Extreme Portfolio Loss Correlations in Credit Risk

Fakultät für Physik, Universität Duisburg-Essen, Lotharstraße 1, 47048 Duisburg, Germany
*
Author to whom correspondence should be addressed.
Risks 2018, 6(3), 72; https://doi.org/10.3390/risks6030072
Submission received: 17 May 2018
/
Revised: 22 June 2018
/
Accepted: 10 July 2018
/
Published: 17 July 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The stability of the financial system is associated with systemic risk factors such as the concurrent default of numerous small obligors. Hence, it is of utmost importance to study the mutual dependence of losses for different creditors in the case of large, overlapping credit portfolios. We analytically calculate the multivariate joint loss distribution of several credit portfolios on a non-stationary market. To take fluctuating asset correlations into account, we use an random matrix approach which preserves, as a much appreciated side effect, analytical tractability and drastically reduces the number of parameters. We show that, for two disjoint credit portfolios, diversification does not work in a correlated market. Additionally, we find large concurrent portfolio losses to be rather likely. We show that significant correlations of the losses emerge not only for large portfolios with thousands of credit contracts, but also for small portfolios consisting of a few credit contracts only. Furthermore, we include subordination levels, which were established in collateralized debt obligations to protect the more senior tranches from high losses. We analytically corroborate the observation that an extreme loss of the subordinated creditor is likely to also yield a large loss of the senior creditor.
1. Introduction
The subprime crisis 2007–2009 had a drastic influence on the world economy, due to the almost concurrent default of many small debtors (Hull 2009). Most of the credit contracts where bundled into credit portfolios in the form of collateralized debt obligations (CDOs). Realistic estimates for credit risks and the possible losses, particularly of large portfolios are important not only for the creditors, also and maybe even more from a systemic viewpoint. There is a wealth of studies on credit risk (see (Bielecki and Rutkowski 2013; Bluhm et al. 2016; Chava et al. 2011; Crouhy et al. 2000; Duffie and Singleton 1999; Glasserman and Ruiz-Mata 2006; Heitfield et al. 2006; Lando 2009; Mainik and Embrechts 2013; McNeil et al. 2005; Schönbucher 2003) and references therein). For a review on credit contagion, see (Avkiran et al. 2018; Egloff et al. 2007; Giesecke and Weber 2004 2006; Hatchett and Kühn 2009), and, for studies on practical investment and Value-at-Risk applications of copula theory in evaluating systemic risk, see (Low et al. 2013; Low 2017).
In a credit portfolio, it is of utmost importance to consider the correlations of the asset values. It has been shown that in the presence of even little correlations the concept of diversification is deeply flawed (Glasserman 2004; Schäfer et al. 2007; Schmitt et al. 2014, 2015; Schönbucher 2001). Hence, it is not possible to lower the tail risk significantly by enlarging the number of credit contracts in a credit portfolio. In general, diversification is not always fruitful (Bardoscia et al. 2017; Corsi et al. 2016; Humphrey et al. 2015; Ibragimov and Walden 2007; Wagner 2010).
To obtain a comprehensive understanding of systemic credit risk, it is important to study and model the mutual dependence of losses of different portfolios. Here, we are interested in the joint probability distribution that contains all the information on the individual loss distributions as well as their dependence structure. We apply the Merton (1974) model to several credit portfolios simultaneously (Münnix et al. 2014). Additionally, we take fluctuating asset correlations into account. These emerge because of the intrinsic non-stationarity of financial markets, which leads to a change of the correlation and covariance matrix in time (Münnix et al. 2012; Sandoval and Franca 2012; Schmitt et al. 2013; Song et al. 2011). To describe this non-stationarity, we use an random matrix approach that was recently introduced (Chetalova et al. 2015); for a comprehensive review, see (Mühlbacher and Guhr 2018). It results in a multivariate asset return distribution averaged over the fluctuating correlation matrices. The validity of this approach has been confirmed by empirical data analysis (Schmitt et al. 2013, 2015). The random matrix approach leads to a drastic reduction of the number of parameters describing the distribution. Remarkably, only two parameters, the average correlation coefficient of the asset values and the strength of the fluctuations are sufficient. The standard method for the Merton model does merely incorporate stationary asset correlations, whereas our model takes non-stationary asset correlations into account. This is an important feature that has a significant influence on the tail of the loss distribution. Furthermore, the random matrix approach reduces the numbers of relevant parameters significantly. With only two parameters, we are able to approximate the formidable complexity of the return distribution of a financial market very well.
From the asset return distribution, we analytically derive a joint probability distribution of credit portfolio losses. In addition, we derive a limiting distribution for infinitely large credit portfolios (Lucas et al. 2001). We analyze in detail two non-overlapping credit portfolios that operate on the same market. Moreover, we include subordination levels (An et al. 2015; Black and Cox 1976; Gorton and Santomero 1990). At maturity time, the senior creditor is paid out first and the junior subordinated creditor is only paid out if the senior creditor regained the full promised payment. This is related to CDO tranches and gives further information on to multivariate credit risk (Benmelech and Dlugosz 2009; Duffie and Garleanu 2001; Longstaff and Rajan 2008).
Furthermore, we consider a single credit portfolio that operates on several markets which are on average uncorrelated. We are able to derive a limiting distribution for an infinitely large credit portfolio. Here, the tail risk is lower than in the case of one market with effective average correlation structure, but still diversification is limited.
2. Model
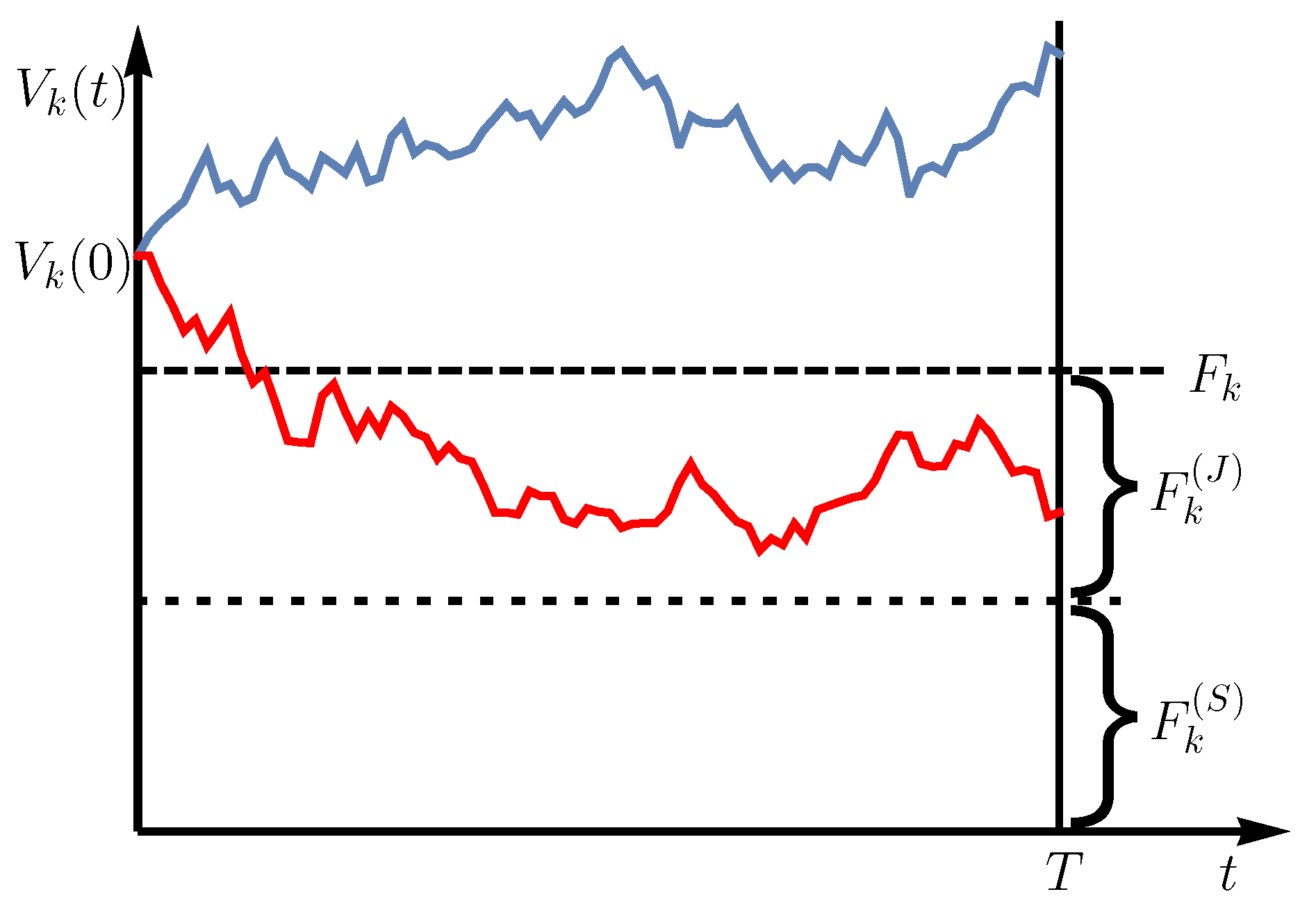
We extend the Merton model to a multivariate scenario with two creditors and K correlated obligors with asset values or economic states , at time t. Each obligor may hold a credit contract from each creditor. In the Merton model, the asset values are estimated by the stock prices of the corresponding obligors. Thus, we assume that all K obligors are companies that can be traded on a stock market. We claim that the asset values follow a geometric Brownian motion. Furthermore, we assume subordinated debt where at maturity time T the senior creditor is paid out first and the junior subordinated creditor is only paid out if the senior creditor regained the full promised payment. Suppose each obligor has to pay back the face value at maturity time T. We consider large time scales such as one year or one month. The face value of each obligor is composed of the face value of the senior creditor and the face value of the junior subordinated creditor , which is . A default occurs if the asset value drops below the face value i.e., for at least one obligor. The severity of the loss depends on the value of the obligors at time maturity. For , the default is completely defrayed by the junior subordinated creditor meaning that the senior creditor does not incur any loss. The senior creditor will incur a loss while the junior subordinated creditor will sustain a total loss only if t. A visualization of the underlying process for a single asset is shown in Figure 1.
The colored lines show two time-dependent asset values . In the blue case, the asset value of the company at maturity is above the face value and the promised payment can be made. In the red case, the asset value at maturity is below the total face value but still above the face value of the senior creditor , which results in a default of the junior creditor, while the senior creditor regains the full promised payment.
