A Fast, Accurate Method for Value-at-Risk and Expected Shortfall

Abstract
:1. Introduction
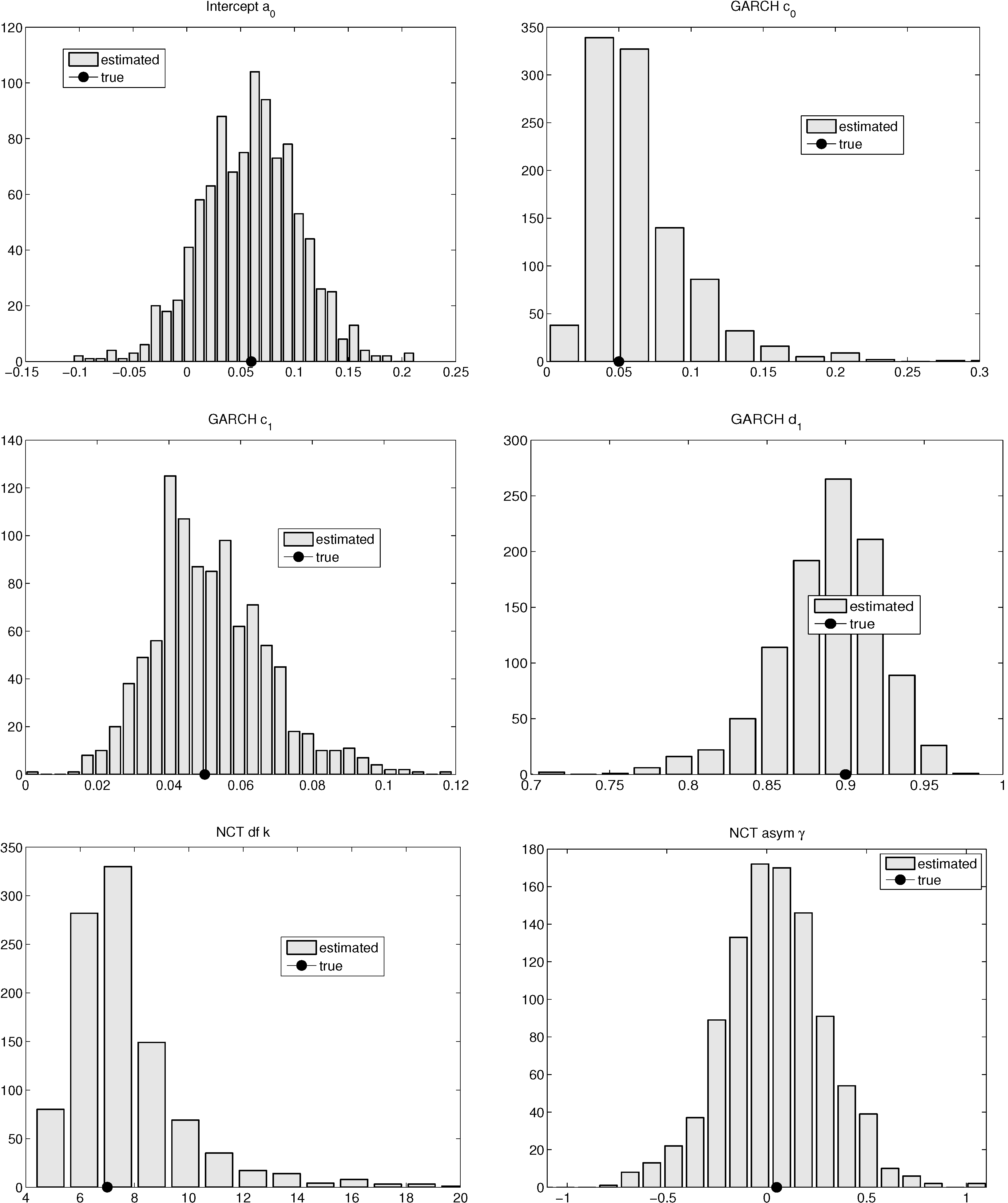
2. NCT-GARCH
2.1. Model
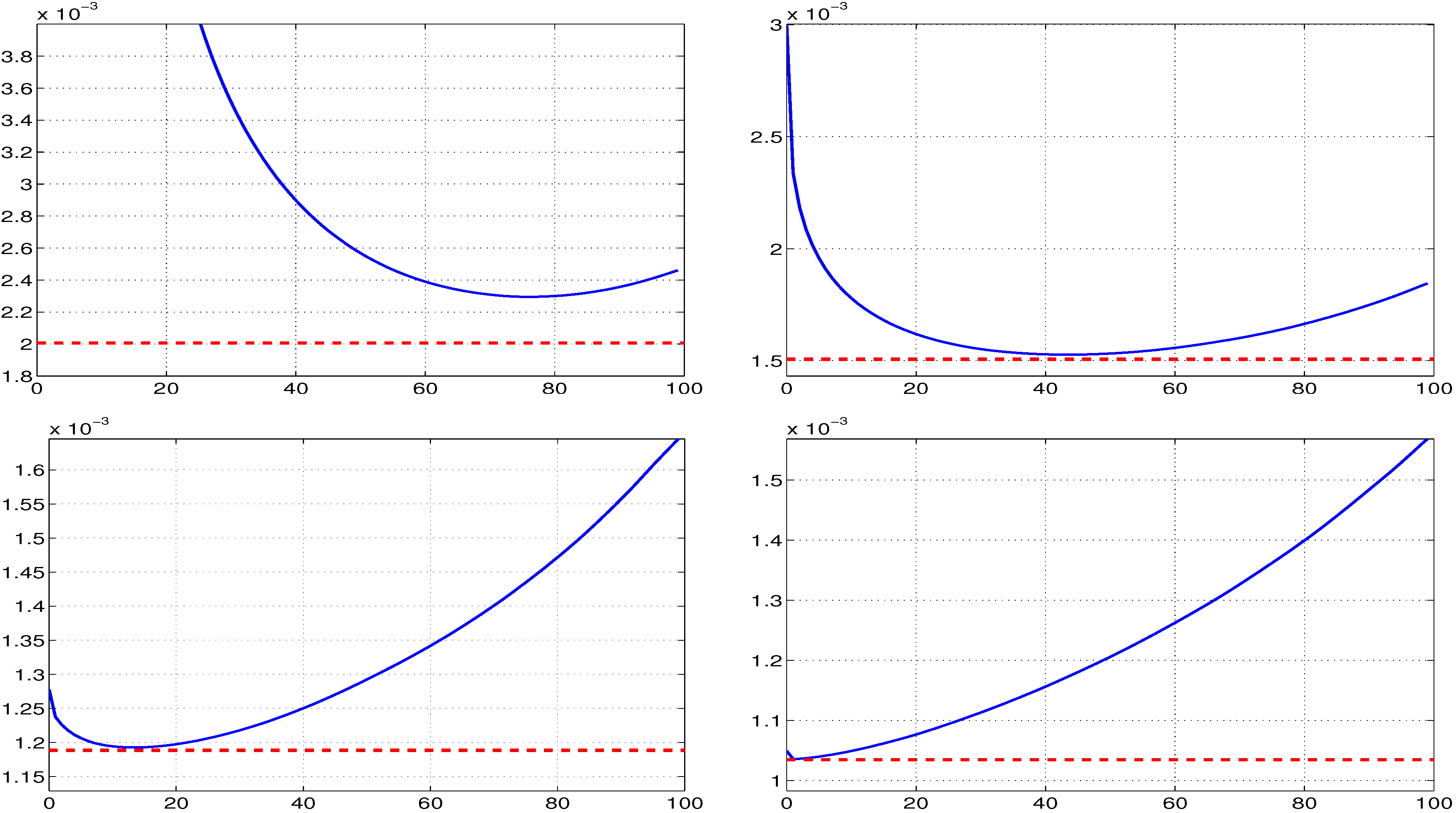
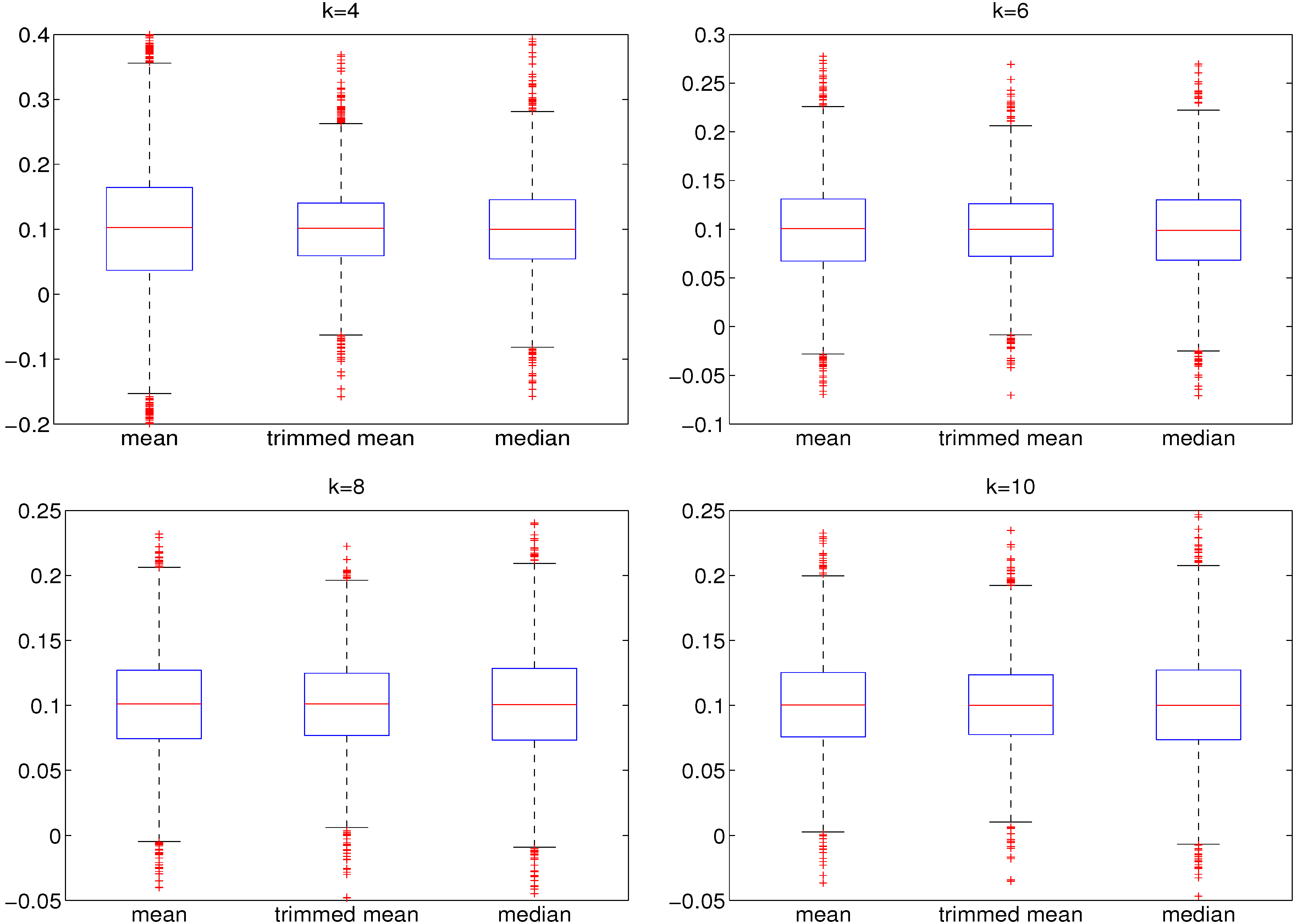
2.2. Faster Estimation Method
2.2.1. Location Term



2.2.2. Use of Fixed GARCH Parameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number Of Entries | Number of Quantiles | k | RMSE of the Mean | RMSE of the Trimmed Mean Procedure | RMSE of the Median |
|---|---|---|---|---|---|---|
| MLE | 4 | 0.372 | 0.191 | 0.204 | ||
| MLE | 6 | 0.098 | 0.083 | 0.095 | ||
| MLE | 8 | 0.080 | 0.073 | 0.085 | ||
| MLE | 10 | 0.072 | 0.069 | 0.082 | ||
| LTE | 3621 | 6 | 4 | 0.308 | 0.183 | 0.197 |
| LTE | 3621 | 6 | 6 | 0.097 | 0.085 | 0.097 |
| LTE | 3621 | 6 | 8 | 0.080 | 0.073 | 0.085 |
