White Paper on Research Data Service Discoverability


Abstract
:1. Introduction
“all services developed by projects should be made discoverable on-line, e.g. by including them in searchable catalogues or registries of (digital) research services with the metadata for describing and accessing the service”.
2. Concepts and Definitions
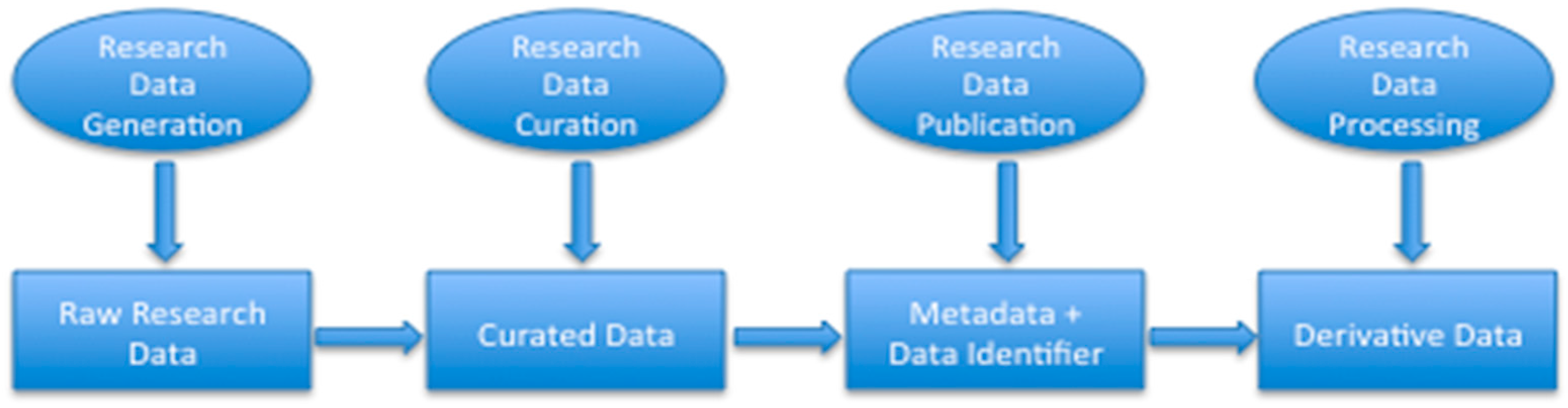
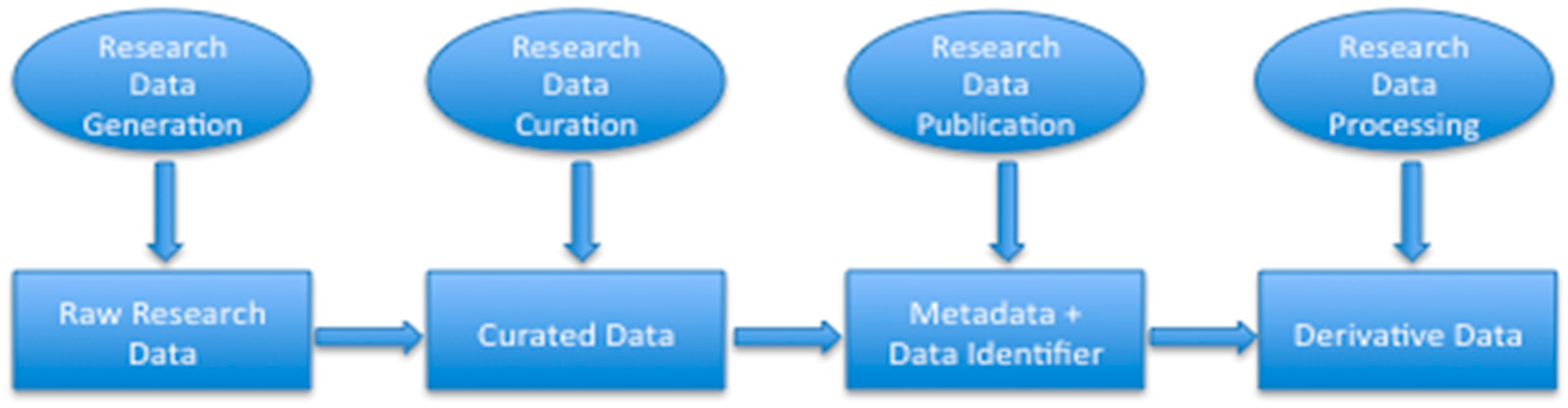
2.1. Research Data
2.2. Research Dataset
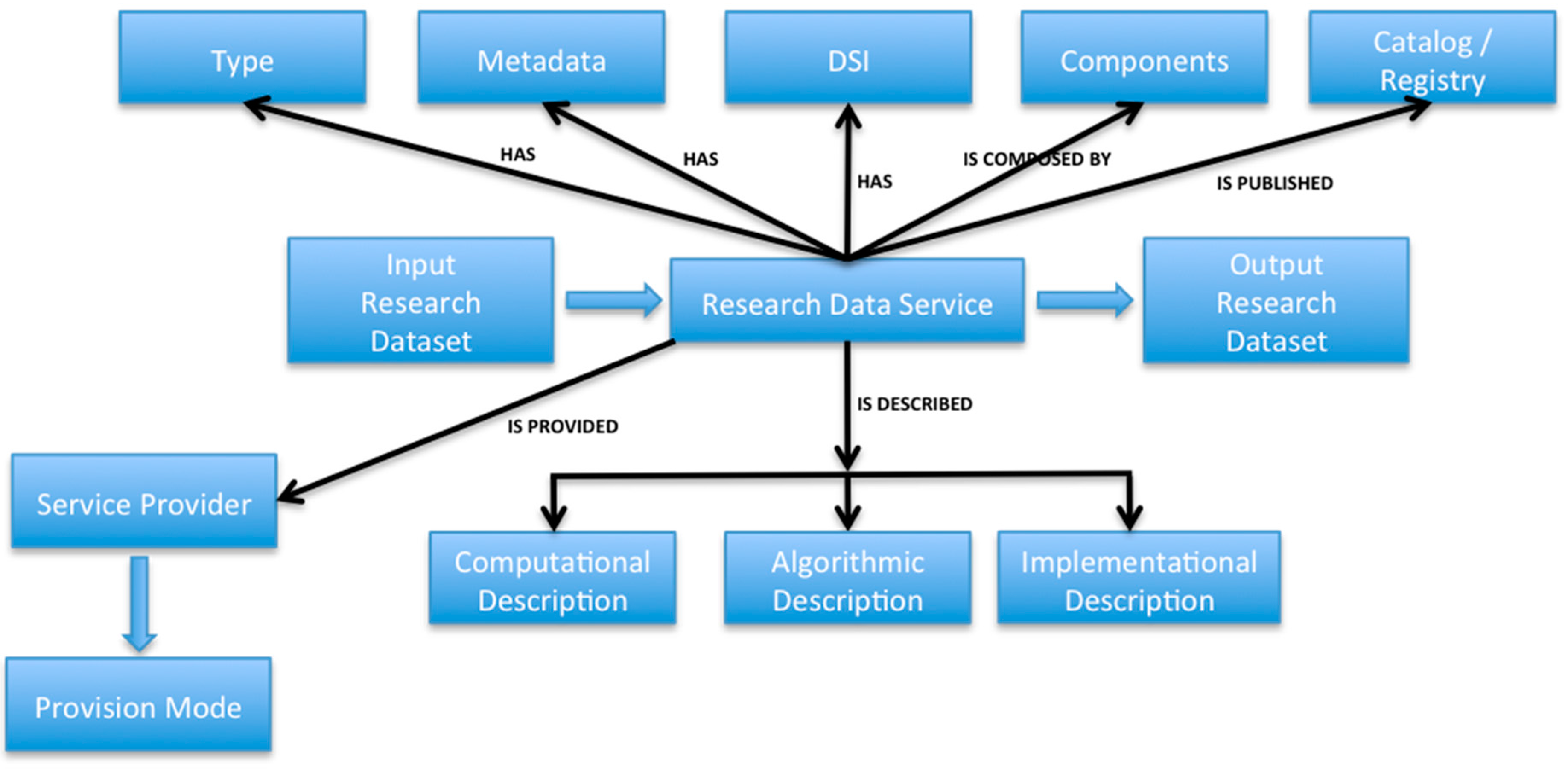
2.3. Description of a Research Data Service (RDS)
- An RDS is a computation characterized as a mapping from one kind of information structure to another (input/output datasets).
- What the goal (functionality) is of the computation (RDS) is described.
- This goal is described as a relationship or dependency between input and output datasets.
- The representation of the input parameter (input dataset) is specified, i.e., the extensional and intensional information of the input dataset is specified.
- The representation of the output parameter (output dataset) is specified, i.e., the extensional and intensional information of the output dataset is specified.
- The pre-conditions, i.e., assertions about certain properties taken by the values of the input parameter before the RDS execution are specified.
- The post-conditions, i.e., assertions about certain properties taken by the values of the output parameter are specified.
- The procedure (algorithm) by which the computational model of the RDS may actually be accomplished is specified.
- A RDS is a software, with a discoverable and invocable interface. A service interface enabling users to invoke the RDS using standard protocols is specified.
- An Institutional Commitment on the RDS, in the form of a Service-Level Agreement (SLA), is specified; in the Service-Level Agreement (see below) the non-functional aspects of the RDS, mainly related to the Quality of Service (QoS )provided by the RDS, are specified.
- The software deployment, including scalability and fault tolerance issues (in the case that the RDS provision model is “as-a-software” – see below), is described.
2.4. Research Data Service Profile/Metadata
2.5. Type of Research Data Service
2.6. Research Data Service Classification
- They are, in general, stateless.
- Their course of action affects only the input dataset.