The normalized loss that a senior creditor and the normalized loss that a junior subordinated creditor is suffering can be expressed as
respectively. The Heaviside step functions
ensure that the losses are strictly positive. We introduce the fractional face values and for the senior and junior subordinated creditors
respectively. This enables us to define the normalized portfolio losses and for the senior and junior subordinated creditors as weighted sums
respectively. Our aim is to derive the bivariate distribution of the portfolio losses, which depends on the covariance matrix . This can be done by integrating over all portfolio values and filtering those that lead to a given bivariate total loss
where is the multivariate distribution of the correlated asset values of the obligors at maturity, is the covariance matrix of the asset values, which is in our model well estimated by that of the stock prices. is the Dirac delta function and is the K component vector of the asset values. The measure is the product of all differentials and the integration domain ranges from zero to infinity for every integral. Using the Fourier representation of the function (Lighthill 1958) as well as Equations (1) and (2), we find
where we split the integrals in three parts. We will use this expression later on, but we first need to specify the multivariate distribution of the correlated asset values .
Our goal is to calculate average joint loss distributions that take the non-stationarity of the covariances into account
and according to Equation (7). We will argue that this is achieved by properly averaging the multivariate distribution , resulting in .
2.1. Average Distribution
Following (Schmitt et al. 2013, 2015) and (Münnix et al. 2014), we use a random matrix concept to capture the non-stationarity of the correlations between the asset values . The covariances of the returns
with the return interval are ordered in the covariance matrix . It can be expressed as with the correlation matrix C and the diagonal matrix containing the volatilities of the different return time series .
In short time intervals where the covariance matrices can be viewed as stationary, the asset return distribution is a multivariate Gaussian (Schmitt et al. 2013). Importantly, we are interested in longer time intervals where non-stationarity is present in the covariances. As the covariance matrices differ significantly for different times, we empirically obtain an existing ensemble of different covariance matrices. These covariance matrices can be modeled by means of random matrices W, which contain as rows the model time series. Thus, is the model random covariance matrix and we replace
where we are free to choose the length N of the model time series. The symbol † denotes the transpose of a vector or matrix. The larger N, the more terms contribute to the elements of the model covariance matrix . In (Münnix et al. 2014; Schmitt et al. 2013, 2015), it was demonstrated that the empirical data ensemble can be very efficiently modeled by such random matrices W distributed according to Wishart (1928)
This distribution defines an ensemble of random covariance matrices which fluctuate around the average covariance matrix that is empirically evaluated over the whole time interval. In the limit , the Wishart distribution fixes the random matrices to the average covariance matrix , which is empirical input. Hence, we replace the covariance matrices with the random matrices according to (10) and average over the Wishart ensemble (11) to account for the non-stationarity. The ensemble average leads to the following general result for the average return distribution in the presence of fluctuating covariance matrices,
where is the Bessel function of second kind and of order (Schmitt et al. 2013). is the covariance matrix averaged over the whole data interval considered and N controls the strength of the fluctuations around the average covariance matrix . The smaller N, the larger are the fluctuations. In this notation and all further notations, we omit the time dependences of r and V. Hence, the heavier the tails of the distribution (12), the smaller the N. The distribution is very non-Gaussian and differs considerably from . Since we assume all credit contracts to have the form of zero coupon bonds, we consider our return intervals to have the same length as the maturity time, i.e., .
Refs. (Schmitt et al. 2013, 2015) have shown that an effective average correlation matrix of the form
with being the unit matrix and being a K component vector containing ones, yields a good description of empirical data in the present setting. If we studied non-averaged quantities depending on a specific correlation structure, this approach would be much less likely to give satisfactory results. The choice has two major advantages. First, we achieve analytical tractability, which can be seen later on in Section 2.2; second, we can describe the complexity of a correlated market with only two parameters. The first parameter c is an effective average correlation coefficient and the second parameter N describes the strength of the fluctuations around this average. Both parameters have to be estimated from empirical data.
Due to the fact that we need the asset values in our loss distribution (6) while covariances are measured by means of returns, we have to perform a change of variables using Itô’s lemma (Itô 1944)
where is the initial asset value. This is a geometric Brownian motion with drift and volatility with , where is the sample standard deviation. Expression (12) can now be rewritten using Fourier integrals. After employing and adjusting the steps in (Schmitt et al. 2014), we arrive at the double integral
The random matrix model of non-stationarity together with the effective average correlation matrix results in an expression for the joint multivariate distribution of the asset values in terms of a bivariate average of the product of geometric Brownian motions over a distribution in z and a Gaussian in u. We do not perform the u integration yet because we will factorize the integrals when computing the loss distribution (6) later on.
2.2. Average Loss Distribution
We work out the average loss distribution (8) using the above results for the average distribution . After inserting Equation (15) into Equation (7), we obtain
with the term
and
and the moments
where we use the change of variables with proper adjustment of the integration bounds and . The moments and are given in Appendix A for . The term formally corresponds to those events that lead to a loss large enough that the senior creditor is affected. We use a binomial sum for the decoupling of the and integrals later on.
Now, we assume large portfolios where all face values are of the same order, to carry out an approximation to the second order in and by performing steps generalizing the one in (Schmitt et al. 2014). This is justified when we consider all face values are of the same order, so all fractional face values are of order . We finally arrive at
for the average distribution with
Thus, we expressed the average loss distribution as double average of Gaussians with mean values and and variances and that non-trivially depend on the integration variables. To keep the notation transparent, we dropped the arguments of the functions and . Due to the complexity of the last two expressions in Equation (22), the z and u integrals have to be evaluated numerically. We notice that the normalization of the average distribution is, for only valid up to the order of our approximation. Later on, we will concentrate on the contributions of no default.
2.3. Homogeneous Portfolio
Apart from the large K approximation, all results above are valid in general and apply to all portfolios for which the individual fractional face values are of order . To further evaluate our results and to obtain a visualization, it is instructive to consider homogeneous portfolios, in which the senior and junior face values are equal:
such that
Furthermore, we assume that the stochastic processes have the same initial values, drifts and volatilities,
Of course, this does not mean that the realized stochastic processes are the same. By dropping the dependence of k, the moments and and thus the average distribution can be computed much faster.
2.4. Distribution of the Loss Given Default
Only the full dynamics of our model without any approximations give us information on the contribution of the non-analytic part of the average loss distribution. In particular, absence of losses is reflected in non-analytic functions at zero. To examine this, we start from the averaged version of Equation (7) by inserting the distribution of asset values for a homogeneous portfolio with an effective average correlation matrix
with
Due to the homogeneity, the product in Equation (7) also becomes a K-th power, to which we apply the multinomial theorem. We thus arrive at
with the multinomial coefficient
From Equation (36), we see that functions only appear under the condition . For , we have no default at all. The only contribution to the distribution stems from the last integral in Equation (36), leading to a peak at the origin. This peak is associated with the absence of default neither on the junior nor on the senior level. The probability therefore is
which obviously decreases with increasing K.
For , we find the contribution of the events that lead to a total junior default but not to a senior default. In this case, we have a single function that represents a moderate loss such that the senior subordinated creditor will not sustain a loss. The special case leads to a sum of functions where runs from 1 to K. This is due to the sum in Equation (36). These functions belong to the events where there is either no default at all or severe defaults such that, for obligors, the junior subordinated creditor has a complete failure i.e., and the senior subordinated creditor may sustain a loss i.e., . All of these functions are not unmated but weighted with some integral prefactors to preserve the normalization of the distribution . Furthermore, the functions disappear when we only consider the loss given default, which in our model means and also . The non-analytic parts cannot be obtained in the second order approximation we used to derive the average loss distribution (22).
2.5. Infinitely Large Portfolios
We now consider the case for the homogeneous portfolio to analyze whether diversification works or not in the discussed multivariate scenarios. It has been shown that diversification does not work in a correlated univariate model with only one bank (see (Schmitt et al. 2014)).
The homogeneous versions of Equations (24) and (26)
imply that as well as for . This means that both Gaussians
in Equation (22) become functions. Thus, we arrive at
To make this equation numerically manageable, we use the identity
where are the roots of the function , with . This result is a direct consequence of the elementary theory of distributions (Lighthill 1958). Using this identity three times allows us to solve the remaining two integrals and we finally obtain the limiting loss distribution
Here, the implicit functions
are unique and have to be calculated numerically. The dependence on and is now implicit in the functions and . The very last derivatives in Equation (43) can be done by using the implicit function theorem. They can be traced back to derivatives of and . The functions and are strictly monotonically increasing in u and z for fixed z and u, respectively. Thus, we can solve Equations (44) and (45) locally to u, where we obtain and . These equations can be derived by z using
and
2.6. Absence of Subordination
Now, we consider the same model as discussed before, but without taking subordination into account. This means that a loss is evenly distributed among the creditors. This model is closely related to that in (Sicking et al. 2018). Here, we have creditors with the face value of obligor k within creditor b and the normalized loss according to obligor k
with the total face value of obligor k and asset value . In Equation (49) for , the losses do not have any dependence on the obligors. In case of default, the creditors are not distinguished and suffer the same normalized loss. Hence, we write instead of . Again, we define the normalized portfolio losses and the fractional face values ,
corresponding to creditor b, respectively. The multivariate distribution of the total average loss is
with and . Adjusting our calculations in the subordinated case above and also applying a second order approximation for , we arrive at the final result
where
with the dyadic matrices
and with
The moments are the same as in Equation (20). For this model, we only consider heterogeneous portfolios for the whole market as homogeneous portfolios would lead to singular matrices as defined in Equation (55), and the losses would be exactly the same for all creditors. Instead, we consider cases where the volume of credit differs among the creditors or we consider cases where the portfolios are non-overlapping or may only partially overlap.
Although our results are general, we now only consider creditors to feasibly render a visualization. We denote them as creditor one and creditor two, respectively. Moreover, we address the most general set-up where two credit portfolios may partially overlap. Again, we consider K obligors in total. Let be the number of obligors with only one credit contract, say from creditor one. Let be the number of creditors that raise credits from both creditors. The proportions correspond to the fractions and . Creditor one deals in credits and creditor two deals in credits. This model, for example, also includes two disjoint portfolios, and we just have to set . The face value of the obligors consist of the sum of two face values that do not necessarily have the same size. For later convenience, we consider homogeneous portfolios and we assume that the face values in the overlapping part of the portfolios are equal within a portfolio but can differ across the portfolios. That means we introduce a parameter with and .
For a market with homogeneous parameters, we find the result (52) with
where
We notice for or .
Absence of Subordination on Several Markets
To treat several uncorrelated markets, we perform the same calculations as in the previous section. We insert the average asset value distribution (16) into Equation (51) with the slight difference that we have to replace the sum over k by two sums over l and k. We arrive at the final result, which is up to a factor formally identical to Equation (52)
with
and . Here, denotes the product of all differentials . The moments and are the same as in Equation (57) including an additional index for each market . In this way, we are able to vary the parameters like drift and volatility across the markets. We found it useful depending on the size of , to use polar or spherical coordinates for the evaluation of the multivariate u integral.
