1. Introduction
Recent trends of chip-miniaturization and CMOS (complementary metal-oxide semiconductor) scaling have led to a large increase in the number of cores on a chip [
1]. To feed data to these cores and avoid off-chip accesses, the size of last level caches has significantly increased, for example, Intel’s Xeon E7-8870 processor has 30 MB last level cache (LLC) [
1]. Conventionally, caches have been designed using SRAM (static random access memory), since it provides high performance and write endurance. However, SRAM also has low density and high leakage energy which leads to increased energy consumption and temperature of the chip. With ongoing scaling of operating voltage, the critical charge required to flip the value stored in a memory cell has been decreasing [
2], and this poses a serious concern for reliability of charge-based memories such as SRAM.
Non-volatile memories (NVMs) hold the promise of providing a low-leakage, high-density alternative to SRAM for designing on-chip caches [
3,
4,
5,
6]. NVMs such as spin transfer torque RAM (STT-RAM) and resistive RAM (ReRAM) have several attractive features, such as read latency comparable to that of SRAM, high-density and CMOS compatibility [
7,
8]. Further, NVMs are expected to scale to much smaller feature sizes than the charge-based memories since they rely on resistivity rather than charge as the information carrier.
A crucial limitation of NVMs, however, is that their write endurance is orders of magnitude lower than that of SRAM and DRAM (dynamic random access memory). For example, while the write-endurance of SRAM and DRAM are in the range of
, this value for ReRAM is only
[
9]. For STT-RAM, although a write-endurance value of
has been predicted [
10], the best write-endurance test so far shows only
[
5,
11]. Process variation may further reduce these values by an order of magnitude [
12].
Further, existing cache management techniques have been designed for optimizing performance and they do not take the write-endurance of device into account. Hence, due to the temporal locality of program access, they may greatly increase the number of accesses to a few blocks of the cache. Due to failure of these blocks, the actual device lifetime may be much smaller than what is expected assuming uniform distribution of writes.
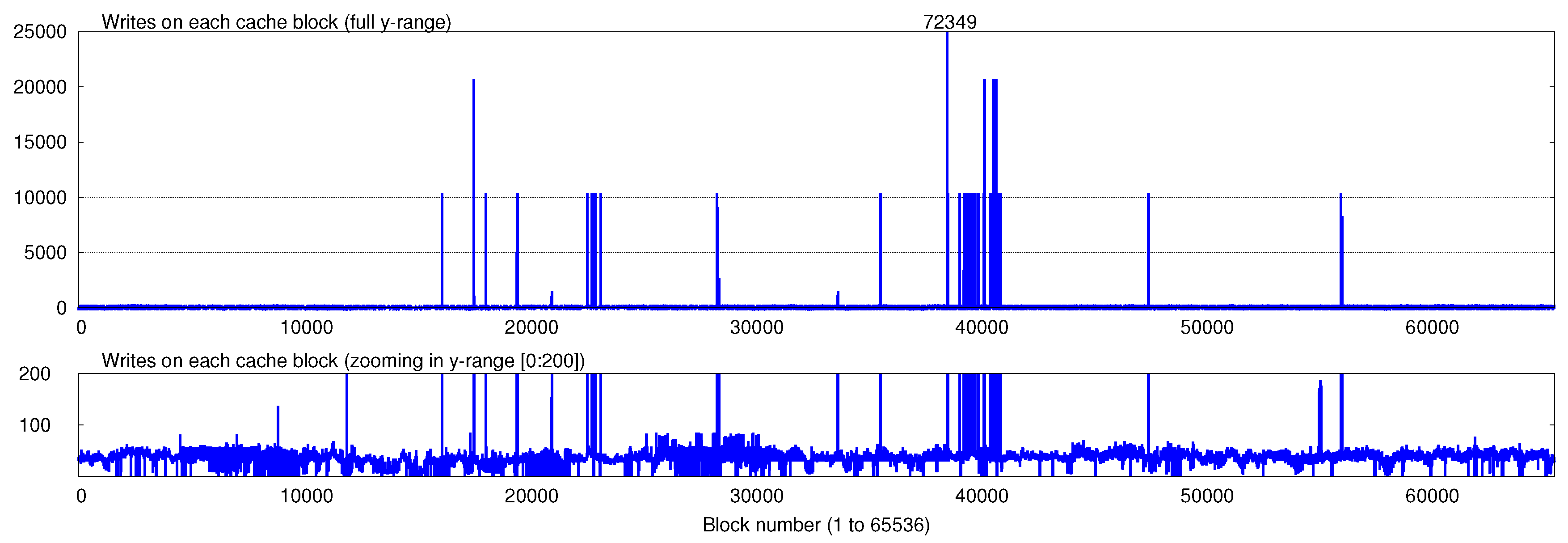
Figure 1 shows an example of this where the number of writes to different cache blocks are plotted for SpPo (sphinx-povray) workload (more details of experimental setup are provided in
Section 4). Clearly, the write-variation across different cache bocks is very large: the maximum write on a block (72349) is 1540 times the average write on any block (47).
