Top Incomes, Heavy Tails, and Rank-Size Regressions

1
Aix-Marseille School of Economics, 5 Boulevard Maurice Bourdet CS 50498, 13205 Marseille CEDEX 01, France
2
Department of Economics, University of Southampton, Highfield, Southampton SO17 1BJ, UK
Econometrics 2018, 6(1), 10; https://doi.org/10.3390/econometrics6010010
Submission received: 19 November 2017
/
Revised: 18 February 2018
/
Accepted: 20 February 2018
/
Published: 2 March 2018
(This article belongs to the Special Issue Econometrics and Income Inequality)
{kind=link}
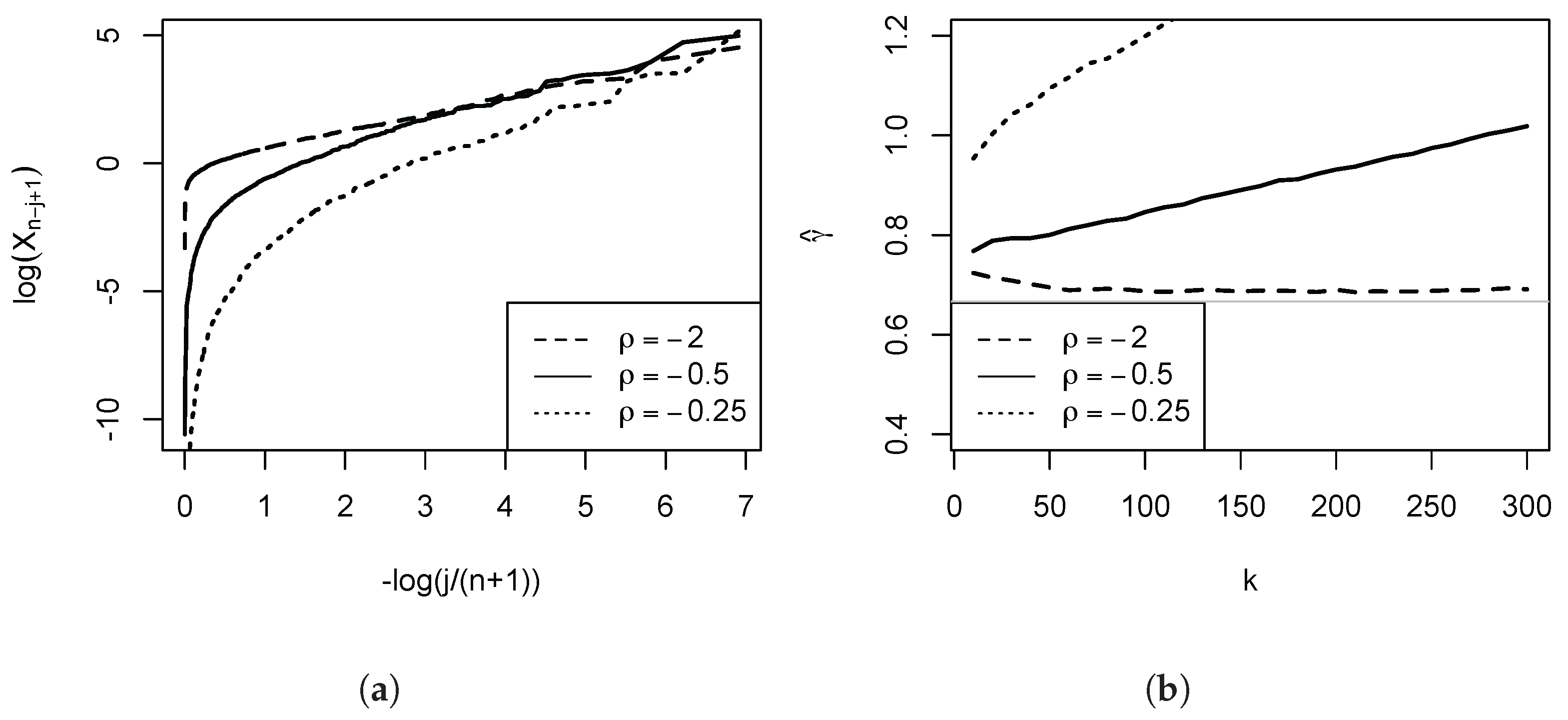{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:In economics, rank-size regressions provide popular estimators of tail exponents of heavy-tailed distributions. We discuss the properties of this approach when the tail of the distribution is regularly varying rather than strictly Pareto. The estimator then over-estimates the true value in the leading parametric income models (so the upper income tail is less heavy than estimated), which leads to test size distortions and undermines inference. For practical work, we propose a sensitivity analysis based on regression diagnostics in order to assess the likely impact of the distortion. The methods are illustrated using data on top incomes in the UK.
JEL Classification:
D31; C13; C141. Introduction
Income distributions exhibit, like many other size distributions in economics and the natural science, upper tails that decay like power functions (see e.g., Schluter and Trede 2017). The recent and rapidly growing literature on top incomes focuses on this upper tail, and its presence has important consequences for the measurement of inequality.1 However, estimating the heaviness of the upper tail is challenging, since real world size distributions usually are Pareto-like (i.e., tails are regularly varying) rather than strictly Pareto.
To be precise, let be a sequence of positive independent and identically distributed random variables (e.g., incomes) with distribution function F that is regularly varying, so for large x
where l is slowly varying at infinity, i.e., as . The parameter , usually referred to as extreme value index (and as the tail exponent), is unknown and needs to be estimated. Many estimators have been proposed in the statistical literature (see e.g., the textbook treatments in (Embrechts et al. 1997 or Beirlant et al. 2004).
An estimator popular among economists is based on a simple ordinary least squares (OLS) regression of log sizes on log ranks (e.g., Jenkins 2017 and Atkinson 2017, and references therein, in the income distribution and top incomes literature, this regression is ubiquitous in the city size literature). The enduring popularity of the OLS estimator is partly due to its simplicity, and partly due to a powerful intuition based on a Pareto quantile-quantile (QQ)-plot, the regression estimating its slope coefficient. However, if the tail of the distribution varies regularly, the Pareto QQ-plot will become linear only eventually. In particular, (1) can be expressed equivalently, using the tail quantile function where , as where is a slowly varying function. Hence, as , since then . Replacing these population quantities with their empirical counterparts gives the Pareto QQ-plot, and is its ultimate slope. This qualification (usually ignored by practitioners in economics) has important consequences for the behaviour of the estimator: Since the OLS estimator estimates the slope parameter of this QQ-plot, deviations from the strict Pareto model -captured by the nuisance function l- will induce distortions.
