1. Introduction
Recently various data mining methods have been successfully utilized to help understand the reservoirs and enhance oil recovery [
1,
2,
3,
4]. Association rule mining is one of the most popular data mining methods and was first proposed for extracting interesting correlations, frequent patterns, associations or casual structures among the item sets from transaction data or other data repositories [
5]. Association rule mining in oil and gas well data is a very promising approach for understanding and improving oil recovery.
Oil and gas well data generally includes well locations and other non-spatial attributes, such as reservoir property parameters (e.g., pore volume, porosity, permeability) and production performance parameters (e.g., peak value and effective yield) [
3]. After the values of the non-spatial parameters are transformed into a set of sub-ranges, association rule mining algorithms such as Apriori [
6] can be applied to the discretized data. The quantitative relationships between reservoir properties influencing oil recovery and oil production performance can then be discovered [
3]. However, there are still some challenges in the understanding and identification of the interesting association rules from oil and gas well data.
The association rules discovered from non-spatial oil and gas well data only include the patterns between reservoir properties and oil production performance. However, oil and gas well data also has geospatial attributes, i.e., well locations. The interestingness of the rules does not depend only on the included patterns, but also relies on the locations and distributions of the wells that the rules match. Therefore, the rules need to be associated with the locations of the wells. However, the existing visualization methods for association rules fall short: most methods, such as scatter plots, matrix visualizations, graphs, mosaic plots and parallel coordinate plots [
7,
8,
9,
10,
11,
12,
13], have been designed to help identify interesting association rules discovered from non-spatial datasets and, thus, focus more on the visualization of the rule content characteristics.
Geovisualization generally refers to a list of tools and techniques supporting geospatial data analysis, integrating cartography, geographic information system (GIS) and scientific visualization [
14]. Geovisualization does not merely include representation of the source or raw geospatial dataset through an accessible and interactive interface (e.g., a map) by simple display techniques (e.g., symbols, colors), but also assists users in learning new geospatial trends and patterns hidden behind the dataset. Therefore, geovisualization can help associate the spatial information of wells with the interesting rules in oil and gas well data.
In addition to relating the well locations with the association rules, the building and visualization of an association rule with respect to applicable areas is also worthy of research. The applicable areas of the rules, i.e., the continuous surfaces where the rule may be relevant, are also very valuable for reservoir engineers. However, the continuous surfaces cannot be directly constructed, since the well locations are an irregular array of discrete points. The geovisualization of the association rules in oil and gas well data needs to be combined with proper spatialization techniques that can fill in data between the wells.
Spatial interpolation is the process of using points with known values to estimate values at other points [
15]. Through spatial interpolation, the value of a certain attribute at a location with no recorded value can be estimated using the corresponding known value of the attribute of nearby sample wells. If the spatial dependence appears in the attributes of the well data, spatial interpolation can be an appropriate spatialization technique.
In this paper, two geovisualization methods—point-based and surface-based—are proposed for association rules in oil and gas well data, in order to better understand wells. The contributions of the paper are summarized as follows:
The point-based geovisualization method links association rules with well locations. The method uses different symbols to highlight the well locations that satisfy the rules. Reservoir engineers can better understand the rules and find possible distribution patterns of the wells by the visualized oil well locations on the map.
Another visualization method, surface-based geovisualization, builds and represents the areas on the map for an interesting rule where the rule may be applicable. The method is based on spatial interpolation and map layer overlapping. The surface-based geovisualization can assist users in making decisions or predictions based on the patterns included by the discovered interesting rules.
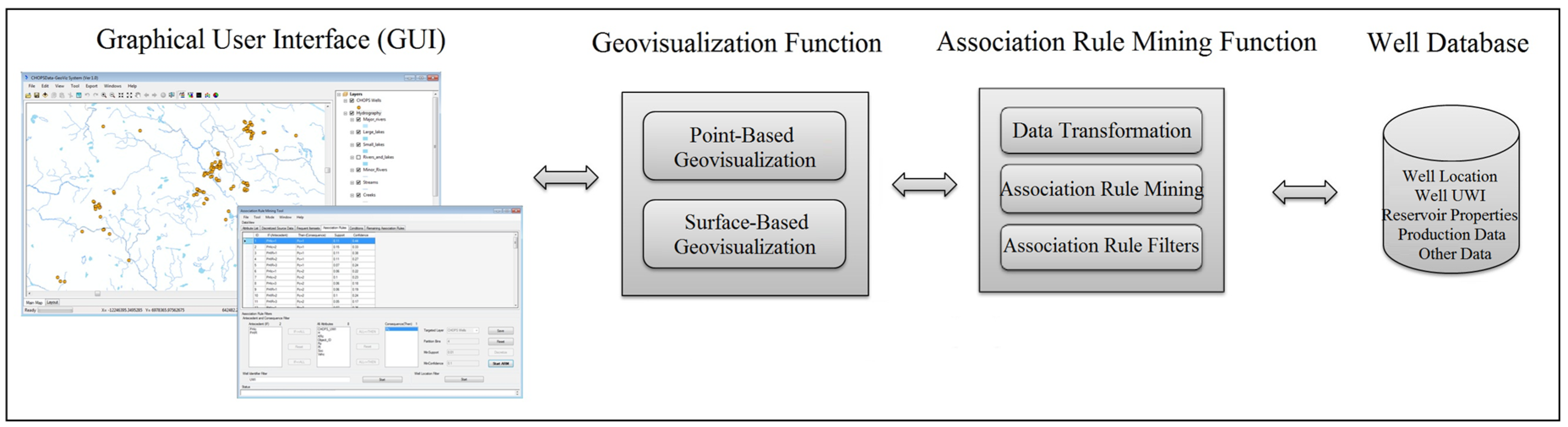
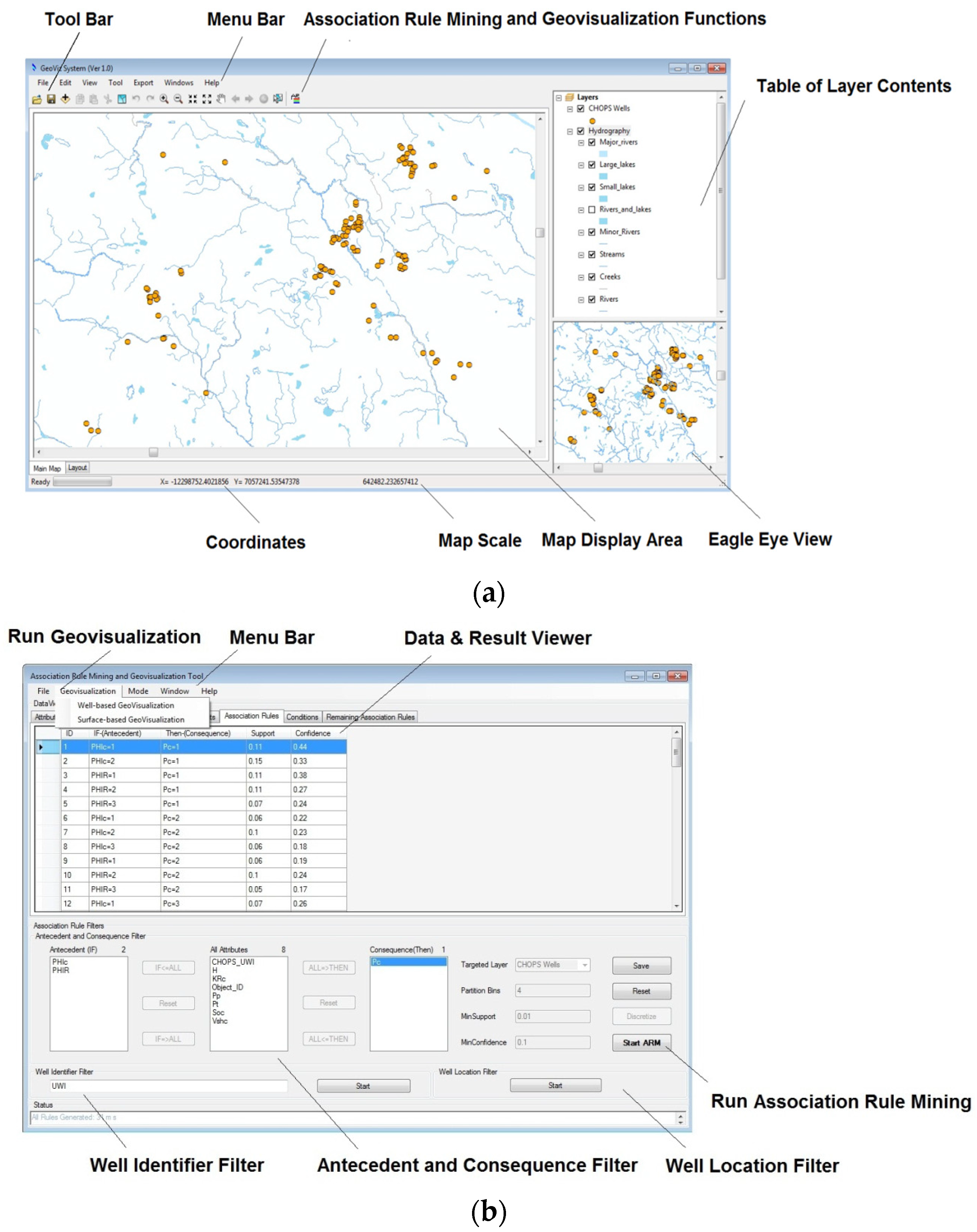
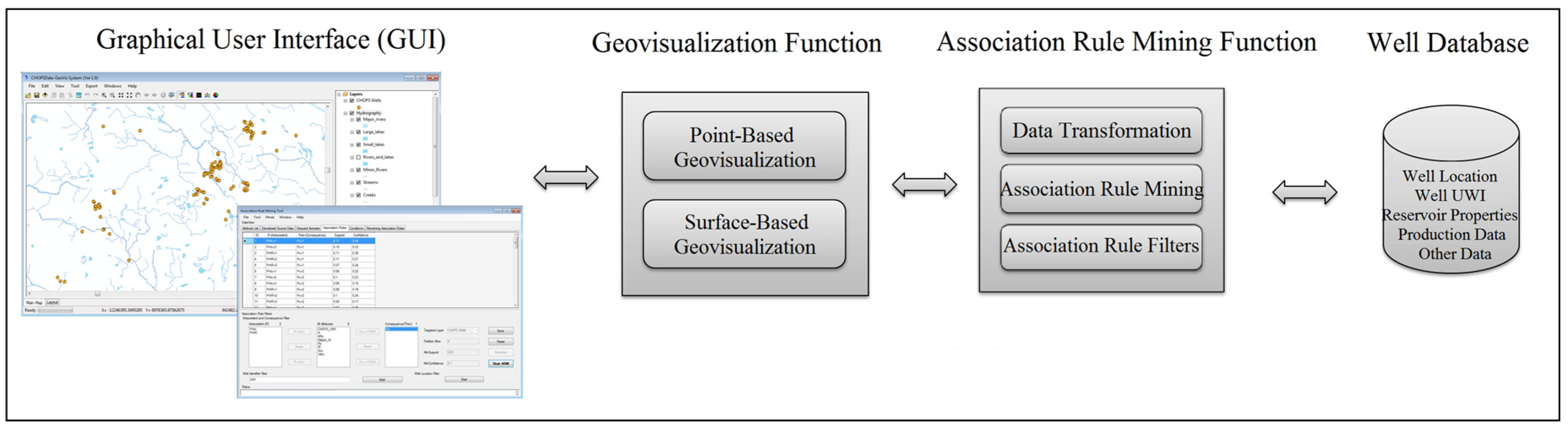
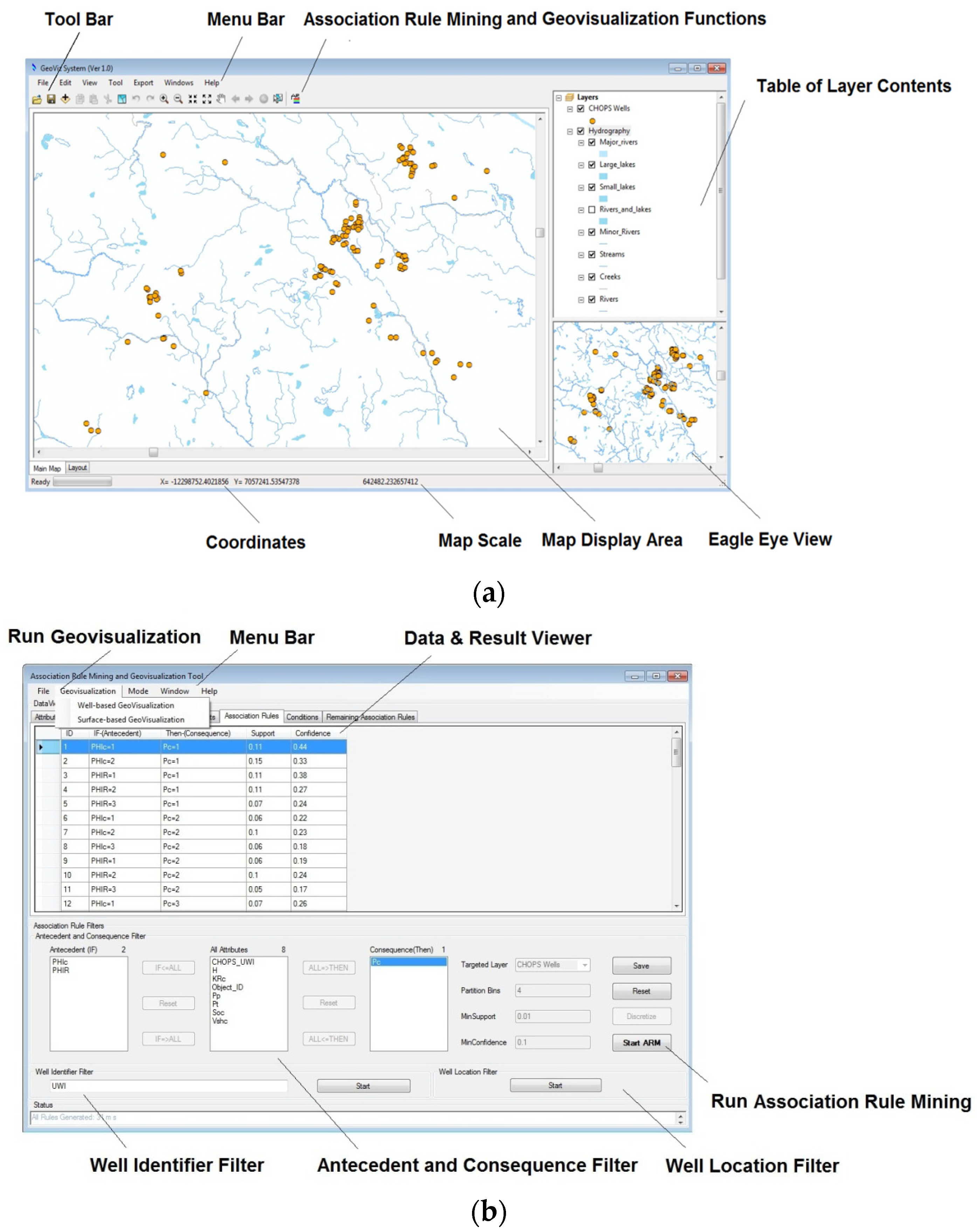
A system prototype for in Oil and Gas Well Data, called Association Rule Mining and Geovisualization (ARM-GEOVIZ) System, is developed for association rule mining and visualization of found rules in oil and gas data. The system prototype integrates association rule mining with the proposed point-based and surface-based visualization methods.