| LTE | 3621 | 6 | 10 | 0.074 | 0.070 | 0.083 |
| LTE | 56,481 | 41 | 4 | 0.302 | 0.168 | 0.181 |
| LTE | 56,481 | 41 | 6 | 0.097 | 0.085 | 0.097 |
| LTE | 56,481 | 41 | 8 | 0.079 | 0.073 | 0.085 |
| LTE | 56,481 | 41 | 10 | 0.074 | 0.070 | 0.082 |
| MLE | 4 | 0.171 | 0.064 | 0.071 | ||
| MLE | 6 | 0.049 | 0.041 | 0.047 | ||
| MLE | 8 | 0.040 | 0.037 | 0.042 | ||
| MLE | 10 | 0.036 | 0.033 | 0.040 | ||
| LTE | 3621 | 6 | 4 | 0.153 | 0.065 | 0.072 |
| LTE | 3621 | 6 | 6 | 0.048 | 0.040 | 0.047 |
| LTE | 3621 | 6 | 8 | 0.040 | 0.036 | 0.042 |
| LTE | 3621 | 6 | 10 | 0.036 | 0.034 | 0.040 |
| LTE | 56,481 | 41 | 4 | 0.272 | 0.064 | 0.070 |
| LTE | 56,481 | 41 | 6 | 0.049 | 0.041 | 0.047 |
| LTE | 56,481 | 41 | 8 | 0.040 | 0.036 | 0.042 |
| LTE | 56,481 | 41 | 10 | 0.037 | 0.034 | 0.040 |


