The Classification of Noise-Afflicted Remotely Sensed Data Using Three Machine-Learning Techniques: Effect of Different Levels and Types of Noise on Accuracy

 , , ,
, , ,
Abstract
:
1. Introduction
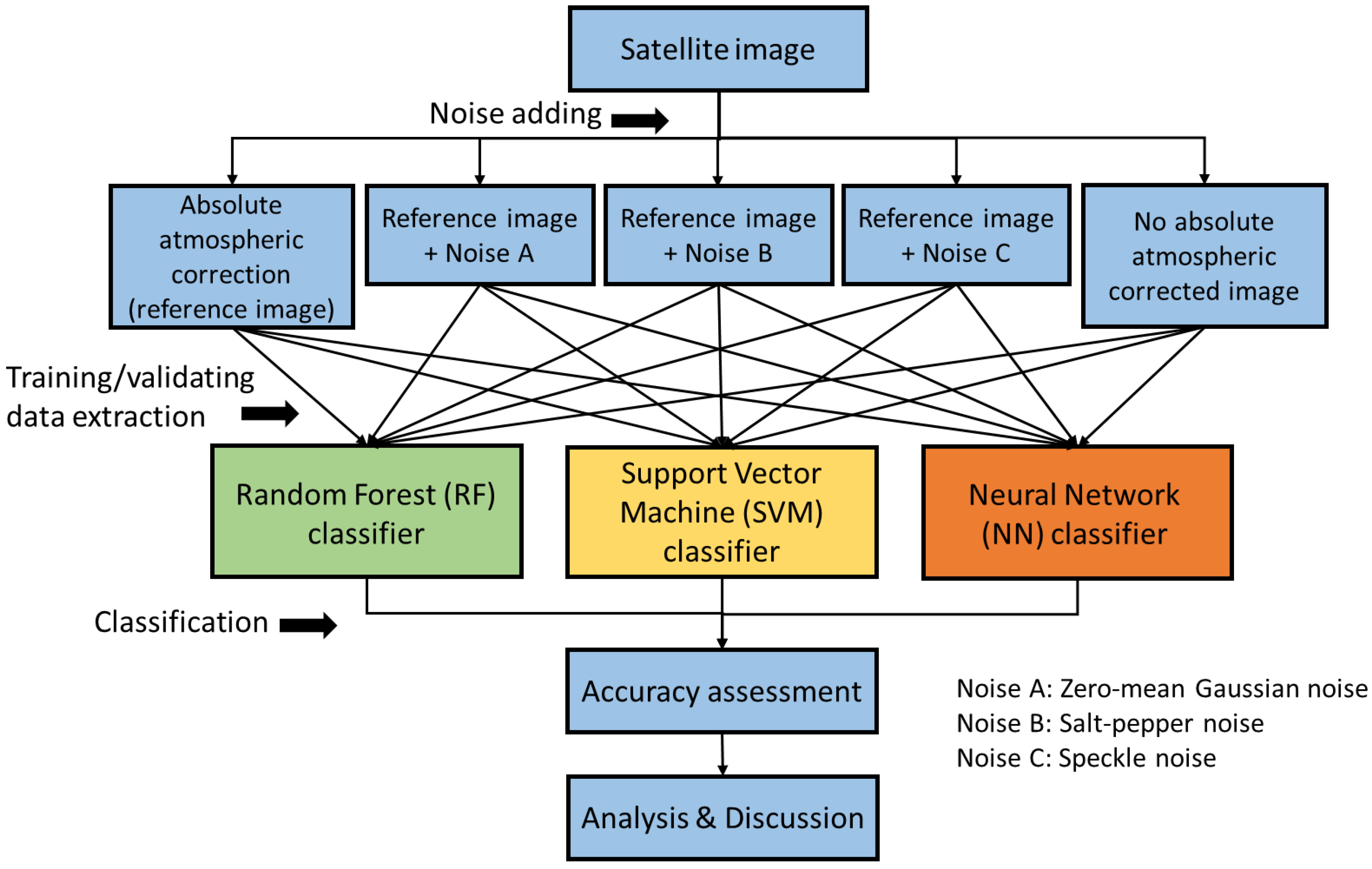
- Fully processed images with absolute atmospheric correction, termed the reference images. (assumed to contain no noise);
- Normal reflectance images without absolute atmospheric correction (mixture of noise, i.e., sensor noise, atmospheric noise);
- Reference images with zero-mean Gaussian noise added;
- Reference images with salt–pepper noise added;
- Reference images with speckle noise added (multiplicative noise).