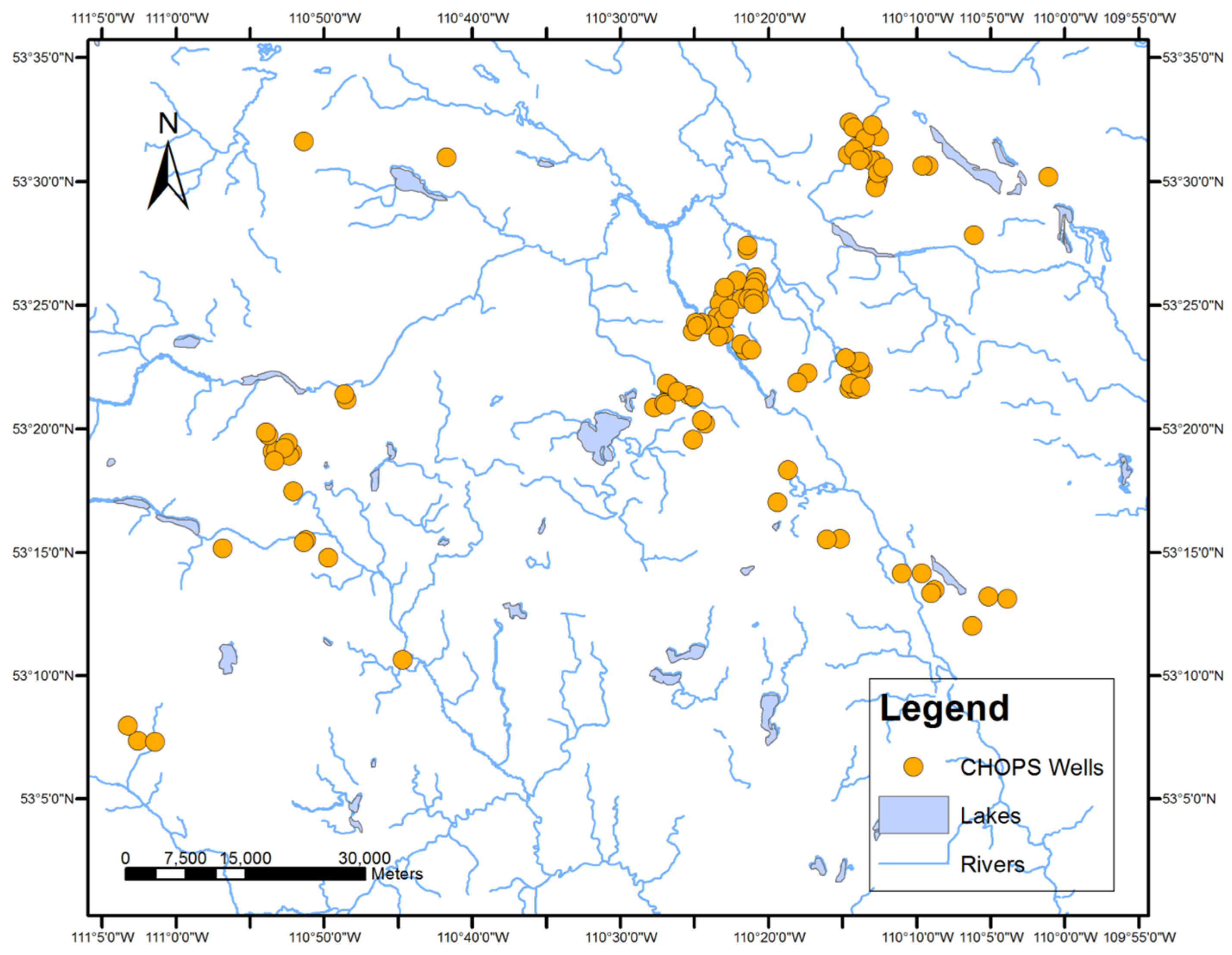
A case study was conducted on a real cold production oil well dataset for the Lloydminster heavy oil block in Alberta, Canada. The case study validated the feasibility of the two new geovisualization methods for association rules.
The rest of this paper is organized as follows:
Section 2 reviews association rule mining, existing visualization techniques for association rules in non-spatial data, and common spatial interpolation techniques.
Section 3 introduces the detailed methodology of the proposed geovisualization techniques for association rules in oil and gas well data. The two geovisualization methods and the ARM-GEOVIZ system prototype are illustrated through a case study with real oil well dataset in
Section 4.
Section 5 presents the conclusion.
2. Related Work
Association rule mining, visualization techniques for association rules and several spatial interpolation techniques are briefly reviewed in the following subsections.
2.1. Association Rule Mining
Association rule mining was first introduced to analyze transaction data and derive association rules [
5]. In the definition of the association rule, let
D be the set of all items and
X and
Y be two subsets of
D. An association rule with respect to
X and
Y can be in the form of (or IF {
X } THEN {
Y }), where,
⊂
,
, and
.
X is called the antecedent and
Y is the consequence.
The concepts of support and confidence are essential in defining the interestingness of an association rule. The support of rule is defined as the percentage of transactions that consist of X and Y to the total number of transactions, i.e., . The confidence of rule is the percentage of transactions that consist of X and Y to the number of transactions that only contain X. The definition is in the form of conditional probability confidence . Traditionally, the rules that are satisfied with large support and confidence values are considered to be strong or interesting.
Apriori is the most well-known algorithm for association rule mining over transactional databases [
6]. It proceeds by identifying the frequent individual items in the database, and then groups of frequent item set candidates are generated and tested against the data. The algorithm terminates when no further frequent item sets are found. The frequent item sets determined by Apriori can be used to determine association rules.
2.2. Traditional Visualization Methods for Association Rules
Several visualization techniques for association rule mining in transaction data or other non-spatial datasets have been recently proposed in order to help users analyze discovered association rules.
Scatter plots visualize association rules as scatter points on two-dimensional or higher coordinate systems. In a two-key plot, the coordinate axes x and y represent the support and confidence values of the rules, and the color of the scatter points represents the total numbers of the antecedent and consequent items within the rules [
7].
In a parallel coordinate plot, association rules are represented as polygonal lines on a coordinate system with shared x and y axes [
8]. The antecedent and consequence items of the rules are used for one coordinate axis, and the other axis is used to represent the corresponding positions of antecedent and consequence items in rules.
Graph-based plots represent association rules as figures with vertices and edges [
9,
10,
11,
12]. The vertices are used for the antecedent and consequence items of the rules. The relationship of the items of one association rule is shown by the connected edges of the items.
The visualization methods can help find the content characteristics hidden behind the association rules. For example, scatter plots can display the distribution of interesting measurements of multiple rules. Parallel coordinate plots are suitable to represent the compositions of the antecedent and consequence items of the rules. The relationships among the rules in terms of certain items can be found by using graph-based plots. However, these methods have been mainly proposed for rules from transactional datasets and do not take spatial attributes into account.
2.3. Geovisualization
On the basis of scientific visualization, geovisualization integrates GIS and cartography to communicate geospatial information in support of geospatial analysis [
14]. The geospatial data can be displayed by a map interface, and unexpected geospatial trends and patterns hidden behind the data can be discovered.
Geovisualization has recently become widely used in many scientific disciplines. Aoidh et al. proposed a geovisualization method where symbology was explored for communicating the landscape genetic information in an intuitive way [
16]. Gienko and Terry introduced a geovisualization method for representing and predicting cyclone behaviour, where several spatial interpolation techniques were successfully combined with geovisualization for identification and analysis of cyclone features [
17]. The above methods are based on symbology and spatialization techniques, but are not aimed at visualization of the association rules from geospatial data.
2.4. Spatial Interpolation
Under the assumption that the estimated value of an interpolation point should be influenced more by nearby control points than distant control points, spatial interpolation can fill in data between sample points. Spatial interpolation methods can be categorized into stochastic and deterministic methods.
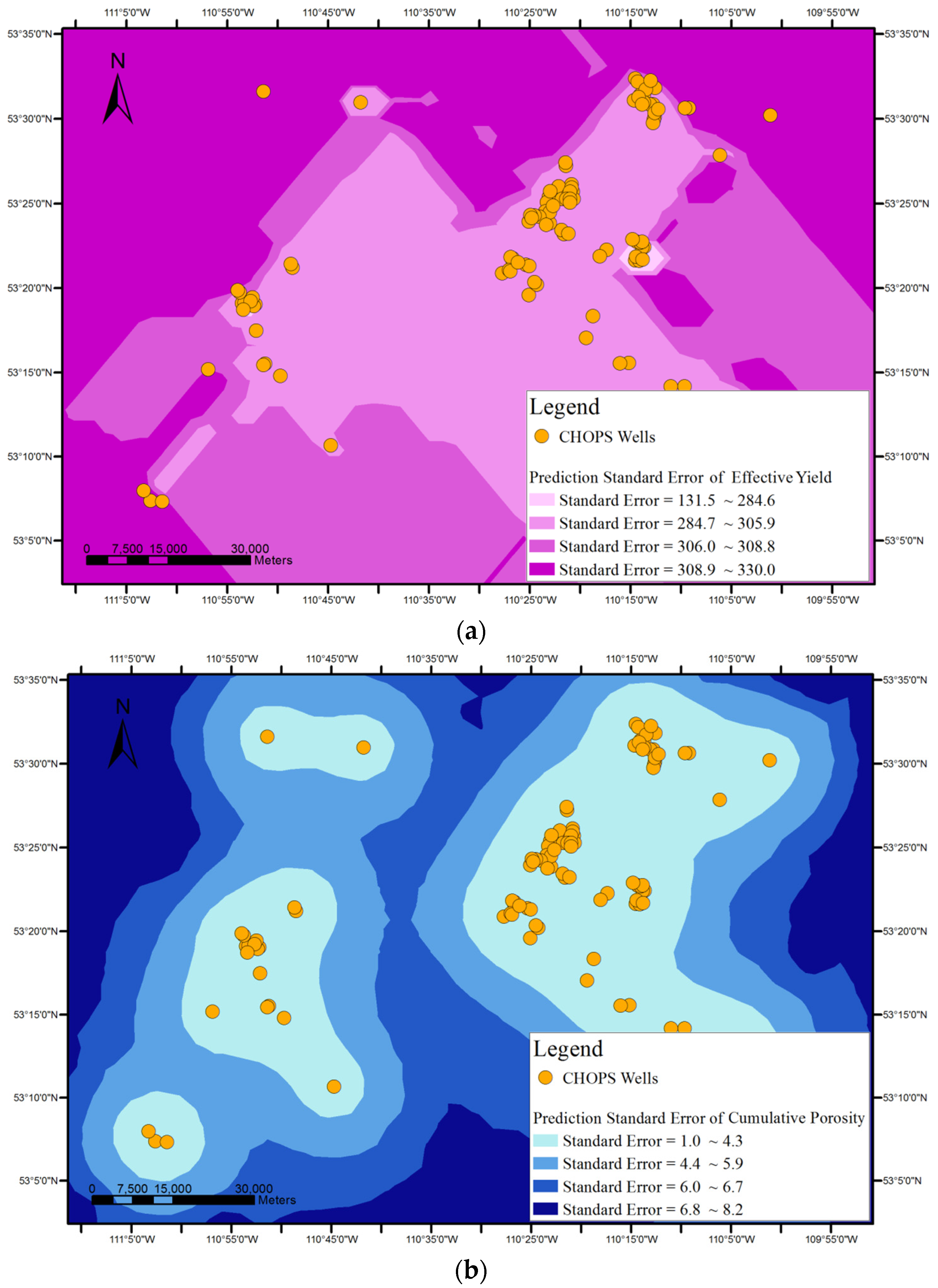
A stochastic interpolation method provides assessment of prediction errors by estimated variances in the form of prediction standard errors with interpolated values. Kriging interpolation is one of most common spatial stochastic interpolation methods. It cannot only interpolate the value of a certain attribute for an unknown (interpolation) point with the known attribute values of its neighbour points, but can also offer prediction errors with estimated values to assess the quality of the interpolation. Kriging assumes that the spatial variation of an attribute to be interpolated may be composed of a spatially correlated component representing the variation of the regionalized variable, a drift representing a trend, and a random error component.
