
Verification of Ensemble Water Supply Forecasts for Sierra Nevada Watersheds

Abstract
:1. Introduction
2. Materials and Methods
2.1. Hydrologic Ensemble Forecast Service
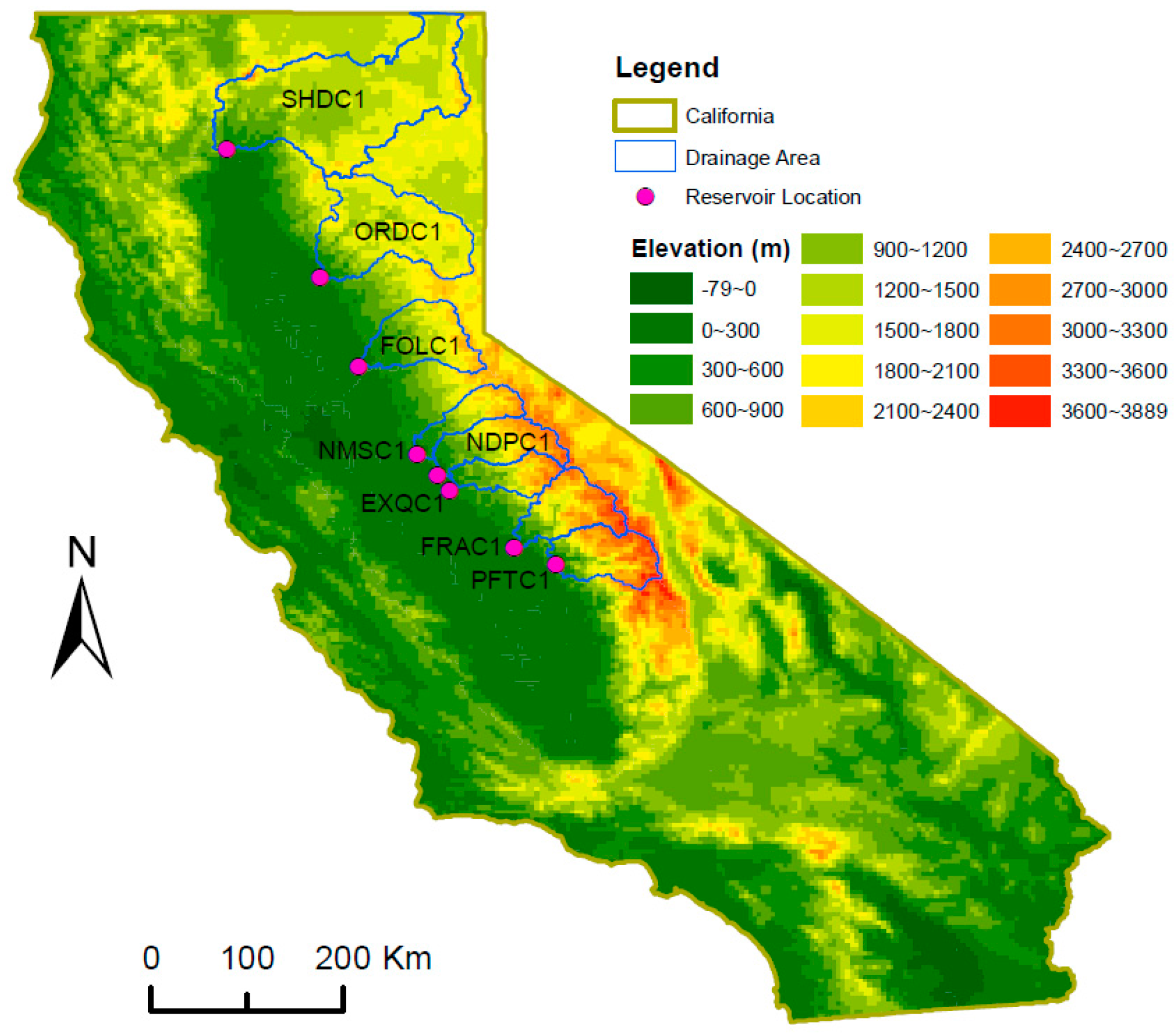
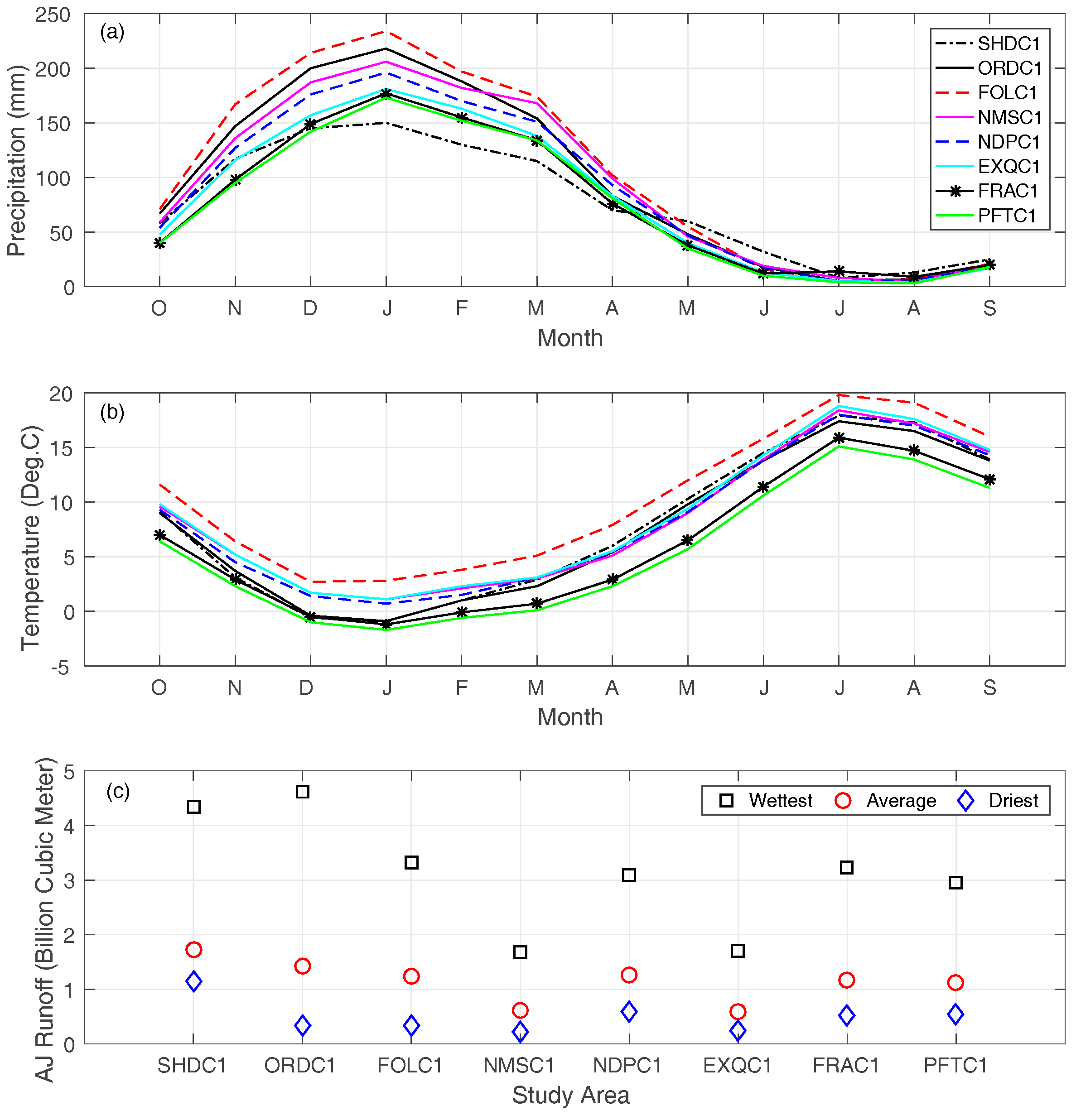