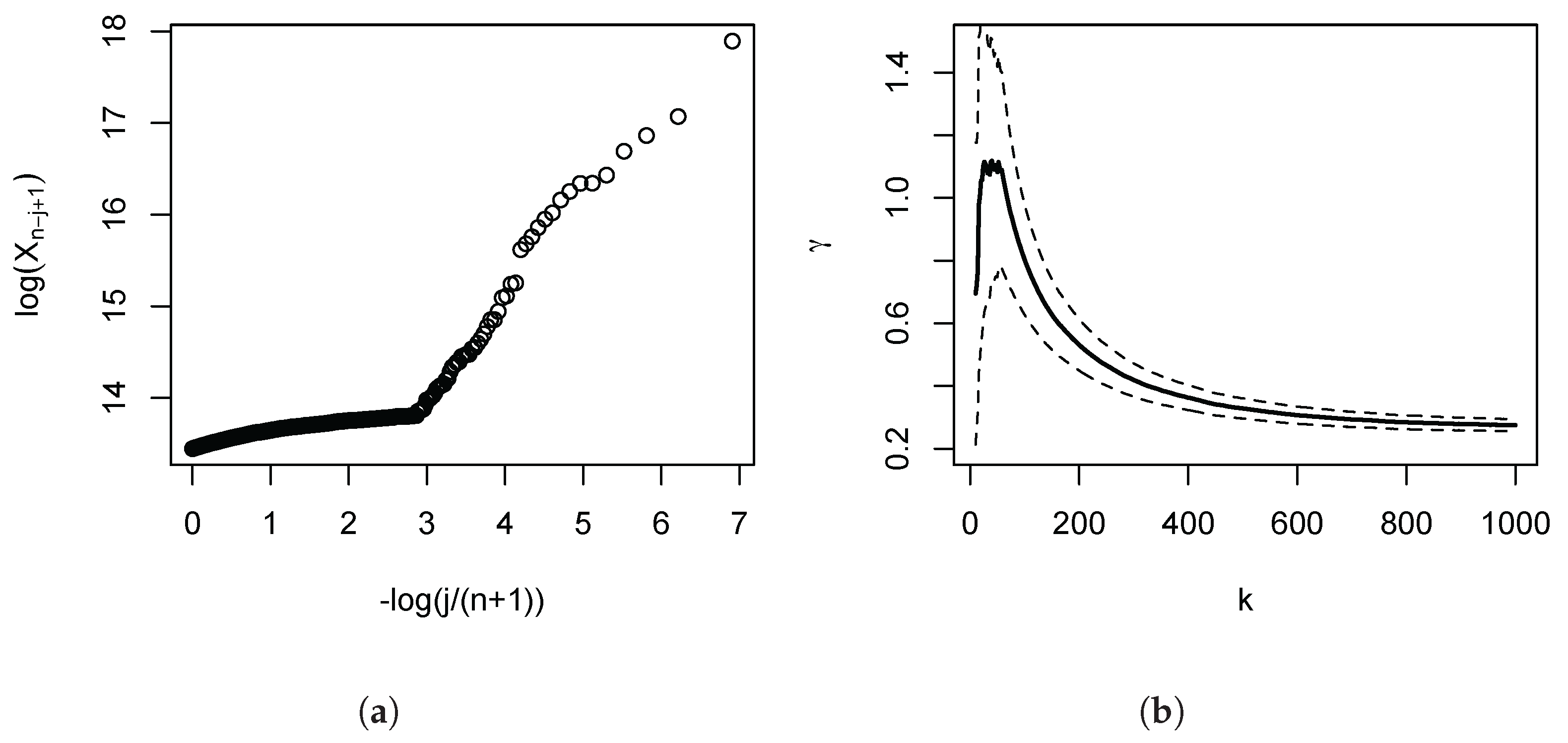
The empirical importance of this is illustrated in Figure 1, which depicts the Pareto QQ-plot for our administrative income data for the UK (the subject of our empirical application developed in Section 4 below), using the 1000 largest incomes. The plot exhibits a pronounced kink, and approximate linearity of the QQ-plot only holds for the very highest upper order statistics. Panel (b) shows the consequences for the OLS estimates: As we move in the QQ-plot from the right to the left, the departures from linearity become progressively more severe, and the OLS estimates progressively fall. Based on this first diagnostic QQ-plot, once the lower upper order statistics have been discarded as a source of downward bias, the subsequent analysis can then more clearly focus on the approximate linear part, the remaining distortions, and the choice of the number of order statistics. Figure 2 provides a further illustration for three Burr (Singh-Maddala) distributions (examined in detail in Section 3 below, being the leading parametric income distribution model) possessing the same . Here, the speed of decay of the nuisance function l is parametrised by the absolute value of the parameter . The smaller the magnitude of , the greater the initial curvature and steepness of the Pareto QQ-plot, and the larger the induced positive distortions of the OLS estimator of the slope coefficient.
In this paper, we examine the asymptotic distortions of the OLS estimator that arise in these circumstances, caused by the slow decay of the nuisance function l and modeled here as higher order regular variation. The theory is presented in Section 2 (proofs are collected in Appendix A), and numerical illustrations and quantifications of the distortions are provided in Section 3, as well as of the stark consequence for inference. More specifically, we show formally that the OLS estimator over-estimates the true value in the leading heavy-tailed model (i.e., the Hall class, which includes the Burr (Singh-Maddala) distribution, as well as the student, Fréchet, and Cauchy distributions). An empirical illustration in the context of top incomes in the UK using data on tax returns is the subject of Section 4.
1.1. The Log-Log Rank-Size Regression
We briefly review the rank size regression. Let denote the order statistics of , and consider the k upper order statistics. Let ranks be shifted by a constant . The regression of sizes on ranks leads to the minimisation of the least squares criterion
with respect to g, where and . The classic case is . However, since the OLS estimator of the slope coefficient is not invariant to shifts in the data, it is conceivable that a purposefully chosen shift could yield an asymptotic refinement (Gabaix and Ibragimov 2011 consider this in the strict Pareto model ). The analysis below allows for this possibility.
The justification of considering regression (2) is based on a Pareto QQ-plot (Beirlant et al. 1996): For a sufficiently high threshold where , the Pareto quantile plot in model (1) with coordinates becomes ultimately linear. The line through point with slope g is thus given by and the data points are . The regression estimator estimates this slope parameter. In particular, the OLS estimator of the slope coefficient g is
Note that the denominator is a Riemann approximation to . An asymptotic expansion of the denominator reveals that
From Kratz and Resnick (1996, proof of their Equation 2.4, p. 704) we know that the numerator converges in probability to , hence the estimator is weakly consistent: as and . We proceed in the next Section to refine this result by obtaining higher order expansions of the estimator in (3).
The literature contains several variants of regression (2). Rather regressing log sizes on log ranks, one could regress log ranks on log sizes, thus obtaining the ‘dual’ regression. In view of (3), our asymptotic analysis of the numerator carries immediately over to this dual regression. Another variant of (2) includes the additional estimation of a regression constant: is regressed on a constant and . Kratz and Resnick (1996) obtain the distributional theory for this alternative estimator and show that its asymptotic variance is , which exceeds, as will be shown below, the asymptotic variance of given by (3). Hence this regression variant is less efficient. Schultze and Steinebach (1996) also prove weak consistency of the estimator in this setting.
2. Asymptotic Expansions and Distributional Theory
2.1. Preliminaries: Higher Order Regular Variation
In order to obtain our asymptotic expansions, we use an equivalent representation of model (1) based on regular variation and extreme value theory. First we recall the definition of first-order regular variation, and then proceed to model the slowly varying nuisance function l in (1) by a refinement to second-order regular variation. We then show that most heavy-tailed distributions of interest (in the income, finance and urban literature) satisfy this condition.
It is well known that model (1) has the equivalent (first-order regular variation) representation (e.g., Dekkers et al. 1989)
for all where a is a positive norming function with the property . The problem for estimating the extreme value index is the behaviour of the slowly varying function l in (1). It is, therefore, common practice in the extreme value literature to model such second-order behaviour, thus strengthening model (1), by strengthening the first-order regular representation (5) to second-order regular variation. Following De Haan and Stadtmüller (1996), we assume that the following refinement of (5) holds
for all , where with . This parameter is the so-called second-order parameter of regular variation, and is a rate function that is regularly varying with index , with as . As falls in magnitude, the nuisance part of l in (1) decays more slowly. Our numerical illustrations will thus consider small magnitudes for .
Examples.
Most heavy-tailed distributions of interest satisfy representation (6). Consider the Hall class of distributions (Hall 1982), given by, for large x,
with , , . In this class, the nuisance function l in model (1) converges to a constant at a polynomial rate. The Hall class nests, for instance, the Burr (Singh-Maddala), Student, Fréchet, and Cauchy distributions.2 The tail quantile function is where , . This Hall class satisfies the second order representation (6) with , and rate function
Figure 2 illustrates the role of for the Burr distribution (examined in greater detail in Section 3) in terms of the Pareto QQ-plot, and the implications for the estimator of its slope parameter. For the plot is close to linear, and the estimates close to the population value. However, as falls in magnitude, the initial curvature increases, and the slope estimates consequently becomes more positively distorted as the number of upper order statistics k entering the estimator increases.
2.2. The Main Results
We first state the higher order asymptotic expansion of the numerator . We then obtain the distributional theory for our estimator , before returning to the distortions induced by deviations from the strict Pareto model (captured by second order regular variation).