- They are a specialization of Web services. Indeed, although all Web services use data, they are essentially a programmatic layer on top of distributed systems, while RDSs serve as “fronts” for data and are based on a richer model of that data [8].
- In contrast to traditional Web services, RDSs need to be model-driven.
- They are, according to the definition given in this paragraph, essentially “research dataset transformation services”.
- They may or may not be implemented as a Web service.
- They are applicable in scenarios implementing some part of a research process.
- They are a subclass of service in a general sense.
“software that is developed within academia and used for the purposes of research: to generate, process and analyze results. This includes a broad range of software, from highly developed packages with significant user bases to short (ten of lines of code) programs written by researchers for their own use”.
2.7. Research Data Service Provision Models
- “as-a-Service”: such modality implies that the RDS is hosted, operated, and delivered over the Internet by the service provider.
- “as-a-software”: such modality implies that the RDS is a software entity that is maintained by a service provider and can be invoked and deployed in the user computational environment before being actually used.
2.8. The Main Actors in the RDS Discovery and Use Process
- RDS Provider: A person or authority who commits to have the service executed.
- RDS Producer: A person or organization that actually performs the actions constituting the delivery of the service.
- RDS Customer: One that requests the data service and then negotiates for its customized delivery.
- RDS Consumer: A person who is the direct beneficiary of the service.
- RDS Provider and RDS Producer may coincide, but this is not always the case.
- RDS Customer and RDS Consumer may coincide, but not necessarily.
- RDS Consumer and RDS Producer may also coincide, in very particular situations.
2.9. Service-Level Agreement (SLA)
2.10. Composite Research Data Service
- User-defined chaining: the user manually composes the service chain.
- Workflow-managed chaining: a pre-defined service chain is executed and controlled by a workflow service.
- Opaque chaining: the service chain appears to the user as a single service.