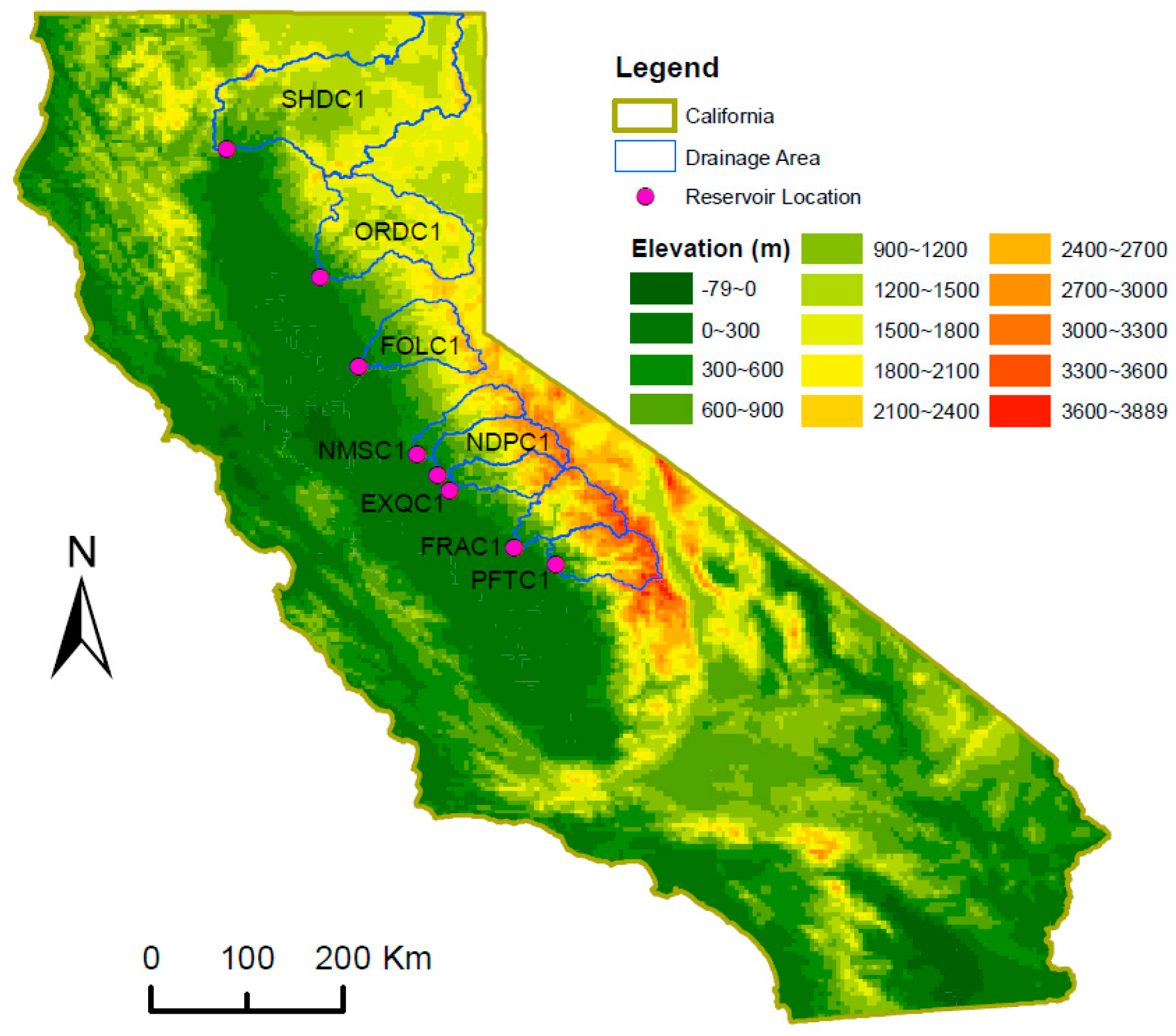
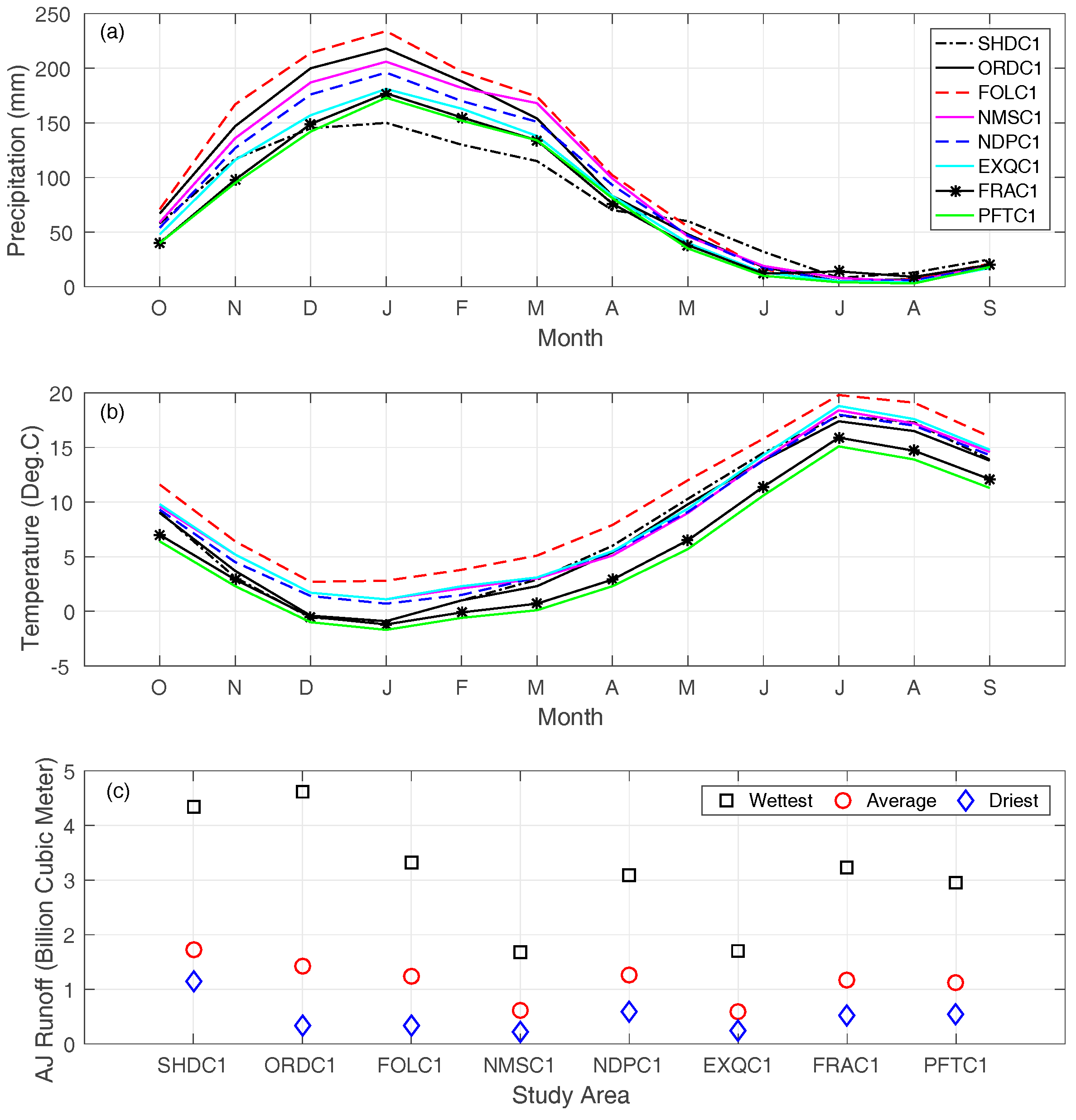
2.2. Study Watersheds and Datasets
2.3. Verification Strategy and Metrics
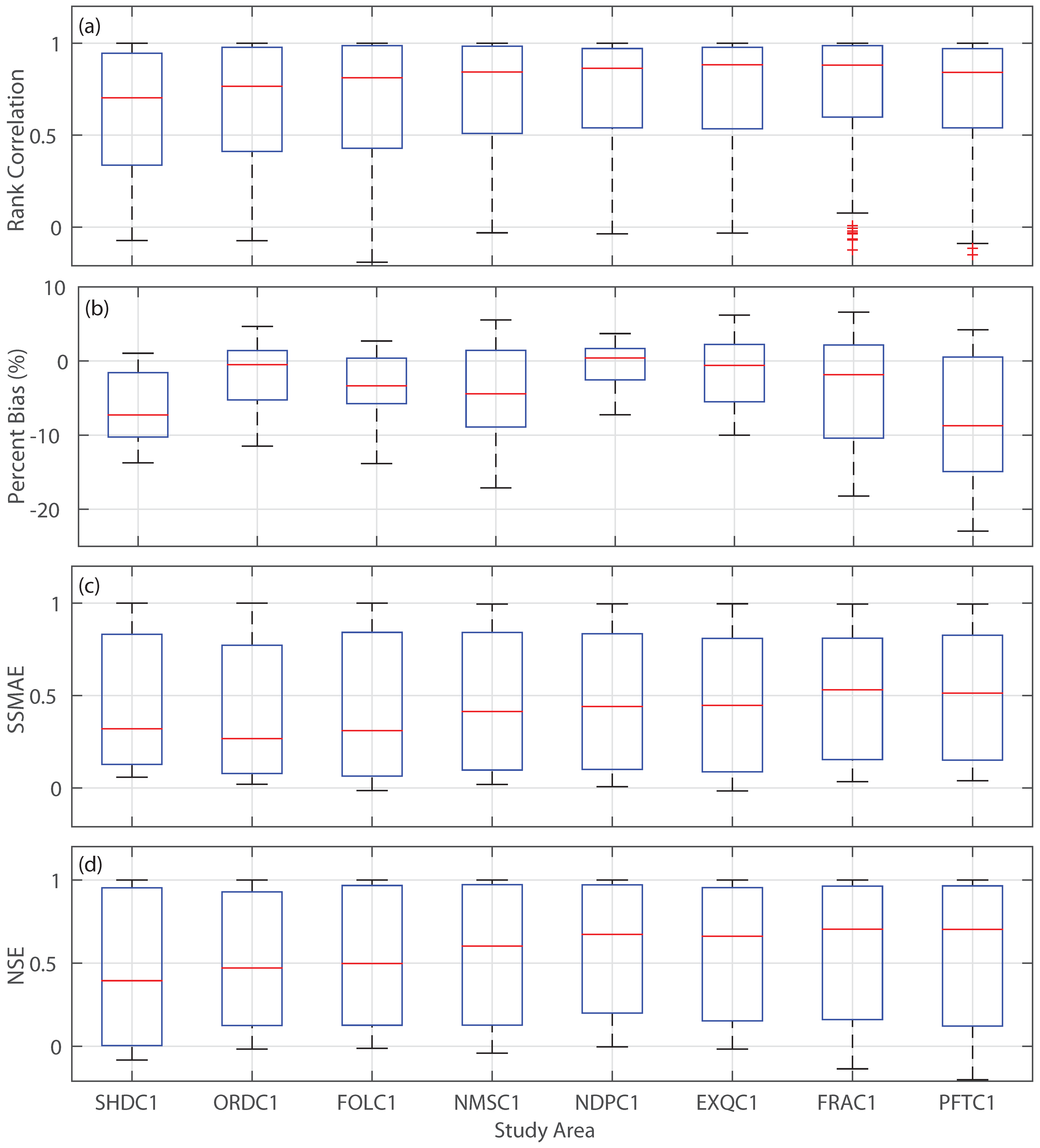