Asymptotic expansion.
In the Appendix A we prove the following higher order expansion of the numerator under the assumption of second-order regular variation (6). Throughout, we will consider an intermediate sequence of positive integers such that and as . It is then true that, for and ,
A few comments are in order. The first two lines of this expression characterise the first-order behaviour of the numerator. It can be seen that setting the regression shift factor to 1/2 eliminates the second and third term. However, the term is still present. The asymptotic refinement due to second-order regular variation is given by the terms of line 3. Although as , this decay might be slow: is regularly varying with index , and as falls in magnitude the nuisance part of l in (1) decays more slowly. A slow decay then introduces a noticeable distortion in finite samples. We examine these distortions after stating the distributional theory for the estimator.
Distributional theory.
Beirlant et al. (1996) observe that our slope estimator , given by (3), is (to first order) a member of the class of kernel estimators discussed in Csorgo et al. (1985) with kernel . Since and not unity, a scale correction is required. Since , the following result obtains as and , and if
Higher order distortions.
Asymptotically, the estimator is thus unbiased if . If this decay is slow, however, the estimator will suffer from a higher order distortion in finite samples. By (7), this distortion equals, for and ,
In particular, in the Hall model, . The sign of the higher order distortion of and hence is, since , then given by -sgn. For the Burr (Singh-Maddala), student, Fréchet, and Cauchy distributions it can be shown that , leading to a positive higher order distortion. We conclude that the higher order distortion induced by higher order regular variation is positive for many popular distribution -i.e., for which the nuisance function l in model (1) converges to a constant at a polynomial rate- leading to an overestimation of .3
Simulation evidence for these theoretical results is presented next. We also quantify the higher order distortions and the consequences for statistical inference about .
3. Numerical Illustrations
We illustrate numerically several of our results in a Monte Carlo study. First, we verify the distributional theory, then show that most of the empirical distortion is captured by the bias function . At the same time, we show that the distortions can be sizeable, leading to substantial test size distortions, while a bias correction using would reconcile nominal and actual test sizes.
Our Monte Carlo study is based on the Burr distribution, a member of the Hall class, parametrised here as with parameters and . In the income distribution and inequality literature, this distribution is also know as the Singh-Maddala distribution, and used frequently in parametric income models. Specifically, we set , and to begin with. Qualitatively similar results are obtained for the student, Fréchet, and Cauchy distributions, all of which are members of the Hall class, and therefore not reported here. Since we consider a situation of fairly heavy tails (as second moments of the distribution do not exist). However, the qualitative insights depend little on the actual choice of . We have chosen as our leading example since we are interested in the consequences of deviating from a strict Pareto model. As falls in magnitude the nuisance part of l in (1) decays more slowly. This is illustrated in Figure 2, where we depict three Pareto QQ-plots for different . For , the plot is almost linear throughout. The deviations from the strict Pareto model become increasingly more pronounced in the left part of the plot as falls in magnitude.
For the simulation study, we draw samples of size at first (then ), and consider the upper k order statistics. In order to choose a particular k, we follow standard practice and minimise the theoretical asymptotic Mean Squared Error (AMSE) (e.g., Hall 1982, or Beirlant et al. 1996), given by , trading off distortion and dispersion. The theoretical higher order bias in induced by higher order regular variation in this Burr case is
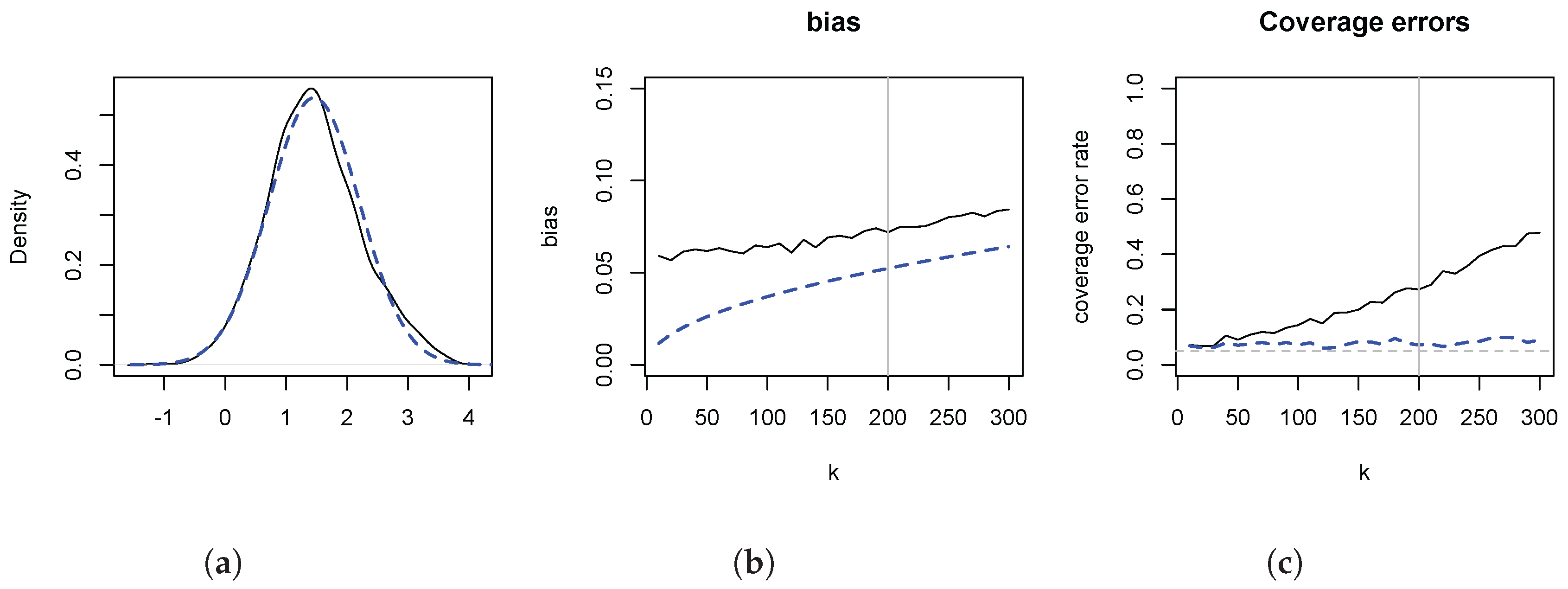
which is, of course, increasing in k. The theoretical AMSE is minimised around , which also corresponds to the minimiser of the empirical AMSE based on the R samples. The mean of at this is 0.739, and exceeds, as predicted by the theory, the population value .
Figure 3 depicts the results. In panel (a) we illustrate the distributional theory, given by (8), for , by plotting a kernel density estimate of (solid line), as well as a normal density with variance , centered on the empirical mean of the simulated data. The two are in close agreement. The figure also implies that any inferential problems are due to location shifts. In panel (b) we contrast the empirical distortions (solid line) with (dashed line). overestimates , and the distortion increases in k. It is evident that most of the distortion is captured by . In panel (c) we illustrate the consequences of the distortions for statistical inference, by plotting the empirical coverage error rates of the usual 95% symmetric confidence intervals. The higher order distortions lead to undermining inference because of the considerable size distortions. For instance, at , the empirical coverage error rate is 30% for a nominal 5% rate. Shifting the estimate by reduces the coverage error rate to 7%.
Next, we consider the role of the sample size n. Reducing the sample sizes in the Monte Carlo to yields results that are in line with the above theory, and therefore not depicted. The bias of increases by a factor predicted by the theory, namely . The optimal shrinks by a factor of 4, as now . The density of is in good agreement with the theory, and empirical coverage error rates at this are 32% for the uncorrected and 11% for the corrected estimator. The empirical coverage error rate for the uncorrected estimator rises steeply after , reaching 64% at . Reducing the sample sizes further to 100 results in , and an empirical coverage error rate for the uncorrected estimator of 46% at this . Biases are increased by a factor .