2.11. Scientific Workflow
2.12. Research Data Service Registration
2.13. Domain-Specific Research Data Service Catalogue/Registry/Directory
- Contain an organized and curated collection of domain-specific RDS descriptions (service metadata and DSI).
- Categorize RDSs according to their type.
- Clearly state how each RDS is delivered.
- Constitute a means of centralizing domain-specific descriptions of RDSs that are available on the Internet.
- Support search of RDSs that provide a set of requested functionalities.
- Act as a knowledge management tool allowing researchers to route their requests for and about RDSs to appropriate service providers who own, are accountable for, and operate them.
2.14. Research Data Service Publication/Advertisement
3. Research Data Service in Context
- Research teams distributed worldwide;
- Research data produced, collected, and/or observed by researchers and distributed worldwide; and
- RDSs developed by researchers and distributed worldwide.
- They are information providing services. This means that there is no “real world” counterpart to the computation performed. The execution of the service does not affect the real world but only the information space in which the service is executed.
- After the RDS execution, either a new fact becomes known or a known fact is updated.
- Do we trust the provider?
- How reliable is the provider with respect to her/his promises?
- Does the provider comply with security standards and has been security-assessed?
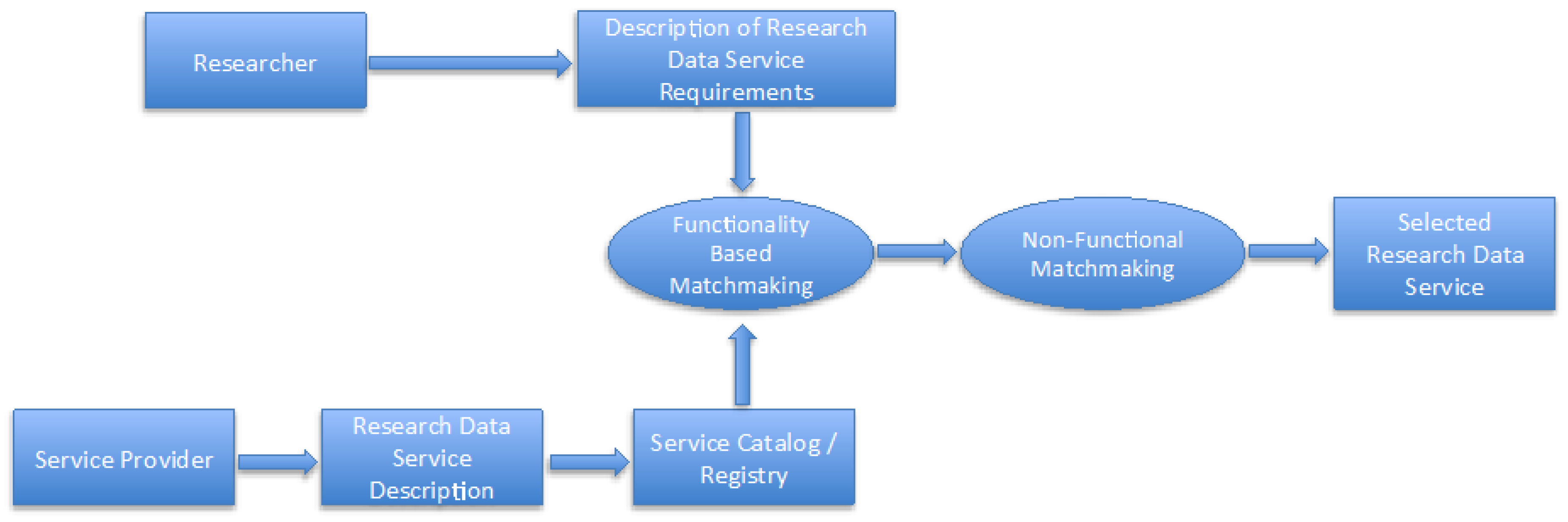
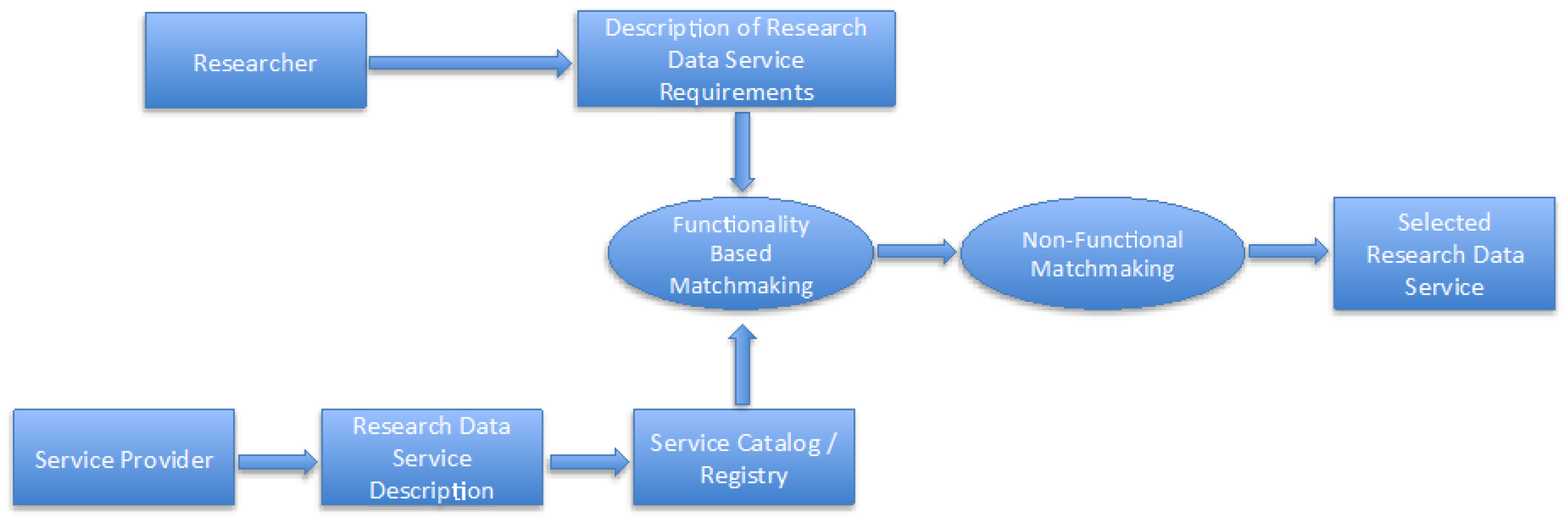
4. The Research Data Service Discovery Process
- The RDS description.
