An Integrated Spatial Clustering Analysis Method for Identifying Urban Fire Risk Locations in a Network-Constrained Environment: A Case Study in Nanjing, China

Abstract
:1. Introduction
2. Data Description and Processing
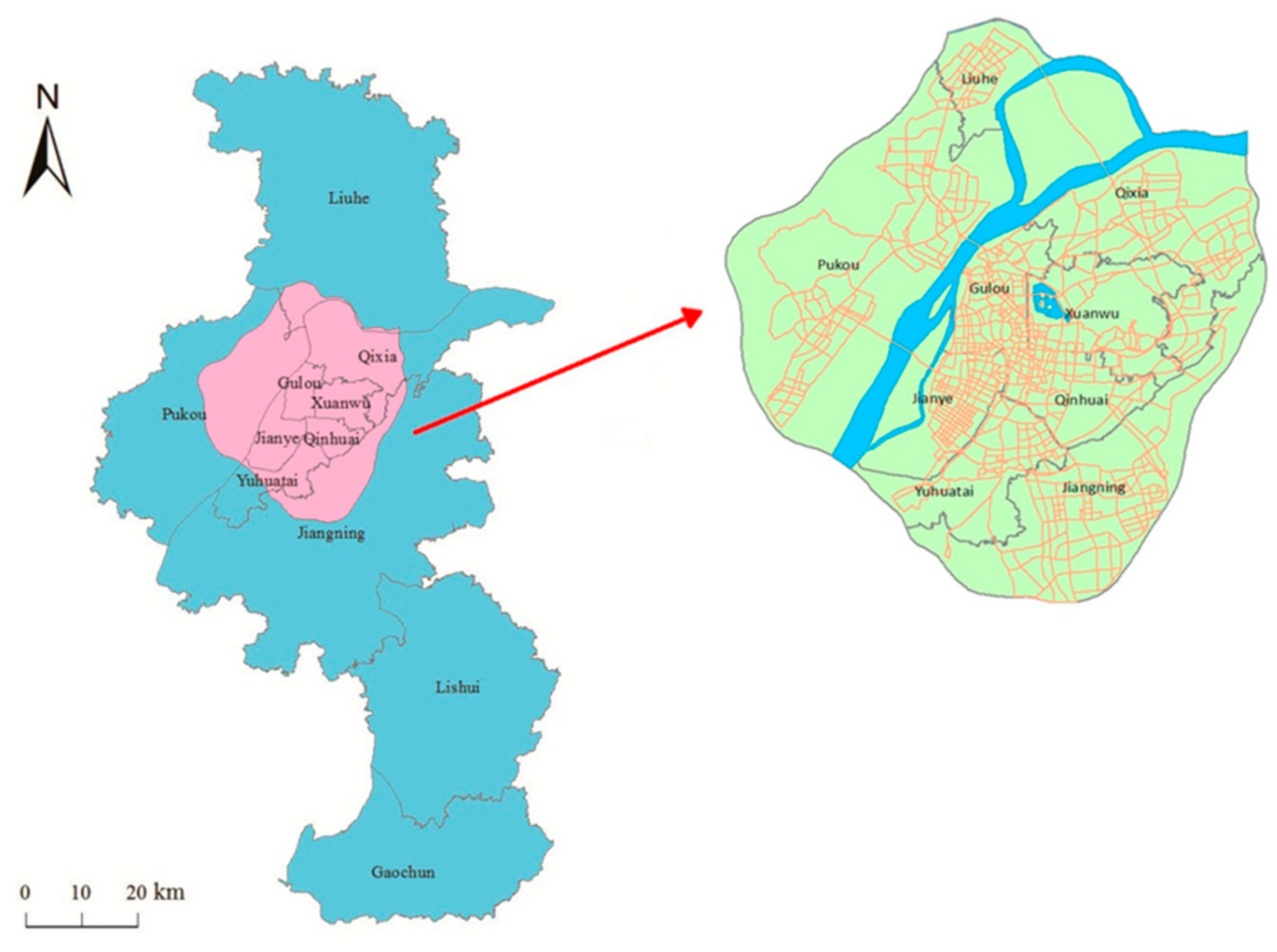
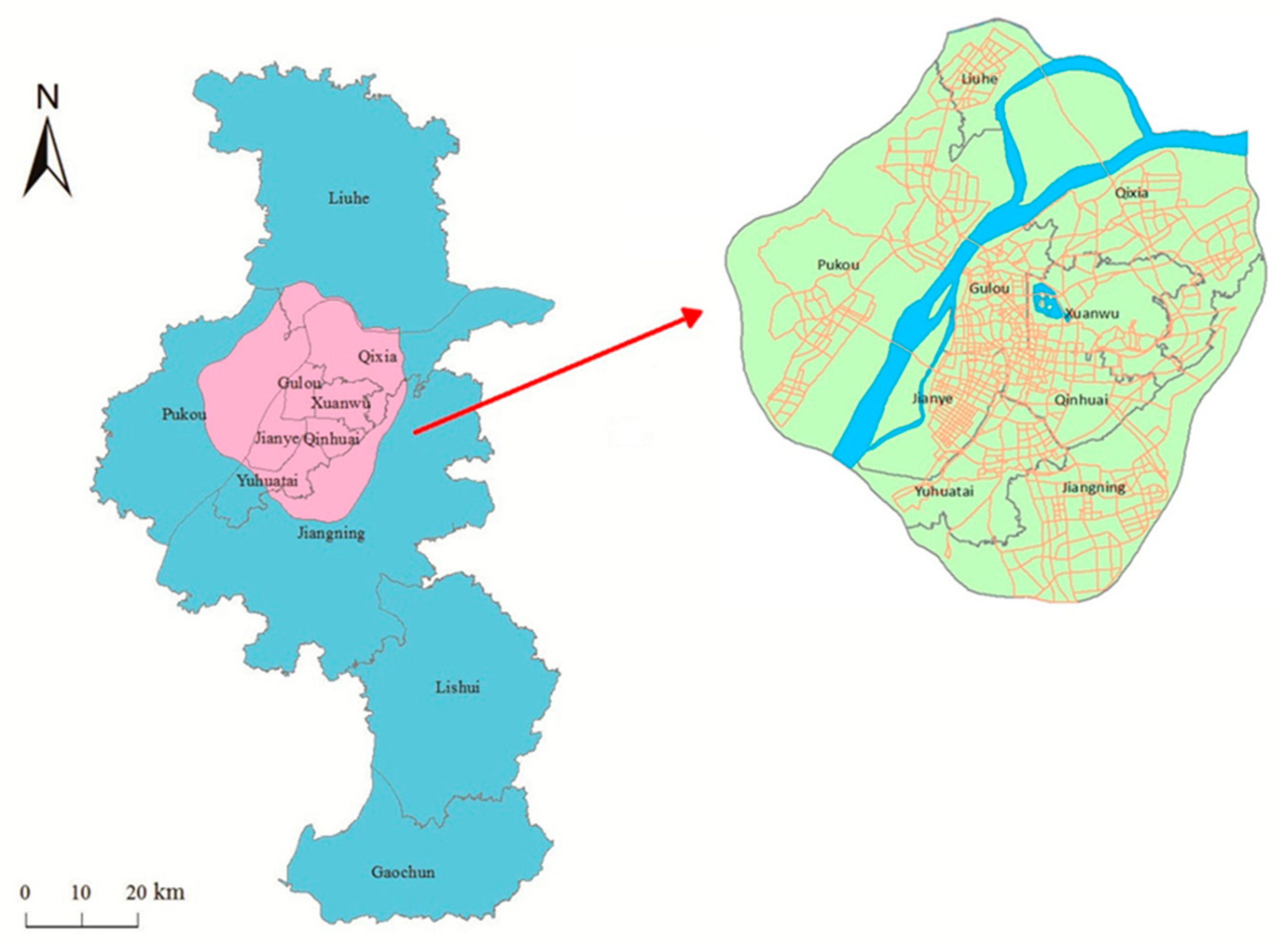
2.1. Study Area
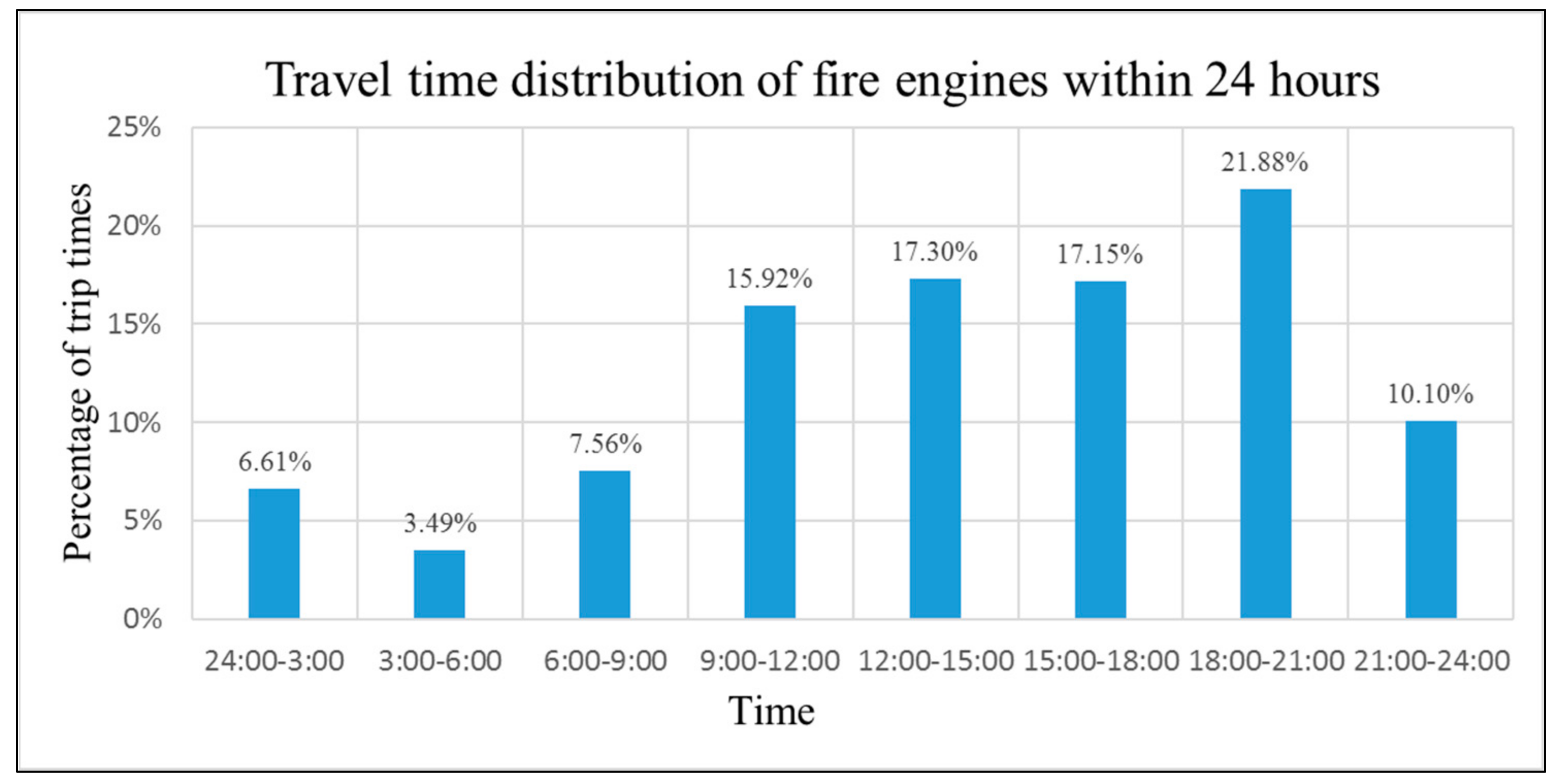
2.2. Road Network and Fire-Engine GPS Data
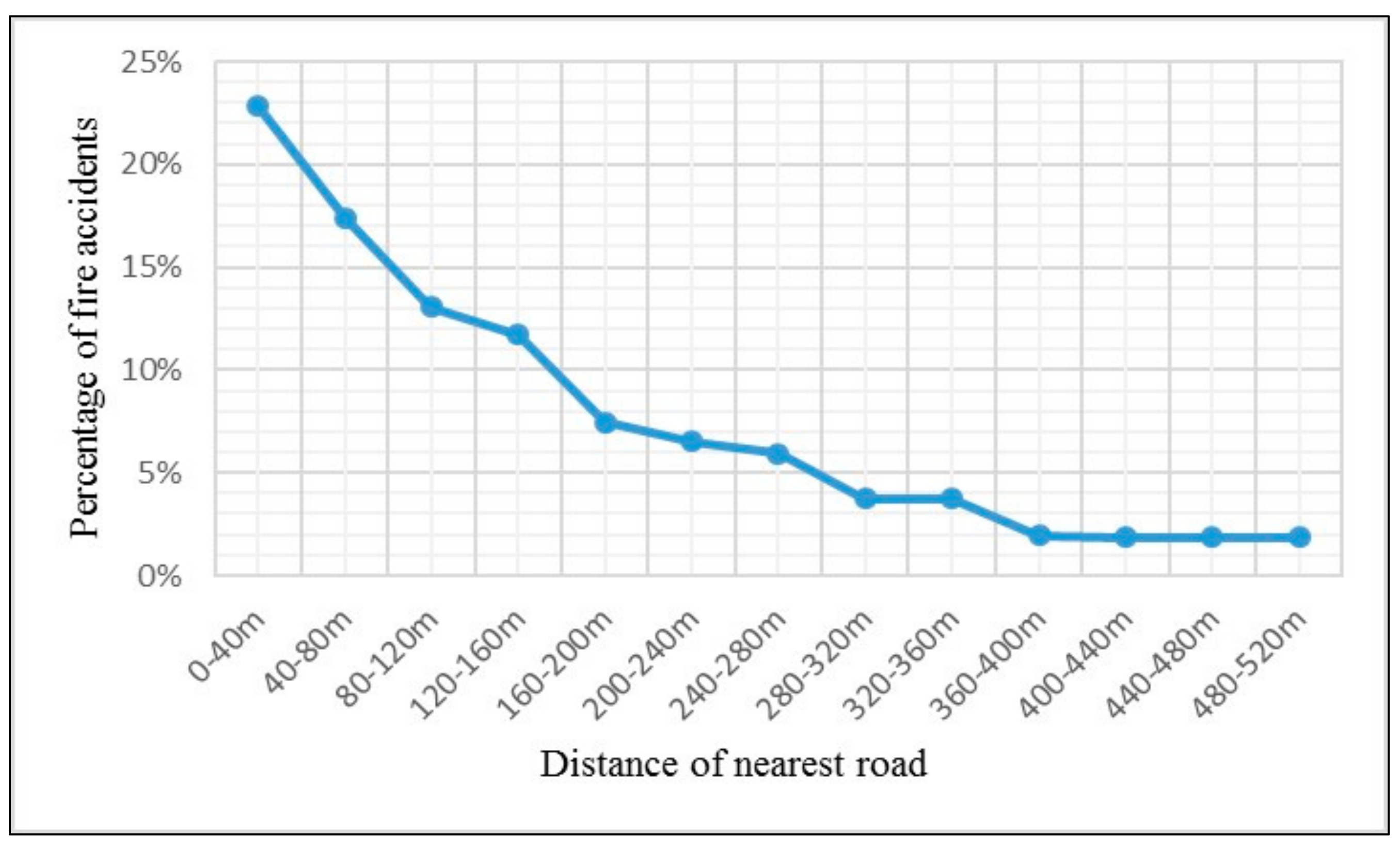
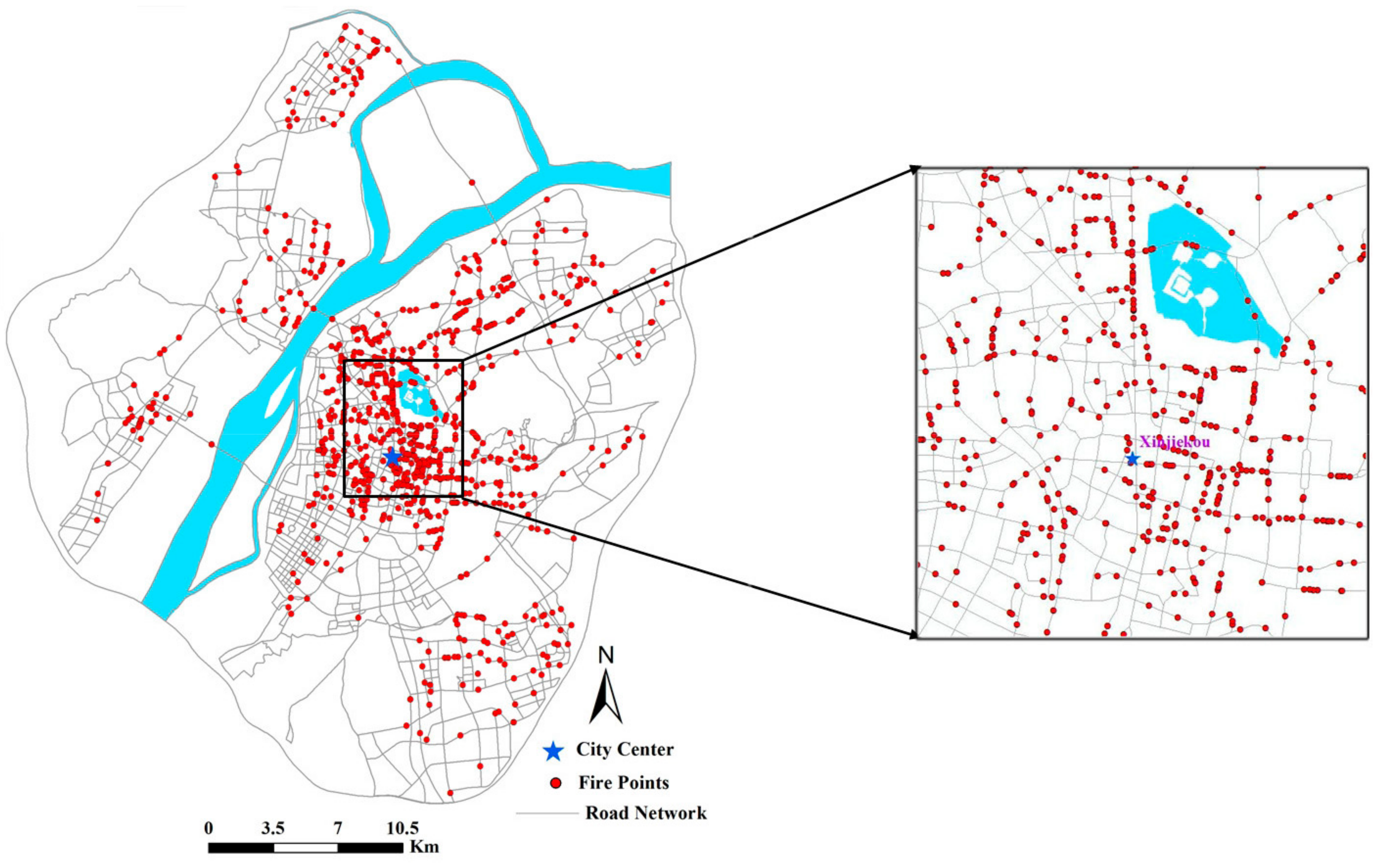
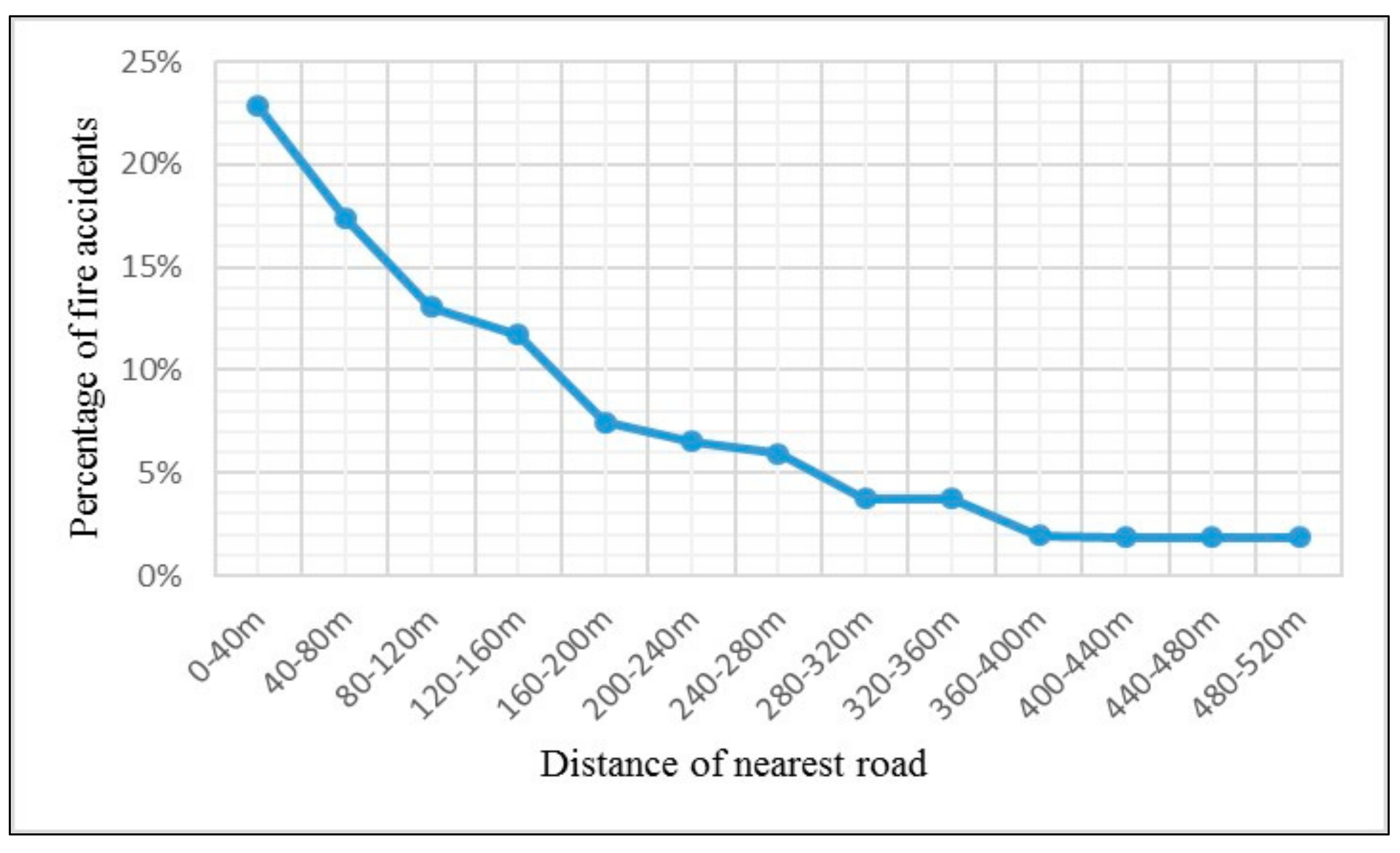
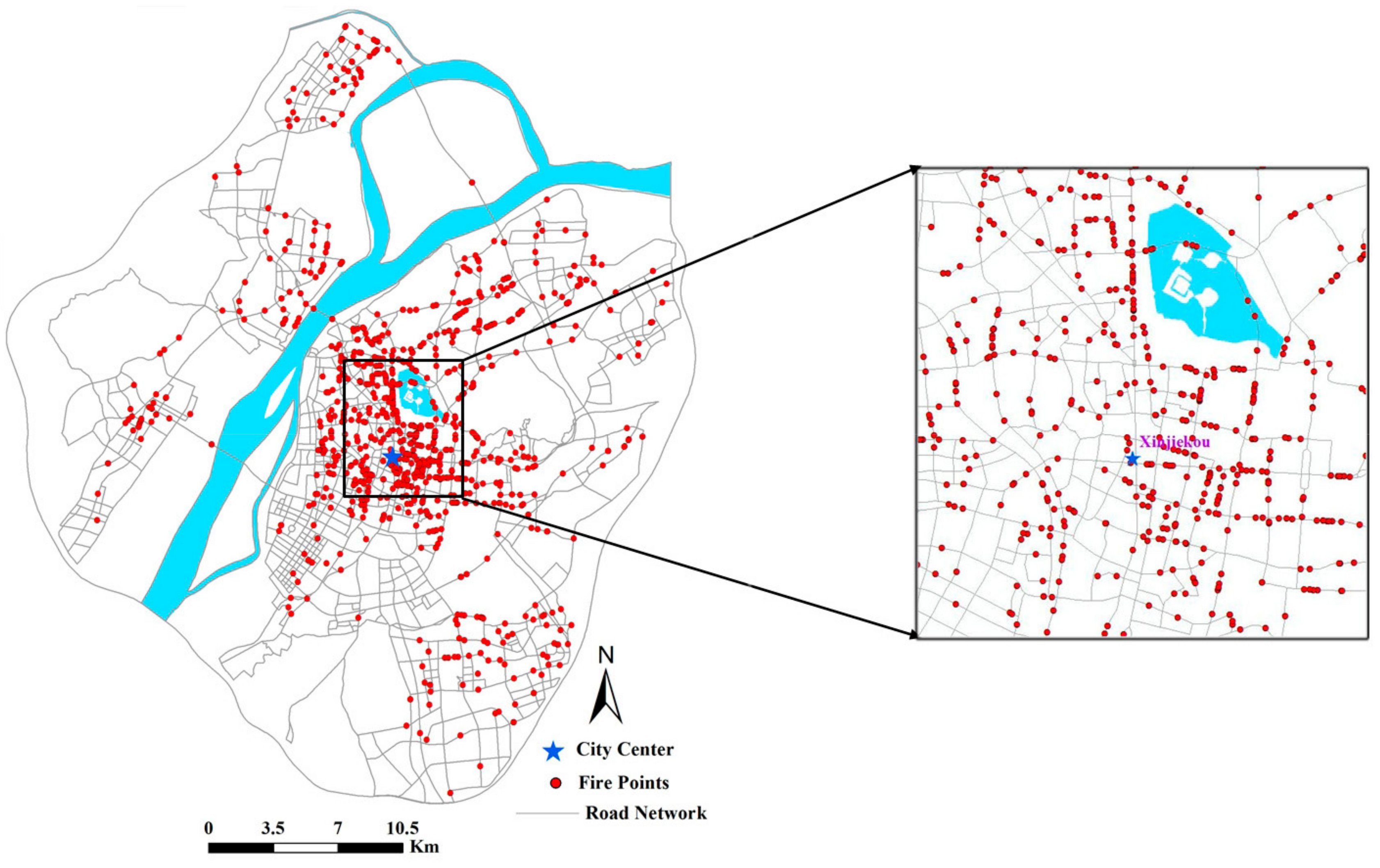
2.3. Fire Accidents Data and Processing
3. Methodology