A deterministic interpolation method does not involve probability theory, thereby offering no assessment of errors with predicted values. Spline interpolation estimates values using a mathematical function that minimizes overall surface curvature, ending up with a smoother statistical surface. The surface passes exactly through the control points. In Inverse Distance Weighted (IDW) interpolation, a weight is assigned to each neighbourhood point within a predefined radius for an interpolation point. The weight decreases as the distance from the interpolation point to its neighbourhood points increases. The estimated value of the interpolation point is the weighted average of its neighbourhood points. Trend surface interpolation approximates the unknown values of interpolation points with a polynomial equation. The order of the polynomial equation can be adjusted according to the complexity of the specific situation.
Given the different characteristics of deterministic and stochastic interpolations, their applicability to oil and gas well data is explored by using real well data in the following sections.
3. Methodology
3.1. Association Rule Mining on Oil and Gas Well Data
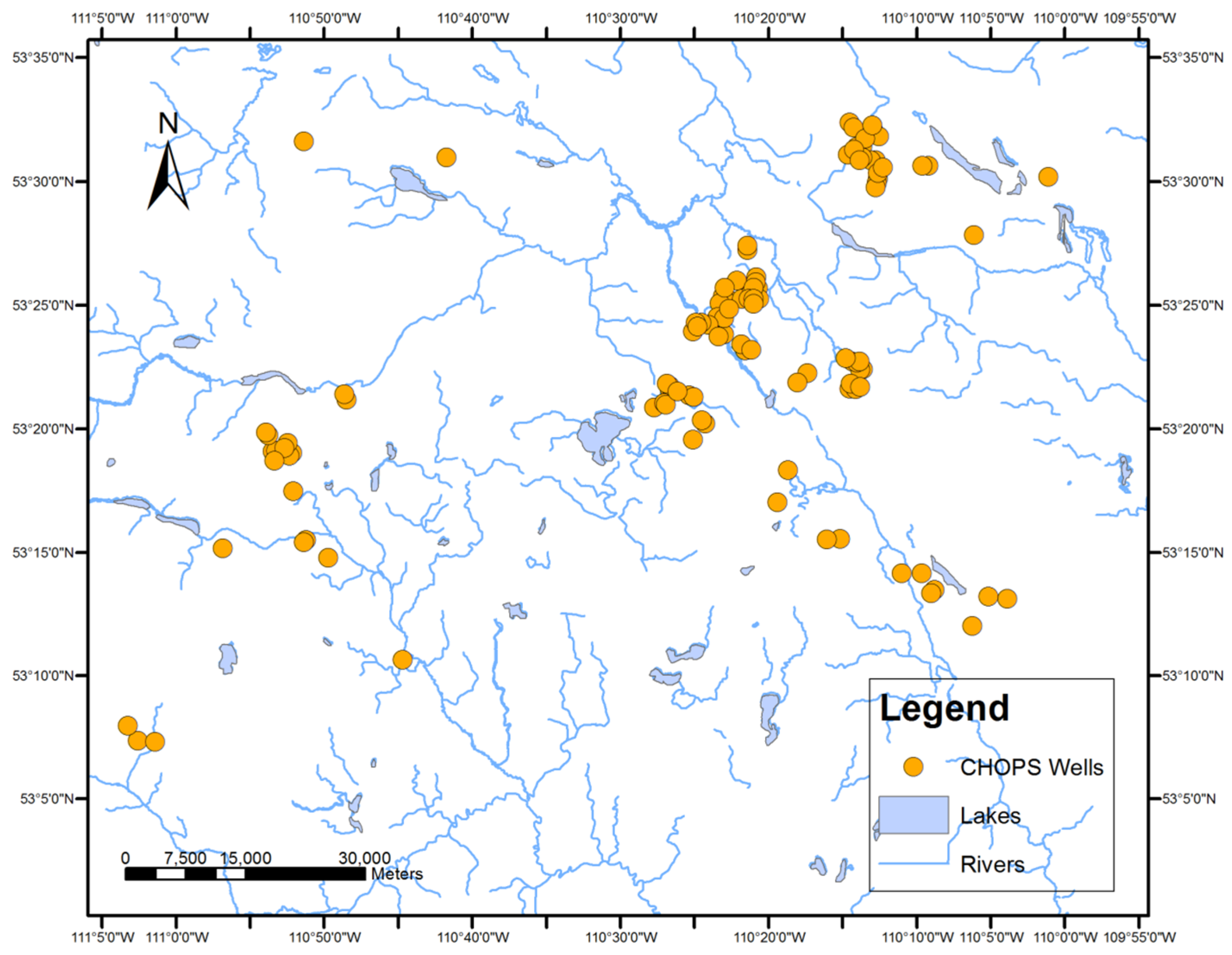
Each well record in the oil and gas dataset contained reservoir properties and oil and gas production performance properties of the well. Moreover, the location of each well was denoted in longitude and latitude coordinates.
The processing of the association rule mining includes the following steps. First of all, the continuous values of the reservoir property and oil production performance parameters in the source oil and gas well data were first discretized. For example, a numeric value (73.2) of the reservoir property attribute cumulative pore volume could be transformed into discretized value “1”, which represented a range of values from 59.2 to 94.4. The discretization process could be accomplished through k-means clustering method. K-mean clustering algorithm is an effective and efficient clustering algorithm. It