Figure 1.
Number of writes on cache blocks for SpPo (sphinx-povray) workload. The top figure shows the full y-range (number of writes), while the bottom figure shows only the range [0:200]. Notice that the write-variation is very large, while the average write-count per block is only 47, the maximum write-count is 72,349.
Figure 1.
Number of writes on cache blocks for SpPo (sphinx-povray) workload. The top figure shows the full y-range (number of writes), while the bottom figure shows only the range [0:200]. Notice that the write-variation is very large, while the average write-count per block is only 47, the maximum write-count is 72,349.
Thus, limited endurance of NVMs, along with the large write-variation introduced by the existing cache management techniques, may cause the endurance limit to be reached in a very short duration of time. This leads to hard errors in the cache [
2] and limits its lifetime significantly. This vulnerability can also be exploited by any attacker by running a code which writes repeatedly to a single block to make it reach its endurance limit (called repeated address attack) for causing device failure. Thus, effective architectural techniques are required for managing NVM caches for making them a universal memory solution.
In this paper, we present ENLIVE, a technique for ENhancing the LIfetime of non-Volatile cachEs. ENLIVE uses a small (e.g., 128 entry) SRAM storage, called HotStore. To reduce the number of writes to the cache, ENLIVE migrates the frequently used blocks into the HotStore, so that the future accesses can be served from the HotStore (
Section 2). This improves the performance and energy efficiency and also reduces the number of writes to the NVM cache, which translates into enhanced cache lifetime. We also discuss the architectural mechanism to manage the HotStore and show that the storage overhead of ENLIVE is less than 2% of the L2 cache (
Section 3), which is small. In this paper, we assume a ReRAM cache, and based on the explanation, ENLIVE can be easily applied to any NVM cache. In the remainder of this paper, for sake of convenience, we use the words ReRAM and NVM interchangeably.
Microarchitectural simulations have been performed using Sniper simulator and workloads from SPEC2006 suite and HPC field (
