy Analytic Hierarchy Process. In Proceedings of the International Conference on Electrical, Electronics, and Optimization Techniques, Chennai, India, 3–5 March 2016; pp. 2390–2395. [Google Scholar]
- Torng, C.; Tseng, K.W. Using Fuzzy Analytic Hierarchy Process to Construct Green Suppliers Assessment Criteria and Inspection Exemption Guidelines. In Proceedings of the International Conference on Human-Computer Interaction; Springer: Berlin/Heidelberg, Germany, 2013; pp. 729–732. [Google Scholar]
- Labib, A.W. A supplier selection model: A comparison of fuzzy logic and the analytic hierarchy process. Int. J. Prod. Res. 2011, 49, 6287–6299. [Google Scholar] [CrossRef]
Figure 1.
The index system.

Figure 2.
The ANP structure of green supplier assessment.

Figure 3.
The green supplier assessment procedure.


{kind=link}
{kind=link}
{kind=link}
Table 1.
The index values of three bearing cage suppliers.
| Supplier | C1,1 | C1,2 | C1,3 | C1,4 | C2,1 | C2,2 | C2,3 | C3,1 | C3,2 | C3,3 | C3,4 | C4,1 | C4,2 | C4,3 | C4,4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6.4 × 101 | 0.01 | 0.7 | 0.1 | [0.1, 0.3] | 0.5 | 0.7 | 0.5 | 0.5 | 0.7 | 0.7 | / | [0.7, 0.9] | 0.5 | 0.7 | |
| 1.9 × 103 | 0.01 | 0.9 | 0.7 | 0.5 | 0.7 | 0.9 | / | 0.7 | [0.5, 0.7] | 0.9 | 0.7 | 0.5 | 0.7 | 0.9 | |
| 2.8 × 104 | 0.03 | 0.1 | 0.7 | 0.7 | 0.1 | 0.3 | 0.1 | 0.5 | 0.1 | 0.3 | 0.1 | 0.5 | / | 0.1 |
Table 2.
The normalized index values of three bearing cage suppliers.
| Supplier | C1,1 | C1,2 | C1,3 | C1,4 | C2,1 | C2,2 | C2,3 | C3,1 | C3,2 | C3,3 | C3,4 | C4,1 | C4,2 | C4,3 | C4,4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.0023 | 1.0000 | 0.7778 | 0.1429 | [0.1429, 0.4286] | 0.7143 | 0.7778 | 1.0000 | 0.7143 | 1.0000 | 0.7778 | / | [0.7778, 1.0000] | 0.7143 | 0.7778 | |
| 0.0669 | 1.0000 | 1.0000 | 1.0000 | 0.7143 | 1.0000 | 1.0000 | / | 1.0000 | [0.7143, 1.0000] | 1.0000 | 1.0000 | 0.5556 | 1.0000 | 1.0000 | |
| 1.0000 | 0.3333 | 0.1111 | 1.0000 | 1.0000 | 0.1429 | 0.3333 | 0.2000 | 0.7143 | 0.1429 | 0.3333 | 0.1429 | 0.5556 | / | 0.1111 |
Table 3.
The utility values of three bearing cage suppliers.
| Supplier | C1,1 | C1,2 | C1,3 | C1,4 | C2,1 | C2,2 | C2,3 | C3,1 | C3,2 | C3,3 | C3,4 | C4,1 | C4,2 | C4,3 | C4,4 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1000 | 0.9000 | 0.7778 | 0.1000 | 0.2857 | 0.6333 | 0.6334 | 0.9000 | 0.1000 | 0.9000 | 0.6334 | / | 0.8889 | 0.1000 | 0.7000 | |
| 0.1518 | 0.9000 | 0.9000 | 0.9000 | 0.6333 | 0.9000 | 0.9000 | / | 0.9000 | 0.8572 | 0.9000 | 0.9000 | 0.1000 | 0.9000 | 0.9000 | |
| 0.9000 | 0.1000 | 0.1000 | 0.9000 | 0.9000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | 0.1000 | / | 0.1000 |
Table 4.
The comparison of assessing results of the proposed method, FSE and FAHP.
| Supplier | Ranking of Three Suppliers | ||
|---|---|---|---|
| Proposed Method | FSE | FAHP | |
| 2 | 3 | 3 | |
| 1 | 1 | 1 | |
| 3 | 2 | 2 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, L.; Wang, H. A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory. Information 2018, 9, 162. https://doi.org/10.3390/info9070162
AMA Style
Li L, Wang H. A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory. Information. 2018; 9(7):162. https://doi.org/10.3390/info9070162
Chicago/Turabian StyleLi, Lianhui, and Hongguang Wang. 2018. "A Green Supplier Assessment Method for Manufacturing Enterprises Based on Rough ANP and Evidence Theory" Information 9, no. 7: 162. https://doi.org/10.3390/info9070162
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.