first partitions the data into k nonempty subsets, and then calculates seed points as the centroids of the clusters of the current partition (i.e., mean point of the cluster). Next, it assigns each data object to the cluster with the nearest seed point. The process continues until no more new assignment. The parameter of k-mean clustering method is the value of k, which must be fixed before the computation.
Next, the association rule mining algorithm such as Apriori [
6] discussed in
Section 2.1 could then be applied to the processed data. The main objective in applying association rule mining is to discover interesting relationships between reservoir properties and oil production performance. Each discovered rules is in the form of:
IF {Reservoir properties hold certain conditions} THEN {Production Performance is within certain range}; [Support = n%; Confidence = m%] where the IF part is called the antecedent; the THEN part is called the consequence; support n% denotes that n% wells in the whole dataset satisfy this rule; confidence m% denotes that, among all wells that satisfy the reservoir property conditions in the antecedent, m% of these wells also satisfy the consequence. Support and confidence are two important measurements for rule interestingness.
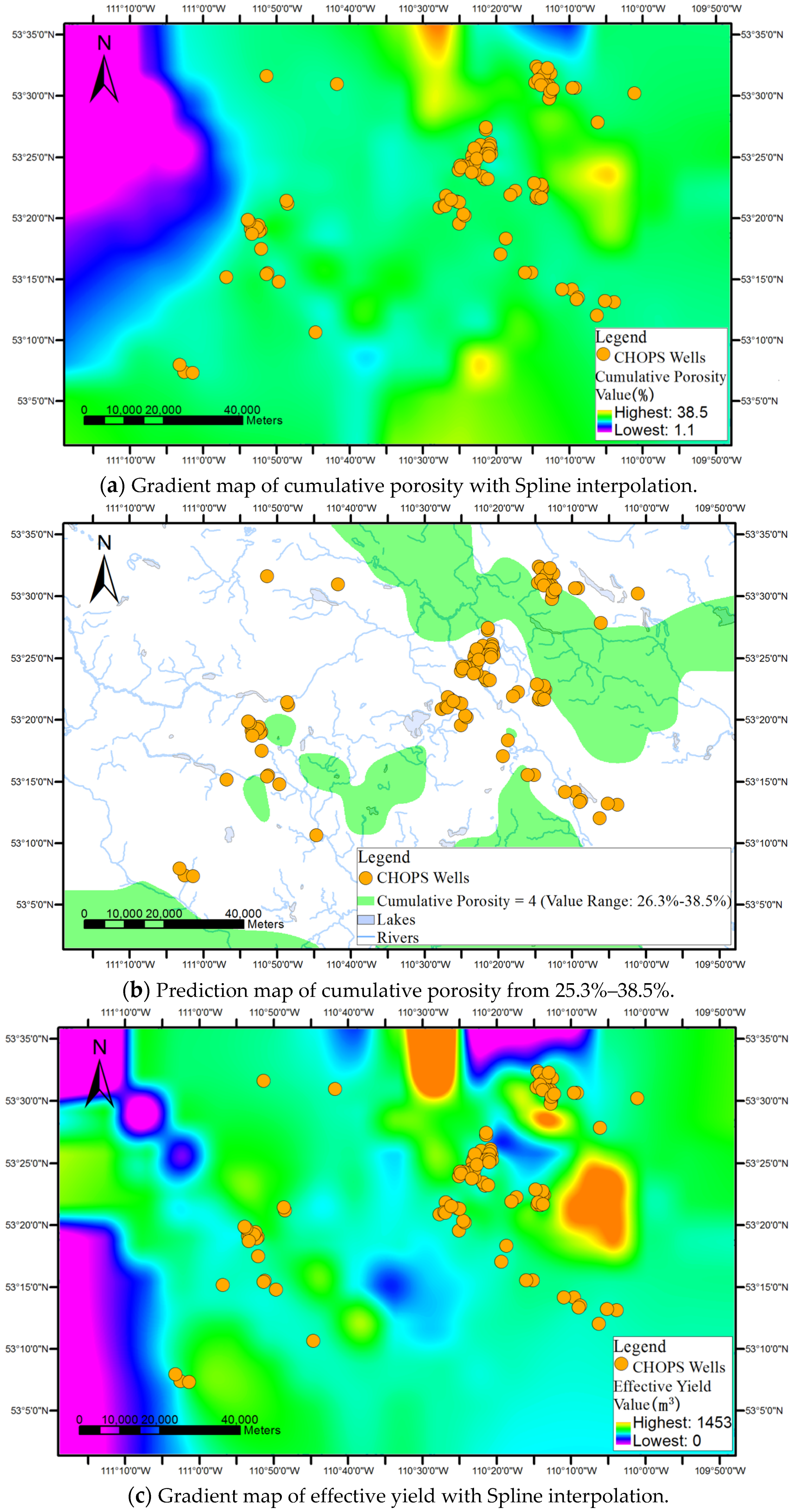
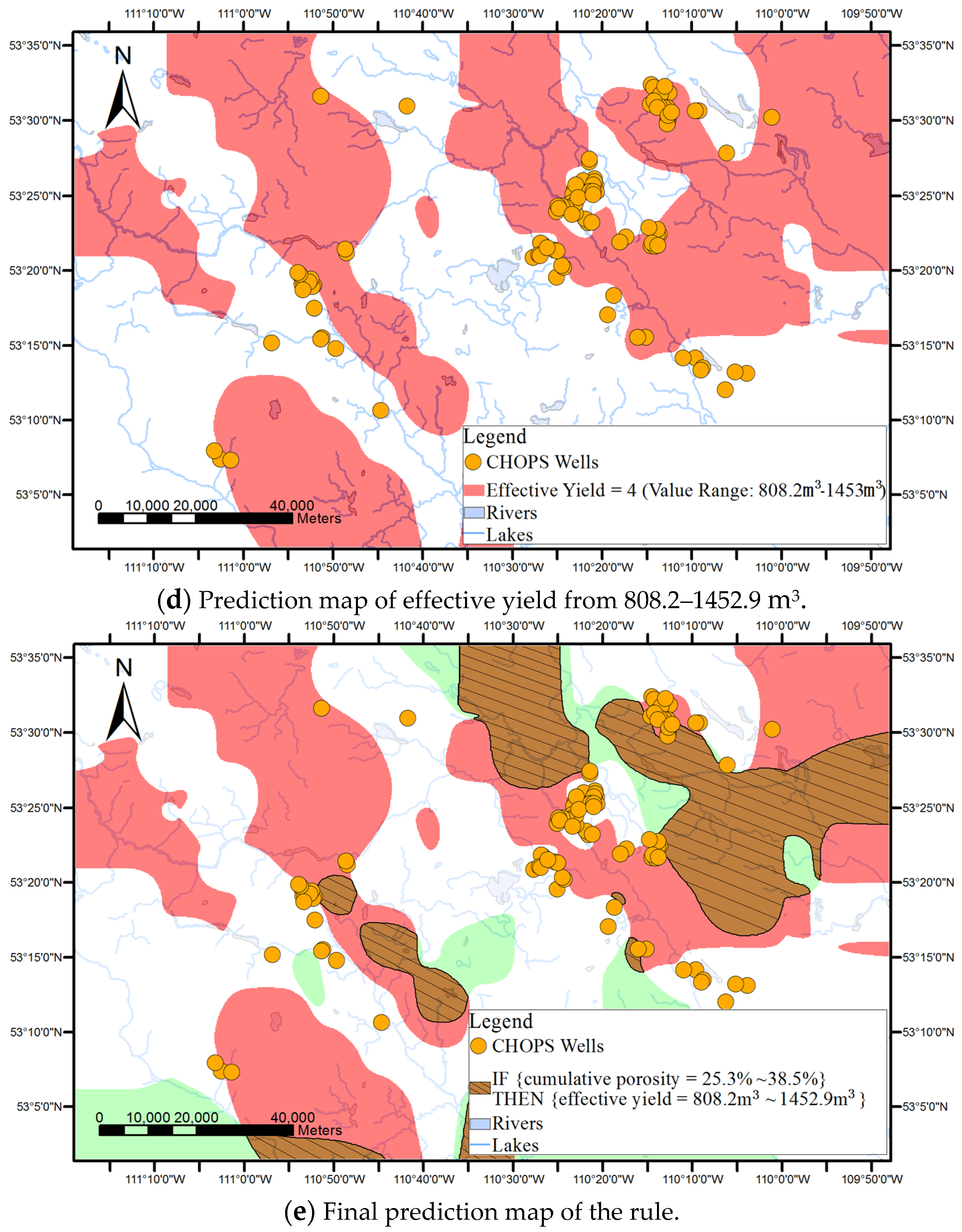
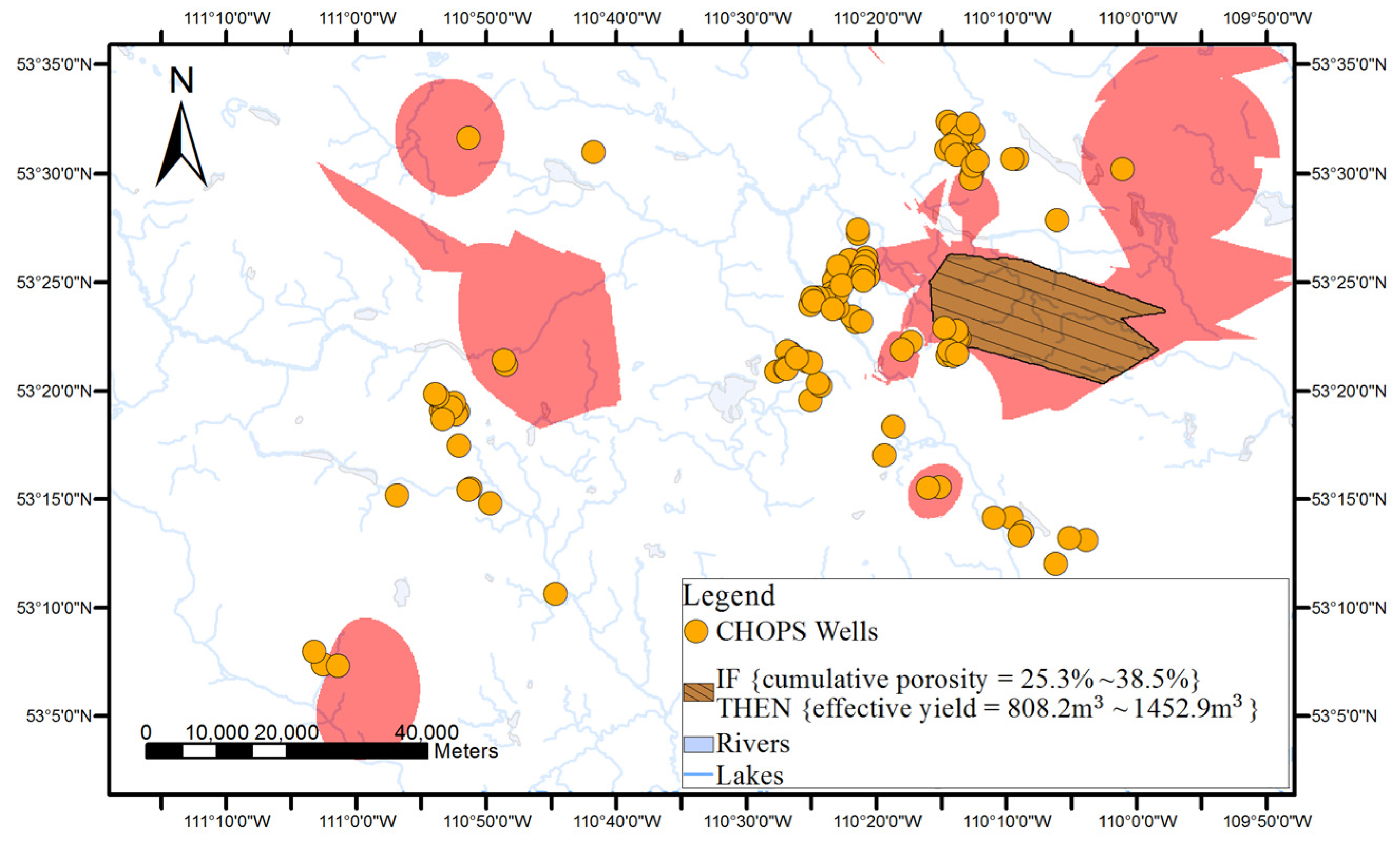
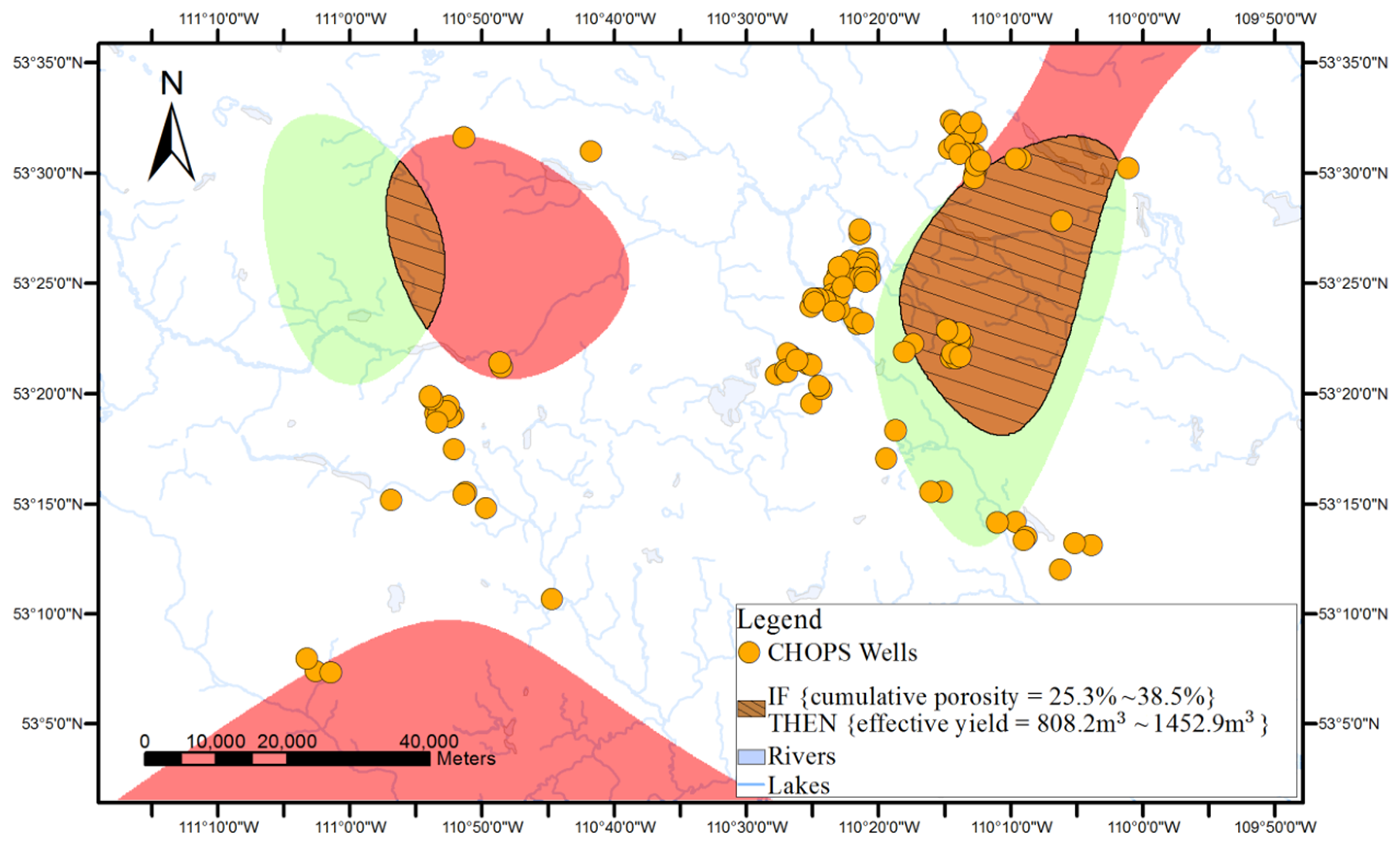
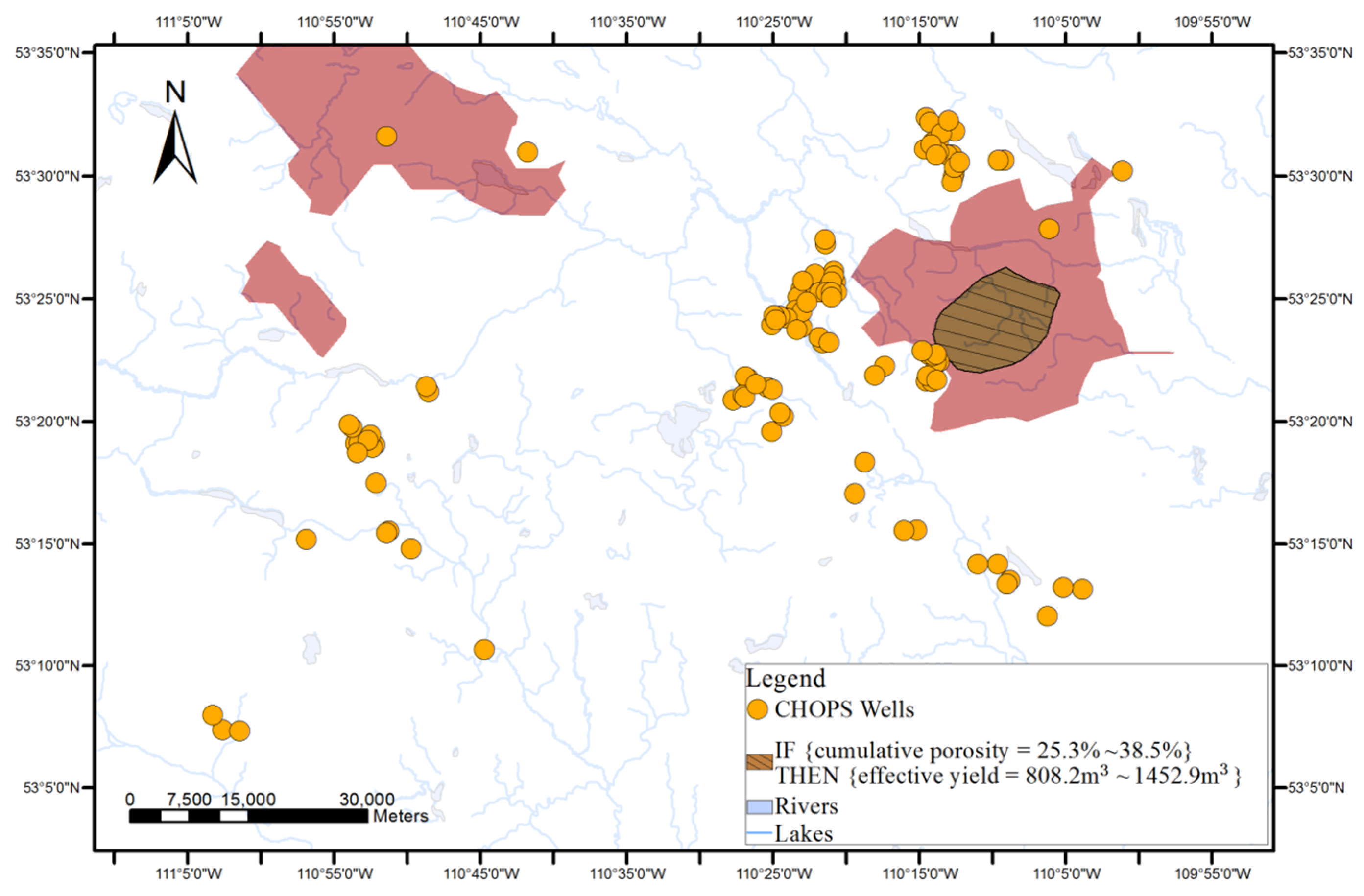
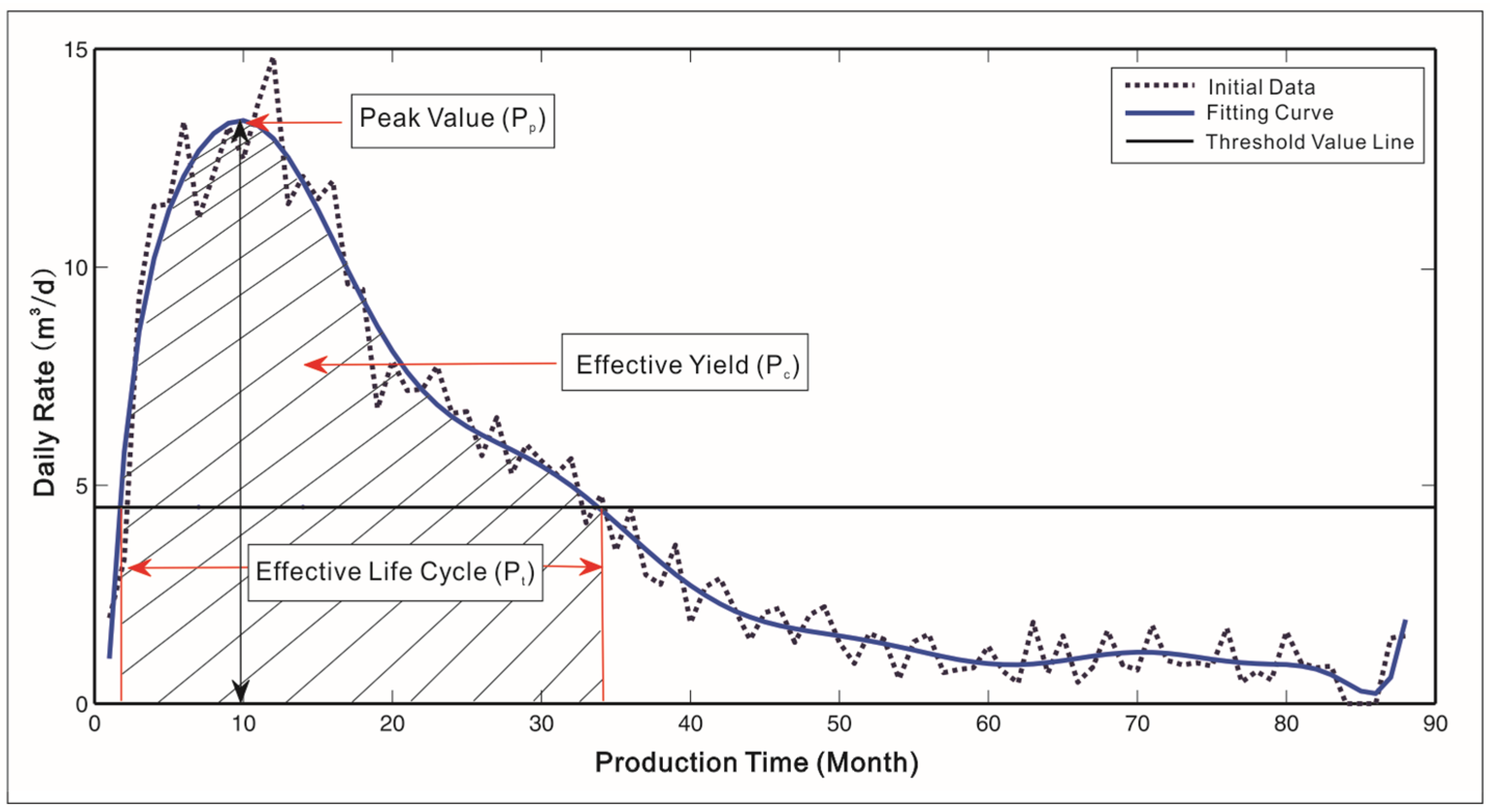
An example of the discovered association rules is IF {cumulative pore volume = 168.8–291.2} THEN {effective yield = 808.2–1452.9 m3}, [support = 15%, confidence = 80%] i.e., if the reservoir property’s cumulative pore volume is between 168.8 and 291.2, then the effective yield is in the range between 808.2 m3 and 1452.9 m3. The rule was supported by 15% of the data in the dataset and among wells with the cumulative pore volume between 168.8 and 291.2, 80% of the wells has the effective yield between 808.2 m3 and 1452.9 m3.
