
A Modifier-Adaptation Strategy towards Offset-Free Economic MPC


Department of Civil and Industrial Engineering, University of Pisa, Largo Lazzarino 2, 56126 Pisa, Italy
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Processes 2017, 5(1), 2; https://doi.org/10.3390/pr5010002
Submission received: 16 November 2016
/
Revised: 15 December 2016
/
Accepted: 20 December 2016
/
Published: 29 December 2016
(This article belongs to the Special Issue Real-Time Optimization)
Abstract
:We address in the paper the problem of designing an economic model predictive control (EMPC) algorithm that asymptotically achieves the optimal performance despite the presence of plant-model mismatch. To motivate the problem, we present an example of a continuous stirred tank reactor in which available EMPC and tracking model predictive control (MPC) algorithms do not reach the optimal steady state operation. We propose to use an offset-free disturbance model and to modify the target optimization problem with a correction term that is iteratively computed to enforce the necessary conditions of optimality in the presence of plant-model mismatch. Then, we show how the proposed formulation behaves on the motivating example, highlighting the role of the stage cost function used in the finite horizon MPC problem.
1. Introduction
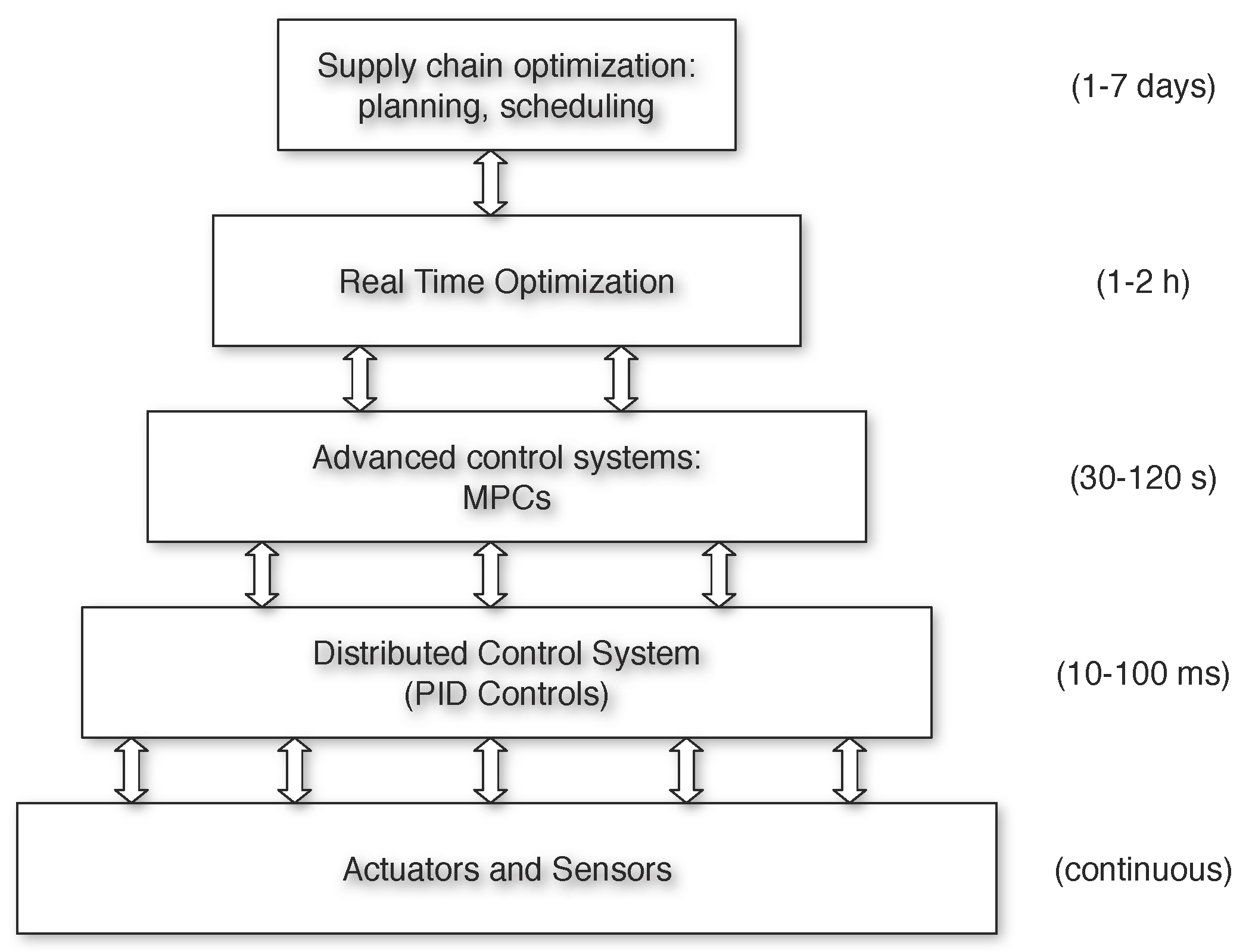
Optimization-based controllers, in general, and model predictive control (MPC) systems, in particular, represent an extraordinary success case in the history of automation in the process industries [1]. MPC algorithms exploit a (linear or nonlinear) dynamic model of the process and numerical optimization algorithms to guide a process to a setpoint reliably, while fulfilling constraints on outputs and inputs. The optimal steady-state setpoint is usually provided by an upper layer, named real-time optimization (RTO), that is dedicated to economic steady-state optimization. The typical hierarchical architecture for economic optimization and control in the process industries is depicted in Figure 1. For an increasing number of applications, however, this separation of information and purpose is no longer optimal nor desirable [2]. An alternative to this decomposition is to take the economic objective directly as the objective function of the control system. In this approach, known as economic model predictive control (EMPC), the controller optimizes directly, in real time, the economic performance of the process, rather than tracking a setpoint.
MPC being a model-based optimization algorithm, in the presence of plant-model mismatch or unmeasured disturbances, it can come across offset problems. Non-economically optimum stationary points can also be the result of a plant-model mismatch in model-based RTO. However, as explained later, some RTO algorithms do not use a model, i.e., extremum-seeking control [3,4], so in this case, the mismatch issue can be associated with unmeasured disturbances. The offset correction in tracking MPC algorithms has been deeply exploited and analyzed. Muske and Badgwell [5] and Pannocchia and Rawlings [6] first introduced the concept of general conditions that allow zero steady-state offset with respect to external setpoints. The general approach is to augment the nominal system with disturbances, i.e., to build a disturbance model and to estimate the state and disturbance from output measurements. A recent review about disturbance models and offset-free MPC design can also be found in [7]. Furthermore, in the RTO literature, many works are focused on plant-model mismatch issues. RTO typically proceeds using an iterative two-step approach [8,9], namely an identification step followed by an optimization step. The idea is to repeatedly estimate selected uncertain model parameters and to use the updated model to generate new inputs via optimization. Other alternative options do not use a process model online to implement the optimization [10,11,12]. Others utilize a nominal fixed process model and appropriate measurements to guide the iterative scheme towards the optimum. In this last field, the term “modifier-adaptation” indicates those fixed-model methods that adapt correction terms (i.e., the modifiers) based on the observed difference between actual and predicted functions or gradients [13,14,15]. Marchetti et al. [16] formalize the concept of using plant measurements to adapt the optimization problem in response to plant-model mismatch, through modifier-adaptation.
As underlined above, the RTO and MPC hierarchical division issue has led to the increased interest in merging the two layers. Many works in the literature consider a combination between RTO and MPC through a target calculation level in the middle that coordinates the communication and guarantees stability to the whole structure calculating the feasible target for the optimal control problem [17,18]. There are also examples of integration between the modifier-adaptation technique and MPC [19]: in this way, the input targets calculated by the MPC are included as equality constraints into the modified RTO problem. In other cases, the target module of the MPC has been modified in various ways, including a new quadratic programming problem that is an approximation of the RTO problem [20].
Another area of the literature aimed at merging the two layers is the so-called dynamic real-time optimization (D-RTO). The objective function of the D-RTO includes an economic objective, subject to a dynamic model of the plant. The optimal control profiles are then determined from the solution of the above dynamic optimization problem and then passed to the underlined MPC layer as trajectory setpoints to follow. The advantages of this formulation in the presence of disturbances have been deeply emphasized in the literature [21,22], also in the case of model-free alternatives [23]. The D-RTO is also seen as a solution for merging economic and control layer, while advances in nonlinear model predictive control and its generalization to deal with economic objective functions taking place [24]. In this sense, a receding horizon closed-loop implementation of D-RTO can be also referred to as economic model predictive control [25].
In the presence of plant-model mismatch, also EMPC can suffer from converging to a non-economically steady-state point and also reaching a steady state different from the one indicated by the target at the same time. The main goal of this work is to build an economic MPC algorithm that, combining the previous ideas of offset-free MPC and modifier-adaptation, achieves the ultimate optimal economic performance despite modeling errors and/or disturbances. In the proposed method, there is no RTO layer because the economic cost function is used directly in the MPC formulation, which however includes a modifier-adaptation scheme.
The rest of this paper is organized as follows. A review of the related technique used in this work is presented in Section 2 along with a motivating example. The proposed method, with a detailed mathematical analysis and description, is presented in Section 3. The algorithm and several variants are then tested over the illustrative example, and the numerical results and associated discussions are reported in Section 4. Finally, Section 5 concludes the paper and presents possible future directions of this methodology.
2. Related Techniques and a Motivating Example
In order to propose an offset-free EMPC algorithm, a review of related concepts and techniques is given. Then, we present a motivating example that shows how neither the standard EMPC formulation nor an offset-free tracking MPC formulation are able to achieve the ultimate optimal economic performance.
2.1. Plant, Model and Constraints
In this paper, we are concerned with the control of time-invariant dynamical systems in the form:
in which , , are the plant state, control input and output at a given time, respectively, and is the successor state. The plant output is measured at each time . Functions : and : are not known precisely, but are assumed to be differentiable. In order to design an MPC algorithm, a process model is known:
in which denote the current and successor model states. The functions f: and h: are assumed to be differentiable. Input and output are required to satisfy the following input and output constraints at all times:
in which and are the bound vectors.
2.2. Offset-Free Tracking MPC
Offset-free MPC algorithms are generally based on an augmented model [5,6,26,27]. The general form of this augmented model can be written as:
in which is the so-called disturbance. The functions F: and H: are assumed to be continuous and consistent with (2), i.e., and .
Assumption 1.
At each time , given the output measurement , an observer for (4) is defined to estimate the augmented state (). For simplicity of exposition, only the current measurement of is used to update the prediction of () made at the previous decision time, i.e., a “Kalman filter”-like estimator is used. We define symbols , and as the predicted estimate of , and , respectively, obtained at the previous time using the augmented model (4), i.e.,
Defining the output prediction error as:
the filtering relations can be written as follows:
where and are the filtered estimate of and in (4) obtained using measurement . We assume that Relations (5)–(7) form an asymptotically-stable observer for the augmented system (4).
Given the current estimate of the augmented state (), an offset-free tracking MPC algorithm computes the steady-state target that ensures exact setpoint tracking in the controlled variable. Hence, in general, the following target problem is solved:
subject to
in which : is the steady-state cost function and , are the output and input setpoints, respectively. We assume (8) is feasible, and we denote its (unique) solution as . Typically, is positive definite in the first argument (output steady-state error) and semidefinite in the second argument (input steady-state error), and relative input and output weights are chosen to ensure that whenever constraints allow it.