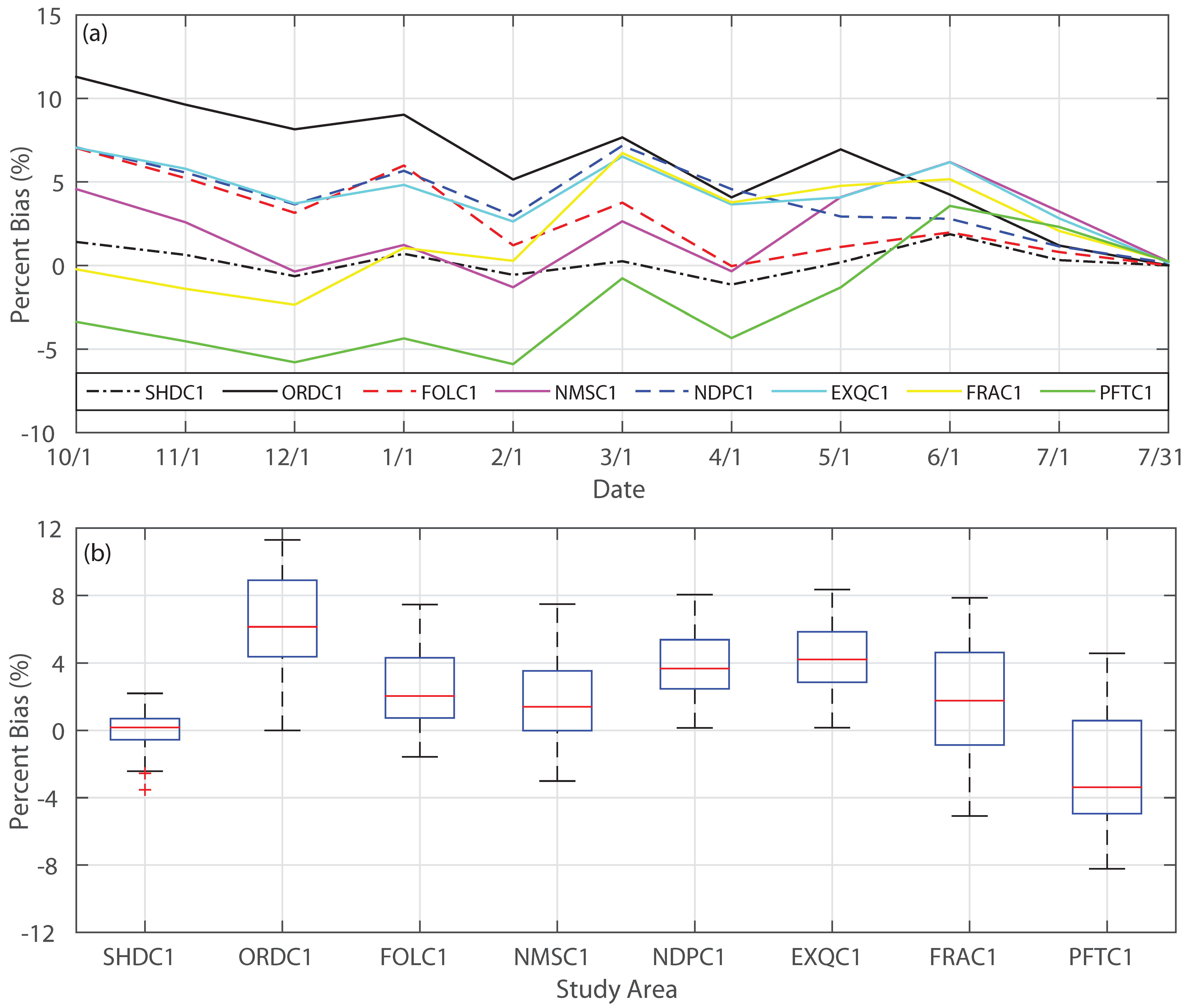
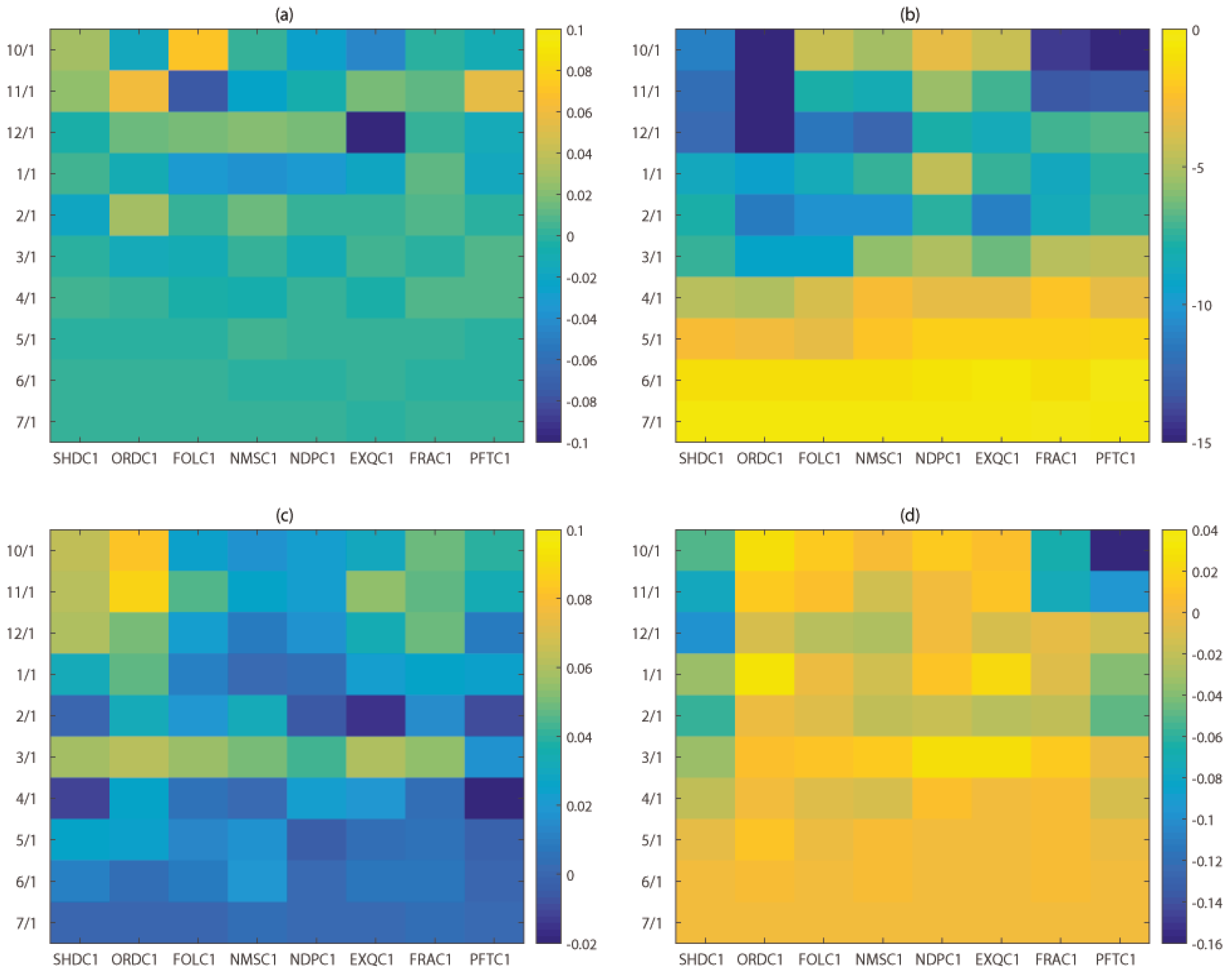
3. Results
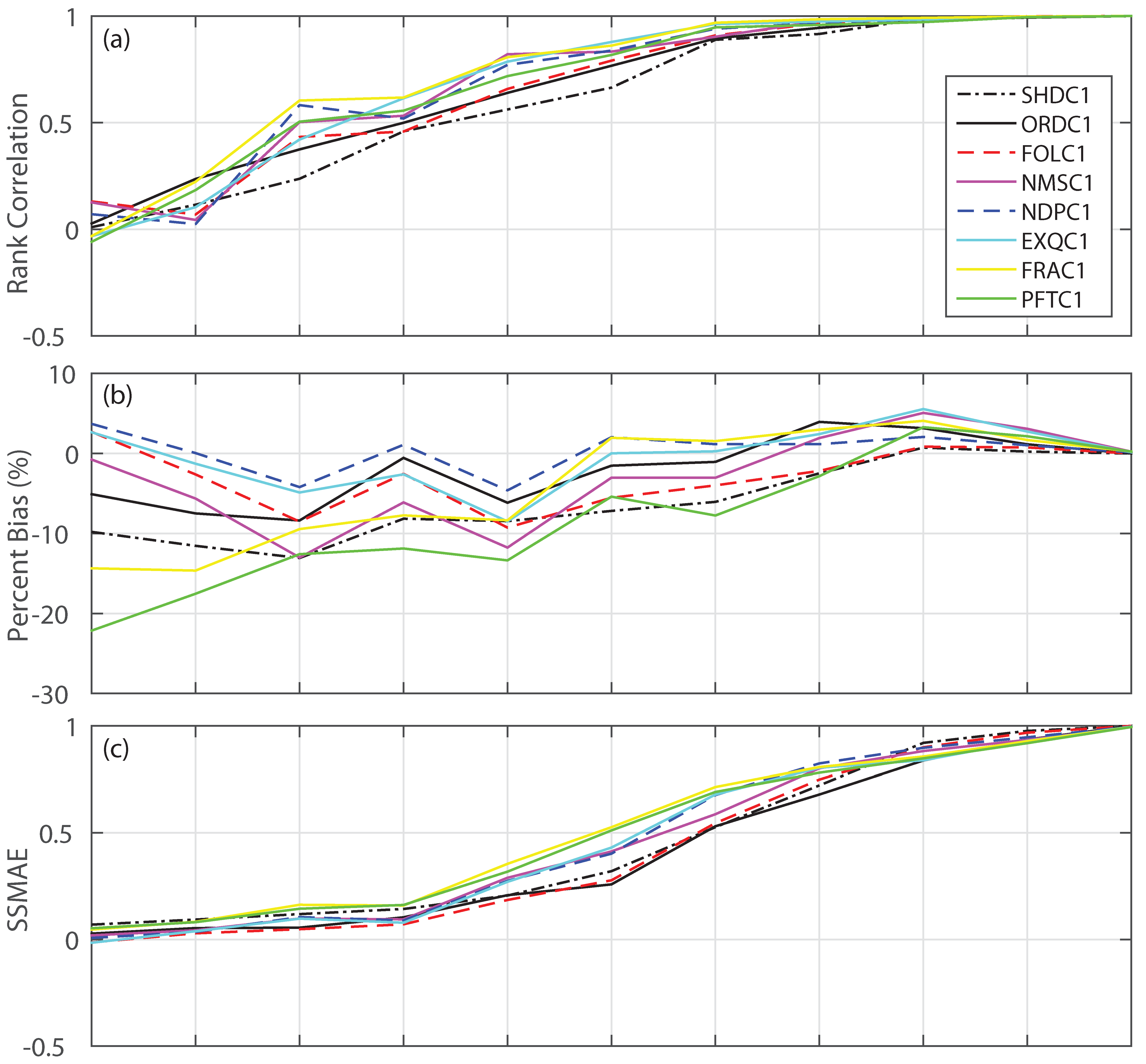
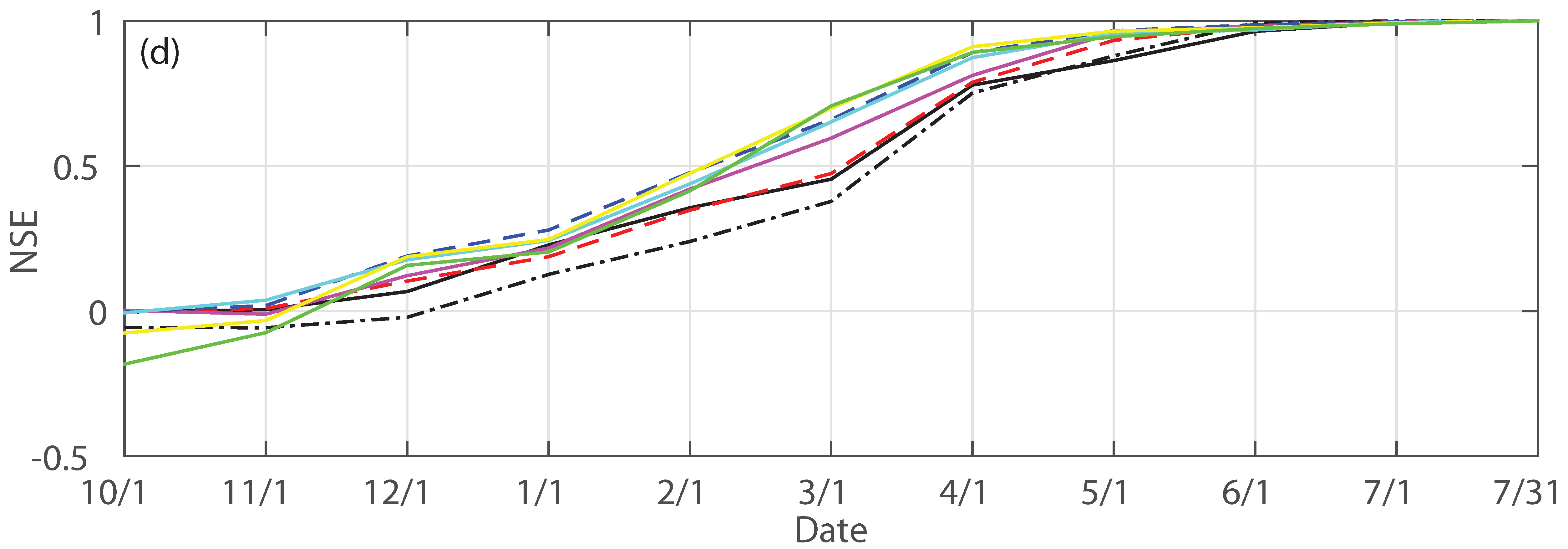
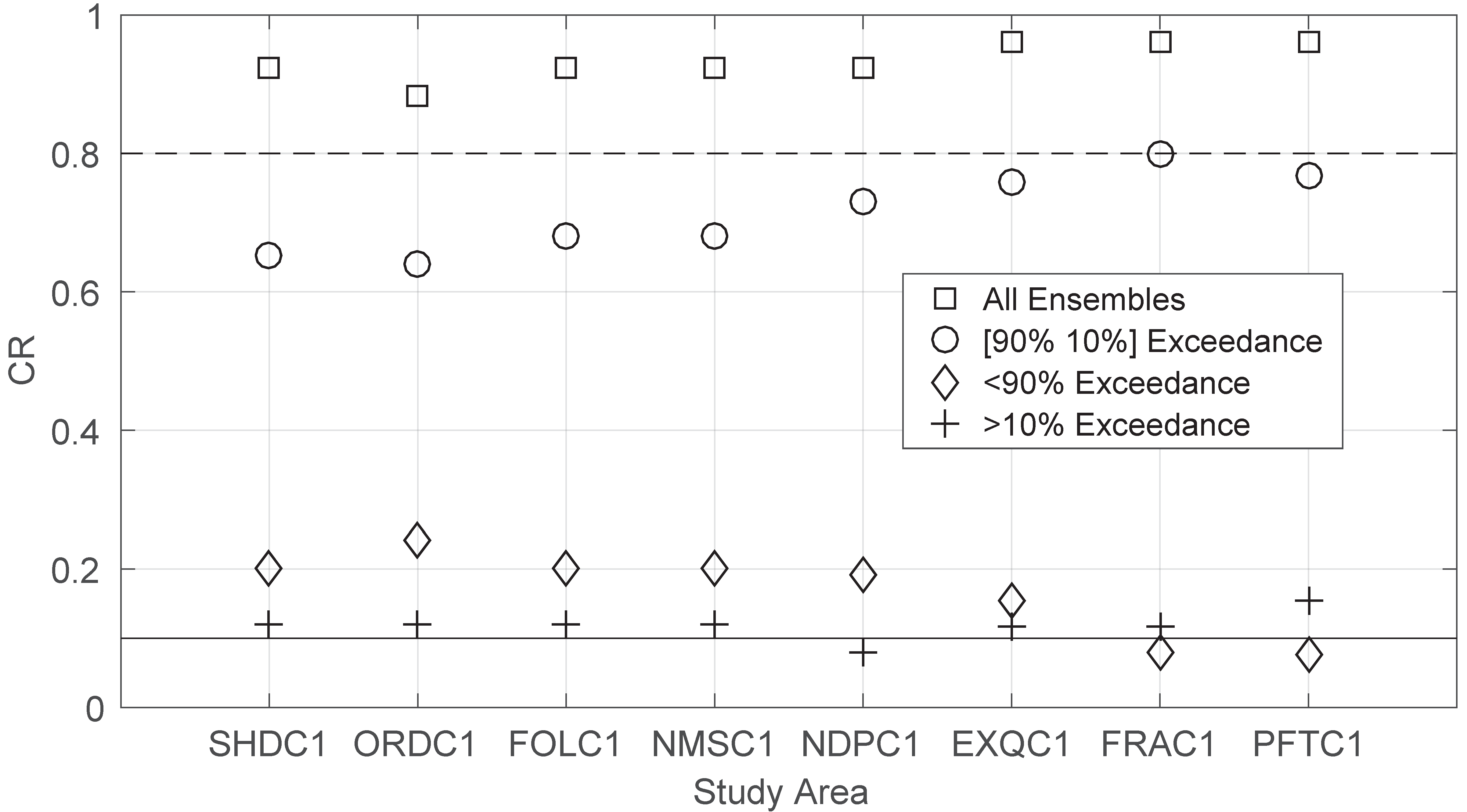
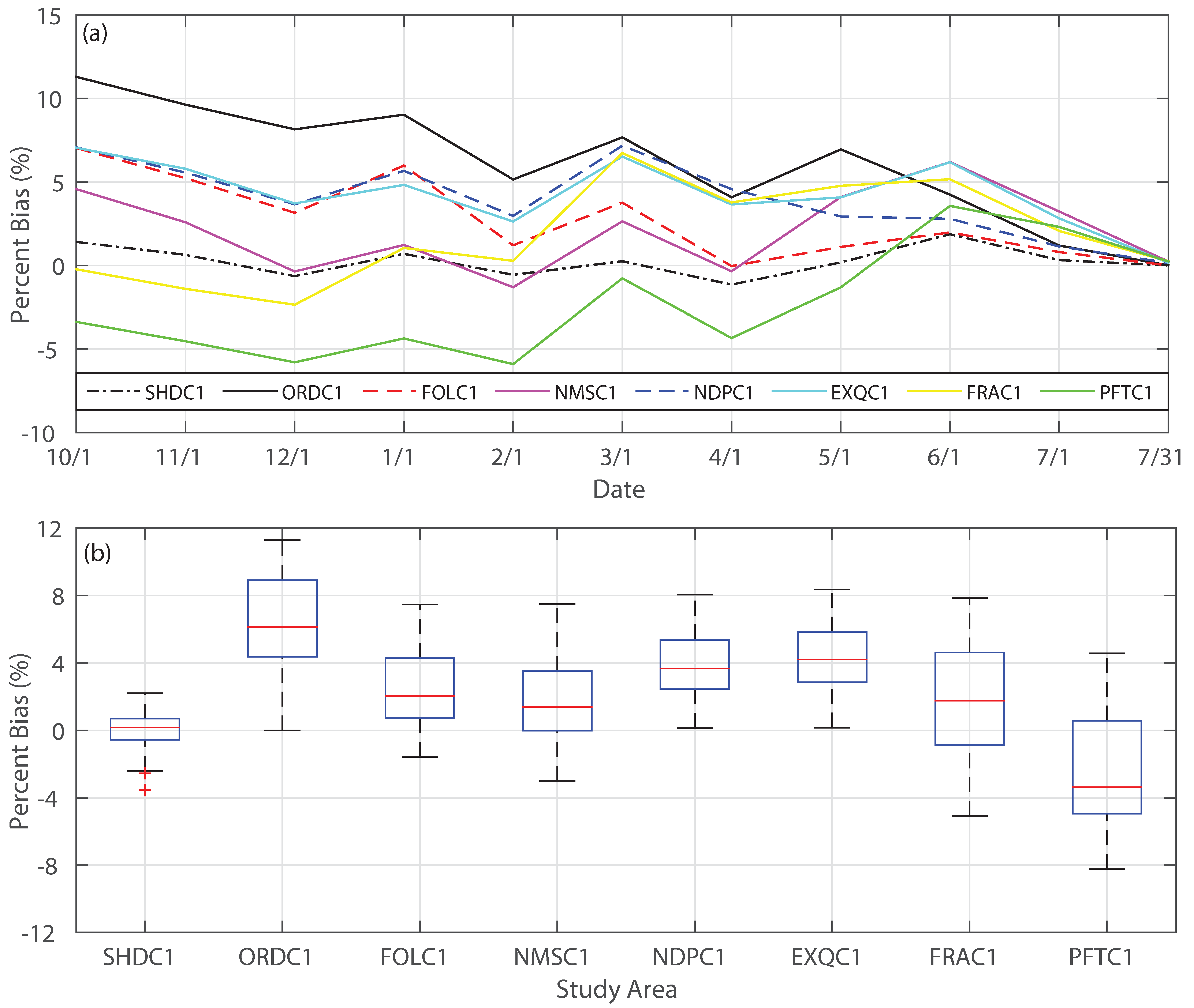