2.7. Absence of Subordination and Infinitely Large Portfolios
We now consider two infinitely large portfolios, taking the limit . We point out that and do not scale with K in the case of two infinitely large portfolios. We will consider the case of one infinitely large portfolio and one portfolio of finite size later on. Now, the matrix converges to a zero matrix. This implies that the exponential term and its prefactor converge to functions and we find the final result
This result is quite remarkable. We first point out that there is no dependence on the structure of the portfolios anymore as the distribution (66) is independent of the parameters and . Second, in the limiting case, the losses of both portfolios will always be equal to each other so that they are perfectly correlated. In other words, the loss of one large creditor can be used as a forecast for the loss of another large creditor on the same market. This holds even if the creditors have disjoint portfolios and it also does not depend on the strength of the correlations across the asset values.
A different situation appears when we consider a portfolio of finite size and another infinitely large one. Due to the high asymmetry of the market shares of the portfolios, we solely examine two disjoint portfolios. Say, portfolio one is the finite one with companies. Then, the matrix element in Equation (59) scales with K and converges to one. By calculating the limit , only one function emerges, and, by using property (42) of the function, we find
where is an implicit function defined by
We note that the dependence on in the limit distribution is encoded in . Moreover, the above result is in line with the second order approximation even though one of the matrix elements does not scale with K.
Finally, we analyze two disjoint infinitely large portfolios, where each portfolio invests in a separate market. We start from distribution (63) and perform the limit . Again, we find two functions and, by applying Equation (42) twice, we obtain
where
define the implicit functions and .
3. Model Calibration and Visualization of the Results
We always employ the approximation (13) to the mean correlation matrix, which yields, as already emphasized, very good fits to empirical data due to the very nature of the ensemble average. Furthermore, we restrict our analysis to homogeneous portfolios.
3.1. Adjustability to Different Market Situations
There are four parameters in our model, the average drift , the average volatility , the average correlation coefficient c and the parameter N, which controls the strength of the fluctuations around the mean correlation coefficient. The values of the parameters are directly estimated from empirical stock price data. The parameter N is determined by a fit of distribution (12) to the data. These consists of stocks that are taken from the S&P500 index traded continuously in the given time interval (Yahoo n.d.).
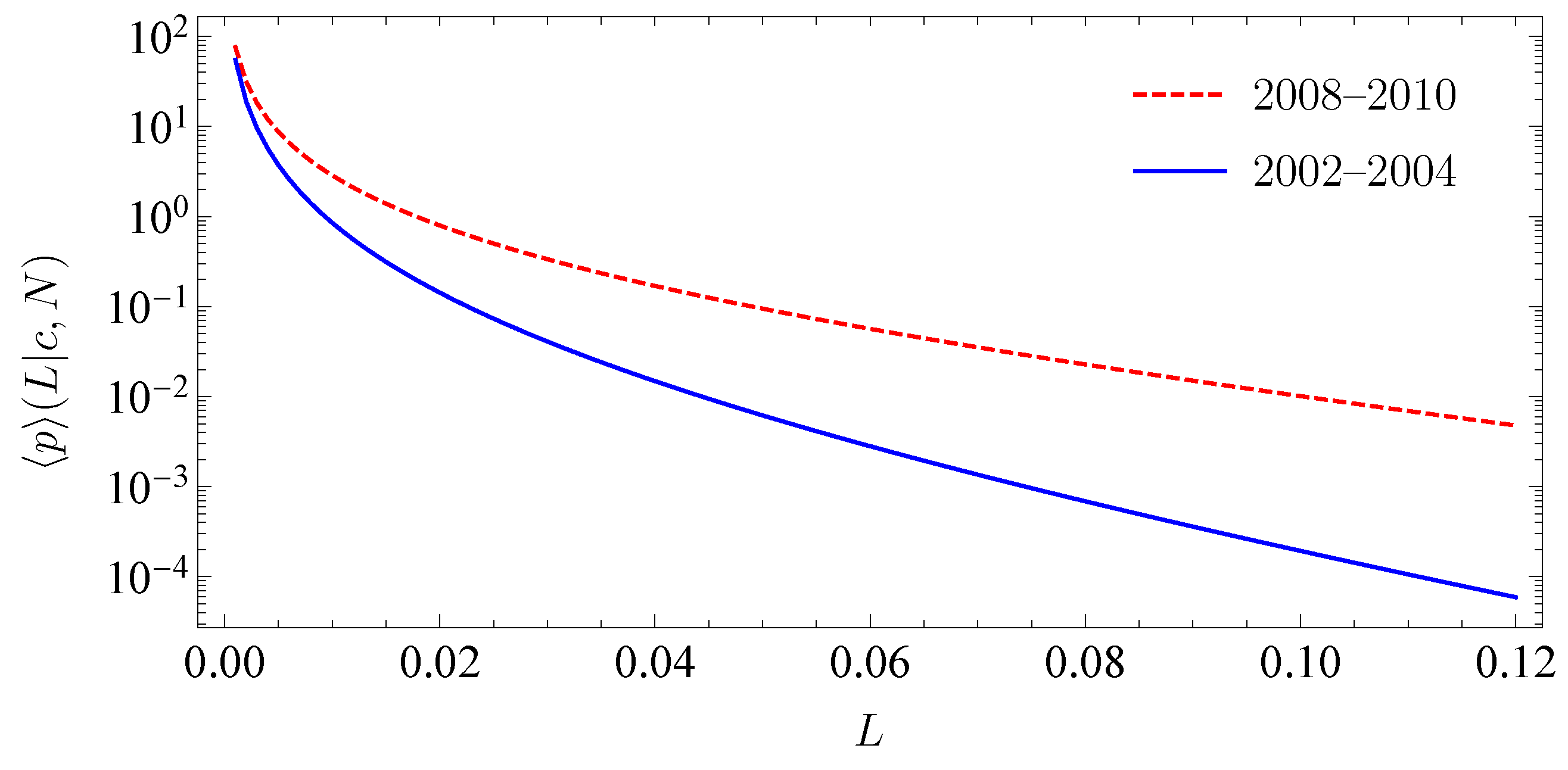
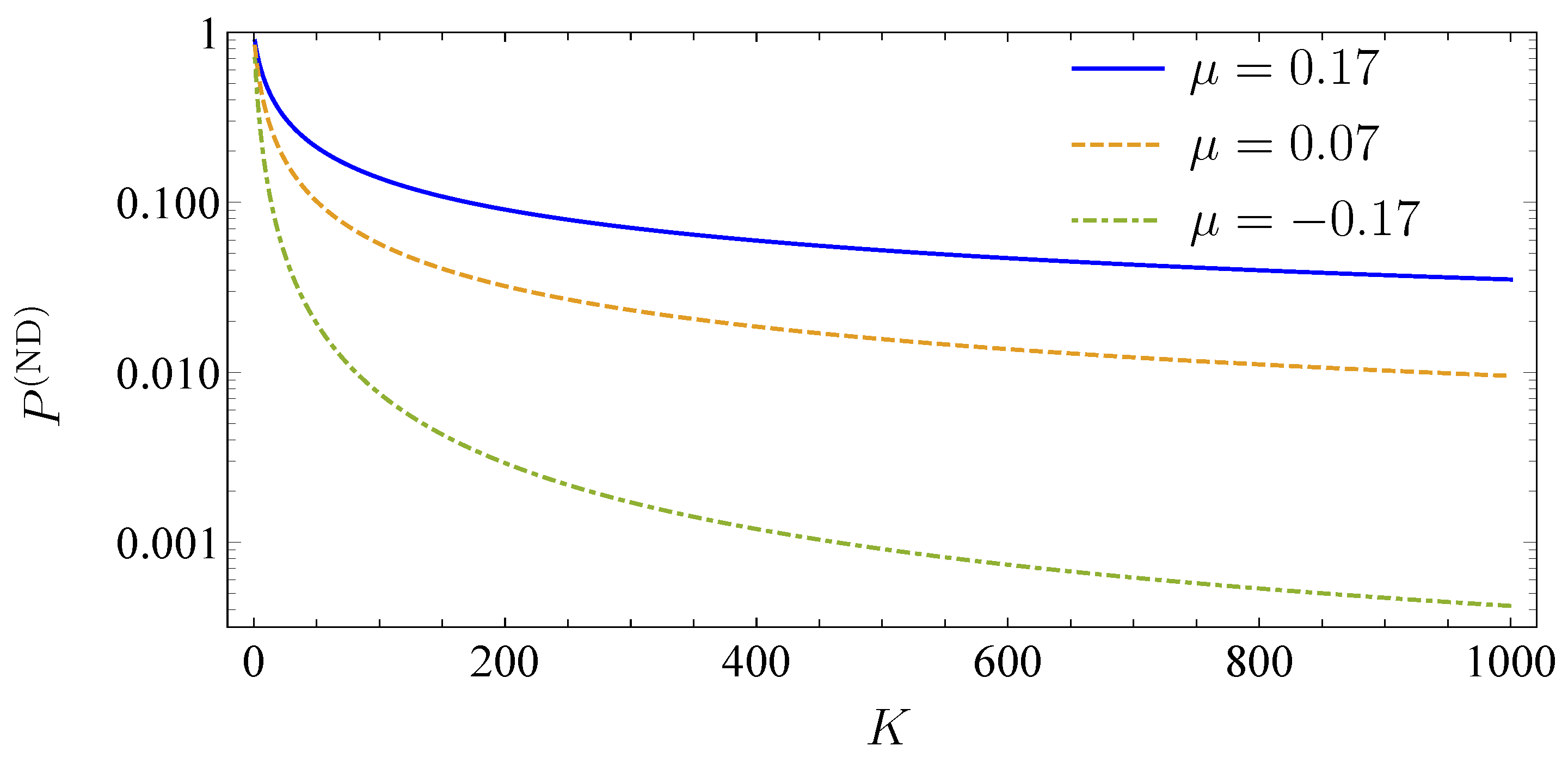
Importantly, we are able to adjust the parameters to different periods, i.e., different market situations. This is a significant feature of the model as the tail of the loss distribution changes for different market situations. The stronger correlations during crises lead to more pronounced tails of the loss distribution. Our model fully grasps this effect. To demonstrate this, we consider two market periods. The first period 2002–2004 is rather calm, whereas the second period 2008–2010 contains the global financial crisis. For simplicity, we solely consider one creditor on one homogeneous market. The empirical results for the period 2002–2004 are 0.015 month, 0.1 month, 0.3 and for the period 2008–2010 0.01 month, 0.12 month and 0.46. For both periods, we find 5, see (Schmitt et al. 2015). In Figure 2, we show the corresponding loss distributions. As anticipated, we find a significantly higher tail in times of crisis.
We estimate the value of the correlations by empirical data. However, the multivariate return distribution (12) that we construct is strongly non-Gaussian and describes the empirical data well. Thus, in the present context copulas, which capture the lower tail dependence, are not needed. However, a comparison with copulas can be found in (Wollschläger and Schäfer 2016).