Let and be, respectively, a state sequence and an input sequence. The finite horizon optimal control problem (FHOCP) solved at each time is the following:
subject to
in which : is a strictly positive definite convex function. : is a terminal cost function, which may vary depending on the specific MPC formulation, according to the usual stabilizing conditions [28]. Assuming Problem (9) to be feasible, its solution is denoted by , and the associated receding horizon implementation is given by:
Proposition 1.
Consider a system controlled by the MPC algorithm as described above. If the closed-loop system is stable, then the output prediction error goes to zero, i.e.,
Furthermore, if input constraints are not active at steady state, there is zero offset in the controlled variables, that is:
2.3. Economic MPC
As can be seen from Figure 1, setpoints that enter in (8) come from the upper economic layer referred to as the RTO. This hierarchical division may limit the achievable flexibility and economic performance that many processes nowadays request. There are several proposals to improve the effective use of dynamic and economic information throughout the hierarchy. As explained in Section 1, the first approach to this merging is the D-RTO. While many D-RTO structures have been proposed throughout the literature [23,30,31], many of the two-layered D-RTO and MPC systems proposed are characterized by a lack of rigorous theoretical treatment, including the constraints. However, as can be seen in the above cited literature, the D-RTO formulations still consider the presence of both RTO and MPC in separated layers. Instead of moving the dynamic characteristic to the RTO level, the interest here is to move economic information into the control layer. This approach involves modifying the traditional tracking objective function in (9) and the target cost function in (8) directly with the economic stage cost function used in the RTO layer. In this latter case, the formulation takes the name of economic MPC (EMPC) [32]. It has to be underlined that, in this case, the economic optimization is provided only by the EMPC layer, while the RTO one is completely eliminated.
In standard MPC, the objective is designed to ensure asymptotic stability of the desired steady state. This is accomplished by choosing the stage cost to be zero at the steady-state target pair, denoted , and positive elsewhere, i.e.,
In EMPC, instead, the operating cost of the plant is used directly as the stage cost in the FHOCP objective function. As a consequence, it may happen that for some feasible pair that is not a steady state. This possibility has significant impact on stability and convergence properties. In fact, while a common approach in the tracking MPC is to use the optimal cost as a Lyapunov function for the closed-loop system to prove its stability, in the EMPC formulation, due to the fact that (13) does not hold, these stability arguments fail. Hence, for certain systems and cost functions, oscillating solutions may be economically more profitable than steady-state ones, giving rise to the concept of average asymptotic performance of economic MPC, which is deeply developed in [32,33]. Despite that, in the literature, there are also formulations of the Lyapunov-based EMPC by taking advantage of an auxiliary MPC problem solution [34,35].
In this work, we assume that operating at steady-state is more profitable than an oscillating behavior. Hence, in order to delineate the concept of convergence in EMPC, two other properties may be useful: dissipativity [32,36] and turnpike [37,38]. These properties play a key role in the analysis and design of schemes for D-RTO and EMPC. It is shown also that in a continuous-time form, the dissipativity of a system with respect to a steady state implies the existence of a turnpike at this steady state and optimal stationary operation at this steady state [39,40]. An extensive review about EMPC control methods can be found in [41,42].
The starting EMPC algorithm considered in this work is taken from [29] and includes an offset-free disturbance model as described in Section 2.2. Given the current state and disturbance estimate (), the economic steady-state target is given by:
subject to
in which : is the economic cost function defined in terms of output and input. Notice that the arguments of the economic cost function are measurable quantities. Let be the steady-state target triple solution to (14). Then, the FHOCP solved at each time is given by:
subject to
While several formulations of economic MPC are possible, in this work, we use a terminal equality constraint to achieve asymptotic stability [36]. We remark that the target equilibrium is recomputed at each decision time by the target calculation problem (14).
2.4. A Motivating Example
2.4.1. Process and Optimal Economic Performance
In order to motivate this work, we show the application of EMPC formulations to a chemical reactor to highlight how available methods are not able to achieve the optimal economic performance in the presence of modeling errors. The chemical reactor under consideration is a continuous stirred tank reactor (CSTR), in which two consecutive reactions take place:
The reactor is described by the following system of ordinary differential equations (ODE):
in which and are the molar concentrations of A and B in the reactor, and are the corresponding concentrations in the feed, Q is the feed flow rate, V is the constant reactor volume and and are the kinetic constants. The feed flow rate entering the reactor is regulated through a valve, i.e., Q is the manipulated variable. For the sake of simplicity, the reactor is assumed to be isothermal, so the fixed parameters of the actual system are shown in Table 1.
The process economics can be expressed by the running cost:
where are the prices for the reactants A and B, respectively, also reported in Table 1.
Using the actual process parameters reported in Table 1, we can compute the process optimal steady-state, by solving the following optimization problem:
subject to
The result of this optimization is , and , which represents the most economic steady state that the actual process can achieve.
2.4.2. Model and Controllers
The definition of the states, input and outputs is the following:
For controller design, the second kinetic constant is supposed to be uncertain, i.e., the value known by the controller is , instead of . With these definitions, the model equations become:
We compare the closed-loop behavior of three EMPC algorithms, all designed according to Section 2.3 using the same nominal model (21), cost function and a sampling time of . Specifically, the target optimization problem is given in (14), and the FHOCP is given in (15), where the economic cost function is:
We note that the use of the cost function integrated over the sampling time is necessary to achieve an asymptotically stable closed-loop equilibrium. As a matter of fact, if the point-wise evaluation of were used as stage cost , the system would not be dissipative [36], i.e., the closed-loop system would not be stable. The three controllers differ in the augmented model:
- EMPC0 is the standard economic MPC and uses no disturbance model, i.e., and .
- EMPC1 uses a state disturbance model, i.e., and .
- EMPC2 uses a nonlinear disturbance model [29], in which the disturbances act as a correction to the kinetic constants, i.e., is obtained by integration of the following ODE system:and .
Since the state is measured, for EMPC0, we use . For EMPC1 and EMPC2, we use an extended Kalman filter (EKF) to estimate the current state and disturbance , given the current measurement of , with the following output noise and state noise covariance matrices:
We note that is chosen small because for simplicity of exposition, we are not including output noise. Furthermore, the ratio between the state covariance (upper diagonal block of ) and the disturbance covariance (lower diagonal block of ) is chosen small to ensure fast offset-free performance [6].
2.4.3. Implementation Details
In order to proceed for further calculations, a few comments on the implementation details are needed. The model in (21) has been discretized through an explicit fourth-order Runge–Kutta method with equal intervals for each time step. The FHOCP in (15) is solved with a multiple shooting approach because it is very advantageous for long prediction horizons and enforces numerical stability. Simulations are performed using a code developed in Python, and the resulting nonlinear programming problems are solved with IPOPT (https://projects.coin-or.org/Ipopt) .
2.4.4. Results
Figure 2 shows the closed-loop flow rate obtained with standard EMPC0 in two cases of uncertainty on . In the first case (left), , i.e., the controller model uses a value of , which is half of the true value. In the second case (right), , i.e., the controller model ignores the second reaction. As can be seen from these plots, in both cases, the controller is unable to drive the flow rate to the most economic target.
Figure 3 shows the corresponding results obtained with EMPC1. Despite the fact that EMPC1 uses a disturbance model, which guarantees offset-free tracking, the controller is still unable to drive the flow rate to the optimal target.
Finally, Figure 4 shows the corresponding results obtained with EMPC2. In this case, the controller is able to drive the closed-loop system to the optimal steady state. The reason is that the augmented model (23) asymptotically converges to the true process because the estimated disturbance ensures that . However, this approach requires to know exactly where the uncertainties are, in order to build an ad hoc disturbance model to correct them. Hence, it cannot be used as a general rule. With this evidence, it is clear that, at the moment, there is no general formulation for an offset-free economic MPC, and this is what motivates the present work. In the end, it has to be noted that the case falls into an unmodeled dynamics problem, i.e., the second reaction is completely ignored by the model.
3. Proposed Method
As introduced in the previous section, we now illustrate the method developed using the modifier-adaptation technique borrowed from the RTO literature. Before coming to the proposed method, we give a brief introduction to this technique, referring the interested reader to [14,16] for more details.
3.1. RTO with Modifier-Adaptation
The objective of RTO is the minimization of some steady-state operating cost function, while satisfying a number of constraints. Finding the optimal steady-state operation point for the actual process can be stated as the solution of the following problem:
subject to
In the above, : is the economic performance cost function of the process and : is the process constraint function. As explained before for the MPC case, the exact process description is unknown, and only a model can be used in the process optimization. Hence, the model-based economic optimization is represented by the problem:
subject to
where Φ: and C: represent the model economic cost function and the model constraint function, which may depend on uncertain parameters . Due to plant-model mismatch, open-loop implementation of the solution to (26) may lead to suboptimal and even infeasible operation.
The modifier-adaptation methodology changes Problem (26) so that in a closed-loop execution, the necessary conditions of optimality (NCO) of the modified problem correspond to the necessary conditions of Process (25), upon convergence of the algorithm. The following problem shows the model-based optimization with additional modifiers [16,43]:
subject to:
in which:
In (27) and (28), represents the operation point, calculated at the previous RTO iteration , and the modifiers , , and are evaluated using the information available at that point. Notice that the model parameters θ are not updated.
Marchetti et al. [16,43] demonstrated that, upon convergence, the Karush–Kuhn–Tucker (KKT) conditions of the modified problem (27) match the ones of the true process optimization problem (25). Hence, if second-order conditions hold at this point, a local optimum of the real plant can be found by the problem modified as in (27). Furthermore, a filtering procedure of the modifiers is also recommended in order to improve stability and convergence and to reduce sensitivity to measurement noise. The filtering step is given by the following equations:
where , and (usually diagonal matrices) represent the respective first-order filter constants for each modifier. An alternative approach to the modifier filtering step (29) is to directly define the modifiers as the gradient or function differences and then filter the computed inputs to be applied to the process [44,45]. From (28) and (29), it is clear how the process gradient estimation stage is the major requirement of this method: actually, the process gradient estimation, is hidden into both and for calculating and . This is also the major and tightest constraint for this method [46].