Section 4). In addition, ENLIVE has been compared with two recently proposed techniques for improving lifetime of NVM caches, namely PoLF (probabilistic line-flush) [
5] and LastingNVCache [
13] (refer
Section 5.1). The results have shown that, compared to other techniques, ENLIVE provides larger improvement in cache lifetime and performance, with a smaller energy loss (
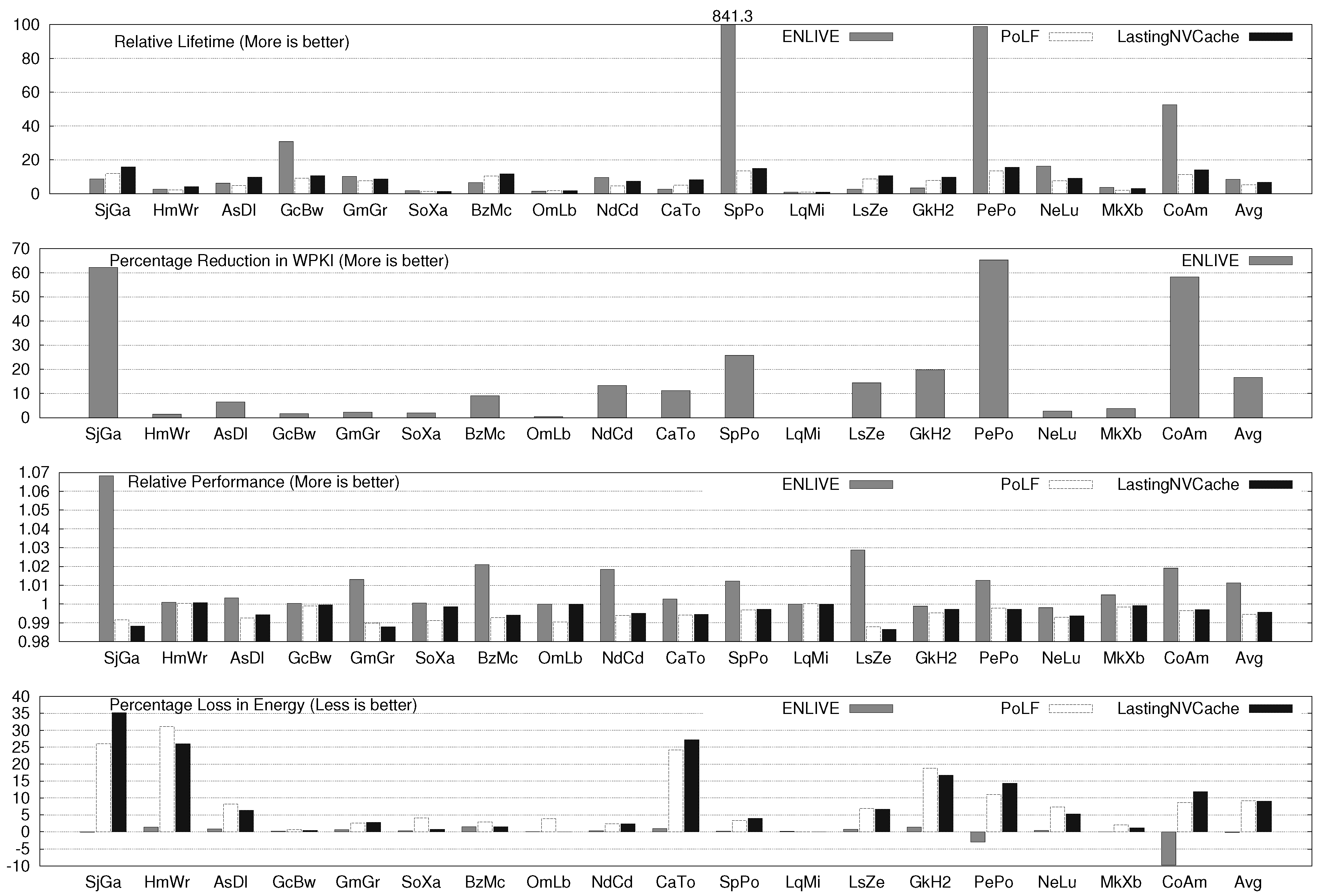
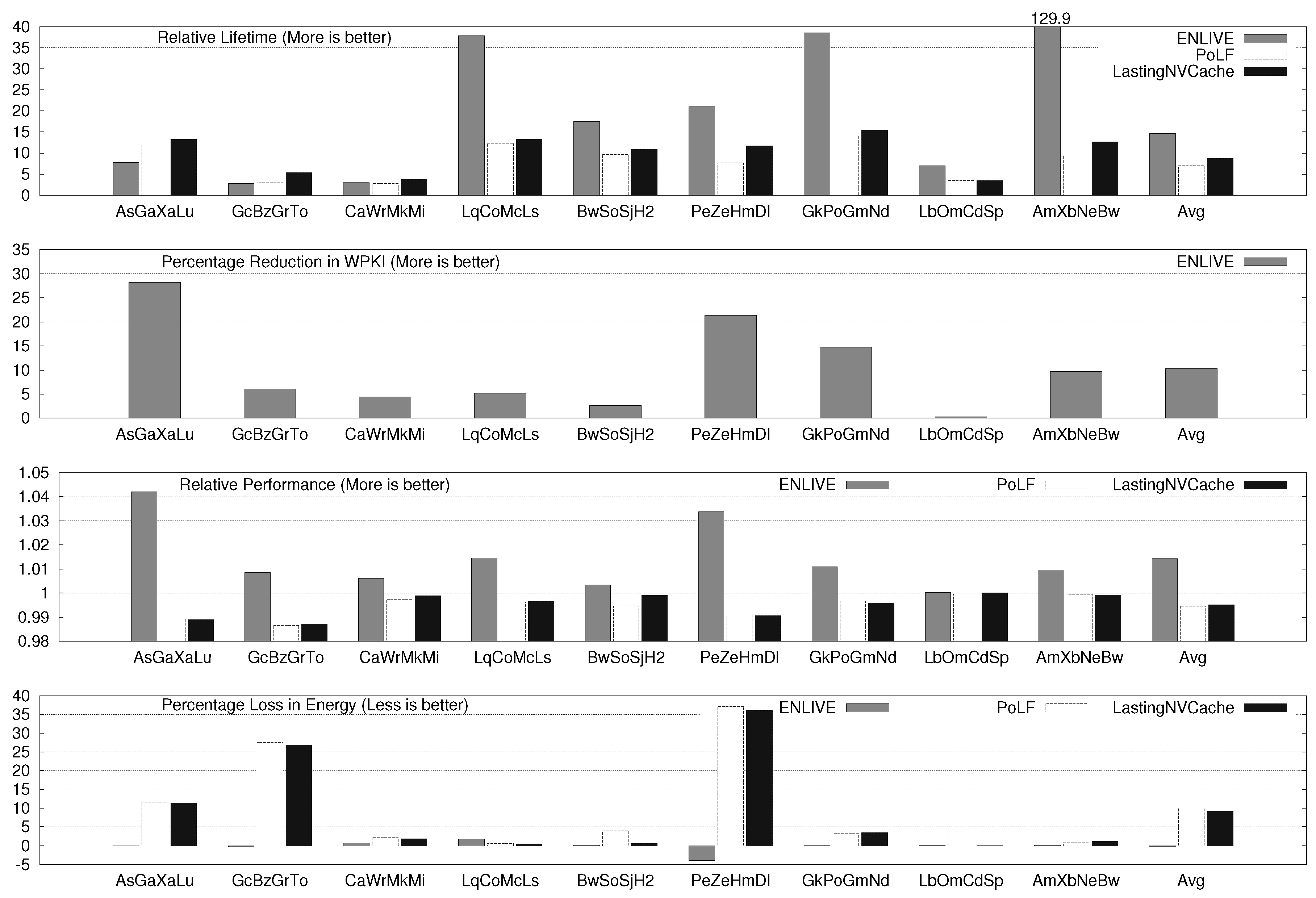
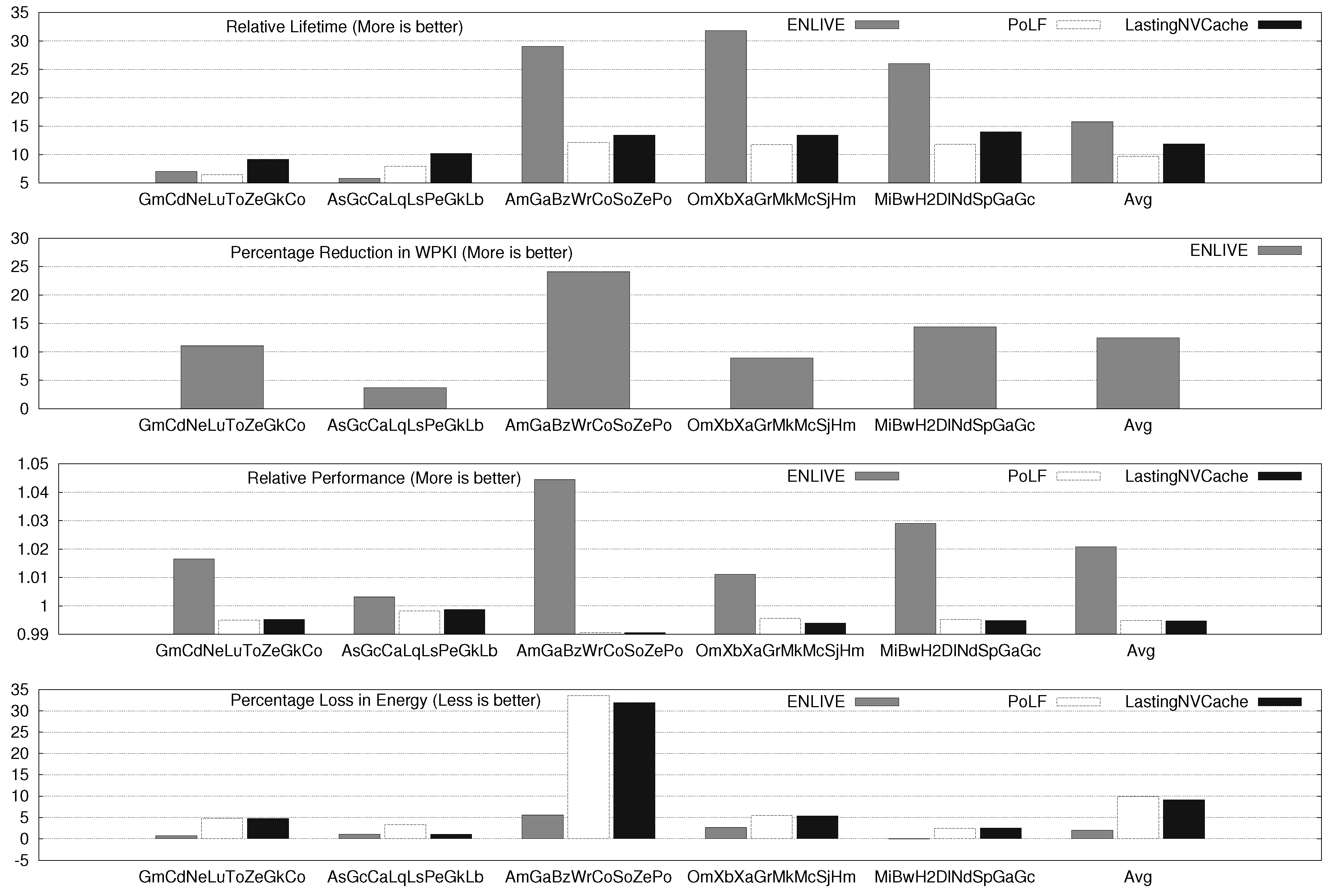
Section 5.2). For two, four and eight core systems, the average improvement in lifetime on using ENLIVE are 8.47×, 14.67× and 15.79×, respectively. By comparison, the average lifetime improvement with LastingNVCache (which, on average, performs better than PoLF) for 2, 4 and 8 core systems is 6.81×, 8.76× and 11.87×, respectively. Additional results show that ENLIVE works well for a wide-range of system and algorithm parameters (
Section 5.3).
The rest of the paper is organized as follows.
Section 2 discusses the methodology.
Section 3 presents the salient features of ENLIVE, evaluates its implementation overhead and discusses the application of ENLIVE for mitigating security threats in NVM caches.