2.2.3. Fixed GARCH Parameters and APARCH

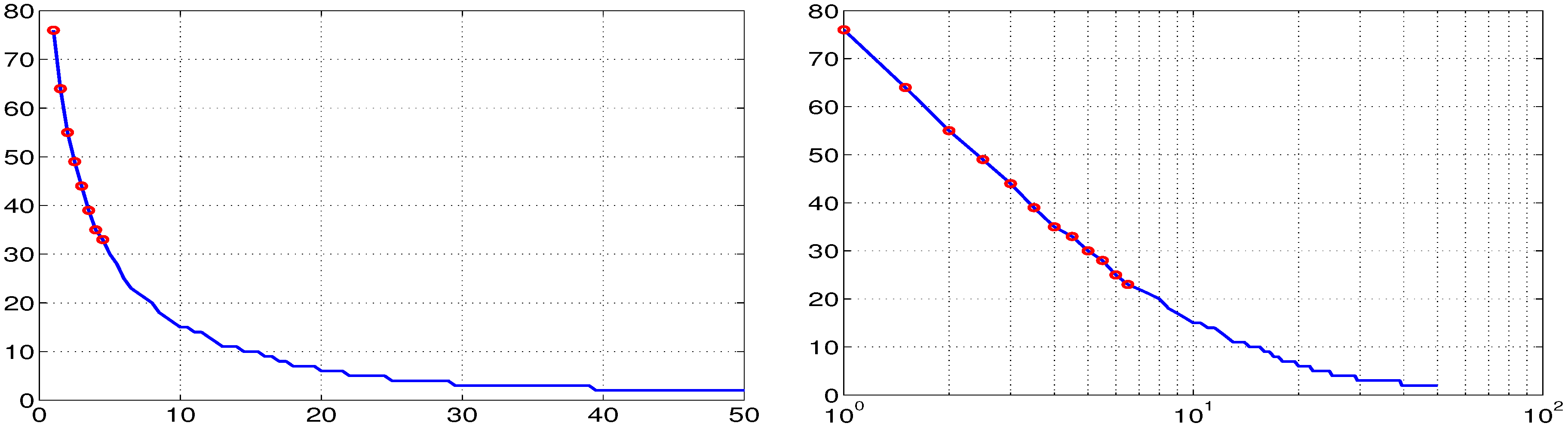
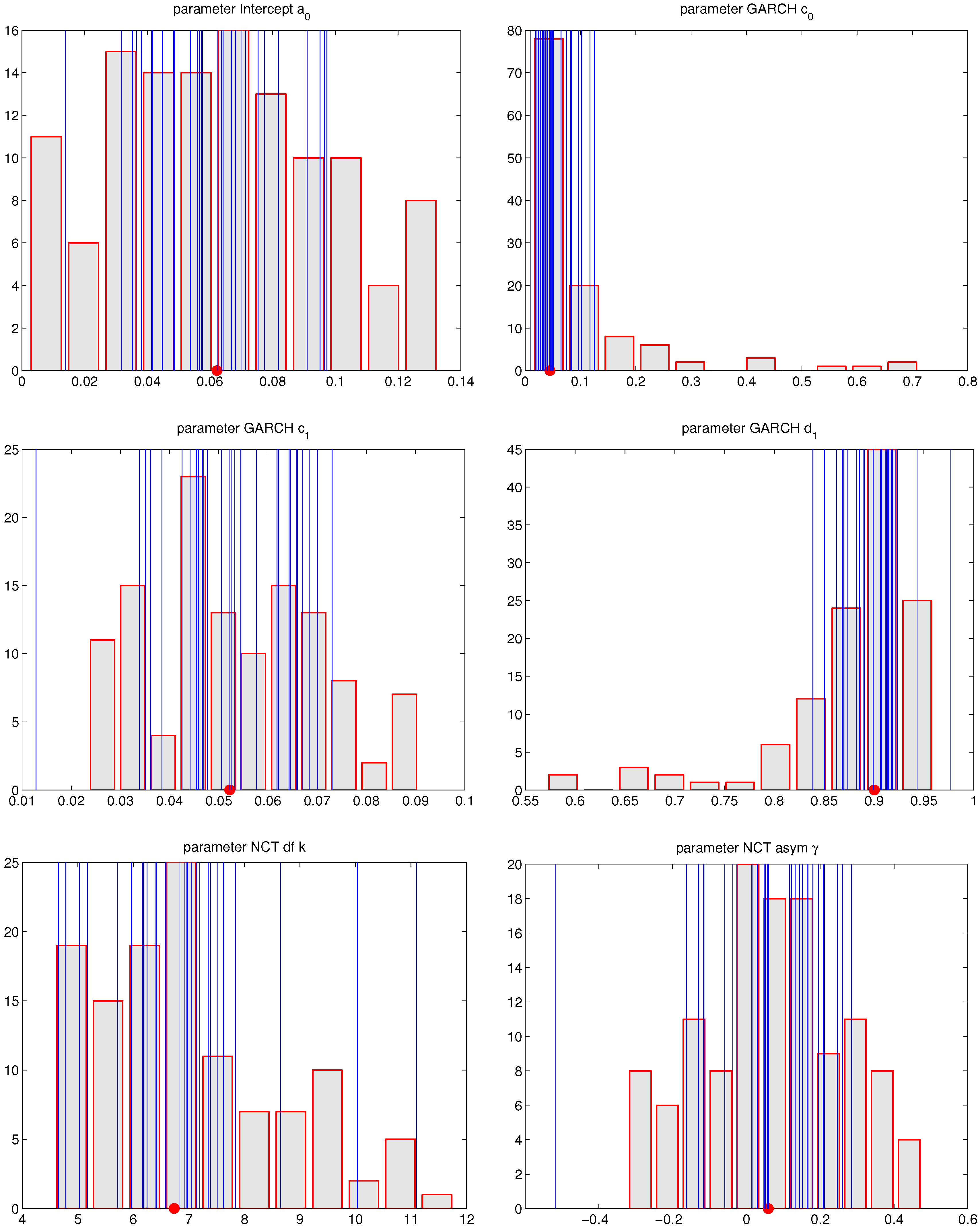
2.3. Lookup Table
| Model | Number of Entries | Number of Quantiles | NCT dfk Steps in | NCT asym. Steps in | Average Runtime | Average Log-lik. | Average RMSE |
|---|---|---|---|---|---|---|---|
| LTE | 3621 | 6 | 71 | 51 | 0.001 s | −391.9075 | 3.804 |
| LTE | 3621 | 11 | 71 | 51 | 0.001 s | −391.8002 | 3.732 |
| LTE | 3621 | 21 | 71 | 51 | 0.002 s | −391.5919 | 3.665 |
| LTE | 3621 | 41 | 71 | 51 | 0.004 s | −391.3617 | 3.585 |
| LTE | 14,241 | 6 | 141 | 101 | 0.002 s | −391.9038 | 3.807 |
| LTE | 14,241 | 11 | 141 | 101 | 0.004 s | −391.7969 | 3.730 |
| LTE | 14,241 | 21 | 141 | 101 | 0.007 s | −391.5920 | 3.668 |
| LTE | 14,241 | 41 | 141 | 101 | 0.010 s | −391.3608 | 3.589 |
