
An Improved DBSCAN Algorithm to Detect Stops in Individual Trajectories

Abstract
:1. Introduction
2. Related Works
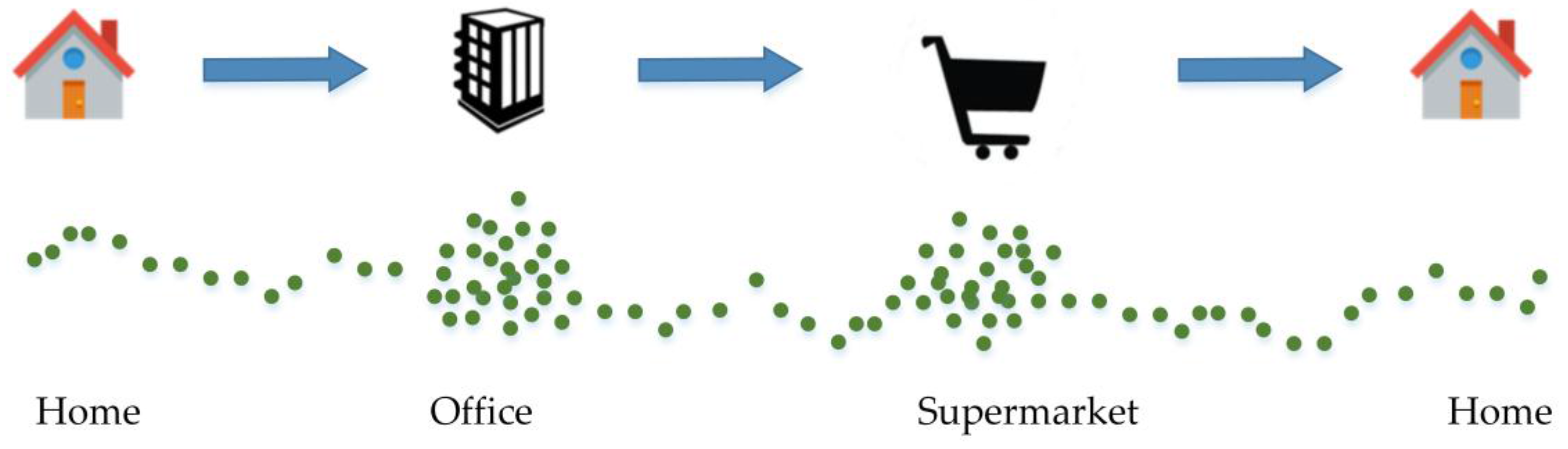
3. Basic Concepts
4. Methodology
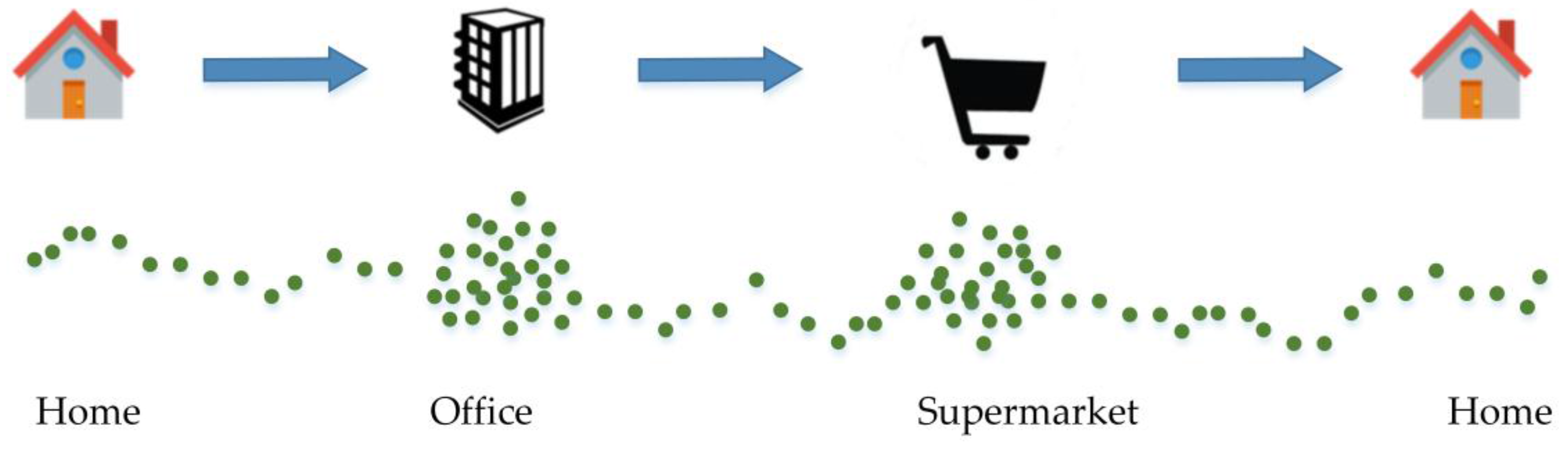
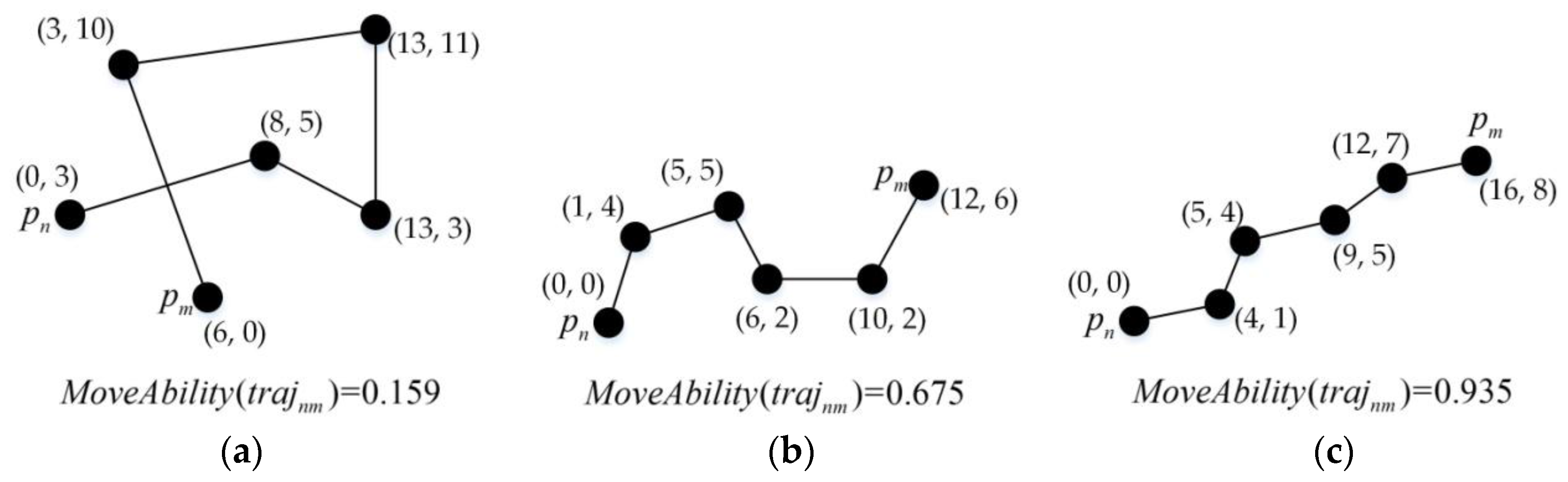
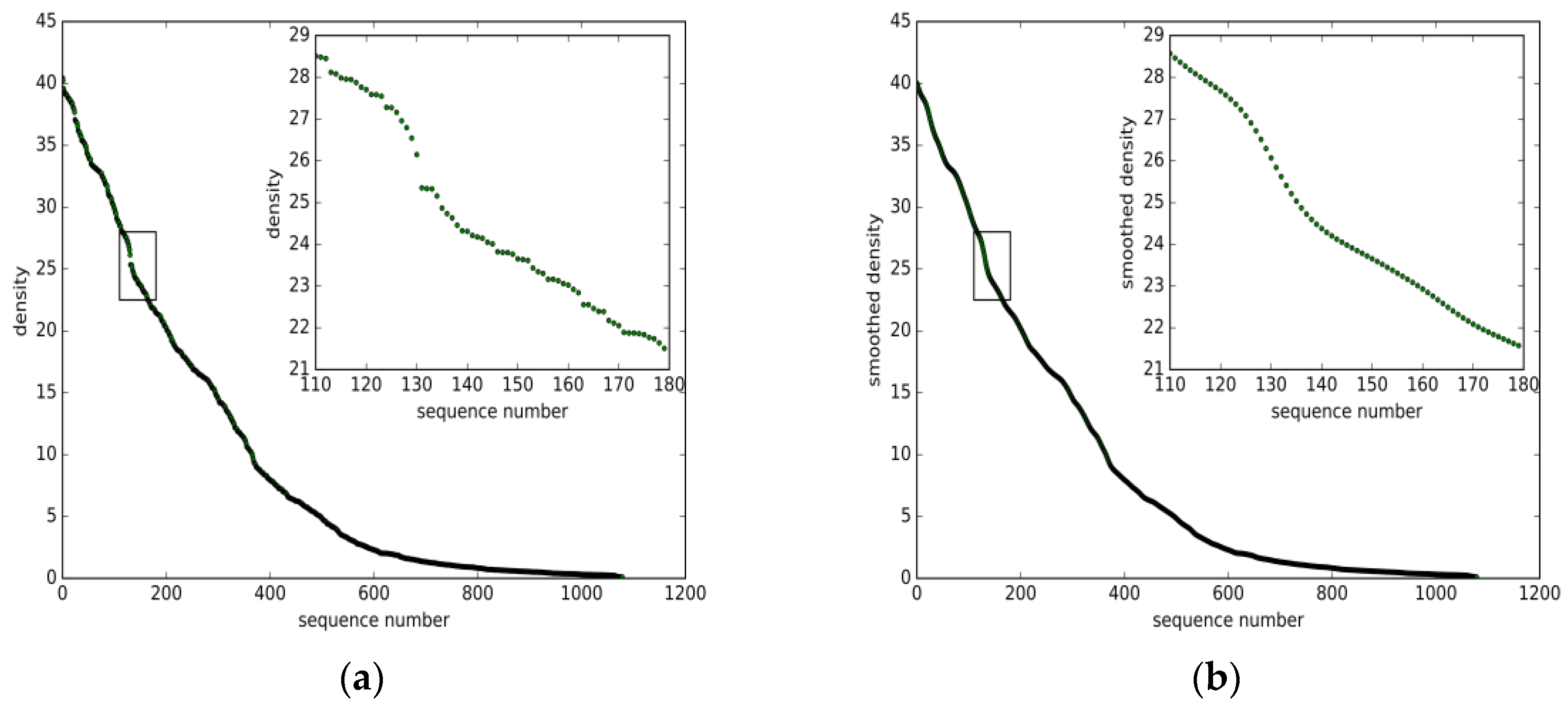