Section 4 discusses the experimental platform, workloads and evaluation metrics.
Section 5 presents the experimental results.
Section 6 discusses related work on NVM cache and lifetime improvement techniques. Finally,
Section 7 concludes this paper.
2. Methodology
Notations: In this paper, the LLC is assumed to be an L2 cache. Let S, W, D and G denote the number of L2 sets, associativity, block-size and tag-size, respectively. In this paper, we take D = 512 bits (64 bytes) and G = 40 bits. Let β denote the ratio of the number of entries in the HotStore and the number of L2 sets. Thus, the number of entries in HotStore is . The typical values of β are 1/32, 1/16, 1/8 etc.
2.1. Key Idea
It is well-known that due to temporal locality of cache access, a few blocks see much more number of cache writes than the remaining blocks. This leads to two issues in NVM cache management. First, NVM write latency and energy are much higher than read latency and energy (refer
Table 1), respectively, and, thus, these writes degrade the performance and energy-efficiency of NVM cache. Second, and more importantly, frequent writes to few blocks lead to failure of these blocks much earlier than what is expected assuming uniformly distributed writes.
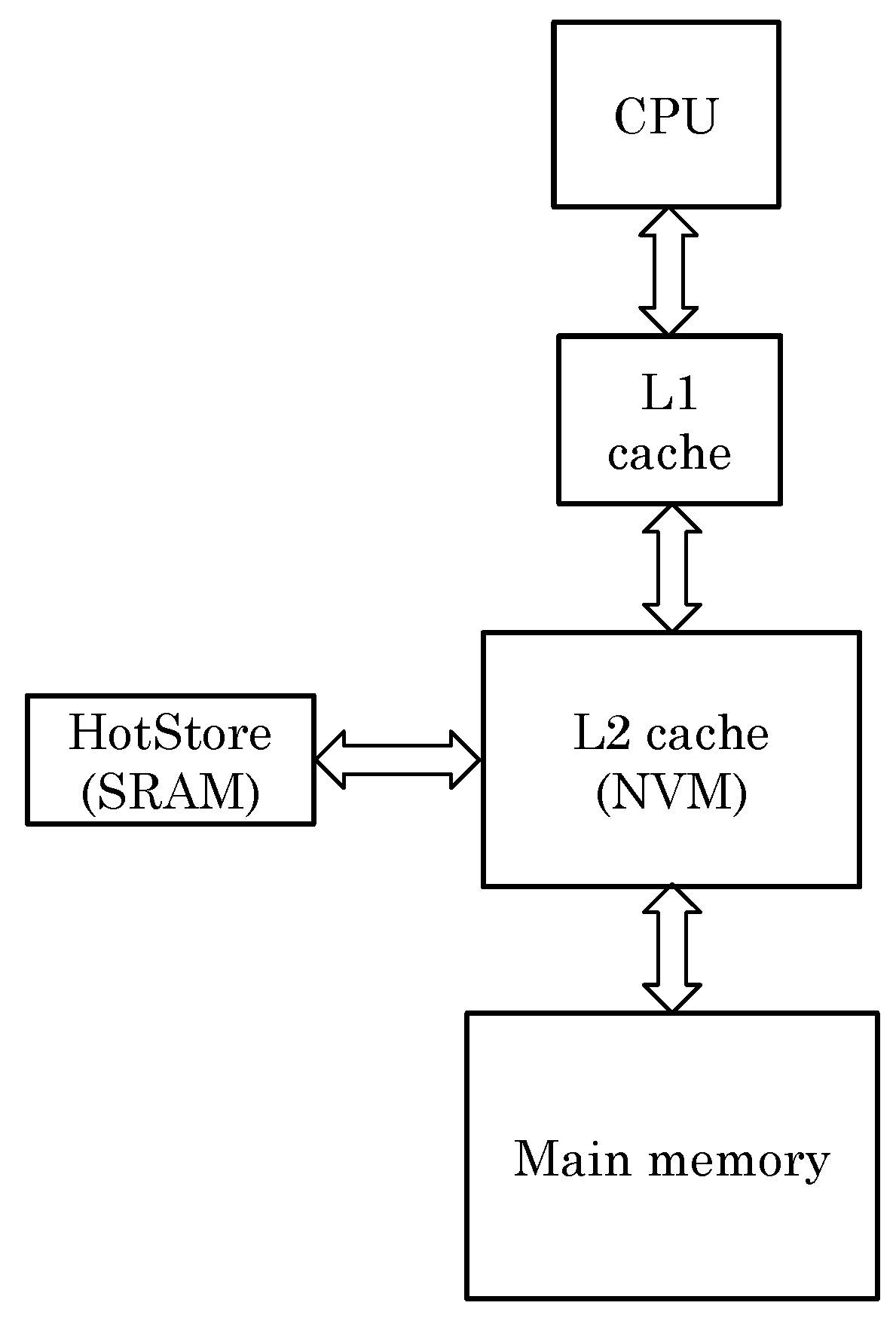
ENLIVE works on the key idea that the frequently written blocks can be stored in a small SRAM storage, called HotStore. Thus, future writes to those blocks can be served from the HotStore, instead of from the NVM cache. Due to the small size of SRAM storage, along with smaller access latency of SRAM itself, these blocks can be accessed with small latency, which improves the performance by making the common-case fast. In addition, since the write-endurance of SRAM is very high, the SRAM storage absorbs most of the writes, and, thus, the writes to NVM cache are significantly reduced. This leads to improvement in the lifetime of the NVM cache. The overall organization of cache hierarchy with addition of HotStore is illustrated in
Figure 2.
