Real-Time Recognition of Action Sequences Using a Distributed Video Sensor Network

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction

1.1. Contributions
- Distributed processing for real-time efficiency: In order to avoid overloading the network with too much data, it is important to ensure that individual frames are locally processed and only relevant data is sent to a fusion center for final classification [5]. At the same time, in the context of real-time recognition, it is equally important to keep the computational overhead low, so that data can be locally processed at a high enough frame rate. Lower frame rates of processing will lead to lower data sampling rates, and key motion information will be lost, resulting in lower classification accuracy. Therefore, there is a need to avoid computationally expensive approaches for local feature extraction.In this paper, we show how aggregated locality-specific motion information obtained from the spatio-temporal shape of a human silhouette, when used concurrently with information from multiple views using our fusion strategy, can yield good classification rates. Relying on such computationally simple operations for local processing lends itself to an efficient distributed implementation.
- Combining multi-view information: When using information from multiple views for action recognition, the angle made by the subject with respect to a camera while performing an action is not known. Pose estimation of a human subject based on body posture itself is a hard problem, and it is, therefore, not practical to assume that information. View-invariant techniques, on the other hand, do not fully utilize the variations in multi-view information that is available for classification [6]. The question then arises as to how view-specific classifiers can be used without knowledge of subject orientation.To address this challenge, instead of feature-level fusion of multi-camera data, we use an output-level score-based fusion strategy to combine information from a multi-view camera network for recognizing human actions [7]. By doing so, we are able to use the knowledge of camera deployment at run-time and seamlessly fuse data without having to re-train classifiers and without compromising on accuracy. Moreover, we note that the cameras acquiring data may not be deployed in any symmetry. It is not feasible to assume that the entire 360 degree view for the action being performed is available; only data from some viewing directions may be available. It