An Automatic K-Means Clustering Algorithm of GPS Data Combining a Novel Niche Genetic Algorithm with Noise and Density

 ,
,
Abstract
:1. Introduction
- The selection of the initial population combining noise with K-means++.
- An improved gene rearrangement technique using cosine similarity.
- Adaptive probabilities of crossover and mutation are used to prevent the NoiseClust from getting stuck at a local optimal solution.
- A novel niche operation is proposed to maintain population diversity.
- NoiseClust works on four real-world taxi GPS data sets.
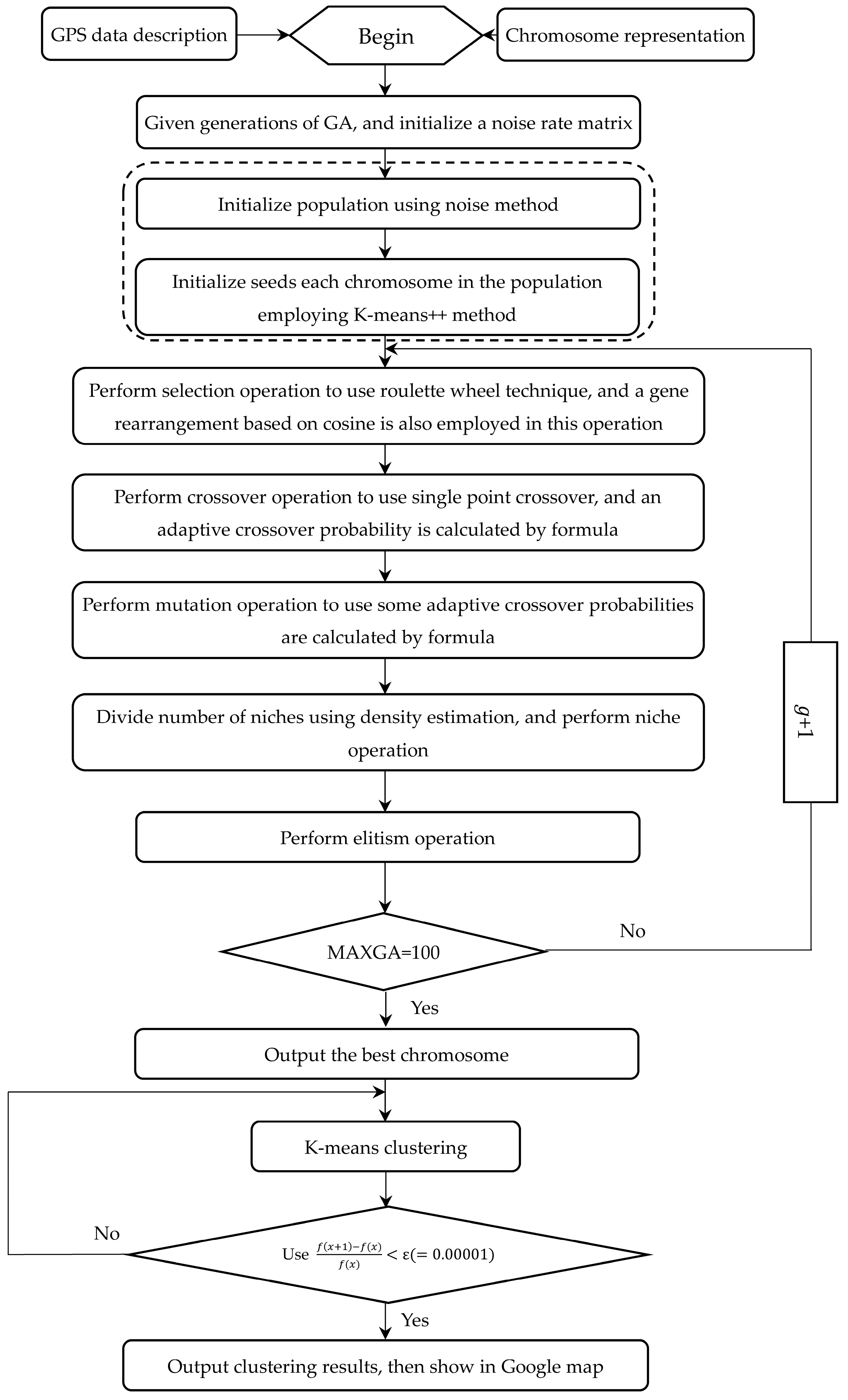
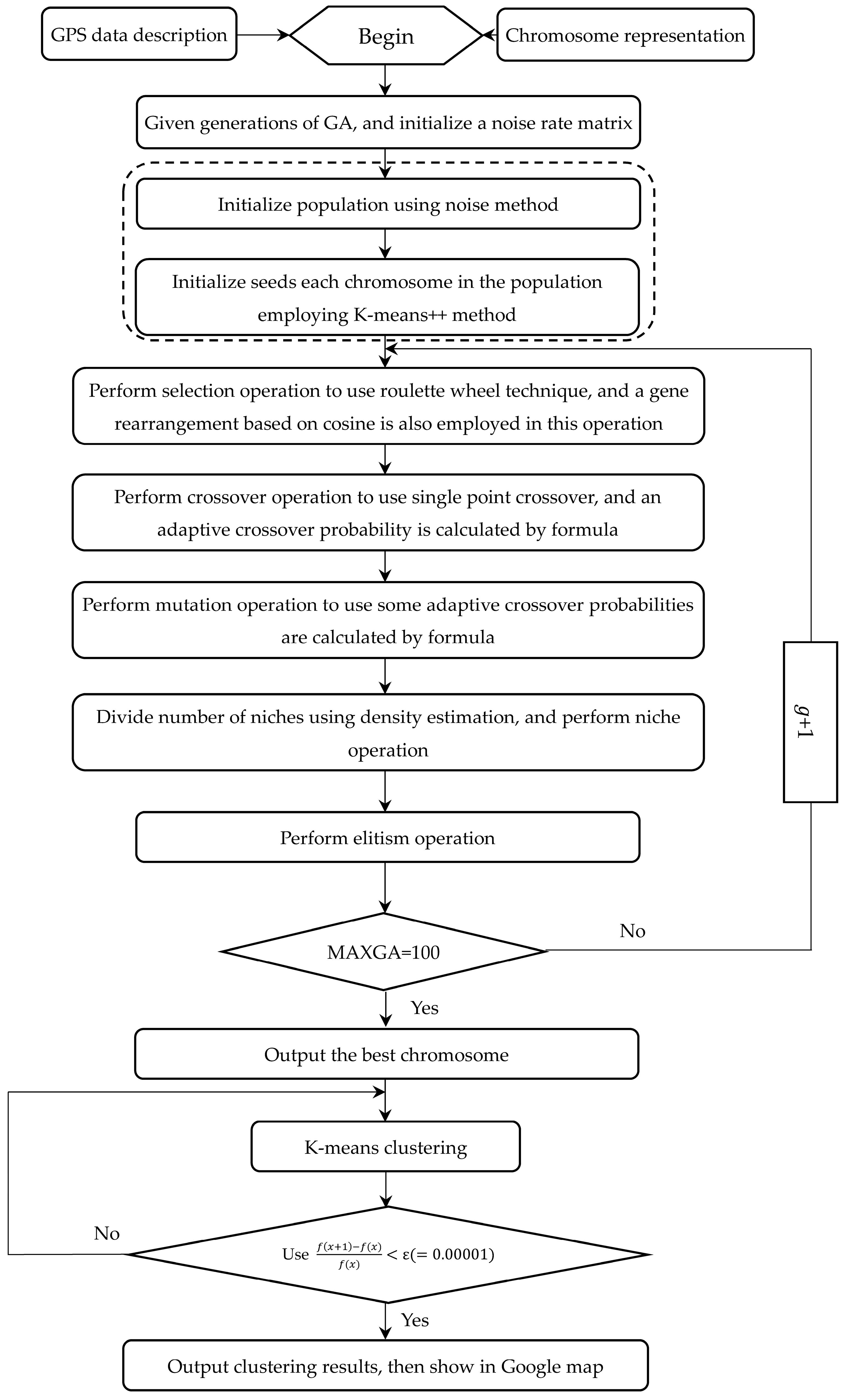
2. The NoiseClust Clustering Algorithm
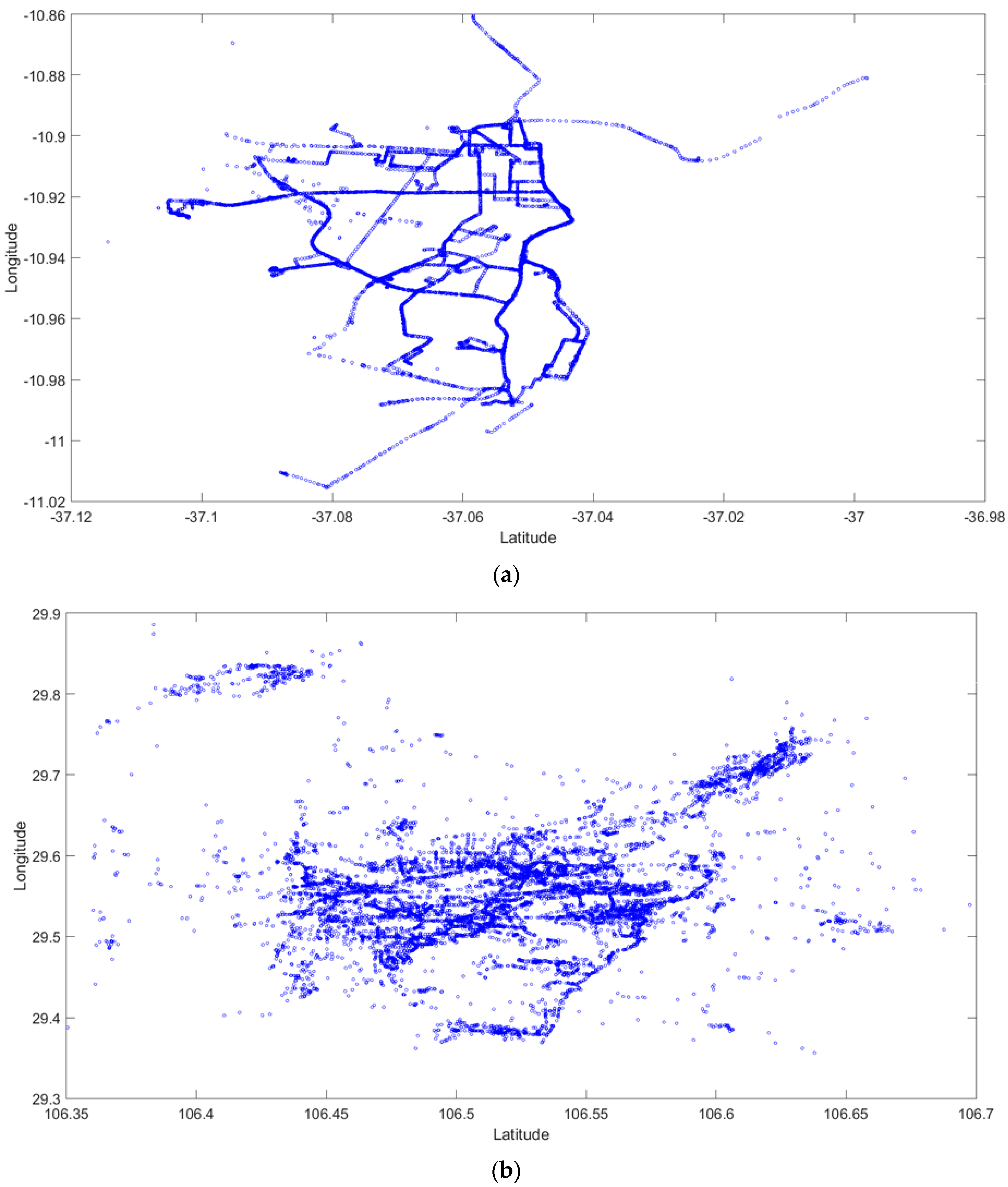
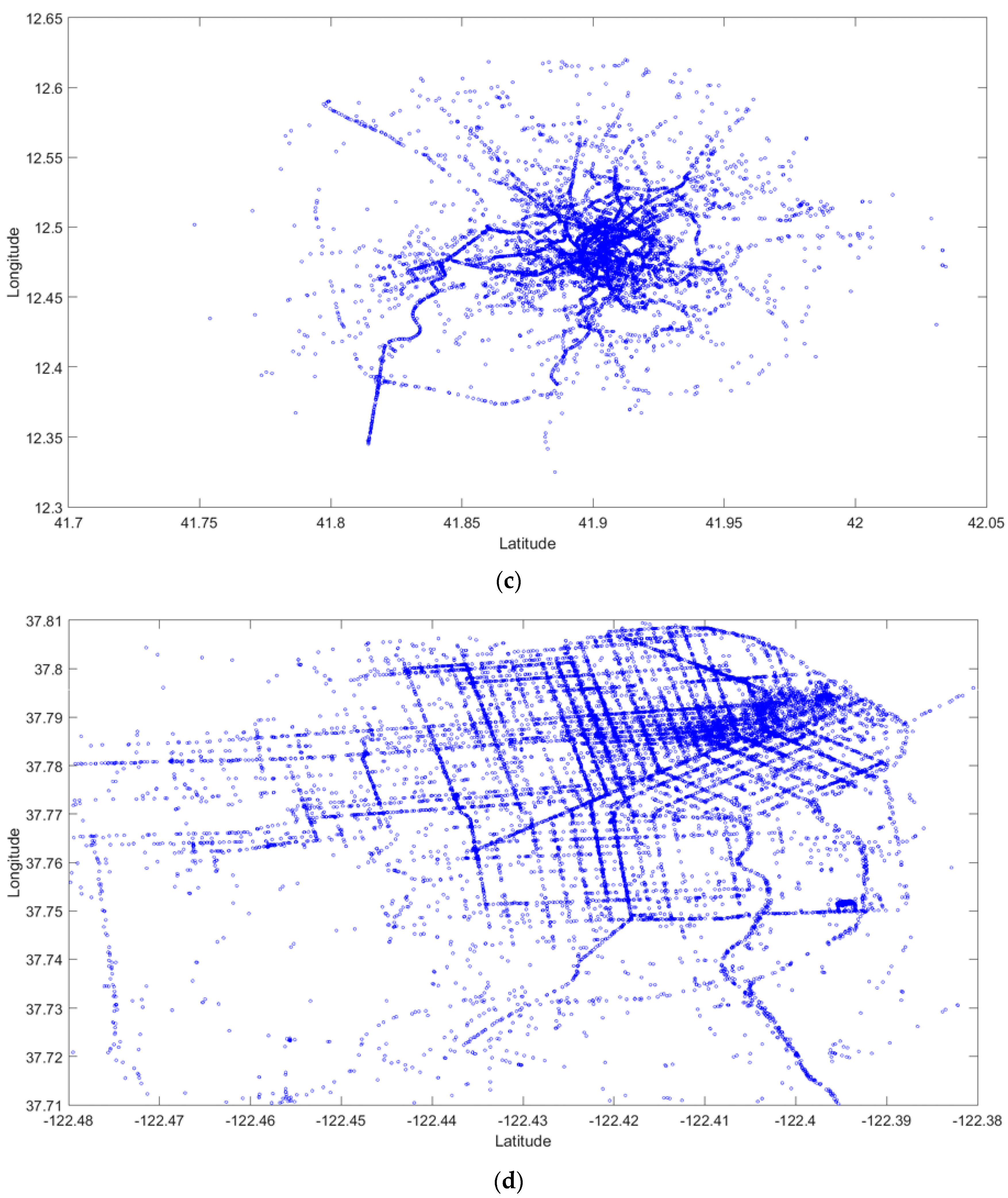
2.1. GPS Data Description
2.2. Chromosome Representation Using a Real-World Data Sequence
2.3. Initial Population Using Noise and K-Means++ Method
| Algorithm 1. Initial population using noise and K-means++ |
| Function: KMeanPlus (data, solution, dimension)//K-means++ [25] is employed to handle objective function value of noise, select initial seeds, and control the decreasing-rate Input: //give a group of the maximum and minimum noise rates (e.g., 30 pairs of noise rates), they are usually equal to population size. NIND//population size (for example NIND = 30). total_noise_ele_num//give the total number of noised elementary, it is usually equal the number of iterations which is used to noising operation. noise_ele_num//give the number of noised elementary, it is usually equal to population size, or set number of noised elementary. NS//it is the size of the neighborhood. data//input