3.2. Geovisualization for Association Rules
Mining association rules in oil and gas well data usually generate a large number of association rules. Setting minimum thresholds for traditional interestingness measurements, such as support and confidence, may help find interesting rules; however, some potentially interesting rules with relatively low interestingness measurements may be missed. For an association rule found in well data, the interestingness of the rule depends not only on its support and the confidence, but also on the locations and distributions of the wells that match the rule. However, there are challenges to determining the interesting rules and to better understanding the discovered rules. Moreover, the potential applicable areas of the interesting rules are critical to reservoir engineers, who make predictions on oil production based on reservoir properties determined with the interesting rules.
In this paper, point- and surface-based geovisualization methods are proposed for the visualization of the association rules in oil and gas well data and are described in the following subsections. Point-based geovisualization conceptualizes an association rule with regards to well locations, and surface-based geovisualization builds the applicable areas for an association rule based on spatial interpolation techniques and then effectively represents the areas on a map.
3.2.1. Point-Based Geovisualization
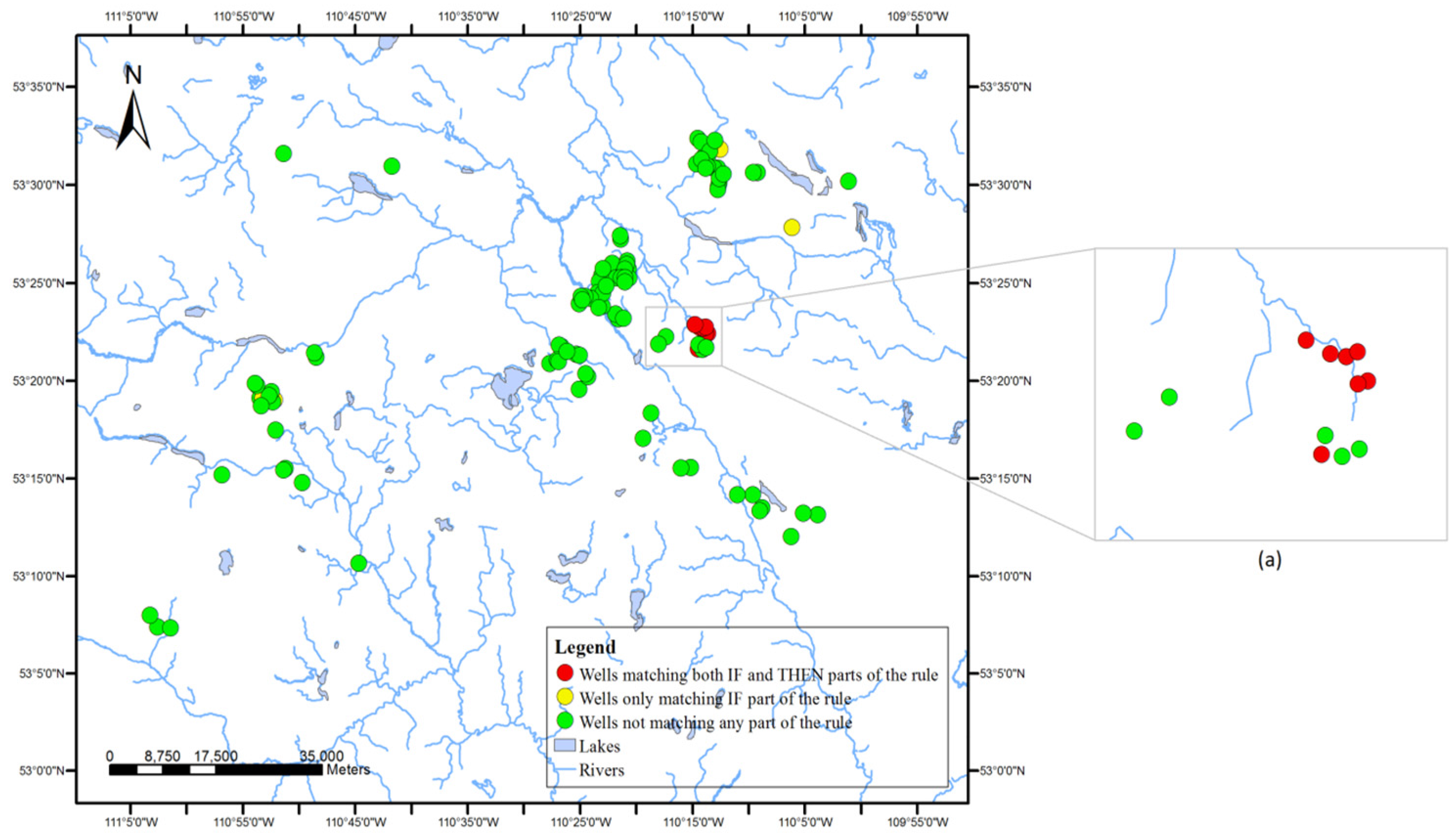
Point-based geovisualization uses different symbols to show the locations (points) of wells, depending on their relationship with association rules in well data. The geospatial distribution of the wells associated with one association rule was visualized on a map with the following steps. First, all wells were categorized into three groups according to the extent of satisfaction of the rule.
Group 1: wells with the same ranges of reservoir properties and production performances described in the rule (i.e., satisfied both antecedents and consequences of the rules).
Group 2: wells with the same range of reservoir properties described in the rule, but a different range of production performance (i.e., satisfied the antecedents but not the consequences of the rule).
Group 3: wells with different reservoir properties and production performances than described in the rule (i.e., neither satisfied the rule).
The above categorization scheme can reflect the two traditional interestingness measurements (support and confidence) on the map. For the association rules in well data, the support is the percentage of the wells in the whole dataset satisfy this rule; and, the confidence is the percentage of the wells among all wells that satisfy the reservoir property conditions in the antecedent. Specifically, by comparing the wells that satisfy the association rule (Group 1) and those that do not (Group 3), support of the rule can be understood; and, the wells that support the rule can be located on the map. Similarly, the confidence of the rule and the locations of the wells giving the confidence of the rule can be identified by comparing the wells satisfying the rule (Group 1) and those only satisfying the antecedents and not the consequences of the rule (Group 2).
After categorization, the well locations of the three different groups were represented on a map using different symbols. Point-based visualization connects the discovered rules with the well locations. Users (i.e., reservoir engineers) can easily identify the wells satisfying the rule and can reversely find rules associated with the well. The comparison and analysis of the geospatial distributions of the three groups of categorized wells on the map can also help users in learning about the support and confidence of each discovered rule.
3.2.2. Surface-Based Geovisualization
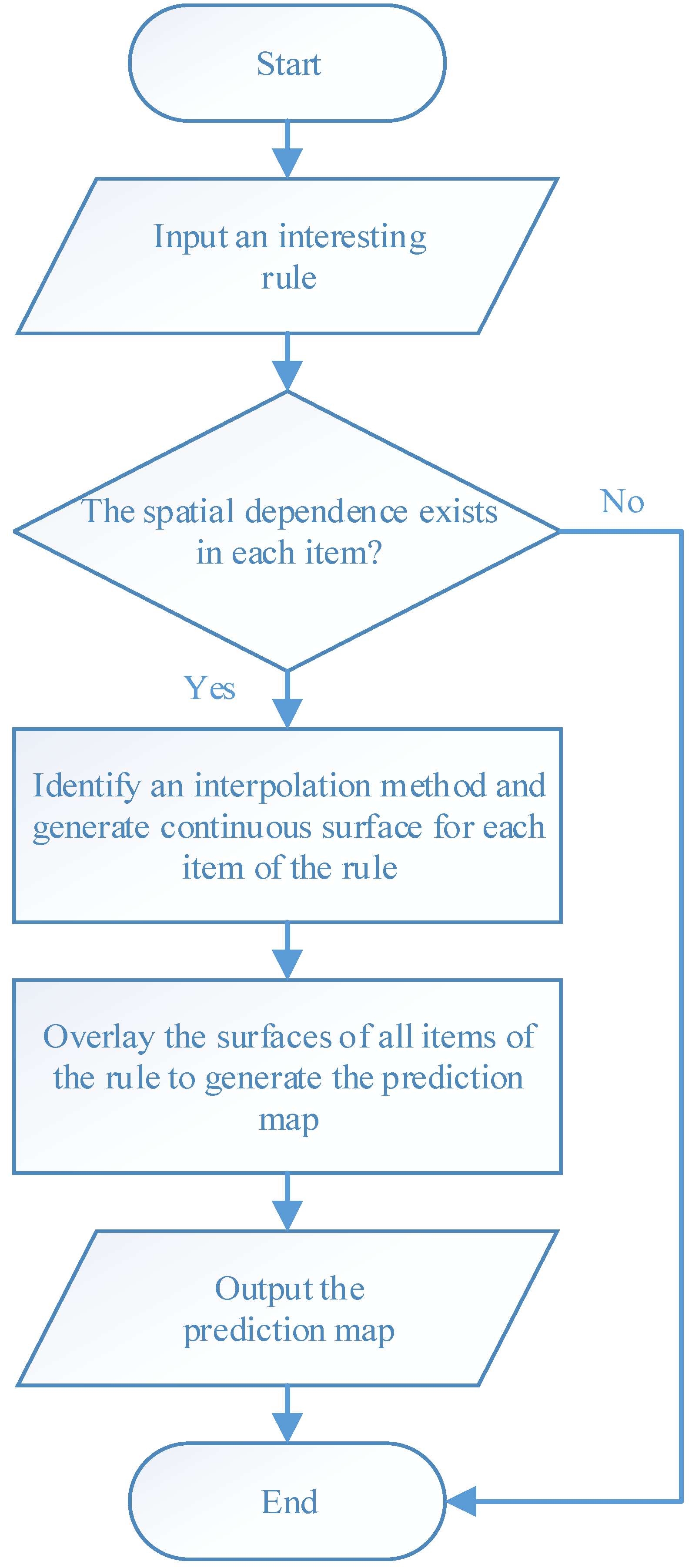
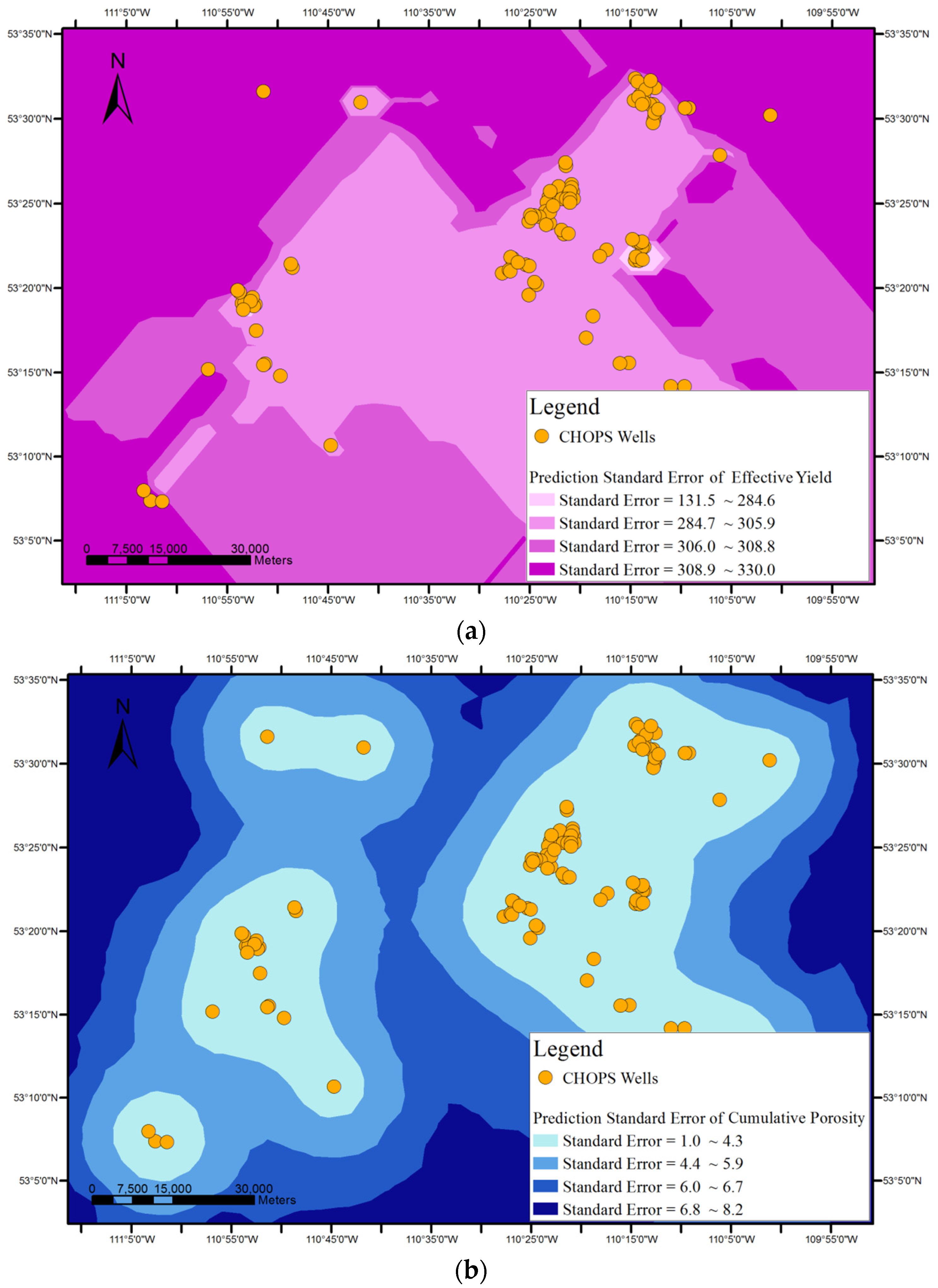
Surface-based geovisualization extends the conceptualization of the rule from discrete points to continuous surfaces, with the aim of generating and representing areas where the rule may be applicable.