3.1. Road Congestion Identification Based on Fire-Engine GPS Data
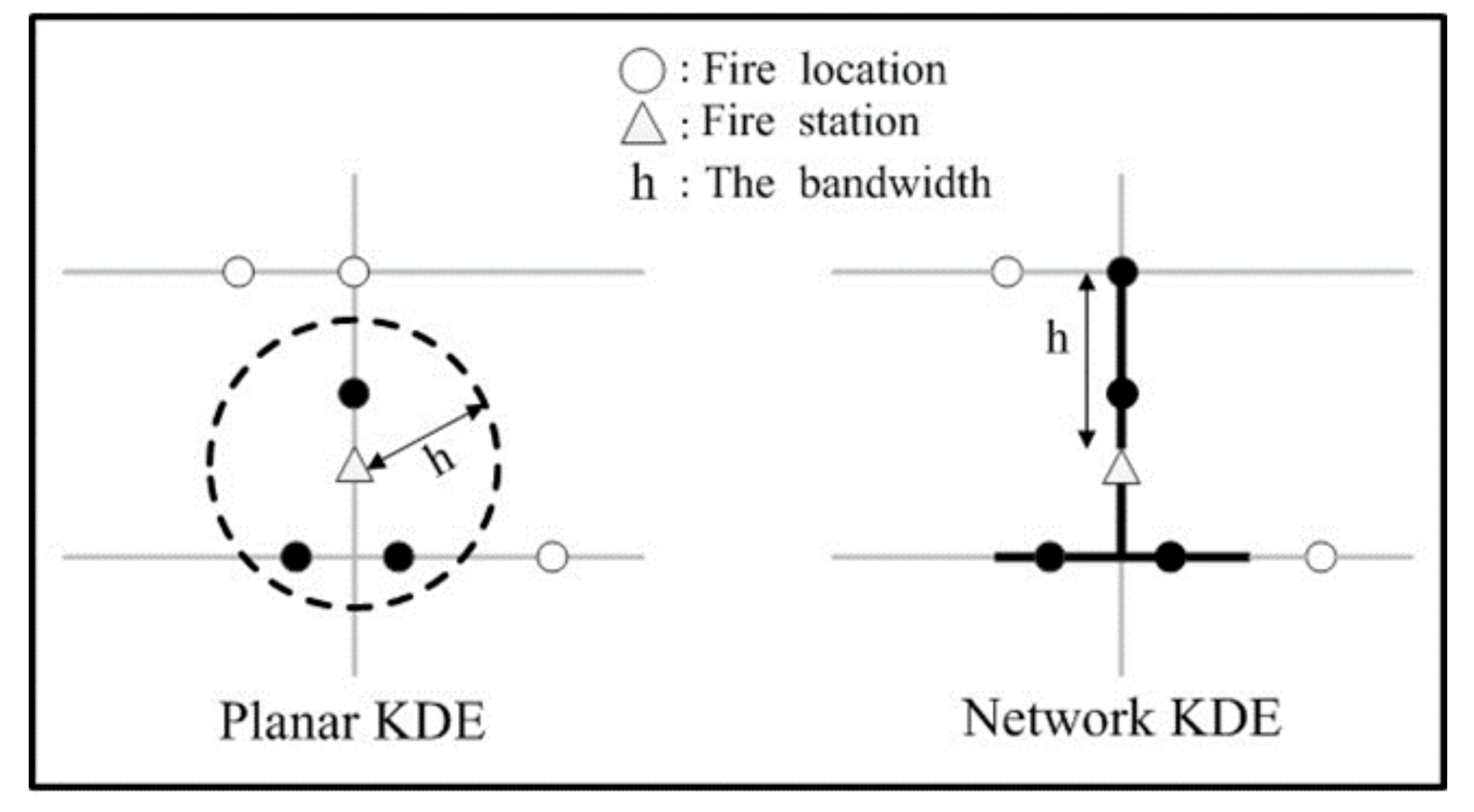
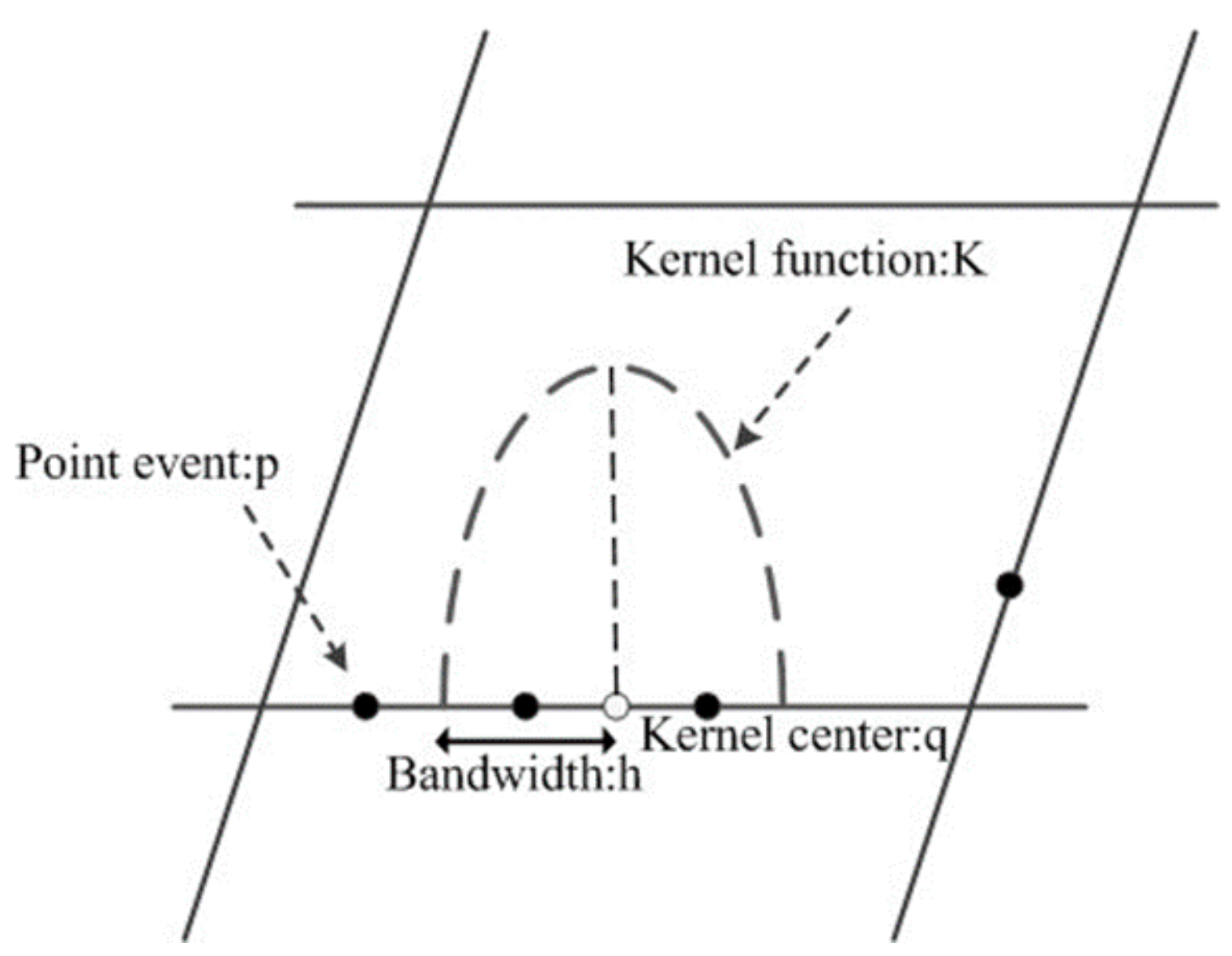
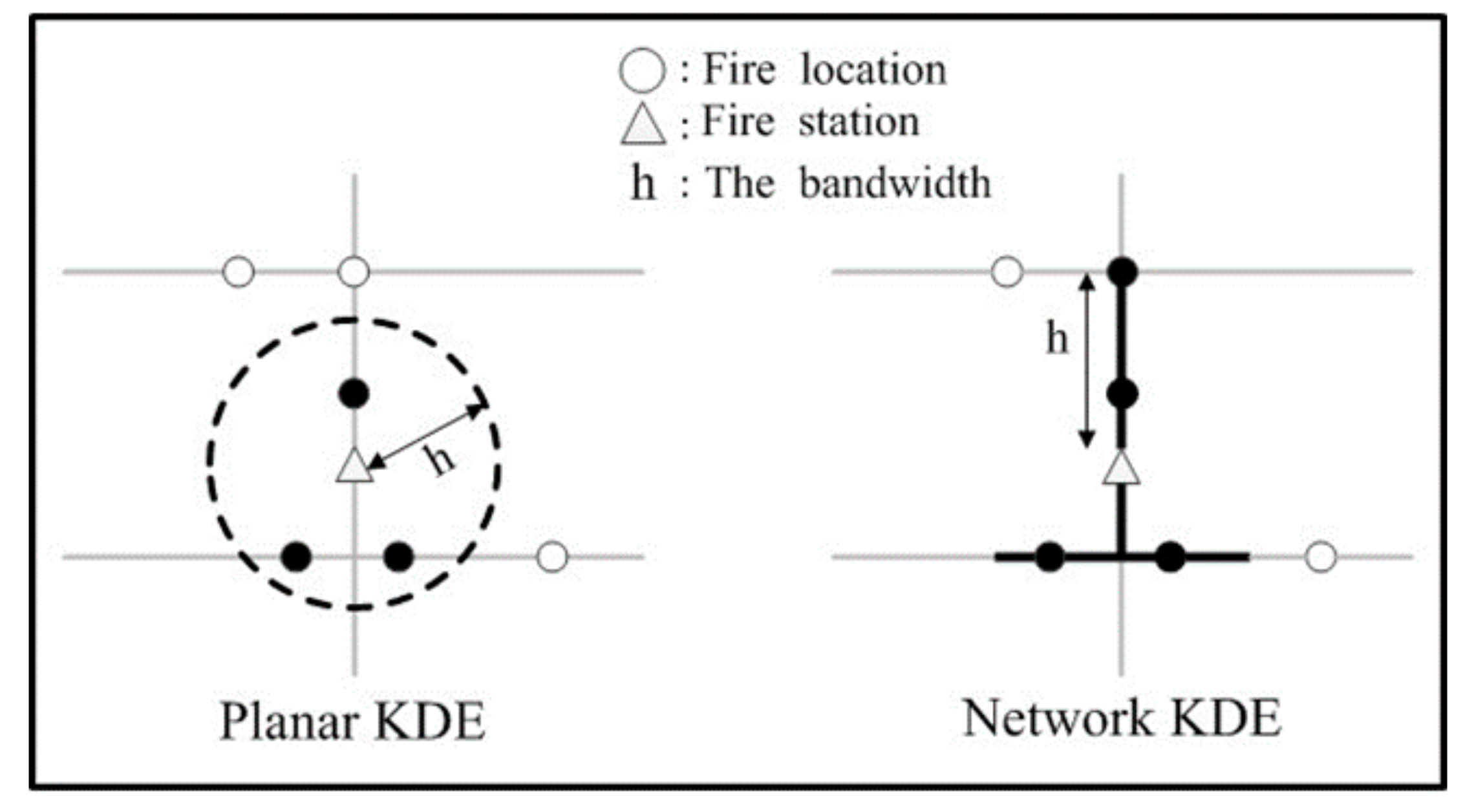
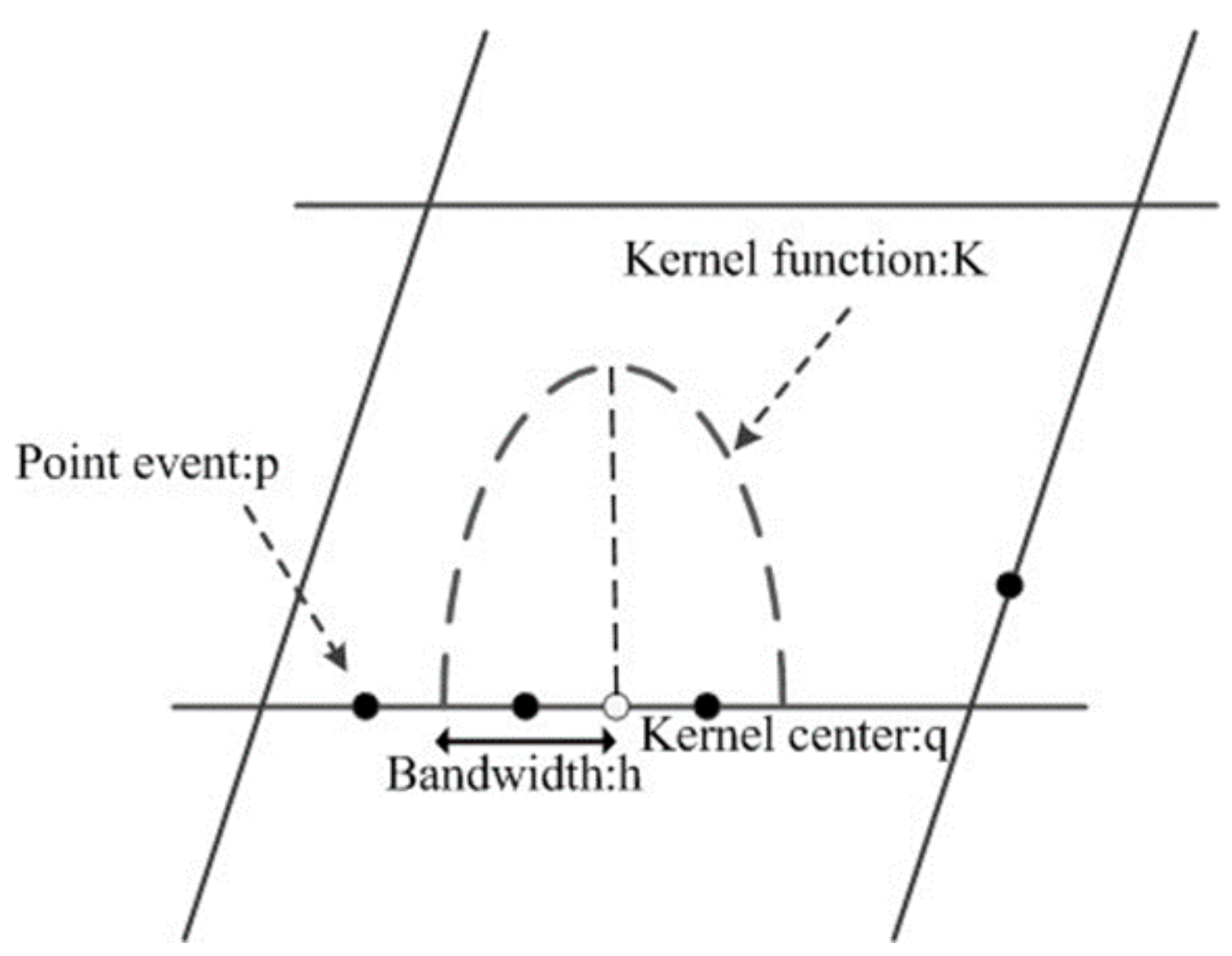
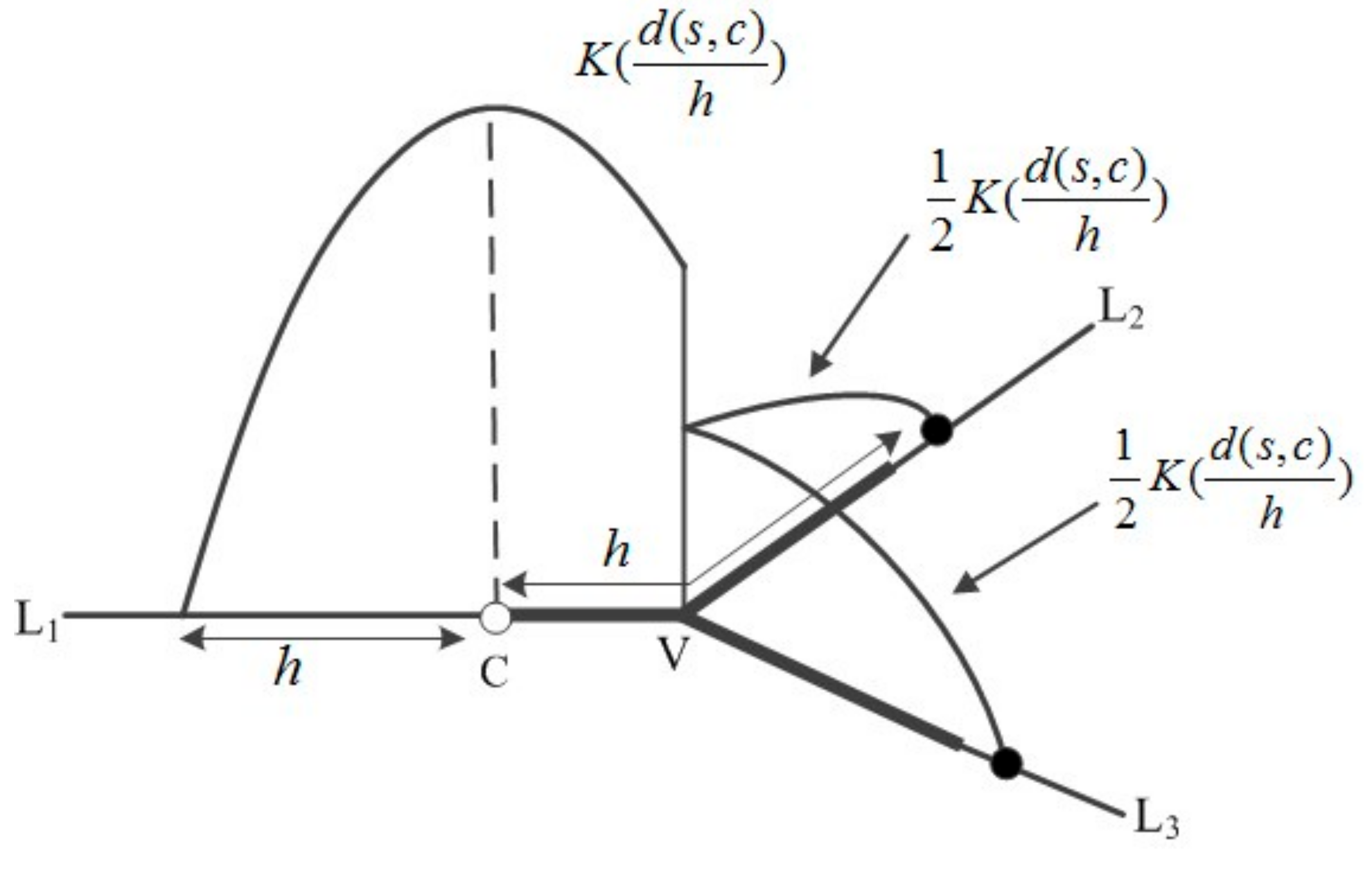
3.2. Network Kernel Density Estimation
3.3. Constrained Network and Traffic Conditions KDE
3.4. Network-Constrained Local Moran’s I Method
4. Network Kernel Density Estimation Algorithm
- (1)
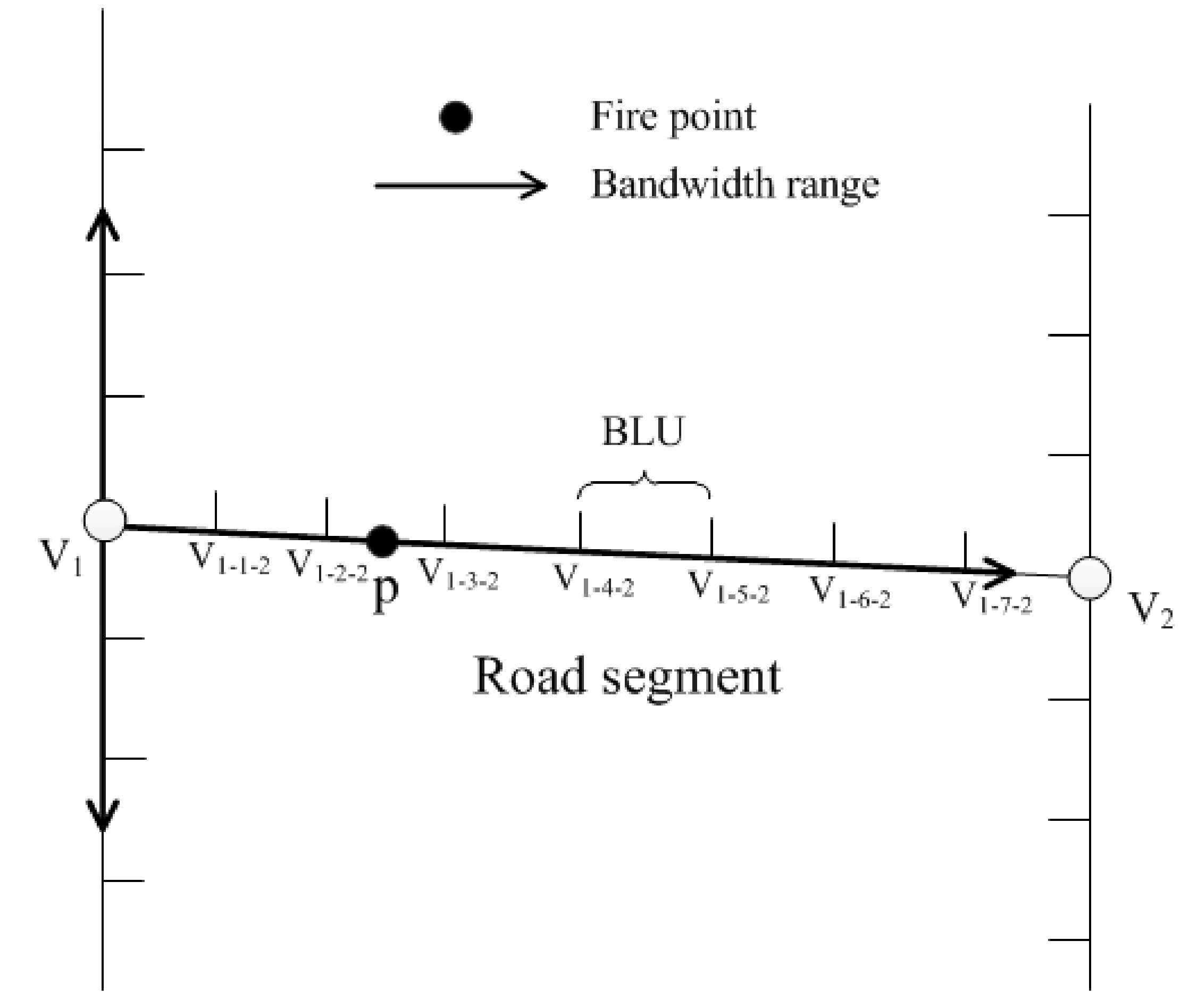
- Divide road segments into basic linear units. The urban road network is abstracted into a linear network system consisting