1. Introduction
An insurance company has several instruments for stochastic control at its disposal. Much studied are dividends, reinsurance and investment; see, e.g., [
1]. The present paper concentrates on premiums and deductibles. These are also obvious instruments, but have been somewhat less studied in the literature as such.
The standard model for the risk reserve
at time
t is the Cramer–Lundberg process:
where
is the initial reserve,
c is the gross premium rate and
is a compound Poisson process with parameters
λ and
F. More explicitly,
where
is a Poisson process with parameter
λ counting the number of claims until time
t, and the
’s represent the (positive) claim sizes assumed to be i.i.d. and independent of
, with common distribution
F on
. Let
and
. The Cramer–Lundberg process can, due to the arguments in [
2], be approximated by the diffusion process:
with
and
. To put it briefly, this diffusion process is the Brownian motion with drift that matches the mean and variance of the Cramer–Lundberg process at any given point in time.
We will describe an insurance contract by a premium p and a deductible K. The purpose, besides loss prevention and retention, of adding a deductible to a contract is to avoid administrating the numerous number of small claims. The deductible is therefore chosen to serve this purpose, and the premium will then be considered as a function of the chosen deductible. We will consider the methods of how to find the premium optimally in a given market. For simplicity, we assume that all (potential) customers are offered the same insurance contract . We will also neglect the market effects by assuming that only one company supplies insurance.
A possible extension is to allow the insurance company to offer different deductibles and let the premium in the contract be regulated accordingly. A simple way of doing so is to say that the entire market can be divided into disjoint sub-markets, for example; one where there is a customer demand for a low deductible , one for a medium deductible and one for a high deductible . Therefore, the offered values of the deductibles will be , where there is a separate market for each. It will then be possible to apply the same approach as considered here to each of the sub-markets.
There are several types of deductibles. We will consider the classical fixed amount deductible where the claims are truncated, so the loss for the insurance company in relation to a claim
can be described by the random variable:
The risk reserve must therefore be modified:
where
is the compound Poisson process with losses
. Let
denote the
n’th moment of
. Notice that
and
, since the claims are assumed to be positive. The results here thus contain the no-deductible case.
Assume that the insurance company is facing a market consisting of
N potential customers. Let
denote the number of customers the insurance company attracts on the market when offering the contract
. Obviously, increasing the premium should lead to a loss of customers; therefore, it must be that
. Furthermore, the average customer claim frequency in the portfolio will be denoted as
. Raising the premium will make it less attractive to insure for customers having low claim frequencies, and so, the average claim frequency of the portfolio increases, i.e.,
. This is commonly known as adverse selection. The gross premium
c and the aggregate claim frequency
λ will then depend on the premium,
p, and the chosen deductible,
K, as follows:
The drift and variance of the diffusion process (
1) are modified accordingly:
In order to avoid trivialities, when minimizing the ruin probability at a later stage, a fixed liability payment rate
L is introduced in the drift. Otherwise, the insurance company can choose
p to be infinitely large such that no customer will insure, and the reserve will remain constantly at
, yielding a ruin probability of zero. The term liability is used in a broad sense. It covers any type of costs the insurance company might have. Let
denote the ruin probability as a function of the initial reserve when the reserve is modeled by the diffusion process. For more background on ruin theory, we refer to [
3]. In this reference, it is also stated that when the drift
in the diffusion approximation is positive, then
, and when the drift is negative, then ruin will be certain, i.e.,
for any initial reserve
.
For a given deductible, changing the premium will have a double-sided effect on the drift (and profit) of the insurance company. Raising the premium will increase the earnings per customer, but will also reduce the size of the portfolio and increase the average claim rate due to adverse selection, and vice versa for decreasing the premium. In order to say which effect is dominating, a specification of the portfolio characteristics is needed.
First of all, we need to gain insight into the decision process of a customer. In this context, we introduce a risk aversion parameter
β and motivate a method for incorporating risk aversion. See [
4] for a microeconomic perspective of insurance.
In a naive setting, the customers would have the same claim rate, implying the average claim frequency to be constant,
, and
could be chosen on some ad hoc form. In a more realistic setting, a market of potential customers is non-homogeneous in the sense that they have different characteristics, namely different
α’s and
β’s. A customer knows her/his own claim rate, but the insurer does not possess this information about the customers. The claim rates are therefore modeled as i.i.d. random variables
over the portfolio. Likewise for the risk aversion parameter, which will be considered as the outcomes of the i.i.d. random variables
. This results in some less ad hoc forms for the functions
and
to characterize the portfolio. Once the portfolio characteristics are known, the insurance company can use these to choose the premium optimally. The main optimization problem considered is minimizing the ruin probability, but this only makes sense in case of a positive drift in the diffusion (
1). In the case of a negative drift ruin is certain, so the premium will be chosen to maximize the time to ruin.
The ideas here are very similar to the ones considered in [
5]. The present paper takes however a different approach to risk aversion and, as said, incorporates deductibles. The work in [
6] also finds the price of insurance as a function of the deductible for different types of deductibles, though not exploiting the aspects of risk aversion. The work in [
7] also controls the gross premium indirectly by controlling the safety loading. All in all, the contributions of this paper are three-fold; analyzing the customer’s behavior in
Section 2, finding portfolio characteristics in
Section 3 and choosing the optimal premium for the insurance company in
Section 4. For examples and illustrations, see
Section 5.
2. Customer’s Problem
A potential customer has to make a decision on whether to insure or not, given that she/he is offered an insurance contract . If the customer chooses to insure, she/he must pay a premium p at constant rate, but the customer can then report claims and get the amount above the threshold K covered. More specifically, if the customer experience a loss , she/he will only report it to the insurance company if in which case she/he has to pay K herself/himself; otherwise, if , there is no purpose of reporting it, and she/he will have to cover the entire loss . On the other hand, if the customer chooses not to insure, she/he no longer has to pay p continuously. She/he will instead have to cover all of the uninsured losses by herself/himself.
For the moment, risk aversion is ignored, and the decision is made solely by comparing the present values of the wealth generated by the two options. Later risk aversion will be incorporated by pricing the excess uncertainty when not insuring using the variance premium principle. Let denote the present value of insuring and of not insuring.
The customer is assumed to have a subjective discount rate d and access to a risk-free asset with interest rate r in which all her/his wealth is assumed to be invested. Furthermore, it is assumed that to ensure finite asset valuation. The customer is characterized by initial wealth and claim frequency α. The customer is furthermore assumed to have infinite life length. Remark 1 comments on this assumption. The problem of the customer will then be identical every period, and the decision will therefore not change over time.
We start by finding the present value of not insuring. As said, if the customer chooses not to insure, she/he will have to cover every loss herself/himself. Therefore, her/his wealth will develop according to:
where
is a compound Poisson process with parameters
α and
F, representing the total loss until time
t for the potential customer when not insuring. Hence,
where
is a Poisson process with parameter
α assumed to be independent of the
’s. Let
denote the arrival times of the Poisson process
. Notice that (
2) is an Ornstein–Uhlenbeck process driven by a Levy process (namely, the compound Poisson process), and the solution is therefore explicitly known as:
The present value of the wealth when not insuring is evaluated as:
Calculations given in
Appendix A show that this can be reduced to:
On the other hand, if the customer chooses to insure, she/he will have to pay a premium continuously and cover the parts of the claims below the deductible. Her/his wealth will then have the following dynamics,
where
is the compound Poisson process representing the total loss associated with claims until time
t for the customer when insuring, that is:
Once again, we are looking at an Ornstein–Uhlenbeck process driven by a Levy process. This can be solved in the same way as seen previously,
The present value of the wealth when insuring will therefore be:
Since the approach and calculations are very similar to the ones used when finding
, the details are skipped. We can now state the following.
