A Data Quality Strategy to Enable FAIR, Programmatic Access across Large, Diverse Data Collections for High Performance Data Analysis


Abstract
:1. Introduction
2. NCI’s Data Quality Strategy (DQS)
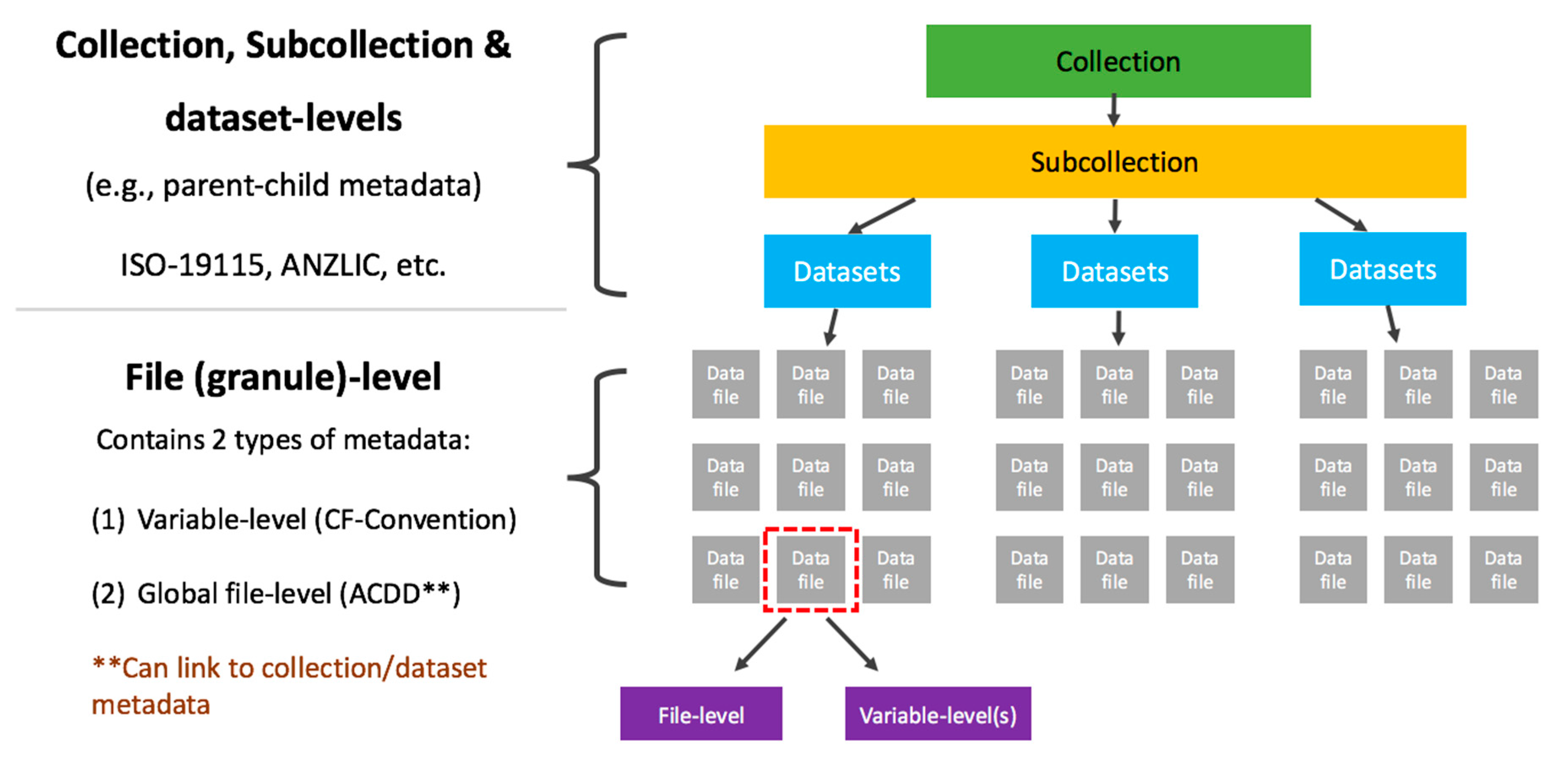
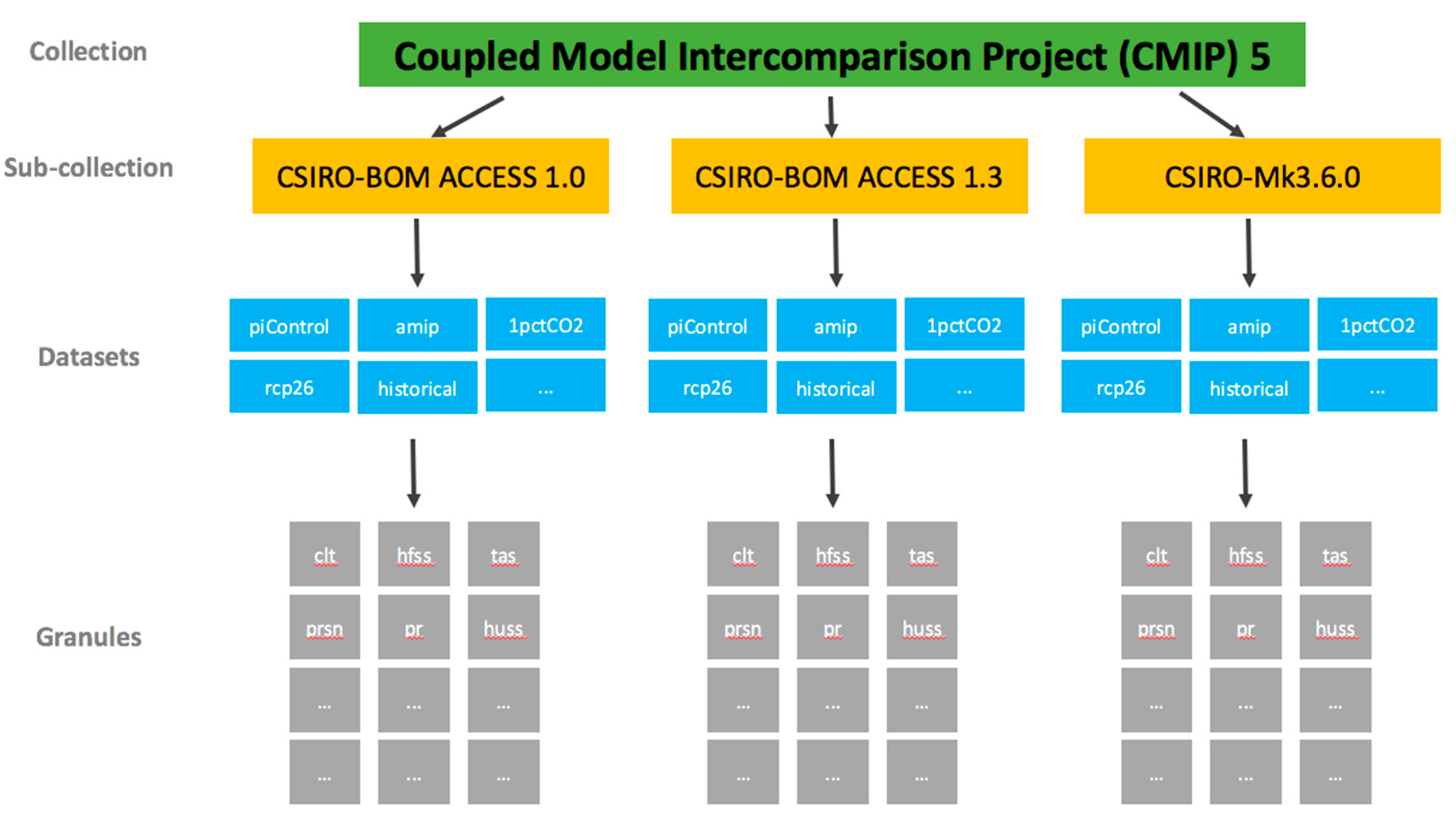
2.1. Data Structure
- A data collection is the highest in the hierarchy of data groupings at NCI. It is comprised of either an exclusive grouping of data subcollections; or, it is a tiered structure with an exclusive grouping of lower tiered data collections, where the lowest tier data collection will only contain data subcollections.