taxi GPS data sets Output: initial population Procedure: FOR 1 to NIND draw the initial current solution s randomly (s, chrom_s(K)) ← Call KMeanPlus (data, s, m)//calculate objective function of noise, and initial seeds, chrom_s denotes seeds of chromosome using K-means ++. best_sol ← s//it is the best solution found since the beginning best_sol(K) ← s//obtain number of clusters each chromosome best_chrom_sol ← chrom_s(K)//produce a chromosome to put into population //denote the value by which rate decrease. //gives the frequency of the restart of the current solution //give the current value of the noise rate //count the number of noise trial which have been applied. WHILE + 1 IF ←rate END solution s translate into binary bits and produce next solution s’//let s’ be the next neighbor of s solution s’ translate into decimal value K and determine K range between 2 and //produce the number of clusters let noise be a random real number uniformly drawn into search s’//search one of its neighbors IF s’ = ∅ Call KMeanPlus (data, s’, m) best_sol ← s’ ELSE perform solution for taxi GPS data sets to start producing chromosome END IF s ← s’ is controlled to produce chromosome END IF //mod is modulo //apply noise rate (=0) descent from s result in a good neighboring solution may be rejected END IF ← s s ← best_sol(K) best_chrom_sol ← chrom_s(K) END IF s ← best_sol(K) ← s END IF IF rate = rate − decrease ELSE rate = r_rate − decrease END END END produce a chromosome and record length of its (the number of clusters) END achieve population (30 chromosomes) initialization |
2.4. Fitness Function
2.5. Genetic Operations
2.5.1. Selection Operation