2. Materials and Methods
2.1. Experimental Design
2.2. Remotely Sensed Data
2.3. Sampling Design
2.4. Noise Afflictions
2.5. Classifiers—Implementation Packages
2.5.1. Random Forests (RF)
2.5.2. Support Vector Machines (SVM)
2.5.3. Back-Propagation Neural Network (BPNN)
3. Results
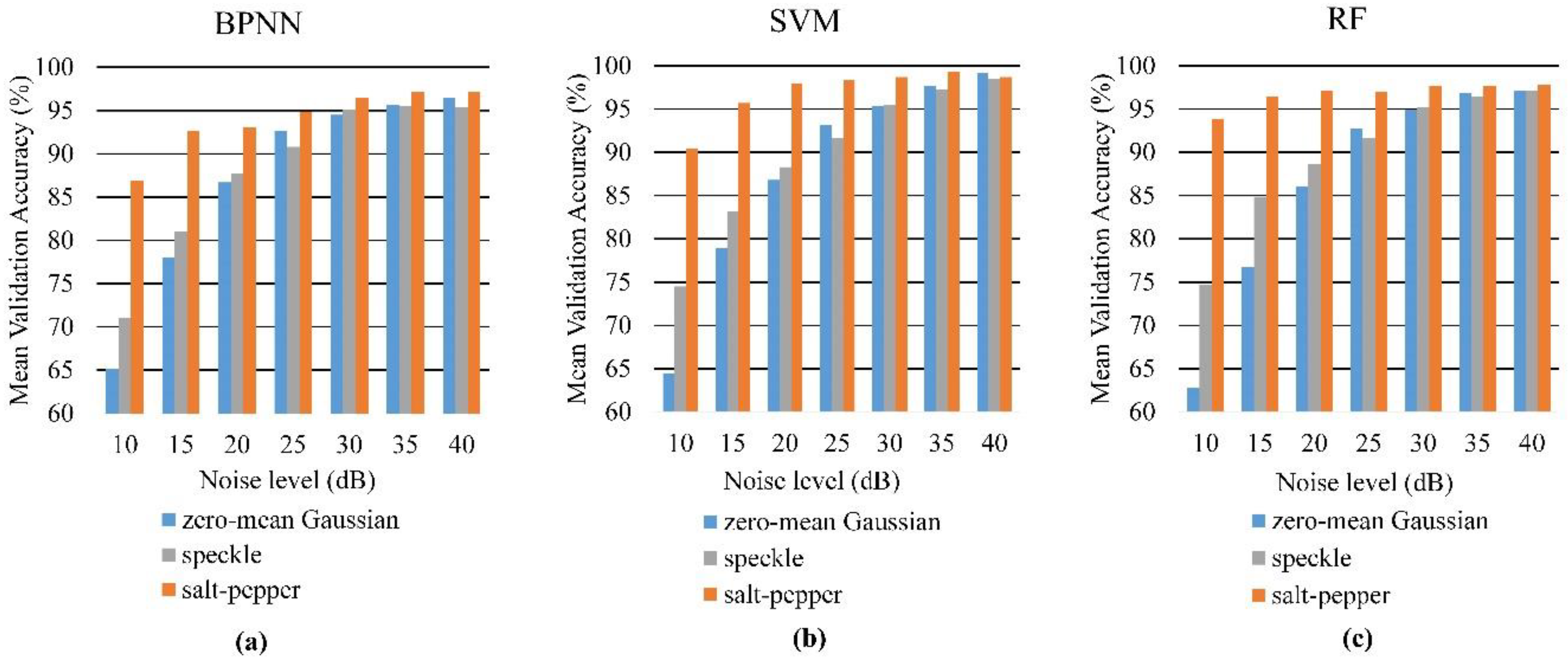
3.1. Image with Added Noise
3.2. Classification Results
3.2.1. BPNN
3.2.2. SVM
3.2.3. RF
4. Discussion
4.1. Performance of the Classifiers vs. the Reference and the Non-Atmospheric-Corrected Image
4.2. Analysis of Noise and Classifiers
4.3. Advanced Extension of the MLs
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Song, M.; Civco, D.L.; Hurd, J.D. A competitive pixel-object approach for land cover classification. Int. J. Remote Sens. 2005, 26, 4981–4997. [Google Scholar] [CrossRef]
- Petrou, Z.I.; Kosmidou, V.; Manakos, I.; Stathaki, T.; Adamo, M.; Tarantino, C.; Tomaselli, V.; Blonda, P.; Petrou, M. A rule-based classification methodology to handle uncertainty in habitat mapping employing evidential reasoning and fuzzy logic. Pattern Recognit. Lett. 2014, 48, 24–33. [Google Scholar] [CrossRef]
- Simonetti, E.; Simonetti, D.; Preatoni, D. Phenology-Based Land Cover Classification Using Landsat 8 Time Series; European Commission Joint Research Center: Ispra, Italy, 2014. [Google Scholar]
- Loosvelt, L.; Peters, J.; Skriver, H.; Lievens, H.; Van Coillie, F.M.B.; De Baets, B.; Verhoest, N.E.C. Random Forests as a tool for estimating uncertainty at pixel-level in SAR image classification. Int. J. Appl. Earth Obs. 2012, 19, 173–184. [Google Scholar] [CrossRef]
- Al-amri, S.; Kalyankar, N.; Khamitkar, S. A Comparative Study of Removal Noise from Remote Sensing Image. IJCSI Int. J. Comput. Sci. 2010, 7, 32–36. [Google Scholar]
- Dierking, W.; Dall, J. Sea Ice Deformation State from Synthetic Aperture Radar Imagery—Part II: Effects of Spatial Resolution and Noise Level. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2197–2207. [Google Scholar] [CrossRef]
- Barber, M.; Grings, F.; Perna, P.; Piscitelli, M.; Maas, M.; Bruscantini, C.; Jacobo-Berlles, J.; Karszenbaum, H. Speckle Noise and Soil Heterogeneities as Error Sources in a Bayesian Soil Moisture Retrieval Scheme for SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 942–951. [Google Scholar] [CrossRef]
- Benz, U.; Hofmann, P.; Willhauck, G.; Lingenfelder, I.; Heynen, M. Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J. Photogramm. Remote Sens. 2004, 58, 239–258. [Google Scholar] [CrossRef] [Green Version]
- Celik, T.; Ma, K.K. Unsupervised Change Detection for Satellite Images Using Dual-Tree Complex Wavelet Transform. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1199–1210. [Google Scholar] [CrossRef]
- Mohammed, K.; Mohamed, D.; Philippe, C. Magnitude-phase of the dual-tree quaternionic wavelet transform for multispectral satellite image denoising. EURASIP J. Image Video Process. 2014, 2014, 1–16. [Google Scholar]
- Vijay, M.; Devi, L.S. Speckle Noise Reduction in Satellite Images Using Spatially Adaptive Wavelet Thresholding. Int. J. Comput. Sci. Inf. Technol. 2012, 3, 3432–3435. [Google Scholar]
- Bhosale, N.P.; Manza, R.R. Analysis of Effect of Noise Removal Filters on Noisy Remote Sensing Images. Int. J. Sci. Eng. Res. 2013, 4, 1151. [Google Scholar]
- Data Loss, Landsat Missions, USGS. Available online: https://landsat.usgs.gov/data-loss (accessed on 5 June 2018).