- A data subcollection is an exclusive grouping of datasets (i.e., belonging to only one subcollection) where the constituent datasets are tightly managed. It must have responsibilities within one organization with responsibility for the underlying management of its constituent datasets. A data subcollection constitutes a strong connection between the component datasets, and is organized coherently around a single scientific element (e.g., model, instrument). A subcollection must have compatible licenses such that constituent datasets do not need different access arrangements.
- A dataset is a compilation of data that constitutes a programmable data unit that has been collected and organized using a self-contained process. For this purpose it must have a named data owner, a single license, one set of semantics, ontologies, vocabularies, and has a single data format and internal data convention. A dataset must include its version.
- A dataset granule is used for some scientific domains that require a finer level of granularity (e.g., in satellite Earth Observation datasets). A granule refers to the smallest aggregation of data that can be independently described, inventoried, and retrieved as defined by NASA [14]. Dataset granules have their own metadata and support values associated with the additional attributes defined by parent datasets.
- A data category allows a broad spectrum of options to encode relationships between data. A data category can be anything that weakly relates datasets, with the primary way of discovering the groupings within the data by key terms (e.g., keywords, attributes, vocabularies, ontologies). Datasets are not exclusive to a single category.
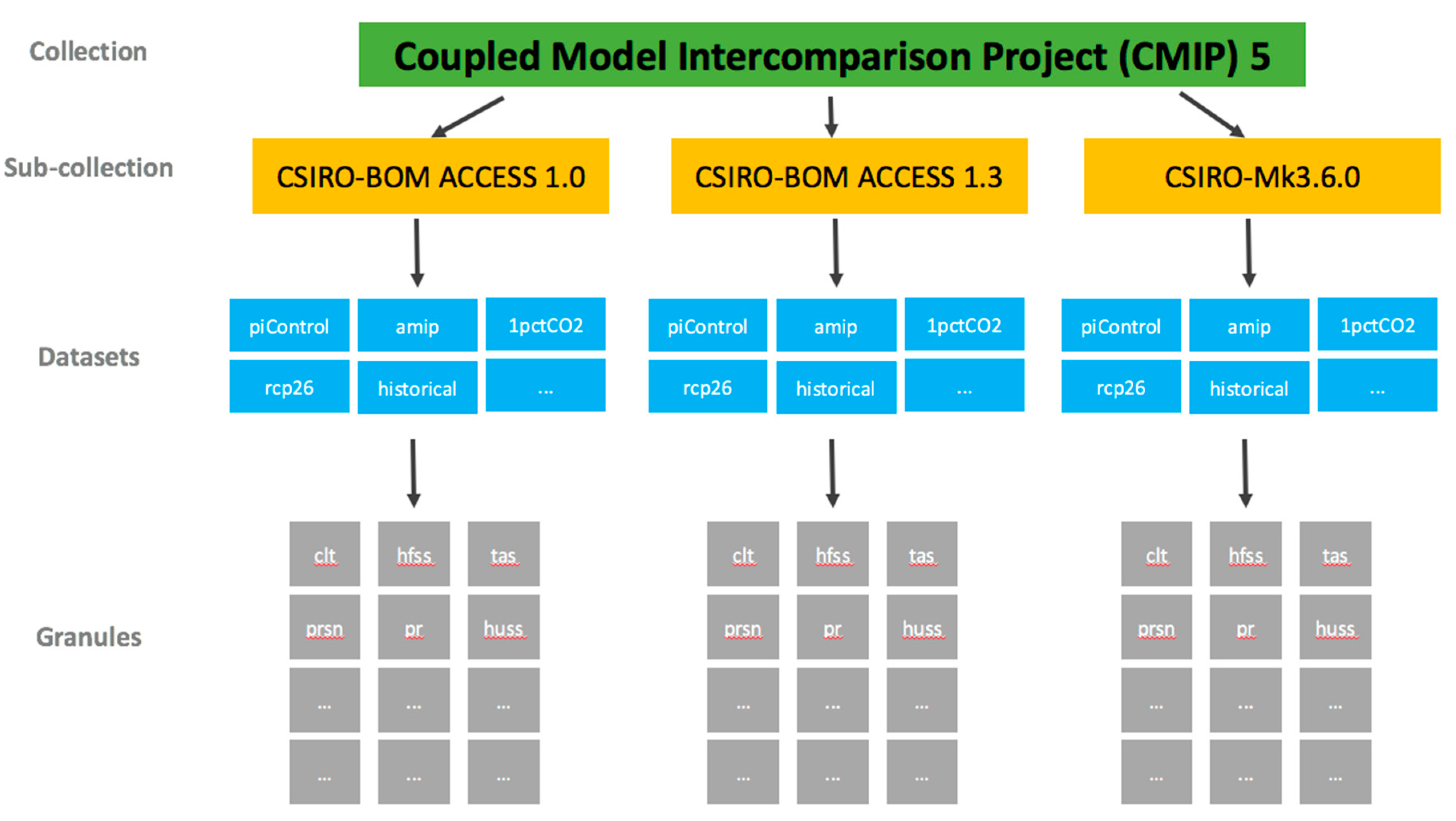
Organization of Data within the Data Structure
2.2. Data QC
2.2.1. Climate and Forecast (CF) Convention
2.2.2. Attribute Convention for Data Discovery (ACDD)
2.3. Benchmarking Methodology
2.4. Data QA
- Open-source Project for a Network Data Access Protocol (OPeNDAP): a protocol enabling data access and subsetting through the web;
- NetCDF Subset Service (NCSS): Web service for subsetting files that can be read by the netCDF java library;
- WMS: OGC web service for requesting raster images of data;
- WCS: OGC web service for requesting data in some output format;
- Godiva2 Data Viewer: Tool for simple visualization of data; and
- HTTP File Download: direct downloading data.