of point features and linear features. First, the road network is broken into road segments at nodes. The road segments are the parts of roads between two neighboring road intersections. Then, a defined network length is used to divide each road segment into a set of basic linear units (BLUs). If there is a residual when dividing the road segments into BLUs, we take the residual as a BLU. Finally, create a BLU-based network topological relationship between BLUs, and stored as a relational table in a database.
- (2)
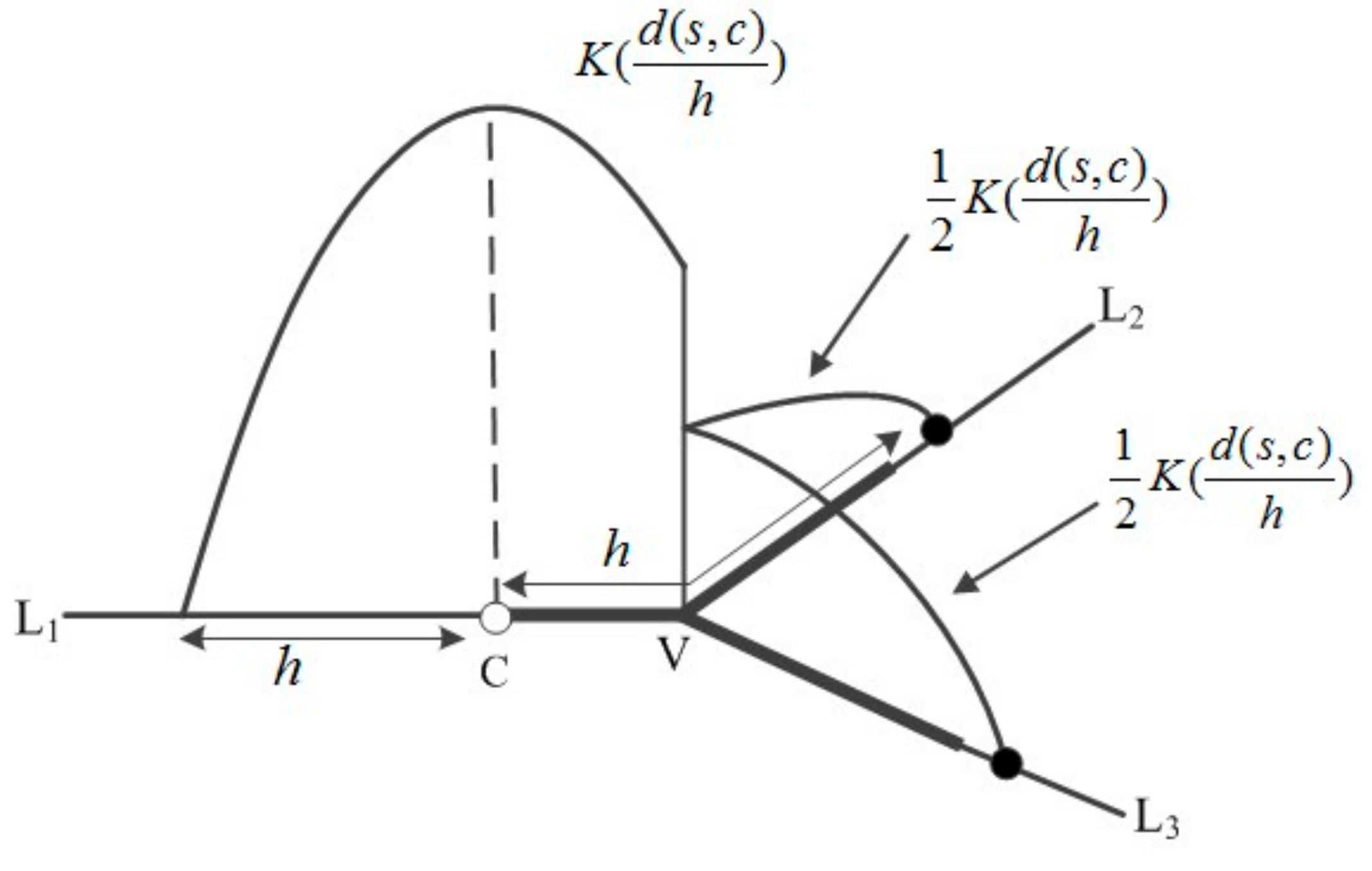
- Find the all nodes around each fire point within the search bandwidth. Define a search bandwidth h, measured with the shortest path network distance. That is, regard each fire point as the kernel center, and find the shortest path based on Dijkstra algorithm within the search bandwidth h [38]. For example, as shown in Figure 10, V1 and V2 indicate the road intersection position, and the fire point p locates 80 m from the intersection V1. Assuming that the bandwidth is set to 100 m, the corresponding length of BLU is 20 m. Starting from the intersection node, a new node is generated every 20 m along the basic linear unit. Thus, we can find all the nodes and their attributes of each fire point within the bandwidth range. The attribute table is shown in Table 2.
- (3)
- Calculate the kernel density of each fire point event within the bandwidth range. The kernel density value is calculated using a search process that spreads from center to surroundings, and then computes the kernel density value at each node.
- (4)
- Calculate the kernel density of each basic linear unit. For each fire point, calculate the kernel density value of each node within a given search bandwidth h. The BLU kernel density value is replaced by the average value of the kernel density for the first and last nodes.