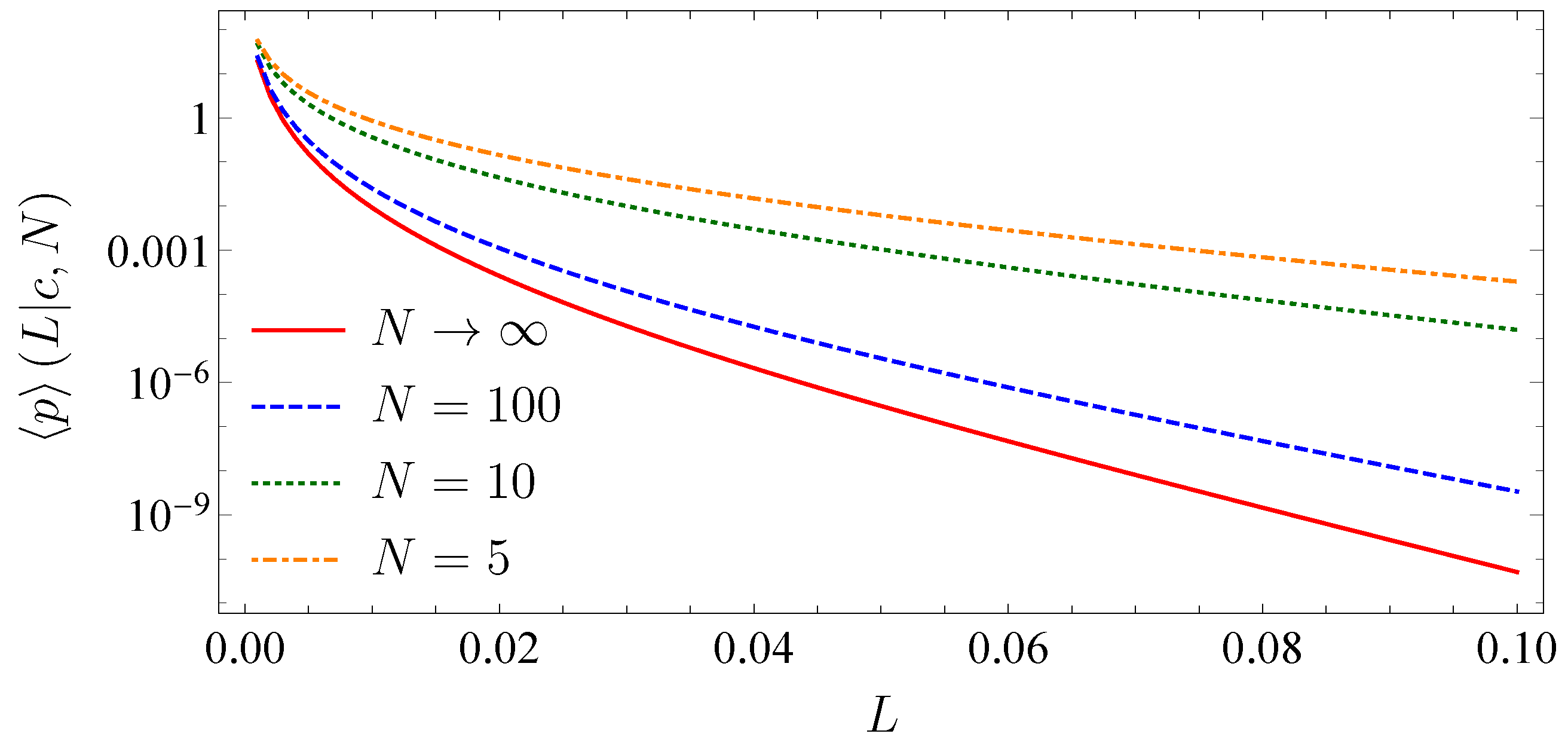
Moreover, by adjusting the parameter N, we are able to control the strength of the fluctuations around the mean correlation coefficient. The larger the N, the smaller the fluctuations are. In the case , the fluctuations are suppressed and the correlation matrix becomes stationary. Hence, the average return distribution (12) becomes a multivariate Gaussian and the benefits of the random matrix approach are not given anymore. The results for the multivariate average portfolio loss distribution in the absence of subordination are
with from (53) and from (54). In Figure 3, we compare the univariate portfolio loss distribution for one creditor on a single homogeneous market and a fixed correlation coefficient of 0.3 for different values of N.
The tail of the loss distribution clearly decreases with increasing N. The larger N becomes, the smaller are the outliers of the random correlations around the mean correlation coefficient. This shows the benefit of our random matrix approach compared to standard methods using stationary asset correlations and a multivariate Gaussian for the asset return distribution. Due to the asymmetry of credit risk, outliers that exceed the average correlation coefficient by far have a much stronger impact on the loss distribution than outliers which remain below the average correlation coefficient. This effect is more pronounced for smaller N and leads to an increasing tail.
3.2. One Portfolio, Two Markets
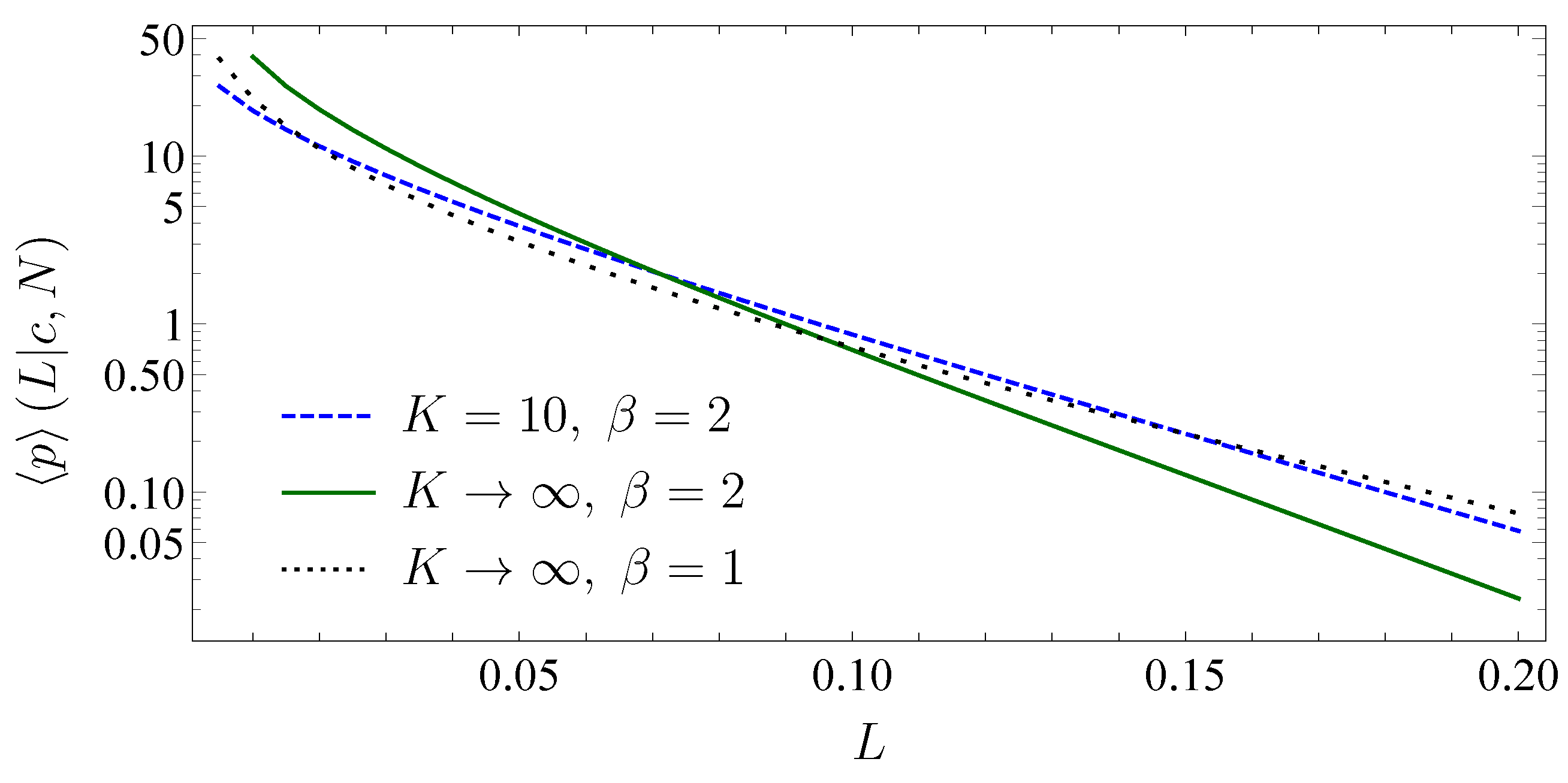
In the following, we use parameters determined by data consisting of 307 stocks that are taken from the S&P500 index traded in the period from 1992 to 2012 (Yahoo n.d.). We find the following empirical results for 1 year: 0.17 year, 0.35 year, 6 and 0.28.
We study the impact of investing into two uncorrelated markets. We thus assume two identical uncorrelated markets with the same average correlation coefficient. Furthermore, we assume the empirical parameters to be the same for both markets. The results are shown in Figure 4.
For a comparison, we also show the limiting distribution for only one market with the same parameters as in the case of two markets. This distribution is the univariate version of the distribution (66) (see also (Schmitt et al. 2015)). As expected, we see that the diversification, i.e., the separation of the correlation matrix into two blocks leads to a reduction of large portfolio losses. Hence, reducing the risk of large losses can be achieved more effectively by splitting the portfolio onto different uncorrelated markets than by solely increasing the number of credit contracts on one single market. Obviously, this is due to the on-average zero correlations in the off-diagonal blocks. A further reduction of the risk can only be achieved by either splitting the portfolio in more than two markets or investing into markets where the average correlation coefficient is low with little fluctuations. Nevertheless, by increasing the number of uncorrelated markets , we obtain for the same scenario as in the case of one market with average correlation zero. Here, the diversification effect is limited to the strength of the fluctuations N, where the tail of the loss distribution would only vanish for large N.
This effect has been discussed before, for example, in (Goetzmann et al. 2005), in an empirical setting. We emphasize that we with our results are able to quantitatively model the effect of diversification. According to the adjustability of our model, the benefits of diversification can be modeled for different markets and different market situations.
3.3. Absence of Subordination and Disjoint Portfolios of Equal Size
We begin with varying the number of companies K and study the impact on the multivariate loss distribution as well as on the default correlation and the default probabilities. Figure 5 shows the average loss distribution (52) with effective average correlation matrix and homogeneous parameters for two disjoint portfolios of equal size, for different numbers of companies and empirical values for the parameters.