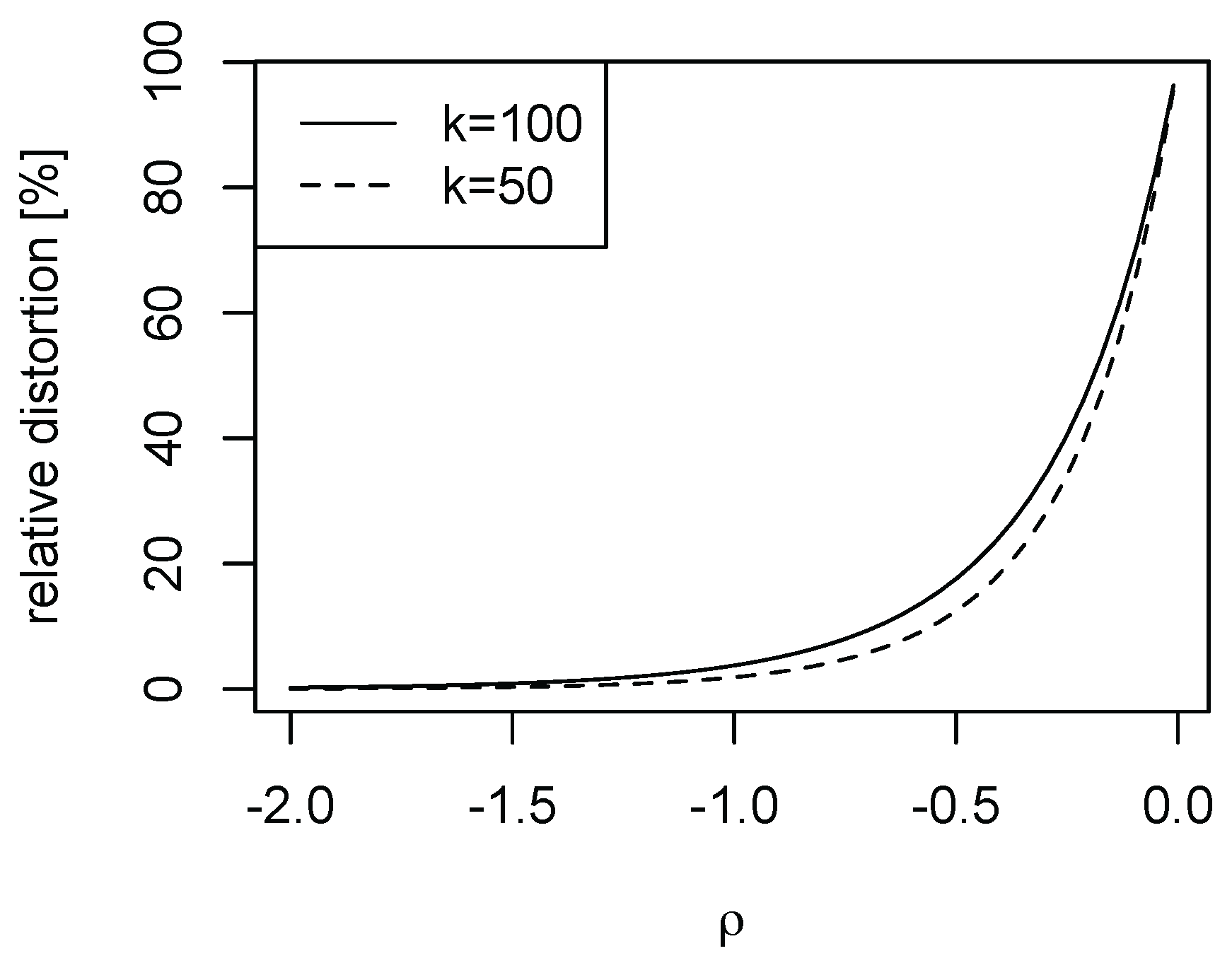
Finally, we illustrate the importance of the speed of decay in the nuisance function l of model (1). As falls in magnitude, the nuisance function l decays more slowly. For the Burr case with , we depict in Figure 4 as falls in magnitude for and selected k. While for the distortions are negligible (in line with Figure 2, it is evident that for small magnitudes of the higher order distortions cannot be ignored).
As the purpose of our simulation study is the provision of numerical evidence for our theory, we have used the theoretical bias function in the Burr case. When no such external knowledge is available, estimating the bias function requires non-parametric estimates of the second order parameter and the function . However, existing methods perform poorly, yielding excessively volatile estimates. The theory then informs a sensitivity analysis which is described in Section 4.1 in the context of our empirical application.
4. Empirical Illustration: Top incomes in the UK
Our empirical application uses administrative income tax return data are from the public-release files of the Survey of Personal Incomes (SPI) for the year 2009/10 (see e.g., Jenkins 2017 for a detailed description, and an analysis that includes rank size regressions). The SPI data underlie the UK top income share estimates in the World Top Incomes Database (WTID), and is a stratified sample of the universe of tax returns. The unit of taxation is the individual, and we use total taxable income as the income variable. The file contains 674,715 individuals, and we consider the n largest incomes.
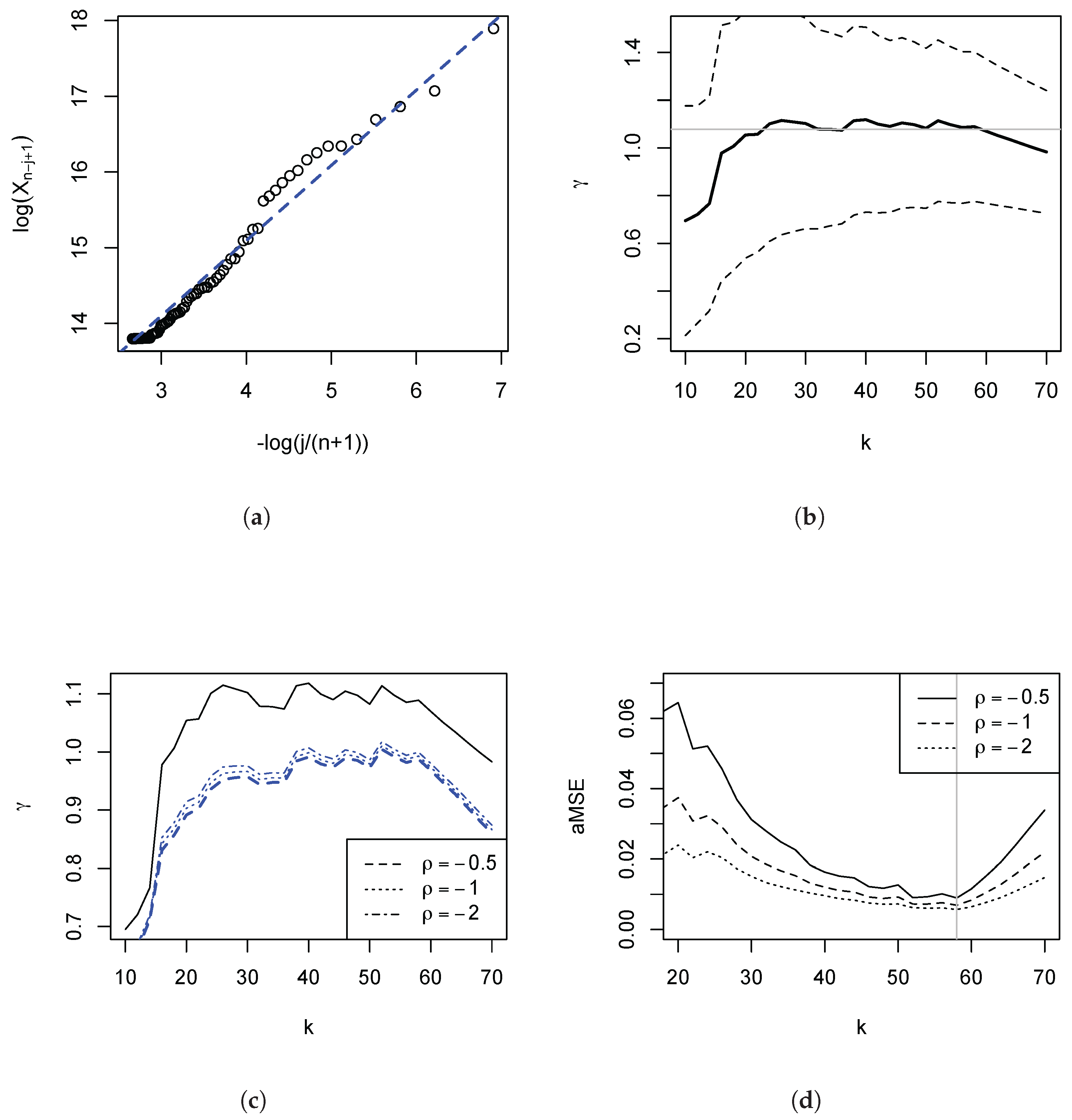
In Figure 1 panel (a), we have depicted the Pareto QQ-plot for the 1000 largest incomes. It is evident that the data clearly reject a strict Pareto model: The plot exhibits a pronounced kink, and approximate linearity of the QQ plot only holds for the very highest upper order statistics. The function l in (1) captures this significant departure from the strict Pareto model. The Pareto QQ-plot thus conveys crucial information that is usually ignored by practitioners in economics, making it a key diagnostic device. For instance, a common mechanical approach is to set k by choosing ‘blindly’ (i.e., without reference to the Pareto QQ-plot) e.g., the top 1% or the top 1000 observations. Since the approximate linearity only obtains for about the 70 largest observations, the estimate of the slope parameter of the Pareto QQ-plot, i.e., the OLS estimator (3), will be severely biased if k is set to 1000 or higher. This is illustrated in panel (b) of the figure: The estimates fall for higher values of k, since the estimation procedure then attributes increasing weights to the left of the kink in the Pareto QQ-plot.