5. Results and Discussion
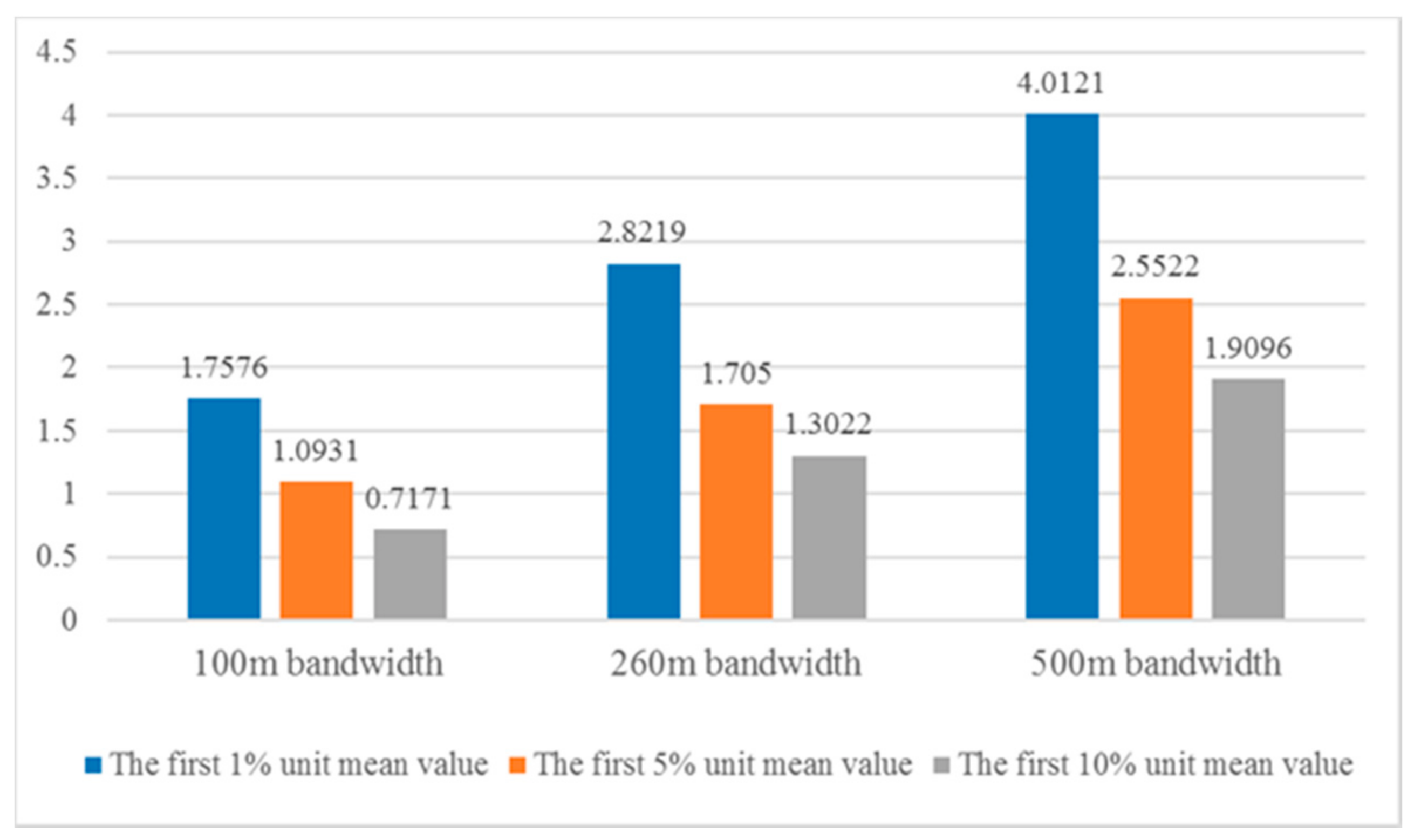
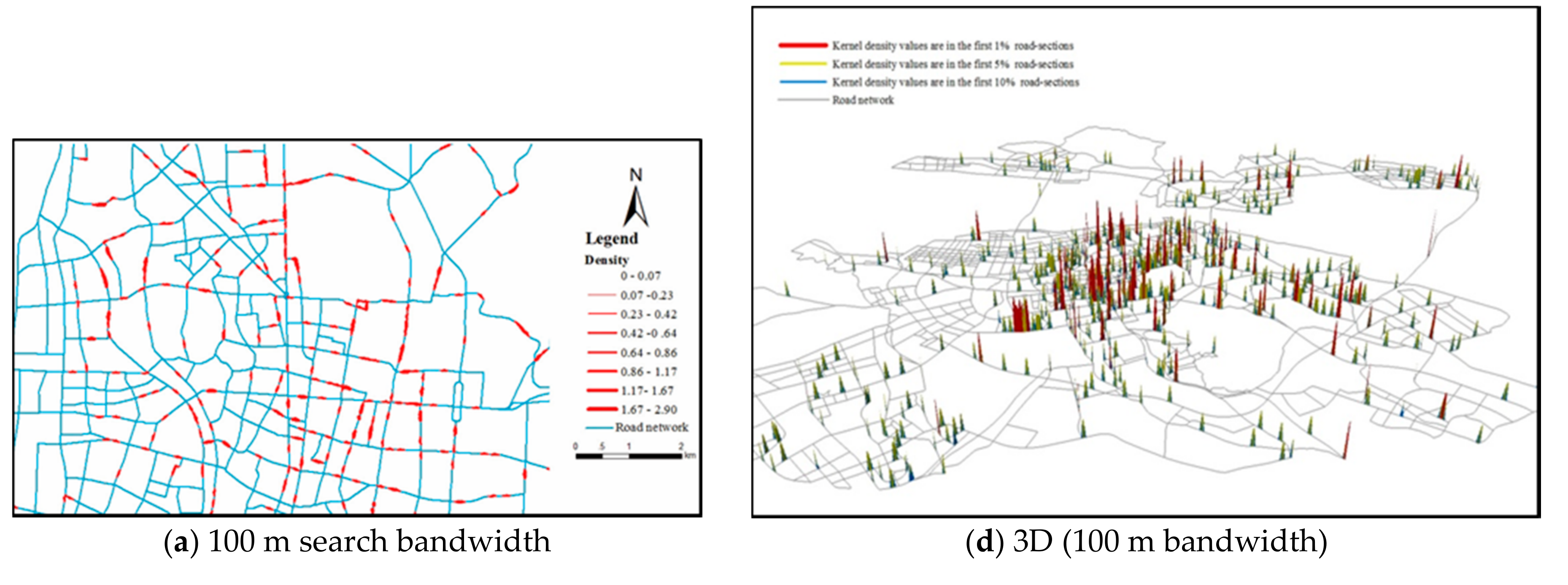
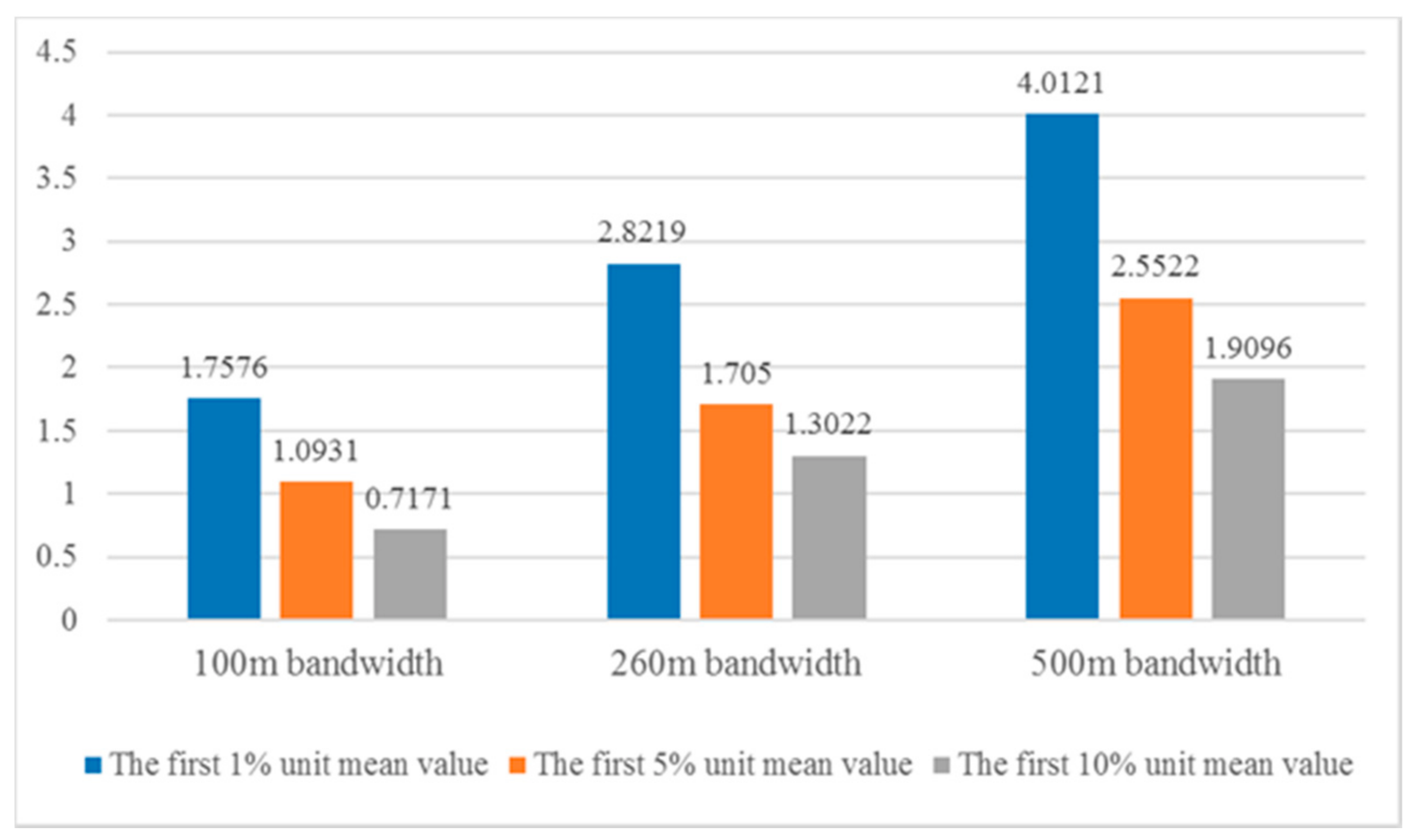
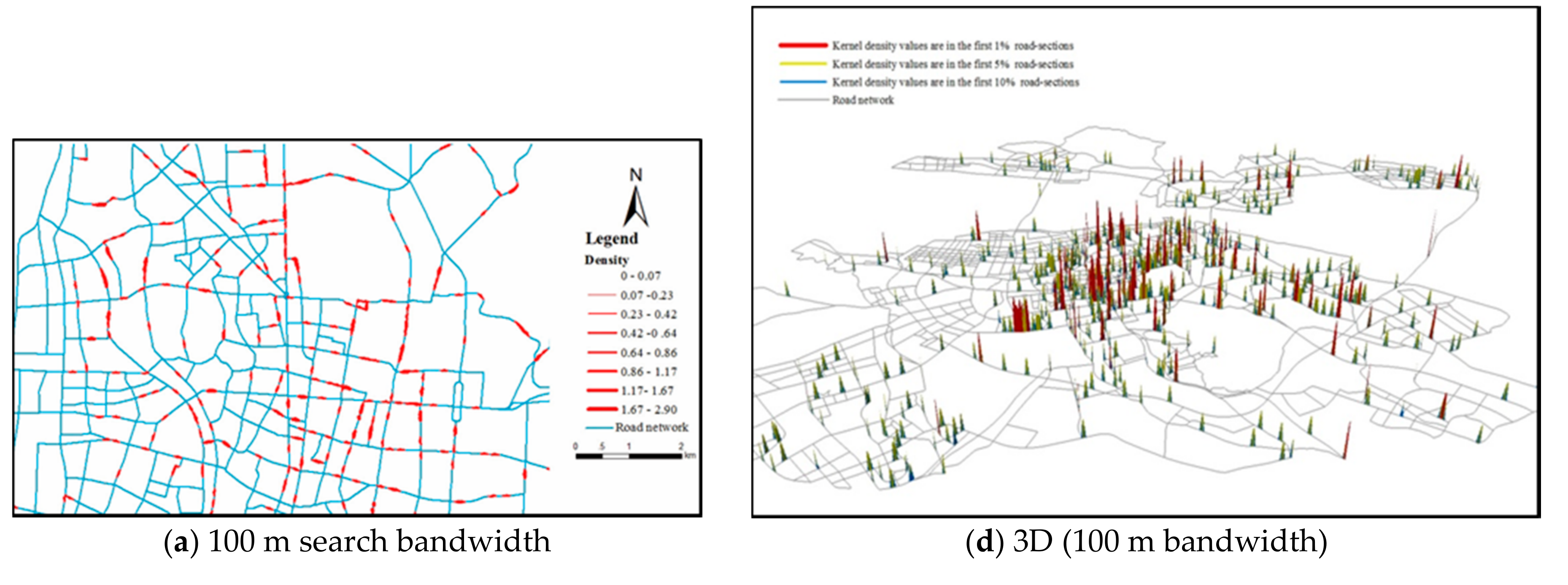
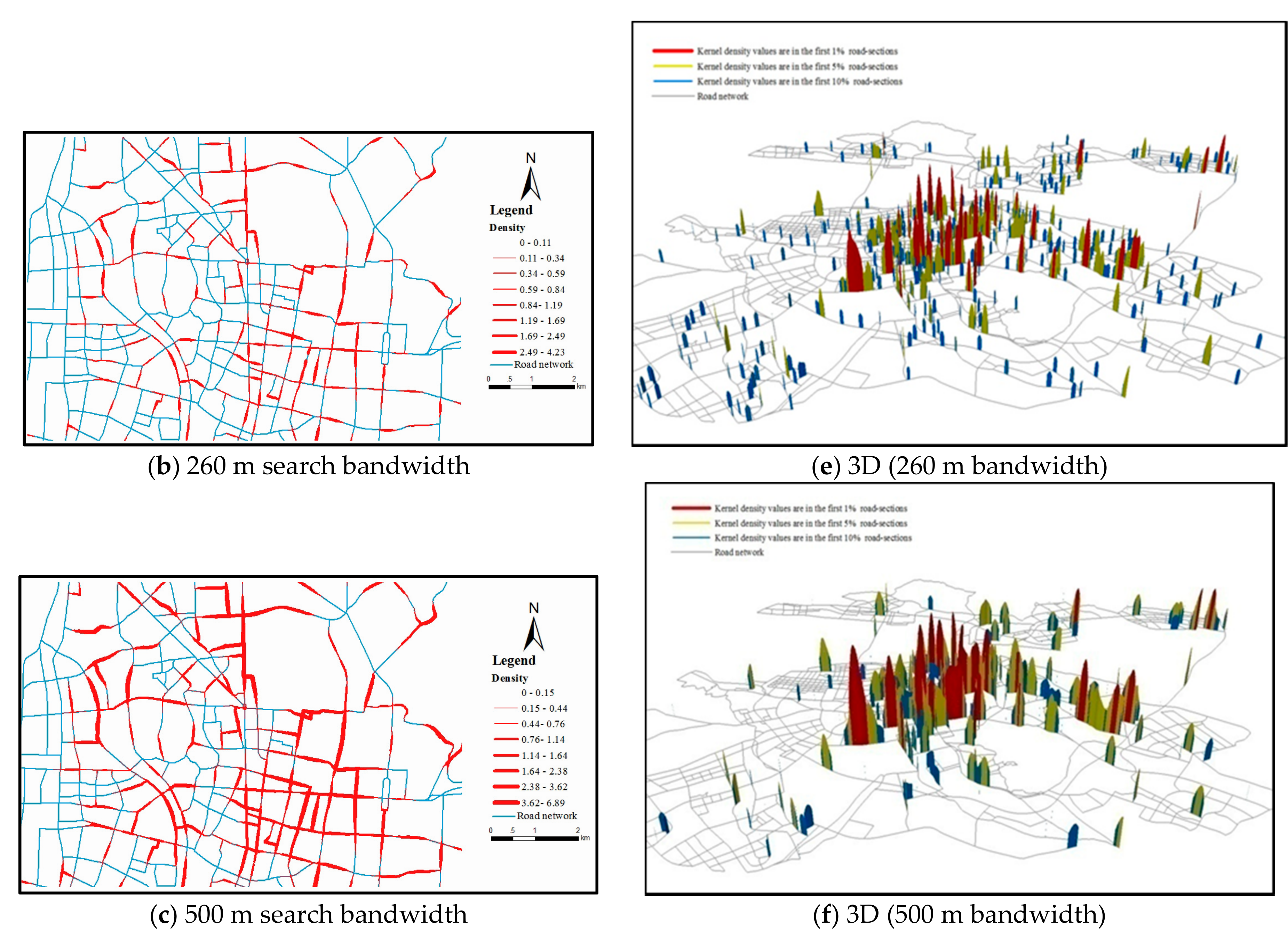
5.1. Impacts of Search Bandwidth on Density Pattern
5.2. ILINCS Based on NKDE
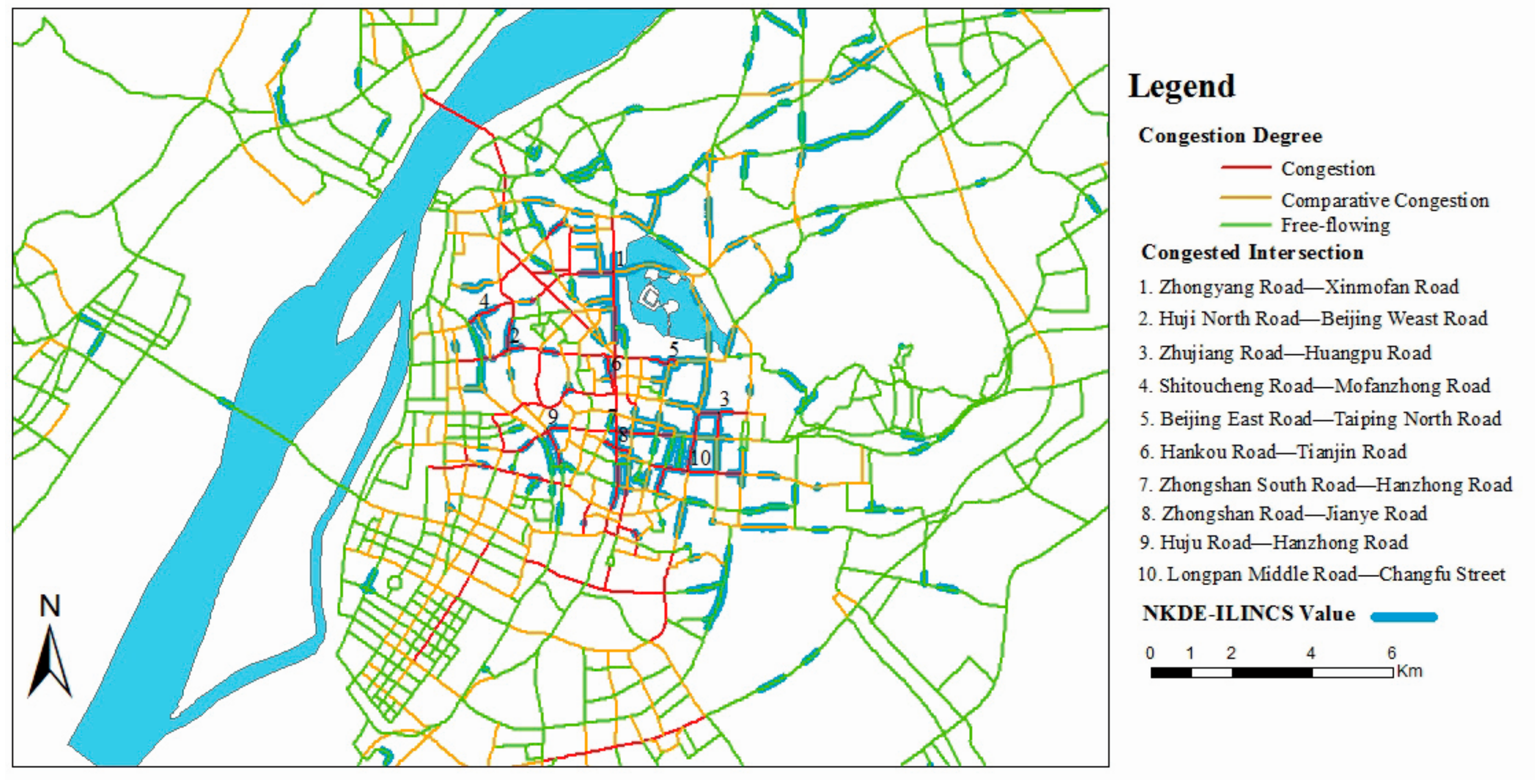
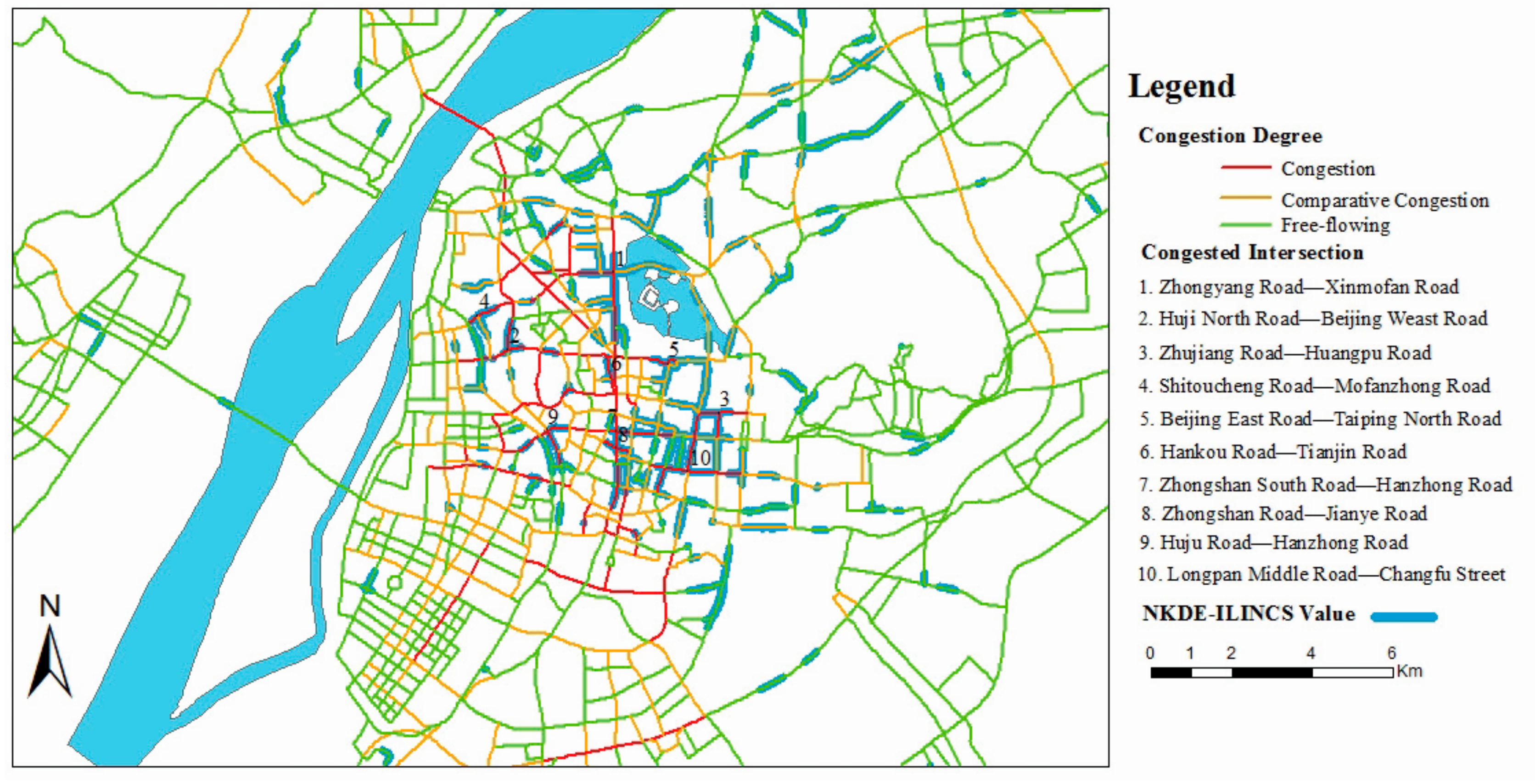
5.3. Detection of Fire Higher-Risk Locations Based on Network-Constrained
6. Summary and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xie, Z.; Yan, J. Kernel density estimation of traffic accidents in a network space. Comput. Environ. Urban Syst. 2008, 32, 396–406. [Google Scholar] [CrossRef]
- Delmelle, E.; Thill, J.-C. Urban bicyclists: Spatial analysis of adult and youth traffic hazard intensity. Transp. Res. Rec. 2008, 2074, 31–39. [Google Scholar] [CrossRef]
- Erdogan, S.; Yilmaz, I.; Baybura, T.; Gullu, M. Geographical information systems aided traffic accident analysis system case study: City of Afyonkarahisar. Accid. Anal. Prev. 2008, 40, 174–181. [Google Scholar] [CrossRef] [PubMed]
- Anderson, T.K. Kernel density estimation and K-means clustering to profile road accident hotspots. Accid. Anal. Prev. 2009, 41, 359–364. [Google Scholar] [CrossRef] [PubMed]
- O’Sullivan, D.; Unwin, D. Geographic Information Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Dai, D.; Taquechel, E.; Steward, J.; Strasser, S. The impact of built environment on pedestrian crashes and the identification of crash clusters on an urban university campus. West. J. Emerg. Med. 2010, 11, 294–301. [Google Scholar] [PubMed]
- Steenberghen, T.; Dufays, T.; Thomas, I.; Flahaut, B. Intra-urban location and clustering of road accidents using GIS: A Belgian example. Int. J. Geogr. Inf. Sci. 2004, 18, 169–181. [Google Scholar] [CrossRef]
- Elgammal, A.; Duraiswami, R.; Harwood, D.; Davis, L.S. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proc. IEEE 2002, 90, 1151–1163. [Google Scholar] [CrossRef]
- Flahaut, B.; Mouchart, M.; Martin, E.S.; Thomas, I. The local spatial autocorrelation and the kernel method for identifying black zones: A comparative approach. Accid. Anal. Prev. 2003, 35, 991–1004. [Google Scholar] [CrossRef]
- Borruso, G. Network density estimation: Analysis of point patterns over a network. In Computational Science and Its Applications–ICCSA; Gervasi, O., Murgante, B., Misra, S., Borruso, G., Torre, C.M., Rocha, A.M.A.C., Taniar, D., Apduhan, B.O., Stankova, E., Cuzzocrea, A., Eds.; Lecture Notes in Computer Science 3482; Springer: Berlin, Germany, 2005; pp. 126–132. [Google Scholar]
- Xie, Z.; Yan, J. Detecting traffic accident clusters with network kernel density estimation and local spatialstatistics: An integrated approach. J. Transp. Geogr. 2013, 31, 64–71. [Google Scholar] [CrossRef]
- Yamada, I.; Thill, J.-C. Local indicators of network-constrained clusters in spatial point patterns. Geogr. Anal. 2007, 39, 268–292. [Google Scholar] [CrossRef]
- Borruso, G. Network density estimation: Analysis of point patterns over a network. In Proceedings of the International Conference on Computational Science and Its Applications—ICCSA 2005, Singapore, 9–12 May 2005; Gervasi, O., Gavrilova, M.L., Kumar, V., Lagana, A., Lee, H.P., Mun, Y., Taniar, D., Tan, C.J.K., Eds.; Springer: Heidelberg, Germany, 2005. [Google Scholar]
- Borruso, G. Network density estimation: A GIS approach for analysing point patterns in a network space. Trans. GIS 2008, 12, 377–402. [Google Scholar] [CrossRef]
- Okabe, A.; Satoh, T.; Sugihara, K. A kernel density estimation method for networks, its computational method and a GIS-based tool. Int. J. Geogr. Inf. Sci. 2009, 23, 7–32. [Google Scholar] [CrossRef]
- Okabe, A.; Yamada, I. The K-function method on a network and its computational implementation. Geogr. Anal. 2001, 33, 271–290. [Google Scholar] [CrossRef]
- Rui, Y.; Ban, Y. Exploring the relationship between street centrality and land use in Stockholm. Int. J. Geogr. Inf. Sci. 2014, 28, 1425–1438. [Google Scholar] [CrossRef]