Before presenting the proposed technique, the example in Section 2.4 is tested on the standard hierarchical architecture RTO plus MPC. The RTO problem is modified as in Marchetti et al. [16] as follows:
subject to
where and are updated by the following law:
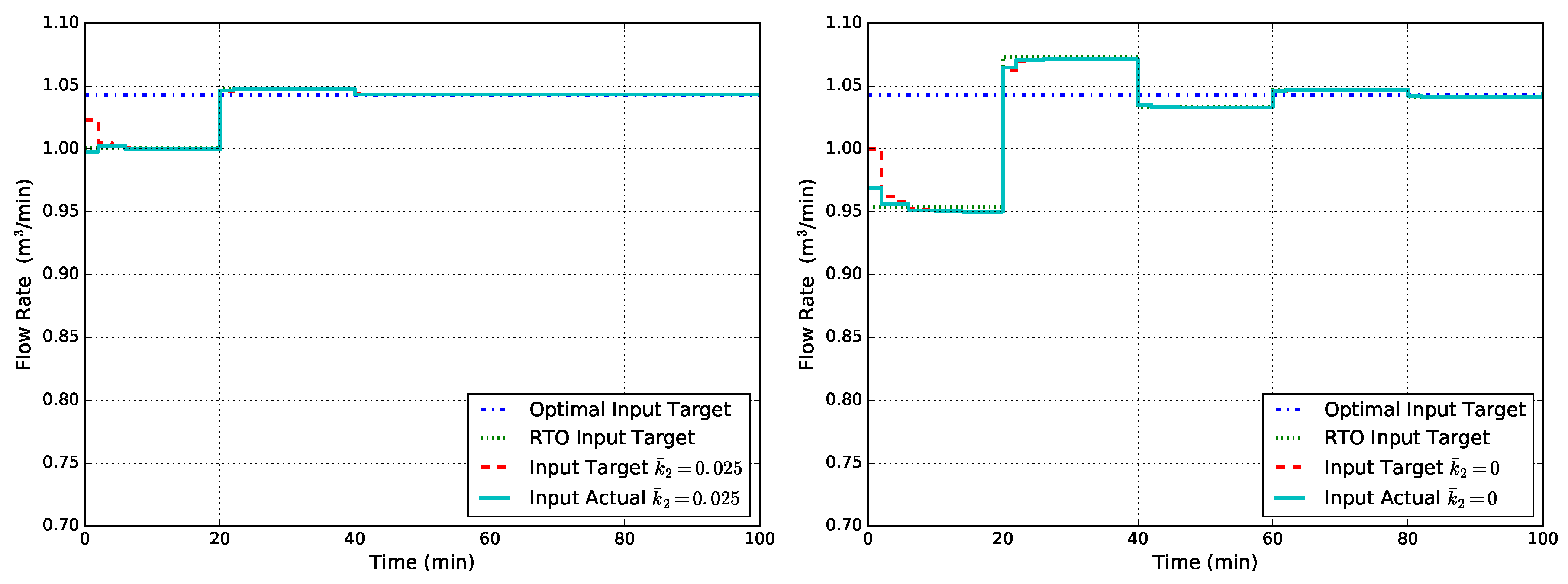
Figure 5 shows the closed-loop flow rate obtained with modified RTO problem followed by tracking MPC with output disturbance model in two cases of uncertainty on . The weight values used are and , and the RTO problem is run every 20 min. As can be seen from Figure 5, in both cases, the system achieves the optimal input value as expected by the modifier-adaptation methodology. However, the hierarchical and multi-rate nature of the standard architecture results in slow convergence towards the economically-optimal target.
3.2. Proposed Technique
Having shown that, in order to apply this technique to the EMPC, some work is needed. First of all, in order to be consistent with the offset-free augmented model and to exploit its properties, an alternative form of the modifier-adaptation technique is adopted. In this way, as illustrated in the work of Marchetti et al. [16], a linear modification of the model output steady-state function, rather than of the cost and constraint functions, independently, in the optimization problem has been preferred. To this aim, we rewrite the model constraints of the target problem (14) in a more compact form:
in which G: . Then, the model output steady-state function is “artificially” modified as follows:
where is a matrix to be defined later on and is the steady-state input target found at the previous sampling time, . We observe that in [16], the modified output function also includes a zero order term, which ensures that . However, such a term is unnecessary in the present framework because the model output convergence is already achieved by the offset-free augmented model formulation. Hence, only a gradient correction of G is necessary. In order to drive the target point towards the plant optimal value, we need to calculate as a result of a KKT matching of the target optimization problem. In this way, similarly to what has been demonstrated in the RTO literature, the necessary condition of optimality can be satisfied.
The KKT matching is developed imposing the correspondence of the Lagrangian function gradient between the plant and model target optimization problems. The procedure is as follows.
Plant: Similarly to Model (32), a steady-state input-output map can be defined also for the actual plant (1). In this way, the plant optimization steady-state problem reads:
subject to:
The Lagrangian function associated with Problem (34) is given by:
then, the first-order necessary optimality KKT conditions for this problem are as follows. If is a (local) solution to (34), there exist vectors satisfying the following conditions:
in which are the multiplier vectors of the input bound constraints (34b), and are the multiplier vectors for output bound constraints (34c).
Model: With the modification introduced in (33), the model optimization steady-state problem can be rewritten as:
subject to:
The Lagrangian function associated with (38) is given by:
then, the first-order necessary optimality KKT conditions for this problem are as follows. If is a (local) solution to (38), there exist vectors satisfying the following:
KKT matching: To reach the KKT matching, conditions in (41) must converge to those in (37). We recall that, due to the offset-free augmented model, upon convergence, we have: . Furthermore, upon convergence from (33), we also have: and therefore . Therefore, in order for (41) to match (37), Conditions (37a) and (41a) have to be the same:
where
We expand the LHS and RHS in (42) to obtain:
Then, the KKT matching condition is:
From (45), we also consider a filtering step and define the following update law for :
where is a scalar first-order filter constant, chosen in the range . In order for the update law (46) to be applicable, we make the following assumption.
Assumption 2.
The gradient of the process steady-state input-output map is known at steady-state points.
In general, the gradient of the process steady-state input-output map can be (approximately) calculated through measurements of u and y [43,47,48,49]. We remark that the gradient of the model steady-state input-output map instead can be computed from its definition (32) using the implicit function theorem. As a matter of fact, the gradient of can be calculated as follows:
Finally, from the above discussion, the following result is established.
Theorem 1.
KKT matching of the target optimization problem: Let the MPC target optimization problem be defined in (38), with updated according to (46), and let be its solution at time k. Let the closed-loop system converge to an equilibrium, with being the limit KKT point of the steady-state problem (38). Then, is also a KKT point for the plant optimization problem (34).
3.3. Summary
Summarizing, the offset-free economic MPC algorithm proposed in this work is the following. The estimation stage is taken from the offset-free tracking MPC as described in Section 2.2. Given the current state and disturbance estimate (), the economic steady-state target problem is modified in this way:
subject to
in which is the steady-state input target found at the previous sampling time , and is defined above in (46). Finally, the FHOCP solved at each time is the one defined in (15), unless differently specified in the next section.
4. Results and Discussion
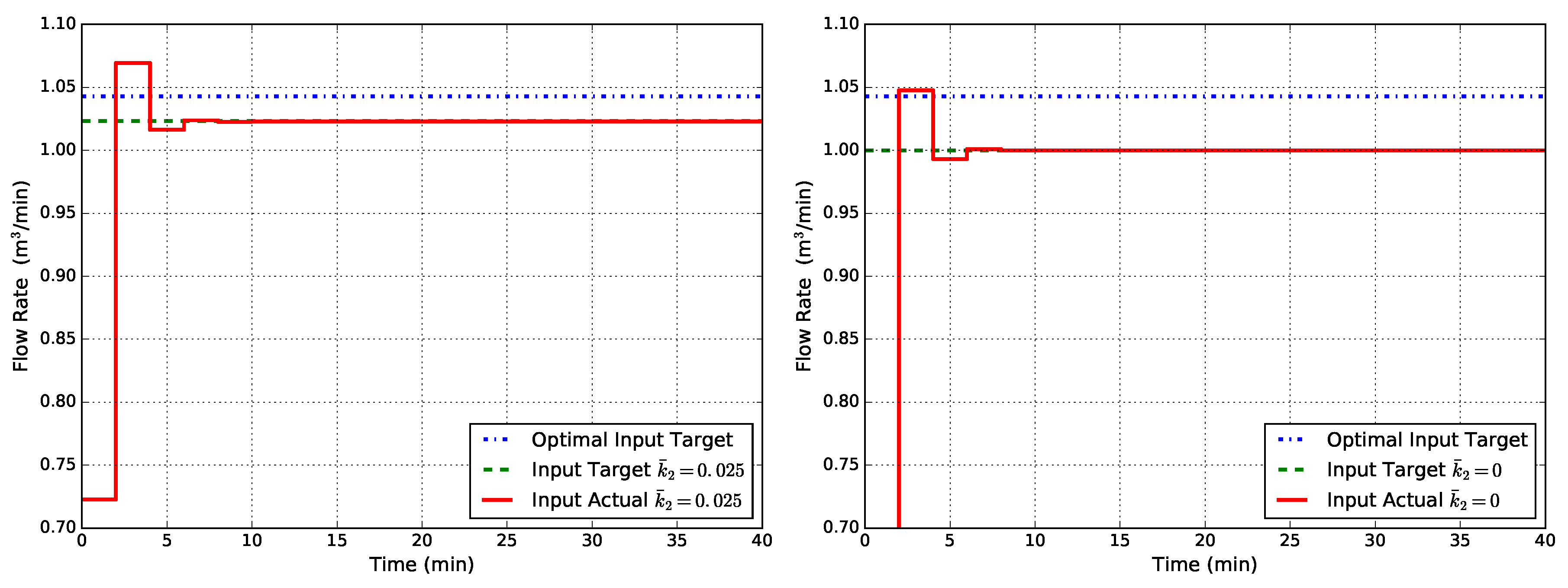
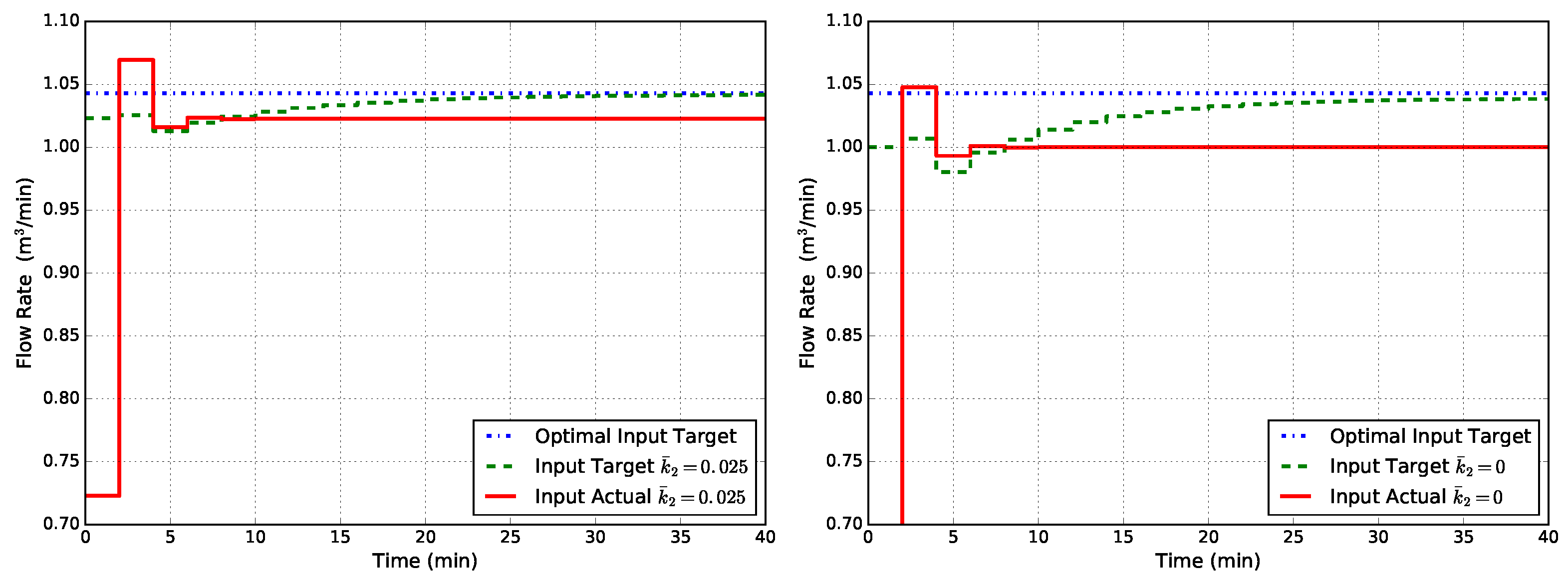
Simulation results of the proposed method applied to the reactor example illustrated in Section 2.4 are here reported. We use all simulation parameters defined in Section 2.4, and in addition, we set for the modifiers update law (46). The first controller that is evaluated, named EMPC1-MT, uses the same augmented system with state disturbance model as EMPC1 and the same FHOCP formulation (15). The target problem instead is the modified one reported in (48). The obtained results are shown in Figure 6. As can be seen from Figure 6, the input target has asymptotically reached the optimal value (or it is very close to it in the case ). The actual input value, instead, reaches an asymptotic value different from the optimal target. As a matter of fact, when the economic stage cost is used in the FHOCP (15), the offset still remains, and the EMPC formulation does not seem to have gained particular advantage from the target modification. This is also why for , the target does not reach perfectly the optimal value: as a recursive algorithm, it is obvious how the dynamic behavior also influences the steady-state target.