Corollary 1. Disregarding risk aversion, the customer will insure if and only if , which is equivalent to: Hence, a risk-neutral customer will insure if the net premium (taking deductibles into account) exceeds the premium. She/he has no incentive to pay a loading in order to avoid the risk.
Remark 1. The customer is assumed to have an infinite life length. This is obviously not realistic, but it is convenient for the analysis and not uncommon in other areas of non-life insurance. For example, it the basis for the standard use of the stationary distribution in bonus-malus systems; see the discussion in [
8].
It would be more realistic with a random life length τ. In this case, the discount factor has to be replaced by in the above formulas for the present values, and . This will in general change the analytic expressions. Though note that in the case where τ is exponential with rate, say, ρ, the same expressions appears with d replaced by . Due to the forgetfulness property of the exponential distribution, the customer is still facing an identical problem every period. This leads to obvious reinterpretations of the analysis of this section. ☐
In order for insurance to make sense, the customer must of course have some degree of risk aversion. We want to find which excess risk the customer is exposed to when not insuring and how to price this risk when risk aversion is essential.
The first step is to notice that
also could have been derived in a more intuitive way. Recall that all wealth is assumed to be invested in the risk-free asset. Therefore, wealth itself has the dynamics
of a bank account. When accumulating interest, this has present value:
When a non-insured customer has to pay a loss
at time
, she/he also loses a possible interest rate income. Therefore, the total loss of paying
at time
can be calculated using the formula (
4) with the discounted loss
as
. Hence,
Note that due to Campbell–Mecke’s formula (see, e.g., [
9] for further details), this is in fact equal to the expression for
found previously. Furthermore, we have the following alternative characterization of
,
which could have been explained with a similar intuitive approach using truncated losses.
The criteria of insuring in Corollary 1 when disregarding risk aversion can then be expressed as the inequality:
The additional risk the customer is exposed to when not insuring can therefore be captured by the random variable:
The next step is to find the maximum premium the risk averse customer is willing to pay, also called her/his reservation price for this risk. Inspired by microeconomics, one can let the customer’s preferences be represented by a concave utility function
. Assume that the only risk the customer is concerned about when pricing is the additional risk
she/he is carrying when not insuring. The losses less than or equal to the deductible is a risk that the customer is also facing, but cannot be insured against; see Remark 3 for further details. Inspired by [
10], the maximal premium
the customer is willing to pay for an insurance of a risk
is the solution to the equation:
Therefore, the customer’s reservation price satisfies that she/he is indifferent between carrying the risk
and paying the premium
.
A possible choice is to let the customer’s preferences be represented by an exponential utility function,
where
γ is a risk aversion parameter. The premium in (
5) can then be solved explicitly as:
This is the same premium as found in [
11], where it is the insurer, not the insured, pricing a risk. It is commonly known as the exponential premium principle and is mostly used by the insurer in the literature.
The object is to obtain an analytic expression for the premium, and this is extremely complicated (if not impossible without having to make a lot of simplifying assumptions) to get for
. This is mainly due to
being a sum of dependent random variables caused by the dependence structure in the
’s. Thus, the additivity property that [
11] proves the exponential premium principle possesses cannot be used. To illustrate this complexity, a simple case example is presented in
Appendix C. In order to obtain a more simple expression, a second order Taylor approximation of the logarithm in (
6) around
is considered,
Assessments about the premium will be based on the right-hand side hereinafter. Let
and introduce the notation:
This the well-known variance premium principle. It expands the net premium principle by adding a risk loading that is proportional by a factor
to the variance of the risk. Therefore, the customer is now further characterized by the risk aversion coefficient
β. Approximating the exponential premium principle by the variance premium principle is a common approach; see, for example, [
10].
It is indeed possible to find an analytic expression for (
7). Applying Campbell–Mecke’s formula, it appears that the expectation term simply is:
The variance term in (
7) is calculated using the total law of variance in
Appendix B, giving the result:
The concluding premium is summarized below.
Corollary 2. Given a deductible K, the customer is facing the excess risk when not insuring and is willing to pay the following price for an insurance: In Example 1, the premium (
8) is calculated explicitly for log-normally-distributed claim sizes.
Remark 2. The approach leads to a fairly classical premium calculation principle, which in the literature is mostly seen from the insurer’s perspective. This motivates the use of other already developed premium calculation principles applied from the the customer’s point of view. An example of such is the standard deviation principle, where the premium depends on the mean and the standard deviation of the risk in a linear structure,
Since we already have expressions for the mean and the variance, we can write this more explicitly as:
Another could simply be the expected value premium principle with a safety loading depending on the individual’s risk aversion:
The latter gives a simple expression, even though it still has a nice intuitive interpretation. All evaluations in the following will be based on the variance premium principle. However, do note that a similar approach can be used with other premium calculation principles. ☐
Remark 3. The risk the customer is facing can be split into two. First of these is the risk the customer cannot insure. This is the (part of the) losses that the customer must pay regardless of insuring or not and is the uncertainty that appears in both
and
. The monetary value at Time 0 of this risk can be deduced to:
Second of these is the additional risk
the customer can buy insurance to cover. The maximum premium that the customer is willing to pay in (
5) will be altered as follows if she/he takes
into consideration,
Using the exponential utility and solving yields:
Proceeding to a similar second order Taylor approximation as seen previously,
it appears that in the final pricing formula, the assumption about the customer only caring about pricing the excess risk
regardless of
corresponds mathematically to assuming that
. A similar comment is also made in [
10]. ☐
3. Portfolio Characteristics
A customer is characterized by her/his claim frequency α and risk aversion β. As previously commented, these characteristics are most likely customer-dependent. The insurance company therefore considers them as random variables being i.i.d. on the market. The claim frequencies are represented by , and the risk aversions by . First, we will consider the claim frequency as being random and the risk aversion as constant. Next, we will reverse it, by modeling the risk aversion as random and letting the claim frequency be constant. A third, more advanced, possibility is of course to let the customer characteristics be represented by random vectors . This complicates the evaluations considerably and is therefore left open by this paper.
In each case, we derive an expression for the portfolio size and for the average claim frequency in the portfolio. These expressions will become explicit functions when assuming a concrete distribution.
3.1. Stochastic Claim Frequencies
Consider the first case mentioned above, where the risk aversion is constant, and the claim frequency of the customer is unknown to the insurance company and, therefore, modeled by a random variable denoted by A. As said, we want to find the expected size of the portfolio and the average claim rate in it.
From the reservation price in (
8), it follows that a customer with characteristics
will insure if the offered insurance contract
satisfies the inequality:
Since the claim frequency is modeled by a random variable,
A, to the insurer, this translates to the relation:
The expected portfolio size will then be the probability of this event happening multiplied by the size of the market, namely:
This is the mean demand curve as a function of the premium and deductible. In the following, it is assumed that
N is large and that there is a continuum of customers, such that the deviation from the actual demand curve is negligible.