2.5.2. Crossover Operation
2.5.3. Mutation Operation
2.6. Sharing-Based Niche Partitioning Using Density
2.6.1. Niches Partitioning Based on Density
| Algorithm 2. Niches partitioning based on density |
| Input: GPS taxi data (data), a given density radius r Output: result of the niche partitioning, including number of niches, and number of GPS points each niche Procedure: WHILE data = = ∅ Num_circles ← radius r is placed in taxi GPS data sets//Num_circle denotes the number of densities Num_points ← counts the number of taxi GPS points each density and record in Num_points Num_niches ← sort Num_points in the ascending order according to the number of taxi GPS points, and obtain a maximum density to separate storage. The remaining taxi GPS points continue operation until data = = ∅ END WHILE |
2.6.2. Sharing-Based Niche Method
2.7. Elitism Operation
2.8. K-Means Clustering Using the Best Chromosome
| Algorithm 3. K-means clustering using the best chromosome |
| Input: taxi GPS data set, the best chromosome Output: K-means clustering result Procedure: Obtain the number of genes (K) of the best chromosome as the number of clusters; Initialize the K seeds using genes of the best chromosome; WHILE //when meet , its number of iterations is record to x FOR 1 to K FOR 1 to m//repeat the number of attributes FOR 1 to n//repeat the number of taxi GPS data points Assign each taxi GPS data point to the closest seed; Update the seeds from the taxi GPS data points assigned to each cluster using SSE //SSE model is described in Section 3.1; END FOR END FOR Remove empty clusters; Remove clusters of the lesser taxi GPS points (<3) and add into the closest clusters; END FOR END WHILE Output clustering results of taxi GPS data set and display in map. |