- The RDS publication.
- The RDS matchmakers.
- First, the service requester submits a query to an RDS registry in order to locate an RDS suitable for her/his research needs.
- Second, a functionality-based matchmaking is performed to discover those services that functionally match the service requester requirements.
- Third, in case of a match, non-functional matchmaking is employed in order to filter the matches according to the service requester’s non-functional requirements (QoS, availability, security, reliability, privacy, pricing).
- Finally, if there are still results retained after the filtering, these results are ranked according to preferences given by the user to respective non-functional terms.
- The service functionality.
- The intensional and extensional information about the dataset in her/his possession (input dataset) as well as this type of information about the expected output dataset.
- The pre- and post-conditions.
- The computational environment that will host the data service (in the case of “as-a-software” modality).
- The RDS profile/metadata.
- A Service-Level Agreement.
5. RDS Discovery: Enabling Technologies
5.1. Knowledge Representation Languages
5.2. Reasoning/Matchmaking Support
- The supported service description language(s) and underlying service model(s).
- The way service matchmaking is accomplished.
- The parts of the service semantics that are considered.
- Whether service composition is supported or not.
- Scalability and retrieval performance in terms of correctness and response time.
- The type of service search which is supported.
- Whether user preferences are considered or not.
- Whether a matchmaker can deal with incomplete or inaccurate information.
5.3. Research Data Service Metadata/Profile
- At the data semantics level, the semantics of the input/output datasets is described; their logical structure (schema) is described as well as the relationship between them. If a standard data model (e.g., the relational model) is considered, the relational schema is appropriate; otherwise, descriptions of standard domain-specific data formats should be used.
- At the operation semantics level, the semantics of the data operations of the RDS is described. This description must be expressed by using appropriate knowledge representation languages based on domain-specific ontologies.
- At the execution semantics level, the non-functional aspects of the RDS are described. This demands management of QoS metrics for RDS. RDSs in different domains can have different quality aspects. QoS metrics need shared semantics for interpreting them as intended by the service provider. This can be achieved by having an ontology that defines domain-specific QoS metrics. The non-functional aspects of an RDS could also be included in a kind of standardized contract (Service-Level Agreement) between the service provider and the potential consumers that specifies specific and measurable aspects related to the service offerings. Appropriate languages, like the WSLA, can be used to specify the SLAs.
- At the operational semantics level, the computational environment where the RDS can run must be described using a shared ontology (in the case where the RDS is delivered with the “as-a-software” modality).
5.4. Mediation Support
- Mediation of data structures that permits data to be exchanged according to structural and semantic matching.
- Mediation of functionalities that makeit possible to overcome logical inconsistencies between representations of service functionality.
5.5. Domain-Specific Ontologies
- Multiple ontology approach: each service or query is described by its own ontology. It cannot be assumed that several local ontologies share the same vocabulary. In this case, the alignment of the local ontologies with the ontology used to annotate a published RDS is of crucial importance.
- Single ontology approach: a global ontology is used, which provides a shared vocabulary for specifying the semantics of all services and queries. Such an approach can be adopted when all service descriptions in the catalogue have been created with a view on a scientific domain that is shared by all the requesters. Such a common ontology is called domain ontology.
5.6. Digital Service Identifier (DSI)
- Discoverability: endowing a research data service with an identifier provides an actionable, interoperable, and persistent link to this service that makes the service discovery much easier.
- Reusability: reusing an RDS instead of replicating it has two main advantages: (i) it allows researchers to invest more time into research and avoid wasting time by replicating software that already exists; and (ii) it permits to save a significant amount of resources, as software is expensive to develop, which could then be invested into new research.
- Reproducibility: it is very important, in order to reproduce a research result, to know the exact version of the RDS used to generate it; therefore, there is a need for making a data service identifiable.
- Credit attribution: each RDS should be recognized as a valuable research object. Therefore, it should become a citable scientific deliverable of equivalent value to researchers as that of a publication. Software citation would allow researchers to gain credit for developing software; after all, most research data services are developed by researchers. When a researcher publishes a scientific result generated by using someone else’s data service it could be a good practice to cite it in the publication. It is also important that publishers recognize the need to cite research data services as a vital part of the publication process.
- The developer of the RDS.
- The date the RDS was published.
- The name of the RDS.
- A unique global identifier, which is a short name or character string, guaranteed to be unique among such names, which permanently identifies the RDS, independent of its location. The unique identifier should resolve to a page containing the functional and non-functional description of the data service (data service metadata). This data service metadata should include a link to the actual RDS.
5.7. Data Service Catalogues
- A description of the RDS.
- An identifier of the RDS (DSI).
- Who is entitled to request the RDS.
- The cost of the RDS (if any).
- How to request the RDS.
- How the service delivery is fulfilled (RDS provision model).
- Service categorization or type that allows it to be grouped with other similar services.
- Adopt a formal registration process that allows RDSs to be properly registered in the registry.
- Adopt a generic model to store all the information.