| LTE | 56,481 | 6 | 281 | 201 | 0.008 s | −391.9032 | 3.807 |
| LTE | 56,481 | 11 | 281 | 201 | 0.010 s | −391.7977 | 3.730 |
| LTE | 56,481 | 21 | 281 | 201 | 0.030 s | −391.5900 | 3.669 |
| LTE | 56,481 | 41 | 281 | 201 | 0.050 s | −391.3601 | 3.589 |
| wLTE | 3621 | 6 | 71 | 51 | 0.001 s | −391.6156 | 3.753 |
| wLTE | 3621 | 11 | 71 | 51 | 0.001 s | −391.4190 | 3.539 |
| wLTE | 3621 | 21 | 71 | 51 | 0.002 s | −391.3269 | 3.312 |
| wLTE | 3621 | 41 | 71 | 51 | 0.005 s | −391.3711 | 3.247 |
| wLTE | 14,241 | 6 | 141 | 101 | 0.002 s | −391.6110 | 3.751 |
| wLTE | 14,241 | 11 | 141 | 101 | 0.005 s | −391.4177 | 3.541 |
| wLTE | 14,241 | 21 | 141 | 101 | 0.009 s | −391.3232 | 3.311 |
| wLTE | 14,241 | 41 | 141 | 101 | 0.020 s | −391.3687 | 3.242 |
| wLTE | 56,481 | 6 | 281 | 201 | 0.010 s | −391.6123 | 3.752 |