3. Examples of Tests and Reports Undertaken on NCI Datasets Prior to Publication
3.1. Metadata QC Checker Reports
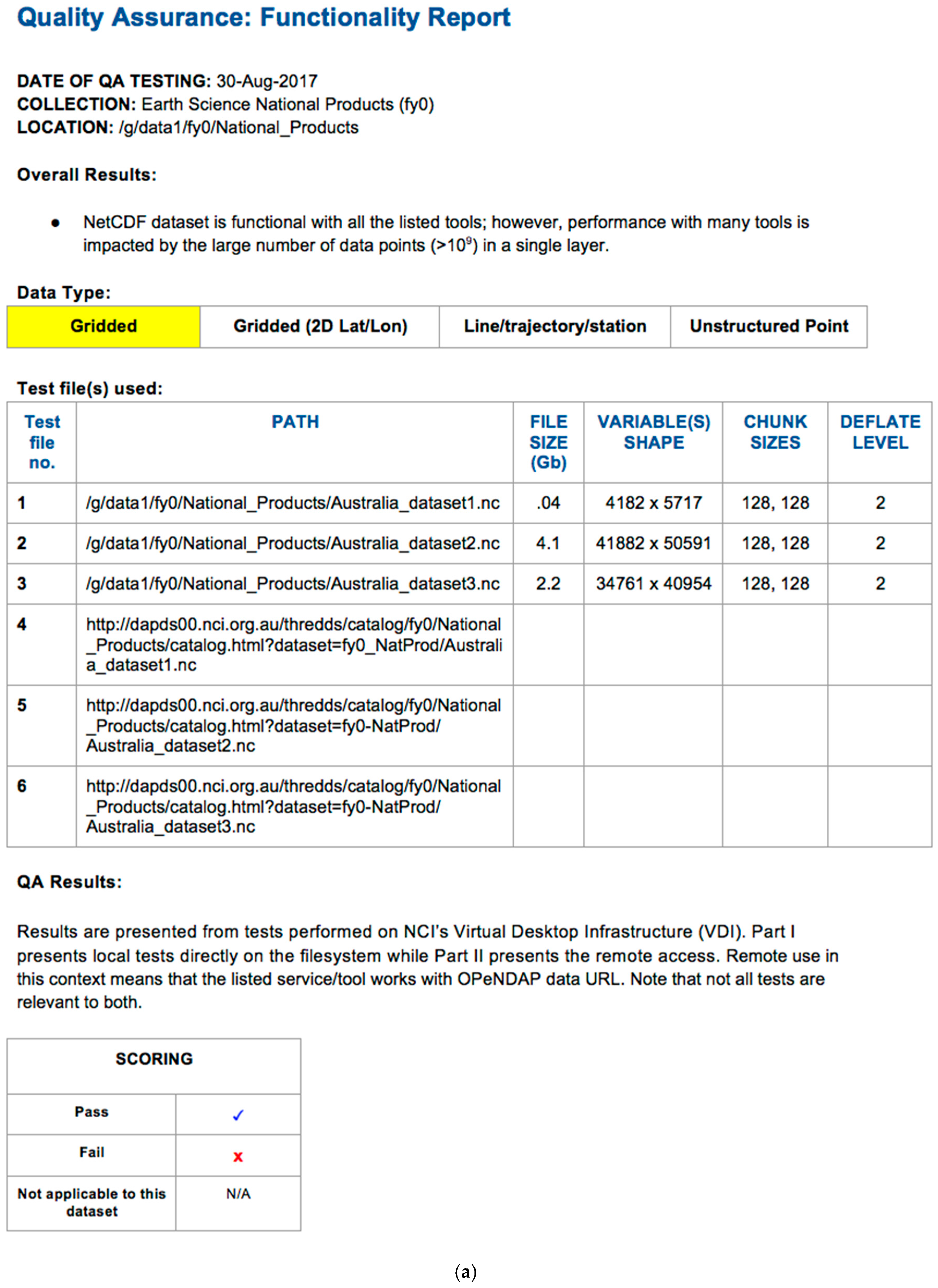
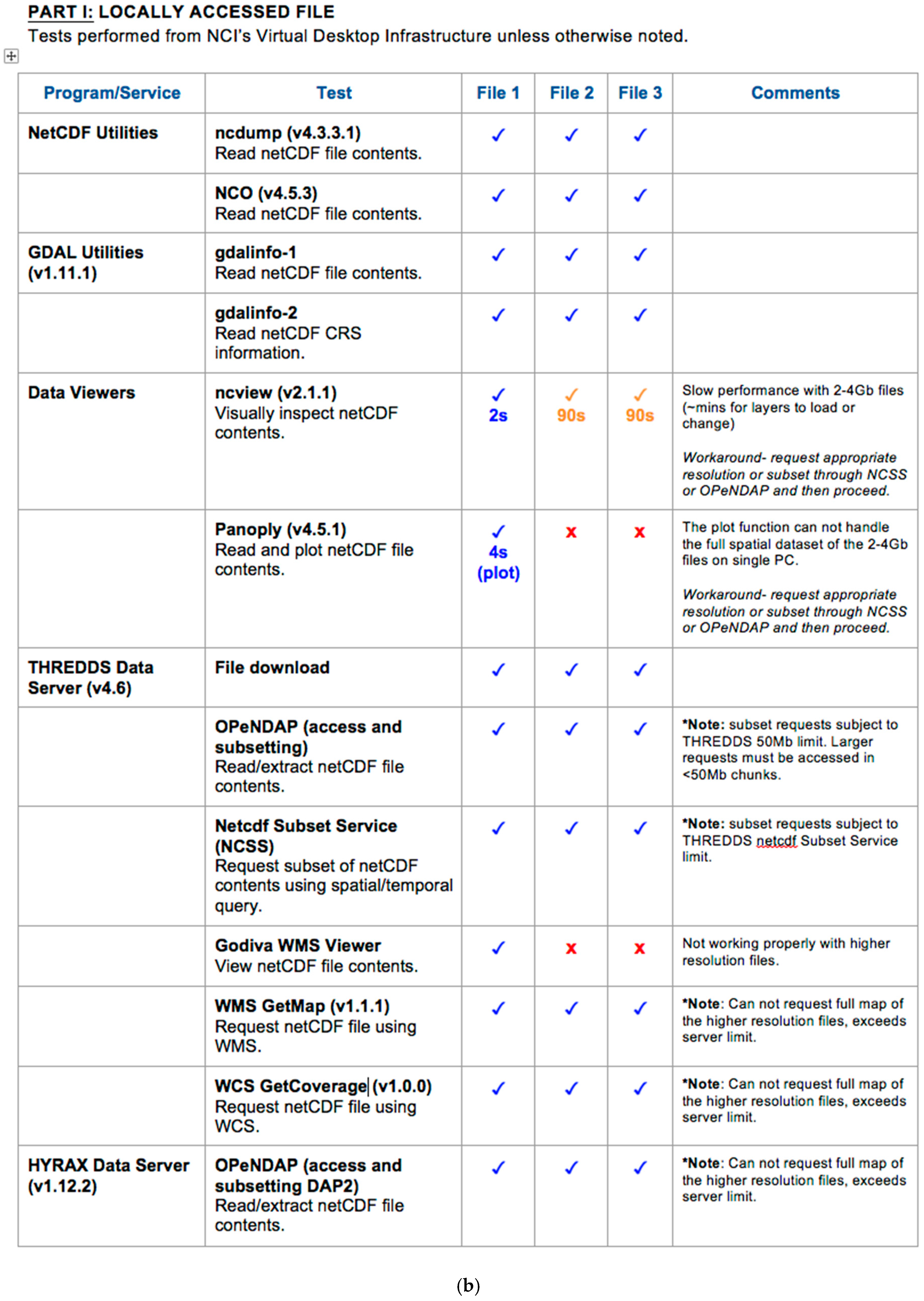
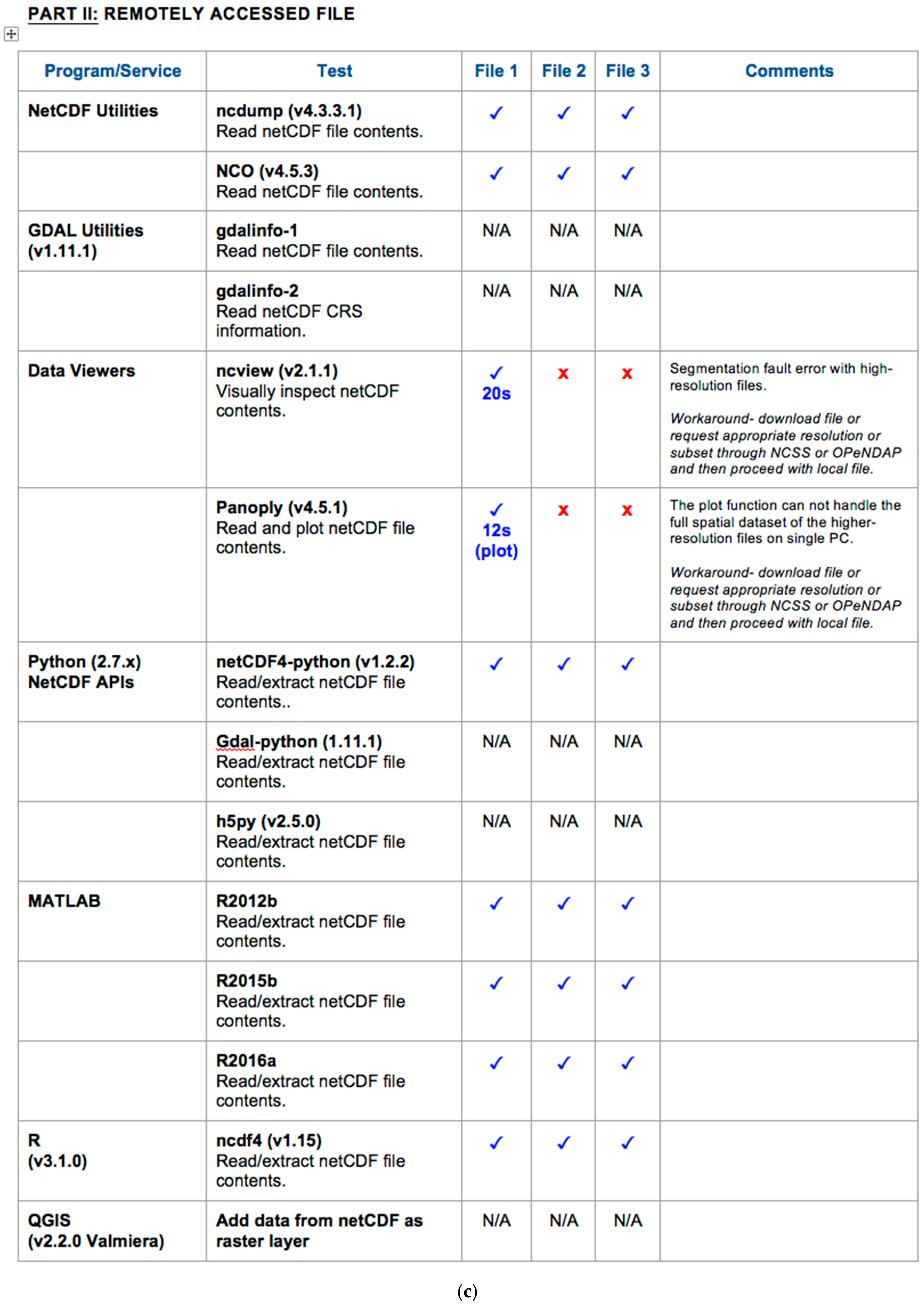
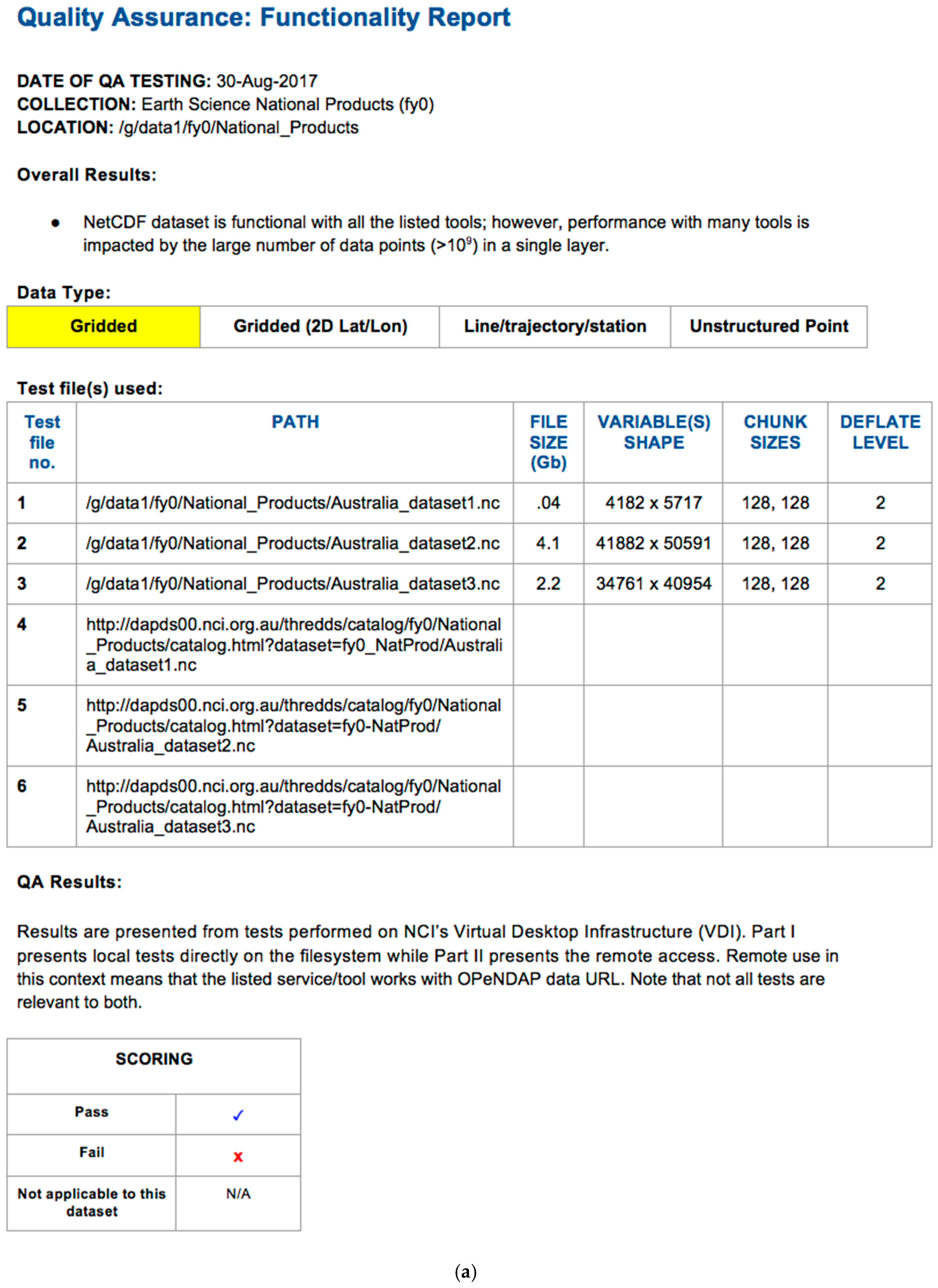
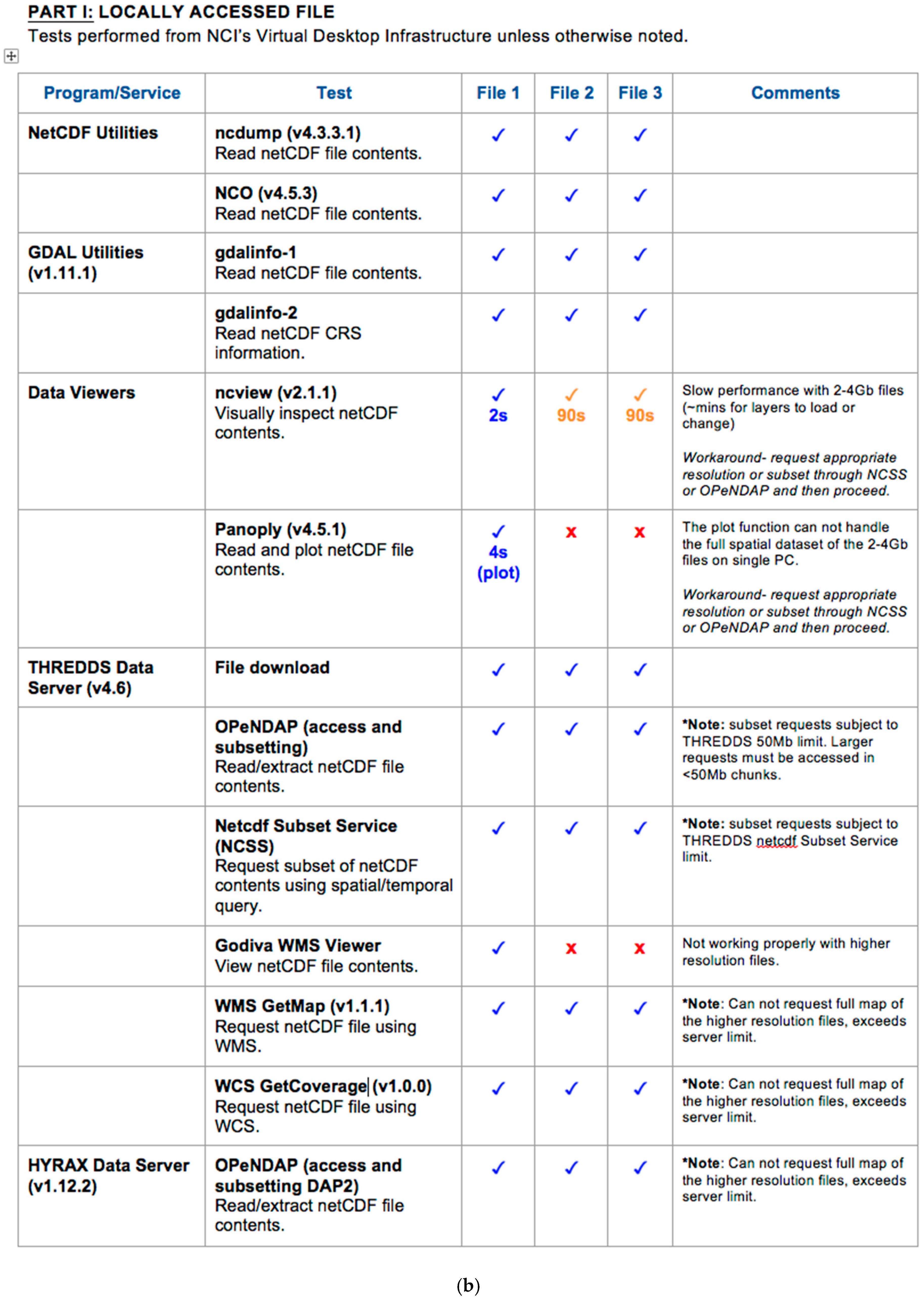
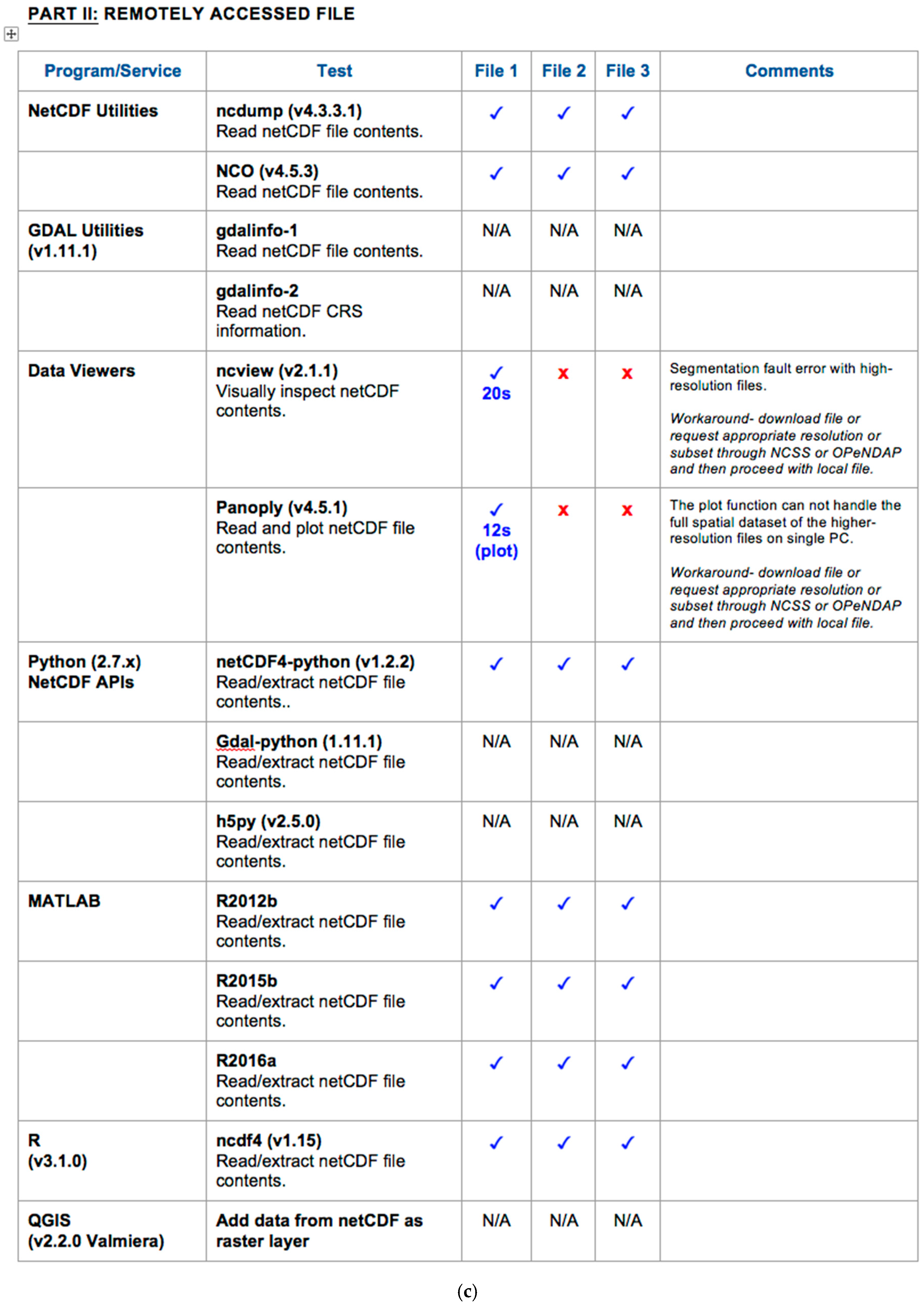
3.2. Functionality Test QA Reports
3.3. Benchmarking Use Cases
3.4. Results Sharing
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| REQUIRED | |
|---|---|
| Global Attribute | Description |
| title | A short phrase or sentence describing the dataset. In many discovery systems, the title will be displayed in the results list from a search, and therefore should be human readable and reasonable to display in a list of such names. This attribute is also recommended by the NetCDF Users Guide and the CF conventions. |
| summary | A paragraph describing the dataset, analogous to an abstract for a paper. |
| source | The method of production of the original data. If it was model-generated, source should name the model and its version. If it is observational, source should characterize it. This attribute is defined in the CF Conventions. Examples: ‘temperature from CTD #1234’; ‘world model v.0.1’. |
| date_created | The date on which this version of the data was created. (Modification of values implies a new version, hence this would be assigned the date of the most recent values modification.) Metadata changes are not considered when assigning the date_created. The ISO 8601:2004 extended date format is recommended, as described in the Attribute Content Guidance section. |
| RECOMMENDED | |
| Global Attribute | Description |
| Conventions | A comma-separated list of the conventions that are followed by the dataset. For files that follow this version of ACDD, include the string ‘ACDD-1.3’. (This attribute is described in the netCDF Users Guide.) |
| metadata_link | A URL that gives the location of more complete metadata. A persistent URL is recommended for this attribute. |
| history | Provides an audit trail for modifications to the original data. This attribute is also in the netCDF Users Guide: ‘This is a character array with a line for each invocation of a program that has modified the dataset. Well-behaved generic netCDF applications should append a line containing: date, time of day, user name, program name and command arguments.’ To include a more complete description you can append a reference to an ISO Lineage entity; see NOAA EDM ISO Lineage guidance. |
| license | Provide the URL to a standard or specific license, enter “Freely Distributed” or “None”, or describe any restrictions to data access and distribution in free text. |