- Support specifications of services and/or ontology-based annotations used to enrich the service specifications. Mechanisms that enable the enrichment of service specifications with ontological annotations can include user input (either guided or based on a specific ontology of his/her choice), semi-automatic annotation (the registry proposes the ontology concept that matches service functionality), as well as automatic semantic annotation (the catalogue alone performs the atomic annotation and selects the best possible match from the alternative ones).
- Encompass smart algorithms which efficiently organize the service advertisement space. In the case of a functionality-based discovery process, the service space is organized according to domain-specific concepts. The discovery process relies on the subsumption relationships between these concepts in order to infer the exact semantic relationship between a service request and a service (functional) advertisement. In the case that the discovery process is based on a service non-functional specification, different approaches have been proposed which rely either on the limits that are posed on quality terms or on relationships between the different non-functional service advertisements [48,49].
- Provide meaningful results to the user even if there are no perfect matches to the user query. Concerning functionality-based service discovery, an interesting categorisation of service matches has been proposed [50] encompassing five main categories, going from the most accurate to the less accurate one. Concerning non-functional service discovery, four main service result categories have been proposed [48]: (i) super: the non-functional service offer promises even better results than those expected by the non-functional service demand/request (e.g., better availability values); (ii) exact: the service offers exhibit the same or a more strict service level than the one expected by the service request; (iii) partial: the service offers solutions that partially satisfy the service request. This means that some quality term constraints of the service request are respected but others are not; and (iv) failed: the service supplies solutions that are totally unacceptable by the service request, meaning that each quality term constraint in the service request is not satisfied/respected.
- Rank the service discovery results according to specific criteria that can include non-functional quality terms (e.g., response time and cost). Such a ranking can really assist the user in selecting the most appropriate service but requires that user preferences are already in place, thus either collected from the user or derived and stored in its user profile.
- Be scalable to handle the publication and discovery of a high number of services. In this respect, decentralised and peer-to peer architectures are advocated in order to also overcome the single point of failure issue. In such decentralized architectures, there should be mechanisms that partition the service advertisement space accordingly by also allowing for some degree of replication for fault-tolerance reasons.
- Be robust enough to deal with change. Different types of changes might occur: (i) the semantic (functional) specification of the service is modified; (ii) the non-functional specification of the service is modified; and (iii) domain ontologies are evolved.
- Be able to monitor the status of the RDS specifications in order to keep them updated. There can be two main approaches that can be followed, either alternatively or in combination: (a) the service providers are responsible for updating the specification of their services; (b) the service catalogue constantly looks for changes in the functional and non-functional RDS specification and applies them. However, this approach is certainly harder than the previous one.
- Allow that service specifications can be specified in different languages and different (domain) ontologies may be used. Language and ontology heterogeneity can be overcome by adopting mediation techniques (see subsection 5.3).
- Support, when functional service discovery fails (i.e., no single service can satisfy the user request), service composition, i.e., a combination of data services that can still satisfy the functional requirements of the user. Different approaches can be used for service composition, e.g., AI-based approaches, graph-based approaches, etc.
- Support data service advertisement. This means that RDS catalogues proactively send to potential users information about newly published RDSs, changes in data service specifications, etc.
- Provide visual facilities which will guide the users in order to provide for their requirements. Indeed, we have assumed that service discovery relies on ontology-based languages to express service requirements, but it is not certain that such languages can be exploited by users as they might not possess the needed expertise and skills. We cannot also expect that agents are employed by scientists to interact with the registry and obtain the respective discovery results.
- Adopt strong stewardship and security controls.
- Finally, provide the description of platforms and infrastructures which can provide support to the execution and provisioning of RDSs. Infrastructure services can include well-known cloud computing and grid computing services, which provide the respective resources to support the software provisioning. Such services can be essential in case of a software that has to be deployed somewhere and run as a service but the scientist/researcher does not have the resources to support this deployment. Before discovering and using infrastructural services, they have to be described in an appropriate manner. While they seem to share common characteristics, the semantics can be sometimes different while also there are some characteristics that are more suitable for one type over the other. In this sense, the catalogue/registry should have the capability to cope with this type of heterogeneity.
6. Recommendations
- At present, guidelines for appropriately describing an RDS are not available. An RDS description must be based on a systematic analysis aimed at revealing those characteristics of RDSs that must be considered in an appropriate RDS model. There is a need for an investigation to be conducted among the members of the research communities in order to collect information about the way researchers are willing to describe their needs for a RDS. Existing approaches to Semantic Web Service description and selection must be evaluated in light of the results derived from such investigation. Similar approaches have been successfully pursued in the Semantic Web Service community. In addition, attempts to catalog research-related services [52,53] and to model and share scientific workflows [54,55,56] can deliver valuable insights and solutions that shall be taken into account.
- RDS models should be compliant with existing and upcoming W3C standards to benefit from the rich set of tools that have been and will be developed.
- Service models for RDSs shall support the architectural style (SOAP-based [57], REST-based, etc.) of services that are prevalent in the Research Data Services domain.
- An RDS should be described at three levels: the computational level, the algorithmic level, and the implementational level (cf. Section 2).
- Ontology-based languages must be used for the description of an RDS as well as for formulating an RDS need. Alternatively, domain-specific vocabularies must be used for annotating RDSs.
- In order to support ontology-based RDS description, each scientific domain must develop its own domain-specific ontologies: one that formally defines the possible data-types of the RDS’s arguments; one that formally describes the possible operations performed by RDSs (functional ontology); and one that describes QoS metrics.
- RDSs should be, like Linked Data, self-describing.
- Existing service models have to be extended to address domain-specific characteristics of RDSs.
- A layered RDS metadata/profile description must be adopted, as it allows a more precise description of the input/output datasets, the data operations, and the non-functional aspects of the RDS.
- Again, we emphasize the need for an investigation aimed at collecting information about the RDS discovery mechanisms adopted by researchers in order to identify promising candidate solutions for the selection of RDSs among the existing approaches and to track down necessary extensions to these.