The HotStore only stores the data of a block and does not require a separate tag-field, since the tag directory of L2 cache itself is used. The benefit of this is that on a cache access, the tag-matching is done only on the L2 tag directory, as in the normal cache. Thus, from the point of view of processor-core, all the tags and corresponding cache blocks are always stored in the L2 cache, although internally, they may be stored in either the main NVM storage or the HotStore. Hence, a fully-associative search in the HotStore is not required. This fact enables use of a relatively large number of entries in the HotStore. From any set, only a single block can be stored in the HotStore and hence, when required, this block can be directly accessed as shown in
Figure 3. In addition, when a block, which is evicted, is in the HotStore, the newly arrived data-item is placed in the HotStore itself.
Figure 2.
Illustration of the cache hierarchy with addition of HotStore.
Figure 2.
Illustration of the cache hierarchy with addition of HotStore.
2.2. An Example of How HotStore Works
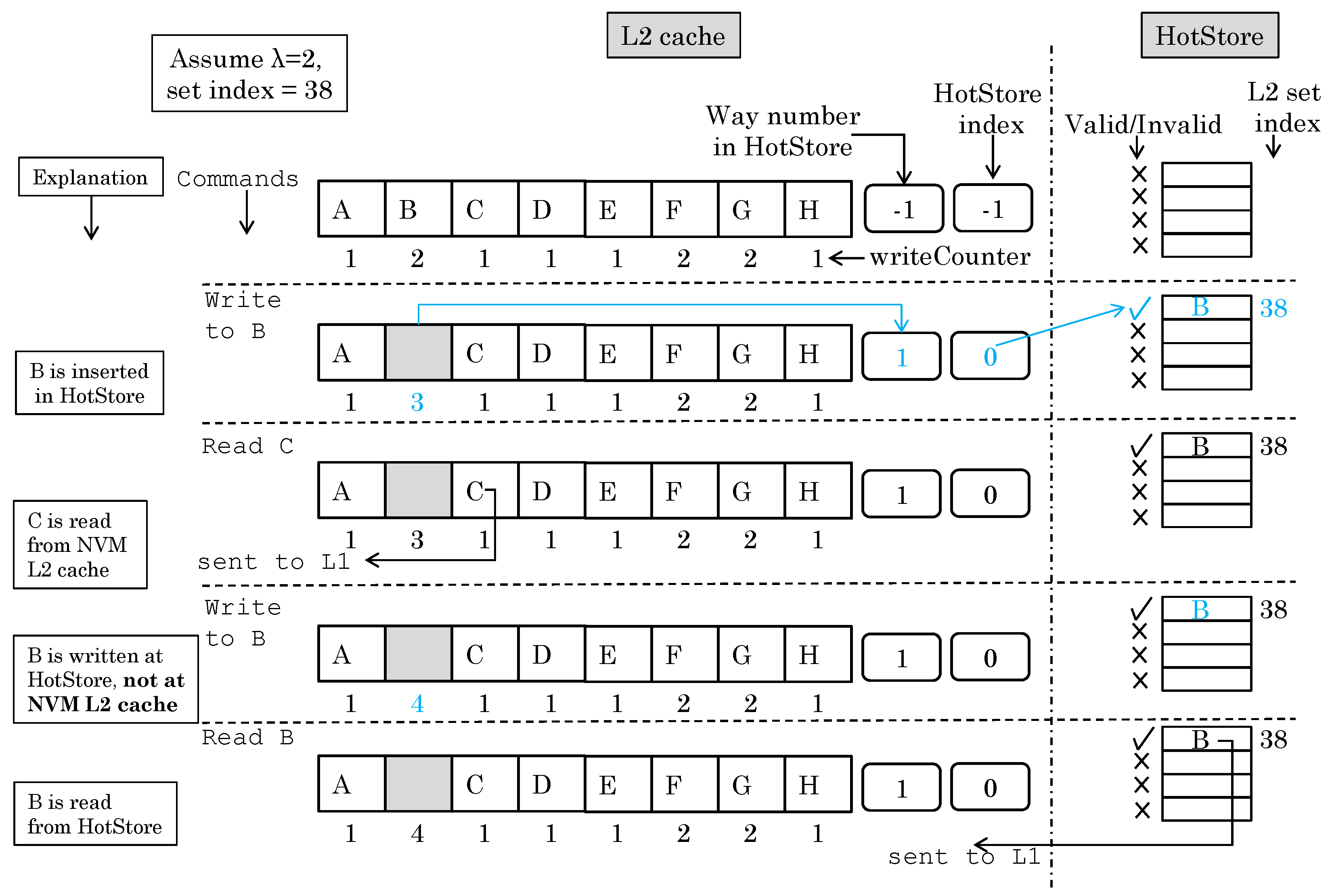
Figure 3 shows an example of how HotStore works to illustrate the basic idea. Initially, the HotStore is empty and a set with set-index 38 has data in all of its ways. On a write-command to block “B”, its write-counter exceeds the threshold (2), and, hence, it is inserted into HotStore. Next, “read C” command is issued, and, hence, the element “C” is read from L2 cache. Next, “write B” command is issued, and since B is stored in HotStore, it is written in HotStore and not in L2 cache. Next, “read B” command is issued and the data are supplied from HotStore and not from L2 cache.