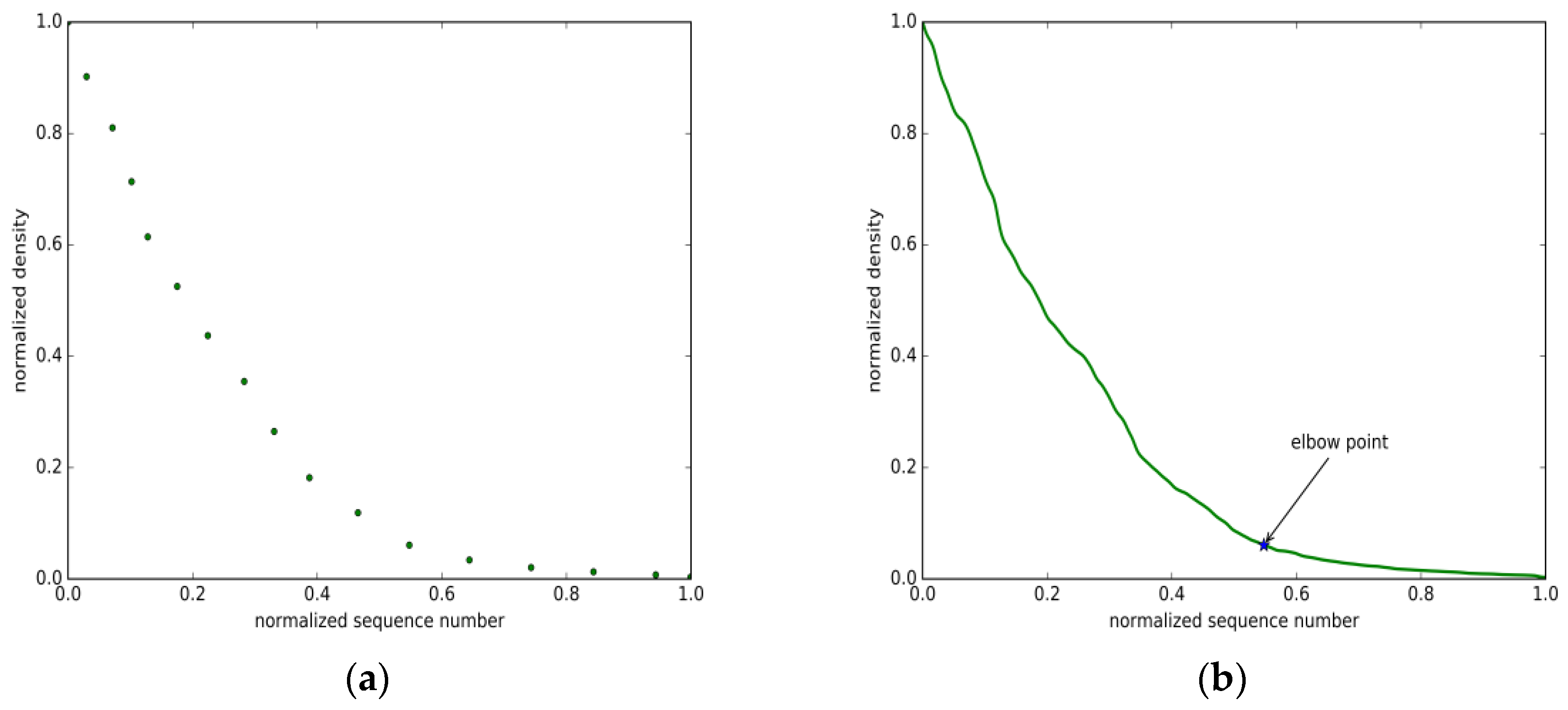
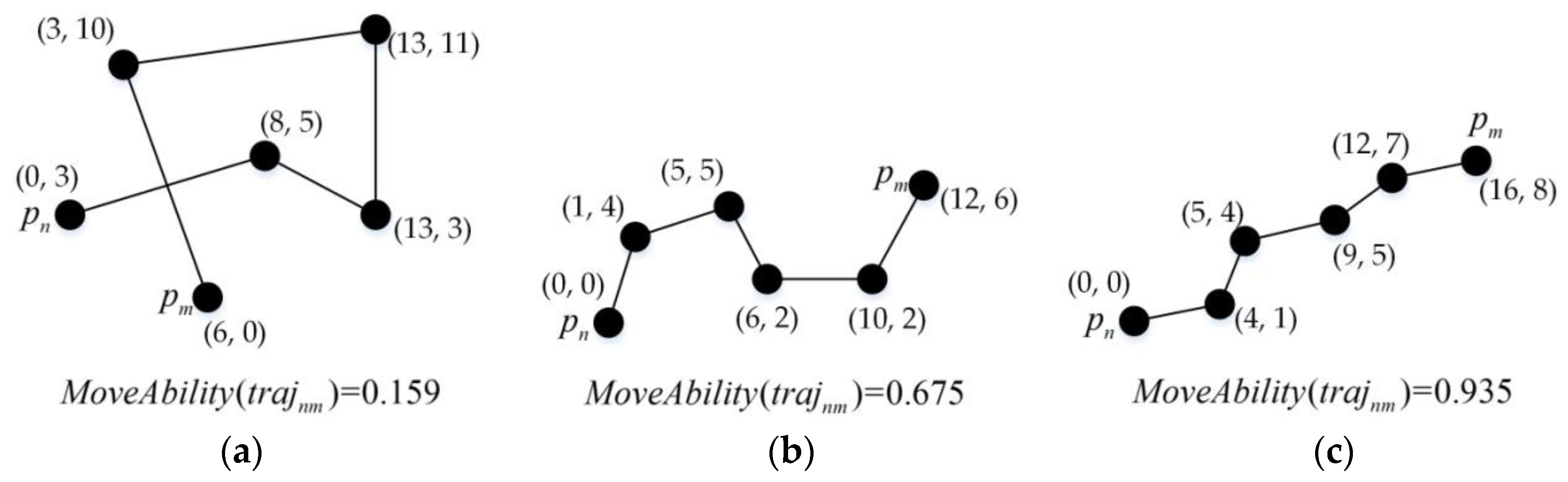
4.1. Density Function
4.2. Improved DBSCAN
5. Experimental Results
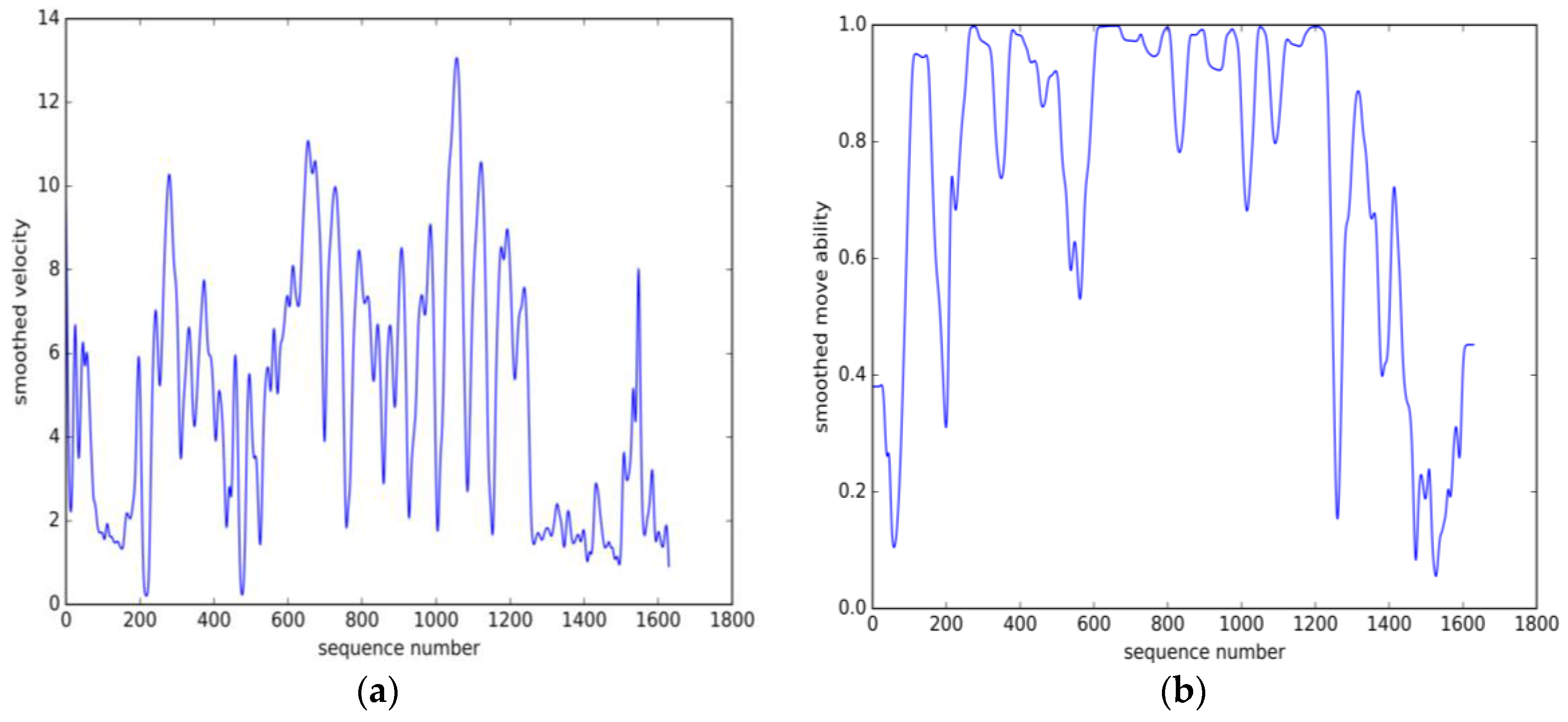
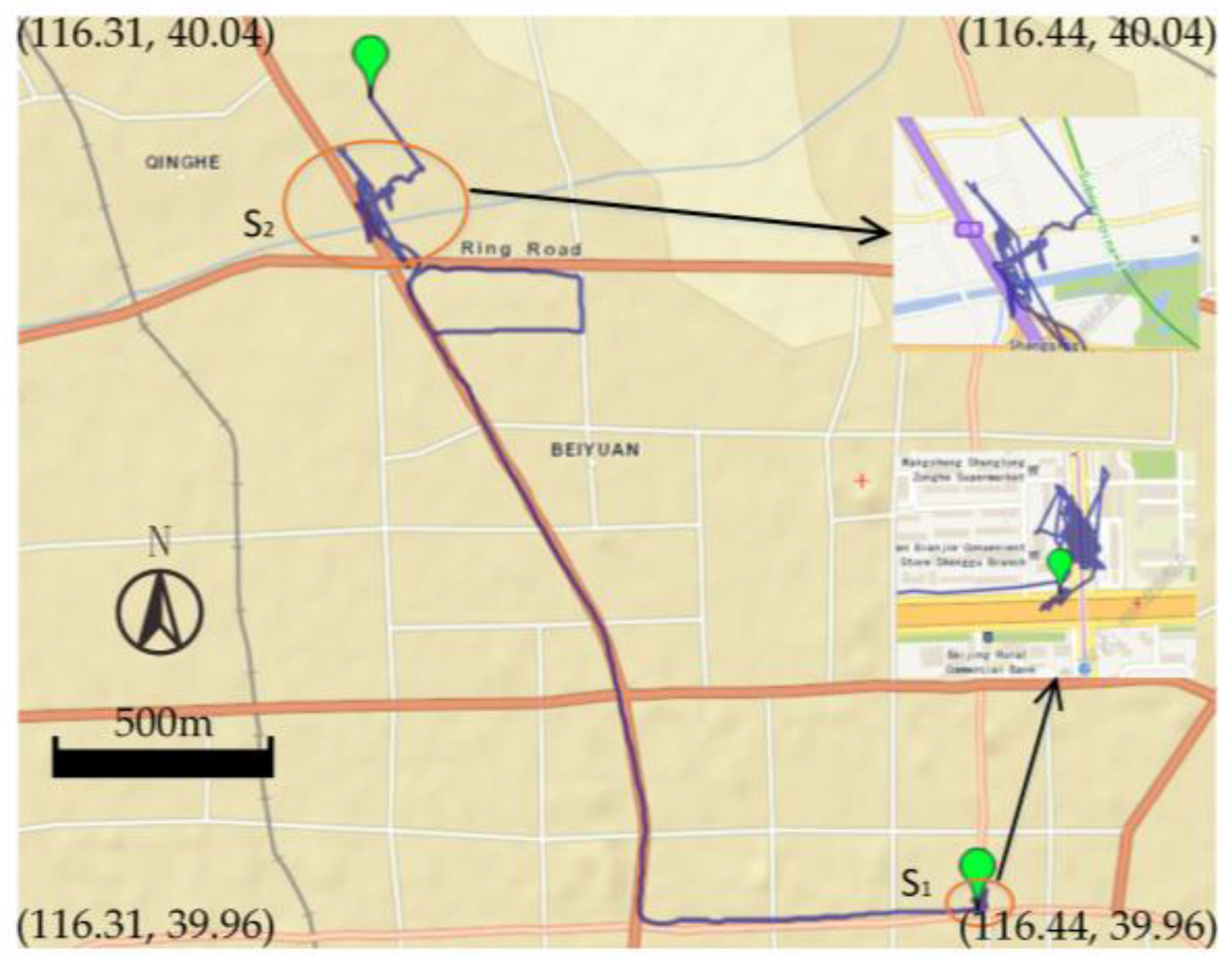
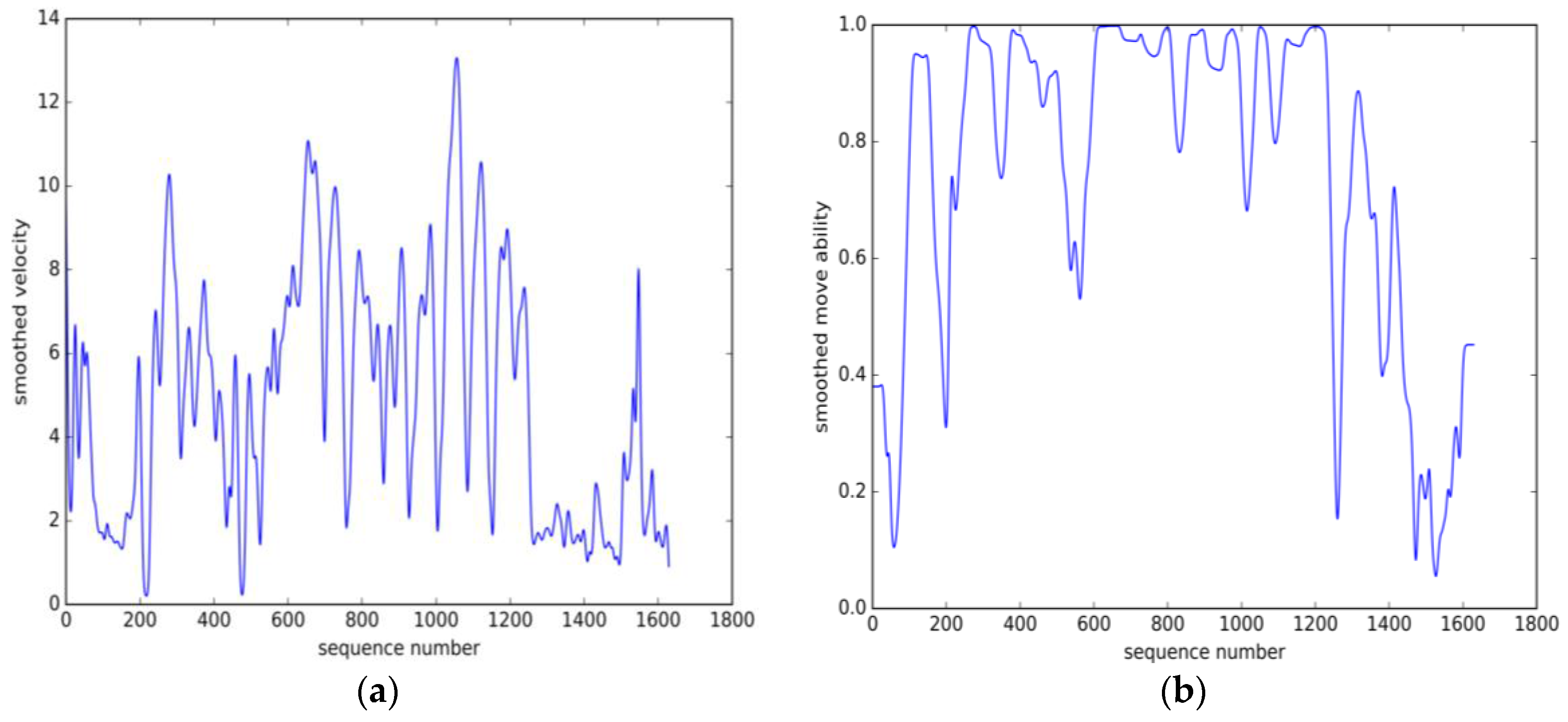
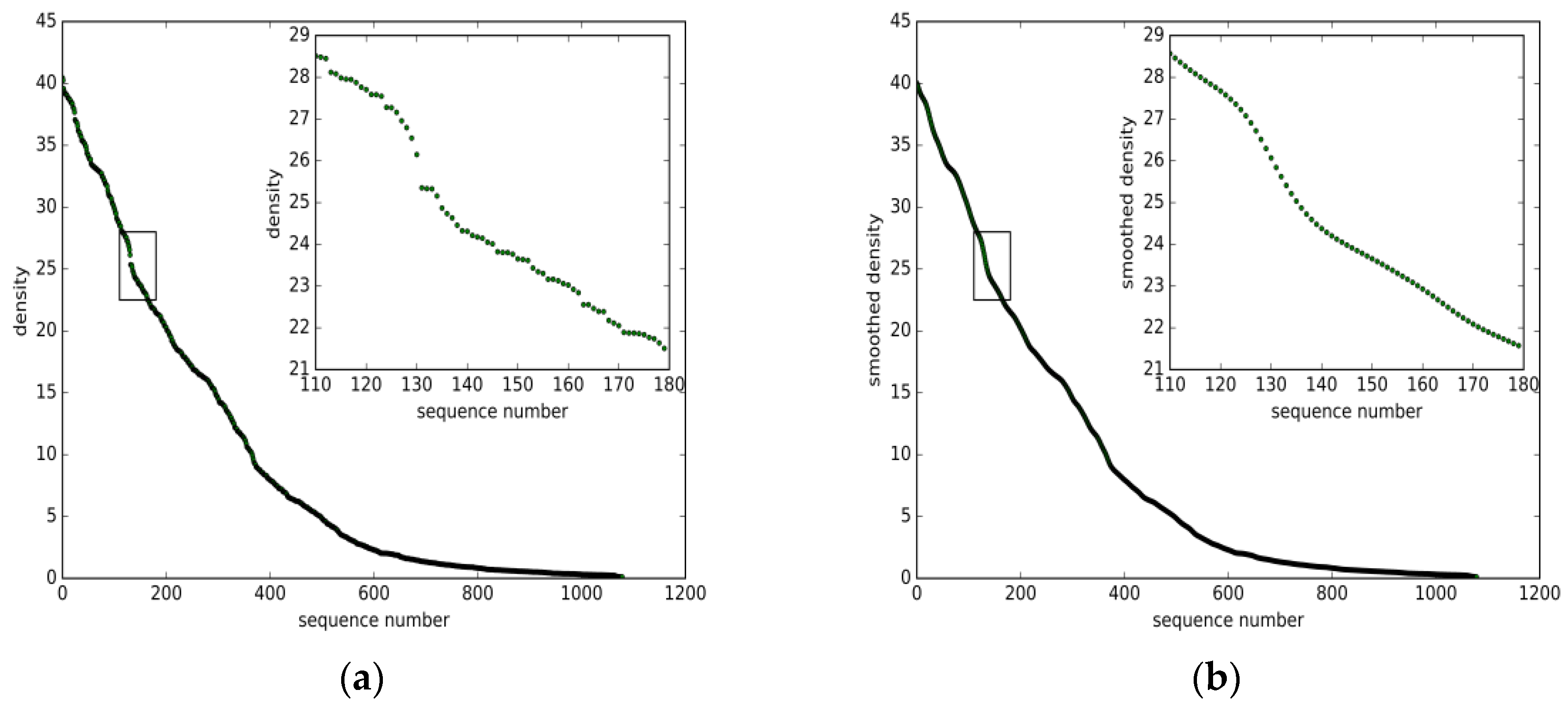
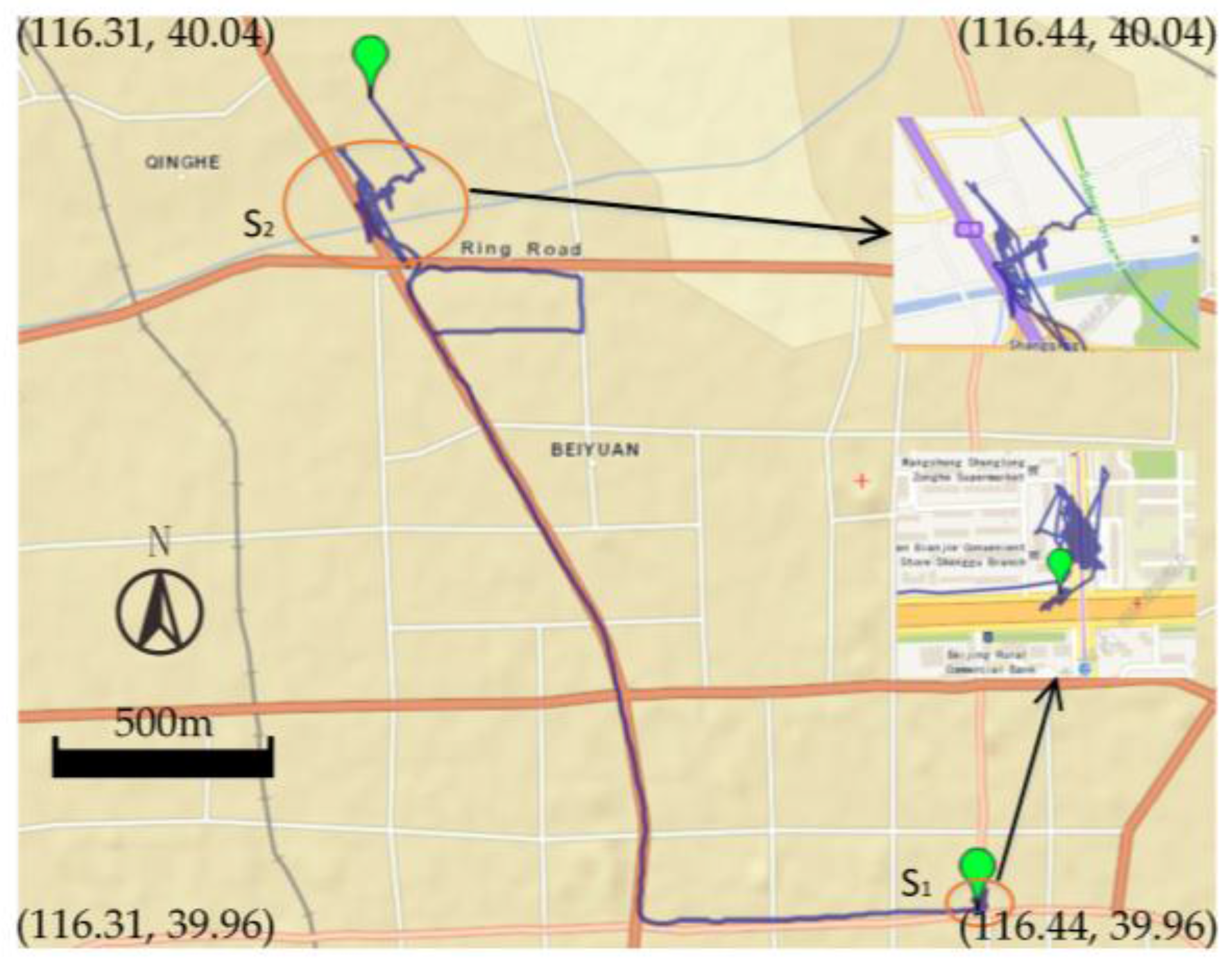