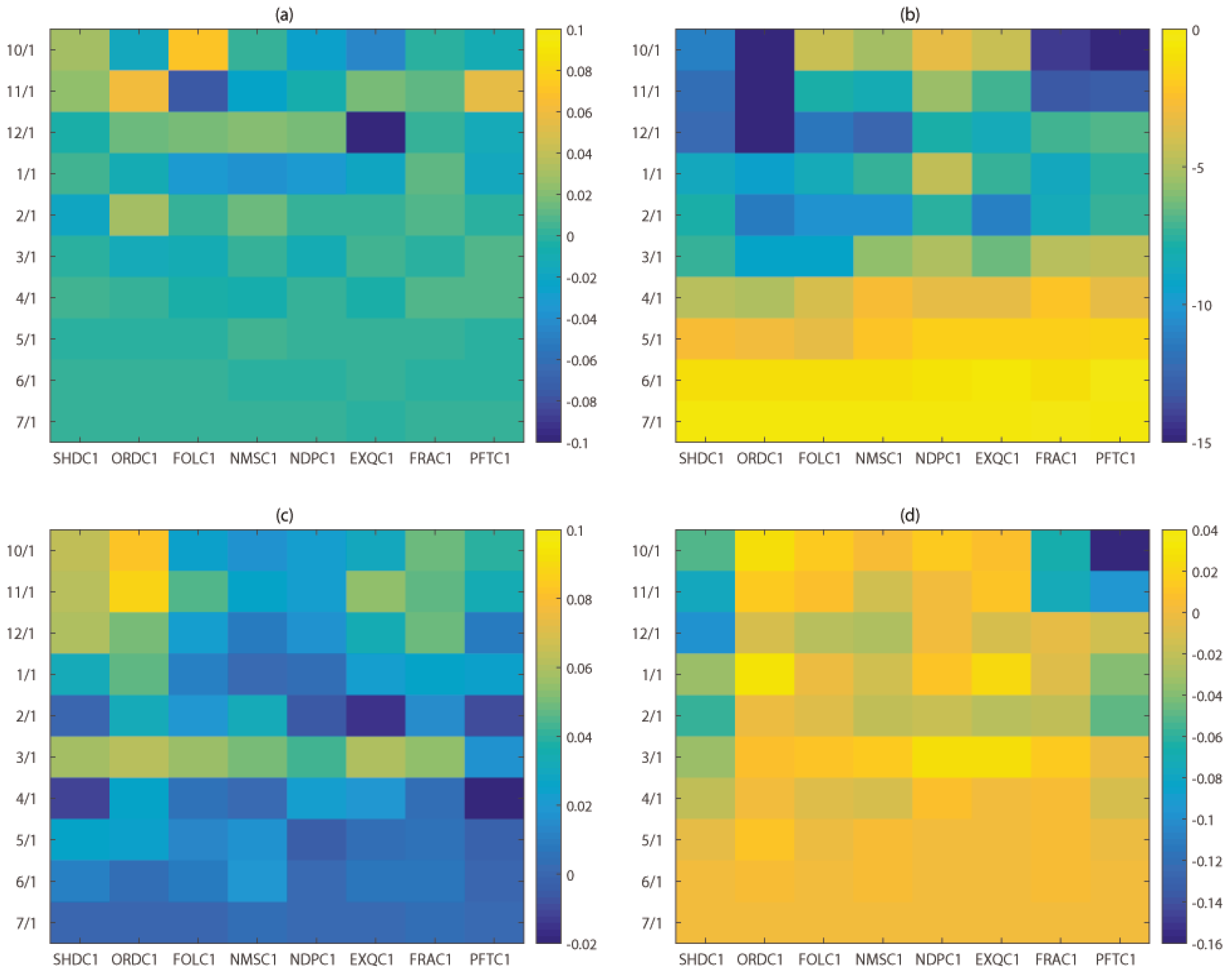
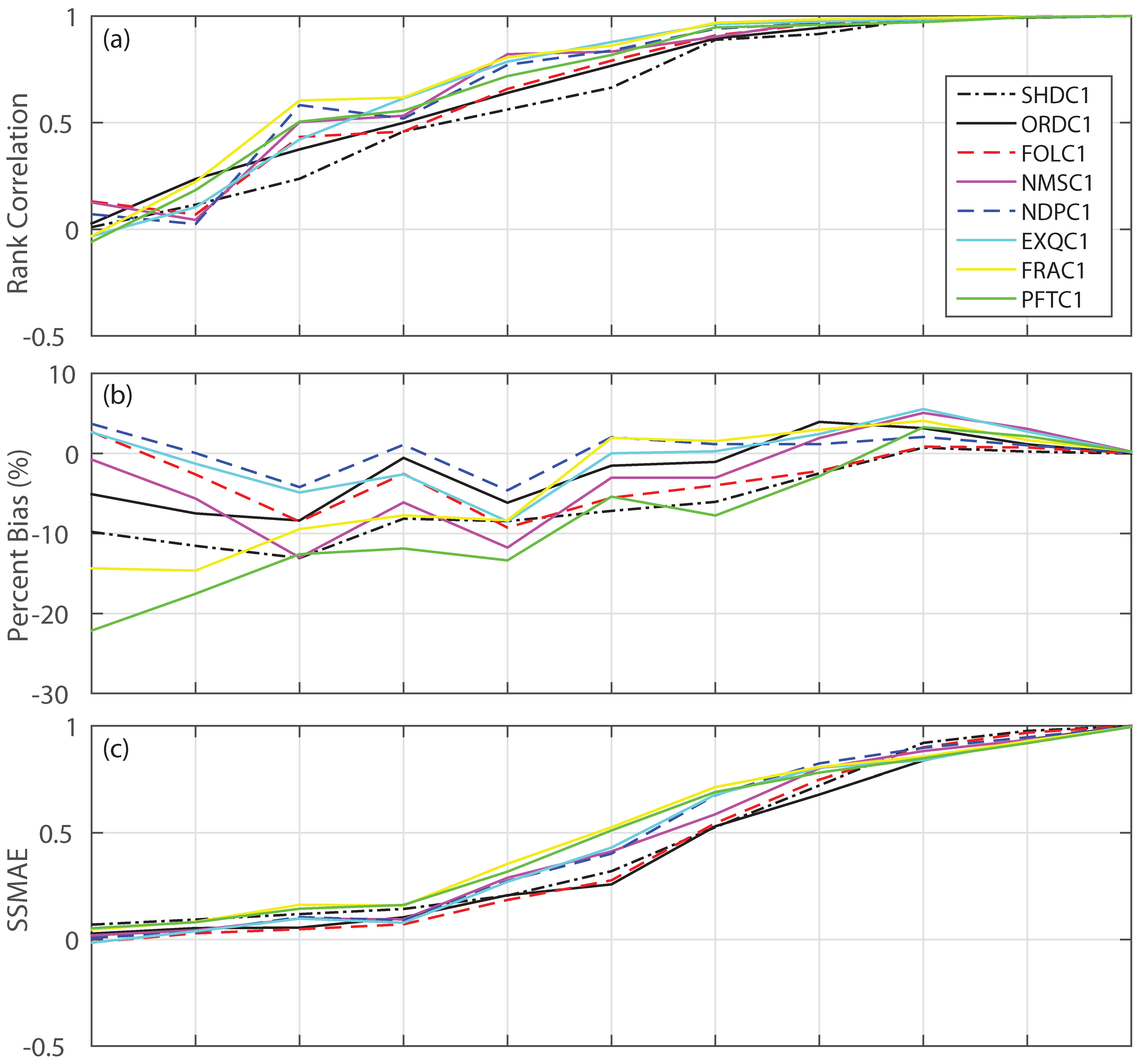
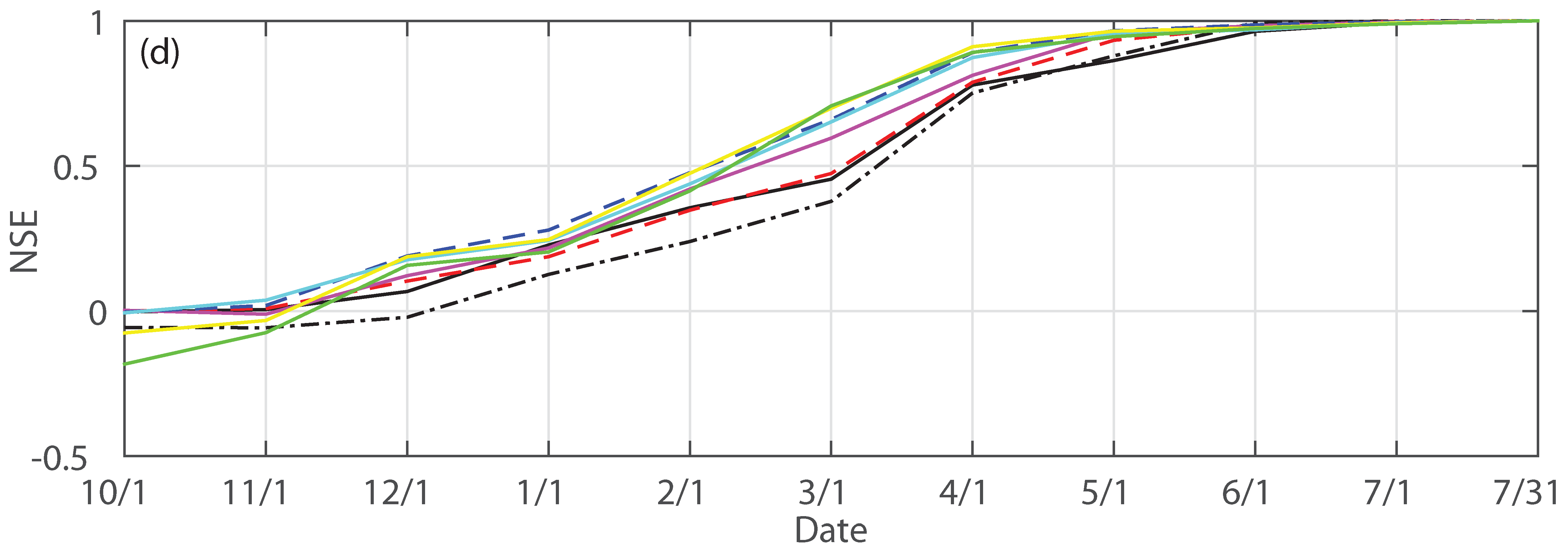
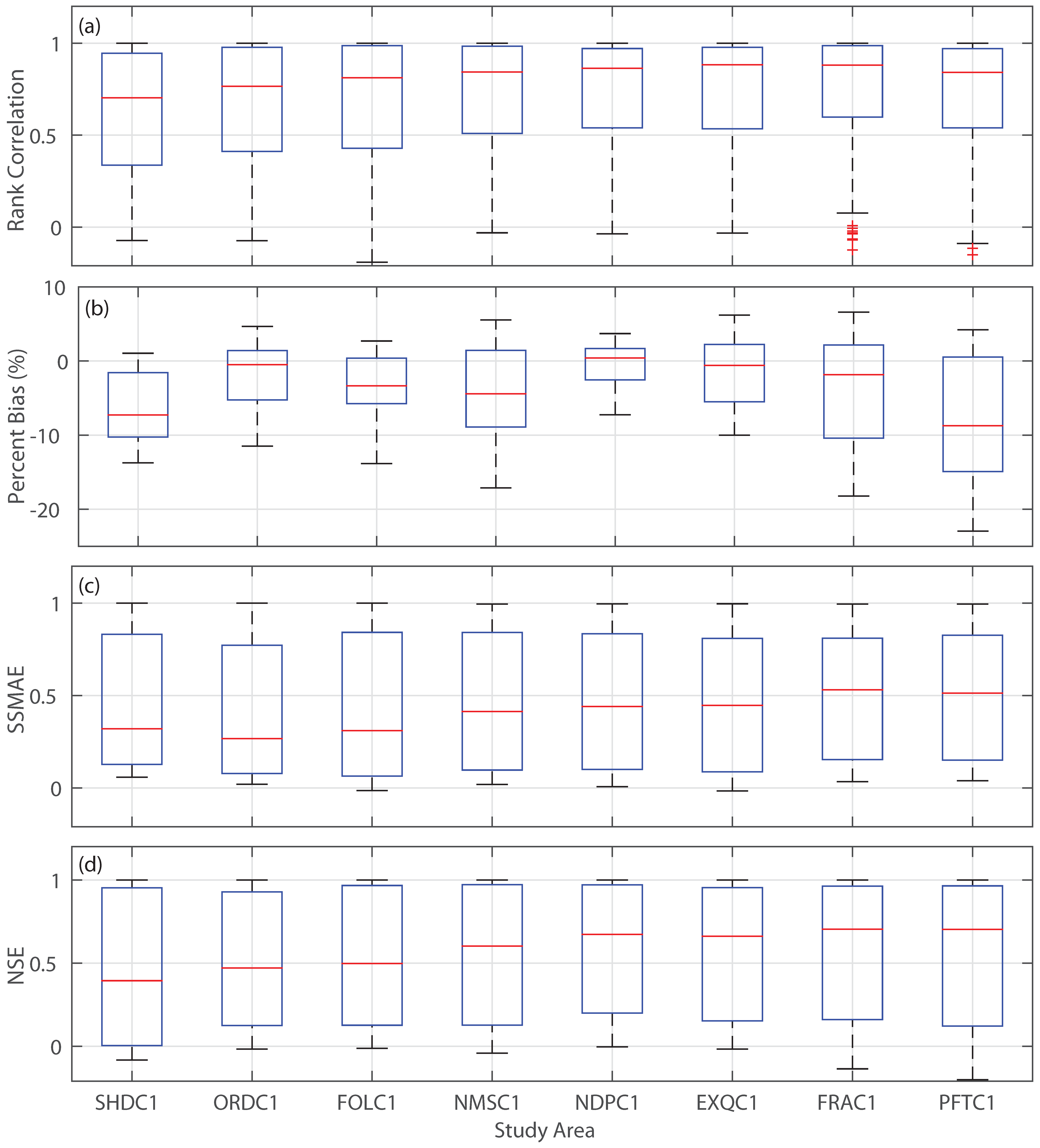
3.1. Forecast Skill and Reliability
3.2. Mean versus Median Forecast