| doi | To be used if a DOI exists. |
| product_version | Version identifier of the data file or product as assigned by the data creator. For example, a new algorithm or methodology could result in a new product_version. |
| processing_level | A textual description of the processing (or QC) level of the data. |
| institution | The name of the institution principally responsible for originating this data. This attribute is recommended by the CF convention. |
| project | The name of the project(s) principally responsible for originating this data. Multiple projects can be separated by commas, as described under Attribute Content Guidelines. Examples: ‘PATMOS-X’, ‘Extended Continental Shelf Project’. |
| instrument | Name of the contributing instrument(s) or sensor(s) used to create this data set or product. Indicate controlled vocabulary used in instrument_vocabulary. |
| platform | Name of the platform(s) that supported the sensor data used to create this data set or product. Platforms can be of any type, including satellite, ship, station, aircraft or other. Indicate controlled vocabulary used in platform_vocabulary. |
| SUGGESTED | |
| Global Attribute | Description |
| id | An identifier for the data set, provided by and unique within its naming authority. The combination of the “naming authority” and the “id” should be globally unique, but the id can be globally unique by itself also. IDs can be URLs, URNs, DOIs, meaningful text strings, a local key, or any other unique string of characters. The id should not include white space characters. |
| date_modified | The date on which the data was last modified. Note that this applies just to the data, not the metadata. The ISO 8601:2004 extended date format is recommended, as described in the Attributes Content Guidance section. |
| date_created | The date on which this version of the data was created. (Modification of values implies a new version, hence this would be assigned the date of the most recent values modification.) Metadata changes are not considered when assigning the date_created. The ISO 8601:2004 extended date format is recommended, as described in the Attribute Content Guidance section. |
| date_issued | The date on which this data (including all modifications) was formally issued (i.e., made available to a wider audience). Note that these apply just to the data, not the metadata. The ISO 8601:2004 extended date format is recommended, as described in the Attributes Content Guidance section. |
| references | Published or web-based references that describe the data or methods used to produce it. Recommend URIs (such as a URL or DOI) for papers or other references. This attribute is defined in the CF conventions. |