- Initiatives similar to the Semantic Web Service challenge [58] that compare existing approaches with respect to their functional capabilities are required. These should be complemented by the creation of domain-specific test collections that allow for a performance analysis of developed solutions.
- Potential knowledge representation languages for the description of RDSs must provide appropriate means to describe aspects of such services that are relevant to their discovery.
- Service models and representation languages for which matchmaking tools with appropriate capabilities and performance are available should be preferred. This choice depends on the kind of search mechanism that shall be supported, e.g., automatic discovery, keyword search, faceted search over service types, or query by example) and whether service composition shall be enabled.
- For an efficient RDS discovery process, it is required that the same domain ontology (or vocabulary) be used by both service providers and requesters. Therefore, the basis for specifying operations and input/output data must be widely agreed upon international standards.
- Functionality-based RDS discovery must be the main approach to the RDS discovery.
- A fully automatic RDS discovery process must be put in action.
- There is a need for developing efficient RDS matchmakers.
- In order to enable compatibility and reuse, RDS models must integrate smoothly with knowledge representation languages and models used to describe (the semantics of) research data (as the input/output of RDSs), metadata, and domain-specific knowledge. These might differ from domain to domain.
- Each RDS must be assigned a “Digital Service Identifier” by a registration agency.
- Each scientific domain has to create its own RDS registry where RDSs relevant for this domain are published.
- An institutional commitment must exist on every published RDS. In particular, the non-functional aspects of an RDS must be included in a kind of standardized contract (Service-Level Agreement) between the service provider and the potential consumers that specifies specific and measurable aspects related to the service offerings.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
A.1. Workshop on “Research Data Service Discoverability”
A.1.1. Rationale
A.1.2. Outcome
A.1.3. Place
A.2. List of Participants
Appendix B. Additional readings
References
- Hey, T.; Tansley, S.; Tolle, K. (Eds.) The Fourth Paradigm: Data Intensive Scientific Discovery; Microsoft Research: Redmond, WA, USA, 2009.
- National Research Council. Bits of Power: Issues in Global Access to Scientific Data; National Academy Press: Washington, DC, USA, 1997. [Google Scholar]
- Committee for a Study on Promoting Access to Scientific and Technical Data for the Public Interest; Commission on Physical Sciences, Mathematics, and Applications; Division on Engineering and Physical Sciences; National Research Council. A Question of Balance: Private Rights and the Public Interest in Scientific and Technical Databases; National Academy Press: Washington, DC, USA, 1999. [Google Scholar]
- National Science Board. Long-Lived Digital Data Collections: Enabling Research and Education in the 21st Century; National Science Foundation: Washington, DC, USA, 2005.
- Parkinson, C.L.; Ward, A.; King, M.D. (Eds.) Earth Science Reference Handbook—A Guide to NASA’s Earth Science Program and Earth Observing Satellite Missions; National Aeronautics and Space Administration: Washington, DC, USA, 2006.
- Paskin, N. Digital Object Identifier for Scientific Data. In Proceedings of the 19th International CODATA Conference, Berlin, Germany, 7–10 November 2004.
- Marr, D. Vision: A Computational Investigation into the Human Representation and Processing of Visual Information; MIT Press: Cambridge MA, USA, 1982. [Google Scholar]
- Carey, M.J.; Onose, N.; Petropoulos, M. Data Services. Commun. ACM 2012, 55, 86–97. [Google Scholar] [CrossRef]
- Hettrick, S. Research Software Sustainability; Report on a Knowledge Exchange Workshop; KE: Berlin, Germany, 3 March 2016. [Google Scholar]
- Assante, M.; Candela, L.; Castelli, D.; Tani, A. Data Science Journal. Are Scientific Data Repositories Coping with Research Data Publishing? Data Sci. J. 2016, 1–24. [Google Scholar] [CrossRef]
- Lutz, M. Ontology-Based Descriptions for Semantic Discovery and Composition of Geoprocessing Services. Geoinformatica 2007, 11, 1–36. [Google Scholar] [CrossRef]
- Martin, D.; Burstein, M.; Hobbs, J.; Lassila, O.; McDermott, D.; McIlraith, S.; Narayanan, S.; Paolucci, M.; Parsia, B.; Payne, T.; et al. OWL-S: Semantic Markup for Web Services. 2004. Available online: http://www.w3.org/Submission/OWL-S (accessed on 30 August 2016).
- McGuinness, D.L.; Harmelen, F.V. OWL Web Ontology Language Overview. 2004. Available online: http://www.w3.org/TR/owl-features (accessed on 30 August 2016).
- Lausen, H.; Polleres, A.; Roman, D. (Eds.) Web Service Modeling Ontology (WSMO). 2005. Available online: http://www.w3.org/Submission/WSMO (accessed on 30 August 2016).
- De Bruijn, J.; Lausen, H. (Eds.) Web Service Modeling Language (WSML). 2005. Available online: http://www.w3.org/Submission/WSML (accessed on 30 August 2016).
- Fensel, D.; Fischer, F.; Jacek Kopecký, J.; Krummenacher, R.; Lambert, D.; Vitvar, T. WSMO-Lite: Lightweight Semantic Descriptions for Services on the Web. 2010. Available online: http://www.w3.org/Submission/WSMO-Lite (accessed on 30 August 2016).
- Cyganiak, R.; Wood, D.; Lanthaler, M. (Eds.) RDF 1.1 Concepts and Abstract Syntax. 2014. Available online: http://www.w3.org/TR/rdf11-concepts (accessed on 30 August 2016).
- Farrell, J.; Lausen, H. Semantic Annotations for WSDL and XML Schema. 2007. Available online: http://www.w3.org/TR/sawsdl (accessed on 30 August 2016).
- Christensen, E.; Curbera, F.; Meredith, G.; Weerawarana, S. Web Services Description Language (WSDL) 1.1. 2001. Available online: http://www.w3.org/TR/wsdl (accessed on 30 August 2016).