- Li, L.; Zhu, L.; Sui, D.Z. A GIS-based Bayesian approach for analyzing spatial-temporal patterns of intra-city motor vehicle crashes. J. Transp. Geogr. 2007, 15, 274–285. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X. An Ontology-Based Traffic Accident Risk Mapping Framework. Lect. Notes Computer Sci. 2011, 6849, 21–38. [Google Scholar]
- Chaikaew, N.; Tripathi, N.K.; Souris, M. Exploring spatial patterns and hotspots of diarrhea in Chiang Mai, Thailand. Int. J. Health Geogr. 2009, 8, 36. [Google Scholar] [CrossRef] [PubMed]
- Carlos, H.A.; Shi, X.; Sargent, J.; Tanski, S.; Berke, E.M. Density estimation and adaptive bandwidths: A primer for public health practitioners. Int. J. Health Geogr. 2010, 9, 39. [Google Scholar] [CrossRef] [PubMed]
- Pulugurtha, S.S.; Krishnakumar, V.K.; Nambisan, S.S. New methods to identify and rank high pedestrian crash zones: An illustration. Accid. Anal. Prev. 2007, 39, 800–811. [Google Scholar] [CrossRef] [PubMed]
- Chainey, S.; Tompson, L.; Uhligm, S. The utility of hotspot mapping for predicting spatial patterns of crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef]
- Ciscal-Terry, W.; Dell’Amico, M.; Hadjidimitriou, N.S.; Iori, M. An analysis of drivers route choice behavior using GPS data and optimal alternatives. J. Trans. Geogr. 2016, 51, 119–129. [Google Scholar] [CrossRef]
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Ratti, C.; Frenchman, D.; Pulselli, R.M.; Williams, S. Mobile landscapes: Using location data from cell phones for urban analysis. Environ. Plan. B Plan. Des. 2006, 33, 727–748. [Google Scholar] [CrossRef]
- Kwan, M.P. Interactive geovisualization of activity-travel patterns using three-dimensional geographical information systems: A methodological exploration with a large data set. Transp. Res. Part C Emerg. Technol. 2000, 8, 185–203. [Google Scholar] [CrossRef]
- Quddus, M.A.; Ochieng, W.Y.; Zhao, L.; Noland, R.B. A general map matching algorithm for transport telematics applications. GPS Solut. 2003, 7, 157–167. [Google Scholar] [CrossRef] [Green Version]
- White, C.E.; Bernstein, D.; Kornhauser, A.L. Some map matching algorithms for personal navigation assistants. Transp. Res. Part C 2000, 8, 91–108. [Google Scholar] [CrossRef]
- Quddus, M.A.; Ochieng, W.Y.; Noland, R.B. Current map-matching algorithms for transport applications: State-of-the art and future research directions. Transp. Res. Part C Emerg. Technol. 2007, 15, 312–328. [Google Scholar] [CrossRef] [Green Version]
- O’Sullivan, D.; Unwin, D.J. Geographic Information Analysis; John Wiley and Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Bíl, M.; Andrášik, R.; Janoška, Z. Identification of hazardous road locations of traffic accidents by means of kernel density estimation and cluster significance evaluation. Accid. Anal. Prev. 2013, 55, 265–273. [Google Scholar] [CrossRef] [PubMed]
- Plug, C.; Xia, J.C.; Caulfield, C. Spatial and temporal visualization techniques for crash analysis. Accid. Anal. Prev. 2011, 43, 1937–1946. [Google Scholar] [CrossRef] [PubMed]
- Nakaya, T.; Yano, K. Visualising Crime Clusters in a Space-time Cube: An Exploratory Data-analysis Approach Using Space-time Kernel Density Estimation and Scan Statistics. Trans. GIS 2010, 14, 223–239. [Google Scholar] [CrossRef]
- Levine, N. CrimeStat III: A Spatial Statistics Program for the Analysis of Crime Incident Locations, version 3.0; Ned Levine & Associates: Houston, TX, USA, 2004. [Google Scholar]
- Gibin, M.; Longley, P.; Atkinson, P. Kernel Density Estimation and Percent Volume Contours in General Practice Catchment Area Analysis in Urban Areas. In Proceedings of the GIScience Research UK Conference GISRUK, Maynooth, Ireland, 11–13 April 2007; Citeseer: Princeton, NJ, USA, 2007. [Google Scholar]
- Anselin, L. Local Indicators of Spatial Association—LISA. Geogr. Anal. 1995, 27, 93–115. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef]
