1. Introduction
As the occurrence of catastrophe events becomes more frequent, the assumption of independence between event occurrence and claim severity is no longer sufficient in insurance risk modeling, given its impact on pricing and reserving, capital allocation solvency, as well as regulatory systems. The February 2009, Victorian bushfire in Australia (10,200 insurance claims amounting to approximately AUD 1.2 billion), the February 2011, Christchurch earthquake (USD 13 billion insured economic losses), the 2011 Great Eastern Japanese earthquake (loss amounting to as much as USD 40 billion), as well as the 2012 Hurricane Sandy (an expected loss of USD 25 billion) are the examples of this effect (see [
1,
2]).
In dealing with the dependency between the inter-claim arrivals and claim sizes, various approaches have been proposed in previous studies that can be noticed in [
3,
4,
5,
6,
7,
8,
9,
10,
11], as well as the references therein. Regardless of the model used, we notice that previous research focused on either examining the expression of the moments of the aggregate discounted claims,
, as can be seen in [
6,
11,
12,
13,
14], or by finding the related ruin measures and the ruin probability expressions, just like in [
3,
4,
5,
10,
15].
Assuming the Poisson claim arrival process with claim sizes following mixed exponential distributions, [
7] obtained the explicit expressions of the actuarial net premiums and the variances of the discounted aggregate claims from the Laplace transform of the distribution of the shot noise process, which was derived using the martingale approach. The first two moments of the aggregate discounted claims were obtained in [
9] assuming the dependency between the claim sizes and the rates of claim occurrence affected by a Markovian environment, called the circumstance process. A delayed renewal process was also explored in [
12,
13,
14,
15], as well as [
11] to accommodate the epochs between claim arrival and the observation of the risk process.
The asymptotical behaviour of a conditional tail probability dependence structure of claim sizes given the inter-claim arrival time was studied in [
5,
8]. Assuming that the conditional tail of claim size given the inter-claim time satisfies a certain condition for a bounded inter-claim time and a really huge claim size, [
5] obtained the asymptotic tail probabilities of the discounted aggregate claims. Three copulas were indicated as fulfilling this assumption, which are the Farlie–Gumbel–Morgenstern (FGM) and the Frank and Ali–Mikhail–Haq (AMH) copulas, and the Weibull claim size was paired with exponential inter-claim arrival time in their numerical example. On the other hand, [
8] explored the analytical properties related to the same dependence structure described by the survival copulas, such as their local and global uniformity.
Conditioning on the first arrival and using a renewal theory argument, [
12] derived a useful expression for the
recursive moment, whereby the inter-claim arrival time and the claim severity are assumed to be independent. The same conditioning argument was then applied in [
6,
10], assuming the FGM copula and then solved using the Laplace transform approach. More recently, [
11] also adopted the same technique to derive the recursive moments of a Sparre Andersen risk process assuming a fairly general dependence structure between the inter-claim time and subsequent claim size variables, providing a simplified moments expression for assuming Erlang weights. Four types of copula were showcased in their examples of joint distribution between the said variables, which are the polynomial copula, the Bernstein copula, the generalized FGM copula, the extended FGM copula (references for these copulas are available in
Section 3 of [
11]).
The recursive moment equation resulting from the technique used in [
6,
12] takes the form of a Volterra integral equation of the second kind, which is widely used in the fields of mathematical physics, such as the electromagnetic and viscoelasticity fields, to represent the dynamics of materials that contain memory (refer to [
16,
17,
18,
19,
20]). We are interested in using the same technique and then extend the recursive moments obtained in [
6], so that it can be applied to any continuous bivariate distribution to accommodate the dependency between the two variables. To do so, we solve the recursive expression of the moments using the Neumann series obtained via the Picard method of successive approximations, upon which a selection of bivariate distributions can be applied, including bivariate copula.
This article is structured as follows.
Section 2 will introduce the general framework of the continuous time renewal risk model together with its recursive moments with exponentially distributed inter-claim time and general claim size distribution. The dependency between the claim size and inter-claim time are then specified using a bivariate copula. For that purpose, we consider three copulas, which are the FGM copula, the Gaussian copula, which is a type of elliptical copula, and the Gumbel copula, an Archimedean type of copula, which is a natural candidate to represent an extreme value copula that caters for the one-sided dependence structure (see [
21]).