| wLTE | 56,481 | 11 | 281 | 201 | 0.020 s | −391.4176 | 3.541 |
| wLTE | 56,481 | 21 | 281 | 201 | 0.040 s | −391.3234 | 3.312 |
| wLTE | 56,481 | 41 | 281 | 201 | 0.070 s | −391.3669 | 3.242 |
| MLE | – | – | – | – | 0.068 s | −391.0015 | 3.470 |
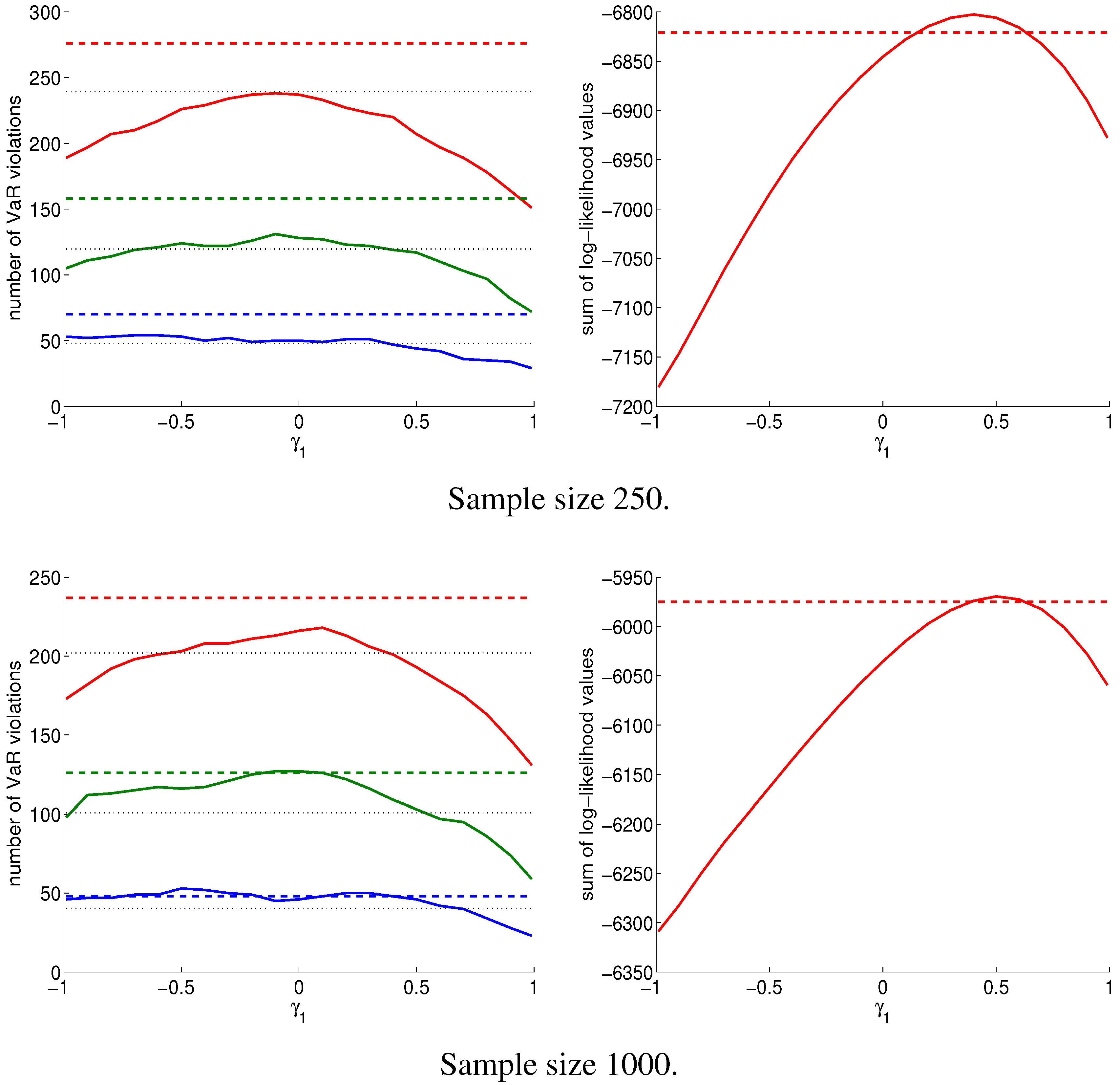
3. Density and VaR Forecasting
- the MixN-GARCH() and the TW-MixN-GARCH() models (see Appendix B), estimated via the extended augmented likelihood estimator (EALE), as introduced in Broda et al. [22]; also see Haas et al. [3],
- the NCT-GARCH model, given by Equation (2) with , estimated by MLE using the NCT density approximation detailed in Appendix A, and
- the NCT-APARCH model, given by Equation (2) with computed, as described in Section 2.2.1, and fixed parameter values, as described in Section 2.2.2 and Section 2.2.3.