We now consider another controller, named MPC1-MT, which is identical to EMPC1-MT, but uses a tracking stage cost in the FHOCP, i.e.,
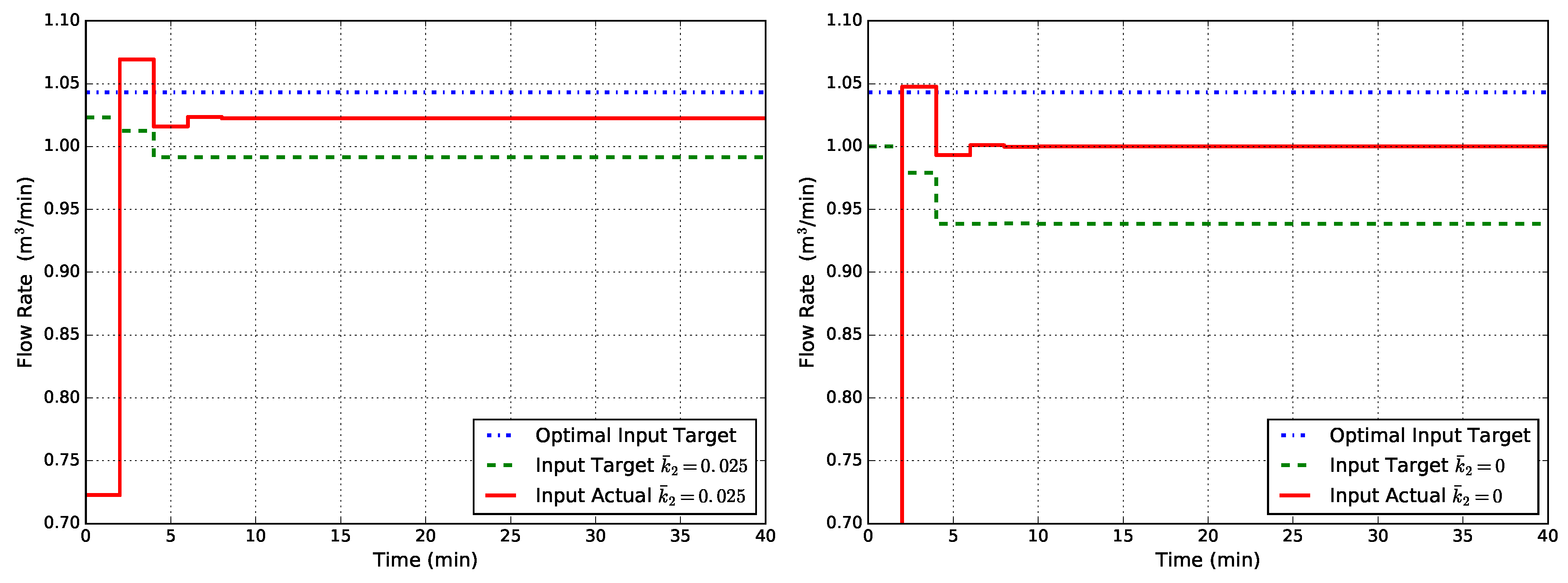
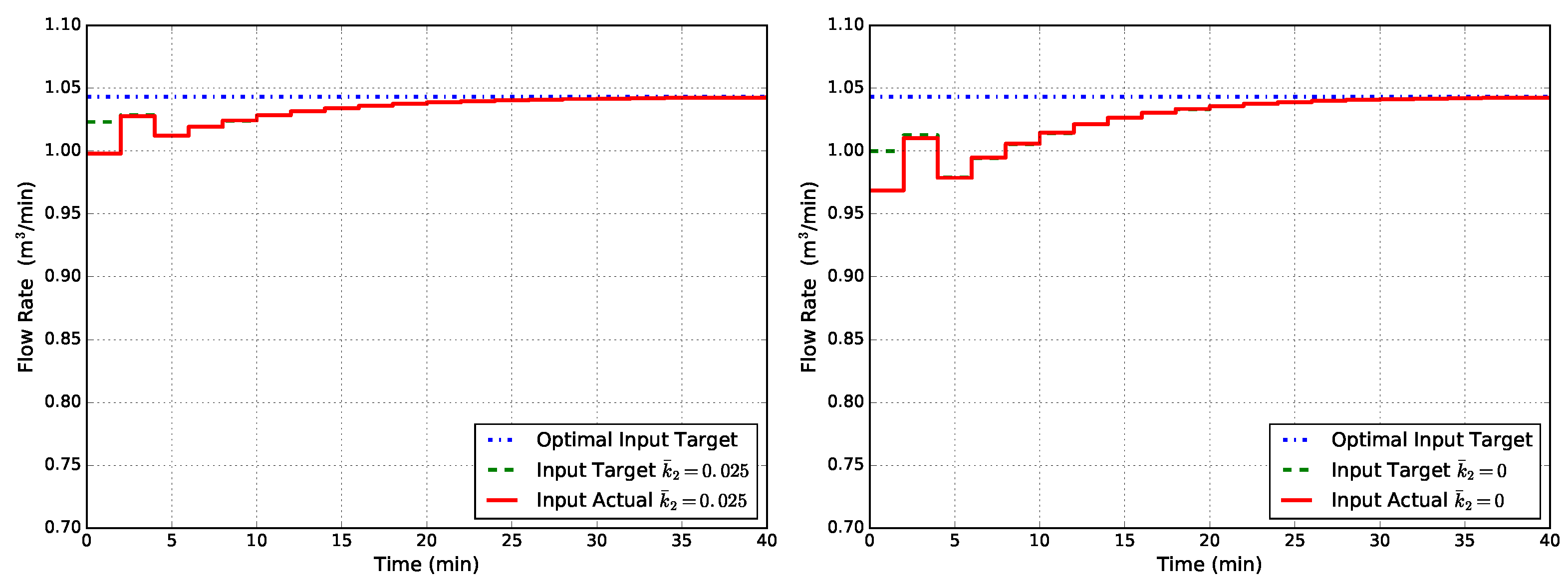
where and are positive definite weight matrices. Results are shown in Figure 7, from which we observe that the offset is completely eliminated since both the input target and the actual input value go to the optimal one.The success of the tracking function can be explained by its design: the goal is to follow the steady-state target, and with the target suitably corrected, the actual value cannot go elsewhere in an offset-free formulation since the FHOCP cost function is positive definite around .
Despite the fact the MPC1-MT asymptotically reaches the optimal steady state, our primary goal is to build an offset-free economic MPC. Since now, the target problem has been adjusted by the modifier, results seem to suggest that a similar correction should be done for the FHOCP. Specifically, we consider the following modified FHOCP:
subject to:
where is the correction term similar to for the target module. A KKT matching performed on the FHOCP reveals that the required modification can be approximated as:
where:
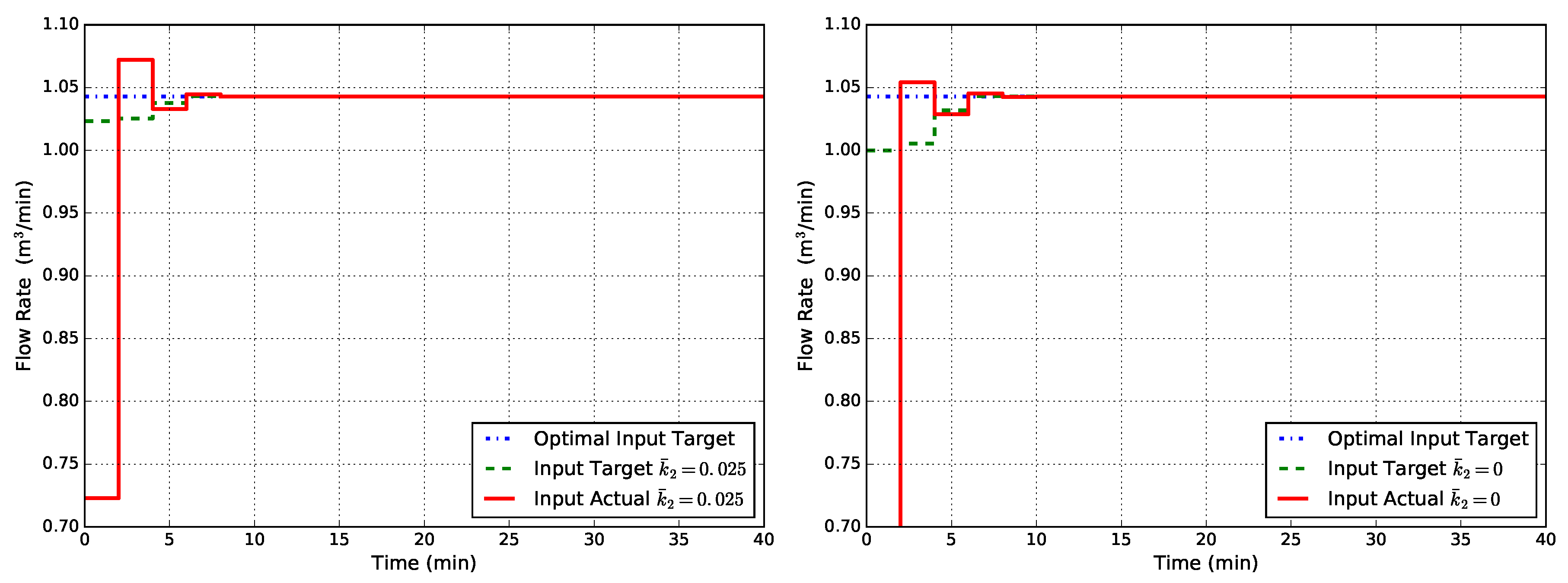
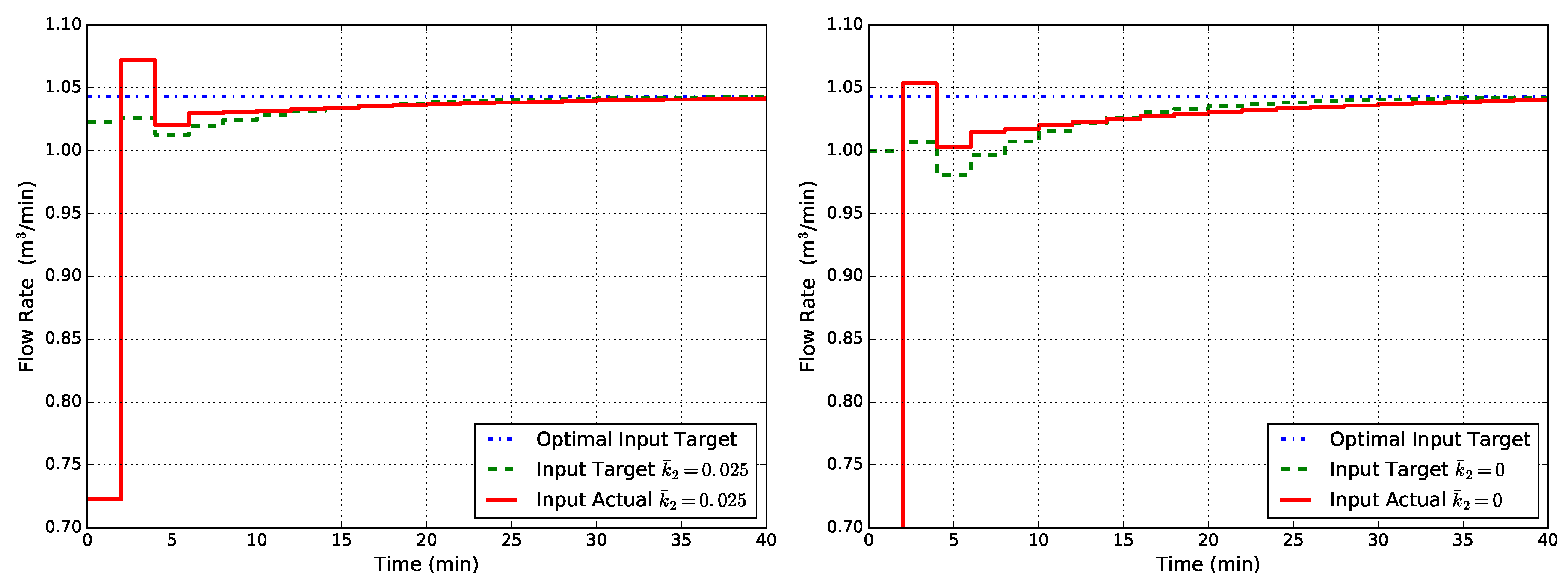
and is the process state in equilibrium with according to (1). Having chosen constant values for , simulation results obtained with this controller, named EMPC1-MT-MD, are shown in Figure 8. From Figure 8, it can be seen that the offset has disappeared for both cases of uncertainty on the kinetic constant .