- Charoenjit, K.; Zuddas, P.; Allemand, P.; Pattanakiat, S.; Pachana, K. Estimation of biomass and carbon stock in Para rubber plantations using object-based classification from Thaichote satellite data in Eastern Thailand. J. Appl. Remote Sens. 2015, 9, 096072. [Google Scholar] [CrossRef] [Green Version]
- Yahya, N.; Kamel, N.S.; Malik, A.S. Subspace-Based Technique for Speckle Noise Reduction in SAR Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6257–6271. [Google Scholar] [CrossRef]
- Raney, R.K. Radar Fundamentals: Technical Perspective. In Principles and Applications of Imaging Radar, Manual of Remote Sensing, 3rd ed.; John Wiley and Sons Inc.: Toronto, ON, Canada, 1998; Chapter 2. [Google Scholar]
- Mansourpour, M.; Rajabi, M.A.; Blais, J.A.R. Effects and Performance of Speckle Noise Reduction Filters on Active Radar and SAR Images. Proc. ISPRS 2006, 36, W41. [Google Scholar]
- Nobrega, R.A.A.; Quintanilha, J.A.; O’Hara, C.G. A noise-removal approach for LIDAR intensity images using anisotropic diffusion filtering to preserve object shape characteristics. In Proceedings of the ASPRS 2007 Annual Conference, Tampa, FL, USA, 7–11 May 2007. [Google Scholar]
- Mulder, V.L.; de Bruin, S.; Schaepman, M.E.; Mayr, T.R. The use of remote sensing in soil and terrain mapping—A review. Geoderma 2011, 162, 1–19. [Google Scholar] [CrossRef]
- Zhu, X.; Wu, X. Class Noise vs. Attribute Noise: A Quantitative Study of Their Impacts. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Alsmadi, M.K.S.; Omar, K.B.; Noah, S.A. Back Propagation Algorithm: The Best Algorithm among the Multi-layer Perceptron Algorithm. Int. J. Comput. Sci. Netw. Secur. 2009, 9, 378–383. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An Empirical Comparison of Supervised Learning Algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Dey, A. Machine Learning Algorithms: A. Review. Int. J. Comput. Sci. Inf. Technol. 2016, 7, 1174–1179. [Google Scholar]
- Kotsiantis, S.B. Supervised Machine Learning: A Review of Classification Techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- Crisci, C.; Ghattas, B.; Perera, G. A review of supervised machine learning algorithms and their applications to ecological data. Ecol. Model. 2012, 240, 113–122. [Google Scholar] [CrossRef]
- Lorena, A.C.; Jacintho, L.F.O.; Siqueira, M.F.; Giovanni, R.D.; Lohmann, L.G.; de Carvalho, A.C.P.L.F.; Yamamoto, M. Comparing machine learning classifiers in potential distribution modelling. Expert Syst. Appl. 2011, 38, 5268–5275. [Google Scholar] [CrossRef]
- Mariana, B.; Lucian, D. Random forest in remote sensing: A review of application and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Loosvelt, L.; Peters, J.; Skriver, H.; De Baets, B.; Verhoest, N.E.C. Impact of Reducing Polarimetric SAR Input on the Uncertainty of Crop Classifications Based on the Random Forests Algorithm. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4185–4200. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Insom, P.; Cao, C.; Boonsrimuang, P.; Liu, D.; Saokarn, A.; Yomwan, P.; Xu, Y. A Support Vector Machine-Based Particle Filter Method for Improved Flooding Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1943–1947. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Fusion of Hyperspectral and LIDAR Remote Sensing Data for Classification of Complex Forest Areas. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1416–1427. [Google Scholar] [CrossRef] [Green Version]