| Model | Estimation | 1% VaR | 2.5% VaR | 5% VaR | |||
|---|---|---|---|---|---|---|---|
| Empirical violation frequency | and SPLL | ||||||
| MixN-GARCH() | EALE | jointly | 1.36 | 3.11 | 5.70 | −6864.52 | |
| TW-MixN-GARCH() | EALE | jointly | 1.32 | 3.05 | 5.62 | −6879.26 | |
| NCT-APARCH (a) | LTE | tr. mean | 1.07 | 2.38 | 4.49 | −6802.75 | |
| NCT-APARCH (b) | LTE | tr. mean | 0.94 | 2.53 | 4.49 | −6796.98 | |
| NCT-APARCH (c) | LTE | tr. mean | 0.94 | 2.53 | 4.49 | −6797.06 | |
| NCT-GARCH | MLE | jointly | 1.69 | 3.51 | 6.23 | −6995.05 | |
| NCT-APARCH | MLE | jointly | 1.59 | 3.36 | 5.93 | −6918.63 | |
| NCT-APARCH (b) | LTE | median | 0.919 | 2.444 | 4.324 | −6806.1 | |
| NCT-APARCH (b) | wLTE | tr. mean | 0.919 | 2.507 | 4.303 | −6799.4 | |
| LLCC | |||||||
| MixN-GARCH() | EALE | jointly | 7.37 ** | 7.98 ** | 6.10 ** | ||
| TW-MixN-GARCH() | EALE | jointly | 4.43 | 6.09 ** | 3.99 | ||
| NCT-APARCH (a) | LTE | tr. mean | 0.52 | 0.49 | 2.88 | ||
| NCT-APARCH (b) | LTE | tr. mean | 0.76 | 0.45 | 2.70 | ||
| NCT-APARCH (c) | LTE | tr. mean | 0.76 | 0.45 | 2.70 | ||
| NCT-GARCH | MLE | jointly | 19.45 *** | 21.68 *** | 15.79 *** | ||
| NCT-APARCH | MLE | jointly | 14.63 *** | 13.31 *** | 8.40 ** | ||
| LLUC | |||||||
| MixN-GARCH() | EALE | jointly | 5.58 ** | 6.86 *** | 4.79 ** | ||
| TW-MixN-GARCH() | EALE | jointly | 4.40 ** | 5.57 ** | 3.74 * | ||
| NCT-APARCH (a) | LTE | tr. mean | 0.20 | 0.28 | 2.69 | ||
| NCT-APARCH (b) | LTE | tr. mean | 0.18 | 0.02 | 2.69 | ||
| NCT-APARCH (c) | LTE | tr. mean | 0.18 | 0.02 | 2.69 | ||
| NCT-GARCH | MLE | jointly | 19.19 *** | 17.84 *** | 14.11 *** | ||
| NCT-APARCH | MLE | jointly | 14.18 *** | 13.25 *** | 8.31 *** | ||
| LLIND | |||||||
| MixN-GARCH() | EALE | jointly | 1.79 | 1.12 | 1.31 | ||
| TW-MixN-GARCH() | EALE | jointly | 0.03 | 0.52 | 0.25 | ||
| NCT-APARCH (a) | LTE | tr. mean | 0.31 | 0.22 | 0.20 | ||
| NCT-APARCH (b) | LTE | tr. mean | 0.58 | 0.44 | 0.01 | ||
| NCT-APARCH (c) | LTE | tr. mean | 0.58 | 0.44 | 0.01 | ||
| NCT-GARCH | MLE | jointly | 0.26 | 3.84 * | 1.68 | ||
| NCT-APARCH | MLE | jointly | 0.45 | 0.07 | 0.09 |
| Model | Estimation | 1% VaR | 2.5% VaR | 5% VaR | |||
|---|---|---|---|---|---|---|---|
| empirical violation frequency | and SPLL | ||||||
| MixN-GARCH() | EALE | jointly | 1.11 | 2.95 | 5.42 | −5996.51 | |
| TW-MixN-GARCH() | EALE | jointly | 1.21 | 2.77 | 5.38 | −5993.15 | |
| NCT-APARCH (a) | LTE | tr. mean | 0.99 | 2.58 | 4.90 | −5969.88 | |
| NCT-APARCH (b) | LTE | tr. mean | 1.19 | 2.65 | 4.90 | −5970.83 | |
| NCT-APARCH (c) | LTE | tr. mean | 1.16 | 2.65 | 4.90 | −5970.88 | |
| NCT-GARCH | MLE | jointly | 1.19 | 3.12 | 5.87 | −5974.90 | |
| NCT-APARCH | MLE | jointly | 1.16 | 2.97 | 5.52 | −5905.26 | |
| NCT-APARCH (b) | LTE | median | 1.19 | 2.70 | 4.98 | −5973.99 | |
| NCT-APARCH (b) | wLTE | tr. mean | 1.29 | 2.75 | 4.95 | −5971.10 | |
| LLCC | |||||||
| MixN-GARCH() | EALE | jointly | 1.53 | 3.96 | 1.50 | ||
| TW-MixN-GARCH() | EALE | jointly | 2.95 | 1.21 | 1.19 | ||
| NCT-APARCH (a) | LTE | tr. mean | 0.80 | 0.30 | 0.09 | ||
| NCT-APARCH (b) | LTE | tr. mean | 2.53 | 0.66 | 0.14 | ||
| NCT-APARCH (c) | LTE | tr. mean | 2.16 | 0.66 | 0.14 | ||
| NCT-GARCH | MLE | jointly | 2.53 | 5.94 * | 6.47 ** | ||
| NCT-APARCH | MLE | jointly | 2.16 | 4.36 | 2.79 | ||
| LLUC | |||||||
| MixN-GARCH() | EALE | jointly | 0.52 | 3.15 * | 1.50 | ||
| TW-MixN-GARCH() | EALE | jointly | 1.75 | 1.21 | 1.18 | ||
| NCT-APARCH (a) | LTE | tr. mean | 3.3e-3 | 0.10 | 0.08 | ||
| NCT-APARCH (b) | LTE | tr. mean | 1.38 | 0.37 | 0.08 | ||
| NCT-APARCH (c) | LTE | tr. mean | 1.05 | 0.37 | 0.08 | ||
| NCT-GARCH | MLE | jointly | 1.38 | 5.94 ** | 6.14 ** | ||