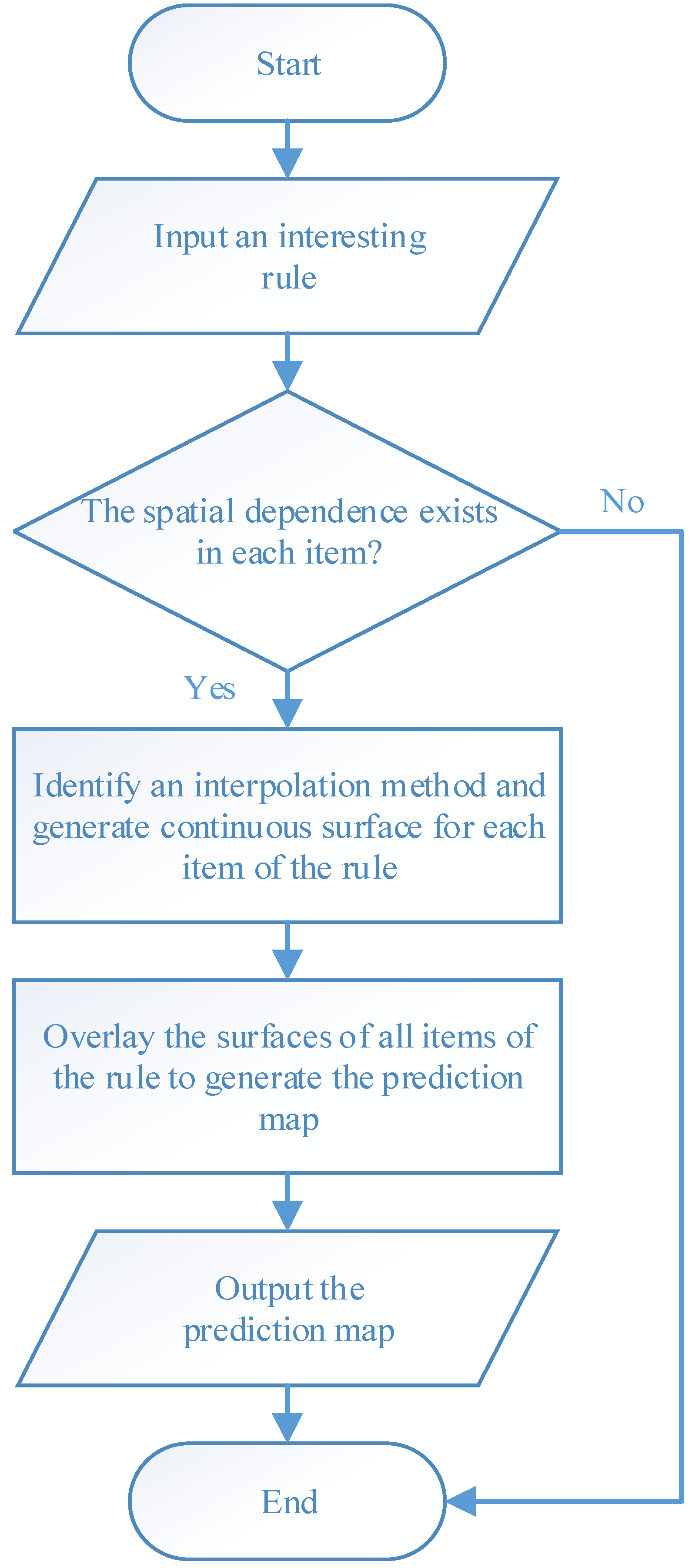
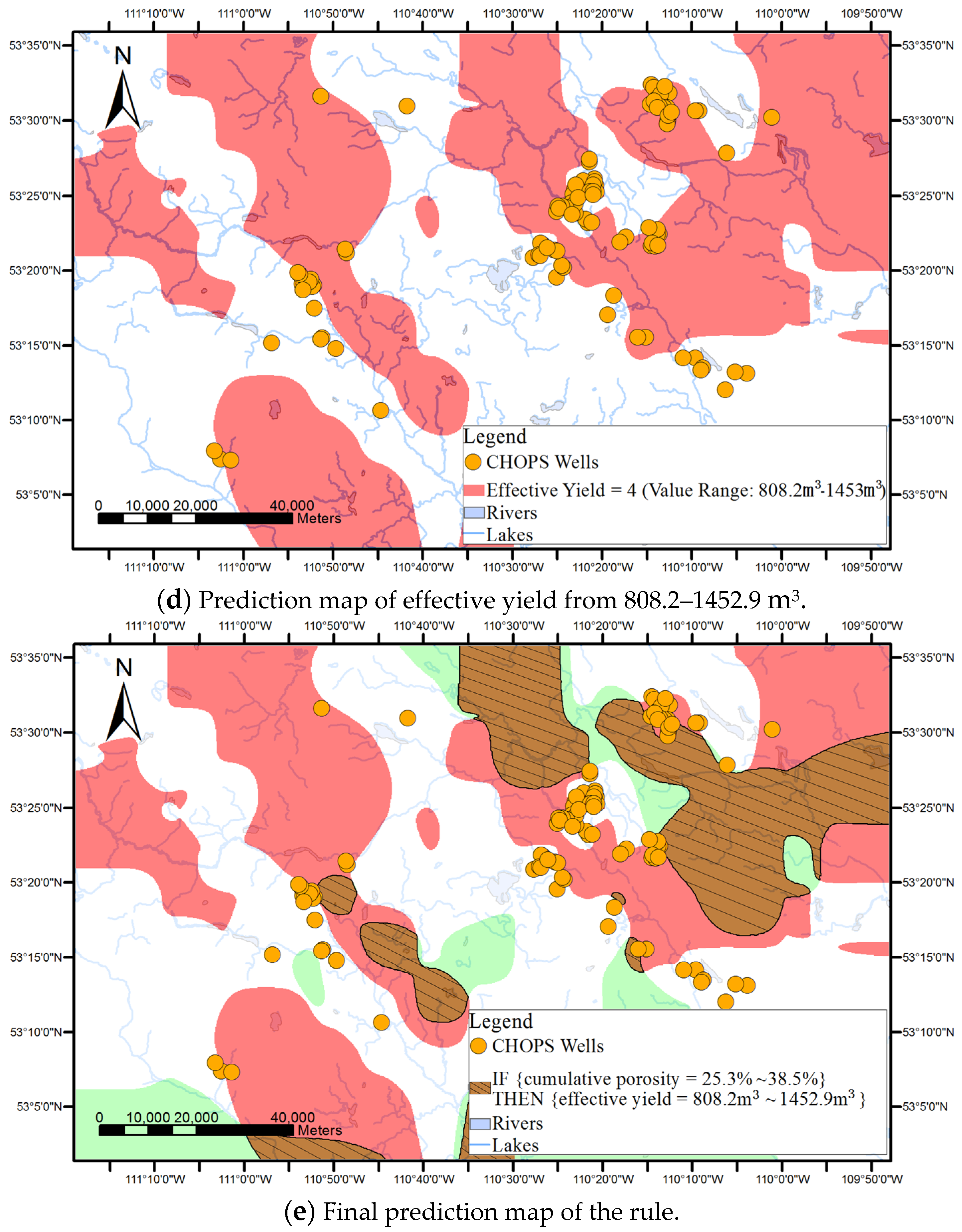
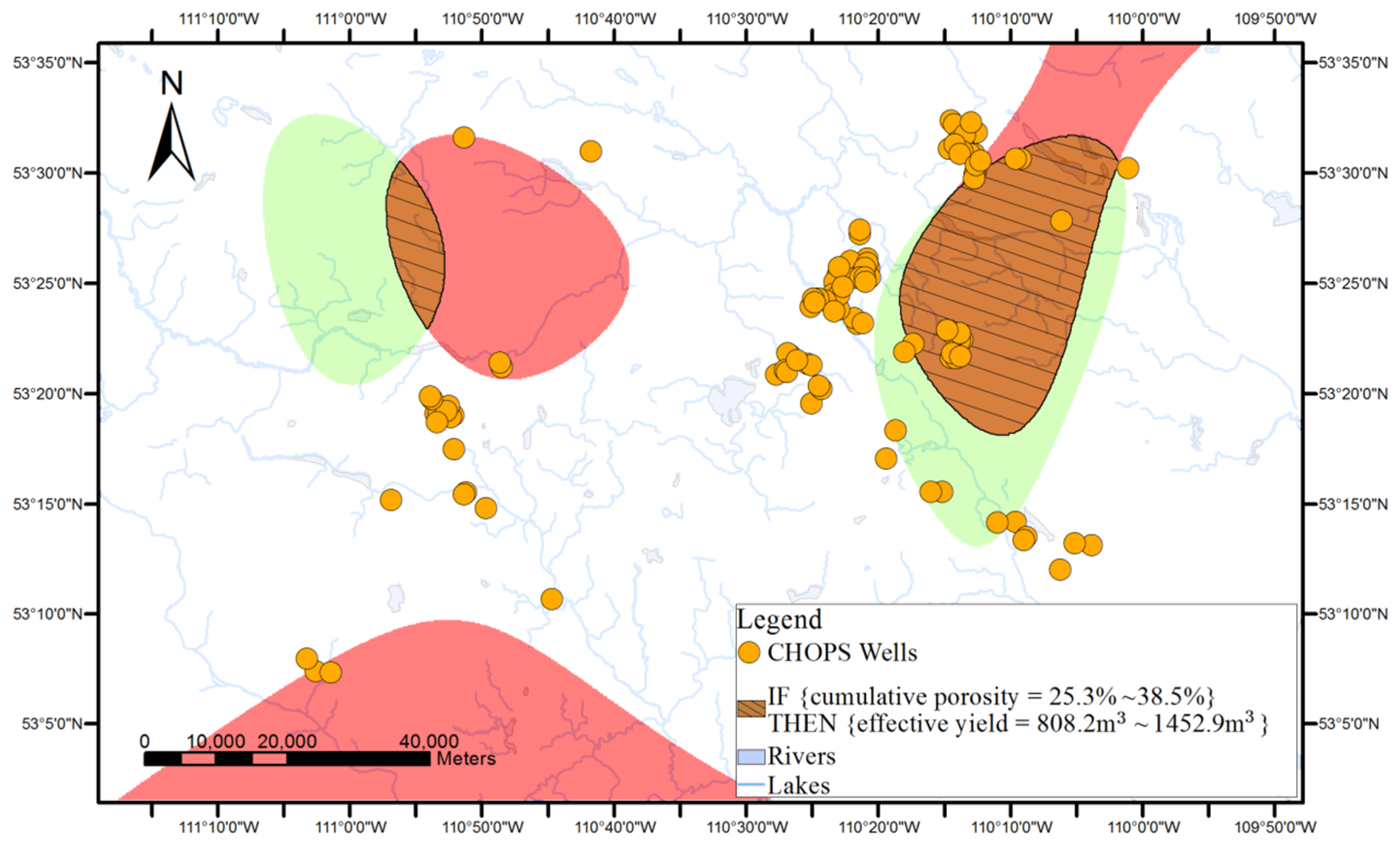
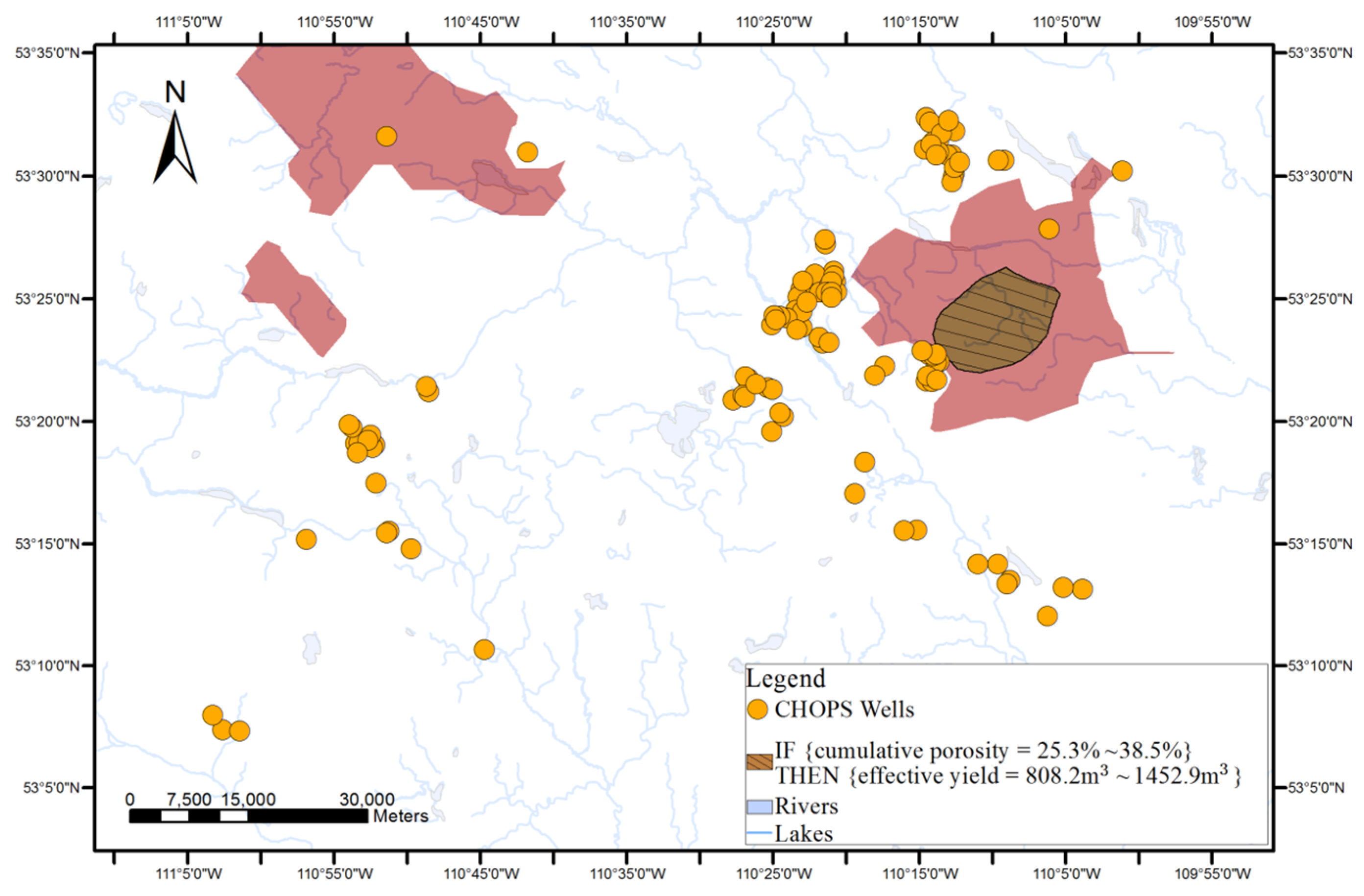
As shown in
Figure 1, surface-based geovisualization of an association rule mainly includes the following steps. First, the spatial dependence of all the attributes appearing in the antecedents and consequences of the rule are examined. If the spatial dependence does not exist in the attributes, the surface-based geovisualization method is not applicable for the rule. Otherwise, continuous surfaces of the attributes are generated by applying a deterministic or stochastic spatial interpolation method on the well data. Next, the corresponding application areas of antecedents and consequences of the rule are extracted from the continuous surfaces and indicated by different colours. Finally, a prediction map of the rule is obtained by overlaying the application areas of the antecedents and consequences of the rule.
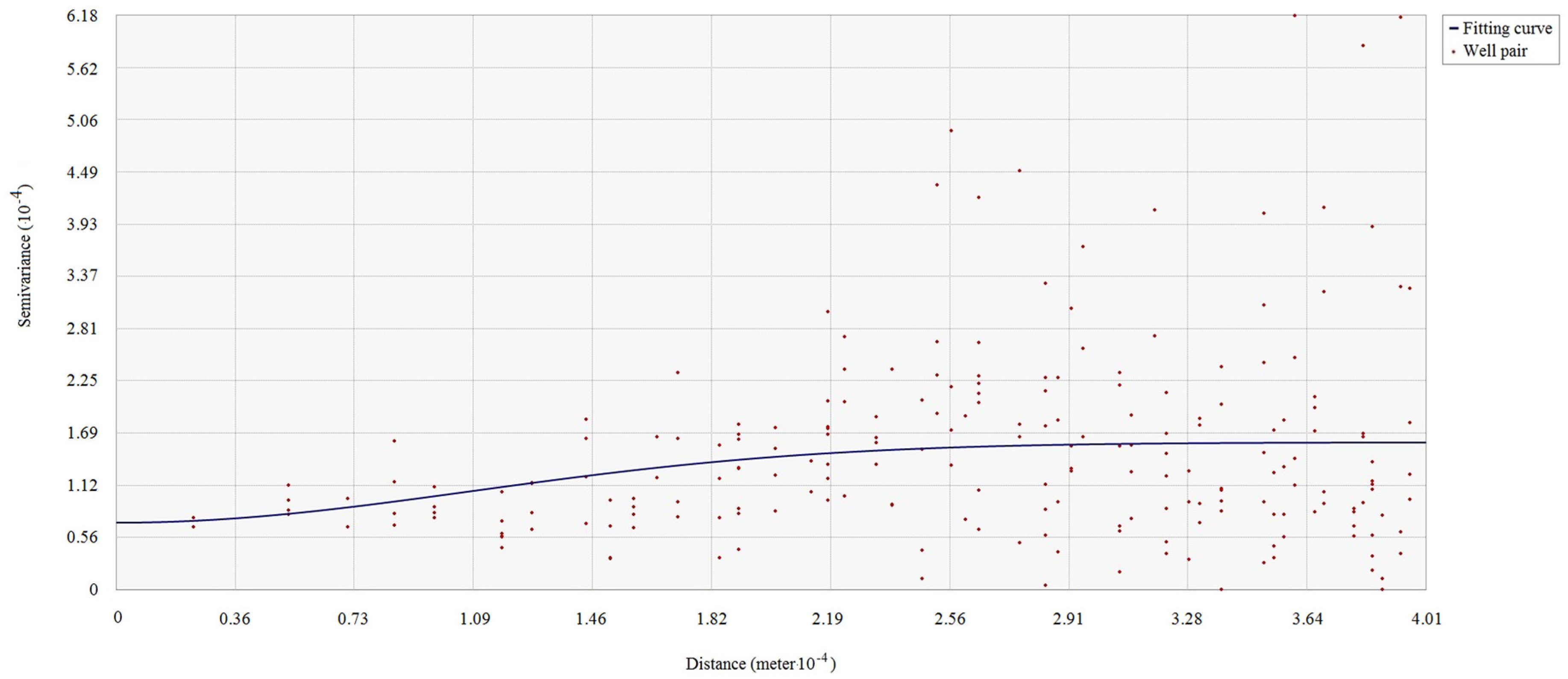
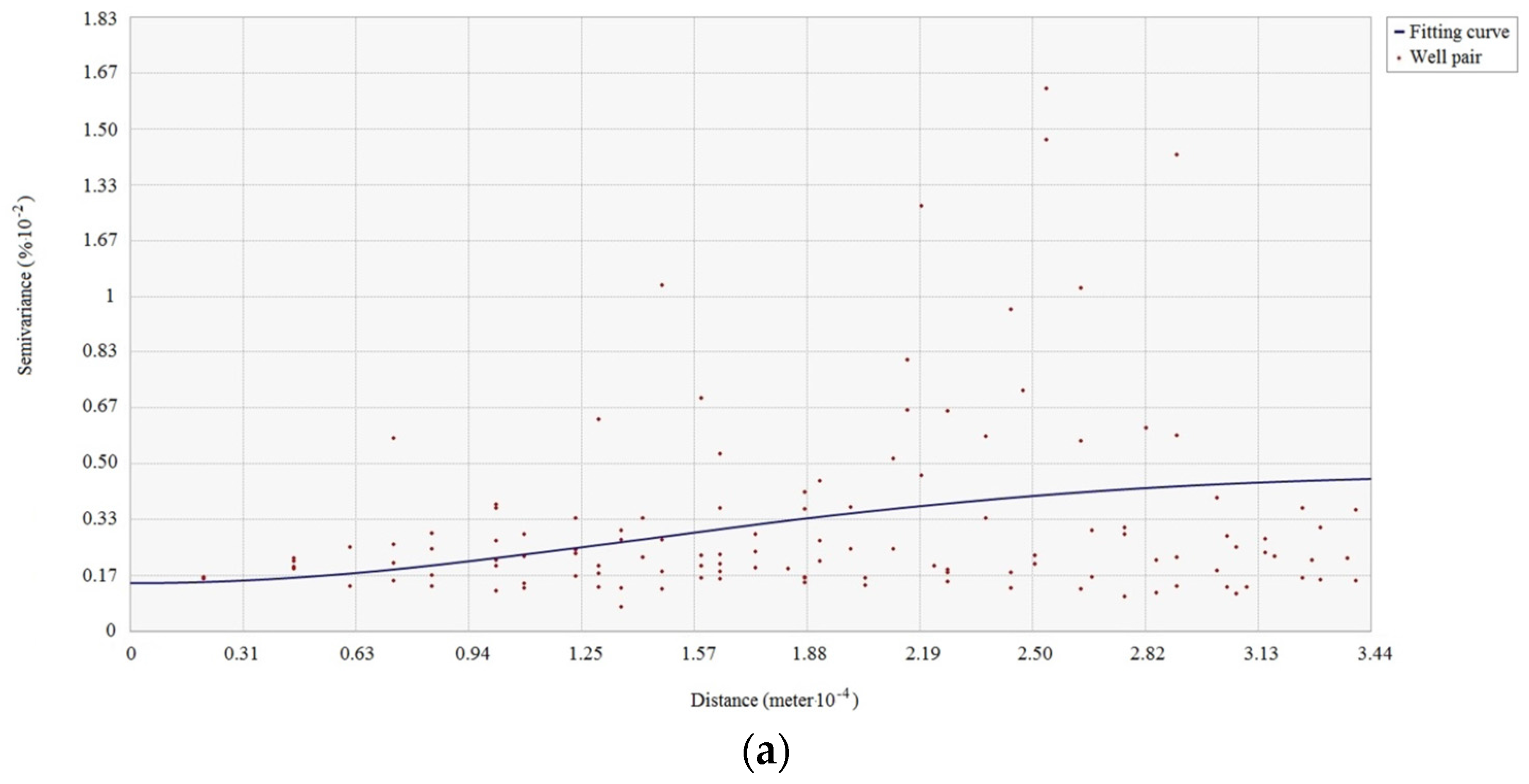
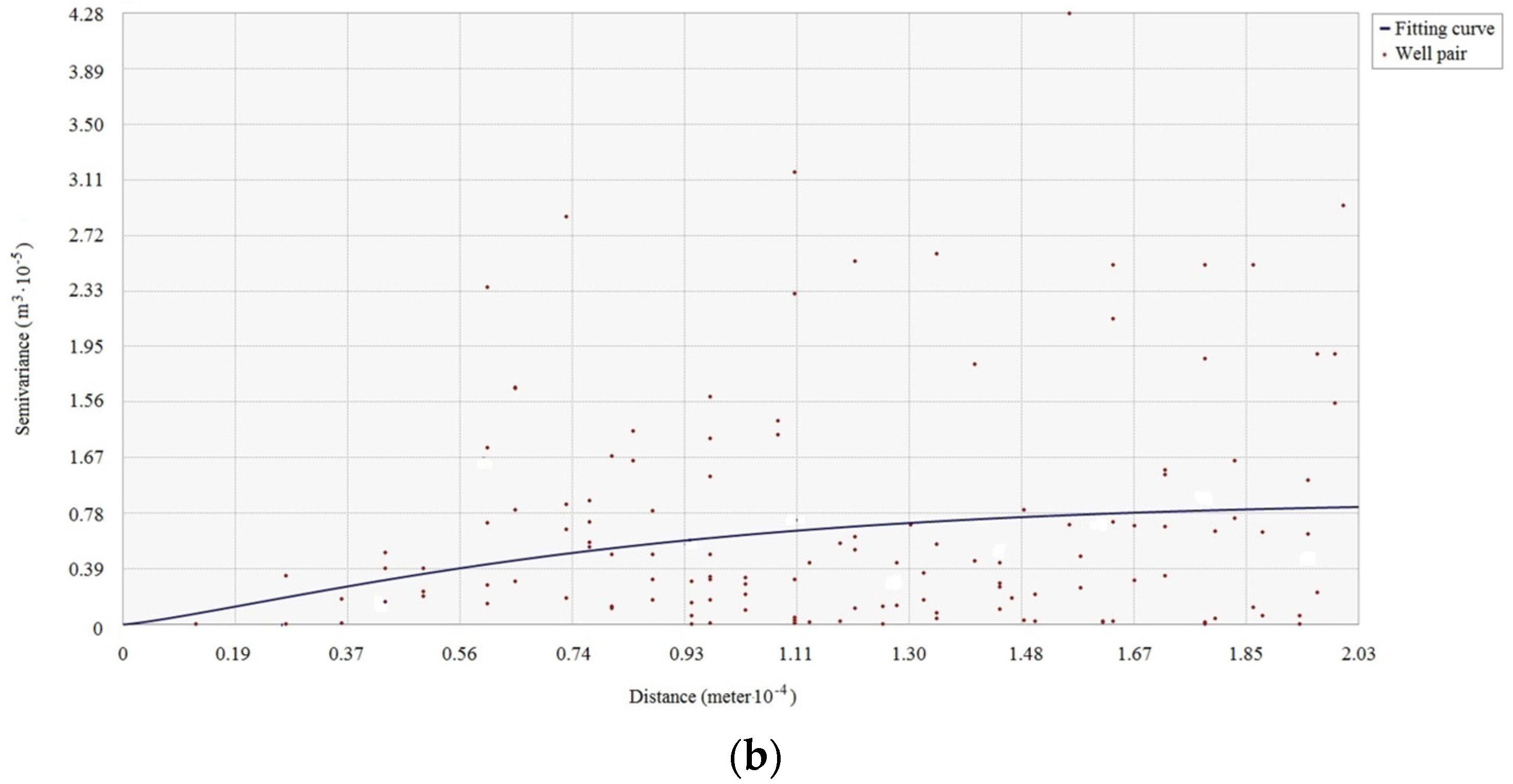
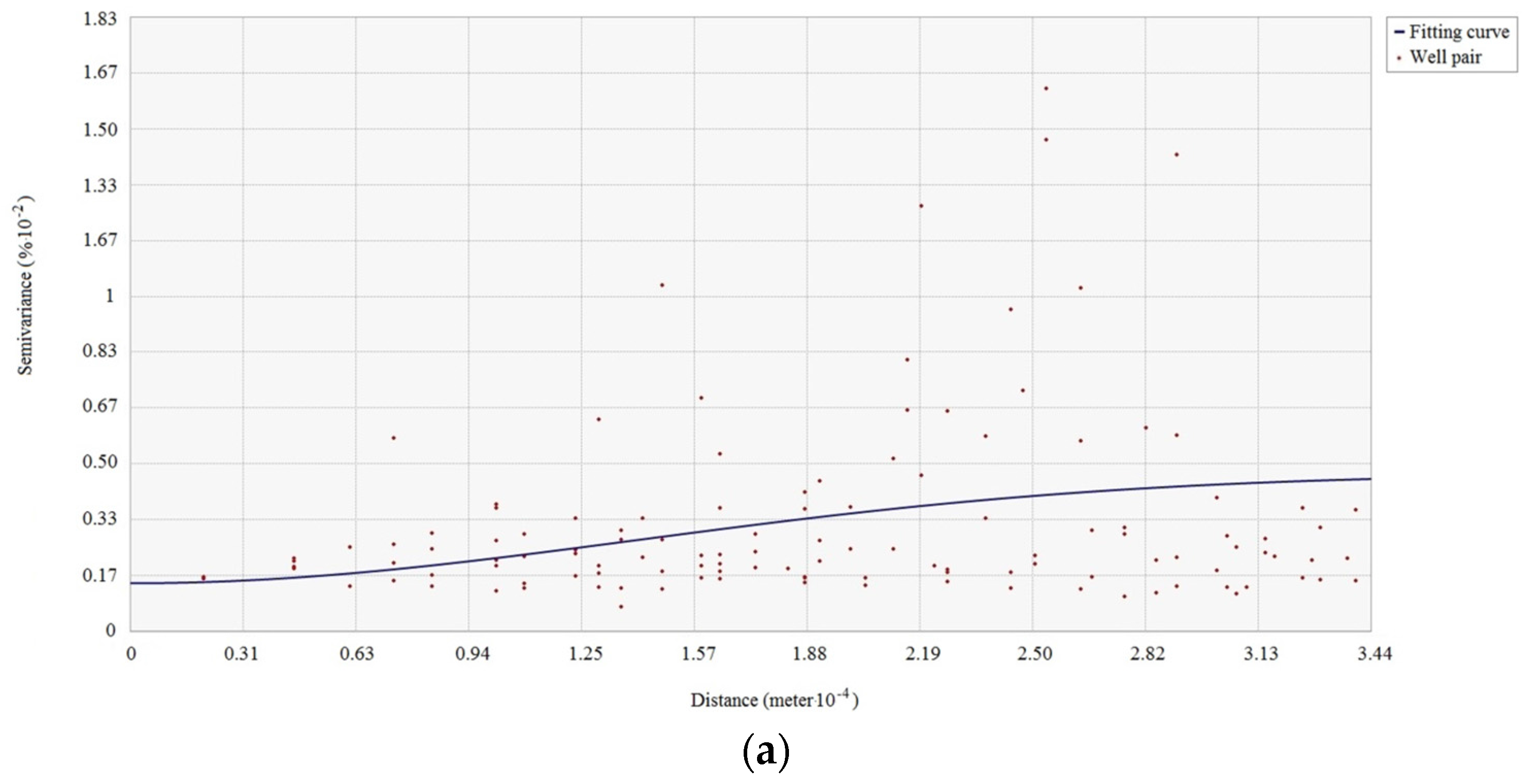
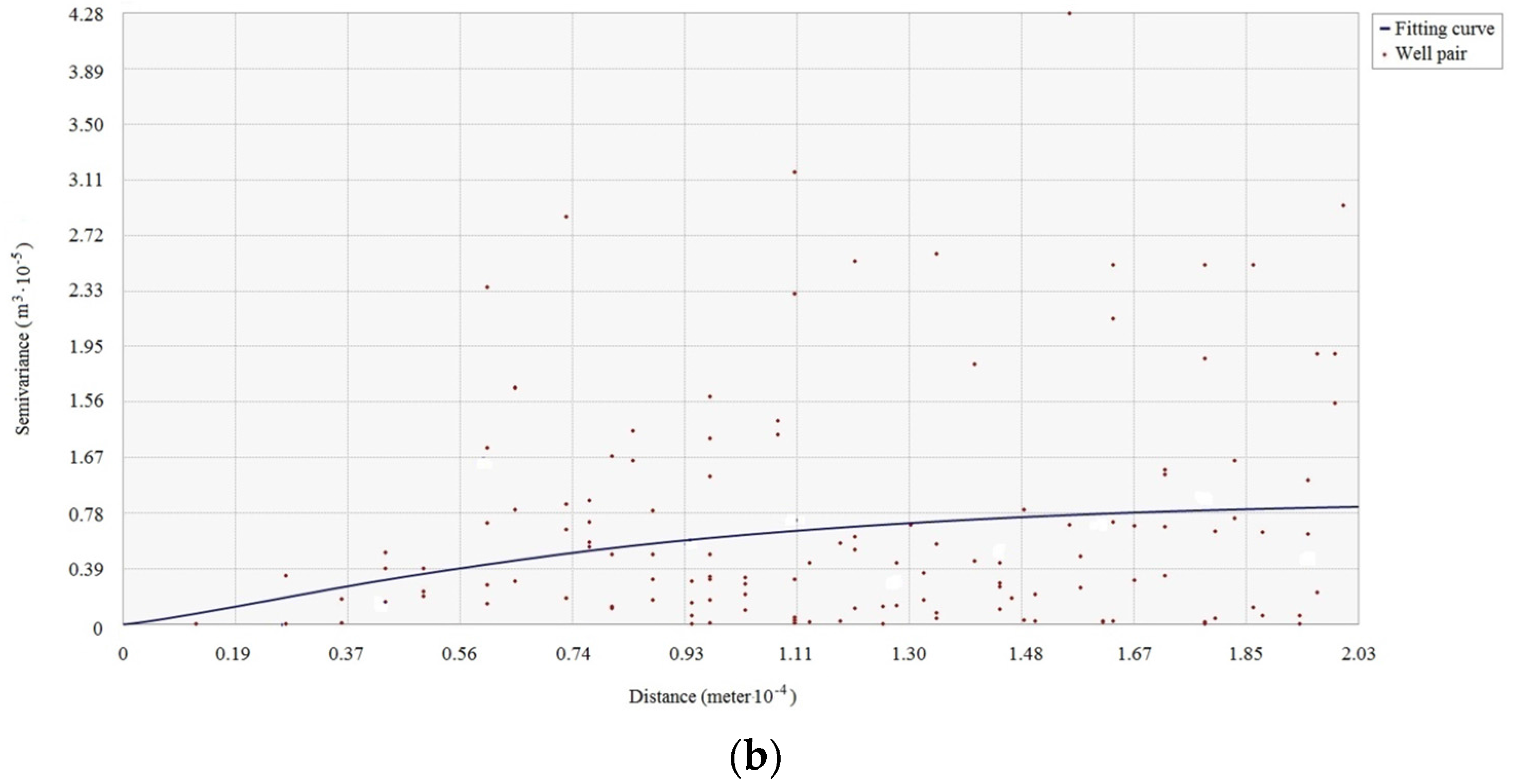
The existence of spatial dependence in the attributes in the studied area is the precondition for the use of spatial interpolation. The spatial dependence of each antecedent or consequence attribute of the association rule should be examined before using spatial interpolation. The spatial dependence of attributes can be checked by semi-variogram clouds. If spatial dependence of a reservoir property attribute exists in the studied reservoir area, the semi-variance decreases with increasing spatial distance in the semi-variogram cloud of the attribute.
Figure 2 shows a semi-variogram cloud of the cumulative pore volume attribute in an area. Since the semi-variance increases as the spatial distance increases in the cloud, the semi-variogram cloud suggests that spatial dependence appears in the cumulative pore volume to some degree. Pairs of sample wells that are closer in distance on X-axis have more similar semi-variance values (Y-axis) for the cumulative pore volume than well pairs that are farther apart.