The average claim frequency rate in the portfolio is the expected claim frequency given that the customer chooses to insure, i.e.,
Exponentially-Distributed Claim Frequencies
When accounting for unobserved heterogeneity in the Bayesian claim experience rating setting, the claim frequency is frequently assumed to be
distributed, for example, as in [
12]. In some cases there are empirical evidence of
s being close to one. See [
13] for more discussion. This motivates the assumption of an exponential distribution with parameter
b of the claim frequency
A. Offering the contract
, the customer will insure with probability:
This yields a portfolio size of:
The exponential distribution has a memoryless property, which implies
. The expected claim frequency of an insured customer will therefore be
:
This equation reflects adverse selection very clearly, since
is linearly increasing in
p.
Remark 4. If the customer’s reservation price was defined by the expected value premium principle (
9), the portfolio characteristics would be:
Assuming an exponentially-distributed claim frequency, the characteristics become:
This is slightly easier to work with and has the advantage that
can be chosen on a simple form.☐
3.2. Stochastic Risk Aversions
Instead of letting a customer being represented by a stochastic claim frequency and constant risk aversion, we now turn it around. Assume that the customer now has a constant claim frequency
α. This is indeed relevant to consider. For example, everyone could be equally disposed to disaster caused by nature. Furthermore, assume that the risk aversion is represented by a random variable
B. The criterion (
8) of insuring for a given contract
can then be stated as:
Therefore, the portfolio size will be characterized by:
Gamma Distributed Risk Aversions
Risk aversion is somewhat an abstract concept. It is therefore difficult to suggest a distribution since there is limited literature available. Since the Gammadistribution is a popular choice for the claim frequency, we choose to consider the same distribution for the risk aversion. Assuming that the risk aversion has an
distribution, the demand curve will have the form:
In the case
, the distribution approximately reduces to an exponential distribution with parameter
ν, and the portfolio size will then simply be:
4. Ruin Probability
In this section, we consider the optimization problem of the insurance company. It mainly wants to minimize the ruin probability, but as this only makes sense for a positive drift, the expected time to ruin is considered in the case of a negative drift. The overall aim is to find the optimal premium as a function of the deductible.
When the controlled reserve develops according to a Brownian motion with positive drift, [
14] shows that minimizing the ruin probability is equivalent to maximizing the following ratio
between the drift and volatility. In our setting, this means maximizing:
This also follows from the relation
. Recall that if the drift is negative, then
.
As previously implied, if the market consists of risk-neutral customers, then the drift of the diffusion process will be negative, making ruin certain. In order to avoid this, it is assumed in the following that there is a sufficiently large degree of risk aversion among the (potential) customers to satisfy the net profit condition for some p. Otherwise, there will be no motivation for selling insurance.
Notice that if , the insurance company will offer insurance for free, and so, for any given K. Furthermore, due to the liability rate, L, the diffusion will also have a negative drift when the premium becomes very high, since no customer will then be interested in insuring, hence . Thus, ruin will be certain for both and .
Now, assume for some K that the premium is zero. What will then happen if the premium was raised marginally? The insurance company will have nearly the same amount of customers and, therefore, also the same amount of claims, but the firm will get a small revenue when collecting premiums. Hence, will increase. Note, that this is under the assumption that the effect from portfolio size decrease and adverse selection is smaller than the effect of raising the premium. Conversely, what if the premium was so high that no customer would be interested in insuring? Recall that there are N customers on the market and that each customer has a reservation price for insurance (depending on the customer characteristics). Therefore, if the insurance company sets the premium so high that it is above the reservation price of all N customers, then no customer will insure. Though if the company lowers the premium enough for it to become below the reservation price of the most risky/risk adverse potential customers on the market, then under the condition of , the insurance company will obtain some revenue to cover at least some of the liability cost. Hence, will also increase when lowering the premium for very large values. This tells us intuitively that if there is an optimal premium, then it is not obtained for , nor in the limit , and we thereby avoid trivialities when finding the optimal premium.
Abbreviate notation by
and similarly for
and
. Assume that there is a unique
that maximizes the drift, i.e., satisfies the first order conditions:
This is equivalent to saying that
must satisfy:
The intuitive interpretation is that the relative marginal change in the demand curve must equal the relative marginal change in average net revenue per customer due to a change in premium. Two cases then arise:
- (i)
If , then for all , and p in some bounded open interval containing .
- (ii)
If , then for all and .
Notice that the drift is positive if the net profit per customer is greater than the liability cost per customer, that is
. This is more strict than the net profit condition.
Since the current framework is very general, so will the results be. In every concrete application, the existence of a unique solution must be verified. In Case (i), an optimization criterion is given and proven in Theorem 1.
Theorem 1. When , the optimal premium minimizing the ruin probability must be a solution to the equation: Proof. Differentiating (
10) with respect to the premium,
yields the first order condition:
Reducing, we obtain the following optimality criterion:
☐
In Case (ii), it no longer makes sense to minimize ruin probability since it is constantly one. Instead, we suggest to choose the control to maximize the expected time to ruin, , and thereby extend the expected lifetime of the company as much as possible. This is a non-standard objective function. Since the controlled reserve is a Brownian motion with drift, we are able to obtain a very simple result.
Theorem 2. When , then will optimize the expected time to ruin.
Proof. As said, when
, then (
1) is a Brownian motion with negative drift. This also has the representation:
Consider the stopping time
. Since
is a continuous process, it must be that
. Furthermore,
is a martingale with mean
. This implies:
Hence,
. Therefore, the expected time to ruin is maximized when the drift is maximized. Due to the assumption of a unique
, such that the first order condition (
11) is satisfied, then this must be the optimal choice. ☐
In Examples 2 and 3 the optimal premium is calculated explicitly for the portfolio characteristics in
Section 3.1 and
Section 3.2, respectively.