- Senf, C.; Leitao, P.J.; Pflugmacher, D.; Linden, S.V.D.; Hostert, P. Mapping land cover in complex Mediterranean landscapes using Landsat: Improved classification accuracies fromintegrating multi-seasonal and synthetic imagery. Remote Sens. Environ. 2015, 156, 527–536. [Google Scholar] [CrossRef]
- Pal, M.; Foody, G.M. Feature Selection for Classification of Hyperspectral Data by SVM. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2297–2307. [Google Scholar] [CrossRef] [Green Version]
- Cherkassky, V.; Ma, Y. Practical selection of SVM parameters and noise estimation for SVM regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef] [Green Version]
- Tseng, M.H.; Chen, S.J.; Hwang, G.H.; Shen, M.Y. A genetic algorithm rule-based approach for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2008, 63, 202–212. [Google Scholar] [CrossRef]
- Suliman, A.; Zhang, Y. A Review on Back-Propagation Neural Networks in the Application of Remote Sensing Image Classification. J. Earth Sci. Eng. 2015, 5, 52–65. [Google Scholar]
- Paola, J.D.; Schowengerdt, R.A. A review and analysis of backpropagation neural networks for classification of remotely-sensed multi-spectral imagery. Int. J. Remote Sens. 2007, 16, 3033–3058. [Google Scholar] [CrossRef]
- Burzzone, L.; Fernandez, P.D.; Cossu, R. An incremental learning classifier for remote-sensing images. In Proceedings of the IEEE 1999 International Geoscience and Remote Sensing Symposium, Hamburg, Germany, 28 June–2 July 1999; pp. 2483–2485. [Google Scholar]
- Avanaki, M.R.N.; Laissue, P.; Podoleanu, A.; Hojjat, S.A. Denoising based on noise parameter estimation in speckled OCT images using neural network. In Proceedings of the 1st Canterbury Workshop and School in Optical Coherence Tomography and Adaptive Optics, Canterbury, UK, 30 December 2008. [Google Scholar] [CrossRef]
- Kofidis, E.; Theodoridis, S.; Kotropoulos, C.; Pitas, I. Application of Neural Networks and Order Statistics Filters to Speckle Noise Reduction in Remote Sensing Imaging. In Neurocomputation in Remote Sensing Data Analysis; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar] [CrossRef]
- Silva, I.B.V.D.; Adeodato, P.J.L. PCA and Gaussian noise in MLP neural network training improve generalization in problems with small and unbalanced data sets. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2664–2669. [Google Scholar] [CrossRef]
- Corner, B.R.; Narayanan, R.M.; Reichenbach, S.E. Noise estimation in remote sensing imagery using data masking. Int. J. Remote Sens. 2003, 24, 689–702. [Google Scholar] [CrossRef]
- Breiman, L. Manual on Setting Up, Using, and Understanding Random Forests v3.1; Department of Statistics, University of California: Berkeley, CA, USA, 2002. [Google Scholar]
- Moller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and Regression by Random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machine. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Rodríguez-Fernández, N.J.; Kerr, Y.H.; van der Schalie, R.; Al-Yaari, A.; Wigneron, J.P.; de Jeu, R.; Richaume, P.; Dutra, E.; Mialon, A.; Drusch, M. Long Term Global Surface Soil Moisture Fields Using an SMOS-Trained Neural Network Applied to AMSR-E Data. Remote Sens. 2016, 8, 959. [Google Scholar] [CrossRef]
- Hu, X.; Yuan, Y. Deep-Learning-Based Classification for DTM Extraction from ALS Point Cloud. Remote Sens. 2016, 8, 730. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Cheng, X.; Wang, L. A Comparison of Machine Learning Algorithms for Mapping of Complex Surface-Mined and Agricultural Landscapes Using ZiYuan-3 Stereo Satellite Imagery. Remote Sens. 2016, 8, 514. [Google Scholar] [CrossRef]