| NCT-APARCH | MLE | jointly | 1.05 | 3.50 * | 2.27 | ||
| LLIND | |||||||
| MixN-GARCH() | EALE | jointly | 1.01 | 0.81 | 1.3e-3 | ||
| TW-MixN-GARCH() | EALE | jointly | 1.20 | 4.0e-3 | 0.01 | ||
| NCT-APARCH (a) | LTE | tr. mean | 0.80 | 0.20 | 0.01 | ||
| NCT-APARCH (b) | LTE | tr. mean | 1.16 | 0.29 | 0.06 | ||
| NCT-APARCH (c) | LTE | tr. mean | 1.11 | 0.29 | 0.06 | ||
| NCT-GARCH | MLE | jointly | 1.16 | 1.2e-3 | 0.34 | ||
| NCT-APARCH | MLE | jointly | 1.11 | 0.86 | 0.52 |
4. Conclusions and Future Research
Acknowledgments
Author Contributions
Appendix
A. Fast Approximation to the Univariate NCT pdf
| RMSE | IQR | |||
|---|---|---|---|---|
| MATLAB’s nctpdf | FastNCT | MATLAB’s nctpdf | FastNCT | |
| factor 7.000 | 0.140 s | 0.020 s | ||
| NCT df k | 205.14 | 277.91 | 6.252 | 6.267 |
| NCT asym. | 0.066 | 0.066 | 0.005 | 0.005 |
| factor 7.941 | 0.270 s | 0.034 s | ||
| NCT df k | 1.246 | 1.247 | 1.385 | 1.386 |
| NCT asym. | 0.033 | 0.033 | 0.001 | 0.001 |
B. Mixture Normal GARCH Models
Conflicts of Interest
References
- Basel Committee on Banking Supervision. “Fundamental Review of the Trading Book: A Revised Market Risk Framework. Basel Committee on Banking Supervision. Consultative Document. Fundamental Review of the Trading Book: A Revised Market Risk Framework.” Available online: http://www.bis.org/publ/bcbs265.pdf (accessed on 10 June 2014).
- K. Kuester, S. Mittnik, and M.S. Paolella. “Value–at–Risk Prediction: A Comparison of Alternative Strategies.” J. Financ. Econometr. 4 (2006): 53–89. [Google Scholar] [CrossRef]
- M. Haas, J. Krause, M.S. Paolella, and S.C. Steude. “Time-varying Mixture GARCH Models and Asymmetric Volatility.” N. Am. J. Econ. Finance 26 (2013): 602–623. [Google Scholar] [CrossRef]
- A.M. Kshirsagar. “Some Extensions of the Multivariate Generalization t distribution and the Multivariate Generalization of the Distribution of the Regression Coefficient.” Proc. Cambr. Philos. Soc. 57 (1961): 80–85. [Google Scholar] [CrossRef]
- S. Kotz, and S. Nadarajah. Multivariate t Distributions and Their Applications. Cambridge, UK: Cambridge University Press, 2004. [Google Scholar]
- E. Jondeau. “Asymmetry in Tail Dependence of Equity Portfolios.” National Centre of Competence in Research, Financial Valuation and Risk Management: Working Paper No. 658. 2010. [Google Scholar]
- S.A. Broda, J. Krause, M.S. Paolella, and P. Polak. “Risk Management and Portfolio Optimization Using the Multivariate Non-Central t Distribution.” 2014, unpublished work. [Google Scholar]
- C.R. Harvey, and A. Siddique. “Autoregressive Conditional Skewness.” J. Finan. Quantit. Anal. 34 (1999): 465–487. [Google Scholar] [CrossRef]
- M.S. Paolella. Intermediate Probability: A Computational Approach. Chichester, UK: John Wiley & Sons, 2007. [Google Scholar]
- Z. Ding, C.W.J. Granger, and R.F. Engle. “A Long Memory Property of Stock Market Returns and a New Model.” J. Empir. Finance 1 (1993): 83–106. [Google Scholar] [CrossRef]
- S. Broda, and M.S. Paolella. “Saddlepoint Approximations for the Doubly Noncentral t Distribution.” Comput. Stat. Data Anal. 51 (2007): 2907–2918. [Google Scholar] [CrossRef]
- S.A. Broda, and M.S. Paolella. “Expected Shortfall for Distributions in Finance. Statistical Tools for Finance and Insurance.” Edited by P. Čížek, W. Härdle and Weron. Rafał. Heidelberg, Germany: Springer Verlag, 2011, pp. 57–99. [Google Scholar]
- S. Nadarajah, B. Zhang, and S. Chan. “Estimation Methods for Expected Shortfall.” Quantit. Finance 14 (2013): 271–291. [Google Scholar] [CrossRef]
- S.A. Broda, and M.S. Paolella. “Saddlepoint Approximation of Expected Shortfall for Transformed Means.” In UvA Econometrics Discussion Paper 2010/08. Amsterdam, The Netherlands: University of Amsterdam, 2010. [Google Scholar]