is also infeasible to assume that camera configuration stays the same between the training phase and the actual testing phase. We show how our fusion technique can seamlessly handle these cases. Also, as opposed to using only the best-view in classification [8], the proposed design utilizes information from all available views, yielding higher accuracy.The proposed score fusion technique is independent of the underlying view-specific classifier applied to generate scores from individual views. In fact, we evaluate the performance of our system using two different supervised-learning classifiers: Support Vector Machines and Linear Discriminant Analysis.
- Variable length inter-leaved action sequences: It is not sufficient to evaluate the performance of an action recognition system assuming that each action is of a fixed length and that each action occurs in isolation. In reality, human activity action recognition involves classification of continuously streaming data from multiple views, which consists of an interleaved sequence of various human actions. Single or multi-layer sequential approaches, such as hidden Markov models (HMMs) [9,10,11], dynamic Bayesian networks (DBNs) [12,13] or context-free grammars [14,15,16,17], have been designed to address this challenge and to recognize longer activities and activities involving multiple subjects. However, sequential approaches for activity recognition have mainly been studied only in the context of single views and not for the case of multi-view camera networks without knowledge of subject orientation. Doing the same in a multi-camera video sensor network setting is much more challenging, because data is continuously streaming in from multiple sources, which have to be parsed in real-time.In this paper, we describe how our multi-camera score fusion technique can be augmented to achieve real-time recognition of interleaved action sequences. We consider a human activity to be composed of individual unit actions that may each be of variable length and interleaved in a non-deterministic order. Our fusion technique is then applied to streaming multi-view data to classify all unit actions in a given sequence.
- Performance evaluation using a portable camera network: We implement our activity recognition framework on an embedded, wireless video sensor network testbed assembled using Logitech 9000 cameras and an Intel Atom 230 processor-based computing platform. We use this system to first evaluate the performance of the score fusion