- Yu, H.; Gao, L.; Li, J.; Li, S.S.; Zhang, B.; Benediktsson, J. Spectral-Spatial Hyperspectral Image Classification Using Subspace-Based Support Vector Machines and Adaptive Markov Random Fields. Remote Sens. 2016, 8, 355. [Google Scholar] [CrossRef]
- Wessels, K.J.; van den Bergh, F.; Roy, D.P.; Salmon, B.P.; Steenkamp, K.C.; MacAlister, B.; Swanepoel, D.; Jewitt, D. Rapid Land Cover Map Updates Using Change Detection and Robust Random Forest Classifiers. Remote Sens. 2016, 8, 888. [Google Scholar] [CrossRef]
- Shrestha, R.; Wynne, R.H. Estimating biophysical parameters of individual trees in an urban environment using small footprint discrete-return imaging Lidar. Remote Sens. 2012, 4, 484–508. [Google Scholar] [CrossRef]
- Boonprong, S.; Cao, C.; Torteeka, P.; Chen, W. A Novel Classification Technique of Landsat-8 OLI Image-Based Data Visualization: The Application of Andrews’ Plots and Fuzzy Evidential Reasoning. Remote Sens. 2017, 9, 427. [Google Scholar] [CrossRef]
- Chang, E.S.; Hung, C.C.; Liu, W.; Yin, J. A Denoising Algorithm for Remote Sensing Images with Impulse Noise. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 2905–2908. [Google Scholar]
- Zadeh, L.A. Fuzzy Sets. Inf. Control 1965, 8, 338–355. [Google Scholar] [CrossRef]
- Bonissone, P.; Cadenas, J.M.; Garrido, M.C.; Díaz-Valladares, R.A. A fuzzy random forest. Int. J. Approx. Reason. 2010, 51, 729–747. [Google Scholar] [CrossRef]
- Zhong, X.; Li, J.; Dou, H.; Deng, S.; Wang, G.; Jiang, Y.; Wang, Y.; Zhou, Z.; Wang, L.; Yan, F. Fuzzy Nonlinear Proximal Support Vector Machine for Land Extraction Based on Remote Sensing Image. PLoS ONE 2013, 8, e69434. [Google Scholar] [CrossRef] [PubMed]
- Goodarzi, R.; Mokhtarzade, M.; Zoej, M.J.V. A Robust Fuzzy Neural Network Model for Soil Lead Estimation from Spectral Features. Remote Sens. 2015, 7, 8416–8435. [Google Scholar] [CrossRef] [Green Version]
- Ozturk, D. Urban Growth Simulation of Atakum (Samsun, Turkey) Using Cellular Automata-Markov Chain and Multi-Layer Perceptron-Markov Chain Models. Remote Sens. 2015, 7, 5918–5950. [Google Scholar] [CrossRef] [Green Version]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1–21. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | Descriptions | M * | A * |
|---|---|---|---|
| Agriculture | Artificial planting area/no harvested area included | 504 | 126 |
| Bare land | Land used without vegetation cover | 440 | 110 |
| Construction | Houses, roads, and any man-made construction | 80 | 20 |
| Water body | Water bodies such as ponds, lakes, and rivers | 344 | 86 |
| Forest | Area covered by natural and unused vegetation, mountain shadow | 2048 | 512 |
| Total | 3416 | 854 | |
| Classifiers | Cross-Validation Approaches/Parameters |
|---|---|
| Random forests (RF) | ntree = {500, 1000, 1500, 2000}, mtry = {2, 3, 4, 5}, 30 replications |
| Support vector machines (SVM) | Grid-search cross-validation approach, radial basis function kernel, 30 replications |
| Back-propagation neural networks (BPNN) | Scale conjugated gradient optimization, 70% training, 15% testing, 15% validating, hidden nodes = {5, 10, 15, 20, 40, 60}, 30 replications |
| RI | NI | G10 | G15 | G20 | G25 | G30 | G35 | G40 | SP10 | SP15 | SP20 | SP25 | SP30 | SP35 | SP40 | SPK10 | SPK15 | SPK20 | SPK25 | SPK30 | SPK35 | SPK40 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PA1 | 99.2 | 97.6 | 7.1 | 38.1 | 69.8 | 87.3 | 92.1 | 91.3 | 96.0 | 78.6 | 94.4 | 90.5 | 95.2 | 96.8 | 98.4 | 96.8 | 27.8 | 46.8 | 72.2 | 84.9 | 94.4 | 91.3 | 93.7 |