5. Examples and Illustrations
Example 1. Assume that the claim sizes are log-normally distributed, that is
. This distribution has tail function
, where Φ denotes the standard normal distribution function. The
k’th moment is given by
. We seek to find a closed form solution to the premium
. The challenge obviously is
and
. Altering these yields:
and:
In [
15], it is shown that the
k’th moment of the truncated random variable is:
From this, it follows that in the log-normal case, (
12) can be written as:
and (
13) as:
Hence, when the claims are log-normally distributed, the maximal premium that a customer with characteristics
is willing to pay for an insurance contract as a function of the deductible is:
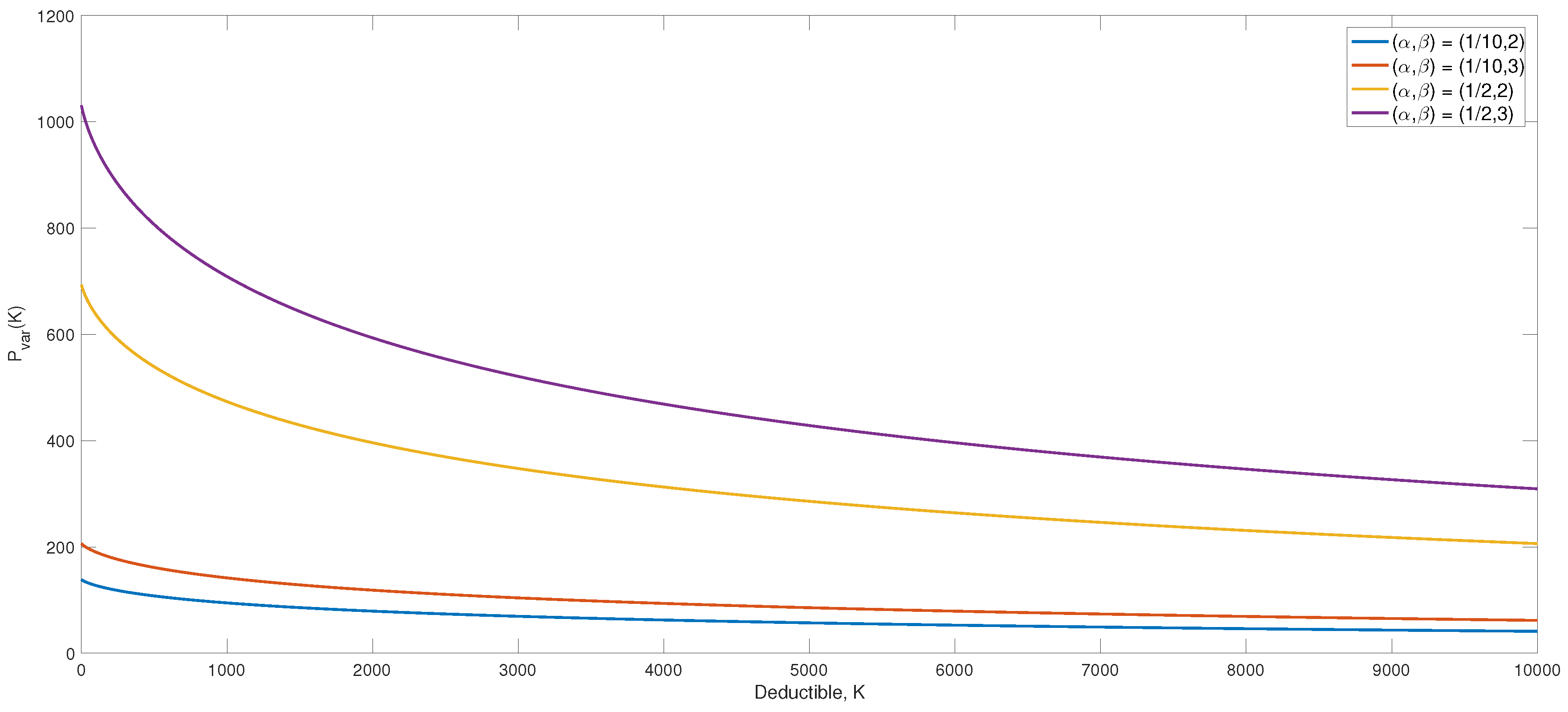
While this is not a straightforward expression, it is computationally easy to evaluate. Some combined data on claims in fire insurance reported 1958–1969 by Swedish fire insurance companies are studied in [
15], where the estimates
and
are obtained. These estimates are used in the following. In
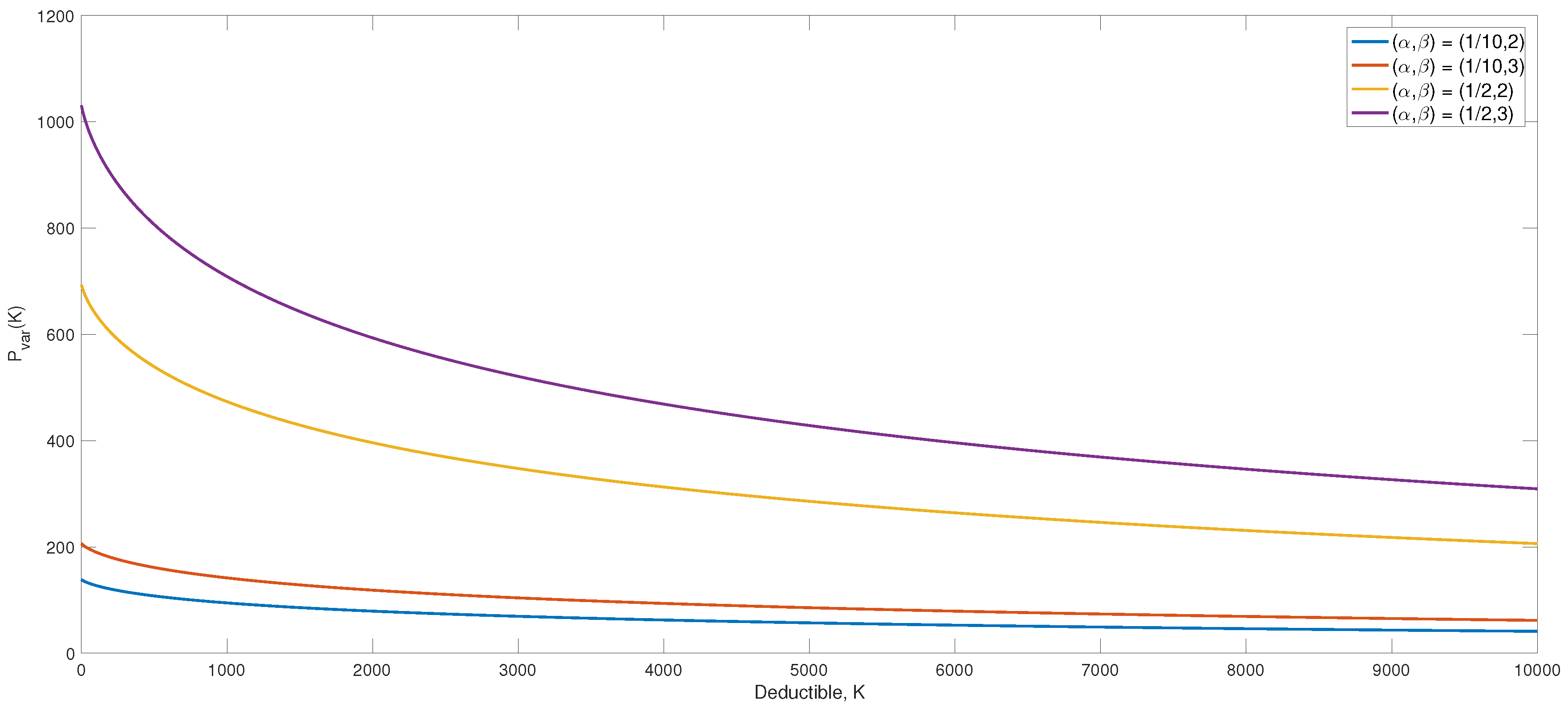
Figure 1, the premium function (
14) for different combinations of characteristics is illustrated. The function appears to be very sensitive towards changes in characteristics and most so for small deductibles. Notice the considerable change from the combination
to
where the premium gets approximately 7.4-times larger.
Example 2. An insurance company wants to supply fire insurance. It is entering a market where the customers have unknown, possibly different claim frequencies and constant risk aversions, namely
β. The claim frequencies are once again assumed to be independent and identically exponentially distributed with parameter
b. The portfolio can thus be characterized as in
Section 3.1.
First, the insurer needs to see which region of the premium is profitable to even supply insurance. The criteria
translates into:
For a given deductible
K, the considered price must exceed this threshold. Otherwise, the insurance company should choose not to supply insurance.