In
Section 3, we introduce the Volterra integral equation, which will be solved using the successive approximations method, leading to the Neumann series expression of the recursive moments, which is the main result of this paper. The Neumann series expression of the recursive moments allows the flexibility to capture various dependence structures provided by copula probability density functions (pdf).
Section 4 starts with the comparison between the value of moments obtained by our Neumann series expression assuming the FGM copula and the closed form solution by [
6]. We then present the numerical analysis, showing the value of moments across the dependence parameter for each copula considered, assuming an exponentially distributed claim size. The illustration and comparison of moments, as well as premium values under the standard deviation principle are also included in this section.
Section 5 concludes the article.
3. Linear Integral Equations
The most general form of linear integral equation (IE) is given by:
where
is the solution to the IE that we need to obtain,
is a given function and
is the kernel for the IE. Equation (
8) can be a homogeneous/non-homogenous, Volterra/Fredholm IE of the 1st/the 2nd kind, for which readers are referred to the conditions given in
Section 2.1 of [
18]. Linear IE can be solved either numerically using methods, such as the Runge–Kutta and collocation methods (see, e.g., [
25,
26]), or solved explicitly, such as by obtaining its Neumann series via the Picard method of successive approximations or using the Laplace transform method.
3.1. Volterra IE of the 2nd Kind
If we have
,
, and
, Equation (
8) becomes:
which is a non-homogeneous Volterra integral equation of the second kind. The Volterra IE is widely used in the areas of viscoelasticity and electromagnetic to compute the dynamics of materials that “contain” memory, other than being useful in renewal theory and demography (see, e.g., [
16,
27], as well as the references therein for a more rigorous treatment on Volterra integral equations).
We easily notice that the moments provided by Equation (
2) and Equation (
3) take the form of Equation (
9) and attempt to derive the explicit solution of the recursive expressions using Neumann series in the next subsection.
A unique and continuous solution,
, is obtainable if we have a combination of a continuous kernel,
, in the region
with a function,
, that is continuous in the region
, even though it is not a requirement for the kernel function,
, to be continuous (see page 1 of [
28] and page 5 of [
20]). For the case of a discontinuous kernel function, we need to check if
fulfills the three regularity conditions set on page 3 of [
27], and, hence is an
-function.
In the case of the first and second moments,
and
, the function,
, is represented by the following equations, respectively:
where
is the inter-claim time cdf.
As
X and
W are continuous r.v.’s, and by corollary 2.2.6 of [
23] on copula continuity,
is the continuous function for
and
, since it is the sum and product of continuous functions. The kernel function is also continuous, as it is an exponential function given by:
Additionally, it is a bounded function in the square
.
3.2. Neumann Series
In this section, we will find the Neumann series of the Volterra IE assuming the exponentially distributed inter-claim arrival time and a general claim size with continuous pdf. To do so, we start with a proposition from Chapter 3 of [
27], which used the Picard method of successive approximation.
Proposition 1. Neumann Series for a Volterra IE of the 2nd Kind
For the Volterra IE of the 2nd kind, as in Equation (
9),
where and are -functions, its Neumann series is given by:where is the unique resolvent kernel and is the n-th-iterated kernel function satisfying the recurrence formula:with .
In order to prove our theorem, it is necessary to find the resolvent kernel, which is obtained in the following lemma.
Lemma 2. Consider the kernel function given by Equation (
12).
For , its resolvent kernel is therefore given by: Proof. Using Equation (
14), we obtain K
starting from
. Letting
and since
for even
n, the resolvent kernel is then obtained by summing up
as follows:
☐
Now, we can obtain the expression for the first and second moment, which is the main result of this article.
Theorem 3. The explicit solution of the first two moments are given by:where with .
Proof. Applying Proposition 1 and Lemma 2 to Equation (
3) with
, the results follow. ☐
Section 4 will numerically illustrate the computation of the first and second moment under three copulas, assuming that the claim sizes are exponentially distributed,
i.e.,
. We do not proceed to obtain the closed form solution of the Neumann series expression for the higher moments, as it is tedious and time consuming. However, they are obtainable using the results provided in this section.