| PA2 | 97.3 | 99.1 | 46.4 | 81.8 | 86.4 | 95.5 | 97.3 | 97.3 | 98.2 | 90.9 | 96.4 | 97.3 | 97.3 | 98.2 | 99.1 | 100 | 44.5 | 76.4 | 90.0 | 95.5 | 97.3 | 97.3 | 99.1 |
| PA3 | 95.0 | 85.0 | 0 | 0 | 0 | 0 | 5.0 | 70.0 | 85.0 | 0 | 0 | 0 | 75.0 | 80.0 | 95.0 | 95.0 | 0 | 0 | 0 | 0 | 30.0 | 65.0 | 80.0 |
| PA4 | 100 | 100 | 39.5 | 76.7 | 91.9 | 100 | 100 | 100 | 100 | 81.4 | 91.9 | 100 | 97.7 | 100 | 100 | 100 | 87.2 | 100 | 100 | 100 | 100 | 100 | 100 |
| PA5 | 99.8 | 99.6 | 91.6 | 91.8 | 94.3 | 96.9 | 98.0 | 99.0 | 99.4 | 97.7 | 97.5 | 97.3 | 97.9 | 99.6 | 99.4 | 99.6 | 92.0 | 93.9 | 94.3 | 96.3 | 97.7 | 98.8 | 99.8 |
| UA1 | 98.4 | 99.2 | 47.4 | 54.5 | 71.5 | 85.3 | 89.9 | 98.3 | 98.4 | 88.4 | 88.8 | 92.7 | 92.3 | 98.4 | 99.2 | 100 | 40.7 | 56.7 | 73.4 | 82.3 | 89.5 | 95.0 | 99.2 |
| UA2 | 98.2 | 95.6 | 57.3 | 81.1 | 87.2 | 90.5 | 91.5 | 93.9 | 94.7 | 84.7 | 92.2 | 90.7 | 94.7 | 96.4 | 98.2 | 98.2 | 53.8 | 75.0 | 84.6 | 87.5 | 93.9 | 93.0 | 97.3 |
| UA3 | 95.0 | 100 | 0 | 0 | 0 | 0 | 50.0 | 87.5 | 100 | 0 | 0 | 0 | 83.3 | 88.9 | 90.5 | 90.5 | 0 | 0 | 0 | 0 | 75.0 | 92.9 | 94.1 |
| UA4 | 100 | 100 | 60.7 | 77.6 | 94.0 | 96.6 | 100 | 100 | 100 | 94.6 | 98.8 | 94.5 | 100 | 100 | 100 | 100 | 87.2 | 93.5 | 100 | 100 | 100 | 100 | 100 |
| UA5 | 99.8 | 99.4 | 68.0 | 82.5 | 89.8 | 95.4 | 96.5 | 97.3 | 99.0 | 91.2 | 95.0 | 95.6 | 98.4 | 99.2 | 99.6 | 99.4 | 79.7 | 88.1 | 91.7 | 95.2 | 97.5 | 97.7 | 98.3 |
| OAm0 | 99.7 | 99.9 | 90.6 | 93.7 | 96.4 | 97.9 | 98.6 | 99.6 | 99.7 | 98.2 | 98.6 | 98.5 | 99.4 | 99.6 | 99.8 | 99.8 | 93.9 | 96.2 | 96.8 | 97.6 | 98.8 | 99.3 | 99.7 |
| OAV0 | 99.3 | 98.9 | 65.9 | 78.9 | 87.2 | 93.3 | 95.1 | 97.1 | 98.5 | 90.0 | 94.0 | 94.3 | 96.8 | 98.6 | 99.2 | 99.2 | 73.8 | 83.1 | 88.9 | 92.6 | 95.8 | 96.8 | 98.4 |
| K0 | 0.99 | 0.98 | 0.31 | 0.62 | 0.78 | 0.89 | 0.92 | 0.95 | 0.97 | 0.83 | 0.90 | 0.90 | 0.95 | 0.98 | 0.99 | 0.99 | 0.52 | 0.70 | 0.81 | 0.87 | 0.93 | 0.95 | 0.97 |
| OAm1 | 99.1 | 99.0 | 90.3 | 93.4 | 96.2 | 97.7 | 98.4 | 98.9 | 99.0 | 96.8 | 98.1 | 98.2 | 98.8 | 98.9 | 99.1 | 99.3 | 92.9 | 95.3 | 96.4 | 97.3 | 98.4 | 98.8 | 98.8 |
| OAV1 | 96.7 | 96.4 | 65.2 | 78.0 | 86.7 | 92.7 | 94.5 | 95.7 | 96.5 | 86.9 | 92.6 | 93.1 | 94.9 | 96.5 | 97.1 | 97.2 | 71.1 | 81.0 | 87.7 | 90.8 | 95.1 | 95.5 | 95.4 |
| K1 | 0.94 | 0.94 | 0.28 | 0.60 | 0.77 | 0.88 | 0.90 | 0.93 | 0.94 | 0.76 | 0.87 | 0.88 | 0.91 | 0.94 | 0.95 | 0.95 | 0.46 | 0.66 | 0.79 | 0.84 | 0.92 | 0.92 | 0.92 |
| OAm2 | 0.60 | 0.95 | 2.51 | 0.33 | 0.19 | 0.34 | 0.28 | 0.41 | 0.34 | 0.28 | 0.15 | 0.15 | 0.11 | 0.10 | 0.29 | 0.28 | 1.34 | 1.17 | 0.62 | 0.79 | 0.14 | 0.20 | 0.93 |
| OAV2 | 2.14 | 3.45 | 0.55 | 0.45 | 0.30 | 0.30 | 0.25 | 0.60 | 0.76 | 5.32 | 0.68 | 0.48 | 1.11 | 0.77 | 1.17 | 1.14 | 3.30 | 3.26 | 2.06 | 2.77 | 0.38 | 0.48 | 3.40 |
| K2 | 0.060 | 0.039 | 0.017 | 0.008 | 0.005 | 0.005 | 0.005 | 0.011 | 0.013 | 0.143 | 0.012 | 0.008 | 0.019 | 0.013 | 0.020 | 0.020 | 0.090 | 0.072 | 0.042 | 0.052 | 0.007 | 0.009 | 0.061 |
| RI | NI | G10 | G15 | G20 | G25 | G30 | G35 | G40 | SP10 | SP15 | SP20 | SP25 | SP30 | SP35 | SP40 | SPK10 | SPK15 | SPK20 | SPK25 | SPK30 | SPK35 | SPK40 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PA1 | 99.2 | 97.6 | 0 | 26.2 | 68.3 | 88.9 | 90.5 | 94.4 | 97.6 | 77.0 | 90.5 | 95.2 | 96.8 | 97.6 | 98.4 | 96.0 | 25.4 | 49.2 | 67.5 | 82.5 | 91.3 | 91.3 | 94.4 |
| PA2 | 100 | 98.2 | 37.3 | 84.5 | 87.3 | 92.7 | 97.3 | 100 | 100 | 90.9 | 97.3 | 98.2 | 99.1 | 96.4 | 99.1 | 98.2 | 52.7 | 73.6 | 89.1 | 90.9 | 98.2 | 98.2 | 99.1 |