2.9. Termination Condition
2.10. Complexity Analysis of NoiseClust
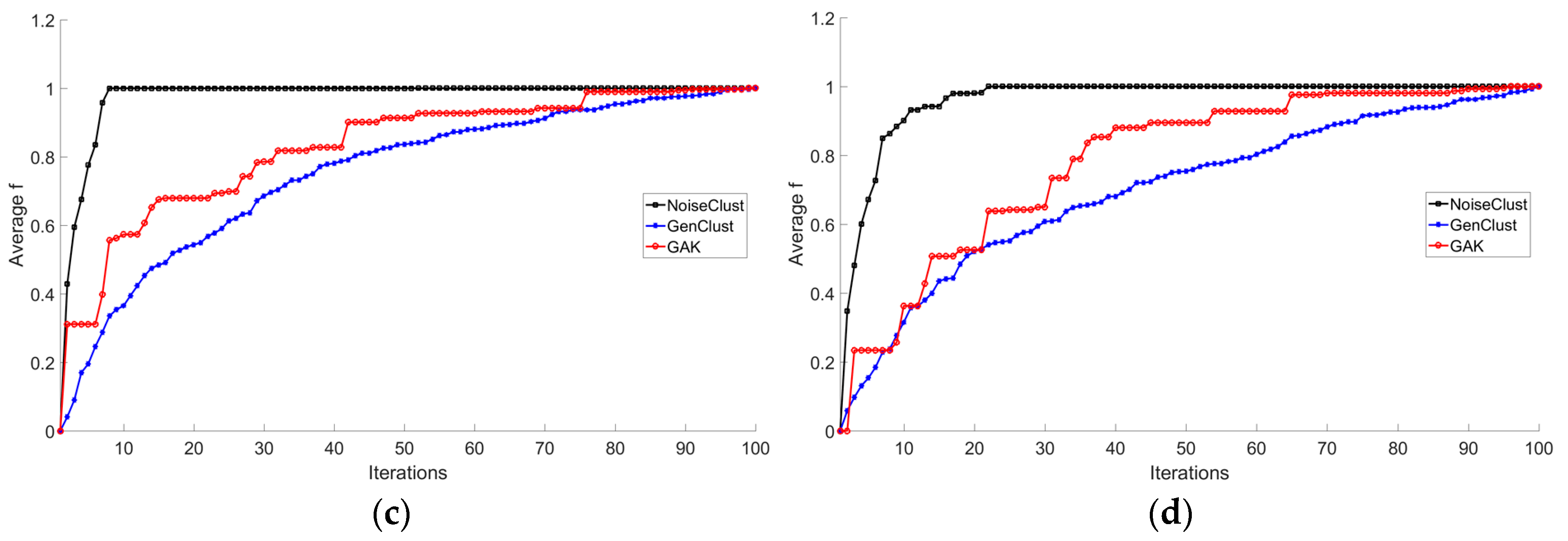
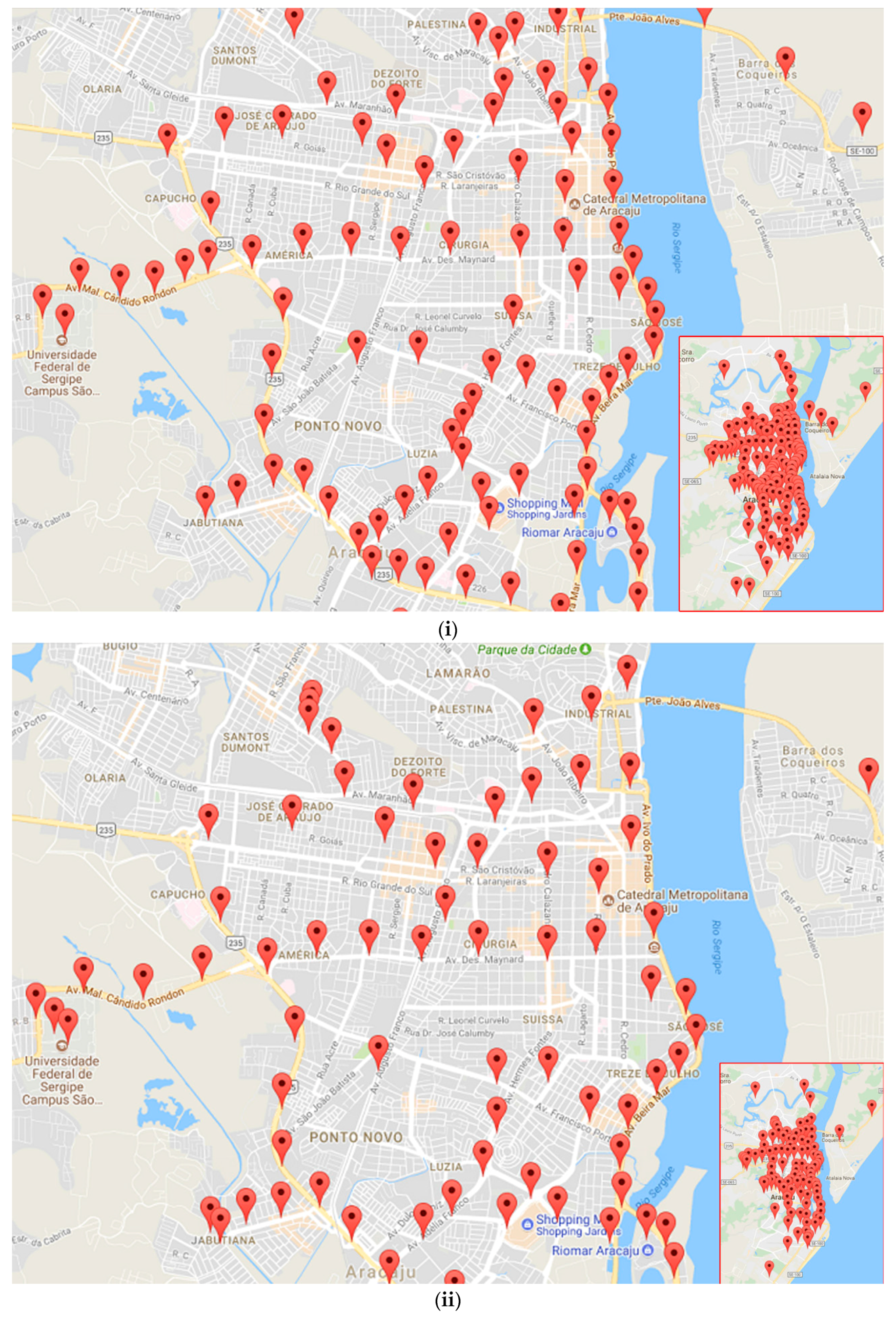
3. Experimental Results and Discussion
3.1. Clustering Evaluation Criteria
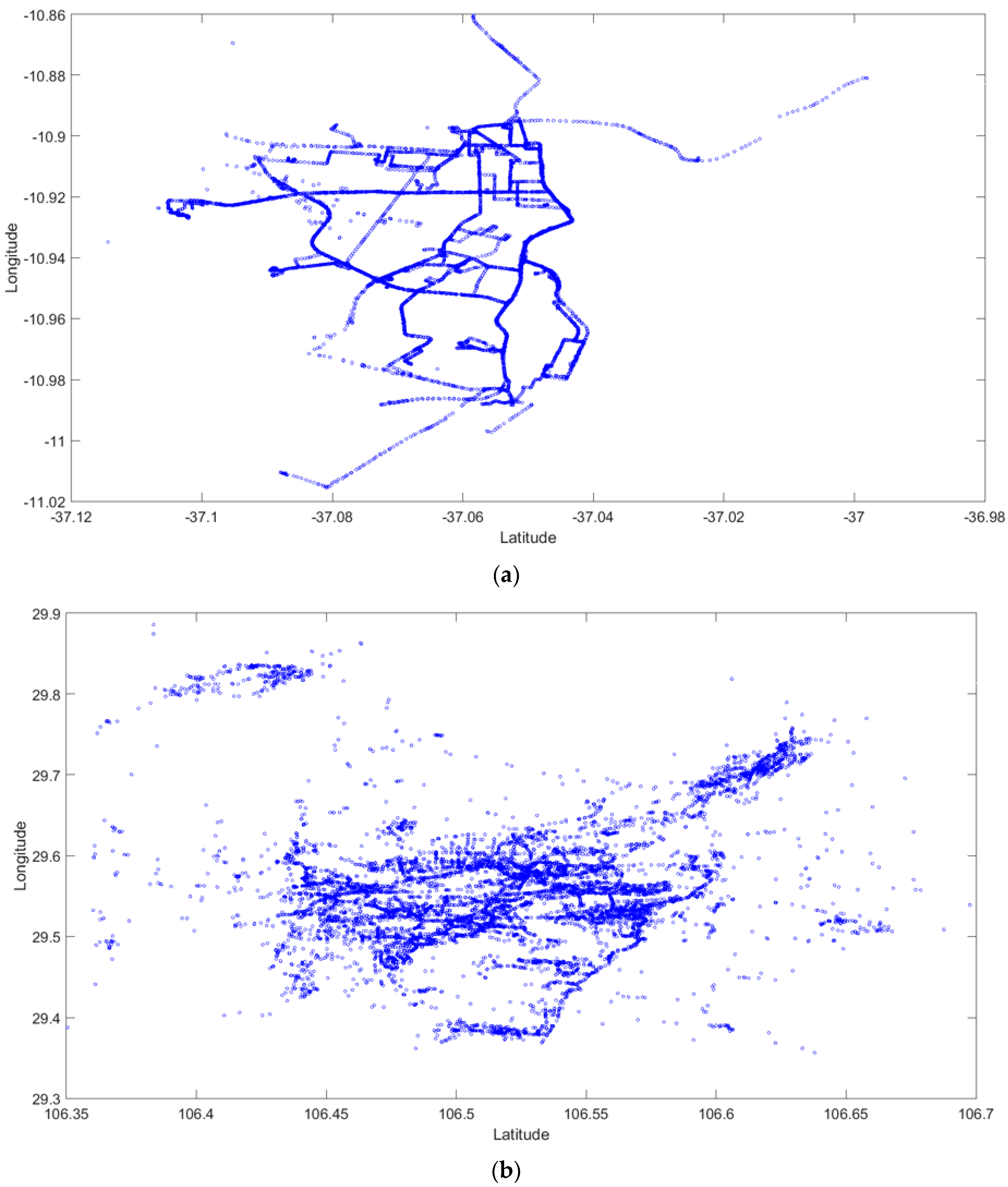
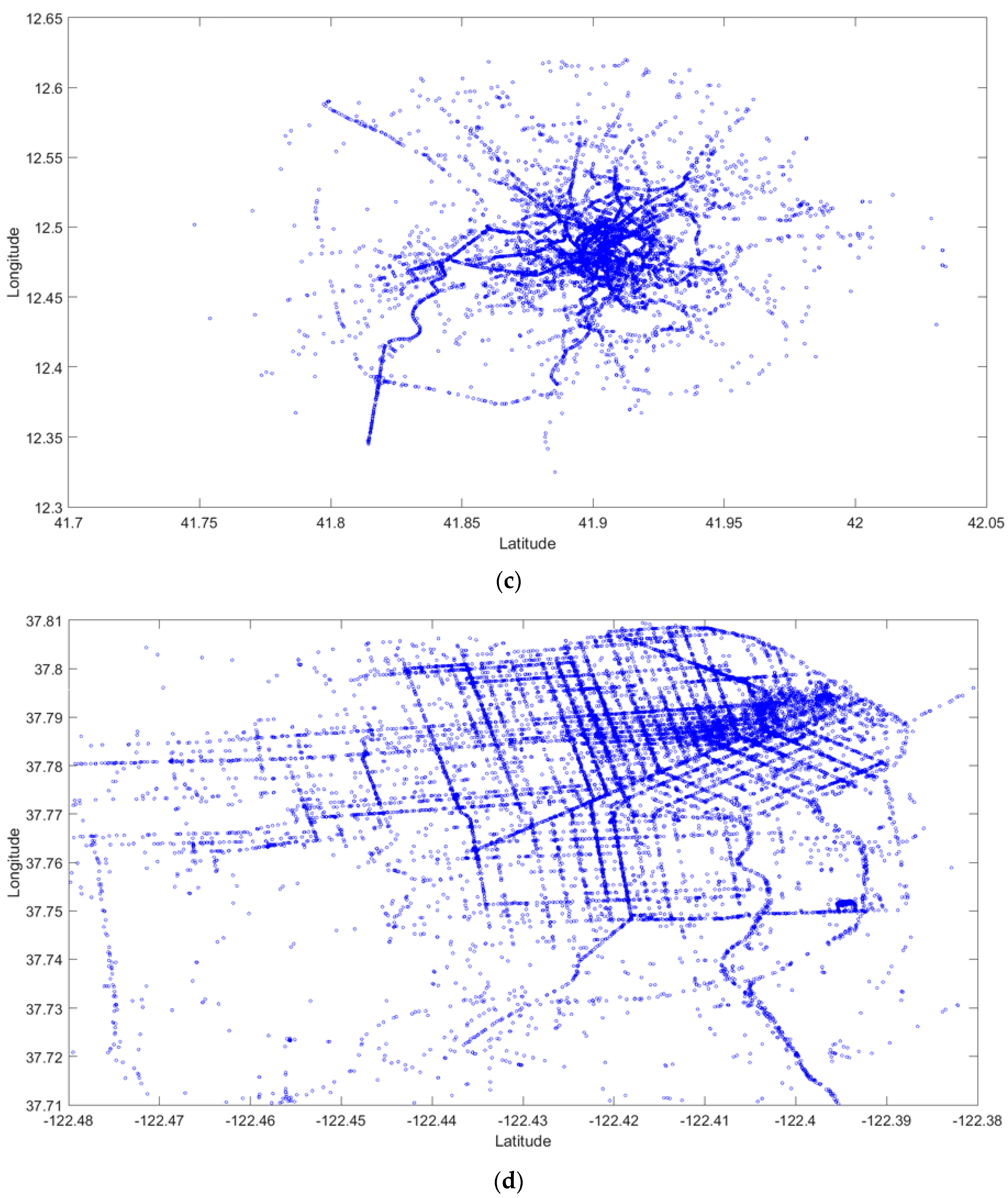
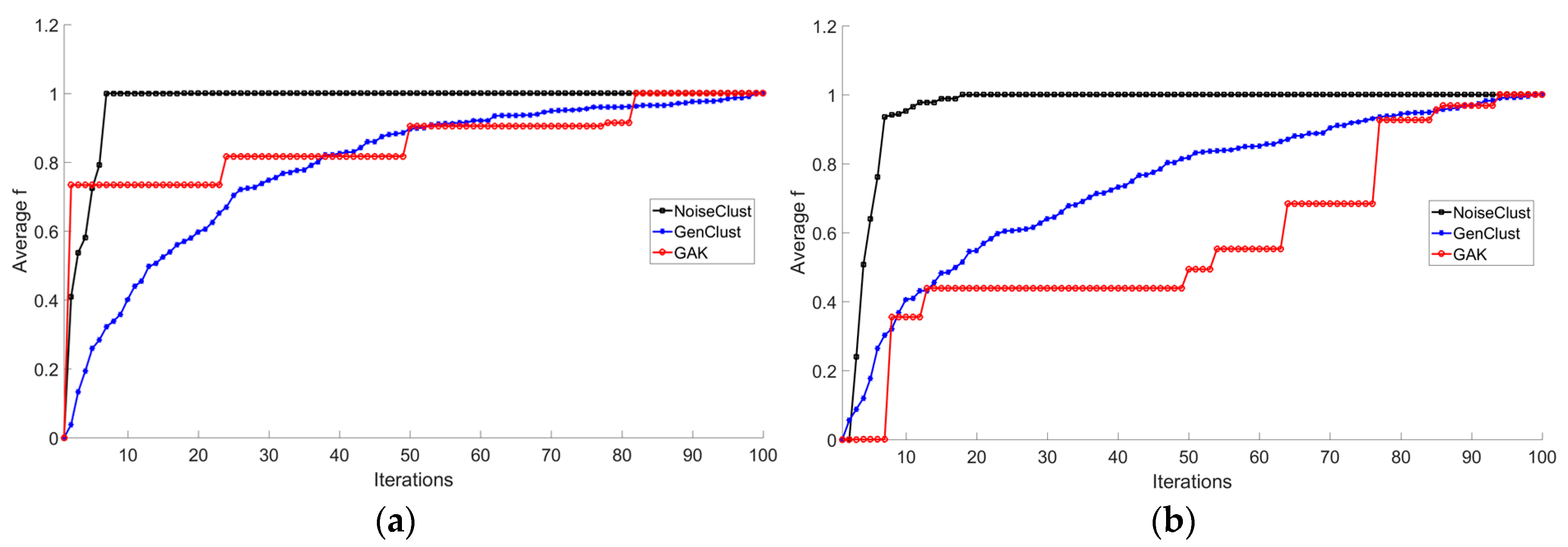
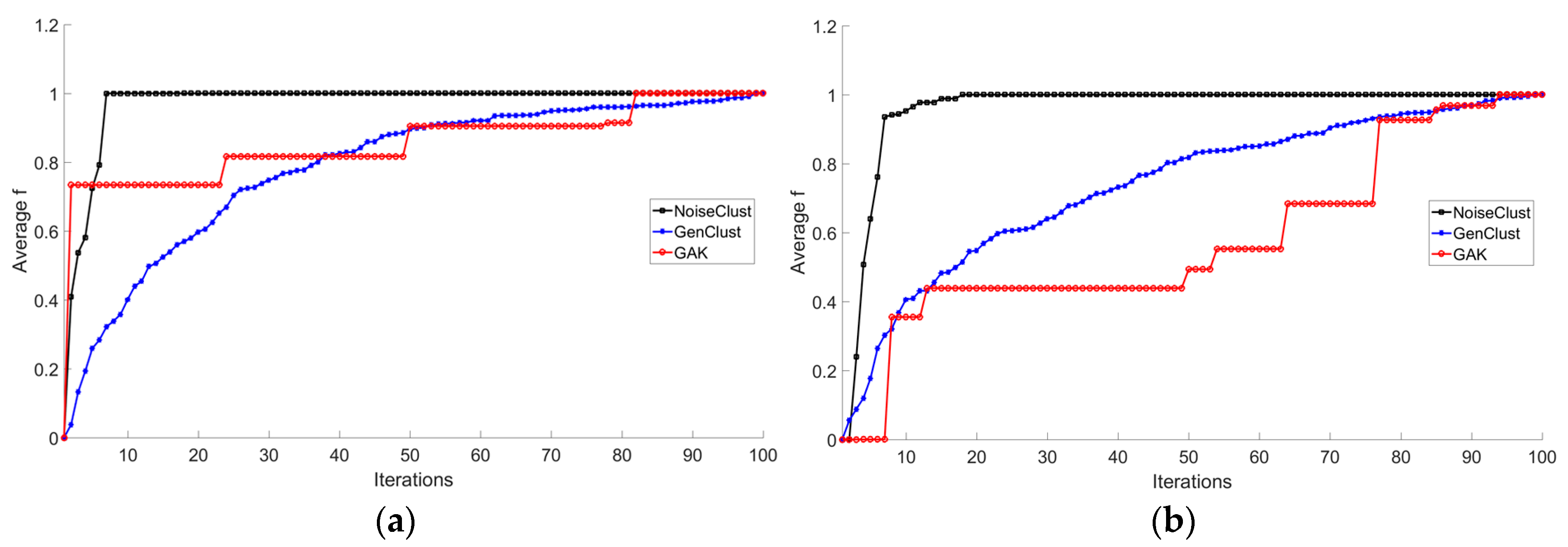
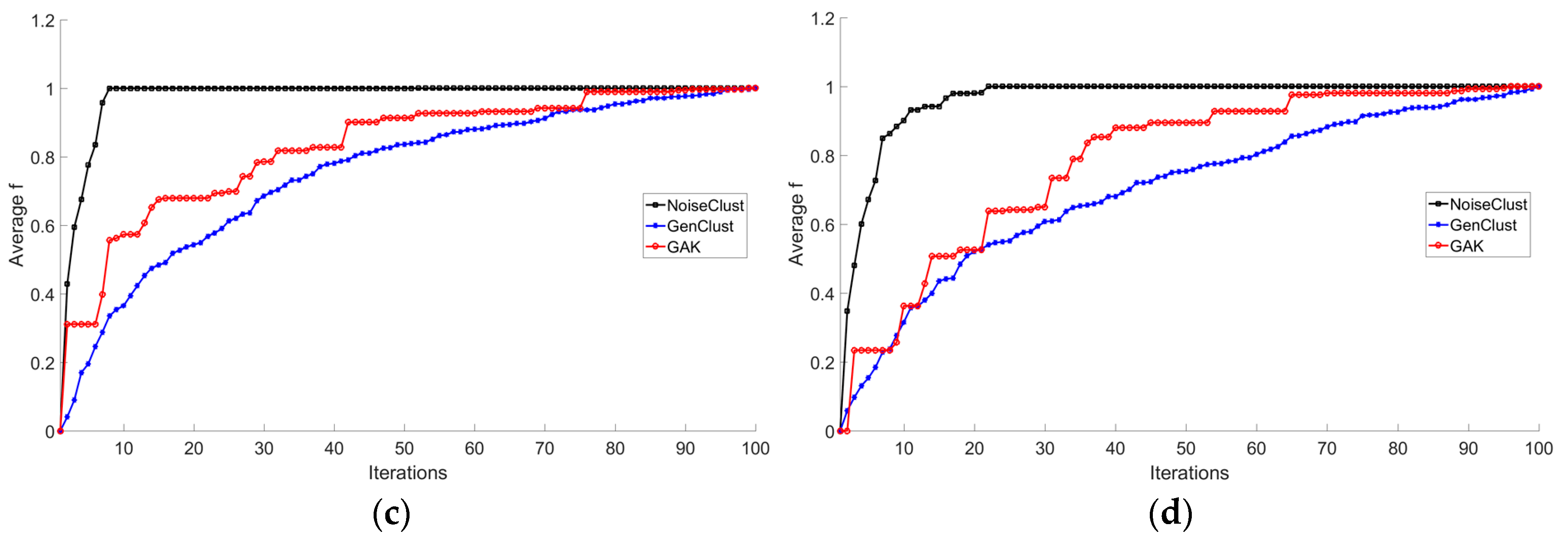
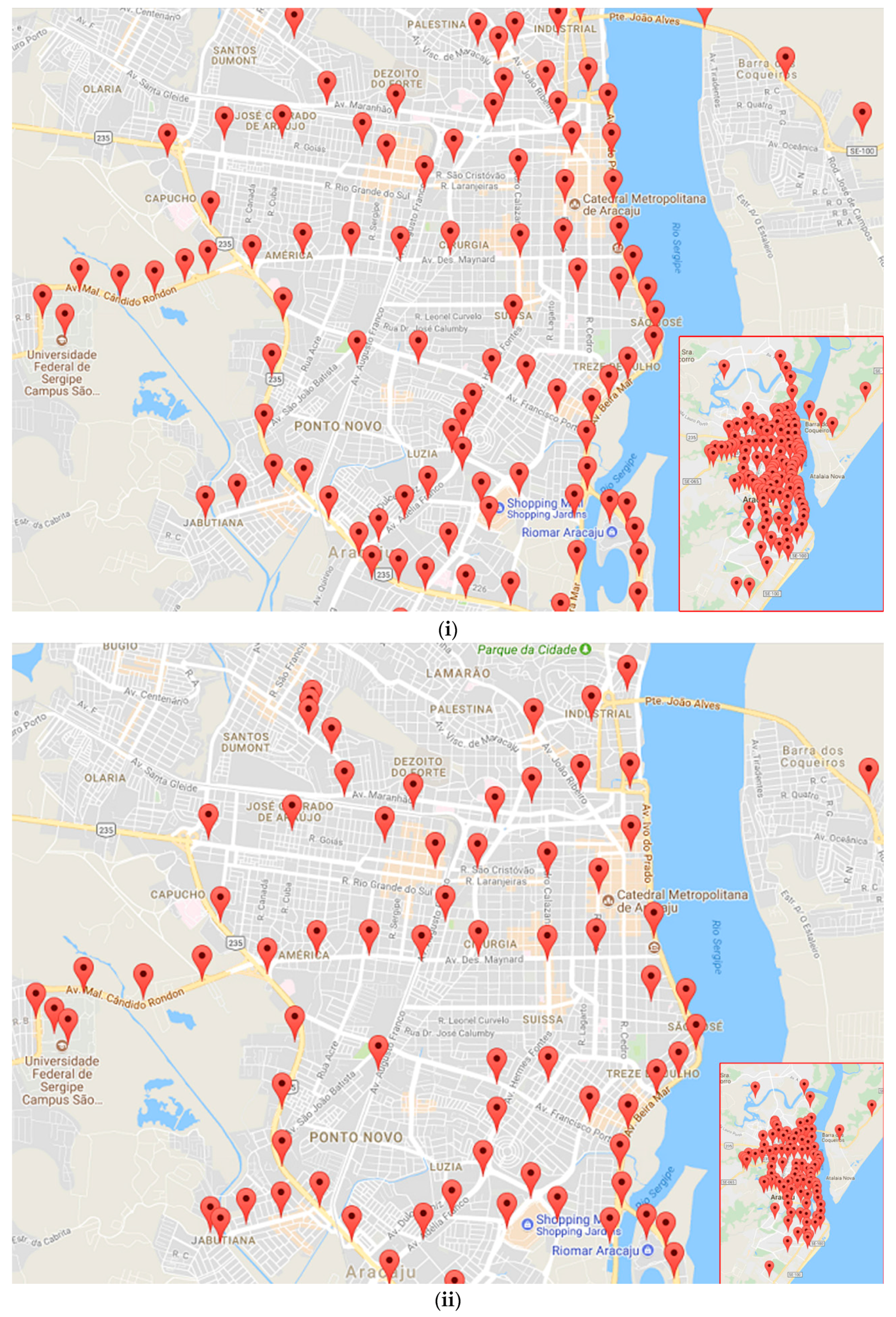
3.2. Experiments on Taxi GPS Data
4. Conclusions and Further Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hung, C.-C.; Peng, W.-C.; Lee, W.-C. Clustering and aggregating clues of trajectories for mining trajectory patterns and routes. VLDB J. 2015, 24, 169–192. [Google Scholar] [CrossRef]
- Moreira-Matias, L.; Gama, J.; Ferreira, M.; Mendes-Moreira, J.; Damas, L. Time-evolving od matrix estimation using high-speed gps data streams. Expert Syst. Appl. 2016, 44, 275–288. [Google Scholar] [CrossRef]
- Lu, M.; Liang, J.; Wang, Z.; Yuan, X. Exploring OD patterns of interested region based on taxi trajectories. J. Vis. 2016, 19, 811–821. [Google Scholar] [CrossRef]
- Ferreira, N.; Poco, J.; Vo, H.T.; Freire, J.; Silva, C.T. Visual exploration of big spatio-temporal urban data: A study of New York city taxi trips. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2149–2158. [Google Scholar] [CrossRef] [PubMed]
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; de Macedo, J.A.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef] [Green Version]