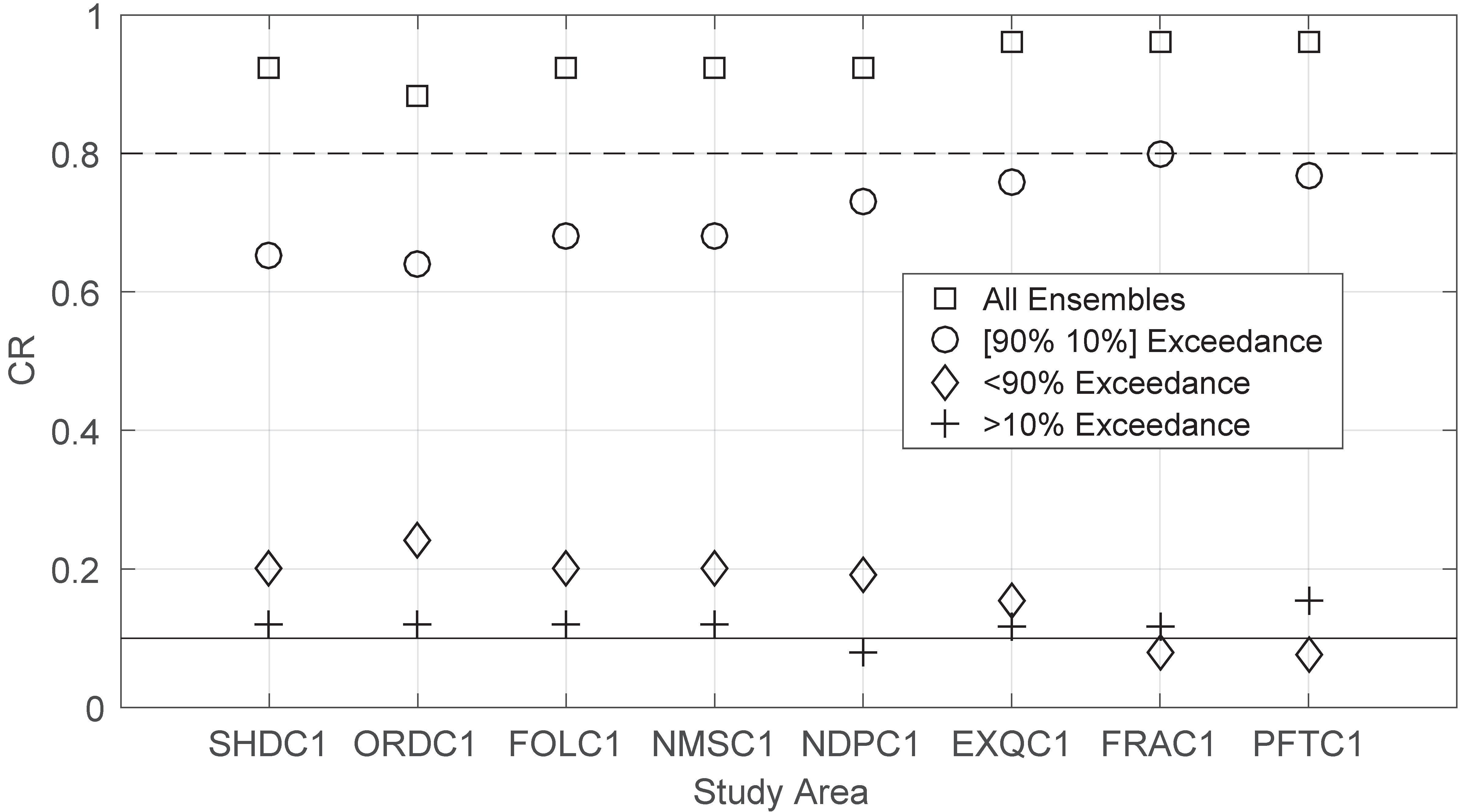
3.3. Impact of Extreme Conditions
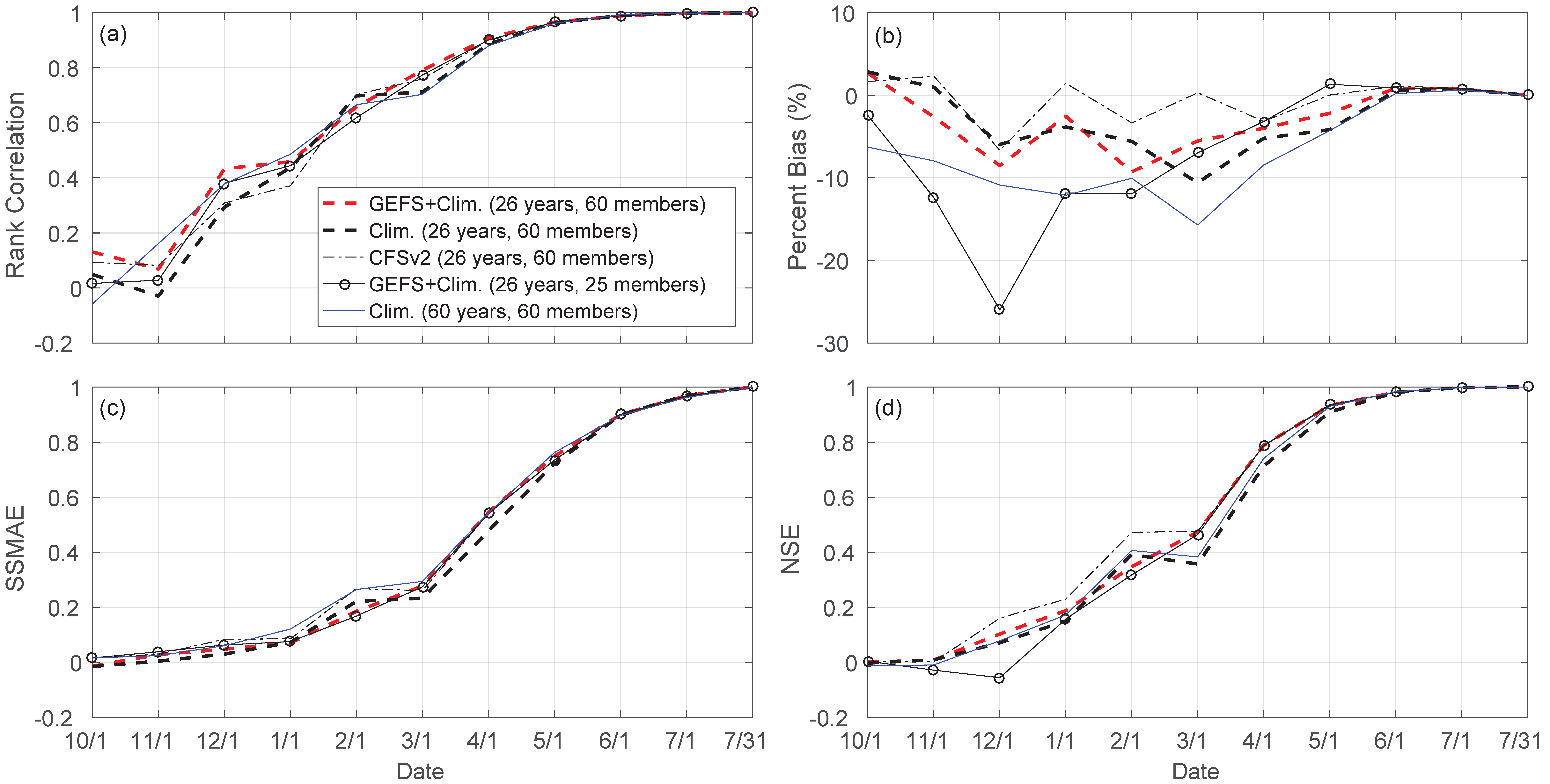
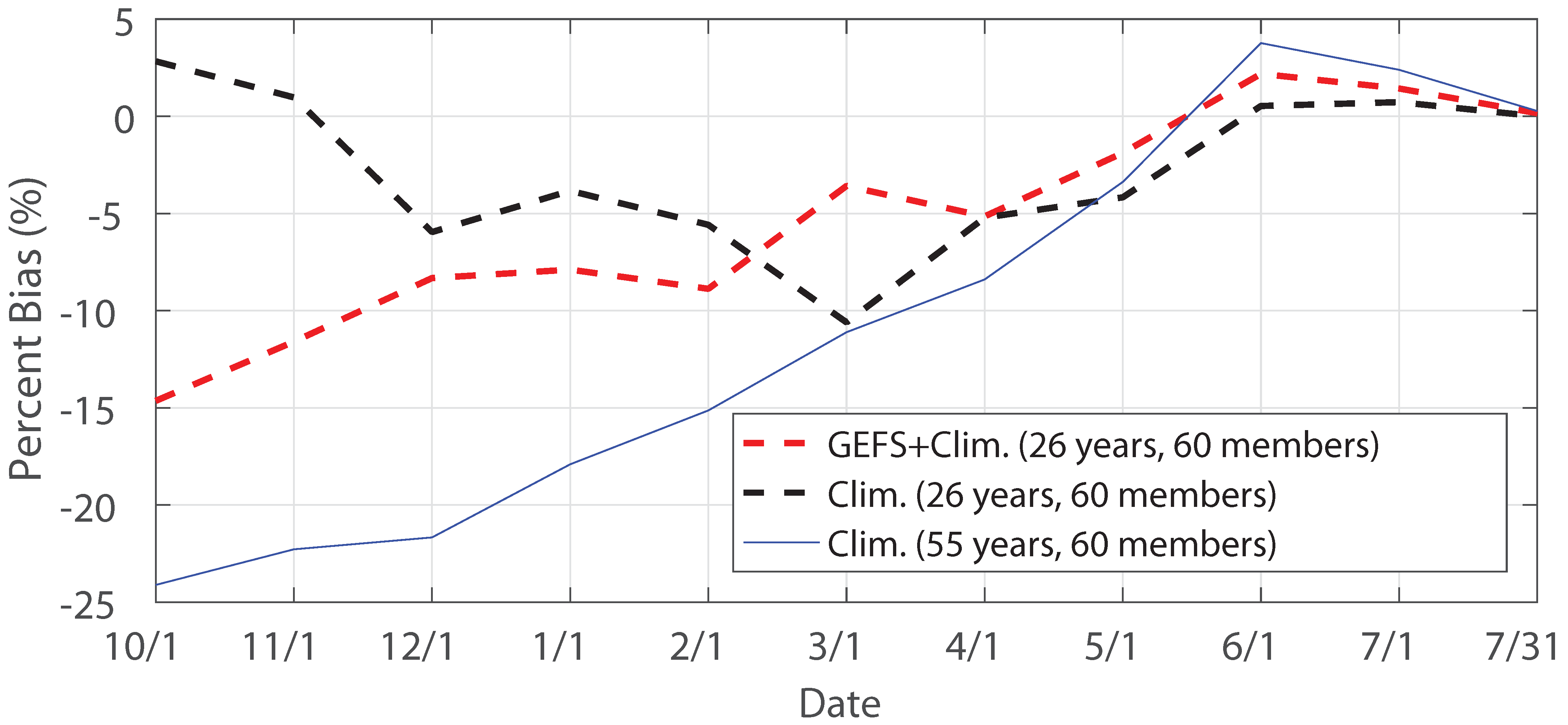
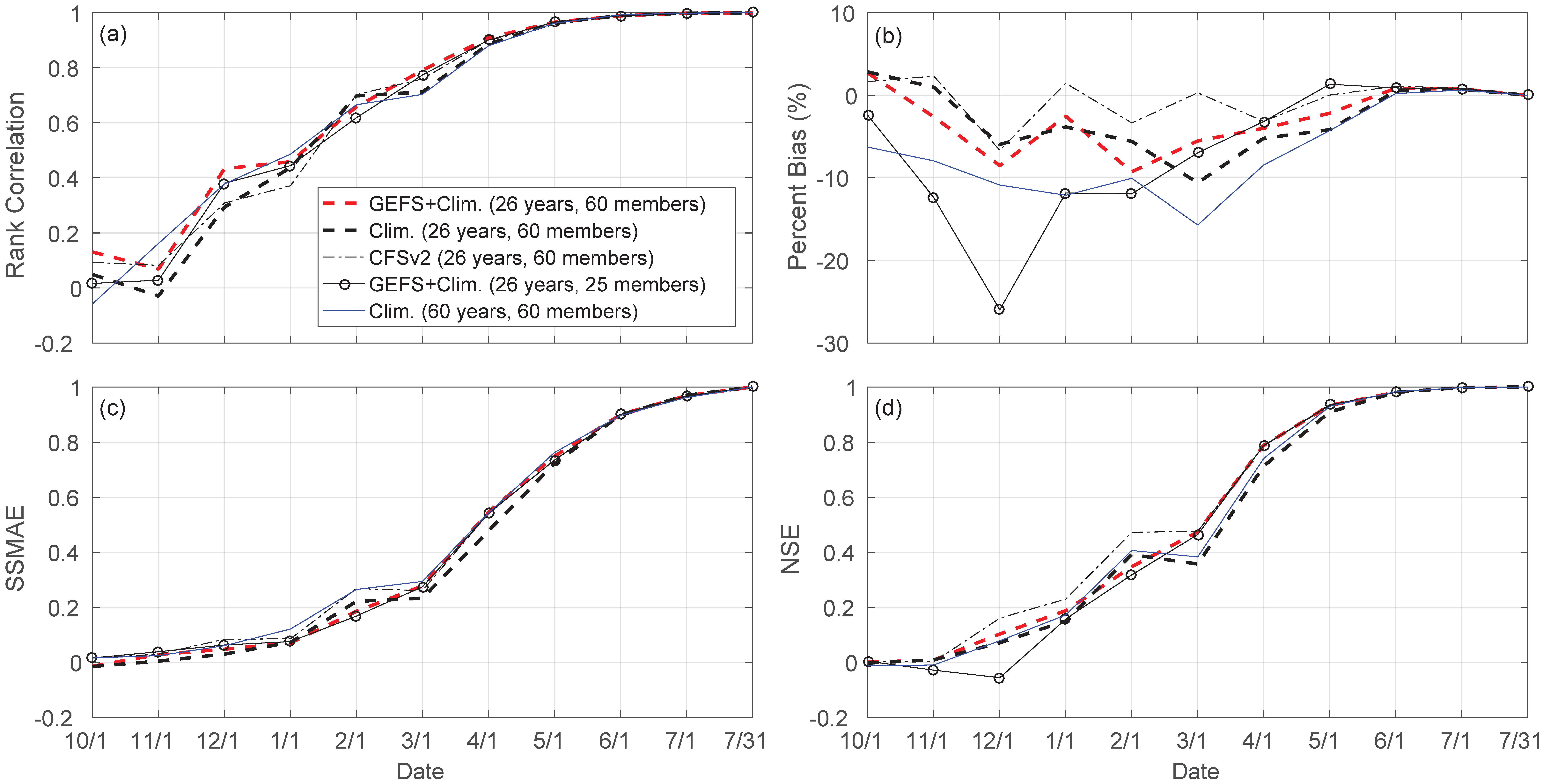
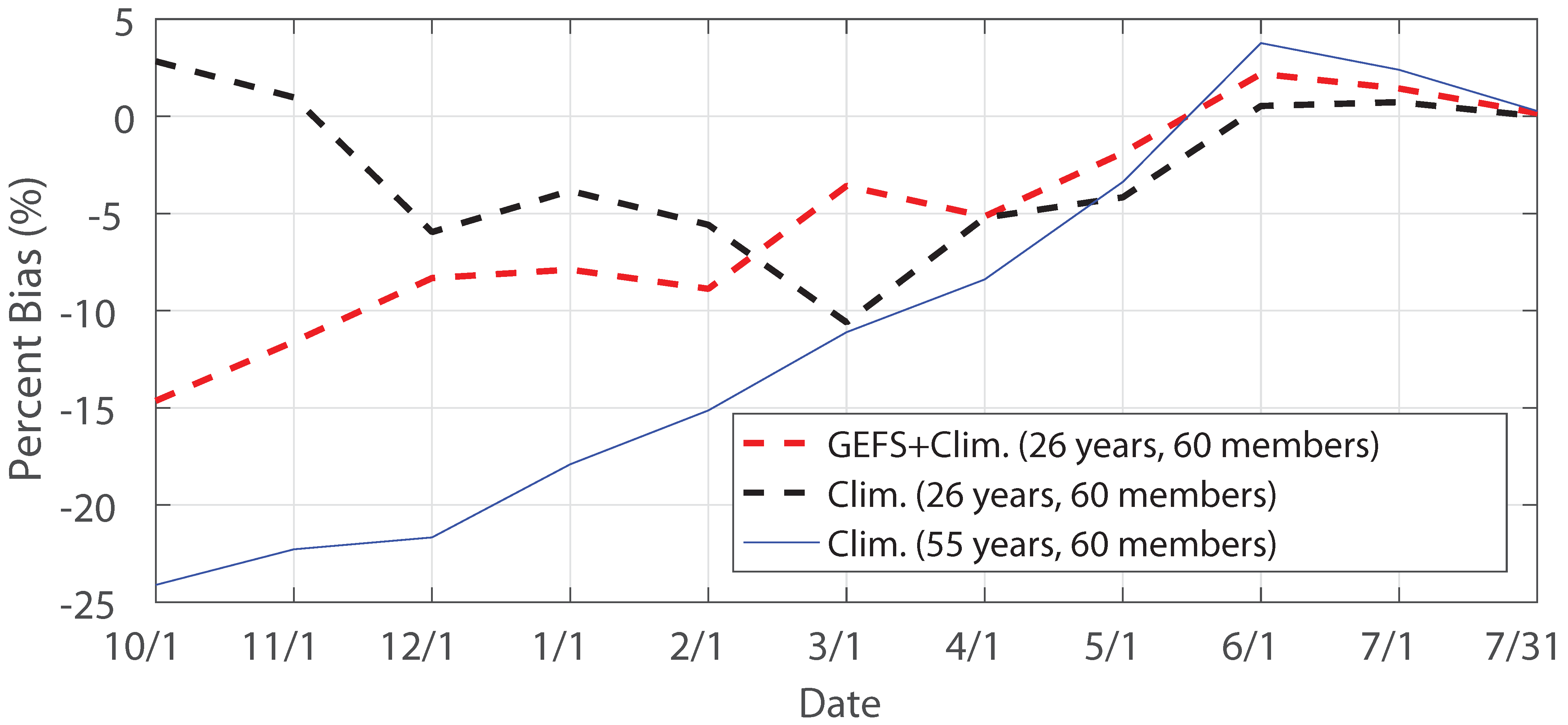
3.4. Impact of Forcing, Ensemble Size and Sample Size
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
- Shasta Lake: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=SHDC1&prodID=13 (accessed on 1 September 2016).