| keywords | A comma-separated list of key words and/or phrases. Keywords may be common words or phrases, terms from a controlled vocabulary (GCMD is often used), or URIs for terms from a controlled vocabulary (see also “keywords_vocabulary” attribute). |
| standard_name_vocabulary | The name and version of the controlled vocabulary from which variable standard names are taken. (Values for any standard_name attribute must come from the CF Standard Names vocabulary for the data file or product to comply with CF.) Example: ‘CF Standard Name Table v27’. |
| geospatial_lat_min | Describes a simple lower latitude limit; may be part of a 2- or 3-dimensional bounding region. Geospatial_lat_min specifies the southernmost latitude covered by the dataset. |
| geospatial_lat_max | Describes a simple upper latitude limit; may be part of a 2- or 3-dimensional bounding region. Geospatial_lat_max specifies the northernmost latitude covered by the dataset. |
| ospatial_lon_min | Describes a simple longitude limit; may be part of a 2- or 3-dimensional bounding region. geospatial_lon_min specifies the westernmost longitude covered by the dataset. See also geospatial_lon_max. |
| geospatial_lon_max | Describes a simple longitude limit; may be part of a 2- or 3-dimensional bounding region. geospatial_lon_max specifies the easternmost longitude covered by the dataset. Cases where geospatial_lon_min is greater than geospatial_lon_max indicate the bounding box extends from geospatial_lon_max, through the longitude range discontinuity meridian (either the antimeridian for −180:180 values, or Prime Meridian for 0:360 values), to geospatial_lon_min; for example, geospatial_lon_min = 170 and geospatial_lon_max = −175 incorporates 15 degrees of longitude (ranges 170 to 180 and −180 to −175). |
| geospatial_vertical_min | Describes the numerically smaller vertical limit; may be part of a 2- or 3-dimensional bounding region. See geospatial_vertical_positive and geospatial_vertical_units. |
| geospatial_vertical_max | Describes the numerically larger vertical limit; may be part of a 2- or 3-dimensional bounding region. See geospatial_vertical_positive and geospatial_vertical_units. |
| geospatial_vertical_positive | One of ‘up’ or ‘down’. If up, vertical values are interpreted as ‘altitude’, with negative values corresponding to below the reference datum (e.g., under water). If down, vertical values are interpreted as ‘depth’, positive values correspond to below the reference datum. Note that if geospatial_vertical_positive is down (‘depth’ orientation), the geospatial_vertical_min attribute specifies the data’s vertical location furthest from the earth’s center, and the geospatial_vertical_max attribute specifies the location closest to the earth’s center. |