- Luo, T.; Zheng, X.; Xu, G.; Fu, K.; Ren, W. An improved DBSCAN algorithm to detect stops in individual trajectories. ISPRS Int. J. Geo-Inf. 2017, 6, 63. [Google Scholar] [CrossRef]
- Frentzos, E.; Gratsias, K.; Pelekis, N.; Theodoridis, Y. Algorithms for nearest neighbor search on moving object trajectories. Geoinformatica 2007, 11, 159–193. [Google Scholar] [CrossRef]
- Nanni, M.; Pedreschi, D. Time-focused clustering of trajectories of moving objects. J. Intell. Inf. Syst. 2006, 27, 267–289. [Google Scholar] [CrossRef]
- Fiori, A.; Mignone, A.; Rospo, G. Decoclu: Density consensus clustering approach for public transport data. Inf. Sci. 2016, 328, 378–388. [Google Scholar] [CrossRef]
- Lv, M.; Chen, L.; Xu, Z.; Li, Y.; Chen, G. The discovery of personally semantic places based on trajectory data mining. Neurocomputing 2016, 173, 1142–1153. [Google Scholar] [CrossRef]
- Lee, J.-G.; Han, J.; Whang, K.-Y. Trajectory clustering: A partition-and-group framework. In Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data, Beijing, China, 11–14 June 2007; pp. 593–604. [Google Scholar]
- Gaffney, S.J.; Robertson, A.W.; Smyth, P.; Camargo, S.J.; Ghil, M. Probabilistic clustering of extratropical cyclones using regression mixture models. Clim. Dyn. 2007, 29, 423–440. [Google Scholar] [CrossRef]
- Xu, R.; Wunsch, D. Survey of clustering algorithms. IEEE. Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Rahman, M.A.; Islam, M.Z. A hybrid clustering technique combining a novel genetic algorithm with K-means. Knowl. Based Syst. 2014, 71, 345–365. [Google Scholar] [CrossRef]