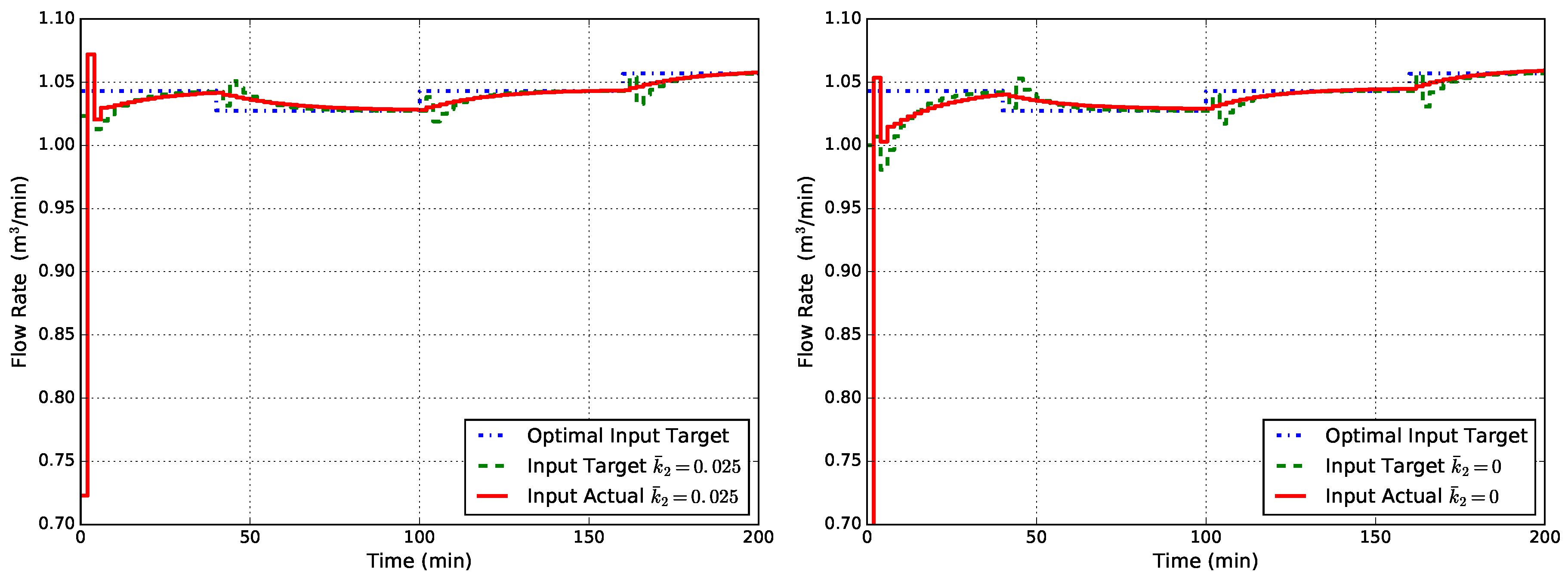
Furthermore, a time-varying simulation case is addressed, in which the true kinetic constant of the process is supposed to be varying during time following this step law:
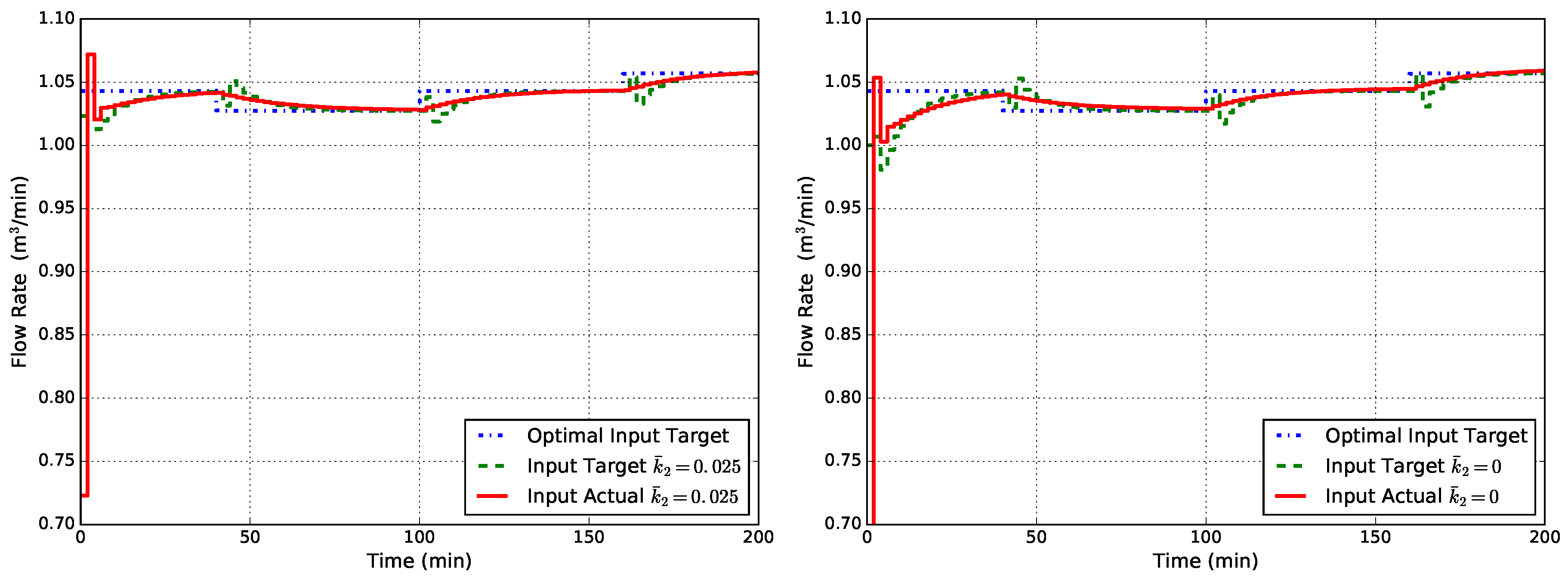
The controller used for this example is the one named EMPC1-MT-MD, and the reaction scheme it knows is still the one defined in (21) with the value fixed. Simulation results obtained with this step time-varying disturbance in (53) are shown in Figure 9 where it can be seen that the offset has disappeared for both cases of uncertainty on the kinetic constant .
In the end, it has to be noted that the majority of methods used for gradient estimation approximate the process gradient using a collection of previous output data to do a sort of identification [43,47,48,49]. Similarly, under the assumption that states are measured, i.e., , gradients and can be calculated if Assumption 2 holds true.
Further Comments
Currently, configurations that achieve optimal asymptotic operations are:
- EMPC2 (non-linear disturbance model). However, this is sort of an unfair choice. The disturbance has been positioned exactly where the uncertainties are, and this is cannot be considered as a general technique.
- MPC1-MT (economic modified target with tracking stage cost). This is the best general achievement at the moment and allows one to obtain offset-free economic performance for arbitrary plant-model mismatch.
As a matter of fact, it has to be underlined that, at the moment, the approximated modification term proposed in (51) works well in this example when there is no uncertainty on the first kinetic constant . In other cases of uncertainty, the offset remains. Hence, further work has to be done to build a general correction strategy for the FHOCP with economic cost. Furthermore, assumptions made in this work deserve some comments. The strongest one is Assumption 2, which requires the availability of process steady-state gradients. For this purpose, we remark that gradient estimation is an active research area in the RTO literature (see, e.g., [19,43,50,51] and the references therein). Further work will investigate these approaches. In the end, it has to be noted that the proposed methodology does not add any computational burden compared to a conventional economic MPC algorithm. The modifiers can be updated after each optimization is concluded and inputs are sent to the plant, and the number of optimization variables is not augmented. Therefore, computation times are not affected.
5. Conclusions
In this paper, we addressed the problem of achieving the optimal asymptotic economic performance using the economic model predictive control (EMPC) algorithms despite the presence of plant-model mismatch.
After reviewing the standard techniques in offset-free tracking MPC and economic MPC, we presented an example where available MPC formulations fail in achieving the optimal asymptotic closed-loop performance. In order to eliminate this offset, the modifier-adaptation strategy developed in the real-time optimization (RTO) field has been taken into consideration and reviewed. Following this idea, a suitable correction to the target problem of the economic MPC algorithm has been formulated in order to achieve the necessary conditions of optimality despite the presence of plant/model mismatch. The proposed modification requires the availability of process gradients evaluated at the steady state. We then showed that the proposed modification is able to correct the steady-state target, but the actual closed-loop input may or may not converge to the optimal target depending on the finite horizon optimal control problem (FHOCP) stage cost. If such a cost is chosen to be positive definite around the target, as in tracking MPC, the optimal asymptotic behavior is achieved, although the dynamic performance may be suboptimal. For some cases of uncertainty, we showed that an economic stage cost can still be used by introducing a modification to the FHOCP.