Section 2.3 explains the implementation and working of HotStore in full detail.
Figure 3.
Example of how the ENLIVE technique works for an arbitrary set-index 38 (changed items are marked in color).
Figure 3.
Example of how the ENLIVE technique works for an arbitrary set-index 38 (changed items are marked in color).
2.3. Implementation and Optimization
To ensure that the HotStore latency is small, its size needs to be small. Due to the limited and small size of the storage, effective cache management is required to ensure that only the most frequently written blocks reside in the HotStore and the cold blocks are soon evicted. Algorithm 1 shows the procedure for handling a cache write and managing the HotStore. If the block is already in the HotStore (Lines 1-3), a read or write is performed from the HotStore. Regardless of whether the block is in HotStore or L2 cache, on a write, the corresponding write-counter in L2 cache is incremented and on any cache read/write access, the information in LRU replacement policy of L2 cache is updated (not shown in Algorithm 1). The insertion into and eviction from HotStore are handled as follows.
![Jlpea 06 00001 i001]()
2.3.1. Insertion into HotStore
We use a threshold
λ. A cache block which sees more than
λ writes is a candidate for promotion to HotStore (Lines 4–42), depending on other factors. A block with less than
λ writes is considered a cold block and need not be inserted in the HotStore (Lines 43–45). Due to the temporal locality, only a few MRU blocks in a set are expected to see most of the access [
14]. Hence, we allow only one block from a set to be stored in the HotStore at a time which also simplifies the management of HotStore. If free space exists in the HotStore, a hot block can be inserted (Lines 6–10), otherwise, a replacement candidate is searched (Line 13) as discussed below.
2.3.2. Eviction from HotStore
If the number of writes to the replacement candidate are less than the incoming block (Line 14), it is assumed that the incoming block is more write-intensive, and, hence, should get priority over the replacement candidate. In such a case, the replacement candidate is copied back to the NVM cache (Lines 16–19), and the new block is stored in the HotStore (Lines 21–23). A similar situation also appears if a block from the same set as the incoming set is already in the HotStore (Lines 29–42). Since only one block from a set can reside in HotStore at any time, the write-counter values of incoming and existing blocks are compared and the one with largest value is kept in the HotStore. If the incoming block is less write-intensive, it is not inserted into HotStore (Lines 24–26 and Lines 39–41).
2.3.3. Replacement Policy for HotStore
To select a suitable replacement candidate, HotStore also uses a replacement policy. An effective replacement policy will keep only the hottest blocks in the HotStore and thus minimize frequent evictions from HotStore. We have experimented with two replacement policies.
LNW (least number of writes), which selects the block with the least number of writes to it as the replacement candidate. It uses the same write-counters as the L2 cache. We assume four-cycle extra latency of this replacement policy, although it is noteworthy that the selection of a replacement candidate can be done off the critical path.
NRU (not recently used) [
15], is an approximation of LRU (least recently used) replacement policy and is commonly used in commercial microprocessors [
15]. NRU requires only one bit of storage for each HotStore entry, compared to the LRU which requires
bits for each entry.
HotStore is intended to keep the most heavily written blocks and hence, LNW aligns more closely with the purpose of the HotStore, although it also has higher implementation overhead. For this reason, we use LNW in our main results and show the results with NRU in the section on parameter sensitivity study (
Section 5.3). Our results show that in general, LNW replacement policy provides higher improvement in lifetime compared to the NRU replacement policy.
3. Salient Features and Applications of ENLIVE
ENLIVE has several salient features. It does not increase the miss-rate, and, thus, unlike previous NVM cache lifetime improvement techniques (e.g., [
4,
5,
16]) it does not cause extra writes to main memory. In addition, it does not require offline profiling or compiler analysis (unlike [
17]) or use of large prediction tables (unlike [
18]). In what follows, we first show that the implementation overhead of ENLIVE is small (
Section 3.1). We then show that ENLIVE can be very effective in mitigating security threats to NVM caches (see
Section 3.2), such as those posed by repeated address attack.