- T. Bollerslev. “A Conditionally Heteroskedastic Time Series Model for Speculative Prices and Rates of Return.” Rev. Econ. Stat. 69 (1987): 542–547. [Google Scholar] [CrossRef]
- V. Chopra, and W. Ziemba. “The Effect of Errors in Means, Variances, and Covariances on Optimal Portfolio Choice.” J. Portf. Manag. 19 (1993): 6–12. [Google Scholar] [CrossRef]
- V. Chavez-Demoulin, P. Embrechts, and S. Sardy. “Extreme-quantile tracking for financial time series.” J. Econom. 1 (2014): 44–52. [Google Scholar] [CrossRef]
- M.S. Paolella. “Multivariate Asset Return Prediction with Mixture Models.” Eur. J. Finance, 2013, in press. [Google Scholar]
- M.S. Paolella, and P. Polak. “ALRIGHT: Asymmetric LaRge-Scale (I)GARCH with Hetero-Tails.” Available online: http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1628146 (accessed on 10 June 2014).
- M. Haas, S. Mittnik, and M.S. Paolella. “Mixed Normal Conditional Heteroskedasticity.” J. Financ. Econometr. 2 (2004): 211–250. [Google Scholar] [CrossRef]
- C. Alexander, and E. Lazar. “Normal Mixture GARCH(1,1): Applications to Exchange Rate Modelling.” J. Appl. Econometr. 21 (2006): 307–336. [Google Scholar] [CrossRef]
- S.A. Broda, M. Haas, J. Krause, M.S. Paolella, and S.C. Steude. “Stable Mixture GARCH Models.” J. Econometr. 172 (2013): 292–306. [Google Scholar] [CrossRef] [Green Version]
- A.A.P. Santos, F.J. Nogales, and E. Ruiz. “Comparing Univariate and Multivariate Models to Forecast Portfolio Value–at–Risk.” J. Financ. Econometr. 11 (2013): 400–441. [Google Scholar] [CrossRef]
- T. Bloomfield, R. Leftwich, and J. Long. “Portfolio Strategies and Performance.” J. Financ. Econ. 5 (1977): 201–218. [Google Scholar] [CrossRef]
- V. DeMiguel, L. Garlappi, and R. Uppal. “Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy? ” Rev. Financ. Stud. 22 (2009): 1915–1953. [Google Scholar] [CrossRef]
- S.J. Brown, I. Hwang, and F. In. “Why Optimal Diversification Cannot Outperform Naive Diversification: Evidence from Tail Risk Exposure.” Available online: http://zh.scribd.com/doc/209934925/Why-Optimal-Diversification-Cannot-Outperform-Naive-Diversification (accessed on 10 June 2014).
- P.F. Christoffersen. “Evaluating Interval Forecasts.” Int.Econ. Rev. 39 (1998): 841–862. [Google Scholar] [CrossRef]
- J. Geweke, and G. Amisano. “Comparing and Evaluating Bayesian Predictive Distributions of Asset Returns.” Int. J. Forec. 26 (2010): 216–230. [Google Scholar] [CrossRef]
- M. McAleer, and B. Da Veiga. “Single-Index and Portfolio Models for Forecasting Value–at–Risk Thresholds.” J. Forec. 27 (2008): 217–235. [Google Scholar] [CrossRef]
- M. Asai, and M. McAleer. “A Portfolio Index GARCH Model.” Int. J. Forec. 24 (2008): 449–461. [Google Scholar] [CrossRef]
- M. Haas, and M.S. Paolella. “Mixture and Regime-switching GARCH Models.” In Handbook of Volatility Models and Their Applications. Edited by L. Bauwens, C.M. Hafner and S. Laurent. Hoboken, NJ, USA: John Wiley & Sons, Inc., 2012. [Google Scholar]
- R.F. Engle, and V.K. Ng. “Measuring and Testing the Impact of News on Volatility.” J. Finance 48 (1993): 1749–1778. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Krause, J.; Paolella, M.S. A Fast, Accurate Method for Value-at-Risk and Expected Shortfall. Econometrics 2014, 2, 98-122. https://doi.org/10.3390/econometrics2020098
Krause J, Paolella MS. A Fast, Accurate Method for Value-at-Risk and Expected Shortfall. Econometrics. 2014; 2(2):98-122. https://doi.org/10.3390/econometrics2020098
Chicago/Turabian StyleKrause, Jochen, and Marc S. Paolella. 2014. "A Fast, Accurate Method for Value-at-Risk and Expected Shortfall" Econometrics 2, no. 2: 98-122. https://doi.org/10.3390/econometrics2020098