Finally, we should remark about the main limitations of the current method and suggest future developments. First of all, the availability of process gradients should be reconsidered and relaxed as much as possible. Then, a general correction strategy for using an economic stage cost in the FHOCP, while enforcing convergence to the targets, has to be obtained.
Acknowledgments
The authors would like to thank Doug Allan and James Rawlings from the University of Wisconsin (Madison) for suggesting the illustrative example.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Qin, S.J.; Badgwell, T.A. A survey of industrial model predictive control technology. Control Eng. Pract. 2003, 11, 733–764. [Google Scholar] [CrossRef]
- Engell, S. Feedback control for optimal process operation. J. Process Control 2007, 17, 203–219. [Google Scholar] [CrossRef]
- Guay, M.; Zhang, T. Adaptive extremum seeking control of nonlinear dynamic systems with parametric uncertainties. Automatica 2003, 39, 1283–1293. [Google Scholar] [CrossRef]
- Guay, M.; Peters, N. Real-time dynamic optimization of nonlinear systems: A flatness-based approach. Comput. Chem. Eng. 2006, 30, 709–721. [Google Scholar] [CrossRef]
- Muske, K.R.; Badgwell, T.A. Disturbance modeling for offset-free linear model predictive control. J. Process Control 2002, 12, 617–632. [Google Scholar] [CrossRef]
- Pannocchia, G.; Rawlings, J.B. Disturbance models for offset-free model-predictive control. AIChE J. 2003, 49, 426–437. [Google Scholar] [CrossRef]
- Pannocchia, G. Offset-free tracking MPC: A tutorial review and comparison of different formulations. In Proceedings of the 2015 European Control Conference (ECC), Linz, Austria, 15–17 July 2015; pp. 527–532.
- Marlin, T.E.; Hrymak, A.N. Real-time operations optimization of continuous processes. AIChE Sympos. Ser. 1997, 93, 156–164. [Google Scholar]
- Chen, C.Y.; Joseph, B. On-line optimization using a two-phase approach: An application study. Ind. Eng. Chem. Res. 1987, 26, 1924–1930. [Google Scholar] [CrossRef]
- Garcia, C.E.; Morari, M. Optimal operation of integrated processing systems: Part II: Closed-loop on-line optimizing control. AIChE J. 1984, 30, 226–234. [Google Scholar] [CrossRef]
- Skogestad, S. Self-optimizing control: The missing link between steady-state optimization and control. Comput. Chem. Eng. 2000, 24, 569–575. [Google Scholar] [CrossRef]
- François, G.; Srinivasan, B.; Bonvin, D. Use of measurements for enforcing the necessary conditions of optimality in the presence of constraints and uncertainty. J. Process Control 2005, 15, 701–712. [Google Scholar] [CrossRef]
- Forbes, J.F.; Marlin, T.E. Model accuracy for economic optimizing controllers: The bias update case. Ind. Eng. Chem. Res. 1994, 33, 1919–1929. [Google Scholar] [CrossRef]
- Chachuat, B.; Marchetti, A.G.; Bonvin, D. Process optimization via constraints adaptation. J. Process Control 2008, 18, 244–257. [Google Scholar] [CrossRef]
- Chachuat, B.; Srinivasan, B.; Bonvin, D. Adaptation strategies for real-time optimization. Comput. Chem. Eng. 2009, 33, 1557–1567. [Google Scholar] [CrossRef]
- Marchetti, A.G.; Chachuat, B.; Bonvin, D. Modifier-adaptation methodology for real-time optimization. Ind. Eng. Chem. Res. 2009, 48, 6022–6033. [Google Scholar] [CrossRef]
- Alvarez, L.A.; Odloak, D. Robust integration of real time optimization with linear model predictive control. Comput. Chem. Eng. 2010, 34, 1937–1944. [Google Scholar] [CrossRef]
- Alvarez, L.A.; Odloak, D. Optimization and control of a continuous polymerization reactor. Braz. J. Chem. Eng. 2012, 29, 807–820. [Google Scholar] [CrossRef] [Green Version]
- Marchetti, A.G.; Luppi, P.; Basualdo, M. Real-time optimization via modifier adaptation integrated with model predictive control. IFAC Proc. Vol. 2011, 44, 9856–9861. [Google Scholar] [CrossRef]
- Marchetti, A.G.; Ferramosca, A.; González, A.H. Steady-state target optimization designs for integrating real-time optimization and model predictive control. J. Process Control 2014, 24, 129–145. [Google Scholar] [CrossRef]
- Kadam, J.V.; Schlegel, M.; Marquardt, W.; Tousain, R.L.; van Hessem, D.H.; van Den Berg, J.H.; Bosgra, O.H. A two-level strategy of integrated dynamic optimization and control of industrial processes—A case study. Comput. Aided Chem. Eng. 2002, 10, 511–516. [Google Scholar]
- Kadam, J.; Marquardt, W.; Schlegel, M.; Backx, T.; Bosgra, O.; Brouwer, P.; Dünnebier, G.; Van Hessem, D.; Tiagounov, A.; De Wolf, S. Towards integrated dynamic real-time optimization and control of industrial processes. In Proceedings of the Foundations of Computer-Aided Process Operations (FOCAPO2003), Coral Springs, FL, USA, 12–15 January 2003; pp. 593–596.
- Kadam, J.V.; Marquardt, W. Integration of economical optimization and control for intentionally transient process operation. In Assessment and Future Directions of Nonlinear Model Predictive Control; Springer: Berlin/Heidelberg, Germany, 2007; pp. 419–434. [Google Scholar]
- Biegler, L.T. Technology advances for dynamic real-time optimization. Comput. Aided Chem. Eng. 2009, 27, 1–6. [Google Scholar]
- Gopalakrishnan, A.; Biegler, L.T. Economic nonlinear model predictive control for periodic optimal operation of gas pipeline networks. Comput. Chem. Eng. 2013, 52, 90–99. [Google Scholar] [CrossRef]
- Maeder, U.; Borrelli, F.; Morari, M. Linear offset-free model predictive control. Automatica 2009, 45, 2214–2222. [Google Scholar] [CrossRef]
- Morari, M.; Maeder, U. Nonlinear offset-free model predictive control. Automatica 2012, 48, 2059–2067. [Google Scholar] [CrossRef]
- Rawlings, J.B.; Mayne, D.Q. Model Predictive Control: Theory and Design; Nob Hill Pub.: San Francisco, CA, USA, 2009. [Google Scholar]
- Pannocchia, G.; Gabiccini, M.; Artoni, A. Offset-free MPC explained: Novelties, subtleties, and applications. IFAC-PapersOnLine 2015, 48, 342–351. [Google Scholar] [CrossRef]
- Würth, L.; Hannemann, R.; Marquardt, W. A two-layer architecture for economically optimal process control and operation. J. Process Control 2011, 21, 311–321. [Google Scholar] [CrossRef]
- Zhu, X.; Hong, W.; Wang, S. Implementation of advanced control for a heat-integrated distillation column system. In Proceedings of the 30th Annual Conference of IEEE Industrial Electronics Society (IECON), Busan, Korea, 2–6 November 2004; Volume 3, pp. 2006–2011.
- Rawlings, J.B.; Angeli, D.; Bates, C.N. Fundamentals of economic model predictive control. In Proceedings of the 51st IEEE Conference on Decision and Control (CDC), Maui, HI, USA, 10–13 December 2012; pp. 3851–3861.
- Angeli, D.; Amrit, R.; Rawlings, J.B. Receding horizon cost optimization for overly constrained nonlinear plants. In Proceedings of the 48th IEEE Conference on Decision and Control (CDC), Shanghai, China, 15–18 December 2009; pp. 7972–7977.
- Heidarinejad, M.; Liu, J.; Christofides, P.D. Economic model predictive control of nonlinear process systems using Lyapunov techniques. AIChE J. 2012, 58, 855–870. [Google Scholar] [CrossRef]
- Ellis, M.; Christofides, P.D. On finite-time and infinite-time cost improvement of economic model predictive control for nonlinear systems. Automatica 2014, 50, 2561–2569. [Google Scholar] [CrossRef]
- Angeli, D.; Amrit, R.; Rawlings, J.B. On average performance and stability of economic model predictive control. IEEE Trans. Autom. Control 2012, 57, 1615–1626. [Google Scholar] [CrossRef]
- Faulwasser, T.; Bonvin, D. On the design of economic NMPC based on an exact turnpike property. IFAC-PapersOnLine 2015, 48, 525–530. [Google Scholar] [CrossRef]
- Faulwasser, T.; Bonvin, D. On the design of economic NMPC based on approximate turnpike properties. In Proceedings of the 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 4964–4970.
- Faulwasser, T.; Korda, M.; Jones, C.N.; Bonvin, D. Turnpike and dissipativity properties in dynamic real-time optimization and economic MPC. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 2734–2739.
- Faulwasser, T.; Korda, M.; Jones, C.N.; Bonvin, D. On Turnpike and Dissipativity Properties of Continuous-Time Optimal Control Problems. arXiv preprint arXiv:1509.07315, 2015; arXiv:1509.07315. [Google Scholar]
- Ellis, M.; Durand, H.; Christofides, P.D. A tutorial review of economic model predictive control methods. J. Process Control 2014, 24, 1156–1178. [Google Scholar] [CrossRef]
- Ellis, M.; Liu, J.; Christofides, P.D. Economic Model Predictive Control: Theory, Formulations and Chemical Process Applications; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Marchetti, A.G.; Chachuat, B.; Bonvin, D. A dual modifier-adaptation approach for real-time optimization. J. Process Control 2010, 20, 1027–1037. [Google Scholar] [CrossRef]
- Brdys, M.A.; Tatjewski, P. Iterative Algorithms for Multilayer Optimizing Control; World Scientific: London, UK, 2005. [Google Scholar]
- Bunin, G.A.; François, G.; Srinivasan, B.; Bonvin, D. Input filter design for feasibility in constraint-adaptation schemes. IFAC Proc. Vol. 2011, 44, 5585–5590. [Google Scholar] [CrossRef]
- Navia, D.; Briceño, L.; Gutiérrez, G.; De Prada, C. Modifier-adaptation methodology for real-time optimization reformulated as a nested optimization problem. Ind. Eng. Chem. Res. 2015, 54, 12054–12071. [Google Scholar] [CrossRef]
- Bunin, G.A.; François, G.; Bonvin, D. Exploiting local quasiconvexity for gradient estimation in modifier-adaptation schemes. In Proceedings of the 2012 American Control Conference (ACC), Montreal, QC, Canada, 27–29 June 2012; pp. 2806–2811.
- Serralunga, F.J.; Mussati, M.C.; Aguirre, P.A. Model adaptation for real-time optimization in energy systems. Ind. Eng. Chem. Res. 2013, 52, 16795–16810. [Google Scholar] [CrossRef]
- Gao, W.; Wenzel, S.; Engell, S. Modifier adaptation with quadratic approximation in iterative optimizing control. In Proceedings of the IEEE 2015 European Control Conference (ECC), Linz, Austria, 15–17 July 2015; pp. 2527–2532.