4. Numerical Illustration
We now present numerical illustration of the Neumann series expression for the first two moments. We start our discussion by presenting the scatter plots of each copula in
Figure 1,
Figure 2 and
Figure 3, where the marginals are exponential distribution, which is in line with the assumptions used in the numerical computations of the moments in this section. All computations were done using Mathematica.
Figure 1.
Farlie–Gumbel–Morgenstern (FGM) copula with exponential margins and dependence parameters −1, zero, one.
Figure 1.
Farlie–Gumbel–Morgenstern (FGM) copula with exponential margins and dependence parameters −1, zero, one.
Figure 2.
Gaussian copula with exponential margins and dependence parameters −1, zero, one.
Figure 2.
Gaussian copula with exponential margins and dependence parameters −1, zero, one.
Figure 3.
Gumbel copula with exponential margins and dependence parameters one, three, 100.
Figure 3.
Gumbel copula with exponential margins and dependence parameters one, three, 100.
4.1. Numerical Accuracy of Neumann Series Expression for Moments
Recall that Equation (
16) has at most triple integration involved, while Equation (
17) has up to sextuple numerical integration. This implies that the computation of Equation (
17) is expected to be close to the solution by [
6], due to numerical approximation error, and the values would vary according to selected software packages. To evaluate the performance of the main results, we compare the numerical values returned by our Neumann series (under the column Neumann of
Table 1), using the FGM copula, with the numerical values given by the closed form solution in [
6] (under the column BCLM of
Table 1).
Table 1.
Moment verification: the case of the FGM copula. Abs. Dev., absolute deviation; Rel. Dev., relative deviation.
Table 1.
Moment verification: the case of the FGM copula. Abs. Dev., absolute deviation; Rel. Dev., relative deviation.
| Moment | θ | BCLM | Neumann | Abs. Dev. | Rel. Dev. |
|---|
| −0.9 | 0.475231 | 0.475231 | 0 | 0 |
| | 0 | 0.453173 | 0.453173 | 0 | 0 |
| | 0.9 | 0.431115 | 0.431115 | 0 | 0 |
| −0.9 | 0.332023 | 0.329774 | 0.002249 | 0.006774 |
| | 0 | 0.287786 | 0.287786 | 0 | 0 |
| | 0.9 | 0.245457 | 0.247706 | 0.002249 | 0.009163 |
The values in
Table 1 were computed using an example of
,
,
,
and
. The absolute deviation (Abs. Dev.) figures are obtained by taking the difference between the two columns, BCLM and Neumann (
i.e., the absolute value of the solution presented in [
6] minus the Neumann series expression), whereas the relative deviation (Rel. Dev.) figures are calculated as
.
Our calculations showed that the Neumann series expression for the first moment gives the same value as the closed form solution presented in [
6]. On the other hand, the second moment gives a slightly different value at
and
, when the r.v.’s,
X and
W, are highly dependent. After a close scrutiny of the programming messages, we noticed that this is caused by numerical approximation errors of the quadruple, quintuple and sextuple integrations that are not present in the calculation of the first moment. To improve the accuracy of the Neumann series expression for higher order moments, the reader can use other software packages or use Monte Carlo simulation.
4.2. Moments of the Aggregate Discounted Claims
Setting
,
and
for the case of exponential claim inter-arrival time and exponential claim sizes, respectively, we show the values of moments of the aggregate discounted claims for each copula used in this study. We present the values of the first and second moments of the compound distribution,
i.e.,
and
, as well as the variance under each copula in
Table 2,
Table 3 and
Table 4. The term “spread”, which is defined as the difference between the values returned by
θ at both ends,
i.e.,
for FGM and Gaussian, and
for Gumbel, are also shown in
Table 2 and
Table 3.
Table 2.
Values of for various copula.
Table 2.
Values of for various copula.
| θ | FGM | θ | Gaussian | θ | Gumbel |
|---|
| −0.95 | 455.543 | −0.95 | 513.470 | 1 | 453.173 |
| −0.9 | 455.419 | −0.9 | 511.887 | 5 | 360.864 |
| −0.5 | 454.421 | −0.5 | 488.903 | 15 | 267.995 |
| 0 | 453.173 | 0 | 453.173 | 30 | 148.317 |
| 0.5 | 451.926 | 0.5 | 409.481 | 50 | 104.457 |
| 0.9 | 450.928 | 0.9 | 368.612 | 75 | 21.486 |
| 0.95 | 450.803 | 0.95 | 363.124 | 100 | 10.712 |
| Spread | 4.74 | | 150.346 | | 431.687 |
Our calculations showed that all copula exhibit decreasing values as
θ increases, in line with [
11]. Intuitively, a negative dependence structure represented by the pair of short inter-claim waiting time (or frequent claim occurrence within a given time period) with huge claim size will only prompt the insurer to charge a higher premium as opposed to the positive dependence structure.