- Lake Oroville: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=ORDC1&prodID=13 (accessed on 1 September 2016).
- Folsom Lake: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=FOLC1&prodID=13 (accessed on 1 September 2016).
- New Melones Reservoir: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=NMSC1&prodID=13 (accessed on 1 September 2016).
- Don Pedro Reservoir: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=NDPC1&prodID=13 (accessed on 1 September 2016).
- Lake McClure: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=EXQC1&prodID=13 (accessed on 1 September 2016).
- Millerton Lake: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=FRAC1&prodID=13 (accessed on 1 September 2016).
- Pine Flat Reservoir: http://www.cnrfc.noaa.gov/ensembleProduct.php?id=PFTC1&prodID=13 (accessed on 1 September 2016).
References
- Twedt, T.M.; Burnash, R.J.C.; Ferral, R.L. Extended streamflow prediction during the California drought. In Proceedings of the 46th Annual Western Snow Conference, Otter Rock, OR, USA, 18–20 April 1978.
- Krzysztofowicz, R. Optimal water supply planning based on seasonal runoff forecasts. Water Resour. Res. 1986, 22, 313–321. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Expected utility, benefit, and loss criteria for seasonal water supply planning. Water Resour. Res. 1986, 22, 303–312. [Google Scholar] [CrossRef]
- Yao, H.; Georgakakos, A. Assessment of Folsom Lake response to historical and potential future climate scenarios: 2. Reservoir management. J. Hydrol. 2001, 249, 176–196. [Google Scholar] [CrossRef]
- Hamlet, A.F.; Huppert, D.; Lettenmaier, D.P. Economic value of long-lead streamflow forecasts for Columbia River hydropower. J. Water Resour. Plan. Manag. 2002, 128, 91–101. [Google Scholar] [CrossRef]
- Maurer, E.P.; Lettenmaier, D.P. Potential effects of long-lead hydrologic predictability on Missouri River main-stem reservoirs. J. Clim. 2004, 17, 174–186. [Google Scholar] [CrossRef]
- Brumbelow, K.; Georgakakos, A. Agricultural planning and irrigation management: The need for decision support. Clim. Rep. 2001, 1, 2–6. [Google Scholar]
- Hayes, M.; Svoboda, M.; Le Comte, D.; Redmond, K.T.; Pasteris, P. Drought monitoring: New tools for the 21st century. In Drought and Water Crises: Science, Technology, and Management Issues; Wilhite, D.A., Ed.; CRC Press: Boca Raton, FL, USA, 2005; p. 53. [Google Scholar]
- Smith, J.A.; Sheer, D.P.; Schaake, J. Use of hydrometeorological data in drought management: Potomac River basin case study. In Proceedings of the International Symposium on Hydrometeorology, Denver, CO, USA, 13–17 June 1982; pp. 347–354.
- Sheer, D.P. Analyzing the risk of drought: The occoquan experience. J. Am. Water Works Assoc. 1980, 72, 246–253. [Google Scholar]
- Zuzel, J.F.; Cox, L.M. A review of operational water supply forecasting techniques in areas of seasonal snowcover. In Proceedings of the 46th Annual Western Snow Conference, Otter Rock, OR, USA, 18–20 April 1978.
- Huber, A.L.; Robertson, D.C. Regression models in water supply forecasting. In Proceedings of the 50th Annual Western Snow Conference, Reno, NV, USA, 19–23 April 1982.
- Garen, D.C. Improved techniques in regression-based streamflow volume forecasting. J. Water Resour. Plan. Manag. 1992, 118, 654–670. [Google Scholar] [CrossRef]
- Svensson, C. Seasonal river flow forecasts for the United Kingdom using persistence and historical analogues. Hydrol. Sci. J. 2016, 61, 19–35. [Google Scholar] [CrossRef]
- Garen, D. ENSO indicators and long-range climate forecasts: Usage in seasonal streamflow volume forecasting in the western United States. Eos Trans. AGU 1998, 79, 45. [Google Scholar]
- Moradkhani, H.; Meier, M. Long-lead water supply forecast using large-scale climate predictors and independent component analysis. J. Hydrol. Eng. 2010, 15, 744–762. [Google Scholar] [CrossRef]
- Oubeidillah, A.A.; Tootle, G.A.; Moser, C.; Piechota, T.; Lamb, K. Upper Colorado River and Great Basin streamflow and snowpack forecasting using Pacific oceanic–atmospheric variability. J. Hydrol. 2011, 410, 169–177. [Google Scholar] [CrossRef]
- Tootle, G.A.; Piechota, T.C. Suwannee River long range streamflow forecasts based on seasonal climate predictors. J. Am. Water Resour. Assoc. 2004, 40, 523–532. [Google Scholar] [CrossRef]
- Piechota, T.C.; Chiew, F.H.; Dracup, J.A.; McMahon, T.A. Seasonal streamflow forecasting in eastern Australia and the El Niño–Southern Oscillation. Water Resour. Res. 1998, 34, 3035–3044. [Google Scholar] [CrossRef]
- Tootle, G.A.; Singh, A.K.; Piechota, T.C.; Farnham, I. Long lead-time forecasting of US streamflow using partial least squares regression. J. Hydrol. Eng. 2007, 12, 442–451. [Google Scholar] [CrossRef]
- Piechota, T.C.; Dracup, J.A. Long-range streamflow forecasting using El Niño-Southern Oscillation indicators. J. Hydrol. Eng. 1999, 4, 144–151. [Google Scholar] [CrossRef]
- Grantz, K.; Rajagopalan, B.; Clark, M.; Zagona, E. A technique for incorporating large-scale climate information in basin-scale ensemble streamflow forecasts. Water Resour. Res. 2005, 41, W10410. [Google Scholar] [CrossRef]
- Twedt, T.M.; Schaake, J.C., Jr.; Peck, E.L. National Weather Service extended streamflow prediction. In Proceedings of the 45th Annual Western Snow Conference, Albuquerque, NM, USA, 18–21 April 1977.
- Day, G.N. Extended streamflow forecasting using NWSRFS. J. Water Resour. Plan. Manag. 1985, 111, 157–170. [Google Scholar] [CrossRef]
- Hartman, R.K.; Henkel, A.F. Modernization of statistical procedures for water supply forecasting. In Proceedings of the 62nd Annual Western Snow Conference, Sante Fe, NM, USA, 18–21 April 1994.
- Hamlet, A.F.; Lettenmaier, D.P. Columbia River streamflow forecasting based on ENSO and PDO climate signals. J. Water Resour. Plan. Manag. 1999, 125, 333–341. [Google Scholar] [CrossRef]
- Souza Filho, F.A.; Lall, U. Seasonal to interannual ensemble streamflow forecasts for Ceara, Brazil: Applications of a multivariate, semiparametric algorithm. Water Resour. Res. 2003, 39, 1307. [Google Scholar] [CrossRef]
- Najafi, M.R.; Moradkhani, H.; Piechota, T.C. Ensemble streamflow prediction: Climate signal weighting methods vs. Climate forecast system reanalysis. J. Hydrol. 2012, 442, 105–116. [Google Scholar] [CrossRef]
- Wood, A.W.; Schaake, J.C. Correcting errors in streamflow forecast ensemble mean and spread. J. Hydrometeorol. 2008, 9, 132–148. [Google Scholar] [CrossRef]
- Wood, A.W.; Kumar, A.; Lettenmaier, D.P. A retrospective assessment of National Centers for Environmental Prediction climate model–based ensemble hydrologic forecasting in the western United States. J. Geophys. Res. Atmos. 2005, 110, D04105. [Google Scholar] [CrossRef]
- Wood, A.W.; Lettenmaier, D.P. A test bed for new seasonal hydrologic forecasting approaches in the western United States. Bull. Am. Meteorol. Soc. 2006, 87, 1699–1712. [Google Scholar] [CrossRef]
- Wood, A.W.; Maurer, E.P.; Kumar, A.; Lettenmaier, D.P. Long-range experimental hydrologic forecasting for the eastern United States. J. Geophys. Res. Atmos. 2002, 107, 4429. [Google Scholar] [CrossRef]
- DeChant, C.M.; Moradkhani, H. Toward a reliable prediction of seasonal forecast uncertainty: Addressing model and initial condition uncertainty with ensemble data assimilation and sequential bayesian combination. J. Hydrol. 2014, 519, 2967–2977. [Google Scholar] [CrossRef]
- Tang, Q.; Lettenmaier, D.P. Use of satellite snow-cover data for streamflow prediction in the Feather River Basin, California. Int. J. Remote Sens. 2010, 31, 3745–3762. [Google Scholar] [CrossRef]
- McGuire, M.; Wood, A.W.; Hamlet, A.F.; Lettenmaier, D.P. Use of satellite data for streamflow and reservoir storage forecasts in the Snake River Basin. J. Water Resour. Plan. Manag. 2006, 132, 97–110. [Google Scholar] [CrossRef]
- DeChant, C.M.; Moradkhani, H. Improving the characterization of initial condition for ensemble streamflow prediction using data assimilation. Hydrol. Earth Syst. Sci. 2011, 15, 3399–3410. [Google Scholar] [CrossRef]
- Li, H.; Luo, L.; Wood, E.F.; Schaake, J. The role of initial conditions and forcing uncertainties in seasonal hydrologic forecasting. J. Geophys. Res. Atmos. 2009, 114, D04114. [Google Scholar] [CrossRef]
- Wood, A.W.; Lettenmaier, D.P. An ensemble approach for attribution of hydrologic prediction uncertainty. Geophys. Res. Lett. 2008, 35, L14401. [Google Scholar] [CrossRef]
- Shi, X.; Wood, A.W.; Lettenmaier, D.P. How essential is hydrologic model calibration to seasonal streamflow forecasting? J. Hydrometeorol. 2008, 9, 1350–1363. [Google Scholar] [CrossRef]
- Wood, A.W.; Hopson, T.; Newman, A.; Brekke, L.; Arnold, J.; Clark, M. Quantifying streamflow forecast skill elasticity to initial condition and climate prediction skill. J. Hydrometeorol. 2016, 17, 651–668. [Google Scholar] [CrossRef]
- Rosenberg, E.A.; Wood, A.W.; Steinemann, A.C. Informing hydrometric network design for statistical seasonal streamflow forecasts. J. Hydrometeorol. 2013, 14, 1587–1604. [Google Scholar] [CrossRef]
- Rosenberg, E.A.; Wood, A.W.; Steinemann, A.C. Statistical applications of physically based hydrologic models to seasonal streamflow forecasts. Water Resour. Res. 2011, 47, W00H14. [Google Scholar] [CrossRef]
- Najafi, M.R.; Moradkhani, H. Ensemble combination of seasonal streamflow forecasts. J. Hydrol. Eng. 2015, 21, 04015043. [Google Scholar] [CrossRef]
- He, M.; Gautam, M. Variability and trends in precipitation, temperature and drought indices in the State of California. Hydrology 2016, 3, 14. [Google Scholar] [CrossRef]
- Pagano, T.; Garen, D.; Sorooshian, S. Evaluation of official western US seasonal water supply outlooks, 1922–2002. J. Hydrometeorol. 2004, 5, 896–909. [Google Scholar] [CrossRef]
- Demargne, J.; Wu, L.; Regonda, S.K.; Brown, J.D.; Lee, H.; He, M.; Seo, D.-J.; Hartman, R.; Herr, H.D.; Fresch, M. The science of NOAA’s operational Hydrologic Ensemble Forecast Service. Bull. Am. Meteorol. Soc. 2014, 95, 79–98. [Google Scholar] [CrossRef]
- Harrison, B.; Bales, R. Skill assessment of water supply forecasts for western Sierra Nevada watersheds. J. Hydrol. Eng. 2016, 21, 04016002. [Google Scholar] [CrossRef]
- Demeritt, D.; Cloke, H.; Pappenberger, F.; Thielen, J.; Bartholmes, J.; Ramos, M.-H. Ensemble predictions and perceptions of risk, uncertainty, and error in flood forecasting. Environ. Hazards 2007, 7, 115–127. [Google Scholar] [CrossRef]
- Cloke, H.; Pappenberger, F. Ensemble flood forecasting: A review. J. Hydrol. 2009, 375, 613–626. [Google Scholar] [CrossRef]
- Demeritt, D.; Nobert, S.; Cloke, H.; Pappenberger, F. Challenges in communicating and using ensembles in operational flood forecasting. Meteorol. Appl. 2010, 17, 209–222. [Google Scholar] [CrossRef]
- Ramos, M.H.; Mathevet, T.; Thielen, J.; Pappenberger, F. Communicating uncertainty in hydro-meteorological forecasts: Mission impossible? Meteorol. Appl. 2010, 17, 223–235. [Google Scholar] [CrossRef]
- Pagano, T.C.; Wood, A.W.; Ramos, M.-H.; Cloke, H.L.; Pappenberger, F.; Clark, M.P.; Cranston, M.; Kavetski, D.; Mathevet, T.; Sorooshian, S. Challenges of operational river forecasting. J. Hydrometeorol. 2014, 15, 1692–1707. [Google Scholar] [CrossRef]
- Hamill, T.M.; Bates, G.T.; Whitaker, J.S.; Murray, D.R.; Fiorino, M.; Galarneau, T.J., Jr.; Zhu, Y.; Lapenta, W. NOAA’s second-generation global medium-range ensemble reforecast dataset. Bull. Am. Meteorol. Soc. 2013, 94, 1553–1565. [Google Scholar] [CrossRef]
- Wu, L.; Seo, D.-J.; Demargne, J.; Brown, J.D.; Cong, S.; Schaake, J. Generation of ensemble precipitation forecast from single-valued quantitative precipitation forecast for hydrologic ensemble prediction. J. Hydrol. 2011, 399, 281–298. [Google Scholar] [CrossRef]
- Anderson, E.A. National Weather Service River Forecast System—Snow accumulation and ablation model. In Technical Memorandum NWS HYDRO-17; U.S. Dept. of Commerce, National Oceanic and Atmospheric Administration, National Weather Service: Silver Spring, MD, USA, 1973. [Google Scholar]
- Burnash, R.J.; Ferral, R.L.; McGuire, R.A. A Generalized Streamflow Simulation System: Conceptual Modeling for Digital Computers; U.S. Department of Commerce, National Weather Service: Sacramento, CA, USA, 1973.