- Brdys, M.A.; Tatjewski, P. An algorithm for steady-state optimising dual control of uncertain plants. In Proceedings of the IFAC Workshop on New Trends in Design of Control Systems, Smolenice, Slovak, 7–10 September 1994; pp. 249–254.
- Costello, S.; François, G.; Bonvin, D. A directional modifier-adaptation algorithm for real-time optimization. J. Process Control 2016, 39, 64–76. [Google Scholar] [CrossRef]
Figure 1.
Typical hierarchical optimization and control structure in process systems.
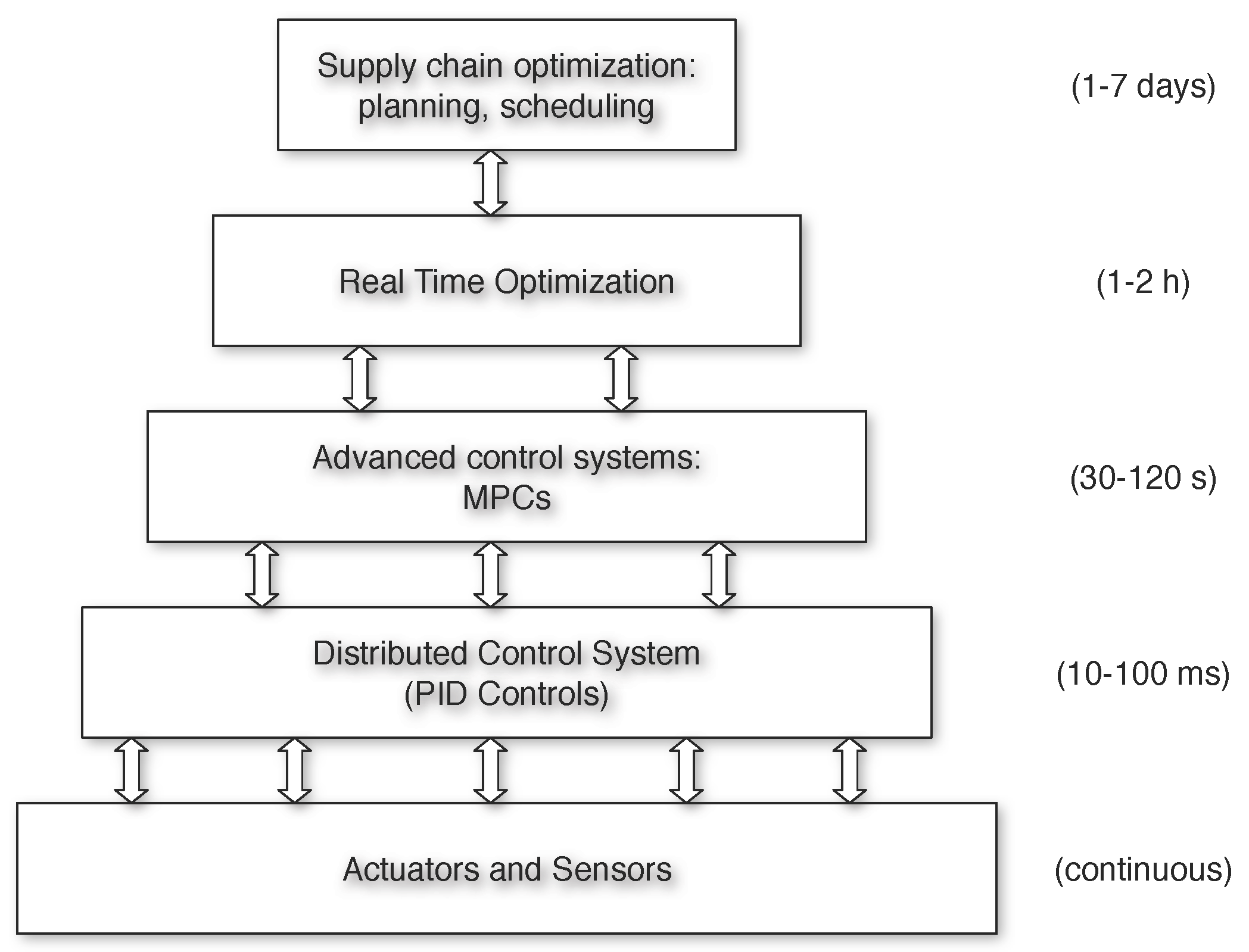
Figure 2.
Closed-loop flow rate Q obtained with standard EMPC0 for two cases of uncertainty in : (left) and (right).
Figure 2.
Closed-loop flow rate Q obtained with standard EMPC0 for two cases of uncertainty in : (left) and (right).
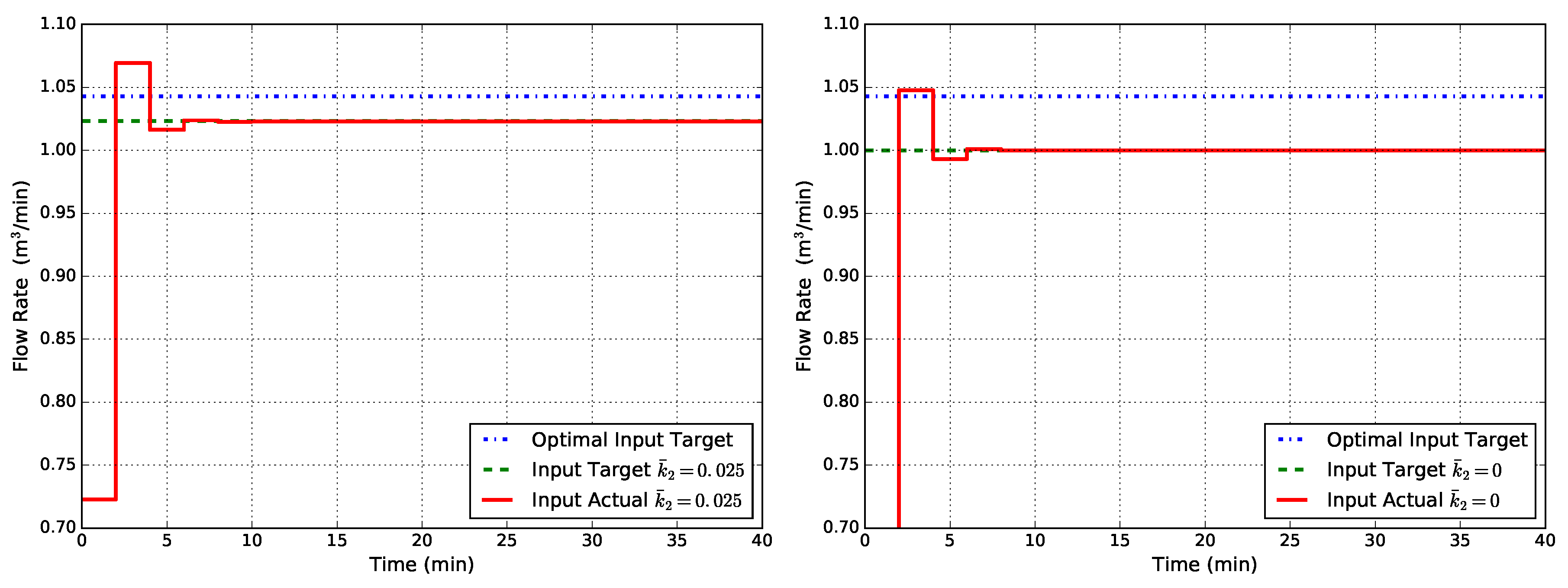
Figure 3.
Closed-loop flow rate Q obtained with EMPC1 (state disturbance model) for two cases of uncertainty in : (left) and (right).
Figure 3.
Closed-loop flow rate Q obtained with EMPC1 (state disturbance model) for two cases of uncertainty in : (left) and (right).
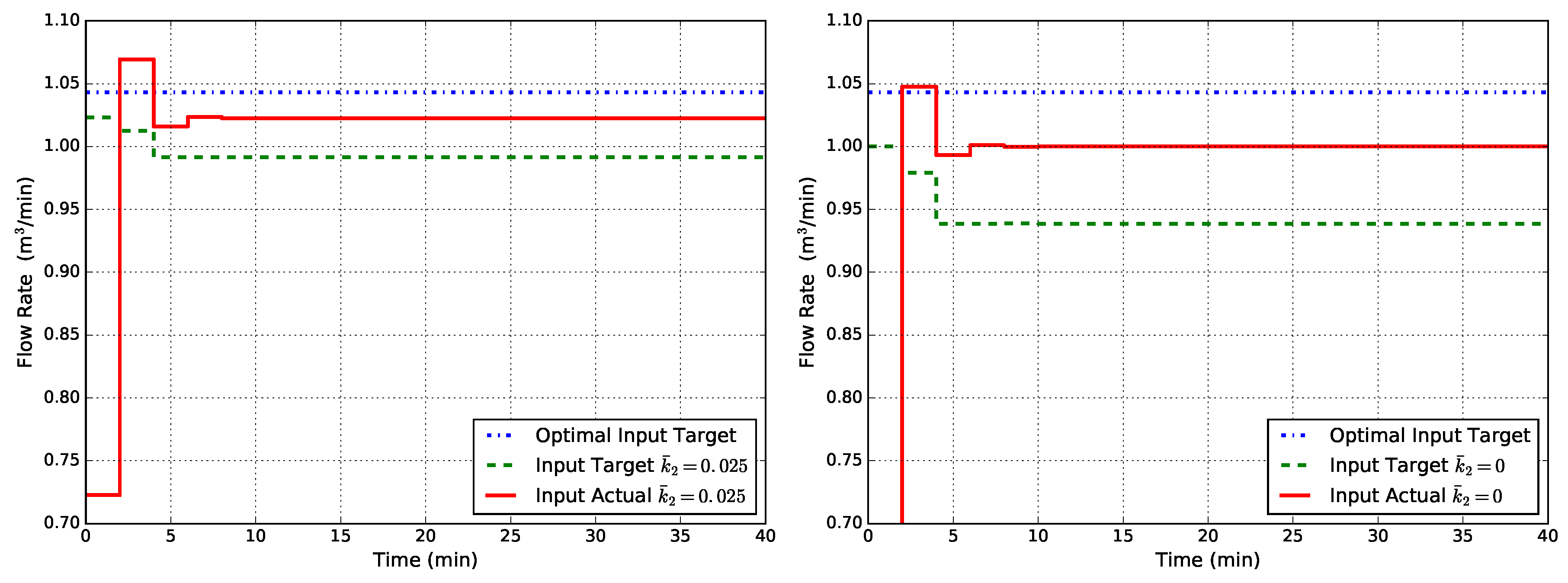
Figure 4.
Closed-loop flow rate Q obtained with EMPC2 (non-linear state disturbance model) for two cases of uncertainty in : (left) and (right).
Figure 4.
Closed-loop flow rate Q obtained with EMPC2 (non-linear state disturbance model) for two cases of uncertainty in : (left) and (right).

Figure 5.
Closed-loop flow rate Q obtained with modified RTO followed by tracking MPC with the output disturbance model for two cases of uncertainty in : (left) and (right).
Figure 5.