| PA3 | 100 | 95 | 0 | 0 | 0 | 10.0 | 40.0 | 55.0 | 90.0 | 10.0 | 65.0 | 85.0 | 85.0 | 90.0 | 95.0 | 95.0 | 0 | 0 | 0 | 0 | 40.0 | 80.0 | 85.0 |
| PA4 | 100 | 100 | 27.9 | 76.7 | 94.2 | 98.8 | 100 | 100 | 100 | 87.2 | 97.7 | 100 | 100 | 100 | 100 | 100 | 89.5 | 98.8 | 100 | 100 | 100 | 100 | 100 |
| PA5 | 99.6 | 99.6 | 94.9 | 94.3 | 93.4 | 96.7 | 98.0 | 99.2 | 99.6 | 97.5 | 97.9 | 99.0 | 99.4 | 99.6 | 99.6 | 99.4 | 92.0 | 94.3 | 94.9 | 96.3 | 97.7 | 99.0 | 99.6 |
| UA1 | 100 | 98.4 | 0 | 62.3 | 68.3 | 83.6 | 91.9 | 98.3 | 99.2 | 85.8 | 94.2 | 96.0 | 98.4 | 98.4 | 99.2 | 98.4 | 47.8 | 59.0 | 70.8 | 80.6 | 89.8 | 95.0 | 99.2 |
| UA2 | 98.2 | 98.2 | 55.4 | 84.5 | 88.1 | 90.3 | 93.9 | 94.8 | 97.3 | 90.9 | 93.0 | 97.3 | 98.2 | 97.2 | 98.2 | 98.2 | 57.4 | 79.4 | 84.5 | 87.7 | 93.1 | 94.7 | 96.5 |
| UA3 | 100 | 100 | 0 | 0 | 0 | 66.7 | 88.9 | 100 | 100 | 25.0 | 81.3 | 100 | 94.4 | 94.7 | 95.0 | 86.4 | 0 | 0 | 0 | 0 | 88.9 | 100 | 100 |
| UA4 | 100 | 100 | 68.6 | 75.9 | 92.0 | 97.7 | 100 | 100 | 100 | 96.2 | 97.7 | 100 | 100 | 100 | 100 | 100 | 84.6 | 95.5 | 100 | 100 | 100 | 100 | 100 |
| UA5 | 99.8 | 99.2 | 65.2 | 80.0 | 90.0 | 95.7 | 96.4 | 97.7 | 99.4 | 91.6 | 97.1 | 98.4 | 98.8 | 99.0 | 99.6 | 99.2 | 79.2 | 87.0 | 91.4 | 94.1 | 97.1 | 98.1 | 98.5 |
| OAm0 | 99.5 | 99.4 | 64.5 | 77.2 | 87.2 | 93.3 | 98.7 | 98.1 | 98.8 | 89.4 | 96.2 | 98.1 | 98.3 | 98.7 | 99.0 | 99.2 | 75.9 | 85.0 | 88.1 | 92.5 | 96.1 | 97.9 | 98.8 |
| OAV0 | 99.6 | 99.1 | 64.5 | 79.0 | 86.8 | 93.2 | 95.7 | 97.7 | 99.2 | 90.5 | 95.9 | 98.1 | 98.7 | 98.7 | 99.3 | 98.7 | 74.7 | 83.3 | 88.4 | 91.7 | 95.7 | 97.4 | 98.5 |
| K0 | 0.99 | 0.98 | 0.23 | 0.61 | 0.77 | 0.88 | 0.93 | 0.96 | 0.99 | 0.83 | 0.93 | 0.97 | 0.98 | 0.98 | 0.99 | 0.98 | 0.54 | 0.70 | 0.80 | 0.86 | 0.93 | 0.96 | 0.97 |
| OAm1 | 99.5 | 99.4 | 64.5 | 77.2 | 87.2 | 93.3 | 98.7 | 98.1 | 98.8 | 89.4 | 96.2 | 98.1 | 98.3 | 98.7 | 99.0 | 99.2 | 75.9 | 85.0 | 88.1 | 92.5 | 96.1 | 97.9 | 98.8 |
| OAV1 | 99.6 | 99.1 | 64.5 | 79.0 | 86.8 | 93.2 | 95.4 | 97.7 | 99.2 | 90.4 | 95.7 | 98.0 | 98.4 | 98.7 | 99.3 | 98.7 | 74.5 | 83.2 | 88.3 | 91.6 | 95.5 | 97.3 | 98.5 |
| K1 | 0.99 | 0.98 | 0.23 | 0.61 | 0.77 | 0.88 | 0.92 | 0.96 | 0.99 | 0.83 | 0.93 | 0.97 | 0.97 | 0.98 | 0.99 | 0.98 | 0.53 | 0.70 | 0.80 | 0.86 | 0.92 | 0.95 | 0.97 |
| OAm2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| OAV2 | 0.02 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | 0.06 | 0.00 | 0.00 | 0.06 | 0.14 | 0.05 | 0.12 | 0.00 | 0.04 | 0.00 | 0.08 | 0.04 | 0.06 | 0.06 | 0.04 | 0.07 | 0.04 |
| K2 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.001 | 0.002 | 0.001 | 0.002 | 0.000 | 0.001 | 0.000 | 0.002 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| RI | NI | G10 | G15 | G20 | G25 | G30 | G35 | G40 | SP10 | SP15 | SP20 | SP25 | SP30 | SP35 | SP40 | SPK10 | SPK15 | SPK20 | SPK25 | SPK30 | SPK35 | SPK40 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PA1 | 97.6 | 95.2 | 10.3 | 23.8 | 66.7 | 84.9 | 92.9 | 96.0 | 94.4 | 87.3 | 93.7 | 94.4 | 94.4 | 94.4 | 95.2 | 95.2 | 27.8 | 57.9 | 71.4 | 83.3 | 92.9 | 93.7 | 95.2 |
| PA2 | 100 | 100 | 45.5 | 81.8 | 90.0 | 96.4 | 97.3 | 98.2 | 98.2 | 95.5 | 99.1 | 98.2 | 99.1 | 100 | 99.1 | 100 | 50.9 | 80.0 | 92.7 | 93.6 | 99.1 | 98.2 | 97.3 |
| PA3 | 95 | 70.0 | 0 | 0 | 0 | 10.0 | 20.0 | 45.0 | 65.0 | 0 | 35.0 | 60.0 | 60.0 | 60.0 | 70.0 | 70.0 | 0 | 0 | 0 | 0 | 25.0 | 55.0 | 65.0 |
| PA4 | 100 | 100 | 31.4 | 69.8 | 90.7 | 98.8 | 100 | 98.8 | 100 | 98.8 | 98.8 | 100 | 100 | 100 | 100 | 100 | 88.4 | 98.8 | 100 | 100 | 100 | 100 | 100 |