- Thurstain-goodwin, M.; Unwin, D. Defining and delineating the central areas of towns for statistical monitoring using continuous surface representations. Trans. GIS 2000, 4, 305–317. [Google Scholar] [CrossRef]
- She, B.; Zhu, X.; Ye, X.; Lee, J. Weighted network Voronoi Diagrams for local spatial analysis. Comput. Environ. Urban Syst. 2015, 52, 70–80. [Google Scholar] [CrossRef]
- Nie, K.; Wang, Z.; Du, Q.; Ren, F.; Tian, Q. A Network-Constrained Integrated Method for Detecting Spatial Cluster and Risk Location of Traffic Crash: A Case Study from Wuhan, China. Sustainability 2015, 7, 2662–2677. [Google Scholar] [CrossRef]
- Jones, A.P.; Haynes, R.; Kennedy, V.; Harvey, I.M.; Jewell, T.; Lea, D. Geographical variations in mortality and morbidity from road traffic accidents in England and Wales. Health Place 2008, 14, 519–535. [Google Scholar] [CrossRef] [PubMed]
- Wier, M.; Weintraub, J.; Humphreys, E.H.; Seto, E.; Bhatia, R. An area-level model of vehicle-pedestrian injury collisions with implications for land use and transportation planning. Accid. Anal. Prev. 2009, 41, 137–145. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| HOSTID | HOSTNO | Time | Latitude | Longitude | Velocity | Angle |
|---|---|---|---|---|---|---|
| 6309 | WJSU6081X | 13 April 2015 08:59:58 | 32.052352 | 118.85066 | 23 | 251 |
| 6309 | WJSU6081X | 13 April 2015 09:00:18 | 32.052587 | 118.859605 | 5 | 263 |
| 6309 | WJSU6081X | 13 April 2015 09:00:35 | 32.052623 | 118.859935 | 8 | 265 |
| 6309 | WJSU6081X | 13 April 2015 09:00:52 | 32.054320 | 118.860167 | 28 | 277 |
| 6309 | WJSU6081X | 13 April 2015 09:01:20 | 32.055433 | 118.861172 | 30 | 271 |
| Node Name | Bandwidth | Whether Contains Node * | Distance ** |
|---|---|---|---|
| V1-2-2 | 100 | No | 10 m |
| ...... | ...... | ...... | ...... |
| V1-7-2 | 100 | No | 90 m |
| Experiments | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Parameters | Input attribute | Kernel density value | Kernel density value | Fire number | Fire number |
| BLU length | 20 m | 40 m | 20 m | 40 m | |
| Simulation times | 99 | 99 | 99 | 99 | |
| p-value | 0.01 | 5374 | 2100 | 0 | 0 |
| 0.05 | 18761 | 7475 | 0 | 0 | |
| ID | Name | Density Value (Mean) | Z (Mean) | Length | Congestion Degree |
|---|---|---|---|---|---|
| 1 | Zhongshan East Road | 5.0290 | 12.3001 | 589 m | free-flowing |
| 2 | Daming Road | 4.8246 | 9.5572 | 900 m | free-flowing |
| 3 | Longyuan East Road | 4.4869 | 7.3708 | 226 m | congestion |
| 4 | Longpan Middle Road | 4.3531 | 6.8773 | 569 m | comparative-congestion |
| 5 | Huju North Road | 4.3494 | 7.3135 | 233 m | congestion |
| 6 | Jinmao Main Street | 4.2200 | 8.3280 | 340 m | congestion |
| 7 | Chahaer Road | 4.1712 | 10.1488 | 320 m | comparative-congestion |
| 8 | Changbai Street | 3.9715 | 10.0531 | 460 m | free-flowing |
| 9 | Zhujiang Road | 3.9093 | 7.5572 | 849 m | comparative-congestion |
| 10 | Shitoucheng Road | 3.7503 | 7.9518 | 223 m | congestion |
| 11 | Zhongyang Road | 3.6002 | 8.8611 | 536 m | congestion |
| 12 | Changfu Street | 3.3741 | 7.4618 | 547 m | congestion |
| 13 | Huangpu Road | 3.2977 | 7.4664 | 284 m | comparative-congestion |
| 14 | Guanghua Road | 3.2089 | 4.1780 | 546 m | comparative-congestion |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, Z.; Li, H.; Chen, Y. An Integrated Spatial Clustering Analysis Method for Identifying Urban Fire Risk Locations in a Network-Constrained Environment: A Case Study in Nanjing, China. ISPRS Int. J. Geo-Inf. 2017, 6, 370. https://doi.org/10.3390/ijgi6110370
Xia Z, Li H, Chen Y. An Integrated Spatial Clustering Analysis Method for Identifying Urban Fire Risk Locations in a Network-Constrained Environment: A Case Study in Nanjing, China. ISPRS International Journal of Geo-Information. 2017; 6(11):370. https://doi.org/10.3390/ijgi6110370
Chicago/Turabian StyleXia, Zelong, Hao Li, and Yuehong Chen. 2017. "An Integrated Spatial Clustering Analysis Method for Identifying Urban Fire Risk Locations in a Network-Constrained Environment: A Case Study in Nanjing, China" ISPRS International Journal of Geo-Information 6, no. 11: 370. https://doi.org/10.3390/ijgi6110370