strategy on individual unit actions and, subsequently, on interleaved action sequences. We systematically evaluate the system in the presence of arbitrary subject orientation with respect to the cameras and under failures of different subsets of cameras. We consider action sequences to be composed of an interleaved set of nine pre-trained actions along with some arbitrary actions for which the system is not pre-trained. We demonstrate that the system is also able to accurately recognize actions that belong to the class of trained actions, as well as reject actions that do not belong to the trained set. (This paper is a substantially extended version of our paper titled Real-time activity recognition using a wireless camera network that appeared at the IEEE Conference on Distributed Smart Cameras (ICDSC 2011). Specifically, we have developed an algorithm that builds on the fusion framework described in [7] to identify interleaved sequences of human actions. We have also evaluated the performance of this system using a portable wireless video sensor network assembled using off-the-shelf components.)
1.2. Related Work
1.3. Outline of the Paper
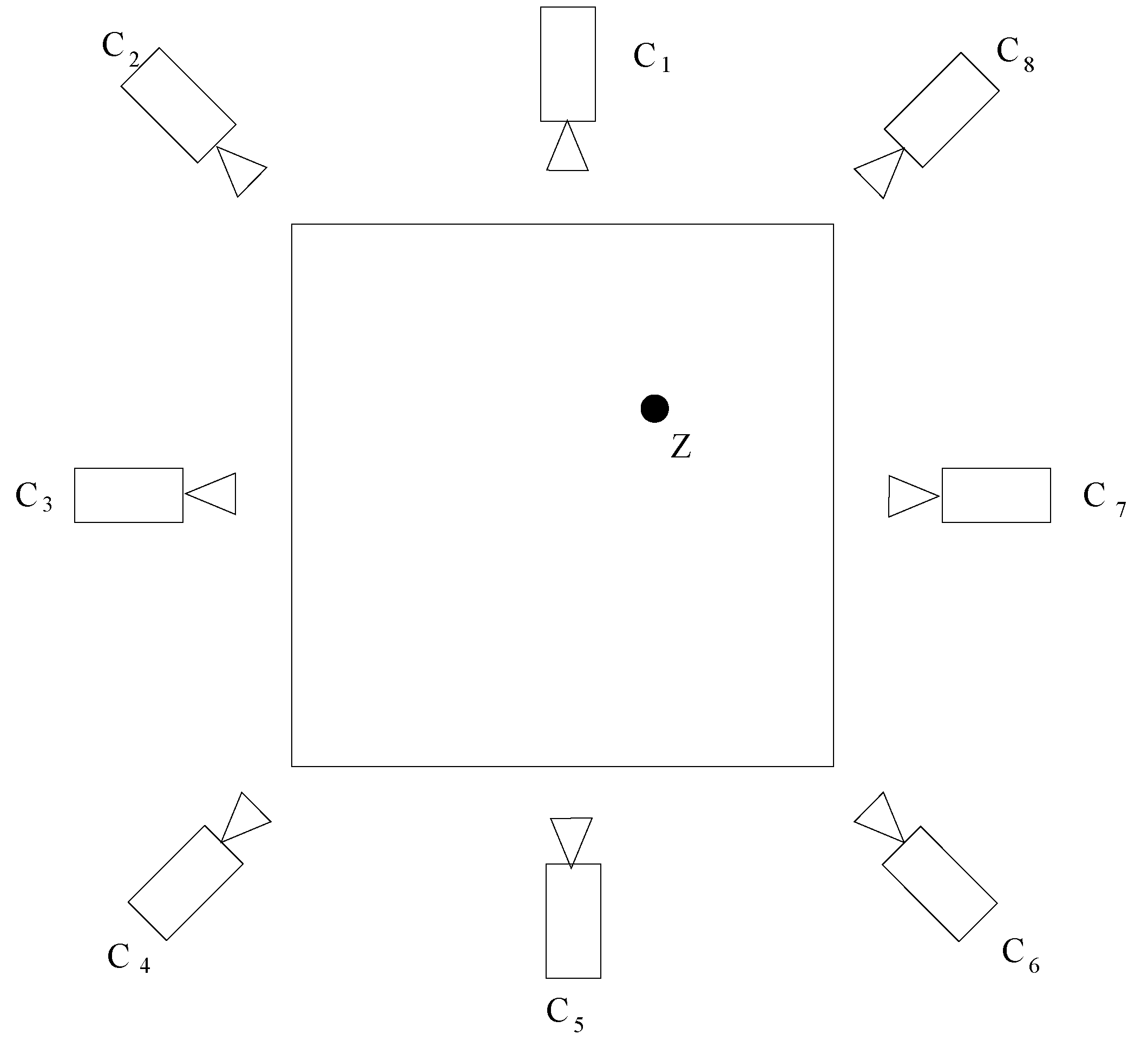
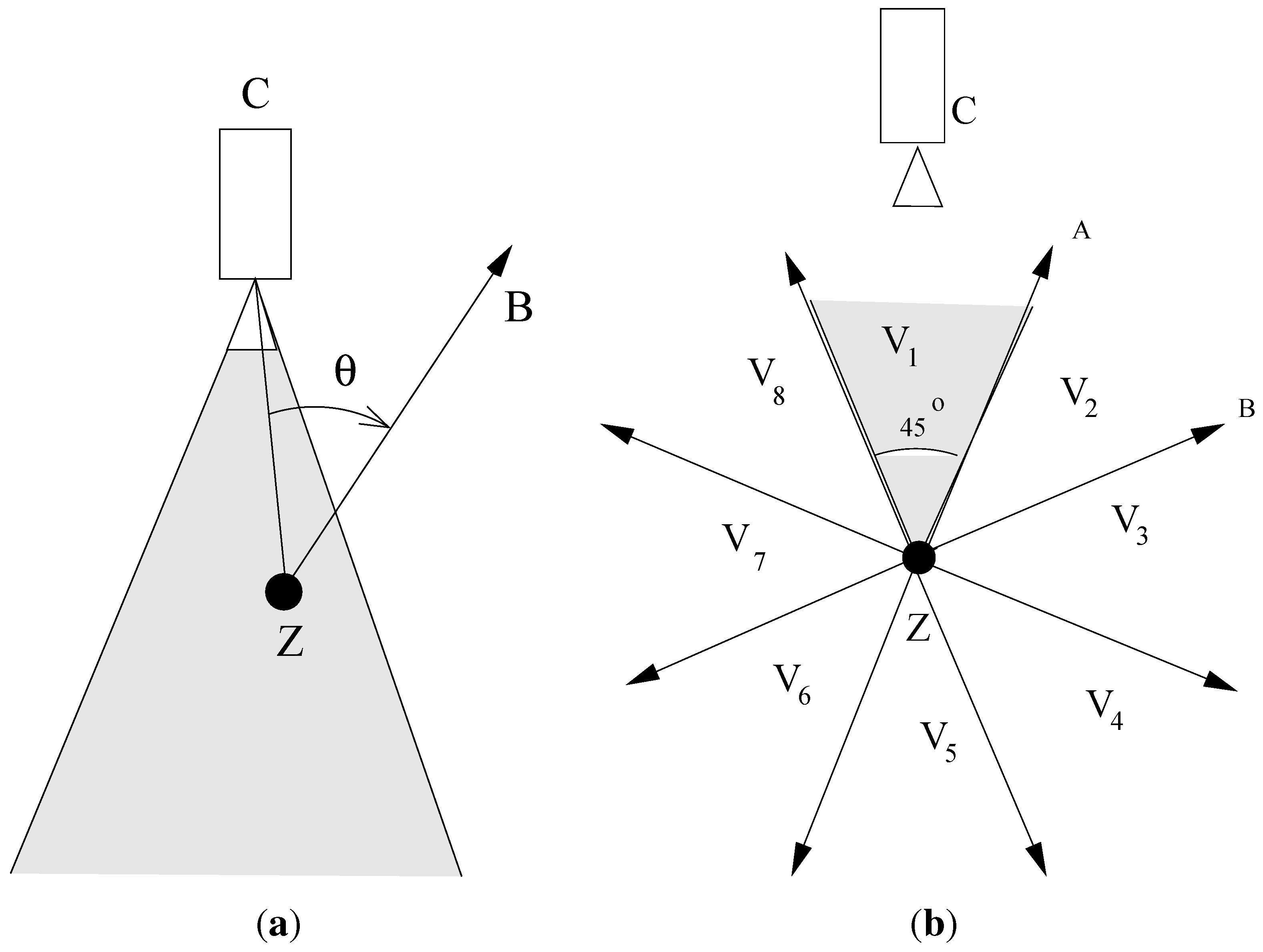
2. Model and Problem Statement