3.1. Overhead Assessment
ENLIVE uses the following extra storage.
- (E1)
The HotStore has -entries, each of which uses D-bits for data storage, one-bit for valid/invalid information and -bits for recording which set a particular entry belongs to (note that for all log values, the base is two).
- (E2)
For each cache set, bit storage is required to record the way number of the block from the set which is in HotStore and -bit storage is required to record the index in the HotStore where this block is stored.
- (E3)
We assume that for each block, eight bits are used for the write-counter. In a single “generation”, a block is unlikely to get larger than writes. If, for a workload, a block gets more than this number of writes, then we allow the counter to get saturated; thus, overflow does not happen.
- (E4)
NRU requires bit additional storage.
Thus, the storage overhead (Θ) of HotStore as a percentage of L2 cache is as follows:
Assuming a 16-way, 4 MB L2 cache and
β = 1/16, the relative overhead (Θ) of ENLIVE is nearly 1.96% of the L2 cache, which is very small. By using smaller value of
β (e.g., 1/32), a designer can further reduce this overhead, although it also reduces the lifetime improvement obtained (refer
Section 5.3.3).
3.2. Application of ENLIVE for Mitigating Security Threat
Due to their limited write-endurance, NVMs can be easily attacked and worn-out using repeated address attack (RAA). Using a simple RAA, a malicious attacker can write a cache block repeatedly which may lead to write endurance failure. Further, it is also conceivable that a greedy-user may run attack-like codes a few months before the warranty of his/her computing system expires, so as to get a new system before the warranty expiration period. An endurance-unaware cache can be an easy target of such attacks and hence, conventional cache management policies leave a serious security vulnerability for NVM caches with limited write endurance. To show the extent of vulnerability, we present the following example.
Assume that L1 is designed with SRAM and its associativity is
. Assume an attack-like write-sequence which circularly writes to
+1 data blocks which are mapped to the same L1 set. Since this set can only hold
blocks, every L1 write will lead to writebacks in the same L2 cache set. Assume that due to this, after every 200 cycles, the same L2 block is written again. In this case, the time required to fail this block is:
For write endurance of and 2GHz frequency, we obtain the time to fail as: 10,000 s or 2.8 h only. Clearly, in absence of any policy for protection from attacks, the L2 cache can be made to fail in less than 3 h. In addition, due to process variation, the write-endurance of weakest block may be smaller than .
ENLIVE can be useful in mitigating such security threats. ENLIVE keeps the most heavily written blocks in an SRAM storage, which has very high write-endurance and thus, the writes targeted for an NVM block are channeled to the SRAM storage. Furthermore, since ENLIVE dynamically changes the block which is actually stored in HotStore, alternate or multiple write-attacks can also be tolerated since other blocks which see large number of writes will be stored in the HotStore.
Further, the threshold
λ can be randomly varied within a predetermined range which makes it difficult for attackers to predict the new block-location which will be stored in the HotStore. For this, note that a change in value of
λ does not affect program correctness but only changes the number of writes absorbed by HotStore. Thus, assume that
λ can be varied between range [
2,
4]. Initially, its value is two and thus, a block receiving more than two writes is promoted to HotStore. Now, on changing
λ to three, a block which sees more than three writes is promoted to HotStore. Thus, some of the blocks, which were previously promoted to HotStore, may not get promoted to HotStore with this change value of
λ. However, the attacker is unaware of this fact since only cache controller is aware of
λ value and can change it. Thus, even if the attacker knows that a HotStore is being used, he/she does not know which blocks are stored in HotStore and hence, he/she cannot design an attack which only targets the blocks not stored in HotStore. Finally, as we show in the results section, use of HotStore can extend the lifetime of cache by an order of magnitude and, in this amount of time, any abnormal attack can be easily identified.
Note that although intra-set wear-leveling techniques (e.g., [
5,
13,
19,
20,
21]) can also be used for mitigating repeated address attack to NVM, ENLIVE offers a distinct advantage over them. An intra-set wear-leveling technique only performs uniform-distribution of writes to a set and does not reduce the total number of writes to a set. Thus, although it can prolong the time taken for the first block in a set to fail, it cannot prolong the time required for all the blocks to fail. Hence, an attacker can continue to target different blocks in a set and finally, all the blocks in a set will fail in the same time as in the conventional cache, even if an intra-set wear-leveling technique is used. By comparison, ENLIVE performs write-minimization since the SRAM HotStore absorbs a large fraction of the writes and thus, it can increase the time required in both, making a single block fail and making all the blocks fail. Clearly, ENLIVE is more effective in mitigating security threats to NVM caches.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