- Kopecký, J.; Gomadam, K.; Vitvar, T. hRESTS: An HTML Microformat for Describing RESTful Web Services. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Sydney, Australia, 9–12 December 2008; pp. 619–625.
- Gomadam, K.; Ranabahu, A.; Sheth, A. SA-REST: Semantic Annotation of Web Resources 2010. Available online: www.w3.org/Submission/SA-REST (accessed on 30 August 2016).
- Kopecký, J.; Vitvar, T. D38v0.1 MicroWSMO. 2008. Available online: www.wsmo.org/TR/d38/v0.1 (accessed on 30 August 2016).
- Stavrakantonakis, I.; Fensel, A.; Fensel, D. Matching Web Entities with Potential Actions. In Proceedings of the Poster and Demo Paper track International Conference on Semantic Systems (I-SEMANTICS 14), CEUR-WS, Leipzig, Germany, 4–5 September 2014; pp. 35–38.
- Prud’hommeaux, E.; Seaborne, A. (Eds.) SPARQL Query Language for RDF. 2008. Available online: www.w3.org/TR/rdf-sparql-query (accessed on 30 August 2016).
- Klusch, M.; Nesbigall, S.; Zinnikus, I. Model-Driven Semantic Service Matchmaking for Collaborative Business Processes. In Proceedings of the 2nd International Workshop on Semantic Matchmaking and Resource Retrieval, CEUR-WS, Karlsruhe, Germany, 27 October 2008; Volume 416.
- Klusch, M.; Kapahnke, P.; Schulte, S.; Lecue, F.; Bernstein, A. Semantic Web Service Search: A Brief Survey. Künstliche Intelligenz; Springer: Berlin, Germany, 2016; Volume 30, pp. 139–147. [Google Scholar]
- Ngan, L.D.; Kanagasabai, R. Semantic Web service discovery: State-of-the-art and research challenges. Pers. Ubiquitous Comput. 2013, 17, 1741–1752. [Google Scholar] [CrossRef]
- Klusch, M. Semantic Web Service Description. CASCOM: Intelligent Service Coordination in the Semantic Web; Birkhäuser: Basel, Switzerland, 2008; pp. 31–57. [Google Scholar]
- Klusch, M.; Kapahnke, P. The iSeM matchmaker: A flexible approach for adaptive hybrid semantic service selection. J. Web Semant. 2012, 15, 1–14. [Google Scholar] [CrossRef]
- Masuch, N.; Hirsch, B.; Burkhardt, M.; Heler, A.; Albayrak, S. SeMa2: A Hybrid Semantic Service Matching Approach. Semantic Web Services; Springer: Berlin, Germany, 2012. [Google Scholar]
- Junghans, M.; Agarwal, S.; Studer, R. Towards practical semantic web service discovery. In Proceedings of the 9th International Semantic Web Conference, Shanghai, China, 7–11 November 2010; Springer: Berlin, Germany, 2010. [Google Scholar]
- Klusch, M. Semantic Web Service Coordination. In CASCOM: Intelligent Service Coordination in the Semantic Web; Birkhäuser: Basel, Switzerland, 2008; pp. 59–104. [Google Scholar]
- Küster, U.; König-Ries, B.; Klein, M.; Stern, M. DIANE—An Integrated Approach to Automated Service Discovery, Matchmaking and Composition. In Proceedings of the 16th International World Wide Web Conference, Banff, AB, Canada, 8–12 May 2007.
- Klusch, M. Overview of the S3 Contest: Performance Evaluation of Semantic Service Matchmakers. In Semantic Web Services; Springer: Berlin, Germany, 2012; pp. 17–34. [Google Scholar]
- Klan, F.; König-Ries, B. A Conversational Approach to Semantic Web Service Selection. In Proceedings of the 12th International Conference on Electronic Commerce and Web Technologies, Toulouse, France, 30 August–1 September 2011.
- Colucci, S.; Di Noia, T.; Di Sciascio, E.; Donini, F.M.; Ragone, A.; Rizzi, R. A semantic-based fully visual application for matchmaking and query refinement in B2C e-marketplaces. In Proceedings of the 8th International Conference on Electronic Commerce, Fredericton, NB, Canada, 13–16 August 2006; pp. 174–184.
- Payne, W.; Bettman, J.R.; Johnson, E.J. Behavioral decision research—A constructive processing perspective. Annu. Rev. Psychol. 1992, 43, 87–131. [Google Scholar] [CrossRef]
- Küster, U.; König-Ries, B.; Margaria, T.; Steffen, B. Comparison: Handling Preferences with DIANE and miAamics. In Semantic Web Service Challenge—Results from the First Year; Springer: Berlin, Germany, 2008. [Google Scholar]
- García, M.; Ruiz, D.; Ruiz-Cortés, A. A Model of User Preferences for Semantic Services Discovery and Ranking. In Proceedings of the 7th International Conference on the Semantic Web: Research and Applications—Volume Part II, Heraklion, Greece, 30 May–2 June 2010; Springer: Berlin, Germany, 2010; pp. 1–14. [Google Scholar]
- Balke, W.-T.; Wagner, M. Towards personalized selection of web services. In Proceedings of the Twelfth International World Wide Web Conference, Budapest, Hungary, 20–24 May 2003.