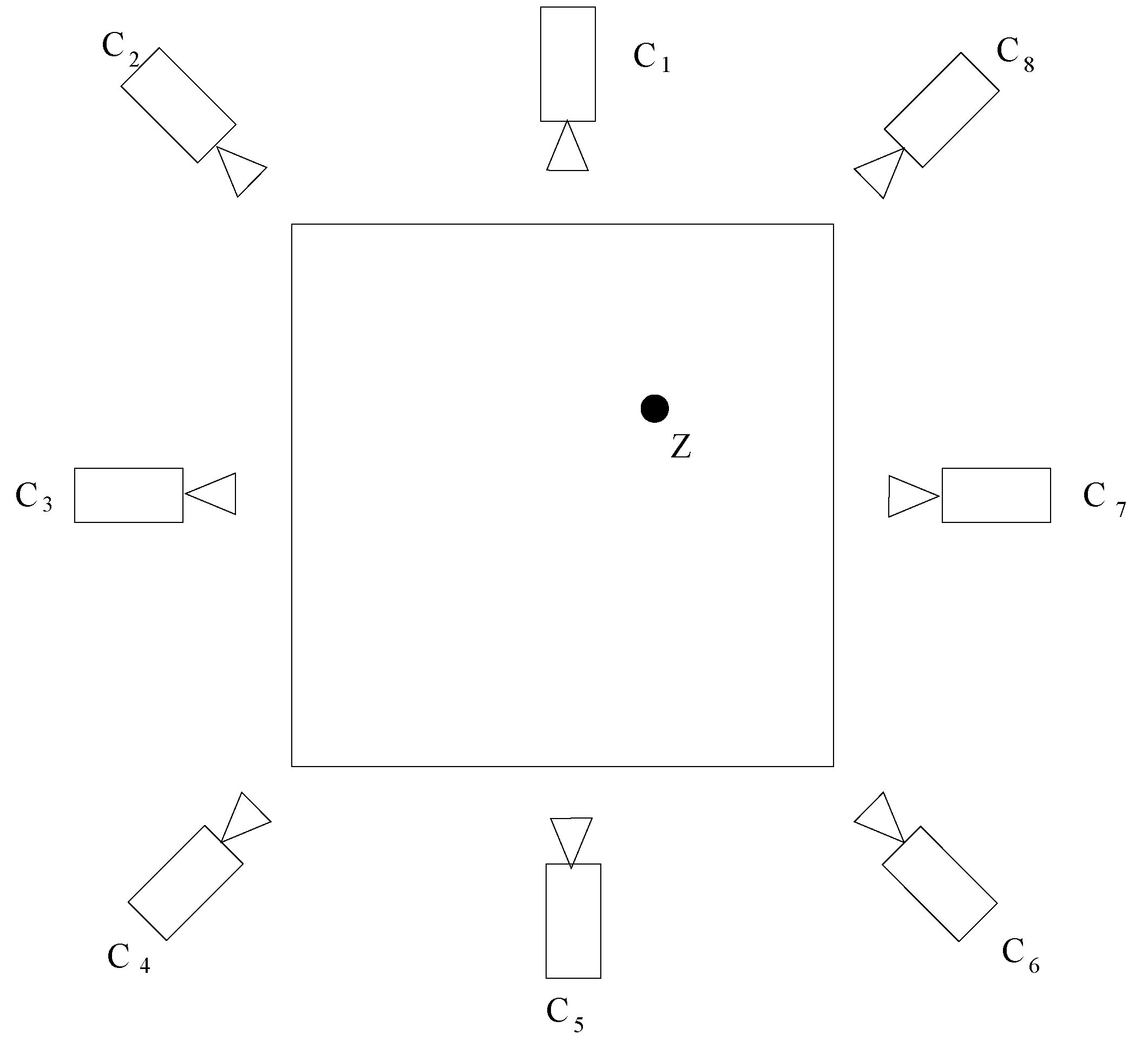
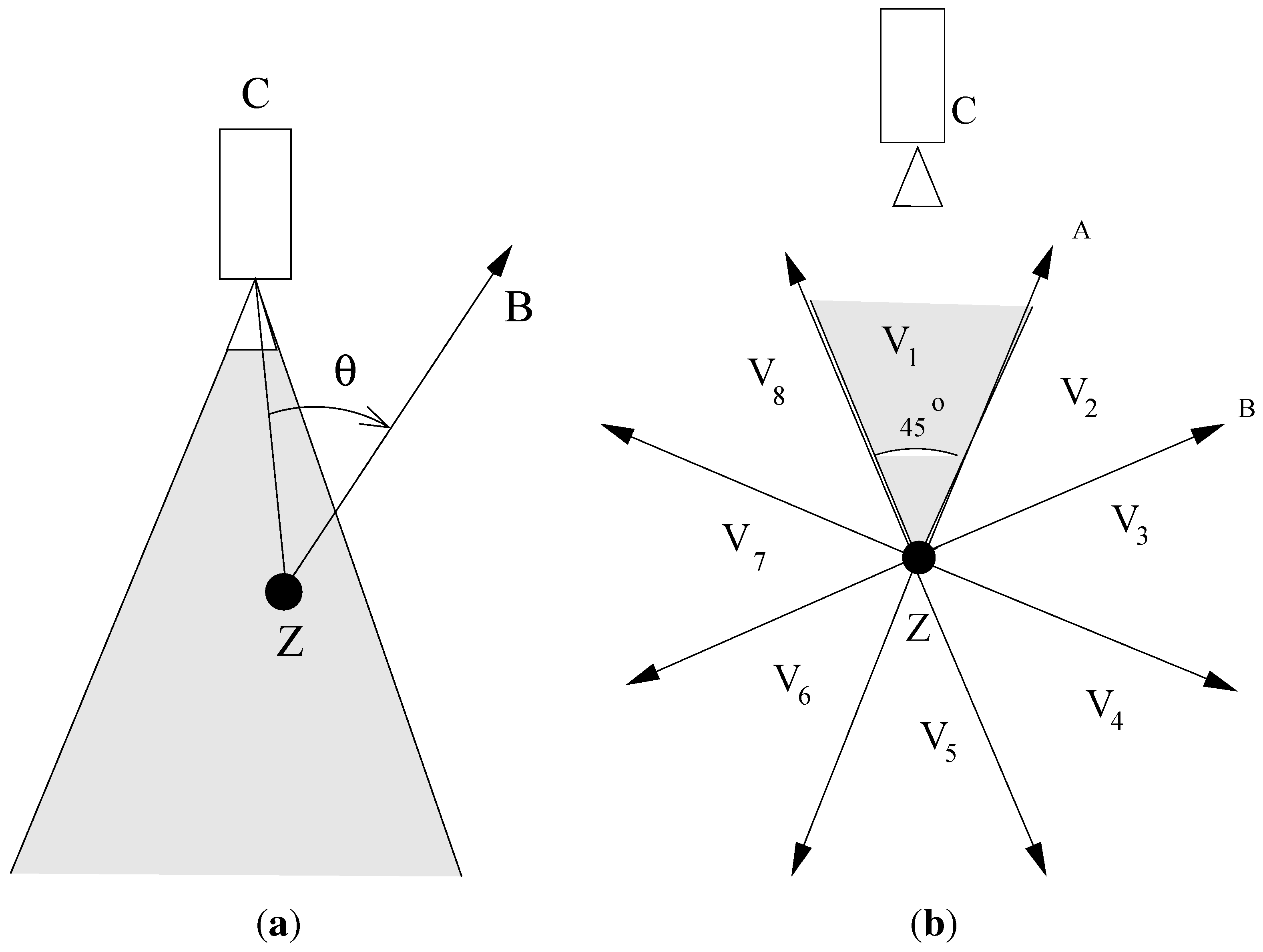
3. System Description
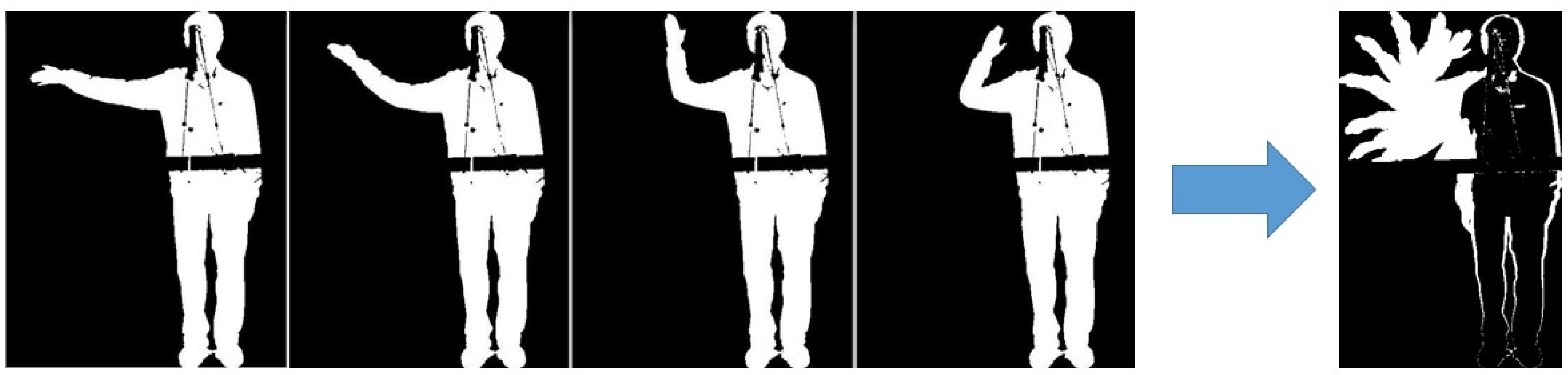
3.1. Extraction of Local Feature Descriptors
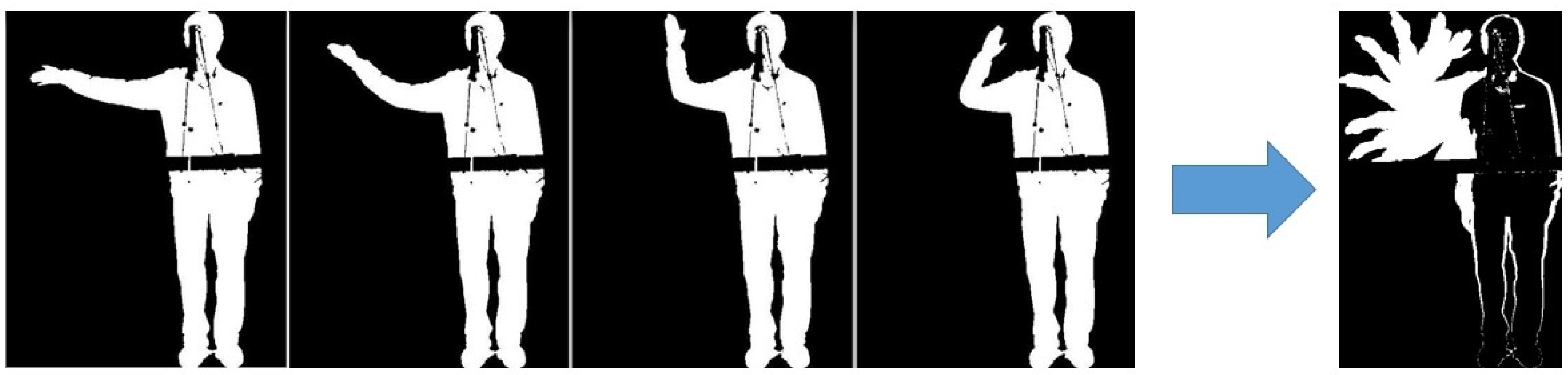
3.2. Collection of Training Data
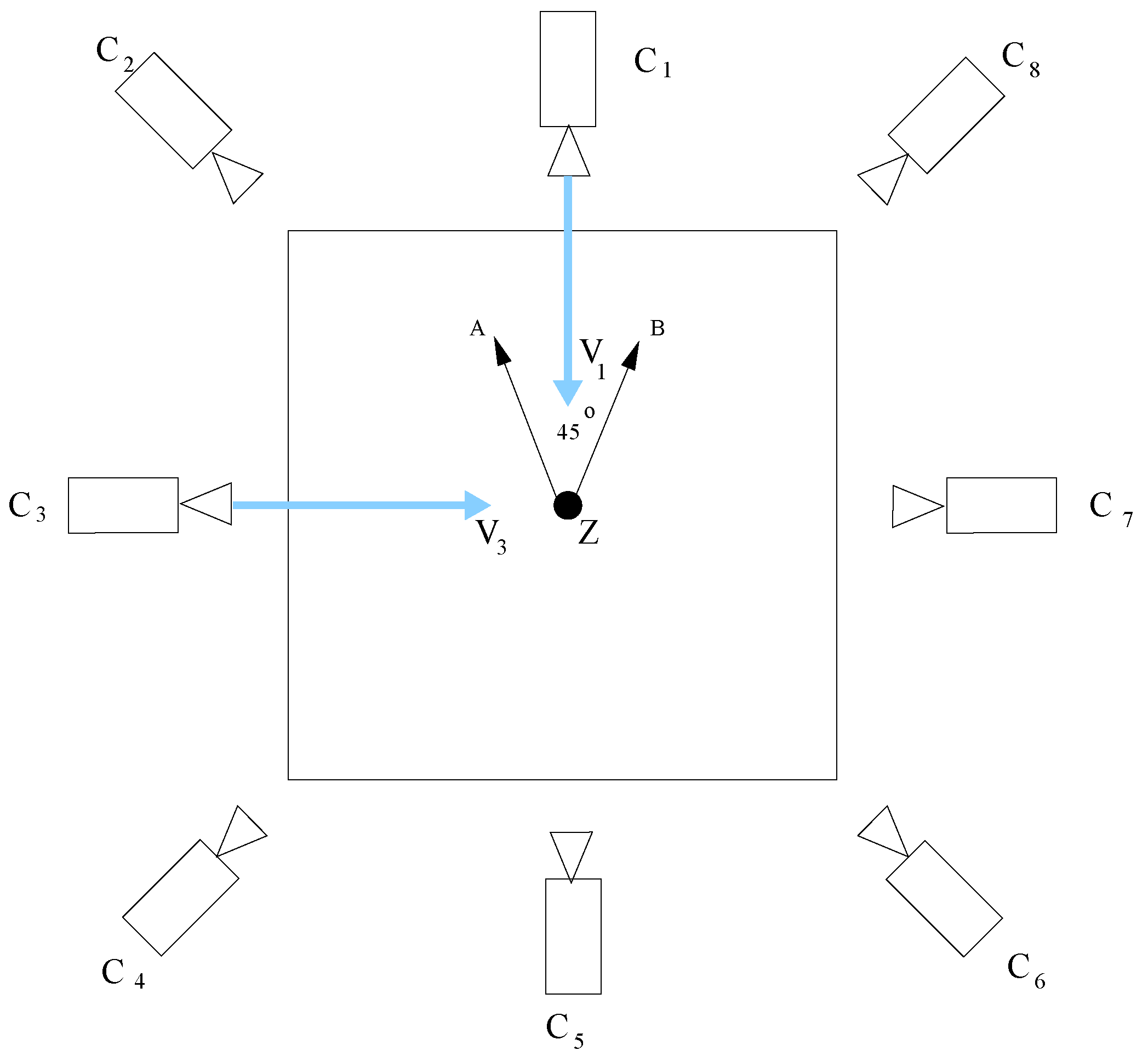
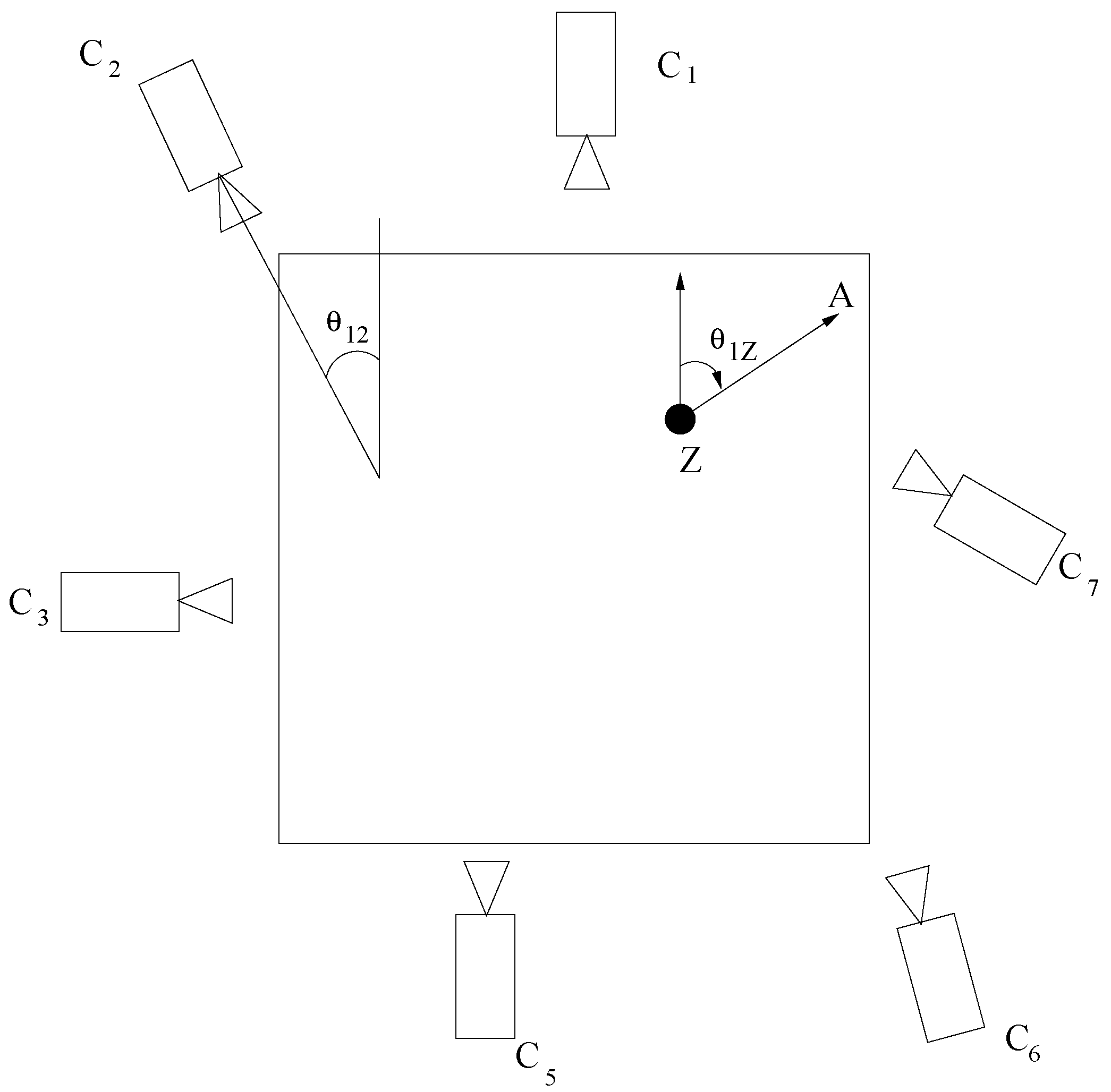
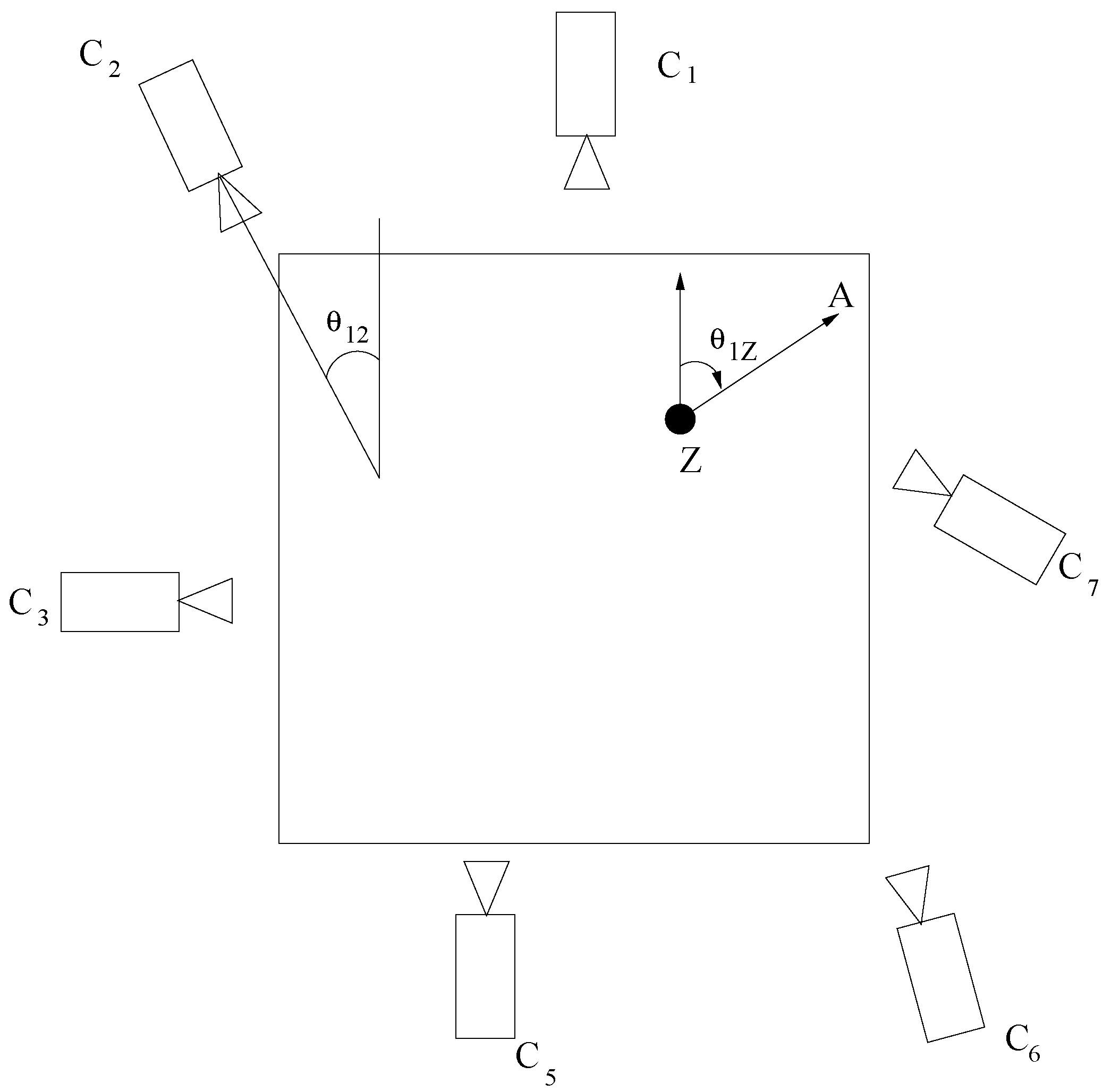
3.3. Score Fusion and Unit Action Classification
3.4. Real-Time Classification of Interleaved Sequences
 |
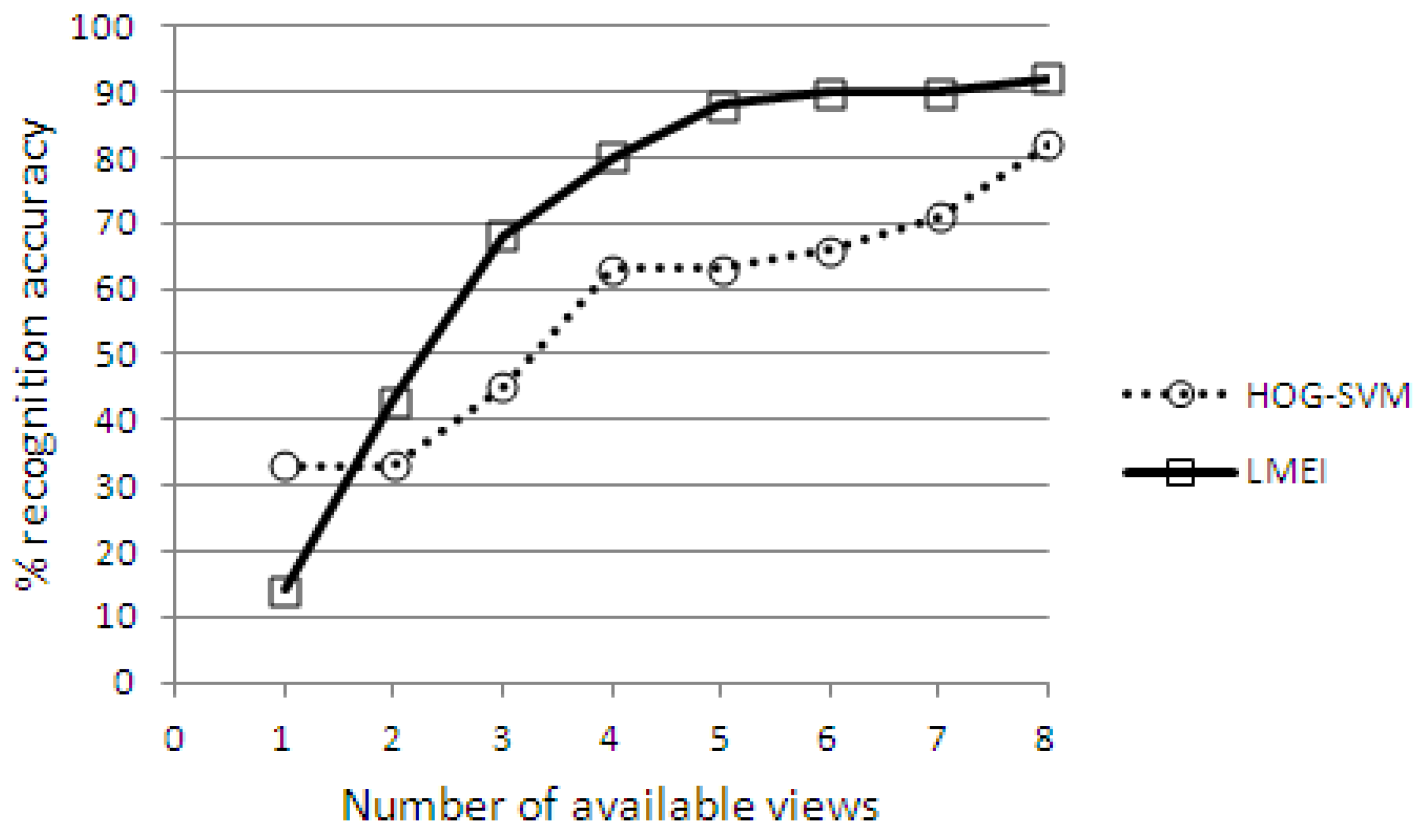
4. Performance Evaluation
4.1. Evaluation with Unit Test Actions

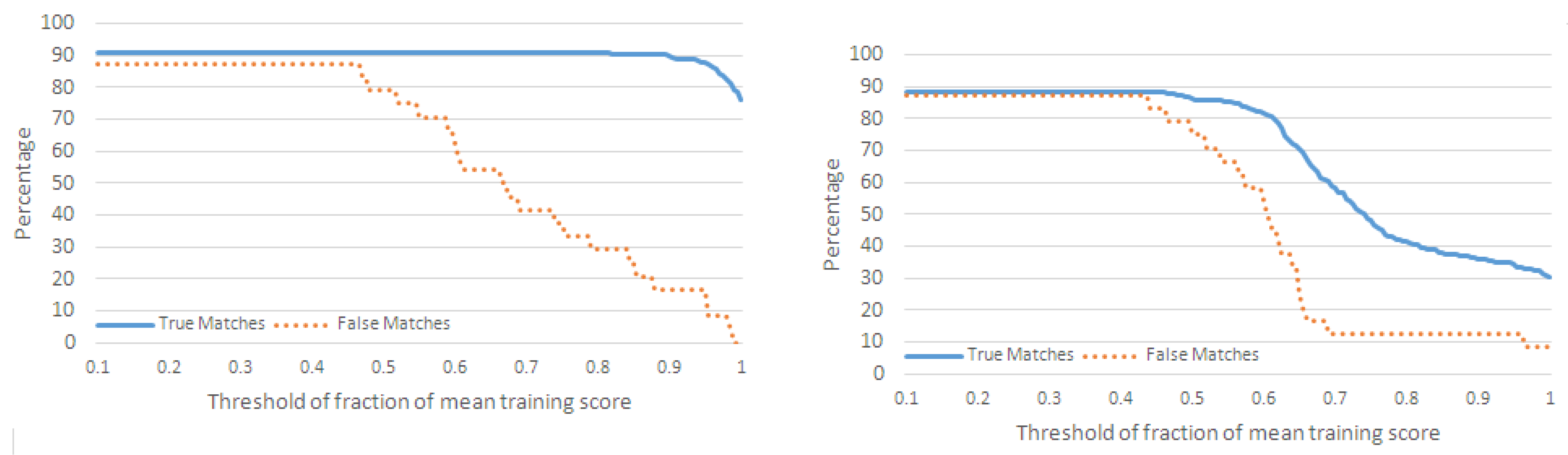
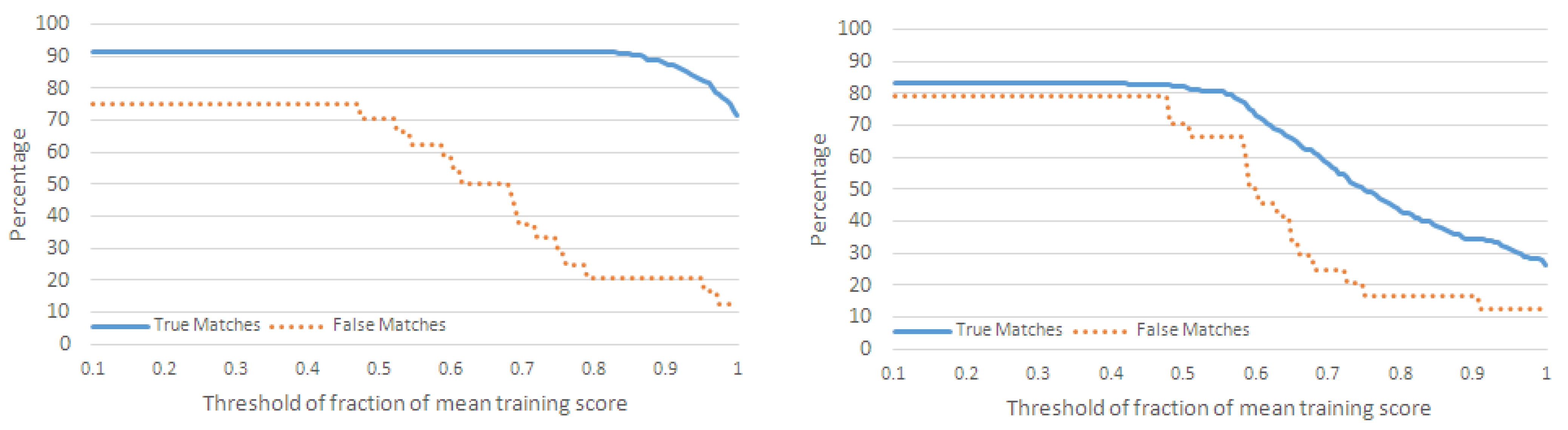
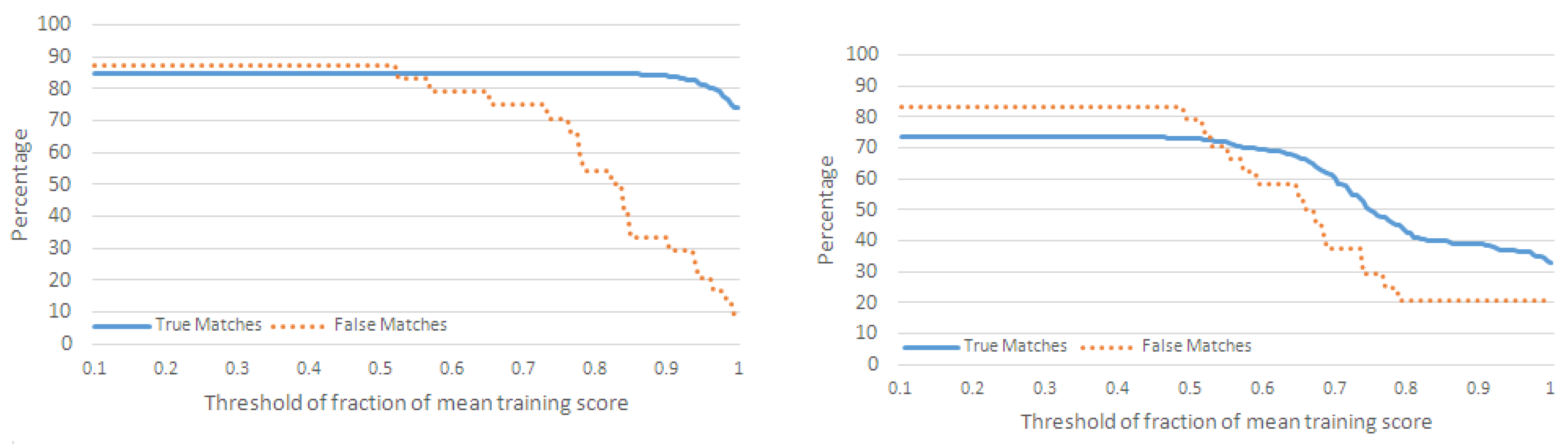
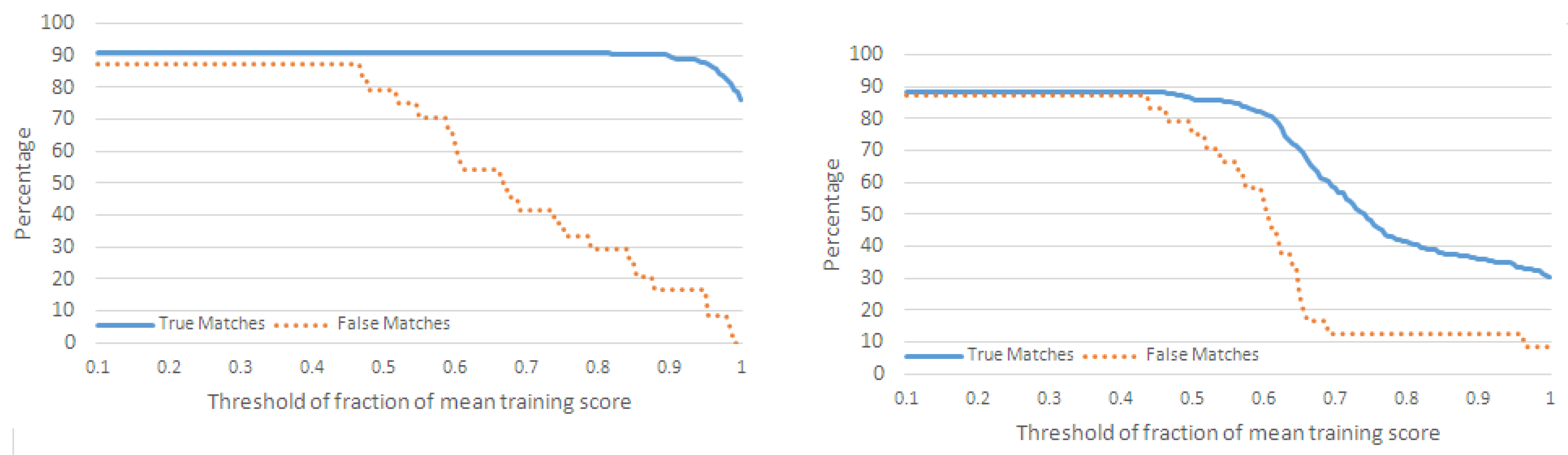
4.2. Evaluation with Interleaved Action Sequences
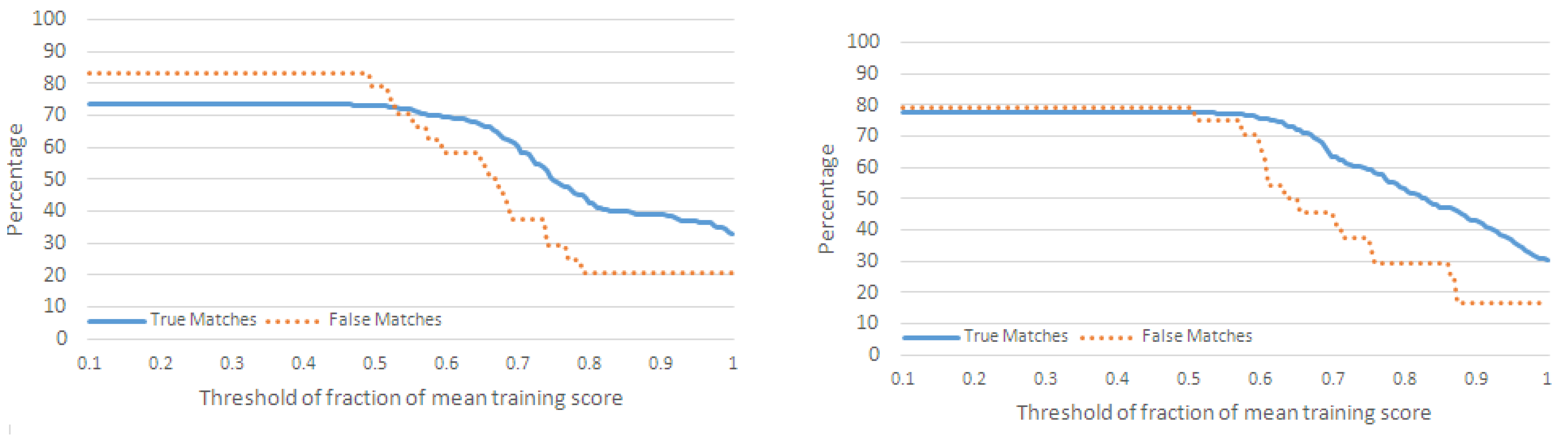
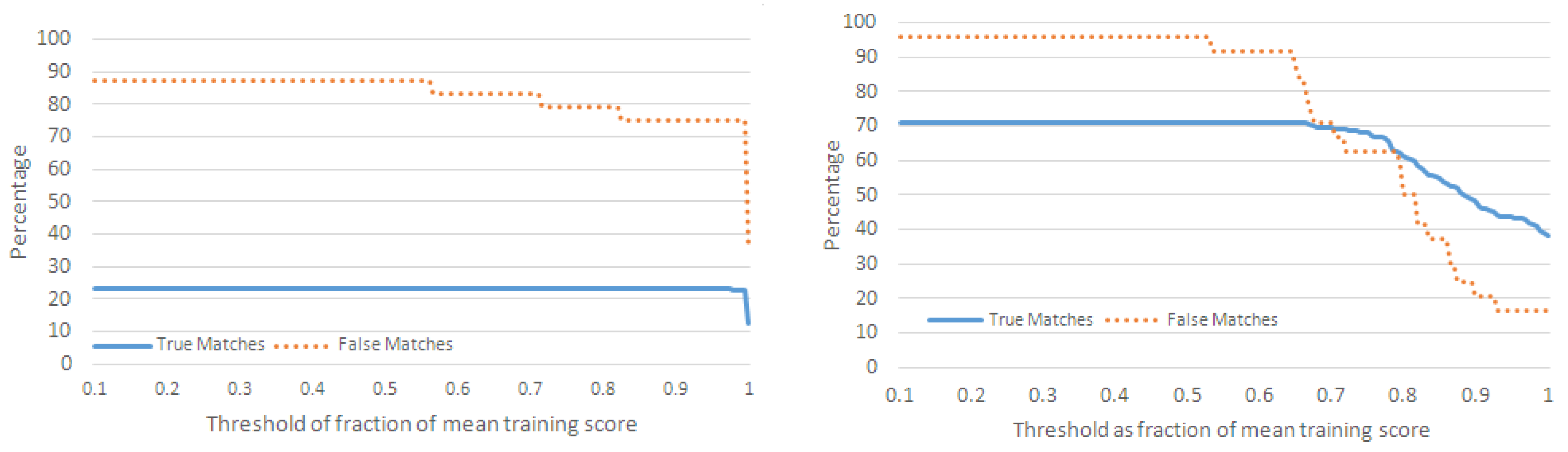
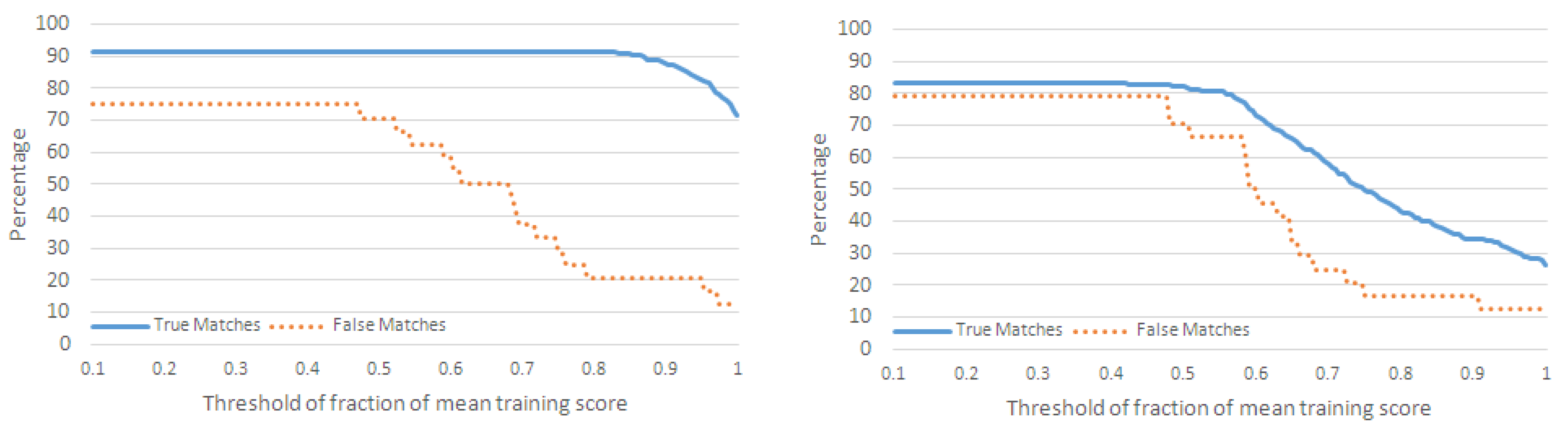
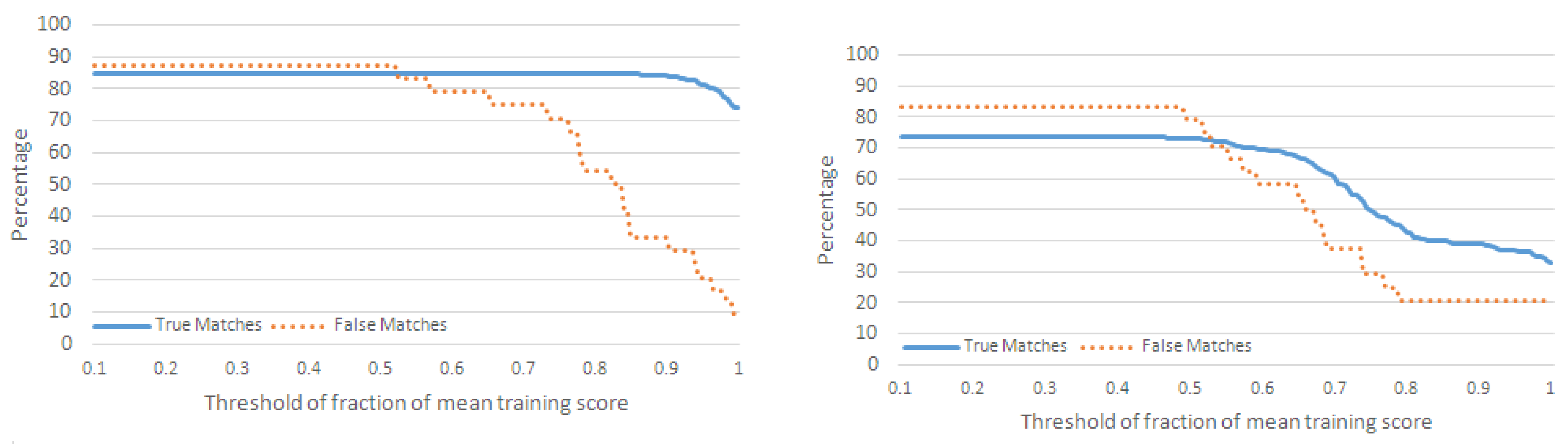
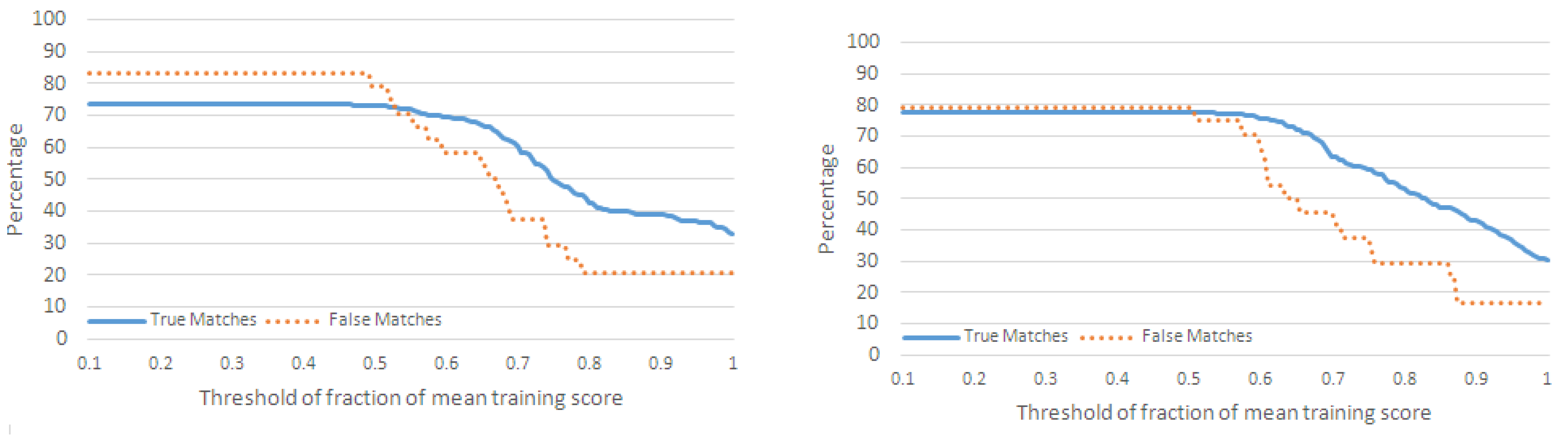
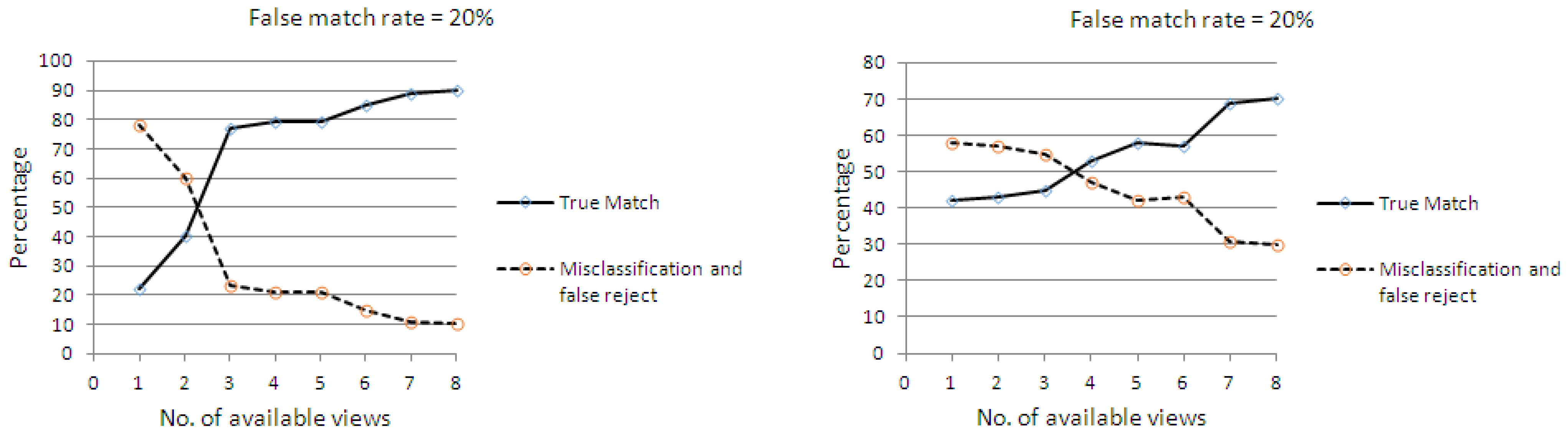
4.2.1. Performance Metrics
- For each action in , if , then we increment the number of true matches (TM) for .
- For each action, , in , if , where and are not neighboring actions of in , then we increment the number of misclassifications for .