Note that directional influences also need to be considered when generating semi-variogram clouds. The spatial dependence of an attribute can be stronger in specific directions. The directional influences may come from geological structures or a variety of other more complex processes. The directional influence of spatial dependence needs to be incorporated into the spatial dependence validation of each antecedent or consequence attribute of the association rule.
If spatial dependence of the antecedent and consequence attributes of the rule exists in the studied area, deterministic or stochastic interpolation methods are used to generate continuous surfaces for the attributes. Wells are represented as the point features discretely distributed on the map. Spatial interpolation then fills in the missing data between the wells based on the attribute values of the wells, i.e., the value of the attribute at a location with no recorded data can be estimated using the corresponding known value of the attribute of nearby sample wells.
In terms of the format of the geospatial data, the spatial interpolation generates a raster layer with estimates made for all cells for each antecedent or consequence attribute of an association rule from a vector layer containing oil wells, where the value of each attribute is known. After this step, each attribute appearing in the association rule to be visualized will have an interpolated continuous surface.
The applicable areas of the antecedents and consequences of the rule are then extracted and rendered from the surface of each attribute. For instance, the applicable areas of an antecedent of an association rule (e.g., cumulative pore volume = 59.2%–94.4%) can be gained by extracting the cells whose interpolated values belong to the range from 59.2% to 94.4% from the interpolated continuous surfaces of the cumulative pore volume.