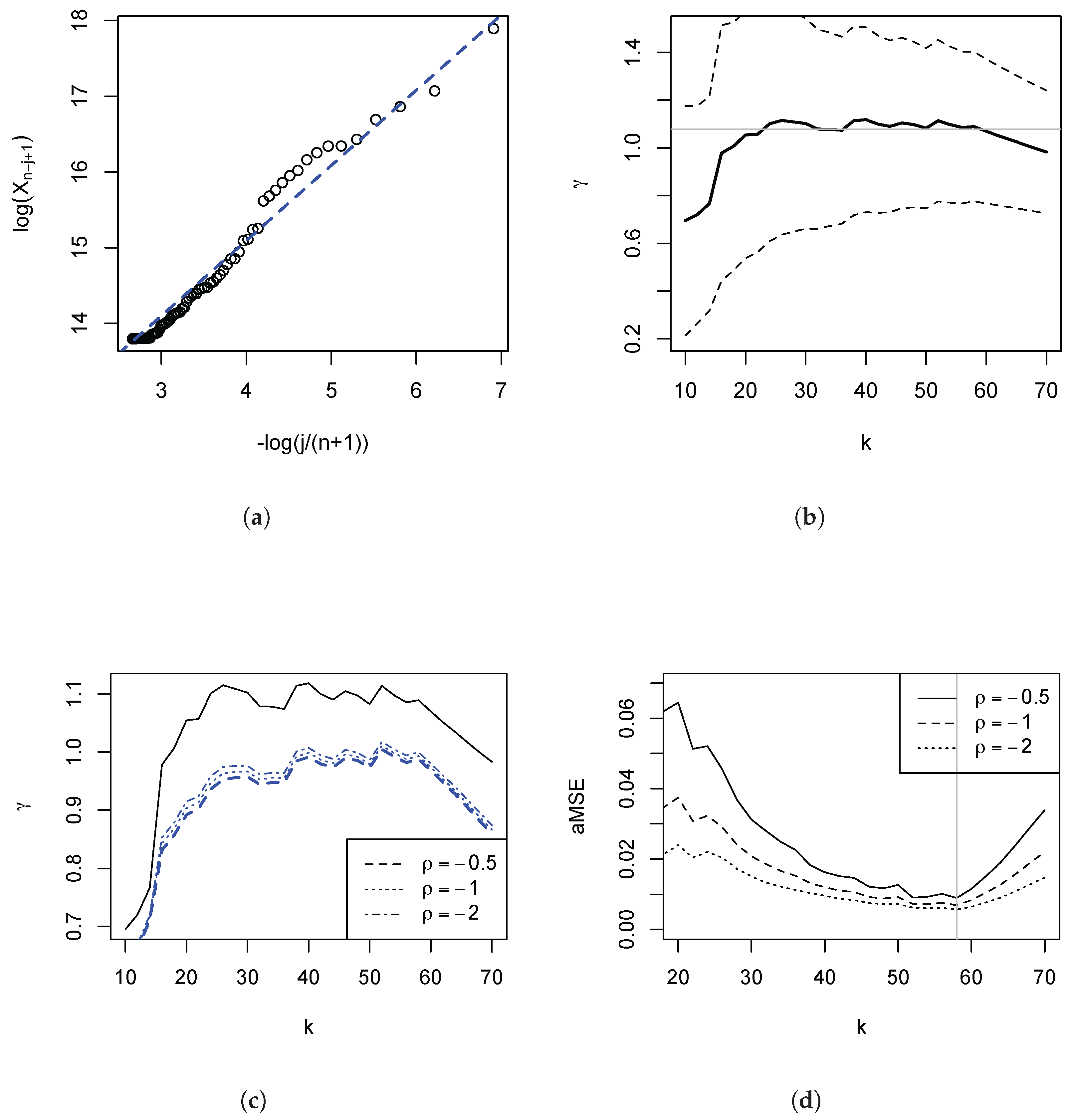
In the light of these observations, we restrict our subsequent analysis to the range of k in which the Pareto QQ-plot is approximately linear. We confirm this in Figure 5 panel (a), having restricted the plot to the highest incomes. The plot now appears fairly linear. In panel (b), we depict the regression estimates and the 95% symmetric pointwise confidence intervals. One first visual way of choosing an estimate is to consider an area of the plot where the estimate is fairly stable (as is done by inspecting Hill or so-called alternative Hill plots) and picking the largest such k since the variance of the estimate falls in k. Such subjective choice would be around with an estimate of (indicated by the horizontal faint line in the figure).4 Overall, the visual method would suggest an estimate of between 0.9 and 1, implying very heavy tails. Taking into consideration the variability of the estimate, one cannot reject the hypothesis that the tail index be unity, i.e., Zipf’s law. Returning to panel (a) we have also plotted the line with slope 1. This line does well in describing the data. We turn to a method that permits an objective choice of a particular k, and examine the remaining distortions in the estimate of .
4.1. Sensitivity Analysis, and the Choice of k
The preceding analysis has shown that is likely to suffer from positive higher order distortions, captured by . Estimating this bias function requires non-parametric estimates of the second order parameter and the function , but existing methods perform poorly, yielding excessively volatile estimates. Hence we limit ourselves to a sensitivity analysis, taking as a sensitivity parameter, whose objective is to gauge plausible values of the potential distortions based on diagnostics of the rank size regression. This approach is sketched next.
Following Beirlant et al. (1996), we observe that the mean weighted theoretical squared deviation
equals, to first order,
for some coefficients depending only on k, and depending on k and (these are stated explicitly in the Appendix A). Set . An estimate of the mean theoretical deviation is the mean of the squared residuals of the rank size regression. In view of the usual bias-variance trade-off for our estimator for fixed n, we ascribe all the measured deviation to the bias, thereby defining a very conservative bound, and let
This conservative sensitivity analysis then consists of examining for a range of values of .
Figure 5 panel (c) reports the results of such a sensitivity analysis for k being restricted to the highest incomes. Since under this restriction the Pareto QQ-plot is approximately linear, we expect that the remaining distortions are fairly modest. This is borne out in the sensitivity plot, as the precise value of now plays only a minor role.