- For each action, in , if , where and are not neighboring actions of in , then we increment the number of false matches for .
4.2.2. Classification of Action Sequences

5. Conclusions and Future Work
Conflict of Interest
References
- Micheloni, C.; Remagnino, P.; Eng, H.; Geng, J. Introduction to intelligent monitoring of complex environments. IEEE Intell. Syst. 2010, 25, 12–14. [Google Scholar] [CrossRef]
- Fatima, I.; Fahim, M.; Lee, Y.; Lee, S. A unified framework for activity recognition-based behavior analysis and action prediction in smart homes. Sensors 2013, 13, 2682–2699. [Google Scholar] [CrossRef] [PubMed]
- Pham, C. Coverage and activity management of wireless video sensor networks for surveillance applications. Int. J. Sens. Netw. 2012, 11, 148–165. [Google Scholar] [CrossRef]
- Akyildiz, I.; Melodia, T.; Chowdhury, K. A survey on wireless multimedia sensor networks. Comput. Netw. 2007, 51, 921–960. [Google Scholar] [CrossRef]
- Wu, C.; Aghajan, H.; Kleihorst, R. Real-Time Human Posture Reconstruction in Wireless Smart Camera Networks. In Proceedings of 7th International Conference on Information Processing in Sensor Networks (IPSN), St. Louis, MO, USA, 22–24 April 2008; pp. 321–331.