- Duan, Q.; Sorooshian, S.; Gupta, V.K. Optimal use of the SCE-UA global optimization method for calibrating watershed models. J. Hydrol. 1994, 158, 265–284. [Google Scholar] [CrossRef]
- Smith, M.B.; Laurine, D.P.; Koren, V.I.; Reed, S.M.; Zhang, Z. Hydrologic model calibration in the National Weather Service. In Calibration of Watershed Models; Duan, Q., Gupta, H., Sorooshian, S., Rousseau, A., Turcotte, R., Eds.; American Geophysical Union: Washington, DC, USA, 2003; pp. 133–152. [Google Scholar]
- Kitzmiller, D.; Van Cooten, S.; Ding, F.; Howard, K.; Langston, C.; Zhang, J.; Moser, H.; Zhang, Y.; Gourley, J.J.; Kim, D. Evolving multisensor precipitation estimation methods: Their impacts on flow prediction using a distributed hydrologic model. J. Hydrometeorol. 2011, 12, 1414–1431. [Google Scholar] [CrossRef]
- Seo, D.-J.; Herr, H.; Schaake, J. A statistical post-processor for accounting of hydrologic uncertainty in short-range ensemble streamflow prediction. Hydrol. Earth Syst. Sci. Discuss. 2006, 3, 1987–2035. [Google Scholar] [CrossRef]
- Brown, J.D.; Wu, L.; He, M.; Regonda, S.; Lee, H.; Seo, D.-J. Verification of temperature, precipitation, and streamflow forecasts from the NOAA/NWS Hydrologic Ensemble Forecast Service (HEFS): 1. Experimental design and forcing verification. J. Hydrol. 2014, 519, 2869–2889. [Google Scholar] [CrossRef]
- Brown, J.D.; He, M.; Regonda, S.; Wu, L.; Lee, H.; Seo, D.-J. Verification of temperature, precipitation, and streamflow forecasts from the NOAA/NWS Hydrologic Ensemble Forecast Service (HEFS): 2. Streamflow verification. J. Hydrol. 2014, 519, 2847–2868. [Google Scholar] [CrossRef]
- Mao, Y.; Nijssen, B.; Lettenmaier, D.P. Is climate change implicated in the 2013–2014 California drought? A hydrologic perspective. Geophys. Res. Lett. 2015, 42, 2805–2813. [Google Scholar] [CrossRef]
- Franz, K.J.; Hogue, T. Evaluating uncertainty estimates in hydrologic models: Borrowing measures from the forecast verification community. Hydrol. Earth Syst. Sci. 2011, 15, 3367. [Google Scholar] [CrossRef] [Green Version]
- Lehmann, E.L.; D’abrera, H. Nonparametrics: Statistical Methods Based on Ranks; Holden-Day: San Francisco, CA, USA, 1975; p. 457. [Google Scholar]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Xiong, L.; O’Connor, K.M. An empirical method to improve the prediction limits of the GLUE methodology in rainfall–runoff modeling. J. Hydrol. 2008, 349, 115–124. [Google Scholar] [CrossRef]
- He, M.; Hogue, T.S.; Franz, K.J.; Margulis, S.A.; Vrugt, J.A. Characterizing parameter sensitivity and uncertainty for a snow model across hydroclimatic regimes. Adv. Water Resour. 2011, 34, 114–127. [Google Scholar] [CrossRef]
- Saha, S.; Moorthi, S.; Wu, X.; Wang, J.; Nadiga, S.; Tripp, P.; Behringer, D.; Hou, Y.-T.; Chuang, H.-Y.; Iredell, M. The NCEP Climate Forecast System version 2. J. Clim. 2014, 27, 2185–2208. [Google Scholar] [CrossRef]
- Brown, J. Verification of Temperature, Precipitation and Streamflow Forecasts from the Nws Hydrologic Ensemble Forecast Service (HEFS): Medium-Range Forecasts with Forcing Inputs from the Frozen Version of NCEP’s Global Forecast System; U.S. National Weather Service Office of Hydrologic Development: Silver Spring, MD, USA, 2013; p. 133.
- Brown, J. Verification of Long-Range Temperature, Precipitation and Streamflow Forecasts from the Hydrologic Ensemble Forecast Service (HEFS) of the U.S. National Weather Service; U.S. National Weather Service Office of Hydrologic Development: Silver Spring, MD, USA, 2013; p. 128.
- Brown, J. Verification of Temperature, Precipitation and Streamflow Forecasts from the Hydrologic Ensemble Forecast Service (HEFS) of the U.S. National Weather Service: An Evaluation of the Medium-Range Forecasts with Forcing Inputs from NCEP’s Global Ensemble Forecast System (GEFS) and a Comparison to the Frozen Version of NCEP’s Global Forecast System (GFS); U.S. National Weather Service Office of Hydrologic Development: Silver Spring, MD, USA, 2014; p. 139.
- He, M.; Hogue, T.; Margulis, S.; Franz, K.J. An integrated uncertainty and ensemble-based data assimilation approach for improved operational streamflow predictions. Hydrol. Earth Syst. Sci. 2012, 16, 815–831. [Google Scholar] [CrossRef]
- Franz, K.J.; Hogue, T.S.; Barik, M.; He, M. Assessment of swe data assimilation for ensemble streamflow predictions. J. Hydrol. 2014, 519, 2737–2746. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reservoir Name | ID | Reservoir Capacity (109 m3) | Drainage Area (km2) | Annual Precipitation 1 (mm) | Annual Temperature 1 (°C) | Runoff | ||
|---|---|---|---|---|---|---|---|---|
| April–July 1,2 (AJ, 109 m3) | Annual 1 (A, 109 m3) | Ratio (AJ/A) | ||||||
| Shasta Lake | SHDC1 | 5.61 | 16,630 | 936 | 8.0 | 2.23/1.83 | 7.30 | 0.31 |
| Lake Oroville | ORDC1 | 4.36 | 9352 | 1174 | 7.9 | 1.88/1.53 | 5.13 | 0.37 |
| Folsom Lake | FOLC1 | 1.21 | 4856 | 1294 | 10.6 | 1.47/1.27 | 3.33 | 0.44 |
| New Melones Reservoir | NMSC1 | 2.96 | 2341 | 1160 | 8.6 | 0.78/0.68 | 1.40 | 0.55 |
| Don Pedro Reservoir | NDPC1 | 2.50 | 3970 | 1093 | 8.4 | 1.51/1.40 | 2.43 | 0.62 |
| Lake McClure | EXQC1 | 1.26 | 2686 | 987 | 8.9 | 0.77/0.66 | 1.23 | 0.62 |
| Millerton Lake | FRAC1 | 0.64 | 4242 | 971 | 6.3 | 1.55/1.30 | 2.28 | 0.68 |
| Pine Flat Reservoir | PFTC1 | 1.23 | 4105 | 913 | 5.8 | 1.52/1.19 | 2.14 | 0.71 |
| Metrics | GEFS and Climatology | Climatology | ||
|---|---|---|---|---|
| 60 Members | 25 Members | 61 Samples | 26 Samples | |
| Rank Correlation | 0.79 | 0.77 | 0.73 | 0.75 |
| Percent Bias | −2.54% | −3.18% | −8.73% | −3.83% |
| Mean Absolute Error Skill Score | 0.28 | 0.27 | 0.30 | 0.23 |
| Nash-Sutcliffe Efficiency | 0.47 | 0.46 | 0.42 | 0.39 |
| Range | GEFS and Climatology | Climatology | ||
|---|---|---|---|---|
| 60 Members | 25 Members | 61 Samples | 26 Samples | |
| Minimum–Maximum | 0.84 | 0.80 | 0.82 | 0.88 |
| 90%–10% Exceedance | 0.58 | 0.62 | 0.62 | 0.61 |
| Minimum–90% Exceedance | 0.27 | 0.27 | 0.20 | 0.27 |
| 10% Exceedance–Maximum | 0.12 | 0.12 | 0.16 | 0.12 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, M.; Whitin, B.; Hartman, R.; Henkel, A.; Fickenschers, P.; Staggs, S.; Morin, A.; Imgarten, M.; Haynes, A.; Russo, M. Verification of Ensemble Water Supply Forecasts for Sierra Nevada Watersheds. Hydrology 2016, 3, 35. https://doi.org/10.3390/hydrology3040035
He M, Whitin B, Hartman R, Henkel A, Fickenschers P, Staggs S, Morin A, Imgarten M, Haynes A, Russo M. Verification of Ensemble Water Supply Forecasts for Sierra Nevada Watersheds. Hydrology. 2016; 3(4):35. https://doi.org/10.3390/hydrology3040035
Chicago/Turabian StyleHe, Minxue, Brett Whitin, Robert Hartman, Arthur Henkel, Peter Fickenschers, Scott Staggs, Andy Morin, Michael Imgarten, Alan Haynes, and Mitchel Russo. 2016. "Verification of Ensemble Water Supply Forecasts for Sierra Nevada Watersheds" Hydrology 3, no. 4: 35. https://doi.org/10.3390/hydrology3040035