| geospatial_bounds | Describes the data’s 2D or 3D geospatial extent in OGC’s Well-Known Text (WKT) Geometry format (reference the OGC Simple Feature Access (SFA) specification). The meaning and order of values for each point’s coordinates depends on the coordinate reference system (CRS). The ACDD default is 2D geometry in the EPSG:4326 coordinate reference system. The default may be overridden with geospatial_bounds_crs and geospatial_bounds_vertical_crs (see those attributes). EPSG:4326 coordinate values are latitude (decimal degrees_north) and longitude (decimal degrees_east), in that order. Longitude values in the default case are limited to the [−180, 180) range. Example: ‘POLYGON ((40.26 -111.29, 41.26 -111.29, 41.26 -110.29, 40.26 -110.29, 40.26 -111.29))’. |
| time_coverage_start | Describes the time of the first data point in the data set. Use the ISO 8601:2004 date format, preferably the extended format as recommended in the Attribute Content Guidance section. |
| time_coverage_end | Describes the time of the last data point in the data set. Use ISO 8601:2004 date format, preferably the extended format as recommended in the Attribute Content Guidance section. |
| time_coverage_duration | Describes the duration of the data set. Use ISO 8601:2004 duration format, preferably the extended format as recommended in the Attribute Content Guidance section. |
| time_coverage_resolution | Describes the targeted time period between each value in the data set. Use ISO 8601:2004 duration format, preferably the extended format as recommended in the Attribute Content Guidance section. |
Appendix B

References
- Wang, J.; Evans, B.; Bastrakova, I.; Ryder, G.; Martin, J.; Duursma, D.; Gohar, K.; Mackey, T.; Paget, M.; Siddeswara, G.; et al. Large-Scale Data Collection Metadata Management at the National Computation Infrastructure. In Proceedings of the American Geophysical Union Fall Meeting, San Francisco, CA, USA, 13–17 December 2014. [Google Scholar]
- The FAIR Data Principles. Available online: https://www.force11.org/group/fairgroup/fairprinciples (accessed on 23 August 2017).
- Evans, B.; Wyborn, L.; Druken, K.; Richards, C.; Trenham, C.; Wang, J. Extending the Common Framework for Earth Observation Data to other Disciplinary Data and Programmatic Access. In Proceedings of the American Geophysical Union Fall Meeting, San Francisco, CA, USA, 15–19 December 2016. [Google Scholar]