- Sclim, S.; Lsmailm, A. Means-type algorithm: A generalized convergence theorem and characterization of local optimality. IEEE. Trans. Pattern Anal. Mach. Intell 1984, 1, 81–87. [Google Scholar]
- Abul Hasan, M.J.; Ramakrishnan, S. A survey: Hybrid evolutionary algorithms for cluster analysis. Artif. Intell. Rev. 2011, 36, 179–204. [Google Scholar] [CrossRef]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the K-means clustering algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Chang, D.-X.; Zhang, X.-D.; Zheng, C.-W. A genetic algorithm with gene rearrangement for K-means clustering. Pattern Recognit. 2009, 42, 1210–1222. [Google Scholar] [CrossRef]
- Agustı, L.; Salcedo-Sanz, S.; Jiménez-Fernández, S.; Carro-Calvo, L.; Del Ser, J.; Portilla-Figueras, J.A. A new grouping genetic algorithm for clustering problems. Expert Syst. Appl. 2012, 39, 9695–9703. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, X.; Shen, Y. Automatic clustering using genetic algorithms. Appl. Math. Comput. 2011, 218, 1267–1279. [Google Scholar] [CrossRef]
- Hruschka, E.R.; Campello, R.J.; Freitas, A.A. A survey of evolutionary algorithms for clustering. IEEE. Trans. Syst. Man Cybern. Part C 2009, 39, 133–155. [Google Scholar] [CrossRef]
- McCallum, A.; Nigam, K.; Ungar, L.H. Efficient clustering of high-dimensional data sets with application to reference matching. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 169–178. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. K-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Hancer, E.; Karaboga, D. A comprehensive survey of traditional, merge-split and evolutionary approaches proposed for determination of cluster number. Swarm Evolut. Comput. 2017, 32, 49–67. [Google Scholar] [CrossRef]