- Ji, X.; Liu, H. Advances in view-invariant human motion analysis: A review. IEEE. Trans. Syst. Man. Cybern. C 2010, 40, 13–24. [Google Scholar]
- Ramagiri, S.; Kavi, R.; Kulathumani, V. Real-Time Multi-View Human Action Recognition Using a Wireless Camera Network. In Proceedings of 2011 Fifth ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC), Ghent, Belgium, 22–25 August 2011; pp. 1–6.
- Wu, C.; Khalili, A.; Aghajan, H. Multiview Activity Recognition in Smart Homes with Spatio-Temporal Features. In Proceedings of International Conference on Distributed Smart Cameras (ICDSC), Atlanta, GA, USA, 31 August–4 September 2010; pp. 142–149.
- Yamato, J.; Ohya, J.; Ishii, K. Recognizing Human Action in Time-Sequential Images Using Hidden Markov Model. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Champaign, IL, USA, 15–18 June 1992; pp. 379–385.
- Natarajan, P.; Nevatia, R. Coupled Hidden Semi Markov Models for Activity Recognition. In Proceedings of IEEE Workshop on Motion and Video Computing, Austin, TX, USA, 23–24 February 2007; pp. 1–10.
- Hongeng, S.; Nevatia, R. Large-Scale Event Detection Using Semi-Hidden Markov Models. In Proceedings of International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 1455–1462.
- Buxton, H.; Gong, S. Visual surveillance in a dynamic and uncertain world. Artif. Intell. 1995, 78, 431–459. [Google Scholar] [CrossRef]
- Remagnino, P.; Tan, T.; Baker, K.D. Agent Orientated Annotation in Model Based Visual Surveillance. In Proceedings of International Conference on Computer Vision, Bombay, India, 4–7 January 1998; pp. 857–862.
- Joo, S.; Chellappa, R. Recognition of Multi-Object Events Using Attribute Grammars. In Proceedings of IEEE International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006; pp. 2897–2900.
- Ryoo, M.S.; Aggarwal, J.K. Recognition of Composite Human Activities through Context-Free Grammar Based Representation. In Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1709–1718.
- Moore, D.J.; Essa, I.A. Recognizing Multitasked Activities from Video Using Stochastic Context-Free Grammar. In Proceedings of AAAI/IAAI, Edmonton, AB, Canada, 28 July–1 August 2002; pp. 770–776.
- Ivanov, Y.A.; Bobick, A.F. Recognition of visual activities and interactions by stochastic parsing. IEEE Trans. Patt. Anal. Mach. Int. 2000, 22, 852–872. [Google Scholar] [CrossRef]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine recognition of human activities: A survey. IEEE Trans. Circ. Syst. Video. T. 2008, 18, 1473–1488. [Google Scholar] [CrossRef]
- Aggarwal, J.K.; Cai, Q. Human motion analysis: A review. Comput. Vis. Image Understand. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Kruger, V.; Kragic, D.; Ude, A.; Geib, C. The meaning of action: A review on action recognition and mapping. Adv. Robot. 2007, 21, 1473–1501. [Google Scholar]
- Xu, X.; Tang, J.; Zhang, X.; Liu, X.; Zhang, H.; Qiu, Y. Exploring techniques for vision based human activity recognition: Methods, systems, and evaluation. Sensors 2013, 13, 1635–1650. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, J.K.; Ryoo, M.S. Human activity analysis: A review. ACM Comput. Surv. 2011, 43, 16:1–16:43. [Google Scholar] [CrossRef]
- Park, S.; Aggarwal, J.K. A hierarchical Bayesian network for event recognition of human actions and interactions. Multimed. Syst. 2004, 10, 164–179. [Google Scholar] [CrossRef]
- Oliver, N.M.; Rosario, B.; Pentland, A. A Bayesian computer vision system for modeling human interactions. IEEE Trans. Patt. Anal. Mach. Int. 2000, 22, 831–843. [Google Scholar] [CrossRef]
- Laptev, I.; Lindeberg, T. Space-Time Interest Points. In Proceedings of IEEE International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 432–439.
- Niebles, J.C.; Wang, H.; Li, F. Unsupervised learning of human action categories using spatial-temporal words. Int. J. Comput. Vis. 2008, 79, 299–318. [Google Scholar] [CrossRef]
- Ryoo, M.S.; Aggarwal, J.K. Spatio-Temporal Relationship Match: Video Structure Comparison for Recognition of Complex Human Activities. In Proceedings of 12th IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1593–1600.
- Shechtman, E.; Irani, M. Space-Time Behavior Based Correlation. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 405–412.
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes. In Proceedings of International Conference on Computer Vision, Beijing, China, 17–21 October 2005; pp. 1395–1402.
- Chandrashekhar, V.; Venkatesh, K.S. Action Energy Images for Reliable Human Action Recognition. In Proceedings of ASID, New Delhi, India, 8–12 October 2006; pp. 484–487.
- Oikonomopoulos, A.; Patras, I.; Pantic, M. Spatiotemporal salient points For visual recognition of human actions. IEEE Trans. Syst. Man. Cybern. 2005, 36, 710–719. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R.; Hebert, M. Spatio-Temporal Shape and Flow Correlation for Action Recognition. In Proceedings of Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8.
- Darrell, T.; Pentland, A. Space-Time Gestures. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 15–17 June 1993; pp. 335–340.
- Gavrila, D.M.; Davis, L.S. Towards 3-D Model-Based Tracking and Recognition of Human Movement: A Multi-view Approach. In Proceedings of International workshop on automatic face-and gesture-recognition, Coral Gables, FL, USA, 21–23 November 1995; pp. 253–258.
- Holte, M.B.; Moeslund, T.B.; Nikolaidis, N.; Pitas, I. 3D Human Action Recognition for Multi-View Camera Systems. In Proceedings of 2011 International Conference on 3D Imaging, Modeling, Processing, Visualization and Transmission (3DIMPVT), Hangzhou, China, 16–19 May 2011; pp. 342–349.
- Aghajan, H.; Wu, C. Layered and Collaborative Gesture Analysis in Multi-Camera Networks. In Proceedings of 2007 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2007), Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV-1377–IV-1380.
- Srivastava, G.; Iwaki, H.; Park, J.; Kak, A.C. Distributed and Lightweight Multi-Camera Human Activity Classification. In Proceedings of Third ACM/IEEE International Conference on Distributed Smart Cameras (ICDSC), Como, Italy, 30 August–2 September 2009; pp. 1–8.
- Natarajan, P.; Nevatia, R. View And Scale Invariant Action Recognition Using Multiview Shape-Flow Models. In Proceedings of International Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; pp. 1–8.
- Weinland, D.; Ronfard, R.; Boyer, E. Free viewpoint action recognition using motion history volumes. Comput. Vis. andImage Underst. 2006, 104, 249–257. [Google Scholar] [CrossRef]
- Yan, P.; Khan, S.; Shah, M. Learning 4D Action Feature Models for Arbitrary View Action Recognition. In Proceedings of International Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 24–26 June 2008; pp. 1–7.
- INRIA. IXMAS action dataset. Available online: http://4drepository.inrialpes.fr/public/datasets (accessed on 1 December 2012).
- Bobick, A.; Davis, J. Real-Time Recognition of Activity Using Temporal Templates. In Proceedings of 3rd IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 2 December 1996; pp. 39–42.
- Platt, J.C. Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods. In Advances in Large Margin Classifiers; MIT Press: Cambridge, MA, USA, 1999; pp. 61–74. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; pp. 886–893.
- Yang, X.; Zhang, C.; Tian, Y. Recognizing Actions Using Depth Mmotion Maps-Based Histograms of Oriented Gradients. In Proceedings of 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1057–1060.
- Huang, C.; Hsieh, C.; Lai, K.; Huang, W. Human Action Recognition Using Histogram of Oriented Gradient of Motion History Image. In Proceedings of First International Conference on Instrumentation, Measurement, Computer, Communication and Control, Beijing, China, 21–23 October 2011; pp. 353–356.
- Kläser, A.; Marszałek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of British Machine Vision Conference, Leeds, UK, 1–4 September 2008; pp. 995–1004.
- Kulathumani, V.; Ramagiri, S.; Kavi, R. WVU multi-view activity recognition dataset. Available online: http://www.csee.wvu.edu/vkkulathumani/wvu-action.html (accessed on 1 April 2013).
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Kavi, R.; Kulathumani, V. Real-Time Recognition of Action Sequences Using a Distributed Video Sensor Network. J. Sens. Actuator Netw. 2013, 2, 486-508. https://doi.org/10.3390/jsan2030486
Kavi R, Kulathumani V. Real-Time Recognition of Action Sequences Using a Distributed Video Sensor Network. Journal of Sensor and Actuator Networks. 2013; 2(3):486-508. https://doi.org/10.3390/jsan2030486
Chicago/Turabian StyleKavi, Rahul, and Vinod Kulathumani. 2013. "Real-Time Recognition of Action Sequences Using a Distributed Video Sensor Network" Journal of Sensor and Actuator Networks 2, no. 3: 486-508. https://doi.org/10.3390/jsan2030486