We choose the face value and the initial asset value . The distribution is symmetric. It converges to the limiting distribution (66) as K increases. We thus infer a high correlation of the portfolio losses even for a small number of obligors. The striking peak around the origin corresponds to those events that lead to little portfolio loss. This peak arises because of the large drift. Due to the positive drift, the overall number of companies that do not default is larger than the number of companies that default at maturity. Still, this peak does not represent the peak at the origin, which stands for the probability of total survival of all companies. This becomes clear when we calculate the survival probability for all companies. This probability does not depend on whether we have subordinated debt or not and it also does not depend on the composition of our portfolios (see Equation (38)). The effect of different drift parameters is shown in Figure 6.
For every value of , the probability of having zero total portfolio loss decreases with an increasing number of companies K. Hence, the weight of the peak on the portfolio loss distribution at becomes smaller. This is quite intuitive; the larger the K, the more likely is the default of at least one company.
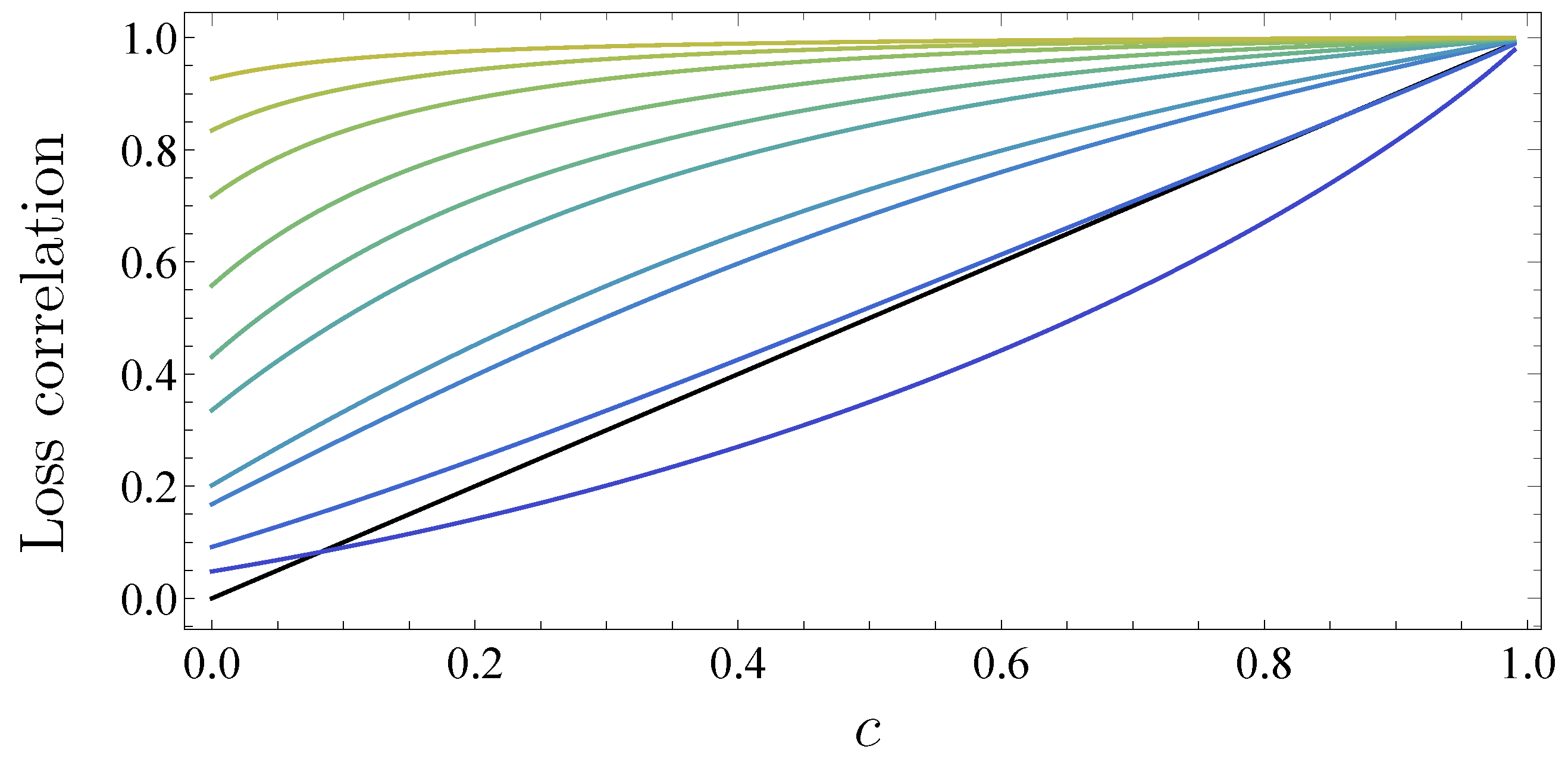
When looking at the portfolio loss correlations, we find large values for little or even zero asset correlation. For a market size of 100, i.e., each portfolio is of size 50, we obtain for an average asset correlation of 0 a correlation of the portfolio losses of 0.71. This high loss correlation is based on the fact that the asset correlations fluctuate around the mean asset correlation of zero. Due to this fluctuation, we have individual positive and negative correlations. The negative correlations only have a limited effect because the asymmetry of credit risk projects all non defaulting events onto zero while only defaulting events contribute to the loss distribution. Hence, the positive asset correlations dominate the negative ones causing a high portfolio loss correlation. The results are shown in Figure 7.
They are in accordance with the simulation results in (Sicking et al. 2018). The portfolio loss correlation is a monotonic function of the asset correlation c and, for a fixed asset correlation, we find with increasing K an increasing portfolio loss correlation. Depending on the number of companies, the portfolio loss correlation is a convex function (namely, ) or a concave function (). However, we emphasize that these results are subject to the second order approximation, which yields better results the larger the K. Large numbers of K lead to very high loss correlations. This confirms that, even without average asset correlation , the loss of one large portfolio serves as a forecast for another large portfolio.
3.4. Absence of Subordination and Disjoint Portfolios of Various Sizes
Looking at portfolios of various sizes yields much improved understanding of whether diversification works or not. To analyze this, we consider portfolio one with fixed size 10 and we consider the overall size of the market 30, 110 and the limit . In this scenario, the market share of portfolio one will steadily decrease and converge to zero in the limiting case. Hereby, we are able to compare somewhat smaller portfolios with very large ones.
For our calculations, we use the same empirical parameters as in Section 3.3. The effect of different market size K on the loss distribution is shown in Figure 8.
There are regions where we have heavy-tailed behavior of the distributions but also others where the distributions decay very fast. In this latter regions that always fulfill the condition , the loss distribution decays considerably faster with increasing market size K. Hence, we find large deviations between the distributions of different market sizes. These deviations only play a minor role because they emerge at a significant low order of the loss distribution. In general, for increasing market size K, the second portfolio describes the market in a better manner. Hence, it is very unlikely for the first portfolio to suffer a big loss in times when the second portfolio of large size exhibits little loss. This explains the fast decay of the loss distribution in the corner. However, the most important fact is that, along the diagonal and in the upper corner , significant deviations between the loss distributions for different market sizes do not occur. Here, we also observe heavy-tails of the loss distribution. Especially when we consider the diagonal, we find no deviations and thus no diversification at all. This means that increasing the size of portfolio 2 while keeping the size of portfolio 1 constant does not yield a decrease of concurrent large portfolio losses of equal size. Interestingly, it is more likely to find an event in the upper off-diagonal corner with than in the lower corner. This can be explained by the fluctuations around the mean correlation coefficient of 0.28 and the positive drift = 0.17 year. The fluctuations ensure that there is a probability for the assets of portfolio one to be adversely correlated to the assets of portfolio two. Accordingly, there is a significant probability that the small portfolio one suffers no or little default while the second portfolio suffers a major one. This probability decreases when we enlarge the size of portfolio one while keeping the size of portfolio two fixed and still larger than the size of portfolio one. Due to the asymmetry of the portfolio loss distributions regarding the diagonal, we find lower loss correlation for the same market size than in the case of two equal sized portfolios (see Figure 9).
In contrast to two portfolios of equal size, there is a limit correlation of the portfolio losses depending on c in the limit . One clearly sees that the limiting curve is reached very quickly for increasing market size. This is due to the fixed size of portfolio one. Increasing its size and the market size would raise the portfolio loss correlation.