Should a researcher wish to choose a particular k by minimising an approximation to the AMSE, Equation (10) is the basis of the procedure proposed in Beirlant et al. (1996): Apply two weighting schemes (), estimate the corresponding two mean weighted theoretical deviations using the residuals, and compute a linear combination thereof such that obtains. We have carried out this programme (see Appendix A for further details) for weights and for given , and Figure 5 panel (d) depicts the results. Minimising this approximation to the AMSE yields , which, for , resulted in across the selected , for which obtains. In view of the results depicted in panel (c) it is not surprising that changing has only a small effect. This estimate of is very close to the subjective visual choice of of 1.075, reported above, based on Figure 5b.
5. Conclusions
The OLS estimator of the slope coefficient in the rank size regression (shifted or unshifted) can suffer significant higher order distortions that arise from the slow decay of the nuisance function l in the model for . Modeling the tail as second order regular variation, we have shown that the estimator over-estimates the true value in models in which l converges to a constant at a polynomial rate (i.e., in the leading heavy-tailed distributions). Our numerical illustrations have shown that these distortions can be dramatic, leading to test size distortions in which actual error rates are multiples of nominal error rates. The empirical illustration based on the Pareto QQ-plot has revealed a further distortion, namely the presence of a pronounced kink. Figure 1 has revealed that using the common rule to choose 1% of the observation for tail estimation would lead to a severe under-estimation of how heavy the tail is.
The higher order distortions are functions of and the second order regular variation parameter . Since existing methods usually result in poor estimates of these, reliable bias corrections are not feasible. In view of this we have proposed a sensitivity analysis based on diagnostics from the rank size regression. When applied to our data on top incomes, we still cannot reject the hypothesis be unity, a situation often described in several fields as Zipf’s law (e.g., Schluter and Trede 2017).
The simplicity of the regression estimator is undoubtedly the principal reason for its popularity among practitioners in economics. This paper has shown that in many situations the naive (i.e., ‘blind’) use of this estimator should be considered with care: Pareto QQ-plot, the sensitivity plot and the AMSE plot convey jointly important information about the behaviour of the estimator.
Acknowledgments
I thank the referees for their constructive comments that have helped to improve the paper.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Proofs
Before proving the main result given by (7), we consider first the behaviour of the numerator under first-order regular variation (5). We then refine the asymptotic expansion by assuming that the second-order regular variation (6) holds.
First-order asymptotic expansion of the numerator .
Assume that (5) holds, and consider an intermediate sequence of positive integers such that and as . It will be shown that
Remark:
The term dominates , and is not eliminated by setting the shift factor to 1/2.
In the proof of (A1) we will make use of the following Euler Maclaurin formulae (e.g., Gabaix and Ibragimov 2011, Equations A.4 and A.5)
and
Proof of (A1).
We adapt the proofs of Kratz and Resnick (1996) (KR henceforth) of their Equations 2.4 and 2.8. The key is the use of Renyi’s representation of exponential order statistics, which implies (e.g., KR, p. 705)
where () denote iid unit exponential random variables, and denotes the -th order statistic. We obtain an asymptotic refinement by using, instead of KR’s Lemmas 2.2 and 2.3, the above Euler Maclaurin formulae, and Lyapunov’s central limit theorem (CLT). Our numerator is denoted there by , and the indices are mapped by setting . From KR (pp. 704-707), we have
where .
We first show that KR’s result (A4) can also be derived from the first order regular variation condition under the stated assumptions. Let Y denote a standard Pareto random variable, and denote the -th order statistic by . Consider the scaled log excesses
where and are defined in representation (5). Then, noting that , and using (5) with and , the scaled log excesses satisfy as and
By Renyi’s representation of exponential order statistics, we have , so
since, using Renyi’s representation again, . From Wellner (1978), we know that , so . Using the definition of , on combining the results we thus obtain
as claimed.
We proceed to examine (A4). Using (A3) yields
By Lyapunov’s CLT,
so . Using again (A3) and substituting the result, we obtain
Note that and . is a Riemann approximation to the integral , and is a Riemann approximation to the integral . By Lyapunov’s CLT, , so . Similarly, the last term is . Hence
which is Equation (A1), as claimed.
Before refining the asymptotic expansion, we briefly consider:
Proof of (4).
. Expanding the quadratic in the definition of
and using the Euler Maclaurin formulae yields the stated result.
We are now in a position to examine the behaviour of the numerator under second order regular variation.
Proof of the higher order expansion (7).
The role of the first term on the right for has already been described above. In what follows, we consider the higher order term. Since , the higher order expansion of requires the analysis of
where . has expectation , so by the CLT . To handle the last sum, note that where V denotes a standard uniform random variable, and we replace the order statistic by its expectation, . A Taylor series expansion then gives . Then
For the third term on the rhs, we use the Euler Maclaurin (A3), for the second term on the rhs we have the following Euler Maclaurin
Combing these two Euler Maclaurin formulae, we can simplify to get
Therefore5
We are now in a position to combine the results. In order to simplify notation, denote the first order expansion of the numerator by , given by the rhs of (A1). Then substituting the higher order expression for the scaled excesses (A5) into the formula for , recalling that (Wellner 1978), and using (A6) yields
Proof of (8).
Their Theorem 2 (or Theorem 1.1 in Beirlant et al. 1996) states the following. Under general conditions on kernel K and distribution function F so that there exists a nonrandom sequence such that converges weakly to a limiting distribution for some sequence with , it is necessary and sufficient that
where b is a function such that as , and that for the tail quantile function with
where as . If this condition is satisfied, then as and
Beirlant et al. (1996) observe that our slope estimator , given by (3), is (to first order) a member of the class of kernel estimators with kernel , and that the above condition holds under the regular variation hypothesis. Turning to the specific kernel , since and not unity, a scale correction is required. As , the stated result (8) follows.
Proof of (10).
Consider the mean weighted theoretical squared deviation
for some weights . Using (A5) this equals, to first order,
Then, recalling that and proceeding as in Beirlant et al. (1996, Section 4), which involves approximating expectations by the leading term when applying the delta method yields, to first order,
with
and with
Finally, we set and to arrive at (10).