Next, evaluating the drift is of interest. Knowing the portfolio characteristics, it can be written explicitly as:
Solving the first order criteria (
11) yields the solution:
Notice that
obviously satisfies being in the region of (
15). We now seek to find the conditions under which the drift will be positive. Solving for
yields:
Assuming that this inequality holds, then one must use Theorem 1 to find the optimal price. The optimality criterion in reduced form is:
This yields the following optimal premium as a function of the deductible,
using the Lambert
W function. The Lambert
W function is defined as the (multivalued) inverse of the function
. For more details, see [
16]. In the case
, it follows from Theorem 2 that
is the optimal choice. Note that due to the Lambert
W function increasing for positive values, then
will be preferred to
if
. Therefore, for a given deductible,
K, it is preferable for the insurance firm to simply choose the maximum of
and
.
Assume that the insurance company evaluates that the market consists of
house owners considering buying insurance and that it calculated the liability costs to be
. It also assesses that
and
. Assume furthermore that the company has some information about the distribution of the claims, and based on this, it believes that the claims are log-normally distributed according to the estimates in [
15]. It also knows how to reasonably choose a deductible
K to serve the purpose described in the introduction. The interest rate applied is
.
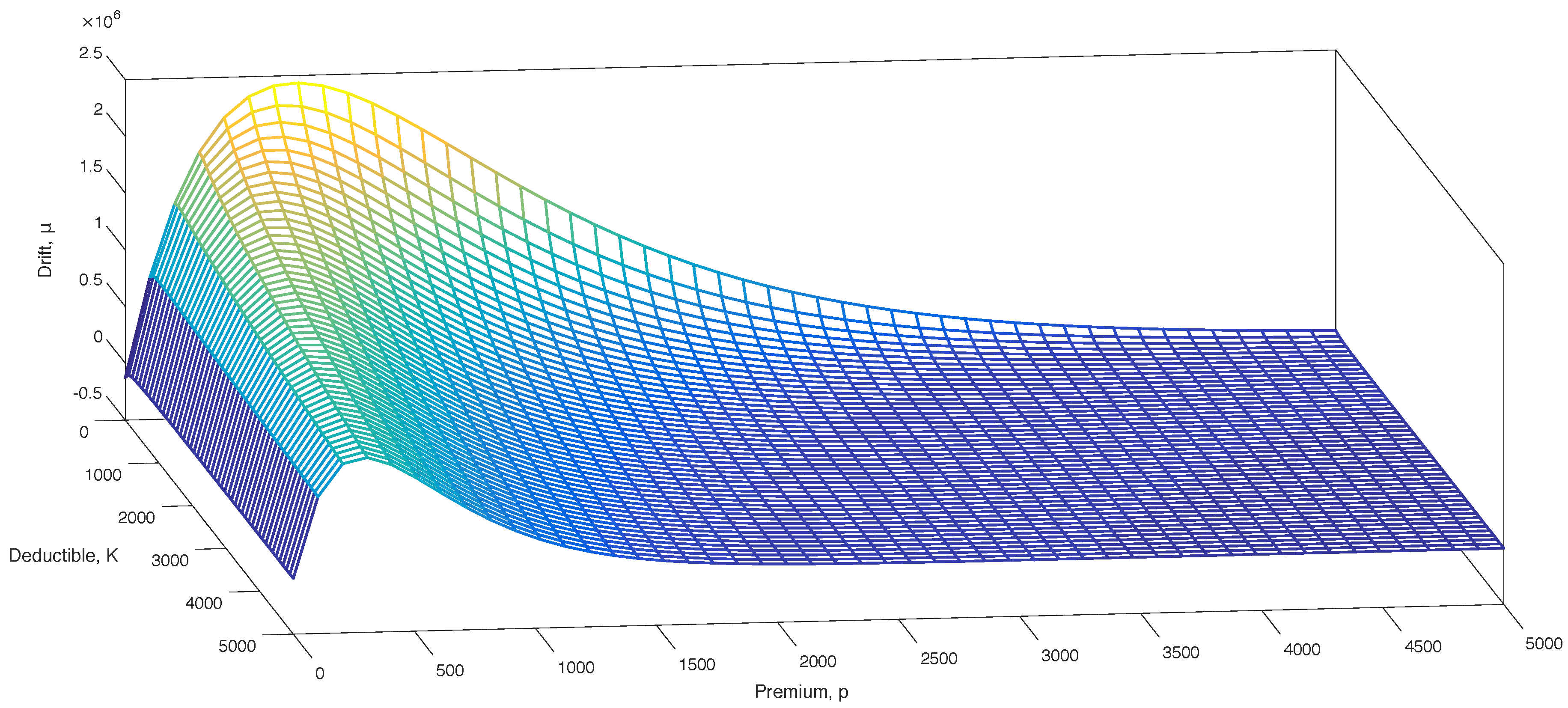
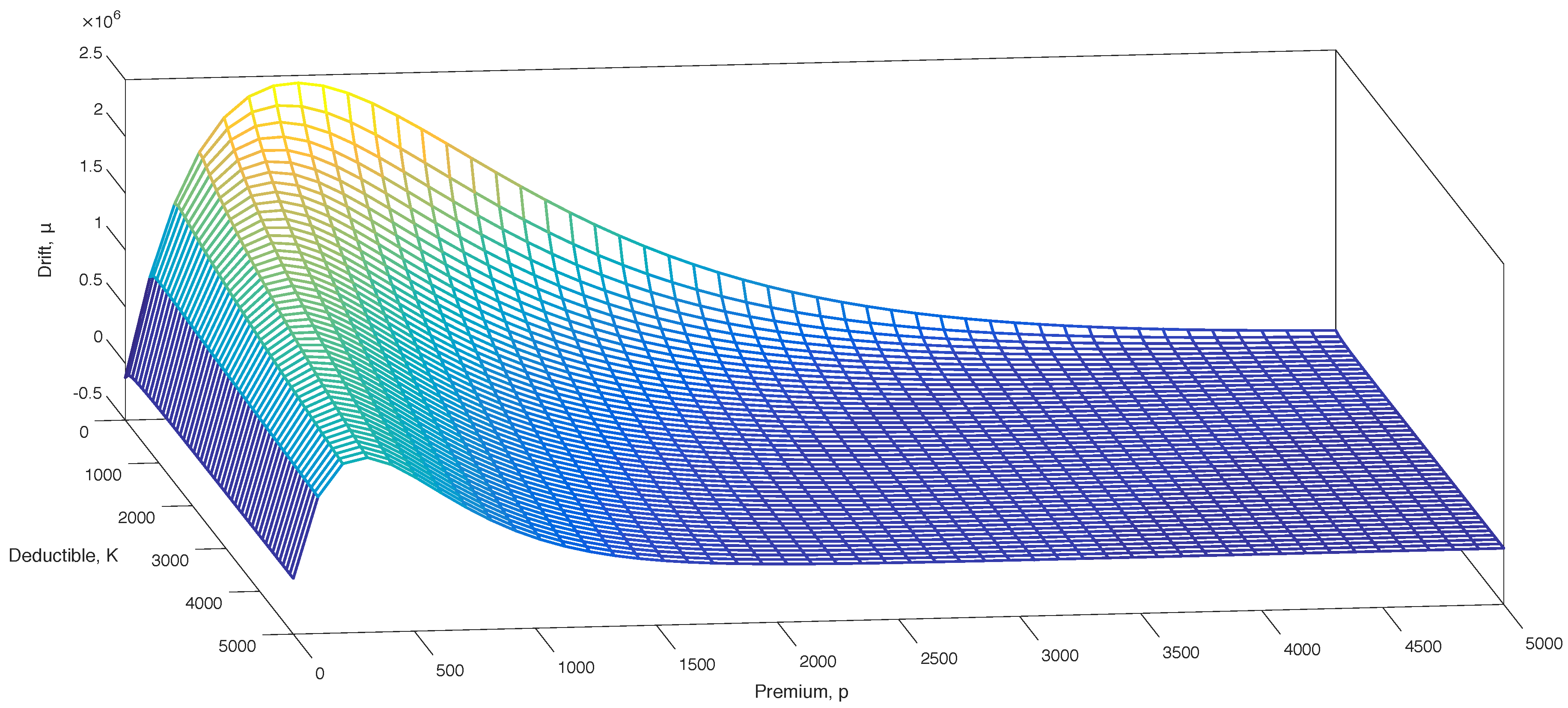
In
Figure 2, a mesh of the drift is presented. The preliminary analysis of the drift in
Section 4 is very well illustrated in this. The concavity in the premium is obvious. For all of the considered deductibles in the range
, the drift will be positive in
.