5.1. Datasets Description
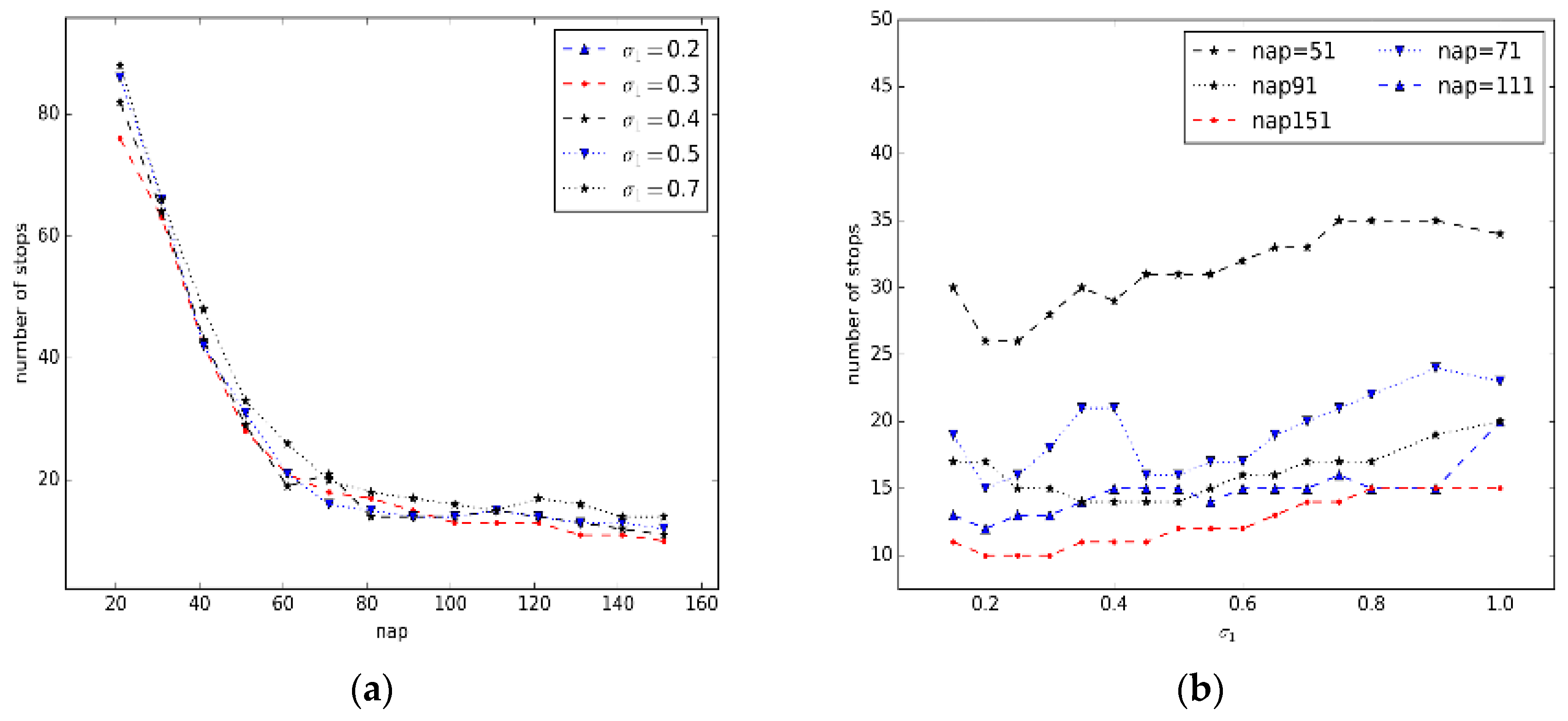
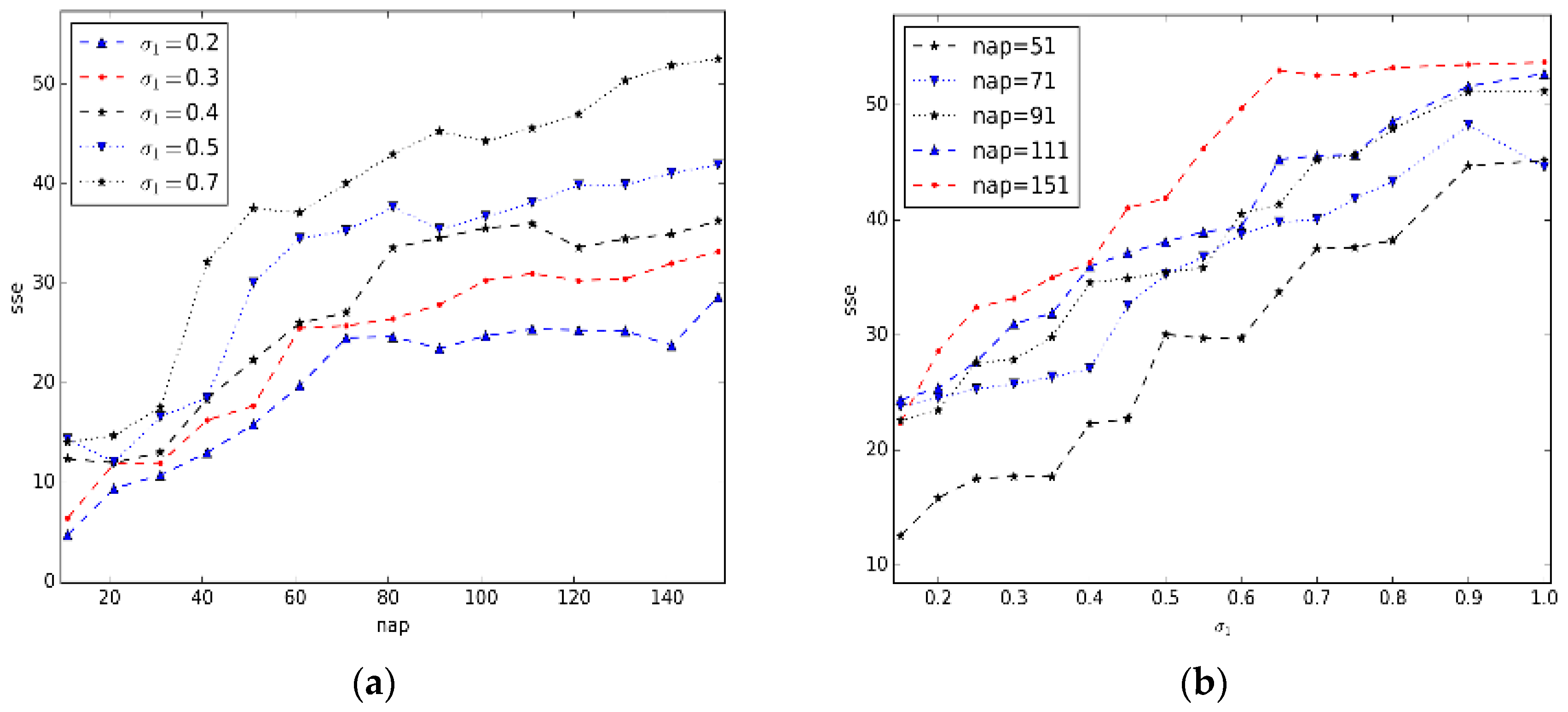
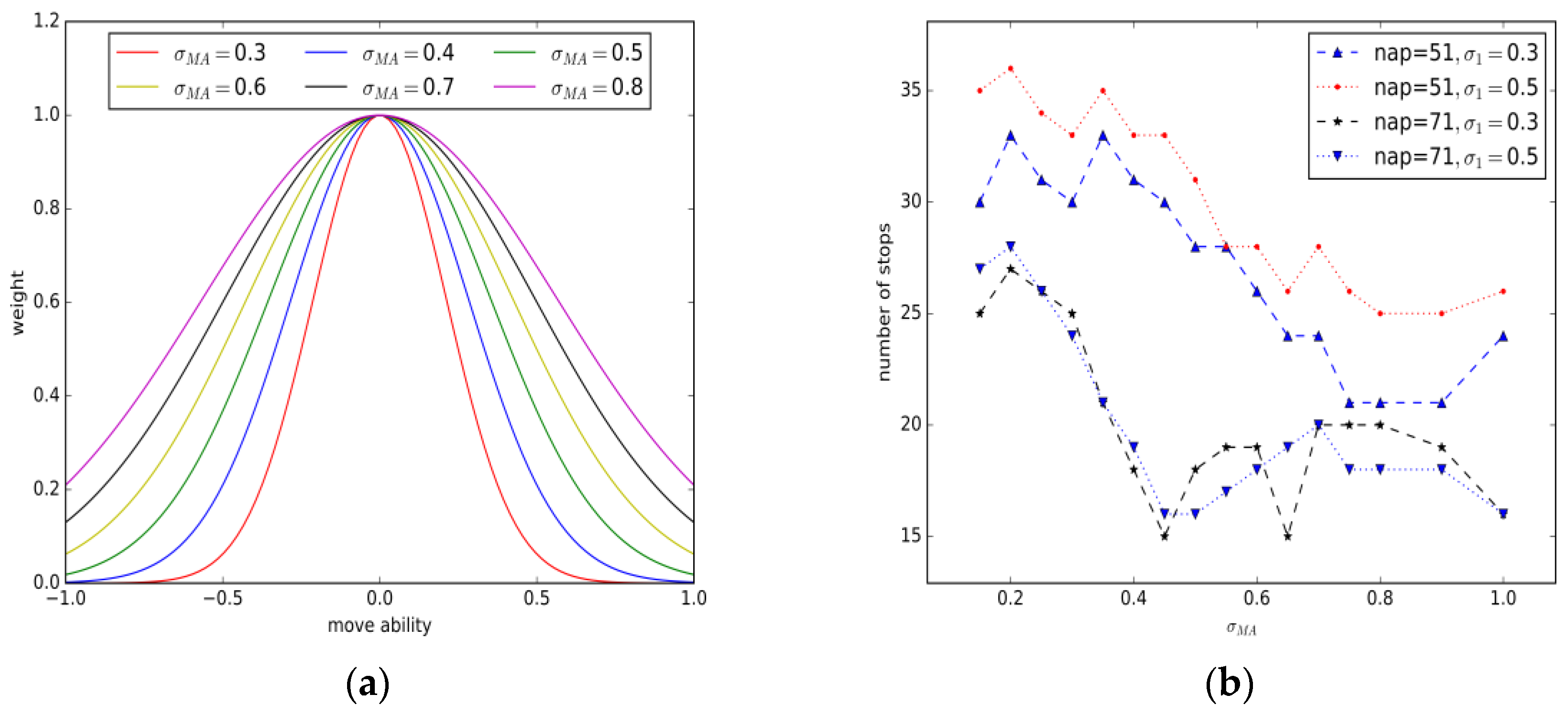
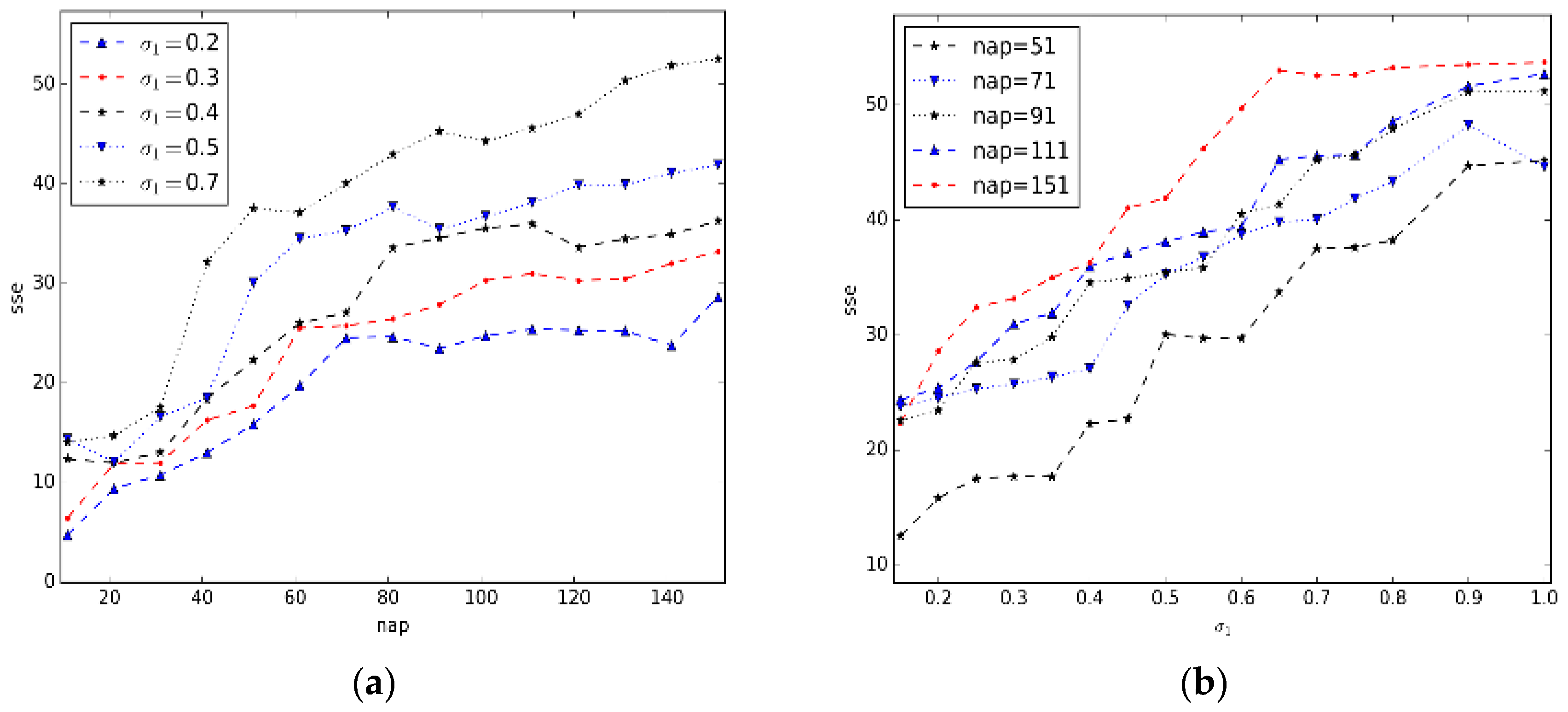
5.2.Parameter Estimation
5.3.Evaluation of Effectiveness
5.4. Evaluation of Efficiency