- Sivashanmugam, K.; Sheth, A.; Miller, J.; Verma, K.; Aggarwal, R.; Rajasekaran, P. Metadata and Semantics for Web Services and Processes. In Datenbanken und Informationssysteme, Festscrift zum 60; von Gunter Schlageter, G., Ed.; Praktische Informatik I: Hagen, Germany, 2003. [Google Scholar]
- Thanos, C. Mediation: The Technological Foundation of Modern Science. Data Sci. J. 2014, 13, 88–105. [Google Scholar] [CrossRef]
- Nativi, S.; Mazzetti, P.; Santoro, M.; Papeschi, F.; Craglia, M.; Ochiai, O. Big Data challenges in building the Global Earth Observation System of Systems. Environ. Model. Soft. 2015, 68, 1–26. [Google Scholar] [CrossRef]
- Khalsa, S.J.; Pearlman, J.; Nativi, S.; Pearlman, F.; Parsons, M.; Browdy, S.; Duerr, R. Brokering for EarthCube Communities: A Road Map, Earth Cube Document. 2013. Available online: http://earthcube.org/document/2012/brokering-earthcube-communities-road-map (accessed on 31 August 2012).
- ICSU World Data System. “Trusted Data Services for Global Science”. Available online: https://www.icsu-wds.org/organization/intro-to-wds (accessed on 12 December 2016).
- Gruber, T. Towards Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum.-Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Poggi, A.; Lembo, D.; Calvanese, D.; De Giacomo, G.; Lenzerini, M.; Rosati, R. Linking Data to Ontologies. In Journal on Data Semantics X; Springer: Berlin, Germany, 2008. [Google Scholar]
- Kritikos, K.; Plexousakis, D. Mixed-Integer Programming for QoS-Based Web Service Matchmaking. IEEE Trans. Serv. Comput. 2009, 2, 122–139. [Google Scholar] [CrossRef]
- Kritikos, K.; Plexousakis, D. Novel Optimal and Scalable Nonfunctional Service Matchmaking Techniques. IEEE Trans. Serv. Comput. 2014, 7, 614–627. [Google Scholar] [CrossRef]
- Klusch, M.; Fries, B.; Sycara, K. Automated semantic web service discovery with OWLS-MX. In Proceedings of the Fifth International Joint Conference on Autonomous Agents and Multiagent Systems, Hakodate, Japan, 8–12 May 2006; pp. 915–922.
- Garofalakis, J.; Panagis, Y.; Sakkopoulos, E.; Tsakalidis, A. Contemporary Web Service Discovery Mechanisms. J. Web Eng. 2006, 5, 265–290. [Google Scholar]
- Bhagat, J.; Tanoh, F.; Nzuobontane, E.; Laurent, T.; Orlowski, J.; Roos, M.; Wolstencroft, K.; Aleksejevs, S.; Stevens, R.; Pettifer, S.; et al. BioCatalogue: A universal catalogue of web services for the life sciences. Nucleic Acids Res. 2010, 38, W689–W694. [Google Scholar] [CrossRef] [PubMed]
- Goble, C.A.; Bhagat, J.; Aleksejevs, S.; Cruickshank, D.; Michaelides, D.; Newman, D.; Borkum, M.; Bechhofer, S.; Roos, M.; Li, P.; et al. myExperiment: A repository and social network for the sharing of bioinformatics workflows. Nucleic Acids Res. 2010, 38, W677–W682. [Google Scholar] [CrossRef] [PubMed]
- Belhajjame, K.; Wolstencroft, K.; Corcho, O.; Oinn, T.; Tanoh, F.; William, A.; Goble, C. Metadata Management in the Taverna Workflow System. In Proceedings of the 8th IEEE International Symposium on Cluster Computing and the Grid (CCGRID’08), Lyon, France, 19–22 May 2008; pp. 651–656.
- Altintas, I.; Berkley, C.; Jaeger, E.; Jones, M.; Ludäscher, B.; Mock, S. Kepler: An extensible system for design and execution of scientific workflows. In Proceedings of the 16th International Conference on Scientific and Statistical Database Management, Santorini Island, Greece, 21–23 June 2004; pp. 423–424.
- McPhillips, T.; Song, T.; Kolisnik, T.; Aulenbach, S.; Belhajjame, K.; Bocinsky, R.K.; Cao, Y.; Cheney, J.; Chirigati, F.; Dey, S.; et al. YesWorkflow: A User- Oriented, Language-Independent Tool for Recovering Workflow Information from Scripts. Int. J. Digit. Curation 2015, 10, 298–313. [Google Scholar] [CrossRef]
- Mitra, N.; Lafon, Y. SOAP Version 1.2 Part 0: Primer (Second Edition). 2007. Available online: http://www.w3.org/TR/soap12-part0 (accessed on 30 August 2016).
- Petrie, C.; Margaria, T.; Lausen, H.; Zaremba, M. (Eds.) Semantic Web Services Challenge: Results from the First Year; Springer: Boston, MA, USA, 2009.
- 1From this point on, with the term catalogue we refer to registries and directories too.

{kind=link}
{kind=link}
{kind=link}
| Section | Field |
|---|---|
| Profile | Documentation URL |
| Profile | Description of endpoints/operations License |
| Profile | Cost |
| Profile | Contact info |
| Profile | Usage conditions |
| Profile | How to cite |
| Profile | Publications about service |
| Profile | Example workflows |
| Profile | Maturity |
| Technical | Description of endpoints/operations example endpoints |
| Technical | Documentation URLs |
| Technical | Input parameters (description, default values, constrained values, example data, required or optional) |
| Technical | Output representations (content type (e.g. text/csv), example data, data formats, data schemas, tag) |
| Technical | Description of endpoints/operations example endpoints |
© 2016 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thanos, C.; Klan, F.; Kritikos, K.; Candela, L. White Paper on Research Data Service Discoverability. Publications 2017, 5, 1. https://doi.org/10.3390/publications5010001
Thanos C, Klan F, Kritikos K, Candela L. White Paper on Research Data Service Discoverability. Publications. 2017; 5(1):1. https://doi.org/10.3390/publications5010001
Chicago/Turabian StyleThanos, Costantino, Friederike Klan, Kyriakos Kritikos, and Leonardo Candela. 2017. "White Paper on Research Data Service Discoverability" Publications 5, no. 1: 1. https://doi.org/10.3390/publications5010001