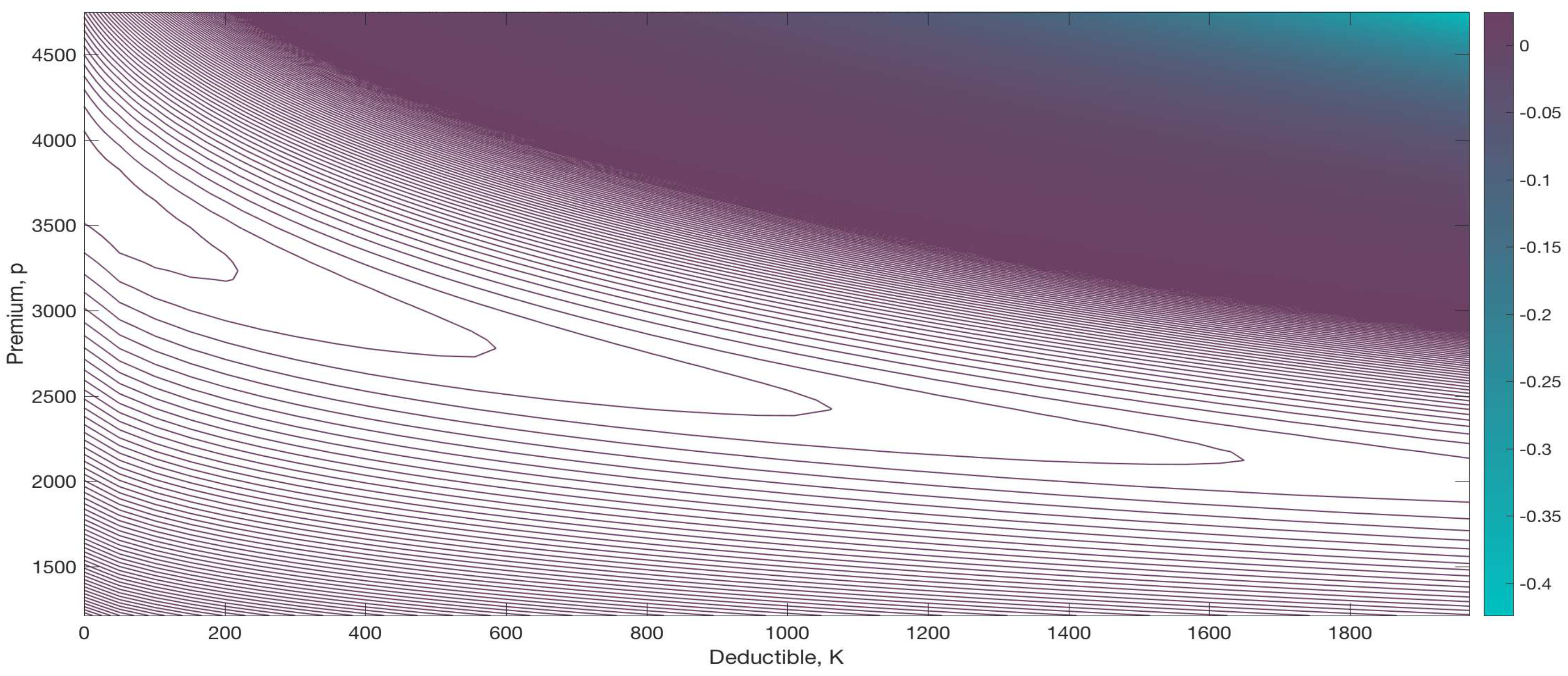
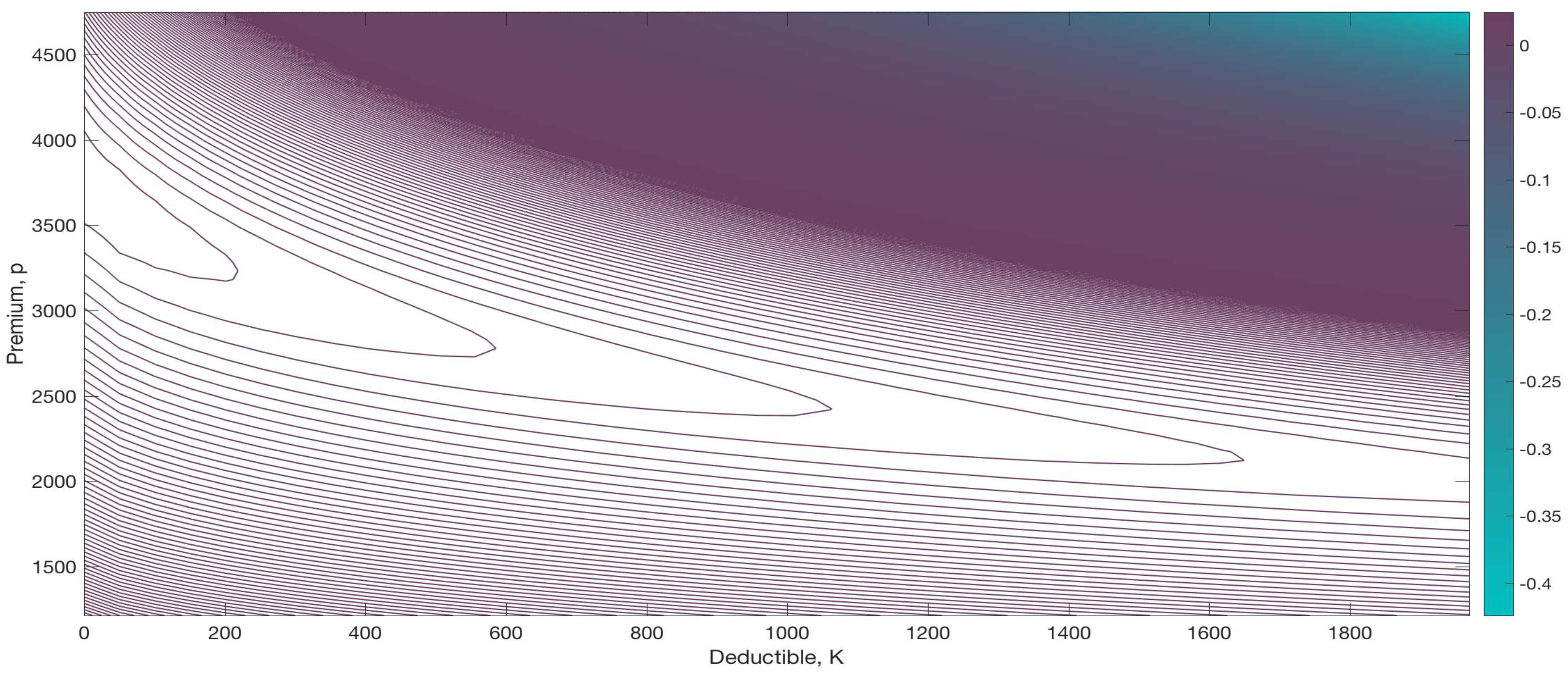
Next, a contour of the ratio
is illustrated in
Figure 3. The concavity in the premium also appears very clearly here. The ratio is at its highest within the region of approximately
, followed by the regions
and then
.