3.5. Subordinated Debt
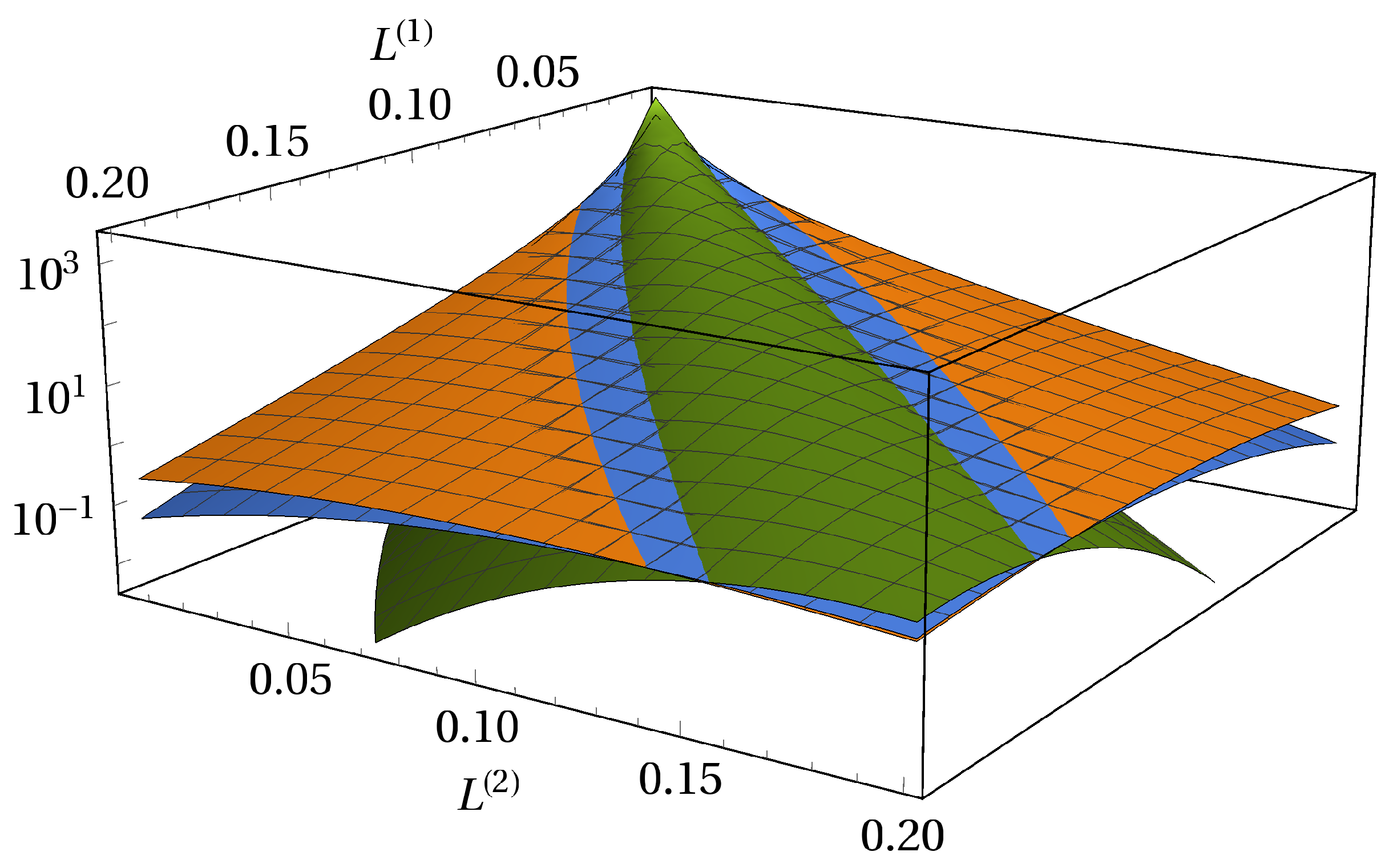
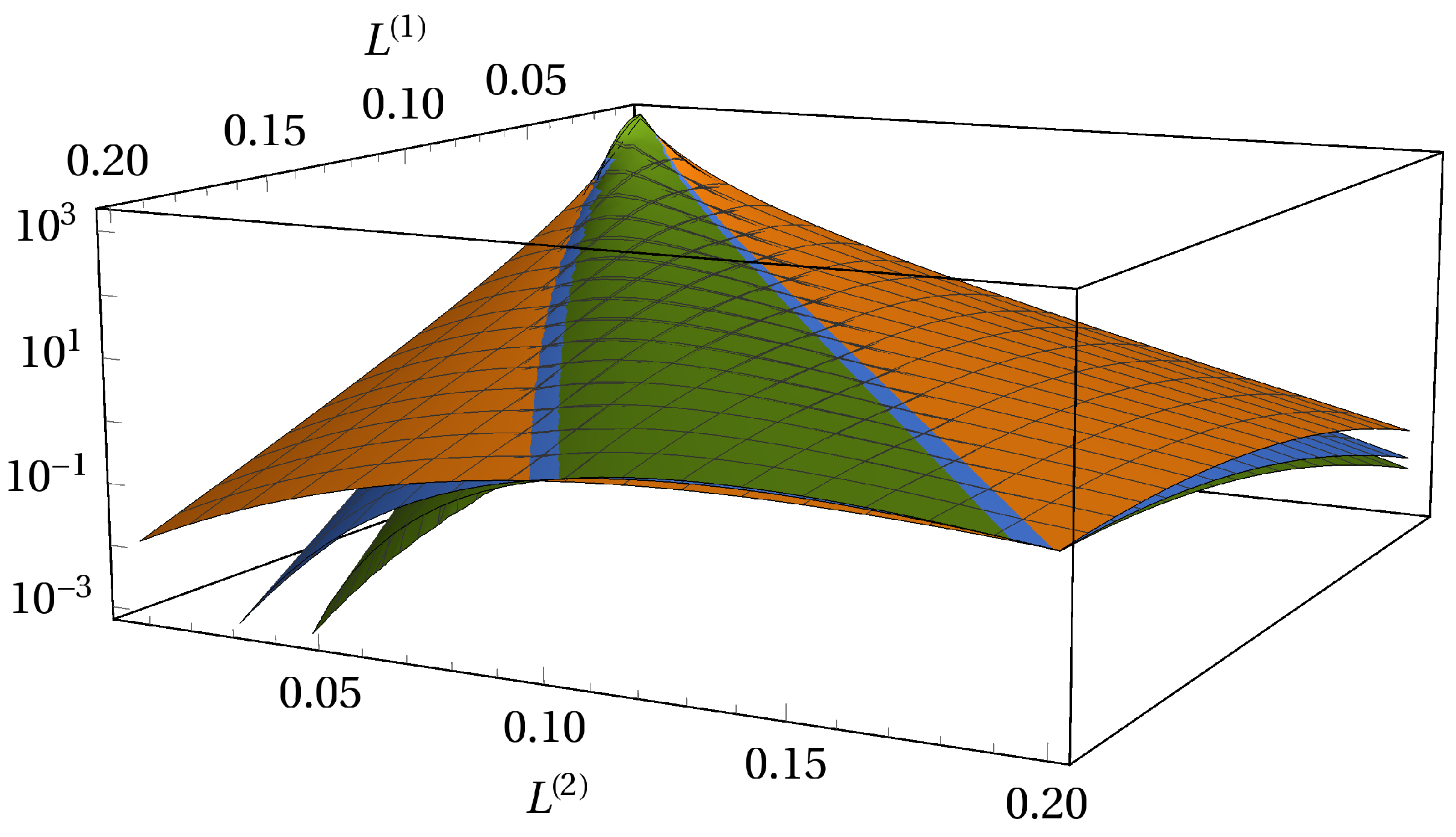
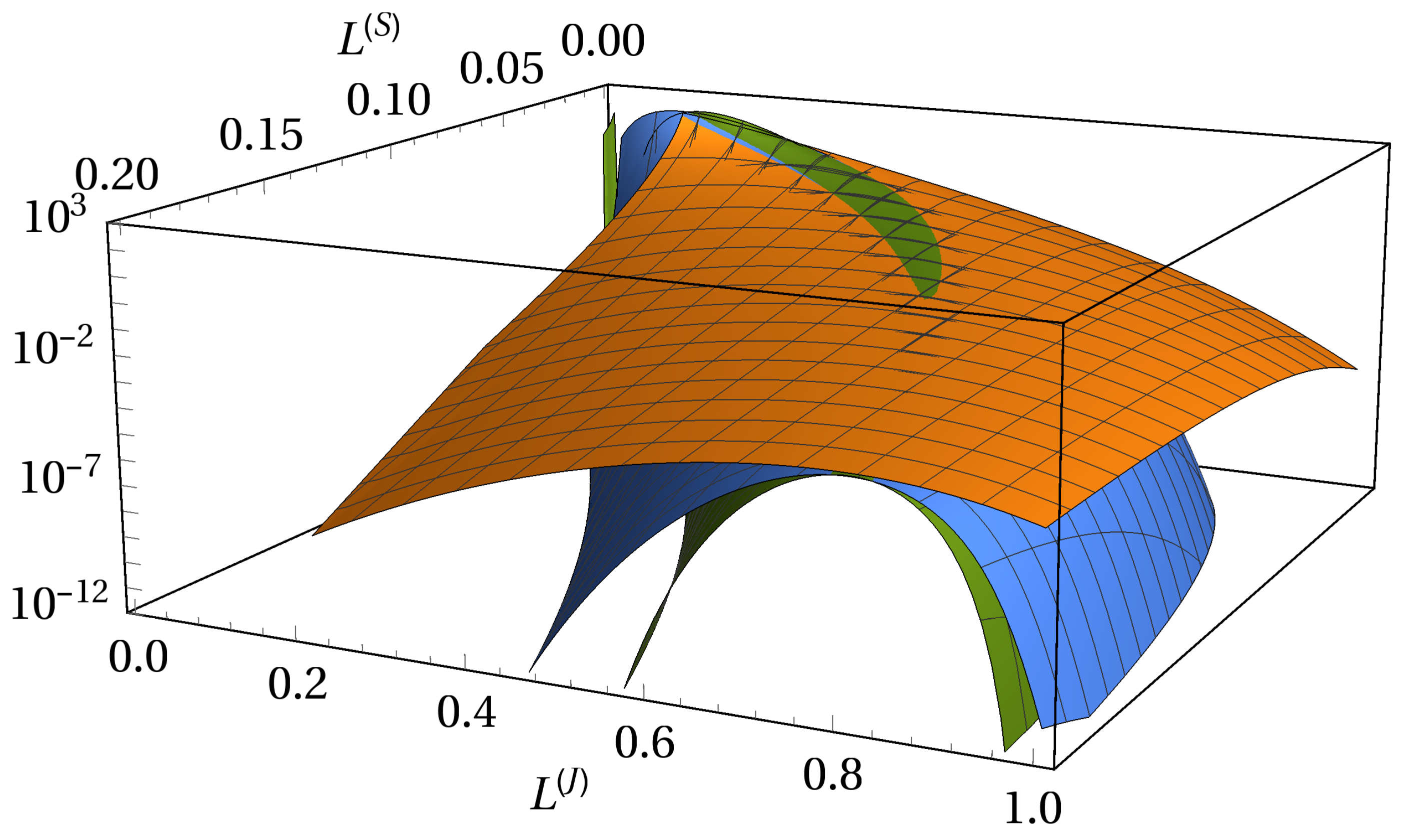
The subordinated debt structure brings a high degree of asymmetry into effect (see Figure 10). We show the joint probability density of two equal-sized portfolios with face values 37 and 38. Both senior and junior subordinated creditors operate on the entire market.
The loss of the junior subordinated creditor is always larger or equal than the loss of the senior creditor. We thus have an cutoff along the diagonal line . Besides the near region of a curved line, which we define as the back of the distribution, the number of obligors K influences the joint probabilities drastically. Along the back of the distribution, there is almost no deviation between the surfaces of the joint probability densities. Independent of K, the back of the distribution shows heavy tails. Importantly, the curvature reaches for high losses of the junior subordinated creditor evermore to higher losses of the senior creditor. This is an important consequence in times of crisis. When the loss of the junior subordinated creditor becomes extremely large, it is most likely that also the senior creditor suffers a significant loss. Furthermore, we show that, in times of crisis, the majority of an additional loss will be distributed to the senior creditor when there is already a large loss of the junior subordinated creditor.