Finally, a prediction map of the applicable areas of the rule is obtained by overlaying all interpolated continuous surfaces of the attributes appearing in the rule.
5. Conclusions
Recently association rule mining was utilized on oil and gas data to find the influence of possible factors on oil production. Due to the lack of connection between found rules and spatial distribution of the wells and application areas, it cannot further be putted into application. In response, this paper proposes two geovisualization methods that aim to bridge the gap. The point-based method visualizes association rules on a map with respect to the locations of relevant wells. Based on spatial interpolation and map overlapping techniques, the surface-based geovisualization method can generate and represent continuous areas on a map where an association rule may be applicable. A GIS system prototype is implemented to support the association rule mining process and the geovisualization of the discovered association rules.
Our future work will focus on the following aspects. First, the data will be extended to larger datasets with more reservoir properties, such as pressure and fluid property, and operational records, such as oil sand production records. K-means clustering method only converges to a local minimum and not to a global minimum. Therefore, in the future optimization approaches on k-means for this application will be further studied. Other unsupervised classification or clustering methods which are possibly more suitable for the dataset will also be explored. Moreover, the point-based and surface-based method will be further improved. We will enrich the categorization scheme of point-based method and deeply study the influences of spatial direction on spatial dependence of oil and gas data attributes for surface-based geovisualization method. Finally, the proposed point- and surface-based geovisualization methods will be extended to multiple association rules.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}