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Spaccapietra, S.; Parent, C.; Damiani, M.L.; Macedo, J.A.D.; Porto, F.; Vangenot, C. A conceptual view on trajectories. Data Knowl. Eng. 2008, 65, 126–146. [Google Scholar] [CrossRef] [Green Version]
- Alvares, L.O.; Bogorny, V.; Kuijpers, B.; de Macedo, J.A.F.; Moelans, B.; Vaisman, A. A model for enriching trajectories with semantic geographical information. In Proceedings of the 15th annual ACM international symposium on Advances in geographic information systems, Seattle, WA, USA, 7–9 November 2007; p. 22.
- Xie, K.; Deng, K.; Zhou, X. From trajectories to activities: A spatio-temporal join approach. In Proceedings of the 2009 ACM International Workshop on Location Based Social Networks, Seattle, WA, USA, 03 November 2009; pp. 25–32.
- Li, D.; Du, Y. Artificial Intelligence with Uncertainty; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Hwang, S.; Evans, C.; Hanke, T. Detecting stop episodes from GPS trajectories with gaps. In Seeing Cities through Big Data; Springer: Cham, Switzerland, 2017; pp. 427–439. [Google Scholar]
- Palma, A.T.; Bogorny, V.; Kuijpers, B.; Alvares, L.O. A clustering-based approach for discovering interesting places in trajectories. In Proceedings of the 2008 ACM symposium on Applied computing, Fortaleza, Brazil, 16–20 March 2008; pp. 863–868.