- Sareni, B.; Krahenbuhl, L. Fitness sharing and niching methods revisited. IEEE. Trans. Evolut. Comput. 1998, 2, 97–106. [Google Scholar] [CrossRef] [Green Version]
- Mukhopadhyay, A.; Maulik, U. Towards improving fuzzy clustering using support vector machine: Application to gene expression data. Pattern Recognit. 2009, 42, 2744–2763. [Google Scholar] [CrossRef]
- Goldberg, D.E.; Richardson, J. Genetic algorithms with sharing for multimodal function optimization. In Proceedings of the Second International Conference on Genetic Algorithms: Genetic Algorithms and Their Applications, Cambridge, MA, USA, 28–31 July 1987; Lawrence Erlbaum: Hillsdale, NJ, USA, 1987; pp. 41–49. [Google Scholar]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE. Trans. Syst. Man Cybern. Part B 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed]
- Pakhira, M.K.; Bandyopadhyay, S.; Maulik, U. Validity index for crisp and fuzzy clusters. Pattern Recognit. 2004, 37, 487–501. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE. Trans. Pattern Anal. 1979, 2, 224–227. [Google Scholar] [CrossRef]
- Tang, J.; Liu, F.; Wang, Y.; Wang, H. Uncovering urban human mobility from large scale taxi GPS data. Phys. A Stat. Mech. Appl. 2015, 438, 140–153. [Google Scholar] [CrossRef]
- Ekpenyong, F.; Palmer-Brown, D.; Brimicombe, A. Extracting road information from recorded GPS data using snap-drift neural network. Neurocomputing 2009, 73, 24–36. [Google Scholar] [CrossRef]
- Taxi-GPS Data Sets. Available online: https://github.com/bigdata002/Location-data-sets (accessed on 26 November 2017).