- Ramapriyan, H.; Peng, G.; Moroni, D.; Shie, C.L. Ensuring and Improving Information Quality for Earth Science Data and Products. D-Lib Magazine. Volume 23, No. 7/8. Available online: https://doi.org/10.1045/july2017-ramapriyan (accessed on 18 October 2017).
- Atkin, B.; Brooks, A. Chapter 8: Service Specifications, Service Level Agreements and Performance. In Total Facilities Management, 2nd ed.; Blackwell Publishing Ltd.: Oxford, UK, 2005; ISBN 978-1-4051-2790-5. [Google Scholar]
- The CoreTrustSeal. Available online: https://www.coretrustseal.org/why-certification/requirements/ (accessed on 24 October 2017).
- Stall, S. AGU’s Data Management Maturity Model. Abstracts SciDataCon 2016. Available online: http://www.scidatacon.org/2016/sessions/100/paper/278/ (accessed on 23 October 2017).
- Stall, S.; Hanson, B.; Wyborn, L. The American Geophysical Union Data Management Maturity Program. Abstracts for eResearch Australasia 2016. Available online: https://eresearchau.files.wordpress.com/2016/03/eresau2016_paper_72.pdf (accessed on 23 October 2017).
- Data Management Maturity Model; CMMI® Institute: Pittsburgh, PA, USA, 2014.
- NCI’s Data Catalogue Websites. Available online: https://datacatalogue.nci.org.au/ and https://geonetwork.nci.org.au (accessed on 23 August 2017).
- CMIP5 Data Reference Syntax. Available online: http://cmip-pcmdi.llnl.gov/cmip5/docs/cmip5_data_reference_syntax.pdf (accessed on 23 August 2017).
- NASA Landsat File Name Convention. Available online: https://landsat.usgs.gov/what-are-naming-conventions-landsat-scene-identifiers (accessed on 23 August 2017).
- ISO 2015 ISO19115-1:2014. Geographic Information—Metadata—Part 1: Fundamentals. Standards document. International Organization for Standardization, Geneva. Available online: http://www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?csnumber=53798 (accessed on 25 May 2016).
- NASA Glossary. Available online: https://earthdata.nasa.gov/user-resources/glossary#ed-glossary-g (accessed on 23 August 2017).
- NetCDF Climate and Forecast Metadata Conventions. Available online: http://cfconventions.org (accessed on 23 August 2017).
- Attribute Convention for Data Discovery 1.3. Available online: http://wiki.esipfed.org/index.php/Attribute_Convention_for_Data_Discovery_(ACDD) (accessed on 23 August 2017).
- IOOS Compliance Checker. Available online: https://github.com/ioos/compliance-checker (accessed on 22 November 2017).
- Wang, J.; Yang, R.; Evans, B.J.E. Improving Seismic Data Accessibility and Performance Using HDF Containers. Abstracts AGU 2017 Fall Meeting. Available online: https://agu.confex.com/agu/fm17/meetingapp.cgi/Paper/222706 (accessed on 24 October 2017).
- ObsPy. Available online: https://github.com/obspy/obspy/wiki (accessed on 6 November 2017).