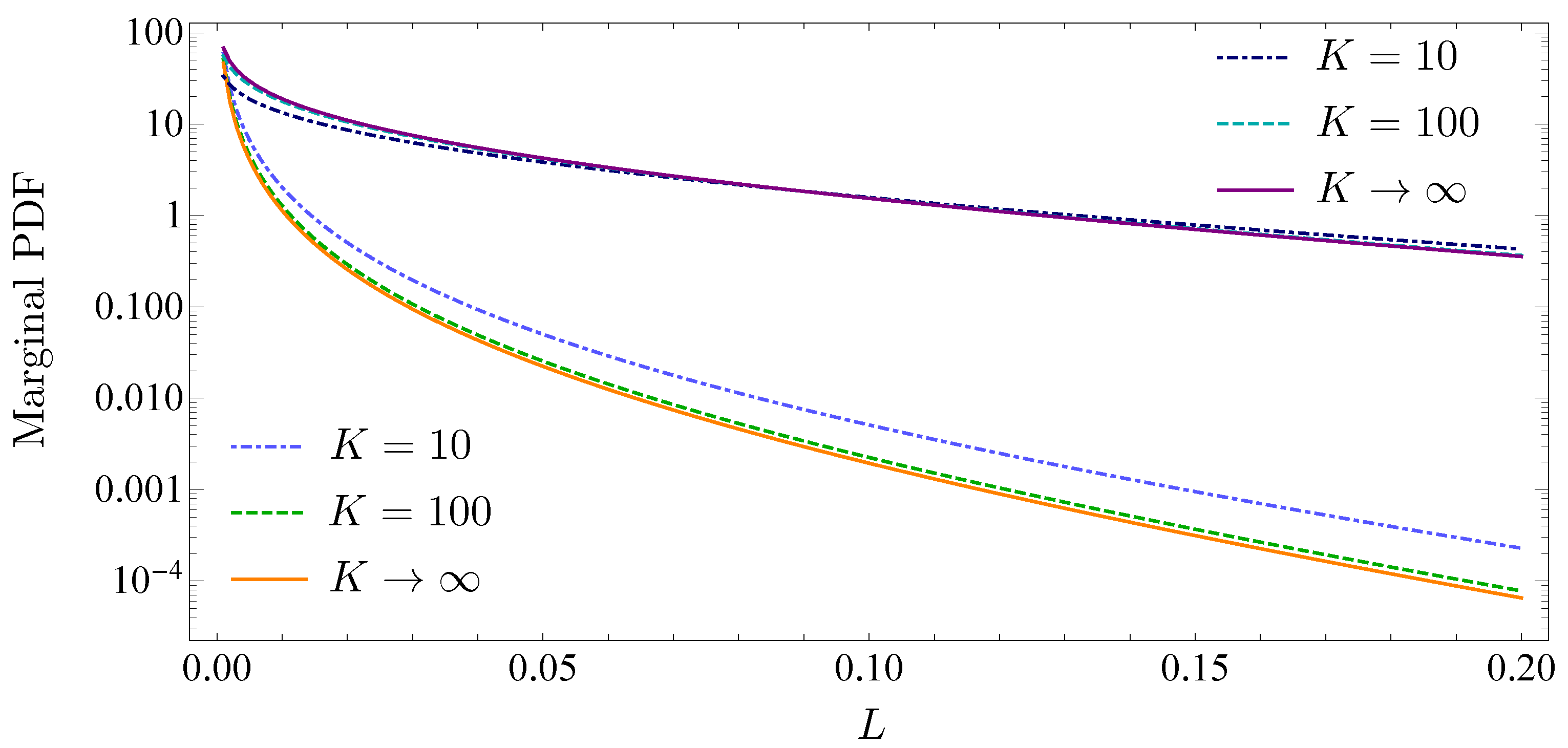
This explains why strong diversification effects do not exist, when we consider the marginal distributions of each creditor (see Figure 11).
The upper three curves belong to the marginal distributions of the junior subordinated creditor and the lower three curves belong to the senior creditor. All distributions show heavy tails and the gap between the senior and junior subordinated creditor enlarges with increasing loss L. The size of this gap becomes smaller when the ratio becomes larger.
4. Conclusions
Within the Merton model, we calculated a multivariate joint average portfolio loss distribution, taking fluctuating asset correlations into account. We used a random matrix model, which is, most advantageously, analytically tractable and also empirically a good match of stock market data. The multivariate average asset value distribution depends on two parameters only, the effective average asset value correlation and the strength of the fluctuations around this average.
We showed that diversification is achieved much more efficiently by splitting a credit portfolio onto different markets that are, on average, uncorrelated than by solely increasing the number of credit contracts on one single market.
For two non-overlapping portfolios of equal size, we found a symmetric portfolio loss distribution. Studying the portfolio loss correlations, we showed that significant correlations emerge not only for large portfolios containing thousands of credit contracts, but also in accordance with a second order approximation, for small portfolios containing only a few credit contracts. Two non-overlapping portfolios of infinite size have a loss correlation of one and will always suffer the same relative loss.
When we analyzed two non-overlapping portfolios of different size, we found the loss correlations to be limited. Nevertheless, the distributions show heavy tails that make large concurrent portfolio losses likely.
Furthermore, we included subordinated debt, related to CDO tranches. At maturity time, the senior creditor is paid out first and the junior subordinated creditor only if the senior creditor regained the full promised payment. Here, we analytically substantiate that, in case of crisis, i.e., when a large loss of the junior subordinated creditor is highly likely, a large loss of the senior creditor is also very likely. Thus, the concept of subordination does not work as intended in times of crisis. In addition, the marginal distributions show that increasing the size of both portfolios fails to reduce the tail risk significantly.
There are some limitations of our model. Our approach is based on the Merton model, which as discussed in the literature, has some weaknesses (see, e.g., (Duan 1994; Elizalde 2005)). Furthermore, due to the second order approximation in and necessary for analytical tractability, we assume that the face values of all companies are of the same order. Hence, in this approximation, we are not able to analyze the influence of one large company in the loss distribution. Credit default data is very hard to get, implying that we are unfortunately not able to compare the results of our model with empirical data. Nevertheless, our results, when compared to credit risk data in the future, provide an excellent test of the Merton model because we use stock market data for calibration.
The novelty of our approach is the ability to quantitatively model diversification effects that have been mainly qualitatively discussed in the economic literature. Hence, we corroborate qualitative reasoning in the economic literature. Additionally, by obtaining the joint portfolio loss distribution, further quantities such as any kind of risk measure can be calculated.
For further research, it is interesting to analyze avalanche and contagion effects. These effects are included only indirectly in our model, namely by calibrating to stock market states of crisis.
Author Contributions
Conceptualization, A.M. and T.G.; Formal Analysis, A.M.; Supervision T.G.; Writing-Original Draft, A.M.; Writing-Review & Editing, A.M. and T.G.
Acknowledgments
We thank Martin T. Hibbeln, Rüdiger Kiesel, Sebastian M. Krause and Tobias Nitschke for fruitful discussions. A.M. acknowledges support from Studienstiftung des deutschen Volkes.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Moments
We define
where and , as well as 1 and . Hence, we can write the moments
With the following definition,
and the error function
we can express the quantities for 0, 1, 2
References
- An, Xudong, Yongheng Deng, Joseph B. Nichols, and Anthony B. Sanders. 2015. What is subordination about? Credit risk and subordination levels in commercial mortgage-backed securities (CMBS). The Journal of Real Estate Finance and Economics 51: 231–53. [Google Scholar] [CrossRef]
- Avkiran, Necmi K., Christian M. Ringle, and Rand K. Y. Low. 2018. Monitoring transmission of systemic risk: Application of partial least squares structural equation modeling in financial stress testing. Journal of Risk. [Google Scholar] [CrossRef]
- Bardoscia, Marco, Stefano Battiston, Fabio Caccioli, and Guido Caldarelli. 2017. Pathways towards instability in financial networks. Nature Communications 8: 14416. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benmelech, Efraim, and Jennifer Dlugosz. 2009. The alchemy of CDO credit ratings. Journal of Monetary Economics 56: 617–34. [Google Scholar] [CrossRef]
- Bielecki, Tomasz R., and Marek Rutkowski. 2013. Credit Risk: Modeling, Valuation and Hedging. Berlin: Springer Science & Business Media. [Google Scholar]
- Black, Fischer S., and John C. Cox. 1976. Valuing corporate securities: Some effects of bond indenture provisions. The Journal of Finance 31: 351–67. [Google Scholar] [CrossRef]
- Bluhm, Christian, Ludger Overbeck, and Christoph Wagner. 2016. Introduction to Credit Risk Modeling. Boca Raton: CRC Press. [Google Scholar]
- Chava, Sudheer, Catalina Stefanescu, and Stuart Turnbull. 2011. Modeling the loss distribution. Management Science 57: 1267–87. [Google Scholar] [CrossRef]
- Chetalova, Desislava, Thilo A. Schmitt, Rudi Schäfer, and Thomas Guhr. 2015. Portfolio return distributions: Sample statistics with stochastic correlations. International Journal of Theoretical and Applied Finance 18: 1550012. [Google Scholar] [CrossRef]
- Corsi, Fulvio, Stefano Marmi, and Fabrizio Lillo. 2016. When micro prudence increases macro risk: The destabilizing effects of financial innovation, leverage, and diversification. Operations Research 64: 1073–88. [Google Scholar] [CrossRef]
- Crouhy, Michel, Dan Galai, and Robert Mark. 2000. A comparative analysis of current credit risk models. Journal of Banking & Finance 24: 59–117. [Google Scholar]
- Duan, Jin-Chuan. 1994. Maximum likelihood estimation using price data of the derivative contract. Mathematical Finance 4: 155–67. [Google Scholar] [CrossRef]
- Duffie, Darrell, and Kenneth J. Singleton. 1999. Modeling term structures of defaultable bonds. The Review of Financial Studies 12: 687–720. [Google Scholar] [CrossRef] [Green Version]
- Duffie, Darrell, and Nicolae Garleanu. 2001. Risk and valuation of collateralized debt obligations. Financial Analysts Journal 57: 41–59. [Google Scholar] [CrossRef]
- Egloff, Daniel, Markus Leippold, and Paolo Vanini. 2007. A simple model of credit contagion. Journal of Banking & Finance 31: 2475–92. [Google Scholar]
- Elizalde, Abel. 2005. Credit Risk Models II: Structural Models. Documentos de Trabajo CEMFI. Madrid: CEMFI. [Google Scholar]
- Giesecke, Kay, and Stefan Weber. 2004. Cyclical correlations, credit contagion, and portfolio losses. Journal of Banking & Finance 28: 3009–36. [Google Scholar]
- Giesecke, Kay, and Stefan Weber. 2006. Credit contagion and aggregate losses. Journal of Economic Dynamics and Control 30: 741–67. [Google Scholar] [CrossRef]
- Glasserman, Paul. 2004. Tail approximations for portfolio credit risk. The Journal of Derivatives 12: 24–42. [Google Scholar] [CrossRef]
- Glasserman, Paul, and Jesus Ruiz-Mata. 2006. Computing the credit loss distribution in the Gaussian copula model: A comparison of methods. Journal of Credit Risk 2: 33–66. [Google Scholar] [CrossRef]
- Goetzmann, William N., Lingfeng Li, and K. Geert Rouwenhorst. 2005. Long-term global market correlations. Journal of Business 78: 1–38. [Google Scholar] [CrossRef]
- Gorton, Gary, and Anthony M. Santomero. 1990. Market discipline and bank subordinated debt: Note. Journal of Money, Credit and Banking 22: 119–28. [Google Scholar] [CrossRef]
- Hatchett, Jon P. L., and Reimer Kühn. 2009. Credit contagion and credit risk. Quantitative Finance 9: 373–82. [Google Scholar] [CrossRef]
- Heitfield, Eric, Steve Burton, and Souphala Chomsisengphet. 2006. Systematic and idiosyncratic risk in syndicated loan portfolios. Journal of Credit Risk 2: 3–31. [Google Scholar] [CrossRef]
- Hull, John C. 2009. The credit crunch of 2007: What went wrong? Why? What lessons can be learned? Journal of Credit Risk 5: 3–18. [Google Scholar] [CrossRef]
- Humphrey, Jacquelyn E., Karen L. Benson, Rand K. Y. Low, and Wei-Lun Lee. 2015. Is diversification always optimal? Pacific-Basin Finance Journal 35: 521–32. [Google Scholar] [CrossRef]
- Ibragimov, Rustam, and Johan Walden. 2007. The limits of diversification when losses may be large. Journal of Banking & Finance 31: 2551–69. [Google Scholar]
- Itô, Kiyosi. 1944. Stochastic integral. Proceedings of the Imperial Academy 20: 519–24. [Google Scholar] [CrossRef]
- Lando, David. 2009. Credit Risk Modeling: Theory and Applications. Princeton: Princeton University Press. [Google Scholar]
- Lighthill, Michael J. 1958. An introduction to Fourier Analysis and Generalised Functions. Cambridge: Cambridge University Press. [Google Scholar]