As we have expected, the values of moments do not vary much across θ when calculated under the FGM copula, as opposed to the Gaussian and Gumbel copulas. Being an extreme copula, values of the first moment calculated under the Gumbel copula also showed the widest spread of the first moment.
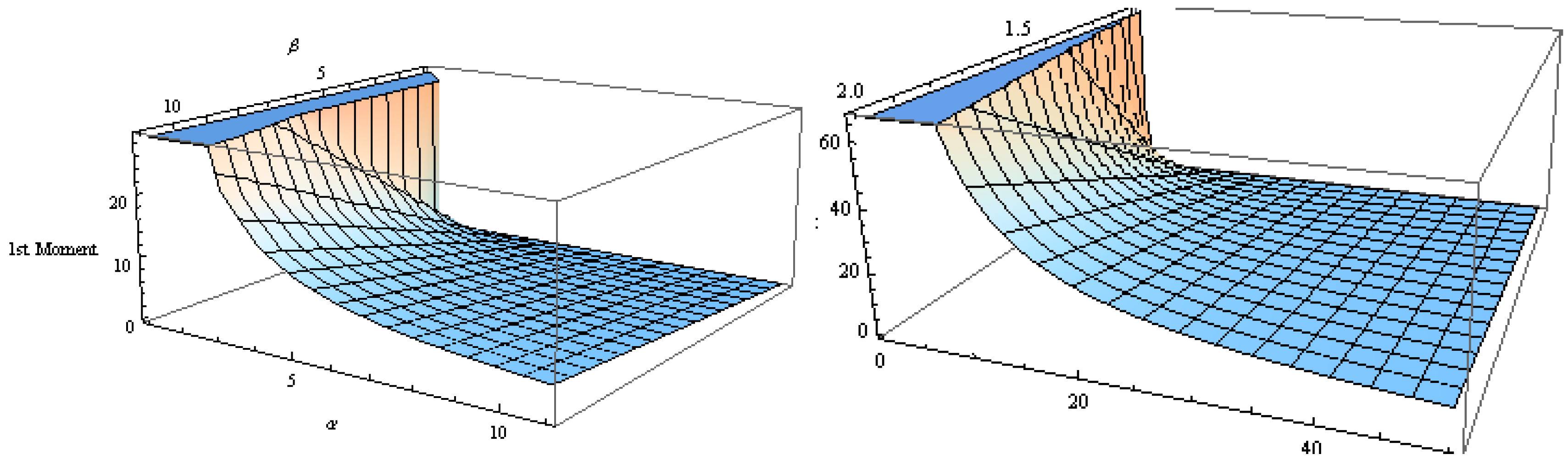
Table 5 shows the values of the first moment as a function of
α and
β, respectively, for which we use the Gaussian copula at
. It shows that increasing the inter-claim waiting time parameter,
β, results in increasing the mean value of the aggregate discounted claims, and
vice versa in the case of the claim size parameter. Given an average value of inter-claim arrival time,
β, the mean of aggregate discounted claims gets lower as we have a lower average claim size, given by
. On the other hand, given an average value of the claim size, the mean of the aggregate discounted claims gets bigger as the inter-claim arrival time gets shorter, which implies more frequent claim occurrences. This scenario is illustrated in
Figure 4 for
(left hand side of the diagram), as well as
(right hand side of the diagram).
Table 3.
Values of for various copula.
Table 3.
Values of for various copula.
| θ | FGM | θ | Gaussian | θ | Gumbel |
|---|
| −0.95 | 336,551.170 | −0.95 | 409,852.140 | 1 | 287,784.972 |
| −0.9 | 332,022.549 | −0.9 | 405,315.216 | 3 | 148,590.220 |
| −0.5 | 312,126.218 | −0.5 | 357,029.617 | 5 | 139,437.15 |
| 0 | 287,785.862 | 0 | 287,785.862 | 40 | 21,804.385 |
| 0.5 | 264,034.461 | 0.5 | 212,119.492 | 75 | 1,088.013 |
| 0.9 | 245,457.386 | 0.9 | 149,988.657 | 80 | 229.608 |
| 0.95 | 241,329.490 | 0.95 | 136,249.086 | 100 | 178.443 |
| Spread | 95,221.68 | | 273,603.054 | | 287,606.529 |
Table 4.