- Mousavi, S.M.; Harwood, A.; Karunasekera, S.; Maghrebi, M. Geometry of interest (GOI): Spatio-temporal destination extraction and partitioning in GPS trajectory data. J. Ambient Intell. Humaniz. Comput. 2016, 1–16. [Google Scholar] [CrossRef]
- Bhattacharya, T.; Kulik, L.; Bailey, J. Automatically recognizing places of interest from unreliable GPS data using spatio-temporal density estimation and line intersections. Pervasive Mob. Comput. 2015, 19, 86–107. [Google Scholar] [CrossRef]
- Kami, N.; Enomoto, N.; Baba, T.; Yoshikawa, T. Algorithm for detecting significant locations from raw GPS data. In Proceedings of the 2010 International Conference on Discovery Science, Canberra, Australia, 6–8 October 2010; pp. 221–235.
- Cao, X.; Cong, G.; Jensen, C.S. Mining significant semantic locations from GPS data. Proc. VLDB Endow. 2010, 3, 1009–1020. [Google Scholar] [CrossRef]
- Ashbrook, D.; Starner, T. Using gps to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; KDD: Portland, OR, USA, 1996; pp. 226–231. [Google Scholar]
- Schoier, G.; Borruso, G. Individual movements and geographical data mining. Clustering algorithms for highlighting hotspots in personal navigation routes. In Proceedings of the International Conference on Computational Science and ITS Applications, Santander, Spain, 20–23 June 2011; pp. 454–465.
- Zhou, C.; Frankowski, D.; Ludford, P.; Shekhar, S.; Terveen, L. Discovering personally meaningful places: An interactive clustering approach. ACM Trans. Inf. Syst. 2007, 25, 12. [Google Scholar] [CrossRef]
- Zhou, C.; Frankowski, D.; Ludford, P.; Shekhar, S.; Terveen, L. Discovering personal gazetteers: An interactive clustering approach. In Proceedings of the ACM International Workshop on Geographic Information Systems, Washington, DC, USA, 8–13 November 2004; pp. 266–273.
- Zhao, X.-L.; Xu, W.-X. A clustering-based approach for discovering interesting places in a single trajectory. In Proceedings of the 2009 IEEE Second International Conference on Intelligent Computation Technology and Automation, ICICTA 2009, Zhangjiajie, China, 10–11 October 2009; pp. 429–432.
- Rocha, J.A.M.; Times, V.C.; Oliveira, G.; Alvares, L.O.; Bogorny, V. Db-smot: A direction-based spatio-temporal clustering method. In Proceedings of the 2010 5th IEEE International Conference Intelligent Systems, London, UK, 7–9 July 2010; pp. 114–119.
- Lv, M.; Chen, L.; Xu, Z.; Li, Y.; Chen, G. The discovery of personally semantic places based on trajectory data mining. Neurocomputing 2016, 173, 1142–1153. [Google Scholar] [CrossRef]
- Yan, Z.; Parent, C.; Spaccapietra, S.; Chakraborty, D. A hybrid model and computing platform for spatio-semantic trajectories. In Proceedings of the International Conference on the Semantic Web: Research and Applications, Heraklion, Greece, 30 May–2 June 2010; pp. 60–75.
- Zheng, Y.; Zhang, L.; Xie, X.; Ma, W.Y. Mining interesting locations and travel sequences from gps trajectories. In Proceedings of the International Conference on World Wide Web, WWW 2009, Madrid, Spain, 20–24 April 2009; pp. 791–800.
- Fu, Z.; Tian, Z.; Xu, Y.; Qiao, C. A two-step clustering approach to extract locations from individual GPS trajectory data. ISPRS Int. J. Geo-Inf. 2016, 5, 166. [Google Scholar] [CrossRef]
- Yuan, Y.; Raubal, M. Measuring similarity of mobile phone user trajectories—A spatio-temporal edit distance method. Int. J. Geogr. Inf. Sci. 2014, 28, 496–520. [Google Scholar] [CrossRef]
- Chen, S.; Meng, H.; Zhang, C.; Liu, C. A KD curvature based corner detector. Neurocomputing 2016, 173, 434–441. [Google Scholar] [CrossRef]
- Guidotti, R.; Trasarti, R.; Nanni, M. TOSCA: Two-steps clustering algorithm for personal locations detection. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015.
- Tran, L.H.; Dang, T.K.; Thoai, N. Hybrid stop discovery in trajectory records. In Proceedings of the 24th International Workshop on Database and Expert Systems Applications (DEXA), Prague, Czech Republic, 26–30 August 2013.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Nap | Precision | Recall | Fmeasure | |
|---|---|---|---|---|---|
| 1 | 0.3 | 51 | 0.92105 | 0.7749 | 0.8417 |
| 2 | 0.3 | 71 | 0.9698 | 0.7122 | 0.8213 |
| 3 | 0.3 | 91 | 0.9267 | 0.6531 | 0.7662 |
| 4 | 0.5 | 51 | 0.7729 | 0.8413 | 0.8057 |
| 5 | 0.5 | 71 | 0.9167 | 0.7712 | 0.8377 |
| 6 | 0.5 | 91 | 0.9289 | 0.7232 | 0.8133 |
| Metrics | OurMethod | CB-SMoT | DBSCAN | DJ-Cluster | Time-Based |
|---|---|---|---|---|---|
| Parameters | = 0.3 | Eps = 50 | Eps = 80 | Eps = 80 | Eps = 80 |
| Nap = 51 | MinTime = 5 | MinPts = 100 | MinPts = 80 | Time = 6 | |
| Labeled | 271 | 271 | 271 | 271 | 271 |
| Detected | 228 | 358 | 241 | 282 | 308 |
| Matched | 210 | 225 | 187 | 215 | 212 |
| Precision | 0.9211 | 0.6285 | 0.7759 | 0.7624 | 0.6883 |
| Recall | 0.7749 | 0.8303 | 0.6900 | 0.7934 | 0.7823 |
| Fmeasure | 0.8417 | 0.7154 | 0.7305 | 0.7776 | 0.7323 |
| Metrics | Our Method | CB-SMoT | DBSCAN | DJ-Cluster | Time-Based |
|---|---|---|---|---|---|
| Parameters | = 0.5 | Eps = 50 | Eps = 50 | Eps = 50 | Eps = 80 |
| Nap = 71 | MinTime = 5 | MinPts = 100 | MinPts = 100 | Time = 6 | |
| Recorded | 48 | 48 | 48 | 48 | 48 |
| Detected | 48 | 51 | 60 | 59 | 49 |
| Matched | 46 | 37 | 42 | 41 | 41 |
| Precision | 0.9583 | 0.7255 | 0.7000 | 0.6949 | 0.8367 |
| Recall | 0.9583 | 0.7292 | 0.8750 | 0.8542 | 0.8542 |
| Fmeasure | 0.9583 | 0.7475 | 0.7778 | 0.7664 | 0.8454 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, T.; Zheng, X.; Xu, G.; Fu, K.; Ren, W. An Improved DBSCAN Algorithm to Detect Stops in Individual Trajectories. ISPRS Int. J. Geo-Inf. 2017, 6, 63. https://doi.org/10.3390/ijgi6030063
Luo T, Zheng X, Xu G, Fu K, Ren W. An Improved DBSCAN Algorithm to Detect Stops in Individual Trajectories. ISPRS International Journal of Geo-Information. 2017; 6(3):63. https://doi.org/10.3390/ijgi6030063
Chicago/Turabian StyleLuo, Ting, Xinwei Zheng, Guangluan Xu, Kun Fu, and Wenjuan Ren. 2017. "An Improved DBSCAN Algorithm to Detect Stops in Individual Trajectories" ISPRS International Journal of Geo-Information 6, no. 3: 63. https://doi.org/10.3390/ijgi6030063