- SPECFEM3D. Available online: https://geodynamics.org/cig/software/specfem3d/ (accessed on 6 November 2017).
- PH5: What Is It? IRIS PASSCAL. Available online: https://www.passcal.nmt.edu/content/ph5-what-it (accessed on 18 October 2017).
- Krischer, L.; Smith, J.; Lei, W.; Lefebvre, M.; Ruan, Y.; Andrade, E.S.; Podhorszki, N.; Bozdag, E.; Tromp, J. An Adaptable Seismic Data Format. Geophys. J. Int. 2016, 207, 1003–1011. [Google Scholar] [CrossRef]

| Convention/Standard | NCI Requirements | Further Information |
|---|---|---|
| CF | Mandatory CF criteria, e.g., no “errors” result from any of the recommended compliance checkers | http://cfconventions.org |
| ACDD * | Required attributes are included within each file: 1. title 2. summary 3. source 4. date_created | http://wiki.esipfed.org/index.php/Attribute_Convention_for_Data_Discovery_1-3 |
| Test | Measures of Success |
|---|---|
| netCDF C-Library | Using the ‘ncdump-h <file>’ function from command line, the file is readable and displays the file header information about the file dimensions, variables, and metadata. |
| GDAL | Using the ‘gdalinfo <file>’ function from command line, the file is readable and displays the file header information about the file dimensions, variables, and metadata. Using the ‘gdalinfo NETCDF:<file>:<subdataset>’ function from command line, the subdatasets are readable and corresponding metadata for each subdataset is displayed. The Open and GetMetadata functions return non-empty values that correspond to the netCDF file contents. The GetProjection function (of the appropriate file or subdataset) returns a non-empty result corresponding to the data coordinate reference system information. |
| NCO (NetCDF Operators) | Using the ‘ncks -m <file>’ function from command line, the file is readable and displays file metadata. |
| CDO (Climate Data Operators) | Using the ‘cdo sinfon <file>’ function from command line, the file is readable and displays information on the included variables, grids, and coordinates. |
| Ferret | Using SET DATA “<file>” followed by SHOW DATA displays information on file contents. Using SET DATA “<file>” followed by SHADE <variable> (or another plotting command) produces a plot of the requested data. |
| Thredds Data Server | Dataset index catalog page loads without timeout and within reasonable time expectations (<10 s) |
| Thredds Data Service Endpoints | HTTP Download: File download commences when selected the HTTPServer option from the THREDDS catalog page for the file. |
| OPeNDAP: When selecting OPeNDAP from the THREDDS catalog page for the file, the OPeNDAP Dataset Access Form page loads without error. From the OPeNDAP Dataset Access Form page, a data subset is returned in ASCII format after selecting data and clicking the Get ASCII option at the top of the page. | |
| Godiva2: When selecting the Godiva2 viewer option from the THREDDS catalog page for the file, the viewer displays the file contents. | |
| WMS: When selecting the WMS option from the THREDDS catalog page for the file, the web browser displays the GetCapabilities information in xml format. After constructing a GetMap request, the web browser displays the corresponding map. | |
| WCS: When selecting the WCS option from the THREDDS catalog page for the file, the web browser displays the GetCapabilities information in xml format. After constructing a GetCoverage request, file download of coverage commences. | |
| Panoply | From the File → Open menu, the file can be opened. File contents and metadata displayed. Using Create Plot for a selected variable, data is displayed correctly in new plot window. |
| QGIS | Using the Add WMS/WMTS menu option, QGIS can request GetCapabilities and/or GetMap operations and layer is visible. |
| The ncWMS GetCapabilities URL accepts and adds the NCI THREDDS Server, the request displays the available layers to select from, and a selected layer displays according to user expectations. | |
| NASA Web WorldWind | The ncWMS GetCapabilities URL accepts and adds the NCI THREDDS Server, the request displays the available layers to select from, and a selected layer displays according to user expectations. |
| PYTHON cdms2 | The file can be opened by the Open function. File metadata is displayed using attributes function. File data contents are displayed when using variables function. |
| PYTHON netCDF4 | The file can be opened by the Dataset function. File metadata is displayed using ncattrs object. File data contents are displayed using variables (and/or groups) objects. |
| PYTHON h5py | The netcdf file can be opened by the File function. The metadata and variables are displayed by the keys and attrs objects. |
| ParaView | From the File → Open menu, the file can be opened and displayed as a layer in the Pipeline Browser. Enabling layer visibility results in data displaying in Layout window. |
| Attributes | File 1 | File 2 | File 3 | |
|---|---|---|---|---|
| lon (double) | Size | 5717 | 59501 | 40954 |
| Chunksize | 128 | 128 | 128 | |
| lat (double) | Size | 4182 | 41882 | 34761 |
| Chunksize | 128 | 128 | 128 | |
| Variable(float) | Name | grav_ir_anomaly | mag_tmi_rtp_anomaly | rad_air_dose_rate |
| Size | (4182,5717) | (41882,59501) | (34761,40954) | |
| Chunksize | (128,128) | (128,128) | (128,128) | |
| Deflate Level | 2 | 2 | 2 | |
| Format | netCDF-4 classic model | netCDF-4 classic model | netCDF-4 classic model | |
| Program/Service | Test | File 1 | File 2 | File 3 |
|---|---|---|---|---|
| NetCDF Utilities | ncdump | 8.630 | 5584.414 | 3246.879 |
| h5dump | 40.547 | 3546.999 | 2373.483 | |
| Python (2.7.x) netCDF APIs | netCDF4-python (1.2.7) | 0.445 | 48.603 | 29.160 |
| GDAL-python (1.11.1) | 0.421 | 42.654 | 25.538 | |
| h5py (v2.6.0) | 0.356 | 40.105 | 23.826 | |
| THREDDS Data Server (TDS) | netCDF4-python (1.2.7) | 3.087 | 282.797 | 185.358 |
| OPeNDAP (TDS v4.6.6) | 3.038 | 277.21 | 194.85 | |
| netCDF Subset Service (TDS v4.6.6) | 2.833 | 248.194 | 158.236 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evans, B.; Druken, K.; Wang, J.; Yang, R.; Richards, C.; Wyborn, L. A Data Quality Strategy to Enable FAIR, Programmatic Access across Large, Diverse Data Collections for High Performance Data Analysis. Informatics 2017, 4, 45. https://doi.org/10.3390/informatics4040045
Evans B, Druken K, Wang J, Yang R, Richards C, Wyborn L. A Data Quality Strategy to Enable FAIR, Programmatic Access across Large, Diverse Data Collections for High Performance Data Analysis. Informatics. 2017; 4(4):45. https://doi.org/10.3390/informatics4040045
Chicago/Turabian StyleEvans, Ben, Kelsey Druken, Jingbo Wang, Rui Yang, Clare Richards, and Lesley Wyborn. 2017. "A Data Quality Strategy to Enable FAIR, Programmatic Access across Large, Diverse Data Collections for High Performance Data Analysis" Informatics 4, no. 4: 45. https://doi.org/10.3390/informatics4040045