Remark:
In order to obtain an estimate of the AMSE, Beirlant et al. (1996) use two weighting schemes, namely leading to coefficients, say, and and mean weighted squared residuals , and leading to , , and . Then a linear combination of two approximate MSE expressions (with coefficients, say, x and y) is sought that yields , which is achieved by solving simultaneously the equations
References
- Atkinson, Anthony Barnes. 2017. Pareto and the upper tail of the income distribution in the UK: 1799 to the present. Economica 84: 129–56. [Google Scholar]
- Beirlant, Jan, Petra Vynckier, and Jozef L. Teugels. 1996. Tail index estimation, Pareto quantile plots, and regression diagnostics. Journal of the American Statistical Association 9: 1659–67. [Google Scholar]
- Beirlant, Jan, Yuri Goegebeur, Johan Segers, and Jozef L. Teugels. 2004. Statistics of Extremes. Wiley Series in Probability and Statistics; Chichester: Wiley. [Google Scholar]
- Burkhauser, Richard V., Shuaiz hang Feng, Stephen Jenkins, and Jeff Larrimore. 2012. Recent trends in top income shares in the USA: Reconciling estimates from March CPS and IRS tax return data. Review of Economics and Statistics 94: 371–88. [Google Scholar]
- Cowell, Frank A. 1989. Sampling variances and decomposable inequality measures. Journal of Econometrics 42: 27–41. [Google Scholar]
- Cowell, Frank A., and Emmanuel Flachaire. 2007. Income distribution and inequality measurement: The problem of extreme values. Journal of Econometrics 141: 1044–72. [Google Scholar]
- Csorgo, Sandor, Paul Deheuvels, and David Mason. 1985. Kernel Estimates of the Tail Index of a Distribution. The Annals of Statistics 13: 1050–77. [Google Scholar]
- Davidson, Russell, and Emmanuel Flachaire. 2007. Asymptotic and bootstrap inference for inequality and poverty measures. Journal of Econometrics 141: 141–66. [Google Scholar]
- De Haan, Laurens, and Ana Ferreira. 2006. Extreme Value Theory. New York: Springer. [Google Scholar]
- De Haan, Laurens, and Ulrich Stadtmüller. 1996. Generalized regular variation of second order. Journal of the Australian Mathematical Society (Series A) 61: 381–95. [Google Scholar]
- Dekkers, Arnold L. M., John H. J. Einmahl, and Laurens de Haan. 1989. A moment estimator for the index of an extreme-value distribution. Annals of Statistics 17: 1833–55. [Google Scholar]
- Embrechts, Paul, Claudia Kluppelberg, and Thomas Mikosch. 1997. Modelling Extremal Events. Berlin: Springer. [Google Scholar]
- Gabaix, Xavier, and Rustam Ibragimov. 2011. Rank - 1/2: A simple way to improve the OLS estimation of tail exponents. Journal of Business and Economic Statistics 29: 24–39. [Google Scholar]
- Hall, Peter. 1982. On some simple estimate of an exponent of regular variation. Journal of the Royal Statistical Society Ser. B 44: 37–42. [Google Scholar]
- Kratz, Marie, and Sidney I. Resnick. 1996. The QQ-estimator and heavy tails. Communications in Statistics. Stochastic Models 12: 699–724. [Google Scholar]
- Jenkins, Stephen P. 2017. Pareto models, top incomes and recent trends in UK income inequality. Economica 84: 261–89. [Google Scholar]
- Schluter, Christian, and Mark Trede. 2002. Tails of Lorenz curves. Journal of Econometrics 109: 151–66. [Google Scholar]
- Schluter, Christian, and Mark Trede. 2017. Size distributions reconsidered. Econometric Reviews. forthcoming. [Google Scholar]
- Schultze, J., and J. Steinebach. 1996. On least squares estimates of an exponential tail coefficient. Statistics and Decisions 14: 353–72. [Google Scholar]
- Wellner, Jon A. 1978. Limit theorems for the ratio of the empirical distribution function to the true distribution function. Zeitschrift fuer Wahrscheinlichkeitstheorie und verwandte Gebiete 45: 73–88. [Google Scholar]
| 1 | See e.g., Schluter and Trede (2002) in the contexts of Lorenz curves, Davidson and Flachaire (2007) who propose a semi-parametric bootstrap, Cowell and Flachaire (2007) who advocate semi-parametric methods, or Burkhauser et al. (2012) who seek to reconcile survey and tax return data. Also observe that the moment of the income distribution is finite only if , so very heavy tails can directly affect the validity of some standard inequality measurement tools. For instance, statistical inference for the Generalised Entropy index with parameter 2 requires the existence of the fourth moment (Cowell 1989). |
| 2 | The Burr distribution is a member of the Hall class with parameters and , and , as is the Student distribution with degrees of freedom where , , , , and (valid for ); so is the Fréchet distribution with , , and , and the Cauchy distribution with , , , and . |
| 3 | De Haan and Ferreira (2006) consider the merit of shifting the tail for tail quantile functions where and are not zero, , and and . It can then be shown that if , the second order parameter satisfies . A data shift that eliminates then results in , so the post shift second order parameter has increased in magnitude, leading to a decrease in the induced distortion. However, the reverse reasoning also applies. In particular, the Hall model is . A data shift by yields , and increases the distortion if . |
| 4 | Alternative estimators lead to similar conclusions. For instance, using the classic Hill estimator, at an estimate of of 1.017 is obtained. The plot (not displayed here) is fairly stable around this value for . |
| 5 | To support this key expression, numerical evidence from a Monte Carlo with , 1000 samples, and yielded for the lhs of (15) v. the following: : 1.105 v. 1.111, : 0.746 v. 0.75, : 0.443 v. 0.444. |
Figure 1.
Pareto quantile-quantile (QQ)-Plot: Top incomes in the UK. Based on administrative income tax return for the UK in 2009/10. The Survey of Personal Incomes (SPI) is described in Section 4. Panel (a): The Pareto QQ-plot (see Section 1.1) is based on the largest 1000 incomes. Panel (b): Estimates of for the k upper order statistics using the OLS regression (solid lines), and pointwise 95% symmetric confidence intervals (dashed lines). The distributional theory is stated in Equation (8).
Figure 1.
Pareto quantile-quantile (QQ)-Plot: Top incomes in the UK. Based on administrative income tax return for the UK in 2009/10. The Survey of Personal Incomes (SPI) is described in Section 4. Panel (a): The Pareto QQ-plot (see Section 1.1) is based on the largest 1000 incomes. Panel (b): Estimates of for the k upper order statistics using the OLS regression (solid lines), and pointwise 95% symmetric confidence intervals (dashed lines). The distributional theory is stated in Equation (8).
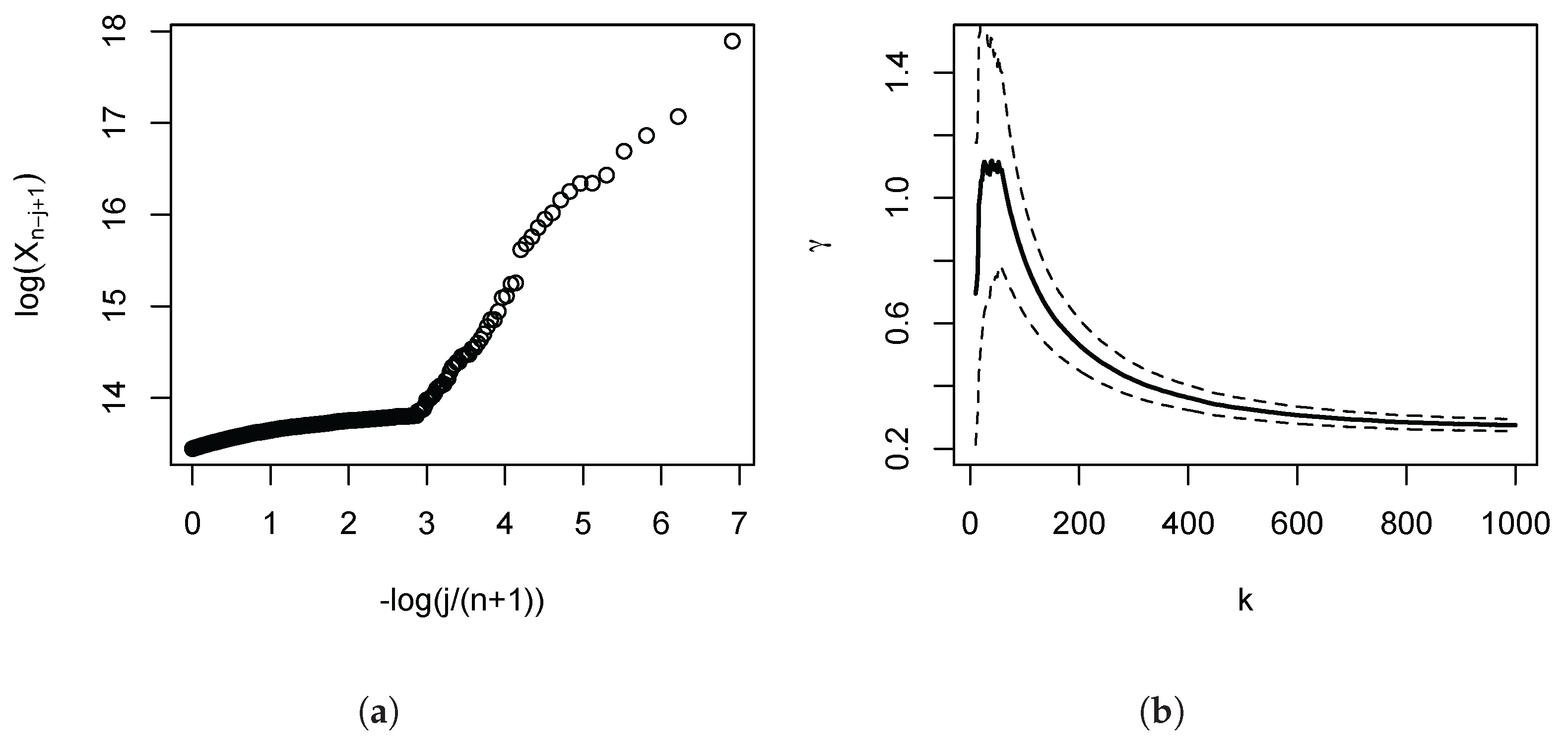
Figure 2.