Closed-loop flow rate Q obtained with modified RTO followed by tracking MPC with the output disturbance model for two cases of uncertainty in : (left) and (right).
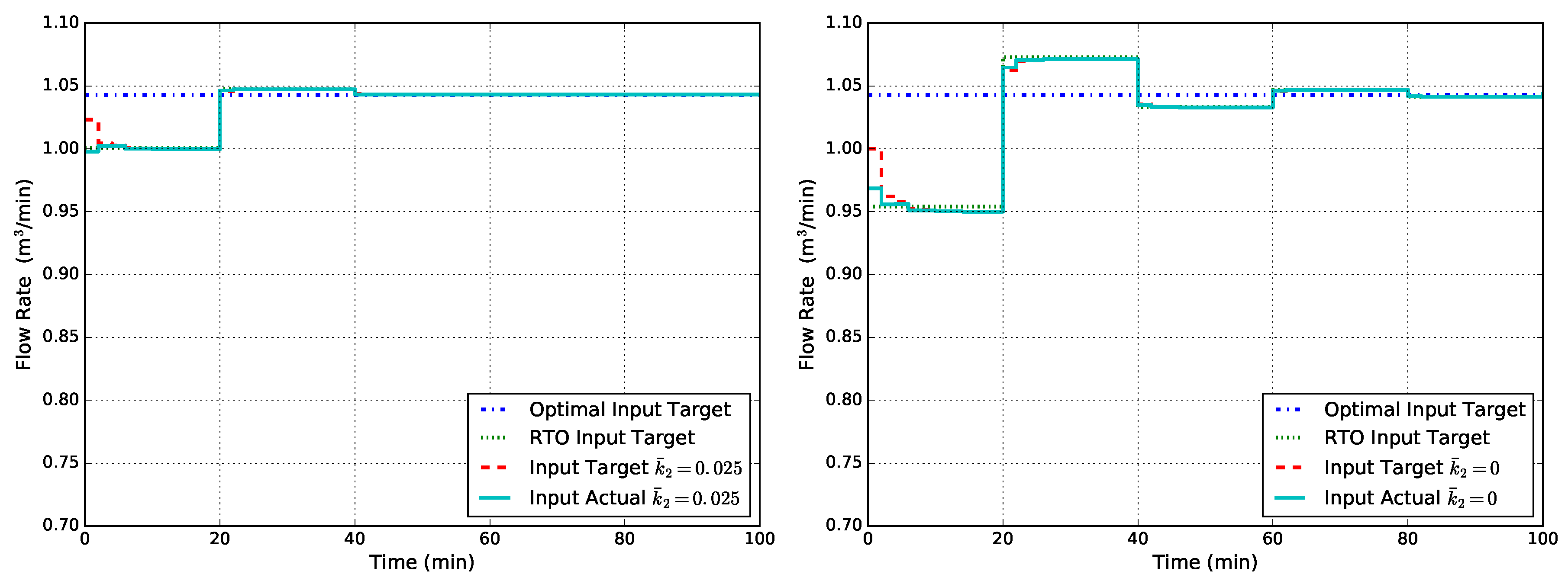
Figure 6.
Closed-loop flow rate Q obtained with EMPC1-MT (state disturbance model, modified target problem) for two cases of uncertainty in : (left) and (right).
Figure 6.
Closed-loop flow rate Q obtained with EMPC1-MT (state disturbance model, modified target problem) for two cases of uncertainty in : (left) and (right).
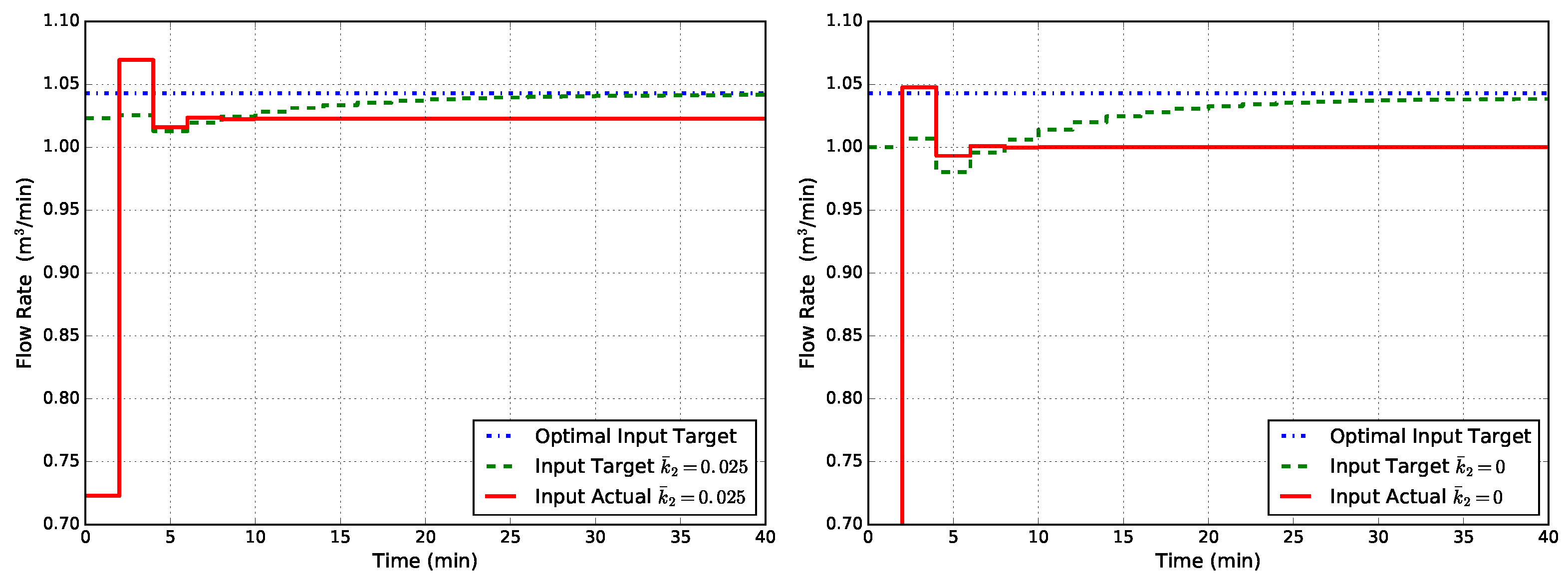
Figure 7.
Closed-loop flow rate Q obtained with MPC1-MT (state disturbance model, modified target problem, tracking cost in the finite horizon optimal control problem (FHOCP)) for two cases of uncertainty in : (left) and (right).
Figure 7.
Closed-loop flow rate Q obtained with MPC1-MT (state disturbance model, modified target problem, tracking cost in the finite horizon optimal control problem (FHOCP)) for two cases of uncertainty in : (left) and (right).
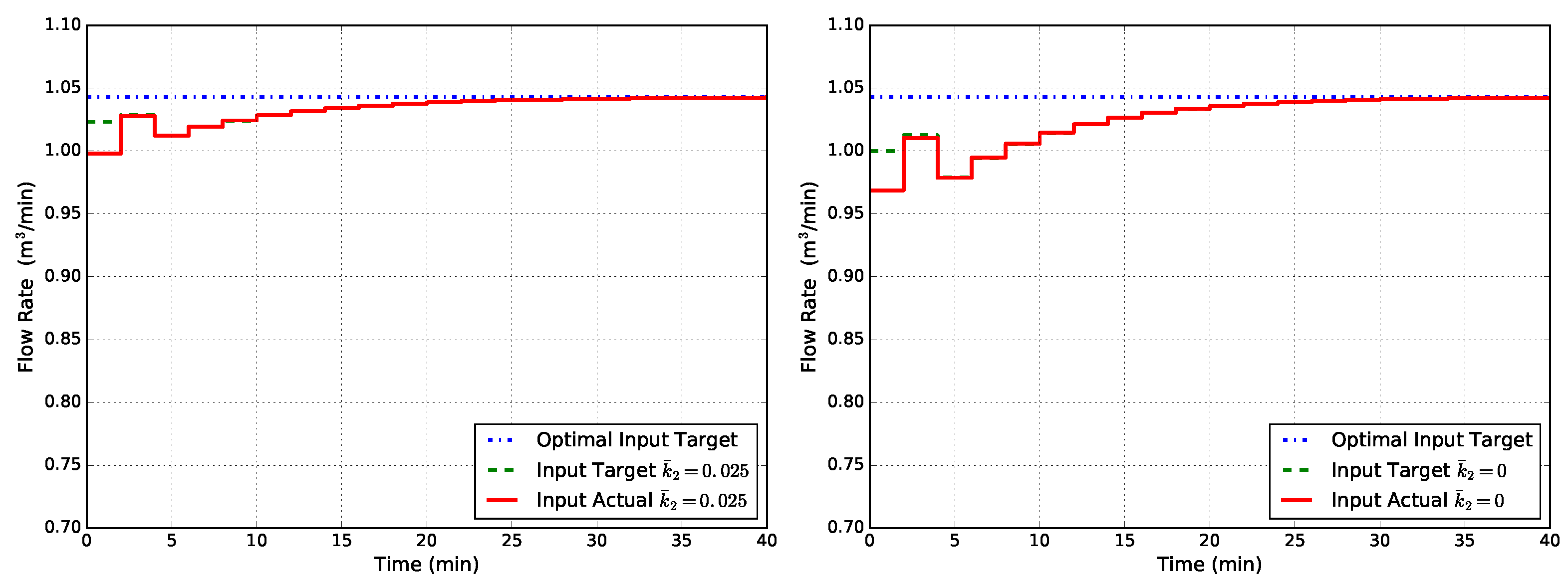
Figure 8.
Closed-loop flow rate Q obtained with EMPC1-MT-MD (state disturbance model, modified target problem, modified FHOCP) for two cases of uncertainty in : (left) and (right).
Figure 8.
Closed-loop flow rate Q obtained with EMPC1-MT-MD (state disturbance model, modified target problem, modified FHOCP) for two cases of uncertainty in : (left) and (right).

Figure 9.
Closed-loop flow rate Q obtained with EMPC1-MT-MD (state disturbance model, modified target problem, modified FHOCP) for cases of unknown time-varying : the MPC model uses a fixed value of (left) and (right).
Figure 9.
Closed-loop flow rate Q obtained with EMPC1-MT-MD (state disturbance model, modified target problem, modified FHOCP) for cases of unknown time-varying : the MPC model uses a fixed value of (left) and (right).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Symbol | Value | Unit |
|---|---|---|---|
| Kinetic Constant 1 | |||
| Kinetic Constant 2 | |||
| Reactor volume | V | ||
| A feed concentration | |||
| B feed concentration | |||
| A price | |||
| B price |
© 2016 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Vaccari, M.; Pannocchia, G. A Modifier-Adaptation Strategy towards Offset-Free Economic MPC. Processes 2017, 5, 2. https://doi.org/10.3390/pr5010002
AMA Style
Vaccari M, Pannocchia G. A Modifier-Adaptation Strategy towards Offset-Free Economic MPC. Processes. 2017; 5(1):2. https://doi.org/10.3390/pr5010002
Chicago/Turabian StyleVaccari, Marco, and Gabriele Pannocchia. 2017. "A Modifier-Adaptation Strategy towards Offset-Free Economic MPC" Processes 5, no. 1: 2. https://doi.org/10.3390/pr5010002
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.