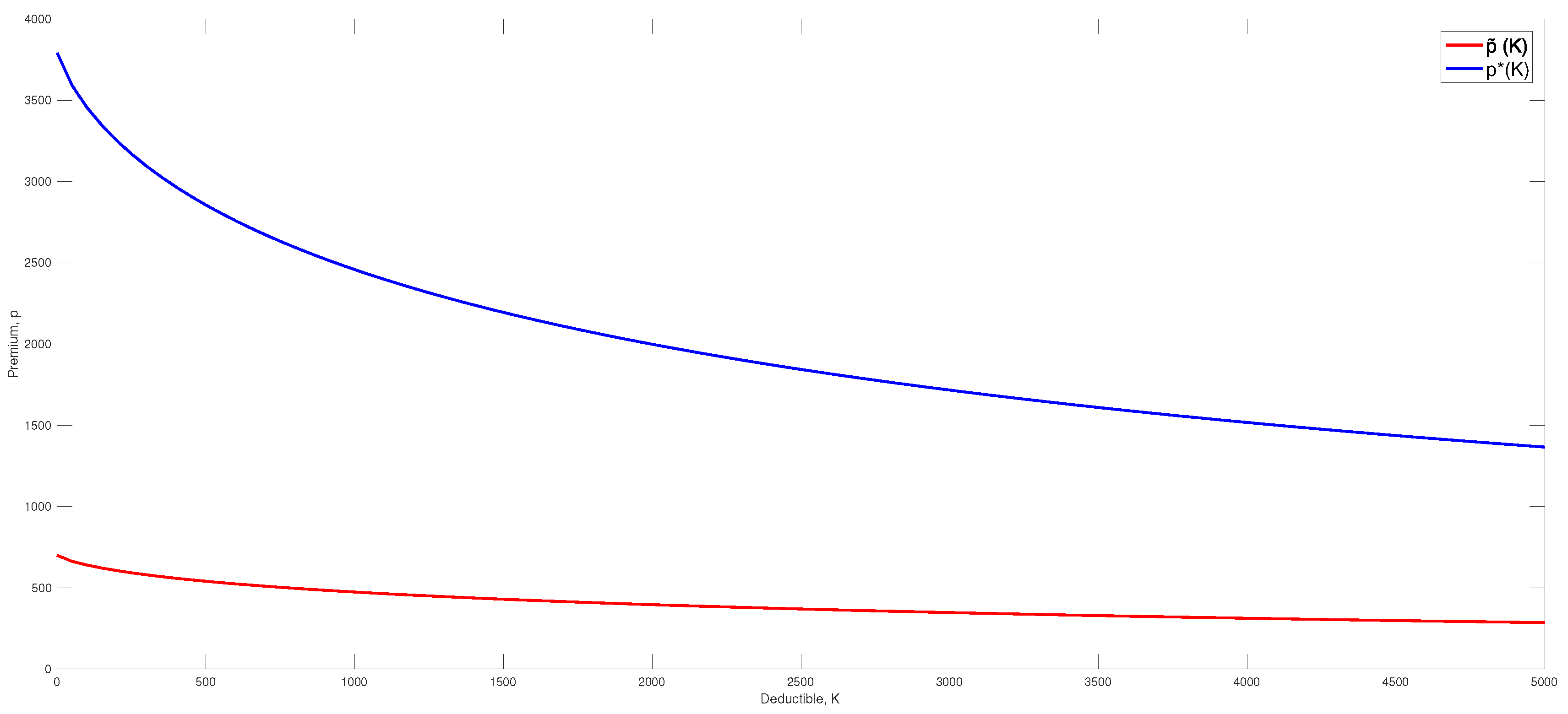
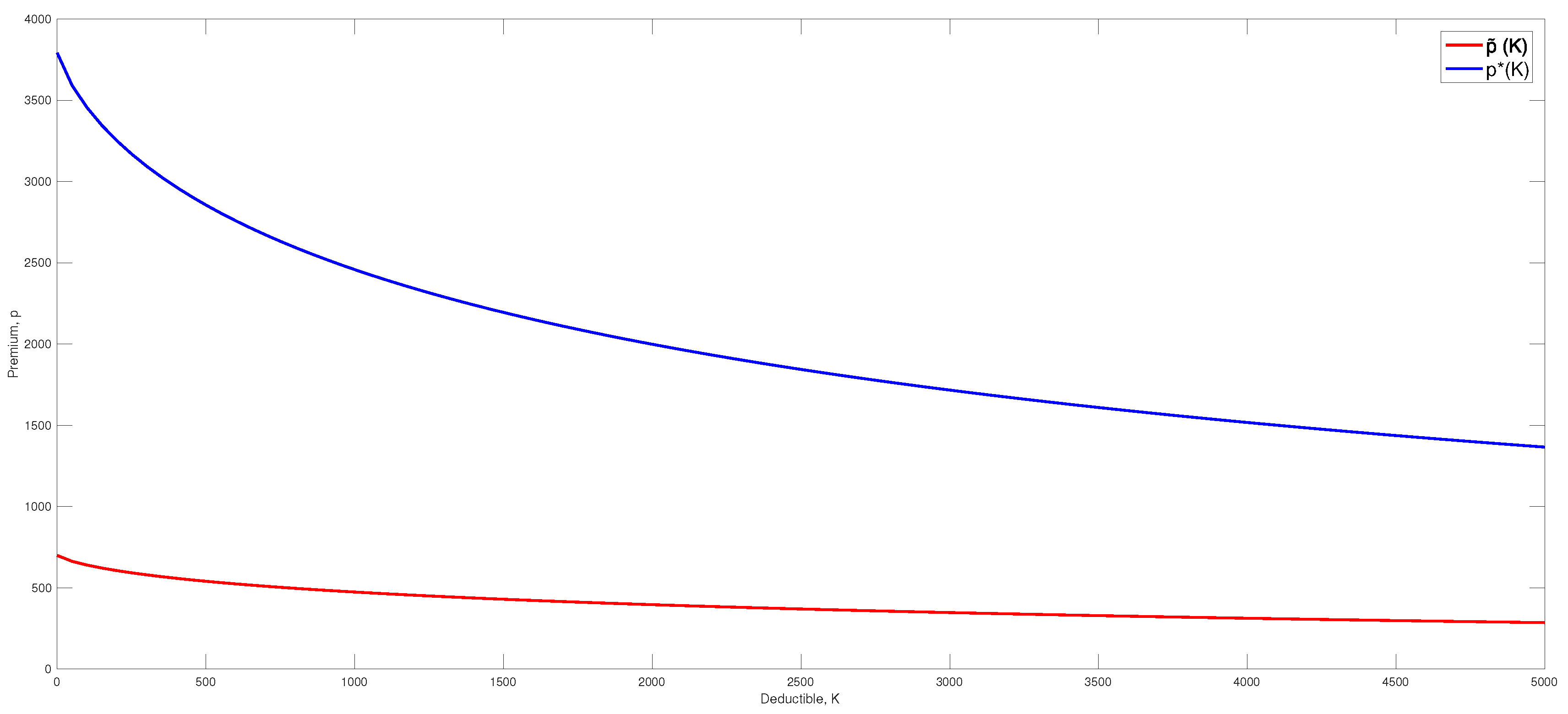
In
Figure 4, the premiums
and
as functions of the deductible are plotted.