Pareto QQ-Plots: The Burr distribution. Based on the Burr distribution given by with , and . Panel (a): Pareto QQ-plots for 3 random samples drawn from the Burr distribution. Sample size is 1000. To aid comparison across cases, the points of each QQ-plot have been connected and rendered as lines. Panel (b): Mean of estimates across 1000 Monte Carlo simulations for given , drawing samples of size 1000 in each iteration. The faint horizontal line is the population value .
Figure 2.
Pareto QQ-Plots: The Burr distribution. Based on the Burr distribution given by with , and . Panel (a): Pareto QQ-plots for 3 random samples drawn from the Burr distribution. Sample size is 1000. To aid comparison across cases, the points of each QQ-plot have been connected and rendered as lines. Panel (b): Mean of estimates across 1000 Monte Carlo simulations for given , drawing samples of size 1000 in each iteration. The faint horizontal line is the population value .

Figure 3.
Bias and Inference: Burr. Monte Carlo study for the Burr distribution with parameters and . Based on samples of size n=10,000 and R=1000 repetitions. minimises the asymptotic Mean Squared Error (AMSE), and is depicted by the vertical lines in panels b and c. Panel (a): Density plot of (solid line) and shifted normal density with variance (dashed line). Panel (b): empirical bias (solid line) and higher order bias function (dashed line). Panel (c): Coverage error rate of the usual 95% symmetric confidence intervals for nominal rate of 5%, with no bias correction (solid line) and correction by the theoretical (dashed line).
Figure 3.
Bias and Inference: Burr. Monte Carlo study for the Burr distribution with parameters and . Based on samples of size n=10,000 and R=1000 repetitions. minimises the asymptotic Mean Squared Error (AMSE), and is depicted by the vertical lines in panels b and c. Panel (a): Density plot of (solid line) and shifted normal density with variance (dashed line). Panel (b): empirical bias (solid line) and higher order bias function (dashed line). Panel (c): Coverage error rate of the usual 95% symmetric confidence intervals for nominal rate of 5%, with no bias correction (solid line) and correction by the theoretical (dashed line).

Figure 4.
Relative distortions in the Burr model. Burr model with and . Depicted is as varies.
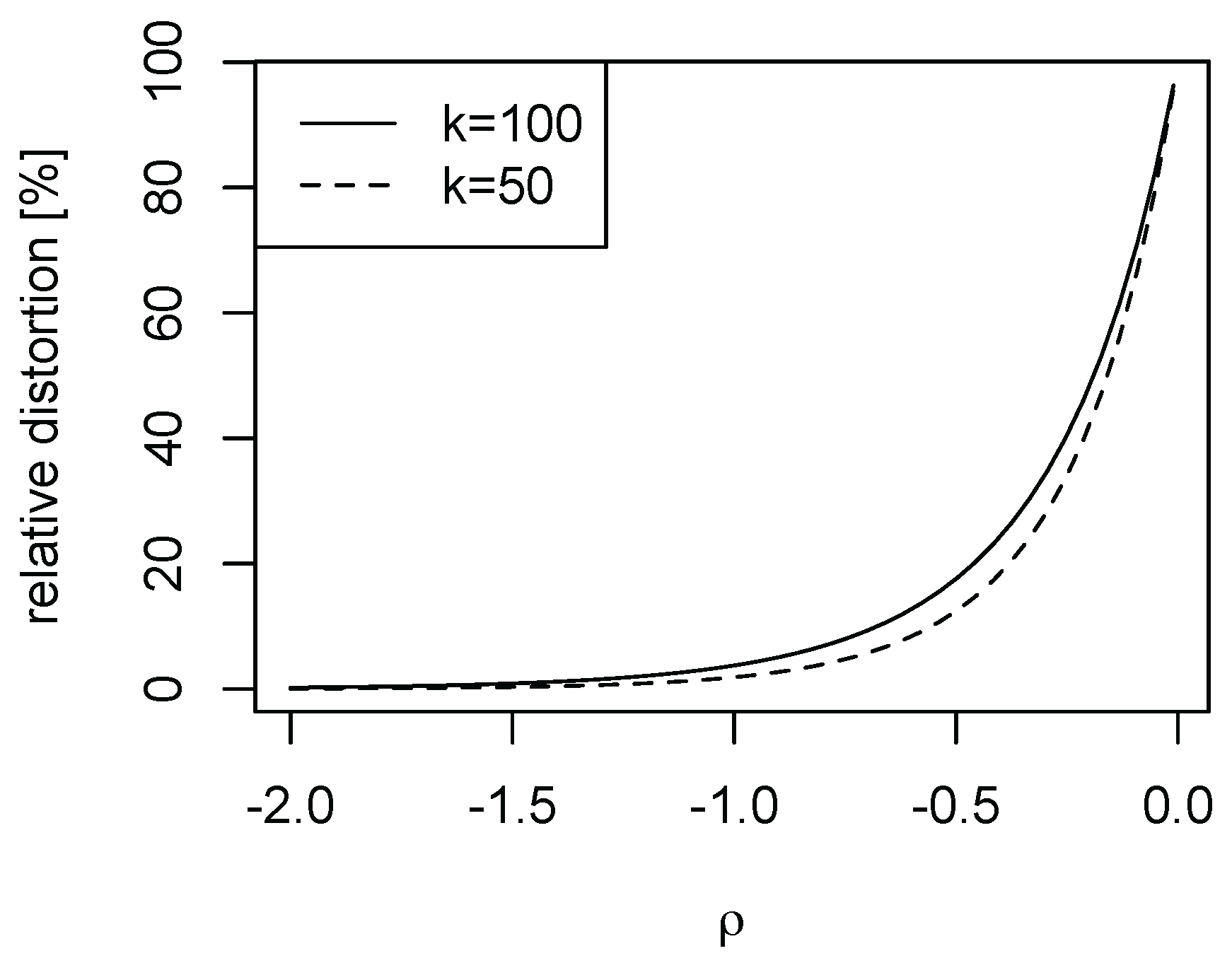
Figure 5.
Estimates of . Based on Survey of Personal IncomeS (SPI) data for 2009/10. Panel (a) Pareto QQ plot for the largest 70 incomes. The dashed line has slope 1. Panel (b): Estimates of (solid line) and the 95% symmetric pointwise confidence interval (dashed line). The faint horizontal line at 1.075 is subjectively chosen. Panel (c): Sensitivity analysis. Plot of (solid line) and for a different values of . Panel (d): Approximation to the AMSE for different values of . Minimising AMSE yields (vertical line) across the selected , for which obtains.
Figure 5.
Estimates of . Based on Survey of Personal IncomeS (SPI) data for 2009/10. Panel (a) Pareto QQ plot for the largest 70 incomes. The dashed line has slope 1. Panel (b): Estimates of (solid line) and the 95% symmetric pointwise confidence interval (dashed line). The faint horizontal line at 1.075 is subjectively chosen. Panel (c): Sensitivity analysis. Plot of (solid line) and for a different values of . Panel (d): Approximation to the AMSE for different values of . Minimising AMSE yields (vertical line) across the selected , for which obtains.
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Schluter, C. Top Incomes, Heavy Tails, and Rank-Size Regressions. Econometrics 2018, 6, 10. https://doi.org/10.3390/econometrics6010010
AMA Style
Schluter C. Top Incomes, Heavy Tails, and Rank-Size Regressions. Econometrics. 2018; 6(1):10. https://doi.org/10.3390/econometrics6010010
Chicago/Turabian StyleSchluter, Christian. 2018. "Top Incomes, Heavy Tails, and Rank-Size Regressions" Econometrics 6, no. 1: 10. https://doi.org/10.3390/econometrics6010010
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.