Values of for various copula.
Table 4.
Values of for various copula.
| θ | FGM | θ | Gaussian | θ | Gumbel |
|---|
| −0.95 | 128,940.627 | −0.95 | 146,200.971 | 1 | 82,420.094 |
| −0.9 | 124,616.083 | −0.9 | 143,286.915 | 3 | 13,837.353 |
| −0.5 | 105,627.773 | 0.5 | 118,003.474 | 5 | 9,214.320 |
| 0 | 82,420.094 | 0. | 82,420.094 | 40 | 5,597.566 |
| 0.5 | 59,797.351 | 0.5 | 44,444.803 | 75 | 626.365 |
| 0.9 | 42,121.325 | 0.9 | 14,113.850 | 80 | 112.770 |
| 0.95 | 38,106.145 | 0.95 | 4,390.216 | 100 | 61.436 |
Table 5.
Values of under the Gaussian copula at .
Table 5.
Values of under the Gaussian copula at .
| β =1 | | α = 1 | |
|---|
| α = 0.01 | 511.887741 | β = 0.01 | 0.165673 |
| α = 0.1 | 51.188786 | β = 0.1 | 0.884887 |
| α = 1 | 5.118887 | β = 1 | 5.118887 |
| α = 10 | 0.511838 | β = 10 | 45.911776 |
| α = 15 | 0.341257 | β = 15 | 67.571651 |
Figure 4.
Sensitivity of the first moment under the Gaussian copula at and with respect to claim size and inter-claim time averages.
Figure 4.
Sensitivity of the first moment under the Gaussian copula at and with respect to claim size and inter-claim time averages.
4.3. Premium Calculation under FGM, Gaussian and Gumbel copulas
We now compute the loaded premium related to the risk of an insurance portfolio represented by
, where the dependence structure is captured by a copula. For that purpose, the first two moments will be useful in the premium calculation based on the expected value principle, the variance principle, as well as the standard deviation (SD) premium principle, as the following:
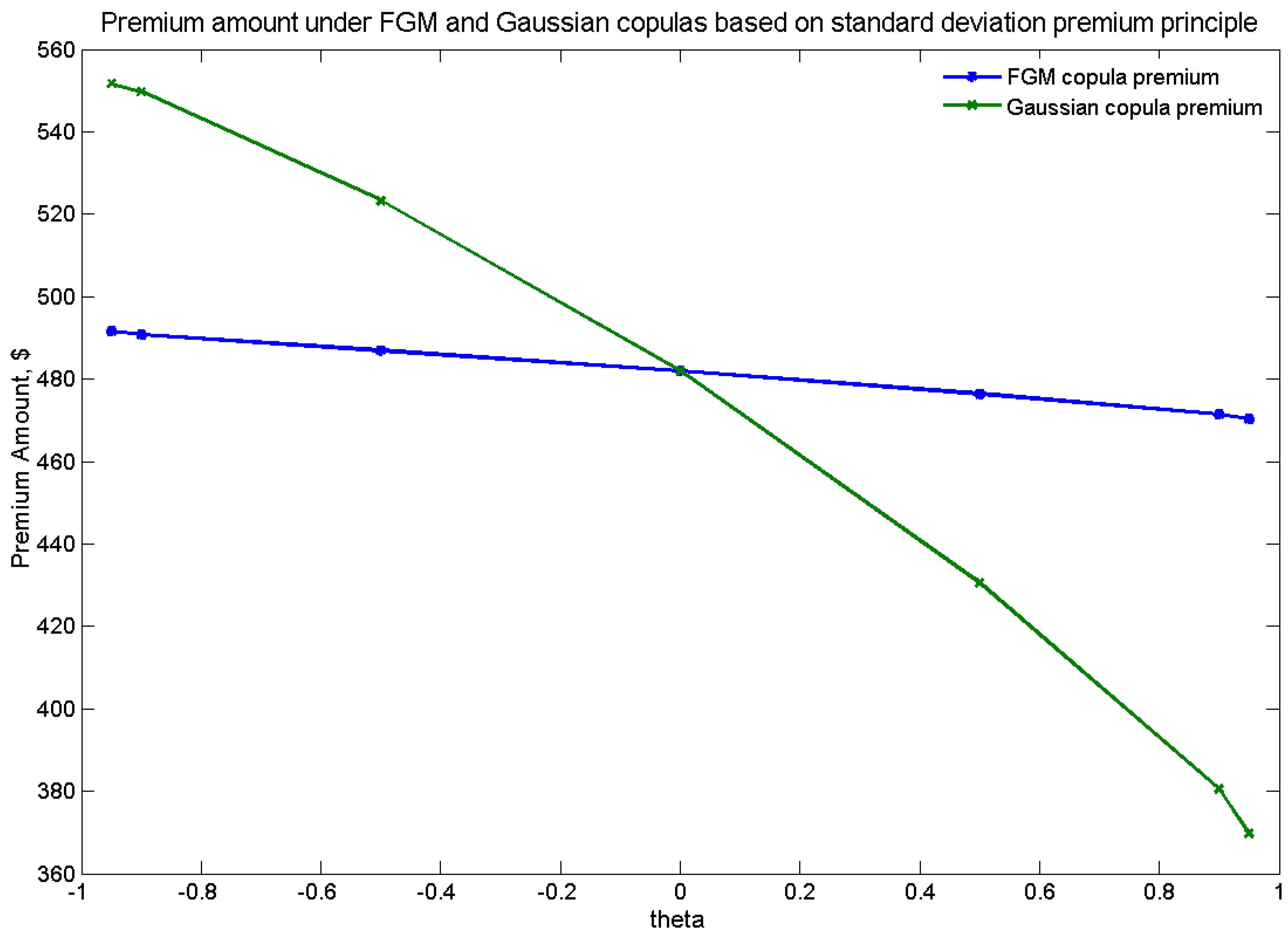
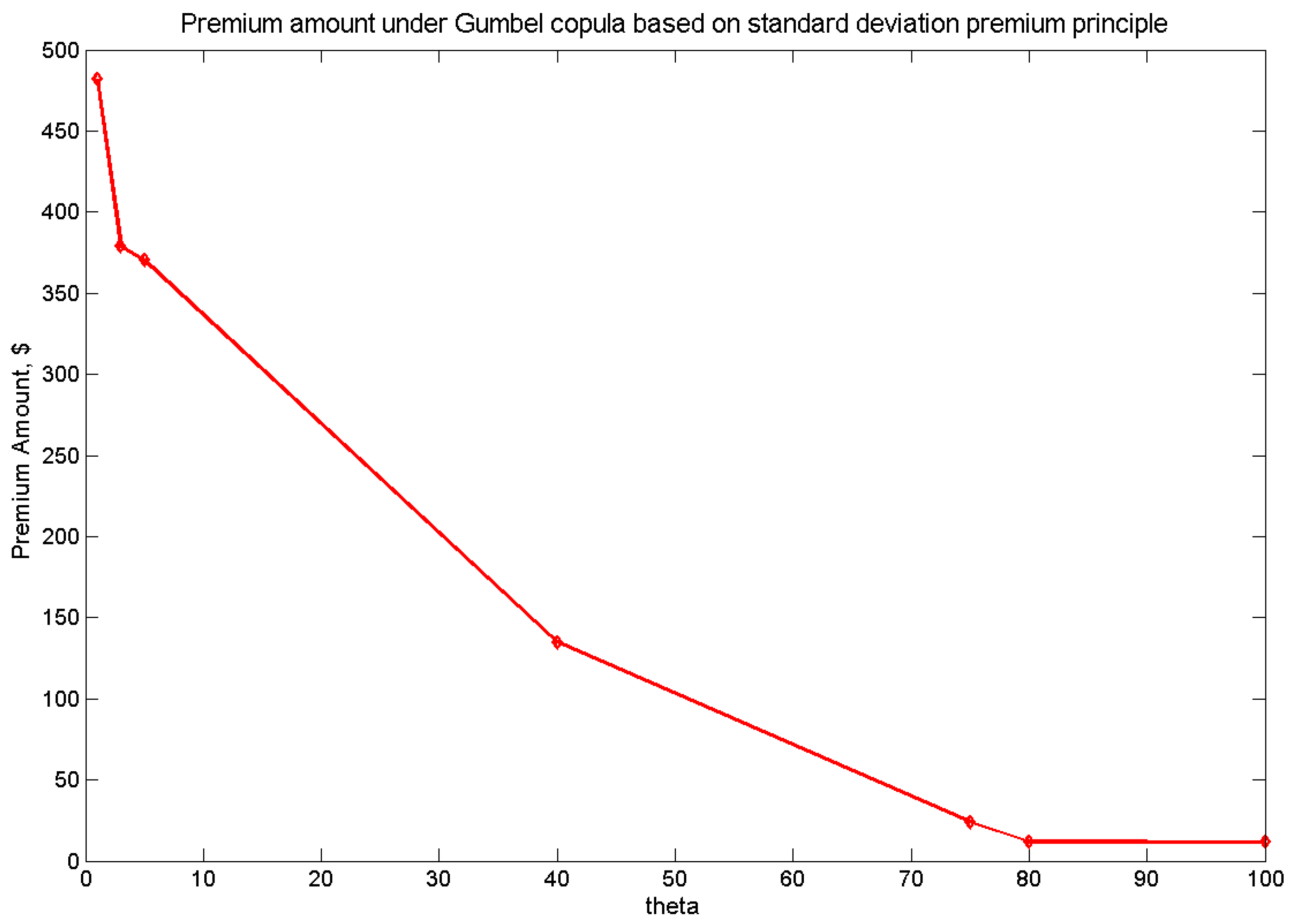
Table 6 exhibits the loaded premium according to the SD principle under the three copulas considered, with
, while
Figure 5 and
Figure 6 illustrate the range of premiums under the copulas studied according to the SD premium principle.
Table 6.
Loaded premium according to the SD principle under various copulas.
Table 6.
Loaded premium according to the SD principle under various copulas.
| θ | FGM | θ | Gaussian | θ | Gumbel |
|---|
| −0.95 | 491.55 | −0.95 | 551.71 | 1 | 481.88 |
| −0.9 | 490.72 | −0.9 | 549.74 | 3 | 378.85 |
| −0.5 | 486.92 | −0.5 | 523.25 | 5 | 370.46 |
| 0 | 481.88 | 0 | 481.88 | 40 | 134.79 |
| 0.5 | 476.38 | 0.5 | 430.56 | 75 | 23.99 |
| 0.9 | 471.45 | 0.9 | 380.49 | 80 | 11.87 |
| 0.95 | 470.32 | 0.95 | 369.75 | 100 | 11.60 |
| Spread | 21.23 | | 181.96 | | 470.28 |
5. Conclusions
In this paper, we utilized copulas to capture the dependence structure between the inter-claim arrival time and claim sizes in classical actuarial risk theory. To do so, we represented the expression for the
order moment proposed in [
6,
12] in the form of the Volterra integral equation (VIE) of the second kind, which is widely used in renewal theory, demographics, electromagnetism and viscoelasticity.
Figure 5.
The loaded premium under FGM and Gaussian copulas based on the SD premium principle.
Figure 5.
The loaded premium under FGM and Gaussian copulas based on the SD premium principle.
Figure 6.
The loaded premium under the Gumbel copula based on the SD premium principle.
Figure 6.
The loaded premium under the Gumbel copula based on the SD premium principle.
We derived the Neumann series expression for this recursive equation using the Picard method of successive approximations, based on which we computed the first two moments of the aggregate discounted claims. For the dependence structure between the inter-claim arrival time and claim sizes, we used a Farlie–Gumbel–Morgenstern copula, a Gaussian copula and a Gumbel copula with exponential marginal distributions. We showed the values of moments of the aggregate discounted claims, as well as the loaded premium for each copula used in this study.
It would be of interest to derive the expression for Equation (
2) and Equation (
3) using other joint pdfs between
X and
W. Other copulas with different claim size distributions for
X may be considered in the proposed approach, which we leave for further research. We can also consider the Monte Carlo simulation, as well as other numerical methods to solve the VIE (such as Runge–Kutta and the collocation methods), as the next objective of further research to deal with the computation of higher moments.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