| PA5 | 99.4 | 99.4 | 88.9 | 93.4 | 93.9 | 96.9 | 97.9 | 99.2 | 99.4 | 98.8 | 99.2 | 99.0 | 99.0 | 99.6 | 99.6 | 99.4 | 93.2 | 94.3 | 94.7 | 96.5 | 97.7 | 98.8 | 99.2 |
| UA1 | 100 | 99.2 | 35.1 | 46.2 | 71.8 | 84.3 | 90.7 | 97.6 | 97.5 | 90.9 | 97.5 | 97.5 | 96.7 | 99.2 | 99.2 | 99.2 | 41.7 | 60.8 | 72.6 | 82.0 | 90.0 | 95.2 | 96.0 |
| UA2 | 96.5 | 94.8 | 53.2 | 78.3 | 85.3 | 92.2 | 92.2 | 95.6 | 93.9 | 92.1 | 92.4 | 93.9 | 94.8 | 93.2 | 94.8 | 95.7 | 57.1 | 80.7 | 84.3 | 88.0 | 92.4 | 93.9 | 94.7 |
| UA3 | 100 | 100 | 0 | 0 | 0 | 66.7 | 100 | 81.8 | 92.9 | 0 | 100 | 92.3 | 85.7 | 100 | 93.3 | 93.3 | 0 | 0 | 0 | 0 | 100 | 91.7 | 100 |
| UA4 | 100 | 100 | 50.9 | 82.2 | 94.0 | 97.7 | 100 | 100 | 100 | 98.8 | 100 | 98.9 | 100 | 100 | 100 | 100 | 91.6 | 97.7 | 100 | 100 | 100 | 100 | 100 |
| UA5 | 99.4 | 98.5 | 67.9 | 79.5 | 89.4 | 95.0 | 96.5 | 97.5 | 98.5 | 94.9 | 97.1 | 98.1 | 98.3 | 98.5 | 98.6 | 98.5 | 81.0 | 89.8 | 92.7 | 94.5 | 97.1 | 97.9 | 98.3 |
| OAm0 | 99.7 | 98.9 | 67.0 | 78.0 | 89.5 | 93.9 | 96.3 | 98.0 | 98.5 | 95.3 | 97.9 | 98.7 | 98.8 | 98.9 | 99.0 | 98.9 | 78.0 | 87.9 | 88.9 | 93.6 | 96.3 | 98.0 | 98.8 |
| OAV0 | 99.2 | 98.2 | 63.8 | 77.8 | 86.9 | 93.2 | 95.4 | 97.3 | 97.8 | 94.4 | 96.8 | 97.4 | 97.5 | 98.0 | 98.2 | 98.2 | 75.4 | 85.4 | 89.3 | 92.3 | 95.7 | 97.1 | 97.7 |
| K0 | 0.99 | 0.97 | 0.28 | 0.58 | 0.77 | 0.88 | 0.92 | 0.95 | 0.96 | 0.90 | 0.95 | 0.96 | 0.96 | 0.97 | 0.97 | 0.97 | 0.55 | 0.75 | 0.82 | 0.87 | 0.93 | 0.95 | 0.96 |
| OAm1 | 99.1 | 98.5 | 63.3 | 76.6 | 86.8 | 92.6 | 95.4 | 97.3 | 97.9 | 94.5 | 97.0 | 97.6 | 97.9 | 98.3 | 98.3 | 98.3 | 76.7 | 85.6 | 88.3 | 92.5 | 95.3 | 97.1 | 97.9 |
| OAV1 | 98.8 | 97.8 | 62.8 | 76.7 | 86.0 | 92.7 | 94.9 | 96.9 | 97.1 | 93.8 | 96.4 | 97.1 | 97.0 | 97.7 | 97.7 | 97.8 | 74.7 | 84.8 | 88.7 | 91.6 | 95.2 | 96.5 | 97.1 |
| K1 | 0.98 | 0.96 | 0.25 | 0.57 | 0.75 | 0.87 | 0.91 | 0.95 | 0.95 | 0.89 | 0.94 | 0.95 | 0.95 | 0.96 | 0.96 | 0.96 | 0.54 | 0.74 | 0.81 | 0.86 | 0.92 | 0.94 | 0.95 |
| OAm2 | 0.27 | 0.25 | 1.35 | 1.05 | 0.91 | 0.71 | 0.60 | 0.41 | 0.49 | 0.58 | 0.47 | 0.47 | 0.44 | 0.33 | 0.37 | 0.35 | 0.79 | 0.92 | 0.50 | 0.62 | 0.53 | 0.51 | 0.46 |
| OAV2 | 0.19 | 0.17 | 0.81 | 0.53 | 0.47 | 0.31 | 0.28 | 0.25 | 0.30 | 0.28 | 0.22 | 0.20 | 0.29 | 0.25 | 0.27 | 0.25 | 0.46 | 0.42 | 0.30 | 0.31 | 0.27 | 0.27 | 0.25 |
| K2 | 0.003 | 0.003 | 0.016 | 0.011 | 0.009 | 0.005 | 0.005 | 0.004 | 0.005 | 0.005 | 0.004 | 0.003 | 0.005 | 0.004 | 0.005 | 0.004 | 0.009 | 0.007 | 0.005 | 0.005 | 0.005 | 0.005 | 0.004 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boonprong, S.; Cao, C.; Chen, W.; Ni, X.; Xu, M.; Acharya, B.K. The Classification of Noise-Afflicted Remotely Sensed Data Using Three Machine-Learning Techniques: Effect of Different Levels and Types of Noise on Accuracy. ISPRS Int. J. Geo-Inf. 2018, 7, 274. https://doi.org/10.3390/ijgi7070274
Boonprong S, Cao C, Chen W, Ni X, Xu M, Acharya BK. The Classification of Noise-Afflicted Remotely Sensed Data Using Three Machine-Learning Techniques: Effect of Different Levels and Types of Noise on Accuracy. ISPRS International Journal of Geo-Information. 2018; 7(7):274. https://doi.org/10.3390/ijgi7070274
Chicago/Turabian StyleBoonprong, Sornkitja, Chunxiang Cao, Wei Chen, Xiliang Ni, Min Xu, and Bipin Kumar Acharya. 2018. "The Classification of Noise-Afflicted Remotely Sensed Data Using Three Machine-Learning Techniques: Effect of Different Levels and Types of Noise on Accuracy" ISPRS International Journal of Geo-Information 7, no. 7: 274. https://doi.org/10.3390/ijgi7070274