- Charon, I.; Hudry, O. The noising methods: A generalization of some metaheuristics. Eur. J. Oper. Res. 2001, 135, 86–101. [Google Scholar] [CrossRef]
- Rahman, A.; Islam, Z. Seed-detective: A novel clustering technique using high quality seed for K-means on categorical and numerical attributes. In Proceedings of the Ninth Australasian Data Mining Conference, Ballarat, Australia, 1–2 December 2011; Australian Computer Society: Sydney, Australia, 2011; pp. 211–220. [Google Scholar]
- Charon, I.; Hudry, O. The noising method: A new method for combinatorial optimization. Oper. Res. Lett. 1993, 14, 133–137. [Google Scholar] [CrossRef]
- Chen, W.H.; Lin, C.S. A hybrid heuristic to solve a task allocation problem. Comput. Oper. Res. 2000, 27, 287–303. [Google Scholar] [CrossRef]
- Hudry, O. Noising Methods for a Clique Partitioning Problem; Elsevier: Amsterdam, The Netherlands, 2006; pp. 754–769. [Google Scholar]
- Sheng, W.; Tucker, A.; Liu, X. A niching genetic K-means algorithm and its applications to gene expression data. Soft Comput. 2010, 14, 9. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Maulik, U. An evolutionary technique based on K-means algorithm for optimal clustering in RN. Inf. Sci. 2002, 146, 221–237. [Google Scholar] [CrossRef]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A clustering-based approach for discovering interesting places in trajectories. In Proceedings of the ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 863–868. [Google Scholar]
- Abido, M. A niched pareto genetic algorithm for multiobjective environmental/economic dispatch. Int. J. Electr. Rower Energy Syst. 2003, 25, 97–105. [Google Scholar] [CrossRef]
- Chang, D.-X.; Zhang, X.-D.; Zheng, C.-W.; Zhang, D.-M. A robust dynamic niching genetic algorithm with niche migration for automatic clustering problem. Pattern Recognit. 2010, 43, 1346–1360. [Google Scholar] [CrossRef]
- Deb, K.; Goldberg, D.E. An investigation of niche and species formation in genetic function optimization. In Proceedings of the 3rd International Conference on Genetic Algorithms, Washington DC, USA, 6–9 July 1989; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1989; pp. 42–50. [Google Scholar]
- He, H.; Tan, Y. A two-stage genetic algorithm for automatic clustering. Neurocomputing 2012, 81, 49–59. [Google Scholar] [CrossRef]
- Milligan, G.W.; Cooper, M.C. A study of standardization of variables in cluster analysis. J. Classif. 1988, 5, 181–204. [Google Scholar] [CrossRef]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On clustering validation techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Hollander, M.; Wolfe, D.A.; Chicken, E. Nonparametric Statistical Methods; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Datta, S.; Satten, G.A. Rank-sum tests for clustered data. J. Am. Stat. Assoc. 2005, 100, 908–915. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Taxi GPS Data Set | Land Area | The Number of Taxi GPS Data Points | The Number of Clusters | ||
|---|---|---|---|---|---|
| GAK | GenClust | NoiseClust | |||
| Aracaju (Brazil) | 0.14 × 0.16 | 16,513 | 100 | 119 | 126 |
| Chongqing (China) | 0.60 × 0.36 | 19,149 | 100 | 138 | 138 |
| Roma (Italy) | 0.35 × 0.50 | 20,254 | 100 | 134 | 138 |
| San Francisco (USA) | 0.10 × 0.10 | 21,826 | 100 | 147 | 146 |
| Taxi GPS Data Set | GAK | GenClust | NoiseClust |
|---|---|---|---|
| Aracaju (Brazil) | |||
| Max | 0.9531 | 0.9600 | 0.9623 |
| Mean | 0.9511 | 0.9570 | 0.9602 |
| Min | 0.9489 | 0.9560 | 0.9584 |
| Chongqing (China) | |||
| Max | 0.9272 | 0.9377 | 0.9379 |
| Mean | 0.9254 | 0.9332 | 0.9333 |
| Min | 0.9223 | 0.9358 | 0.9258 |
| Roma (Italy) | |||
| Max | 0.9155 | 0.9302 | 0.9315 |
| Mean | 0.9133 | 0.9277 | 0.9285 |
| Min | 0.9115 | 0.9194 | 0.9231 |
| San Francisco (USA) | |||
| Max | 0.9226 | 0.9350 | 0.9367 |
| Mean | 0.9206 | 0.9331 | 0.9345 |
| Min | 0.9188 | 0.9293 | 0.9294 |
| Taxi GPS Data Set | GAK | GenClust | NoiseClust |
|---|---|---|---|
| Aracaju (Brazil) | |||
| Max | 0.0318 | 0.0308 | 0.0322 |
| Mean | 0.0308 | 0.0298 | 0.0313 |
| Min | 0.0292 | 0.0288 | 0.0306 |
| Chongqing (China) | |||
| Max | 0.0630 | 0.0554 | 0.0657 |
| Mean | 0.0614 | 0.0543 | 0.0577 |
| Min | 0.0589 | 0.0531 | 0.0515 |
| Roma (Italy) | |||
| Max | 0.0230 | 0.0227 | 0.0234 |
| Mean | 0.0223 | 0.0221 | 0.0224 |
| Min | 0.0213 | 0.0207 | 0.0215 |
| San Francisco (USA) | |||
| Max | 0.0123 | 0.0123 | 0.0126 |
| Mean | 0.0115 | 0.0116 | 0.0118 |
| Min | 0.0109 | 0.0109 | 0.0110 |
| Taxi GPS Data Set | GAK | GenClust | NoiseClust |
|---|---|---|---|
| Aracaju (Brazil) | |||
| Max | 23.2770 | 19.9240 | 18.5936 |
| Mean | 22.3815 | 19.3685 | 17.8602 |
| Min | 21.7317 | 18.5425 | 17.3135 |
| Chongqing (China) | |||
| Max | 120.5015 | 101.7441 | 108.0067 |
| Mean | 118.8668 | 99.6069 | 99.6021 |
| Min | 117.1122 | 96.8339 | 98.8250 |
| Roma (Italy) | |||
| Max | 69.8426 | 54.7804 | 55.5474 |
| Mean | 66.8438 | 51.6713 | 51.3814 |
| Min | 65.3811 | 50.8660 | 49.6680 |
| San Francisco (USA) | |||
| Max | 43.8589 | 36.0487 | 36.3695 |
| Mean | 42.6248 | 34.6544 | 34.2504 |
| Min | 41.7780 | 33.7309 | 33.2264 |
| Taxi GPS Data Set | Evaluation Criteria | NoiseClust Versus GenClust | NoiseClust Versus GAK | ||||||
|---|---|---|---|---|---|---|---|---|---|
| p | h | Stats | p | h | Stats | ||||
| Zval | Ranksum | Zval | Ranksum | ||||||
| Aracaju (Brazil) | SC | 5.8284 × 10−4 | 1 | 3.4395 | 151 | 1.8267 × 10−4 | 1 | 3.7418 | 155 |
| PBM | 2.4613 × 10−4 | 1 | 3.6663 | 154 | 0.3075 | 0 | 1.0205 | 119 | |
| SSE | 2.4613 × 10−4 | 1 | –3.6663 | 56 | 1.8267 × 10−4 | 1 | –3.7418 | 55 | |
| Chongqing (China) | SC | 5.8284 × 10−4 | 1 | –3.4395 | 59 | 0.0010 | 1 | 3.2883 | 149 |
| PBM | 0.0073 | 1 | 2.6835 | 141 | 0.0046 | 1 | –2.8347 | 67 | |
| SSE | 0.0013 | 1 | 3.2127 | 148 | 1.8267 × 10−4 | 1 | –3.7418 | 55 | |
| Roma (Italy) | SC | 0.6232 | 0 | 0.4914 | 112 | 1.8267 × 10−4 | 1 | 3.7418 | 155 |
| PBM | 0.3447 | 1 | 0.9449 | 118 | 0.0539 | 0 | –1.9276 | 79 | |
| SSE | 0.8501 | 0 | –0.1890 | 102 | 1.8267 × 10−4 | 1 | –3.7418 | 55 | |
| San Francisco (USA) | SC | 0.0640 | 1 | 1.8520 | 130 | 1.8267 × 10−4 | 1 | 3.7418 | 155 |
| PBM | 0.2730 | 0 | 1.0961 | 120 | 5.8284 × 10−4 | 1 | –3.4395 | 59 | |
| SSE | 0.1620 | 1 | –1.3985 | 86 | 1.8267 × 10−4 | 1 | –3.7418 | 55 | |
| Taxi GPS Data Set | GAK | GenClust | NoiseClust |
|---|---|---|---|
| Aracaju (Brazil) | 1.2325 | 43.6278 | 9.9180 |
| Chongqing (China) | 1.5697 | 61.0394 | 14.0991 |
| Roma (Italy) | 1.7072 | 61.1348 | 17.0211 |
| San Francisco (USA) | 2.0596 | 65.3391 | 18.8498 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Gu, J.; Shen, S.; Ma, H.; Miao, F.; Zhang, H.; Gong, H. An Automatic K-Means Clustering Algorithm of GPS Data Combining a Novel Niche Genetic Algorithm with Noise and Density. ISPRS Int. J. Geo-Inf. 2017, 6, 392. https://doi.org/10.3390/ijgi6120392
Zhou X, Gu J, Shen S, Ma H, Miao F, Zhang H, Gong H. An Automatic K-Means Clustering Algorithm of GPS Data Combining a Novel Niche Genetic Algorithm with Noise and Density. ISPRS International Journal of Geo-Information. 2017; 6(12):392. https://doi.org/10.3390/ijgi6120392
Chicago/Turabian StyleZhou, Xiangbing, Jianggang Gu, Shaopeng Shen, Hongjiang Ma, Fang Miao, Hua Zhang, and Huaming Gong. 2017. "An Automatic K-Means Clustering Algorithm of GPS Data Combining a Novel Niche Genetic Algorithm with Noise and Density" ISPRS International Journal of Geo-Information 6, no. 12: 392. https://doi.org/10.3390/ijgi6120392