- Longstaff, Francis A., and Arvind Rajan. 2008. An empirical analysis of the pricing of collateralized debt obligations. The Journal of Finance 63: 529–63. [Google Scholar] [CrossRef]
- Low, Rand Kwong Yew, Jamie Alcock, Robert Faff, and Timothy Brailsford. 2013. Canonical vine copulas in the context of modern portfolio management: Are they worth it? Journal of Banking & Finance 37: 3085–99. [Google Scholar]
- Low, Rand Kwong Yew. 2017. Vine copulas: Modeling systemic risk and enhancing higher-moment portfolio optimisation. Accounting and Finance. [Google Scholar] [CrossRef]
- Lucas, André, Pieter Klaassen, Peter Spreij, and Stefan Straetmans. 2001. An analytic approach to credit risk of large corporate bond and loan portfolios. Journal of Banking & Finance 25: 1635–64. [Google Scholar]
- Mainik, Georg, and Paul Embrechts. 2013. Diversification in heavy-tailed portfolios: Properties and pitfalls. Annals of Actuarial Science 7: 26–45. [Google Scholar] [CrossRef]
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2005. Quantitative Risk Management: Concepts, Techniques and Tools. Princeton: Princeton University Press. [Google Scholar]
- Merton, Robert C. 1974. On the pricing of corporate debt: The risk structure of interest rates. The Journal of Finance 29: 449–70. [Google Scholar]
- Mühlbacher, Andreas, and Thomas Guhr. 2018. Credit risk meets random matrices: Coping with non-stationary asset correlations. Risks 6: 42. [Google Scholar] [CrossRef]
- Münnix, Michael C., Takashi Shimada, Rudi Schäfer, Francois Leyvraz, Thomas H. Seligman, Thomas Guhr, and H. Eugene Stanley. 2012. Identifying states of a financial market. Scientific Reports 2: 644. [Google Scholar] [CrossRef] [PubMed]
- Münnix, Michael C., Rudi Schäfer, and Thomas Guhr. 2014. A random matrix approach to credit risk. PLoS ONE 9: e98030. [Google Scholar] [CrossRef] [PubMed]
- Nitschke, Tobias. 2014. Ensemble-Ansatz zur Modellierung des Kreditrisikos im Falle im Mittel unkorrelierter Märkte. Bachelor’s thesis, University of Duisburg-Essen, Duisburg, Germany. [Google Scholar]
- Sandoval, Leonidas, and Italo De Paula Franca. 2012. Correlation of financial markets in times of crisis. Physica A 391: 187–208. [Google Scholar] [CrossRef] [Green Version]
- Schäfer, Rudi, Markus Sjölin, Andreas Sundin, Michal Wolanski, and Thomas Guhr. 2007. Credit risk—A structural model with jumps and correlations. Physica A 383: 533–69. [Google Scholar] [CrossRef]
- Schmitt, Thilo A., Desislava Chetalova, Rudi Schäfer, and Thomas Guhr. 2013. Non-stationarity in financial time series: Generic features and tail behavior. Europhysics Letters 103: 58003. [Google Scholar] [CrossRef] [Green Version]
- Schmitt, Thilo A., Desislava Chetalova, Rudi Schäfer, and Thomas Guhr. 2014. Credit risk and the instability of the financial system: An ensemble approach. Europhysics Letters 105: 38004. [Google Scholar] [CrossRef] [Green Version]
- Schmitt, Thilo A., Desislava Chetalova, Rudi Schäfer, and Thomas Guhr. 2015. Credit risk: Taking fluctuating asset correlations into account. Journal of Credit Risk 11: 73–94. [Google Scholar] [CrossRef]
- Schönbucher, Philipp J. 2001. Factor models: Portfolio credit risks when defaults are correlated. The Journal of Risk Finance 3: 45–56. [Google Scholar] [CrossRef]
- Schönbucher, Philipp J. 2003. Credit Derivatives Pricing Models: Models, Pricing and Implementation. Hoboken: John Wiley & Sons. [Google Scholar]
- Sicking, Joachim, Thomas Guhr, and Rudi Schäfer. 2018. Concurrent credit portfolio losses. PLoS ONE 13: e0190263. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Song, Dong-Ming, Michele Tumminello, Wei-Xing Zhou, and Rosario N. Mantegna. 2011. Evolution of worldwide stock markets, correlation structure, and correlation-based graphs. Physical Review E 84: 026108. [Google Scholar] [CrossRef] [PubMed]
- Wagner, Wolf. 2010. Diversification at financial institutions and systemic crises. Journal of Financial Intermediation 19: 373–86. [Google Scholar] [CrossRef]
- Wishart, John. 1928. The generalised product moment distribution in samples from a normal multivariate population. Biometrika 20A: 32–52. [Google Scholar] [CrossRef]
- Wollschläger, Marcel, and Rudi Schäfer. 2016. Impact of nonstationarity on estimating and modeling empirical copulas of daily stock returns. Journal of Risk 19: 1–23. [Google Scholar] [CrossRef] [Green Version]
- Yahoo! n.d. Finance. Available online: http://finance.yahoo.com (accessed on 15 May 2018).
Figure 1.
Schematic visualization of the Merton model. A default occurs if the asset value at maturity drops below the face value . In the red sketched scenario, a default occurs only to the junior subordinated creditor while the senior creditor obtains no loss.
Figure 1.
Schematic visualization of the Merton model. A default occurs if the asset value at maturity drops below the face value . In the red sketched scenario, a default occurs only to the junior subordinated creditor while the senior creditor obtains no loss.

Figure 2.
Average portfolio loss distribution for one creditor with size on a homogeneous market and different periods. The dashed line corresponds to the global financial crisis 2008–2010; the solid line corresponds to the calm period 2002–2004.
Figure 2.
Average portfolio loss distribution for one creditor with size on a homogeneous market and different periods. The dashed line corresponds to the global financial crisis 2008–2010; the solid line corresponds to the calm period 2002–2004.

Figure 3.
Average portfolio loss distribution for one creditor on a homogeneous market and different values of N.
Figure 3.
Average portfolio loss distribution for one creditor on a homogeneous market and different values of N.

Figure 4.
Average loss distribution on a logarithmic scale for a different number of markets and market size. The markets are homogeneous and we choose a face value of and the initial asset value .
Figure 4.
Average loss distribution on a logarithmic scale for a different number of markets and market size. The markets are homogeneous and we choose a face value of and the initial asset value .

Figure 5.
Average loss distribution for two disjoint portfolios of same sizes on a logarithmic scale. We show different market sizes, orange, blue and green. The parameters are , , , and a maturity time of .
Figure 5.
Average loss distribution for two disjoint portfolios of same sizes on a logarithmic scale. We show different market sizes, orange, blue and green. The parameters are , , , and a maturity time of .

Figure 6.
Probability of zero portfolio loss depending on the portfolio size K for different drift parameters on a logarithmic scale.
Figure 6.
Probability of zero portfolio loss depending on the portfolio size K for different drift parameters on a logarithmic scale.

Figure 7.
Portfolio loss correlation on a linear scale depending on the asset correlation c. Both portfolios are homogeneous and have the same size. The market size K ranges from 2 (blue) over 4, 8, 10, 20, 30, 50, 100, 200 to 500 (green). The bisecting line is shown in black.
Figure 7.
Portfolio loss correlation on a linear scale depending on the asset correlation c. Both portfolios are homogeneous and have the same size. The market size K ranges from 2 (blue) over 4, 8, 10, 20, 30, 50, 100, 200 to 500 (green). The bisecting line is shown in black.

Figure 8.
Average loss distribution for portfolios of different sizes on a logarithmic scale. Portfolio one is of fixed size and the market size is (orange), (blue) and (green). The parameters are , , , and a maturity time of .
Figure 8.
Average loss distribution for portfolios of different sizes on a logarithmic scale. Portfolio one is of fixed size and the market size is (orange), (blue) and (green). The parameters are , , , and a maturity time of .

Figure 9.
Portfolio loss correlation as a function of asset correlation c on a linear scale. Portfolio one is of fixed size and the market size K ranges from 30 (blue) over 50, 100, 200 to 500 (green). The limiting curve is shown in black and the bisecting line is shown in red.
Figure 9.
Portfolio loss correlation as a function of asset correlation c on a linear scale. Portfolio one is of fixed size and the market size K ranges from 30 (blue) over 50, 100, 200 to 500 (green). The limiting curve is shown in black and the bisecting line is shown in red.

Figure 10.
Average portfolio loss distribution of a subordinated debt structure on a logarithmic scale. Both portfolios operate on the entire market. We show different market sizes orange, blue and green.
Figure 10.
Average portfolio loss distribution of a subordinated debt structure on a logarithmic scale. Both portfolios operate on the entire market. We show different market sizes orange, blue and green.

Figure 11.
Marginal distributions of senior and junior subordinated creditor on a logarithmic scale. The upper three lines belong to the junior subordinated creditor and the lower three lines to the senior creditor.
Figure 11.
Marginal distributions of senior and junior subordinated creditor on a logarithmic scale. The upper three lines belong to the junior subordinated creditor and the lower three lines to the senior creditor.

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Mühlbacher, A.; Guhr, T. Extreme Portfolio Loss Correlations in Credit Risk. Risks 2018, 6, 72. https://doi.org/10.3390/risks6030072
AMA Style
Mühlbacher A, Guhr T. Extreme Portfolio Loss Correlations in Credit Risk. Risks. 2018; 6(3):72. https://doi.org/10.3390/risks6030072
Chicago/Turabian StyleMühlbacher, Andreas, and Thomas Guhr. 2018. "Extreme Portfolio Loss Correlations in Credit Risk" Risks 6, no. 3: 72. https://doi.org/10.3390/risks6030072
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.