Notice that the model does not take the cost of processing an increasing number of claims into consideration. The company therefore evaluates that a deductible of
is suitable. This yields the following values:
Since
, then
is the optimal premium.
The optimal premium
will of course depend on the parameters chosen, namely the market size
N, the liability rate
L, the risk aversion
β and the exponential parameter
b. An illustration of how sensitive the optimal premium are towards changes in these parameters is viewed in
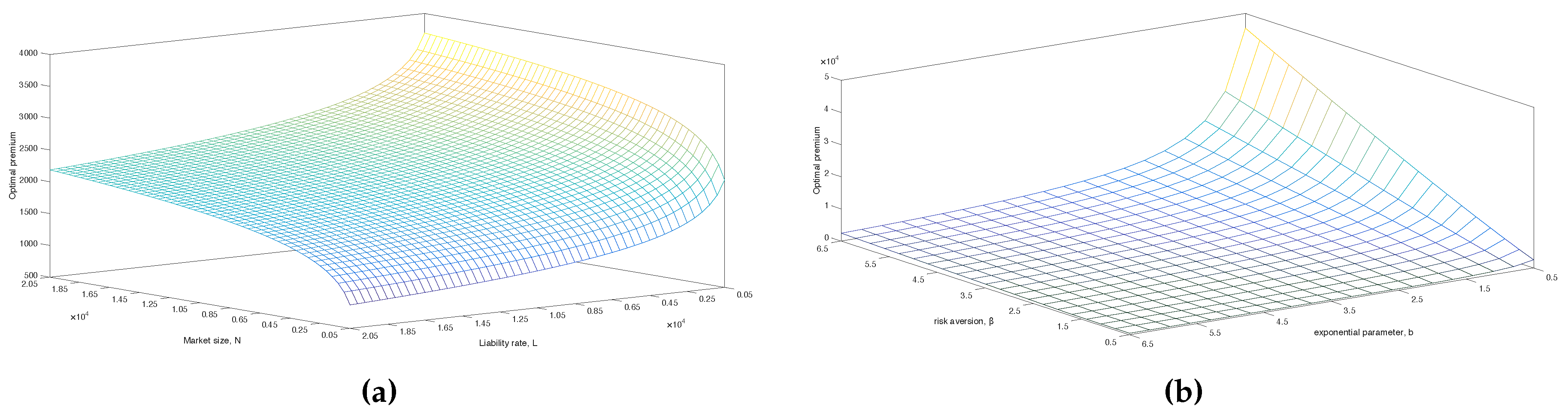
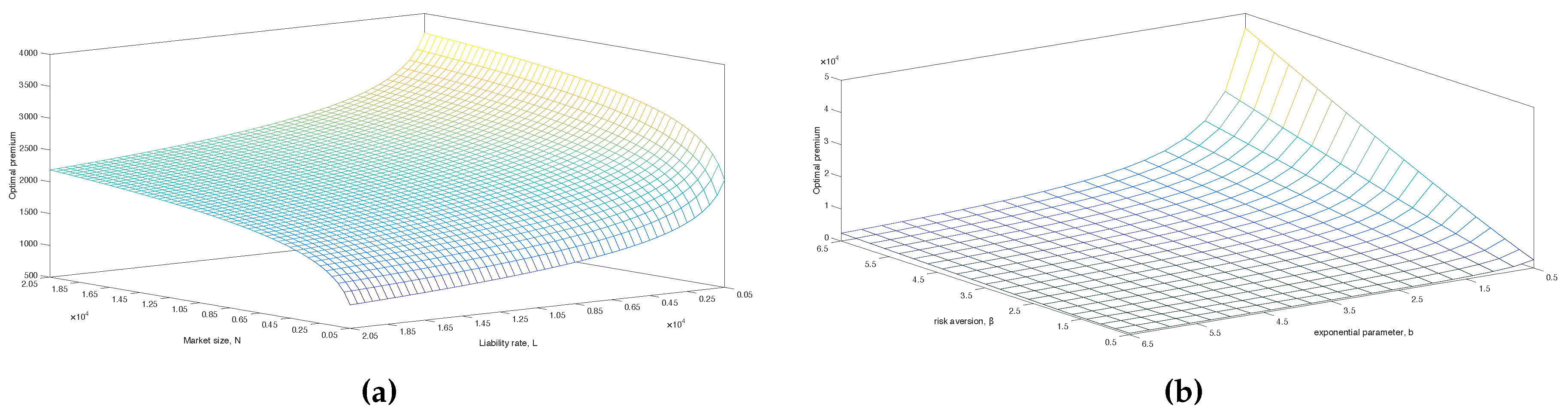
Figure 5.
Figure 5a shows a mesh of the optimal premium where
N and
L take values in a grid of
. Here, we can see that the premium is most sensitive towards changes in these parameters for small values. A low liability rate
L will yield a high premium. The insurance company does not need many customers when they have small liabilities payments; hence, they can afford to choose a high premium. On the contrary, when
N is small, then we see that the premium tends to be low. In
Figure 5b, a similar mesh of the optimal premium is shown for values of
β and
b in a grid of
. It is observed that when
b gets too high or
β too low, then the optimal premium will tend towards
. Conversely, when
b takes on low values and
β gets high, the optimal premium increases considerably. The values
,
and
are chosen such that any of the extremes mentioned above are avoided.
Example 3. Assume now that the insurance company believes that the claim frequency is constant in the portfolio, but does not possess any information about the customer’s risk aversion. The risk aversion is therefore modeled by a random variable, which is assumed to have an exponential distribution with parameter
ν. Portfolio characteristics are then as in
Section 3.2. The existence criteria of the insurance company will be
, i.e., the premium must simply be larger than the net premium. First, we seek to find the solution of (
11), namely:
Next is to find the region for which the drift evaluated in
is positive:
In this region:
is optimal. Otherwise,
is optimal. Again, due to the logarithm being an increasing function, one can simply state that the insurance company should choose the maximum of
and
.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}